
Abstract
New optimal proximity-based imputation, K-nearest neighbour (K-NN) classification and K-means clustering methods are proposed and developed for estimation of missing daily precipitation records. Mathematical programming formulations are developed to optimize the weighting, classification and clustering schemes used in these methods. Ten different binary and real-valued distance metrics are used as proximity measures. Two climatic regions, Kentucky and Florida, (temperate and tropical) in the USA, with different gauge density and network structure, are used as case studies to evaluate the new methods. A comprehensive exercise is undertaken to compare the performances of the new methods with those of several deterministic and stochastic spatial interpolation methods. The results from these comparisons indicate that the proposed methods performed better than existing methods. Use of optimal proximity metrics as weights, spatial clustering of observation sites and classification of precipitation data resulted in improvement of missing data estimates.
Editor D. Koutsoyiannis; Associate editor C. Onof
Résumé
Nouveau imputation basée sur la proximité optimale, voisin K plus proches (K-NN) de classification et K-means méthodes sont proposées et développées pour l’estimation de manquer des relevés quotidiens de précipitations. Les formulations de programmation mathématique sont mis au point pour optimiser les systèmes de pesage, de classification et de regroupement utilisées dans ces méthodes. Dix différentes métriques de distance binaires et valeurs réelles sont utilisés comme mesures de proximité. Deux régions climatiques, Kentucky et en Floride, (tempérées et tropicales) aux Etats-Unis, avec une structure différente de la densité de la jauge et du réseau, sont utilisés comme études de cas pour évaluer les nouvelles méthodes. Un exercice complet est effectué pour comparer les performances des nouvelles méthodes avec celles de plusieurs méthodes d’interpolation spatiale déterministes et stochastiques. Les résultats de ces comparaisons indiquent que les méthodes proposées de meilleurs résultats que les méthodes existantes. L’utilisation de mesures de proximité optimales comme poids, regroupement spatial des sites d’observation et la classification des données sur les précipitations a entraîné une amélioration des estimations de données manquantes.
INTRODUCTION
Spatial interpolation methods ranging from conceptually simple weighting techniques to methods using stochastic variance-dependent techniques are now available for estimation or imputation of missing precipitation data (Teegavarapu Citation2008). In this study, optimal proximity-based imputation using distance metrics derived from numerical taxonomy similarity concepts, nearest-neighbour classification and cluster-based methods are proposed and developed for estimation of missing precipitation data at a single raingauge. Weighting methods, inverse distance-based methods, nonlinear deterministic and stochastic variance-dependent interpolation methods (e.g. kriging) (Teegavarapu Citation2007, Citation2008) and regression and time series analysis methods (Tabios and Salas Citation1985) are among the most commonly used methods for estimating missing precipitation records. Variants of local regression models incorporating meteorological variables that change in the spatial domain (i.e. elevation) were proposed by Daly et al. (Citation2002). The coefficient of correlation weighting method (CCWM) proposed by Teegavarapu and Chandramouli (Citation2005) and adopted in a few recent studies (Westerberg et al. Citation2010) provides a method using gauge-to-gauge correlations. Optimization methods for objective selection of raingauges, optimal cluster identification and improvised traditional distance and quadrant-based methods were recently reported by Teegavarapu (Citation2012). These methods provided improved estimates compared to those from several deterministic and stochastic interpolation methods. Grid-based transformation of precipitation estimates using geospatial interpolation methods were reported by Teegavarapu et al. (Citation2012). The methods used grid structure, overlay of grids along with areal extents and nearest neighbours to transform multi-sensor precipitation estimates from one grid system to another.
Variants of the inverse distance weighting method (IDWM) or reciprocal distance weighting method have been provided by Teegavarapu and Chandramouli (Citation2005) and Lu and Wong (Citation2008). Teegavarapu (Citation2009) used an association rule mining (ARM) approach to improve estimates of missing precipitation data. Trend surface analysis methods with polynomial equations of spatial coordinates are equally applicable for spatial interpolation of precipitation data. However, selection of the appropriate functional form to model the trend poses a major problem due to the large number of possible candidate functions. Xia et al. (Citation2001) also reported the use of thin-plate-splines, closest-gauge and multiple linear regression techniques for estimation of daily climatological data. They indicated that the thin-splines method was the best among all the methods investigated. Variants of kriging have been used in the past to estimate missing precipitation data, as well as to interpolate precipitation from point measurements (Teegavarapu Citation2007). Comparative analysis of optimal spatial interpolation methods and multiple regression models was reported by Teegavarapu (Citation2012). The study confirmed the one main disadvantage of multiple regression was negative estimates. Applications of artificial neural networks (ANNs) for estimation of missing precipitation data were documented by Teegavarapu and Chandramouli (Citation2005) and Teegavarapu (Citation2007). Recent work of Teegavarapu et al. (Citation2009) has focused on the development of optimal functional forms using genetic algorithms and mathematical operators for estimating missing precipitation data. The functional forms provided better estimates compared to those by traditional geographical distance-based methods.
Limitations of spatial interpolation methods when used for estimation of missing data are documented by Teegavarapu (Citation2008, Citation2009) and Teegavarapu et al. (Citation2009). Reciprocal distances as weights in many interpolation methods may not serve as surrogate measures for spatial correlation. Numerical metrics strictly based on observations replacing Euclidean distances can be developed. If rainfall surface or field estimation is not of interest and only estimation of missing data at one single location in a region is essential, methods which rely directly on observed data are well suited for interpolation schemes. The new methods developed and investigated in this study are data-dependent and objective weighting schemes using proximity measures adopted from numerical taxonomy and conceptual ideas from K-nearest neighbour (K-NN) classification and clustering techniques. Utilization of proximity measures based only on data, classification of data into different classes and grouping of gauges to form clusters to estimate missing precipitation data was not attempted before in the literature. The contents of this paper are organized as follows. An introduction to distance metrics as proximity measures is provided first. The development of optimal K-NN classification and K-means clustering methods using nearest-neighbour techniques is discussed next. Then, applications of these methods for estimating missing precipitation data in two case study regions are presented. Finally, the results and analysis, general remarks and conclusions are presented.
PROXIMITY MEASURES FOR PRECIPITATION DATA
Proximity of two observation datasets based on real or categorical attribute values can be calculated using numerical proximity metrics. The metrics provide a measure of proximity between any two observed datasets and, in turn, can be used to assign weights in the interpolation schemes to estimate missing data. Distance metrics are calculated using pairs of observations at any two raingauges at a specific temporal scale. One of the raingauges always used in the calculations is referred to as a base raingauge, at which missing precipitation data are assumed to exist. These metrics are calculated based on historical precipitation data available at all gauges including the base raingauge. For all the metrics and formulations reported in this paper, the index n is used for time interval (i.e. day), ns is the total number of raingauges including the gauge with missing data in a region and no is the total number of historical temporal observations common to any two raingauges. All the metrics are defined between any two raingauges (β,α) with observations referred to by variables θβ,n and θα,n. Ling (Citation2010) lists more than 30 distance measures that are available in the literature. However, for this study 10 commonly used real and binary distance measures are used. The Euclidean distance or L2 norm is the simplest measure of distance between a pair of raingauge observations and is represented by equation (1). The squared Euclidean is a minor variant of the Euclidean distance and is the sum of the squares of the difference between the two raingauge observations, as given by equation (2). This metric magnifies distances between observations that are further apart.
The Manhattan distance (equation (3)) (Krause Citation1987), referred to as city block or taxicab distance, or L1 norm, is less affected by outliers compared to Euclidean and squared Euclidean distances (Fielding Citation2007). The maximum distance metric is the maximum separation between two observations defined by their magnitudes. The absolute difference between two observations is determined and the largest difference, as defined by equation (4).
The Minkowski distance (Basilevski Citation1983) is a generalized measure given by equation (5). The value of λ defines a specific distance. When λ = 1, the measure is Manhattan and when λ = 2, the measure becomes Euclidean distance or L2 norm. The Gower distance (Gower and Legendre Citation1986) is used for mixed variables (continuous and discrete) and is given by equation (6). The variable ωn is the weight, which is equal to one when both observations in a given time interval, n, are available, and zero when one of them is not available. The variable τn is the maximum range value based on the observations.
The Cosine distance is based on a numerical measure that evaluates the similarity between two sets of observations. The distance is calculated by subtracting the similarity measure from unity and is provided by equation (8). The Canberra distance (Lance and William Citation1966) given by equation (9) defines the sum of the fractional differences for each variable.
The correlation distance (equation (10)) is conceptually based on similarity between observations defined by correlation coefficient or a measure of linear relationship between two datasets. The cosine distance calculated based on the transformed values of observations using z scores is the same as correlation distance. The Mahalanobis distance (Myatt and Johnson Citation2009) takes into account correlations within a dataset between the variables. The distance is scale independent and is calculated using equation (11). The calculated distance requires covariance ( and transformed matrices using the datasets. The variables
and
are vectors and not individual observations (i.e. single observation at each raingauge) and
is the inverse of the covariance matrix of the data.
BINARY DISTANCE MEASURES FOR PRECIPITATION DATA
Binary distance measures can be defined for observations that assume binary values (i.e. 0 and 1) and also for categorical variables when these variables can be expressed as binary variables. Similarity measures indicate how alike two observations are to each other. Lower magnitudes in the case of distance measures indicate that observations from the two series are alike. The precipitation data at any raingauge are converted into binary time series using the following expression:
The variable θj,n is the observed precipitation value at gauge j, in time interval n, and θth is the threshold value (lower limit) that helps in the assignment of binary values. The count (number) for these specific conditions is obtained from the historical data using observations at all the raingauges, including the gauge with the missing precipitation data. The countsrequired for distance metrics are calculated for each time interval, n, using conditions expressed by conditions (13)–(16). The variable θ*β,n is the transformed precipitation data at gauge β and θ*α,n is the similar transformed value at the base raingauge (i.e. the gauge with missing precipitation data referred with index m = α).
The aggregated values of these counts (,
,
and
) are calculated using equations (17)–(20) with all the available observations, no.
The values of counts given by equations (17)–(20) are used to define several different binary distance metrics. The simple matching metric calculates the similarity measure linked to the total number of times any two raingauges have conditions (17) and (18) satisfied. The distance is calculated by subtracting this similarity coefficient from the one in equation (21). The Jaccard (Jaccard Citation1908) distance is given by equation (22).
The Russell and Rao distance (Russell and Rao Citation1940) is based on a similarity coefficient that relates to the total number of times any two gauges have condition (17) satisfied compared to all conditions. The similarity coefficient is then transformed to a distance measure given by equation (23). The Dice distance (Dice Citation1945, Sorensen Citation1948) calculated by equation (24) gives more importance to common ones. This is a measure in which joint absences are excluded and matches are doubled (Fielding Citation2007).
The Rogers and Tanimoto distance (Rogers and Tanimoto Citation1960) (equation (25)) gives importance to common ones and zeros and was mainly developed for classifying plant species. The Pearson distance (Ellis et al. Citation1993), as defined by equation (26), was initially used to measure the degree of similarity between objects in text retrieval systems. The Yule distance (Yule Citation1912) given by equation (27) was developed as a method for identifying association between two attributes. The Sokal-Michener distance (Sokal and Michener Citation1958, Sneath and Sokal Citation1962) is one of the distance metrics used in numerical taxonomy for classifying organisms and building evolutionary trees, and is defined by equation (28).
Kulzinsky distance (Holliday et al. Citation2002) defined by equation (29) is used in ecology for finding similarity in sites with similar species and also in calculation of intermolecular similarity and dissimilarity. The Hamming distance (Hamming Citation1950) as given by equation (30) was originally developed to identify and correct errors in digital communication systems.
Optimal exponent weighting of proximity measures
The real and binary proximity measures discussed earlier are used to develop an optimal weighting method with the objective function and the constraints specified by equations (31), (32) and (33), respectively.
Subject to:
The formulation is solved using historical spatio-temporal precipitation data to minimize the objective function (equation (33)) and obtain optimal exponent value (ke) using a nonlinear optimization solver.
OPTIMAL K-NEAREST NEIGHBOUR CLASSIFICATION METHOD
The optimal K-nearest neighbour (K-NN) classification method combines a classification and an optimal weighting scheme. The method classifies precipitation data into several groups to develop separate (i.e. local) optimization models. Arbitrary definitions of classes yielded inferior results in the previous study (Teegavarapu Citation2012). Initially, the K-NN method is used as a classifier to group spatial and temporal precipitation data into several pre-defined classes. These classes are set as the training dataset, which contains training tuples (Han and Kamber Citation2006), and the classification is achieved based on learning by analogy, by comparing a given test tuple with training tuples that are similar to it. When given an unknown tuple, a K-NN classifier searches the pattern space for the K training tuples that are closest to the unknown tuple. These K training tuples are the K-‘nearest neighbours’ of the unknown tuple (Fielding Citation2007). Closeness is defined in terms of any distance metric (e.g. Euclidean distance). The distance between two points or tuples, say, X = (θ1,1, θ1,2,… θ1,ns-1) and Xc=1 = () defined by equations (34) and (35) respectively is a function given by equation (36).
Here, X represents the no × ns–1 matrix of observed precipitation values at ns-1 gauges for no time intervals and Xc represents a c × ns–1 matrix of pre-defined classes of precipitation data. The historical observations at ns–1 gauges are evaluated for their proximity to each of the classes defined in Xc and each observation is designated to a specific class, c using a distance metric, D:
Once the precipitation data are designated to specific classes, then correlation between the observations in a specific class, c, and observations at gauge at which missing data exist are obtained. The variable nc is the index for observation that belongs to class c and tnc is the total number of observations that belongs to class c.
The correlation coefficients obtained from equation (37) are then used in a coefficient of correlation weighting method (CCWM) (Teegavarapu and Chandramouli Citation2005) for estimation of missing precipitation data at gauge, , as given by:
Alternatively, optimal weights for each class can be obtained by solving an optimization formulation given by the following objective function (equation (39)) and constraint (inequality (40)). The formulation is solved for each class, c.
where A is the nc × j matrix of values, x is the matrix j × 1 of
weight values and B is the matrix of nc × 1 values of data at the base raingauge (
belonging to a specific cluster, c. The norm minimized is defined as the square of 2-norm, which equivalent to the sum of the squares of the differences between estimated values (Ax) and observed values (B).
Subject to:
The formulation minimizes the norm given by equation (39) with constraint on the weights () in inequality (40). This formulation provides non-negative optimal coefficients when solved. The missing precipitation data are then estimated by:
OPTIMAL K-MEANS CLUSTERING METHOD
Clustering of observations for analysis is common in spatial ecology (Fortin and Dale Citation2005), geosciences and data mining applications. In this study, clustering was used to create one ‘virtual’ gauge out of a number of gauges (i.e. cluster) where only one weight is attached to this gauge (i.e. group of gauges). Grouping (clustering) of gauges can be achieved by K-means clustering algorithms (Han and Kamber Citation2006) where proximity (distance-based) metrics are used to define the clusters and the members belonging to each cluster. In a previous study (Teegavarapu Citation2012), clustering was achieved by optimization using binary variable-mixed integer nonlinear programming (MINLP) formulation. The K-means clustering method is used in this study to identify spatial clusters of raingauges from the network of gauges in a region. Initially, the method is used to obtain a pre-specified number (i.e. K) of spatial clusters of precipitation gauges. The steps involved in the K-mean clustering method are:
initial spatial partitioning of precipitation gauges into K random clusters;
re-partitioning of the gauges by assigning each gauge to the nearest centre of cluster by using a proximity measure (e.g. a distance metric); and
re-calculation of the cluster centres as centroids.
Optimal weights for selected clusters
The K-means clustering method is used to identify possible spatial clusters of raingauges and weights are assigned to these clusters using an optimization formulation. Non-negative constraint requirements to obtain positive weights are enforced using the nonlinear least square constraint formulation defined by:
Subject to:
E is the no × cl matrix of values, x is the matrix cl × 1 of
weight values and F is the matrix of no × 1 values of data at base raingauge θα,n. The formulation minimizes the norm given by equation (42) with constraint on the weights (inequality (43)). This formulation provides non-negative optimal coefficients when solved. The variable
is the number of gauges in a cluster cl. The variable
is based on observations at all gauges (
, or one gauge in a cluster cl, as defined by equation (44) or (45), respectively:
In equation (44), is equated to the sum of all the observations from all the gauges in a cluster cl for time interval n, while in equation (45),
is equated to observations (
at gauge, z, belonging to a specific cluster of gauges having maximum correlation with the gauge with missing data:
Using the weights obtained by solution of the optimization formulation given by equations (42)–(43), the estimation of missing precipitation data is given by equation (46), with the value of obtained by either equation (44) or (45). The variable Ncl is the number of clusters.
CASE STUDY APPLICATION AND EVALUATION OF METHODS
The imputation methods developed herein this study were used for estimating missing daily precipitation data at two selected gauges in two case study regions, Kentucky and Florida, referred hereafter to as Region I and Region II, respectively. Region I has a temperate climatic zone in which the storm events are mainly due to frontal precipitation, whereas Region II is predominantly tropical with convective type rainfall events. Region II has three times more raingauges than Region I and this benefits spatial interpolation. Considering the high spatial variability of precipitation in Region II in the wet season, the proximity of several gauges to the base raingauge is also crucial for accurate interpolation of precipitation data. For Region I, the methods were used to estimate missing rainfall data at gauge 15 (shown in ). Historical daily precipitation data from the period 1971–2001 available at 15 raingauges in the state of Kentucky, USA, were used for analysis. This dataset was further filtered to obtain a time-consistent observation set of a total of 10 645 days. The locations of the gauges are shown in ; they are numbered for convenience. The data used in this study were compiled and provided by Kentucky Agricultural Weather Center, University of Kentucky. A total of 7756 days of precipitation data (73% of data) were used to develop the methods and 2889 days (27% of data) of data were used for testing the methods. For Region II, located in southwest Florida, daily historical data from the period 1994–1999 available from 43 rainfall gauges were used. A filtered and time-consistent dataset of 2129 days was used, with data assumed to be missing at gauge 3 (shown in ) for testing the methods.
Fig. 1 Location of raingauges in the state of Kentucky, USA (Region I).
Fig. 2 Location of raingauges and the gauge with missing data in the state of Florida, USA (Region II).
The training and testing datasets used for this region are 1419 (67% of data) and 710 days (33% of the data), respectively. The methods were applied to the test data and the performances compared using error measures such as root mean squared error (RMSE), absolute error (AE), mean absolute error (MAE) and a goodness-of-fit measure criterion, the correlation coefficient (ρ), based on actual and estimated rainfall values at the base raingauges. The Nelder-Mead Simplex method (Lagarias et al. Citation1998) was used for all formulations that involve estimation of optimal exponent values. The performances of several deterministic and stochastic spatial interpolation methods were also used to compare with those of new methods developed herein. These methods include: gauge mean estimator (GME); normal ratio; inverse distance and exponential weighting; trend surface models with linear, quadratic and cubic functions; thin-plate spines; and ordinary kriging with spherical, circular and Gaussian semivariogram models. The GME, trend surface and thin-plate spline methods do not require any parameters to be estimated from historical data.
Error and performance measures were used to evaluate intuitive reasonableness of method, conceptual accuracy, simplicity of the method and objective assessment, and, finally, selection of the methods. When multiple performance measures are used in the selection of any method from a set of equally competitive methods, identification of that best method is often difficult. Linear or nonlinear weighting functions can be developed to transform the performance measures (i.e. RMSE, AE, MAE, ρ) into an accumulated dimensionless total performance measure. This total measure was used for objective comparison and selection of the best method from a set of competing methods. In this study all the performance measures were added to transform them to a score (or weight) between zero and one. The total weighted performance measure (Wtotal) is given by equation (51).
The variables Ωρ, ΩAE, ΩRMSE and ΩMAE, and ρ′, AE′, RMSE′ and MAE′, are the weighting factors, and the maximum values of corresponding performance measures based on all the methods, respectively. Equations (47)–(50) define weighting functions for Wρ (correlation coefficient), WAE (absolute error), WRMSE (root mean squared error) and WMAE (mean absolute error) respectively. These functions resemble fuzzy membership functions (Teegavarapu and Elshorbagy Citation2005), and they transform performance measures to unitless values. The method with lowest value of overall performance measure (Wtotal) is the best among all the competing methods.
RESULTS AND ANALYSIS
The results from proximity-based metrics, K-NN classification and clustering are first discussed and then the results from traditional deterministic and stochastic methods along with their variants are presented and analysed. The distance metrics were obtained using historical data for both regions I and II. It is evident from the case study descriptions that the number of years of data available for Region II is much smaller than that for Region I. A threshold value (θth) of zero was used for binary distance measures for both the regions. provides the performance measures for real-valued distance metrics for Region I with optimal exponents. In general, for all proximity-based methods, optimal exponents provided better performance measures compared to non-optimized versions. Therefore, the results related to performance measures from non-optimized methods are not provided. Higher variability in the performance measures is noted for optimized distance metrics compared to non-optimized metrics. The variability may be associated with non-global solutions from optimization formulations. The best two methods based on total weights before and after optimization are Minkowski and Correlation, and Cosine and Canberra, respectively. The performance measures for binary distance measures are provided in for Region I. The two best methods with and without optimization are Kulzinksky and Jaccard, respectively. The Cosine, Kulzinsky, Jaccard and Yule distance-based methods were ranked as the top four among all the real-valued and binary distance-based methods for Region I. and provide the performance measures for real-valued and binary distance metrics, respectively, for Region II. Higher variability in the performance measures is also noticed for optimized distance metrics compared to non-optimized distance metrics. The two best methods before and after optimization are Manhattan and Euclidean, and Cosine and squared Euclidean, respectively. The average performance values for binary distance measures were better than the real-valued distance metrics. The two best methods are Pearson and Yule, respectively. The methods Manhattan, Euclidean, Canberra and Cosine are ranked high among all the real-valued and binary metrics for Region II. Optimization of exponents attached to reciprocal distances provided substantial improvement in the performance measures for real-valued and binary distance metrics.
Table 1 Performance measures based on different real-valued distance metrics used in optimal proximity-based imputation for Region I.
Table 2 Performance measures based on different binary proximity measures used in optimal proximity-based imputation for Region I.
Table 3 Performance measures based on different real-valued distance metrics used in optimal proximity-based imputation for Region II.
Table 4 Performance measures based on different binary distance metrics used in optimal proximity-based imputation for Region II.
The threshold value (θth) has a significant influence on the performance of binary proximity measures in imputation of missing precipitation data. A binary distance metric defined by Sokal-Michener that performed well in both regions I and II was used to evaluate the changes in performance measures based on different threshold values. It is evident from the results provided in that an increase in the threshold value resulted in deterioration of performance measures. Similar results were obtained for Region II also. Any increase in threshold value increases the number of observations equated to zero after binary transformation and therefore will affect the outcome of the conditions given by equations (17)–(20) and counts required for calculation of distance metrics. The length of the historical spatio-temporal precipitation data has influence on the performance of real and binary distance metrics. As the length of the data increases, the amount of information available to obtain accurate proximity measures increases thus improving the estimates. The methods are not constrained by a specific minimum data length. However, the larger the dataset the better are the proximity metrics in characterizing the inter-gauge data relationships.
Table 5 Performance measures based on different threshold values of precipitation for binary distance metric-based imputation for Region I.
The K-NN classification method was used to group the available precipitation data into several pre-specified classes using maximum and minimum possible values of data. The maximum value of all observations from all gauges, except for the base raingauge, is 204 mm for Region I and 189 mm for Region II. Four classes were evaluated for regions I and II, and the classification is based on historical precipitation data (i.e. training dataset) at gauges and pre-defined classes using Euclidean distance. Once the precipitation data have been grouped into classes, coefficient of correlation weighting (Teegavarapu and Chandramouli Citation2005) and optimization methods are used to obtain weights for gauges for each class. The weights are then used for estimation of missing precipitation data at the base raingauge using pre-defined classes for test dataset. The results related to correlation and optimal weighting schemes for Region I are given in and those from the application of similar schemes for Region II are given in . In general, the performance improved when the number of classes was increased for both regions I and II. The optimal weighting scheme provided better results compared to correlation weighting in both the regions. For Region I, the best performance was obtained based on the total weighted score (equation (51)), when 10 and three classes are used for correlation and optimization-based methods, respectively. For Region II, the best performance was achieved when 14 and three classes are used for correlation and optimization-based methods, respectively. In both the regions, the optimal K-NN classification with three classes provided the best performance measures. It is important to note that definition of too many classes may result in failure of any observations being assigned to a specific class. This poses difficulty in estimation of correlations and also weights.
Table 6 Performance measures based on different classes used in correlation and optimization-based K-NN classification imputation for Region I.
Table 7 Performance measures based on different classes used in correlation and optimization-based K-NN classification imputation for Region II.
The application of the K-means clustering approach required spatial partitioning of raingauges into a number of clusters using Euclidean distance as the distance metric. Different cluster sizes were experimented in this study. Two approaches described earlier indicated the use of one gauge (i.e. the gauge with maximum correlation with base gauge) in each cluster or the weighted sum of observations from all the gauges in each cluster. The results related to application of this method to regions I and II are provided in . The number of clusters used and the gauges selected in each cluster are also presented in this table. In both the regions, based on limited experiments conducted, a total of six clusters resulted in the best performance measures. The method using weighted summation of observations from clusters provided better performance measures compared to that in which the highest correlated gauge with the base gauge in each cluster is selected.
Table 8 Performance measures based on different distance metrics used in optimal K-means cluster imputation for regions I and II.
The results from imputation methods using different stochastic and deterministic interpolation methods are provided in . The performance measures for gauge mean estimator (GME) using all the raingauges are substantially inferior to those when nearest neighbours are selected using the Euclidean distance criterion. Even though the performance measures improved when compared to those from the methods using all the gauges, the method provides a substantial number of under-estimations. In the case of Region II, the GME method provided the best results when eight nearest neighbours were used. The clustering of raingauges around the gauge assumed to be having missing data is higher in Region II compared to that in Region I. The best results for the normal ratio method for Region I were obtained when nine nearest neighbours based on the Euclidean distance criterion were selected. In the case of Region II, for the same method, the best performance measures were obtained when three nearest neighbours were selected based on distance. The inverse exponential method provided the best performance when nine nearest neighbours (selected by defining a pre-specified radius) were used. The trend surface and thin-spline models provided better results in Region II compared to Region I, as high gauge density provided help in generating rainfall surfaces that are representative of spatial variations of precipitation in that region. Local versions of the trend surface models were also investigated. However, these versions did not provide better results than global versions. Among the trend surface models, the global linear and cubic trend surface models provided the best performances for region I and region II, respectively. Ordinary kriging methods were developed using procedures outlined by Teegavarapu (Citation2007) for the selection of variogram parameters (nugget and sill values) for three semi-variogram models. The effect of anisotropy on variogram parameters was neglected. The Gaussian semi-variogram model provided the best performance for Region I and the spherical semi-variogram for Region II. The best three methods among all the deterministic and stochastic methods evaluated for Region II are normal ratio (distance-based), ordinary kriging using circular semi-variogram and thin-plate splines.
Table 9 Performance measures based on different methods for regions I and II.
The methods developed in this study were evaluated and ranked based on total performance measure (equation (51)) with all weighting factors equal to one. The highest ranked 25 methods for regions I and II are provided in . The top 10 ranked models in Region I included several proximity metric-based optimal weighting methods and variants of optimal K-NN classification methods. In Region II, with its dense raingauge network, the ranking of models is different from that of Region I. In Region II, a conceptually simple interpolation method (i.e. inverse distance) and ordinary kriging method are also among the top 10 methods along with several proximity metric-based optimal weighting methods.
Table 10 Ranking of different imputation methods and their variants for regions I and II.
The variability of performance measures from real and binary metric-based methods are compared for regions I and II in and respectively. Binary metrics provided better performance measures compared to those from real metrics for Region I and vice versa for Region II. The top eight imputation methods from: (a) the deterministic and stochastic interpolation methods and (b) the optimal proximity-based and K-NN classification and K-means clustering methods developed in this study were used to form two separate groups: Group 1 and Group II, respectively for comparison purposes. The average values of performance measures for Group II are better than those for Group I for both regions I and II. The deviations in performance measures among proximity-based methods within Group II are smaller compared to those from the methods in Group I. This result is no surprise, as all the methods that use distance-based metrics in Group II are conceptually similar. Variations in performance measures for group I and II methods for regions I and II are shown in and , respectively. The median values of RMSE and MAE are lower for Group II than for Group I in both the regions. Similarly, the median values of correlation coefficients are higher for Group II compared to Group I in both the regions.
Fig. 3 Variability of performance measures for real and binary metric-based methods for Region I.
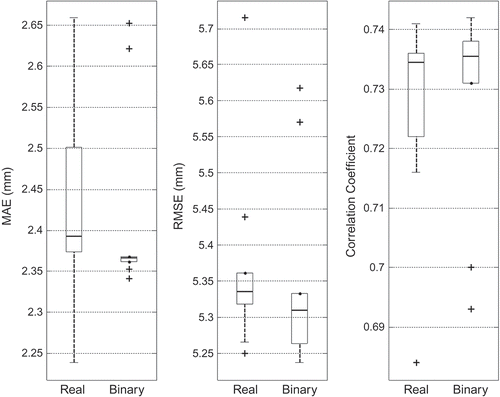
Fig. 4 Variability of performance measures for real and binary metric-based methods for Region II.
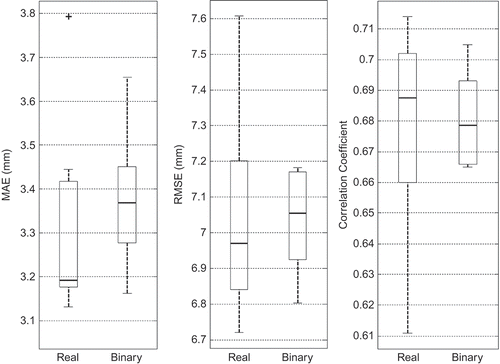
Fig. 5 Variability of performance measures for two groups for Region I.
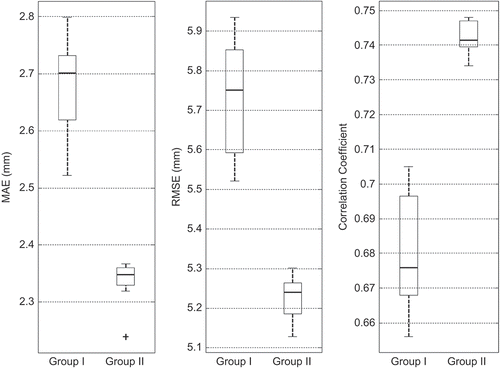
Fig. 6 Variability of performance measures for two groups for Region II.
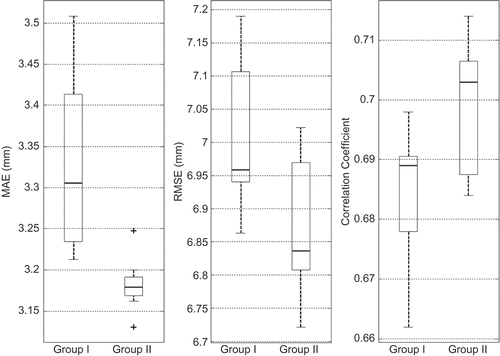
Region II has a large number of raingauges with a higher density compared to Region I. Also, Region I has approximately five times more historical precipitation data compared to Region II. The test dataset for Region II is four times smaller than that of Region I. The influence of data length on binary-valued distance metrics is higher compared to real-valued metrics. An experiment was conducted in which the available historical data length for development of distance metrics in Region I was reduced to 1489 days (the same number of days in the test dataset used for Region I). The performance measures obtained for optimal Sokal-Michener metric () based on this dataset were inferior when compared to those from the complete dataset used for the same metric. This result confirms the strong influence of data length on distance metrics and thereby the estimates. Cross-validation of five methods for three base raingauges was carried out for three raingauges in regions I and II. Two real-valued and binary distance-based methods were also evaluated. The results related to these cross-validation exercises are provided in and for regions I and II, respectively. The results suggest that the binary and real-valued proximity-based weighting methods developed in this study provide better performance measures compared to those from several traditional interpolation methods.
Table 11 Performance measures based on application of different methods to different base raingauges in Region I.
Table 12 Performance measures based on application of different methods to different base raingauges in Region II.
The proximity measures based on distance metrics are sensitive to the length of the historical data and the threshold value used for the calculation of binary metrics. A threshold value of zero that defines rain or no rain conditions is ideal. The estimation of missing precipitation data from real-valued and binary distance metrics can be improved using data that is representative of specific storm types or a season. The proximity-based methods always provide non-negative precipitation estimates unlike several other methods such as multiple linear regression, artificial neural networks, ordinary kriging, and trend surface and thin-plate splines. The methods developed in this study are specific to a site with missing data. The parameters (weights and exponents), and number of gauges used in interpolation will be different if another site with missing data is filled. The ability of methods to preserve site and regional data statistics (Teegavarapu Citation2012, Citation2013) was not evaluated in this study. However, the methods were evaluated for precipitation estimation in temperate and tropical climate zones, and the applicability of these methods to other climatic zones needs to be thoroughly assessed.
CONCLUSIONS
New spatial interpolation methods are proposed and developed using optimal proximity-based weighting methods, K-nearest neighbour classification and K-means-clustering approaches for estimating missing precipitation records. In this study, 10 real-valued and binary distance metric-based imputation methods were evaluated and also compared with several deterministic and stochastic spatial interpolation methods. The proposed methods were evaluated for estimation of missing precipitation data at multiple raingauges in temperate and tropical climate zones. The optimal nearest neighbour classification and clustering methods provided mechanisms to identify groups of spatial precipitation data in time and space, and virtual gauges respectively that led to improved local models as opposed to global models which do not consider classification of data or clustering of observation sites. Several proximity metric-based imputation, K-NN classification and K-means clustering methods were ranked among the top 10 methods investigated for two climatic regions in this study. The new methods and optimization formulations developed in this study are objective, data-driven and generic, and they can be easily applied for estimating missing precipitation at a site in any other region.
Acknowledgements
The author thanks the Kentucky Agricultural Weather Center, University of Kentucky, USA, for providing the data required for the research study reported herein. The author sincerely thanks the anonymous reviewers and associate editor for their feedback, objective and constructive criticism that led to substantial improvement of the manuscript.
REFERENCES
- Basilevsky, A., 1983. Applied matrix algebra in the statistical sciences. New York: Dover Publications.
- Daly, C., et al., 2002. A knowledge-based approach to the statistical mapping of climate. Climate Research, 22, 99–113. doi:10.3354/cr022099
- Dice, L.R., 1945. Measures of the amount of ecologic association between species. Ecology, 26, 297–302. doi:10.2307/1932409
- Ellis, D., Furner-Hines, J., and Willett, P., 1993. Measuring the degree of similarity between objects in text retrieval systems. Perspectives in Information Management, 3 (2), 128–149.
- Fielding, A.H., 2007. Cluster and classification techniques for the biosciences. New York: Cambridge University Press.
- Fortin, M.-J. and Dale, M., 2005. Spatial analysis: a guide for ecologists. New York: Cambridge University Press.
- Gower, J.C. and Legendre, P., 1986. Metric and Euclidean properties of dissimilarity coefficients. Journal of Classification, 3, 5–48. doi:10.1007/BF01896809
- Hamming, R.W., 1950. Error detecting and error correcting codes. Bell System Technical Journal, 29 (2), 147–160. doi:10.1002/j.1538-7305.1950.tb00463.x
- Han, J. and Kamber, M., 2006. Data mining: concepts and techniques. Waltham: Morgan Kaufmann.
- Holliday, J.D., Hu, C.Y., and Willett, P., 2002. Grouping of coefficients for the calculation of intermolecular similarity and dissimilarity using 2D fragment bit-strings. Combinatorial Chemistry and High Throughput Screening, 5 (2), 155–166. doi:10.2174/1386207024607338
- Jaccard, P., 1908. Nouvelles recherches sur la distribution florale. Société Vaudoise des Sciences Naturelles, 44, 223–270.
- Krause, E.F., 1987. Taxicab geometry. New York: Dover Publications.
- Lagarias, J.C., et al., 1998. Convergence properties of the Nelder-Mead Simplex method in low dimensions. SIAM Journal on Optimization, 9 (1), 112–147. doi:10.1137/S1052623496303470
- Lance, G.N. and Williams, W.T., 1966. Computer programs for hierarchical polythetic classification (“Similarity Analyses”). The Computer Journal, 9, 60–64. doi:10.1093/comjnl/9.1.60
- Ling, H.T.M., 2010. Distance coefficients between two lists or sets. The Python Papers, 2, 1–31.
- Lu, G.Y. and Wong, D.W., 2008. An adaptive inverse-distance weighting spatial interpolation technique. Computers and Geosciences, 34 (9), 1044–1055. doi:10.1016/j.cageo.2007.07.010
- Myatt, G.J. and Johnson, W.P., 2009. Making sense of data II: a practical guide to data visualization, advanced data mining methods, and applications. Hoboken, NJ: Wiley.
- Rogers, D.J. and Tanimoto, T.T., 1960. A computer program for classifying plants. Science, 132, 1115–1118. doi:10.1126/science.132.3434.1115
- Russell, P.F. and Rao, T.R., 1940. On habitat and association of species of Anopheline larvae in southeastern Madras. Journal of Malaria Institute of India, 3, 153–178.
- Sneath, P.H. and Sokal, R.R., 1962. Numerical taxonomy. Nature, 193, 855–860. doi:10.1038/193855a0
- Sokal, R.R. and Michener, C.D., 1958. A statistical method for evaluating systematic relationships. University of Kansas Scientific Bulletin, 38 (22), 1409–1438.
- Sorensen, T., 1948. A method of establishing groups of equal amplitude in plant sociology based on similarity of species content and its application to analyses of the vegetation on Danish commons. Danske Videnskabernes Selskab. Biologiske Skrifter, 5, 1–34.
- Tabios, G.Q.III. and Salas, J.D., 1985. A comparative analysis of techniques for spatial interpolation of precipitation. Journal of the American Water Resources Association, 21, 365–380. doi:10.1111/j.1752-1688.1985.tb00147.x
- Teegavarapu, R.S.V., 2007. Use of universal function approximation in variance-dependent surface interpolation method: an application in hydrology. Journal of Hydrology, 332, 16–29. doi:10.1016/j.jhydrol.2006.06.017
- Teegavarapu, R.S.V., 2008. Innovative spatial interpolation methods for estimation of missing precipitation records: concepts and applications. In: J. Bruthans, K. Kovar and Z. Hrkal, eds. Proceedings of hydropredict-2008. Prague: International Association of Hydrogeologists, 79–82.
- Teegavarapu, R.S.V., 2009. Estimation of missing precipitation records integrating surface interpolation techniques and spatio-temporal association rules. Journal of Hydroinformatics, 11 (2), 133–146. doi:10.2166/hydro.2009.009
- Teegavarapu, R.S.V., 2012. Spatial interpolation using nonlinear mathematical programming models for estimation of missing precipitation records. Hydrological Sciences Journal, 57 (3), 383–406. doi:10.1080/02626667.2012.665994
- Teegavarapu, R.S.V., 2013. Statistical corrections of spatially interpolated missing precipitation data estimates. Hydrological Processes. doi:10.1002/hyp.9906
- Teegavarapu, R.S.V. and Chandramouli, V., 2005. Improved weighting methods, deterministic and stochastic data-driven models for estimation of missing precipitation records. Journal of Hydrology, 312, 191–206. doi:10.1016/j.jhydrol.2005.02.015
- Teegavarapu, R.S.V. and Elshorbagy, A., 2005. Fuzzy set-based error measure for hydrologic model evaluation. Journal of Hydroinformatics, 7, 199–208.
- Teegavarapu, R.S.V., Meskele, T., and Pathak, C., 2012. Geo-spatial grid-based transformations of precipitation estimates using spatial interpolation methods. Computers and Geosciences, 40, 28–39. doi:10.1016/j.cageo.2011.07.004
- Teegavarapu, R.S.V., Tufail, M., and Ormsbee, L., 2009. Optimal functional forms for estimation of missing precipitation data. Journal of Hydrology, 374, 106–115. doi:10.1016/j.jhydrol.2009.06.014
- Westerberg, I., et al., 2010. Precipitation data in a mountainous catchment in Honduras: quality assessment and spatiotemporal characteristics. Theoretical Applied Climatology, 101 (3–4), 381–396. doi:10.1007/s00704-009-0222-x
- Xia, Y., et al., 2001. Forest climatology: estimation and use of daily climatological data for Bavaria, Germany. Agricultural and Forest Meteorology, 106, 87–103. doi:10.1016/S0168-1923(00)00210-0
- Yule, G.U., 1912. On the methods of measuring association between two attributes. Journal of the Royal Statistical Society, 75 (6), 579–652. doi:10.2307/2340126