
Abstract
Spatial error regression is employed to regionalize the parameters of a rainfall–runoff model. The approach combines regression on physiographic watershed characteristics with a spatial proximity technique that describes the spatial dependence of model parameters. The methodology is tested for the monthly abcd model at a network of gauges in southeast United States and compared against simpler regression and spatial proximity approaches. Unlike other comparative regionalization studies that only evaluate the skill of regionalized streamflow predictions in ungauged catchments, this study also examines the fit between regionalized parameters and their optimal (i.e. calibrated) values. Interestingly, the spatial error model produces parameter estimates that better resemble the optimal parameters than either of the simpler methods, but the spatial proximity method still yields better hydrologic simulations. The analysis suggests that the superior streamflow predictions of spatial proximity result from its ability to better preserve correlations between compensatory hydrological parameters.
Editor D. Koutsoyiannis; Associate editor Y. Gyasi-Agyei
Résumé
La régression spatiale des erreurs a été utilisée pour régionaliser les paramètres d’un modèle pluie-débit. L’approche combine la régression sur les caractéristiques physiographiques des bassins versants et une technique de proximité spatiale qui décrit la dépendance spatiale des paramètres du modèle. La méthodologie a été testée avec le modèle mensuel abcd sur un réseau de stations de jaugeage du Sud-Est des Etats-Unis, et comparée à des approches plus simples par régression et proximité spatiale. Contrairement à d’autres études comparatives de régionalisation qui n’évaluent que la qualité des simulations régionalisées de débits sur des bassins non jaugés, cette étude examine également l’adéquation entre les paramètres régionalisés et leurs valeurs optimales (c’est-à-dire calées). De manière intéressante, le modèle spatial d’erreur produit des estimations de paramètres qui ressemblent davantage aux paramètres optimaux que n’importe quelle autre méthode plus simple, mais la méthode par proximité spatiale donne encore de meilleures simulations hydrologiques. L’analyse suggère que les meilleures simulations de débits de l’approche par proximité spatiale résultent de sa capacité à mieux préserver les corrélations entre les paramètres hydrologiques qui peuvent se compenser.
1 INTRODUCTION
Accurate estimates of continuous streamflow in ungauged catchments are crucial for water resource studies of natural and engineered systems in poorly monitored watersheds. Hydrologists often rely on rainfall–runoff models (RRM) to produce streamflow estimates for ungauged catchments, especially when those estimates must reflect possible future scenarios subject to changing climate conditions (Ewen and Parkin Citation1996). Regionalization methods are often used to overcome the challenge of data scarcity for RRM calibration at ungauged sites by informing parameter values with information embedded in parameters calibrated at nearby gauged locations (Sivapalan et al. Citation2003). Despite significant research efforts dedicated to the development of regionalization techniques over the past decade, there remains a pressing need to improve upon current methodologies (Hrachowitz et al. Citation2013).
Many studies have explored different methods to estimate the parameters of a RRM for an ungauged catchment, but most proposed techniques fall into one of three primary categories (Parajka et al. Citation2005, Oudin et al. Citation2008). The first is based in regression theory. RRM parameters at an ungauged site are estimated using regression relationships, often linear, developed between RRM parameters calibrated for gauged sites and physiographic watershed characteristics (Magette et al. Citation1976, Abdulla and Lettenmaier Citation1997, Sefton and Howarth Citation1998, Seibert Citation1999, Kay et al. Citation2006, Young Citation2006). This approach assumes that components of the model relate to physical structures within each catchment that can be measured using current Earth monitoring capabilities. Methodologies in the second category map parameters calibrated at gauged sites to an ungauged catchment based on spatial proximity (Vandewiele and Elias Citation1995, Parajka et al. Citation2007). These methods assume that the continuity of physical and climatic properties justify the transfer of RRM parameters from gauged to ungauged sites as a function of distance. The third regionalization technique, referred to here as a physical similarity regionalization (Burn and Boorman Citation1993, Kokkonen et al. Citation2003), directly transfers RRM parameters from one or more donor catchments selected to have a similar set of predetermined watershed characteristics to that of the ungauged catchment. This approach is similar to that of regression because of its dependence on basin descriptors, but it also resembles spatial proximity approaches because a full parameter set is directly transferred from one or more selected catchments.
Recent reviews of these techniques have found that certain regionalization methods tend to outperform others. Oudin et al. (Citation2008) found that regionalization based on spatial proximity performed best for an extensive network of gauges in France, though recognized that the skill of that approach was similar to that of regression when the density of the network was sufficiently decreased. The results of several other comparative regionalization studies support the use of spatial proximity approaches, and also suggest that regression methods tend to consistently underperform both spatial proximity and physical similarity techniques (Merz and Blöschl Citation2004, McIntyre et al. Citation2005, Parajka et al. Citation2005).
Several reasons have been proposed to explain why spatial proximity and physical similarity approaches outperform regression methods. Some argue that regression techniques are inappropriate because there may not exist a unique relationship between watershed characteristics and RRM parameters. This theory has emerged from past studies showing that there is not always a unique set of parameters to define the best-fit model (i.e. the problem of equifinality) (Beven Citation2006). For instance, Bárdossy (Citation2007) showed for a simple two-parameter RRM how near-equal model performance can be achieved across a wide range of parameter combinations as long as one parameter compensates for the effect of the other. He argued, therefore, that parameters from gauged catchments should be transferred to an ungauged location as complete sets to preserve the effect of their interactions (as is done in spatial proximity and physical similarity methods). Some alternative regression approaches, such as regional calibration (Fernandez et al. Citation2000, Parajka et al. Citation2007) and sequential regression (Kay et al. Citation2006, Wagener and Wheater Citation2006), have been developed to account for equifinality by imposing relationships between parameters and catchment descriptors either a priori or iteratively during the calibration process. Both of these methods improve the identifiability of parameters, but have met with limited success in improving regionalization results.
Another reason that regression methods for regionalization have proven difficult is that structural errors in hydrologic models prevent the identification of parameters to represent specific hydrologic processes, precluding meaningful relationships between conceptual model components and physical catchment characteristics that can be used for regionalization (Wagener and Wheater Citation2006, Gupta et al. Citation2012). This issue is further complicated by the difficulty in selecting informative performance criteria to guide the selection of appropriate model structures (Gupta et al. Citation1998), making it difficult to select one structure for regionalization to an ungauged site. Furthermore, it is often challenging to select relevant catchment descriptors that can adequately characterize the subsurface properties of a watershed, even though these properties often dominate catchment response. Spatial proximity can potentially act as a better surrogate for these unobserved hydrologic controls (Merz and Blöschl Citation2004). Finally, recent work has shown that lumped watershed models may be altogether inadequate for regionalization based on relationships with catchment descriptors because calibrated parameter values at gauged sites can become biased from the physical properties they are designed to represent due to the effects of sub-basin scale variability (Kling and Gupta Citation2009).
Despite the challenges discussed above, we believe that information embedded in a relationship between physiographic watershed characteristics and calibrated RRM parameters should improve regionalization results when the relationship is significant. However, these regressions often explain only a moderate proportion of the variance in the calibrated parameter set, depreciating the utility of regression regionalization methods in isolation. Spatial dependence amongst fitted parameter values provides a potentially different source of information for regionalization. Therefore, we hypothesize that a combined approach that leverages information from spatial dependencies and catchment descriptors should improve regionalization performance over either approach in isolation.
Despite the potential benefits of a combined approach, conjunctive use of physiographic watershed characteristics and spatial organization in RRM parameter sets appears to be underexplored in the regionalization literature. To the authors’ knowledge, there are only three studies that have proposed methods to directly combine these different sources of information for RRM regionalization (Parajka et al. Citation2005, Zhang and Chiew Citation2009, Samuel et al. Citation2011). Parajka et al. (Citation2005) utilized local georegression, where the residuals of regressions based on physiographic catchment descriptors were interpolated across space using ordinary kriging. Zhang and Chiew (Citation2009) combined physical similarity and spatial proximity approaches by using physical distance between watersheds as another property to determine the similarity between catchments, while Samuel et al. (Citation2011) used spatial proximity on a subset of catchments selected through physical similarity. All three of these studies found only marginal improvement in regionalization results with a combined approach, but the methods employed suffered from one of two major weaknesses: either (1) they did not weigh information from watershed characteristics and nearby calibration site parameters conditional on their information content; or (2) they did not account for overlap of information between spatial proximity and catchment descriptors (which generally vary continuously across space).
This work contributes to the RRM regionalization literature by proposing a statistical method (the spatial error regression model) that combines information from spatial dependencies in RRM parameters and physiographic watershed characteristics into a single statistical framework that can weigh the relevance of each information source and account for overlap between them. The approach is tested with a monthly abcd hydrologic model (Thomas Citation1981) for a network of gauges in the southeast United States. To assess the additional value of the proposed method, simpler regression and spatial proximity methods are also considered, as well as a naïve approach based on the mean parameter set across all sites. This work also contributes to the literature by comparing both the parameter estimates and streamflow predictions of each regionalization method to those of the optimal model in a jack-knifing ‘leave-one-out’ procedure; although often neglected, a comparison of parameter estimates allows for a better understanding of why a given approach outperforms the others. The remainder of the paper proceeds as follows. The proposed regionalization model is presented in Section 2. Details of the case study experiment are described in Section 3, and results are presented in Section 4. The article then concludes with a discussion in Section 5.
2 SPATIAL ERROR REGRESSION FOR RRM REGIONALIZATION
A spatial error regression model for the regionalization of RRM parameters to ungauged sites is presented here. We consider a case where N gauged stream sites are available for RRM calibration. Let be the hth model parameter for the nth site, with h = 1, …, H and n = 1, .., N. Let
be an N × K matrix of physiographic watershed characteristics, assumed to be measured without error, where
is an N × 1 vector with elements equal to the kth basin characteristic for each gauged site. There are potential relationships between the fitted model parameters
and
that can be utilized for regionalization through regression:
Here, equals an N × 1 vector of the hth RRM parameter at all N gauged sites,
is a K × 1 vector of model parameters, and
equals an N × 1 vector of normal disturbances with an expected value of zero and constant variance.
Quite often a spatial relationship exists between the residuals of the regression in equation (1), where nearby gauges tend to have similar regression residuals and this relationship decays with distance. This situation can arise when important catchment descriptors that determine the fitted parameter values are missing from the regression model, and these catchment descriptors are spatially correlated. To account for spatial structure in the residuals, the error term is modeled using a spatial autoregressive (SAR) model (Ord Citation1975):
Here, equals the spatial lag coefficient for the residuals,
is a spatial weights matrix of dimension N × N, and
is a spatially uncorrelated, normally distributed random variable with an expected value of zero and constant variance. Equation (2) describes the regression residuals for the nth site as a linear combination of residuals at all other sites, weighted by their spatial proximity, and adjusted by some lag coefficient that describes the strength of the spatial relationship. The matrix
is developed a priori to represent the spatial proximity of the gauged network. The elements wi,j indicate the spatial proximity of units i and j, and in this study are taken as the inverse distance between catchment centroids. If desired, certain elements of
can be set to zero to remove any spatial coupling between catchments i and j. By convention, the diagonal elements of
are set equal to zero to remove any spatial relationship designated between a spatial unit with itself. If the rows of
are normalized (sum to unity), the parameter
will approach unity if there is a strong spatial relationship between residuals, while a relatively weak spatial relationship will drive
towards zero.
Through a rearrangement of (2) and substitution back into (1), the regionalization regression can be re-expressed as (Anselin Citation2002):
Here, is an N × N identity matrix. This formulation expresses the hth RRM parameter at one location as a linear combination of catchment descriptors and a spatial average of that parameter at all other locations. The expression
serves as a spatial filter on the catchment descriptors to ensure that the information contributed by those predictors does not overlap with the information embedded in the spatially weighted average of parameter values at nearby sites. We note that the presence of the dependent variable on the right-hand side of equation (4) leads to endogeneity in the model structure and complicates the estimation process. A standard ordinary least squares (OLS) estimation procedure can lead to inconsistent parameter estimates in the presence of model endogeneity (Lee Citation2002). Therefore, an alternative maximum likelihood procedure is used to circumvent this issue (Anselin Citation1988).
Once the parameters of the model are estimated (), the hth RRM parameter for an ungauged location (
) can be predicted. Note that the subscript * is used to delimit an ungauged site, and a parameter estimate is denoted by a caret. Parameter prediction is conducted in three steps. First, an N × 1 vector
of inverse distances between the ungauged site and all the neighboring gauged sites in the network is developed. Second, a vector of appropriate watershed characteristics for the ungauged site (
) is generated. The hth RRM parameter at the ungauged site can then be estimated as
Note that the catchment descriptors at the ungauged site are spatially filtered (i.e. differenced) using the catchment descriptors at the gauged locations.
The primary benefits afforded by the spatial error model approach are that (1) the predictive capabilities of both basin characteristics and spatial proximity are quantified through the estimation of the parameters and
, and (2) any overlap of information between the spatial pattern of RRM parameters and catchment descriptors is removed by applying a spatial filter to the catchment properties. These benefits allow the model to better extract the appropriate amount of independent information from both sources to produce a more robust prediction of RRM parameters at an ungauged site.
3 CASE STUDY: REGIONALIZATION OF THE ABCD MODEL IN THE SOUTHEAST USA
To assess the utility of the spatial error model for RRM regionalization, a case study is presented examining regionalization skill across rivers in a sub-region of southeast USA spanning the states of Virginia and North Carolina (). The approach is compared against three simpler methods, including a standard linear regression on catchment descriptors, a spatial proximity method that utilizes a spatial weighted average of the parameters from nearby gauged sites, and a naïve approach that uses the mean of the parameters at all gauged sites. To conduct the regionalization comparison: a hydrologic model structure must be chosen a priori; the RRM must be calibrated for a set of gauged catchments; physiographic watershed characteristics must be selected for use in the regionalization regression models; and weighting matrices W need to be constructed for each spatial error regression and spatial proximity model. Details on these various components are presented below.
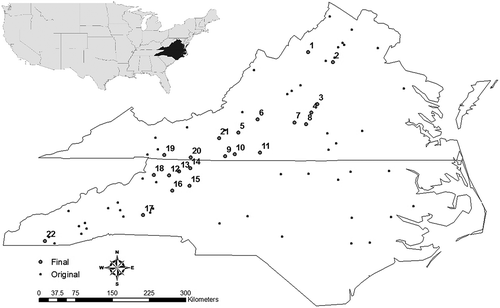
Fig. 1 Location of USGS gauges used in the study. The small points represent the initial 73 gauges considered in the analysis, while the larger points represent the final 22 gauges selected for regionalization.
3.1 Selecting the model structure
The abcd hydrologic model was selected to model monthly streamflow in rivers across the study region. This model is a four-parameter (a,b,c,d), conceptual rainfall–runoff model designed through a control volume analysis on upper soil moisture zone storage (Thomas Citation1981). The model takes as input cumulative monthly precipitation and potential evapotranspiration. This data is converted to estimates of monthly streamflow by diverting water between two soil storage zones, losses to evapotranspiration, and the stream. A detailed review of the mathematical formulation can be found in Fernandez et al. (Citation2000).
The abcd model structure was chosen because it has been recommended as an effective parsimonious model capable of efficiently reproducing monthly water balance dynamics. This has been shown both in theory (Vogel and Sankarasubramanian Citation2003) and in practical applications (Alley Citation1984, Vandewiele and Xu Citation1992). Martinez and Gupta (Citation2010) examined the suitability of the abcd model structure for catchments throughout the United States, testing the model using several diagnostic statistics including Nash-Sutcliffe efficiency, bias, and variability error. That study found that the abcd model is a suitable structure for many catchments in and around the study region, showing good or acceptable performance over both calibration and evaluation time periods. These results support the use of the abcd model in this case study, but we note that other regionalization studies must carefully address the issue of model structure adequacy if previous research is not available to suggest a structure for a particular region a priori.
3.2 Data
To calibrate the abcd model, time series of monthly streamflow, precipitation, and potential evapotranspiration are required for each location. Monthly streamflow was gathered at 73 United States Geological Survey (USGS) gauging locations throughout the study region (). These 73 watersheds were screened amongst many available in the GAGES II database (Falcone et al. Citation2010) to meet the following criteria: (1) all watersheds had at least 30 years of monthly streamflow and climate data records over the period from 1 October 1970 to 30 September 2010 and (2) the gauges were designated as appropriate for hydro-climatic studies (‘reference’ gauges in the database) because they exhibit limited alterations from anthropogenic activity. All physiographic watershed characteristics analyzed in this study were available from the GAGES II database (described in Section 3.4).
Cumulative monthly precipitation and average minimum and maximum monthly temperatures were gathered between 1 October 1970 and 30 September 2010 from the gridded dataset presented in Maurer et al. (Citation2002). The gridded data has a 1/8 degree resolution. A geographic information system (GIS) and digital elevation model (DEM) were used to define the watershed boundaries associated with each gauge and then identify the climate grid cells that overlapped with that area. If multiple grid cells were assigned to a watershed then an average of the data from all grid cells was taken and used as the precipitation and temperature time series for that basin. Monthly averages of maximum, minimum, and mean monthly temperatures were combined with estimates of monthly extra-terrestrial solar radiation to produce a time series of potential evapotranspiration using the Hargreaves method (Hargreaves and Samani Citation1982). Solar radiation was calculated using the method presented in Allen et al. (Citation1998).
3.3 Gauged site model calibration
To implement the regionalization scheme, calibrated model parameters are required at each of the gauged sites. There has been significant research exploring the different benefits of various objective functions and their implications for model calibration (Gupta et al. Citation1998, Madsen Citation2000). This study employs a relatively new performance criterion proposed in Gupta et al. (Citation2009), termed the Kling-Gupta efficiency (KGE) measure. This criterion is composed of three independent error components, including terms for mean bias, variability bias, and the correlation between the simulated and observed flows. This criterion is maximized during calibration using the shuffled complex evolution (SCE) optimization algorithm (Duan et al. Citation1992). This performance metric has advantages over traditional skill measures like the Nash-Sutcliffe efficiency (NSE) because it removes interactions between error components and reduces negative variability bias in simulation results. At each site, the initial groundwater and soil moisture storage levels in the model are also made available for calibration. This ensures that ill-specified initial conditions do not bias parameter estimates and removes the need to spin up each model before calibration. Model calibration is conducted over the first 20-year period of data available for each gauge between the months of October and September, leaving at least 10 years available in the later part of the record for model evaluation.
One final note concerning model structure is required. The study in Martinez and Gupta (Citation2010) showed that, for certain catchments, the c and d parameters can take values near their extreme endpoints, in which case a simpler model structure with only a single soil moisture storage unit is justified. Also, previous work has suggested that poorly performing models from the initial calibration should not be included in the regionalization because the model structure may be inappropriate for those poorly simulated catchments (Oudin et al. Citation2008). In this study, any catchments with c or d values less than 0.05 or greater than 0.95 after calibration or a KGE value for the calibration period less that 0.65 were discarded because the full structure of the abcd model was considered inappropriate for further analysis. This narrowed the number of catchments down from 73 to 22. The vast majority of the discarded catchments (>95%) were removed because of the c and d calibrated values rather than low KGE measures. Also, almost all of the final selected catchments are located within a particular stretch of the Appalachian Mountain range running along the western portion of the study area, suggesting that the full abcd model structure is most appropriate in this focused geographic region (). These 22 catchments generally exhibit average slopes that range between 5 and 20%, and lie near the middle of the distribution of slopes across the 73 original catchments, being neither very steep nor shallow. These particular catchments appear to be transition watersheds in the Appalachian Range, with slopes shallow enough to require modeling of deep groundwater storage on a monthly time step.
3.4 Choice of physiographic watershed characteristics for regression
The parameters of the abcd model each have a physical interpretation, improving the likelihood that relationships may emerge between calibrated parameters and physical basin characteristics (Fernandez et al. Citation2000). For instance, parameter a reflects the tendency for water to run off into the stream before the soil zone is fully saturated (Thomas et al. Citation1983). As such, we hypothesize that parameter a will likely relate to measures of catchment impermeability. Parameter b acts as an upper bound on the sum of actual evapotranspiration and soil moisture storage, and therefore might relate to basin characteristics describing the water-retention capacity of the soil. Parameter c dictates the fraction of available water that forms direct runoff vs groundwater recharge, and the inverse of parameter d describes the average groundwater residence time. Both of these parameters could relate to soil and subsurface geologic characteristics of the catchment.
The GAGES II dataset provides a vast array of basin characteristics from which to choose predictors. A large subset of these characteristics was chosen as initial candidates for the regionalization (). A two-step procedure was used to develop the final set of basin characteristics used to predict each RRM parameter. First, correlation coefficients and scatter plots were used to identify those basin characteristics that exhibited a possible relationship with each RRM parameter. This procedure identified a small subset of candidate predictors to be used for each regionalization model, but in most cases these predictors were significantly correlated with one another. Principal component analysis was used to eliminate collinearity amongst predictors. The first principal component of each predictor set was used as the final predictor for each RRM parameter. If only one predictor was identified for a RRM parameter, then the original variable was used in the regression. Thus, each regionalization regression has only a single independent variable, minimizing the number of regression parameters that require estimation.
Table 1 Physiographic watershed characteristics considered in the regionalization.
3.5 Construction of the spatial weights matrix
The spatial error model requires that a weighting matrix be constructed for the regression residuals of each hydrologic model parameter. As mentioned earlier, the i,jth element of
is populated with the inverse distance between the centroids of catchments i and j. However, previous studies have shown that it is not always optimal to use all gauged catchments when regionalizing RRM parameters using spatial proximity, but rather suggest the use of a subset of the M nearest sites (Oudin et al. Citation2008). This can be accomplished in the spatial error approach by setting all elements in the ith row of the matrix
to zero except for M elements that are set equal to the inverse distances between the ith location and the M nearest gauges. A simple search algorithm is used to choose the appropriate number of neighbors for each RRM parameter that optimizes the predictive potential of the weighting scheme. For the residuals of a standard regression between RRM parameters and their associated predictors (described in Section 3.4), a weighting matrix
is created for all possible neighborhoods, from those that include just the closest gauge (M = 1) to those neighborhoods that include all gauges in the network (M = N–1). Each weighting matrix is then used to estimate the residuals as a weighted average of the residuals at neighboring sites (i.e.
), and these estimates are compared against the actual residuals from the regression. The neighborhood size M that generates residual predictions that are closest to the original residuals (as measured by the sum of squared errors between them) is then chosen for that RRM parameter. Note that four different weighting matrices are constructed for the spatial error models fitted to the four different RRM parameters (a,b,c,d).
3.6 Comparison of regionalization methods
Three other regionalization approaches are considered for comparison. The first is a standard regression on physiographic watershed characteristics. The same catchment descriptors identified through the approach described in Section 3.4 are used for the spatial error model and the simpler regression method. The second comparative method is a parameter transfer technique based on spatial proximity. Here, a weighted average of model parameters from nearby gauges is used to estimate the parameters at the ungauged site. The weights used are developed in a similar manner to those for the spatial error model, but are based on actual parameter values rather than regression residuals. A weighting matrix of inverse distances is developed for each neighborhood size M and used to estimate the RRM parameters as a weighted average of the parameters at neighboring sites (i.e. ). These estimates are compared against the optimal parameter values, and the neighborhood size M that minimizes the sum of squared errors between the parameter predictions and the optimal parameters is used in the spatial proximity method for that RRM parameter. Finally, a naïve approach is also considered in which the mean of model parameters across all gauged sites are used at an ungauged site.
The skill of each method is assessed using a jack-knifing ‘leave-one-out’ approach in which a single gauged site is considered ungauged and parameter estimates are then produced for that site from all other gauges in the network. The regionalization models are re-calibrated for each iteration of the jack-knifing procedure, although the weighting matrices and choice of predictors do not change from iteration to iteration. The skill of all regionalization approaches is compared against that of the optimal (i.e. calibrated) model for each site, which serves as an upper bound on hydrologic model performance.
Two different approaches are used to assess the skill of the regionalization techniques. First, we compare the predicted RRM parameters under each regionalization method to the optimal parameters calibrated for each site. This type of assessment has not been conducted before in comparative regionalization studies (Vandewiele and Elias Citation1995, Merz and Blöschl Citation2004, McIntyre et al. Citation2005, Parajka et al. Citation2005, Kay et al. Citation2006, Oudin et al. Citation2008, Zhang and Chiew Citation2009, Samuel et al. Citation2011), yet it could provide an important insight into which method can best reproduce the optimal parameter sets and whether this reproduction guarantees superior streamflow simulations at ungauged sites. The second, more standard analysis compares streamflow simulation skill between each regionalization method. Several diagnostic statistics of streamflow simulation skill are considered in this study, including the KGE, NSE, mean flow bias, and variability bias. Mean flow bias is defined as the ratio between the observed and estimated long-term mean of streamflow, while variability bias is taken as the ratio between the observed and estimated standard deviation of flow.
Finally, we note that prior to any regionalization, parameter a is transformed using a logit function, and all parameters are centered about their mean and scaled by their standard deviation. The logit transformation is employed to improve the normality of the residuals for parameter a in the regression-based regionalization methods. All transformations are reversed only after the transformed versions of the four parameters are estimated for an ungauged site.
4 RESULTS
4.1 Physical and spatial patterns in the calibrated abcd parameters
After calibrating the abcd models to each gauged site, the two-stage procedure described in Section 3.4 was used to identify significant catchment descriptors that relate with each RRM parameter. displays the results of the procedure, including the subset of descriptors selected for each parameter, the loading of each descriptor in the first principal component (PC), the variability described by the first PC of those descriptors, the R2 value of the regression fit between the final predictors and the RRM parameters, and the associated p-value. The Shapiro-Wilk test (Shapiro and Wilk Citation1965) and density plots (not shown) were used to verify the normality of all of the regression residuals, with Shapiro-Wilk p-values of 0.20, 0.46, 0.43, and 0.09 suggesting that the normality assumption cannot be rejected at the 0.05 significance level for regression residuals of parameters a, b, c, and d, respectively. The four regressions produced R2 values ranging between 0.37 and 0.44. All regressions were significant at the 0.05 level, although it is important to recognize that common statistical tests and goodness-of-fit metrics assume independent, identically distributed (i.i.d) residuals, which are unlikely due to spatial autocorrelation. We note that the low to moderate skill of these regression models is not uncommon in regionalization studies and further stresses the potential need to incorporate other information (e.g. spatial proximity) when regionalizing RRM models.
Table 2 Principal component and regression results for physical predictors of each RRM parameter.
Some of the regression relationships that emerged in the analysis are consistent with the physical controls represented by the RRM parameters. In order to interpret the results in , it is important to recognize that the sign of the relationship between a parameter value and a catchment descriptor is equal to the product of the sign of the regression coefficient and the sign of the loading associated with that descriptor in the principal component. For instance, the amount of developed open land is inversely related to a, because the regression coefficient is negative and the loading is positive, while the clay composition of a watershed is directly related to parameter a. These relationships make sense because more developed open land can increase the tendency of water to run off directly into the stream before becoming available for evapotranspiration, a behavior that is simulated in the model with lower values of a. Conversely, clay-rich watersheds generally have slower moving water that is more available for evapotranspiration (because slower speeds are necessary for the clay to settle and deposit), supporting the direct relationship between clay composition and a.
Parameter b dictates the upper bound on the sum of actual evapotranspiration and soil moisture storage, and therefore its negative relationship to both watershed slope and elevation (positive regression coefficient, negative loadings) is logical because steeper and higher-elevation watersheds tend to have a smaller water-retention capacities. The inverse relationships between parameter c and mainstem sinuosity, silt contents, and soil depth seem to indicate that deep-soiled, high-sinuosity catchments with more silt have more flow contributed from shallow groundwater (which is simulated with smaller c values). The negative relationship between d and stream density suggests that watersheds with more stream reaches per unit area have a longer residence time for deep groundwater. We note that the physical reasoning behind the relationships associated with parameters c and d is not immediately clear. However, these relationships, which are statistically significant, are still used in the regression and spatial error regionalization schemes.
There is also potential information for regionalization in the spatial dependencies among the RRM parameter values, as well as the residuals of the regressions above. shows Moran I scatter plots for each of the four model parameters, as well as for the residuals of each regression. The Moran I statistic can be thought of as a measure of correlation extended to a spatial context (O’Sullivan and Unwin Citation2002). The Moran I scatter plot shows this correlation, with the spatial lag of a variable plotted against the original variable ( versus
). Here, the spatial lag of the hth RRM parameter (or its regression residuals) for the ith site is given by the inner product of the parameter (residual) values taken at neighboring sites and the ith row of the weighting matrix. If there is significant, positive spatial autocorrelation, the scatter plot will show a positive trend, while a lack of spatial autocorrelation will be manifested as a random scatter. Formal tests are available to assess the statistical significance of these spatial patterns. Here, we classify levels of spatial autocorrelation as strong or weak if the Moran I statistic is statistically different from zero at the 0.05 and 0.10 significance levels, respectively. Neighborhood sizes of 9, 5, 3, and 3 locations were used to construct the weighting matrices for parameters a, b, c, and d, respectively. The neighborhoods for the regression residuals of each parameter included 6, 2, 11, and 3 locations. These neighborhood sizes were chosen as detailed in sections 3.4 and 3.6.
Fig. 2 Moran I scatter plots for all four RRM parameters (open circles) and their regression residuals (filled circles). The slope of the solid and dashed angled lines correspond to the Moran I statistic for the parameters and their residuals, respectively.
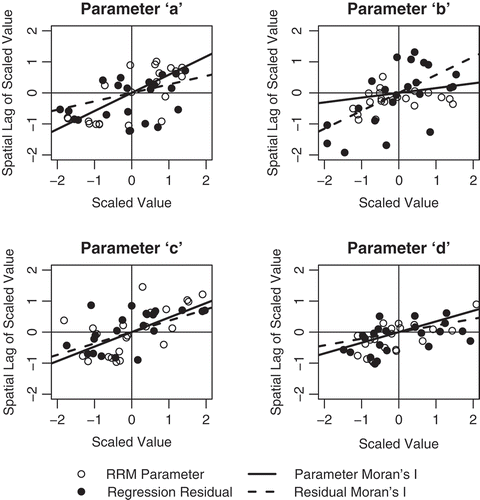
Moran I scatter plots for the original RRM parameters and their regression residuals are shown in . The Moran I statistics for the calibrated parameter values suggest that there are strong spatial autocorrelations for parameters a, c, and d, while there are weak spatial dependencies for parameter b. The spatial autocorrelation is non-negligible for all parameters. These results, when coupled with , suggest that there is some potential information that can be leveraged in a spatial proximity regionalization approach, but the value of this information is variable across parameters and extremely limited for some. For the regression residuals, the Moran I statistics indicate that there are strong spatial autocorrelations for parameters a, b and c, and weak spatial autocorrelation for d. These spatial patterns can be leveraged in the spatial error model to improve the predictions of each parameter at an ungauged location.
4.2 Relationships between regionalized and optimal parameter values
The physical and spatial relationships discussed above were utilized to varying degrees in the four regionalization techniques (naïve mean, regression, spatial proximity, spatial errors) in order to estimate the abcd parameters at each site in a jack-knifing ‘leave-one-out’ procedure. These estimated parameters are compared against the optimal values obtained from a direct calibration at the ungauged site. provides the average Akaike’s information criterion (AIC) for all jack-knifing iterations and each regionalization method, as well as the 25th and 75th percentiles across the iterations. This statistic conveys the relative merits of each regionalization approach by measuring the trade-off between the goodness-of-fit of the model (i.e. how well the regionalized parameters predict the optimal parameters) and its complexity. Smaller AIC values indicate a more suitable model. A common heuristic approach generally considers a difference of 4 or greater between AIC values as meaningful (Burham and Anderson Citation2002). The spatial error approach has significantly smaller AIC values for parameters b and c compared to the other two approaches. It also has the smallest AIC for parameter a and the second smallest for parameter d, but these AIC values are very close to those of spatial proximity and do not really suggest one approach over the other. Also, in all cases besides parameter b, the regression method has the largest AIC. However, spatial proximity has a significantly larger AIC for parameter b, which reflects the limited spatial autocorrelation in that parameter (see ). Overall, the AIC values suggest that the spatial error approach is the most suitable model for parameters b and c, but it appears no better or worse than spatial proximity for parameters a and d.
Table 3 Akaike information criterion for different regionalization models. The mean AIC values across ‘leave-one-out’ iterations are reported, along with the 25th and 75th percentiles in parentheses.
shows the estimated parameter values from the jack-knifing process for the regression, spatial proximity, and spatial error regionalization models plotted against the optimal parameter values calibrated to each location. displays the root mean squared error (RMSE) of each of these fits. For each RRM parameter, the RMSE is expressed as a percentage of the difference between the maximum and minimum optimal parameter value. Many conclusions can be drawn from and . First, we note that the spatial error approach has the smallest RMSE for each of the RRM parameters. This outperformance is largest for parameter b. For this parameter, the information embedded in the regression with catchment descriptors helps improve the estimation of some of the largest b values. This is seen for both the spatial error and regression models. For parameter a, the spatial proximity approach exhibits some more noise around the optimal values for smaller a values than does the regression model, but the regression approach produces the largest outliers. By combining these two approaches, the spatial error model tends to reduce the largest discrepancies of either of the simpler methods in isolation. The spatial error model also produces estimates of parameter c that better resemble their optimal values than either of the other methods, although this outperformance is small. All methods produce very similar predictions for parameter d, with little difference in their fit to the optimal values.
Fig. 3 The optimal values for parameters a, b, c, and d versus their regionalized estimates under the regression (first row), spatial proximity (second row), and spatial error (third row) approaches.
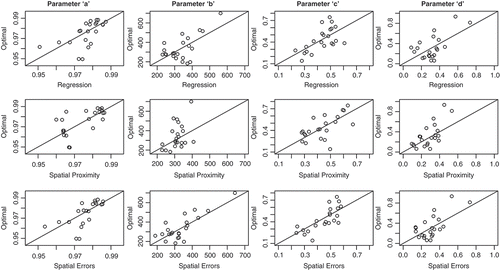
Table 4 Root mean squared error of ‘leave-one-out’ predictions, expressed as a percentage of the difference between the maximum and minimum optimal parameter value.
In summary, and and all suggest that the spatial error approach tends to produce RRM parameter estimates that better resemble the optimal parameter sets than either of the simpler methods in isolation. This outperformance varies by RRM parameter and is marginal for some, and for at least one parameter (d), the spatial error approach is no better than simpler methods. However, the spatial error approach appears robust in that its parameter estimates tend to be either better or equal in their fit to the optimal values, but are never worse than either of the other methods.
4.3 Streamflow simulations of regionalized RRMs
The regionalized and optimal parameter sets are used to simulate streamflow at each site for the entire available record. The four diagnostic statistics are calculated separately for the calibration time period () and the evaluation time period (). Good performance is associated with KGE and NSE values closer to unity, with efficiency values above 0.65 considered adequate. Mean bias and variability bias metrics near unity indicate better model performance. Several conclusions emerge from and . First, the performance of the optimal (i.e. calibrated) models at each of the 22 gauging sites is, in general, good or adequate. Over three quarters of all sites have KGE (NSE) values over 0.88 (0.78) in the calibration period and 0.70 (0.68) in the evaluation period. Both efficiency values drop below 0.65 for two or three catchments (depending on the metric) in the evaluation period, but never fall below 0.50. The optimal models are almost perfectly unbiased in mean and variability in the calibration phase, which has been shown to result when using the KGE measure as an objective function (Gupta et al. Citation2009). These biases are slightly positive in the evaluation period, although they are generally centered around zero, and for over 50% of the gauges, do not exceed ±10%. Overall, the calibrated models tend to perform well in both calibration and evaluation time periods.
Fig. 4 The performance of each tested regionalization procedure over the calibration period, including the naïve-mean, standard regression, spatial proximity, and spatial error approaches. The performance of the optimal (i.e. calibrated) models is also included. The four performance metrics shown include the Kling-Gupta efficiency, Nash-Sutcliffe efficiency value, mean flow bias, and variability bias. The median statistic is given by the horizontal bars, the lower and upper ends of the box give the 25th and 75th percentiles, and the ends of the whiskers give the extreme data point that is no more than 1.5 times the interquartile range. Outliers are represented by open circles.
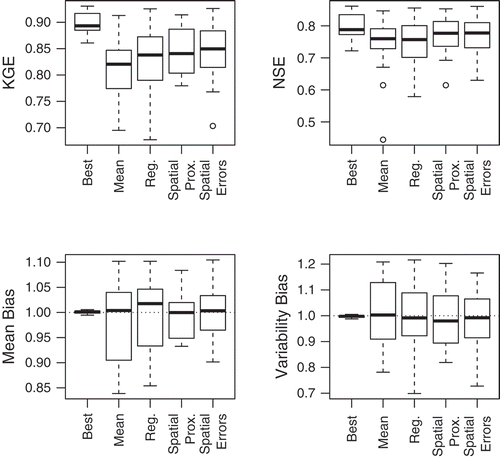
Fig. 5 The same as , but for the evaluation period.
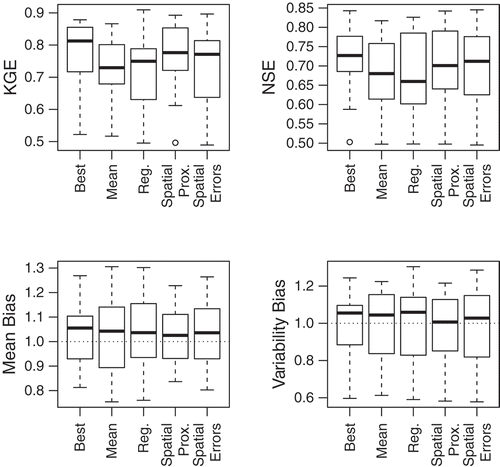
and also show interesting results for the performance of each regionalization technique. First, the spatial proximity method tends to outperform both the standard regression and naïve mean results. This is especially true in the evaluation period. Not only are both efficiency values higher for the spatial proximity approach, but also the spread in mean and variability biases are generally smaller. In fact, the spatial proximity method competes with the performance of the optimal parameter sets in the evaluation period. Both efficiency metrics are comparable between them, and spatial proximity even yields higher NSE values and smaller mean biases for some catchments. This suggests that some of the ‘optimal’ models were possibly over-fit in the calibration period, and the spatial proximity method is able to smooth out some of this over-calibration. Also of interest, it could be argued that the naïve-mean results slightly outperform the regression results, particularly in the evaluation period. This is consistent with the results of previous studies comparing these regionalization methods (Oudin et al. Citation2008).
Most important, the results show that the spatial error regionalization technique does not provide the best streamflow simulations of all the regionalization approaches. While the spatial error approach does tend to provide better performance than simple regression, this improvement is marginal in the evaluation period. Furthermore, both the regression and spatial error models produce some RRMs that exhibit worse performance than even the naïve method using mean parameter sets in the evaluation period. The spatial proximity method performs significantly better in the evaluation period than any of the other methods, particularly for the KGE and mean bias. The Diebold-Mariano test (Diebold and Mariano Citation1995), which compares the forecast accuracy of two models, shows statistically significant differences between the forecast accuracy of the spatial error and spatial proximity methods in the evaluation period for 11 of the 22 gauges at the 0.05 level, and for 14 gauges at the 0.10 significance level.
These results are very interesting and somewhat counter-intuitive, given that the spatial error model tends to produce parameter estimates that better resemble the optimal parameter sets than either of the simpler regression or spatial proximity techniques. To examine this further, shows streamflow simulations for two catchments in more detail (gauges #13 and #22 from ). This figure shows the observed mean monthly hydrographs for two locations, as well as the simulated hydrographs under the RRMs predicted by the spatial proximity and spatial error approaches. shows the differences between the optimal parameters for these two catchments and the predicted parameters under the spatial proximity and spatial error methods. The mean monthly hydrographs for both of these regionalization approaches are very similar, generally exhibiting the same errors when compared against the observed data. However, the parameter sets predicted by these two methods are quite different, and the spatial error approach produces parameter estimates much more similar to those of the optimized parameter sets. shows that the spatial error model estimates the b and c parameters much closer to their optimal values than does spatial proximity, while the estimate for a and d are very similar between the two methods. Essentially, the spatial proximity method predicts an abcd model that produces very similar streamflow estimates to the abcd model under the spatial error approach using a completely different parameter set, suggesting that the abcd model applied to these locations suffers from substantial equifinality.
Fig. 6 Mean monthly hydrographs for catchments #13 (left) and #22 (right). The observed hydrograph (black solid) is shown along with the simulated streamflow under the spatial proximity (dashed grey) and spatial error (dotted grey) methods.
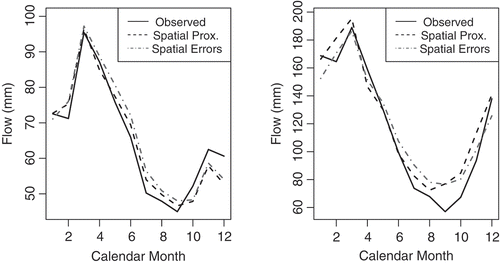
Table 5 Absolute value of the difference between optimal RRM parameters and regionalized predictions from the spatial proximity and spatial error methods for two catchments.
5 DISCUSSION
The results of this study lead to the very interesting conclusion that a regionalization method can, on average, estimate RRM parameters closer to their calibrated values than other methods, yet still produce worse streamflow simulations. This result has not been explicitly shown in other regionalization studies, yet it has significant implications for the future design of RRM regionalization procedures. A common strategy for advancing RRM regionalization assumes that the results of the regionalization will improve if the method can extract more information from patterns in the optimal parameter sets and produce regionalized parameter values that better resemble these optimal values. This was in fact the strategy that motivated the hypothesis of this study, which proposed that a spatial error regionalization approach could leverage more information in the calibrated parameter sets to produce more robust regionalized parameters. However, this assumption does not hold if sufficient parameter equifinality exists for the particular hydrologic model structure under investigation. This appears to be the case for the abcd model as applied in the study region of this work.
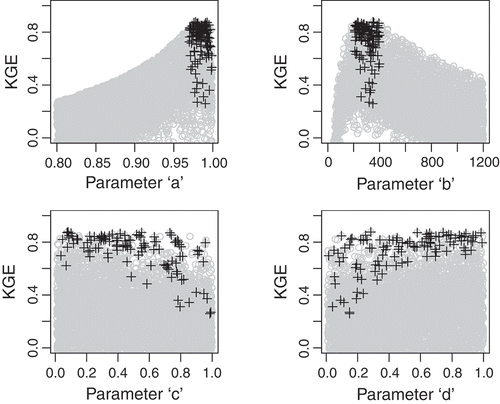
If better reproduction of the optimal parameter values does not guarantee better RRM simulations, then some other characteristic of those optimal parameters is likely being reproduced by the spatial proximity method and not the other methods, thus leading to the superior performance of spatial proximity. One final analysis is conducted to further explore this issue. First, a large Monte Carlo analysis is used to explore the equifinality of the abcd model for a single location (gauge #1 in ). 5000 random parameter values are sampled from uniform distributions and used to simulate flow for this catchment. shows the NSE efficiency plotted against all parameter samples. shows very clearly that narrow ranges for parameters a and b lead to better model performance, suggesting that these parameters are identifiable for this catchment. also highlights samples for all four parameters that contain values of a and b within their narrow ranges of high performance. These highlighted values show that a wide range of values for c and d can achieve acceptable, near-equal model performance. In fact, only values near one extreme of both parameters degrade model skill. This suggests that these parameters are difficult to identify for this model and can compensate for one another, leading to multiple different parameter sets that produce very similar model performance.
Fig. 7 NSE values for catchment #1 plotted against 5000 Monte Carlo samples for parameters a, b, c, and d. All samples with parameter a between 0.97 and 1.00 and parameter b between 200 and 400 are highlighted by black crosses.
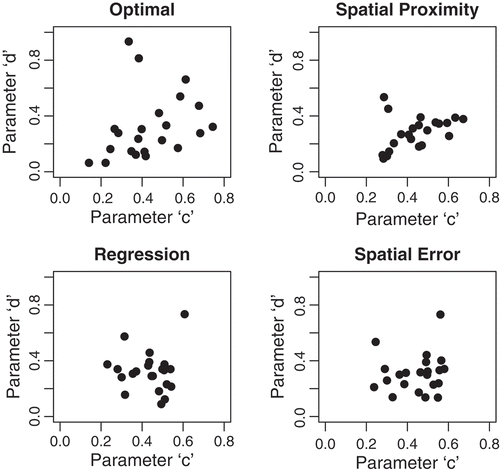
Since parameters c and d are difficult to identify and can take multiple, compensatory values to achieve good model performance, it is possible that the spatial proximity method performs the best for RRM regionalization because it can replicate the correlations between these two parameters. shows the relationships between c and d across all 22 catchments for the optimal parameter sets and for the regionalized parameter sets from the spatial proximity, regression, and spatial error methods. clearly shows that spatial proximity better reproduces the positive correlation between c and d seen in the optimal parameters compared to the other two methods. Spatial proximity is even able to capture two outlier values that do not follow the general pattern. When coupled with , these results suggest that the superior streamflow predictions of spatial proximity result from its ability to better preserve correlations between the compensatory parameters of the abcd model that are difficult to identify.
Fig. 8 The relationship between parameters c and d for the optimal parameter sets and the regionalized parameters in the ‘leave-one-out’ procedure.
6 CONCLUSIONS
The struggle to develop reliable RRMs at ungauged sites necessitates innovative regionalization methods. This paper explored spatial error regression as a regionalization method to synthesize regression and spatial proximity approaches into a consistent statistical framework in order to leverage more information in the regionalization process. The advantages of the spatial error approach include a means to weigh the relevance of physical and spatial relationships during the development of the regionalization model and the ability to account for any overlap between the two information sources.
The case study presented for a network of gauges in southeast United States demonstrated that the spatial error approach generally produced parameter estimates that better resembled the optimal parameter sets than any of the other regionalization techniques tested. However, the streamflow simulations under the spatial error approach did not outperform the other methods, and in fact, consistently underperformed those of the spatial proximity method. Further analysis suggested that the superior streamflow predictions of spatial proximity result from its ability to better preserve correlations between hydrologic parameters and manage issues of equifinalty.
The final results of this work provide one more piece of evidence suggesting that advances to the science of RRM regionalization is significantly hindered by the problems of parameter equifinality and other deficiencies in conceptual, lumped-parameter hydrologic models for representing physical hydrologic processes. The results of this study support arguments made elsewhere in the literature that regression methods on physiographic catchment descriptors may be altogether inappropriate for RRM regionalization (Bárdossy Citation2007, Kling and Gupta Citation2009, Hrachowitz et al. Citation2013). While strict spatial proximity methods can provide improved RRM estimation for operational uses in applied studies, serious challenges still face a scientific understanding of physical catchment dynamics that can be used to develop conceptual, regionalized models of hydrologic response.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Acknowledgements
We thank three anonymous reviewers for their thoughtful criticisms and advice that helped to significantly improve this article.
Additional information
Funding
REFERENCES
- Abdulla, F.A. and Lettenmaier, D.P., 1997. Development of regional parameter estimation equations for a macroscale hydrologic model. Journal of Hydrology, 197 (1–4), 230–257. doi:10.1016/S0022-1694(96)03262-3
- Allen, R.G., et al., 1998. Crop evapotranspiration-guidelines for computing crop water requirements-FAO irrigation and drainage paper 56. Rome: FAO, 300, 6541.
- Alley, W.M., 1984. On the treatment of evapotranspiration, soil moisture accounting, and aquifer recharge in monthly water balance models. Water Resources Research, 20 (8), 1137–1149. doi:10.1029/WR020i008p01137
- Anselin, L., 1988. Spatial econometrics: methods and models. Dordrecht: Kluwer Academic.
- Anselin, L., 2002. Under the hood issues in the specification and interpretation of spatial regression models. Agricultural Economics, 27 (3), 247–267. doi:10.1111/j.1574-0862.2002.tb00120.x
- Bárdossy, A., 2007. Calibration of hydrological model parameters for ungauged catchments. Hydrology and Earth System Sciences, 11, 703–710. doi:10.5194/hess-11-703-2007
- Beven, K., 2006. A manifesto for the equifinality thesis. Journal of Hydrology, 320 (1), 18–36.
- Burn, D.H. and Boorman, D.B., 1993. Estimation of hydrological parameters at ungauged catchments. Journal of Hydrology, 143 (3–4), 429–454. doi:10.1016/0022-1694(93)90203-L
- Burnham, K.P. and Anderson, D.R., 2002. Model selection and multi-model inference: a practical information-theoretic approach. New York: Springer-Verlag.
- Diebold, F.X. and Mariano, R.S., 1995. Comparing predictive accuracy. Journal of Business and Economic Statistics, 13 (3), 253–263.
- Duan, Q., Sorooshian, S., and Gupta, V., 1992. Effective and efficient global optimization for conceptual rainfall–runoff models. Water Resources Research, 28 (4), 1015–1031.
- Ewen, J. and Parkin, G., 1996. Validation of catchment models for predicting land-use and climate change impacts. 1. Method. Journal of Hydrology, 175 (1–4), 583–594. doi:10.1016/S0022-1694(96)80026-6
- Falcone, J.A., et al., 2010. GAGES: A stream gage database for evaluating natural and altered flow conditions in the conterminous United States. Ecology, 91 (2), 621–621. doi:10.1890/09-0889.1
- Fernandez, W., Vogel, R., and Sankarasubramanian, A., 2000. Regional calibration of a watershed model. Hydrological Sciences Journal, 45 (5), 689–707. doi:10.1080/02626660009492371
- Gupta, H.V., Sorooshian, S., and Yapo, P.O., 1998. Toward improved calibration of hydrologic models: multiple and noncommensurable measures of information. Water Resources Research, 34 (4), 751–763. doi:10.1029/97WR03495
- Gupta, H.V., et al., 2009. Decomposition of the mean squared error and NSE performance criteria: implications for improving hydrological modelling. Journal of Hydrology, 377, 80–91. doi:10.1016/j.jhydrol.2009.08.003
- Gupta, H.V., et al., 2012. Towards a comprehensive assessment of model structural adequacy. Water Resources Research, 48, W08301. doi:10.1029/2011WR011044.
- Hargreaves, G.H. and Samani, Z.A., 1982. Estimating potential evapotranspiration. Journal of the Irrigation and Drainage Division, 108 (3), 225–230.
- Hrachowitz, M., et al., 2013. A decade of Predictions in Ungauged Basins (PUB) – a review. Hydrological Sciences Journal, 58, 1–58. doi:10.1080/02626667.2013.803183.
- Kay, A., et al., 2006. A comparison of three approaches to spatial generalization of rainfall–runoff models. Hydrological Processes, 20 (18), 3953–3973. doi:10.1002/hyp.6550
- Kling, H. and Gupta, H.V., 2009. On the development of regionalization relationships for lumped watershed models: the impact of ignoring sub-basin scale variability. Journal of Hydrology, 373, 337–351. doi:10.1016/j.jhydrol.2009.04.031
- Kokkonen, T.S., et al., 2003. Predicting daily flows in ungauged catchments: model regionalization from catchment descriptors at the Coweeta hydrologic laboratory, North Carolina. Hydrological Processes, 17 (11), 2219–2238. doi:10.1002/hyp.1329
- Lee, L.F., 2002. Consistency and efficiency of least squares estimation for mixed regressive, spatial autoregressive models. Econometric Theory, 18 (2), 252–277. doi:10.1017/S0266466602182028
- Madsen, H., 2000. Automatic calibration of a conceptual rainfall–runoff model using multiple objectives. Journal of Hydrology, 235 (3–4), 276–288. doi:10.1016/S0022-1694(00)00279-1
- Magette, W., Shanholtz, V., and Carr, J., 1976. Estimating selected parameters for the kentucky watershed model from watershed characteristics. Water Resources Research, 12 (3), 472–476. doi:10.1029/WR012i003p00472
- Martinez, G.F. and Gupta, H.V., 2010. Toward improved identification of hydrological models: a diagnostic evaluation of the “abcd” monthly water balance model for the conterminous united states. Water Resources Research, 46 (8), W08507. doi:10.1029/2009WR008294.
- Maurer, E., et al., 2002. A long-term hydrologically based dataset of land surface fluxes and states for the conterminous United States. Journal of Climate, 15 (22), 3237–3251. doi:10.1175/1520-0442(2002)015<3237:ALTHBD>2.0.CO;2
- McIntyre, N., et al., 2005. Ensemble predictions of runoff in ungauged catchments. Water Resources Research, 41 (12), W12434. doi:10.1029/2005WR004289.
- Merz, R. and Blöschl, G., 2004. Regionalisation of catchment model parameters. Journal of Hydrology, 287 (1–4), 95–123. doi:10.1016/j.jhydrol.2003.09.028
- Ord, K., 1975. Estimation methods for models of spatial interaction. Journal of the American Statistical Association, 70 (349), 120–126. doi:10.1080/01621459.1975.10480272
- O’Sullivan, D. and Unwin, D.J., 2002. Geographic information analysis. Los Angeles, CA: John Wiley & Sons.
- Oudin, L., et al., 2008. Spatial proximity, physical similarity, regression and ungaged catchments: a comparison of regionalization approaches based on 913 French catchments. Water Resources Research, 44 (3), W03413. doi:10.1029/2007WR006240
- Parajka, J., Blöschl, G., and Merz, R., 2007. Regional calibration of catchment models: potential for ungauged catchments. Water Resources Research, 43 (6), W06406. doi:10.1029/2006WR005271.
- Parajka, J., Merz, R., and Blöschl, G., 2005. A comparison of regionalisation methods for catchment model parameters. Hydrology and Earth System Sciences, 9, 157–171. doi:10.5194/hess-9-157-2005
- Samuel, J., Coulibaly, P., and Metcalfe, R.A., 2011. Estimation of continuous streamflow in Ontario ungauged basins: comparison of regionalization methods. Journal of Hydrologic Engineering, 16, 447–459. doi:10.1061/(ASCE)HE.1943-5584.0000338
- Sefton, C. and Howarth, S., 1998. Relationships between dynamic response characteristics and physical descriptors of catchments in England and Wales. Journal of Hydrology, 211 (1–4), 1–16. doi:10.1016/S0022-1694(98)00163-2
- Seibert, J., 1999. Regionalisation of parameters for a conceptual rainfall–runoff model. Agricultural and Forest Meteorology, 98–99, 279–293. doi:10.1016/S0168-1923(99)00105-7
- Shapiro, S.S. and Wilk, M.B., 1965. An analysis of variance test for normality (complete samples). Biometrika, 52 (3–4), 591–611. doi:10.1093/biomet/52.3-4.591
- Sivapalan, M., et al., 2003. IAHS decade on predictions in ungauged basins (PUB), 2003–2012: shaping an exciting future for the hydrological sciences. Hydrological Sciences Journal, 48 (6), 857–880.
- Thomas, H., 1981. Improved methods for national water assessment. Report WR15249270. Washington, DC: US Water Resource Council.
- Thomas, H., et al, 1983. Methodology for water resource assessment, report to US Geological Survey. Rep. NTIS, 84-124163.
- Vandewiele, G. and Elias, A., 1995. Monthly water balance of ungauged catchments obtained by geographical regionalization. Journal of Hydrology, 170 (1–4), 277–291. doi:10.1016/0022-1694(95)02681-E
- Vandewiele, G. and Xu, C.Y., 1992. Methodology and comparative study of monthly water balance models in Belgium, China and Burma. Journal of Hydrology, 134 (1–4), 315–347. doi:10.1016/0022-1694(92)90041-S
- Vogel, R.M. and Sankarasubramanian, A., 2003. Validation of a watershed model without calibration. Water Resources Research, 39, 1292. doi:10.1029/2002WR001940
- Wagener, T. and Wheater, H.S., 2006. Parameter estimation and regionalization for continuous rainfall–runoff models including uncertainty. Journal of Hydrology, 320 (1–2), 132–154. doi:10.1016/j.jhydrol.2005.07.015
- Young, A.R., 2006. Stream flow simulation within UK ungauged catchments using a daily rainfall–runoff model. Journal of Hydrology, 320 (1–2), 155–172. doi:10.1016/j.jhydrol.2005.07.017
- Zhang, Y. and Chiew, F.H.S., 2009. Relative merits of different methods for runoff predictions in ungauged catchments. Water Resources Research, 45, W07412. doi:10.1029/2008WR007504.