
Résumé
L’information sur les valeurs des précipitations extrêmes et leurs fréquences est nécessaire pour les différents projets liés à l’eau. Dans cette étude, l’analyse fréquentielle régionale basée sur les L-moments a été utilisée pour améliorer la qualité d’estimation des quantiles des précipitations journalières maximales annuelles de la région située au Nord-Est de l’Algérie représentée, par 50 stations de mesure. Il a été défini que la région d’étude est homogène en termes de rapports des L-moments. Parmi les différentes distributions testées, la distribution GEV (generalized extreme value) a été identifiée comme la distribution régionale la plus adéquate pour la modélisation des précipitations de la région. La courbe de croissance a été établie. Ainsi, les quantiles des précipitations dans un site sont déterminés en multipliant la moyenne des précipitations par les quantiles régionaux correspondants. La comparaison des quantiles estimés à partir de l’approche régionale et locale a montré que dans la majorité des stations (62%) le modèle local sous estime les quantiles de fortes périodes de retour.
Editeur Z.W. Kundzewicz
Abstract
Information on maximum rainfalls and their frequencies is required for various water-related projects. In this study, regional frequency analysis based on L-moments was used to improve the quality of estimates of annual maximum daily precipitation in the northeastern region of Algeria, represented by 50 gauging stations. It was determined that the investigated region is homogeneous in terms of L-moment ratios. Among the different distributions tested; the generalized extreme value (GEV) distribution was identified as the most appropriate regional distribution for modelling precipitation in the region. A growth curve, derived from the regional distribution, was established. Then, to estimate the precipitation quantiles of the different return periods for a given site, the mean rainfall of the site was multiplied by the corresponding regional quantile. Comparison of estimated quantiles given by the regional and local approach showed that in the majority of stations (62%), the at-site model underestimates the quantiles having high return periods.
1 INTRODUCTION
L’estimation des précipitations associées aux événements extrêmes est un sujet qui suscite de plus en plus d’intérêt dans tous les domaines liés à l’eau. La connaissance des quantiles des précipitations de fréquences rares est nécessaire pour la conception des ouvrages hydrauliques tels que les ouvrages de protection contre les inondations, les réseaux d’assainissement pluvial et dans de nombreuses applications d’ingénierie. L’estimation de ces fréquences est difficile car les événements extrêmes sont par définition rares et que les données disponibles localement proviennent souvent des observations de courte durée, insuffisantes pour pouvoir estimer les quantiles extrêmes de manière fiable. Pour résoudre ce problème on a recours à l’analyse régionale. Dans le concept de régionalisation, introduit par Dalrymple (Citation1960), « trading space for time », on utilise les données de plusieurs sites pour estimer les quantiles de la variable à chaque site d’une région bien définie. Les estimations des quantiles obtenues à partir de l’échantillon régional sont considérées comme plus précises (Hosking et Wallis Citation1997).
Initialement, les méthodes d’analyse fréquentielle ont été élaborées pour l’estimation des crues. Les méthodes de régionalisation des crues introduites par Dalrymple en Citation1960 ont été continuellement développées depuis. GREHYS (Citation1996), Ouarda et al. (Citation1999, Citation2008) ont présenté et comparé les différentes méthodes de régionalisation des crues. L’application de l’analyse fréquentielle des crues s’est étendue ensuite à la régionalisation des précipitations et a été à la base de nombreux travaux sur ces dernières. Alila (Citation1999) a développé un modèle hiérarchique régional fréquentiel pour la régionalisation des précipitations de courte durée au Canada. En France, les travaux de Djerboua (Citation2001) et de Mora et al. (Citation2005) ont porté sur l’estimation régionale des précipitations journalières. Nguyen et al. (Citation2002) ont proposé deux méthodes alternatives d’estimation des précipitations extrêmes de différentes durées. Kysely et Picek (Citation2007) ont utilisé une méthode basée sur les L-moments pour l’estimation régionale des précipitations.
Dans la bibliographie sur la régionalisation des précipitations présentée par St-Hilaire et al. (Citation2003), on remarque que les étapes communes à la plupart des méthodes d’analyse régionale sont généralement : (a) la détermination de régions définies par le regroupement de stations hydrologiquement homogènes, (b) l’identification d’une fonction de distribution régionale, et finalement (c) la détermination des paramètres de cette distribution et l’estimation des quantiles des précipitations.
L’analyse fréquentielle régionale basée sur les L-moments proposée par Hosking et Wallis (Citation1997) est appliquée pour l’estimation des quantiles des précipitations journalières maximales annuelles en tout site disponible de la région étudiée. Après la description de la méthode utilisée et de la région d’étude et des données, les résultats d’application des étapes de l’analyse fréquentielle régionale seront présentés et discutés dans la Section 4 ; ces étapes sont la formation des régions homogènes, l’identification de la distribution fréquentielle régionale et l’estimation des paramètres et quantiles de la distribution ajustée. Nous terminerons par une conclusion.
2 METHODE DE REGIONALISATION
2.1 Méthode d’analyse fréquentielle régionale
La méthode d’analyse fréquentielle régionale des précipitations extrêmes appliquée est basée sur les L-moments et associée à la procédure de la méthode de l’« indice de crue » (Dalrymple Citation1960) appliquée aux données hydrologiques. La procédure utilisée est une procédure d’invariance d’échelle, les distributions de fréquences des sites d’une région homogène étant identiques à un facteur d’échelle spécifique au site près. Généralement, le facteur d’échelle est la moyenne de la population au site (Hosking et Wallis Citation1993). Par conséquent, les quantiles de fréquence F au site i d’une région homogène de N sites peuvent être déterminés comme suit :
Les paramètres de la distribution régionale sont estimés à partir de l’ensemble des statistiques locales de la région homogène. L’estimation des statistiques locales est obtenue par la méthode des L-moments.
2.2 L-moments
La théorie des L-moments a été développée par Hosking (Citation1990). Les L-moments ont pour but de rendre les ajustements statistiques plus robustes contrairement aux moments traditionnels d’ordre élevé dont les valeurs sont très sensibles à la variabilité d’échantillonnage. Les L-moments sont analogues aux moments traditionnels mais ils sont estimés à partir de combinaisons linéaires des données ordonnées.
Pour un échantillon ordonné où
les moments de probabilité pondérés (PWM; probability weighted moments) sont estimés par :
L-coefficient de variation, L-Cv :
L-coefficient d’asymétrie, L-Cs :
L-coefficient d’aplatissement, L-Ck :
2.3 Test de discordance
La première étape de l’analyse régionale fréquentielle est un examen des données, de sorte que les erreurs et les incohérences des données puissent être éliminées. Dans ce contexte, le test de discordance (Hosking et Wallis Citation1993) est appliqué à l’ensemble des données des sites d’une région. La mesure de discordance permet d’identifier les sites dont les rapports des L-moments sont nettement différents de leur moyenne régionale et indique les sites où les données doivent être analysées plus attentivement.
Pour déterminer la mesure de discordance d’un site d’une région de N sites, on procède de la manière suivante : soit un vecteur contenant les échantillons des valeurs des rapports des L-moments
du site i ; et T désigne la transposée d’un vecteur ou d’une matrice.
On calcule d’abord la moyenne non pondérée des ui :
La mesure de discordance du site i est définie alors comme suit :
2.4 Test d’homogénéité
Pour valider l’homogénéité d’une région (groupe de stations) en termes de rapports des L-moments on utilise le test d’homogénéité statistique proposé par Hosking et Wallis (Citation1993). Dans ce test, les paramètres représentatifs d’une région sont les moyennes pondérées des statistiques des L-moments. Ainsi, pour une région de N stations ayant chacune ni enregistrements, les rapports des L-moments et les L-moments régionaux sont calculés comme suit :
Le test de simulation de Monte Carlo est utilisé afin de tester l’homogénéité d’une région. Un grand nombre des données de régions sont générées à partir de la distribution Kappa à quatre paramètres. La distribution Kappa est ajustée en utilisant les rapports des L-moments moyens pondérés.
Chacune des simulations doit refléter la configuration de la base de données de la région considérée. Plus précisément, au cours d’une simulation, le nombre de sites et le nombre d’observations à chaque site doivent être reproduits. Pour chaque région générée, les trois mesures suivantes de la variabilité intersites des rapports des L-moments sont calculées comme suit (Hosking et Wallis Citation1993) :
La variance pondérée du L-Cv :
L’écart-type pondéré pour les rapports des L-moments t et :
L’écart-type pondéré pour les rapports des L-moments et
:
où ,
et
désignent respectivement les L-Cv, L-Cs et L-Ck du site i ;
,
et
désignent respectivement les L-Cv, L-Cs et L-Ck régionaux calculées selon l’équation (10) et N est le nombre de sites. Si on désigne par V l’une de ces trois valeurs V1, V2 et V3, le critère d’homogénéité d’une région est calculé comme suit :
où Vobs est la valeur observée de V et μv et σv sont respectivement la moyenne et l’écart-type de V obtenus par simulations. La variable H mesure la dispersion des observations à celle des simulations. Selon Hosking et Wallis (Citation1993), une région peut être considérée comme étant acceptablement homogène si H < 1, probablement hétérogène si 1 ≤ H < 2 et définitivement hétérogène si H ≥ 2.
2.5 Identification de la distribution régionale
Parmi les différentes distributions, la distribution Gumbel est celle qui est le plus souvent utilisée en Algérie dans l’analyse fréquentielle des précipitations extrêmes dans un site donné. Cette distribution a été utilisée par Mebarki (Citation2005) dans l’analyse fréquentielle ponctuelle des précipitations journalières maximales annuelles de l’Est Algérien.
Cette loi à deux paramètres est aussi largement utilisée dans différents contextes climatiques. Le comportement asymptotique de la distribution Gumbel est cependant remis en question par Koutsoyiannis (Citation2004), qui confirme qu’elle a pour effet de sous estimer les valeurs des précipitations de fréquences élevées par rapport à la distribution GEV (EV2) (generalised extreme value type 2). Alila (Citation1999) émet certaines réserves quant à l’application de la loi Gumbel dans un contexte régional. Dans son étude de la régionalisation des précipitations de courte durée au Canada, différentes distributions ont été testées. Parmi ces distributions la distribution GEV a été identifiée comme étant la distribution régionale la plus appropriée. La distribution GEV est la plus utilisée tant pour l’analyse fréquentielle régionale des précipitations que pour celle des crues. Par exemple, Overeem et al. (Citation2007) l’ont utilisée pour la régionalisation des précipitations de courte durée pour l’ensemble de la Hollande. Djerboua (Citation2001), Versiani et al. (Citation1999), Cannarozzo et al. (Citation1995) ont choisi comme modèle statistique régional des précipitations journalières maximales annuelles la distribution à deux composantes, TCEV (« two component extreme value »). Pour déterminer les courbes de croissance régionales des précipitations de courte durée Sveinsson et al. (Citation2002) ont utilisé une approche régionale fréquentielle basée sur la méthode de l’indice de crue en prenant en considération différentes distributions : log-normale à trois paramètres (LN3), GEV, log-normale (LN) et Pearson type 3 (P3).
Dans cette étude, nous faisons l’hypothèse que les distributions GEV, LN3, P3 et GLO (« generalized logistic ») s’ajustent aux séries des valeurs réduites des précipitations maximales annuelles journalières de la région d’étude. La pertinence de l’ajustement de chacune de ces distributions à trois paramètres est évaluée en termes de différence entre le L-aplatissement théorique de la distribution ajustée et le L-aplatissement régional. La signification de cette différence est estimée par la statistique Z (Hosking et Wallis Citation1993) :
2.6 Estimation des paramètres et quantiles de la distribution régionale
Pour estimer les paramètres de la distribution régionale les trois premiers L-moments régionaux sont utilisés. La courbe de croissance régionale sera établie sur la base des paramètres de la distribution régionale en appliquant la moyenne comme facteur d’échelle. Dans cette approche les L-coefficients d’asymétrie et de variation régionaux sont supposés constants. Ainsi, pour estimer les précipitations associées aux différentes périodes de retour en un site donné d’une région homogène, il faut multiplier les valeurs du quantile régional correspondant aux mêmes périodes de retour par la moyenne des précipitations journalières maximales.
3 REGION D’ETUDE ET DONNEES
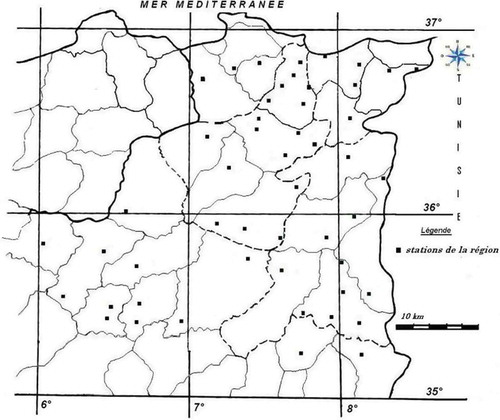
La région d’étude est située au Nord-Est de l’Algérie et couvre les bassins versants de deux grands oueds, la Seybouse et la Medjerda (). Les séries des précipitations journalières maximales annuelles des 50 stations de mesure ont été retenues pour cette étude. Les observations s’étendent, en général, sur la période de 1970 à 2007. La taille moyenne des échantillons est égale à 36 ans. La période des observations pour les différentes stations varie de 14 à 49 années. La région d’étude est caractérisée par un climat méditerranéen dans la partie Nord et par un climat semi-aride dans la partie Sud. Les précipitations moyennes annuelles varient de 804 à 233 mm et la moyenne des précipitations journalières maximales annuelles de 25,11 à 62,24 mm. Leurs gradients diminuent du Nord vers le Sud de la région.
Fig. 1 Région d’étude et localisation des stations. Les bassins versants des deux grands oueds, la Seybouse et la Medjerda, sont délimités par une ligne discontinue.
4 RESULTATS ET DISCUSSION
Lors de la première étape de l’application de la méthode d’analyse régionale fréquentielle les données de 50 stations de la région d’étude ont été vérifiées en termes de mesure de discordance pour identifier les stations dont les paramètres statistiques diffèrent nettement de l’ensemble du groupe. Des valeurs de mesure de discordance (Di) supérieures à la valeur critique ont été trouvées pour trois stations. Pour les deux stations situées à l’Ouest et à l’Est de la région, la valeur de Di est égale respectivement à 3,81 et 3,85 et est égale à 5,15 pour la station située au Sud. Les fortes valeurs de la mesure de discordance dans ces sites sont dues à la présence d’une valeur exceptionnelle de pluie. Par exemple, pour la station située à l’Ouest de la région 130 mm de pluie sont tombés en 24 h. Le même cas a été observé pour les deux autres stations. La présence de valeurs exceptionnelles de pluie a été la cause des valeurs élevées des L-statistiques en particulier de L-Ck. La durée d’observation de ces trois stations est relativement courte (15, 17 et 18 ans). L’objectif de l’étude étant l’amélioration des estimations des précipitations extrêmes des stations, en particulier celles dont la taille de l’échantillon est faible, nous allons appliquer l’analyse fréquentielle aux données des 50 stations.
Pour évaluer le degré d’homogénéité de la région, 500 régions de données ont été générées en utilisant la distribution Kappa. Selon les valeurs de la mesure d’hétérogénéité H obtenues (), la région est homogène en termes de L-Cv, L-Cs et L-Ck. D’après les résultats du on constate la présence de valeurs négatives de Hv2 et Hv3. Selon Hosking et Wallis (Citation1997), cela indique que la variabilité des statistiques des séries est moindre que ce qui serait attendu d’une région homogène avec des distributions de fréquences indépendantes du site. Il s’agit généralement d’une indication d’une importante corrélation croisée entre les distributions de fréquences des sites. Les statistiques régionales sont présentées dans le . L’écart maximal de L-Cv par rapport à la moyenne pondérée régionale pour 50 stations est égal à 0,132 et celui de L-Cs à 0,166.
Tableau 1 Résultats du test d’homogénéité et statistiques moyennes pondérées de la région d’étude.
La région étant homogène, pour identifier la distribution régionale parmi les distributions GEV, P3, LN3 et GLO, la statistique a été calculée pour chaque distribution. Les valeurs de cette dernière obtenues par la réalisation de 500 simulations en utilisant la distribution Kappa et les valeurs de L-aplatissement théorique de chaque distribution ajustées sont données dans le .
Parmi les quatre distributions considérées, les deux distributions GEV et LN3 sont les distributions dont l’ajustement aux données régionales sont le plus satisfaisantes. De plus, la valeur de la statistique Z de la distribution GEV est inférieure à celle de LN3.
La fonction quantile de la distribution GEV est la suivante :
Tableau 2 L-coefficient d’aplatissement théorique et Z-statistique des différentes distributions.
Pour la distribution GEV :
Pour la distribution LN3 :
où représente la fonction Gamma ; erf est la fonction d’erreur ; et
et
sont les constantes d’approximation.
Les paramètres régionaux de ces distributions () ont été estimés à partir des rapports des L-moments régionaux comme expliqué dans la deuxième section.
Tableau 3 Paramètres régionaux de la distribution GEV et LN3.
Le test basé sur la statistique Z a donc montré qu’il y a deux distributions régionales plausibles. Pour choisir la distribution la plus appropriée parmi ces deux distributions deux tests supplémentaires ont été effectués.
Le premier test est basé sur la comparaison de L-Ck des données réelles avec celui de la distribution à tester pour chaque station de la région (Lin et Vogel Citation2006). Pour chaque distribution testée on calcule la racine carrée de l’erreur quadratique moyenne (REQM) pondérée suivante :
Dans le second test la robustesse de l’ajustement de ces deux distributions est testée en supposant que des changements se sont produits dans la distribution de la population. Le test se fait par le biais de la simulation et comporte les étapes suivantes :
Sélection d’une des deux distributions comme population, pour laquelle les vrais paramètres () et les valeurs des quantiles qT de périodes de retour spécifiées T sont connues.
Génération, par une simulation de Monte Carlo, des variables de 50 stations relatives aux stations de la région d’étude de taille n définie.
En appliquant la méthode de l’analyse régionale, les quantiles
sont estimés à partir de la distribution GEV et de la distribution LN3 pour chacune des 50 stations.
Ensuite, les biais relatifs sont calculés :
Les étapes (b) et (c) sont itérées 1000 fois de façon à obtenir des valeurs moyennes de biais et ceci pour différentes tailles des échantillons. La même procédure est appliquée avec la seconde distribution parente. Les résultats obtenus sont présentés dans le . D’après ces résultats on constate que l’ajustement des deux lois sur un échantillon de taille limitée conduit à une sous-estimation des quantiles, les valeurs des biais sont positives. La sous-estimation est d’autant plus importante que l’échantillon est petit. Du point de vue de l’estimation basée sur les L-moments, la distribution GEV est plus robuste que LN3 (valeurs moindres de biais). La différence est assez faible, mais on observe la même tendance que dans les résultats obtenus par les deux tests précédents.
Tableau 4 Biais dans l’estimation des quantiles à partir des distributions GEV et LN3. n est la taille d’échantillon.
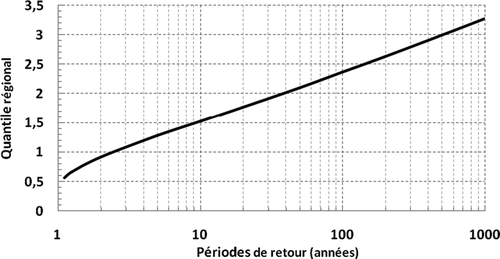
Sur la base des résultats des trois tests, la distribution GEV a été retenue comme la plus robuste pour l’estimation des quantiles de précipitations extrêmes de la région d’étude. La courbe de croissance régionale, dérivée de la distribution régionale GEV a été tracée pour les périodes de retour spécifiées T (). Cette courbe de croissance traduit la variation du quantile régional q(F) en fonction de la probabilité au non dépassement F ou en fonction de la période de retour T (T = 1/(1 – F)).
Fig. 2 Courbe de croissance régionale.
La présente la distribution de fréquences empiriques des valeurs réduites des précipitations observées de l’échantillon régional. Les fréquences empiriques ont été calculées par la formule de Cunnane ((i – 0,4)/(N – 0,2) où N désigne l’effectif total de l’échantillon et i le rang de l’observation, par ordre décroissant).
Fig. 3 Ajustement de la distribution régionale GEV et LN3 aux valeurs réduites des précipitations de l’echantillon régional.
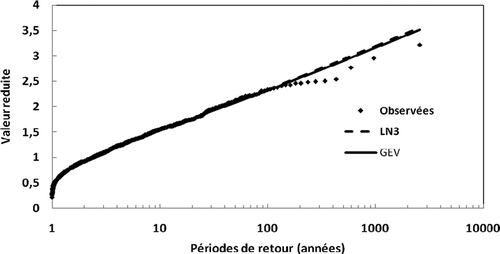
La courbe de croissance régionale, reportée sur la figure, s’ajuste bien à la distribution des valeurs réduites observées. On y observe aussi que l’ajustement de la courbe de croissance de distribution GEV est meilleur que celui de la distribution LN3 pour les périodes de retour élevées. Ceci confirme une fois de plus le choix de GEV comme distribution régionale.
On constate également que le comportement asymptotique de la distribution régionale GEV est quasi exponentiel étant donné que son paramètre de forme est proche de zéro (k = –0,047). Pour déterminer la précision et quantifier les incertitudes d’estimation des quantiles régionaux, l’algorithme de simulation Monte Carlo (Hosking et Wallis Citation1997) a été utilisé. Cet algorithme est basé sur l’application de la procédure de ré-échantillonnage (« bootstrap ») pour calculer l’intervalle de confiance des quantiles régionaux de période de retour spécifiée (qT). Pour réaliser la corrélation entre les sites une matrice de corrélation à été utilisée avec un coefficient de corrélation pris égal à 0,65 selon Hosking et Wallis (Citation1997). En décomposant la matrice de corrélation (décomposition de Cholesky) on obtient la matrice triangulaire qui sert à générer une matrice de Nnmax variables aléatoires corrélées uniformes (N est le nombre des stations et nmax est la taille maximale d’un site de la région). Les 10 000 (R) réalisations de la région ont été effectuées. Pour chaque réalisation les quantiles régionaux spécifiés ont été estimés à partir de l’ajustement des échantillons générés à la loi GEV. Ainsi on constitue une série des quantiles simulés
. Dans la série triée les quantiles empiriques
et
de probabilité au non dépassement de respectivement α/2 et 1 – α/2 ont été déterminés. On obtient donc l’intervalle de confiance de qT au niveau 1 – α:
.
Les valeurs de la REQM relative régionale et de L’intervalle de confiance (90%) de la courbe de croissance estimée pour les différentes périodes de retour sont présentées dans le . Les faibles valeurs de la REQM démontrent la fiabilité de la méthode d’analyse fréquentielle régionale appliquée. L’intervalle de confiance (90%) obtenu est étroit du fait de la distribution régionale quasi exponentielle (le paramètre de forme est proche de zéro).
Tableau 5 REQM relative et intervalle de confiance (90%) dans l’estimation des quantiles régionaux q(T) de période de retour T.
Pour voir l’efficacité de l’analyse fréquentielle régionale, les valeurs des quantiles estimés à partir de l’analyse régionale et locale ont été comparées. Dans l’analyse locale la distribution de Gumbel est utilisée puisque cette distribution est la plus utilisée dans le pays pour l’estimation des précipitations extrêmes. Le test du chi-carré a été appliqué pour tester l’adéquation de la distribution de Gumbel. Ce test a montré que cette distribution peut être adoptée avec un niveau de signification de 5% à toutes les séries de données, sauf à celles de deux stations. Pour ces stations, elle est acceptée au seuil de 1%.
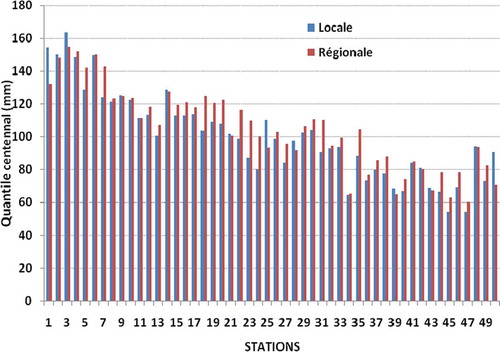
Sur la sont présentées les valeurs des quantiles centennaux estimés à partir de l’approche régionale et locale. La comparaison de ces valeurs montre que l’ajustement local a tendance à sous estimer les quantiles pour la majorité des stations avec un écart relatif maximal égal à 25,6%. Cet écart augmente avec l’accroissement de la période de retour pour attendre la valeur maximale de 46,5% pour T = 1000 ans. Les valeurs des quantiles centennaux estimés à partir du modèle régional diminuent du Nord au Sud de la région. Pour les stations situées dans la partie Nord caractérisée par un climat méditerranéen (numérotées de 1 à 23 sur la ) ces valeurs varient de 155 à 102 mm. Pour les stations de la partie Sud caractérisée par un climat semi-aride (numérotées de 24 à 50 sur la ) elles varient de 100 à 60 mm.
Fig. 4 Comparaison des quantiles centennaux estimés par les méthodes régionale et locale aux 50 stations de la région.
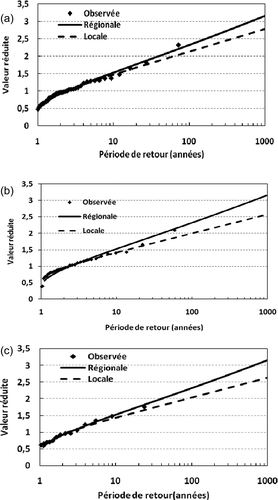
Pour vérifier la cohérence des résultats obtenus avec l’hypothèse d’homogénéité et la loi régionale GEV, la distribution GEV a été reportée sur la distribution en fréquences empiriques des valeurs réduites observées aux trois stations de différentes tailles (). On note le bon ajustement de la distribution régionale GEV aux échantillons des précipitations observées de trois stations en particulier aux précipitations de période de retour élevée. Donc, les résultats obtenus sont cohérents avec l’hypothèse d’homogénéité selon laquelle les valeurs réduites des précipitations suivent en tous points d’une région homogène la même loi de distribution. Pour les trois stations le modèle local sous estime les quantiles. La différence entre les quantiles réduits des courbes de croissance régionale et locale apparaît à partir de la période de retour de 20 ans.
Fig. 5 Ajustement de la distribution régionale GEV et locale aux valeurs réduites des précipitations observées des séries de différentes tailles (n) : (a) n = 43 ; (b) n = 34 ; et (c) n = 14.
CONCLUSIONS
Cette étude a porté sur la régionalisation des précipitations journalières maximales annuelles, dans le but d’obtenir une qualité fiable de l’estimation des quantiles extrêmes dans les stations de la région d’étude. La méthode d’analyse régionale fréquentielle basée sur les L-moments introduite par Hosking et Wallis (Citation1997) a été utilisée.
Le test d’homogénéité a permis de définir que la région représentée par 50 stations est homogène en termes des rapports des L-moments malgré les différences climatiques au sein de la région. L’étape importante de l’analyse régionale a été l’indentification de la distribution régionale. Les distributions à trois paramètres GEV, LN3, GLO et P3 ont été testées. En utilisant le test de la Z-statistique, on a pu constater que les distributions GEV et LN3 ont un ajustement satisfaisant à l’échantillon régional. Suite aux deux autres tests statistiques appliqués, la distribution GEV a été retenue comme étant plus robuste que LN3. Pour évaluer la précision et quantifier les incertitudes de l’estimation des quantiles régionaux le test de simulation Monte Carlo a été effectué. Les faibles valeurs de la REQM relative démontrent la fiabilité de la méthode appliquée. L’intervalle de confiance (90%) obtenu est étroit du fait de la distribution régionale quasi exponentielle (le paramètre de forme est proche de zéro). La comparaison des quantiles estimés à partir des approches régionale et locale a montré que dans la majorité des stations (62%) le modèle local sous estime les quantiles de fortes périodes de retour.
REFERENCES
- Alila, Y., 1999. A hierarchical approach for the regionalization of precipitation annual maxima in Canada. Journal Geophysical Research, 104 (D24), 31645–31655.
- Cannarozzo, M., D’Asaro, F., et Ferro, V., 1995. Regional and frequency analysis for Sicily using the two component extreme value distribution. Hydrological Sciences Journal, 40 (1), 19–42. doi:10.1080/02626669509491388
- Djerboua, A., 2001. Prédétermination des pluies et crues extrêmes dans les Alpes franco-italiennes. Prévision quantitative des pluies journalières par la méthode des analogues. Thèse de doctorat. Institut National Polytechnique de Grenoble. http://hydrologie.org/THE/djerboua/DJERBOUA.htm
- Dalrymple, T., 1960. Flood frequency methods. US Geological Survey. US Geological Survey Water Supply Paper 1543A, 11–51. http://pubs.usgs.gov/wsp/1543a/report.pdf
- GREHYS (Groupe de recherche en hydrologie statistique), 1996. Presentation and review of some methods for regional flood frequency analysis. Journal of Hydrology, 186, 63–84.
- Hosking, J.R.M., 1990. L-moments: analysis and estimation of distribution using linear combination of order statistics. Journal of the Royal Statistical Society, B52 (1), 105–124.
- Hosking, J. R. M., et Wallis, J. R., 1993. Some statistics useful in regional frequency analysis. Water Resource Research, 29(2), 271–281.
- Hosking, J. R. M., et Wallis, J. R., 1997. Regional frequency analysis: an approach based on L-moments. Cambridge: Cambridge University Press.
- Koutsoyiannis, D., 2004. Statistics of extremes and estimation of extreme rainfall: II. Empirical investigation of long rainfall records. Hydrological Sciences Journal, 49 (4), 591–610. doi:10.1623/hysj.49.4.591.54424.
- Kysely. J. et Picek, J., 2007. Regional growth curves and improved design value estimates of extreme precipitation events in the Czech Republic. Climate Research, 33, 243–255.
- Lin, B., et Vogel, J. L., 2006. A comparison of L-moments with method of moments. In: Chin Y. Kuo, ed. Engineering hydrology. New York: American Society of Civil Engineers, 443–448.
- Mebarki, A., 2005. Hydrologie des bassins de l’est Algérien: Ressources en eau, aménagement et environnement. Thèse de doctorat d’état. Université Mentouri de Constantine. http://hydrologie.org/THE/mebarki/MEBARKI.htm
- Mora, R.D., et al., 2005. Regional approach for the estimation of low-frequency distribution of daily rainfall in the Lanquedoc-Roussiillon region, France. Hydrological Sciences Journal, 50 (1), 85–109. doi:10.1623/hysj.50.1.17.56332.
- Nguyen, V.T.V., Nguyen, T.D., et Ashkar, F., 2002. Regional frequency analysis of extreme rainfall. Water Science and Technology, 45 (2), 75–81.
- Ouarda, T.B.M., St-Hilaire, A., et Bobée, B., 2008. Synthèse des développements récents en analyse régionale des extrêmes hydrologiques. Revue des Sciences de l’eau, 21 (2), 219–232. http://www.erudit.org/revue/rseau/2008/v21/n2/018467ar.pdf
- Ouarda, T.B.M., et al., 1999. Synthèse de modèles régionaux d’estimation de crues utilises en France et au Québec. Revue des Sciences de l’Eau, 12 (1), 155–182. http://www.rse.inrs.ca/art/volume12/v12n1_155.pdf
- Overeem, A., Buishand, A., et Holleman, I., 2007. Rainfall depth–duration–frequency curves and their uncertainties. Journal of Hydrology, 348, 124–134.
- St-Hilaire, A., et al., 2003. La régionalisation des précipitations : une revue bibliographique des développements récents. Revue des Sciences de l’Eau, 16 (1), 27–54. http://www.rse.inrs.ca/art/volume16/v16n1_27.pdf
- Sveinsson, O. G. B., Salas, J., et Duane, G. B., 2002. Regional frequency analysis of extreme precipitation in northern Colorado and the Fort Collins flood of 1997. Journal of Hydrologic Engineering, 7(1), 49–63.
- Versiani, B. R., De Andrade Pinto, E. J., et Bois, P., 1999. Analyse des pluies extrêmes annuelles sur la région de Ninas Gerais (Brésil) : modèle de régionalisation TCEV. In: L. Gottschalk, et al., eds. Hydrological extremes: Understanding, predicting, mitigating. Wallingford: International Association of Hydrological Sciences, IAHS Publ. 255, 201–207. http://iahs.info/uploads/dms/iahs_255_0201.pdf