
ABSTRACT
Regional flood frequency analysis (RFFA) was carried out on data for 55 hydrometric stations in Namak Lake basin, Iran, for the period 1992–2012. Flood discharge of specific return periods was computed based on the log Pearson Type III distribution, selected as the best regional distribution. Independent variables, including physiographic, meteorological, geological and land-use variables, were derived and, using three strategies – gamma test (GT), GT plus classification and expert opinion – the best input combination was selected. To select the best technique for regionalization, support vector regression (SVR), adaptive neuro-fuzzy inference system (ANFIS), artificial neural network (ANN) and nonlinear regression (NLR) techniques were applied to predict peak flood discharge for 2-, 5-, 10-, 25-, 50- and 100-year return periods. The GT + ANFIS and GT + SVR models gave better performance than the ANN and NLR models in the RFFA. The results of the input variable selection showed that the GT technique improved the model performance.
Editor R. Woods Associate editor E. Volpi
1 Introduction
Estimating accurate flood magnitudes for various return periods is essential for many hydrological and hydraulic engineering projects (Srinivas et al. Citation2008). Determining the design flood is also necessary for hydrological analysis and integrated flood control projects (Stedinger and Griffis Citation2008). Regional flood frequency analysis (RFFA) is used to transfer information on flood characteristics from gauged to ungauged watersheds (Blöschl and Sivapalan Citation1997, Pallard et al. Citation2009, Rahman et al. Citation2014). An RFFA usually involves data preparation, the identification of homogeneous regions, and development of regional estimation models (Dalrymple Citation1960, Jingyi and Hall Citation2004, Hosking and Wallis Citation2005, Rahman et al. Citation2014, Vafakhah and Eslamian Citation2014). To develop the regional flood prediction equations, commonly used techniques include the rational method, index flood method and quantile regression technique (QRT). Most of the above RFFA methods assume a linear relationship between flood statistics and predictor variables, generally in the log domain, when developing the regional prediction equations. However, most hydrological processes are nonlinear and exhibit a high degree of spatial and temporal variability; hence, a simple log transformation cannot guarantee achievement of linearity in modelling (Aziz et al. Citation2014).
In recent years, there has been increasing interest in the use of artificial neural network (ANN) and adaptive neuro-fuzzy inference system (ANFIS) techniques for modelling the stage–discharge relationship (Vafakhah and Kahneh Citation2016); daily and monthly discharge (Nayak et al. Citation2004, Kurtulus and Razack Citation2010, Vafakhah Citation2012); daily and monthly suspended sediment prediction (Kisi et al. Citation2008, Cobaner et al. Citation2009); rainfall–runoff prediction (Talei et al. Citation2010, Ghafari and Vafakhah Citation2012, Kisi et al. Citation2013); evaporation prediction (Kişi Citation2006, Dogan et al. Citation2010); flood forecasting (Chau et al. Citation2005, Chen et al. Citation2006); and regional analysis of flow duration curves (Bozchaloei and Vafakhah Citation2015).
Studies by Jingyi and Hall (Citation2004), Shu and Burn (Citation2004), Dawson et al. (Citation2006), Shu and Ouarda (Citation2007, Citation2008) and Aziz et al. (Citation2014, Citation2015, Citation2017) show the importance of data-driven techniques such as ANN and ANFIS in RFFA. Jingyi and Hall (Citation2004) compared four approaches, namely the geographical approach, Ward’s cluster method, the fuzzy c-means method and a Kohonen neural network, for the delineation of homogeneous regions using the index flood method via multiple linear regression analysis and ANN in the southeast of China. The results showed that the ANN model was superior to the regression model. Shu and Burn (Citation2004) applied ANN in RFFA in the UK, and their results indicated that regional analysis based on ANN was better than a nonlinear regression (NLR) approach. Dawson et al. (Citation2006) compared an ANN approach, an empirical model (as presented in the Flood Estimation Handbook, FEH) and a NLR approach to estimate the T-year flood and the median of the annual maximum flood (index flood) over the UK. The results showed that ANNs were the same as FEH models for estimating the index flood. The ANN was superior to NLR for predicting the T-year flood. Shu and Ouarda (Citation2007) compared two canonical correlation analysis (CCA)-based ANN models including a single ANN model and an ensemble ANN model in RFFA at 151 gauged catchments located in Quebec Province, Canada. They concluded that the CCA-based ensemble ANN model was superior to the single ANN models. Shu and Ouarda (2008) used ANFIS, ANN and NLR techniques in RFFA, using the same dataset as Shu and Ouarda (Citation2007), and found that the ANFIS approach had similar results to the ANN approach and was better than both NLR and NLR with regionalization. Seckin and Guven (Citation2012) compared gene-expression programming (GEP), linear genetic programming (LGP) and logistic regression (LR) for estimating the peak flood discharges at 543 catchments across Turkey. They found that the GEP was superior to the LGP and LR methods. Alobaidi et al. (Citation2015) applied a generalized ensemble-based ANN in RFFA using the same dataset as Shu and Ouarda (Citation2007). Their model showed similar performance compared to the CCA-based ensemble ANN models.
Aziz et al. (Citation2014) applied ANN-based RFFA methods on a database consisting of 452 gauged catchments in eastern Australia. They found that ANN-based RFFA models outperformed the traditional QRT. Aziz et al. (Citation2015) optimized the ANN model using a genetic algorithm (GA) – GAANN – and compared it with the ANN model and traditional QRT in RFFA using the Aziz et al. (Citation2014) dataset. The results showed that the ANN model was superior to the GAANN model, but both the GAANN and ANN methods outperformed the traditional QRT model. Again using the 2014 dataset, Aziz et al. (Citation2017) compared the ANN model, GEP and traditional QRT in RFFA, and found that the ANN model was superior to GEP and both ANN and GEP methods outperformed the traditional QRT method.
The support vector machine (SVM) is one of the most widely used groups of data-driven techniques in hydrology (Dibike et al. Citation2001, Liong and Sivapragasam Citation2002, Bray and Han Citation2004, Asefa et al. Citation2006, Lin et al. Citation2006, Yu et al. Citation2006, Afiq et al. Citation2013). Gizaw and Gan (Citation2016) compared support vector regression (SVR) and ANN models in RFFA for two study areas: southeastern British Columbia (26 catchments) and southern Ontario (23 catchments), Canada. The SVR model outperformed the ANN model for the two study areas.
The choice of catchment characteristics plays an important role in an RFFA (Rahman et al. Citation2014). One possible concern with an RFFA study is the multi-collinearity problem, because many catchment characteristics may be correlated. Multi-collinearity can be tested by variance inflation factor (VIF), principal component analysis (PCA), gamma test (GT) and stepwise regression (SR) (Kheirfam and Vafakhah Citation2015). The GT is a new method for selecting the best input combination and can determine the minimum number of data points required to build a good model (Kheirfam and Vafakhah Citation2015). Surveys such as that conducted by Moghaddamnia et al. (Citation2009b) and Noori et al. (Citation2011) showed that the GT technique improved the performance of ANN, ANFIS and SVM models. To our knowledge, no research has been done that surveyed SVR with three strategies for selecting the best input combination in RFFA. The primary aims of this study are: (1) to ascertain the effect of input variable selection using either GT, GT plus classification, or expert opinion-based selection on the performance of SVR, ANFIS, ANN and NLR models; and (2) to compare the SVR model with the ANFIS, ANN and NLR models in RFFA of the Namak Lake watershed, Iran.
2 Materials and methods
2.1 Study area and dataset
The Namak Lake watershed (watershed no. 41) (48°00′–53°00′E; 33°00′–36°00′N), with an area of 92 550 km2, was selected as the study area. The mean catchment altitude varies between 800 and 4375 m a.s.l., with large variations within the watershed. The data for all the hydrometric stations in the Namak Lake watershed were obtained from the Iran Water Resources Research Company. The selected hydro-metric stations are distinguished by having a range of historical flood records of 20 years or longer, and the absence of hydraulic structures and direct water utilization from the river. For this study, 55 hydrometric stations with the same period of 20 years (1992–2012) were considered (Fig. 1). To complete the missing flood records, a regression equation was used between at-site flood peak discharge and maximum annual discharge.
2.2 Methodology
2.2.1 Calculation of flood peak discharge in various return periods
In order to compute flood peak discharge in various return periods for each hydrometric station, flood records were fitted, with the help of Easy Fit software, to seven probability distribution functions (pdfs): log Pearson Type III, three-parameter lognormal, two-parameter lognormal, Pearson Type III, Gumbel, normal and two-parameter gamma. The Kolmogorov-Smirnov (K-S) test was employed as a goodness-of-fit test. To determine the suitable regional pdf, an arbitrary ranking was used: the best fitted pdf was given a score of 1 and the worst a score of 7. Then, the sum of scores and the number of first-rank pdfs were computed for all 55 hydrometric stations. Finally, the suitable regional pdf was recognized. Flood discharge with 2-, 5-, 10-, 25-, 50- and 100-year return periods was estimated based on the suitable regional pdf (Ahn et al. Citation2014).
2.2.2 Derivation of data and features
At this stage, different variables including physiographical, meteorological, geological and land use in the upstream basins of the 55 hydrometric stations were derived. Catchment boundaries were extracted using ArcHydro extension based on the hydrometric station position and a digital elevation model (DEM) at a scale of 1:50 000 obtained from the Iran National Cartographic Centre. Physiographic characteristics of area, perimeter, drainage density, maximum height, minimum height, weighted average slope, average height, main stream length and main stream slope were extracted. To determine land use, a land-use map was derived using a 2002 land-use map, at a scale of 1:250 000, obtained from the Iran Forest, Ranges and Watershed Management Organization. The land-use map for each selected watershed was categorized into six types: water body, orchard, rangeland, irrigated farming, dryland farming and residential land, using Arc/GIS9.3 software. To determine impermeable formations, geological maps at a scale of 1:100 000 were obtained from the Iran Geological Survey and Mineral Exploration. Rock types (unconsolidated and consolidated) were derived using geological maps based on lithological categories. Meteorological characteristics: annual mean rainfall, annual mean evaporation, maximum 24-h rainfall and annual mean temperature, were obtained from the Iran Water Resources Research Company. shows the descriptive statistics of watershed characteristics used in the study.
Table 1. Descriptive statistics of basin characteristics used in the study.
2.2.3 Gamma test and M-test
The GT is a nonlinear analysis tool that can be used to select the best independent variables for modelling. The GT assesses the best minimum mean square error (MSE) on output, which is indicated by the gamma statistic (Г). Taking a set of observed data as:
where the input vectors x ∈ Rm are m-dimensional vectors (with a record length of m) confined to some closed bounded set C ∈ Rm and, without loss of generality, the corresponding outputs y ∈ Rm are scalars. The following equation is established between an input x and the corresponding output y:
where f is a smooth unknown function and r is a random variable that illustrates the noise of the equation. GT estimates the variance of the noise as Г.
The GT is based on N[i,k], which includes a set of nearest neighbours from k (1 ≤ k ≤ p) for each vector xi (1 ≤ i ≤ M) .The gamma function of the output values is computed as follows:
Specifically, “error” is derived by:
In order to compute Г, a least squares regression line is constructed for the p points δM(k) and γM(k):
The intercept on the vertical axis (δ = 0) is Г and its value is shown mathematically as follows:
The M-test curve can be used to determine optimum size in the training stage (Vafakhah and Kahneh Citation2016). Practically, the GT and M-test algorithm can be carried out through winGamma™ Software (Durrant Citation2001).
2.2.4 Description of models used
2.2.4.1 Nonlinear regression (NLR)
The general purpose of multiple regression (MLP) is to determine the relationship between several independent variables and a dependent variable (Yilmaz and Kaynar Citation2011). The regression model for RFFA can be expressed as follows:
where x1, x2, …, xn are watershed characteristics, m is a regression constant; a, b, …, z are regression coefficients; and n is the number of catchment characteristics.
2.2.4.2 Artificial neural network (ANN)
The ANN used in this study is the feedforward multilayer perceptron (MLP) with back-propagation (BP) learning rule and Levenberg-Marquardt algorithm (Kurtulus and Razack Citation2010, Kalteh Citation2013). The MLP with three layers, i.e. an input layer, one hidden layer and an output layer, was used in this study. The number of neurons in the hidden layer was determined by trial-and-error procedure. Different activation functions (logarithm sigmoid, tangent sigmoid, linear) were tried for the hidden and output nodes.
2.2.4.3 Support vector regression (SVR)
The term SVR is simply used to describe regression with SVM. It employs the structural risk minimization principle, and is a relatively new approach that has been successfully used for modelling nonlinear real-world problems (Kalteh Citation2013). The main relationship for a linear SVR with one dependent variable (y) and many independent variables (x1, x2, …, xn) is as follows:
where wi and b are model parameters. The parameters of Equation (8) are determined to minimize as:
subject to:
where ε is considered as a band around the function f(x); points outside of this band cause a training error termed ξ.
The traditional linear SVR can solve the following optimization problem using Lagrange multipliers.
subject to:
where αi,αi* ≥ 0 are the Lagrange multiplier factors and C is the cost factor. The linear SVR equation is as follows:
This developed SVR equation is not proper for many hydrological analyses of nonlinear regression and, therefore, nonlinear kernel functions can be used to convert the input data into a high-dimensional space. The kernel function is defined as
. The most commonly used kernel functions are the linear kernel (LN), the polynomial kernel (PL), the radial basis function (RBF) and the sigmoid kernel (SIG).
2.2.4.4 Adaptive network-based fuzzy inference system (ANFIS)
There are two types of FIS, the Sugeno-Takagi FIS and the Mamdani FIS (Jang et al. Citation1997). In this study, the Sugeno-Takagi FIS model was used. The Sugeno-Takagi system is a more computationally efficient representation than the Mamdani system and works well with linear techniques, optimization and adaptive techniques. shows the structure of ANFIS used in this study, which consists of five layers.
Figure 1. Hydrometric stations used in this study.
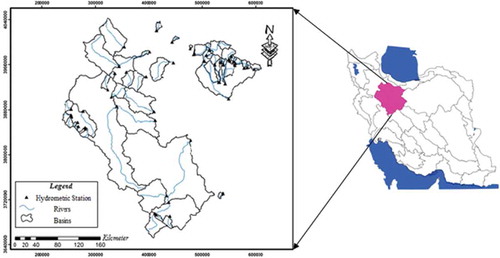
Figure 2. Structure of ANFIS used in this study.
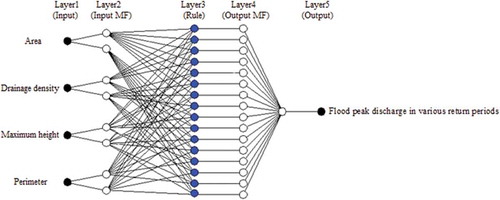
Input fuzzification is carried out in the first layer; the nodes are fixed nodes in the second (multiplies incoming signals) and third (calculates the normalized firing strength) layers; and the nodes in the fourth layer are called adaptive nodes. Parameters are referred to as consequent parameters. The fifth layer is a single fixed node, which computes the overall output by summing all incoming signals. In the present study, the triangular, trapezoidal, sigmoidal, generalized bell-shaped, Gaussian and Gaussian2 membership functions (MFs) were applied. In each application, different numbers of MFs were tried, and the best one, giving the minimum of errors, was selected. More information on ANFIS can be found in Jang (Citation1993).
2.2.5 Standardization of data
In this study, before the training of the models, both input and output variables were normalized within the range 0.1–0.9 as follows:
where Ni is the normalized value of a certain parameter, xi is the measured value for this parameter, and xmin and xmax are, respectively, the minimum and maximum values in the database for this parameter (Dogan et al. Citation2010, Besalatpour et al. Citation2013).
2.2.6 Evaluation of model performance
To assess the model performance, three statistical criteria, root mean squared error (RMSE), Nash-Sutcliffe coefficient of efficiency (NSC) and coefficient of determination (R2) were used as follows:
where qo(t) is the observed discharge for a certain period, t; qp(t) is the predicted discharge; n is the number of observed data; and and
are, respectively, the observed and the predicted mean discharge for a certain period, t.
Legates and McCabe (Citation1999) showed that the coefficient of determination (R2) alone is not appropriate to evaluate the goodness-of-fit of model simulations. Therefore, other statistical indexes, for example, RMSE and NSC, should be applied to evaluate the models’ performance. The RMSE describes the average magnitude of the errors by attributing more weight to large errors; it ranges between 0 and ∞, with lower values corresponding to better model performance. The NSC can also provide good insight into the performance of a model. The optimal value of the NSC is 1, representing the best fit of the applied model to the observed data. The combined use of these measures can provide good insight into model performance. As indicated by Legates and McCabe (Citation1999), NSC and RMSE criteria can adequately be used to evaluate model simulations (Kisi et al. Citation2013, Shiri et al. Citation2013).
3 Results and discussion
shows the results obtained from the selected pdfs. As can be seen from , log-Pearson Type III had the lowest summing scores and the highest first rank and, therefore, was selected as the most suitable regional distribution (Vasant and Talegaokar Citation2014).
Table 2. Summing scores and the number of first rank for the selected pdfs in the studied area.
To determine more important variables, the gamma value was calculated based on omitting variables one by one. Omitting important variables results in increasing gamma value in comparison with the gamma value of other variables. The results for different combinations are shown in .
Table 3. Gamma test results.
As can be seen from , area, drainage density, maximum height and perimeter are the best input combination for RFFA, having the highest gamma value. Selection of variables using GT was considered as the first strategy (Strategy A). Since the selected variables using GT are physiographical characteristics, a second strategy (Strategy B) was used to compare with GT. In Strategy B, one variable with high gamma value was selected from each of the physiographic, meteorological, geological and land-use characteristics through considering the GT results (). Accordingly, area (from the physiographic characteristics), annual mean rainfall (meteorological characteristics), impermeable formation area (geological characteristics) and irrigated farming area (land-use characteristics) were selected as the best input combination. In addition, the selection of variables was considered based on expert opinion (Strategy C). Accordingly, area, impermeable formation area, maximum 24-h rainfall and rangeland area were chosen as the best input combination.
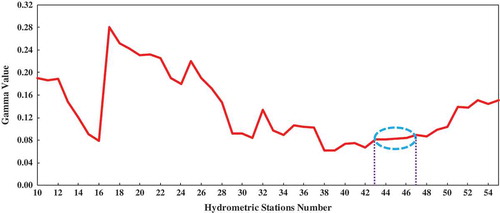
In addition, the suitable number of data points required for training and testing the model was determined using the M-test. The results obtained from M-test analysis are shown in . In , there is a clear stabilizing of the gamma statistic with a value of 0.08 between data points 43 and 47. Thus, we selected data point 45 as the marginal point for determination of training and testing data. Accordingly, samples (hydrometric stations) of training and testing sets were determined, respectively, as 45 and 10.
Figure 3. M-test diagram gamma value.
The optimal values of the parameters used in SVR are given in for the three strategies. The constant-cost C and the radius of the insensitive tube ε are the nonlinear SVR parameter and the kernel parameter. These parameters are mutually dependent, so changing the value of one parameter changes other parameters. In this study, to determine parameters γ and d by trial-and-error method and for optimization of parameters C and ε, a grid search algorithm, namely a two-step grid search method with 10-fold cross-validation, was used. A two-step grid search algorithm, dividing the search process in two stages, was used to solved this problem. First, the search space becomes smaller, therefore determining the best region. Then the optimum parameters in the smaller search space are searched until finally optimal values of parameters are determined (Chen and Yu Citation2007). For 10-fold cross-validation, the hydrometric stations were divided into 10 subsets, and the leave-one-out (LOO) validation method was repeated 10 times. Each repetition, one of the 10 subsets was used as the test set and the other nine subsets were put together to form a training set. Then the average error across all 10 trials was computed. SVR models with these parameters were simulated, and the best-performing were selected.
Table 4. Optimal values of the parameters used in SVR.
– show the performance of the SVR, ANFIS, ANN and NLR models, respectively, in the test phase, for the three strategies through the statistical indicators R2, RMSE and NSC.
As can be seen from , the RBF kernel for the SVR model performed better than the other kernels in all return periods. This finding is in agreement with those of Moghadamnia et al. (Citation2009a), Goel and Pal (Citation2012) and Ibrahim and Wibowo (Citation2014). As shown in , the generalized bell-shaped (Gbell) membership function for the ANFIS model, at return periods of 2, 5 and 10 years, is the best fuzzification function. This finding supports previous research (Wu and Kuo Citation2010), which used the Gbell membership function. For return periods of 25, 50 and 100 years, the Gaussian2 membership function was selected. This seems to be consistent with other research (Soyguder and Alli Citation2009, Zheng et al. Citation2011, Kisi et al. Citation2013).
Table 5. Results of SVR for the test phase.
Table 6. Results of ANFIS for the test phase.
The summary of results obtained from the best models (–) is shown in . shows that SVR and ANFIS have similar performance and can be used to successfully estimate flood discharge. A possible explanation for this might be that ANFIS combines the capabilities of fuzzy logic and ANN in modelling, especially in RFFA. However, SVR uses the kernel function to model nonlinear relationships. Since flood magnitudes with different return periods are nonlinear, and exhibit a high degree of spatial and temporal variability, SVR and ANFIS models could guarantee achievement of nonlinearity in modelling. The present finding seems to be consistent with other research in this field (Shu and Ouarda 2008, Wu et al. Citation2008, Dogan et al. Citation2010, He et al. Citation2014).
Table 7. Results of ANN for the test phase.
Table 8. Results of NLR for the test phase.
Table 9. Comparison of statistics of each model in the test period.
Table 10. Performance of the developed models.
In general, selection of variables using GT (Strategy A) produced better results than the other two strategies. Moriasi et al. (Citation2007) suggested a quality class for watershed models using NSC (Fatehi et al. Citation2015). Therefore, the developed models were classified using this approach i.e. NSC ≤ 0.50 (Unsatisfactory), 0.50 < NSC ≤ 0.65 (Satisfactory), 0.65 < NSC ≤ 0.75 (Good) and 0.75 < NSC ≤ 1.00 (Very good) ().
As shown in , the selected models () were classified between Satisfactory and Very good. The SVR and ANFIS models are classified as Good and Very good, but the majority of ANN and NLR models are classified as Satisfactory and Good. shows the observed and estimated data for different return periods in the test phase.
Figure 4. Graph of observed and estimated data for different return periods (Tr) in the test phase.
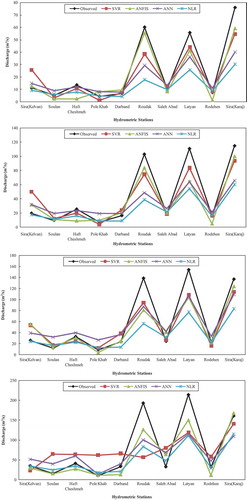
Figure 4. (Continued).
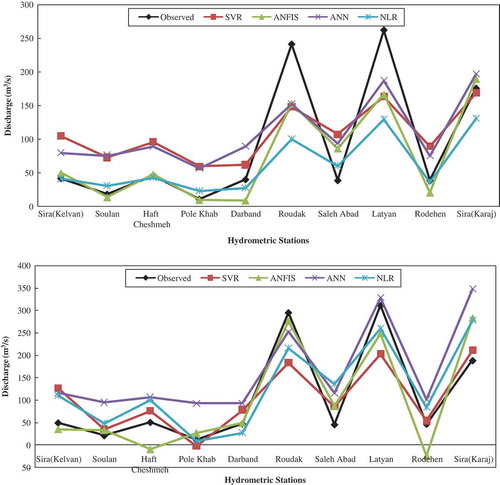
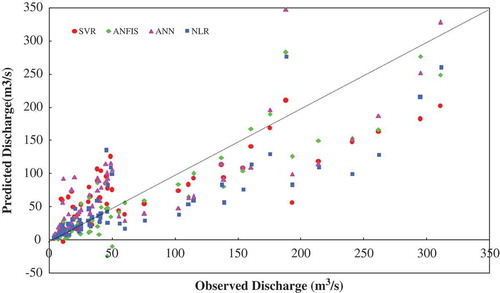
A qualitative assessment of various RFFA models is shown in . As can be seen from , the difference in prediction appears to increase with increase in return period. However, there is a minor difference in prediction between NLR and ANFIS models, while a large difference in prediction is observed particularly between ANN model and other models. The scatter plots of observed and estimated flood discharge using various RFFA models are shown in . As shown in , there is a slight difference for predicting flood discharge lower than 100 m3 s−1.
Figure 5. A comparison of RFFA models (a) on ordinary scale, and (b) on semi-log scale in the test phase.
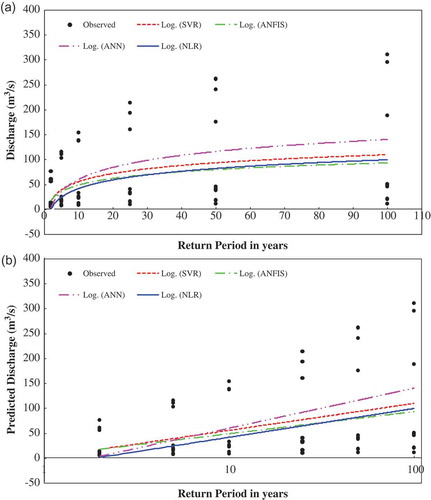
Figure 6. Estimated vs observed flood discharge for different return periods in the test phase.
4 Conclusions
In this paper, we compared the SVR, ANFIS, ANN and NLR models for RFFA in the Namak Lake watershed, Iran. The study was carried out using data of 55 hydrometric stations for the 20-year period between 1992/93 and 2011/12. The Kolmogorov-Smirnov test was used to rank probability distribution functions (pdfs) for estimating flood discharge with a certain return period. Hence, the log-Pearson Type III distribution was selected as the best pdf with the minimum error. Three strategies, GT, GT + classification and expert opinion, were used to select variables. Finally, the GT technique was selected as the best strategy. Indeed the GT reduces numbers of variables and provides the essential input variables for modelling. Therefore, area, drainage density, maximum height and perimeter were selected using GT as input variables. This study has found that, generally, the RBF kernel for SVR models performed better than the other kernels. The second major finding was that the Gbell membership function for ANFIS in return periods of 2, 5 and 10 years is the best fuzzification function. For return periods of 25, 50 and 100 years, the Gaussian2 membership function performed better than the other functions. These findings suggest that SVR and ANFIS have similar performance and can be used to successfully estimate flood discharge in the study region. Since the estimated return period quantiles refer to return periods of up to 100 years based on a 20-year record, further research is required to be conducted with longer time series.
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Afiq, H., et al., 2013. Daily forecasting of dam water levels: comparing a support vector machine (SVM) model with adaptive neuro fuzzy inference system (ANFIS). Water Resources Management, 27, 3803–3823. doi:10.1007/s11269-013-0382-4
- Ahn, J., et al., 2014. Flood frequency analysis for the annual peak flows simulated by an event-based rainfall-runoff model in an urban drainage basin. Water, 6 (12), 3841–3863. doi:10.3390/w6123841
- Alobaidi, M.H., et al., 2015. Regional frequency analysis at ungauged sites using a two-stage resampling generalized ensemble framework. Advances in Water Resources, 84, 103–111. doi:10.1016/j.advwatres.2015.07.019
- Asefa, T., et al., 2006. Multi-time scale stream flow predictions: the support vector machines approach. Journal of Hydrology, 318 (1–4), 7–16. doi:10.1016/j.jhydrol.2005.06.001
- Aziz, K., et al., 2014. Application of artificial neural networks in regional flood frequency analysis: a case study for Australia. Stochastic Environmental Research and Risk Assessment, 28 (3), 541–554. doi:10.1007/s00477-013-0771-5
- Aziz, K., et al., 2017. Flood estimation in ungauged catchments: application of artificial intelligence based methods for Eastern Australia. Stochastic Environmental Research and Risk Assessment, 31 (6), 1499–1514. doi:10.1007/s00477-016-1272-0
- Aziz, K., Rai, S., and Rahman, A., 2015. Design flood estimation in ungauged catchments using genetic algorithm-based artificial neural network (GAANN) technique for Australia. Natural Hazards, 77 (2), 805–821. doi:10.1007/s11069-015-1625-x
- Besalatpour, A., et al., 2013. Estimating wet soil aggregate stability from easily available properties in a highly mountainous watershed. Catena, 111, 72–79. doi:10.1016/j.catena.2013.07.001
- Blöschl, G. and Sivapalan, M., 1997. Process controls on regional flood frequency: coefficient of variation and basin scale. Water Resources Research, 33 (12), 2967–2980. doi:10.1029/97WR00568
- Bozchaloei, S.K. and Vafakhah, M., 2015. Regional analysis of flow duration curves using adaptive neuro-fuzzy inference system. Journal of Hydrologic Engineering, 20 (12), 06015008. doi:10.1061/(ASCE)HE.1943-5584.0001243
- Bray, M. and Han, D., 2004. Identification of support vector machines for runoff modelling. Journal of Hydroinformatics, 6 (4), 265–280.
- Chau, K., Wu, C., and Li, Y., 2005. Comparison of several flood forecasting models in Yangtze River. Journal of Hydrologic Engineering, 10 (6), 485–491. doi:10.1061/(ASCE)1084-0699(2005)10:6(485)
- Chen, S.-H., et al., 2006. The strategy of building a flood forecast model by neuro-fuzzy network. Hydrological Processes, 20 (7), 1525–1540. doi:10.1002/(ISSN)1099-1085
- Chen, S.-T. and Yu, P.-S., 2007. Real-time probabilistic forecasting of flood stages. Journal of Hydrology, 340 (1–2), 63–77. doi:10.1016/j.jhydrol.2007.04.008
- Cobaner, M., Unal, B., and Kisi, O., 2009. Suspended sediment concentration estimation by an adaptive neuro-fuzzy and neural network approaches using hydro-meteorological data. Journal of Hydrology, 367 (1–2), 52–61. doi:10.1016/j.jhydrol.2008.12.024
- Dalrymple, T., 1960. Flood-frequency analyses, manual of hydrology: part 3. Washington, DC: USGPO.
- Dawson, C.W., et al., 2006. Flood estimation at ungauged sites using artificial neural networks. Journal of Hydrology, 319 (1–4), 391–409. doi:10.1016/j.jhydrol.2005.07.032
- Dibike, Y.B., et al., 2001. Model induction with support vector machines: introduction and applications. Journal of Computing in Civil Engineering, 15 (3), 208–216. doi:10.1061/(ASCE)0887-3801(2001)15:3(208)
- Dogan, E., et al., 2010. Modelling of evaporation from the reservoir of Yuvacik dam using adaptive neuro-fuzzy inference systems. Engineering Applications of Artificial Intelligence, 23 (6), 961–967. doi:10.1016/j.engappai.2010.03.007
- Durrant, P.J., 2001. winGamma TM: a non-linear data analysis and modelling tool with applications to flood prediction. Citeseer. PhD dissertation, Department of Computer Science, Cardiff University, Wales, UK.
- Fatehi, I., et al., 2015. Modeling the relationship between catchment attributes and in-stream water quality. Water Resources Management, 29 (14), 5055–5072. doi:10.1007/s11269-015-1103-y
- Ghafari, G. and Vafakhah, M., 2012. Rainfall-runoff modeling using artificial neural networks and adaptive neuro-fuzzy inference system models. In: C. Kahraman, E.E. Kerre, and F.T. Bozbura, eds. Uncertainty modeling in knowledge engineering and decision making. Singapore: World Scientific, 951–956.
- Gizaw, M.S. and Gan, T.Y., 2016. Regional flood frequency analysis using support vector regression under historical and future climate. Journal of Hydrology, 538, 387–398. doi:10.1016/j.jhydrol.2016.04.041
- Goel, A. and Pal, M., 2012. Stage-discharge modeling using support vector machines. International Journal of Engineering, 25 (1), 1–9. doi:10.5829/idosi.ije.2012.25.01a.01
- He, Z., et al., 2014. A comparative study of artificial neural network, adaptive neuro fuzzy inference system and support vector machine for forecasting river flow in the semiarid mountain region. Journal of Hydrology, 509, 379–386. doi:10.1016/j.jhydrol.2013.11.054
- Hosking, J.R.M. and Wallis, J.R., 2005. Regional frequency analysis: an approach based on L-moments. New York: Cambridge University Press.
- Ibrahim, N. and Wibowo, A., 2014. Support vector regression with missing data treatment based variables selection for water level prediction of Galas River in Kelantan Malaysia. Wseas Transactions on Mathematics, 13 (1), 69–78.
- Jang, J.-S.R., 1993. ANFIS: adaptive-network-based fuzzy inference system. IEEE Transactions on Systems, Man and Cybernetics, 23 (3), 665–685. doi:10.1109/21.256541
- Jang, J.-S.R., Sun, C.-T., and Mizutani, E., 1997. Neuro-fuzzy and soft computing; a computational approach to learning and machine intelligence. 1 ed. Upper Saddle River, NJ: Prentice Hall.
- Jingyi, Z. and Hall, M., 2004. Regional flood frequency analysis for the Gan-Ming River basin in China. Journal of Hydrology, 296 (1–4), 98–117. doi:10.1016/j.jhydrol.2004.03.018
- Kalteh, A.M., 2013. Monthly river flow forecasting using artificial neural network and support vector regression models coupled with wavelet transform. Computers & Geosciences, 54, 1–8. doi:10.1016/j.cageo.2012.11.015
- Kheirfam, H. and Vafakhah, M., 2015. Assessment of some homogeneous methods for the regional analysis of suspended sediment yield in the south and southeast of the Caspian Sea. Journal of Earth System Science, 124 (6), 1247–1263. doi:10.1007/s12040-015-0604-7
- Kişi, Ö., 2006. Daily pan evaporation modelling using a neuro-fuzzy computing technique. Journal of Hydrology, 329 (3–4), 636–646. doi:10.1016/j.jhydrol.2006.03.015
- Kisi, O., Shiri, J., and Tombul, M., 2013. Modeling rainfall-runoff process using soft computing techniques. Computers & Geosciences, 51, 108–117. doi:10.1016/j.cageo.2012.07.001
- Kisi, O., Yuksel, I., and Dogan, E., 2008. Modelling daily suspended sediment of rivers in Turkey using several data-driven techniques. Hydrological Sciences Journal, 53 (6), 1270–1285. doi:10.1623/hysj.53.6.1270
- Kurtulus, B. and Razack, M., 2010. Modeling daily discharge responses of a large karstic aquifer using soft computing methods: artificial neural network and neuro-fuzzy. Journal of Hydrology, 381 (1–2), 101–111. doi:10.1016/j.jhydrol.2009.11.029
- Legates, D.R. and McCabe, G.J., 1999. Evaluating the use of “goodness-of-fit” measures in hydrologic and hydroclimatic model validation. Water Resources Research, 35 (1), 233–241. doi:10.1029/1998WR900018
- Lin, J.-Y., Cheng, C.-T., and Chau, K.-W., 2006. Using support vector machines for long-term discharge prediction. Hydrological Sciences Journal, 51 (4), 599–612. doi:10.1623/hysj.51.4.599
- Liong, S.-Y. and Sivapragasam, C., 2002. Flood stage forecasting with support vector machines. Journal of the American Water Resources Association, 38 (1), 173–186. doi:10.1111/jawr.2002.38.issue-1
- Moghaddamnia, A., et al., 2009a. Evaporation estimation using support vector machines technique. International Journal of Engineering and Applied Sciences, 5 (7), 415–423.
- Moghaddamnia, A., et al., 2009b. Evaporation estimation using artificial neural networks and adaptive neuro-fuzzy inference system techniques. Advances in Water Resources, 32 (1), 88–97. doi:10.1016/j.advwatres.2008.10.005
- Moriasi, D.N., Arnold, J.G., Van Liew, M.W., Bingner, R.L., Harmel, R.D., and Veith, T.L., 2007. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Transactions of the ASABE, 50 (3), 885–900. doi:10.13031/2013.23153
- Nayak, P.C., et al., 2004. A neuro-fuzzy computing technique for modeling hydrological time series. Journal of Hydrology, 291 (1–2), 52–66. doi:10.1016/j.jhydrol.2003.12.010
- Noori, R., et al., 2011. Assessment of input variables determination on the SVM model performance using PCA, Gamma test, and forward selection techniques for monthly stream flow prediction. Journal of Hydrology, 401 (3–4), 177–189. doi:10.1016/j.jhydrol.2011.02.021
- Pallard, B., Castellarin, A., and Montanari, A., 2009. A look at the links between drainage density and flood statistics. Hydrology and Earth System Sciences, 13 (7), 1019–1029. doi:10.5194/hess-13-1019-2009
- Rahman, A., Haddad, K., and Eslamian, S., 2014. Regional flood frequency analysis. In: S. Eslamian, ed. Handbook of engineering hydrology: modeling, climate change, and variability. Boca Raton, FL: CRC Press, 451–469.
- Seckin, N. and Guven, A., 2012. Estimation of peak flood discharges at ungauged sites across Turkey. Water Resources Management, 26, 2569–2581. doi:10.1007/s11269-012-0033-1
- Shiri, J., et al., 2013. Predicting groundwater level fluctuations with meteorological effect implications—a comparative study among soft computing techniques. Computers & Geosciences, 56, 32–44. doi:10.1016/j.cageo.2013.01.007
- Shu, C. and Burn, D.H., 2004. Artificial neural network ensembles and their application in pooled flood frequency analysis. Water Resources Research, 40 (9). doi:10.1029/2003WR002816
- Shu, C. and Ouarda, T.B.M.J., 2007. Flood frequency analysis at ungauged sites using artificial neural networks in canonical correlation analysis physiographic space. Water Resources Research, 43, W07438. doi:10.1029/2006WR005142
- Shu, C., and Ouarda, T.B.M.J., 2008. Regional flood frequency analysis at ungauged sites using the adaptive neuro-fuzzy inference system. Journal of Hydrology, 349 (1–2), 31–43. doi:10.1016/j.jhydrol.2007.10.050
- Soyguder, S. and Alli, H., 2009. Predicting of fan speed for energy saving in HVAC system based on adaptive network based fuzzy inference system. Expert Systems with Applications, 36 (4), 8631–8638. doi:10.1016/j.eswa.2008.10.033
- Srinivas, V., et al., 2008. Regional flood frequency analysis by combining self-organizing feature map and fuzzy clustering. Journal of Hydrology, 348 (1–2), 148–166. doi:10.1016/j.jhydrol.2007.09.046
- Stedinger, J.R. and Griffis, V.W., 2008. Flood frequency analysis in the United States: time to update. Journal of Hydrologic Engineering, 13 (4), 199–204. doi:10.1061/(ASCE)1084-0699(2008)13:4(199)
- Talei, A., Chua, L.H.C., and Wong, T.S., 2010. Evaluation of rainfall and discharge inputs used by Adaptive Network-based Fuzzy Inference Systems (ANFIS) in rainfall–runoff modeling. Journal of Hydrology, 391 (3–4), 248–262. doi:10.1016/j.jhydrol.2010.07.023
- Vafakhah, M., 2012. Application of artificial neural networks and adaptive neuro-fuzzy inference system models to short-term streamflow forecasting. Canadian Journal of Civil Engineering, 39 (4), 402–414. doi:10.1139/l2012-011
- Vafakhah, M. and Eslamian, S., 2014. Regionalization of hydrological variables. In: S. Eslamian, ed. Handbook of engineering hydrology: modeling, climate change, and variability. Boca Raton, FL: CRC Press, 471–499.
- Vafakhah, M. and Kahneh, E., 2016. A comparative assessment of adaptive neuro-fuzzy inference system, artificial neural network and regression for modelling stage-discharge relationship. International Journal of Hydrology Science and Technology, 6 (2), 143–159. doi:10.1504/IJHST.2016.075581
- Vasant, S.A. and Talegaokar, S., 2014. Hydrological study of man (Chandrabhaga) river. International Journal of Advances in Engineering & Technology, 7 (3), 807–817.
- Wu, C., Chau, K., and Li, Y., 2008. River stage prediction based on a distributed support vector regression. Journal of Hydrology, 358 (1–2), 96–111. doi:10.1016/j.jhydrol.2008.05.028
- Wu, J.-D. and Kuo, J.-M., 2010. Fault conditions classification of automotive generator using an adaptive neuro-fuzzy inference system. Expert Systems with Applications, 37 (12), 7901–7907. doi:10.1016/j.eswa.2010.04.046
- Yilmaz, I. and Kaynar, O., 2011. Multiple regression, ANN (RBF, MLP) and ANFIS models for prediction of swell potential of clayey soils. Expert Systems with Applications, 38 (5), 5958–5966. doi:10.1016/j.eswa.2010.11.027
- Yu, P.-S., Chen, S.-T., and Chang, I.-F., 2006. Support vector regression for real-time flood stage forecasting. Journal of Hydrology, 328 (3–4), 704–716. doi:10.1016/j.jhydrol.2006.01.021
- Zheng, H., Jiang, B., and Lu, H., 2011. An adaptive neural-fuzzy inference system (ANFIS) for detection of bruises on Chinese bayberry (Myrica rubra) based on fractal dimension and RGB intensity color. Journal of Food Engineering, 104 (4), 663–667. doi:10.1016/j.jfoodeng.2011.01.031