
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
This study aimed to review the existing research focalizing on the missing data imputation techniques for the systems enabling actual evapotranspiration calculation (such as eddy covariance, Bowen ratio, and lysimeters) and divergent evapotranspiration related variables, i.e. temperature, wind speed, humidity, and solar radiation. Thus, the Scopus engine was utilized to scan the entire literature and 62 articles were diligently investigated. Results show classical approaches have been widely used by researchers due to their ease of implementation. However, the applicability and validity of these methods heavily rely on assumptions made about the distribution and characteristics of missing data. Hence, advanced imputation techniques produce more accurate outcomes as they handle complex and non-linear problems. Also, current trends embraced by the research community revealed that employing deep learning techniques and incorporating explainable artificial intelligence into imputations have significant potential to make insightful contributions to the body of knowledge.
Editor S. Archfield; Associate Editor (not assigned)
1 Introduction
The quality of measurements is of utmost importance for the majority of research areas, such as hydrology, meteorology, and earth science (Yozgatligil et al. Citation2013). Despite the notable advancements in technology over the past few decades, the acquisition of highly accurate measurements remains a significant challenge due to the potential for measurement errors. Such errors can occur due to various factors such as inadequate calibration, imprecise measurement readings, and environmental influences (e.g. proximity to man-made or natural structures, air pollution, etc.), which can negatively impact all stages of data analysis (Lin and Tsai Citation2020). To tackle these challenges, one can either remove missing data or employ imputation methods to assign substitute values (Langkamp et al. Citation2010). Here, the amount of missing data plays a critical role; missing data accounting for less than 10% or 15% of the entire dataset can be removed (Strike et al. Citation2001), whereas one should pay considerable attention to addressing missing values exceeding 15%.
The research community has increasingly focused on statistical models with varying degrees of complexity to minimize the efforts required to handle the missing data problem. The aim is to develop methods that require minimal assumptions while producing accurate estimations that closely align with the actual measured data. The pertinent literature recognized the critical role played by the classical methods, e.g. linear regression (LR) analysis, principal component analysis (PCA), and expectation-maximization (EM) (Hron et al. Citation2010). Despite their practical utilization, these algorithms require some prerequisites that pushed researchers to adopt different methods for accomplishing missing data imputation attempts. In this sense, modern algorithms (mostly concentrated on machine learning applications) are used for a plethora of purposes, such as imputation of river flow data (Ng et al. Citation2009, Sidibe et al. Citation2018), imputation of water quality data (Tabari and Talaee Citation2015, Zhang and Thorburn Citation2022), imputation of meteorological data (Sattari et al. Citation2020, Wang and Shi Citation2021), etc. The pertinent literature indicates that modern modelling techniques tend to produce more accurate estimations compared to classical imputation methods, thus offering promising solutions for addressing the challenges of missing data (Gautam and Ravi Citation2015, Silva-Ramírez et al. Citation2015, Zhang et al. Citation2015). Studies using modern techniques are explained in detail in the following sections.
The current paper focuses on the imputation of missing values observed in various systems to facilitate the computation of actual evapotranspiration (ETa), along with variables aiding in the calculation of reference evapotranspiration (ETo). Hence, this research encapsulates a comprehensive investigation of data imputation techniques for the parameters utilized in ET measurements and calculations. In this vein, studies carrying out imputation of actual ET values based on eddy covariance (EC), Bowen ratio, and lysimeter measurements as well as other efforts devoted to reconstructing temperature, humidity, wind speed, and solar radiation to assist in calculating the reference ET were diligently investigated. The present research sheds light on the selection of input parameters for imputation methods, the selection of hyperparameters in algorithms used during the imputation process, and the determination of iteration numbers for multiple imputation techniques. The software tools used in the imputation process were further investigated within the scope of the current study. The outcomes of this study are anticipated to not only enhance researchers’ understanding of the imputation techniques employed in ET-related research for the purpose of completing missing data, and their consequent impact on research outcomes, but also provide valuable insights for future investigations in this domain.
2 Mechanisms and patterns of missing data
The mechanisms and patterns also play a significant role in the resultant research outcomes, which may have a greater impact than the extent of missing data itself. visualizes the missing data mechanisms and patterns.
Figure 1. Mechanisms and patterns of missing data. MAR = Missing at Random; MCAR = Missing Completely at Random; MNAR = Missing Not at Random.
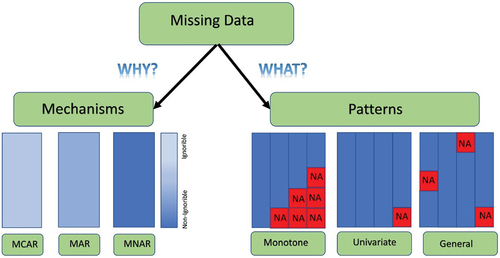
2.1 Missing data mechanisms
In imputing missing data, it is crucial to first identify the structural features of the missing data. In particular, it is necessary to designate whether the missing data in the observations are randomly distributed or follow a certain pattern. In this context, the classification system of missing data that was summarized by Rubin (Citation1976), which treats missing data as a probabilistic process, has been widely used in recent decades. Here, among three different mechanisms, missing completely at random (MCAR) is regarded as the least challenging mechanism for statistical analyses as it grounded on the independent relationship between the missing data and other variables in the dataset. On the other hand, missing at random (MAR) assumes that there is a dependent relationship between the variable having missing values and other variables. In this mechanism, the probability of missing data relies on the observed values of other variables, rather than the other missing values of the target variable. In addition, missing not at random (MNAR) is based on a direct dependent relationship between missing data and the nature of the corresponding variable. Hence, datasets having relatively longer gaps are generally characterized by the MNAR mechanism.
2.2 Missing data patterns
According to potential indicator emerges regarding the possibility of data deletion within certain groups in the context of missing data mechanisms. When missing data is deemed negligible, this implies that the likelihood of observing a variable is not contingent upon the value of that variable, while the converse denotes non-negligible missing data (Beaulieu-Jones et al. Citation2018). On the one hand, in instances where the missing data mechanism is MCAR or MAR, data deletion may result in minimal information loss. On the other hand, in the case of an MNAR mechanism, it is recommended to employ data imputation as the missingness is attributable to the impact of other independent variables.
Furthermore, the utilization of missing data imputation techniques is based on the patterns of missing data as the corresponding patterns indicate the location of missing values in the focalized time series. The existing literature covers many missing data patterns, mainly divided into two groups, i.e. monotone or non-monotone (general) and univariate or multivariate. Let the data be represented by the matrix. In the presence of missing data,
is partially observed. Notation
is the
column in
, and
indicates the complement of
– that is, all columns in
except
. The missing data pattern of
is the
binary response matrix
A missing data pattern can be regarded as univariate if there is only one variable with missing data, whereas, once a set of series are all observed or missing on the same set of cases, the corresponding pattern is called multivariate. In addition, a missing data pattern is regarded as monotone if the variables
can be ordered such that if
is missing then all variables
with
are also missing. However, if the pattern is not monotone, it is called non-monotone or general.
3 Methods for measuring and calculating ET
3.1 The eddy covariance method
The EC method is widely used to measure fluxes in ecosystem studies across the globe. Flux refers to the amount of matter passing through a closed surface per unit area in a unit of time. The EC method describes the airflow in the atmosphere as consisting of vertical movements that transport materials through turbulence. The difference between the number of gas molecules transported upwards and those transported downwards at any given moment results in net convection. In the EC method, the concentration of the gas being measured and the covariance of the vertical wind speed are the fundamental principles used for estimating gas exchange between the atmosphere and the surface (Burba et al. Citation2013). EquationEquation (1)(1)
(1) shows how the evaporation latent heat flux (LE) is calculated:
Here, LE represents the latent heat of evaporation (W m−2), ρa is the air density (kg m−3), w′ represents the deviation of the vertical wind speed from the mean (m s−1), q′ represents the deviation of the water vapor concentration from the mean (kg m−3), and represents the covariance of these deviations (Jiang et al. Citation2014).
3.2 Bowen ratio energy balance method
The Bowen ratio energy balance (BREB) method is used to determine the actual ET based on the ratio of distribution of the convective flux between the evaporative latent heat flux and the sensible heat flux (Oke Citation2002). The BREB method involves measuring the temperature and humidity gradient, as well as net radiation and soil heat flux. The BREB method is based on the energy balance equation (Bowen Citation1926):
Here, Rn represents net radiation (W m−2), G represents the soil heat flux (W m−2), LE represents evaporative latent heat flux (W m−2), and H represents sensible heat flux (W m−2). The method is based on the Bowen ratio calculation introduced by Bowen, which shows the ratio of distribution of the receiving energy between LE and H (Bowen Citation1926).
where β represents the Bowen ratio, γ indicates the psychrometric coefficient (kPa °C−1), T1 represents the air temperature (°C) measured at the lower level, T2 represents the air temperature (°C) measured at the upper level, ea1 represents the actual vapor pressure (kPa) of the air at the lower level, and ea2 represents the actual vapor pressure (kPa) of the air at the upper level. With the determination of the Bowen ratio, LE (W m−2) can be calculated using the expression given in EquationEquation (4)(4)
(4) .
3.3 Weighing lysimeter method
The water budget equation was used for ET measurements in lysimeters. For a typical lysimeter tank insulated from the environment, the water budget equation can be written as in EquationEquation (5)(5)
(5) .
where P is precipitation and I is irrigation water. Also, Cp and Rfc denote capillary rise and runoff, respectively. In Equation (5), ET, Dp, and Rfo indicate evapotranspiration, deep infiltration or drainage water, and runoff, respectively. ΔW shows the changes in soil water content. It is worth mentioning that all units are in millimetres. In general, Cp,Rfc, and Rfo values are zero in lysimeters. Thus, the equation for ET ends up in the form of EquationEquation (6)(6)
(6) :
3.4 FAO-56 Penman-Monteith method
The FAO Penman-Monteith method is an equation derived from the original Penman-Monteith equation along with the aerodynamic and surface resistance equations (Allen et al. Citation1998).
where ETo is the reference evapotranspiration [mm day−1], Rn is the net radiation at the crop surface [MJ m−2 day−1], G is the soil heat flux density [MJ m−2 day−1], T is the mean daily air temperature at 2 m height [°C], U2 is the wind speed at 2 m height [m s−1], es is the saturation vapor pressure [kPa], ea is the observed vapor pressure [kPa], es – ea refers to the saturation vapor pressure deficit [kPa], Δ represents the slope of vapor pressure curve [kPa °C−1], and γ denotes the psychrometric constant [kPa °C−1].
4 Literature review rationale
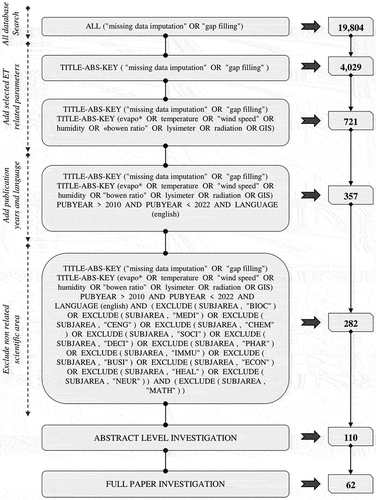
In this study, missing data imputation studies of the parameters used to obtain actual and reference ET values were examined. The Scopus search engine was used to conduct the comprehensive literature survey. To ensure relevance, the search was limited to articles published in English between 2002 and 2022, reflecting the most recent research trends in the field. A total of 282 articles were subjected to the abstract-level investigation, after which the number of studies was reduced to 110. Finally, the articles deemed directly relevant to the missing data imputation of the variables taken into account were further analysed through full-text investigation, which resulted in a total of 62 articles. The entire process of the literature review is illustrated in .
Figure 2. The steps of the literature review conducted via Scopus.
5 Results
Three methods, i.e. EC, Bowen ratio, and lysimeter systems, that are used to measure actual ET values were examined in the present research. For reference ET calculation, the parameters (i.e. temperature, wind speed, pressure, insolation, radiation, and humidity) of the FAO-56 Penman-Monteith method, which is one of the most commonly adopted empirical approaches in the literature, were considered. It is also worth noting that the review of the pertinent literature revealed that there is no study on the imputation of missing data during the measurement of pressure and insolation times.
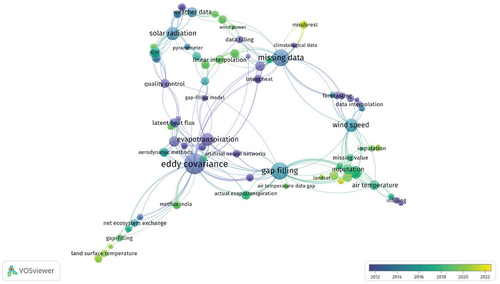
Along with the content-based investigation, the present work also aimed to highlight the scientometrics of the relevant studies. Therefore, a total of 62 articles extracted through the Scopus engine were subjected to the VOSviewer software and a keyword-based analysis was performed to explore the knowledge distribution over years. In , elements’ size is directly related to the occurrence frequency of the keywords, while the colour represents distinct time periods associated with the keywords, and the links between the nodes symbolize the co-occurrence relationship between the words. The corresponding analysis revealed that the early studies (represented by deep blue) mainly concentrated on the ET calculations were linked with climatic data, data obtained from EC and Bowen-ratio systems. However, most studies primarily focused on filling gaps to perform further processes rather than directly embracing the missing data imputation objective. In addition, recent attempts tend to discover the contribution of air temperature, land surface temperature (LST), and wind speed, while the research community also focalized on the integration of classical techniques in gap filling. Still, few studies have acknowledged the role of advanced modelling techniques such as machine learning approaches.
Figure 3. Keyword networks generated by VOSviewer based on the Scopus database.
5.1 Missing data imputation techniques
The existing literature recognized the critical role played by divergent approaches (e.g. statistical, data-based, machine learning techniques, etc.) in missing data imputation to acquire precise estimations. Hence, in the present research we diligently reviewed the pertinent literature and extracted the commonly utilized methodologies to provide a better overview regarding the definitions, pros, and cons of the corresponding techniques ().
Table 1. Commonly applied missing data imputation methods.
5.2 Missing data imputation attempts concentrated on Bowen ratio data
The pertinent literature illustrated that studies investigated to impute the missing values in Bowen ratio measurements account for 5% of the total number of studies. The corresponding attempts mostly concentrated on the utilization of classical approaches, such as regression and linear interpolation techniques. For instance, Guo et al. (Citation2007) employed two distinct imputation methods for completing missing LE and H values. Initially, the Priestly-Taylor method was utilized to estimate the missing LE values, followed by the completion of missing H values using the energy balance equation. This sequential imputation approach was effective in simulating both daytime evaporation and night-time condensation. The imputed fluxes closely matched the quality-controlled data for each flow scenario in terms of their temporal distribution. Similarly, in other studies using the Bowen ratio method, linear interpolation was the most widely adopted method, as can be seen from (Balogun et al. Citation2009, Sexstone et al. Citation2016, Burakowski et al. Citation2018).
Table 2. Details regarding the missing value imputation studies utilizing the Bowen-Ratio technique.
5.3 Missing data imputation attempts concentrated on EC data
EC measurements are significant for determining ET as they provide direct and continuous measurements of the turbulent fluxes of water vapor, heat, and momentum between the Earth’s surface and the atmosphere. presents the studies devoted to attempts regarding the imputation of missing values encountered in EC measurements. For instance, Tang et al. (Citation2019) performed the classical LR method to impute missing data in LE and H values that were measured using the EC method over four years in a tropical peat forest in Sarawak, Malaysia. Concerning the software that can be directly used in missing data imputation attempts, Deb Burman et al. (Citation2019) implemented the REddyProc software package compiled with the R program to impute missing data in H, LE, Rn, short wave incoming solar radiation (RSWin), G, and photosynthetic photon flux densities (PPFD) provided by the EC method in a tropical forest located in Northeast India. Similar attempts further illustrated the effectiveness of the REddyProc package regarding the imputation of missing data in LE values (Zitouna-Chebbi et al. Citation2018, Foltýnová et al. Citation2020).
Table 3. Details regarding the missing value imputation studies utilizing the eddy-covariance technique.
In addition, there are many studies in which missing LE data were imputed with machine learning algorithms, such as artificial neural networks (ANN) (Schmidt et al. Citation2008, Abudu et al. Citation2010, Eamus et al. Citation2013, Mahabbati et al. Citation2021), k-nearest neighbours (KNN) (Chen et al. Citation2012) and Kalman filter (KF) (Alavi et al. Citation2006). Kunwor et al. (Citation2017) used three non-linear regression approaches to fill artificially created gaps of different sizes via light and temperature response curves: (1) “traditional” fixed monthly window, (2) moving window and (3) moving window with parameter estimation using physiological drivers. The results of the incomplete data-imputation simulations showed that the net ecosystem exchange (NEE) estimates made with the moving window and parameter estimation methods were closer to those of observed NEE, while the traditional method had yielded lower overall accuracy.
5.4 Missing data imputation attempts concentrated on lysimeter data
Lysimeter measurements are a valuable tool for understanding the water balance of a specific area and can provide important insights into the complex processes that drive ET. They ensure direct measurement of the water balance of a certain region, and can also be used to validate and improve remote sensing-based estimates of ET. Despite their importance, limited studies have been conducted due to the scarcity of the corresponding systems across the globe. Still, Huang et al. (Citation2020) (which is the 62nd study investigated within the scope of the present research) artificially generated random gaps for the three time series attained by the lysimeter systems from Basel (Switzerland), Rheindahlen (Germany), and Rietholzbach (Switzerland) to explore the utility of four techniques: potential ET, ratio, FAO-based water balance and HYDRUS modelling methods. Interestingly, the results suggested that the ratio method was well suited for imputing missing values of lysimeter data for Basel (Switzerland), while the HYDRUS method outperformed its counterparts concerning Rheindahlen (Germany). For Rietholzbach (Switzerland), all methods yielded very similar results but greater root mean square error (RMSE) values were observed with the FAO method.
5.5 Missing data imputation attempts concentrated on humidity data
Measuring the humidity for a region plays a crucial role in calculating the vapor pressure deficit (VPD), which is a key factor in the rate of ET and is important in understanding the overall water balance of a region. For instance, Costa et al. (Citation2021) used the multiple imputations by chained equations (MICE) algorithm to impute missing humidity data. Despite the usage of classical approaches, related studies mostly rely on the application of machine learning techniques, such that along with the adoption of Kalman smoothing and autoregressive integrated moving average (ARIMA) in their study, Afrifa-Yamoah et al. (Citation2020) further benchmarked them with multiple linear regression (MLR) methods for missing humidity data estimation. In a similar vein, Hasanpour Kashani and Dinpashoh (Citation2012) used ANN, adaptive neuro fuzzy inference system (ANFIS), and genetic programming (GP) methods, while Körner et al. (Citation2018) and Lara-Estrada et al. (Citation2018) discovered the performance of gradient boosting and Bayesian network methods, respectively ().
Table 4. Details regarding the studies devoted to imputing missing humidity data.
5.6 Missing data imputation attempts concentrated on solar radiation data
Measurements pertaining to the solar radiation variable help researchers understand the ET mechanisms as they provide insights into the energy available for photosynthesis, transpiration, and soil evaporation, and can be used to estimate the net radiation balance. Among the missing data imputation studies in solar radiation values (), Zainudin et al. (Citation2015) assessed the utility of one of the commonly adopted machine learning algorithms, KNN, by comparing its performance with three classical techniques (i.e. linear interpolation, spline interpolation, and cubic interpolation). Likewise, Kim et al. (Citation2019) employed not only different conventional techniques (including linear interpolation (LI), mode imputation, and MICE) but also the KNN to complete missing solar radiation data. The authors reported that LI produced optimal results when the proportion of missing data was below 15%. However, as the proportion of missing data increased, the KNN method, producing lower error rates, outperformed its counterparts. Still, relevant research has generally focused on classical imputation methods, such as the LR method (Dimas et al. Citation2011, Turrado et al. Citation2014, Žliobaitė et al. Citation2014). Demirhan and Renwick (Citation2018) created a comprehensive comparison scheme encompassing 36 models with different variants of interpolation, Kalman filters, persistence, weighted moving average (WMA), and random sample techniques. From a different perspective, Ernst and Gooday (Citation2019) utilized an equation consisting of direct normal irradiance (DNI) and diffuse horizontal irradiance (DHI) values instead of interpolation methods to complete missing solar radiation data.
Table 5. Details regarding the studies devoted to imputing missing solar radiation data.
5.7 Missing data imputation attempts concentrated on wind speed data
Wind speeds impact the rate of air movement over the surface, which in turn affects the rate of water vapour transfer from the surface to the atmosphere. As shown in , the use of machine learning methods predominates in studies related to completing wind speed missing data. For instance, the ANFIS approach was adopted by Hocaoglu et al. (Citation2009) and Zhiling Yang et al. (Citation2011) for Turkey and China, respectively. To illustrate the effectiveness of classical and modern techniques, Liu et al. (Citation2018) combined the multiple imputation (MPI) and Gaussian process regression (GPR) approaches to perform predictions regarding various datasets containing missing values. In this regard, a plethora of research further validated the superiority of the machine learning rationale for similar purposes, such as back propagation neural network (BPNN) (Basheer Shukur and Hisyam Lee Citation2015, Mao and Jian Citation2016), generalized regression neural network (GRNN) (Du et al. Citation2019), and recurrent neural network (RNN) (Li et al. Citation2019), in the pertinent literature. Similar to the NN-based methods, other machine learning techniques have been proven to be practical tools; for example, Chen et al. (Citation2016) integrated the least-squares support vector machine (LSSVM) model with comprehensive learning particle swarm optimization (CLPSO) to reveal that the data tested with the optimized LSSVM model has better imputation sensitivity and the interpolation results of the missing wind speed data are suitable for the variation of the wind speed data at the adjacent level. de Oliveira et al. (Citation2021) developed machine learning models to predict tropospheric ozone concentrations and completed missing values in the input parameters using the MissForest algorithm. Wind speed, which is one of the parameters in the input set, had varying degrees of missing data in different seasons, with the smallest and largest missing rates being 1.69% and 43.75%, respectively. Prior to imputing missing data, the statistical characterization of the dataset was ensured with PCA, and following the imputation process, further controls showed no significant change in the dataset characteristics, leading the researchers to conclude that the imputation process was successful.
Table 6. Details regarding the studies devoted to imputing missing wind speed data.
5.8 Missing data imputation attempts concentrated on temperature data
demonstrates the attempts focused on the imputation of missing temperature data in the relevant literature. For instance, Xu et al. (Citation2013) introduced a neoteric approach, called Biased Sentinel Hospitals-based Area Disease Estimation (P-BSHADE) point estimation model, and benchmarked it with the kriging, inverse distance weighting (IDW), and spatial regression testing (SRT). The effectiveness of the technique was empirically evaluated in terms of the annual temperature dataset from 1950 to 2000 in China and the scholars concluded that the P-BSHADE is applicable to the annual Chinese temperature datasets.
Table 7. Details regarding the studies devoted to imputing missing temperature data.
Among other attempts devoted to imputing missing temperature values, several studies have been carried out using machine learning approaches for different regions across the globe, such as multi-layer perceptron (MLP), radial basis function (RBF), RNN, time-lagged feedforward network (TLFN), time delay recurrent neural network (TDRNN), and counter propagation fuzzy-neural network (CFNN) methods for Canada (Coulibaly and Evora Citation2007), the LSTM method in South Korea (Park et al. Citation2019), and NN and KNN methods in Chile. In a study using the temperature data of four neighbouring stations with complete temperature data records pertaining to the same climatological area, Thevakaran and Sonnadara (Citation2018) estimated the missing temperature data at the target station and performed accurate predictions due to the inter-stational correlation. Regarding Europe, Shtiliyanova et al. (Citation2017) applied a kriging-based interpolation in the spatial dimension to fill the data gaps in air temperatures and a data-driven machine learning-based approach for the temporal dimension.
In addition, Geographic Information System (GIS)-related data plays a pivotal role in estimating ET by providing information on the spatial heterogeneity of environmental factors, including topography, land cover, soil type, and meteorological variables. Moreover, GIS data facilitate the assessment of catchment surface area and characteristics that are fundamental in ET calculations. The GIS data can also be utilized to evaluate energy balance components of the land surface, which are necessary for determining the energy available for ET. Hence, several efforts have been devoted to acquiring complete records regarding GIS-related datasets (). For instance, to accomplish the imputation of raw images containing between 1.1% and 58.4% incomplete LST data, Cheval et al. (Citation2020) utilized the data interpolating empirical orthogonal functions (DINEOF) algorithm via the R software. A void-filled LST dataset with high spatial resolution was used to investigate LST climatology on a monthly, seasonal, and annual scale over an urban area in Bucharest, Romania. In addition, to reduce uncertainties in climate records, Kadow et al. (Citation2020) proposed a new deep learning approach, while Dumitrescu et al. (Citation2020) used two class regression models (i.e. MLR and generalized additive model [GAM]) characterized by differing complexity and flexibility to impute the missing LST data.
The study conducted by Koksal et al. (Citation2017) focused on estimating incomplete hourly climate data in the semi-humid Bafra plain of northern Turkey, which plays a significant role in terms of agricultural facilities. They utilized the ANN technique and found that it not only accurately mapped the missing ET data but also estimated the data for areas where the ET was not recorded. Along with the adoption of machine learning algorithms, signal processing approaches have also been employed in the imputation of GIS-related data. For instance, Williams et al. (Citation2018) incorporated two signal processing methods into the missing temperature values attained from remote sensing products. They only used time series with missing data and disregarded the information of nearby stations. The results showed that the BCS-on-Signal method outperformed the bayesian compressive sensing (BCS)-on-intrinsic mode functions (IMF) method, highlighting the effectiveness of incorporating signal processing methods to estimate missing temperature data from remote sensing products.
6 Discussion
Missing data is a common problem in data analysis, and a plethora of algorithms have been introduced to overcome the corresponding challenge. In addition, the reliability and consistency of the imputation attempts should be diligently examined in various aspects. Hence, this research assessed the 62 existing studies based on three major phases, called pre-imputation (in terms of assumptions, mechanism and pattern control, and standardization), during-imputation (in terms of software used and the number of iterations), and post-imputation (model run times, statistical distribution checks, time series variance, and validation), that must be taken into account to pinpoint the crucial issues in implementing data imputation strategies and ensuring the accuracy and validity of the imputed datasets. The following subsections briefly discuss the corresponding elements.
6.1 Assessment of the pre-imputation stage
The pre-imputation stage is a crucial step in missing data imputation, as the foundation for the entire imputation process is set in this stage. Hence, scholars are advised to evaluate the corresponding step concerning different aspects including the pattern and extent of missing data, and assess the causes of missing data, statistical assumptions and data standardization. Failing to adequately address these issues during the pre-imputation stage can lead to biased and inaccurate imputation results, which can have serious consequences for subsequent analysis and the interpretation of the adopted models. This research assessed the pertinent literature based on whether the existing works concerned the statistical assumptions, checked mechanisms and patterns, and performed the standardization of datasets.
Concerning the statistical assumptions, it was found that the vast majority of studies utilizing the classical linear regression-based imputation techniques lack a proper reporting of statistical assumptions. Specifically, Kunwor et al. (Citation2017) rigorously tested the normality of the data and homogeneity of the variances in imputing their missing EC measurements. Furthermore, Afrifa-Yamoah et al. (Citation2020) suggested the use of non-parametric regression models for the imputation of humidity data. This aspect was further emphasized by Rezvan et al. (Citation2015), who reported that such imputations lack reliability and the direct use of data following imputation may lead to spurious results. Therefore, it is imperative that researchers acknowledge the importance of adhering to appropriate statistical assumptions prior to the missing data imputation in order to ensure the validity and accuracy of subsequent analyses.
The present study also examined the existing studies in terms of the mechanisms of the missing data. It is of utmost importance that researchers possess a prior understanding of the mechanism underlying missing data before imputation procedures. Such knowledge is critical for the development of input sets utilized in the imputations (Ali et al. Citation2023, Başakın et al. Citation2023). Here, incorporating parameters believed to be associated with missingness as auxiliary variables into the model can positively influence imputation results. Various methods exist that enable the statistical testing of the corresponding mechanisms, with some R programming language packages offering ready-made solutions (Jamshidian et al. Citation2014). However, only six of the reviewed studies (Hui et al. Citation2004, Alavi et al. Citation2006, Lo Presti et al. Citation2010, Demirhan and Renwick Citation2018, Liu et al. Citation2018, Kim et al. Citation2019, Afrifa-Yamoah et al. Citation2020) provided information regarding the mechanism underlying missing data. Similarly, the investigation of missing data patterns is of vital importance in missing data imputation studies. However, only three of the reviewed studies (Lo Presti et al. Citation2010, Lin and Wang Citation2014, Goodrich et al. Citation2021) provided information regarding the pattern of missing data. It is therefore crucial for researchers to consider the mechanism and pattern underlying missing data before imputation and toincorporate such information in their analyses to ensure accurate and valid results.
The last facet inspected under the umbrella of the pre-imputation stage is the standardization of the parameter values incorporated into the imputations. To define the parameters involved in the estimations, it is essential to standardize the input variables (Sovilj et al. Citation2016, Hasan et al. Citation2021). Multiple imputation procedures generally focus on solving a regression problem, and reducing the dataset to a dimensionless and evenly distributed structure (such as [0,1]) is regarded as a routine procedure in almost every regression model in the literature. Despite the vitality of standardization, only limited attempts (Lee and Chou Citation2004, Coulibaly and Evora Citation2007, Schmidt et al. Citation2008, Kim and Ahn Citation2009, Chen et al. Citation2016, Mao and Jian Citation2016) reported information regarding the standardization of parameters among the investigated articles.
6.2 Assessment of the during-imputation stage
The existing literature further recognized the critical role played by the essential points during the imputation of missing data. This paper examined the literature based on two aspects, i.e. the software used and the number of iterations in multiple imputations. Concerning the software utilized, the investigated studies reported the use of various programs to perform their imputation attempts. Among them, it was concluded that the most widely used tool is the R programming language (Wesonga Citation2015, Demirhan and Renwick Citation2018, Körner et al. Citation2018, Williams et al. Citation2018, Zitouna-Chebbi et al. Citation2018, Meher and Das Citation2019, Cheval et al. Citation2020, Costa et al. Citation2021). In addition, Schmidt et al. (Citation2008) employed both STATISTICA and MATLAB. Likewise, Miró et al. (Citation2017) utilized MATLAB, whereas many other software programs, such as Neuto-Solution (Abudu et al. Citation2010), SAS (Hui et al. Citation2004, Alavi et al. Citation2006), GeneXPro (Hasanpour Kashani and Dinpashoh Citation2012), C# (Altan and Ustundag Citation2012), and SPSS (Zainudin et al. Citation2015), were also adopted to perform the imputation of missing values that exist in the records of the variables related to ET.
Furthermore, in multiple imputation algorithms, the imputation process is repeated for different numbers of iterations. The appropriate number of iterations can vary depending on the size of the dataset, the number of independent variables, and the pattern of missingness. For instance, the default value for the number of iterations in the MICE package is 5. When examining studies that utilized multiple imputations, Hui et al. (Citation2004), Turrado et al. (Citation2014), Xie and Sun (Citation2018), Kim et al. (Citation2019), and Costa et al. (Citation2021) selected the iteration value as “m = 5.” However, Miró et al. (Citation2017) chose a value of 20. When considering datasets with varying sizes, it may be beneficial to explore different combinations of iteration values.
6.3 Assessment of the post-imputation stage
The evaluation of results obtained regarding imputation processes should essentially be carried out based on several aspects. Various methods can be used to evaluate the imputed data, including comparison with the observed data and comparison of the imputed data with the data from a complete case analysis. Furthermore, visual inspection of the imputed data can be helpful in detecting any systematic patterns or outliers that may indicate problems with the imputation model. Along with these essential aspects, this review further underpinned the role of run time evaluations, statistical distribution checks, assessing time series variance, and validation of the obtained results. Concerning the first aspect, one can conclude that the run time of imputation algorithms may vary depending on the size of the dataset as well as the utilized algorithms and computer capabilities. However, it is well known that the classic methods typically have shorter run times compared to modern techniques such as machine learning algorithms. Here, machine learning methods may require longer run times due to the optimization of hyperparameters. This can pose a challenge for researchers who need to make quick decisions in time-sensitive situations. Therefore, sharing information regarding the run times of different imputation techniques is crucial to provide a better overview for interested researchers in similar domains. Among the papers investigated within the scope of the current research, only three studies (Lin and Wang Citation2014, Turrado et al. Citation2014, Körner et al. Citation2018) have comparatively reported the computational costs of the utilized algorithms.
This study also assessed the previous work based on statistical distribution checks. Scholars who perform imputation attempts typically aim to minimize error regardless of the chosen method. Error levels can be measured through various approaches, providing important quantitative results regarding the imputation success. However, these quantitative metrics do not necessarily account for the distributional properties of the imputed values, which ideally should align with the distribution of the original dataset (Zhao et al. Citation2022). Here, the existing literature highlighted that testing the similarity between distributions can be achieved through statistical tests (Özger et al. Citation2020). Therefore, if the imputed values do not correspond to the dataset distribution, the imputation procedure should be reviewed and/or re-operated in order to achieve accurate imputation outcomes. We found only eight studies (Hui et al. Citation2004, Lo Presti et al. Citation2010, He et al. Citation2013, Wesonga Citation2015, Miró et al. Citation2017, Demirhan and Renwick Citation2018, Körner et al. Citation2018, Liu et al. Citation2018) that have investigated the similarity between imputed values and dataset distributions, highlighting the need for more research in this area.
Furthermore, when performing imputations for time series data, only the values of the parameter under investigation can be used for the imputation process. Therefore, it is crucial to ensure that the variance of the time series remains the same after imputations (Gao et al. Citation2018). Among 62 investigated papers, only Anjomshoaa and Salmanzadeh (Citation2019) and Kunwor et al. (Citation2017) checked the variance of the time series. The first used a quantitative metric to measure the variance values of imputed and gapped time series, while the latter provided a detailed analysis of the variance values after the imputation process. In order to reliably impute missing data, another important step that should diligently be taken into account is to conduct a training and validation process using the complete parts of the dataset used (Aghili et al. Citation2022). This process serves to demonstrate the accuracy of the imputation model and allows for the conclusion that the completed values are close to real values.
Using the entire dataset to obtain the imputation model without subjecting the models to any validation process, i.e. using the entire dataset for training, can lead to overfitting and result in completed values that are underestimated and/or overestimated. To tackle the overfitting phenomenon, cross-validation is one of the most commonly used methods in the pertinent literature (Yang et al. Citation2021, Eum and Yoo Citation2022). Of the studies examined within the scope of current research, 25% of the focalized research considered embracing a validation rationale, while others did not report the differentiation of training and validation stages.
The assessment of whether missing data imputation algorithms achieve optimal performance can be determined by utilizing various statistical evaluation metrics. These metrics are used to assess the degree of agreement between the predicted values and the actual values. Some of these metrics can be used to express the adequacy of a single model/algorithm quantitatively, while others are utilized to compare the results of multiple models (Zouzou and Citakoglu Citation2023). In this sense, metrics such as mean square error (MSE), root mean square error (RMSE), mean absolute error (MAE), and mean bias (MB) are used to measure which of two or more models makes predictions with lower errors, while some other metrics (such as coefficient of determination [R2], Nash-Sutcliffe efficiency [NSE], and Kling-Gupta efficiency [KGE]) measure the performance of a single model. Metrics that measure individual model performance typically range between [−1,1] or [0,1] and are able to measure the goodness of fit independently of the unit used (Bayram and Çıtakoğlu Citation2023). Hence, in evaluating the performance of these algorithms, it is crucial to diligently consider the choice of metric and its interpretability, as well as the potential implications of the missing data imputation process for subsequent statistical analyses and modelling outcomes.
It is worth mentioning that nearly 20% of the studies examined do not provide any information regarding the metric used for determining imputation accuracy, while 25% of them paid regard to only one metric. On the other hand, nearly half of the pertinent literature considered two or more metrics in assessing the accuracy of the imputation attempts. Diligent investigation demonstrated that the most commonly used metric is RMSE, with 34 occurrences, followed by MAE and R2 with 17 and 16 occurrences, respectively. One can conclude that using different performance evaluation indicators helps increase the reliability of the obtained imputation results due to the various data structures representing divergent data-gathering processes.
7 Conclusions
Missing data is a common problem in meteorological data for many reasons, including instrument and equipment malfunction, errors in data collection, natural events, and lack of resources. In addition, the existence of missing data poses serious challenges for many modelling approaches in the hydrology domain, especially considering the importance of having complete datasets that allow for accurate and reliable analysis of water-related phenomena. Hence, the present research carried out an investigation of the existing literature with reference to calculating ET, which is one of the significant components of the hydrologic cycle. Among nearly 20,000 studies directly or indirectly related to the ET, a total of 62 studies were extracted to draw a comprehensive representation regarding the efforts devoted in the last two decades. As a result, the following conclusions and implications are drawn:
The applicability and validity of the classical/parametric imputation methods rely heavily on various assumptions; hence, it is essential to approach these methods with caution and rigorously assess their underlying assumptions to avoid inaccurate conclusions or biased results.
Assessment of the distribution of data is essential prior to commencing imputation procedures, while optimizing the run time of the imputation model and fine-tuning the model parameters allow efficient performance to be achieved in the during-imputation stage. Furthermore, within the post-imputation step, it is important to verify the stability of the imputed values; hence, assessing the constancy of variance and similarity of the distributions can help identify potential issues and provide insight into the robustness of the imputation model.
Although various conventional techniques have been employed to handle missing data due to their ease of implementation, advanced imputation techniques that are particularly leveraged by the introduction of machine learning algorithms have emerged as more reliable alternatives to address missing data.
Although attempts regarding the incorporation of deep learning techniques are limited thus far, these techniques show great potential for enhancing the performance of imputation models, particularly in datasets with a large number of observations.
Interpretability of machine learning algorithms is an emerging concept in recent years; however, there was no study exploring the comprehensibility of missing data imputation procedures. Hence, integration of explainable artificial intelligence (e.g. SHapley Additive exPlanations [SHAP], Local Interpretable Model-Agnostic Explanations [LIME], etc.) can enhance the interpretability and transparency of the imputation results.
Furthermore, it is especially worth mentioning that, despite numerous studies examined within the scope of the current research, Scopus was the only database used to extract the relevant studies that exist in the literature. However, subsequent attempts could include different research databases to extend the scope of missing data imputation studies by the inclusion of conference papers, reports, and dissertations. Overall, a thorough investigation of the ET-related literature and the conclusions made in the current study are expected to assist the pertinent research community in understanding the dynamics of missing data imputation strategies and provide valuable insights regarding decision making processes for downstream analyses.
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Abudu, S., Bawazir, A.S., and King, J.P., 2010. Infilling missing daily evapotranspiration data using neural networks. Journal of Irrigation and Drainage Engineering, 136 (5), 317–325. doi:10.1061/(ASCE)IR.1943-4774.0000197
- Afrifa-Yamoah, E., et al., 2020. Missing data imputation of high-resolution temporal climate time series data. Meteorological Applications, 27 (1), 1–18. doi:10.1002/met.1873
- Aghili, M., Tabarestani, S., and Adjouadi, M., 2022. Addressing the missing data challenge in multi-modal datasets for the diagnosis of Alzheimer’s disease. Journal of Neuroscience Methods, 375 (March), 109582. doi:10.1016/j.jneumeth.2022.109582
- Alavi, N., Warland, J.S., and Berg, A.A., 2006. Filling gaps in evapotranspiration measurements for water budget studies: evaluation of a Kalman filtering approach. Agricultural and Forest Meteorology, 141 (1), 57–66. doi:10.1016/j.agrformet.2006.09.011
- Ali, A., et al., 2023. Missing values imputation using Fuzzy K-Top Matching Value. Journal of King Saud University - Computer and Information Sciences, 35 (1), 426–437. doi:10.1016/j.jksuci.2022.12.011
- Allen, R.G., et al., 1998. FAO Irrigation and Drainage Paper No. 56 - Crop Evapotranspiration.
- Altan, N.T. and Ustundag, B.U., 2012. Reconstruction of missing meteorological data using wavelet transform. 2012 1st international conference on agro-geoinformatics (agro-geoinformatics) 2012, Shanghai, China, 225–231.
- Anjomshoaa, A. and Salmanzadeh, M., 2019. Filling missing meteorological data in heating and cooling seasons separately. International Journal of Climatology, 39 (2), 701–710. doi:10.1002/joc.5836
- Balogun, A.A., et al., 2009. Surface energy balance measurements above an exurban residential neighbourhood of Kansas City, Missouri. Boundary-Layer Meteorology, 133 (3), 299–321. doi:10.1007/s10546-009-9421-3
- Başakın, E.E., Ekmekcioğlu, Ö., and Özger, M., 2023. Developing a novel approach for missing data imputation of solar radiation: a hybrid differential evolution algorithm based eXtreme gradient boosting model. Energy Conversion and Management, 280 (February), 116780. doi:10.1016/j.enconman.2023.116780
- Basheer Shukur, O. and Hisyam Lee, M., 2015. Imputation of missing values in daily wind speed data using hybrid AR-ANN method. Modern Applied Science, 9 (11), 11. doi:10.5539/mas.v9n11p1
- Bayram, S. and Çıtakoğlu, H., 2023. Modeling monthly reference evapotranspiration process in Turkey: application of machine learning methods. Environmental Monitoring and Assessment, 195 (67). doi:10.1007/s10661-022-10662-z
- Beaulieu-Jones, B.K., et al., 2018. Characterizing and managing missing structured data in electronic health records: data analysis. JMIR Medical Informatics, 6 (1), e11. doi:10.2196/medinform.8960
- Boudhina, N., et al., 2018. Evaluating four gap-filling methods for eddy covariance measurements of evapotranspiration over hilly crop fields. Geoscientific Instrumentation, Methods and Data Systems, 7 (2), 151–167. doi:10.5194/gi-7-151-2018.
- Bowen, I.S., 1926. The ratio of heat losses by conduction and by evaporation from any water surface. Physical Review, 27 (6), 779–787. doi:10.1103/PhysRev.27.779
- Burakowski, E., et al., 2018. The role of surface roughness, albedo, and Bowen ratio on ecosystem energy balance in the Eastern United States. Agricultural and Forest Meteorology, 249 (October 2017), 367–376. doi:10.1016/j.agrformet.2017.11.030
- Burba, G., Madsen, R., and Feese, K., 2013. Eddy covariance method for CO2 emission measurements in CCUS applications: principles, instrumentation and software. Energy Procedia, 40, 329–336. doi:10.1016/j.egypro.2013.08.038
- Chen, X., et al., 2016. The interpolation of missing wind speed data based on optimized LSSVM model. 2016 IEEE 8th International Power Electronics and Motion Control Conference, IPEMC-ECCE Asia 2016, (1), 1448–1451.
- Chen, Y.Y., Chu, C.R., and Li, M.H., 2012. A gap-filling model for eddy covariance latent heat flux: estimating evapotranspiration of a subtropical seasonal evergreen broad-leaved forest as an example. Journal of Hydrology, 468–469, 101–110. doi:10.1016/j.jhydrol.2012.08.026
- Cheval, S., Dumitrescu, A., and Amihaesei, V.-A., 2020. Exploratory analysis of urban climate using a gap-filled landsat 8 land surface temperature data set. Sensors, 20 (18), 5336. doi:10.3390/s20185336
- Costa, R.L., et al., 2021. Gap filling and quality control applied to meteorological variables measured in the northeast region of Brazil. Atmosphere, 12 (10), 1–20. doi:10.3390/atmos12101278
- Coulibaly, P. and Evora, N.D., 2007. Comparison of neural network methods for infilling missing daily weather records. Journal of Hydrology, 341 (1–2), 27–41. doi:10.1016/j.jhydrol.2007.04.020
- de Oliveira, R.C.G., et al., 2021. Forecasts of tropospheric ozone in the Metropolitan Area of Rio de Janeiro based on missing data imputation and multivariate calibration techniques. Environmental Monitoring and Assessment, 193, 531. doi:10.1007/s10661-021-09333-2
- Deb Burman, P.K., et al., 2019. Seasonal variation of evapotranspiration and its effect on the surface energy budget closure at a tropical forest over north-east India. Journal of Earth System Science, 128 (5), 1–21. doi:10.1007/s12040-019-1158-x
- Demirhan, H. and Renwick, Z., 2018. Missing value imputation for short to mid-term horizontal solar irradiance data. Applied Energy, 225 (March), 998–1012. doi:10.1016/j.apenergy.2018.05.054
- Dimas, F., Gilani, S., and Aris, M., 2011. Hourly solar radiation estimation from limited meteorological data to complete missing solar radiation data. International Conference on Enviroment Science and Engineering IPCBEE, 8, 14–18.
- Du, J., et al., 2019. Ensemble interpolation of missing wind turbine nacelle wind speed data in wind farms based on robust particle swarm optimized generalized regression neural network. International Journal of Green Energy, 16 (14), 1210–1219. doi:10.1080/15435075.2019.1671396
- Dumitrescu, A., Brabec, M., and Cheval, S., 2020. Statistical gap-filling of SEVIRI land surface temperature. Remote Sensing, 12 (9), 1–15. doi:10.3390/rs12091423
- Eamus, D., et al., 2013. Carbon and water fluxes in an arid-zone acacia savanna woodland: an analyses of seasonal patterns and responses to rainfall events. Agricultural and Forest Meteorology, 182–183, 225–238. doi:10.1016/j.agrformet.2013.04.020
- Ernst, M. and Gooday, J., 2019. Methodology for generating high time resolution typical meteorological year data for accurate photovoltaic energy yield modelling. Solar Energy, 189 (December 2018), 299–306. doi:10.1016/j.solener.2019.07.069
- Eum, Y. and Yoo, E., 2022. Imputation of missing time-activity data with long-term gaps: a multi-scale residual CNN-LSTM network model. Computers, Environment and Urban Systems, 95 (May), 101823. doi:10.1016/j.compenvurbsys.2022.101823
- Foltýnová, L., Fischer, M., and McGloin, R.P., 2020. Recommendations for gap-filling eddy covariance latent heat flux measurements using marginal distribution sampling. Theoretical and Applied Climatology, 139 (1–2), 677–688. doi:10.1007/s00704-019-02975-w
- Gao, Y., et al., 2018. A review on missing hydrological data processing. Environmental Earth Sciences, 77 (2), 47. doi:10.1007/s12665-018-7228-6
- Gautam, C. and Ravi, V., 2015. Data imputation via evolutionary computation, clustering and a neural network. Neurocomputing, 156, 134–142. doi:10.1016/j.neucom.2014.12.073
- Goodrich, J.P., et al., 2021. Improved gap filling approach and uncertainty estimation for eddy covariance N2O fluxes. Agricultural and Forest Meteorology, 297 (November 2020), 108280. doi:10.1016/j.agrformet.2020.108280
- Guo, X., et al., 2007. Quality control and flux gap filling strategy for Bowen ratio method: revisiting the Priestley-Taylor evaporation model. Environmental Fluid Mechanics, 7 (5), 421–437. doi:10.1007/s10652-007-9033-8
- Hasan, K., et al., 2021. Informatics in Medicine Unlocked Missing value imputation affects the performance of machine learning : a review and analysis of the literature (2010–2021). Informatics in Medicine Unlocked, 27, 100799. doi:10.1016/j.imu.2021.100799
- Hasanpour Kashani, M. and Dinpashoh, Y., 2012. Evaluation of efficiency of different estimation methods for missing climatological data. Stochastic Environmental Research and Risk Assessment, 26 (1), 59–71. doi:10.1007/s00477-011-0536-y
- He, H., et al., 2013. Ensemble learning for wind profile prediction with missing values. Neural Computing and Applications, 22 (2), 287–294. doi:10.1007/s00521-011-0708-1
- Hocaoglu, F.O., Oysal, Y., and Kurban, M., 2009. Missing wind data forecasting with adaptive neuro-fuzzy inference system. Neural Computing and Applications, 18 (3), 207–212. doi:10.1007/s00521-008-0172-8
- Hron, K., Templ, M., and Filzmoser, P., 2010. Imputation of missing values for compositional data using classical and robust methods. Computational Statistics and Data Analysis, 54 (12), 3095–3107. doi:10.1016/j.csda.2009.11.023
- Huang, Y., et al., 2020. Evaluation of different methods for gap filling of long-term actual evapotranspiration time series measured by lysimeters. Vadose Zone Journal, 19 (1), 1–15. doi:10.1002/vzj2.20020
- Hui, D., et al., 2004. Gap-filling missing data in eddy covariance measurements using multiple imputation (MI) for annual estimations. Agricultural and Forest Meteorology, 121 (1–2), 93–111. doi:10.1016/S0168-1923(03)00158-8
- Jamshidian, M., Jalal, S., and Jansen, C., 2014. MissMech: an R package for testing homoscedasticity, multivariate normality, and Missing Completely at Random (MCAR). Journal of Statistical Software, 56 (6). doi:10.18637/jss.v056.i06
- Jiang, X., et al., 2014. Crop coefficient and evapotranspiration of grain maize modified by planting density in an arid region of northwest China. Agricultural Water Management, 142, 135–143. doi:10.1016/j.agwat.2014.05.006
- Kadow, C., Hall, D.M., and Ulbrich, U., 2020. Artificial intelligence reconstructs missing climate information. Nature Geoscience, 13 (6), 408–413. doi:10.1038/s41561-020-0582-5
- Katipoğlu, O.M., 2022. Prediction of missing temperature data using different machine learning methods. Arabian Journal of Geosciences, 15 (1), 1–11. doi:10.1007/s12517-021-09290-7
- Kim, T., Ko, W., and Kim, J., 2019. Analysis and impact evaluation of missing data imputation in day-ahead PV generation forecasting. Applied Sciences (Switzerland), 9 (1), 204.
- Kim, T.W. and Ahn, H., 2009. Spatial rainfall model using a pattern classifier for estimating missing daily rainfall data. Stochastic Environmental Research and Risk Assessment, 23 (3), 367–376. doi:10.1007/s00477-008-0223-9
- Koksal, E.S., et al., 2017. Estimating missing hourly climatic data using artificial neural network for energy balance based ET mapping applications. Meteorological Applications, 24 (3), 457–465. doi:10.1002/met.1644
- Körner, P., et al., 2018. Introducing Gradient Boosting as a universal gap filling tool for meteorological time series. Meteorologische Zeitschrift, 27 (5), 369–376. doi:10.1127/metz/2018/0908
- Kunwor, S., et al., 2017. Preserving the variance in imputed eddy-covariance measurements: alternative methods for defensible gap filling. Agricultural and Forest Meteorology, 232, 635–649. doi:10.1016/j.agrformet.2016.10.018
- Langkamp, D.L., Lehman, A., and Lemeshow, S., 2010. Techniques for handling missing data in secondary analyses of large surveys. Academic Pediatrics, 10 (3), 205–210. doi:10.1016/j.acap.2010.01.005
- Lara-Estrada, L., et al., 2018. Inferring missing climate data for agricultural planning using Bayesian networks. Land, 7 (1), 1–13. doi:10.3390/land7010004
- Lee, H.S. and Chou, M.T., 2004. Fuzzy forecasting based on fuzzy time series. International Journal of Computer Mathematics, 81 (7), 781–789. doi:10.1080/00207160410001712288
- Lee, K., Yoo, H., and Levermore, G.J., 2010. Generation of typical weather data using the ISO Test Reference year (TRY) method for major cities of South Korea. Building & Environment, 45 (4), 956–963. doi:10.1016/j.buildenv.2009.10.002
- Li, S.G., et al., 2007. Evapotranspiration from a Mongolian steppe under grazing and its environmental constraints. Journal of Hydrology, 333 (1), 133–143. doi:10.1016/j.jhydrol.2006.07.021
- Li, T., et al., 2019. Fill missing data for wind farms using long short-term memory based recurrent neural network. Proceedings of 2019 IEEE 3rd International Electrical and Energy Conference, CIEEC 2019, Beijing, China, 705–709.
- Lin, Q. and Wang, J., 2014. Vertically correlated echelon model for the interpolation of missing wind speed data. IEEE Transactions on Sustainable Energy, 5 (3), 804–812. doi:10.1109/TSTE.2014.2304971
- Lin, W.C. and Tsai, C.F., 2020. Missing value imputation: a review and analysis of the literature (2006–2017). Artificial Intelligence Review, 53 (2), 1487–1509. doi:10.1007/s10462-019-09709-4
- Liu, T., Wei, H., and Zhang, K., 2018. Wind power prediction with missing data using Gaussian process regression and multiple imputation. Applied Soft Computing Journal, 71, 905–916. doi:10.1016/j.asoc.2018.07.027
- Lompar, M., et al., 2019. Filling gaps in hourly air temperature data using debiased ERA5 data. Atmosphere, 10 (13), 1–24. doi:10.3390/atmos10010013
- López, J.L., et al., 2021. Effect of missing data on short time series and their application in the characterization of surface temperature by detrended fluctuation analysis. Computers and Geosciences, 153 (March), 104794. doi:10.1016/j.cageo.2021.104794
- Lo Presti, R., Barca, E., and Passarella, G., 2010. A methodology for treating missing data applied to daily rainfall data in the Candelaro River Basin (Italy). Environmental Monitoring and Assessment, 160 (1–4), 1–22. doi:10.1007/s10661-008-0653-3
- Mahabbati, A., et al., 2021. A comparison of gap-filling algorithms for eddy covariance fluxes and their drivers. Geoscientific Instrumentation, Methods and Data Systems, 10 (1), 123–140. doi:10.5194/gi-10-123-2021
- Mao, Y. and Jian, M., 2016. Data completing of missing wind power data based on adaptive BP neural network. 2016 International Conference on Probabilistic Methods Applied to Power Systems, PMAPS 2016 - Proceedings, Beijing, China, 1–6.
- Meher, J.K. and Das, L., 2019. Gridded data as a source of missing data replacement in station records. Journal of Earth System Science, 128 (3), 58. doi:10.1007/s12040-019-1079-8
- Miró, J.J., Caselles, V., and Estrela, M.J., 2017. Multiple imputation of rainfall missing data in the Iberian Mediterranean context. Atmospheric Research, 197 (February), 313–330. doi:10.1016/j.atmosres.2017.07.016
- Ng, W.W., Panu, U.S., and Lennox, W.C., 2009. Comparative studies in problems of missing extreme daily streamflow records. Journal of Hydrologic Engineering, 14 (1), 91–100. doi:10.1061/(ASCE)1084-0699(2009)14:1(91)
- Ogunsola, O.T. and Song, L., 2014. Restoration of long-term missing gaps in solar radiation. Energy & Buildings, 82, 580–591. doi:10.1016/j.enbuild.2014.07.088
- Oke, T.R., 2002. Boundary layer climates. Routledge.
- Özger, M., et al., 2020. Comparison of wavelet and empirical mode decomposition hybrid models in drought prediction. Computers and Electronics in Agriculture, 179 (September), 105851. doi:10.1016/j.compag.2020.105851
- Park, I., et al., 2019. Temperature prediction using the missing data refinement model based on a long short-term memory neural network. Atmosphere, 10 (11), 1–16. doi:10.3390/atmos10110718
- Rezvan, P.H., Lee, K.J., and Simpson, J.A., 2015. The rise of multiple imputation : a review of the reporting and implementation of the method in medical research. BMC Medical Research Methodology, 15 (30), 1–14. doi:10.1186/s12874-015-0022-1
- Rubin, D.B., 1976. Inference and missing data. Biometrika, 63 (3), 581–592. doi:10.1093/biomet/63.3.581
- Sattari, M.T., et al., 2020. Potential of kernel and tree-based machine-learning models for estimating missing data of rainfall. Engineering Applications of Computational Fluid Mechanics, 14 (1), 1078–1094. doi:10.1080/19942060.2020.1803971
- Schmidt, A., Wrzesinsky, T., and Klemm, O., 2008. Gap filling and quality assessment of CO2 and water vapour fluxes above an urban area with radial basis function neural networks. Boundary-Layer Meteorology, 126 (3), 389–413. doi:10.1007/s10546-007-9249-7
- Schwandt, M., et al., 2014. Development and test of gap filling procedures for solar radiation data of the Indian SRRA measurement network. Energy Procedia, 57, 1100–1109. doi:10.1016/j.egypro.2014.10.096
- Sexstone, G.A., et al., 2016. Comparison of methods for quantifying surface sublimation over seasonally snow-covered terrain. Hydrological Processes, 30 (19), 3373–3389. doi:10.1002/hyp.10864
- Shtiliyanova, A., et al., 2017. Kriging-based approach to predict missing air temperature data. Computers and Electronics in Agriculture, 142 (October), 440–449. doi:10.1016/j.compag.2017.09.033
- Sidibe, M., et al., 2018. Trend and variability in a new, reconstructed streamflow dataset for West and Central Africa, and climatic interactions, 1950–2005. Journal of Hydrology, 561 (March), 478–493. doi:10.1016/j.jhydrol.2018.04.024
- Silva-Ramírez, E.L., Pino-Mejías, R., and López-Coello, M., 2015. Single imputation with multilayer perceptron and multiple imputation combining multilayer perceptron and k-nearest neighbours for monotone patterns. Applied Soft Computing, 29, 65–74. doi:10.1016/j.asoc.2014.09.052
- Sovilj, D., et al., 2016. Extreme learning machine for missing data using multiple imputations. Neurocomputing, 174, 220–231. doi:10.1016/j.neucom.2015.03.108
- Strike, K., Emam, K.E., and Madhavji, N., 2001. Software cost estimation with incomplete data. IEEE Transactions on Software Engineering, 27 (10), 890–908. doi:10.1109/32.962560
- Tabari, H. and Talaee, P.H., 2015. Reconstruction of river water quality missing data using artificial neural networks. Water Quality Research Journal of Canada, 50 (4), 326–335. doi:10.2166/wqrjc.2015.044
- Tang, A.C.I., et al., 2019. The exchange of water and energy between a tropical peat forest and the atmosphere: seasonal trends and comparison against other tropical rainforests. Science of the Total Environment, 683, 166–174. doi:10.1016/j.scitotenv.2019.05.217
- Thevakaran, A. and Sonnadara, D.U.J., 2018. Estimating missing daily temperature extremes in Jaffna, Sri Lanka. Theoretical and Applied Climatology, 132 (1–2), 145–152. doi:10.1007/s00704-017-2082-0
- Turrado, C.C., et al., 2014. Missing data imputation of solar radiation data under different atmospheric conditions. Sensors (Switzerland), 14 (11), 20382–20399. doi:10.3390/s141120382
- Wang, L. and Shi, J., 2021. A comprehensive application of machine learning techniques for short-term solar radiation prediction. Applied Sciences (Switzerland), 11 (13), 5808.
- Wesonga, R., 2015. On multivariate imputation and forecasting of decadal wind speed missing data. SpringerPlus, 4 (1). doi:10.1186/s40064-014-0774-9
- Williams, D.A., et al., 2018. A comparison of data imputation methods using Bayesian compressive sensing and Empirical Mode Decomposition for environmental temperature data. Environmental Modelling and Software, 102, 172–184. doi:10.1016/j.envsoft.2018.01.012
- Xie, Z.X. and Sun, X.F., 2018. Imputation of missing wind speed data based on low-rank matrix approximation. 2017 2nd International Conference on Power and Renewable Energy, ICPRE 2017, Chengdu, China, 397–401.
- Xu, C.D., et al., 2013. Interpolation of missing temperature data at meteorological stations using P-BSHADE. Journal of Climate, 26 (19), 7452–7463. doi:10.1175/JCLI-D-12-00633.1
- Yang, Z., Liu, Y., and Li, C., 2011. Interpolation of missing wind data based on ANFIS. Renewable Energy, 36 (3), 993–998. doi:10.1016/j.renene.2010.08.033
- Yang, Z., Xue, F., and Lu, W., 2021. Handling missing data for construction waste management: machine learning based on aggregated waste generation behaviors. Resources, Conservation and Recycling, 175 (June), 105809. doi:10.1016/j.resconrec.2021.105809
- Yozgatligil, C., et al., 2013. Comparison of missing value imputation methods in time series: the case of Turkish meteorological data. Theoretical and Applied Climatology, 112 (1–2), 143–167. doi:10.1007/s00704-012-0723-x
- Zainudin, M.L., Saaban, A., and Bakar, M.N.A., 2015. Estimation of missing values in solar radiation data using piecewise interpolation methods: case study at Penang city. AIP conference proceedings, 1691 (December).
- Zhang, L., Bing, Z., and Zhang, L., 2015. A hybrid clustering algorithm based on missing attribute interval estimation for incomplete data. Pattern Analysis and Applications, 18 (2), 377–384. doi:10.1007/s10044-014-0376-8
- Zhang, Y. and Thorburn, P.J., 2022. Handling missing data in near real-time environmental monitoring: a system and a review of selected methods. Future Generation Computer Systems, 128, 63–72. doi:10.1016/j.future.2021.09.033
- Zhao, F., et al., 2022. Multiple imputation method of missing credit risk assessment data based on generative adversarial networks. Applied Soft Computing, 126, 109273. doi:10.1016/j.asoc.2022.109273
- Zhou, Q., Xian, G., and Shi, H., 2020. Gap fill of land surface temperature and reflectance products in landsat analysis ready data. Remote Sensing, 12 (7), 1–16. doi:10.3390/rs12071192
- Zitouna-Chebbi, R., et al., 2018. Observing actual evapotranspiration from flux tower eddy covariance measurements within a hilly watershed: case study of the Kamech site, Cap Bon Peninsula, Tunisia. Atmosphere, 9 (2), 1–17. doi:10.3390/atmos9020068
- Žliobaitė, I., Hollmén, J., and Junninen, H., 2014. Regression models tolerant to massively missing data: a case study in solar-radiation nowcasting. Atmospheric Measurement Techniques, 7 (12), 4387–4399. doi:10.5194/amt-7-4387-2014
- Zouzou, Y. and Citakoglu, H., 2023. General and regional cross-station assessment of machine learning models for estimating reference evapotranspiration. Acta Geophysica, 71 (2), 927–947. doi:10.1007/s11600-022-00939-9