
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The dependency structure between hydrological variables is of critical importance to hydrological modelling and forecasting. When a copula capturing that dependence is fitted to a sample, information on the uncertainty of the fit is needed for subsequent hydrological calculations and reasoning. A new method is proposed to report inferential uncertainty in a copula parameter. The method is based on confidence curves constructed with the use of a pseudo maximum likelihood estimator for the copula parameter. The method was tested on synthetic data and then used as a tool in two hydrological examples. The first examines the probability of major floods in two locations on the Rhine River and its tributaries in the same calendar year. In the second example, rainfall–runoff from a karst region in Tunisia was analysed to determine a confidence interval for the delay between precipitation and runoff.
Editor A. Castellarin; Associate Editor T. Kjeldsen
1 Introduction
Properly dealing with uncertainty in all its variations is an important aspect of both the science of hydrology and its engineering applications (Blöschl et al. Citation2019, problem 21). This study focuses on inferential uncertainty. In hydrology, this is dealt with either through Bayesian analysis and summarized by posterior distributions or with the help of frequentist methods and reported in terms of confidence intervals. A third option is presented here: the confidence curve. A confidence curve provides much more information to the user than a confidence interval. In fact, a curve provides information similar to that contained in a Bayesian posterior distribution but in a frequentist context and without the need for a prior distribution. Moreover, confidence curves from different studies can be combined, and the result is a valid representation of the information on the parameter of interest contained in those studies (Cunen and Hjort Citation2021).
While a confidence curve is more generally applicable and can be defined without first introducing the confidence distribution concept, the idea behind the modern approach to confidence curves and confidence distributions is the same. According to Schweder (Citation2018, p. 116), “the confidence of confidence intervals and confidence distributions is a concept of epistemic probability” and “By presenting the confidence curve, and thus confidence intervals of all levels, the reader is given a complete picture of the inferential uncertainty ...” (ibid., p. 118). To translate a confidence curve into such a picture, consider the following interpretation of the confidence curve. The width of a confidence interval at a given confidence level shows the trade-off between confidence and uncertainty. If a confidence interval is small, then the estimate has low uncertainty. Since a confidence curve is comprised of confidence intervals at all confidence levels, the shape of it will provide insight into the uncertainty in the parameter estimate: the smaller the confidence intervals at high confidence levels, the lower the uncertainty.
The popularity of the Bayesian approach to statistics in the hydrological community is clear from the literature. It is also easily understood, because a Bayesian method produces a posterior distribution for the parameter value. However, a Bayesian approach requires a prior distribution, construction of the posterior, which can be computationally intensive, and acceptance of the Bayesian viewpoint. Finally, Bayesian and frequentist methods may well complement each other (Bayarri and Berger Citation2004). Therefore, it is worthwhile to study confidence curves and confidence distributions as they provide information on the uncertainty in parameter estimates that resembles the information obtained from Bayesian methods. Confidence curves can be used in many situations (Zhou et al. Citation2020, Citation2023). In this study, a new confidence curve construction method is proposed that is intended to represent inferential uncertainty in copula parameters. Ko and Hjort (Citation2019) also construct confidence curves for copula parameters, but they use a two-stage process (first fitting the marginals, and then the copula), while the method presented here can build a confidence curve for the copula parameter without first fitting the marginals. After the introduction of the method, its properties are studied using synthetic time series generated from the Clayton, Frank, and Gumbel copulas. These are one-parameter copulas. Such copulas are popular in hydrology because the time series under study are often relatively short, so the number of parameters that can realistically be estimated is limited. Next, two examples of the application of confidence curves constructed with this method are given. The first examines the probability of major floods in two different locations on the Rhine River and its tributaries occurring in the same calendar year. In the second example, rainfall–runoff from a karst region in Tunisia was analysed to determine a confidence interval for the delay between precipitation and runoff. Finally, we present our conclusions. An overview of the notation used, the definition of a confidence curve, and some other useful facts are provided in the appendices.
2 Methodology
This section describes the construction of a confidence curve for the parameter of a one-parameter copula. In this article random variables (RVs), random vectors, and random matrices will be marked by an underscore (Hemelrijk Citation1966, Koutsoyiannis et al. Citation2017). The confidence curve will be constructed from a given observed time series of length n. It is assumed that this time series can be modelled as a sequence of two-dimensional random vectors . This
has two associated time series of RVs that correspond to the components of the random vectors
and
. It is assumed that the
are independent identically distributed (iid) RVs with cumulative distribution function (cdf) F, and that the same holds for the
, but with cdf G. It is also assumed that for a given i the RVs
and
have a joint distribution with cdf H and that H does not depend on the value of i. In the remainder of the paper,
will stand for the random sample
; x will represent a realization
of that sample, and
will stand for a specific observed time series. The same holds for
, y, and
. The cdf H will be modelled by a copula C
where C is a Frank, Clayton, or Gumbel copula (for details, see Appendix C). The construction method of the confidence curve has as its most important ingredient the algorithm used to estimate the copula parameter.
2.1 Copula parameter estimation
In most cases, it is not known what type of parametric distribution best fits the marginals of H, which complicates copula parameter estimation. To avoid this complication, Genest et al. (Citation1995) proposed a pseudo log-likelihood approach, where instead of parametric marginals, a rescaled version of the empirical cumulative distribution function (ecdf) was used. The rescaled ecdfs for and
are
As pseudo log-likelihood Genest et al. (Citation1995) took
where c is the probability density function (pdf) of the copula, and introduced
as pseudo maximum likelihood estimator (pmle) for , which is a consistent and asymptotically normal estimator. Chen and Fan (Citation2005) showed this holds even under model mis-specification.
For a given set of observations , the calculation is performed as follows:
which results in the estimate
for the copula parameter .
Note that if is a strictly increasing function, then a calculation of
from
,
will give the same result as a calculation of
directly from
. In fact, one could even replace
by its rank in the sorted sequence of the
. The same holds for the
.
2.2 The construction of approximate confidence curves
Construction of an exact confidence curve (Appendix A, Definition 3) is quite difficult, because, like the construction of confidence distributions, it is not (yet) a question of applying a simple standard approach. However, there is a standard method to construct an approximate confidence curve for a parameter (Schweder and Hjort Citation2016). It assumes that a log-likelihood function is available. In this article, the pseudo log-likelihood defined earlier will be used. The construction of the approximate confidence curve is based on the deviance function D, defined by
For , this function assumes its minimum value. The statistical properties of the deviance follow from
The cdf for
is defined as
which, in this case, is unknown. If were a true likelihood, then, according to Wilks’ theorem (Wilks Citation1938), for the true parameter value
, the deviance
would be approximately
distributed. As Chen and Fan (Citation2005) have shown that the limit distribution for the estimator
is approximately normal, it is reasonable to assume that a version of Wilks’ theorem could be proved for the current deviance (see also Schweder and Hjort Citation2016). Therefore
will be approximated by a
distribution with one degree of freedom to avoid the additional computation time needed for a Monte Carlo approximation. With
as notation for the cdf of the
distribution with one degree of freedom, the approximate confidence curve is given by
. For known
and
, the value of the confidence curve for
can be calculated as follows:
calculate
and
determine the value
use
use the cdf
2.3 Properties of confidence curves
To allow for proper comparison between copulas, the confidence curves for have been transformed into confidence curves for Kendall’s
using .
Table 1. Parameter ranges and the relation between and Kendall’s
, where
is the first Debye function (Abramowitz and Stegun Citation1970).
The value of Kendall’s corresponding to
is denoted by
. To examine the usefulness of the confidence curves constructed according to the given algorithm, a statistical analysis of several key properties was performed. The following properties of these confidence curves were examined:
Actual coverage versus nominal coverage at all confidence levels (see also Appendix A). The actual coverage probability should be close to the nominal coverage probability. If the actual coverage probability is lower than the nominal one, then a confidence curve has a permissive coverage; it is too optimistic about finding the parameter in the interval. If the actual coverage probability is higher than the nominal one, then a confidence curve has conservative coverage, so it is unnecessarily pessimistic about finding the parameter in the interval.
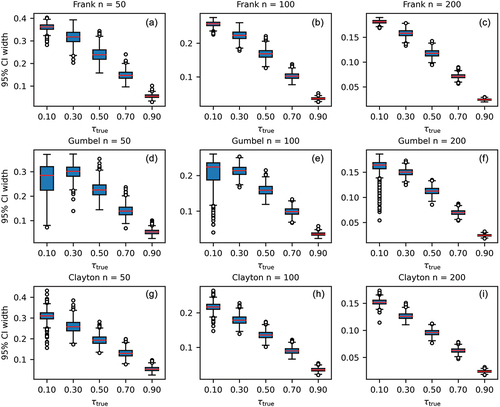
The width of the 95% confidence interval. For all confidence levels, confidence intervals can be extracted from the confidence curve. Of most interest are those with a confidence above 50%. As a representative of that group, the 95% confidence interval was chosen. The size of a confidence interval gives an indication of its usefulness. In fact, for a parameter whose value is restricted to the interval [–1,1], such as Kendall’s
The difference between
3 Evaluation of the method with synthetic data
In order to evaluate the method, synthetic datasets from the three copulas (Frank, Gumbel, Clayton) were generated. The different copulas have different parameter ranges (see ). Because the parameter ranges all extend to positive infinity, it would be difficult to directly compare results for confidence intervals for different copulas. Fortunately, for all three copulas, there is a strictly increasing function that maps the copula parameter to a value of Kendall’s . This allows displaying the results for the copula in terms of
. Because the Gumbel copula cannot model negative correlations, only samples from copulas with positive
were used.
3.1 Synthetic time series generation
To determine the statistical properties of the method, synthetic time series of length were generated by drawing from the Clayton, Frank, and Gumbel copulas for
. For each combination of copula family, length, and
, a set of N = 1000 time series was generated. For each set, the resulting 1000 confidence curves were used to analyse the coverage of the associated confidence intervals, the frequency distribution of the estimate
, and the frequency distribution of the width of the confidence intervals at the 95% level. For each
value the corresponding value of
for a given copula was calculated using the formula from and is listed in . The parameter value that was used to generate a specific series will be denoted by
and the corresponding
by
.
Table 2. Copula parameter for given Kendall’s
.
3.2 Examples of synthetic data
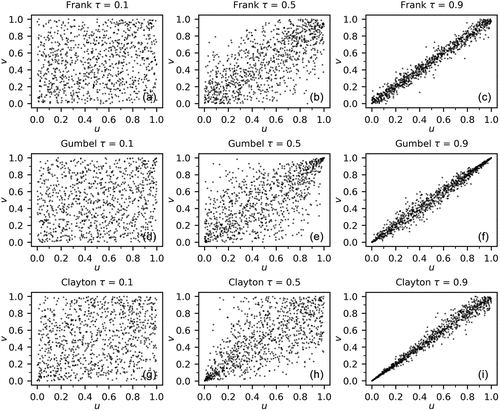
Several synthetic samples are shown in . When (), the correlation between u and v is clearly visible. For
(), a plot of the
pairs does not show a clear pattern. For the Frank copula with
, ) shows correlation over the whole range, but with peaks of equal height in the lower left and upper right corner. For Gumbel with
, the plot in ) displays some correlation over the whole range, somewhat stronger in the lower left corner, and very strong correlation in the upper right corner. For Clayton with
, the role of the corners is reversed ().
Figure 1. Scatter plots of a sample from a copula with τ = 0.1, 0.5, 0.9 and n = 100.
The approximate confidence curves for for the bivariate copula samples () are shown in . A confidence curve reaches its lowest point,
, at the pseudo maximum likelihood estimate
. For other positions of
,
lies within
. A traditional 95% confidence level is presented in a dashed line in each plot, and one can extract a nominal confidence interval for
with a confidence level of 95% from each confidence curve.
Figure 2. Example of confidence curves for τ for one of the synthetic samples for each copula with = 0.1, 0.5, 0.9 and n = 100.
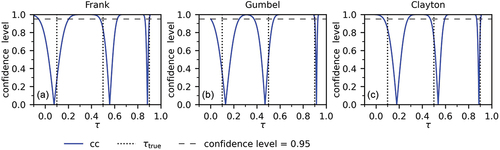
shows that, in principle, a confidence curve for contains more information than one confidence interval for a single confidence level. It also shows that, as
increases, the widths of the confidence intervals that make up the curve decrease. However, shows that the actual coverage for high
is permissive, so part of the decrease may be due to an underestimation of the interval width. shows that some of the decrease is real.
Figure 3. Box plots of for different copulas and different sample sizes.
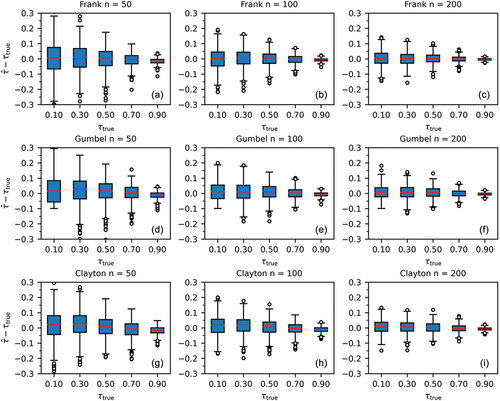
3.3 Spread in the estimate of Kendall’s τ
The box plots in show that for both the spread of the outliers and the interquartile distance decrease with increasing sample length for all copulas. The spread of the outliers and the interquartile distance for
also decrease with increasing
.
This decrease in spread may be caused by the high correlation associated with high values. However, as shown by , the spread in the copula parameter increases with increasing parameter values. The non-linear relation between
and
and between
and the copula shape make it difficult to determine what the actual variation in the copula shape is for a given variation in
.
Figure 4. Box plots of for different copulas and different sample sizes.
3.4 Actual coverage probability for Kendall’s τ
The actual coverage of the confidence interval associated with the confidence curve was examined for all confidence levels. The actual versus nominal coverage probability for random copula samples is shown in , and the coverage at the 95% confidence level is listed in . According to the results shown in , sample length has little effect on the actual coverage probability up to , and the actual coverage probability does not change much when n increases from 50 to 200. For
, the sample length has a visible effect on the actual coverage probability for the Frank and Gumbel copulas but not for the Clayton copula ().
Table 3. Actual coverage probability (%) of a confidence interval with a nominal coverage probability of 95%.
Figure 5. Actual coverage probability versus the nominal one for in copulas.
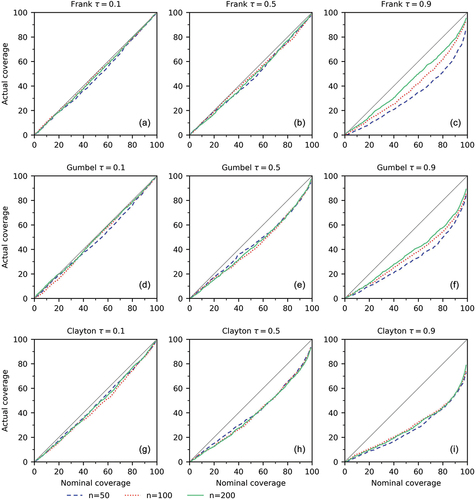
The dependence level strongly influences the coverage. If the samples are weakly dependent, for instance when , then the actual coverage probability is close to nominal (). For samples with high dependence, for instance for
, the actual coverage probability is lower than the nominal ().
For bivariate samples from a Frank copula with and nominal coverage probability of 95%, the actual coverage probability is only 73% for n = 50, 84.6% for n = 100, and 86.5% for n = 200. Results are similar for the other copulas ().
The statistics for in show that the error in the estimate of
decreases with increasing
. The results in are in line with this, but shows that the interval widths for high
are overly optimistic. So, while strong dependence is associated with lower uncertainty, the approximate confidence curves calculated by the current version of our code are too optimistic for values of
close to 1. Better coverage could perhaps be obtained by using the techniques suggested in Schweder and Hjort (Citation2016) to improve the accuracy of the approximation of the confidence curve.
3.5 The width of 95% confidence intervals for the dependence parameter in copulas
Information on the distribution of the widths of the 95% confidence intervals is shown in . The figure shows that the sample length n has a significant effect: the interval width decreases as n gets larger. Therefore, the uncertainty about decreases as the sample length gets larger. These results are in qualitative agreement with those shown in .
Figure 6. Box plots of the width of confidence intervals for a 95% confidence level.
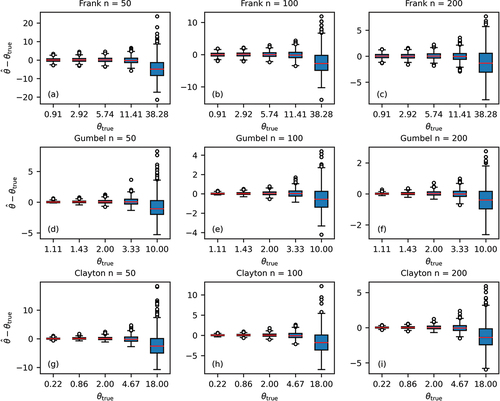
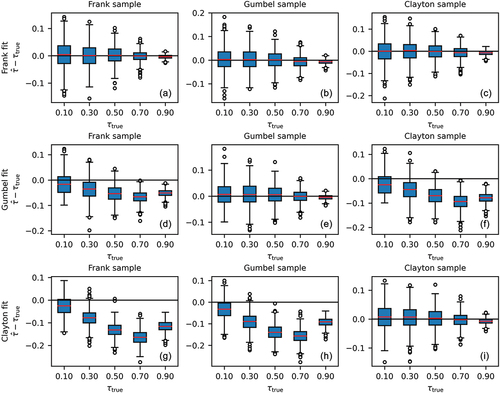
3.6 Effects of the mis-specification of copula
Box plots of the difference between the true value and the estimate of in the synthetic experiments are given in . If the Clayton or Gumbel copula was used to fit a sample from one of the other copula families and calculate, then this resulted in a biased estimate (). The Frank copula did much better in this respect (). While it is not unexpected that mis-specification has an adverse effect, because of the different shape of the three copulas, it is still worth noting that the Frank copula provides a good estimate of
, even when applied to a Gumbel or Clayton copula, while the reverse does not hold.
Figure 7. Box plots of the difference between the true value and the estimate of τ in the synthetic experiments with n = 200.
4 Two examples of the use of the method on observed hydrological time series
The method introduced in this study can be used to examine the uncertainty about dependence between time series and the effects of this uncertainty on an analysis based on that dependence. Two examples are given. In the first example the method is used to show the uncertainty about the dependence structure for yearly extremes for several pairs of measurement stations on the Rhine River and its tributaries. The second example investigates estimating the lag between rainfall and runoff for a karst area and the uncertainty in that estimate.
4.1 The relation between time series of annual maxima in the Rhine and its tributaries
In this section the dependency structure of annual minimum or maximum flows will be examined. This structure can be used to answers questions such as
What is the probability that high flows will occur in different parts of the same catchment within a given year? This question may be of interest from an insurance, government budget, or disaster preparation point of view.
If only series of annual maximum flows are available for branches of a given river system, then can these series provide any information about links between high flows upstream and high flow downstream? If only a time series of annual maximum flows is available, without dates of occurrence, then the probability that two flows will augment each other cannot be determined. However, the probability of a combination of two high flows in the same year is a definite upper bound on the probability that they would combine to generate high discharges downstream. The accuracy of the approximation depends on the way the yearly maximum is determined.
If only series of annual minimum flows are available, then can these series provide any information about navigability of the system?
Are all parts of the catchment responding in the same way to climate change? In this case dependence between yearly statistics should not change from one period to another.
4.1.1 Methodology used to examine uncertainty of the dependency of return periods
The mapping from annual maximum flows to return periods is a strictly increasing function. In Section 2.1 it was shown that due to the preparatory step for the fitting method used in this article, mapping discharges to return periods or vice versa will not change the result of the fitting process. This implies that using the fitting method to determine the copula parameters for the three different copulas and the associated uncertainty will tell us something about the dependence structure of the return periods. More specifically, are high return periods correlated, and if yes, then how? For the corresponding copula, this would mean that there should be a peak in the pdf in the upper right hand corner of the (u,v) plane. The uncertainty in the dependence structure can be examined by looking at the copula corresponding to the estimated parameter and the difference between that copula and copulas corresponding to the lower or upper bound of a confidence interval for a given confidence level.
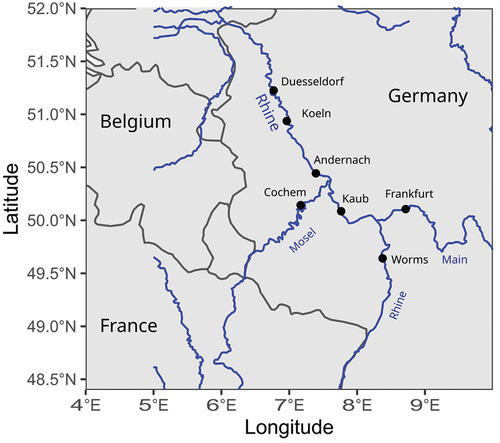
Time series of annual daily maximum flows for several stations for the Rhine and one station each for the Mosel and the Main were obtained from the Global Runoff Data Center (GRDC Citation2021). The stations are shown in . As the time series are series of annual maxima, a copula package by Hofert et al. (Citation2020) was used to extend the collection of one-parameter copulas applied to the series with additional copulas specifically suited for extreme values: Galambos and Huesler-Reiss (Appendix C.2). Of the other extreme value copulas, the Tawn copula was not considered because it is limited to values for Kendall’s below 0.418, and the t-EV copula was not considered because it has two parameters. To allow for high correlation both for low and for high return periods, the copulas that have different correlation structure for low and high parameters (Clayton, Gumbel, Galambos, Huesler-Reiss) were tried both in their standard orientation and after a 180 degree rotation; the rotated copula will be denoted by adding “180°” after the copula name. As in the rest of the paper, the uncertainty in the parameter is represented by a confidence curve for Kendall’s
. For a given
, the shape of the Galambos and Huesler-Reiss copulas is very close to that of the Gumbel copula.
Figure 8. Station locations.
4.1.2 Results found for uncertainty in dependency structure of return periods
To illustrate the type of results that would be obtained, four pairs of measurement stations were selected that were expected to have different dependency structures. For each pair the discharge at a station downstream of the confluence point was determined. The pair Andernach and Koeln serves as a test case. For these stations a near perfect correlation was expected because no major tributaries enter the river between the stations. ) confirms this. ) shows that high discharges at the downstream station tend to be correlated as well. Values of the parameter and
values can be found in , respectively. The other station pairs combine a station on a tributary with a station on the Rhine upstream of the confluence. All pairs show definite correlation, as the bounds of the confidence intervals up to 99% are well away from zero (). For all pairs the best fit was obtained with the version of Gumbel, Galambos or Huesler-Reiss that is rotated 180° around the point (0.5,0.5) in the (u,v) plane. Given the shape of the pdf of these copulas, with a peak in the lower left quadrant, this could suggest stronger correlation for short return periods than for long return periods. However, the scarcity of points in the upper right corner could also have caused this preference for the rotated version ().
Table 4. Dependence parameters between time series and width of the 95% confidence intervals for the estimate of dependence parameter.
Table 5. Kendall’s values between time series and width of the 95% confidence intervals.
Figure 9. Confidence curves and scatter plots for pairs of stations. Discharge at the downstream station is indicated by the colour of the dots in the scatter plots.
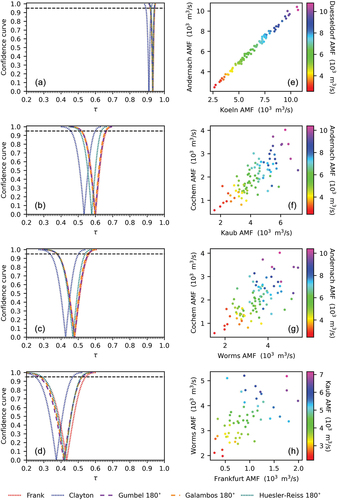
In the scatter plots () colour is used to show the discharge at a station downstream of the confluence of tributary and main river. These plots were added to show that even the (at first sight oversimplified) approach of looking for dependence between high discharges in the same calendar year may provide at least some information on high flows.
An illustration of the variation in shape of the pdf of a copula over a 95% confidence interval can be found in for the pair Cochem and Kaub. For example, for the Frank copula ) shows the pdf for ; ) shows the difference between the pdf at
and the pdf at the lower bound of the confidence interval, and ) shows the difference between the pdf at
and the pdf at the upper bound of the confidence interval. Similar plots are shown for the other copulas.
Figure 10. The pdfs for copulas for the station pair Cochem and Kaub.
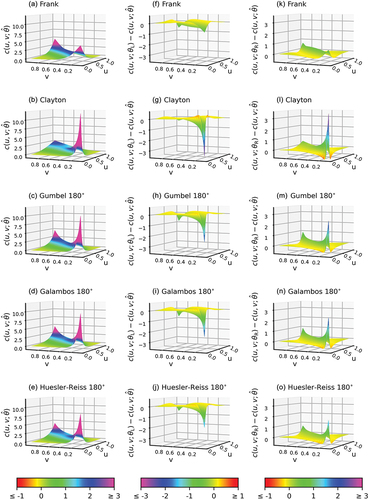
The confidence curves provide the variation in the copula at different confidence levels and therefore provide insight into the effect of uncertainty on specific joint return times. While the whole upper quadrant ([0.5,1] × [0.5,1]) would be of interest, limitations deriving from viewing three-dimensional information in two dimensions usually lead to examination of exceedance frequencies or, equivalently, return periods. The relation between return periods and copulas is discussed by Salvadori et al. (Citation2007, sec. 3.3). For instance, the probability that in a specific year the discharges in both rivers are in the top 10% of return periods corresponds with the integral of the pdf of the copula over the rectangle [0.9,1] × [0.9,1], which corresponds to the value where
which relates to a return period by , where
is the the mean inter-arrival time (for annual maxima this is one year). We can now relate the copula to return periods for combined
,
floods. The confidence curve allows us to pick a copula parameter range associated with a given confidence level. As a result, we get a confidence interval for the return period of two floods within the same year.
4.2 Dependence structure between rainfall and discharge for a karst area
The relation between rainfall onto and runoff out of a catchment is determined by physical processes and therefore it is a deterministic one. However, there is considerable epistemic uncertainty about the processes and their parameters. As a result, the relation between rainfall and runoff may seem to be different at different times. The simplest possible deterministic model for this relation would be one in which the runoff is a shifted and scaled version of the rainfall. A first improvement would be replacement of the simple scaling relationship by a joint distribution of runoff and shifted rainfall. The model would be constructed by fitting a dependence structure to the shifted rain and the runoff for a range of shifts. The shift would be chosen by assuming that the dependence would be strongest for a shift that best corresponded to the delay between rainfall and runoff. This approach would only work if the shift could be determined with sufficient certainty. It was decided to investigate the uncertainty in the estimate of the shift with the confidence curve method proposed in this article, using a dataset from the Djebel Zaghouan region in Tunisia.
The Djebel Zaghouan is the most important Jurassic formation of the Zaghouan massif and lies about 50 km to the south of Tunis. The massif consists mainly of overlapping limestone monoclines. It is also contains marls of the Cretaceous and Eocene (Castany Citation1951). The Djebel Zaghouan is characterized by the presence of southern and transverse faults that have created blocks (Ferjani et al. Citation2020). These faults facilitate infiltration. The Zaghouan karst aquifer covers an area of approximately 19.6 km2 (). In the eastern part, conditions are favourable for the storage of seepage water, whereas in the western part marl deposits result in a much lower storage coefficient (Djebbi et al. Citation2001).
Figure 11. Location of the karst area. Both figures combine Google Map data ©2015 with material from Natural Earth.
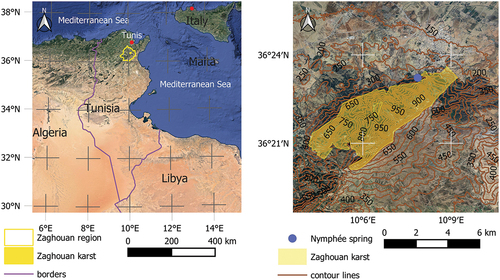
The Zaghouan region lies on the border between the upper semi-arid and the sub-humid climate zones. It is characterized by an average annual rainfall of 467 mm (values ranging from 245 to 625 mm) with a heterogeneous spatial and temporal distribution. Rainfall measurements were taken on a daily basis at the “Zaghouan controle” station (latitude: 36.39583N; longitude: 10.14917E) during the period from 1915 to 1944. However, there are gaps in the data for the entire year of 1929 and for January 1930. These gaps were filled by using data from the nearby station “Zaghouan SM” (latitude: 36.40306N; longitude: 10.14472E). This resulted in a complete series of daily and weekly cumulative rainfall. The discharge series used was recorded from 1915 to 1943 at the Nymphée spring. It was originally recorded in graphical form only. Measurements were taken at irregular intervals with frequencies varying from twice weekly to monthly. To extract information, the graphical data was digitized. The time series contains two atypical years: a very wet one during the hydrological year running from September 1920 to August 1921 and a relatively dry hydrological year starting in 1926. These resulted in total volumes of 6.5 × 106 m3 and 1.9 × 106 m3, respectively. A fragment of the original document from the archive of hydrological yearbooks of the General Directorate of Water Resources (abbreviated DGRE, in French) containing the hydrograph (curve) from 1924 to 1926 is shown in . Major engineering works were performed in 1944, but the data from 1915 to 1943 reflects the natural flow conditions.
Figure 12. The hydrograph (curve) for Nymphée spring from 1924 to 1926. The figure also contains a monthly hyetograph (bars).
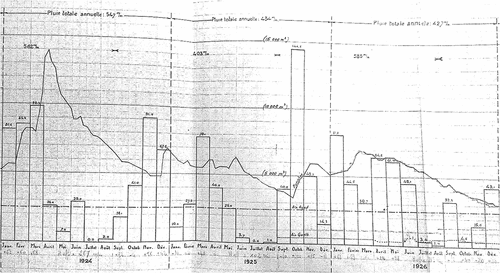
These observations are consistent with the natural flow of the resurgences during this period. According to the criteria in Olarinoye et al. (Citation2020), the accuracy and quality of the hydrograph is class A: the discharge observation measurement is known, recognition of individual events on the spring’s hydrograph, recognition of seasonal events on the spring’s hydrograph, and identification of recession events on the hydrograph (see ). The karst falls into class 6 as defined by Cinkus et al. (Citation2021) in the Karst Aquifer Resources availability and quality in the Mediterranean Area (KARMA) project. The karst has a minimum inertia of two months, so it was deemed appropriate to acquire consistent time series of daily, weekly, and monthly flows by linear interpolation. The daily flow series was used primarily to test the algorithm. Today, the aquifer is fully exploited to provide drinking water to the city of Zaghouan. Unfortunately, this overexploitation has hindered the natural reemergence of springs in this region for many years.
4.2.1 Methodology used to determine the shift between rainfall and runoff
The lag between rainfall and runoff was estimated by fitting copulas to the rainfall time series and a version of the runoff series that was shifted by m steps for m ranging from 0 up to . To avoid artefacts due to different time series lengths for different lags, the last
points of the rainfall time series were dropped and the shifted runoff series length was adjusted to match. Different copulas were fitted to see if this made an appreciable difference in the results. The lag was estimated by
where is the estimate of the copula parameter. The pmle is asymptotically normal (Genest et al. Citation1995). An estimate of the standard deviation of this normal distribution was obtained by taking the 95% confidence interval and translating this into a standard deviation for the normal distribution. For selected values, this was checked against calculations using the R copula package, which gave very similar results but took much longer to perform the calculations and sometimes ran into problems when the procedure did not converge. The lag estimate was used to get bounds on the lag as follows:
Construct an interval
For each
For each m draw random values
For all
For each i, determine the lag corresponding to the maximum value of
4.2.2 Results found for the lag
shows daily rainfall and runoff for the karst area. In addition, a line is plotted representing the runoff shifted backward in time over a number of days corresponding to the estimated lag. Frank, Gumbel, and Clayton confidence curves for are shown in , and for time steps of one day, one week, and one month, respectively. The results for a time step of one day served mainly to test the algorithm.
Figure 13. Daily rainfall, runoff, and shifted runoff.
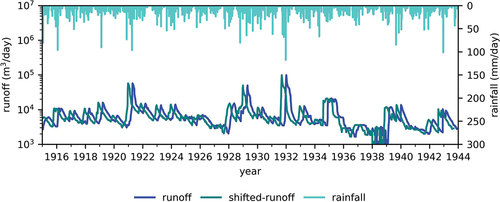
Figure 14. Kendall’s τ for different lags and confidence curves for the selected lag (CI = confidence interval).
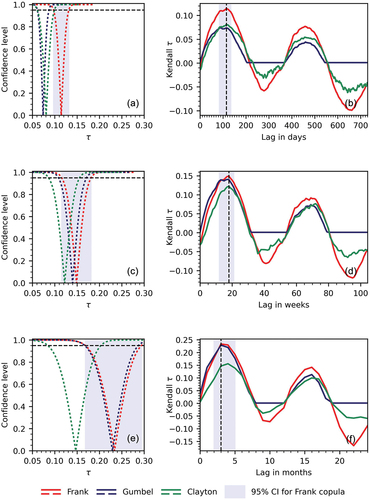
The curves of versus the lag m for Frank, Gumbel, and Clayton are shown in , and for time steps of one day, one week, and one month, respectively. The estimated lag and confidence interval are shown for the Frank copula only. Please note that the Gumbel copula can only model positive correlations, so a result of zero was returned when the dependence would result in a negative
. The Frank copula consistently delivered the highest values. Lags of about 3 to 4 months were found at all temporal scales. provides values of the lag estimates and the 90% and 95% confidence intervals for these estimates. The confidence intervals show that the results for all time scales and all copulas are compatible. This was in accordance with results obtained with the conceptual KarstMod model and with neural networks in the KARMA project (Mazzilli et al. Citation2019, KARMA Citation2021).
Table 6. Table of lags and confidence intervals.
5 Conclusions
In this article, a new method was developed that uses confidence curves as a means to represent epistemic uncertainty in the estimate of the copula parameter for one-parameter copulas. A pseudo maximum likelihood estimator (pmle), denoted by , was used to estimate the copula parameter
for synthetic and real data. For the copulas used here, there is a one-to-one correspondence between the
and Kendall’s
that respects ordering. This allows better comparison between results of different copulas and a more convenient interpretation, so the parameter
of each copula was transformed into the corresponding
and
was transformed into
.
Confidence curves have the advantage that they offer much more information than just one confidence interval. In fact, they offer about the same amount of information as an a posteriori Bayes distribution, but without the need to first find the correct prior. In hydrology, such information is especially important because the decisions based on hydrological analyses usually have a large impact, and the questions posed can rarely be adequately answered with a simple yes or no. A confidence curve allows the exploration of a range of answers based on different levels of confidence.
Statistical analysis of confidence curves constructed from synthetic time series resulted in the following findings:
For all copulas a box plot showed that
For all copulas a comparison of actual and nominal coverage shows that the confidence curves are permissive, especially for
For all copulas, the width of the 95% confidence interval decreased with increasing time series length and increasing
The pmle for the Frank copula provided good estimates for
For the Rhine River case study, two results stand out. Firstly, all extreme value copulas fit best when rotated 180°, and, secondly, the parameter estimate and the confidence curve for Kendall’s delivered by the Frank copula are very close to the estimates and the confidence curves corresponding to the extreme value copulas. This suggests that the effect observed for synthetic data, namely that Frank seemed to give good results for Kendall’s
even when the time series was drawn from another copula, may well extend to real time series.
For the Tunisian karst region, the pmle estimate was mapped to a value, and this was used to estimate the lag between rainfall and runoff. The confidence curve for the
corresponding to the chosen lag served as an initial check on the relevance of the correlation. It was also used to approximate the distribution of the points on the curve of the estimated
versus the lag m. This in turn allowed the generation of alternative curves and an estimate of a confidence interval for the lag. The lag found was in accordance with results of earlier research. As the Gumbel copula cannot model negative correlations, this copula gave no results when the actual correlation was negative. When calculating
for the different lags, the Frank copula gave values that were larger in magnitude than the Clayton and Gumbel copulas. The delays found are in accordance with the results obtained with the conceptual KarstMod model and with neural networks in the KARMA project (Mazzilli et al. Citation2019, KARMA Citation2021).
In both cases, the confidence curves for the copula parameter allowed simple propagation of the uncertainty in the parameter to quantities of direct hydrological significance, and in both cases, the Frank copula gave the highest estimate for Kendall’s .
All results show that confidence curves for copula parameters are a valuable addition to the hydrological tool set and can be used in a wide variety of hydrological settings. Earlier work already showed the value of confidence curves for change point analysis (Zhou et al. Citation2020, Citation2023). In certain cases confidence curves may provide an alternative to Bayesian methods. Further research is planned to see whether the coverage can be corrected either by a correction factor, as suggested for a more general case by Schweder and Hjort (Citation2016), or through the use of Monte Carlo simulation to generate an approximate probability distribution for the deviance.
Acknowledgements
This work was partially developed within the framework of the Panta Rhei research initiative (Montanari etal. Citation2013, McMillan etal. Citation2016) of the International Association of Hydrological Sciences (IAHS) by members of the working group on ‘Natural and man-made control systems in water resources’. The authors thank the Regional Commissariat for Agricultural Development of Zaghouan (CRDA Zaghouan) for providing the rainfall–runoff data for the Zaghouan karst region.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Abramowitz, M. and Stegun, I.A., 1970. Handbook of mathematical functions. New York: Dover Publications Inc.
- Bayarri, M.J. and Berger, J.O., 2004. The interplay of Bayesian and frequentist analysis. Statistical Science, 19 (1), 58–80. doi:10.1214/088342304000000116.
- Blöschl, G., et al., 2019. Twenty-three Unsolved Problems in Hydrology (UPH) – a community perspective. Hydrological Sciences Journal, 64 (10), 1141–1158. doi:10.1080/02626667.2019.1620507.
- Castany, G., 1951. Geological study of the Tunisian Eastern Atlas. Besançon: Imp de l’IEST.
- Chen, X. and Fan, Y., 2005. Pseudo-likelihood ratio tests for semiparametric multivariate copula model selection. Canadian Journal of Statistics, 33 (3), 389–414. doi:10.1002/cjs.5540330306.
- Cinkus, G., Mazzilli, N., and Jourde, H., 2021. Identification of relevant indicators for the assessment of karst systems hydrological functioning: proposal of a new classification. Journal of Hydrology, 603 (December), 127006. doi:10.1016/j.jhydrol.2021.127006.
- Cunen, C. and Hjort, N.L., 2021. Combining information across diverse sources: the II-CC-FF paradigm. Scandinavian Journal of Statistics, 49 (2), 625–656. doi:10.1111/sjos.12530.
- Djebbi, M., et al., 2001. Les sources karstiques de Zaghouan. Recherche d’un opérateur pluie-débit. In: Conference on limestone hydrology and fissured media, 125–128.
- Favre, A.C., et al., 2004. Multivariate hydrological frequency analysis using copulas. Water Resources Research, 40 (1). doi:10.1029/2003wr002456.
- Ferjani, A.H., et al., 2020. Enhanced characterization of water resource potential in Zaghouan region, Northeast Tunisia. Natural Resources Research, 29 (5), 3253–3274. doi:10.1007/s11053-020-09647-x.
- Genest, C. and Favre, A.C., 2007. Everything you always wanted to know about copula modeling but were afraid to ask. Journal of Hydrologic Engineering, 12 (4), 347–368. doi:10.1061/(ASCE)1084-0699(2007)12:4(347).
- Genest, C., Ghoudi, K., and Rivest, L.P., 1995. A semiparametric estimation procedure of dependence parameters in multivariate families of distributions. Biometrika, 82 (3), 543–552. doi:10.1093/biomet/82.3.543.
- GRDC, 2021. Long-term statistics and annual characteristics of GRDC timeseries data. The Global Runoff Data Centre, 56068 Koblenz, Germany. Available from: https://www.bafg.de/GRDC.
- Hemelrijk, J., 1966. Underlining random variables. Statistica Neerlandica, 20 (1), 1–7. doi:10.1111/j.1467-9574.1966.tb00488.x.
- Hofert, M., et al, 2020. Copula: multivariate dependence with copulas. Available from: https://CRAN.R-project.org/package=copula.
- KARMA, 2021. Karst aquifer resources availability and quality in the Mediterranean area. Available from: http://karma-project.org/ .
- Ko, V. and Hjort, N.L., 2019. Model robust inference with two-stage maximum likelihood estimation for copulas. Journal of Multivariate Analysis, 171 (May), 362–381. doi:10.1016/j.jmva.2019.01.004.
- Koutsoyiannis, D., et al., 2017. From fractals to stochastics: seeking theoretical consistency in analysis of geophysical data. In: A. Tsonis, ed. Advances in nonlinear geosciences. Cham: Springer, 237–278. doi:10.1007/978-3-319-58895-7_14.
- Mazzilli, N., et al., 2019. KarstMod: a modelling platform for rainfall-discharge analysis and modelling dedicated to karst systems. Environmental Modelling & Software, 122 (December), 103927. doi:10.1016/j.envsoft.2017.03.015.
- McMillan, H., et al., 2016. Panta Rhei 2013-2015: global perspectives on hydrology, society and change. Hydrological Sciences Journal, 61 (7), 1174–1191. doi:10.1080/02626667.2016.1159308.
- Montanari, A., et al., 2013. “Panta Rhei - everything flows”: change in hydrology and society - the IAHS scientific decade 2013–2022. Hydrological Sciences Journal, 58 (6), 1256–1275. doi:10.1080/02626667.2013.809088.
- Olarinoye, T., et al., 2020. Global karst springs hydrograph dataset for research and management of the world’s fastest-flowing groundwater. Scientific Data, 7 (1). doi:10.1038/s41597-019-0346-5.
- Salvadori, G. and De Michele, C., 2004. Frequency analysis via copulas: theoretical aspects and applications to hydrological events. Water Resources Research, 40 (12), W12511, 1–17. doi:10.1029/2004WR003133.
- Salvadori, G. and De Michele, C., 2007. On the use of copulas in hydrology: theory and practice. Journal of Hydrologic Engineering, 12 (4), 369–380. doi:10.1061/(asce)1084-0699(2007)12:4(369).
- Salvadori, G., et al., 2007. Extremes in nature. Dordrecht, The Netherlands: Springer. doi:10.1007/1-4020-4415-1.
- Schweder, T., 2018. Confidence is epistemic probability for empirical science. Journal of Statistical Planning and Inference, 195 (May), 116–125. doi:10.1016/j.jspi.2017.09.016.
- Schweder, T. and Hjort, N.L., 2016. Confidence, likelihood, probability. statistical inference with confidence distributions. Cambridge: Cambridge University Press. doi:10.1017/CBO9781139046671.
- Sklar, A., 1959. Fonctions de répartition à n dimensions et leurs marges. Publications de l’Institut de Statistique de l’Université de Paris, 8, 229–231.
- Wilks, S.S., 1938. The large-sample distribution of the likelihood ratio for testing composite hypotheses. The Annals of Mathematical Statistics, 9 (1), 60–62. doi:10.1214/aoms/1177732360.
- Zhou, C., van Nooijen, R., and Kolechkina, A., 2023. Capturing the uncertainty about a sudden change in the properties of time series with confidence curves. Journal of Hydrology, 617 (February), 129092. doi:10.1016/j.jhydrol.2023.129092.
- Zhou, C., et al., 2020. Confidence curves for change points in hydrometeorological time series. Journal of Hydrology, 590 (November), 125503. doi:10.1016/j.jhydrol.2020.125503.
Appendices Appendix A.
Notations and definitions
The probability of a given event E is denoted by Pr(E). The indicator function is a very useful function in statistics, but the notation used for it varies widely. In this article, an abbreviated form of the traditional notation is used. If A is a set, then the indicator function is 1 for elements of A and 0 elsewhere:
In probability theory, it is often applied to RVs with as set an interval like ; in that case the following abbreviation is used:
Let be a random sample of size n where the
are independent identically distributed random vectors, and
a realization of such a sample. In the following definitions,
is a property of the distribution of
that can be expressed as a real number; it can be one of the distribution parameters, one of its moments, or perhaps a specific quantile.
Definition 1. A confidence set for at a given confidence level
is a set valued function
such that for the true value
of
the expression
is a random set that satisfies
The value is the nominal coverage probability. In practice, (A2) may not hold exactly, either because it holds only when the sample size n tends to infinity, or because it was derived under assumptions on the sample that are only approximately satisfied during the experiment. The actual coverage probability of a confidence interval is the probability of the confidence interval containing the true value of a statistic
in the experiment as it was performed. A confidence interval is a special case of a confidence set.
Definition 2. If f is a function from to
, then a sub-level set of f at level
is a set
Definition 3. A confidence curve is a function from
to [0,1] that satisfies the following conditions (Schweder and Hjort Citation2016, Definition 4.3):
The sub-level set of
There is a function
For all realizations
For the true value
For a confidence curve , the actual coverage probability of a confidence interval at a confidence level of
for a sample of size n can be estimated by
It should be close to the nominal coverage probability .
Appendix B.
An uninformative confidence interval for τ
It is known that . Now suppose that
and there is no a priori information on the location of
. If a point y is selected at random in the interval
, then
so
This implies that, as long as there is no a priori reason to assume the parameter has a certain value, it is possible to obtain a confidence interval at level without using the sample, as long as an interval length of (at least)
is allowed.
Appendix C.
Copulas
Copulas were introduced by Sklar (Citation1959). For a modern overview and hydrological examples see, for instance, Salvadori and De Michele (Citation2004, Citation2007), Favre et al. (Citation2004), or Genest and Favre (Citation2007).
Appendix C.1 Some Archimedean copulas
Appendix C.1.1. Frank copula
The cdf for the Frank copula is
where or
. The pdf for the Frank copula is
Appendix C.1.2. Clayton copula
The cdf for the Clayton copula is
where . The pdf for the Clayton copula is
where
Appendix C.1.3. Gumbel copula
The cdf for the Gumbel copula is
where . The pdf for the Gumbel copula is
Appendix C.2 Some extreme value copulas
A bivariate extreme value copula is a copula that satisfies
The Gumbel copula described earlier is an extreme value copula.
Appendix C.2.1. Galambos copula
The cdf for the Galambos copula is
where .
Appendix C.2.2. Huesler-Reiss copula
The cdf for the Huesler-Reiss copula is
where and
is the cdf of the univariate standard normal distribution.