
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
There is a growing interest to get a fully MR based radiotherapy. The most important development needed is to obtain improved bone tissue estimation. The existing model-based methods perform poorly on bone tissues. This paper was aimed at obtaining improved bone tissue estimation. Skew-Gaussian mixture model and Gaussian mixture model were proposed to investigate CT image estimation from MR images by partitioning the data into two major tissue types. The performance of the proposed models was evaluated using the leave-one-out cross-validation method on real data. In comparison with the existing model-based approaches, the model-based partitioning approach outperformed in bone tissue estimation, especially in dense bone tissue estimation.
1. Introduction
Magnetic resonance (MR) imaging and computed tomography (CT) are the most widely used diagnostic imaging technologies in medicine. They are used to obtain more detailed cross-sectional images of the human body. CT uses ionizing radiation to record a pattern of radiodensities to obtain cross-sectional images. The ionizing radiations are attenuated as they pass through the tissues of patients. The amount of attenuations depends on the tissue types. The differences in attenuation between adjacent tissues create contrast on CT images. Tissues with higher (or lower) attenuation appear brighter (or darker) on grayscale CT images. As a result, air, soft, and bone tissues appear as darkest, darker, and white on grayscale CT images. Therefore, the CT image is excellent for identifying and assessing the structures of bone tissues. On the other hand, exposing a patient to ionizing radiation in CT imaging may have a risk for radiation-related cancer.
MR imaging is remarkably different from CT. It does not depend on ionizing radiations. MR imaging relies on the absorption and emission of radio waves from tissue protons exposed to a strong magnetic field. Thus, MR imaging is safer than CT imaging. The relative MR signal intensity differences between adjacent anatomic structures determine tissue contrast on MR images. In comparison with CT images, MR images show much better soft tissue contrast and noticeably improves the delineation of tumors. However, MR images are poor in depicting bone tissues. The reason is that bone, air, and rapidly flowing blood appear black on grayscale MR images.
A new innovation MR-only based radiotherapy enhances tissue contouring and precision in soft tissue therapy setup. It also improves biological information at treatment planning and avoids registration errors, which are errors due to the transformation of different images of the same scene into one coordinate system, between CT and MR images. Moreover, MR-only based radiotherapy is a cost-effective approach as it reduces redundant imaging. However, co-registered CT and MR image complement each other due to better bone tissue imaging of CT [Citation8,Citation10,Citation20]. MR images are not directly applicable for attenuation correction. Attenuation refers to the loss of signals due to absorption or scattering out of the signals in the body. CT images are vital for attenuation correction in positron emission tomography (PET) imaging. This is due to the direct relation between CT image intensities and PET attenuation coefficients. However, the CT scanner is not available in recently combined PET/MR imaging scanner. Therefore, MR-only based radiotherapy and the combined PET/MR imaging scanner can be successful if one can obtain a reliable CT image estimation. As a result, we need to develop a reliable CT image estimation method from MR images.
Huynh et al. [Citation14] used a learning-based method to estimate CT image from the MR image. A patch of CT image is estimated directly from a given MR image patch using the structured random forest. The robustness of the estimation has been evaluated using a new ensemble model. Nie et al. [Citation30] proposed a 3D deep learning-based method for patch-wise estimation of CT images from MR images. The neural network generates structured output and it preserves the neighborhood information in the estimated CT image. Arabi et al. [Citation1] suggested a two-step atlas-based algorithm to estimate CT image from MR image sequences. The estimation is mainly concerned with pinpointing of bone tissues.
Johansson et al. [Citation16] used a Gaussian mixture model (GMM) to obtain CT substitute from MR images without taking spatial dependence between neighboring voxels into account. Johansson et al. [Citation17] investigated the uncertainty associated to the voxel-wise estimation of CT images. By considering spatial dependence between neighboring voxels, Kuljus et al. [Citation22] extended the work of Johansson et al. [Citation16] by using hidden Markov model (HMM) and Markov random field (MRF) model. Kuljus et al. [Citation22] compared the estimation quality of GMM, HMM, and MRF. In terms of mean absolute error, HMM outperformed the other models and it was computationally robust than MRF. However, it had a weaker estimation quality on dense bone tissues. Even though MRF had superior performance on bone tissue estimation, it was computationally expensive.
The main aim of this article is to further investigate the voxel-wise estimation of CT images from MR images by partitioning the data into non-bone and bone tissues. According to Johansson et al. [Citation17] and Kuljus et al. [Citation22], the estimation of CT image was poor on air and bone tissues. It is this result that motivated the partitioning of the data into non-bone and bone tissues in order to further explore the estimation of CT images. Even though there is no clear-cut CT image intensity boundary between these tissue types, Waterstram-Rich and Gilmore [Citation33] and Washington and Leaver [Citation34] provide informative threshold delimiting these tissues. Waterstram-Rich and Gilmore [Citation33] used 150 Hounsfield units (HU) as a lower limit for bone tissues. On the other hand, Washington and Leaver [Citation34] utilized 200 HU as an approximate delimiting value of the tissues.
The partitioning of the data may introduce skewness. Consequently, there is a need to relax the normality assumption used in [Citation16,Citation17,Citation22]. Azzalini [Citation4] proposed a univariate skew-normal model that relaxed the normality assumption by incorporating a skewness parameter in the distributional assumption. Azzalini and Dalla Valle [Citation5] extended the univariate skew-normal to a multivariate skew-normal. A multivariate skew-normal is a tractable extension of a multivariate normal distribution with an extra parameter to regulate skewness. Lin et al. [Citation27] introduced a univariate skew-normal mixture model in order to deal with population heterogeneity and skewness. Lin [Citation25] extended the univariate skew-normal mixture model to a multivariate skew-normal mixture model which is an alternative to the most widely used multivariate Gaussian mixture model.
Kahrari et al. [Citation19] developed a multivariate skew-normal-Cauchy distribution and represented it as a shape mixture of the multivariate skew-normal distribution. Kahrari et al. [Citation18] modified the multivariate skew-normal-Cauchy distribution and the modified version becomes a shape mixture of a special case of the fundamental skew-normal distribution developed by Arellano-Valle and Genton [Citation3] with a univariate half-normal mixing distribution. The class of scale mixtures of skew-normal-Cauchy distributions has been represented as a shape mixture of the class of scale mixtures of skew-normal distributions with a univariate half-normal mixing distribution [Citation18]. Jamalizadeh and Lin [Citation15] presented the scale-shape mixtures of skew-normal distributions for modeling asymmetric data. Arellano-Valle et al. [Citation2] established a flexible class of multivariate distributions obtained by both scale and shape mixtures of multivariate skew-normal distributions. Based on the skew-t-normal distribution [Citation13], Tamandi et al. [Citation32] introduced the shape mixtures of the skew-t-normal distributions that contain one additional shape parameter to regulate skewness and kurtosis. The shape mixtures of the skew-t-normal distributions are a flexible extension of the skew-t-normal distribution. Lin et al. [Citation26] developed a multivariate extension of the skew-t-normal distribution that is obtained as a scale mixture of the multivariate skew-normal distribution introduced by Azzalini and Dalla Valle [Citation5]. Based on the multivariate skew-t-normal distribution, Lin et al. [Citation26] introduced a robust probabilistic mixture model which is composed of a weighted sum of a finite number of different multivariate skew-t-normal densities. The flexible mixture model based on the multivariate skew-t-normal distribution includes mixtures of normal, t and skew-normal distributions as special cases. Cabral et al. [Citation9] proposed mixture models which consist of members of skew-normal independent distributions (the skew-normal, the skew-t, the skew-slash and the skew-contaminated normal) and the mixture models are developed using the multivariate skew-normal distribution in [Citation5].
The most common approach to estimate the parameters of these skew-mixture models is the EM algorithm [Citation11]. However, its M-step for the recent skew-mixture models is computationally intractable. Alternatively, we use an EM-type algorithm to estimate these skew-mixture models. That is, we make further assumptions at the M-step of the EM algorithm. For instance, expectation conditional maximization (ECM) algorithm [Citation29], which replaces the M-step of EM with several computationally simple conditional maximization steps, can be enough to estimate the parameters of some mixture models. In mixtures of multivariate skew-t-normal distributions and shape mixtures of skew-t-normal distributions, expectation conditional maximization either (ECME) algorithm [Citation28] was exploited to estimate its parameters by replacing some conditional maximization-steps of ECM with the conditional maximization likelihood step that maximizes the correspondingly constrained actual-likelihood function. Cabral et al. [Citation9] developed an EM-type algorithm that removed some obstacles (for instance, Monte Carlo integration) during the parameter estimation process in mixture models of skew-normal independent distributions. In this article, we used a mixture model based on the multivariate skew-normal distribution in [Citation5] and developed EM-algorithm for its parameter estimation. That is, further assumption is not required at the M-step of EM algorithm to estimate the parameters of the skew-Gaussian mixture model.
In this work, we use skew-Gaussian mixture model (SGMM) and Gaussian mixture model (GMM) to further explore the estimation of CT images by partitioning the data into two major tissue types: non-bone and bone tissues. Non-bone tissues consist of subclasses such as white matter, blood, water, fat, gray matter, air, etc. while bone tissues consist of subclasses such as cranium, mandible, frontal bone, nasal bone, orbital bones, cortical bone, cancellous bone, etc. These facts motivated us to apply mixture models on these tissue types. SGMM involves a weighted sum of the joint skew-normal distributions of a CT image intensity and its corresponding intensities of MR images. The number of skew-normal distributions in the mixture depends on the number of underlying tissue types or clusters. Latent variables that represent the underlying tissue types are utilized during the parameter estimation process of the model through incomplete data assumption in EM-algorithm framework [Citation11]. Voxel-wise point estimator of CT image was obtained as a weighted sum of the conditional expected value of a CT image intensity given its corresponding intensities of MR images and the underlying tissue type. The probability that an underlying tissue type is determined based on the intensities of MR images was used as a weight of the conditional expected value.
In summary, this study is concerned with comparing the CT image estimation performance of the partitioning approach with HMM, MRF, and GMM on bone tissues. The models HMM, MRF, and GMM are trained on the full data (data that are not partitioned into non-bone and bone tissues). We are also interested to compare the predictive quality of the partitioning approaches, SGMM and GMM (GMM applied to each partition), on bone tissues.
This article is organized as follows. The second section describes data acquisition and demonstrates statistical methods. The third section presents the results obtained and the final section discusses the implication of the results.
2. Statistical methodology
In this section, we describe the data, formulate SGMM, and develop the parameter estimation method. We also demonstrate the CT image estimation method and present evaluation method of the estimation. For the remaining models (GMM, HMM and MRF), we refer to Kuljus et al. [Citation22] and the references therein.
2.1. Data acquisition
CT and MR images were obtained from the head of five patients. Four MR images were acquired from each patient using two dual echo ultrashort echo-time sequences with flip angles of 10 degrees and 30 degrees. The ultrashort echo-time sequences sampled a first echo (free induction decay) and a second echo (gradient echo) from the same excitation with an echo time of 0.07 and 3.76 ms. MR image of a patient was reconstructed to matrix. An entry in the matrix represents a signal intensity corresponding to a three-dimensional tissue (voxel) with size
. One CT image of a patient was acquired using gradient echo Lightspeed with 2.5 mm slice thickness. The acquired CT image was reconstructed with an in-plane resolution of
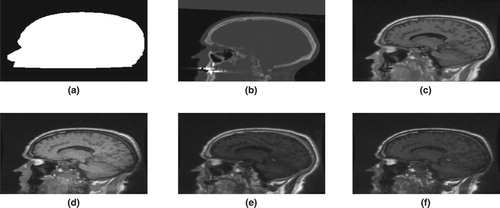
. One binary mask (an image with voxel value 1 (or 0) representing the region of interest (or the surrounding air)) was also developed to demarcate the head of a patient from its surrounding air. The main use of the binary mask is to exclude the surrounding air from the acquired CT and MR images. For each patient, the binary mask, the CT image, and the four MR images were co-registered and resampled to the same resolution (voxel-to-voxel correspondence and set to the same voxel dimension) using linear interpolation. For further technical details, we refer to Johansson et al. [Citation16]. Voxel values of the CT image, the binary mask, and the four MR images were organized into six columns to obtain data for a patient. The organized data of each patient were column stacked and the surrounding air removed to obtain data for model fitting. Figure shows a slice data for a given patient.
Figure 1. Binary mask (a), CT image (b) and MR images (c)–(f).
2.2. Data partitioning
This subsection describes data partitioning during model training. It also demonstrates how MR images of new patients are utilized during CT image prediction.
2.2.1. Data partition: model training
CT image intensity threshold was utilized to partition the data into two major tissue types. Using 150 HU CT image intensity as a limit, 50 HU (is selected to take the delimiting value provided by Washington and Leaver [Citation34]) overlap was allowed during the parameter estimation process. The overlap of the major tissue types was motivated in order to minimize the effect of fuzzy boundary of the tissue types. Accordingly, CT image intensities in (− 1024 HU, 200 HU) and ( 100 HU, 3071 HU] were assumed to represent non-bone and bone tissues. The minimum number of voxels for non-bone and bone tissues are 6,214,160 and 1,292,068.
2.2.2. MR images partition: CT image estimation
We are interested to predict CT images from MR images of new patients. Since we only have MR images of the new patients, there is a need to partition the MR images of the new patients into non-bone and bone tissues. There is poor bone tissue information on MR images and following that we estimate CT images for the new patients using a model trained on the full data, which is the data not partitioned into non-bone and bone tissues. The CT image intensity threshold and the estimated CT images are used to obtain MR data corresponding to the two major tissue types (non-bone and bone tissues). The trained models on the major tissue types are utilized to obtain the desired CT images of the new patients.
2.3. Statistical model: mixture of multivariate skew-normal model
Let and
represent voxel i of CT image and its corresponding MR images. In our real data,
. A d-dimensional random vector
is assumed to follow a multivariate skew-normal distribution
with a d-dimensional location parameter vector
, a
-dimensional positive definite dispersion matrix
, and a d-dimensional skewness parameter vector
. Its density can be given by
(1)
(1) where
,
is a univariate standard normal distribution function,
, and n is the number of voxels. According to Lachos et al. [Citation24], the stochastic representation of
may be given by
(2)
(2) where
(3)
(3) In Equation (Equation2
(2)
(2) ),
and
are assumed to be independent. The notations
,
, and
in Equation (Equation3
(3)
(3) ) represent d-dimensional zero vector,
-dimensional identity matrix, and half-normal distribution, respectively. Using Equation (Equation2
(2)
(2) ), a hierarchical model can be given by
(4)
(4)
where
Let
be a categorical random variable representing the underlying tissue types at voxel i. Define an indicator variable:
where
. The definition implies that
. Let
=
, which represents the weight that the
observation belongs to a tissue class k. To incorporate tissue heterogeneity into the statistical modeling,
is assumed to follow a multivariate skew-normal distribution
. This means that
follows a mixture of multivariate skew-normal distributions. Its density may be given by
where
The unknown parameters in
are estimated from the independent observations
.
2.4. Parameter estimation method
The log-likelihood function of the data can be given by
In general, there is no explicit analytical solution for
. However, iterative maximizing procedure under the idea of incomplete data via EM-algorithm can be used to obtain an optimal estimate of the parameters. Let
be a K-dimensional column vector of
. Its realization is a K-dimensional vector consisting 1 at only one location and 0 at the remaining locations. The latent random vector
follows a multinomial distribution with one trial and
. Using the indicator variable
, the hierarchical model (Equation4
(4)
(4) ) can be extended to
where
The observed data
is assumed to be incomplete data. It is augmented with the latent matrix
and the latent vector
to form a complete dataset
in EM-algorithm framework. Assuming that
is independent of
for every
, the complete-data log-likelihood is given by
(5)
(5)
where
and const is a constant function of parameters.
The E-step of EM-algorithm involves computing the expected value of the complete-data log-likelihood given and the current estimate
of
. It may be given by the Q-function:
(6)
(6) Using Equation (Equation5
(5)
(5) ), the expected value in Equation (Equation6
(6)
(6) ) involves computing
The expected value
can be given by
where
is the responsibility that the component k of the mixture takes for explaining the observation
. Let
, and
. Then
can be simplified as follows:
(7)
(7)
Using similar procedure,
may be given by
(8)
(8)
If Equations (Equation1(1)
(1) ) and (Equation4
(4)
(4) ) are satisfied, then using inverse matrix adjustment formula in [Citation31] and matrix determinant lemma in [Citation12],
where
is a truncated normal with location parameter μ, scale parameter σ and support
. Based on the truncated normal probability distribution,
(9)
(9)
(10)
(10)
where
and
is a univariate standard normal density. The expected values
in Equations (Equation7
(7)
(7) ) and (Equation8
(8)
(8) ) are obtained from Equations (Equation9
(9)
(9) ) and (Equation10
(10)
(10) ) by replacing
,
, and
with their corresponding estimates
,
, and
. The M-step of the EM-algorithm is given by
and it is available in closed form. Using EM-algorithm, the estimates of the parameter
can be updated as shown in Algorithm 1.
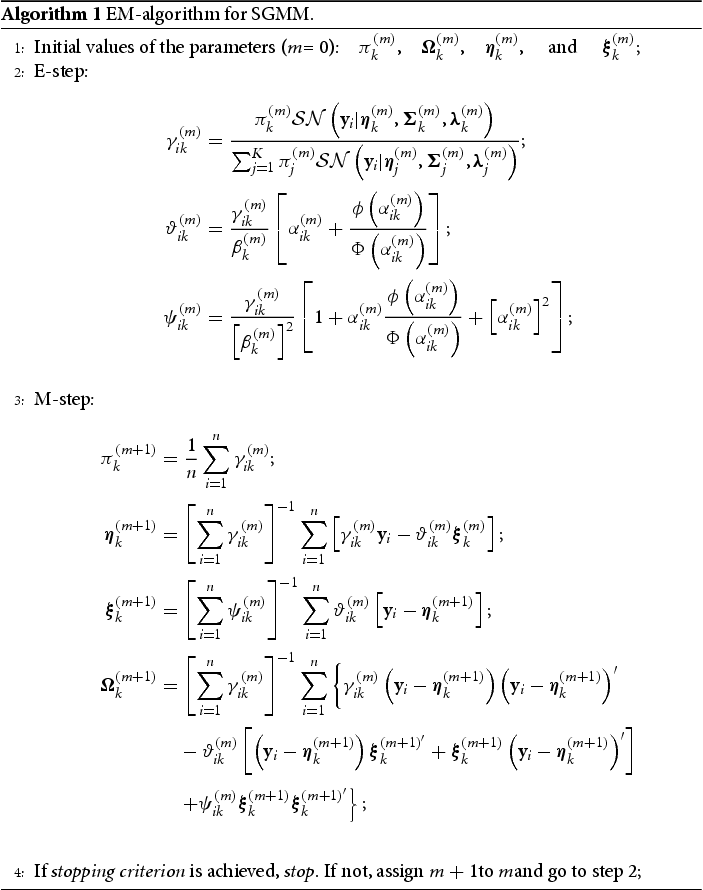
At mth iteration of the E-step, we need to compute the following expressions:
In general, EM-algorithm converges to a local optimum. As a result, different initial values for the parameters are utilized during the estimation process to select the optimal estimates. A clustering method K-means has been employed to initialize the location parameters, the mixing coefficients, and the dispersion matrices. This clustering method is used to partition the observations into clusters in which each observation belongs to the cluster with the nearest mean. In this study, the clusters may represent tissue types or mixture of tissue types such as white matter, blood, water, fat, gray matter, air, cortical bone, cancellous bone, etc. We randomly initialize the remaining parameters of SGMM. Log-likelihood value cannot be computed analytically for MRF [Citation22] and therefore, we cannot use it for selecting the optimal estimates. Following that we used mean squared error as criterion for selecting optimal estimates in SGMM in order to utilize the same criterion for the models used in this work. Two steps are employed during parameter estimation process. For a given number of tissue types, we estimated the parameters of the models and repeated this step to select the optimal parameter estimates using mean squared error. We selected the number of classes or tissue types through cross-validation using mean squared error. The stopping criterion for the convergence of the parameter estimation process is
with an upper limit
, where m denotes the iteration number of EM-algorithm.
2.5. Estimation of CT images
Let a d-dimensional vectors ,
, and a
dispersion matrix
be partitioned as follows:
The dimension of
,
,
, and
is a
. The random variable
represents the
voxel in CT image, and the random vector
denotes the corresponding voxel in MR images. If we assume that
follows SGMM:
(11)
(11) then
where
According to Khounsiavash et al. [Citation21], if Equation (Equation11
(11)
(11) ) holds, then the probability density function of
can be given by
(12)
(12) where
Proposition 2.1
Using Equation (Equation12(12)
(12) ), the expected value of
can be given by
(13)
(13)
Proof.
Let and
. The expected value of
can be given by
where
The result in Equation (Equation13
(13)
(13) ) follows from well known properties of the truncated normal distribution and inverse matrix adjustment formula.
Using Equation (Equation13(13)
(13) ), we can obtain the point estimator of
by
In this framework, the latent variable
represents the underlying tissue classes. The weight
can be computed using Bayes' theorem. The expected value
is obtained from Equation (Equation13
(13)
(13) ) by indexing the parameters with k.
2.6. Model validation
The main focus of this work is to investigate CT image predictive quality of SGMM and GMM by partitioning the data into two major tissue types. It is also aimed at comparing the estimation quality of the partitioning approach with GMM, HMM, and MRF on the bone tissues.
We used leave-one-out cross-validation method to compare the predictive quality of the models. That is, we keep one head to validate the models and use the remaining heads for training the models. Using the threshold CT image intensity, CT image in a validation dataset is partitioned into non-bone and bone tissues. Let and
be CT image and its corresponding estimated CT image intensities in a given tissue region t. One can use the square and the absolute loss functions to assess the estimation cost. They can be given by
where t=1,2. Since the mean square error heavily weights the outliers, the mean absolute error (MAE) can be employed as a main tool to evaluate the estimation performance of the models. The MAE can be given by
where
is the number of voxels in partition t.
The peak signal-to-noise ratio (PSNR) can also be used to quantify the overall quality of the estimation. It takes square loss function into account through the mean squared error. The PSNR may be given by
where
and
represent CT image and the estimated CT image intensities at voxel i, respectively, and M is the maximal intensity in CT image. We exploited patient-wise leave-one-out cross-validation and mean absolute error to compare the estimation quality of the models. One can also use peak signal-to-noise ratio to compare the estimation performance of the models. The better model has lower MAE and higher PSNR. Since MAE and PSNR are crude estimation quality measures, we utilized smoothed residual and absolute residual plots to further evaluate the estimation quality of the models through the tissues of the heads. A moving average over non-overlapping windows in CT image intensities can be used as a main tool to investigate and identify the model that outperforms in bone tissue estimation. Over the non-overlapping windows on
with a window size of 20 HU, the averages for
,
, and
over the windows can be computed to obtain the smoothed residual and absolute residual plots.
In addition to the above model performance evaluation methods, we assessed the performance of the models using Bland-Altman plot [Citation6,Citation7], which is a graphical method to compare two measurements by plotting the differences between the two measurements against their averages
. If one of the two measurements is a reference measurement, then the differences can be plotted against the reference measurement [Citation23] and that coincides with the smoothed residual plot via cross-validation. The main advantage of the Bland-Altman plot is that it reveals a relationship between the differences and the magnitude of the measurements, to examine possible systematic bias, and outliers.
We can also complement the MAE based performance evaluation of the methods by Wilcoxon signed-rank test, which is a non-parametric alternative to the paired Student's t-test. To compare SGMM to every one of the remaining methods, the paired method-method differences in MAEs were examined by using the one-sided Wilcoxon signed rank test, with the null hypothesis that SGMM is the same as one of the other methods with respect to the MAE values and the research hypothesis that SGMM is better than the method being compared.
3. Results
A CT image intensity 100 HU was utilized as a delimiting value during CT image estimation. The optimal parameter estimates were received for K=8 in GMM and K=5 for both HMM and MRF. In the case of SGMM and GMM, we have received the optimal parameter estimates for K=6 for both major tissue types. Table demonstrates a summary of mean absolute errors for the bone tissues and p-values of the Wilcoxon signed-rank test.
Table 1. Mean absolute errors and p-values for bone tissues.
The rows of the table represent validation datasets. The table presents mean absolute errors received for the models. In terms of MAE, it is apparent that for each head the partitioning approach (SGMM and GMM) and MRF had better performance than HMM and GMM. Moreover, the differences of the average MAEs show that the partitioning approach and MRF achieved better results than HMM and GMM. For instance, SGMM outperforms HMM with the method-to-method difference of average MAEs
and the standard deviation of the method-to-method differences of MAEs 8.23. The p-values of Wilcoxon signed-rank test show that SGMM outperforms HMM and GMM significantly on bone tissues.
The results in Table show that the partitioning approach has noticeable outperformance on dense bone tissues (approximately with CT image intensities greater than 900 HU according to Washington and Leaver [Citation34]) as compared to the remaining models. Even though MRF is computationally expensive, it had better performance than HMM and GMM on dense bone tissues. The p-values of Wilcoxon signed-rank test reveal that SGMM has significantly better performance than the remaining methods except for GMM on dense bone tissues.
Table 2. Mean absolute errors and p-values for dense bone tissues.
Table demonstrates the estimation quality of the models on non-bone tissues. The best result was received for HMM. However, there is already a good contrast between soft tissues and air on MR images. The remaining models had similar behavior on non-bone tissues.
Table 3. Mean absolute errors and p-values for non-bone tissues.
Table presents the overall summary of CT image estimation quality. In comparison to the other models, we received better result for HMM. The reason is that HMM outperformed the other models on non-bone tissues. However, this is not the main interest in this work.
Table 4. Combined mean absolute errors and p-values.
Table demonstrates the prediction accuracy of the models in terms of PSNR. The results show that the models had similar behavior. On the bone tissues, PSNR has shown that the models have similar estimation performance.
Table 5. Evaluation of the methods based on PSNR and p-values.
On the basis of average, mean absolute error was utilized to compare CT image prediction accuracy of the models. Smoothed absolute residual plots were also employed to assess the estimation quality of the models. In comparison to MAE, smoothed absolute residual plots are powerful to evaluate the estimation performance of the models through the tissues of the heads. Figure presents smoothed absolute residual plots for the models. The absolute residuals were averaged over non-overlapping windows in CT image intensities with window size 20 HU.
Figure 2. Smoothed absolute residual plot for the five patients.
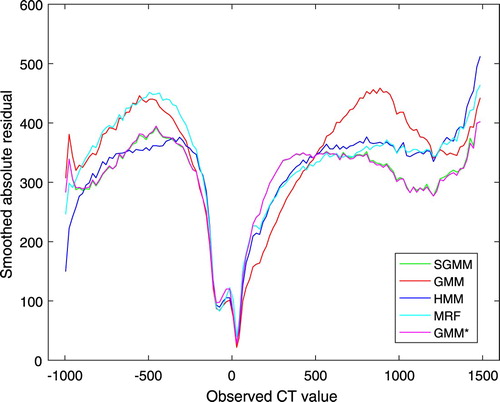
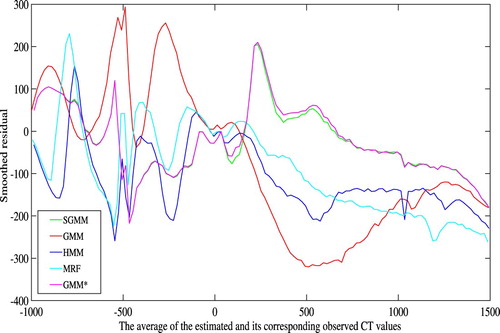
It is clear from Figure that none of the models outperformed throughout the tissues of the head. However, SGMM and GMM outperformed the other models on dense bone tissues. Figure shows smoothed residual plot. The deviations of observed CT image intensities from the estimated CT image intensities were exploited to obtain average residuals over non-overlapping windows in CT image intensities with window size 20 HU. It is evident from the plot that bone tissues were underestimated. However, the partitioning approach has improved underestimation of bone tissues.
Figure 3. Smoothed residual plot for the five patients.
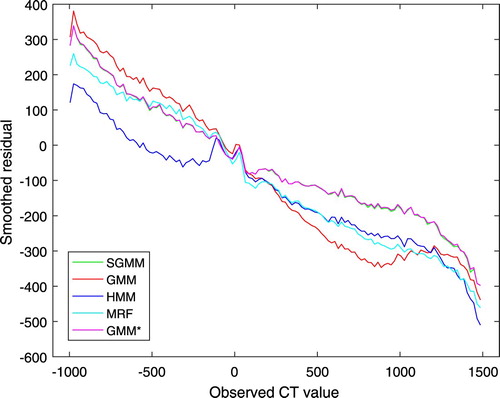
The Bland-Altman plots of the methods are shown in Figure . It shows the bias of the methods in estimating the CT images. The bias is higher for higher CT image values. However, the partitioning approach has improved the bias in bone tissue estimation as compared to the remaining methods. The Bland-Altman plots also show higher variability on lower CT image values. In comparison to Figure , we observe that the higher variability on lower CT image values in Figure is due the estimated CT image values. Notice, however, that this work is mainly concerned with improving bone tissue estimation.
Figure 4. Bland-Altman plot for the five patients.
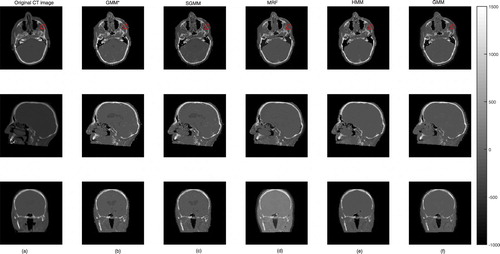
The partitioning approach had better performance in tracing bone tissues. Bone tissues appear as bright white on CT images, see Figure . The figure shows slices of CT image and its corresponding predicted slices for a representative patient. The top right portion of the images in the first row of the figure clearly shows that the partitioning approaches are better in identifying bone tissues.
Figure 5. The first column (a) presents the original CT image slices and the remaining columns (b)–(f) show the corresponding predicted slices of CT image.
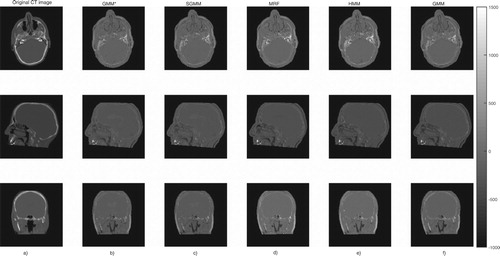
We presented the prediction errors in Figure , which corresponds to the predicted slices in Figure . It can be seen that the images of the prediction errors corresponding to the bone tissues appear darker for the partitioning approach: GMM and SGMM.
Figure 6. The first column (a) presents the original CT image slices and the remaining columns (b)–(f) show the prediction errors for each model.
4. Discussion
Statistical model for voxel-wise CT image estimation from MR images have been presented and evaluated using cross-validation on five datasets. Kuljus et al. [Citation22] and Johansson et al. [Citation16] have used voxel-wise estimation approach to study CT image estimations. Existing works suggest that the estimation quality on the bone tissues is poor. This study was aimed at probing the estimation of CT images by partitioning the data into two major tissue types: non-bone and bone tissues. Specifically, the focus of the study was to obtain improved bone tissue estimations. We proposed SGMM to relax the distributional assumption utilized by Kuljus et al. [Citation22] and Johansson et al. [Citation16]. The model was motivated to take the asymmetrical distribution that could arise from the partitioning of the data into account. We also used GMM in addition to SGMM to examine the effect of the distributional nature of the partitioned data on the estimation process. The study was also aimed at comparing CT image estimation performance of SGMM, HMM, GMM, and MRF on the bone tissues. In MRF and HMM, spatial dependence between neighboring voxels has been taken into account.
EM-algorithm was developed for SGMM parameter estimation. EM-gradient algorithm was used to estimate the parameters of MRF while EM-algorithm was utilized to estimate the parameters of GMM and HMM. For MRF, the updates of the parameters at M-step of EM-algorithm were difficult to obtain in an explicit form and thereby, a gradient based optimization was utilized during parameter estimation process. Moreover, Gibbs sampling was used at E-step of the algorithm. Thus, the estimation process was expensive in MRF. Unlike the other models, log-likelihood function in MRF involves Gibbs field and it is not computable. This means that log-likelihood based selection of optimal parameter estimate is not feasible analytically. Consequently, mean squared error was employed in selecting the optimal parameter estimates of the models.
Table demonstrated that HMM outperformed the other models. This was essentially due to its best estimation performance on non-bone tissues, see Table . According to Karlsson et al. [Citation20], the key task in CT image estimation from MR images is to obtain an improved bone tissue estimation. Table revealed that GMM (GMM trained on each major tissue type), SGMM, and MRF had better prediction accuracy than HMM and GMM on the bone tissues. In addition, Table shows that GMM
and SGMM had noticeable outperformance on dense bone tissues. Based on the mean absolute error, HMM and GMM perform similarly on the bone tissues.
To provide statistical evidence for the CT image estimation performance of SGMM in comparison with the remaining methods, the Wilcoxon signed-rank tests have been carried out. The tests have shown that SGMM has better performance on bone tissues than HMM and GMM. In addition, the Wilcoxon signed-rank tests provided an evidence that SGMM has significant outperformance than MRF, HMM, and GMM on dense bone tissues.
The skewness assumption allowed to recognize skewness in the partitions of the data. The estimates of the skewness parameters demonstrated that the partitions have skewness property and the nature of skewness was dependent on the subtissue types. The estimates of the skewness parameters ranged from to 3.03. In this particular application, however, the skewness assumption did not improve CT image estimation quality as compared to the symmetric assumption in GMM
, see Tables –.
Figure shows that the models performed better on soft tissues, that is tissues having CT image intensity closer to 0 HU. On the other hand, the models had weaker prediction accuracy on the two extremes that is on air and bone tissues. This pattern of residual plots has been observed in [Citation16,Citation22]. Moreover, the figure shows that none of the models outperformed throughout the tissues of the head. Tables – demonstrate that the predictive accuracy of the models was dependent on the heads. That is the results were not uniform over the heads. This might have a problem in real applications and needs a further investigation.
The bias of the methods in estimation of the CT images was manifested in the smoothed residual and Bland-Altman plots in Figures and . Though the bias is higher on bone tissues, it was improved by our approach as compared to the remaining methods. This was the main concern of this work. The Bland-Altman plots also demonstrated higher variability of the estimation on lower CT image values.
5. Conclusions
In this study, we examined CT image estimation by partitioning the data into two major tissue types. This partitioning approach is an efficient way to get a good quality CT image substitute with improved estimation of bone tissues. Moreover, the SGMM and the developed algorithm to estimate its parameters is general and can be applied to other applications.
Acknowledgments
The authors thank Adam Johansson and Thomas Asklund for providing us data and David Bolin for providing us Mathlab code for MRF. Moreover, the authors thank Kristi Kuljus for HMM results. The computations were performed on resources provided by the Swedish National Infrastructure for Computing (SNIC) at High Performance Computing Center North (HPC2N).
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- H. Arabi, N. Koutsouvelis, M. Rouzaud, R. Miralbell and H. Zaidi, Atlas-guided generation of pseudo-CT images for MRI-only and hybrid PET-MRI-guided radiotherapy treatment planning, Phys. Med. Biol. 61 (2016), pp. 6531–6552. doi: 10.1088/0031-9155/61/17/6531
- R.B. Arellano-Valle, C.S. Ferreira and M.G. Genton, Scale and shape mixtures of multivariate skew-normal distributions, J. Multivar. Anal. 166 (2018), pp. 98–110. doi: 10.1016/j.jmva.2018.02.007
- R.B. Arellano-Valle and M.G. Genton, On fundamental skew distributions, J. Multivar. Anal. 96 (2005), pp. 93–116. doi: 10.1016/j.jmva.2004.10.002
- A. Azzalini, A class of distributions which includes the normal ones, Scand. J. Stat. 12 (1985), pp. 171–178.
- A. Azzalini and A. Dalla Valle, The multivariate skew-normal distribution, Biometrika 83 (1996), pp. 715–726. doi: 10.1093/biomet/83.4.715
- J.M. Bland and D.G. Altman, Statistical methods for assessing agreement between two methods of clinical measurement, The Lancet 327 (1986), pp. 307–310. doi: 10.1016/S0140-6736(86)90837-8
- J.M. Bland and D.G. Altman, Measuring agreement in method comparison studies, Stat. Methods Med. Res. 8 (1999), pp. 135–160. doi: 10.1177/096228029900800204
- T. Boettger, T. Nyholm, M. Karlsson, C. Nunna and J.C. Celi, Radiation therapy planning and simulation with magnetic resonance images, Proc. SPIE 6918 (2008), p. 69181C. Available at: http://dx.doi.org/10.1117/12.770016
- C.R.B. Cabral, V.H. Lachos and M.O. Prates, Multivariate mixture modeling using skew-normal independent distributions, Comput. Stat. Data Anal. 56 (2012), pp. 126–142. doi: 10.1016/j.csda.2011.06.026
- L. Chen, R.A. Price, L. Wang, J. Li, L. Qin, S. McNeeley, C-M. Ma, G.M. Freedman and A. Pollack, MRI-based treatment planning for radiotheraphy: domestic verification for prostate IMRT, Int. J. Radiat. Oncol. Biol. Phys. 60 (2004), pp. 636–647. doi: 10.1016/j.ijrobp.2004.05.068
- A.P. Dempster, N.M. Laird and D.B. Rubin, Maximum likelihood from incomplete data via the EM-algorithm, J. R. Stat. Soc. 39 (1977), pp. 1–38.
- J. Ding and A. Zhou, Eigenvalues of rank-one updated matrices with some applications, Appl. Math. Lett. 20 (2007), pp. 1223–1226. doi: 10.1016/j.aml.2006.11.016
- H.W. Gómez, O. Venegas and H. Bolfarine, Skew-symmetric distributions generated by the distribution function of the normal distribution, Environ.: Off. J. Int. Environ. Soc. 18 (2007), pp. 395–407.
- T. Huynh, Y. Gao, J. Kang, L. Wang, P. Zhang, J. Lian and D. Shen, Estimating CT image from MRI data using structured random forest and auto-context model, IEEE Trans. Med. Imaging 35 (2016), pp. 174–183. doi: 10.1109/TMI.2015.2461533
- A. Jamalizadeh and T.I. Lin, A general class of scale-shape mixtures of skew-normal distributions: properties and estimation, Comput. Stat. 32 (2017), pp. 451–474. doi: 10.1007/s00180-016-0691-1
- A. Johansson, M. Karlsson and T. Nyholm, CT substitute derived from MRI sequences with ultrashort echo time, Med. Phys. 38 (2011), pp. 2708–2714. doi: 10.1118/1.3578928
- A. Johansson, M. Karlsson, J. Yu, T. Asklund and T. Nyholm, Voxel-wise uncertainty in CT substitute derived from MRI, Med. Phys. 39 (2012), pp. 3283–3290. doi: 10.1118/1.4711807
- F. Kahrari, R.B. Arellano-Valle, M. Rezaei and F. Yousefzadeh, Scale mixtures of skew-normal-Cauchy distributions, Stat. Probab. Lett. 126 (2017), pp. 1–6. doi: 10.1016/j.spl.2017.02.027
- F. Kahrari, M. Rezaei, F. Yousefzadeh and R.B. Arellano-Valle, On the multivariate skew-normal-Cauchy distribution, Stat. Probab. Lett. 117 (2016), pp. 80–88. doi: 10.1016/j.spl.2016.05.005
- M. Karlsson, M.G. Karlsson, T. Nyholm, C. Amies and B. Zackrisson, Dedicated magnetic resonance imaging in the radiotherapy clinic, Int. J. Radiat. Oncol. Biol. Phys. 74 (2009), pp. 644–651. doi: 10.1016/j.ijrobp.2009.01.065
- M. Khounsiavash, M. Ganjali and T. Baghfalaki, A stochastic version of the EM algorithm to analyze multivariate skew-normal data with missing responses, Appl. Appl. Math. 6 (2011), pp. 412–427.
- K. Kuljus, F.L. Bayisa, D. Bolin, J. Lember and J. Yu, Comparison of hidden Markov chain models and hidden Markov random field models in estimation of computed tomography images, Commun. Stat.: Case Stud., Data Anal. Appl. 4 (2018), pp. 46–55.
- J.S. Krouwer, Why Bland-Altman plots should use X, not (Y+ X)/2 when X is a reference method, Stat. Med. 27 (2008), pp. 778–780. doi: 10.1002/sim.3086
- V.H. Lachos, H. Bolfarine, R.B. Arellano-Valle and L.C. Montenegro, Likelihood-based inference for multivariate skewnormal regression models, Commun. Stat. Theory Methods 36 (2007), pp. 1769–1786. doi: 10.1080/03610920601126241
- T.I. Lin, Maximum likelihood estimation for multivariate skew normal mixture models, J. Multivar. Anal. 100 (2009), pp. 257–265. doi: 10.1016/j.jmva.2008.04.010
- T.I. Lin, H.J. Ho and C.R. Lee, Flexible mixture modelling using the multivariate skew-t-normal distribution, Stat. Comput. 24 (2014), pp. 531–546. doi: 10.1007/s11222-013-9386-4
- T.I. Lin, J.C. Lee and S.Y. Yen, Finite mixture modelling using the skew normal distribution, Stat. Sin. 17 (2007), pp. 909–927.
- C. Liu and D.B. Rubin, The ECME algorithm: a simple extension of EM and ECM with faster monotone convergence, Biometrika 81 (1994), pp. 633–648. doi: 10.1093/biomet/81.4.633
- X.L. Meng and D.B. Rubin, Maximum likelihood estimation via the ECM algorithm: a general framework, Biometrika 80 (1993), pp. 267–278. doi: 10.1093/biomet/80.2.267
- D. Nie, X. Cao, Y. Gao, L. Wang and D. Shen, Estimating CT image from MRI data using 3D fully convolutional networks, Proceedings 10008 LNCS, 2016, pp. 170–178.
- J. Sherman and W.J. Morrison, Adjustment of an inverse matrix corresponding to changes in the elements of a given column or a given row of the original matrix, Ann. Math. Stat. 20 (1949), pp. 621.
- M. Tamandi, A. Jamalizadeh and T.I. Lin, Shape mixtures of skew-t-normal distributions: characterizations and estimation, Comput. Stat. 34 (2018), pp. 1–25.
- K.M. Waterstram-Rich and D. Gilmore, eds., Nuclear Medicine and PET/CT: Technology and Techniques, Elsevier, USA, 2016.
- C.M. Washington and D.T. Leaver, eds., Principles and Practice of Radiation Therapy, Elsevier, USA, 2015.