
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this paper, reparameterization and student-t are applied to Stochastic Volatility (SV) model. We aim to reduce the amount of autocorrelation of the SV parameters and to introduce heavy-tailed model via the Bayesian computation of the Markov Chain Monte Carlo (MCMC) samplers. This research paper helps support better MCMC estimation of the SV model for volatile Asian FX series during Covid-19.
1. Introduction
The Stochastic Volatility (SV) type models have been popular in financial volatility research since the early 1970s, see for example Clark [Citation6]. Hull et al. [Citation12] paper led us to the famous option pricing where modern derivative pricing theory is based on a continuous-time stochastic process to which SV models have a close resemblance. Morgan [Citation16] introduced the SV processes in the CreditMetrics technical document for the use of risk management banking system for all banks. SV models have been extensively used by many researchers due to their easy understanding properties as introduced in Ghysels et al. [Citation9]. In volatility financial time series, it is also difficult to see the choice of the estimation methods, the process uses within the estimation, and the non-normality distributions. The inference of the SV model seems to be more computational complex in term of their likelihood function as introduced by Kim et al. [Citation14] for the Maximum Likelihood (ML), and by Harvey et al. [Citation11] for the Quasi ML (QML). It is also popular amongst the financial economics using the Generalized Method of Moments (GMM) like in Jacquier et al. [Citation13], and the recent work of Chausse et al. [Citation5] using the Monte Carlo simulation. In general, the SV findings with GMM seems to fail to capture the persistence of volatility effect. The use of Bayesian computation is popular amongst statistician for SV models. For examples, Bernardo et al. [Citation1] introduced this in great details. Jacquier et al. [Citation13] suggested that for the SV model the Bayesian computation is more efficient use than the GMM. West et al. [Citation23] and Carter et al. [Citation3] used the Gaussian State Space (GSS) Model via Bayesian inference for SV model. Pitt et al. [Citation17] shown how Bayesian inference could be used with more dynamic linear models of SV. When the GSS was extended to the non-GSS type of model as seen in Shepard et al. [Citation19], the Bayesian inference using the Markov Chain Monte Carlo (MCMC) simulation for SV model became more popular in most time series estimations as shown for examples in Harvey et al. [Citation11], Carter et al.[Citation4], Geweke et al. [Citation8] and Surapaitoolkorn [Citation20]. Further detailed discussion of the GSS and the Non-GSS models can be found in Durbin et al. [Citation7]. SV model was introduced using the variable dimension by Surapaitoolkorn [Citation22] via the changepoint analysis to see the location estimates for each FX return series.
Bayesian MCMC for SV model often have some problematic in high correlation between sampled SV parameters as well as high autocorrelation in the Markov chain process. This leads to slow process of the chain and longer convergence time consuming as found in our empirical studied of Surapaitoolkorn [Citation20] and [Citation22]. In this paper, we aim to solve these problematics of the SV model by introducing a reparameterization technique that may be utilized the computational convenience and reduce the amount of autocorrelation in the Markov chain process. This is the newest research findings for the SV where we also aim to remove posterior correlations in the sample parameters. This will be done in Section 2. Section 3 introduces the heavy tail SV model via the Bayesian computational MCMC approach by extending the SV to the Student t-SV models as suggested in Surapaitoolkorn [Citation20] that it is necessarily to do so for some Asian FX series. The conclusion will be in the last section.
For data analysis, we used the same type of high frequency financial data taken from the Olsen & Associates (www.oanda.com) as introduced in our papers [Citation20] and [Citation22]. There are 8 Asian FX series altogether. The 4 daily (D) series are the D-THB (Thai Baht), the D-SGD (Singapore Dollar), the D-JPY (Japanese Yen), and the D-HKD (Hong Kong Dollar). The 4 hourly (H) series are the H-THB, the H-SGD, the H-JPY, and the H-HKD. Each data set contains a total sample size of 2,300, which cover the time period from 12 December 1996 until 30
March 2003. The purpose is to use the data that covered during the Asian Financial crisis to help investigate more on volatility movements as suggested by Goodhart et al. [Citation10] and highlighted in Campbell et al. [Citation2]. We extended the data time series from 31
March 2003 to 24
November 2021 that downloaded from yahoo finance which covered the present volatility time period of Covid-19. This is to conclude in Section 4 on the effectiveness of the financial market risk model using the Value at Risk (VaR) for the normal distribution as introduced in [Citation16] and historical simulation as noted in [Citation21]. The findings of this paper are to be conclude in Section 5.
2. Reparameterizations for the discrete SV model
Following [Citation14], the simplest discrete time SV model can be defined by
(1)
(1)
where
is the average corrected return on the asset price at time t, (
for all
.
follows the first-order autoregressive (AR(1)) process.
is assumed to be a series of independent, identically distributed random disturbances where
. Consider the parameters
where
(2)
(2)
(3)
(3)
and
assumed to be independent Footnote1 normal white noise random processes. The parameters
are the log-volatility parameters, where
is the conditional variance at time t, and
Parameter μ is a constant scaling factor, and parameter ϕ is the persistence parameter in this model. Parameter
is the conditional variance in the autoregressive log-volatility sequence Footnote2. Equation (Equation2
(2)
(2) ) gives the so-called LogNormal SV model. It can be shown that, by stationarity (constancy and finiteness of the first two moments, and the autocovariance), the implied model for the initial state (and the implied marginal model for general t) is
(4)
(4)
Squaring and logging Equation (Equation2
(2)
(2) ) gives log
which then has a linear, non-Gaussian state space representation
(5)
(5)
The one-step-ahead forecast density of the SV model can be defined as
(6)
(6)
where
. Following [Citation14], the one-step ahead predictive can also be approximated in the Monte Carlo sense as
where the state parameter
,
is being sampled from the appropriate (posterior) probability distribution and
The full (augmented) likelihood function under our discrete SV model is given by
(7)
(7)
(8)
(8)
(9)
(9)
The full posterior distribution for SV Model can be written as
where
and
A joint prior distribution can be specified as
where (following from [Citation14])),
(10)
(10)
and
The full conditional posterior distributions needed for implementation of the MCMC approach for this model can be written as follows: If
then
For μ:
where
For
For
For
For
For ϕ:
Note that the conditional density for ϕ and are not available in closed form, and so will be sampled using the Metropolis-Hasting (MH) approach.
2.1. The autocorrelation function (ACF) plots of and
The Autocorrelation Function (ACF) plot is used to examine the MCMC inferential capability for ϕ and Figure shows high autocorrelation plots of the D-THB for ϕ and
at all lags and is slightly higher for
. This leads to the possibilities of reparameterization techniques to help improve the performance. We also observed that the two parameters are highly negatively correlated for other data series. The highest posterior correlation coefficient (
value occurs at −0.9192 for the D-THB. Similarly, the high negative ρ values between these parameters also occur with other seven data series; where the ρ values can be found in Table . In contrast, the D-JPY produces value of ρ to be relatively small i.e. −0.4254. With this respect, we shall not include the D-JPY series for the reparameterize discrete SV model.
Figure 1. ACF plots of for the SV model using the D-THB.
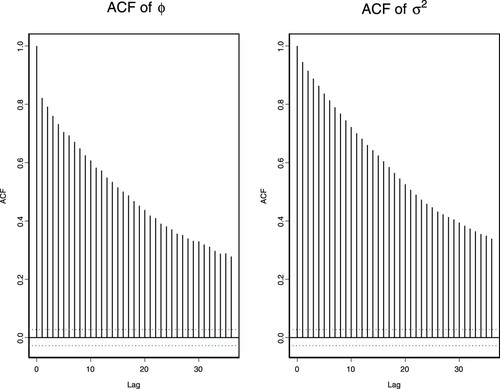
Table 1. Posterior statistics and correlation for the reparameterization SV model: 7 Asian FX series.
In order to decorrelate , several combinations for both joint and univariate transformation are to be considered. The purpose here is to find the most appropriate transformation available for the two parameters. Let us consider the followings transformations.
Multivariate transformation: For
Univariate transformation of ϕ: For
We now consider the reparameterization of in the following three sections, including the specification of the full likelihood function and thus the full conditional for each parameter.
2.2. Parameterization 1
From (Equation12(12)
(12) ), we let
. The Jacobian of this transformation is given by
Hence, the full conditional for ψ (by inspection of Equation9
(9)
(9) and Equation10
(10)
(10) ) takes the form
2.3. Parameterization 2
Under reparameterization 2, consider the new parameter from (Equation13(13)
(13) ) where
so that ξ takes values on R. The Jacobian of the transformation is given by
Hence, the full conditional for ξ takes the form
2.4. Parameterization 3
Consider a joint transformation of (Equation11(11)
(11) ), with new parameters,
so that
takes values on
. The Jacobian of the transformation is given by
By inspection of Equation9
(9)
(9) and Equation10
(10)
(10) , the joint (conditional) posterior for
takes the form
which is proportional to the univariate conditional for
.
The univariate conditional for θ is given up to proportionality by
These two conditionals are not available in closed form but may be sampled using a Metropolis step.
2.5. Results for the reparameterized SV model
For each parameterization mentioned above, the full conditionals will either be sampled directly where possible or using a local or independent Metropolis-Hasting (MH) step as in [Citation18]. Broadly, the local step will be based on a symmetric (normal) proposal for parameters on R and using a Gamma proposal or a mirror move for parameters on . Parameters in the MH proposal are chosen to optimize mixing of the chain; typical values used are
(in the normal case) and
(in the Gamma case).
Here, we provide the results of the discrete SV model under the most suitable parameterization with the aim of removing the posterior correlation in the sampled parameters of this model, we consider and test various joint transformations. We find that the most appropriate parameterization is obtained from (Equation11(11)
(11) ). We start with parameterizations 1 and 2 (as detailed in Subsections 2.2 and 2.3), by combining them we form the reparameterization of
By using parameterization 3 Footnote3, the new parameters used are
log θ instead of ϕ or ξ.
We applied this to 7 Asian FX series (i.e. exclude the D-JPY) as suggested by Surapaitoolkorn [Citation20], all new parameters have converged in this MCMC analysis. The estimated values of posterior statistics for these parameters and the posterior correlations are displayed in Table . From these values, we find no significant difference between the posterior correlation values and
produced from the two parameterization cases of
and
, respectively. We also found that an extremely high negative correlation value occurs in the D-THB with 92% correlation between the persistence and the variance (of the variance) parameter in the SV model. To conclude, there is no improvement in reducing the posterior correlation using this reparameterization.
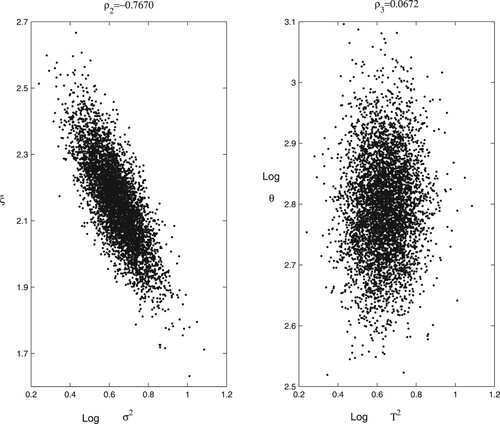
Taking the D-HKD as an example, the correlation plots are presented in Figure . From the plots, we found a significant improvement (that is, reduction in correlation) using this new parameterization. This is true for all other seven series where the estimated values of (which is the coefficient correlation for
) is reduced greatly when compared with values obtained from
and
. Furthermore, apart from the D-THB and the D-SGD, low positive correlations in
are found for all other data series. The D-HKD produces the lowest correlation value in
where the value is reduced from 0.76 (in
) and - 0.77 (in
) to 0.067 (in
). This suggests a significant improvement; the parameterization is working well to reduce posterior parameter correlation in this model. In contrast,
is estimated to be about 0.5 for the D-THB currency, where
,
are estimated to be about 0.92. Therefore, we managed to reduce the posterior correlation significantly for this currency.
Figure 2. Plots of and
for the D-HKD using the reparameterization in SV model.
3. The student t-SV model
From Surapaitoolkorn [Citation20] empirical results, an extension to the standard SV model that allows the inclusion of a heavy-tailed component for some FX series is required. We will perform this in this section by formulating the Student-t version of the Gaussian SV model in the usual way by introducing a scale mixture. The t-SV model can be formulated where we consider
(14)
(14)
(15)
(15)
where
is the average corrected return on the asset price at time t as described in Ghysels et al [Citation9]. The remainder of the model has the same definition as in the AR(1) SV model. The parameter
for t = 1,.., n is introduced to modify the model so that
follows a Student-t distribution with ν degree of freedom. Specifically,
where k is a constant term. Setting each
will recover the original SV model, where
and
remain the same as in (Equation14
(14)
(14) ) and (Equation15
(15)
(15) ), respectively. For the conditional variance of
to be finite, we require
The constant k is easily chosen so that the conditional variance of
remains equal to
Elementary calculations as in Martin et al. [Citation15] show that the conditional variance of
implied by (Equation14
(14)
(14) ) is
which implying
Footnote4.
Typically, for effective heavy tail modeling, the degrees of freedom parameter, ν, is allowed us to take some small positive integer values (for example, In our initial analysis, ν is chosen to be 5, but inference about ν is also possible, and in later models we regard ν as further unknown parameter to be inferred from the data.
3.1. Likelihood function for the t-SV model
The full likelihood function under the t-SV model of (Equation14(14)
(14) ) is given as
(16)
(16)
where
and
. Please refer to likelihood function for
in Surapaitoolkorn [Citation20] page 11(14) for
where
is an extra parameter. Following from Bernardo et al. [Citation1, page 123], y now follows a Student-t distribution and the conditional density function for the y can be written as
(17)
(17)
where
and ν provides small results in for greater kurtosis. For
, the conditional kurtosis for the t-SV model is
(18)
(18)
As
, (Equation17
(17)
(17) ) tends to a standard Gaussian density and for finite ν it produces greater kurtosis than the normal distribution. The kurtosis expression in (Equation18
(18)
(18) ) does not take into account the volatility process; therefore, it is really the conditional kurtosis measure. All odd moments are zero. Specifically in a finance context, Bauwens et al. [Citation3] notes that the Student-t distribution only has finite kurtosis if
Therefore, our initial specification for this model will involve setting
giving
. This implies that the initial Student t-SV model is considerably more robust to outlying returns than the equivalent Gaussian SV model.
3.2. Bayesian inference for the t-SV model
For the t-SV model, we have our prior specification to be
(19)
(19)
where
and the prior of (
remains the same as in Bayesian inference of the discrete SV model, Surapaitoolkorn [Citation20, page 11(15)]. If ν is also to be included as an unknown parameter, we could use a discrete (Geometric, negative Binomial or truncated Poisson) prior, or if continuous parameterization is used, a Pareto, lognormal or Gamma prior. Our first choice is to let
a priori, where
so that
(20)
(20)
To get a prior mean of 5, (Equation20
(20)
(20) ) implies
Note that this model does not necessarily produce finite kurtosis (recall that the kurtosis is not finite if
). Although this requirement could easily be incorporated by setting the prior to be
.
The full joint conditional for given
and ν for t = 1,.., n is
(21)
(21)
with
(22)
(22)
where the parameter
has a prior distribution given in (Equation15
(15)
(15) ).
3.3. The student t-SV model with
For this heavy tail model, we consider two MCMC studies. The first study takes ν to be fixed at 5, and the second study assumes that ν is a parameter to be estimated in the MCMC scheme. For both studies, we use the same MCMC implementation as explained in Surapaitoolkorn [Citation20] and [Citation18], where we obtained 5000 samples for each parameter. This subsection summarizes the first study, and next Subsection 3.4 summarizes the second study. The posterior output for all data series is displayed in Table . Using the same MCMC implementation details as in the Gaussian SV model, the posterior values obtained can be seen in Table . All three SV parameters in all data series appear to have converged after this number of iterations. From this table, the posterior median values of ϕ are estimated to be much higher for the hourly rates. Such estimates are quite close to 1 for the hourly JPY and the daily THB. This means that with this model, most hourly data series exhibit more persistence in volatility. This implies that there is more predictive capability for the variance of the returns for these series. For the hourly JPY, the posterior median values are highest for the ϕ and lowest for the . Therefore this currency is the most predictable in terms of volatility than the other data series. All posterior values of constant term μ are estimated to be similar as those with discrete SV model in Surapaitoolkorn [Citation20], as might be expected. Furthermore, all posterior variances are estimated to be closer to zero than those in Surapaitoolkorn [Citation20].
Table 2. Posterior statistics for the t-SV model with ν=5 for 5 Asian FX series.
3.4. The student t-SV model with ν unknown
We describe further aspects of the MCMC analysis for the t-SV model, now assuming that the degrees of freedom parameter ν is a further unknown parameter of the system. This step is more challenging than those in previous analyses. Using the same MCMC implementation as the previous study, it is found that not all parameters have converged in the same number of iterations for all data series. In fact, we found that most trace plots indicate slow mixing chain and imply that an increase in the number of iterations is necessary. However, after increasing the burn-in from 50,000 to 10,00,000 iterations, there is still no improvement sign for the convergence of most parameters. This indicates that either the prior used for ν or the local Metropolis move or both is not suitable for this sampling.
The main difficulty is the introduction of the sampling step for ν, but other difficulties are also evident for all parameters. The results illustrate that the Markov chain still moves slowly around the parameter space. However, for most series, ϕ converges rapidly even from extreme starting values. This is not true for most ν parameters. The reason is in fact due to a low probability of acceptance in the naive Metropolis algorithm and thus special MCMC proposals are evidently required. A further difficulty appears to arise as an unforeseen facet of the Pareto prior distribution for ν. This prior has an extremely long right tail. Initially, this was seen as an advantage as it effectively allowed support for the Gaussian limiting case of the Student model to be handled in a straightforward fashion, where ν could be allowed to become extremely large if this was implied by the data. However, it does introduce some difficulties in a MCMC context when sampling ν conditionally on the other parameters as in the Metropolis Gibbs sampler. As ν gets large, the likelihood contribution to the full conditional for ν becomes negligible, and if the prior for ν is also fairly flat for large ν (as in the Pareto case), the Metropolis algorithm can have long excursions in the tails of the posterior – this is a common phenomenon for Metropolis samplers in flat-tailed problems.
We note that the prior for ν did make a substantial difference to the behavior of the sampler. The sampler used, however, has been checked carefully. The reason for this behavior can be explained in terms of posterior distribution. The posterior distribution for the unknown degrees of freedom parameter ν can be quite sensitive to the specification of the prior distribution. In particular, as the likelihood is quite flat for large ν, the tail behavior of the prior is extremely influential. We thus suggest two alternative strategies for effective solution of the problems associated with the MCMC analysis of this model. The first is the implementation of the local Metropolis move where we propose a new Metropolis move. Firstly, we propose a ‘mirror move’, then a multiplicative Metropolis step (which allows large moves when the parameter is large), and finally mixture Metropolis move (that uses a mixture of local and multiplicative steps). The latter is what we found to be the most suitable move for this sampling. The second development is the adjustment of the prior distribution used for ν. Instead of the Pareto prior suggested above, an alternative (shifted) Gamma prior may be preferable. In this model, we shall instead use the prior model where
with prior mean and variance equal to five and three respectively. Furthermore, in order to study robustness of the inference to prior specification, it is appropriate to consider alternative prior models. For example, keep the prior mean of ν fixed but to increase its prior variance, a prior where
with prior variance equal to six might be used. We shall use the mixture Metropolis move for the MCMC sampling for the Student t-SV model. Recall the two extensions of this model, one using the Gamma prior, and another using the Pareto prior which introduced in Subsection 3.2 and used in the previous five Sub-subsection. In both cases, ν is allowed to move freely. The results for this t-SV model can be summarised are as follow:
Posterior output analysis summary
Posterior samples for the three SV parameters results using and
are displayed in Table . We found that all parameters
have converged for both cases, with the burn-in of
and the posterior sample sizes of 5,000. The two tables indicate that the estimated posterior values for
are similar.
Table 3. Posterior statistics for the t-SV model using Gamma prior for ν for 5 FX series.
The posterior medians of ϕ are estimated to be at 0.96 (for D-JPY) and 0.98 (for D-THB and H-JPY). This means that with this model these data series exhibit more persistence in volatility changes than the other series. In addition, the last two series are the most predictable in terms of volatility compared with the other series. The H-JPY still has the highest persistence parameter when compared with all others SV models. However, the D-JPY series exhibits more persistence in volatility in this model for both priors (with value of 0.960) than those in the previous model with value of 0.468).
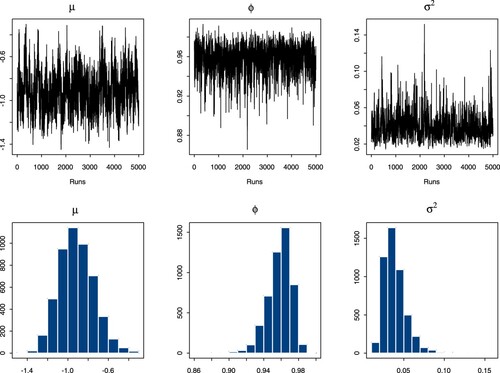
We note that the daily series of SGD, HKD and the hourly HKD are excluded for all cases of the t-SV models. The reason is because not all parameters converged for this model, even when we try to use different prior for ν. We find that these series provide a high number of returns that are zero. The reason is because the exchange rate for these currencies is more stable than other series for certain time periods. The D-HKD provides the most zero returns of 516 or 22.5%. Because of this, none of the parameters converge for this currency. Similarly, there are 213 or 16% zero returns in the H-HKD currency. For the D-SGD, we report that there are 248 or 10.8% zero returns, although this is 3% less than the number of zero returns in the D-THB. The fact that the zero returns are more spread out in the D-SGD case presents the problem for this model. For illustration, we present the plots of for the D-THB using the Gamma prior for ν in Figure , and for the D-JPY using the Pareto prior for ν in Figure . All trace plots obtained for other data series are similar, showing the full convergence of these three parameters.
Figure 3. Plots of the t-SV Model for with
for the D-THB.
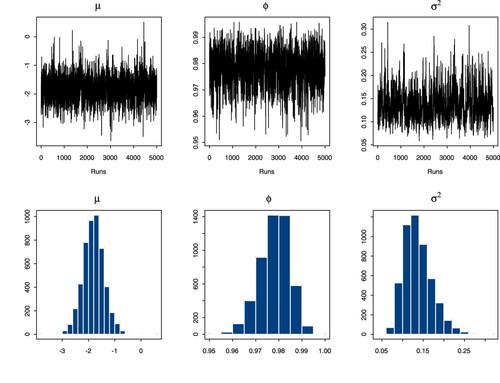
Figure 4. Plots of the t-SV model for with
for the D-JPY.
Convergence and histogram plots for
Results analysis for ν
The posterior support for ν using both priors are displayed in the last two columns of Table , where the Gamma prior are estimated to be from 3 to 10. There are 3 FX currencies (2 daily and 1 hourly) that estimated ν to be around 3 to 4. The highest posterior median for ν is estimated to be 8.1295 for the daily SGD. From the same table, posterior median support for ν using the Pareto prior is found to be between 3 to 12. The result is the same as in the Gamma prior for the case where ν is around 3 to 4. We conclude that both Pareto and Gamma prior used for ν are appropriate for this modeling exercise and often give similar results.
Table 4. Posterior correlation with both priors for ν and posterior statistics for ν with both priors in the t-SV model for 5 FX series.
Posterior autocorrelation of μ and ν
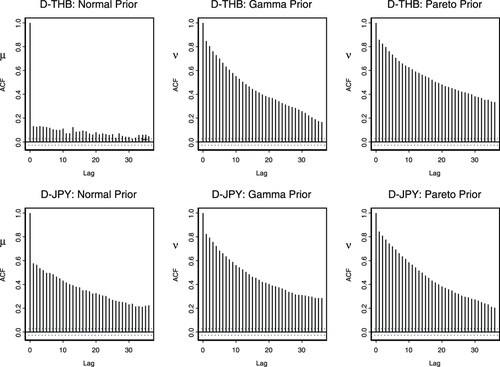
We briefly investigate the autocorrelation of the two parameters and ν. The prior is used where μ
;
and
Figure presents the ACF plots for these parameters for both priors using the D-THB, and D-JPY. The results for ν indicate that there exists a high autocorrelation for both cases. The results for μ are that the autocorrelations are relatively small for all cases of the D-THB, H-SGD, and the H-JPY. The rest of the series produce relatively high autocorrelation for μ. We shall now examine whether these autocorrelations indicate the strength of relationship between these two parameters in the posterior.
Figure 5. ACF plots for with both priors of ν using the D-THB and D-JPY.
Posterior correlation of μ and ν
Following from the last subsection, we compute the posterior correlation in the sampled parameters of μ and ν for all 5 data series. These values are displayed in Table for both priors of ν. The overall results are that the two parameters are negatively correlated and specific issues are as follows:
The value of
The value of
The value of
The value of
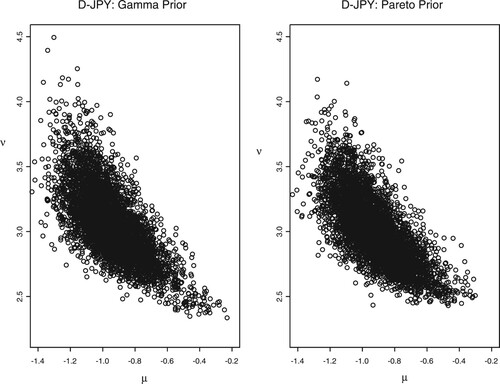
We present the correlation plots for of -0.3327, -0.3713 for the D-THB and –0.6979, -0.7210 for the D-JPY using both priors in Figures and , respectively. This depicts the first and fourth analyzed results above. The two figures suggest that μ and ν are negatively correlated where the results obtained from both priors are almost identical. In conclusion, we see that the introduction of a heavy tail component to the SV model presents some additional implementation problems due to the correlation between the parameter ν controlling the amount of heavy-tailedness and the scaling parameter μ that is present in the posterior. However, we find that the data samples are more adequately represented by the heavy-tailed model.
Figure 6. Correlation plots for with both priors of ν using the D-THB.
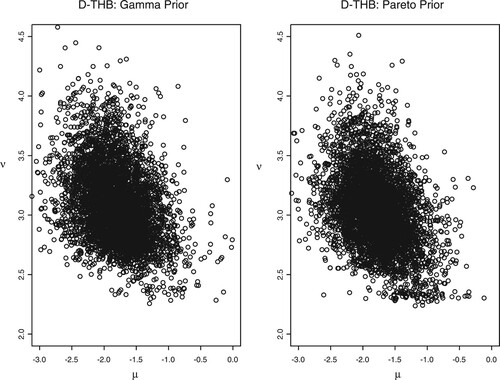
Figure 7. Correlation plots for with both priors of ν using the D-JPY.
4. Financial Asian FX data and VaR
In order to see the effectiveness of a market risk model during the current financial Covid19 for our four Asian FX rates. We downloaded the most updated available 4 Daily Asian FX data from the yahoo finance web site. The time period is continued from 31March 2003 to 24
November 2021 where possible. We then applied the VaR model using the 95% Confidence Interval (CI) of the normality and historical approach as detailed in [Citation16] and [Citation21] respectively. The results are displayed in Table .
Table 5. VaR model for 4 Asian FX series.
From this table, we can see that under the normal distribution curve the worse daily returns losses will not exceed between -0.0054% to -1.0089% for the 95% CI. If we invest 1 million for each currency, we can be 95% confident that our worst daily loss will not be more than 1% for both D-HKD and D-THB. This is because during the time period since the Asian until the Covid19 crises, Hong Kong Dollar and Thai Baht remained relatively the same price of 7.7771 and 33.5427 respectively. This shown the same existence of high number zeros returns. The historical VaR values are estimated to be similar to the Normal VaR as expected.
For HKD, the FX rates was shifted from 7.75–7.80 starting from the 1st April 1999 until 14th August 2000 even when the currency went under a great attack from speculators during Asian Crisis. Such currency is then remained at this rate up until now as it was pegged within this range to the U.S. Dollar since 2005.
Amongst the four currencies, the Singapore Dollar shown similar result where the zero returns are more spread out throughout time series. The currency is more narrowed in the range 1.35–1.40 during Covid19 period. Similarly for the JPY, the covid19 effected the currency to remain stable with average price of 104.6907 against the U.S. Dollar since 31st March 2003 until now.
5. Conclusion
An effort to reduce the amount of autocorrelation in the MCMC samplers within the algorithm has been made where we managed to reduce highly negative correlation between the two parameters and ϕ in the discrete SV model. We conclude that by reparameterizing
to
and ϕ to
, we manage to reduce both the high autocorrelation of these parameters for all of our volatile Asian FX return series. When a local MH move is applied for sampling
and ϕ an appropriate univariate reparameterization is ψ
for
, and
for
. This seems to be a more appropriate parameterization, with greatly reduced posterior correlation. This impact the reduction of autocorrelation in the Markov Chain process which lead to faster convergence time in the iteration runs. This result suggests that ξ and
are more appropriate parameters to use instead of ϕ and
under this MCMC sampling scheme. This is useful for the future use of the discrete (i.e. AR(1)) SV model for all volatile financial time series data.
When Student t-SV model is introduced, where initially, the degrees of freedom parameter ν is set equal to 5, and is analyzed using the same MCMC sampling as in the ordinary SV model. The empirical results obtained from this model appeared to be similar in many aspects as those in the SV model. The t-SV model also indicates another result that the persistence parameters are closer to 1 than the normal SV model. For the second implementation of the t-SV model, ν is allowed to move freely in the MCMC sampling scheme. We find that the local Metropolis move needed to be adjusted significantly. The prior for ν did make a substantial difference to the behavior of the sampler. The sampler used however has been checked carefully. The reason for this behavior can be explained in terms of posterior distribution. The posterior distribution for the unknown degrees of freedom parameter ν can be quite sensitive to the specification of the prior distribution. In particular, as the likelihood is quite flat for large ν, the tail behavior of the prior is extremely influential. In fact, if an improper flat prior distribution is used, the conditional posterior itself is improper.
We conclude that the mixture Metropolis move is the most appropriate one to be used for this model in order to obtain appropriate convergence results. The results suggest that using the newly implemented MH sampler, both Gamma and Pareto models are suitable priors to be used for ν. In both cases, the posterior values of ν are estimated to be around 3 to 4 for most data series. This evidence suggests that fixing ν to be 5 in the first case of the t-SV model is not that far away from the estimated values, although perhaps a more suitable true value of ν should be between 3 and 4. The drawback of choosing is that the implied kurtosis is not finite. We conclude that the majority of our FX series are moving away from normality, and that the random errors in the return's series have a heavy-tailed distribution. Furthermore, in the t-SV model all posterior estimates of
are estimated to be closer to zero than those estimated from an ordinary SV model. From all of the SV models, we find that the daily THB and the hourly JPY appear to be the most predictable time series in terms of volatility price returns. These two series obtain the highest persistence value and relatively small stochastic variance.
When we applied the most recent Asian FX data series for all 4 currencies, we found that the currencies are not significantly volatile during the Covid-19 period when compared with the time period during the Asian crisis. A currency like Hong Kong Dollar was pegged against the U.S. Dollar right after the Asian crisis up until now thus it is not rational to invest or predict on this type of currency due to its continuous zero returns. The 95% CI for the VaR models using both the normality curve assumption and the historical VaR model show that it is more rational to invest for the daily SGD and JPY than the HKD and THB currencies.
Acknowledgements
The author (former name was known as ”Wantanee Surapaitoolkorn”) would like to thank Professor David A Stephens (Department of Mathematics and Statistics, McGill University, Montreal, Canada) for excellent Bayesian MCMC research supervisor during my time at the Department of Mathematics, Imperial College of Science, Technology and Medicine, University of London, UK.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Notes
1 Note that if and
are allowed to be correlated with each other, there might be a kind of asymmetric behavior in the model, normally found in stock prices. On another hand, if they found to be negatively correlated then one might expect to have a leverage effect in the model.
2 Note that the correct symbol to use here should be however for convenience and consistency we shall use
throughout this paper.
3 as detailed in Subsection 2.4, this is the parameterization obtained from (Equation11(11)
(11) ) thus it is the most appropriate parameterization for our data series as we have tested (Equation11
(11)
(11) ) before approaching to model it using our MCMC modeling.
4 Note that allowing for stationarity we have included k in (Equation14(14)
(14) ) and assumed that the conditional variance of
remains as
where
so that
References
- J.M. Bernardo and A.F.M. Smith, Bayesian Theory, John Wiley and Sons, New York, 1994.
- J.Y. Campbell, A.W. Lo and A.C. MacKinlay, The Econometrics of Financial Markets, Princeton University Press, Princeton, NJ, 1997. pp. 233–244.
- C.K. Carter and R. Kohn, On Gibbs sampling for state space models, Biometrika. 81 (1994), pp. 541–553.
- C.K. Carter and R. Kohn, Markov Chain Monte Carlo (MCMC) in conditionally Gaussian state space models, Biometrika. 83 (1996), pp. 589–601.
- P. Chausse and D. Xu, GMM estimation of a realized Stochastic volatility model: A Monte Carlo study, J. Econom. Rev. 37 (2018), pp. 719–743.
- P.K. Clark, A subordinated stochastic process model with finite variances for speculative prices, Econometrica 41 (1973), pp. 135–136.
- J. Durbin and S.J. Koopman, Time series analysis of non-Gaussian observations based on state space models from both classical and Bayesian perspectives, J. Royal Stat. Soc. Ser. B. 62 (2000), pp. 1–26.
- J. Geweke and H. Tanizaki, Bayesian estimation of state-space models using the Metropolis-Hastings algorithm within Gibbs sampling, Comput. Stat. Data Anal. 37 (2001), pp. 151–170.
- E. Ghysels, A.C. Harvey and E. Renault, Stochastic Volatility, in Statistical Methods in Finance, Rao, C. R. and Maddala, G. S., eds., Handbook of Statistics, North-Holland, Amsterdam, Vol. 14 (3), 1996, pp. 209–235.
- C.A.E. Goodhart and M. O'Hara, High Frequency Data in Financial Markets: Issues and Applications, Introductory Lecture paper presented at conference in Zurich, J. Empir. Finance 4 (1997), pp. 73–114.
- A.C. Harvey, E. Ruiz and N. Shephard, Multivariate stochastic variance models, Rev. Econom. Stud. 61 (1994), pp. 247–264. Reprint in R.F. Engle, ed., ARCH: Selected Readings, Oxford University Press, Oxford, 1995, pp. 256–276.
- J. Hull and A. White, The pricing of options on assets with stochastic volatilities, J. Financ. 42 (1987), pp. 281–200.
- E. Jacquier, N.G. Polson and P.E. Rossi, Bayesian analysis of stochastic models (with discussion), J. Business Econom. Stat. 12 (1994), pp. 371–417.
- S. Kim, N. Shephard and S. Chib, Stochastic volatility: likelihood inference and comparison with ARCH models, Rev. Econom. Stud. 65 (1998), pp. 361–393.
- R.D. Martin, H.Y. Gao, Y. Zhan and Z. Ding, S+ GARCH User's Manual. Version 1.0, Data Analysis Products Division, MathSoft, Inc. Seattle, Washington, 1996.
- J.P. Morgan, Introduction to CreditMetrics: The benchmark for understanding credit risk. Tech Rep., New York, 1997.
- M.K. Pitt and N. Shephard, Analytic convergence rates and parameterization issues for the Gibbs sampler applied to state space models, J. Time Ser. Anal. 20 (1999), pp. 63–85.
- W. Poonvoralak, Local Metropolis Move in Variable Dimension Model for Finance: A Bayesian Markov Chain Monte Carlo Approach, Frontiers in Artificial Intelligence and Applications: Fuzzy Systems and Data Mining (FSDM) V: Proceedings of FSDM, IOS Press, 2019, pp. 331–336.
- N. Shephard and M.K. Pitt, Likelihood analysis of non-Gaussian measurement time series, Biometrika. 84 (1997), pp. 653–667.
- W. Surapaitoolkorn, Bayesian Stochastic volatility Model For FX Asian Crisis Market, Conference Proceedings Paper, Quantitative Methods in Finance, Australia, 2006.
- W. Surapaitoolkorn, Market risk VaR historical simulation model with autocorrelation effects, Int. J. Bank. Financ. 6 (2009), pp. 155–165.
- W. Surapaitoolkorn, Variable dimension via Stochastic volatility model using FX rates, J. Appl. Stat. 40 (2013), pp. 2110–2128.
- M. West and J. Harrison, Bayesian Forecasting and Dynamic Model, Springer-Verlag, New York, 1989.