
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Autoregressive models in time series are useful in various areas. In this article, we propose a skew-t autoregressive model. We estimate its parameters using the expectation-maximization (EM) method and develop the influence methodology based on local perturbations for its validation. We obtain the normal curvatures for four perturbation strategies to identify influential observations, and then to assess their performance through Monte Carlo simulations. An example of financial data analysis is presented to study daily log-returns for Brent crude futures and investigate possible impact by the COVID-19 pandemic.
1. Introduction
Autoregressive (AR) modeling is an essential technique in time series data analysis and is widely applied in biology, economics, finance, health and other areas. Several AR models and their statistical inference have been well established [Citation29,Citation47,Citation48]. Furthermore, influence diagnostics for statistical modeling is equally important nowadays [Citation13,Citation22,Citation28,Citation35].
The local influence technique [Citation9] examines how a minor perturbation affects the model fitting and is a powerful tool for statistical diagnostics when identifying potentially influential observations. Influence diagnostics has been conducted in regression models [Citation45,Citation46] and time-series analysis [Citation31,Citation32]. Among others, [Citation7,Citation13,Citation20,Citation27,Citation40,Citation49] investigated the sensitivity of estimates for regression parameters with AR disturbances or similar assumptions employing influence diagnostics. A number of authors, as [Citation17,Citation24,Citation25,Citation30,Citation33,Citation36,Citation51,Citation52], studied the estimation and its validity with diagnostic methods for time series models and related structures.
Note that the standard assumption for many circumstances is that all errors mutually independently follow normal or Student-t (simply t from now) distributions for regression and time-series analysis. For example, [Citation26,Citation34] investigated the inference by maximum likelihood (ML) and its stability by influence diagnostic methods for a vector AR model under normal and t distributions, However, certain economic, financial and other data are known to exhibit errors following skewed distributions. To study such characteristics, distributions proposed by [Citation2–4], related to the skew-normal (SN) and skew-t (ST) models, have had a great receptivity by researchers in recent years. Instead of the Student-t and Gaussian models, they are appealing candidates and can therefore be adopted. As a result, they are becoming increasingly popular; see, for example, [Citation4,Citation5,Citation21]. Moreover, [Citation6–8,Citation13,Citation14,Citation50] studied SN partially linear and nonlinear regression models and/or score test statistics. Robust mixture structures under an ST model have been analyzed by [Citation15,Citation23].
For financial applications, [Citation47,Citation48] discussed the ST distributions for their generalized autoregressive conditional heteroscedastic (GARCH) models, and [Citation12] advocated and compared SN and ST distributions. Liu et al. [Citation31] focused on diagnostic analystics for an AR model with SN errors (SNAR model), while [Citation32] studied estimation and other statistical aspects for an SNAR model and especially made a real-world application of financial data affected during the COVID-19 pandemic. However, we are not aware of any studies that have reported results about influence diagnostics measures in an AR model with ST errors (STAR model).
In the present article, we conduct inference and validation of the STAR model with the financial data analysis which relates to the COVID-19 pandemic. Our main contributions are threefold:
we propose the STAR model with a systematic methodology of estimation and diagnostics. We consider on likelihood methods to fit the STAR model using the EM algorithm and conduct its influence diagnostics based on four perturbation schemes including a brand new one of skewness. The STAR model complements the ST innovation-based GARCH models discussed in [Citation47,Citation48] and an AR model under the SN distribution studied in [Citation31,Citation32].
we establish our mathematical results for the STAR model using the standard matrix differential calculus and examine their statistical implementations using simulations. We compare the ST with normal, t and skew-normal distributions, especially for the diagnostics. Our findings demonstrate the ST model is preferred to the other alternatives which were previously considered in [Citation26,Citation31,Citation32,Citation34].
we conduct an empirical study of real-world financial data to illustrate both the STAR model and our methodology to be effective in practical applications and data analytics.
We proceed as follows. In Section 2, we explain the STAR model and develop an efficient algorithm for calculating the ML estimates, whereas in Section 3 we present our curvature diagnostics under the four perturbation schemes using the local influence technique. Section 4 carries out our simulation studies to examine the influence diagnostics, and compare the ST model with the normal, t, and SN distributions. Section 5 provides an empirical example involving an STAR model to show potential applications of the results. Our concluding comments are provided in Section 6. Finally, our matrix results for curvature diagnostics are derived in the appendix.
2. Formulation and estimation
In this section, we propose our STAR model, obtain its parameters' ML estimates, and establish the corresponding Hessian matrix.
2.1. STAR(p) model
We assume an STAR(p) time series model formulated as , with
being the response observed at t, for
, and p previous values denoted by
;
if the i-th regression coefficient, for
; and
is the t-th innovation following an ST distribution denoted as
, with
being the scale, λ being the skewness, and ς being the degrees of freedom. Conveniently, the model
is rewritten as
(1)
(1)
where
and
are
vectors. The parameters are collected by a
vector
.
Lemma 1
[Citation47]
Let be a characteristic polynomial, and its modulus of all zero solutions is greater than one. Then, the associated AR data are stationary.
Lemma 1 is used in the numerical analysis of Sections 4 and 5, and it offers a necessary and sufficient condition for us to test if our data are stationary. Note that, if Y follows an ST model with μ, , λ, and ς being location, scale, skewness, and degrees of freedom parameters, we denote it as
. Thus, if
, its density, which we denote by PDF, is established by
(2)
(2)
with
and
being the distribution function, CDF in short, and PDF of the Student-t model. If
, the PDF of Y stated in (2) corresponds to the t PDF; if
, then the PDF of Y becomes the SN PDF; and if
and
, then the PDF of Y is the normal PDF. Observe that the mean of Y and its variance are represented by
with
.
Lemma 2
[Citation23]
Let . Then, we get
where
represents the truncated normal distribution with
lying within the interval
.
2.2. EM based ML estimation
In practice, directly maximizing the function associated with the logarithmic likelihood structure using the ML method to find the estimate of can be a no easy task. Instead, we implement the ML method based on the EM algorithm with incomplete data proposed by [Citation11]. Here,
denotes the set of complete data, where
stands for the set of missing data and
for the set of observed data. Given a starting estimate
, which can be taken from the fit with the normal distribution, we get
, for
, iteratively between the E and M steps until reaching convergence as in [Citation13,Citation32]. To reach convergence, we use
, same as used in the simulation study.
According to Lemma 2, the model defined as can be presented hierarchically as
The observed and missing (unobserved) data are
and
. Let
and
, with
being the complete observations. In such conditions, the function related to the logarithmic likelihood function of the set of complete-data for
is given by
where
. For the E step, we obtain, with
, the
-function defined as follows:
(3)
(3)
with
In the case of the M step, we use
to update
using an iterative algorithm, with
and
denoting the Hessian matrix and gradient vector. Now, if
, then we get that
. Under mild conditions, and considering appropriate starting values of
, which as mentioned can be taken from the fit with the normal distribution,
converges to the ML estimate
.
Note that there is an alternative approach as taken by reparametrizating and estimating the parameters in their regression models; see [Citation42]. Thus, we could use a reparametrization to find closed expressions for the estimators of the parameters of the STAR(p) model as well.
2.3. Observed information matrix
We calculate the observed information matrix starting from
and
(4)
(4)
where
and
(5)
(5)
(6)
(6)
(7)
(7)
(8)
(8)
with
Theorem 1
For the STAR model, the observed Fisher information matrix
with
is obtained, whose diagonal and off-diagonal submatrices are provided in the appendix.
3. Diagnostic analysis
We obtain our normal curvatures for the influence diagnostic analysis considering the following perturbation strategies: case-weights, data, variance and skewness.
3.1. Influence diagnostics
For the STAR model postulated in (Equation1(1)
(1) ), we use the logarithmic likelihood function of complete-data,
, where
is a
parameter vector. We consider a minor modification denoted by
perturbation vector
belonging to
, and
is the function of logarithmic likelihood for the set of complete data under
. Consider
as the a
vector of non-perturbation satisfying
, and this vector can be
or
or an alternative as properly chosen, and the dimension q depends on the perturbation strategy adopted. Denote by
and
the ML estimates for the postulated model and perturbed model, respectively. Then, as in [Citation13,Citation14], we compare
and
using the influence measure named Q-displacement, and derive the normal curvature at
vector l (with
) stated as
(9)
(9)
with a
matrix
, evaluated at
, as well as a
matrix
, evaluated at
. We use the expression given in (Equation9
(8)
(8) ) for our perturbation strategies proposed, by calculating
and
, for which the derivatives are presented in the appendix. Poon and Poon [Citation41] proposed a measure of conformal normal curvature to classify an observation to be potentially influential. Note that for linear regression models, but not restricted to these, to assess the influence of
, [Citation9] utilized the influence measure named likelihood displacement (LD). Then, a high value of
provides us information that ML estimates
and
to differ significantly. For details, see [Citation26,Citation27,Citation31,Citation32,Citation34,Citation41].
3.2. Perturbation strategies
3.2.1. Perturbation of case-weights
As in [Citation32], we make a minor perturbation on the residual of the STAR model using instead of
, where
is the modification. We consider
vectors
and
. Then, the expression for
is presented as
Thus, we express the Q-function (perturbed) by means of
(10)
(10)
where
and
are the same as in the formulations given in (Equation5
(4)
(4) )–( Equation8
(7)
(7) ).
Theorem 2
For case-weights perturbation strategy, we get the matrix given by
(11)
(11)
evaluated at
, where
are the same as in the expressions stated by (Equation5
(4)
(4) )–(Equation8
(7)
(7) ).
3.2.2. Perturbation of data
As in [Citation32], we make a perturbation to replace by
. Let
and
be
vectors. For the response perturbation
, where
and
, we reach
Thus, we get the Q-function (perturbed) by means of
(12)
(12)
where
and
are the same as in (Equation5
(5)
(5) ) –(Equation8
(8)
(8) ).
Theorem 3
For the data perturbation strategy, we get the matrix given by
(13)
(13)
evaluated at
, where
are the same as in the formulations given in (Equation5
(4)
(4) )–(Equation8
(7)
(7) ).
3.2.3. Perturbation of variance
As in [Citation32], we replace the variance by
, that is,
. Consider
vectors
and
. Thus, we reach that
Then, we get the Q-function (perturbed) by means of
(14)
(14)
where
and
are the same as in the expressions stated by (Equation5
(5)
(5) ) –(Equation8
(8)
(8) ).
Theorem 4
For the variance perturbation strategy, we attain the matrix expressed as
(15)
(15)
where
are the same as in the formulations given in (Equation5
(5)
(5) )–(Equation8
(8)
(8) ).
3.2.4. Perturbation of skewness
In particular, due to the characteristic of skew distribution of our proposed model, we study its impact by making a small modification in λ, that is, changing by
. Consider
vectors
and
. Then, we get
Hence, the Q-function (perturbed) is presented by means of
(16)
(16)
where
and
are the same as in the expressions presented in (Equation5
(5)
(5) ) –(Equation8
(8)
(8) ).
Theorem 5
For the skewness perturbation strategy, we get the matrix formulated as
(17)
(17)
where
are the same as in (Equation5
(4)
(4) )–(Equation8
(7)
(7) ).
3.3. Benchmark of influential observations
To assess if a case is influential, we use the benchmark stated as , where q = n−p, n is the sample size, c is a pre-chosen positive constant and
is the sample standard deviation (SD) of
, for
; see [Citation41]. Then, if a diagnostic value is greater than
, we identify the corresponding case to be influential.
4. Numerical simulation
We present five simulation studies to examine our estimators and diagnostic results. The results in Sections 4 and 5 are calculated with the software Matlab [Citation44].
4.1. EM algorithm
The first simulation study uses the results found in Section 3. For the STAR(p) model with ), we choose sample sizes n belonging to
, and parameters:
and
. The results are presented in Tables and . Note that the mean and median of the estimates are coherent with the values stated. In addition, the standard errors (SEs) are very small to indicate our estimates are stable. In short, the results prove our proposal is suitable.
Table 1. Values of the SE, median, and mean with ,
and
using the STAR model.
Table 2. Values of the SE, median, and mean with ,
and
using the STAR model.
4.2. Influence diagnostic analysis
The second study proceeds the steps as follows:
| [S1] | The STAR(1) model is | ||||
| [S2] | The model in [S1] is used to generate 1000 samples of 400 observations each. | ||||
| [S3] | A perturbed scalar ε is added to the 200th observation of each sample obtained in [S2]. Note that | ||||
| [S4] | Our influence diagnostic is used to detect influential observations for the each of 1000 samples obtained in [S3]. Under each perturbation strategy, 1000 diagnostic values are calculated inspecting an eigenvector linked to its corresponding largest eigenvalue. Then, the index of largest element in absolute value of this vector is registered as an influential observation. | ||||
| [S5] | How well our diagnostics performs is examined in terms of how many diagnostic values of the 1000 samples in [S3] fulfill the above criteria, with ε run from 0 to 2, and the number of diagnostic values of the 200th position is counted. The number of correct identifications versus ε for the schemes are displayed in Figure (left). | ||||
Figure 1. Number of correct identifications related to the four perturbation strategies for the STAR(1) (left) and STAR(2) (right) models.
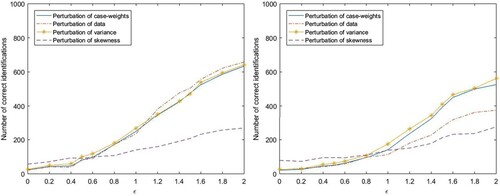
From Figure (left), we see clearly that the number of samples with correct identification of the influential observation has followed the scale of the perturbed vector to increase in the four perturbation strategies. When , the four strategies are becoming apparent. Under 1000 samples, the influential observation of the four schemes are 634, 658, 642 and 269 times, respectively. These results are expected.
Next, we further study the STAR(2) model stated as , where
, with
. It is easy to prove that the AR(2) model is stationary. We use the same 5 steps for the AR(1) model to get Figure (right).
From Figure (right), we note that the number of samples with correct identification of the influential observation has follewed the scale of the perturbed vector to increase in the four schemes. When , the four schemes become apparent. Under 1000 samples, the influential observation of the four schemes are 525, 375, 561 and 277 times, respectively. From both figures, the AR(1) model's pattern appears stronger than the AR(2) model's patter. However, diagnostic ability of the four schemes are different so they should be used in combination in practice.
4.3. Student-t versus Gaussian models
Liu et al.[Citation26] investigated about a methodology to detect influential points in an AR model with the normal distribution. Here, we generate 1000 samples following the procedure provided in Section 4.2 (with in [3]) based on the ST distribution with
, and then make an influence analysis under the ST and normal distributions to compare our result with those provided in [Citation26]. Using the method stated in Step 5 of Section 4.2, the comparison is made in Table .
Table 3. Comparison between the ST and normal distributions with ε = 2.
There are both similarities and differences. The similarities are obvious in the study under both distributions as the number of correct outlier detections are all large, that is, 634, 658, 642 and 603, 596, 122 out of 1000. This indicates that the diagnostic results works well. However, there are also differences. In the case of , the number of 1000 samples with influential points is 634 and 603 under case-weights strategy; the number of 1000 samples with influential points is 658 and 596 under the data strategy; and the number of 1000 samples with influential points is 642 and 122 under the variance strategy. In terms of diagnostics, the ST model is better than the normal model. Utilizing a correctly specified model in analyzing data is particularly important.
4.4. Skew-student-t versus student-t models
Liu et al. [Citation34] diagnosed influential points in an AR model with the t distribution. We generate 1000 samples following the procedure provided in Section 4.2 (with ε = 2 in Step 3) based on the ST distribution with to evaluate the performance of local influence analysis under the ST and t distributions. The comparison is reported in Table . The number of samples where influential observations were detected are all large in scale, namely, 634, 658 and 637, 613 out of 1000, implying that the method works well. There are differences in employing the ST and t distributions. In the case of
, the number of samples with influential observations is 634 and 658 under case weights strategy; and the number of samples with influential observations is 658 and 613 under the data strategy; both with a total 1000 samples. The diagnostic effect under the ST distribution is better than under the t distribution.
Table 4. Comparison between the ST and t distributions with ε = 2.
4.5. Skew-student-t versus skew-normal models
Liu et al. [Citation31,Citation32] detected influential observations in an SNAR model. We generate 1000 samples following the procedure provided in Section 4.2 (with in Step 3) based on the ST distribution with
, and then apply a local influence analysis under the ST and SN distributions. The comparison is provided in Table .
Table 5. Comparison between the ST and SN distributions with .
The similarities are noticeable in the local diagnostic study under the ST and SN models as the number of samples with the influential points are most large enough in the most strategies of perturbation: 634, 658, 642, 269 and 611, 609, 124, 46 out of 1000, meaning that the diagnostic results are effective. However, there are also differences. In the case of , these can be observed for the variance and skewness perturbation strategies, which influential observations are 642 and 124 under the variance strategy; and 269 and 46 under the skewness strategy; both with a total 1000 samples. The local influence analysis performance is better assuming a ST distribution that an SN distribution, as shown in the previous cases.
5. Empirical analysis
In this section, we use our values stated in Section 3 to analyze financial data and discuss the performance of our proposed methodology. The Brent crude futures (BIPE hereafter) daily log-return data from 16 January 2007 to 11 March 2021 are chosen to construct an STAR model and perform our diagnostic analysis.
5.1. STAR model for BIPE
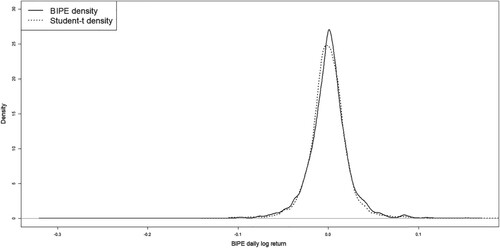
Figure (left) shows BIPE daily log-return time series data from 16 January 2007 to 11 March 2021. An exploratory data analysis based on basic statistics of the daily financial returns is the following: n = 3442 (sample size); minimum and maximum returns of −0.30856 and 0.15449; first and third quartiles of −0.010586 and 0.011026; sample mean and median of 0.0000669 and 0.00013246; sample coefficient of skewness of −0.93637; and sample excess kurtosis of 18.812. Figures (right) and present a histogram and a kernel plot employing the t model of the BIPE daily data. From this exploratory data analysis, we detect an asymmetrical distributional feature and a high kurtosis level of the data. We can observe that the adjustment with the t model is unsuitable. Furthermore, we use the D'Agostino skewness test [Citation10] and Anscombe-Glynn kurtosis test [Citation1] to assess for skewness and kurtosis of our data, where the D'Agostino statistic is -19.25 and Anscombe-Glynn statistic is 27.754, with their p-values both significantly less than 0.01. These indicate that the distribution of BIPE is skewed, with an obvious peak and two fat tails. We first select an STAR model and determine its order using the following steps as stated as [Citation31,Citation32,Citation47] for their t and SN models.
Figure 2. Time-series (left) and histogram with kernel PDF (right) of BIPE daily returns.
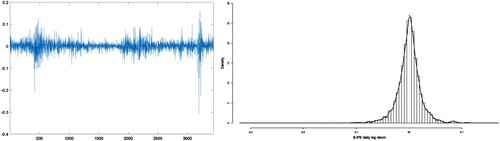
Figure 3. BIPE daily returns with t and ST PDFs.
[S1] Consider an AR(p) model
(18)
(18)
with
.
[S2] In the ith equation of (Equation19(18)
(18) ), that is, the AR(i) model, the ordinary least squares estimate of
is
, the residual is
and the estimate of
is
[S3] The th and ith equations in (Equation19
(18)
(18) ) are used to test if coefficient
is equal to zero or not, that is, to compare the AR(i−1) with AR(i) models. For this hypothesis testing the statistic is stated as
, which follows an asymptotic
distribution. Values of
for
are presented in Table . As the 95% quantile of
distribution is 3.841, we use the empirical values of
presented in Table to determine the value of p of the AR(p) model. Hence, p = 1 because
. Using the EM algorithm, we calculate
. Then, as the absolute value of
is less than one, we cannot reject the BIPE data to be stationary. From Figure , we find that the ST distribution fits better than the t distribution. Thus, we fit the STAR(1) model
, with
,
, and
. According to Lemma 1, the data being fitted by the STAR(1) model are stationary.
Table 6. Empirical values of , with
for BIPE daily data.
5.2. Diagnostic analysis for BIPE
We conduct the local influence analysis in the STAR(1) model for BIPE under the four perturbation strategies proposed. Based on the idea given in Section 3.3 and the results in [Citation31,Citation32], we choose c = 3 and as the benchmark, obtaining the values of 0.0021, 0.0022, 0.0015 and 0.0012 for the four respective perturbation strategies. In each plot, the red line symbolizes the benchmark to determine if an observation to be potentially influential or not, that is, when its value is beyond the red line. The influential observations are in Table where * denotes the case that is identified as potentially influential for BIPE. We can observe that these cases are mainly related to the 2008–2009 ‘The Great Recession”, as well as to the 2020-2021 SARS-CoV-2 pandemic, which conducted to a large volatility. For example, on 3 October 2008, the U.S. government signed a financial rescue plan with a total of about 700 billion dollars. On 24 February 2020, the global stock markets fell after the global number of COVID-19 cases increased significantly. In summary, Figure and Table justify the effectiveness and practicability of the diagnostics methods for an STAR model.
Figure 4. BIPE diagnostics under skewness, variance, case-weights, and data perturbations.
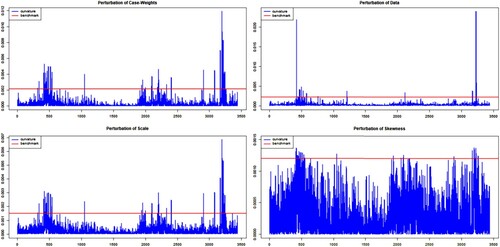
Table 7. Summary of the diagnostic analysis by perturbation strategy.
Finally, we compare the two models for AR(1) with outliers and STAR(1) without outliers in Table . The two models’ mean square errors of their predicted values are 0.0014874 and 0.0013266, respectively. It can be seen that the prediction results made after the outliers' removal are better than those made before.
Table 8. Predicted results by the listed structure.
6. Conclusions
In this article, our STAR model was studied with an ML estimation methodology. Its validation was performed using local diagnostic analysis inspired by the EM algorithm, which allowed us to obtain normal curvatures for four perturbation strategies of interest. Our model was compared with the alternative models based on skew-normal, normal, and Student-t distributions. Our findings showed that the proposed STAR model was more accurate, applicable, and usable to diagnose longer time data and identify more abnormal cases.
The curvature results for our STAR(p) model with four perturbation strategies, including the newly proposed perturbation of skewness, were presented. Monte Carlo simulation studies were conducted to asses adequacy of our methodology. Approximate numerical benchmark values for detecting the possible influential observations were employed to analyze the daily log-returns of Brent crude futures for a period of time covering the events related to 2008 financial crisis and COVID-19 pandemic. Many of the influential observations with the BIPE data were identified to be related to historical events. Our methodology and findings are evidenced to be effective.
Further works are related to the study of statistical structures generated from settings associated with data functional, partial least squares, quantile, multivariate, and spatial regression frameworks [Citation16,Citation38,Citation39,Citation43]. Similarly, considering censored data may also be of interest to analyze in the context of the current investigation [Citation19]. We are planning to conduct studies on these issues in the future.
Acknowledgments
We would like to thank the Editor, Professor Jie Chen, the Associate Editor, and the reviewers for their constructive comments which led an improved presentation of this article.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- F.J. Anscombe and W.J. Glynn, Distribution of the kurtosis statistic b2 for normal samples, Biometrika 70 (1983), pp. 227–234.
- A. Azzalini, A class of distribution which includes the normal ones, Scand. J. Stat. 12 (1985), pp. 171–178.
- A. Azzalini, The Skew-Normal and Related Families, Cambridge University Press, Cambridge UK, 2014.
- A Azzalini, An overview on the progeny of the skew-normal family – a personal perspective, J. Multi. Anal. 188 (2022), 104851.
- A. Azzalini and A. Capitanio, Distributions generated by perturbation of symmetry with emphasis on a multivariate Student-t distribution, J. R. Stat. Soc. 65 (2003), pp. 367–389.
- V.G. Cancho, V.H. Lachos, and E.M.M. Ortega, A nonlinear regression model with skew-normal errors, Stat. Pap. 51 (2010), pp. 547–558.
- C.Z. Cao, J.G. Lin, and J.Q. Shi, Diagnostics on nonlinear model with scale mixtures of skew-normal and first-order autoregressive errors, Statistics 48 (2014), pp. 1033–1047.
- B. Carmichael and A. Coën, Asset pricing with skewed-normal return, Finance Res. Lett. 10 (2013), pp. 50–57.
- D. Cook, Assessment of local influence, J. R. Stat. Soc. B 48 (1986), pp. 133–169.
- R.B. D'Agostino, Transformation to normality of the null distribution of g1, Biometrika 57 (1970), pp. 679–681.
- A.P. Dempster, N.M. Laird, and D.B. Rubin, Maximum likelihood from incomplete data via the EM algorithm, J. R. Stat. Soc. B 39 (1977), pp. 1–38.
- M. Eling, Fitting asset returns to skewed distributions: Are the skew-normal and skew-Student good models? Insur. Mathem. Econom. 59 (2014), pp. 45–56.
- C.S. Ferreira, G.A. Paula, and G.C. Lana, Estimation and diagnostic for partially linear models with first-order autoregressive skew-normal errors, Comput. Stat. 37 (2022), pp. 445–468.
- A.M. Garay, V.H. Lachos, F.V. Labra, and E.M.M. Ortega, Statistical diagnostics for nonlinear regression models based on scale mixtures of skew-normal distributions, J. Stat. Comput. Simul. 84 (2014), pp. 1761–1778.
- H.J. Ho and T.I. Lin, Robust linear mixed models using the skew-t distribution with application to schizophrenia data, Biom. J. 52 (2010), pp. 449–469.
- M. Huerta, V. Leiva, S. Liu, M. Rodriguez, and D Villegas, On a partial least squares regression model for asymmetric data with a chemical application in mining, Chemom. Intell. Lab. Syst. 190 (2019), pp. 55–68.
- L. Jin, X. Dai, A. Shi, and L. Shi, Detection of outliers in mixed regressive-spatial autoregressive models, Commun. Stat.: Theory Methods 45 (2016), pp. 5179–5192.
- T. Kollo and D. von Rosen, Advanced Multivariate Statistics with Matrices, Springer, Dordrecht, the Netherlands, 2005.
- J. Leao, V. Leiva, H. Saulo, and V Tomazella, Incorporation of frailties into a cure rate regression model and its diagnostics and application to melanoma data, Stat. Med. 37 (2018), pp. 4421–4440.
- V. Leiva, S. Liu, L. Shi, and F.J.A. Cysneiros, Diagnostics in elliptical regression models with stochastic restrictions applied to econometrics, J. Appl. Stat. 43 (2016), pp. 627–642.
- V. Leiva, H. Saulo, R. Souza, R.G. Aykroyd, and R. Vila, A new BISARMA time series model for forecasting mortality using weather and particulate matter data, J. Forecast. 40 (2021), pp. 346–364.
- W.K. Li, Diagnostic Checks in Time Series, Chapman and Hall/CRC, Boca Raton, 2004.
- T.I. Lin, J.C. Lee, and W.J. Hsieh, Robust mixture modeling using the skew t distribution, Stat. Comput. 17 (2007), pp. 81–92.
- S. Liu, On diagnostics in conditionally heteroskedastic time series models under elliptical distributions, J. Appl. Probab. 41A (2004), pp. 393–405.
- S. Liu and C.C. Heyde, On estimation in conditional heteroskedastic time series models under non-normal distributions, Stat. Pap. 49 (2008), pp. 455–469.
- Y. Liu, G. Ji, and S. Liu, Influence diagnostics in a vector autoregressive model, J. Stat. Comput. Simul. 85 (2015), pp. 2632–2655.
- S. Liu, V. Leiva, T. Ma, and A.H. Welsh, Influence diagnostic analysis in the possibly heteroskedastic linear model with exact restrictions, Stat. Methods Appl. 25 (2016), pp. 227–249.
- S. Liu, V. Leiva, D. Zhuang, T. Ma, and J Figueroa-Zuniga, Matrix differential calculus with applications in the multivariate linear model and its diagnostics, J. Multivar. Anal. 188 (2022), 104849.
- T. Liu, S. Liu, and L. Shi, Time Series Analysis Using SAS Enterprise Guide, Springer, Singapore, 2020.
- S. Liu, T. Ma, A. SenGupta, K. Shimizu, and M.Z. Wang, Influence diagnostics in possibly asymmetric circular-linear multivariate regression models, Sankhya B 79 (2017), pp. 76–93.
- Y. Liu, G. Mao, V. Leiva, S. Liu, and A Tapia, Diagnostic analytics for an autoregressive model under the skew-normal distribution, Mathematics 8 (2020), 693.
- Y. Liu, C. Mao, V. Leiva, S. Liu, and W.A. Silva Neto, Asymmetric autoregressive models: Statistical aspects and a financial application under COVID-19 pandemic, J. Appl. Stat. 49 (2022), pp. 1323–1347.
- S. Liu and H. Neudecker, On pseudo maximum likelihood estimation for multivariate time series models with conditional heteroskedasticity, Math. Comput. Simul. 79 (2009), pp. 2556–2565.
- Y. Liu, R. Sang, and S. Liu, Diagnostic analysis for a vector autoregressive model under t distributions, Stat. Neerl. 71 (2017), pp. 86–114.
- S. Liu and A.H. Welsh, Regression diagnostics, in International Encyclopedia of Statistical Science, M. Lovric, ed., Springer, Berlin, Heidelberg, 2011, pp. 1206–1208
- J. Lu, L. Shi, and F. Chen, Outlier detection in time series models using local influence method, Commun. Stat. Theory Methods 41 (2012), pp. 2202–2220.
- J.R. Magnus and H. Neudecker, Matrix Differential Calculus with Applications in Statistics and Econometrics, 3rd ed. Wiley, Chichester, 2019.
- C. Marchant and V. Leiva, Robust multivariate control charts based on Birnbaum–Saunders distributions, J. Stat. Comput. Simul. 88 (2018), pp. 182–202.
- S. Martinez, R. Giraldo, and V Leiva, Birnbaum–Saunders functional regression models for spatial data, Stoch. Environ. Res. Risk Assess 33 (2019), pp. 1765–1780.
- G.A. Paula, Influence diagnostics for linear models with first-order autoregressive elliptical errors, Stat. Probab. Lett. 79 (2009), pp. 339–346.
- W.Y. Poon and Y.S. Poon, Conformal normal curvature and assessment of local influence, J. R. Stat. Soc. Ser B 61 (1999), pp. 51–61.
- C.B. Zeller, V.H. Lachos, and F.E. Vilca-Labra, Local influence analysis for regression models with scale mixtures of skew-normal distributions, J. Appl. Stat. 38 (2011), pp. 348–363.
- L. Sanchez, V. Leiva, M. Galea, and H. Saulo, Birnbaum–Saunders quantile regression models with application to spatial data, Mathematics 8 (2020), 1000.
- The MathWorks Inc. MATLAB Version: 9.13.0 (R2022b), The MathWorks Inc, Natick, Massachusetts, 2022. Available at https://www.mathworks.com.
- A. Tapia, V. Leiva, M.P. Diaz, and V. Giampaoli, Influence diagnostics in mixed effects logistic regression models, TEST 28 (2019), pp. 920–942.
- A. Tapia, V. Giampaoli, M.P. Diaz, and V. Leiva, Sensitivity analysis of longitudinal count responses: A local influence approach and application to medical data, J. Appl. Stat. 46 (2019), pp. 1021–1042.
- R.S. Tsay, Analysis of Financial Time Series, Wiley, New York, 2010.
- R.S. Tsay, An Introduction to Analysis of Financial Data with R, Wiley, New York, 2013.
- I. Vidal and L.M. Castro, Influential observations in the independent student-t measurement error model with weak nondifferential error, Chil. J. Stat. 1 (2010), pp. 17–34.
- F.C. Xie, J.G. Lin, and B.C. Wei, Diagnostics for skew-normal nonlinear regression models with AR(1) errors, Comput. Stat. Data Anal. 53 (2009), pp. 4403–4416.
- F. Zhu, S. Liu, and L. Shi, Local influence analysis for poisson autoregression with an application to stock transaction data, Stat. Neerl. 70 (2016), pp. 4–25.
- F. Zhu, L. Shi, and S. Liu, Influence diagnostics in log-linear integer-valued GARCH models, AStA Adv. Stat. Anal. 99 (2015), pp. 311–335.
Appendix
In this appendix, we obtain the matrix derivatives involved in our diagnostic analytics [Citation18,Citation28,Citation37].
A.1 Proof (Theorem 1)
Proof.
The Q-function is established as
Its derivatives are expressed as
The second derivatives are formulated as
Hence, we obtain
with
.
A.2. Proof (Theorem 2)
Proof.
The Q-function (perturbed) is stated as
Taking the differentials of the Q-function (perturbed) with respect to
,
,
, ς and then
, for
, the derivatives are calculated as
and the second derivatives are stated as
Letting
and
, we obtain the expression presented in (Equation11
(10)
(10) ).
A.3. Proof (Theorem 3)
Proof.
We get the -function (perturbed)
Taking the differentials of the Q-function (perturbed) with respect to
,
,
, ς and then
, for
, the derivatives are found by
and the second derivatives are established as
Noting
and
, we reach the formula given in (Equation13
(12)
(12) ).
A.4. Proof (Theorem 4)
Proof.
We attain Q-function (perturbed)
Taking the differentials of the Q-function (perturbed) with respect to
,
,
, ς and then
, for
, the derivatives are stated as
and the second derivatives are presented as
Noting
and
, we get the expression formulated in (Equation15
(14)
(14) ).
A.5. Proof (Theorem 5)
Proof.
We obtain the -function (perturbed)
Taking the differentials of the Q-function (perturbed) with respect to
,
,
, ς and then
, for
, we obtain the first-order derivatives
and the second derivatives are
Using
and
, we get the expression introduced in (Equation17
(16)
(16) ).