
ABSTRACT
Background
Collation of aphasia research data across settings, countries and study designs using big data principles will support analyses across different language modalities, levels of impairment, and therapy interventions in this heterogeneous population. Big data approaches in aphasia research may support vital analyses, which are unachievable within individual trial datasets. However, we lack insight into the requirements for a systematically created database, the feasibility and challenges and potential utility of the type of data collated.
Aim
To report the development, preparation and establishment of an internationally agreed aphasia after stroke research database of individual participant data (IPD) to facilitate planned aphasia research analyses.
Methods
Data were collated by systematically identifying existing, eligible studies in any language (≥10 IPD, data on time since stroke, and language performance) and included sourcing from relevant aphasia research networks. We invited electronic contributions and also extracted IPD from the public domain. Data were assessed for completeness, validity of value-ranges within variables, and described according to pre-defined categories of demographic data, therapy descriptions, and language domain measurements. We cleaned, clarified, imputed and standardised relevant data in collaboration with the original study investigators. We presented participant, language, stroke, and therapy data characteristics of the final database using summary statistics.
Results
From 5256 screened records, 698 datasets were potentially eligible for inclusion; 174 datasets (5928 IPD) from 28 countries were included, 47/174 RCT datasets (1778 IPD) and 91/174 (2834 IPD) included a speech and language therapy (SLT) intervention. Participants’ median age was 63 years (interquartile range [53, 72]), 3407 (61.4%) were male and median recruitment time was 321 days (IQR 30, 1156) after stroke. IPD were available for aphasia severity or ability overall (n = 2699; 80 datasets), naming (n = 2886; 75 datasets), auditory comprehension (n = 2750; 71 datasets), functional communication (n = 1591; 29 datasets), reading (n = 770; 12 datasets) and writing (n = 724; 13 datasets). Information on SLT interventions were described by theoretical approach, therapy target, mode of delivery, setting and provider. Therapy regimen was described according to intensity (1882 IPD; 60 datasets), frequency (2057 IPD; 66 datasets), duration (1960 IPD; 64 datasets) and dosage (1978 IPD; 62 datasets).
Discussion
Our international IPD archive demonstrates the application of big data principles in the context of aphasia research; our rigorous methodology for data acquisition and cleaning can serve as a template for the establishment of similar databases in other research areas.
Background
Big data approaches to data synthesis and analysis typically involve collation of large datasets to reveal patterns, trends, and associations which would be overlooked in single trials due to a lack of statistical power. These approaches generate data “high in volume and diversity, gathered from single participants to large groups, at one or more time points” (Auffray et al., Citation2016), and can be applied to a range of health care settings. Big data methods have several advantages, the most important being sample size (Fan et al., Citation2014). Synthesising large volumes of data, facilitates greater representation of the population under investigation, whilst also reducing research waste (Rumsfeld et al., Citation2016). Collating data at the level of the individual, instead of at the level of aggregated, group or summary data, permits analyses that can account for individual confounders and missing data, and mitigates ecological bias, which can arise when using aggregated or group level data.
Historically, primary aphasia research studies in the stroke population have enrolled and analysed smaller sample sizes due to the heterogeneity of the population (Plowman et al., Citation2012), recruitment challenges (Wallace, Citation2010), the assessment of a variety of outcomes (Flowers et al., Citation2016), with data gathered on a range of stroke, aphasia and language measurement tools, capturing information on selected language modalities and conducting assessments in a range of different languages. Additionally, there is heterogeneity in the availability of participant, intervention and outcome data across existing aphasia research (Brady et al., Citation2020), limiting clinical implementation of research findings. The feasibility of developing a large aphasia individual participant data (IPD) database is challenging due to the differences in study designs (e.g., randomised controlled trials ‘RCTs’, case studies, cohorts), data collection time points, approaches for collecting, processing and interpreting data (Brady et al., Citation2016). Generating high-quality data, which is representative of people affected by post-stroke aphasia, representing the different language domains (e.g., everyday communication, auditory comprehension, naming, reading comprehension and writing), time since stroke, overall aphasia severity and therapy data (e.g., approaches, frequency, intensity, duration, and dosage) in large numbers would facilitate important language recovery analyses, both within and between sub-populations. Pooling pre-existing IPD from international studies in a large, multi-disciplinary, multi-lingual database offers a cost and time-effective (Nishimura et al., Citation2016) approach to addressing current aphasia research priorities (Franklin et al., Citation2018; Pollock et al., Citation2012).
The specialised nature of aphasia research provides opportunities to work collaboratively with internationally renowned research hubs to collate datasets across languages, research settings, and using different measurement tools. However, this can also pose a challenge to synthesising and standardizing IPD into a uniform format for analyses, and relies on working closely with collaborators, ensuring trust in how data are to be collated, stored, used, analysed and acknowledged in subsequent publications. Each of these aspects of international collaborative work is essential in order to build an IPD resource which can be adopted internationally. Yet the feasibility of the development and aggregation of such diverse research and clinical datasets into a big-data archive is currently unknown within the field of aphasia rehabilitation.
We report here on the outcome of an international, multidisciplinary collaborative effort to systematically develop the REhabilitation and recovery of peopLE with Aphasia after StrokE (RELEASE) IPD database, highlighting the feasibility of developing a big data post-stroke aphasia research resource and providing a template for replication by researchers in other areas of neuro-rehabilitation and communication research.
Methods
Full details on the search strategy, study selection, collation, data management, data extraction and synthesis are described in our published protocol (Brady et al., Citation2020)
Ethical approval and study registration
We received university ethical approval to collate data in the RELEASE archive (HLS/NCH/15/09). Principal investigators of included studies obtained local ethical approval for sharing their data to the RELEASE database as required. Our protocol was registered with the international prospective register of systematic reviews (PROSPERO CRD42018110947), and the database was approved by the UK’s Integrated Research Application System (IRAS; 179,505).
Dataset identification & management
We conducted a systematic search of existing literature to identify potential datasets in any language that met our eligibility criteria; IPD for a minimum of ten participants with stroke-related aphasia, time since stroke information and a measurement of language ability (Brady et al., Citation2020). Working copies of original datasets were given a unique identifier, standardised to SAS Inc. 9.4 software for data management, and stored with all available associated dataset documents (e.g., study protocols, papers and data dictionaries). Extracted data items were recorded in a data extraction table in accordance with the Template for Intervention Description and Replication (TIDieR) guidelines in reporting complex interventions (Hoffmann et al., Citation2014). We standardised the format, coding and units of measurement of variables, maximising the number of available IPD for analysis and documented this on a decision log. At primary dataset level, we described study design, inclusion/exclusion criteria, recruitment date (or publication date as a proxy when recruitment date was unavailable), sample size, country and language, data collection time point(s), blinding of assessors, dropouts and for RCTs, randomisation method and allocation concealment. Participant level data included demographic, stroke and language impairment information. Data cleaning and categorisation decisions were taken in collaboration with the wider RELEASE group. Where possible, each dataset profile summary was sent to the collaborating investigator for review and approval prior to inclusion in the final RELEASE database.
Risk of bias assessment in individual studies
We assessed methodological quality according to selection, detection, attrition and other potential sources of bias as previously detailed (Brady et al., Citation2020). We coded studies with potential risk of bias as low, unclear, or high risk, and appraised the impact of these potential biases.
Risk of bias across studies
We maintained an inclusive approach to dataset acceptance. Our systematic review used a broad search strategy and intentionally inclusive pre-defined eligibility criteria. Data extraction errors were minimised by two researchers independently reviewing data, and through verification of electronic contributions with primary researchers.
Outcomes
In collaboration with the contributing researchers, we categorised language measurements into the following language domains: overall language ability, spoken language production (including a sub-category for naming), auditory comprehension, reading comprehension, writing and functional communication. Data for each outcome measurement instrument were investigated for validity, for example, by examining ranges, outliers and missing-ness of data with queries resolved (where possible) through communication with collaborators.
Summary statistics
We described the contents of the database using summary statistics. Continuous variables were described using medians and interquartile ranges (IQR), while categorical variables were described using frequencies and percentages. Where possible, we described the measurement tools that were used to capture each of the language domains of interest, the number of studies that used the measurement, the IPD available and missing, and instances where the measurement tool was used but the data was not reported.
Results
Datasets
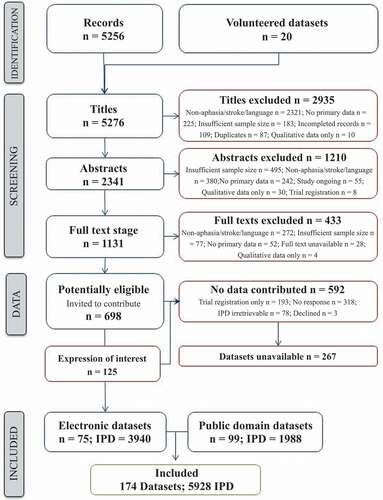
Following the systematic search, 11,314 records were identified. After the removal of duplicates, we screened 5256 records, excluding 2935 ineligible records. We excluded a further 1210 following abstract review and an additional 433 records after a review of the full texts (). We invited the authors of 698 potentially eligible reports to contribute the associated IPD. Of which, 592 did not result in data contribution as 193/592 were trial registration records, no responses were received from 318/592 research teams, IPD from 78 datasets were unavailable IPD, and 3/592 declined to participate. We received 125 expressions of interest relating to eligible datasets and identified a further 99 eligible datasets in the public domain (). Our RELEASE database thus comprised of 174 datasets with 5928 IPD from 28 countries, in 23 languages; 13 were unpublished. We received 75/174 (43.1%) datasets electronically (3940/5928, 66.5% IPD), and included 99 (56.9%) from the public domain (1988, 33.5% IPD).
Figure 1. PRISMA flow diagram: Eligible database identification and contribution.
Study types
More than a quarter of the primary research studies 47/174 (27.0%) were RCTs (1778/5928, 30.0% IPD); over half 104/174 (59.8%) were a case series or cohort design (2886, 48.7% IPD); non-randomized controlled trial studies whereby participants were recruited to groups, but random allocation was not applied (non RCTs) accounted for 18/174 (10.3%) datasets (n = 411, 6.9% IPD). The remaining 2.9% (5/174) of datasets came from registries (853, 1.4% IPD). Data inclusion in each planned analysis was on a dataset-by-dataset basis and did not necessarily reflect the primary research study designs. For example, in some cases, participants were randomly allocated to two (non-SLT) interventions but all received the same SLT treatment. In such cases, the IPD were variously analysed as a single cohort or by group depending on the nature of the dataset and the planned analyses. Availability of data on randomised allocation also impacted the analysis; for example one primary research report described an RCT study design but IPD on group allocation was unavailable as the researchers reported the dataset as a single cohort.
Participants
Participants had a median age of 63 (IQR 53–72) years, most 3407/5550 IPD (61.4%) were male () and median formal education was 12 years (IQR 10–16). Median participant recruitment time was 321 days (IQR 30–1156) after stroke (5841/5928 IPD, 98.5%). Three quarters of participants (1116/1475 IPD, 75.5%) were White and a majority lived with others (473/701 IPD, 67.5%, ). Ischaemic stroke (2795/3416 IPD, 81.8%) predominated stroke aetiology and stroke typically affected the left hemisphere (3965/4130, 96.0%). The majority of participants were right-handed (3719/3879, 95.9%) with no visual impairment (1122/1494; 75.1% IPD); 111 participants (11.8%) were classified as also having dysarthria, and 329 (32.5%) were recorded as having aphasia along with apraxia of speech ().
Table 1. RELEASE database participant descriptors
Data were collected across 28 countries, in 23 languages, the majority in English (3162/5928, 53.3% IPD). Of the 79 datasets reporting date of recruitment, participants were recruited between 1973 and 2018. Of 161 published datasets, 26 (16.1% datasets; 664/4627 IPD, 14%) were published before 2000.
Outcomes
A total of 64 language measurement tools, which captured the outcomes relevant to our database across 174 datasets were included (). The measurement tool used by the most datasets for each language outcome became an “anchor measure” to which the scores of all other tools measuring the same domain were transformed (see for anchor and minority measures of overall language and each language domain). Many datasets (80/174;46.0%) included a measure of overall language ability (2699/5928, 45.5% IPD), 75 (43.0%) used a naming measure (2886, 48.7% IPD), and 71 (40.8%) measured auditory comprehension (2750, 46.4% IPD). Other language domains of interest (functional communication, writing, reading comprehension and other spoken language) were also measured but by smaller numbers of primary research teams (). Available measurement tools were profiled by language modality (). For some datasets measurement tools described in accompanying study documentation, were unavailable in a format that could be profiled or analysed for each language domain and were unavailable from the primary research team. For example, the Aachen Aphasia Test (AAT), while described in reports relating to 17 datasets, only 16/17 had AAT IPD available for one or more of the language outcomes relevant to our database.
Table 2. Data availability for language outcomes
Table 3. Overall language ability assessment tools (at baseline) included in RELEASE – Datasets and IPD where measure is reported, available, missing from report, or unavailable
Table 4 a.Naming assessments (at baseline) included in RELEASE – Datasets and IPD where measure is reported, available, missing from report or unavailable
Table b.Other spoken language assessments (at baseline) included in RELEASE – Datasets and IPD where measure is reported, available, missing from report or unavailable
Table 5. Auditory comprehension assessments (at baseline) included in RELEASE – Datasets and IPD where measure is reported, available, missing from report or unavailable
Table 6 a.Reading comprehension and writing assessments (at baseline) included in RELEASE – Datasets and IPD where measure is reported, available, missing from report or unavailable
Table 6 b.Reading comprehension and writing assessments (at baseline) included in RELEASE – Datasets and IPD where measure is reported, available, missing from report or unavailable
Table 7 a.Functional Communication (observer-rated) included in RELEASE – Datasets and IPD where measure is reported, available, missing from report or unavailable
Table 7 b.Functional Communication (self-rated) included in RELEASE – Datasets and IPD where measure is reported, available, missing from report or unavailable
Interventions
Just over half the datasets described an SLT intervention (91/174 52.3%; 2746/5928, 46.3% IPD). Data on language measurements were available at pre- and post-intervention time points for 67/174 (38.5%) datasets, comprising 2330/5928 IPD (39.3%). These 67 intervention studies were profiled by method of delivery, theoretical approach, and language treatment targets (). In 7/174 (4%) datasets, participants were allocated across three groups (different SLT interventions, in some cases with a control comparison group), (128/5928, 0.02% IPD), and in three datasets (1.7%) across four groups (84 IPD). Five datasets (4%) employed a delayed treatment start for one group (128/5928, 0.02% IPD). Therapy regime was described according to intensity (hours per week, 1882 IPD; 60 datasets), frequency (number of sessions per week, 2057 IPD; 66 datasets), duration (total number of days, 1960 IPD; 64 datasets) and dosage (total hours, 1978 IPD; 62 datasets). Furthermore, interventions were delivered by professionals in 62 datasets (92.5%) and non-professionals in seven datasets (10.4%); in clinics, hospitals or rehabilitation settings in 48 datasets (71.6%) and at home in 17 datasets (23.4%).
Table 8. Speech and language therapy (SLT) Interventions in the RELEASE dataset
Risk of meta-bias – across studies
From the 47 RCTs identified in a previous systematic review (Brady et al., Citation2016), we included IPD from 17 eligible trials, in addition to IPD from five trials that were on-going, and a further four trials that were unavailable at the time of that review. As a consequence of our systematic searching, we included 122 more datasets in our IPD database than we had identified a priori, increasing our original estimate from 3181 IPD to 5928. This reduced the risk of selection bias and increased the availability of IPD. Due to the nature of our dataset, generation of funnel plots to assess publication bias were not possible. Instead, we checked distribution between sample size and studies reporting significant results. Of the 164 published datasets, no evidence of publication bias by sample size was evident (chi-squared, p = 0.77 ).
Table 9. Significant and non-significant results reported, by participant number
Risk of bias – within studies
Across the included RCTs there was a low risk of bias (random sequence generation, allocation concealment, blinding of outcome measure and a small number with unexplained attrition) (). Of the total 47 RCTs included , 27 reported adequate generation of a random sequence; 22 described an adequate method to ensure concealment of allocation. Within RCTs, baseline differences between participants in the treatment groups were assessed for age (3/47 showing baseline differences), time since stroke (2/47 showing baseline differences) and language impairment (1/47 showing baseline differences) using the Wilcoxon signed rank test (Brady et al., Citationin press). Between group baseline differences in sex were assessed using the chi-square test (1/47 showing baseline differences).
Figure 2. Randomised controlled trials included in the RELEASE database and risk of bias.
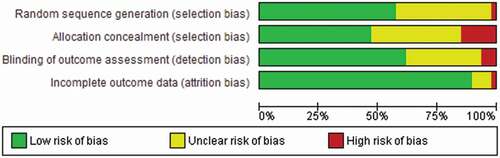
Blinding of outcome assessment was reported in 49/174 datasets (28.2%) though in many cases blinding was not relevant to the primary dataset study design (e.g., a clinical registry or observational study). An additional nine datasets (5.2%) described blinding for a subset of data and 117 datasets either did not report blinding (91/117) or had indicated that blinding was not present (25/117).
A third of the IPD were available in the public domain; some of these IPD datasets were only partially reported in those publications (for example, baseline data only) while in other cases full RCT datasets were available . Some primary research dataset electronic contributions were only partially available with published reports relating to that dataset indicatinghat additional data items were available at the time of publication.
Discussion
Using an international multidisciplinary collaborative approach, robust methodology, and applying big data principles within the context of aphasia research, we systematically created an international IPD database that adhered to data sharing guidelines (Knoppers, Citation2014), and which ensured the feasibility of our analysis plan (Brady et al., Citation2020). Working with our collaborators and accessing data in the public domain, allowed us to include demographic, stroke, aphasia, language impairment and SLT intervention IPD from 28 countries and language outcomes gathered using 64 measurement tools. Over half the datasets included an SLT intervention, IPD that can be used to inform future analyses to optimise the delivery of SLT in people with aphasia. Our database is representative of available aphasia research datasets and reflects the heterogeneity in data collection practices across a range of different study designs and contexts. Collation of these data highlighted variation in the measurement tools that were used to capture data within the same language domain and strengthens the evidence to support greater consistency in the use of an aphasia core outcome set (Wallace et al., Citation2019) in future aphasia research. Similarly, the need for greater consistency in the collection of participant descriptors in future aphasia studies was evident (The RELEASE Collaboration, Citation2020), and an international consensus initiative to address this need is currently ongoing within the Collaboration of Aphasia Trialists (www.aphasiatrials.org/describe).
A key strength in our study was our international, collaborative approach, which involved multidisciplinary aphasia researchers and permitted the sharing of expertise and greater clarity on international aphasia research practice. Primary researchers were actively involved in the development and cleaning of data, thereby contributing to the validity, accuracy and robustness of the data contained within the archive.
The research landscape across a range of health settings has highlighted the importance of minimising research waste (Chan et al., Citation2014; Doubal et al., Citation2017), resulting in encouragement and recognition of the value (Taichman et al., Citation2016), in sharing research datasets to facilitate new analyses. Guidelines exist to support IPD sharing (Waithira et al., Citation2019), with appropriate approvals, accreditation and acknowledgement (Wilkinson et al., Citation2016), but the feasibility of such an approach in the context of aphasia rehabilitation research had not yet been examined; we set out to explore this.
Previous work has highlighted that health research protocols, full study reports, and participant-level datasets are not widely available in the public domain (Chan et al., Citation2014). However, recent initiatives that require the lodging of datasets in publicly available resources have changed the landscape of health research (Taichman et al., Citation2016). Additionally, in one study publications reporting study findings were available for only half of all studies (Chan et al., Citation2014), and can be subject to selective reporting or other sources of bias. A strength in our method of identifying eligible studies was that it relied not only on searches of the existing literature, but also on communication with existing international research networks such as the Collaboration of Aphasia Trialists (www.aphasiatrials.org) to identify potentially eligible datasets for inclusion. Our model builds on historical examples of in-house research activities that have included data sharing amongst specific research teams. Use of datasets based on availability and access within research groups can often bias dataset selection, impacting upon the representativeness of the data and limiting the generalisability of results.
Our study highlighted some restrictions to collaborative approaches. Despite our wide eligibility criteria and our systematic identification of, and open invitation to principal investigators with potentially eligible datasets, we were only able to acquire a subset of potentially eligible datasets; of 698 datasets identified as potentially eligible, 267 were unavailable for data sharing.
We highlighted several important methodological steps that were required to develop this international database. These included the establishment of relevant but inclusive eligibility criteria, the systematic identification of eligible studies using multiple information sources, open invitation to international researchers to contribute data, collaborative working and consensus building to agree on variable parameters and categories, cleaning and standardisation of the data, and finally transparent description of the database to facilitate informed exploratory analyses. This model can be used by investigators in other health research areas to create similar data repositories within which to conduct exploratory analyses. Beyond the RELEASE project, a long-term legacy, big data repository for aphasia datasets is under development within the Collaboration of Aphasia Trialists, using the principles set out above. We invite further contributions of eligible datasets to this aphasia archive, to facilitate future analyses for the benefit of people with aphasia.
Disclaimer
The views and opinions expressed in this publication are those of the authors and do not necessarily reflect those of the NHS, the NIHR, MRC, CCF, NETSCC, the HS&DR programme, the Department of Health and Social Care, the Tavistock Trust for Aphasia, the Chief Scientist Office or the Scottish Government Health and Social Care Directorates.
Acknowledgements
Open Access funding provided by the Qatar National Library.
Disclosure statement
No potential conflict of interest was reported by the authors.
Marian Brady reports grants from Chief Scientist Office (CSO), Scottish Government Health and Social Care Directorates, grants from EU Cooperation in Science and Technology (COST) funded Collaboration of Aphasia Scientists (IS1208 www.aphasiatrials.org), and grants from The Tavistock Trust for Aphasia during the conduct of the study, and is a member of the Royal College of Speech and Language Therapists.
Audrey Bowen reports that data from her research is included within the analyses in the RELEASE report. Her post at the University of Manchester is partly funded by research grants and personal awards from NIHR and Stroke Association.
Caterina Breitenstein reports grants from the German Federal Ministry of Education and Research (BMBF) during the conduct of the study.
Erin Godecke reports Western Australian State Health Research Advisory Council (SHRAC) Research Translation Project Grants RSD-02720; 2008/2009 during the conduct of the study.
Neil Hawkins reports grants from National Institute for Health Research during the conduct of the study.
Katerina Hilari reports grants from The Stroke Association, grants from European Social Fund and Greek National Strategic Reference Framework, and grants from The Tavistock Trust for Aphasia outside the submitted work.
Petra Jaecks reports a PhD grant from Weidmüller Stiftung.
Brian MacWhinney reports grants from National Institutes of Health.
Rebecca Marshall reports grants from National Institute of Deafness and Other Communication Disorders, NIH, USA during the conduct of the study.
Rebecca Palmer reports grants from NIHR senior clinical academic lectureship, grants from NIHR HTA, and grants from Tavistock Trust for Aphasia outside the submitted work.
Ilias Papathanasiou reports funding from European Social Fund and Greek National Strategic Reference Framework.
Elizabeth Rochon reports funding from the Heart and Stroke Foundation of Canada.
Jerzy Szaflarski reports personal fees from SK Life Sciences, personal fees from LivaNova Inc, personal fees from Lundbeck, personal fees from NeuroPace Inc, personal fees from Upsher-Smith Laboratories, Inc, grants and personal fees from SAGE Pharmaceuticals, grants and personal fees from UCB Pharma, grants from Biogen, grants from Eisai Inc, and other from GW Pharmaceuticals, outside the submitted work.
Shirley Thomas reports research grants from NIHR and The Stroke Association outside the submitted work.
Ineke van der Meulen reports grants from Stichting Rotterdams Kinderrevalidatiefonds Adriaanstichting, other from Stichting Afasie Nederland, other from Stichting Coolsingel, and other from Bohn Stafleu van Loghum during the conduct of the study.
Linda Worrall reports a grant from the National Health and Medical Research Council of Australia.
All other authors have declared no competing interests
Data availability statement & Data deposition
Contributing trialists who have granted permission for extended use of their datasets beyond RELEASE have deposited their data in the Collaboration of Aphasia Trialists’ (CATs) Aphasia Resource (available at https://www.aphasiatrials.org/aphasia-dataset/).
Additional information
Funding
References
- Auffray, C., Balling, R., Barroso, I., Bencze, L., Benson, M., Bergeron, J., Bernal-Delgado, E., Blomberg, N., Bock, C., Conesa, A., Del Signore, S., Delogne, C., Devilee, P., Di Meglio, A., Eijkemans, M., Flicek, P., Graf, N., Grimm, V., Guchelaar, H. J., Guo, Y. K., Gut, I. G., . . . Zanetti, G. (2016). Making sense of big data in health research: Towards an EU action plan. Genome Medicine, 8(1), 71. https://doi.org/https://doi.org/10.1186/s13073-016-0323-y
- Brady, M. C., Ali, M., VandenBerg, K., Williams, L. J., Williams, L. R., Abo, M., Becker, F., Bowen, A., Brandenburg, C., Breitenstein, C., Bruehl, S., Copland, D. A., Cranfill, R. B., Di Pietro-bachmann, M., Enderby, P., Fillingham, J., Galli, F. L., Gandolfi, M., Glize, B., Godecke, E., Harris Wright, H., et al. (2020). RELEASE a protocol for a systematic review based, individual participant data, meta-and network meta-analysis, of complex speech-language therapy interventions for stroke-related aphasia. Aphasiology, 34(2), 137–157. https://doi.org/https://doi.org/10.1080/02687038.2019.1643003
- Brady, M. C., Ali, M., VandenBerg, K., Williams, L. J., Williams, L. R., Abo, M., Becker, F., Bowen, A., Brandenburg, C., Breitenstein, C., Bruehl, S., Copland, D. A., Cranfill, R. B., Di Pietro-bachmann, M., Enderby, P., Fillingham, J., Galli, F. L., Gandolfi, M., Glize, B., Godecke, E., Harris Wright, H., et al. (in press). RELEASE: An individual participant data meta-analysis, incorporating systematic review and network meta-analysis, of complex speech-language therapy interventions for stroke related aphasia. National Institute of Health Research: Health Services and Delivery Research. https://www.journalslibrary.nihr.ac.uk/programmes/hsdr/140422/#/
- Brady, M. C., Kelly, H., Godwin, J., Enderby, P., & Campbell, P. (2016). Speech and language therapy for aphasia following stroke. Cochrane Database of Systematic Reviews, (6). Art. No: CD000425. https://doi.org/https://doi.org/10.1002/14651858.CD000425.pub4
- Chan, A.-W., Song, F., Vickers, A., Jefferson, T., Dickersin, K., Gotzsche, P. C., Krumholz, H. M., Ghersi, D., & Bart Van Der Worp, H. (2014). Increasing value and reducing waste: Addressing inaccessible research. The Lancet, 18(9913), 257–266. 383 https://doi.org/https://doi.org/10.1016/S0140-6736(13)62296-5
- Doubal, F. N., Ali, M., Batty, G. D., Charidimou, A., Eriksdotter, M., Hofmann-Apitius, M., Kim, Y.-H., Levine, D. A., Mean, G., Mucke, H. A. N., Ritchie, C. W., Roberts, C. J., Russ, T. C., Stewart, R., Whiteley, W., & Quinn, T. J. (2017). Big data and data repurposing - using existing data to answer new questions in vascular dementia research. BMC Neurology, 17(1), 72. https://doi.org/https://doi.org/10.1186/s12883-017-0841-2
- Fan, J., Han, F., & Liu, H. (2014). Challenges of big data analysis. National Science Review, 1(2), 293–314. https://doi.org/https://doi.org/10.1093/nsr/nwt032
- Flowers, H. L., Skoretz, S. A., Silvers, F. L., Rochon, E., Fang, J., Flamand-Rose, C., & Martino, R. (2016). Poststroke aphasia frequency, recovery and outcomes: A systematic review and meta-analysis. Archives of Physical Medicine and Rehabilitation, 97(12), 2188–2201. https://doi.org/http://dx.doi.org/10.1016/j.apmr.2016.03.006
- Franklin, S., Harhen, D., Hayes, M., McManus, S., & Pollock, A. (2018). Top 10 research priorities relating to aphasia following stroke. Aphasiology, 32(11), 1388–1395. https://doi.org/https://doi.org/10.1080/02687038.2017.1417539
- Hoffmann, T. C., Glasziou, P. P., Boutron, I., Milne, R., Perera, R., Moher, D., Altman, D. G., Barbour, V., MacDonald, H., Johnston, M., Lamb, S. E., Dixon-Woods, M., McCulloch, P., Wyatt, J. C., Chan, A.-W., & Michie, S. (2014). Better reporting of interventions: Template for intervention description and replication (TIDieR) checklist and guide. BMJ, 348(mar07 3), g1687. https://doi.org/https://doi.org/10.1136/bmj.g1687
- Knoppers, B. M. (2014). Framework for responsible sharing of genomic and health-related data. The HUGO Journal, 8(1), 3. https://doi.org/https://doi.org/10.1186/s11568-014-0003-1
- Nishimura, A., Nishimura, K., Kada, A., & Iihara, K., & J-ASPECT Study GROUP. (2016). Status and future perspectives of utilizing big data in neurosurgical and stroke research. Neurologica Medico-Chirurgica, 56(11), 655–663. https://doi.org/https://doi.org/10.2176/nmc.ra.2016-0174
- Plowman, E., Hentz, B., & Ellis, C. (2012). Post-stroke aphasia prognosis: A review of patient-related and stroke related factors. Journal of Evaluation in Clinical Practice, 18(3), 689–694. https://doi.org/https://doi.org/10.1111/j.1365-2753.2011.01650.x
- Pollock, A., St George, B., Fenton, M., & Firkins, L. (2012). Top ten research priorities relating to life after stroke. Lancet Neurology, 11(3), 209. https://doi.org/https://doi.org/10.1016/S1474-4422(12)70029-7
- Rumsfeld, J. S., Joynt, K. E., & Maddox, T. M. (2016). Big data analytics to improve cardiovascular care: Promise and challenges. Nature Reviews Cardiology, 13(6), 350–359. https://doi.org/https://doi.org/10.1038/nrcardio.2016.42
- Taichman, D. B., Backus, J., Baethge, C., Bauchner, H., De Leeuw, P. W., Drazen, J. M., Fletcher, J., Frizelle, F. A., Groves, T., Haileamlak, A., James, A., ., Laine, C., Peiperl, L., Pinborg, A., Sahni, P., & Wu, S. (2016). Sharing Clinical Trial Data — A proposal from the International Committee of Medical Journal Editors. The New England Journal of Medicine, 374(4), 384–386. https://doi.org/https://doi.org/10.1056/nejme1515172
- The RELEASE Collaboration. (2020). Communicating simply, but not too simply: Reporting of participants and speech and language interventions for aphasia after stroke. International Journal of Speech-Language Pathology, 22(3), 302–312. https://doi.org/https://doi.org/10.1080/17549507.2020.1762000
- Waithira, N., Mutinda, B., & Cheah, P. Y. (2019). Data management and sharing policy: The first step towards promoting data sharing. BMC Medicine, 17(1), Article: 80. https://doi.org/https://doi.org/10.1186/s12916-019-1315-8
- Wallace, G. L. (2010). Profile of life participation after stroke and aphasia. Topics in Stroke Rehabiliation, 17(6), 432–450. https://doi.org/https://doi.org/10.1310/tsr1706-432
- Wallace, S. J., Worrall, L., Rose, T., Le Dorze, G., Breitenstein, C., Hilari, K., Babbitt, E., Bose, A., Brady, M., Cherney, L. R., Copland, D., Cruice, M., Enderby, P., Hersh, D., Howe, T., Kelly, H., Kiran, S., Laska, A.-C., Marshall, J., Nicholas, M., & Webster, J. (2019). A core outcome set for aphasia treatment research: The ROMA consensus statement. International Journal of Stroke, 14(2), 180–185. https://doi.org/https://doi.org/10.1177/1747493018806200
- Wilkinson, M., Dumontier, M., Aalbersberg, I., Appleton, G., Axton, M., Baak, A., Blomberg, N., Boiten, J.-W., Da Silva Santos, L. B., Bourne, P. E., Bouwman, J., Brookes, A. J., Clark, T., Crosas, M., Dillo, I., Duon, O., Edminds, S., Evelo, C. T., Finkers, R., Gonzalez-Beltran, A., & Mons, B. (2016). The FAIR guiding principles for scientific data management and stewardship. Scientific Data, 3(1), 1-9. https://doi.org/http://dx.doi.org/10.1038/sdata.2016.18