
ABSTRACT
In this study, we investigated the lexical tones and vowels produced by ten speakers diagnosed with aphasia and coexisting apraxia of speech (A-AOS) and ten healthy participants, to compare their tone and vowel disruptions. We first judged the productions of both A-AOS and healthy participants and classified them into three categories, i.e. those by healthy speakers and rated as correct, those by A-AOS participants and rated as correct, and those by A-AOS participants and rated as incorrect. We then compared the perceptual results for the three groups based on their respective acoustic correlates to reveal the relations among different accuracy groups. Results showed that the numbers of tone and vowel disruptions by A-AOS speakers occurred on a comparable scale. In perception, approximately equal numbers of tones and vowels produced by A-AOS participants were identified as correct; however, acoustic parameters showed that, unlike vowels, the patients’ tones categorised as correct by native Mandarin listeners differed considerably from those of the healthy speakers, suggesting that for Mandarin A-AOS patients, tones were in fact more disrupted than vowels in acoustic terms. Native Mandarin listeners seemed to be more tolerant of less well-targeted tones than less-well targeted vowels. The clinical implication is that tonal and segmental practice should be incorporated for Mandarin A-AOS patients to enhance their overall motor speech control.
Introduction
Aphasia is a condition in which a person is unable to comprehend or formulate language due to the impairment of a specific brain region. It affects one (or more) of the four communication components, including auditory understanding, vocal expression, reading and writing, and functional communication. On the other hand, Apraxia of speech (AOS) is a term for motor speech disorder in which the ability to coordinate the sequential, articulatory actions required to make speech sounds is hampered. AOS has been described as disruption of motor planning or programming (Van Der Merwe, Citation2021), and is typically seen in patients with lesions to Broca’s area, the left frontal and temporoparietal cortex, the left, superior, anterior region of the insula, as well as left subcortical structures (Ogar et al., Citation2005; Ogar et al., Citation2006; Ackermann & Ziegler, Citation2010). Because AOS symptoms frequently coexist with non-fluent aphasia, examples of aphasia with concomitant apraxia have been well documented (Haley, Citation2002; Kurland et al., Citation2012; Weiss et al., Citation2016). Both conditions are thought to affect articulation and prosody.
As a tone language, Mandarin Chinese differentiates words by both segmental and tonal structures in the lexicon. Each syllable in Mandarin is a morpheme, carrying one of the four tones and a vowel. In Mandarin monosyllabic words, Tone 1 (T1), Tone 2 (T2), Tone 3 (T3) and Tone 4 (T4) have a high level, low rising, falling-rising and high falling fundamental frequency (f0) contour, respectively. Segmentally identical syllables produced with different tones convey different meanings in Mandarin. For example, the syllable /ma/ means ‘mother’, ‘hemp’, ‘horse’ and ‘scold’ when produced with the four different tones (Duanmu, Citation2007). The primary and sufficient perceptual cue for Mandarin tone is the f0 contour. All other auditory cues, such as amplitude, vowel duration, or vocal quality, are unimportant when f0 information is available, though they have been proven to serve as cues in tone perception in the absence of f0 contours (Fu & Zeng, Citation2000; Whalen & Xu, Citation1992). Mandarin tones are processed in the fronto-parietal areas (including the left posterior IFG, adjacent PMC and left SMG/IPS), bilateral temporo-parietal and subcortical regions (Myers et al., Citation2009). Impairments to these regions cause production errors like tone substitutions (e.g. T2 where T3 should appear, Packard, Citation1986), abnormal changes in f0 contours (e.g. a level tone with a sudden fall midway), f0 range (e.g. larger or smaller compared to healthy speakers) or f0 position (e.g. elevated or lowered; Gandour et al., Citation1988, Citation1992) and unusual tone duration (e.g. abnormally longer or shorter than healthy speakers, Ryalls & Reinvang, Citation1986). In comparison to the four lexical tones, Mandarin has a large number of vowels, 22 in all (Lee & Zee, Citation2003). Common sensorimotor activation during vowel processing was observed on a left postero-dorsal stream, including the opercular part of Broca’s area, the adjacent ventral premotor cortex, and the temporo-parietal junction (Leff et al., Citation2009; Wilson et al., Citation2009). Damage to these areas led to vowel substitution or distortion errors, such as incorrect tongue positioning, abnormal prolongation, and so on, resulting in formant (e.g. the first and second formant, i.e. F1, F2) or vowel duration aberrations (Ackermann et al., Citation1999; Haley et al., Citation2001; Odell et al., Citation1991). The processing of lexical tones and vowels in Mandarin involves both the left frontal (Broca) and temporal areas, as well as other sensorimotor areas. Disruptions of these areas are likely seen in either non-fluent aphasic patients or patients with AOS.
Clinically, Mandarin speakers with brain damage face the risk that both tonal and segmental structures are impaired. However, previous research has only focused on either tonal or segmental disruption alone (Gandour et al., Citation1988; Kent & Rosenbek, Citation1983; Haley et al., Citation2001; Yiu & Fok, Citation1995), with few comparisons of the two for those tone-language speakers. This is surprising, given the importance of such comparison in therapeutic practice and linguistic theory. One possible reason for this could be that separate mechanisms (articulatory vs. laryngeal) are involved in the generation of segmental and tonal aspects (Liu et al., Citation2006; Kent et al., Citation2022),so the connection between them isn’t always obvious. However, as Mandarin vowels and any voiced segment in syllable codas could also carry tonal information (Howie & Howie, Citation1976), it is reasonable to assume that the vocalic and tonal structures are interdependent in speech production. As both elements are part of the motor control of speech, which is frequently impaired in patients with aphasia and apraxia of speech, a thorough comparison of acoustic/perceptual characteristics of tone and vowel disruptions would be informative in how speech impairments occur.
One technical issue is that most prior studies used the same acoustic measures, such as f0 range or f0 overall shape, to examine the pitch contours of all disrupted tones (Gandour et al., Citation1988, Citation1989, Citation1992; Kadyamusuma et al., Citation2011). More exact acoustic features, such as f0 height, f0 slope, and so on, should be used to describe the f0 contours of each tone type, so that their extreme (highest or lowest) values may be better captured. As for vowels, the static cues of vowel formants are the major acoustic parameters in assessing vowels produced by patients with brain damage now (Haley et al., Citation2001; Jacks et al., Citation2010; Kurowski et al., Citation1998; J. H. Ryalls, Citation1986). However, as dynamic properties also contribute to vowel production and perception (Elvin et al., Citation2016; Renwick & Stanley, Citation2020; Hualde et al., Citation2021), the acoustic measures in vowel analysis can be further improved for this topic.
Thus, the present study aims to provide a detailed account of the severity of tone vs. vowel disruptions for Mandarin aphasic patients with coexisting apraxia of speech (A-AOS). The specific aims include: (1) to provide a detailed acoustic account of the correct and incorrect tones and vowels in monosyllabic words produced by Mandarin A-AOS patients; (2) to see if tones and vowels are disrupted separately or in combination, and what impacts the disruptions may have on the speech output.
Method
Design
This experiment compared the tones and vowels produced by Mandarin A-AOS patients with healthy controls (All work was conducted with the formal approval of the human subjects committee of Shanghai YangZhi Rehabilitation Hospital). To achieve this, we made perceptual judgments and acoustic descriptions of participants’ tone and vowel productions. The productions by A-AOS patients and healthy controls were first evaluated and categorised by ten Mandarin Chinese listeners. Here we followed Wong’s (Citation2012) practice for the token categorisation, in which tones or vowels identified correctly by 8 to 10 raters were scored as ‘correct’, whereas those identified correctly by only 4 or fewer judges were scored as ‘incorrect’. In this way, all the productions can be classified into three groups: ‘Healthy speakers’ correct productions’ (HC), ‘Patients’ correct productions’ (PC) and ‘patients’ incorrect productions’ (PI). Productions correctly identified by 5 to 7 judges were excluded from the analysis. The acoustic parameters of the productions in each group were then tested and compared. This was to determine if A-AOS patients’ ‘correct’ output differed acoustically from the healthy speakers, and if the patients’ ‘incorrect’ productions had any acoustic regularity that identified them from the ‘correct’ ones. Finally, an overall comparison of tone and vowel disruptions was conducted.
Participants
Ten speakers diagnosed with A-AOS (age range = 25–63, M = 47.3, SD = 11.1) and ten age-matched healthy controls (age range = 28–61, M = 46.7, SD = 9.8) participated in the study (). All participants demonstrated aphasia with AOS at least six months post-onset (M = 15 months, SD = 6.4) of left hemisphere cerebral vascular accident. The following inclusion criteria for participants were met: (1) Mandarin monolingual, (2) right-handed, (3) minimum of high school education, (4) passed an audiometric pure-tone screening at 35 – dB HL at 500, 1000, and 2000 Hz for at least one ear, (5) assessed through Mini-Mental State (Folstein et al., Citation1975) to rule out any dementia. If a participant spoke a dialect other than Mandarin, had a medical history of depression or other psychiatric illness, degenerative neurological illnesses, chronic medical illness, or dysarthria, they were excluded from the study. When dysarthria was suspected, a speech mechanism evaluation was performed (Duffy, Citation2019).
Table 1. Speaker characteristics for the healthy control and A-AOS groups.
The type and severity of aphasia were determined by each subject’s performance on Western Aphasia Battery Chinese adaptation (Gao, Citation2006). Presence of AOS was determined primarily by characteristics observed during the performance on the Apraxia Battery of Adults (2nd edition, subsets I, II, IV, Dabul, Citation2000). A motor speech evaluation (Duffy, Citation2019) was audio-recorded and presented to three speech-language pathologists (native Mandarin speakers) for AOS diagnosis. Each pathologist had more than ten years of experience identifying neurogenic communication disorders and had no knowledge of the study purpose. The audio-recorded A-AOS speech samples were mixed with those of the healthy controls. To diagnose AOS and assess severity, speech-language pathologists utilised an 8-point rating scale ranging from 0 (no AOS) to 7 (severe AOS). Criteria for the presence of AOS included: (a) effortful speech with self-correcting attempts; (b) frequent articulatory errors, such as substitutions, distortions, omissions, and additions; (c) atypical prosody; and (d) articulatory variability across repeated productions of the same utterance (Wertz et al., Citation1984). The pathologists first listened independently and then discussed their findings until they reached an agreement on a diagnosis and severity level. Rated severity of AOS ranged from 2 to 5 for the patients and 0 for all the healthy controls.
All patients spoke only Mandarin at home and in their respective job settings; each A-AOS participant was paired with a relative who was close in age and had a similar educational background, they constituted the control group.
Stimuli
Twenty monosyllabic words were chosen, each having one of the four lexical tones and a monophthong from the five point vowels /a, y, u, i, ɤ/ in standard Chinese (Lee & Zee, Citation2003). These words were chosen after discussion between the authors and the speech-language therapists, and also by consultation with patients’ families or caregivers. The stimuli were related to all the patients’ daily routines, and thus expected to be easily recognisable ().
Table 2. Stimuli of the experiment.
Recording procedures
Recordings were made in the soundproof laboratory office at the hospital. All samples were recorded as wave files using a Korg audio MR-1 recorder (AKG miniature condenser model C520) with a headset microphone positioned 5 cm away from the participants’ mouths. Each subject was provided with 20 monosyllabic words, represented by 20 photographs in random order. Each photo had an image in the centre and a Chinese character in the bottom right corner, representing the same word. The participants could thus probe the connotations of the stimuli either graphically or by the monosyllabic words. An experimenter held up one picture at a time in front of the participant to encourage word production. A practice session was held before the recording began, in which participants were asked to label 6 to 8 pictures with monosyllabic words in isolation. If a bisyllabic or trisyllabic word was produced, they were instructed to repeat it with only the first or last syllable (usually the target ones). For example, if a participant identified a picture of a ‘duck’ as the disyllabic word ‘/ja/(T1) /zɨ/’, the experimenter would say ‘请再试一遍, 注意这次只能说第一个字哦’, meaning ‘please try it again, just say the first word this time’. Throughout the recording session, the patients were instructed to pronounce the target words in isolation, with a normal voice and volume. If they had difficulties retrieving the target words, the experimenter would provide prompts on the words’ meanings or collocations, to aid elicitation. For example, when eliciting the target verb ‘/ba/ (T2)’(which means ‘to pull’), the experimenter pointed to the picture and ask: ‘他在做一个动作, 我们叫‘什-么-’萝卜?’, meaning ‘He is performing an action that we call ‘w-h-a-t’ the radish’? The word ‘what’ was lengthened and the experimenter performed the action of ‘pulling the radish’ at the same time. After being prompted by the experimenter, the participants were given enough time to try again. They were also allowed to self-correct. All participants labelled each picture twice. If the first production could not be used due to a lack of isolation, the second was chosen. All the non-isolated words were eventually excluded. The principal investigator was present during the recording process to ensure that all speakers received the same instructions and procedures. The final set of usable productions involved 200 monosyllabic words produced by healthy speakers and 191 by A-AOS participants.
Perceptual identification of tones and vowels
The 391 productions by A-AOS patients (191) and healthy controls (200) were excised and saved as individual sound files. Ten Mandarin listeners were recruited to identify the tone and vowel productions. The listeners were speech and language therapy students who were all Mandarin natives trained in phonetic transcription. All listeners had normal hearing (better ear pure-tone threshold ≤ 20 dB HL for octave frequencies of 0.125 kHz to 8 kHz). They were unaware of the patients’ diagnosis, and were required to transcribe the stimuli only with Pinyin.Footnote1 Methods for controlling lexical bias were used for the tone and vowel judgments respectively: for tone judgments, all the productions were low-pass filtered at 400 Hz to remove most of the segmental information while keeping the fundamental frequency information (Wong, Citation2012); for vowel judgments, the initial consonant of each word was excised and only the vowel section was kept as a stimulus, to avoid any lexical influence (Following Mousikou & Rastle, Citation2015; New et al., Citation2008; Singh et al., Citation2015). All productions were normalised to the same root mean square value of 65 dB SPL using Praat v6.1.24 (Boersma & Weenink, Citation2020).
Prior to the formal experiment, a practice session was conducted to familiarise listeners with the task. During the tone identification task, the listeners were instructed to write down the tone categories (T1-T4) on an answer sheet, with the Pinyin marks and tone type abbreviations ‘ ̶ (T1)’ ‘ ̷ (T2)’ ‘˅ (T3)’ ‘\(T4) ’. In the vowel identification task, the same listeners were told that only vowels from the Chinese Pinyin inventory would be presented to them, and they should write them down on another answer sheet.Footnote2 All productions were delivered to these listeners via PowerPoint slides in a sound-treated booth with high-quality headphones (Sennheiser HDA200). They were presented in a quasi-random order so that listeners would not hear samples from the same speaker consecutively. Listeners could repeat a stimulus as many times as they wanted before writing down their response in this self-paced identification task. They were also allowed to take breaks whenever they wanted, and to spread out the duties across several days to avoid listening fatigue (Vitti et al., Citation2021).
Although differential token manipulation for the vowel and tone identification tasks (low pass filter vs. vowel extraction) might help avoid a lexical effect, an anonymous reviewer pointed out that it could have different impacts on listeners’ judgment of tones and vowels. Considering this, we conducted a second identification task on the non-manipulated productions. With all other experimental conditions remaining the same, the listeners were required to identify the tones and vowels of the non-manipulated stimuli, using symbols in the Pinyin system.
Acoustic measurements
Acoustic features of tones
To measure the acoustic properties of the tones, we investigated the f0 of each tone. We used the custom-written Praat script Prosodypro-3.1(Xu, Citation2005–2010) to extract and measure f0 on the rime of each word.
First, for the level tone T1, ‘pitch shift’ was used to measure and compare the flatness of the f0 contour. Then, the ‘height of mean f0’ and ‘height of min f0’, which indexed the mean and minimum level of the pitch of the produced tone (token mean) relative to the speaker’s mean f0 (speaker mean), were used to determine how the speaker achieved the high and low tonal targets for T1 and T3(dipping tone), respectively. We also utilised ‘directional excursion’ to quantify the degree of positive and negative f0 span for T2 and T4, with the parameter ‘slope’ determining the range and steepness. Finally, the terms ‘timing of min f0’ and ‘timing of max f0’ were used to measure when the maximum and minimum f0 arrived for both T2 and T4 targets. These tone parameters were obtained following Wong’s (Citation2012) approach. The algorithms for the f0 parameters (except duration) are presented in (in semitones). Duration values were extracted from the entire length of the tone stimuli.
Table 3. Algorithms for f0 parameters.
Acoustic features of vowels
The current study looked at both the static and dynamic spectral features of vowel formants, as the combination of the two proved to be highly effective in the identification of different vowels (Chen, Citation2008; Hillenbrand et al., Citation2001; Zahorian & Jagharghi, Citation1991). Here we incorporate duration, F1, F2 and F1, F2 spectral change values of each vowel as parameters for acoustic analysis (Adank et al., Citation2007; Chen, Citation2008; Sarvasy et al., Citation2020).
Vowel duration was measured between the vowel onset and offset boundaries which were identified manually (Ordin & Polyanskaya, Citation2015; Perterson & Lehiste, Citation1960): vowel onset was placed at the onset of visible voicing. In the case of nasal or approximant initials, the onset boundary was established at the point where formants began to change rapidly out of the stricture of the preceding consonants. Changes in the waveform and the higher formant regions (F3, F4) were also considered when determining the exact point; vowel offset boundaries were identified by the termination of voicing and the formant structure. The authors double-checked all segmentations for correctness and consistency to reduce experimenter bias.
Based on formant trajectories, the values (in Hertz) at the 25%, 50% and 75% points of the F1 and F2 duration were extracted (Chen, Citation2008). Therefore, the static values of the formants were the ones taken at the midpoint of F1 and F2 (50% of the duration), whereas the spectral change values of F1 and F2 were calculated as the difference in the formant values between the 25% and 75% points.
Results
Disruption of tones
The listeners identified 197 tone productions as ‘Healthy speakers’ correct (HC)’ (50, 50, 48 and 49 productions for T1, T2, T3 and T4, respectively), 125 as ‘Patients’ correct (PC)’ (35, 39, 13 and 38 productions for T1, T2, T3 and T4, respectively) and 35 as ‘Patients’ incorrect (PI)’ (9, 4, 12 and 10 productions for T1, T2, T3 and T4, respectively). The inter-rater reliability was 0.989 (Cronbach’s alpha). Average tone disruption rate was 18.3%, with by-speaker ranging from 0 to 35% (mean = 18%, SD = 0.11). The PI/PC ratio was 28%. The accuracy rates for T1, T2, T3 and T4 were 74% (35), 80% (39), 28% (13) and 79% (38), respectively. Among these, patients’ T3 was least identifiable to listeners. Overall, the disruption of tones pervasively existed in the patients’ articulation, with the majority of the patients having at least two or more productions identified as ‘incorrect’ (For A-AOS1 to A-AOS10, the incorrect numbers of tokens produced were 3,3,2,2,3,0,6,7,6,3, respectively). The numbers of the HC, PC and PI groups are shown in .
Table 4. Numbers of tone and vowel productions in each group.
Time normalised f0 contours at the rime of the syllables were plotted for the HC, PC and PI groups in . For the HC group, we observe very clear f0 contours that are high and level for T1, rising for T2, dipping for T3 and falling for T4. The PC group’s contours, on the other hand, show the general shape of each tone type but are overall flatter than the HC group. By contrast, the f0 contours in the PI group show a lot of variations. To facilitate a better comparison, we plotted the average f0s of the four tones in for each accuracy group. The graphs show that the differences between the HC and PC groups are more likely to be a matter of degree, but the contours of the HC and PI groups appear to be different in nature.
Figure 1. f0 plots of the four tones produced by HC, PC and PI groups. The X-axes represent the normalised duration of the tone productions, while the Y-axes show the mean fundamental frequency of the pitch contours (in semitones). The rising-falling contours of two T2 and one T4 (all produced by A-AOS 9) were categorised as correct by listeners, as indicated by the red arrows.
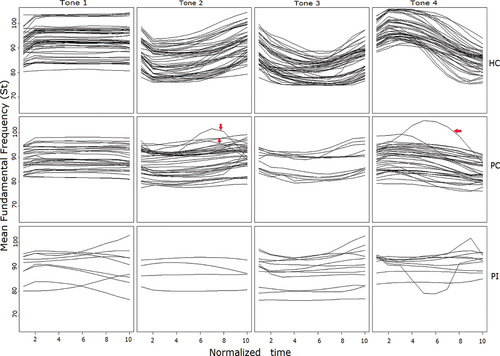
Figure 2. Average f0 plots of the four tones produced by HC, PC and PI groups. The X-axes represent the normalised time of the average tone production, while the mean fundamental frequency of the pitch contour (in semitones) is given along the Y-axis.
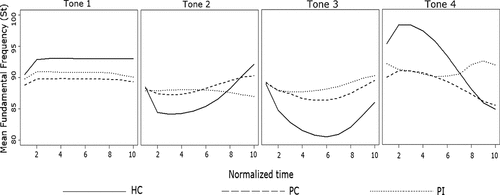
As there were three accuracy groups in the study, and the assumption of normality and homogeneity of variance was violated in the parametric statistics (the values of the acoustic parameters are shown in ), a Kruskal-Wallis test was carried out (SPSS version 24) to measure the differences between the f0 parameters among the three groups. For each type of tones, the Kruskal-Wallis test provided evidence of a difference (p < 0.05) between the mean ranks of at least one pair of groups. Group differences were then subjected to Dunn’s pairwise test (). It turned out that Patients’ correct productions (PC) of T1 were lower in height than healthy speakers, as indicated by the significantly smaller height of mean f0 (p < 0.001) and height of min f0 (p < 0.001) in the f0 contour. The relative flatness of patients’ correct T2 output compared to the HC group was also reflected by significantly smaller degrees of slope (p < 0.001) and directional excursion (p < 0.001). T2 in the PC group also had a shorter durationFootnote3 (p < 0.01) and reached its maximum f0 earlier than healthy speakers (p < 0.001), suggesting that patients were not very good at keeping the f0 low and steep for an extended period. Both of the two T3 parameters, ‘height of mean f0’ and ‘height of min f0’, were significantly smaller in the PC than HC group(p < 0.001), indicating that the patients had difficulties in maintaining the f0 either as low or as dipped as the healthy speakers. Patients’ correct T4 productions were also less ranged and steep compared to healthy speakers, as seen by much lower values in directional excursion (p < 0.001) and slope (p < 0.001).
Table 5. Mean values of the acoustic parameters for tones and vowels.
Table 6. Results of the Kruskal-Wallis test for tones and pairwise comparisons.
Patients’ incorrect tone productions (PI) were also significantly different from Patients’ correct (PC) or Healthy speakers’ correct (HC) tone productions. For example, T1 in PI had a significantly larger pitch fluctuation (p < 0.001) and a lower minimum f0 height (p < 0.05) than T1 in PC or HC, which distinguished it from a level tone. T4 in PI also showed different timing in reaching the maximum f0 than T4 in PC or HC (p < 0.01).
Disruption of vowels
The raters identified 200 vowel productions as Healthy speakers’ correct (HC) (40 for each of the vowels /a/, /y/, /u/, /i/,/ɤ/), 135 as Patients’ correct (PC) (31, 27, 27, 34, and 16 productions for /a/, /y/, /u/, /i/ and /ɤ/, respectively) and 48 as Patients’ incorrect (PI) (6, 13, 10, 5 and 14 productions for /a/, /y/, /u/, /i/ and /ɤ/, respectively). Inter-rater reliability for vowel identification was also good (α = 0.974). Average vowel disruption rate was 24%, with by-speaker rate ranging from 0 to 60% (Mean = 25%, SD = 0.26). The PI/PC ratio was 36%. Accuracy rates for the vowels /a/, /y/, /u/, /i/, /ɤ/ were 78% (31), 68% (27), 69% (27), 87% (34) and 48% (16), respectively. The vowel /i/ had the largest number of correct productions (34) and smallest number of incorrect productions (5). Compared with tones, the ‘incorrect’ vowels were more unevenly distributed, with most of them clustering around several patients (For A-AOS5, A-AOS7, A-AOS8, A-AOS9, and A-AOS10, the incorrect number of vowels produced was 12,7,11,7,10, respectively), see also, .
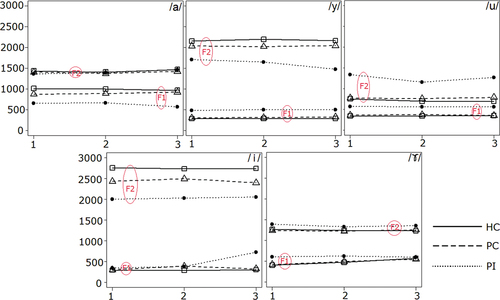
Average F1 and F2 trajectories for each vowel were plotted based on 25%, 50%, and 75% of the vowel duration (). The F1 and F2 trajectories of the HC (solid lines) and PC (dash lines) groups are broadly similar in terms of formant position and shape. The trajectories of the PI group (dotted lines) are, on the other hand, clearly distinct from the other two groups. Specifically, there is a noticeable tendency for vowel centralisation in the PI group.
Figure 3. Mean formant trajectories (F1 and F2) for each vowel uttered by different accuracy groups. The numbers 1, 2, and 3 on the X-axes represent 25%, 50%, and 75% of the vowel duration, respectively, while the Y-axes display the frequency (Hertz) value of the averaged formant trajectories.
A Kruskal-Wallis test (with Dunn’s post hoc pairwise tests) was also performed on the difference in the spectral parameters among the three accuracy groups (). No statistical difference was found in any of the spectral parameters between the HC and PC groups, indicating that – unlike tones, where PC productions were perceptually judged as correct but acoustically different from HC productions – PC productions of vowels were both perceptually and acoustically very close to the HC productions.
Table 7. Results of the Kruskal-Wallis test for vowels and pairwise comparisons.
By contrast, there were some spectral differences between the PC and PI outputs. For example, the vowel /a/ in PI exhibited significantly smaller F1 value (indicating a higher tongue position) than in PC (p < 0.05); and the vowel /i/in PI had significantly smaller F2 scores (reflecting a more retracted tongue position) than in PC (p < 0.01). Furthermore, the PI group had statistically greater F1 values for /u/ and /y/ (indicating a lower tongue position) than the PC group (p < 0.05), and the larger F1 spectral changes for /i/ and /ɤ/ than the HC group (p <0.05), indicating that patients had difficulty maintaining the intrinsic spectral dynamics for certain vowels. No difference was found for the vowel duration among the three accuracy groups.
Finally, we performed a Spearman correlation analysis where the number of incorrect tones was compared to the number of incorrect vowels of each patient. A strong and significant (p < 0.05) correlation of 0.69 was observed, showing that incorrect production of tones tended to coincide with incorrect production of vowels.
Difference in Mandarin Tone and vowel disruption
In the current study, the numbers of disrupted tones and vowels for the A-AOS patients were close. The PI/PC ratios for tones and vowels were 28% and 36%, respectively, across 10 A-AOS participants. Chi-square analysis revealed no significant difference between the number of patients’ incorrect tones and incorrect vowels (χ2(1) = 0.882, p > 0.05). Thus, our findings suggest that from a perceptual viewpoint, both tones and vowels were equally damaged for the patients. However, based on the acoustic parameters measured, even the patients’ tones categorised as correct by native Mandarin listeners were different from the healthy speakers in acoustic terms: Patients’ correct productions of T1 were lower (with smaller ‘height of mean f0’ and ‘height of min f0’ value), their T2 and T4 were flatter (T2 was produced with smaller ‘slope’, ‘directional excursion’ and ‘timing of maximum f0’, while T4 had smaller ‘directional excursion’ and ‘slope’), and their T3 was less dipped (with smaller values for ‘height of mean f0’ and ‘height of min f0’) than healthy speakers. By contrast, the acoustic correlates of vowels tended to be consistent with the perceptual judgments across the three accuracy groups. Patients’ correct production of vowels did not differ significantly from healthy speakers in terms of acoustic parameters (F1, F2, F1 spectral change, and F2 spectral change), whereas Patients’ incorrect (PI) productions showed signs of acoustic discrepancies from both the PC or HC group (productions in the PI group had a lower F1 for /a/, a lower F2 for /i/, a higher F1 for /y/, /u/ and larger values for F1 spectral change in /i/ and /ɤ/). The relations among the three accuracy groups are presented schematically in .
Figure 4. Acoustic relationships for the three accuracy groups: left panel for tones and right panel for vowels. Line length was calculated based on the mean value of Euclidean distance of the four tones (or five vowels) between groups.
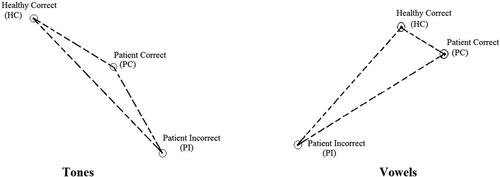
Unlike vowels, the patients’ tones identified as correct were acoustically different from the healthy controls, indicating that Mandarin listeners were fairly tolerant of the less-targeted tone productions which went undetected. We even observed that two T2 and one T4 (all by A-AOS 9) exhibited anomalous rising-falling contours (see ), which was atypical in the Mandarin tonal system. Surprisingly, these three cases were all categorised as correct by the listeners. Visual examination of the three cases revealed that the maximum f0 of the two T2 tokens was reached rather early in contours, whereas the maximum f0 of the T4 token was achieved very late (near the midpoint of the contour), but listeners ignored the atypical parts of the contours and still perceived the tones as the target ones. By contrast, the native listeners were much less tolerant to any deviation in the acoustic realization of vowels (F1, F2, F1 spectral change). Taken together, these findings suggestthat tones are actually more damaged than vowels.
Error types
Errors included the ‘less-targeted’ and the ‘substitution’ types. The less-targeted errors were tones and vowels articulated in a pattern that was ‘less exact’ than ‘totally erroneous’. If the intended sound was articulated as something completely different, however, it was a substitution error. Specifically, many target vowels identified as diphthongs or triphthongs could be considered ‘distorted substitutions’ because these vowels were produced with a prolonged duration (a typical AOS symptom, McNeil et al., Citation2004) and were ultimately transcribed as combinations of several vowels. Both distorted substitutions and off-target articulation reflected the patients’ articulatory control deficit, presumably stemming from the motor planning problems.
Many examples can be found where tones were articulated in a less precise way (e.g. T1ʹs pitch contour was less high and level, T2 and T4ʹs pitch contours were less steep, or T3ʹs pitch contour was less dipped, etc.). In contrast, cases that target tones were entirely substituted by other tones can be found in, for example, T3 misidentified as T1, T2, or T4 (see . Vowel can also be less-targeted, as evidenced by the vowel centralisation tendency in .On the other hand, vowel substitution errors were common. For example, some target vowels were identified as other monophthongs (e.g. /a/ was identified as /ɤ/, /y/ as /u/, or /ɤ/ as /u/, etc.). Certain vowels were even identified as diphthongs or triphthongs (as distorted substitutions, e.g. /a/ was identified as /ai/ or /au/, /u/ as /ao/ or /ou/, /y/ as /iao/ or /uei/, etc., cf., ). In general, the less-targeted tones were very likely to be considered ‘correct’, whereas the ‘less-targeted’ vowels could possibly be mistaken for other vowels when transcribed with Pinyin symbols.
Table 8. Identification of the tones and vowels in the PI group.
Tasks with non-manipulated stimuli
A second experiment was conducted to determine what happens when non-manipulated stimuli were employed for identification. It turned out that when presented with the non-manipulated stimuli, listeners often responded faster and played the stimuli less often. Listeners also showed more agreements on the identification of the stimuli: for example, more items received 10 (identifiable by all the listeners) or 0 (none) in the new task. Although this change of score pattern occurred for both tone and vowel identification, it was more evident in the latter.
The listeners identified 197 as ‘Healthy speakers’ correct (HC)’ tone productions (50, 50, 48 and 49 productions for T1, T2, T3 and T4, respectively), 124 ‘Patients’ correct (PC)’ productions (32, 40, 15 and 37 productions for T1, T2, T3 and T4, respectively) and 31 ‘Patients’ incorrect (PI)’ productions (10, 4, 8 and 9 productions for T1, T2, T3 and T4, respectively). On the other hand, the listeners identified 200 ‘Healthy speakers’ correct (HC)’ vowel productions (40 for each /a/, /y/, /u/, /i/, /ɤ/), 136 ‘Patients’ correct (PC)’ productions (31, 28, 28, 31, and 18 productions for /a/, /y/, /u/, /i/ and /ɤ/, respectively) and 44 ‘Patients’ incorrect (PI)’ productions (6, 11, 10, 4, and 13 productions for /a/, /y/, /u/, /i/ and /ɤ/, respectively). Chi-square analysis revealed no significant difference between the numbers of patients’ incorrect tones and incorrect vowels (as well as the numbers of correct tones and correct vowels) (χ2(1) = 0.947, p > 0.05).
Acoustic analysis showed that the tone properties (e.g. pitch shift, height of mean f0, height of min f0, timing of max f0, or timing of min f0) between the ‘Healthy speakers’correct (HC)’ and the ‘Patients’ correct (PC)’ groups, as well as between the ‘Patients’ correct (PC)’ and ‘Patients’ incorrect (PI)’ groups, differed significantly. By contrast, the vowel properties of the three groups showed a different pattern: the ‘Healthy speakers’ correct (HC)’ and ‘Patients’ correct (PC)’ groups exhibited no statistical difference for any vowel parameter, but both the ‘Healthy speakers’ correct (HC)’ and ‘Patients’ correct (PC)’ groups differed significantly from the ‘Patients’ incorrect (PI)’ group in F1, F2, and F2 change values. These results mirrored that identification task previously performed with the manipulated stimuli.
Discussion
Tone vs. vowel disruptions in Mandarin A-AOS patients
Although Mandarin A-AOS patients may have the same amount of perceived tone and vowel disruptions in the utterance, lexical tones were acoustically more damaged than vowels. However, Mandarin listeners were relatively tolerant of the inaccurate tones so tone disruptions often went unnoticed. To understand the phenomenon, we could consider that Mandarin vowels have different information entropy from tones (Do & Lai, Citation2021). Vowels outperform tones in revealing the meaning of an utterance and accurately predict speech intelligibility (Wiener & Turnbull, Citation2016). They have a high entropy value, carry important information in words and are thus essential in conveying the linguistic message. In contrast, tones may have a lower value in differentiating words, which explains Mandarin listeners’ perceptual tolerance for them.
While Mandarin speakers may interpret tone and vowel disruption differently, the two may be intrinsically connected. Previous studies on tone or vowel disruption in Mandarin-speaking individuals with brain damage suggested that tone and vowel loss were two separate processes that were unlikely to interact (Liang & van Heuven, Citation2004; Packard, Citation1986). This is because the laryngeal structure responsible for vocal pitch generation and the supralaryngeal structure responsible for vowel production were separate and essentially independent operating systems. In the current study, we observed tonal impairment in many patients, whereas vowel disruption appeared to have a certain degree of clustering. However, there was still a high association (0.69) between incorrect tones and incorrect vowels. This does not necessarily mean the laryngeal system interacted directly with the supralaryngeal system. Still, it is reasonable to suspect that these two operating systems, which are both regulated by motor speech control, were impaired side by side when this control was damaged in A-AOS patients, in such a way that the tonal and vowel disruption could occur on a comparable scale.
Neuroscience also adds support to the findings of the current research. Neural imaging studies show that Mandarin tone processing occurs in the fronto-parietal areas (Myers et al., Citation2009): the left posterior IFG, the adjacent PMC and the left SMG/IPS, to be exact. Activity in these areas reflects phonological processing of pitch contours of tones. Among others, The left IPS has been linked to a variety of functions, including sensorimotor ones (Kouider et al., Citation2010), which are frequently disrupted in A-AOS patients. Additionally, Mandarin speakers also display bilateral temporo-parietal and subcortical activation specific to tone processing (including bilateral AG/pMTG, SPL and PCC), which is likely for semantic purposes (Myers et al., Citation2009; Specht et al., Citation2009). By contrast, vowel representations are distributed mainly over left sensorimotor brain areas (Leff et al., Citation2009; Wilson et al., Citation2009). Common sensorimotor activation during vowel processing is observed on a left postero-dorsal stream, including the opercular part of Broca’s area, the adjacent ventral premotor cortex and the temporo-parietal junction, all of which are important for vowel processing and also for motor control (Wilson et al., Citation2009). In the current research, most A-AOS patients had brain lesions in the left posterior IFG (typical Broca’s area), the left temporoparietal or the left sensorimotor area. Because these areas were involved in both tone and vowel processing, damage to them could cause either tonal or vowel disruption, or potentially both, with correlated impairment degrees. On the other hand, as tones are processed through two channels, one phonological in the left fronto-parietal area and the other (automatic) semantic in the bilateral temporo-parietal regions, they may be easier for Mandarin listeners to perceive, thanks to the separation of phonological and semantic components and the involvement of the right temporo-parietal lobes in tone processing. Therefore, in addition to the claims that tones carry less information than vowels, differences in the neurological correlates of tones and vowels may also contribute to the disparity in the listeners’ tolerance for their disruptions.
Speech mechanisms involved in the disruption of Mandarin tones and vowels
The current research demonstrated that among the four tones, T3 was the most disrupted. This finding is consistent with the previous research indicating that T3 is the most challenging tone for Chinese children to learn at a young age and is most likely to be disrupted in people with language disabilities (Gandour et al., Citation1988; Wong, Citation2012). The phenomenon may have its roots in the complexity of motor speech control. T3 might be the most difficult tone to generate because, unlike other types of tones, it necessitates complex coordination of two laryngeal muscles – a pitch-raising muscle ‘cricothyroid (CT)’ and a pitch lowering muscle ‘sternohyoid (SH)’(Hallé, Citation1994). At the start of the tone, the CT muscle relaxes and the SH muscle activates to produce a very low initial f0, which is followed by the SH relaxing and the CT activating to achieve the final high f0. (Hallé, Citation1994). Fine motor planning and programming could be required for this sophisticated muscle coordination, which is problematic for A-AOS patients.
As for vowels, the highest accuracy rates were seen in the patients’ production of /i/ and /a/. In particular, the word ‘/ji/ T1’ (Chinese character ‘一’, signifying ‘one’) was accurately pronounced by all ten patients. We first suspected that this was due to a practice effect because this word was regularly practiced by the A-AOS patients in their daily counting exercise (they always began with ‘/ji/T1’). But this doesn’t explain why all other stimuli involving /i/ were as well articulated (‘qi’, T2, 7 correct; ‘yi’, T3, 9 correct; ‘xi’, T4, 8 correct), nor why the /a/-related stimuli also had a high accuracy rate. In fact, the high accuracy rates of vowels /i/ and /a/ in the current study led to the assumption that vowels articulated with the overt oral postures (for the tongue, lips, etc.) would be easier for the patients to generate. The vowel /i/ was articulated with the mouth relatively open, lips retracted (or not) and tongue protracted to the high front (reflected by a comparatively low F1 and high F2 value). On the other hand, the vowel /a/ was articulated with the mouth wide open and the body of the tongue lowered (reflected by a high F1 value). In either situation, the posture of the articulatory organs could be observed, so when the patients produced words containing these vowels, the overt tongue (or lips, etc.) position in their memories may help them better calibrate their articulatory organs. By contrast, the vowels /y/ and /u/ were generated with rounded lips, which obscured the tongue position inside the mouth and may have made it difficult for the patients to map out their articulatory postures. That is why some patients produced /y, u/ with clear lip rounding but ambiguous tongue placement. Whether the oral posture of the vowel was overt enough for the patients to see (or recall) could be important for the successful articulation of the vowel itself, and this could be part of the reason why Liang and van Heuven (Citation2004) also found that /y,u/ were produced with the lowest accuracy rate among other vowels for aphasic patients, and the vowel /u/ was produced with extremely deviant formant pattern by patients with AOS in Kent and Rosenbek’s (Citation1983) research. Another possibility for the vowel accuracy difference might again be the degrees of muscle coordination complexity (like for the tones). The vowel /i/ was produced with an even higher accuracy rate than /a/ because it mainly requires the voluntary activation of the posterior genioglossus, constriction of which protrudes the tongue anteriorly. In contrast, the vowel /a/ is produced with the coordination of the hyoglossus which pulls the tongue backward and downward, and the anterior genioglossus which flattens the tongue tip and maintains its contact with the inner surface of the mandible. The vowels /y/ and /u/, on the other hand, require the activation of multiple tongue muscles as well as lip muscles (orbicularis oris and mentalis), which are more difficult for A-AOS patients to manage (Buchaillard et al., Citation2009).
Differentially manipulated stimuli versus non-manipulated stimuli
When we used non-manipulated stimuli in the identification task, the rating scores were a little different from the task with manipulated stimuli, indicating that the lexical effect likely played a role in the identification process. However, using non-manipulated stimuli was insufficient to substantially impact the general pattern of tonal or vowel perception, so the findings in the identification test with non-manipulated stimuli followed the same pattern as the perceptual task with manipulated stimuli.
Conclusion
Both tones and vowels could be impaired in Mandarin A-AOS speech. In perception, about equal numbers of tones and vowels produced by A-AOS patients were identified as correct, but acoustic parameters showed that even patients’ tones rated as correct by the native Mandarin listeners were different from those of healthy speakers, implying that tones were actually more disrupted than vowels in acoustic terms. These findings could be relevant to the assessment and treatment of Mandarin patients with A-AOS (or aphasia). Unlike vowels, disruption of Mandarin tones can go undetected more easily, indicating that the tone output may be acoustically inaccurate but perceptually acceptable. The evaluation of tone impairment should therefore be based on different goals and criteria, such as determining whether the goal is to learn how well patients make themselves understood (generate perceptually acceptable tones), or to assess how motor speech control is impaired (by examining the acoustic deviation of tones). Different goals result in varying evaluation measures.
Second, in the treatment of aphasic speech (with or without apraxia), many methods have been explored to improve patients’ articulatory control (Ludlow et al., Citation2013; Maas et al., Citation2008;), because articulatory control provides information about kinematic parameters of speech production, which are often specified at the planning and/or programming levels of articulation (Haley et al., Citation2001). In Mandarin, lexical tones generated by laryngeal activities are also very important for speech output, but there have been few attempts at tone training to improve patients’ ‘laryngeal control’. Further, because Mandarin vocalic and tonal information is combined to form the phonological identity, the different operating systems (oral vs. laryngeal) must work together to generate meaningful utterance. The involvement of both articulatory and ‘laryngeal’ control could, however, make it rather challenging for Mandarin A-AOS patients to process at the motor planning and programming stage, so a collaborative practice of tones and vowels would also be necessary. In the current research, we find a comparable decline in Mandarin tones and vowels. Thus, we propose that a lexical tone training be devised and incorporated into the vowel (or other segmental elements) practice to enhance A-AOS patients’ overall motor speech control. Specifically, multiple combinations of tonal and vowel structures could be developed to maximise the treatment effect, followed by a definitive test investigating tonal and vowel enhancements. Future research should look into the effectiveness of tone practice for the improvement of lexical tones, as well as the efficacy of combining tone and vowel practice to improve the overall speech control for A-AOS patients; neuroimaging, which shows how changes in the brain occur under various treatment conditions (tone vs. vowel), can also be used in the future study.
Ethical statement
This research was conducted ethically in accordance with the World Medical Association Declaration of Helsinki. All subjects (speakers and listeners) have given their written informed consent.
Acknowledgments
This research was supported by the Shanghai YangZhi Rehabilitation Hospital (Shanghai Sunshine Rehabilitation Center); we thank all the therapists who helped with data collection.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
1 The use of the International Phonetic Alphabet was discouraged, because the goal of the transcription was to identify the participants’ tone or vowel productions within the Mandarin phonological system. The identification, on the other hand, was not concerned with the degrees of distortion for each stimulus in its most delicate form.
2 The phonemes /i/ and /ɨ/ in Chinese phonology were represented by the same Pinyin symbol ‘i’, so raters were informed that when an ‘i’ was identified, he/she must specify if it was as that in ‘si’ (/sɨ/) or that in ‘xi’ (/ʃi/).
3 Tone duration was measured for the entire word, which means that the type of onset consonant in each word affects the duration. For a more rigorous analysis, a subset of words for the HC group that are matched with the PC group should be considered.
References
- Ackermann, H., Gräber, S., Hertrich, I., & Daum, I. (1999). Phonemic vowel length contrasts in cerebellar disorders. Brain and Language, 67(2), 95–109. https://doi.org/10.1006/brln.1998.2044
- Ackermann, H., & Ziegler, W. (2010). Brain mechanisms underlying speech motor control. In W. J. Hardcastle, J. Laver & F. E. Gibbon (Eds.), The handbook of phonetic sciences (pp. 202–250). Wiley Blackwell.
- Adank, P., Van Hout, R., & Velde, H. V. D. (2007). An acoustic description of the vowels of northern and southern standard Dutch II: Regional varieties. The Journal of the Acoustical Society of America, 121(2), 1130–1141. https://doi.org/10.1121/1.2409492
- Boersma, P., & Weenink, D. (2020). Praat: Doing phonetics by computer [Computer program](Version 6.1. 24).
- Buchaillard, S., Perrier, P., & Payan, Y. (2009). A biomechanical model of cardinal vowel production: Muscle activations and the impact of gravity on tongue positioning. The Journal of the Acoustical Society of America, 126(4), 2033–2051. https://doi.org/10.1121/1.3204306
- Chen, Y. (2008). The acoustic realization of vowels of Shanghai Chinese. Journal of Phonetics, 36(4), 629–648. https://doi.org/10.1016/j.wocn.2008.03.001
- Dabul, B. (2000). ABA-2: Apraxia battery for adults. Austin, TX: Pro-ed.
- Do, Y., & Lai, R. K. Y. (2021). Accounting for lexical tones when modeling phonological distance. Language, 97(1), e39–e67. https://doi.org/10.1353/lan.2021.0008
- Duanmu, S. (2007). The phonology of standard Chinese. Oxford University Press.
- Duffy, J. R. (2019). Motor speech disorders e-book: Substrates, differential diagnosis, and management. Elsevier Health Sciences.
- Elvin, J., Williams, D., & Escudero, P. (2016). Dynamic acoustic properties of monophthongs and diphthongs in Western Sydney Australian English. The Journal of the Acoustical Society of America, 140(1), 576–581. https://doi.org/10.1121/1.4952387
- Folstein, M. F., Folstein, S. E., & McHugh, P. R. (1975). “Mini-mental state”: a practical method for grading the cognitive state of patients for the clinician. Journal of Psychiatric Research, 12(3), 189–198. https://doi.org/10.1016/0022-3956(75)90026-6
- Fu, Q, and Zeng, F. (2000). Identification of temporal envelope cues in Chinese tone recognition. Asia Pacific Journal of Speech, Language and Hearing, 5(1), 45–57. https://doi.org/10.1179/136132800807547582
- Gandour, J., Petty, S. H., & Dardarananda, R. (1988). Perception and production of tone in aphasia. Brain and Language, 35(2), 201–240. https://doi.org/10.1016/0093-934X(88)90109-5
- Gandour, J., Petty, S. H., & Dardarananda, R. (1989). Dysprosody in Broca’s aphasia: A case study. Brain and Language, 37(2), 232–257. https://doi.org/10.1016/0093-934X(89)90017-5
- Gandour, J., Ponglorpisit, S., Khunadorn, F., Dechongkit, S., Boongird, P., Boonklam, R., & Potisuk, S. (1992). Lexical tones in Thai after unilateral brain damage. Brain and Language, 43(2), 275–307. https://doi.org/10.1016/0093-934X(92)90131-W
- Gao, S. (2006). Aphasia. Beijing: Peking University Medical Press.
- Haley, K. L., Ohde, R. N., & Wertz, R. T. (2001). Vowel quality in aphasia and apraxia of speech: Phonetic transcription and formant analyses. Aphasiology, 15(12), 1107–1123. https://doi.org/10.1080/02687040143000519
- Haley, K. L. (2002). Temporal and spectral properties of voiceless fricatives in aphasia and apraxia of speech. Aphasiology, 16(4–6), 595–607. https://doi.org/10.1080/02687030244000257
- Hallé, P. A. (1994). Evidence for tone-specific activity of the sternohyoid muscle in modern standard Chinese. Language and Speech, 37(2), 103–123. https://doi.org/10.1177/002383099403700201
- Hillenbrand, J. M., Clark, M. J., & Nearey, T. M. (2001). Effects of consonant environment on vowel formant patterns. The Journal of the Acoustical Society of America, 109(2), 748–763. https://doi.org/10.1121/1.1337959
- Howie, J. M., & Howie, J. M. (1976). Acoustical studies of Mandarin vowels and tones (Vol. 18). Cambridge University Press.
- Hualde, J. I., Barlaz, M., & Luchkina, T. (2021). Acoustic differentiation of allophones of /aɪ/ in Chicagoland English: Statistical comparison of formant trajectories. Journal of the International Phonetic Association, 1–31. https://doi.org/10.1017/S0025100320000158
- Jacks, A., Mathes, K. A., & Marquardt, T. P. (2010). Vowel acoustics in adults with apraxia of speech. Journal of Speech, Language, and Hearing Research, 53(1), 61–74. https://doi.org/10.1044/1092-4388(2009/08-0017)
- Kadyamusuma, M. R., De Bleser, R., & Mayer, J. (2011). Lexical tone disruption in Shona after brain damage. Aphasiology, 25(10), 1239–1260. https://doi.org/10.1080/02687038.2011.590966
- Kent, R. D., & Rosenbek, J. C. (1983). Acoustic patterns of apraxia of speech. Journal of Speech, Language, and Hearing Research, 26(2), 231–249. https://doi.org/10.1044/jshr.2602.231
- Kent, R. D., Kim, Y., & Chen, L. M. (2022). Oral and Laryngeal Diadochokinesis Across the Life Span: A Scoping Review of Methods, Reference Data, and Clinical Applications. Journal of Speech, Language, and Hearing Research, 65(2), 574–623. https://doi.org/10.1044/2021_JSLHR-21-00396
- Kouider, S. E. A., de Gardelle, V., Dehaene, S., Dupoux, E., & Pallier, C. (2010). Cerebral bases of subliminal speech priming. Neuroimage, 49(1), 922–929. https://doi.org/10.1016/j.neuroimage.2009.08.043
- Kurland, J., Pulvermuller, F., Silva, N., Burke, K., & Andrianopoulos, M. (2012). Constrained versus unconstrained intensive language therapy in two individuals with chronic, moderate-to-severe aphasia and apraxia of speech: behavioral and fMRI outcomes. American Journal of Speech-Language Pathology, 21(2), S65–S65. https://doi.org/10.1044/1058-0360(2012/11-0113)
- Kurowski, K. M., Blumstein, S. E., & Mathison, H. (1998). Consonant and vowel production of right hemisphere patients. Brain and Language, 63(2), 276–300. https://doi.org/10.1006/brln.1997.1939
- Lee, W.-S., & Zee, E. (2003). Standard Chinese (Beijing). Journal of the International Phonetic Association, 33(1), 109–112. https://doi.org/10.1017/S0025100303001208
- Leff, A. P., Iverson, P., Schofield, T. M., Kilner, J. M., Crinion, J. T., Friston, K. J., & Price, C. J. (2009). Vowel-specific mismatch responses in the anterior superior temporal gyrus: An fMRI study. cortex, 45(4), 517–526. https://doi.org/10.1016/j.cortex.2007.10.008
- Liang, J., & van Heuven, V. J. (2004). Evidence for separate tonal and segmental tiers in the lexical specification of words: A case study of a brain-damaged Chinese speaker. Brain and Language, 91(3), 282–293. https://doi.org/10.1016/j.bandl.2004.03.006
- Liu, L., Peng, D., Ding, G., Jin, Z., Zhang, L., Li, K., & Chen, C. (2006). Dissociation in the neural basis underlying Chinese tone and vowel production. Neuroimage, 29(2), 515–523. https://doi.org/10.1016/j.neuroimage.2005.07.046
- Ludlow, C., Morgan, N., Dold, G., Lowell, S., & Dietrich-Burns, K. (2013). U.S. Patent No. 8,388,561. Washington, DC: U.S. Patent and Trademark Office.
- Maas, E., Robin, D. A., Hula, S. N. A., Freedman, S. E., Wulf, G., Ballard, K. J., & Schmidt, R. A. (2008). Principles of motor learning in treatment of motor speech disorders. American Journal of Speech-Language Pathology, 17(3), 277–298. https://doi.org/10.1044/1058-0360(2008/025)
- McNeil, M. R., Pratt, S. R., & Fossett, T. R. D. (2004). The differential diagnosis of apraxia of speech. In B. R. Maassen, R. Kent, H. Peters, P. van Lieshout, & W. Hulstijn (Eds.), Speech motor control in normal and disordered speech (pp. 389–413). New York, NY: Oxford University Press.
- Mousikou, P., & Rastle, K. (2015). Lexical frequency effects on articulation: A comparison of picture naming and reading aloud. Frontiers in Psychology, 6(2015), 1571. https://doi.org/10.3389/fpsyg.2015.01571
- Myers, E. B., Blumstein, S. E., Walsh, E., & Eliassen, J. (2009). Inferior frontal regions underlie the perception of phonetic category invariance. Psychological Science, 20(7), 895–903. https://doi.org/10.1111/j.1467-9280.2009.02380.x
- New, B., Araújo, V., & Nazzi, T. (2008). Differential processing of consonants and vowels in lexical access through reading. Psychological Science, 19(12), 1223–1227. https://doi.org/10.1111/j.1467-9280.2008.02228.x
- Odell, K., McNeil, M. R., Rosenbek, J. C., & Hunter, L. (1991). Perceptual characteristics of vowel and prosody production in apraxic, aphasic, and dysarthric speakers. Journal of Speech, Language, and Hearing Research, 34(1), 67–80. https://doi.org/10.1044/jshr.3401.67
- Ogar, J., Slama, H., Dronkers, N., Amici, S., & Luisa Gorno-Tempini, M. (2005). Apraxia of speech: an overview. Neurocase, 11(6), 427–432. https://doi.org/10.1080/13554790500263529
- Ogar, J., Willock, S., Baldo, J., Wilkins, D., Ludy, C., & Dronkers, N. (2006). Clinical and anatomical correlates of apraxia of speech. Brain and Language, 97(3), 343–350. https://doi.org/10.1016/j.bandl.2006.01.008
- Ordin, M., & Polyanskaya, L. (2015). Perception of speech rhythm in second language: the case of rhythmically similar L1 and L2. Frontiers in Psychology, 6(2015), 316. https://doi.org/10.3389/fpsyg.2015.00316
- Packard, J. L. (1986). Tone production deficits in nonfluent aphasic Chinese speech. Brain and Language, 29(2), 212–223. https://doi.org/10.1016/0093-934X(86)90045-3
- Peterson, G. E., & Lehiste, I. (1960). Duration of syllable nuclei in English. The Journal of the Acoustical Society of America, 32(6), 693–703. https://doi.org/10.1121/1.1908183
- Renwick, M. E., & Stanley, J. A. (2020). Modeling dynamic trajectories of front vowels in the American South. The Journal of the Acoustical Society of America, 147(1), 579–595. https://doi.org/10.1121/10.0000549
- Ryalls, J., & Reinvang, I. (1986). Functional lateralization of linguistic tones: Acoustic evidence from Norwegian. Language and Speech, 29(4), 389–398. https://doi.org/10.1177/002383098602900405
- Ryalls, J. H. (1986). An acoustic study of vowel production in aphasia. Brain and Language, 29(1), 48–67. https://doi.org/10.1016/0093-934X(86)90033-7
- Sarvasy, H., Elvin, J., Li, W., & Escudero, P. (2020). An acoustic phonetic description of Nungon vowels. The Journal of the Acoustical Society of America, 147(4), 2891–2900. https://doi.org/10.1121/10.0001003
- Singh, L., Goh, H. H., & Wewalaarachchi, T. D. (2015). Spoken word recognition in early childhood: Comparative effects of vowel, consonant and lexical tone variation. Cognition, 142(2015), 1–11. https://doi.org/10.1016/j.cognition.2015.05.010
- Specht, K., Osnes, B., & Hugdahl, K. (2009). Detection of differential speech‐specific processes in the temporal lobe using fMRI and a dynamic “sound morphing” technique. Human Brain Mapping, 30(10), 3436–3444. https://doi.org/10.1002/hbm.20768
- Van Der Merwe, A. (2021). New perspectives on speech motor planning and programming in the context of the four-level model and its implications for understanding the pathophysiology underlying apraxia of speech and other motor speech disorders. Aphasiology, 35(4), 397–423. https://doi.org/10.1080/02687038.2020.1765306
- Vitti, E., Mauszycki, S., Bunker, L., & Wambaugh, J. (2021). Stability of Speech Intelligibility Measures Over Repeated Sampling Times in Speakers With Acquired Apraxia of Speech. American Journal of Speech-Language Pathology, 30(3S), 1429–1445. https://doi.org/10.1044/2020_AJSLP-20-00135
- Weiss, P. H., Ubben, S. D., Kaesberg, S., Kalbe, E., Kessler, J., Liebig, T., & Fink, G. R. (2016). Where language meets meaningful action: a combined behavior and lesion analysis of aphasia and apraxia. Brain Structure and Function, 221(1), 563–576. http://doi.org/10.1007/s00429-014-0925-3
- Wertz, R. T., LaPointe, L. L., & Rosenbek, J. C. (1984). Apraxia of speech in adults: The disorder and its management. Orlando, FL: Grune & Stratton.
- Whalen, D. H., & Xu, Y. (1992). Information for Mandarin tones in the amplitude contour and in brief segments. Phonetica, 49(1), 25–47. https://doi.org/10.1159/000261901
- Wiener, S., & Turnbull, R. (2016). Constraints of tones, vowels and consonants on lexical selection in Mandarin Chinese. Language and Speech, 59(1), 59–82. https://doi.org/10.1177/0023830915578000
- Wilson, S. M., Isenberg, A. L., & Hickok, G. (2009). Neural correlates of word production stages delineated by parametric modulation of psycholinguistic variables. Human Brain Mapping, 30(11), 3596–3608. https://doi.org/10.1002/hbm.20782
- Wong, P. (2012). Acoustic characteristics of three-year-olds’ correct and incorrect monosyllabic Mandarin lexical tone productions. Journal of Phonetics, 40(1), 141–151. https://doi.org/10.1016/j.wocn.2011.10.005
- Xu, Y. (2005-2010). Prosody Pro.praat. <http://www.phon.ucl.ac.uk/home/yi/ProsodyPro/>
- Yiu, E. M. L., & Fok, A. Y. Y.(1995). Lexical tone disruption in Cantonese aphasic speakers. Clinical Linguistics & Phonetics, 9(1), 79–92. https://doi.org/10.3109/02699209508985326
- Zahorian, S. A., & Jagharghi, A. J. (1991). Speaker normalization of static and dynamic vowel spectral features. The Journal of the Acoustical Society of America, 90(1), 67–75. https://doi.org/10.1121/1.402350