
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
This study explores the influence of lexicality on gradient judgments of Swedish sibilant fricatives by contrasting ratings of initial fricatives in words and word fragments (initial CV-syllables). Visual-Analogue Scale (VAS) judgments were elicited from experienced listeners (speech-language pathologists; SLPs) and inexperienced listeners, and compared with respect to the effects of lexicality using Bayesian mixed-effects beta regression. Overall, SLPs had higher intra- and interrater reliability than inexperienced listeners. SLPs as a group also rated fricatives as more target-like, with higher precision, than did inexperienced listeners. An effect of lexicality was observed for all individual listeners, though the magnitude of the effect varied. Although SLP’s ratings of Swedish children’s initial voiceless fricatives were less influenced by lexicality, our results indicate that previous findings concerning VAS ratings of non-lexical CV-syllables cannot be directly transferred to the clinical context, without consideration of possible lexical bias.
Introduction
Within the first few years of life, typically developing children manage the tremendous feat of mastering speech to such a level that they are intelligible to strangers at 4–5 years of age (e.g. Hustad et al., Citation2021). Age of acquisition of specific speech sounds is characterised by huge individual variation, although the order of acquisition is constrained by, for example, oro-motor maturation and phoneme frequency in the ambient language/s (e.g. Li & Munson, Citation2016). Sibilant fricatives, such as /s/ and /ɕ/ are produced with complex tongue configurations and are reported to be relatively late-acquired across many structurally different languages (e.g. McLeod & Crowe, Citation2018). Studies of voiceless sibilant fricatives in the process of acquisition indicate that young children gradually differentiate between the sibilants of their ambient language(s) and show increased contrast with age (see e.g. Holliday et al., Citation2015; Wikse Barrow et al., Citationin review). Young children’s sibilant fricatives are often less distinct and show overlap in acoustic features that distinguish adult sounds, resulting in productions that may be perceived as somewhere ‘in-between’ the target sibilants. Fine phonetic variation that lies within adult phoneme boundaries, such as the ‘in-between’ alluded above, can be referred to as covert contrast. Covert contrasts are systematically conveyed by the child but will nonetheless often go undocumented in transcription of speech, given the categorical nature of the transcription task (see Munson et al., Citation2010 for a first-rate treatise). However, given fine-grained perceptual tasks, listeners have been shown to be sensitive to fine phonetic detail in child speech. The Visual Analogue Scale (VAS) is an example of such a gradient rating scale, consisting of a horizontal line with two anchors, upon which a listener marks their perception of the sound presented. VAS has been used in many studies concerning covert contrast in child speech (Munson & Urberg Carlson, Citation2016; Munson et al., Citation2010; Munson, Johnson, et al., Citation2012; Munson, Schellinger et al., Citation2012; Schellinger et al., Citation2017; Strömbergsson et al., Citation2015) and is recommended for use in clinical practice by some (e.g. Munson, Schellinger, et al., Citation2012). In the clinical setting, speech-language pathologists (SLPs) are faced with highly variable speech input from children with speech difficulties. Indeed, children with Speech Sound Disorder (SSD) are a distinctly heterogeneous group with respect to aetiology, coexistent language difficulties and speech profiles (Dodd, Citation2014). Assessment of speech is essential in the clinical care of children with SSD (e.g. Rvachew & Brosseau-Lapré, Citation2017; Skahan et al., Citation2007; Wikse Barrow et al., Citation2023) and VAS provides an interesting alternative to the categorical tool that is transcription of speech. However, questions remain regarding possible lexical bias in VAS ratings, which may threaten the clinical validity of the rating scale. It is well established that lexicality of speech stimuli affects perception of speech. In his seminal study from 1980, Ganong explored the effect of lexical knowledge on speech perception by enlisting participants to rate acoustic continua between /d/ and /t/-initial real words and non-words (e.g. ‘dask’ and ‘task’), for which the voice onset time (VOT) of the initial sound varied systematically. He showed that listeners were more likely to categorise acoustically ambiguous stimuli as real words, as opposed to non-words, particularly when VOT values were close to phoneme boundaries (Ganong, Citation1980). The ‘Ganong effect’ refers to this lexical effect, namely that lexical knowledge influences auditory perception, making listeners more likely to make phonetic classifications that result in real words rather than non-words.
As for previous investigations of phonetic detail in child speech using VAS, most studies have used CV-syllables as stimuli for perceptual evaluations (see e.g. Ancel et al., Citation2023; Munson et al., Citation2010; Meyer & Munson, Citation2021; Munson, Johnson, et al., Citation2012; Strömbergsson et al., Citation2015, although see Coniglio et al., Citation2022; Harel et al., Citation2017 for exceptions). In most cases, this has resulted in stimuli consisting of word fragments without lexical meaning. With the Ganong effect in mind, it is possible that VAS ratings of fine phonetic variation could be affected by stimuli lexicality, that is, meaningless syllable or meaningful word.
Although there are obvious benefits of basing perceptual evaluations on cut-out CV syllables in cross-linguistic speech perception research (see e.g. Li et al., Citation2011, who explored perception of English and Japanese children’s voiceless sibilants, through a speeded classification task), the use of such stimuli does not necessarily reflect perceptual evaluation conducted in the clinic. Indeed, clinical speech samples are most often elicited through picture naming, repetition or spontaneous speech (e.g. McLeod & Baker, Citation2014; Skahan et al., Citation2007; Wikse Barrow et al., Citation2023), resulting in whole-word productions containing lexical information that could bias perceptual ratings. However, it has been suggested that experienced clinicians might be less vulnerable to lexical bias than inexperienced listeners (Meyer & Munson, Citation2021; Munson, Johnson, et al., Citation2012). Although this hypothesis has not been explicitly tested, experience has previously been shown to impact VAS ratings of children’s speech; Munson, Johnson, et al. (Citation2012), compared ratings elicited from speech-language pathologists (SLPs) with those from inexperienced listeners in a category goodness rating task. Participants rated the initial consonants of open syllable pairs beginning with /s/-/θ/, /t/-/k/ or /d/-/g/ via a digital VAS. Overall, SLPs’ ratings were more clearly associated with acoustic features of the stimuli, showed higher intrarater reliability and less bias towards more frequent sounds compared to the ratings of the untrained listeners (Munson, Johnson, et al., Citation2012).
In a recent online experiment, aiming to investigate whether length of clinical experience influenced ratings of child speech, Meyer and Munson (Citation2021) utilised a 9-point scale to explore the same contrasts as Munson, Johnson et al. (Citation2012) as well as /s/-/ʃ/. They found that more experienced SLPs tended to be more categorical in their ratings than less experienced SLPs and inexperienced listeners. The authors speculate that the observed difference in response categoricity could be due to long-term use of phonetic transcription, which might strengthen categorical percepts (Meyer & Munson, Citation2021).
A recent exception to syllable-based VAS investigations can be found in Coniglio et al. (Citation2022) study on perception of /l/ by three listener groups with varying experience, SLPs, SLP students and inexperienced listeners. They used whole words as stimuli in their three-way (/j/-/l/-/w/) VAS, also presenting the intended word so as to ‘ … simulate the actual clinical setting’. (p. 396), and found that more experienced listeners used the VAS more continuously than inexperienced listeners. The authors interpreted their results as evidence for more gradient scale use in SLPs, and express support for clinical use of VAS in ratings of /l/. However, how the findings in Coniglio et al. (Citation2022) relate to previous work is unclear, as both the scale, the target sounds and the instructions to listeners differ. Moreover, the effect of lexical context on experienced and inexperienced listeners’ VAS ratings is, as of yet, unknown.
Aims
In the current study, we investigate how experienced (SLPs) and inexperienced listeners rate Swedish children’s initial fricatives when presented in lexical and non-lexical contexts, using VAS. We explore the rating behaviour and reliability of ratings for individuals and for each listener group. The effects of listener experience and lexicality, as well as possible interactions between them, are modelled using Bayesian mixed-effects beta regression. The present study thus attempts to replicate and expand upon the findings from Munson, Johnson et al. (Citation2012) and Meyer and Munson (Citation2021), as well as to explore possible interactions between lexicality and listener experience.
Research questions
Do experienced and inexperienced adult listeners differ in their gradient category goodness ratings of children’s voiceless fricatives? Specifically, does listener experience influence the reliability of ratings?
Does lexicality affect experienced and inexperienced adult listener ratings of children’s voiceless fricatives?
Method
Speech material
Recording
The speech material was selected from recordings of 26 children between 3 and 8 years of age, who performed an audio-prompted picture naming task. Recordings were performed in a quiet room at the Department of Linguistics at Stockholm University or in the child’s home, with a caregiver present. A Sennheiser HSP-2 head-mounted microphone, placed approximately 2 cm from the corner of the child’s mouth, with a sampling rate of 48 kHz was used for recordings. For details regarding the recording procedure, see Wikse Barrow et al., (Citationin review). A set of two minimal word pairs and two near-minimal word pairs (i.e. words with minimal initial CV-syllables) were selected for the present study; [suːl]-[ɕuːl], [sʉːɹ]-[ɕʉːɹ], [sɑːɹa]-[ɕɑːt] and [siːda]-[ɕiːlo]. See for a description of speech stimuli.
Table 1. Orthographic and phonetic transcriptions of the word pairs and extracted syllables used in the perceptual evaluation.
Stimuli selection
To select appropriate and varied stimuli, all productions of the relevant words were extracted through a Praat (Boersma & Weenink, Citation2024) script and normalised for amplitude. The extracted words were then rated independently by the Authors CWB and SS, and the initial sound was categorised as one of the four transcription categories: [s], [ɕ], [s:ɕ] when the sound was deemed intermediate, but more similar to /s/ and [ɕ:s] when the sound was deemed intermediate but more similar to /ɕ/. This procedure is similar to the intermediate transcription categories suggested by Stoel-Gammon (Citation2001) although the target sound was not taken into consideration in the present analysis. Productions that included disturbances or background noise, and productions that were not appropriately described on the /s/-/ɕ/ continua (e.g. [θ]) were excluded.
The speech stimuli selected for the perception task included 9–12 words from each transcription category (i.e. [s], [ɕ] and intermediate; [s:ɕ] or [ɕ:s]), for each word pair, resulting in a total of 126 words. Note that [ɕ] for /s/ but not [s] for /ɕ/ substitutions occurred in the material, making the stimuli unbalanced in this respect. Age and gender of the speakers were balanced as best as possible. Once the choice of words was finalised, the initial syllable of each word (i.e. the initial fricative and 150 ms of the following vowel) was extracted via a Praat script, thus generating 126 CV-syllables to parallel the 126 whole words. Vowel onset was marked at the start of periodicity and/or low-frequency energy in the spectrogram. Note, however, that some productions had long and diffuse fricative-vowel transitions, and the vowel onset annotation is therefore less reliable for these tokens. In total, 252 tokens (126 syllables) from 25 children (10 female) between three and eight were included in the perceptual task. See for an overview of the speech stimuli included. Due to an error in the wordlist preparation, one syllable was rated by only 22 listeners. This syllable and the associated word were excluded from the analysis and the summary in . As such, a total of 250 tokens, excluding duplicate presentations, were included in the analysis.
Table 2. An overview of the speech stimuli included in the perceptual evaluation. Note that both words and the extracted syllables are presented, although the fricative was always assigned to the same transcription category regardless of lexical context.
To provide a coarse acoustic description of the speech stimuli, the first spectral moment (spectral centre of gravity; CoG) of each initial fricative was calculated and is shown in . CoG is related to place of articulation in lingual fricatives, and has previously been used to quantify the acquisition of the English sibilant contrast /s/-/ʃ/ (see e.g., Holliday et al, Citation2015; Romeo et al., Citation2013). Note, however, that spectral moments analysis has been criticized as the method only provides a gross description of the spectral envelope, and the moments have an ambiguous relation to fricative articulation (see discussion in Shadle, Citation2023). However, for the present purposes, a course-grained description of acoustics was deemed acceptable.
Figure 1. Spectral centre of gravity (CoG) of word-initial fricatives across transcription categories [ɕ], [s/ɕ] and [s]. Each point shows the value of one sound (total = 125).
![Figure 1. Spectral centre of gravity (CoG) of word-initial fricatives across transcription categories [ɕ], [s/ɕ] and [s]. Each point shows the value of one sound (total = 125).](/cms/asset/71f21609-88c9-41b2-904e-05d0ba2260a8/iclp_a_2371121_f0001_b.gif)
First, the fricatives were segmented in Praat (Boersma & Weenink, Citation2024); a stable region of frication, visible in the spectrogram (0–10 kHz) from the whole-word view was annotated. The boundaries of the segment were set conservatively, excluding gradual onsets and vowel transitions. A 30 ms (rectangular) window from the middle of the annotated fricative segment was extracted with a Praat script. The excised sounds were run through an R (R Core Team, Citation2024) script, to generate multi-taper spectra (k = 8, n = 4) and calculate the CoG (range = 0.3–15 kHz), with the spectRum (Reidy, Citation2016) package. One fricative segment included a brief mid-fricative silence, and for this sound, the fricative region closest to the vowel was used for acoustic analysis.
As indicated by the distributions of CoG in , there is overlap between transcription categories as well as substantial variation within categories (primarily for /s/). Nevertheless, the general increasing trend with increasingly anterior sounds indicates that the stimuli chosen reflect the anticipated acoustic distribution for the three transcription categories.
Perceptual evaluations
Participants
Inexperienced listeners (n = 27, 14 self-reported male and 13 self-reported female) were recruited through social networks, and clinically active speech-language pathologists (SLPs) (n = 18) were recruited through social media, email and telephone. All participants were between 19 and 58 years of age, had Swedish as their first language and reported a typical hearing. All SLPs were required to work clinically with children with SSD. SLP students were not included in this study. None of the inexperienced listeners reported having studied phonetics or speech-language pathology. provides a summary of participant demographics, including age, work experience (for SLPs) and time spent with children between 1 and 6 years of age or children with SSD.
Table 3. Description of participant demographics for the two listener groups (inexperienced listeners and SLPs).
Ethical considerations
The present study is part of a PhD project that involves recordings of children as well as perceptual judgments presented herein. The project has been approved by the Swedish Ethics Review Authority (registration numbers: 2019–02854, 2020–03306, 2022–02168–02). Informed written consent was collected from all listeners prior to data collection. Participants were also informed that they could withdraw from the study at any time without consequences and were compensated for their time with one cinema ticket.
Procedure
The perceptual task was administered through PsychoPy (Peirce et al., Citation2019) on a laptop computer. The sounds were presented at a fixed level via BeyerDynamic DT 770 PRO headphones. All participants performed the listening task in a quiet room, bar one who sat in a quiet location outdoors. The test leader (Author LO) was available for questions throughout the experiment.
Participants were instructed to rate the first sound of each syllable or word on a digital VAS, by clicking on the location that corresponded to their perception of the sound. The VAS ranged from ‘s’ to ‘tj’ (i.e. the most common orthographic representation of /ɕ/). For an illustration of the digital VAS used in the present study, see . The click location of each response corresponds to a whole number between 0 (i.e. ‘s’) and 100 (i.e. ‘tj’). The written instructions ‘Listen and rate the first sound’ (Swe: Lyssna och bedöm det första ljudet) were printed above the scale throughout the experiment. Participants were encouraged to use the entire scale and to rely on their first impression of the initial sound for their judgment. Sounds were presented only once, although the test leader could repeat a sound in cases of intermittent background noise. Prior to the presentation of the test items, a training block containing six adult productions (three syllables), was presented, to ensure that all participants understood the procedure.
Figure 2. The digital VAS used in the present study.

The speech stimuli were presented in two blocks, separated by a short break. Words and their constituent syllables were presented in different blocks. Participants were counterbalanced across four conditions with different pseudo-random wordlists. To explore intrarater reliability, 9.5% of the child recordings (12 words, 12 syllables) were duplicated. Duplicates were presented in the opposite block to their twin, and the second presentation of each sound was used only for analysis of reliability. In addition to the child recordings, 31 adult tokens (18 syllables) were included in the test blocks as perceptual anchors. The adult tokens were produced by two female native speakers of Swedish from the Svealand region (Author CWB and SS), and were recorded in the anechoic chamber of the Phonetics Laboratory at Stockholm University.
Analysis
The ratings were summarised and analysed in R (R Core Team, Citation2024). Adult speech tokens and responses with reaction times of less than 200 ms after onset of audio presentation were removed prior to analysis. The second presentation of the duplicates was only included in the analysis of intrarater reliability. A total of 11,245 ratings of the 250 sounds were used in analyses of rating behaviour and in the statistical model.
The raw responses were tallied and visualised through a variety of plots in R, to gauge the visible effects of lexical context, experience and individual variation. Anonymised data and code to generate statistics, tables and figures presented in this paper (including model evaluation and additional visualisations of the data), are publicly available at https://doi.org/10.5281/zenodo.11943307.
Reliability analysis
Intra- and interrater reliability were calculated with Intraclass Correlation (ICC), a two-way model of consistency. For intrarater reliability, ratings of the first and second presentation of the duplicated sounds were used. For interrater reliability, all ratings excluding the second presentations of the duplicated items were used (i.e. two ratings from each participant for each sound; from syllable and word contexts). Interrater reliability was calculated for all listeners (n = 45) as well as within the groups; SLPs (n = 18) and inexperienced listeners (n = 27).
Bayesian mixed-effects Beta regression
Bayesian mixed-effects beta regression was used to analyse VAS responses. Beta regression recognised that the VAS is bounded on both sides (Smithson & Verkuilen, Citation2006), which can help reduce issues with the assumption of homoscedasticity that would come with linear regression. Beta regression also enables the study of effects, not only on the mean of VAS responses but also in their variability through the phi parameter (for an application in the domain of language research, see Babel, Citation2022). The phi parameter corresponds to precision, which is inversely related to the variance (i.e. high precision corresponds to highly consistent responses). Though a Bayesian formulation of beta regression wass not critical for the present purpose, it was chosen as standard weakly regularising priors facilitates model convergence, while keeping statistical inferences conservative. Moreover, Bayes Factors (BF) as a measure of empirical support provides an intuitive alternative to null hypothesis significance testing (for a review, see Wagenmakers, Citation2007, for an accessible introduction, see McElreath, Citation2018 and for a tutorial on Bayesian models directed at researchers in the phonetic sciences, seeVasishth et al., Citation2018).
To facilitate interpretation, VAS responses were transformed from [s]-to-[ɕ] ratings into ratings of typicality or category goodness, for the intended fricative; responses for intended /s/ tokens were transposed by subtracting them from 100. Therefore, higher VAS responses designated a more ‘target-like’ rating for both intended fricative targets (i.e. /s/ or /ɕ/). All responses were then scaled to a range from 0.00004 to 0.99996 to remove 0 and 1 values (Smithson & Verkuilen, Citation2006).Footnote1
Beta regression analysed both the mean and precision of these transformed VAS responses as a function of participants’ experience (weighted effect coded: 18 = SLP vs. 27 = inexperienced listener) and lexicality (weighted effect coded: 125 = word vs. 125 = syllable), and their interaction. The analysis employed the maximal random effects structure justified by the design, including random by-participant and by-item intercepts as well as slopes for the full factorial of experience and lexicality. Following recommendations in the statistical literature, we used weakly regularising priors – specifically, the same settings as employed in Xie et al. (Citation2021): Student priors (3, 0, 2.5) for all population-level effects, Cauchy priors (0, 2.5) for the standard deviations of group-level effects, and LKJ (1) priors for the correlation matrix of group-level effects.
Model syntax
VASresponse ~ 1 + SLP * lexical_context +(1 + lexical_context | participant) +(1 + lexical_context * SLP | item),phi ~ 1 + SLP * lexical_context +(1 + lexical_context | participant) +(1 + lexical_context * SLP | item),family = Beta(link = “logit”, link_phi = “log”))The model was fit with the brms library (Bürkner, Citation2017) in R, with 1000 warm-up and 4000 posterior samples for each of four chains (i.e. a total of 16 000 posterior samples). All indicators suggested convergence (e.g. all Řs 1.001). We report the results of Bayesian hypothesis testing using brms’s hypothesis function (Bürkner, Citation2017).
Note that the minimal/near-minimal word pair environment could affect perceptual ratings, particularly in the whole word context. However, substitutions were unbalanced across minimal and near-minimal word pairs (8 [s] for /ɕ/ substitutions in minimal word pairs and 4 in near-minimal word pairs). To avoid over-parameterisation of the model and possible interference from substitution errors in the speech material, minimal word pair status was not included in the model.
Results
Visualisations of the click locations show a wide range of VAS responses, although many tokens were classified as close to one of the two scale endpoints (i.e. [s] or [ɕ]). shows the density distributions of the VAS responses for the three transcription categories [s], [ɕ] and in-between (i.e. [s/ɕ]). As is revealed in , the sounds that were transcribed as [s] or [ɕ] were to a high degree rated as very [s]-like and [ɕ]-like, respectively. The ratings of the in-between transcription category [s/ɕ] were instead dispersed across a larger range of scales, although an increase in ratings close to the intended fricative endpoint is visible, as well as a small bump in the middle of the scale.
Figure 3. Density distributions of VAS responses across all participants, separated by transcription category ([s], [ɕ] and in-between [s/ɕ]).
![Figure 3. Density distributions of VAS responses across all participants, separated by transcription category ([s], [ɕ] and in-between [s/ɕ]).](/cms/asset/b2cd049a-2a22-4160-aa16-ddd12050df87/iclp_a_2371121_f0003_b.gif)
Plots of individual participants’ ratings were visually inspected to gauge the variation of VAS responses. shows individual responses for three participants, revealing differences in categoricity and use of the VA scale. Most participants used the whole scale, but some showed a visually salient categorical pattern (n = 2, both inexperienced), with few ratings across the middle of the scale, and many located at the scale endpoints (see e.g. the rightmost panel of ). Most listeners exhibited a pattern similar to the participant in the left and middle panels of , with the majority of ratings for the [s] and [ɕ] transcription categories close to the end of the scale adjacent to the intended fricative label and a decreasing number of responses towards the middle. The ‘in-between’ category elicited more varied responses across the whole scale with few ratings at the very endpoints. Note, however, that no statistical quantification of rating categoricity was performed. Visualisations of all individual listeners’ ratings are available at 10.5281/zenodo.11943307.
Figure 4. Distribution of three listeners’ ratings across the three transcription categories ([s], [ɕ] and in-between [s/ɕ]). Each point corresponds to one rating (total=250 per listener) and density is illustrated by the opacity of the points.
![Figure 4. Distribution of three listeners’ ratings across the three transcription categories ([s], [ɕ] and in-between [s/ɕ]). Each point corresponds to one rating (total=250 per listener) and density is illustrated by the opacity of the points.](/cms/asset/3dcdb10f-12a5-4d12-b769-36a1f142261f/iclp_a_2371121_f0004_b.gif)
Reliability
Intrarater reliability was estimated through ICC (model: two-way, type: consistency), calculated across the duplicated sounds for each individual listener and is presented in . ICC scores ranged from 0.57 (95%-CI: 0.23–0.79; poor-to-good reliability) to 0.98 (95%-CI: 0.95–0.99; excellent reliability) with an overall mean of 0.83 (good reliability).
Figure 5. Violin plot of intrarater reliability (ICC) for SLPs and inexperienced listeners. Each point represents one individual listeners’ ICC score.
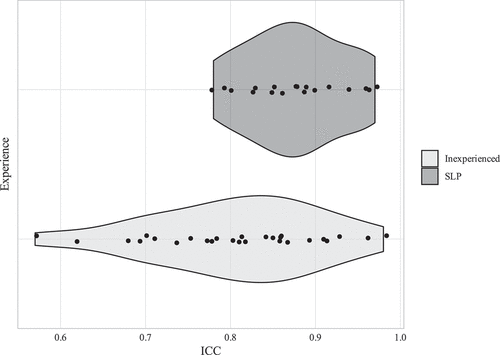
On a group level, SLPs were more consistent than inexperienced listeners, although many inexperienced listeners had ICC scores at the same level as SLPs. ICC scores from less (5 years or less of work experience) and more experienced (6 years or more of work experience, ranging up to 15 + years) SLPs were plotted, but no clear differences came to light; less experienced SLPs had both the highest and lowest scores, and variation within the group was large.
To investigate interrater reliability, ICC (two-way model, consistency) was calculated, including only the first repetition of all sounds. Overall ICC including all ratings and all listeners was 0.729 (95%-CI: 0.693–0.764, F(244,10736) = 122, p < 0.001). Comparing the two groups, the interrater reliability for SLPs (ICC = 0.79, 95%-CI: 0.759–0.82, F(248,4216) = 68.8, p < 0.001) was higher than that for inexperienced listeners (ICC = 0.697, 95%-CI: 0.658–0.736, F(245,6370) = 63, p < 0.001). This corresponds to good reliability for SLPs, and moderate-to-good reliability for inexperienced listeners (Koo & Li, Citation2016).
Effects of lexicality and experience
summarises the results of Bayesian hypothesis tests over Bayesian mixed-effects beta regression. As a guide for interpretation; BFs > 10 are considered to be strong support and BFs > 30 as very strong support (Raftery, Citation1995; Schönbrodt et al., Citation2017). The posterior probability presented in reflects the proportion of posterior samples that support the hypothesis. A model summary and plots of posterior distributions for all population-level effects can be found in the online material (10.5281/zenodo.11943307).
Table 4. Summary of Bayesian hypothesis tests. For each effect, the estimate , its standard error (SE), directional 90% Credible Intervals (CrI), Bayes Factors (BF), and posterior probabilities are listed. As is the standard for Beta regression, estimates of effects on response means are expressed in log-odd units and estimates of effects on response precision are expressed in log units.
We found strong evidence for main effects of both experience and lexicality (see estimates of effects on response mean and precision in ). SLPs gave overall higher (more prototypical) ratings than inexperienced listeners (BF = 155.9) and fricatives in words were rated as more target-like than fricatives in syllables (BF > 16,000). These main effects exhibited a credible interaction (BF = 7999), as shown in . Simple slope analyses, not shown here, found that lexicality had credible effects in the same direction for both groups of participants ( Estimate was 0.49, 95%-CrI: 0.38–0.61 for inexperienced listeners and 0.23, 95%-CrI: 0.1–0.35 for SLPs). The effect was, however, reduced for SLPs (as indicated by the interaction).
As shown in , all effects found for the mean of VAS responses were also found for the precision of VAS responses: SLPs had more precise (less variable) responses than inexperienced listeners (BF = 72), and VAS ratings of fricatives in word context were more precise than VAS ratings of fricatives in syllable contexts (BF = 1453.6). As was the case for means, the effect of lexicality on precision was reduced for SLPs (although the effect of the interaction on the precision of ratings received weaker support; BF = 7.5).
The Bayesian regression used herein also enables assessment of the extent to which the effects reported above held within each participant and/or item. Hypothesis testing revealed that the effect of lexicality on the mean of responses was credible in all participants (BFs from 11.3 to >16000, although all but two had BFs > 24) but not all items (BFs from 0.08 to >16000). The latter is expected given that the fricatives varied in terms of prototypicality; highly prototypical sounds are expected to elicit higher VAS ratings regardless of whether appearing in a whole word or in a word fragment. The effect of the experience was not found to hold within each item either (BFs from 0 to 15,999).
Discussion
In the present study, we explored experienced (SLPs) and inexperienced listeners’ ratings of Swedish children’s word-initial voiceless sibilant fricatives, specifically investigating whether the lexical context in which a sound stimulus is presented affects the VAS rating of said sound. We begin by addressing our research questions in relation to previous research on VAS ratings of child speech, then discuss listener experience and consider the possible clinical implications of our findings. Finally, limitations of the current work and future directions of research are discussed.
Do experienced and inexperienced adult listeners differ in their gradient category goodness ratings of children’s voiceless fricatives? Specifically, does listener experience influence the reliability of ratings?
On a group level, no large differences regarding the use of scale were visible. However, individual variation was apparent, with different response patterns across individual listeners in both groups. Most listeners used the whole scale, although a couple showed more categorical patterns. Collectively, SLPs had higher intra- and interrater reliability than inexperienced listeners, reflected in both the ICC score and the phi parameter of the beta regression model. These findings are expected and are consistent with Munson, Johnson, et al. (Citation2012), regarding higher intrarater reliability for SLPs as compared to inexperienced listeners, despite different measures of reliability being used.
Does lexicality affect experienced and inexperienced adult listeners ratings of children’s voiceless fricatives?
The Bayesian mixed-effect Beta regression model showed an effect of lexicality for both groups (SLPs and inexperienced listeners) and for all individual listeners. An interaction between lexicality and experience was found, such that the effect of lexicality was more pronounced in the inexperienced group of listeners. In other words, SLPs’ ratings of children’s initial voiceless fricatives were less influenced by the lexical status of the stimuli presented. Moreover, an effect of both experience and lexicality on precision of VAS ratings was revealed, reflected in the phi parameter of the model. SLPs had higher precision (i.e. lower variance) than inexperienced listeners and words were rated with higher precision than syllables/word fragments.
Overall, these results lend support for the hypothesis expressed in Munson, Johnson et al. (Citation2012), specifically that the percepts of listeners with more experience should be more stable across levels of lexical complexity (i.e. word fragments vs. whole words), compared to those of less experienced listeners.
Moreover, we found that SLPs rated initial voiceless fricatives as more target-like than did inexperienced listeners, in line with findings from Meyer and Munson (Citation2021) who discovered that more-experienced SLPs used scale endpoints (corresponding to target-like ratings) to a higher extent than did less-experienced SLPs and inexperienced listeners.
Notably, however, the difference between inexperienced and experienced listeners’ VAS ratings was larger for syllables than for whole words. Inexperienced listeners are undoubtedly more familiar with whole words compared to word fragments, so this difference is perhaps not unexpected. However, it could indicate that the effect of listener experience is exaggerated in previous work. That is, had we conducted an experiment to parallel previous procedures, including only CV-syllables (Ancel et al., Citation2023; Meyer & Munson, Citation2021; Munson et al., Citation2010; Munson, Johnson, et al., Citation2012; Strömbergsson et al., Citation2015), we might have found a more pronounced effect of listener experience.
On surface level, the present results may seem contradictory to Coniglio et al. (Citation2022), who reported a more gradient use of the VA scale among clinically experienced listeners compared to less experienced listeners. However, as the task and analysis in their study differ to ours in many respects, results cannot easily be compared and differences in rating categoricity may be due to study-specific features (e.g. stimuli or task design).
A note on experience
As described above, a clear effect of experience was found in the present study. However, the definition of experience used herein is broad and ambiguous, resulting in a number of uncertainties related to the effects observed. That is to say, we do not know whether the ‘SLP effect’ is driven by experience with children (with highly variable speech) and/or experience with transcription of speech and systematic listening.
Indeed, although the inexperienced listener group in the present study was highly heterogeneous with respect to time spent with children (see ), most had limited experience interacting with young children.
In a recent study, exploring different types of experience in perception of child speech, Yu et al. (Citation2023) compared accuracy on a speech-in-noise transcription task including child speech (isolated words) from four listener groups with varying experience interacting with young children. They found no experience-based advantage for child speech intelligibility (i.e. mothers of young children and early childhood educators did not perform better than undergraduate students), although SLPs were more accurate than the other listener groups. However, as SLPs performed better than the other groups for both adult and child speech, Yu et al. (Citation2023) speculate that their performance might be related to a ‘task advantage’. Hence, listener experience is a multifaceted construct, and further exploration into how different aspects of experience contribute to listener ratings of child speech, in different listening tasks, is warranted.
A clinical perspective
The overarching raison d’être of speech therapy is arguable to reach and maintain functional communication and intelligible speech for the client/patient. Thus, it is reasonable for clinicians to assess speech in naturally occurring forms, for example words. However, words come accompanied by lexical bias, among others, and SLPs need to be able to shift their focus from communication to fine phonetic detail in children’s speech, in order to capture gradient development in speech sound contrast acquisition and to choose appropriate targets in speech intervention (see e.g. Macken & Barton, Citation1980, Munson, Citation2010; Tyler et al., Citation1993). While there are examples of whole-word stimuli in VAS perception studies (e.g. Coniglio et al., Citation2022; Harel et al., Citation2017), much previous work has utilised CV-syllables. The present study indicates that clinically active SLPs are, as a group, less affected by lexicality of the sound stimuli they are rating, compared to laypeople (denoted herein as inexperienced listeners). This supports the validity of VAS ratings as a clinically viable assessment tool. Nevertheless, a lexical effect was present for all individual listeners, with higher (more prototypical) and more consistent ratings for whole word stimuli. The clinical impact of this effect is not known, although it is conceivable that lexical bias could reduce the listener’s sensitivity to fine phonetic detail. Our results indicate that lexical bias should be considered when attempting to apply findings from previous studies on speech perception using VAS (Ancel et al., Citation2023; Munson & Urberg Carlson, Citation2016; Munson et al., Citation2010; Munson, Johnson, et al., Citation2012, Citation2012; Schellinger et al., Citation2017; Strömbergsson et al., Citation2015) to the clinic.
Limitations & future research
One possible caveat of the current design is that the stimuli used were natural speech, chosen to reflect a perceptual variation across the /s/-/ɕ/ continua. This choice hopefully mirrors some of the variation that SPLs encounter in the clinic but limits experimental control of the physical characteristics of the speech stimuli. It is unclear how much of the rating behaviour observed in the present study is influenced by the specific stimuli used herein. To increase generalisability, more research with other speech material and speech sound contrasts is needed.
With respect to the lexicality of stimuli, the excised word fragments/CV sequences used do sound slightly strange. However, the format was explicitly chosen to increase comparability across vowel contexts and to mirror previous VAS investigations (e.g. Julien & Munson, Citation2012). Additionally, the use of whole-word productions introduces auxiliary information, such as f0, voice quality and additional speech errors, which could also bias perceptual ratings. However, as speaker-specific characteristics vary substantially among SLP clients, rich and variable stimuli are vital to explore the validity of clinical assessment instruments.
The acoustic characteristics of the stimuli might also affect ratings, and although we present a course acoustic description of the sounds used herein, we do not relate acoustic characteristics to listener percepts. As such, we did not explore the accuracy of the VAS ratings provided. We argue that acoustic-perception investigations should include all potentially relevant acoustic cues, especially when exploring subtle phonetic variation, and should ideally explore both individual differences and group trends in listeners’ cue-weighting. Considering the complexity of fricative acoustics, we believe such a study to be beyond the scope of the present article. Nevertheless, the lack of acoustic investigation does lead to some open questions about the effects of experience and lexicality presented above. For example, do ratings of high prototypicality correspond to acoustically canonical tokens? Is acoustic gradience mirrored in the gradience of VAS ratings? Do these patterns differ between the listener groups? Future studies of the relationship between perception and acoustic characteristics of Swedish children’s voiceless fricatives are welcome and would advance our knowledge concerning cue-weighting and cross-linguistic tendencies in speech perception.
Finally, the group sizes for SLPs and inexperienced listeners were unbalanced due to difficulties recruiting clinicians. The difference in size was taken into account in the effect weighting of the model and the number of SLPs is comparable to previous work (e.g. Coniglio et al., Citation2022; Munson, Johnson, et al., Citation2012). Nevertheless, perceptual experiments with larger and more balanced groups are needed to further evaluate the effects found here. Online perception experiments, where large groups are easier to recruit, could be a valuable avenue for future research.
Conclusion
The present study reveals differences in the reliability and the effect of lexicality on experienced (SLPs) and inexperienced listeners’ ratings of Swedish children’s voiceless fricatives. Overall, SLPs had higher intra- and interrater reliability for VAS ratings, although individual variability was sizeable. The Bayesian mixed-effects beta regression and subsequent hypothesis testing lends strong support for an effect of lexicality on VAS ratings for both groups, which holds also for all individuals. The results of this investigation indicate that while SLPs are less affected by stimuli lexicality, the findings of previous research concerning VAS ratings of non-lexical initial syllables cannot be directly transferred to the clinical context, without consideration of possible lexical bias. Questions concerning the impact of level and type of experience that may affect gradient ratings of fine phonetic detail in child speech remain open.
Author contribution
Conceptualisation and design, Data & experiment preparation: CWB & SS.
Data collection: LO.
Statistical analysis: CWB with input from FJ (as described in Acknowledgements).
Data Curation, Visualisations, Writing – Original Draft: CWB
Writing – Review & Editing: CWB & SS.
All authors read and approved the final version of the manuscript.
Acknowledgments
Sincere thanks to Professor Florian Jaeger for generously sharing his knowledge and time and for providing feedback on a previous version of the manuscript. Prof. Jaeger hosted a workshop on statistics at Stockholm University, during which the foundation of the Bayesian model in this paper was built. Nevertheless, any mistakes in model implementation and interpretation are CWBs. Thank you also to Marcin Włodarczak for his help with coding mishaps.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The data (anonymous ratings) and code used to generate the results presented in this paper are publicly available at 10.5281/zenodo.11943307. Audio is not shared.
Additional information
Funding
Notes
1. This ‘shrinkage’ or ‘squeezing’ is required for beta regression, which does not allow values of 0 and 1 (21.6% of our data). The degree of shrinkage constitutes a researcher degree of freedom. To reduce the risk of anti-conservativity, we committed to the same degree of shrinkage as in previous work (Smithson & Verkuilen, Citation2006).
References
- Ancel, E. E., Smith, M. L., Rao, V. V., & Munson, B. (2023). Relating acoustic measures to listener ratings of children’s productions of word-initial/ɹ/and/w/. Journal of Speech, Language, and Hearing Research, 66(9), 3413–3427. https://doi.org/10.1044/2023_JSLHR-22-00713
- Babel, M. (2022). Adaptation to social-linguistic associations in audio-visual speech. Brain Sciences, 12(7), 845. https://doi.org/10.3390/brainsci12070845
- Boersma, P., & Weenink, D. (2024). Praat: Doing phonetics by computer [Computer program]. Version 6.2.23. http://www.praat.org/
- Bürkner, P. (2017). Advanced Bayesian multilevel modeling with the R package brms. PsyArxiv Preprints. https://www.arxiv.org/abs/1705.11123
- Coniglio, E. A., Chung, H., & Schellinger, S. K. (2022). Perception of children’s productions of/l/: Acoustic correlates and effects of listener experience. Folia Phoniatrica et Logopaedica, 74(6), 392–406. https://doi.org/10.1159/000524395
- Dodd, B. (2014). Differential diagnosis of pediatric speech sound disorder. Current Developmental Disorders Reports, 1(3), 189–196. https://doi.org/10.1007/s40474-014-0017-3
- Ganong, W. F. (1980). Phonetic categorization in auditory word perception. Journal of Experimental Psychology, 6(1), 110–125. https://doi.org/10.1037//0096-1523.6.1.110
- Harel, D., Hitchcock, E. R., Szeredi, D., Ortiz, J., & McAllister Byun, T. (2017). Finding the experts in the crowd: Validity and reliability of crowdsourced measures of children’s gradient speech contrasts. Clinical Linguistics & Phonetics, 31(1), 104–117. https://doi.org/10.3109/02699206.2016.1174306
- Holliday, J. J., Reidy, P. F., Beckman, M. E., & Edwards, J. (2015). Quantifying the robustness of the English sibilant fricative contrast in children. Journal of Speech, Language, and Hearing Research, 58(3), 622–637. https://doi.org/10.1044/2015_JSLHR-S-14-0090
- Hustad, K. C., Mahr, T. J., Natzke, P., & Rathouz, P. J. (2021). Speech development between 30 and 119 months in typical children I: Intelligibility growth curves for single-word and multiword productions. Journal of Speech, Language, and Hearing Research, 64(10), 3707–3719. https://doi.org/10.1044/2021_JSLHR-21-00142
- Julien, H. M., & Munson, B. (2012). Modifying speech to children based on their perceived phonetic accuracy. Journal of Speech- Language Hearing Research, 55(6), 1836–1849. https://doi.org/10.1044/1092-4388(2012/11-0131)
- Koo, T. K., & Li, M. Y. (2016). A guideline of selecting and reporting intraclass correlation coefficients for reliability research. Journal of Chiropractic Medicine, 15(2), 155–163. https://doi.org/10.1016/j.jcm.2016.02.012
- Li, F., & Munson, B. (2016). The development of voiceless sibilant fricatives in Putonghua- speaking children. Journal of Speech, Language, and Hearing Research, 59(4), 699–712. https://doi.org/10.1044/2016_JSLHR-S-14-0142
- Li, F., Munson, B., Edwards, J., Yoneyama, K., & Hall, K. (2011). Language specificity in the perception of voiceless sibilant fricatives in Japanese and English: Implications for cross-language differences in speech-sound development. The Journal of the Acoustical Society of America, 129(2), 999–1011. https://doi.org/10.1121/1.3518716
- Macken, M. A., & Barton, D. (1980). The acquisition of the voicing contrast in English: A study of voice onset time in word-initial stop consonants. Journal of Child Language, 7(1), 41–74. https://doi.org/10.1017/S0305000900007029
- McElreath, R. (2018). Statistical rethinking: A Bayesian course with examples in R and Stan. Chapman and Hall/CRC.
- McLeod, S., & Baker, E. (2014). Speech-language pathologists’ practices regarding assessment, analysis, target selection, intervention, and service delivery for children with speech sound disorders. Clinical Linguistics & Phonetics, 28(7–8), 508–531. https://doi.org/10.3109/02699206.2014.926994
- McLeod, S., & Crowe, K. (2018). Children’s consonant acquisition in 27 languages: A cross-linguistic review. American Journal of Speech-Language Pathology, 27(4), 1546–1571. https://doi.org/10.1044/2018_AJSLP-17-0100
- Meyer, M. K., & Munson, B. (2021). Clinical experience and categorical perception of children’s speech. International Journal of Language & Communication Disorders, 56(2), 374–388. https://doi.org/10.1111/1460-6984.12610
- Munson, B., Edwards, J., Schellinger, S. K., Beckman, M. E., & Meyer, M. K. (2010). Deconstructing phonetic transcription: Covert contrast, perceptual bias, and an extraterrestrial view of vox humana. Clinical Linguistics & Phonetics, 24(4–5), 245–260. https://doi.org/10.3109/02699200903532524
- Munson, B., Johnson, J. M., & Edwards, J. (2012). The role of experience in the perception of phonetic detail in children’s speech: A comparison between speech-language pathologists and clinically untrained listeners. American Journal of Speech-Language Pathology, 21(2), 124–139A. https://doi.org/10.1044/1058-0360(2011/11-0009)
- Munson, B., Schellinger, S. K., & Carlson, K. U. (2012). Measuring speech-sound learning using visual analog scaling. Perspectives on Language Learning and Education, 19(1), 19–30. https://doi.org/10.1044/lle19.1.19
- Munson, B., & Urberg Carlson, K. (2016). An exploration of methods for rating children’s productions of sibilant fricatives. Speech, Language and Hearing, 19(1), 36–45. https://doi.org/10.1080/2050571X.2015.1116154
- Peirce, J., Gray, J. R., Simpson, S., MacAskill, M., Hochenberger, R., Sogo, H., Kastman, E., Lindelov, J. K. (2019). Psychopy2: Experiments in behavior made easy. Behavioural Research Methods, 51(1), 195–203. https://doi.org/10.3758/s13428-018-01193-y
- R Core Team. (2024). R: A language and environment for statistical computing. R Foundation for Statistical Computing. https://www.R-project.org/
- Raftery, A. E. (1995). Bayesian model selection in social research. Sociological Methodology, 25, 111–163. https://doi.org/10.2307/271063
- Reidy, P. (2016). spectRum [R package]. https://github.com/patrickreidy/spectRum.git
- Romeo, R., Hazan, V., & Pettinato, M. (2013). Developmental and gender-related trends of intra-talker variability in consonant production. The Journal of the Acoustical Society of America, 134(5), 3781–3792. https://doi.org/10.1121/1.4824160
- Rvachew, S., & Brosseau-Lapré, F. (2017). Introduction to speech sound disorders. Plural Publishing.
- Schellinger, S. K., Munson, B., & Edwards, J. (2017). Gradient perception of children’s productions of/s/and/theta/: A comparative study of rating methods. Clinical Linguistics & Phonetics, 31(1), 80–103. https://doi.org/10.1080/02699206.2016.1205665
- Schönbrodt, F. D., Wagenmakers, E. J., Zehetleitner, M., & Perugini, M. (2017). Sequential hypothesis testing with Bayes factors: Efficiently testing mean differences. Psychological Methods, 22(2), 322. https://doi.org/10.1037/met0000061
- Shadle, C. H. (2023). Alternatives to moments for characterizing fricatives: Reconsidering Forrest et al. (1988). The Journal of the Acoustical Society of America, 153(2), 1412–1426. https://doi.org/10.1121/10.0017231
- Skahan, S. M., Watson, M., & Lof, G. L. (2007). Speech-language pathologists’ assessment practices for children with suspected speech sound disorders: Results of a national survey. American Journal of Speech-Language Pathology, 16(3), 246–259. https://doi.org/10.1044/1058-0360(2007/029)
- Smithson, M., & Verkuilen, J. (2006). A better lemon squeezer? Maximum-likelihood regression with beta-distributed dependent variables. Psychological Methods, 11(1), 54–71. https://doi.org/10.1037/1082-989X.11.1.54
- Stoel-Gammon, C. (2001). Transcribing the speech of young children. Topics in Language Disorders, 21(4), 12–21. https://doi.org/10.1097/00011363-200121040-00004
- Strömbergsson, S., Salvi, G., & House, D. (2015). Acoustic and perceptual evaluation of category goodness of/t/and/k/in typical and misarticulated children’s speech. Journal of the Acoustical Society of America, 137(6), 3422–3435. https://doi.org/10.1121/1.4921033
- Tyler, A. A., Figurski, G. R., & Langsdale, T. (1993). Relationships between acoustically determined knowledge of stop place and voicing contrasts and phonological treatment progress. Journal of Speech, Language, and Hearing Research, 36(4), 746–759. https://doi.org/10.1044/jshr.3604.746
- Vasishth, S., Nicenboim, B., Beckman, M. E., Li, F., & Kong, E. J. (2018). Bayesian data analysis in the phonetic sciences: A tutorial introduction. Journal of Phonetics, 71, 147–161. https://doi.org/10.1016/j.wocn.2018.07.008
- Wagenmakers, E. J. (2007). A practical solution to the pervasive problems of p values. Psychonomic Bulletin & Review, 14(5), 779–804. https://doi.org/10.3758/BF03194105
- Wikse Barrow, C., Körner, K., & Strömbergsson, S. (2023). A survey of Swedish speech-language pathologists’ practices regarding assessment of speech sound disorders. Logopedics Phoniatrics Vocology, 48(1), 23–34. https://doi.org/10.1080/14015439.2021.1977383
- Wikse Barrow, C., Strömbergsson, S., Włodarczak, M., & Heldner, M. (in review). Individual variation in the realisation and contrast of Swedish children’s voiceless fricatives. Journal of Phonetics.
- Xie, X., Liu, L., & Jaeger, T. F. (2021). Cross-talker generalization in the perception of nonnative speech: A large-scale replication. Journal of Experimental Psychology: General, 150(11), e22–e56. https://doi.org/10.1037/xge0001039
- Yu, M. E., Cooper, A., & Johnson, E. K. (2023). Who speaks “kid?” how experience with children does (and does not) shape the intelligibility of child speech. Journal of Experimental Psychology: Human Perception and Performance, 49(4), 441–450. https://doi.org/10.1037/xhp0001088