
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Swift detection of faces with emotional meaning underlies fruitful social relationships. Although previous studies using a visual search paradigm have demonstrated rapid detection of emotional facial expressions, whether it is attributable to emotional/motivational significance remains to be clarified. We examined this issue by excluding the influence of visual factors on the rapid detection of faces with emotional meaning. First, participants were engaged in an associative learning task wherein neutral faces were associated with either monetary rewards, monetary punishments, or zero outcome in order for the neutral faces to acquire positive, negative, and no emotional value, respectively. Then, during the visual search task, the participants detected a target-neutral face associated with high reward or punishment from among newly presented neutral faces. In Experiment 1, neutral faces associated with high reward and punishment values were more rapidly detected than those without monetary outcomes. In Experiment 2, highly rewarded and highly punished neutral faces were more rapidly detected than neutral faces associated with low monetary reward/punishment. Analyses of ratings confirmed that the learned neutral faces acquired emotional value, and the reaction times were negatively related to arousal ratings. These results suggest that the emotional/motivational significance promotes the rapid detection of emotional faces.
The ability to detect faces with emotional meaning is fundamental for adaptive behaviour in social interaction. Visual attention to emotional faces constitutes an integral part of components leading to well-coordinated social behaviours and relationships.
Prior experimental psychological studies have demonstrated an efficient search for emotional faces using a visual search paradigm (Eastwood et al., Citation2003; Hansen & Hansen, Citation1988; Sato & Yoshikawa, Citation2010; Skinner & Benton, Citation2012; Williams et al., Citation2005). Williams et al. (Citation2005), for example, asked participants to detect one discrepant emotional face such as a sad or happy face, embedded among several homogenous distractor faces. They demonstrated that the reaction times (RTs) for identifying sad or happy faces were quicker than those for identifying neutral faces among distractor faces. This visual search paradigm has been acknowledged as a prominent behavioural task capable of examining, in a strictly controlled fashion, the processes underlying the identification of a given object within a cluttered environment during daily activities (Kristjánsson et al., Citation2010).
However, issues remain regarding the rapid detection of emotional faces. First, whether emotional faces do indeed capture attention in a fully automatic fashion continued to be debated (Puls & Rothermund, Citation2018; Tannert & Rothermund, Citation2020). Moreover, it remains unclear whether the rapid detection of emotional faces is due to the factor of the emotional significance of the faces. Whereas emotional significance of emotional faces has been claimed to give rise to an efficient search for emotional faces (Hahn, Citation2017; Sato & Yoshikawa, Citation2010), it is also possible that the mere visual characteristics of emotional faces may speed up their detection because such faces inevitably entail visual saliency (i.e. oblique eyebrows displayed on angry faces) (Calvo & Nummenmaa, Citation2008); it has been known that visual saliency modulates visual attention (Theeuwes, Citation1992). No previous studies employing a visual search paradigm were able to disentangle the effect of visual saliency (a potential confounder) from the effect of emotional significance on the detection speed for emotional faces. In practice, it is difficult to remove salient physical features from real emotional faces in order to exclude the confounds with visual saliency.
Based on the above considerations, instead of using emotional faces, we employed inherently neutral faces as target stimuli in our visual search task. Because neutral faces do not have any salient visual features, they can be considered free from the visual saliency confounder. Then, we adopted an associative learning procedure in order to imbue these neutral faces with positive or negative emotional values. We assumed that such manipulation would create a situation where neutral faces can contain emotional meaning as emotional faces do but without any influence of visual features. In this regard, value-associated neutral faces might be a suitable form of stimuli to test the influence of emotional significance on rapid detection of emotional faces, excluding the effects of visual saliency.
Regarding the issue of whether neutral faces can indeed acquire emotional and/or motivational value via associative learning, prior studies of value association learning have provided supporting evidence for the claim (Gupta et al., Citation2016; Hammerschmidt et al., Citation2017; Müller et al., Citation2016; Wentura et al., Citation2014). For instance, Gupta et al. (Citation2016) have demonstrated that neutral faces associated with monetary reward or loss interfered with performance in cognitive tasks with low load, whose magnitude was comparable to the interference effect caused by emotional faces and emotional scenes. Similarly, Hammerschmidt et al. (Citation2017) have reported that neutral faces associated with monetary reward more rapidly induced enhanced activity in the posterior cortices, which are usually activated when emotional faces are presented. Furthermore, using a priming procedure, Wentura et al. (Citation2014) have provided evidence that neutral, value-associated, non-face stimuli induced a significant distracting effect in a visual search task and also exhibited the same magnitude of priming effect as real emotional stimuli on the subsequent evaluative priming task. Taken together, these findings suggest that neutral stimuli, including faces, acquired emotional values via associative learning and were processed in the same way as emotional faces. Given these findings, it is likely that neutral faces can be associated with emotional/motivational value through learning so that they are recognised in learners’ minds as faces that have emotional/motivational value but without any salient visual characteristics.
In the current study, we examined whether neutral faces that acquired emotional/motivational value would be more rapidly detected than neutral face without such value. Because there are no differences in terms of visual saliency between neutral faces associated with emotional-motivational value and neutral faces without such value, this comparison will enable us to test the effect of emotional-motivational significance on the detection of emotional faces; if neutral faces are more rapidly detected after acquiring emotional-motivational value, compared to neutral faces without such value, it would provide convincing evidence for the claim that emotional-motivational significance promote efficient search for emotional faces.
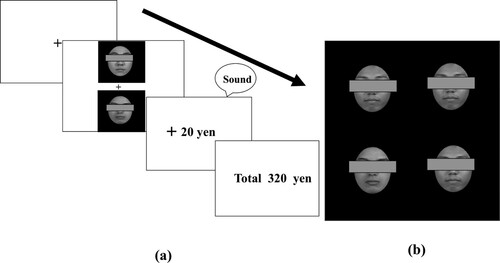
We tested this hypothesis in two experiments using two tasks: a value learning task and a subsequent visual search task as used in previous value learning studies (Anderson et al., Citation2011; Chen & Wei, Citation2019). In the learning task ((a)), participants were required to choose one face from a pair of neutral faces to maximise their earnings (three pairs of faces from the six neutral faces, in total). Each of the three pairs was associated with either monetary gain (reward), monetary loss (punishment), or no monetary outcome (zero-outcome). We assumed that faces associated with reward or punishment would induce positive and negative emotions, respectively, in participants’ minds. After the value associations were established, highly rewarded and highly punished neutral faces were presented as targets in the subsequent visual search task ((b)).
Figure 1 . Illustration of the sequence of the trials in the learning task (a) and the stimuli presented on the visual search display (b). In the learning task (a), participants were required to choose one of the faces in each pair to maximise their earnings. In the visual search task (b), participants were required to identify one discrepant face embedded among distractor faces (Figure (b) illustrates the search display for the target-present condition). The faces were not covered with eye masks in the actual experiment.
Experiment 1
In Experiment 1, we compared the detection performance of highly rewarded and highly punished neutral faces to that of neutral faces associated with zero outcome, which allowed us to test the genuine effect of emotional/motivational significance on the detection of faces with emotional meaning because there are supposedly no prominent visual differences among these neutral faces. We predicted that highly rewarded and highly punished neutral faces would acquire emotional/motivational value and would be detected more rapidly than the neutral faces without value associations.
Materials and methods
Participants
Twenty-nine undergraduate or graduate students at Kyoto University participated in the experiment (16 males and 13 females, mean ± SD age = 22.6 ± 2.1 years). The required sample size was determined using an a priori power analysis using G*Power software ver. 3.1.9.2 (Faul et al., Citation2007). We assumed the detection of reward versus zero and punishment versus zero conditions in multiple comparisons with an α level of 0.05 and power (1 − β) of 0.80. We expected an effect size of d = 1.00 based on the data of a previous study testing the detection of emotional versus anti-expressions using the visual search paradigm (Sato et al., Citation2017). The results indicated that more than 14 participants were required. All participants were Japanese and were given monetary compensation (1500 Japanese yen) for their participation in the 90-min-long session in addition to a predetermined monetary bonus in the learning task (1000 Japanese yen). The participants reported that they had normal or corrected-to-normal visual acuity and no history of psychiatric or neurological disorders. The local ethics committee of the Unit for Advanced Studies of the Human Mind at Kyoto University approved the present study. The experiments were conducted in accordance with institutional ethical provisions and the Declaration of Helsinki. Prior to the experiment, the participants gave written informed consent to take part in the study.
Experimental design
A one-factorial design with three value types (reward [monetary gain], punishment [monetary loss], and zero [no outcome]) as within-participant factors was employed for the main visual search task.
Apparatus
Stimuli were displayed on a 19-inch monitor (HM903D-A, Iiyama, Tokyo, Japan) with a refresh rate of 150 Hz and a resolution of 1024 × 768 pixels, which was controlled by Presentation 14.9 (Neurobehavioral Systems, San Francisco, CA). Presentation was implemented in a Windows personal computer (HP Z200 SFF, Hewlett-Packard Company, Tokyo, Japan). The participants’ responses were obtained using a response box (RB-530, Cedrus, San Pedro, CA) that offered 2–3 ms RT resolution.
Stimuli
Six greyscale photographs of real male faces bearing neutral expressions were employed as the target stimuli. The stimuli were selected from a database of Japanese faces (Sato et al., Citation2019). Each image was adjusted for light and shade by using Photoshop 5.0 (Adobe, San Jose, CA). All stimuli were cropped into an ellipsoid form to be embedded inside an ellipsoid frame. Each face subtended a visual angle of 3.5° horizontal × 4.5° vertical. A preliminary experiment confirmed that the detection speed did not differ significantly among all target faces (F(5,35) = 2.18, p < .10).
For the associative learning task, we assembled three pairs of faces from the six neutral faces, following a previous study (Raymond & O’Brien, Citation2009). Then each pair was assigned to one of the three value type conditions, which were counter-balanced across the participants. The pairing of the faces was fixed throughout the learning task. In each pair of reward and punishment conditions, one face was assigned to a target, and selection of that target yielded a monetary reward (plus 20 yen in each trial) in the reward condition or incurred a monetary loss (minus 20 yen in each trial) in the punishment condition with a probability of 80%, otherwise, 20% of zero outcome. The non-target face in each pair in the reward and punishment conditions was assigned to the reverse probability pattern of that of the target (selecting them produced monetary reward or loss with a probability of 20%, otherwise 80% of zero outcome). In the zero-outcome pair, one face was assigned to a target, but the selection of the target in this condition produced no outcome (selection of non-target produced zero outcome, too). Target assignments in each condition were counter-balanced across the participants.
For the visual search task, the target faces in each value condition that an individual participant received in the learning task were used as targets (discrepant faces) in addition to one neutral face as a distractor. The distractor face was selected from the abovementioned database. Four positions were prepared for the presentation of the faces on the search display. Each face was separated by 40° and located in a square configuration (11.0° × 11.0°). For the target-present condition, one target face along with three identical distractor faces was placed in each of the four positions in the square configuration. Each target face appeared in each of the four positions equally. For the target-absent condition, identical distractor faces appeared in each of the four positions on the search display.
Procedure
The experiment was conducted in a dimly lit, soundproofed room (Science Cabin, Takahashi Kensetsu, Tokyo, Japan). The participants took part in the associative learning and visual search experiments as part of a larger study that included other cognitive tasks. They were seated in a chair and instructed to keep their chins stable in a fixed position at a viewing distance of 80 cm in front of the monitor screen.
Associative learning task. The participants were presented with a pair of neutral faces in each trial, one placed 2.5° above and the other 2.5° below a fixation cross (0.9° × 0.9°) that appeared in the centre of the computer screen (their appearance positions were pseudo-randomized). They were instructed to select without significant deliberation one of the faces in each pair presented on the screen to maximise their earnings. The participants were informed that the money they earned would be given to them after the experiment and asked to do their best to earn as much as possible. Each trial began with the presentation of a fixation cross for 500 ms, followed by the presentation of each pair’s two faces on the screen. The participants had to select one of the faces in each pair by pressing the corresponding button on the response box. After they had selected one face on each trial, a price message (either plus 20 yen, minus 20 yen, or 0 yen) appeared on the screen, accompanied by a sound indicating either a correct or an incorrect answer (no sound was provided in the cases of 0 yen). The running total of money earned then appeared for 1800 ms. Ten blocks of 30 trials (300 trials total) were administered to the participants, with each pair appearing on the screen 10 times in each block. The presentation of the face pairs was pseudo-randomized to prevent more than two consecutive presentations of the same pair in the same position within each block. Before the main experiment, the participants performed 30 practice trials to familiarise themselves with the task.
Visual search task. Before the task, the participants were informed that the task had no monetary reward or loss element. Each trial started with the display of a fixation cross for 500 ms, followed by a stimulus array of four faces. The participants were asked to identify whether or not a discrepant face appeared among an array of four faces presented on the screen and to press the corresponding button on the response box as quickly and accurately as possible. Each block included 24 trials for each target-present or target-absent trial (48 trials total), where each target from the reward, loss, or zero-outcome condition in the learning task appeared eight times as a target (the total presentation times were 32 trials for each condition). The trials were presented in a pseudo-random order such that no successive trials comprised identical target stimuli appearing in identical positions. Twenty-four practice trials preceded the main experimental trials consisting of four blocks of 48 trials (totalling 192 trials).
Debriefing was conducted after the visual search task, and the participants were asked whether they had recognised that the target faces in the visual search task were those that appeared in the associative learning task.
Data analyses
Statistical analyses were conducted using SPSS 10.0 J software (SPSS Japan, Tokyo, Japan). The α level was set to 0.05.
Associative learning task. The paired t-test was conducted to compare the mean proportion of target choice for block 10 with that for block 1 in each condition.
Visual search task. We calculated the mean RTs of the correct responses for each condition of the target-present trials after excluding responses longer than 3 s and the measurement ± 2 SD from the mean for each participant as artefacts. One-way repeated-measures analysis of variance (ANOVA) with the value type as a within-participant factor was conducted to analyze the RTs. Subsidiary analyses were performed using the Ryan method. For supplementary analyses testing cognitive confounding factors (Kyllingsbæk et al., Citation2001; Sha & Jiang, Citation2016), we analyzed the one-way ANOVA with the same design only in participants who did not recognise that the target faces in the visual search task that had been presented in the learning task. In addition, we calculated a correlation coefficient between the choice rate of zero target and their subsequent visual search performance. The results of the subsidiary analyses suggested that recognition asymmetries and selection frequency of faces were not able to explain the detection advantage of value-associated faces (for details of the results, see the supplement).
Preliminary analyses for accuracy using one-way repeated-measures ANOVA with the value type revealed the insignificant main effect of value type (F(2,48) = 1.82, p > .10), meaning that the degree of search difficulty did not differ across conditions.
The dataset is available in the supplement.
Results
Associative learning task
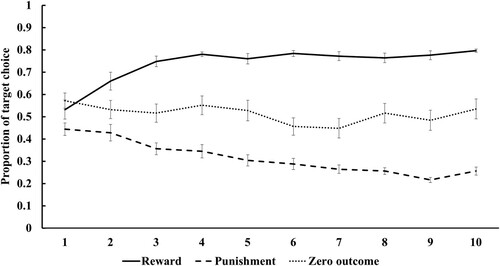
We set the selection of optimal faces (i.e. targets and non-targets in the reward and punishment conditions, respectively) to more than 65% during the last block (i.e. 30 trials) as an index of successful learning, in accordance with previous studies (Gupta et al., Citation2016; O’Brien & Raymond, Citation2012). We tested a total of 29 participants and excluded 4 participants from the subsequent analyses based on this criterion of successful learning. We calculated the mean proportion of selecting the target faces for each block in each condition for the remaining 25 participants (). t-tests comparing the selection rates of the target face between the first and last blocks showed that the selection of target faces significantly increased under the reward condition (t(24) = −6.44, p < .001), decreased under the punishment condition (t(24) = 5.89, p < .001), and did not significantly change in the zero-outcome condition (t(24) = 0.95, p > .10).
Figure 2. Mean (± standard error) proportion of target face selection for each block in the reward, punishment, and zero-outcome conditions in Experiment 1.
Visual search task
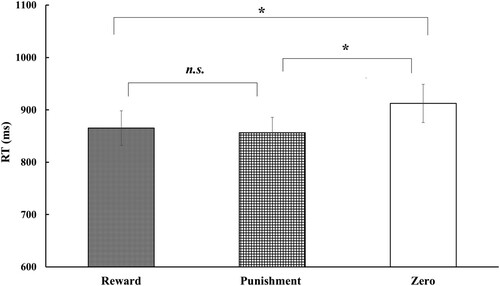
Data from the participants who performed successfully on the learning criterion were analyzed. The mean RTs in each target condition are shown in . First, we tested whether value-associated neutral faces were more rapidly detected than neutral faces without learned values. One-way ANOVA with value type (reward, punishment, and zero outcome) as a within-participant factor revealed a significant main effect of value type (F(2,48) = 5.82, p < .01, = 0.195). Multiple comparisons using the Ryan method showed that the speed with which target faces were detected both in the reward and punishment conditions was significantly faster than that in the zero-outcome condition (t = 2.67 and 3.18, p < .05 and .005, respectively). These results indicate that faces associated with reward or punishment through learning are detected more rapidly than those without value associations. No significant difference was observed between the reward and punishment conditions with respect to the detection of target faces (t = 0.50, p > .10), demonstrating that rewards and punishments had comparable effects on the swift detection of target faces.
Figure 3. Mean (± standard error) reaction times (RTs) for the detection of neutral faces associated with reward, punishment, and zero outcome. Asterisks denote significant differences between conditions (*p < .05; n.s.: not significant).
Discussion
The results of the learning task revealed significant increase and decrease in target choice in the reward and punishment conditions, respectively, while no change was observed in the selection of targets withouht value associations. These results indicate that both the reward and punishment value associations of neutral faces were successfully established via learning.
Most importantly, the visual search results demonstrated that neutral faces associated with reward and punishment via associative learning were more rapidly detected than those associated with no monetary outcomes. Our results support the claim that emotional/motivational significance, rather than visual appearance/saliency, can promote an efficient search for emotional faces (Sato & Yoshikawa, Citation2010), since only neutral faces associated with emotional/motivational value were detected rapidly, which did not differ with respect to visual saliency from neutral faces that were not associated with value. Comparable effects of reward and punishment on visual search performance could be explained by the assumption that maximising rewards and minimising punishments are both crucial for the selection of appropriate behaviour for one’s survival and well-being (Anderson, Citation2013; Watson et al., Citation2019).
Our results are consistent with previous findings that non-facial neutral stimuli associated with value via learning, such as shapes, are detected efficiently (Kiss et al., Citation2009; Kristjánsson et al., Citation2010; Störmer et al., Citation2014), suggesting that social stimuli (i.e. faces) that have acquired emotional meaning attract attention in a similar fashion as non-social neutral stimuli (Anderson et al., Citation2011; Della Libera & Chelazzi, Citation2006; Jahfari & Theeuwes, Citation2017; Mulckhuyse et al., Citation2013; Müller et al., Citation2016; Nissens et al., Citation2017; Theeuwes & Belopolsky, Citation2012; Wentura et al., Citation2014; but see Batty et al., Citation2005). Although behavioural measurements differ, our results are also compatible with those of previous studies that have examined the value association effects of neutral faces on subsequent memory recognition (Raymond & O’Brien, Citation2009) and gender decision tasks (Hammerschmidt et al., Citation2017).
Experiment 2
We conducted Experiment 2 to investigate two unresolved issues from Experiment 1. First, in Experiment 1, we contrasted the detection performance of neutral faces associated with reward and punishment with neutral faces associated with zero outcome. While the results showed a clear difference in detection performance between the value associated faces and the faces with zero outcome, the difference may be too explicit to compare because it has already been observed or established during the learning phase. To address this issue, some previous studies of value learning have compared value associated neutral stimuli with high probability (80%) to those with low probability (20%) (Raymond & O’Brien, Citation2009; Störmer et al., Citation2014), which corresponds to a target face and a non-target face in each value condition in our study. Along the same lines, we compared the visual search performance of high probability faces with those of low-probability faces in each value condition.
Second, we assumed that associative learning would confer emotional value for neutral faces (as in previous value learning studies with neutral stimuli; Gupta et al., Citation2016; Hammerschmidt et al., Citation2017; Müller et al., Citation2016; Wentura et al., Citation2014), in turn facilitating the detection of value-associated neutral faces in a manner similar to emotional expressions (Sato & Yoshikawa, Citation2010; Sawada et al., Citation2014a, Citation2014b, Citation2016); however, we did not directly test whether participants actually acquired positive or negative value. To investigate this issue, after the visual search task we asked the participants to provide subjective valence and arousal ratings of neutral faces, then make preference choice in response to each pair of neutral faces; we compared the ratings and choices between neutral faces with and without reward/punishment values. We further analyzed the relationship between the visual search RTs and the subjective ratings.
Materials and methods
Participants
Ninety-four young adults, with similar demographic and health conditions to the participants in Experiment 1, were recruited from a local community through an employment agency. The required sample size was determined using an a priori power analysis using G*Power software ver. 3.1.9.2 (Faul et al., Citation2007). We assumed to conduct a 2 (value type) × 2 (value probability) repeated-measures ANOVA with an α level of 0.05, power (1 − β) of 0.80, a correlation among measures of 0.8 estimated from the data in Experiment 1, non-sphericity correction of 1, and weak effect size of f = 0.10. The results indicated that more than 56 participants were required. After giving informed consent, the participants took part in the experiment (56 females; mean ± SD age = 22.3 ± 2.6 years); none of them had participated in Experiment 1. They were given monetary compensation through the employment agency for their participation in the 90-min-long session, in addition to a predetermined monetary bonus in the learning task (1,000 Japanese yen).
Experimental design
A two-factorial design with value type (reward, punishment) and value probability (high and low) as within-participant factors was employed for the main visual search task.
In the rating task of emotional valence and arousal of learned faces, a two-factorial design with value type (reward, punishment, zero) and value probability (high and low) was employed.
Apparatus
The apparatus was the same as that utilised in Experiment 1.
Stimuli
The stimuli used were the same as those in Experiment 1, except that low probability faces were presented in addition to high probability faces for each value condition on the learning task as discrepant faces in the visual search task. In the subsequent subjective rating task and the preference selection tasks, faces with zero outcome (target and non-target faces) were presented, in addition to high and low probability faces in each value condition.
Procedure
Associative learning task. The procedure employed in this task was the same as that in Experiment 1.
Visual search task. The procedure was the same as that in Experiment 1 except for the number of trials for each block (both target-present or target-absent trials), because in this experiment, low probability faces as well as high probability faces for each value condition were included in the trials. Hence, the main experimental trials consisted of four blocks of 64 trials (totalling 256 trials), where each block contained 32 trials for each target-present or target-absent trial (64 trials in total).
Valence and arousal rating task. After performing the visual search task, participants engaged in the rating task of valence and arousal of faces for the three value conditions in the learning task (6 faces). For each trial, one face appeared in the centre of the computer screen in random order. Participants were required to think about how they felt upon seeing each face and, based on their feelings, to rate each face in terms of both emotional valence and the intensity of arousal, on a nine-point scale ranging from 1 (extremely negative or low arousal) to 9 (extremely positive or high arousal), using a numerical keypad. Almost half of the participants first performed valence ratings for faces, followed by the arousal ratings. The remaining participants completed the task in reverse order.
Emotional preference selection task. This task followed ratings of the valence and arousal of the learned faces. Two faces (a pair consisting of an optimal face and a non-optimal face) for each value condition simultaneously appeared on the left or right side of the computer screen (their positions of appearance were not fixed) (in total, three pairs of six faces). Participants were asked which face was preferable and to indicate this by pressing the corresponding number key on the numerical keypad (1 or 2, where 1 indicated a face on the left side and 2 indicated a face on the right side on the screen).
Data analyses
Associative learning task and visual search task. Analyses of these tasks were the same as those in Experiment 1, except that in the visual search task, a two-way ANOVA with value type (reward and punishment) and value probability (high and low) as within-participant factors was conducted.
Valence and arousal rating task. Mean rating scores measuring valence and arousal were analyzed separately using ANOVA, with value type (reward, punishment, zero) and value probability (high and low) as within-participant factors. Subsidiary analyses were performed using the Ryan method. Moreover, a multiple regression analysis with mean RTs as the dependent variable was performed to investigate the relationship between visual search performance (RTs) and emotional ratings. The independent variables were the mean ratings of valence and arousal, as well as the interaction between valence and arousal, and dummy variables for participants. Adjusted RTs were calculated by partialing out the effects of variables of no-interest to determine the relationship between the emotional ratings and RTs.
We carried out a preliminary analysis of accuracy in visual search performance, using two-way repeated-measures ANOVA with the value type and value probability for 71 participants, of which associative learning had been established. The analysis revealed that neither the main effect of value type (F(1,70) = 2.75, p = .102) nor the assigned value probability (F(1,70) = 0.42, p = .519) was significant. No interactions were observed between the two factors (F(1, 70) = 0.51, p = .478). These results suggest that accuracy did not modify the participants’ RTs.
Emotional preference selection assessment. Rating scores were analyzed by binominal test.
Results
Associative learning task
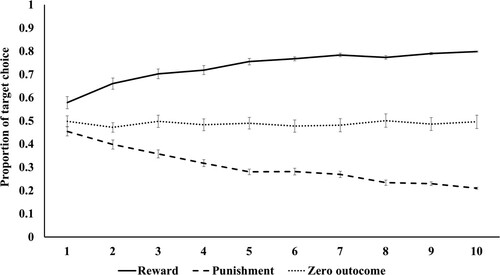
The same criterion of successful learning used in Experiment 1 was employed so that we excluded 18 of the 89 participants from the subsequent analyses (data from 5 other participants were also excluded because of a problem concerning visual acuity, procedural errors, or the fact that the same participant took part in the same experiment twice). In total, data from 71 participants were analyzed. Comparison of the selection rates of target faces between the first and last blocks in the three conditions using t-tests showed a significant increase and decrease of target face selection in the reward and the punishment conditions, respectively (t(70) = −8.46, p < .001) (t(70) = 12.88, p < .001). In the zero-outcome condition, no significant changes appeared (t(70) = 0.08, p = .937) (shown in ).
Figure 4. Mean (± standard error) proportion of target face selection for each block in the reward, punishment, and zero-outcome conditions in Experiment 2.
Visual search task
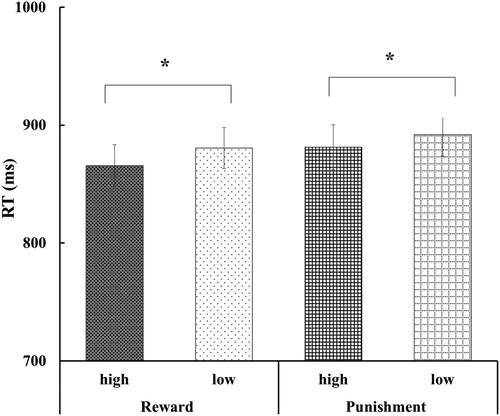
71 participants, who performed successfully on the learning criterion of associative learning were subjected to analyze. shows the mean RTs of the faces for each assigned probability value in each value condition. Two-way ANOVAs with value type (reward and punishment) and value probability (high and low) as within-participant factors revealed a significant main effect of value probability (F(1,70) = 6.21, p = .015, = 0.081), demonstrating the rapid detection of high probability faces. No significant interaction between the assigned value probability and value type was observed (F(1,70) = 0.18, p = .671), and there was no significant main effect of value type (F(1,70) = 2.74, p = .103).
Figure 5. Mean (± standard error) RTs for the detection of high- and low-probability faces in the reward and punishment conditions for successful learners. Asterisks represent, as a whole, a significant main effect of the assigned value probability (*p < .05.).
Emotional rating task
shows the mean scores of valence and arousal ratings of faces in the three value conditions for the data from the same 71 participants described above. With regard to the ratings of emotional valence, the results of two-way ANOVAs with value type (reward, punishment, zero) and value probability (high and low) as within-participant factors revealed a significant interaction between the value type and value probability (F(2,140) = 16.19, p < .001, = 0.188), as well as a significant main effect of the value type (F(2, 140) = 6.97, p = .001,
= 0.091). No significant main effect of value probability was observed (F(1,70) = 0.27, p = .609).
Table 1. Mean scores (with standard error) of subjective ratings of valence and arousal for 71 participants.
Next, we conducted follow-up analyses of the two-way interactions. There was a significant simple main effect of the value type on high probability faces (F(2,280) = 20.41, p < .001). In contrast, no simple main effect of the value type on low probability faces was observed (F(2, 280) = 1.08, p = .341). Multiple comparisons using the Ryan method showed that high probability faces gained higher scores in the reward condition than did such faces in the punishment and target faces in the zero condition (t = 6.30, p < .001) (t = 4.06, p < .001). Scores for high probability faces were lower in the punishment than were scored for target faces in the zero condition (t = 2.24, p = .026). The simple main effect of assigned value probability was significant for both the reward (F(1,210) = 20.03, p < .001) and punishment (F(1, 210) = 5.73, p = .018) conditions, indicating that scores on high probability faces were significantly higher than those on low probability faces in the reward condition, whereas high probability faces attained lower scores than did low probability faces in the punishment condition. No significant effect of assigned value probability on faces in the zero condition was observed (F(1, 210) = 1.08, p = .299).
Analysis of arousal ratings showed a significant main effect of value type (F(2,140) = 6.29, p = .002, = 0.082). No significant main effect of value probability (F(1,70) = 0.35, p = .557) or interaction (F(2,140) = 2.01, p = .138) was observed. Multiple comparisons using the Ryan method showed that faces both in the reward and punishment conditions gained significantly higher scores than did faces in the zero condition (t = 3.18, p = .002) (t = 2.96, p = .004). No significant differences were observed in the rating scores between the reward and punishment conditions (t = 0.22, p = .826).
Emotional preference selection
In the reward condition, 49 of 71 participants selected the optimal face (target face) as their preferable face (p < .001). In the punishment condition, 42 of 71 participants showed a preference for the optimal face (non-target face) (p = .048). In the zero outcome condition, 32 of 71 participants preferred the target to non-target faces (p = .762). These results show that the participants significantly preferred optimal faces to non-optimal faces in each value condition, whereas in the zero-outcome condition, there was no such difference in preference.
Relationship between visual search RTs and emotional ratings
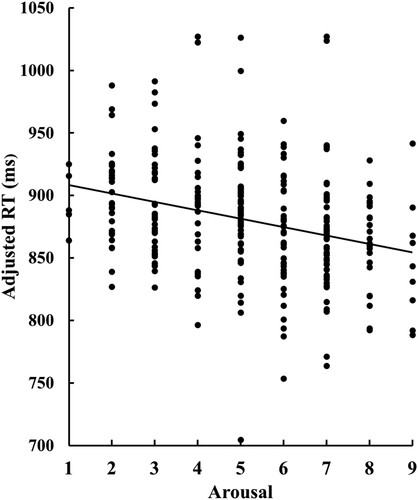
A multiple regression analysis, with RTs in the visual search task as the dependent variable and emotional ratings (valence, arousal, and their interaction) as the independent variables, was performed to examine the relationship between attentional capture and emotional reactions by value-associated neutral faces. The results showed a significant negative relationship between arousal ratings and RTs (standardised β = −0.09, t = 3.39, p < .001) (). The relationship between valence ratings and RTs, as well as the interaction between arousal and valence, showed trends toward significance (standardised β = −0.04, t = 1.69, p = .092; and standardised β = −0.05, t = 1.97, p = .050, respectively).
Figure 6. Scatter plot and regression line demonstrating the significant relationship between visual search performance (adjusted RTs) and arousal ratings.
Discussion
The results of the associative learning replicated the results of Experiment 1, in which target choice increased in the reward condition and decreased in the punishment condition compared to that in the zero condition. Hence, both the reward and punishment value associations of neutral faces appear to be successfully established via learning, as in Experiment 1.
With regard to the visual search performance, the 71 participants who successfully met the learning criterion showed a detection advantage for strongly valued faces (high probability faces). Thus, the result suggests that how strongly faces are associated with emotional value determines the detection speed in subsequent visual search tasks for these faces. Demonstration of the detection advantage for high probability faces is consistent with the results of a previous study showing that accuracy in the recognition of faces with a high probability of a monetary win or loss was higher than for faces with low probability in an attentional blink paradigm (Raymond & O’Brien, Citation2009). Our results are also in line with prior studies demonstrating the preponderance of non-facial stimuli with high versus low reward in the visual search paradigm (Anderson et al., Citation2011; Kiss et al., Citation2009; Kristjánsson et al., Citation2010; Theeuwes & Belopolsky, Citation2012). The present findings extend these findings and indicate that faces with strongly associated with value facilitate the rapid detection of faces in visual searches.
The main result of subjective ratings of value-associated faces consists of the simple main effect of value type on high probability faces for emotional valence. Significant differences among high probability faces across the three conditions indicate that high probability faces in the reward condition were considered the most pleasant, whereas those in the punishment condition were considered the least pleasant among the three conditions. Taken together with the emotional preference results, high probability faces in the reward and the punishment conditions were presumed to acquire positive and negative emotional value, respectively, via successful learning. It is, therefore, plausible that this acquired emotional value might drive efficient search for high probability faces. It is of note that even low-probability faces acquired some degree of emotional value, according to our analysis of the arousal ratings of faces; the arousal scores of value-associated faces were significantly higher than the arousal scores of faces associated with no monetary outcome. Thus, value-associated faces, overall, seem to be more emotionally evocative, compared to faces with no value in participants’ minds. The acquisition of emotional value by value-associated neutral faces is consistent with the findings from previous value learning studies using neutral faces or non-faces (Gupta et al., Citation2016; Hammerschmidt et al., Citation2017; Müller et al., Citation2016; Wentura et al., Citation2014).
Importantly, the results of the regression analysis demonstrated a significant negative relationship between arousal ratings and visual search speed for value-associated neutral faces; higher the ratings scores of the faces, the faster these faces were detected. This pattern of results was also observed in the relationship between real emotional faces and their arousal ratings (e.g. Sato & Yoshikawa, Citation2010). Because arousal ratings are assumed to represent the degree of emotional intensity (Lang et al., Citation1998), this result was thought to reflect the attentional capture for emotional faces induced by emotional significance. Considered this, it is likely that an efficient search for value-associated neutral faces demonstrated in our study was promoted by the emotional-motivational significance of these faces.
General discussion
The present study demonstrated that value-associated neutral faces are more rapidly detected than neutral faces without value associations (Experiment 1), and the detection advantage is stronger for faces relatively strongly associated with values than those relatively weakly associated with values (Experiment 2). Based on the participants’ performance in the emotional rating task and its relationship with visual search performance, the results suggest that neutral faces acquired emotional/motivational values, which then facilitated the detection of value associated neutral faces.
More importantly, there were no prominent differences in terms of visual saliency between neutral faces with and without value associations or between high- and low probability faces in our study. Given this fact, the present results suggest that an efficient search for emotional faces can emerge without any influence of visual saliency. It is, therefore, can be concluded that our results support the claim that emotional/ motivational value promotes the rapid detection of emotional faces, a claim which has been proposed through the visual search paradigm using emotional facial expression stimuli (Eastwood et al., Citation2003; Hansen & Hansen, Citation1988; Sato & Yoshikawa, Citation2010; Skinner & Benton, Citation2012; Williams et al., Citation2005).
A final issue that has to be addressed concerns with how our results can be reconciled with previous findings that demonstrate no attentional effect for emotional faces (Puls & Rothermund, Citation2018; Tannert & Rothermund, Citation2020). For instance, using a flanker task, Tannert and Rothermund (Citation2020) revealed that emotional faces do not automatically capture attention, except in the situation under which they were task-relevant. Puls and Rothermund (Citation2018) similarly demonstrated no validity effects in a dot-probe task (i.e. an index of attentional capture by emotional faces), and they suggested that attentional capture by emotional faces is a conditional, context-dependent phenomenon. Thus, if the emotions depicted are task-relevant, or relevant to the person such as a depressed patient experiencing chronic negative emotions, faces displaying such emotions automatically capture attention. In our study, participants were likely highly motivated to gain rewards and avoid punishments. We speculate that such motivational qualities, in addition to emotional ones, might have induced an automatic attention for value associated emotional faces, since the motivational qualities possibly increase self-relevance, creating a specific task context. In this respect, we believe that our results are compatible with these previous findings.
From a practical perspective, our results suggest that the association of faces with emotional value can be established and reflected in subsequent visual search performance at a behavioural level. This implies that value association learning of faces may potentially provide useful cognitive–behavioural therapeutic interventions for individuals suffering from a compromised ability to detect facial expressions, including those with autism spectrum disorders. It has been acknowledged that clinical approaches based on value association learning (reward learning) are conceived as a beneficial intervention method for individuals with autism (Dawson et al., Citation2010). Modulation of reward learning on the behavioural visual search performance demonstrated in our study would reinforce the effectiveness of such clinical approaches based on reward learning.
A limitation of our study was that only male faces were used as stimuli, preventing us from generalising the results to neutral female faces. Further studies are needed to ascertain whether the rapid detection of neutral faces associated with the value might emerge regardless of the gender of the face.
To conclude, this study demonstrated that inherently neutral faces, once they have acquired emotional value, are rapidly detected in visual searches. This suggests that the emotional/motivational significance promotes the rapid detection of emotional faces.
Supplementary_Material
Download MS Word (41.3 KB)Acknowledgements
The authors would like to thank Kiyoshi Yoshikawa, Shigeru Takami, and Hirofumi Tanimoto for their helpful advice on this work.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Anderson, B. A. (2013). A value-driven mechanism of attentional selection. Journal of Vision, 13(3), 7–7. https://doi.org/https://doi.org/10.1167/13.3.7
- Anderson, B. A., Laurent, P. A., & Yantis, S. (2011). Value-driven attentional capture. Proceedings of the National Academy of Sciences, 108(25), 10367–10371. https://doi.org/https://doi.org/10.1073/pnas.1104047108
- Batty, M. J., Cave, K. R., & Pauli, P. (2005). Abstract stimuli associated with threat through conditioning cannot be detected preattentively. Emotion, 5(4), 418–430. https://doi.org/https://doi.org/10.1037/1528-3542.5.4.418
- Calvo, M. G., & Nummenmaa, L. (2008). Detection of emotional faces: Salient physical features guide effective visual search. Journal of Experimental Psychology: General, 137(3), 471–494. https://doi.org/https://doi.org/10.1037/a0012771
- Chen, N., & Wei, P. (2019). Reward association alters brain responses to emotional stimuli: ERP evidence. International Journal of Psychophysiology, 135(October), 21–32. https://doi.org/https://doi.org/10.1016/j.ijpsycho.2018.11.001
- Dawson, G., Rogers, S., Munson, J., Smith, M., Winter, J., Greenson, J., Donaldson, A., & Varley, J. (2010). Randomized, controlled trial of an intervention for toddlers with autism: The early start Denver model. Pediatrics, 125(1), e17–e23. https://doi.org/https://doi.org/10.1542/peds.2009-0958
- Della Libera, C., & Chelazzi, L. (2006). Visual selective attention and the effects of monetary rewards. Psychological Science, 17(3), 222–227. https://doi.org/https://doi.org/10.1111/j.1467-9280.2006.01689.x
- Eastwood, J. D., Smilek, D., & Merikle, P. M. (2003). Negative facial expression captures attention and disrupts performance. Perception & Psychophysics, 65(3), 352–358. https://doi.org/https://doi.org/10.3758/BF03194566
- Faul, F., Erdfelder, E., Lang, A. G., & Buchner, A. (2007). G*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39(2), 175–191. https://doi.org/https://doi.org/10.3758/BF03193146
- Gupta, R., Hur, Y. J., & Lavie, N. (2016). Distracted by pleasure: Effects of positive versus negative valence on emotional capture under load. Emotion, 16(3), 328–337. https://doi.org/https://doi.org/10.1037/emo0000112
- Hahn, S. (2017). Emotion and attention: When the heart’s eye guides the mind’s eye. Journal of Cognitive Science, 18(2), 103–115. https://doi.org/https://doi.org/10.17791/jcs.2017.18.2.103
- Hammerschmidt, W., Sennhenn-Reulen, H., & Schacht, A. (2017). Associated motivational salience impacts early sensory processing of human faces. NeuroImage, 156(December 2016), 466–474. https://doi.org/https://doi.org/10.1016/j.neuroimage.2017.04.032
- Hansen, C. H., & Hansen, R. D. (1988). Finding the face in the crowd: An anger superiority effect. Journal of Personality and Social Psychology, 54(6), 917–924. https://doi.org/https://doi.org/10.1037/0022-3514.54.6.917
- Jahfari, S., & Theeuwes, J. (2017). Sensitivity to value-driven attention is predicted by how we learn from value. Psychonomic Bulletin & Review, 24(2), 408–415. https://doi.org/https://doi.org/10.3758/s13423-016-1106-6
- Kiss, M., Driver, J., & Eimer, M. (2009). Reward priority of visual target singletons modulates event-related potential signatures of attentional selection. Psychological Science, 20(2), 245–251. https://doi.org/https://doi.org/10.1111/j.1467-9280.2009.02281.x
- Kristjánsson, Á, Sigurjonsdottir, Ó, & Driver, J. (2010). Fortune and reversals of fortune in visual search: Reward contingencies for pop-out targets affect search efficiency and target repetition effects. Attention, Perception & Psychophysics, 72(5), 1229–1236. https://doi.org/https://doi.org/10.3758/APP.72.5.1229
- Kyllingsbæk, S., Schneider, W. X., & Bundesen, C. (2001). Automatic attraction of attention to former targets in visual displays of letters. Perception & Psychophysics, 63(1), 85–98. https://doi.org/https://doi.org/10.3758/BF03200505
- Lang, P. J., Bradley, M. M., & Cuthbert, B. N. (1998). Emotion and motivation: Measuring affective perception. Journal of Clinical Neurophysiology, 15(5), 397–408. https://doi.org/https://doi.org/10.1097/00004691-199809000-00004
- Mulckhuyse, M., Crombez, G., & Van der Stigchel, S. (2013). Conditioned fear modulates visual selection. Emotion, 13(3), 529–536. https://doi.org/https://doi.org/10.1037/a0031076
- Müller, P., Rothermund, K., & Wentura, D. (2016). Relevance drives attention: Attentional bias for gain- and loss-related stimuli is driven by delayed disengagement. Quarterly Journal of Experimental Psychology, 69(4), 752–763. https://doi.org/https://doi.org/10.1080/17470218.2015.1049624
- Nissens, T., Failing, M., & Theeuwes, J. (2017). People look at the object they fear: Oculomotor capture by stimuli that signal threat. Cognition and Emotion, 31(8), 1707–1714. https://doi.org/https://doi.org/10.1080/02699931.2016.1248905
- O’Brien, J. L., & Raymond, J. E. (2012). Learned predictiveness speeds visual processing. Psychological Science, 23(4), 359–363. https://doi.org/https://doi.org/10.1177/0956797611429800
- Puls, S., & Rothermund, K. (2018). Attending to emotional expressions: No evidence for automatic capture in the dot-probe task. Cognition and Emotion, 32(3), 450–463. https://doi.org/https://doi.org/10.1080/02699931.2017.1314932
- Raymond, J. E., & O’Brien, J. L. (2009). Selective visual attention and motivation. Psychological Science, 20(8), 981–988. https://doi.org/https://doi.org/10.1111/j.1467-9280.2009.02391.x
- Sato, W., Hyniewska, S., Minemoto, K., & Yoshikawa, S. (2019). Facial expressions of basic emotions in Japanese laypeople. Frontiers in Psychology, 10(February), 259. https://doi.org/https://doi.org/10.3389/fpsyg.2019.00259
- Sato, W., Sawada, R., Uono, S., Yoshimura, S., Kochiyama, T., Kubota, Y., Sakihama, M., & Toichi, M. (2017). Impaired detection of happy facial expressions in autism. Scientific Reports, 7(1), 1–12. https://doi.org/https://doi.org/10.1038/s41598-017-11900-y
- Sato, W., & Yoshikawa, S. (2010). Detection of emotional facial expressions and anti-expressions. Visual Cognition, 18(3), 369–388. https://doi.org/https://doi.org/10.1080/13506280902767763
- Sawada, R., Sato, W., Uono, S., Kochiyama, T., Kubota, Y., Yoshimura, S., & Toichi, M. (2016). Neuroticism delays detection of facial expressions. PLoS ONE, 11(4), e0153400. https://doi.org/https://doi.org/10.1371/journal.pone.0153400
- Sawada, R., Sato, W., Uono, S., Kochiyama, T., & Toichi, M. (2014a). Electrophysiological correlates of the efficient detection of emotional facial expressions. Brain Research, 1560, 60–72. https://doi.org/https://doi.org/10.1016/j.brainres.2014.02.046
- Sawada, R., Sato, W., Uono, S., Kochiyama, T., & Toichi, M. (2014b). Sex differences in the rapid detection of emotional facial expressions. PLoS ONE, 9(4), e94747. https://doi.org/https://doi.org/10.1371/journal.pone.0094747
- Sha, L. Z., & Jiang, Y. V. (2016). Components of reward-driven attentional capture. Attention, Perception, & Psychophysics, 78(2), 403–414. https://doi.org/https://doi.org/10.3758/s13414-015-1038-7
- Skinner, A. L., & Benton, C. P. (2012). Visual search for expressions and anti-expressions. Visual Cognition, 20(10), 1186–1214. https://doi.org/https://doi.org/10.1080/13506285.2012.743495
- Störmer, V., Eppinger, B., & Li, S. C. (2014). Reward speeds up and increases consistency of visual selective attention: A lifespan comparison. Cognitive, Affective, & Behavioral Neuroscience, 14(2), 659–671. https://doi.org/https://doi.org/10.3758/s13415-014-0273-z
- Tannert, S., & Rothermund, K. (2020). Attending to emotional faces in the flanker task: Probably much less automatic than previously assumed. Emotion, 20(2), 217–235. https://doi.org/https://doi.org/10.1037/emo0000538
- Theeuwes, J. (1992). Perceptual selectivity for color and form. Perception & Psychophysics, 51(6), 599–606. https://doi.org/https://doi.org/10.3758/BF03211656
- Theeuwes, J., & Belopolsky, A. V. (2012). Reward grabs the eye: Oculomotor capture by rewarding stimuli. Vision Research, 74(1), 80–85. https://doi.org/https://doi.org/10.1016/j.visres.2012.07.024
- Watson, P., Pearson, D., Wiers, R. W., & Le Pelley, M. E. (2019). Prioritizing pleasure and pain: Attentional capture by reward-related and punishment-related stimuli. Current Opinion in Behavioral Sciences, 26(April), 107–113. https://doi.org/https://doi.org/10.1016/j.cobeha.2018.12.002
- Wentura, D., Müller, P., & Rothermund, K. (2014). Attentional capture by evaluative stimuli: Gain- and loss-connoting colors boost the additional-singleton effect. Psychonomic Bulletin & Review, 21(3), 701–707. https://doi.org/https://doi.org/10.3758/s13423-013-0531-z
- Williams, M. A., Moss, S. A., Bradshaw, J. L., & Mattingley, J. B. (2005). Look at me, I’m smiling: Visual search for threatening and nonthreatening facial expressions. Visual Cognition, 12(1), 29–50. https://doi.org/https://doi.org/10.1080/13506280444000193