
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The permutation flowshop scheduling problem is a vital production management concern of industries such as electronic product manufacturing and integrated circuit fabrication. In many studies, jobs are prioritized independently according to their features or properties. This article develops a new perspective by introducing the self-attention mechanism into scheduling for the first time. The job similarities are characterized by the dot-product of processing time matrices and taken as job priorities. Based on this idea, a new priority rule denoted by PRSAT is proposed, and a heuristic named NEHLJP2 is presented with makespan minimization. The computational results with the Taillard and VRF benchmarks and 640 random instances demonstrate that the new priority rule and heuristic dominate the existing ones at a nominal cost of computation time.
1. Introduction
The flowshop scheduling problem, along with its variants (Gao, Chen, and Deng Citation2013; Choi, Kim, and Lee Citation2005; Alfieri Citation2009), has been extensively studied as it is employed across various industries. For example, a fabrication factory may use a large amount of customized machinery to produce one or many similar goods. In practice, an extra constraint is generally included and studied, ensuring that the job routings are all the same through the machines and are not allowed to change. This constraint is derived from either technical requirements or the simplification of management work. A real-world case is presented by Erseven et al. (Citation2019), in which a local company that produces apparel and garments has to schedule several jobs with different processing times on each station. Nevertheless, the job sequences on each station are kept the same. The scheduling for this type of production is defined as the permutation flowshop scheduling problem (PFSP) in the research field.
For PFSPs, heuristic algorithms are developed to obtain an optimal or a near-optimal schedule in a short time. Priority rules or dispatching rules, as one typical heuristic, have been studied extensively for decades in both academia and industry (Tay and Ho Citation2008). The rule for job scheduling is commonly defined as the dispatching rule, while the rule to provide initial solutions for the composite heuristic is called the priority rule. Many simple dispatching rules, including the shortest processing time (SPT), longest processing time (LPT), earliest due date (EDD) and first come, first served (FCFS) rules, are used directly for job scheduling. The composite dispatching rules are commonly developed by including several job features or properties, such as job due date, job arrival time, job processing time, job weight and remaining job processing time. For example, Xiong et al. (Citation2017) developed four priority rules considering operation slack time for a dynamic jobshop scheduling problem. Vallada, Ruiz, and Minella (Citation2008) evaluated several dispatching rules concerning job due date, slack time and processing time, with the criterion of total tardiness. Job tardiness, due date and processing time are included in the dispatching rules for the flexible jobshop scheduling problem (Kianfar, Fatemi Ghomi, and Karimi Citation2009).
In general, the job features are carefully selected, and the dispatching rule is designed for a given problem. The advantage of this idea is that the addition or deletion of a job will not change the relative positions of the remaining jobs (Koulamas and Panwalkar Citation2018). However, the job position in the sequence should be a relative instead of an absolute parameter, and it should depend on the interrelationship among jobs. This article proposes a new perspective by calculating job similarity with a self-attention mechanism for developing a priority rule, and the PFSP is used for validation. To investigate the effectiveness of the new rule, it is implemented with the NEH heuristic (Nawaz, Enscore, and Ham Citation1983) as well as existing tie-breaking rules (Dong, Huang, and Chen Citation2008; Kalczynski and Kamburowski Citation2008; Liu, Jin, and Price Citation2017a), in terms of makespan minimization.
The remainder of this article is structured as follows. In Section 2, the related literature is reviewed. The terminology and performance measures are given in Section 3. Section 4 provides the background and physical meaning of the new perspective associated with the new priority rule. In Section 5, test cases and computational results are presented, demonstrating the newly proposed priority rule and heuristic effectiveness. Finally, conclusions are presented in Section 6.
2. Literature review
One priority rule is constructed with two elements for effective job scheduling: the indicators based on job features and the sorting method. The indicators are the main factors considered in the priority rule and are used for job differentiation. Jayamohan and Rajendran (Citation2004) proposed priority rules based on operation due date, job slack time, job processing time, etc., for minimizing penalties for job flowtime and tardiness. The adjusted processing times and job completion time are considered for the weighted total job completion time. Weng and Ren (Citation2006) developed a composite priority rule based on job slack time and queue length for the dynamic jobshop scheduling problem while minimizing mean job tardiness. Sha et al. (Citation2006) considered the length of the queue in the dispatching rule while considering the rework of defective products. Swaminathan et al. (Citation2007) developed the EDD-based dispatching rule for dynamic flowshop with uncertain processing times for minimizing total weighted tardiness. Natarajan et al. (Citation2007) designed several dispatching rules concerning job finishing time, arrival time and starting time for the assembly jobshop with the criteria of weighted flowtime and job tardiness. To deal with the blocking flowshop scheduling problem, Wang et al. (Citation2012) developed an initial job priority rule considering job average processing time and standard deviation for the three-phase algorithm. To schedule the new orders in the dynamic flowshop, Liu, Jin, and Price (Citation2017b) developed a priority rule for the match-up and real-time (MR) strategy by assigning different weights to job processing times.
Along with the indicators in priority rules, the sorting method determines the job positions. Framinan, Leisten, and Rajendran (Citation2003) summarized eight different sorting criteria, namely DECR, INCR, VALLEY, HILL, HI/HILO, HI/LOHI, LO/HILO and LO/LOHI. The DECR means that jobs are sorted according to the decreasing indicator values, while the INCR is according to the increasing indicator values. The VALLEY sets low indicator values in the middle of the initial sequence and high figures at the beginning and the end, whereas HILL is the opposite, with high indicator values in the middle of the initial sequence and low figures at the beginning and the end. The sorting methods HI/HILO, HI/LOHI, LO/HILO and LO/LOHI select low and high indicator values alternately. Swaminathan et al. (Citation2007) used a composite ranking scheme in which three criteria are used simultaneously and the sum of rank positions is adopted. Therefore, by combining different job indicators and sorting methods, priority or dispatching rules can be generated for various problems.
As a typical combination optimization problem, the PFSP has been thoroughly studied, and the priority rules have been applied in many algorithms (Nagano and Moccellin Citation2002). The optimization criteria for the PFSP are commonly makespan, flowtime or machine idletime (Framinan, Leisten, and Rajendran Citation2003; Liu, Jin, and Price Citation2016), to satisfy various requirements from production practice. The PFSP is an NP-hard problem with the makespan criterion (Rinnooy Kan Citation1976) and flowtime criterion (Framinan, Leisten, and Ruiz-Usano Citation2005), so that many heuristics are designed to obtain optimal or near-optimal solutions in a short time. For the makespan criterion, the NEH heuristic is commonly regarded as the most effective (Dong, Huang, and Chen Citation2008; Kalczynski and Kamburowski Citation2009), and many variants have been developed for various criteria (Nagano and Moccellin Citation2002; Liu, Jin, and Price Citation2016). Many new NEH improvements have also been developed in terms of tie-breaking rules, such as those presented by Sharma, Sharma, and Sharma (Citation2021), Sauvey and Sauer (Citation2020), Baskar and Xavior (Citation2021), Benavides et al. (Citation2018) and Wu et al. (Citation2021).
Regarding the makespan minimization, the original priority rule of the NEH heuristic uses the LPT dispatching rule. The N&M algorithm (Nagano and Moccellin Citation2002) is a variant of the NEH heuristic in which jobs are arranged according to the total job processing times and the maximum lower bound of the job waiting times between machines. Framinan, Leisten, and Rajendran (Citation2003) tested 177 different initial job priority rules, and the results show that the LPT rule achieves the best makespan minimization performance. In the NEH-D heuristic (Dong, Huang, and Chen Citation2008), the average and standard deviation of job processing times are considered, and the non-increasing order of job indicators is chosen. For the NEHKK1 (Kalczynski and Kamburowski Citation2008) and NEHKK2 (Kalczynski and Kamburowski Citation2009) heuristics, different weights are allocated to job processing times according to their position in the flow line. Ribas, Companys, and Tort-Martorell (Citation2010) tested four priority rules with the NEH-insertion method, including rules from NEHKK1, N&M, LPT and a random job sequence. In the NEHLJP1 heuristic (Liu, Jin, and Price Citation2017a), the job processing times are assumed as a set of discrete random numbers, and the first, second and third moments, namely, the average, standard deviation and skewness, are included. The fourth moment of the job processing times is included and tested for the bi-criteria of makespan and idletime for the PFSPs (Liu, Jin, and Price Citation2016). Note that the non-increasing order of indicators is commonly adopted in the priority rules for the makespan criterion. All of the above priority rules are constructed by selecting appropriate job features, and the interrelationships between jobs are not considered.
In summary, many studies assume that jobs are sorted independently based on their features, and job priority rules are developed with sorting methods for the given problems. A full consideration of job interrelationships should be further studied to differentiate jobs precisely. In this article, the job similarities are studied, allowing a new perspective to be developed on constructing a new priority rule.
3. Terminology and measures of performance
In the permutation flowshop environment, n jobs are assumed to be available at time zero, to be processed on m machines in the same order. Machines can only process one job at a time, and failures are not considered in this article. Buffers between machines are assumed to be infinite. Denoted by , the processing time of job i on machine j, including the machine set-up time, is known and deterministic. Job pre-emption is not allowed. To understand the various rules in this article, the terminology used in herein is listed in Table .
Table 1. Terminology.
The makespan of the schedule is given by
(1)
(1)
where
(2)
(2)
(3)
(3)
4. New perspective
4.1. Self-attention mechanism
To calculate the similarity of jobs, the self-attention mechanism from the deep learning network (Vaswani et al. Citation2017; Kool, van Hoof, and Welling Citation2018; Bengio, Lodi, and Prouvost Citation2018) is introduced into scheduling. To provide an explicit introduction, the scaled dot-product attention mechanism (Vaswani et al. Citation2017) is presented first; this can be formulated as follows:
(4)
(4)
where
is the query matrix,
is the key matrix,
is the transpose of
,
is the value matrix, and
is the scaling factor, with
as the dimension of
.
is a set of vectors to calculate attention for, and
is a set of vectors to calculate attention against. The result of the dot-product multiplication shows how attended each query is against
, which are used as weights to matrix
. The Softmax function performs the following transform on m numbers:
(5)
(5)
From Equation Equation(5)(5)
(5) , it can be seen that the result of the attention mechanism is a convex combination of the row vectors of the value matrix
, where the weights assigned to each row are determined by the dot-product of matrix
with matrix
.
When the query matrix , the key matrix
and the value matrix
are set to be the same, this is called the self-attention mechanism, as shown in Equation Equation(6)
(6)
(6) :
(6)
(6)
Herein, the dot-product of the matrices is used to calculate the similarities among the rows of the matrix and then taken as weights for each element of
.
To introduce the self-attention mechanism into PFSP scheduling, the matrix as the arithmetic object should be built. In this article, each job is deemed to be a vector of m elements, representing the processing times with m machines. All n jobs are grouped, constructing the (n × m)-dimensional processing time matrix, denoted by . Each row of T consists of the processing times of the corresponding job on all machines. As the jobs with similar processing patterns may affect the scheduling of a job more strongly than those with a different pattern, the similarity between two rows can be viewed as the influence between the related jobs. In this sense, the result of the dot-product is another matrix, where the (jk)th element represents the influence of job j’s features on job k. Then, the similarities are assigned as weights to each row of
after composition with the Softmax function. The Softmax function can turn arbitrary real values into probabilities. An extra dimension for adjustment,
, is added to prevent the inner product from becoming too large.
If the self-attention mechanism is implemented with the job processing time matrix, the Softmax function will convert the dot-product of s into a job similarity matrix, which is then used as a weighting parameter for matrix
.
4.2. New priority rule
For the PFSPs, the processing times of n jobs with m machines are generally assumed to be larger than 1 (Taillard Citation1993; Vallada, Ruiz, and Framinan Citation2015). As a result, the dot-product of the processing time matrix will be large, which will increase the risk of large variance. Two strategies are employed to prevent this problem. First, the processing time matrix is standardized so that the matrix element values are mapped to [0, 1], denoted by . Secondly, a scaling factor is introduced after the dot-product of the processing time matrices. In the new rule,
is formulated as
(7)
(7)
where
is the processing time matrix;
for n < 100, else
for n ≥ 100. The row sum of
is taken as the job priorities. The rationality behind the scaling factor setting is that
depends on n and m differently. The result of
is an n × n matrix in which each element is the sum of m product values of two job processing times. Therefore, the impact of m on the Softmax function is larger than n, and it should be limited. Besides, a nonlinear function is used to control the scale of n or m further, and the log function is selected based on preliminary tests. Note that the specified hyperparameters of the scaling factor are based on the authors’ two-year calculation and heuristic design experience. Readers are welcome to optimize them further.
The (ij)th element of measures the similarity between job i and job j, considering the processing times with all machines. Treating this as a multiplicative weight, each row of the matrix
is a weighted sum of all jobs, which measures the influence of the target job on all of the jobs. The bigger it is, the larger the impact of this job will be. That is, this job is likely to have a significant impact on other jobs.
The result of the self-attention mechanism is a matrix with size n × m, and its row sum is used as a job sorting indicator. Regarding the sorting method, many existing rules adopt the non-increasing sorting method for the makespan criterion owing to its optimality rates, such as rules from NEH, NEHKK1, NEHKK2, NEH-D and NEHLJP1. In this article, the non-increasing order is implemented with the above indicator for the makespan criterion, and the new priority rule is denoted by PRSAT.
By combining PRSAT and the tie-breaking rule developed by the authors (Liu, Jin, and Price Citation2017a), TBLJP1, a new heuristic denoted by NEHLJP2, is presented.
4.3. Numerical example
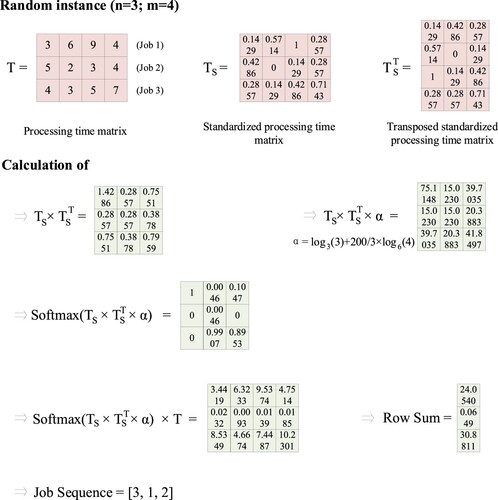
A numerical example is demonstrated with calculation details as follows, to improve the understanding of the new priority rule. As illustrated in Figure , three jobs are to be processed in a four-machine permutation flowshop. The processing times of job 1 with machines 1, 2, 3 and 4 are 3, 6, 1 and 4, respectively. The processing time matrix can be formulated if all job processing times are grouped and the size of
is 3 × 4. The results of each step are given in detail below.
Figure 1. Sample demonstration of PRSAT with four digits shown.
4.4. Computational complexity and running time comparison
As matrix is of size n × m and matrix
, m × n, the multiplication
takes O(n2m) arithmetic operations. When carrying out the Softmax computation, the complexity depends on the value of the numbers involved. Assuming that the element value of
is upper bounded by some constant, the complexity of the Softmax function is O(n2). Finally, the matrix
is of size n × n, and the matrix multiplication with
will take O(n2m) operations. Above all, the complexity upper bound for the computation of
is O(n2m), as well as the priority rule of PRSAT.
Table summarizes the computational complexities of some existing priority rules for the NEH heuristic. The current rules, such as PRAVG, PRSTD and PRSKE, share the same complexity of O(nlog(n)), while for PRSAT, it is O(n2m). Since the complexity of NEH insertion is O(n2m), all of these rules implemented with the NEH heuristic will achieve O(n2m).
Table 2. Complexities and running times (in seconds) of priority rules.
The average computation times of each rule implemented with the NEH heuristic are also listed in Table , and the Taillard (Taillard Citation1993) and VRF (Vallada, Ruiz, and Framinan Citation2015) instances are used for the test. All priority rules and the NEH heuristic are coded with MATLAB® R2020a and run on an Intel Core CPU i9-9900 K computer with 32 GB memory. It can be seen that with both benchmarks, the original priority rule PRAVG with the NEH heuristic needs the least running time, followed by PRSTD. The rule PRSKE requires more running time than both PRAVG and PRSTD, since an extra indicator of job skewness is considered. For the rule of PRSAT, the running time is slightly larger than for PRSKE, although it has the largest computational complexity. This is because the complexities of all NEH-based heuristics are the same, and priority rules have a minor impact on the overall running time.
5. Experimental results
To validate the effectiveness of the new priority rule PRSAT and the heuristic NEHLJP2, two classic benchmarks, namely Taillard (Taillard Citation1993) and VRF (Vallada, Ruiz, and Framinan Citation2015), are employed simultaneously, associated with one new set of random instances. In the Taillard benchmark, there are 120 instances, with n = 20, 50, 100, 200, 500, and m = 5, 10, 20. For the VRF benchmark, the small instance set includes 240 instances, with n = 10, 20, 30, 40, 50, 60, 70, 80, and m = 5, 10, 15, 20. In the large instance set, 240 instances are included, with n = 100, 200, 300, 400, 500, 600, 700, 800, and m = 20, 40, 60. To further test the new priority rule and the new heuristic performance, 640 instances are randomly generated, including 320 small instances and 320 large instances. For small instances, the number of jobs is assumed to be 20, 50, 100, 200, and the number of machines is 5, 10, 15, 20. Regarding the large random instances, n is defined as 300, 400, 500, 600, and m as 20, 30, 40, 50. Twenty instances are generated for each problem combination. Job processing times are independently drawn from the uniform distribution U({1, 2, … , 99}). Therefore, in this article, 1240 instances are used for performance validation.
To demonstrate the performance of each rule, the relative percentage deviation (RPD) is used. The RPD is calculated as follows:
where
is the objective function value obtained by a specific algorithm on a given test instance, and
is the upper bound of each instance. The average relative percentage deviation (ARPD) on all instances is used to demonstrate the algorithm’s overall performance.
In the following subsections, the performance of the new priority rule is first verified. Two different verification scenarios are defined. One is that the new priority rule is implemented with the NEH heuristic directly. The second scenario is that the tie-breaking rules are adopted and run with the new priority rule to fully validate the performance and compatibility of the priority rule. Note that, to confirm the effectiveness of the new priority rule, some existing priority rules for the NEH heuristic are referenced, including the original rule PRAVG from the NEH heuristic, PRSTD from NEH-D (Dong, Huang, and Chen Citation2008) and PRSKE from NEHLJP1 (Liu, Jin, and Price Citation2017a).
Next, the performance of the heuristic NEHLJP2 is validated. Two independent test scenarios are set as well. First, NEHLJP2 is tested directly with three groups of instances. The existing heuristics NEH, NEHKK1, NEHKK2, NEH-D, NEHFF and NEHLJP1 are taken as references. Secondly, the iterated greedy (IG) algorithm (Ruiz and Stützle Citation2007) is selected for further performance tests by taking the heuristic result as its initial solution.
For a fair performance comparison, all algorithms are coded in MATLAB R2020a and run on an Intel Core CPU i9-9900 K computer with 32 GB memory.
5.1. Performance of the new priority rule
Table shows the ARPD values of some existing priority rules when the makespan is minimized with the Taillard benchmark. The PRSAT achieves the best ARPD value, 3.0488, followed by PRSKE, PRSTD and PRAVG. Performance improvements of 8.30%, 5.46% and 0.38% are realized by the new priority rule compared to PRSKE, PRSTD and PRAVG. Moreover, the PRSAT rule has the best performance on six out of 12 problems, namely, the 20 × 5, 50 × 10, 50 × 20, 100 × 10, 200 × 10 and 500 × 20 problems. PRSKE outperforms the others on four out of 12 problems.
Table 3. Average relative percentage deviation (ARPD) values of priority rules with the Taillard benchmark.
The results with VRF instances are shown in Table . The priority rule PRSAT is at the first level among all priority rules, achieving 3.4442 in ARPD, followed by PRSKE, PRSTD and PRAVG. Concerning the best ARPD value for each problem, PRSAT performs best on 17 out of 48 problems, followed by PRSKE on 16 out of 48 problems, PRSTD on 11 out of 48 problems and PRAVG on four out of 48 problems.
Table 4. Average relative percentage deviation (ARPD) values of priority rules with the VRF benchmark.
Table presents the results of priority rules with random instances. PRSAT achieves the best overall performance in terms of small and large instances. Primarily, it outperforms the other reference priority rules on 10 out of 16 problems.
Table 5. Average relative percentage deviation (ARPD) values of priority rules with random instances.
To check whether the ARPD differences in priority rules are significant, a paired sample t-test was conducted with Taillard, VRF and randomly generated instances. As shown in Table , significant differences between PRSAT, PRSKE, PRSTD and PRAVG can be observed, with p < 0.05. Note that PRSAT and PRSKE are significantly better than PRSTD, but there is no significant performance difference between PRSAT and PRSKE. This is because the performance of the existing priority rules is excellent, and it becomes harder to propose a new priority rule that can outperform the existing ones significantly. However, the contribution of developing a priority rule still exists, in that significantly better results can be obtained by combining it with other heuristics or metaheuristics, as demonstrated in Sections 5.3 and 5.5.
Table 6. Paired sample t-test results of priority rules, with 95% confidence intervals (CIs).
5.2. Compatibility of the new priority rule
To further test the PRSAT rule, it is implemented with the tie-breaking rules from NEHKK1, NEHKK2, NEH-D, FF (Fernandez-Viagas and Framinan Citation2014) and NEHLJP1. In addition, the above existing priority rules are referenced for comparison. Therefore, there are four priority rules and five tie-breaking rules included, and 20 different combinations are tested with different benchmarks.
The results of each combination with the Taillard benchmark are shown in Figure . It can be seen that PRSAT works best with the tie-breaking rules from NEHKK1, NEH-D, NEHFF and NEHLJP1, but not NEHKK2. Specifically, with the NEHKK1, NEH-D, NEHFF and NEHLJP1 tie-breaking rules, PRSAT achieves the best performance compared to other priority rules. Also, PRSAT is the best with the NEHLJP1 tie-breaking rule, reaching 2.7025 in terms of ARPD value. Figure shows the results of each combination with the VRF benchmark. Again, PRSAT offers better performance than the other priority rules on five out of five tie-breaking rules.
Figure 2. Average relative percentage deviation (ARPD) values of each combination with the Taillard benchmark.
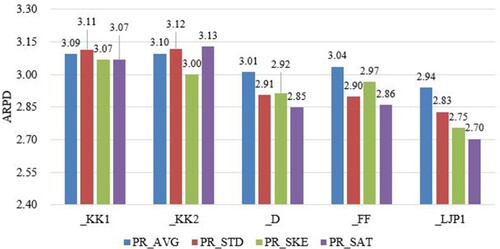
Figure 3. Average relative percentage deviation (ARPD) values of each combination with the VRF benchmark.
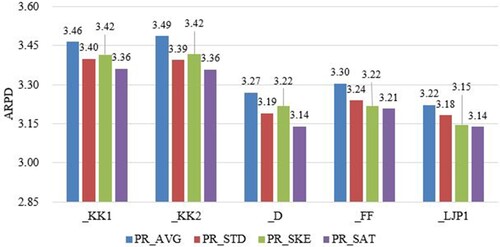
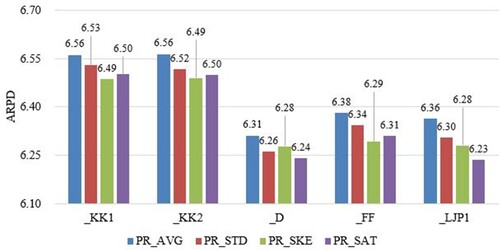
Figure illustrates the performance of different combinations with randomly generated instances. It can be seen that PRSAT obtains the best performance with the NEHLJP1 tie-breaking rule. To conclude, PRSAT is compatible with the tie-breaking rules of NEHKK1, NEHKK2, NEH-D, NEHFF and NEHLJP1.
Figure 4. Average relative percentage deviation (ARPD) values of each combination with random instances.
5.3. Performance of NEHLJP2
In this section, the performance of NEHLJP2 is tested. To conduct a fair comparison, the existing NEH-based heuristics, NEH, NEHKK1, NEHKK2, NEH-D and NEHLJP1 are referenced and compared, and the ARPD value is taken as the performance measure.
Table shows the ARPD values of each heuristic with Taillard instances. NEHLJP2 obtains the best ARPD performance, with an ARPD value of 2.7025, and 1.87% performance improvement is achieved compared to NEHLJP1, 6.98% compared to NEH-D, 13.16% compared to NEHKK2, 14.23% compared to NEHKK1 and 18.72% compared to NEH. Also, NEHLJP2 can achieve the best performance on five out of 12 problems, followed by NEHLJP1 on four out of 12 problems, NEHKK2 on two out of 12 problems and NEH-D on one out of 12 problems.
Table 7. Average relative percentage deviation (ARPD) values of heuristics with the Taillard benchmark.
Similar results can be obtained with the VRF benchmark, as shown in Table . NEHLJP2 has the best overall ARPD value of 3.1382, and 0.27% performance improvement is achieved compared to NEHLJP1, 1.64% compared to NEH-D, 10.37% compared to NEHKK2, 9.34% compared to NEHKK1 and 12.50% compared to NEH. NEHLJP1 generates the best performance on most problems, 19 out of 48, followed by NEHLJP2, NEH-D, NEHKK2 and NEHKK1 with VRF instances.
Table 8. Average relative percentage deviation (ARPD) values of heuristics with the VRF benchmark.
The heuristic results with 640 randomly generated instances are shown in Table . Overall, the new heuristic NEHLJP2 demonstrates the best solution quality compared to existing heuristics, with the lowest ARPD values in terms of small and large instances. NEH-D and NEHLJP1 are located at the second level of heuristic performance. Similarly, NEHLJP2, NEHLJP1 and NEH-D generate the best ARPD values for different problems. It can be concluded that NEHLJP2 shows a robust capability for developing high-quality solutions.
Table 9. Average relative percentage deviation (ARPD) values of heuristics with random instances.
To validate the significant differences between heuristic performance, the paired sample t-test was conducted. The results in Table show that the performance differences between NEH-D, NEHKK2, NEHKK1, NEH and the heuristic NEHLJP2 are significant. However, since NEHLJP1 and NEHLJP2 adopt the same tie-breaking rule, the performance difference is not statistically significant, with p = 0.193.
Table 10. Paired sample t-test results of heuristics, with 95% confidence intervals (CIs).
5.4. Efficiency evaluation of NEHLJP2
To confirm the computational efficiency of the NEHLJP2 heuristic, the ARPD, the average central processing unit time (ACPU) and the average relative percentage time (ARPT) are employed at the same time (Fernandez-viagas, Ruiz, and Framinan Citation2017). The ACPU and ARPT of heuristic p are defined as ,
, where
is the computation time on instance j by heuristic p,
is the total number of instances,
, and P is the total number of heuristics considered. ACPU and ARPT are two main performance measures in terms of computational efficiency, although the solution quality is also to be considered as a key performance factor, which is represented by ARPD.
Each heuristic is run 10 times independently. As stated in Fernandez-viagas, Ruiz, and Framinan (Citation2017), NEHKK2 and the heuristic NEHFF implemented with PRD and TBFF are deemed to be efficient, and they are taken as references in this article. The remaining reference heuristics in this article are also included in the efficiency evaluation.
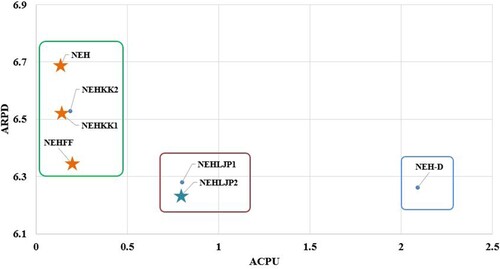
Figures illustrate the ARPD values versus ARPT and ACPU of each reference heuristic. Several clusters can be found in each figure, and it is shown that NEH, NEHKK1, NEHKK2 and NEHFF are located in the cluster with computational efficiency. The cluster of NEHLJP1 and NEHLJP2 shows excellent ARPD values at the nominal cost of ACPU or ARPT. The non-dominated heuristics are marked with stars in each figure. It can be seen that NEHLJP2 is a new dominating heuristic that outperforms the existing ones in terms of ARPD. This is the main contribution of this article, in developing a new priority and presenting a new heuristic, NEHLJP2.
Figure 5. Average relative percentage deviation (ARPD) versus average relative percentage time (ARPT) of heuristics on a logarithmic scale on the Taillard benchmark.
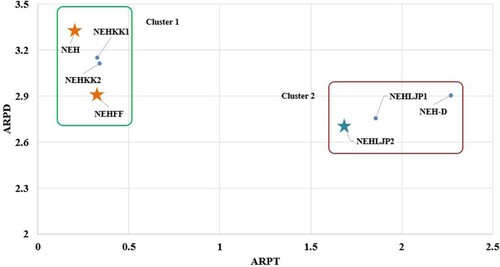
Figure 6. Average relative percentage deviation (ARPD) versus average central processing unit time (ACPU) of heuristics on a logarithmic scale on the Taillard benchmark.
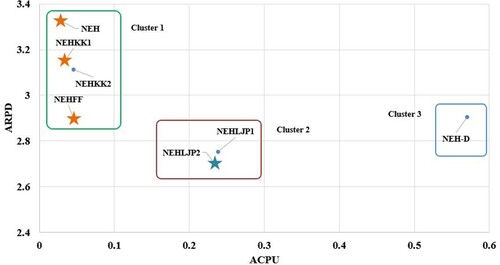
Figure 7. Average relative percentage deviation (ARPD) versus average relative percentage time (ARPT) of heuristics on a logarithmic scale on the VRF benchmark.

Figure 8. Average relative percentage deviation (ARPD) versus average central processing unit time (ACPU) of heuristics on a logarithmic scale on the VRF benchmark.
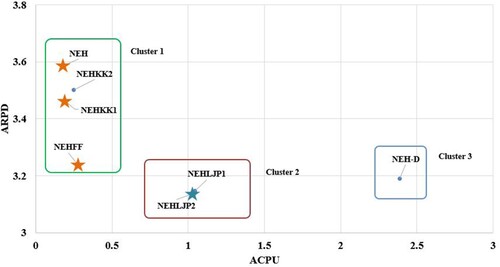
Figure 9. Average relative percentage deviation (ARPD) versus average relative percentage time (ARPT) of heuristics on a logarithmic scale on random instances.
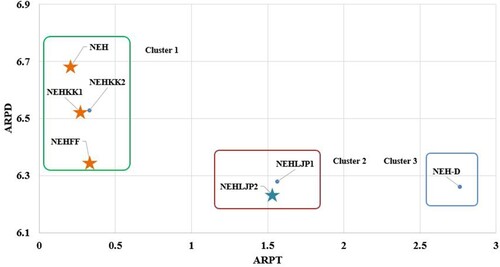
Figure 10. Average relative percentage deviation (ARPD) versus average central processing unit time (ACPU) of heuristics on a logarithmic scale on random instances.
5.5. Compatibility of NEHLJP2 with the IG algorithm
To further validate the new heuristic performance, all of the above NEH-based heuristics are used to generate an initial solution for the IG heuristic (Ruiz and Stützle Citation2007). The same hyperparameters from Liu, Jin, and Price (Citation2018) are configured for the IG algorithm to conduct a fair performance comparison. Since the running time of the IG heuristic has an evident impact on the final results, different stopping criteria are defined. For example, the running time for the IG algorithm is set as n × m × 10 (milliseconds).
Figure shows the results of NEH-IG, NEHKK1-IG, NEHKK2-IG, NEH-D-IG, NEHLJP1-IG and NEHLJP2-IG with the Taillard, VRF and random instances. It can be seen that NEHLJP2-IG can always obtain the best solution compared to the other heuristics.
Figure 11. Heuristic performance with the iterated greedy (IG) algorithm.
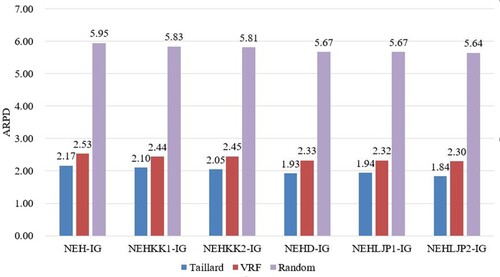
Table show the results of the paired sample t-test of heuristics with the IG algorithm. By setting the running time of n × m × 10 milliseconds, NEHLJP2-IG shows significantly better performance than the heuristics. Again, the contribution of the new priority rule can be confirmed, in that it can be used for other metaheuristics with dominating performance.
Table 11. Paired sample t-test results of heuristics with the iterated greedy (IG) algorithm.
6. Conclusions
In this article, a new perspective is developed to construct a new job priority rule, and the PFSP is studied. With the new perspective, the self-attention mechanism is introduced into production scheduling for the first time. The job similarities are calculated with the dot-product of job processing time matrices and taken as job weights to achieve job differentiation and ordering. Based on the new perspective, one new priority rule, namely PRSAT, is proposed for makespan minimization, and by combining the TBLJP1 tie-breaking rule, a heuristic, NEHLJP2, is presented.
A systematic performance evaluation of the new priority rule and NEHLJP2 heuristic is conducted with Taillard, VRF and 640 randomly generated instances. The experimental results confirm that the new priority rule with O(n2m) complexity achieves the best performance compared with existing rules in terms of makespan. The heuristic NEHLJP2 shows the best and a robust performance with different benchmarks. It obtains the best performance with the IG heuristic as well.
In the future, the new perspective can be further investigated and developed for the PFSP variants, such as no-idle or no-wait PFSPs. Different optimization criteria can be studied with the new perspective by adjusting the scaling factor. The new priority rule or NEHLJP2 can also be used for job dispatching or to provide an initial solution for other composite algorithms.
Acknowledgements
The authors are sincerely thankful to the editors and the anonymous referees who provided valuable and constructive comments to improve the technical content and presentation of the article.
Disclosure statement
No potential conflict of interest was reported by the authors.
Data availability statement
The data sets generated in the current study are available in the Mendeley Data repository, doi: 10.17632/gx8657vph2.1.
Additional information
Funding
References
- Alfieri, A. 2009. “Workload Simulation and Optimisation in Multi-criteria Hybrid Flowshop Scheduling: A Case Study.” International Journal of Production Research 47 (18): 5129–5145. doi:10.1080/00207540802010823
- Baskar, A., and M. Anthony Xavior. 2021. “New Idle Time-Based Tie-Breaking Rules in Heuristics for the Permutation Flowshop Scheduling Problems.” Computers and Operations Research 133 (April): 105348. doi:10.1016/j.cor.2021.105348
- Benavides, Alexander J, Alexander J Benavides, Universidad Católica, and San Pablo. 2018. “A New Tiebreaker in the NEH Heuristic for the Permutation Flow Shop Scheduling Problem.” EasyChair Preprint 440. doi:10.29007/ch1l.
- Bengio, Yoshua, Andrea Lodi, and Antoine Prouvost. 2018. “Machine Learning for Combinatorial Optimization: A Methodological Tour d’Horizon,” 1–34. http://arxiv.org/abs/1811.06128.
- Choi, S.-W., Y.-D. Kim, and G.-C. Lee. 2005. “Minimizing Total Tardiness of Orders with Reentrant Lots in a Hybrid Flowshop.” International Journal of Production Research 43 (11): 2149–2167. doi:10.1080/00207540500050071
- Dong, X., H. Huang, and P. Chen. 2008. “An Improved NEH-Based Heuristic for the Permutation Flowshop Problem.” Computers & Operations Research 35 (12): 3962–3968. doi:10.1016/j.cor.2007.05.005
- Erseven, Göksu, Gizem Akgün, Aslıhan Karakaş, Gözde Yarıkcan, Özgün Yücel, and Adalet Öner. 2019. “An Application of Permutation Flowshop Scheduling Problem in Quality Control Processes.” Proceedings of the International Symposium for Production Research 2018.
- Fernandez-Viagas, V., and J. M. Framinan. 2014. “On Insertion Tie-Breaking Rules in Heuristics for the Permutation Flowshop Scheduling Problem.” Computers & Operations Research 45: 60–67. doi:10.1016/j.cor.2013.12.012
- Fernandez-viagas, Victor, Rubén Ruiz, and Jose M. Framinan. 2017. “A New Vision of Approximate Methods for the Permutation Flowshop to Minimise Makespan: State-of-the-Art and Computational Evaluation.” European Journal of Operational Research 257 (3): 707–721. doi:10.1016/j.ejor.2016.09.055
- Framinan, J. M., R. Leisten, and C. Rajendran. 2003. “Different Initial Sequences for the Heuristic of Nawaz, Enscore and Ham to Minimize Makespan, Idletime or Flowtime in the Static Permutation Flowshop Sequencing Problem.” International Journal of Production Research 41 (1): 121–148. doi:10.1080/00207540210161650
- Framinan, Jose M, Rainer Leisten, and Rafael Ruiz-Usano. 2005. “Comparison of Heuristics for Flowtime Minimisation in Permutation Flowshops.” Computers and Operations Research 32 (5): 1237–1254. doi:10.1016/j.cor.2003.11.002
- Gao, Jian, Rong Chen, and Wu Deng. 2013. “An Efficient Tabu Search Algorithm for the Distributed Permutation Flowshop Scheduling Problem.” International Journal of Production Research 51 (3): 641–651. doi:10.1080/00207543.2011.644819
- Jayamohan, M. S., and Chandrasekharan Rajendran. 2004. “Development and Analysis of Cost-Based Dispatching Rules for Job Shop Scheduling.” European Journal of Operational Research 157 (2): 307–321. doi:10.1016/S0377-2217(03)00204-2
- Kalczynski, P. J., and J. Kamburowski. 2008. “An Improved NEH Heuristic to Minimize Makespan in Permutation Flow Shops.” Computers & Operations Research 35 (9): 3001–3008. doi:10.1016/j.cor.2007.01.020
- Kalczynski, P. J., and J. Kamburowski. 2009. “An Empirical Analysis of the Optimality Rate of Flow Shop Heuristics.” European Journal of Operational Research 198 (1): 93–101. doi:10.1016/j.ejor.2008.08.021
- Kianfar, K., S. M. T. Fatemi Ghomi, and B. Karimi. 2009. “New Dispatching Rules to Minimize Rejection and Tardiness Costs in a Dynamic Flexible Flow Shop.” The International Journal of Advanced Manufacturing Technology 45 (7–8): 759–771. doi:10.1007/s00170-009-2015-x
- Kool, Wouter, Herke van Hoof, and Max Welling. 2018. “Attention Solves Your TSP, Approximately.” http://arxiv.org/abs/1803.08475.
- Koulamas, Christos, and S. S. Panwalkar. 2018. “New Index Priority Rules for No-Wait Flow Shops.” Computers and Industrial Engineering 115 (November 2017): 647–652. doi:10.1016/j.cie.2017.12.015
- Liu, Weibo, Yan Jin, and Mark Price. 2016. “A New Nawaz–Enscore–Ham-Based Heuristic for Permutation Flow-Shop Problems with Bicriteria of Makespan and Machine Idle Time.” Engineering Optimization 48 (10): 1808–1822. doi:10.1080/0305215X.2016.1141202
- Liu, Weibo, Yan Jin, and Mark Price. 2017a. “A New Improved NEH Heuristic for Permutation Flowshop Scheduling Problems.” International Journal of Production Economics 193 (June 2016): 21–30. doi:10.1016/j.ijpe.2017.06.026
- Liu, Weibo, Yan Jin, and Mark Price. 2017b. “New Scheduling Algorithms and Digital Tool for Dynamic Permutation Flowshop with Newly Arrived Order.” International Journal of Production Research 55 (11): 3234–3248. doi:10.1080/00207543.2017.1285077
- Liu, Weibo, Yan Jin, and Mark Price. 2018. “New Meta-heuristic for Dynamic Scheduling in Permutation Flowshop with New Order Arrival.” The International Journal of Advanced Manufacturing Technology 98: 1817–1830. doi:10.1007/s00170-018-2171-y
- Nagano, M. S., and J. V. Moccellin. 2002. “A High Quality Solution Constructive Heuristic for Flow Shop Sequencing.” Journal of the Operational Research Society 53 (12): 1374–1379. doi:10.1057/palgrave.jors.2601466
- Natarajan, K., K. M. Mohanasundaram, B. Shoban Babu, S. Suresh, K. Antony Arokia Durai Raj, and C. Rajendran. 2007. “Performance Evaluation of Priority Dispatching Rules in Multi-level Assembly Job Shops with Jobs Having Weights for Flowtime and Tardiness.” International Journal of Advanced Manufacturing Technology 31 (7–8): 751–761. doi:10.1007/s00170-005-0258-8
- Nawaz, M., E. E. Enscore, Jr., and I. Ham. 1983. “A Heuristic Algorithm for the m-Machine, n-Job Flow-Shop Sequencing Problem.” Omega 11 (1): 91–95. doi:10.1016/0305-0483(83)90088-9
- Ribas, Imma, Ramon Companys, and Xavier Tort-Martorell. 2010. “Comparing Three-Step Heuristics for the Permutation Flow Shop Problem.” Computers and Operations Research 37 (12): 2062–2070. doi:10.1016/j.cor.2010.02.006
- Rinnooy Kan, A. H. G. 1976. Machine Scheduling Problems: Classification, Complexity and Computations. The Hague, The Netherlands: Martinus Nijhoff. doi:10.1016/0377-2217(77)90029-7.
- Ruiz, R., and T. Stützle. 2007. “A Simple and Effective Iterated Greedy Algorithm for the Permutation Flowshop Scheduling Problem.” European Journal of Operational Research 177 (3): 2033–2049. doi:10.1016/j.ejor.2005.12.009
- Sauvey, Christophe, and Nathalie Sauer. 2020. “Two NEH Heuristic Improvements for Flowshop Scheduling Problem with Makespan Criterion.” Algorithms 13 (5): 1–14. doi:10.3390/a13050112
- Sha, D. Y., S. Y. Hsu, Z. H. Che, and C. H. Chen. 2006. “A Dispatching Rule for Photolithography Scheduling with an On-Line Rework Strategy.” Computers & Industrial Engineering 50 (3): 233–247. doi:10.1016/j.cie.2006.04.002
- Sharma, Meenakshi, Manisha Sharma, and Sameer Sharma. 2021. “An Improved Neh Heuristic to Minimize Makespan for Flow Shop Scheduling Problems.” Decision Science Letters 10 (3): 311–322. doi:10.5267/j.dsl.2021.2.006
- Swaminathan, Rajesh, Michele E. Pfund, John W. Fowler, Scott J. Mason, and Ahmet Keha. 2007. “Impact of Permutation Enforcement When Minimizing Total Weighted Tardiness in Dynamic Flowshops with Uncertain Processing Times.” Computers & Operations Research 34 (10): 3055–3068. doi:10.1016/j.cor.2005.11.014
- Taillard, E. 1993. “Benchmarks for Basic Scheduling Problems.” European Journal of Operational Research 64: 278–285. doi:10.1016/0377-2217(93)90182-M
- Tay, Joc Cing, and Nhu Binh Ho. 2008. “Evolving Dispatching Rules Using Genetic Programming for Solving Multi-objective Flexible Job-Shop Problems.” Computers and Industrial Engineering 54 (3): 453–473. doi:10.1016/j.cie.2007.08.008
- Vallada, E., R. Ruiz, and J. M. Framinan. 2015. “New Hard Benchmark for Flowshop Scheduling Problems Minimising Makespan.” European Journal of Operational Research 240 (3): 666–677. doi:10.1016/j.ejor.2014.07.033
- Vallada, Eva, Rubén Ruiz, and Gerardo Minella. 2008. “Minimising Total Tardiness in the m-Machine Flowshop Problem: A Review and Evaluation of Heuristics and Metaheuristics.” Computers & Operations Research 35 (4): 1350–1373. doi:10.1016/j.cor.2006.08.016
- Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. “Attention Is All You Need,” no. Nips.
- Wang, Cheng, Shiji Song, Jatinder N.D. Gupta, and Cheng Wu. 2012. “A Three-Phase Algorithm for Flowshop Scheduling with Blocking to Minimize Makespan.” Computers and Operations Research 39 (11): 2880–2887. doi:10.1016/j.cor.2012.02.020
- Weng, Michael X., and Haiying Ren. 2006. “An Efficient Priority Rule for Scheduling Job Shops to Minimize Mean Tardiness.” IIE Transactions (Institute of Industrial Engineers) 38 (9): 789–795. doi:10.1080/07408170600710523
- Wu, Qinghua, Qingxuan Gao, Weibo Liu, and Shuai Cheng. 2021. “Improved NEH-Based Heuristic for the Blocking Flow-Shop Problem with Bicriteria of the Makespan and Machine Utilization.” Engineering Optimization. doi:10.1080/0305215X.2021.2010727
- Xiong, Hegen, Huali Fan, Guozhang Jiang, and Gongfa Li. 2017. “A Simulation-Based Study of Dispatching Rules in a Dynamic Job Shop Scheduling Problem with Batch Release and Extended Technical Precedence Constraints.” European Journal of Operational Research 257 (1): 13–24. doi:10.1016/j.ejor.2016.07.030