
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The estimation of a precision matrix has an important role in several research fields. In high dimensional settings, one of the most prominent approaches to estimate the precision matrix is the Lasso norm penalized convex optimization. This framework guarantees the sparsity of the estimated precision matrix. However, it does not control the eigenspectrum of the obtained estimator. Moreover, Lasso penalization shrinks the largest eigenvalues of the estimated precision matrix. In this article, we focus on D-trace estimation methodology of a precision matrix. We propose imposing a negative trace penalization on the objective function of the D-trace approach, aimed to control the eigenvalues of the estimated precision matrix. Through extensive numerical analysis, using simulated and real datasets, we show the advantageous performance of our proposed methodology.
1. Introduction
The estimation of a high dimensional inverse covariance or precision matrix has attracted significant interest recently. It is an important problem in genetics (Stifanelli et al. Citation2013), medicine (Ryali et al. Citation2012), climate studies (Zerenner et al. Citation2014), finance (Goto and Xu Citation2015), etc. Moreover, it has a crucial role in various machine learning methodologies, such as classification and forecasting (McLachlan Citation2004).
Under the assumption of multivariate normality of data, the zero entry of the precision matrix at the position (i, j) indicates the conditional independence between the variables Xi and Xj, given all the other variables (Dempster Citation1972). In other words, the precision matrix represents the statistical dependency among normally distributed variables. In high dimensional settings, the precision matrix is usually sparse, since some of the variables do not interact.
The sparse precision matrix is related to the Gaussian Graphical Models (GGM) (Lauritzen Citation1996). It is an undirected graph where the set of nodes,
contains the indexes of the variables. The set of edges,
consists of the pair indexes
that correspond to
for
Thus, the GGM is a useful framework for illustrating the structure of dependencies among normally distributed variables.
In this article, we focus on estimating a high dimensional precision matrix and the selection of corresponding GGM (known as covariance selection). Throughout the article we assume that observed sample data matrix, is mean centered, where each row
is a p-variate normal random vector, i.i.d. for
and has a covariance matrix Σ with corresponding precision matrix
A considerable research is devoted to the estimation of precision matrices in high dimensional settings, where the number of variables may potentially exceed the number of observations. The regularization framework has gained a substantial attention. The most popular approach is the Lasso or norm regularization (Tibshirani Citation1996), which is convex and addresses the sparsity requirement of the estimated matrix. Banerjee et al. (Citation2006) proposed the
norm penalized log-likelihood maximization approach, which is known in literature as Graphical Lasso or GLASSO estimator (see also Yuan and Lin Citation2007; Friedman, Hastie, and Tibshirani Citation2008; Rothman et al. Citation2008). On the other hand, Fan, Feng, and Wu (Citation2009) proposed to employ adaptive
norm and SCAD (Smoothly Clipped Absolute Deviation) penalties to reduce the bias of the GLASSO estimator. van Wieringen and Peeters (Citation2016) proposed the estimation of the precision matrix through
norm penalized log-likelihood maximization. Finally, Avagyan, Alonso, and Nogales (Citation2017) proposed to improve the performance of the GLASSO estimator through k-root transformation of the sample covariance matrix.
Several authors studied non-likelihood based approaches for estimating either the precision matrix or the GGM. Meinshausen and Bühlmann (Citation2006) introduced the Neighborhood Selection approach to estimate the GGM. Yuan (Citation2010) proposed a similar approach to estimate each column of the precision matrix by using a Dantzig selector. Cai, Liu, and Luo (Citation2011) proposed the constrained norm minimization estimator known as CLIME. Zhang and Zou (Citation2014) proposed a precision estimation method through
norm penalized D-trace loss minimization (hereafter, DT estimator) and Avagyan, Alonso, and Nogales (Citation2016) proposed DT estimator using adaptive
norm penalization.
In this article, we focus on the DT estimator. As mentioned earlier, the regularization induces sparsity in the estimated precision matrix. However, this framework does not control the eigenvalues of the estimated matrix. Moreover, as the penalty parameter increases (i.e., the matrix becomes sparser), the largest eigenvalues of the estimator decrease considerably and the smallest eigenvalues increase insignificantly. As a result, the eigenspectrum of the estimator shrinks. Therefore, it would be natural to expect that by controlling the eigenvalues of the estimated precision matrix through an additional constraint we may potentially improve the performance of the estimated matrix. Moreover, in practice, one may require the estimated precision matrix to have proper determinant, condition number or trace.
We propose an extension of DT estimator with an eigenvalue constraint. We employ an additional regularization of the objective function of the DT estimator through negative trace penalization. This penalty sustains the stability of the eigenvalues and diminishes the significant decrease of the largest eigenvalues. Thus, the estimator becomes sparse without having to shrink its eigenspectrum significantly. Through extensive simulation study, we show that the proposed methodology outperforms the DT in terms of several measures. Further, we propose a new penalty parameter selection procedure based on Hannan-Quinn Information Criterion (HQIC). In the simulation study, we employ BIC and HQIC approaches to select the penalty parameters.
The rest of the manuscript is organized as follows. In Sec. 2, we describe the proposed methodology. In Sec. 3, we describe the penalty parameter selection process. In Sec. 4, we exhaustively evaluate the statistical loss and GGM prediction performance of the proposed methodology and compare them with that of DT and GLASSO methods. In Sec. 5, we apply the proposed methodology to an empirical application: prediction of breast cancer state using Linear Discriminant Analysis. Finally, we provide the conclusions in Sec. 6.
2. Proposed methodology
Before proceeding with the proposed methodology, we introduce the following notations. For any vector we define the
norm by
For any symmetric matrix
we denote the Frobenius norm by
the
norm by
the matrix
norm by
the componentwise
norm by
and the spectral norm by
For any two symmetric p × p matrices A and B, we write
if the matrix A – B is positive semidefinite.
Zhang and Zou (Citation2014) have proposed the D-trace loss function, defined as:
(1)
(1)
By regularizing the function through a
norm of Ω, Zhang and Zou (Citation2014) proposed the
penalized D-trace loss minimization estimator or DT. This estimator is defined as the solution of the following optimization problem:
(2)
(2)
where
is the sample covariance matrix,
is the associated penalty parameter and ϵ is a small positive value (we fix
). The constraint
guarantees the positive definiteness of the matrix
In this article, we also penalize the diagonal entries of Ω. To solve the problem (2), Zhang and Zou (Citation2014) developed an algorithm based on the Alternating Direction Method.
As discussed in Sec. 1, this article addresses the eigenvalue control of DT estimator. The norm penalization guarantees the sparsity of the estimated precision matrix for a well-selected parameter τ. However, as τ increases (i.e.,
becomes sparser), the eigenspectrum of the estimated matrix shrinks, i.e., the largest eigenvalues decrease significantly and the smallest eigenvalues increase insignificantly.
In order to illustrate the shrinkage of the eigenvalues, we consider a simple example. Assume that the true precision matrix has a known sparse structure given by Model 2 described in Sec. 4.1. We set the values p = 100 and n = 100. shows the eigenvalues of DT estimator for different values of τ. Note that, as the parameter τ increases (i.e., the matrix becomes sparser), the largest eigenvalues of the DT estimator decrease significantly towards a constant. As a result, the trace of the matrix decreases significantly due to norm penalization (see ).
Figure 1. (a) Eigenvalues of DT estimator for different penalty parameters, where (b) Trace of DT estimator for
![Figure 1. (a) Eigenvalues of DT estimator for different penalty parameters, where τ1<…<τ5, (b) Trace of DT estimator for τ∈[0.03;0.3].](/cms/asset/1398fb71-db2f-49da-81d0-c53cab7f8c0c/lssp_a_1580730_f0001_b.jpg)
In order to control the eigenspectrum of the estimator an additional constraint is required (see Liu, Wang, and Zhao Citation2014, for covariance matrix estimation). We note that the decrement of the largest eigenvalues of the estimated matrix is associated with the decrease of its trace. We propose to impose an additional penalization in the problem (2) through a negative trace of Ω. In this way, we propose the DT estimator with Eigenvalue Control (or shortly, DTEC). Our proposed estimator is the solution of the following optimization problem.
(3)
(3)
where
and
are penalty parameters. More specifically, the additional penalty term
in problem (3) endorses the trace (and, therefore, the largest eigenvalues) of the estimated precision matrix not to decrease significantly. Thus, the eigenvalues (especially the largest ones) of the matrix
will be closer to the true ones, than those of the matrix
Even though in practice the true eigenvalues are unknown, the estimated precision matrix will have more proper eigenspectrum (or condition number, determinant, etc.) if we employ an additional constraint. This in turn will lead to better performance of the estimated precision matrix. Note that a similar approach (although with a different reasoning) has been considered to improve GLASSO estimator (Maurya Citation2014). In this context, the results indicated that the joint penalization provides better results than standard GLASSO estimator.
Furthermore, we can write our proposed estimator as the solution of the following optimization problem:
(4)
(4)
Note that we can solve the problem (4) using a the same algorithm as for the problem (2), with minor modifications. We illustrate the performance of the proposed methodology on a particular example. Assume that the true precision matrix has the structure used above. In , we present the eigenvalues of true matrix Ω and the eigenvalues of the estimators DT and DTEC. illustrates the eigenvalues of the optimal (i.e., oracle) estimators in terms of the Frobenius norm loss (see Sec. 4.2 for a formal definition). In other words, DT and DTEC estimators are obtained using the penalty parameters that minimize the Frobenius norm loss assuming that Ω is known. shows the eigenvalues of DT and DTEC estimators obtained through BIC approach described in Sec. 3. From both figures we can see that the eigenvalues of DTEC estimator are larger than those of DT estimator. Moreover, the largest eigenvalues of DTEC estimator are much closer to the eigenvalues of Ω than those of DT. Therefore, the trace penalization diminishes the significant decrease of the largest eigenvalues of DT estimator.
Figure 2. Eigenvalues of the true precision matrix and estimators DT, DTEC obtained through (a) optimal penalty parameters, (b) BIC selection approach.
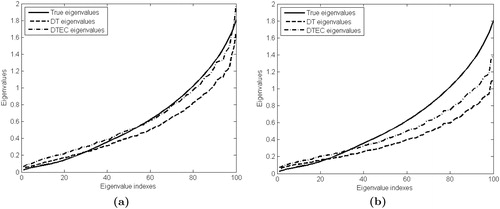
In Sec. 4, through an exhaustive simulation study, we show that our proposed DTEC estimator outperforms the DT estimator in terms of several statistical performance measures including those for graphical models.
3. Penalty parameter selection
The performance of the estimated precision matrix greatly depends on the penalty parameter. Moreover, the penalty parameter controls the sparsity pattern of the estimated matrix. In this article, we suggest the use of a criterion based on the log-likelihood function of the Gaussian model. We define the score function as
(5)
(5)
where
and
is degrees of freedom. We select the parameter by
The advantage of the suggested criterion is twofold. First, it is more effective than the techniques based on the cross-validation in terms of the computational time. Second, it accounts the sparsity characteristics of
Further, we consider the following degrees of freedom:
(6)
(6)
(7)
(7)
The choice corresponds to the Bayesian Information Criterion (BIC) which is proposed by Yuan and Lin (Citation2007) for precision matrix estimation methodologies. On the other hand, the choice
corresponds to the Hannan-Quinn Information Criterion (HQIC) (Hannan and Quinn Citation1979), which is consistent and asymptotically well-behaved (van der Pas and Grünwald Citation2014). This is a novel criterion in this framework (to the best of our knowledge, it has not been employed for selecting the penalty terms of the precision matrix estimation methods) and a little attention has been paid to the HQIC, in general.
We note that our proposed methodology requires selection of two parameters, τ and γ. For this reason, we define the following multivariate score function to select these parameters simultaneously:
(8)
(8)
where
is the estimated precision matrix for given values τ and γ. We select the parameters
and
by
4. Simulation study
In this section, we conduct a simulation analysis to evaluate the performance of our proposed methodology. In Sec. 4.1, we detail the considered models (i.e., patterns) for the true precision matrix Ω. In Sec. 4.2, we describe the performance evaluation. Finally, in subsection 4.3, we provide the discussion of the results.
4.1. Considered models
We perform a simulation study through six different patterns for the precision matrix with varying sizes. The considered models for the matrix Ω are the following:
Deterministic patterns
Model 1. Tridiagonal design:
and others are 0.
Model 2. Tridiagonal design with varying entries:
Model 3. Light-tailed (decaying) design:
Model 4. A block-diagonal matrix, with four equally sized blocks along the diagonal, with a light-tailed model in each block.
Random patterns (generated using the MATLAB command sprandsym)
Model 5. A random p.d. matrix, with approximately 20% of non-zero entries.
Model 6. A random p.d. matrix, with approximately 50% of non-zero entries.
For each precision matrix model, we simulate multivariate normal random samples with zero mean. We set n = 100 and p = 100, 200 and 300. The number of replications is 100.
4.2. Performance evaluation
To evaluate the performance of a precision matrix estimator, we use several losses and measures. In particular, we consider the Kullback–Leibler loss (KLL) and the Reverse Kullback–Leibler loss (RKLL), defined as
(9)
(9)
(10)
(10)
respectively. We also consider matrix losses: the Frobenius norm, the spectral norm and the matrix
norm, defined respectively as
(11)
(11)
(12)
(12)
(13)
(13)
In order to evaluate the sparsity pattern of the precision matrix estimator (i.e., GGM selection performance), we compute Specificity, Sensitivity, Matthews Correlation Coefficient (Matthews Citation1975) and F1 score (Powers Citation2011), defined as
(14)
(14)
(15)
(15)
(16)
(16)
(17)
(17)
where TP, TN, FP and FN are the number of correctly estimated non-zero entries (true positives), the number of correctly estimated zero entries (true negatives), the number of incorrectly estimated non-zero entries (false positives) and the number of incorrectly estimated zero entries (false negatives), respectively. In (17), we define
and
The values of MCC are in [-1,1], and the closer the MCC to one is, the better the classification is. On the other hand, the values of F1 score are in [0,1], and the closer the F1 to one is, the better the classification is. It is worth to note that both MCC and F1 are commonly used to evaluate the performance of binary classifiers (in our context, we consider these measures for the overall evaluation of the GGM selection). However, we put MCC above F1 score, because MCC takes into account all four classification categories (thus, it is more informative), whereas F1 score highly depends on the specification of positive categories (Chicco Citation2017).
We compare our proposed estimator with DT and GLASSO. We select the penalty parameters of these methods using univariate BIC and HQIC criteria. On the other hand, the parameters τ and γ of the proposed estimator DTEC are selected using multivariate BIC and HQIC criteria. Moreover, since the trace of the estimated matrix decreases when τ increases, we consider in the proposed problem (3) as a naive case. We call the obtained estimator simplified DTEC or SDTEC, which is defined as the solution of the following optimization problem:
(18)
(18)
In this way, we can calibrate only one parameter instead of two, which leads to saving the computational time.
4.3. Discussion of results
summarize the simulation results. Each table reports the averages over 100 replications and the standard deviations of the corresponding measures. We organize the discussion of our results as follows. First, we compare our proposed estimator DTEC with DT and GLASSO estimators when the penalty parameters are selected using the BIC approach. Next, we discuss the same comparison when the parameters are selected using the HQIC approach. Finally, we compare BIC and HQIC approaches through the corresponding measures.
Table 1. Average measures (with standard deviations) over 100 replications for Model 1.
Table 2. Average measures (with standard deviations) over 100 replications for Model 2.
Table 3. Average measures (with standard deviations) over 100 replications for Model 3.
Table 4. Average measures (with standard deviations) over 100 replications for Model 4.
Table 5. Average measures (with standard deviations) over 100 replications for Model 5.
Table 6. Average measures (with standard deviations) over 100 replications for Model 6.
First, we observe that when the parameters are selected through BIC approach, the estimator DTEC outperforms DT in terms of all statistical losses for almost all the models (except of model 3, in terms of KLL). The estimator DTEC outperforms DT for models 2, 4, 5, 6 in terms of MCC, for model 2 in terms of F1. On the other hand, DT outperforms DTEC for model 1 in terms of MCC, for models 1, 3, 4, 5, 6 in terms of F1. Furthermore, we observe that GLASSO provides high statistical losses and low GGM prediction measures.
Second, the results show that when the parameters are selected through HQIC approach, the estimator DTEC outperforms DT in terms of all statistical losses for almost all the models (except of model 2, in terms of KLL). On the other hand, DTEC outperforms DT for models 1, 2, 4, 5 in terms of MCC, for models 1, 2 in terms of F1. DT method outperforms DTEC for models 3, 4, 5 in terms of F1. Furthermore, we observe that GLASSO outperforms all the other estimators for model 6 in terms of F1. However, for the other models GLASSO provides poor results.
Finally, we conduct a comparison BIC and HQIC based on the corresponding losses and measures. We observe, that BIC provides higher statistical losses, whereas HQIC provides lower statistical losses for all considered approaches (including DT and GLASSO methods). Moreover, estimators obtained through BIC provide higher MCC than those for HQIC, and higher F1 for models 1, 2. Estimators obtained through HQIC provide higher F1 for models 3, 4, 5, 6 than those for BIC.
In sum, the proposed DTEC estimation method provides better performance than DT and GLASSO methods for most of the models in terms of several statistical losses and GGM prediction measures. Moreover, we observe that this conclusion holds if we consider the simplified SDTEC method (i.e., when ), since it performs as good as DTEC estimator. This finding leads to saving significantly the computational time without sacrificing too much the performance.
5. Real data application
In this section, we conduct an empirical analysis through real-data example. In particular, we focus on the problem of predicting breast cancer patients (subjects) with pathological complete response (pCR) using Linear Discriminant Analysis (LDA). For this application we use a dataset which contains gene expression levels of subjects with different stages of breast cancer. The dataset consists of 22,283 gene expression levels of 271 subjects. There are 58 subjects with pCR and 213 subjects with residual disease (RD). The applied dataset is available in the website of the National Center for Biotechnology Information (http://www.ncbi.nlm.nih.gov/).
First, following the analysis by Cai, Liu, and Luo (Citation2011), we divide the dataset into training and testing sets with sizes 227 and 44 (almost 5/6 and 1/6 of the observations), respectively. For the testing set, we randomly select 9 subjects with pCR and 35 subjects with RD (roughly 1/6 of the subjects in each group). The training set contains the remaining subjects. Second, based on the training set we perform two sample t-tests between two groups and select the most significant 200 genes with the smallest p-values. Third, using the training set, we estimate the precision matrix Ω with the DT, DTEC, SDTEC and GLASSO methods. Finally, we use the estimated precision matrix in the LDA score function, defined as where t = 1, 2 (t = 1 for pCR and t = 2 for RD) and
is the within group average, calculated using the training data. We classify the subject Y through the classification rule
To measure the prediction accuracy, we use Specificity, Sensitivity, MCC and F1. We consider TP and TN as the number of correctly predicted RD and pCR, respectively, and FP and FN as the number of erroneously predicted RD and pCR, respectively. We repeat this process 100 times. We report the average measurements in .
Table 7. Average pCR/RD classification measurements over 100 replications.
Our findings show that for both selection criteria the GLASSO method provides the highest Sensitivity, but it attains the lowest Specificity and MCC. On the other hand, the DTEC approach provides the highest Specificity and dominates all the other estimators in terms of MCC. We note that all methods provide very similar results in terms of the F1 score. However, as mentioned earlier, we find MCC more informative than F1 score. The results also show that SDTEC performs as good as the DTEC estimator. Furthermore, we observe that the obtained Specificity and MCC of the considered estimators are higher for BIC than the same for HQIC, whereas the Sensitivity and F1 of the estimators are higher for HQIC than the same for BIC.
In sum, for the considered application our proposed DTEC method (and its simplified version SDTEC) provides better classification performance than DT and GLASSO approaches. Therefore, employing additional penalization on the estimated precision matrix eigenvalues improves the estimate, even though the true precision matrix eigenvalues are unknown in this example.
6 Conclusions
In this article, we develop a new approach for estimating high dimensional precision matrices, using the penalization framework. The proposed method imposes a negative trace penalization on the recently introduced DT estimator. The additional penalty term controls the eigenvalues of the precision matrix estimator and diminishes the reduction of its largest eigenvalues. We conduct an extensive simulation study where we use several statistical losses and measures for the estimation evaluation. The results show that our proposed methodology outperforms DT and GLASSO methods for most of the considered scenarios. In line with the popular BIC method we study the performance of another technique based on HQIC for selecting the penalty parameters. In contrast to its little use in practice, HQIC demonstrates lower statistical losses than BIC in the simulation study. Moreover, we illustrate the performance of our proposed approach through an empirical application aimed at predicting the patients with pCR using LDA. Furthermore, we propose a simplified version of our methodology, which leads to saving the computational time without having to sacrifice the performance.
Acknowledgments
The author would like to thank the anonymous referee and the Editor for their helpful comments that led to an improvement of this article.
References
- Avagyan, V., A. M. Alonso, and F. J. Nogales. 2016. D-trace estimation of a precision matrix using adaptive lasso penalties. Advances in Data Analysis and Classification 12 (2):425–47. doi: 10.1007/s11634-016-0272-8.
- Avagyan, V., A. M. Alonso, and F. J. Nogales. 2017. Improving the graphical lasso estimation for the precision matrix through roots of the sample covariance matrix. Journal of Computational and Graphical Statistics 26 (4):865–72. doi: 10.1080/10618600.2017.1340890.
- Banerjee, O., L. El Ghaoui, A. d’Aspremont, and G. Natsoulis. 2006. Convex optimization techniques for fitting sparse gaussian graphical models. Pittsburg. Proceedings of the
- Cai, T., W. Liu, and X. Luo. 2011. A constrained ℓ1 minimization approach to sparse precision matrix estimation. Journal of the American Statistical Association 106 (494):594–607. doi: 10.1198/jasa.2011.tm10155.
- Chicco, D. 2017. Ten quick tips for machine learning in computational biology. BioData Mining 10 (1):35doi: 10.1186/s13040-017-0155-3.
- Dempster, A. 1972. Covariance selection. Biometrics 28 (1):157–75. doi: 10.2307/2528966.
- Fan, J., J. Feng, and Y. Wu. 2009. Network exploration via the adaptive Lasso and Scad penalties. The Annals of Applied Statistics 3(2):521–41. doi: 10.1214/08-AOAS215SUPP.
- Friedman, J., T. Hastie, and R. Tibshirani. 2008. Sparse inverse covariance estimation with the graphical lasso. Biostatistics 9(3):432–41. doi: 10.1093/biostatistics/kxm045.
- Goto, S., and Y. Xu. 2015. Improving mean variance optimization through sparse hedging restrictions. Journal of Financial and Quantitative Analysis 50 (06):1415–41. doi: 10.1017/S0022109015000526.
- Hannan, E. J., and B. G. Quinn. 1979. The determination of the order of an autoregression. Journal of the Royal Statistical Society: Series B 41 (2):190–5. doi: 10.1111/j.2517-6161.1979.tb01072.x.
- Lauritzen, S. 1996. Graphical models. Oxford: Clarendon Press.
- Liu, H., L. Wang, and T. Zhao. 2014. Sparse covariance matrix estimation with eigenvalue constraints. Journal of Computational and Graphical Statistics 23 (2):439–59. doi: 10.1080/10618600.2013.782818.
- Matthews, B. W. 1975. Comparison of the predicted and observed secondary structure of t4 phage lysozyme. Biochimica et Biophysica Acta 405(2):442–51. doi: 10.1016/0005-2795(75)90109-9.
- Maurya, A. 2014. A joint convex penalty for inverse covariance matrix estimation. Computational Statistics & Data Analysis 75:15–27. doi: 10.1016/j.csda.2014.01.015.
- McLachlan, S. 2004. Discriminant analysis and statistical pattern recognition. New York: Willey Interscience.
- Meinshausen, N., and P. Bühlmann. 2006. High-dimensional graphs and variable selection with the lasso. The Annals of Statistics 34 (3):1436–62. doi: 10.1214/009053606000000281.
- Powers, D. M. 2011. Evaluation: from precision, recall and f-measure to roc, informedness, markedness and correlation. Journal of Machine Learning Technologies 2 (1):37–63.
- Rothman, A., P. Bickel, E. Levina, and J. Zhu. 2008. Sparse permutation invariant covariance estimation. Electronic Journal of Statistics 2 (0):494–515. doi: 10.1214/08-EJS176.
- Ryali, S., T. Chen, K. Supekar, and V. Menon. 2012. Estimation of functional connectivity in fMRI data using stability selection-based sparse partial correlation with elastic net penalty. NeuroImage 59(4):3852–61. doi: 10.1016/j.neuroimage.2011.11.054.
- Stifanelli, P. F., T. M. Creanza, R. Anglani, V. C. Liuzzi, S. Mukherjee, F. P. Schena, and N. Ancona. 2013. A comparative study of covariance selection models for the inference of gene regulatory networks. Journal of Biomedical Informatics 46 (5):894–904. doi: 10.1016/j.jbi.2013.07.002.
- Tibshirani, R. 1996. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society: Series B 58 (1):267–88. doi: 10.1111/j.2517-6161.1996.tb02080.x.
- van der Pas, S. L., and P. D. Grünwald. 2014. Almost the best of three worlds: Risk, consistency and optional stopping for the switch criterion in single parameter model selection. arXiv Preprint arXiv:1408.5724.
- van Wieringen, W. N., and C. F. Peeters. 2016. Ridge estimation of inverse covariance matrices from high-dimensional data. Computational Statistics & Data Analysis 103:284–303. doi: 10.1016/j.csda.2016.05.012.
- Yuan, M. 2010. High dimensional inverse covariance matrix estimation via linear programming. Journal of Machine Learning Research 11:2261–86.
- Yuan, M., and Y. Lin. 2007. Model selection and estimation in the Gaussian graphical model. Biometrika 94 (1):19–35. doi: 10.1093/biomet/asm018.
- Zerenner, T., P. Friederichs, K. Lehnertz, and A. Hense. 2014. A gaussian graphical model approach to climate networks. Chaos: An Interdisciplinary Journal of Nonlinear Science 24 (2):023103. doi: 10.1063/1.4870402.
- Zhang, T., and H. Zou. 2014. Sparse precision matrix estimation via lasso penalized d-trace loss. Biometrika 88:1–18.