
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We consider two classes of exponential dispersion models of discrete probability distributions which are defined by specifying their variance functions in their mean value parameterization. These classes were considered in our earlier paper as models of overdispersed zero-inflated distributions. In this paper we analyze the application of these classes to fit count data having overdispersed and zero-inflated statistics. For this reason, we first elaborate on the computational aspects of the probability distributions, before we consider the data fitting with our models. We execute an extensive comparison with other statistical models that are recently proposed, on both real data sets, and simulated data sets. Our findings are that our framework is a flexible tool that gives excellent results in a wide range of cases. Moreover, specifically when the data characteristics show also large skewness and kurtosis our models perform best.
1. Introduction
In many scientific fields, one deals with systems, experiments, or phenomena that have random discrete outcomes. These outcomes are revealed typically through a set of data obtained by observing the system and counting the occurrences. The next issue is to describe statistically the system, modeling the occurrences by a discrete random variable, or just by a discrete probability distribution. Indeed, this is our starting point: we consider a number of sets of different count data, each from another application, and our goal is to fit suitable discrete distributions. In Bar-Lev and Ridder (Citation2021) we have developed a framework of exponential dispersion models for count data, which resulted in two classes of parametric families of discrete distributions presented in terms of their variance functions. We proved that these two classes have some desirable properties. Each of these classes was shown to be overdispersed and zero inflated in ascending order, making them as competitive statistical models for those in use in statistical modeling.
The contribution of this paper is, firstly, that we elaborate on the computational aspects of these distributions, and secondly, that we use our framework for fitting data sets. We shall examine the goodness-of-fit of the proposed distributions when applied not only to real data sets, but also to simulated data sets that were generated to have certain statistical characteristics. Moreover, we shall compare our fits with known fits from literature. Specifically, we consider data that show (i) overdispersion, meaning the variance is greater than the mean; and (ii) zero-inflation, i.e. a high occurrence of zero values. We shall see that our framework allows for very flexible modeling in all kinds of different statistical situations. Finally, we show empirically that our models outperform specifically in the cases with large skewness and kurtosis.
1.1. Literature review
Modeling count data by parametric families of discrete distributions has always been part of the statistical literature. Traditional models of count data were based on the Poisson and the negative binomial distributions, for instance in case of
actuarial sciences for car insurance claims (Gossiaux and Lemaire Citation1981), hospitalizations (Klugman, Panjer, and Willmot Citation1998), motor vehicle crashes (Lord, Washington, and Ivan Citation2005);
health economics for kidneys cysts (Chan et al. Citation2010), Thalassemia disease among children (Zafakali and Ahmad Citation2013), bovine tuberculosis cases (Coly et al. Citation2016);
psychology and behavioral sciences for cigarette smoking (Siddiqui et al. Citation1999), alcohol drinking (Armeli et al. Citation2005), prison incidents (Walters Citation2007).
The advantages of the Poisson and negative binomial distributions are their easy computations and parameter estimation. The main disadvantage of the Poisson distribution is its variance being equal to its mean. Thus, this distribution does not fit the data properly in case of overdispersion. The negative binomial distribution is an improvement since it can model overdispersion, however it could give poor fits to data with an excessive number of zeros (Coly et al. Citation2016).
In view of this, many other statistical models have been proposed and studied. An abundance of studies of new models can be observed in recent years, the reason being the availability of many diverse data sources, but more importantly, the advances in computational techniques. Commonly, the purpose is to handle overdispersion, or to handle zero-inflation; less frequently to handle both.
To name a few concerning handling overdispersion which are relevant for our study, generalized negative binomial (Jain and Consul Citation1971), Poisson-inverse Gaussian distribution (Willmot Citation1987), strict arcsine distribution (Kokonendji and Khoudar Citation2004), Poisson-Tweedie (Kokonendji, Dossou-Gbété, and Demétrio Citation2004), discrete Lindley distribution (Gomez-Deniz and Calderin-Ojeda Citation2011), a new logarithmic distribution (Gomez-Deniz, Sarabia, and Calderin-Ojeda Citation2011), discrete Gamma distribution (Chakraborty and Chakravarty Citation2012), and discrete generalized Rayleigh distribution (Alamatsaz et al. Citation2016). See Coly et al. (Citation2016), for a review on other models and applications.
Concerning the development of models to handle zero-inflation, we mention zero-inflated Poisson (Lambert Citation1992), zero-inflated negative binomial (Ridout, Hinde, and Demétrio Citation2001), and a modeling based on copula functions (Zhao and Zhou Citation2012), and for a review on more models and applications we refer to Yip and Yau (Citation2005). A few studies considered the development of models for both overdispersed and zero-inflated data, for instance, generalized Poisson (Consul Citation1989), and geometric discrete Pareto distribution (Bhati and Bakouch Citation2019), exponentiated discrete Lindley distribution (El-Morshedy, Eliwa, and Nagy Citation2020).
All above mentioned models deal with parametric distributions. The parameters are estimated directly from the data by moment matching or maximum likelihood estimation. Another statistical way of estimating the parameters of these distributions is by considering the concept of generalized linear models. For instance, Poisson regression is a generalized linear model with Poisson distribution error structure and the natural logarithm link function. We refer to Fahrmeir and Osuna Echavarría (Citation2006) for an overview of regression models dealing with both overdispersed and zero-inflated data.
The approach that we followed for developing our fitted models is based on the concept of natural exponential families, and its generalization to exponential dispersion models (Bar-Lev and Kokonendji Citation2017; Jørgensen Citation1997). These models play an important role in probabilistic and statistical modeling. Many well-known distributions and families of distributions are included in these models. For instance, when considering counting distributions, the Poisson, negative binomial, genaralized Poisson, generalized negative binomial, and Poisson-inverse Gaussian distributions are special cases of exponential dispersion models. Moreover, they show nice mathematical properties which are convenient for the practical fitting of data. We defer theoretical details on natural exponential families, exponential dispersion models, and our usage of these models to Sec. 2. In Sec. 3 we will elaborate on the computation of the probabilities and show some descriptive properties. Sec. 4 concerns fitting our models to real data and to simulated data, and compare with seven models recently developed in the literature for the same purposes. The performance of a model is expressed by the loglikelihood value, the statistic and its p-value, the root mean square error (RMSE), and the Kullback-Leibler divergence . Based on the results, we discuss the suitability of our models, specifically in case the data show large skewness and kurtosis.
2. Families of probability distributions
In this section we first summarize the techniques of modeling probability distributions based on the concepts of natural exponential families, exponential dispersion models, and mean parameterization. For more details we refer to Bar-Lev and Kokonendji (Citation2017); Jørgensen and Kokonendji (Citation2016); Letac and Mora (Citation1990). Also, we present our specific classes of these models.
2.1. Natural exponential families
Natural exponential families of distributions form a classic tool in statistical modeling and analysis, e.g. see Barndorff-Nielsen (Citation1978). We give the definition here to introduce our notation. Let μ be a positive Radon measure on the Borel sets of the real line with convex support, and define
where we use the symbol
for “defined to be equal to”. Assume that Θ is nonempty and open. According to the Hölder’s inequality, Θ is an interval. We define for
the cumulant transform
Then, the natural exponential family generated by μ is defined by the set of probability distributions
(1)
(1)
The measure μ is called the kernel of the family. The family is parameterized by the natural parameter θ. Differentiation is permitted and gives the mean and variance
2.2. Exponential dispersion models
The concept of natural exponential families generalizes in the following manner to exponential dispersion models which gives the statistical practitioner a convenient framework (Jørgensen Citation1997). Given a natural exponential family with kernel μ and cumulant
let Λ be the set of p > 0 such that
is the cumulant transform for some measure μp. Thus for any
we get a natural exponential family of the form
(2)
(2)
This family of distributions, parameterized by pairs is called the exponential dispersion model. Parameter p is called the dispersion parameter. Many useful families of discrete distributions belong to exponential dispersion models (Kokonendji, Dossou-Gbété, and Demétrio Citation2004), and for this reason these models are important for fitting discrete data. Furthermore, exponential dispersion models show convenient properties, such as closure under convolution, and infinite divisibility (iff
), see Jørgensen (Citation1997) for more details.
2.3. Mean parameterization
For our purposes it is convenient to consider a reparameterization of the exponential dispersion model, similarly as has been introduced in Letac and Mora (Citation1990) for natural exponential families. Starting point is the family of distributions defined in (2), in which we denote the cumulant by Recall that any distribution
of the family has mean
and variance
The image of the differentiation of the cumulant, i.e.
is called the mean domain of the family
Because the map
is one-to-one, its inverse function
is well defined, i.e.
(3)
(3)
The corresponding variance function is Furthermore, we define
(4)
(4)
In this way the natural exponential family is modeled by its mean parameterization,
(5)
(5)
Note that the mean parameterization has an associated variance function on the mean domain
Conversely, when an exponential dispersion model
is given by the pair
we find the distributions by
(6)
(6)
In our study we are interested in discrete distributions, say with probability mass functions where X represents the associated random variable. Specifically, we consider distributions belonging to exponential dispersion models, using the mean parameterization. Thus, the probability mass functions are represented by
(7)
(7)
2.4. Variance function classes
Here we present the two models (or families) of distributions that were considered in Bar-Lev and Ridder (Citation2021) as a means of a general framework for zero-inflated, overdispersed probability distributions. The models are defined through their variance function classes of the mean parameterization.
ABM class, named after Awad, Bar-Lev, and Makov (Citation2016), with mean m > 0, and variance function
(8)
Note that we exclude the r = 0 case, which would give the Poisson distribution. The case r = 1 gives the negative binomial distribution. The case r = 2 is called generalized Poisson (Consul Citation1989), or Abel distribution (Letac and Mora Citation1990).
LM class with mean m > 0 and variance function
Note that the mean domain of this class is a finite interval,
It has been shown in Letac and Mora (Citation1990) that the natural exponential families associated with these classes of variance functions are concentrated on the nonnegative integers. To our best knowledge these distributional models have not been used before in statistical fitting to real data, except for the trivial cases. We have considered in Bar-Lev and Ridder (Citation2019) the Abel distribution for modeling insurance claim data.
It is easy to see that both two classes show overdispersion, and that the dispersion increases with the power r in the expressions (8)-(9) of the variance functions. Moreover, in Bar-Lev and Ridder (Citation2021) we have shown that both classes satisfy also an increasing zero-inflation property. This means, denoting
for the probability mass in zero given mean m, dispersion parameter p and power r in the variance function, then
These properties make the two classes a flexible tool for fitting overdispersed, zero-inflated data, which we will show in the sequel. For this purpose, however, we have to consider a method for computing the probability dsitributions.
2.5. Poisson-tweedie mixtures
Our two classes are two special exponential dispersion models in the sense that (i) they satisfy to be concentrated on the nonnegative integers, and (ii) their variance functions are exponential functions. Moreover, we consider the power parameter to be integer, which leads to a polynomial variance function (ABM), or a rational function (LM). Property (i) is a consequence of the sufficient and necessary conditions for variance functions that are established in Letac and Mora (Citation1990). Other exponential dispersion models satisfying (i) and (ii) are the Hinde-Demétrio class with variance (Hinde and Demétrio Citation1998; Kokonendji, Dossou-Gbété, and Demétrio Citation2004), Poisson-Tweedie mixture class with variance
(Jørgensen and Kokonendji Citation2016; Kokonendji, Dossou-Gbété, and Demétrio Citation2004), and Poisson-exponential-Tweedie models which have the variance function
(Jørgensen and Kokonendji Citation2016), where exponent
may be non-integer. All these classes are based on mixing Poisson probabilities by a Tweedie distribution, which is inherently different from our approach. Also these classes are useful for overdispersed zero-inflated data as has been exposed in Jørgensen and Kokonendji (Citation2016). In Sec. 4 of our data fitting analysis we shall include the Poisson-Tweedie mixture model.
3. Computing distributions
In this section we elaborate the numerical methods concerning computation of our distributions. The general procedure follows the guidelines of Letac and Mora (Citation1990). Let be given a variance function V(m) of a natural exponential family of discrete distributions, where we have dropped the subscript dispersion parameter p for ease of notation and exposition. Recall the integral Equationequations (6)(6)
(6) .
We solve for primitives
The specific constants c0 and d0 are obtained by the boundary conditions
Note that the d0 constant of the
It is convenient to introduce
3. The main difficulty lies in computing the kernel as in (12). Define for
and Thus,
It is easy to see that
The next step is to compute the
-st derivative of
in (12). Apply the chain rule:
where the sum is over all nonnegative integer solutions of the Diophantine equation and where
In the next sections we compute the derivatives
for the separate classes. The final computation for kernel
involves evaluating these expressions in m = 0, and dividing by
Thus,
(14)
(14)
3.1. Computing ABM distribution
Recall that the variance function is given by
The integral equations are solved by (Bar-Lev and Ridder Citation2021)
where the coefficients
are,
Furthermore,
We get
with
The j-th derivative of the function becomes
Thus, by defining
we obtain for the kernel
in (14),
3.2. Computing LM distribution
The variance function is
The procedure is similar to computing the ABM and LMS distributions. Now it holds that (Bar-Lev and Ridder Citation2021)
where
Thus
Now we get
with
And,
where
This becomes
3.3. Plotting the distributions
Before we discuss the results of the data analysis and the fit of our distributions, we present graphs of the probability mass functions of these distributions as an illustration of their shape and properties. From these figures we observe that the probability mass functions are either decreasing or unimodal. Furthermore, we see that both classes allow for zero-inflation, but also for skewness to the right with less heavy probability mass in zero. Generally, we conclude that our framework of the two variance function classes for exponential families of distributions is a flexible tool for describing discrete data.
3.3.1. ABM class
and show the probability mass functions of ABM distributions with the same mean m = 5, the same power r = 4 of the variance function, but with increasing dispersion parameter p. When computing the features of these distributions, one observes decreasing zero probability, dispersion, skewness and kurtosis.
Figure 1. Probability mass functions of the ABM class for and p = 1, 3, and 5, respectively.
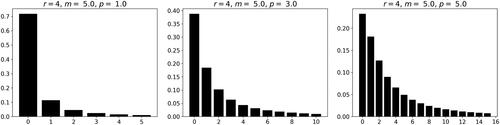
Figure 2. Probability mass functions of the ABM class for and
and 15, respectively.
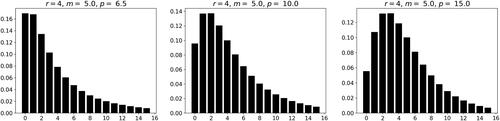
We obtain similar histograms in reversed order when mean m and dispersion p are fixed, and the variance function power r is increasing. Then, the distributions show increasing zero probability, dispersion, skewness and kurtosis.
3.3.2. LM class
and show the probability mass functions of LMNS distributions with the same mean m = 2, the same power r = 4 of the variance function, but with increasing dispersion parameter p. Similar to the ABM distributions, we see decreasing zero probability, dispersion, skewness and kurtosis.
Figure 3. Probability mass functions of the LM class for and
and 8, respectively.
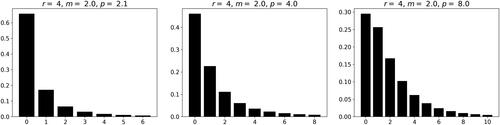
Figure 4. Probability mass functions of the LM class for and p = 12, 16, and 20, respectively.
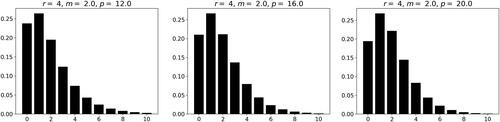
Again, when the variance function power r is increasing at a constant m and p, the distributions have increasing zero probability, dispersion, skewness and kurtosis.
4. Data applications
Well-known data sets that are used very often for validation and comparison reasons, concern automobile insurance claims because these show heavy overdispersion and zero inflation. Other sets can be found in diverse fields such as marketing, biometry, health and social sciences. In this section we investigate a number of these sets that were used in recent literature on the development of fitting models. We consider the following two-parameter models and their probability mass functions. These seven distributions are a mix of traditional ones, and some recently developed. We leave out models with one parameter, with three or more parameters, and regression models.
PIG (Poisson-inverse Gaussian distribution) in Willmot (Citation1987),
NLD (new logarithmic distribution) in Gomez-Deniz, Sarabia, and Calderin-Ojeda (Citation2011),
with parameters (
), and
NGDP (a new geometric discrete Pareto distribution) in Bhati and Bakouch (Citation2019),
with parameters and
EDLID (an exponentiated discrete Lindley distribution in from El-Morshedy, Eliwa, and Nagy (Citation2020),
where with parameters
and b > 0.
BTD (Bell-Touchard discrete distribution) in Castellares, Lemonte, and Moreno–Arenas (Citation2020),
with positive parameters and where the
are Touchard polynomials; i.e,
ZIP (zero-inflated Poisson), in Lambert (Citation1992),
where and
PTD (Poisson-Tweedie distribution) in (Bonat et al. Citation2018; Kokonendji, Dossou-Gbété, and Demétrio Citation2004),
where is a Tweedie density function with parameters p > 0, t < 0,
The probabilities are computed by the recursion
where satisfies
We have included this distribution because it is associated to an exponential dispersion model with variance function
which is an exponential function, similar to our classes. For a fixed exponent γ is it as a two-parameter distribution.
We applied maximum likelihood for estimating the parameters of all distributions. Concerning our distributions, we fix the power r in the range we set the mean parameter
and then compute the dispersion parameter p by maximum likelihood estimation. We follow the same procedure for the Poisson-Tweedie distribution by fixing the power parameter γ.
4.1. Performance measures
Consider a data set of counts, meaning, n0 observations of value 0, n1 observations of value 1, etc. Let
be the total number of observations. The empirical probability mass function is
We shall characterize such a data set by five features: zero mass, average, index of dispersion, skewness, and kurtosis. These are well-known, but for completeness we summarize them. Recall moments and central moments of order by
and that one usually denotes s2 for the variance (central 2-nd moment
). Then,
Furthermore, consider a (theoretical) probability model of a discrete random variable X on with probability mass function
The objective is to find a ‘good fitting’ model of the data. The performance of a model is expressed through the following measures.
The logarithm of the likelihood:
p-value of the
Root mean squared error (RMSE):
Kullback-Leibler divergence (KL):
In the literature there are usages of a few other measures, such as mean square error (MSE), Akaike information criterion (AIC), or Bayesian information criterion (BIC). These are related to the measures mentioned earlier, and do not give more information.
4.2. Real data
We chose four data sets with various characteristics as summarized in . Data set 1 was considered in the literature for fitting by PIG, NLD, NGDP, and PTB, data set 2 by NGDP, data set 3 by EDLID, and data set 4 by NLD. Note that in this order of the sets, the zero mass probability, skewness and kurtosis are decreasing.
Table 1. Characteristics of data sets.
4.2.1. Data set 1
Insurance claims in Zaire in 1974 (Gossiaux and Lemaire Citation1981) ().
Table 2. Data set 1.
summarizes the performances of the distributions that we mentioned earlier. We have computed our fitting models for power parameter r in the range of As selection criterion we used the chi-squared test on goodness-of-fit (Andrews Citation1988a, Citation1988b). This was the comparison measure for these data in Gossiaux and Lemaire (Citation1981), and since then it has been considered for instance in Willmot (Citation1987); Kokonendji and Khoudar (Citation2004); Kokonendji, Dossou-Gbété, and Demétrio (Citation2004). Thus, we choose the model that gave the the lowest
-value, equivalently, the one that gave the highest p-value. For the Poisson-Tweedie distribution we did a similar experiment concerning the power parameter γ, with step sizes 0.001.
Table 3. Performance of fitting data set 1.
When we consider the criterion, we find the best fit by the LM model (r = 4), however the ABM and model gives better (smaller) root mean squared error and Kullback-Leibler distance. The PIG and NGDP were proposed to model these data, and they are clearly performing as good as LM/ABM. Note that PTD is competetive in all criteria. The classic ZIP model shows bad performance, we will see this also in the other experiments.
4.2.2. Data set 2
The number of accidents experienced by machinists (Bliss and Fisher Citation1953) ().
Table 4. Data set 2.
summarizes the performances. Also here, the ABM and LM models perform best, with PTD competing close. The NGDP was proposed to model these data, it gives also a good fit in all criteria. We found the best PTD for close to γ = 3 in which case the PTD is in fact the PIG distribution. Indeed we see that the PTD performs slightly better than PIG.
Table 5. Performance of fitting data set 2.
4.2.3. Data set 3
The counts of cysts of kidneys using steroids (Chan et al. Citation2010) ().
Table 6. Data set 3.
summarizes the performances. The EDLID was proposed to model these data, it gives indeed the best fit. The ABM-r = 1 and PTD-γ = =nd PTD-indeed the best fit. The ABM- ABM-proposed to model these data, it gives indeed the best fit. The ABM-lham, A. S. Woolf, and D. A. L
Table 7. Performance of fitting data set 3.
4.2.4. Data set 4
Number of claims of automobile liability policies (Klugman, Panjer, and Willmot Citation1998) ().
Table 8. Data set 4.
summarizes the performances. The NLD was proposed to model these data, and it gives indeed a good fit, but also distribution EDLID. Remarkebly, the BTD performs excellent. The data set shows low zero-inflation and low higher moments, resulting that our models are not as good.
Table 9. Performance of fitting data set 4.
4.3. Simulated data
We saw in the results of our models in comparison with recently proposed others, that the larger zero-mass probability, skewness, and kurtosis data have, the better our models perform. When these data characteristics are rather large, our models outperform even models that were proposed for fitting these data sets. When the data characteristics are rather small, our models may be competitive, but they seem not to be the best for fitting purposes compared to the other models that we considered.
For testing this hypothesis we have executed an extensive numerical study on a total of 20 data sets found in literature, see our report Bar-Lev and Ridder (Citation2020) which is available on the arXiv. When we order these sets by decreasing skewness and kurtosis, and when we consider the and p-value performances, the first 13 data were fitted best by ABM or LMNS with one exception. The last 7 data were fitted best by (one of) the other four models.
For further testing our claim that our models are suitable for fitting purposes when data show high zero-inflation, skewness and kurtosis, we ran a simulation experiment. First we constructed a probability distribution on a finite support having the required properties of zero-mass and the first four moments. The probability distribution was obtained by applying the maximum entropy method with these constraints (Jaynes Citation1957). From the distribution we generated N = 10000 simulated data, and then apply our fitting models to these data. We present here three data sets that were simulated in this manner. All data have values ().
Table 10. Three sets of simulated data.
The first two sets were obtained from distributions with relative large zero-mass, skewness and kurtosis, see the characteristics in , though the second set is slightly more flat. The third set is much more flat with relative small zero-mass, skewness and kurtosis.
Table 11. Characteristics of simulated data sets.
Finally, the performances of our ABM and LM models against the seven models that we consider in our study for comparisons, are summarized in . The results confirm our suggestion that our models are well-suited for fitting zero-inflated overdispersed data with relative large skewness and kurtosis. Moreover, ABM is more suited than LM when the tail is flatter.
Table 12. Performance of fitting data set 5.
Table 13. Performance of fitting data set 6.
Table 14. Performance of fitting data set 7.
summarizes the performances for fitting data set 5. For this data set with high skewness and kurtosis, and large zero-inflation, we found excellent fitting by the LM class. Note also the competitive perfromance of PTD with power parameter γ close to 3, and therefore the PIG is not too bad. Most other distributions are not suited to model such data.
summarizes the performances for fitting data set 6. Here we see that an ABM distribution has the best fit when considering the p-value criterion, but for the other criteria, either the NGDP or the PTD perform best. Most other distributions perform basdly.
summarizes the performances for fitting data set 7. Remarkebly all but one model (EDLID) has difficulty with finding a good fit. The data set is rather flat with relative low zero-inflation and low higher moments.
5. Conclusion
In this paper we investigated two classes of exponential dispersion models for fitting data sets showing zero-dispersion and overdispersion. These models act as alternatives not only to classic distributions such as Poisson, generalized Poisson, negative binomial, discrete Lindley, and Poisson-inverse Gaussian, but also to recently proposed models, such as discrete Gamma, discrete Rayleigh, new logarithmic, geometric discrete Pareto, and exponentiated discrete Lindley, to name a few. Our two classes are given by specifying their variance functions in the mean parameterization of their exponential forms. The variance functions are particular polynomials of the mean. This is a convenient and flexible way of specifying families of probability distributions, namely by a functional form of the first two moments. Moreover, we were able to to develop a numerical procedure to compute the actual associated probability distributions. Further investigation of these distributions showed that they show a monotonic behavior for zero-inflation, skewness, and kurtosis, by varying the dispersion parameter, or by varying the degree of the variance polynomials. Finally, the main purpose was to determine how good fits our models are to discrete count data such as insurance claims. We executed an extensive numerical study on twenty real data sets, four of which are reported in this paper, and on three sets of simulated data, where we compared our models with four recently developed in the literature. The conclusion is that our models are very well suited to fit zero-inflated overdispersed data with large skewness and kurtosis.
Acknowledgements
The authors are grateful to the reviewers for their comments and suggestions for improvements.
Additional information
Funding
References
- Alamatsaz, M. H., S. Deey, T. Dey, and S. Shams Harandi. 2016. Discrete generalized Rayleigh distribution. Pakistan Journal of Statistics 32 (1):1–20.
- Andrews, D. 1988a. Chi-square diagnostic tests for Econometric models: Introduction and application. Journal of Econometrics 37 (1):135–56. doi:10.1016/0304-4076(88)90079-6.
- Andrews, D. 1988b. Chi-square diagnostic tests for Econometric models: Theory. Econometrica 56 (6):1419–53. doi:10.2307/1913105.
- Armeli, S., C. Mohr, M. Todd, N. Maltby, H. Tennen, M. A. Carney, and G. Affleck. 2005. Daily evaluation of anticipated outcomes from alcohol use Aamong college students. Journal of Social and Clinical Psychology 24 (6):767–92. doi:10.1521/jscp.2005.24.6.767.
- Awad, Y., S. K. Bar-Lev, and, and U. Makov. 2016. A new class counting distributions embedded in the Lee-Carter model for mortality projections: A Bayesian approach. Technical report No. 146, Actuarial Research Center, University of Haifa, Israel.
- Bar-Lev, S. K., and C. C. Kokonendji. 2017. On the mean value parameterization of natural exponential families - a revisited review. Mathematical Methods of Statistics 26 (3):159–75. doi:10.3103/S1066530717030012.
- Bar-Lev, S. K., and A. Ridder. 2019. Monte Carlo methods for insurance risk computation. International Journal of Statistics and Probability 8 (3):54–74. doi:10.5539/ijsp.v8n3p54.
- Bar-Lev, S. K., and A. Ridder. 2020. Supplementary data analyses of exponential dispersion models for overdispersed zero-inflated count data. Available as arXiv:2003.13854.
- Bar-Lev, S. K., and A. Ridder. 2021. New exponential dispersion models for count data - the ABM and LM classes. ESAIM: Probability and Statistics 25:31–52. doi:10.1051/ps/2021001.
- Barndorff-Nielsen, O. 1978. Information and exponential families in statistical theory. Chichester: Wiley.
- Bhati, D., and H. S. Bakouch. 2019. A new infinitely divisible discrete distribution with applications to count data modelling. Communications in Statistics - Theory and Methods 48 (6):1401–16. doi:10.1080/03610926.2018.1433847.
- Bliss, C. I., and R. A. Fisher. 1953. Fitting the negative binomial distribution to biological data. Biometrics 9 (2):176–200. doi:10.2307/3001850.
- Bonat, W. H., B. Jørgensen, C. C. Kokonendji, J. Hinde, and C. G. B. Demétrio. 2018. Extended poisson–tweedie: Properties and regression models for count data. Statistical Modelling 18 (1):24–49. doi:10.1177/1471082X17715718.
- Castellares, F., A. J. Lemonte, and G. Moreno–Arenas. 2020. On the two-parameter Bell–Touchard discrete distribution. Communications in Statistics - Theory and Methods 49 (19):4834–52. doi:10.1080/03610926.2019.1609515.
- Chakraborty, S., and D. Chakravarty. 2012. Discrete Gamma distributions: Properties and parameter estimations. Communications in Statistics - Theory and Methods 41 (18):3301–24. doi:10.1080/03610926.2011.563014.
- Chan, S.-K., P. R. Riley, K. L. Price, F. McElduff, P. J. Winyard, S. J. M. Welham, A. S. Woolf, and D. A. Long. 2010. Corticosteroid-induced kidney dysmorphogenesis is associated with deregulated expression of known cystogenic molecules, as well as indian hedgehog. American Journal of Physiology-Renal Physiology 298 (2):F346–356. doi:10.1152/ajprenal.00574.2009.
- Coly, S., A.-F. Yao, D. Abrial, and M. Charras-Garrido. 2016. Distributions to model overdispersed count data. Journal de la Société Française de Statistique 157 (2):39–63.
- Consul, P. C. 1989. Generalized poisson distributions: Properties and applications. New York: Marcel Dekker.
- El-Morshedy, M., M. S. Eliwa, and H. Nagy. 2020. A new two-parameter exponentiated discrete Lindley distribution: Properties, estimation and applications. Journal of Applied Statistics 47 (2):354–75. doi:10.1080/02664763.2019.1638893.
- Fahrmeir, L., and L. Osuna Echavarría. 2006. Structured additive regression for overdispersed and zero-inflated count data. Applied Stochastic Models in Business and Industry 22 (4):351–69. doi:10.1002/asmb.631.
- Gomez-Deniz, E., and E. Calderin-Ojeda. 2011. The discrete Lindley distribution: Properties and applications. Journal of Statistical Computation and Simulation 81:1405–16.
- Gomez-Deniz, E., J. M. Sarabia, and E. Calderin-Ojeda. 2011. A new discrete distribution with actuarial applications. Insurance: Mathematics and Economics 48 (3):406–12. doi:10.1016/j.insmatheco.2011.01.007.
- Gossiaux, A., and J. Lemaire. 1981. Methodes d’ajustement de distributions de sinistres. Bulletin of the Association of Swiss Actuaries 81:87–95.
- Hinde, J., and C. G. B. Demétrio. 1998. Overdispersion: Models and estimation. Computational Statistics & Data Analysis 27 (2):151–70. doi:10.1016/S0167-9473(98)00007-3.
- Jain, G. C., and P. C. Consul. 1971. A generalized negative binomial distribution. SIAM Journal on Applied Mathematics 21 (4):501–13. doi:10.1137/0121056.
- Jaynes, E. T. 1957. Information theory and statistical mechanics. Physical Review 106 (4):620–30. doi:10.1103/PhysRev.106.620.
- Jørgensen, B. 1997. The theory of exponential dispersion models, Monograph on statistics and probability. Vol. 76. London: Chapman and Hall.
- Jørgensen, B., and C. C. Kokonendji. 2016. Discrete dispersion models and their Tweedie asymptotics. AStA Advances in Statistical Analysis 100 (1):43–78. doi:10.1007/s10182-015-0250-z.
- Klugman, S., H. Panjer, and G. Willmot. 1998. Loss models. From data to decisions. 3rd ed. New York: John Wiley and Sons.
- Kokonendji, C. C., S. Dossou-Gbété, and C. G. B. Demétrio. 2004. Some discrete exponential dispersion models: Poisson-Tweedie and Hinde-Demétrio classes. Statistics and Operations Research Transactions 28 (2):201–14.
- Kokonendji, C. C., and M. Khoudar. 2004. On strict arcsine distribution. Communications in Statistics - Theory and Methods 33 (5):993–1006. doi:10.1081/STA-120029820.
- Lambert, D. 1992. Zero-inflated Poisson regression, with an application to defects in manufacturing. Technometrics 34 (1):1–14. doi:10.2307/1269547.
- Letac, G., and M. Mora. 1990. Natural real exponential families with cubic variance functions. The Annals of Statistics 18 (1):1–37. doi:10.1214/aos/1176347491.
- Lord, D., S. P. Washington, and J. N. Ivan. 2005. Poisson, poisson-gamma and zero-inflated regression models of motor vehicle crashes: Balancing statistical fit and theory. Accident Analysis & Prevention 37 (1):35–46. doi:10.1016/j.aap.2004.02.004.
- Ridout, M., J. Hinde, and C. G. B. Demétrio. 2001. A score test for testing a zero-inflated Poisson regression model against zero-inflated negative binomial alternatives. Biometrics 57 (1):219–23. doi:10.1111/j.0006-341X.2001.00219.x.
- Siddiqui, O., J. Mott, T. Anderson, and B. Flay. 1999. The application of Poisson random-effects regression models to the analyses of adolescents’ current level of smoking. Preventive Medicine 29 (2):92–101. doi:10.1006/pmed.1999.0517.
- Walters, G. D. 2007. Predicting institutional adjustment with the lifestyle criminality screening form and the antisocial features and aggression scales of the PAI. Journal of Personality Assessment 88 (1):99–105. doi:10.1080/00223890709336840.
- Willmot, G. 1987. The Poisson-inverse Gaussian distribution as an alternative to the negative binomial. Scandinavian Actuarial Journal 1987 (3-4):113–27. doi:10.1080/03461238.1987.10413823.
- Yip, K. C. H., and K. K. W. Yau. 2005. On modelling claim frequency data in general insurance with extra zeros. Insurance: Mathematics and Economics 36 (2):153–63. doi:10.1016/j.insmatheco.2004.11.002.
- Zafakali, N. S., and W. M. A. W. Ahmad. 2013. Modelling and handling overdispersion health science data with zero-inflated Poisson model. Journal of Modern Applied Statistical Methods 12 (1):255–60. doi:10.22237/jmasm/1367382420.
- Zhao, X., and X. Zhou. 2012. Copula models for insurance claim numbers with excess zeros and time-dependence. Insurance: Mathematics and Economics 50 (1):191–9. doi:10.1016/j.insmatheco.2011.11.004.