
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this article, we propose generalized two-parameter (GTP) estimators and an algorithm for the estimation of shrinkage parameters to combat multicollinearity in the multinomial logit regression model. In addition, the mean squared error properties of the estimators are derived. A simulation study is conducted to investigate the performance of proposed estimators for different sample sizes, degrees of multicollinearity, and the number of explanatory variables. Swedish football league dataset is analyzed to show the benefits of the GTP estimators over the traditional maximum likelihood estimator (MLE). The empirical results of this article revealed that GTP estimators have a smaller mean squared error than the MLE and can be recommended for practitioners.
1. Introduction
The multinomial logit regression (MNLR) model introduced by Luce (Citation1959) and is often used when the dependent variable comprises more than two categories. Mostly, the MNLR is used to model nominal output variables in which the log odds of the outputs are modeled as a linear combination of explanatory variables. Nowadays, the MNLR is a very common choice among applied researchers for analyzing the categorical response variable having at least three categories. For example, blood types of humans and animals give different diagnostic tests, determination of socioeconomic factors that affect major choices made by consumers, getting unrestricted credit, restricted credit, or no credit by different corporations due to their financial and official characteristics and among others. It is a general practice to use an ordinary maximum likelihood estimator (MLE) to estimate the parameters vector of the MNLR. Multicollinearity is a situation in MNLR where two or more explanatory variables are highly correlated with each other. The problem of multicollinearity can have numerous adverse effects on regression coefficients. The main drawback of multicollinearity is that the variance of the MLE becomes inflated (Månsson et al., Citation2018). In addition, on average estimates are too large and can have wrong signs of the estimated parameters. Consequently, the probability of type-II error of estimated parameter will be increased, which result in decreased statistical power; the Wald statistic gives insignificant results in the presence of multicollinearity (Qasim, Kibria, et al. Citation2020a).
Different biased estimation methods have been proposed to solve the problem of multicollinearity for a different type of regression models. Some of the biased estimation methods for popular regression models are: Hoerl and Kennard (Citation1970) proposed a ridge regression (RR) estimator to deal the problem of multicollinearity for the linear regression model (LRM). Schaefer, Roi, and Wolfe (Citation1984), Schaefer (Citation1986) introduced ridge regression and Stein estimators for the logistic regression model. Kejian (Citation1993, 2003) proposed a Liu and Liu-type estimators for the LRM. Månsson and Shukur (Citation2011a) and Månsson, Kibria, and Shukur (Citation2012) developed ridge regression and Liu estimators for the logit regression model, respectively. Månsson and Shukur (Citation2011b), Qasim, Kibria, et al. (Citation2020a), Qasim, Månsson, et al. (Citation2020b), Lukman et al. (Citation2020) and Noori Asl et al. (Citation2020) suggested Poisson RR, Poisson Liu regression, biased adjusted Poisson RR, modified Poisson ridge-type, and penalized and ridge-type shrinkage estimators in the Poisson regression model, respectively. Månsson (Citation2012, Citation2013) introduced ridge negative binomial ridge and Liu regression estimators, respectively. Kurtoğlu and Özkale (Citation2016), Qasim, Amin, and Amanullah (Citation2018), Mandal et al. (Citation2019), Amin, Qasim, Yasin, et al. (Citation2020b), Amin, Qasim, Amanullah, et al. (Citation2020a) and Lukman et al. (Citation2020) developed Liu estimation, Liu shrinkage parameters, Stein-type shrinkage estimators, bias and almost unbiased RR and modified ridge-type estimators for the gamma regression, respectively. Karlsson, Månsson, and Kibria (Citation2020) and Qasim, Månsson, and Golam Kibria (Citation2021) proposed beta Liu and ridge regression estimators, respectively.
Özkale and Kaciranlar (Citation2007) proposed a two-parameter biased estimator by grafting contraction estimator into modified RR estimator in the LRM. They stated that as the value of k (ridge parameter) becomes increases then the RR has an unnecessary amount of bias. Yang and Chang (Citation2010) suggested another efficient two-parameter estimator. Toker, Üstündağ Şiray, and Qasim (Citation2019) proposed a first-order two-parameter estimator in the generalized linear models (GLM). Regarding the considerable literature on a two-parameter estimator for a different form of the GLM, we refer to Huang and Yang (Citation2014), Asar and Genç (Citation2018), Abonazel and Farghali (Citation2019), Rady, Abonazel, and Taha (Citation2019), Amin, Qasim, and Amanullah (Citation2019), Farghali (Citation2019), Akram, Amin, and Qasim (Citation2020), Naveed et al. (Citation2020) and among others. El-Dash, El-Hefnawy, and Farghali (Citation2011) proposed Stein-type ridge regression and generalized ridge regression estimators for the MNLR and Månsson et al. (Citation2018) suggested ridge estimators for the MNLR. By extending the work of Månsson, Kibria, and Shukur (Citation2012), Farghali (Citation2014) proposed a multinomial Liu estimator. Asl et al. (Citation2021) proposed the Stein-type shrinkage ridge estimator when the regression coefficients are restricted to a linear subspace in the GLM and derive the asymptotic biases and risks of the proposed estimators.
The main purpose of this article is to develop two different generalized two-parameter (GTP) estimators for the MNLR by following the work of Abonazel and Farghali (Citation2019) and Yang and Chang (Citation2010). In addition, we suggest a new algorithm for the selection of optimal shrinkage parameters for GTP estimators. The proposed GTP estimators are general estimators which include the MLE, RR, generalized RR, Liu estimator, and generalized Liu-type estimator. The mean square error (MSE) properties of the estimators are examined and show the superiority of the proposed estimators under certain conditions. Besides, the Monte Carlo simulation and Swedish football league dataset are analyzed to demonstrate the benefit of the proposed estimators over the existing classical MLE.
The rest of the article is arranged as follows: The MNLR model, GTP estimators and MSE properties are well defined in Sec. 2. Estimation methods for selection of generalized optimal shrinkage parameters are explained in Sec. 3. Simulation experiment and their results are discussed in Sec. 4. The advantage of our recommended estimators is demonstrated by analyzing empirical application in Sec. 5 and finally, some concluding remarks are given in Sec 6.
2. Model and proposed GTP estimators
This section illustrates the methodology of the MNLR and MLE. In addition, we propose two new GTP estimators by considering the work of Abonazel and Farghali (Citation2019), and Huang and Yang (Citation2014) in the MNLR model.
2.1. Multinomial logit regression
The multinomial logistic regression model assumes that the response variable has a multinomial distribution. Consider a trial that results in exactly one of some fixed finite number of
possible outcomes, with probabilities
…
and
. The random variable
for n independent trials represents the multinomial trial for observation
and
takes the following values:
Thus, The probability density function of multinomial distribution is defined as
(1)
(1)
where
Using the value of
in (1) the density function can be written as
To develop the MNLR, assume that the explanatory variables are measured for observations
which follow a multinomial distribution with probability parameters
…
Then the conditional probabilities of each response variables’ level given the explanatory variables vector are
Thus, the MNLR is
(2)
(2)
where
is the sample size,
is the number of explanatory variables,
is the number of levels of the response variable (in model (2) level
is the reference level),
parameters at the
level of the response variable.
The most common method for estimating the model parameters is to apply the MLE, which maximizes the log-likelihood function
Let .
Then
(3)
(3)
The MLE can be found by setting the first derivative of (3) to zero. Thus, is obtained by solving the following nonlinear system of equations:
(4)
(4)
(5)
(5)
The solution to EquationEquations (4)(4)
(4) and Equation(5)
(5)
(5) is found by applying numerical methods such as Newton- Raphson or scoring method see Agresti (Citation2013) and Hosmer, Lemeshow, and Sturdivant (Citation2013) and
asymptotic variance-covariance matrix of
is calculated as follows:
where
is a
matrix of the explanatory variables which the first column contains one and
is a
diagonal matrix with its general element
is an
diagonal matrix with its general element
The scalar mean squared error
of
is obtained as:
where
is the
th eigenvalue at the
th level of the response variable.
2.2. New generalized two-parameter estimators
2.2.1. Generalized Liu-type multinomial logistic estimator
Hoping that the combination of two different estimators might inherit the advantages of both estimators, and following the work of Abonazel and Farghali (Citation2019) and Farghali (Citation2019), we propose generalized Liu-type estimator for the MNLR as follows
(6)
(6)
where
and
The variance-covariance matrix of
is defined as
Lemma 1.
The proposed biased estimator in (6) represents a general estimator which includes, the MLE, the generalized RR and Liu estimators as special cases
the generalized RR estimator.
To provide the explicit form of we use the following transformations, suppose that there exists a matrix
such that:
(7)
(7)
where
are the ordered eigenvalues of the matrix
and
is a
orthogonal matrix whose columns are the corresponding eigenvectors of
so that the suggested biased estimator can be defined as:
(8)
(8)
Note that, and
The scalar MSE for is computed as:
(9)
(9)
(10)
(10)
It is obvious that are two continuous functions of
2.2.2. Generalized Huang and Yang multinomial logistic estimator
Huang and Yang (Citation2014) proposed a two-parameter biased estimator to remedy multicollinearity in the negative binomial regression model. Their estimator was considered as a general estimator since this estimator is included the MLE, RR estimator, and Liu estimator as special cases. Also, they proved the superiority of this estimator over other biased estimators ().
In this article, we extend and generalized Huang and Yang (Citation2014) estimator to combat multicollinearity in the MNLR model. The proposed estimator is defined as:
(11)
(11)
where
and
The variance-covariance matrix of
is defined as
Lemma 2.
The proposed biased estimator in (11), represents a general case, as it is easy to see that
Rewriting EquationEquation (11)(11)
(11) using the eigenvalues of
and its corresponding eigenvectors, the proposed biased estimator can be written as:
(12)
(12)
Note that, . The scalar MSE of
is computed as:
(13)
(13)
2.3. Matrix MSE properties
The matrix MSE (MMSE) of an estimator of the parameter vector
is defined as
where
represents the covariance matrix of
and
indicates the bias which equals to
Let
and
be the two estimators of
the estimator
is said to be superior to the estimator
in the sense of MMSE criterion, if and only if
The scalar MSE is another criterion to gauge the goodness of an estimator and it is defined as
If then
The converse in scalar MSE is not true (Rao et al., 2008), therefore, we consider MMSE criterion to gauge the goodness of proposed estimators. The following two Lemmas 3 and4 are defined to demonstrate the MMSE properties of the estimators.
Lemma 3
(Farebrother Citation1976). Let be a positive-definite matrix,
be a vector of nonzero constants, then
if and only if
Proof.
See Farebrother (Citation1976).□
Lemma 4.
Let
be two competing estimators of
. Suppose
, where
denotes the covariance matrix of
. Then
, where
denote the bias vector of
Proof.
See Trenkler and Toutenburg (Citation1990). □
2.3.1. Comparison between and
The MMSE of is computed as
(14)
(14)
where
To compere with
in the sense of MMSE, we compute the MMSE difference as:
Theorem 1.
Let and
under MNLR model with correlated regressors, the
is superior to
in the sense of MMSE, namely
if and only if
Proof.
The difference between and
can be written as
As observes the performance of and
we can see that
will be positive-definite matrix iff
or
for
and
Simplifying the above inequality one can find that
Therefore, it can be concluded that one of the proposed GTP estimators
has a smaller variance-covariance matrix than the existing MLE for the MNLR model with correlated regressors. By using Lemma 3, the proof is completed. □
2.3.2. Comparison between and
The MMSE of is computed as
(15)
(15)
To compere with
in the sense of MMSE, we compute the MMSE difference as:
(16)
(16)
Theorem 2.
Let and
under MNLR model with correlated regressors, the
is superior to
in the sense of MMSE, namely
iff
, where
Proof.
As observing the comparison of and
by variance–covariance matrices as
We can see that the matrix
will be positive definite iff
for
and
Simplifying the above inequality one can find that
The variance-covariance matrix of
has smaller value than the
iff
and
then the proof is completed by employing Lemma 3.
3. An algorithm for selection of shrinkage parameters
There are several ways to estimate the parameters k and d are available in literature. However, we propose two methods: first using of the optimal second using the optimal
The following lemmas are present the optimal shrinkage parameters of
and
Lemma 5.
Optimal
The optimal shrinkage parameter
Since then
The optimal shrinkage parameter
Lemma 6.
Optimal
The optimal shrinkage parameter for
and
, for all
, are given by
For GLT-M estimator, we suggest two methods to select the shrinkage parameters: in the first, we use with different proposed estimation of
based on the work of Kibria (Citation2003):
where
While in the second proposed method for selecting shrinkage parameters of GLT-M estimator, we use that satisfy the condition of
in Lemma 5 with one of the following suggested formulas of
Note that, is the original estimation of the ridge parameter proposed by Hoerl and Kennard (Citation1970a), while other estimations (
…,
) are completely new for Liu- type estimator in the multinomial logistic regression model. For GHY-M estimator, we use Huang and Yang (Citation2014) algorithm for selecting shrinkage parameters but based on the generalized parameters (
).
4. Monte Carlo simulation
A Monte Carlo simulation study has been conducted to compare the performances of MLE, GLT-M (based on …,
), and GHY-M estimators. Monte Carlo experiments are carried out based on the response variable
obtained by using the multinomial distribution
where parameters
are chosen to be
which is a commonly used restriction in many simulation studies in the field. See for example, Kibria (Citation2003. In this simulation study, we assume that the probability of each level of the response variable is equal. Following the work of Kibria (Citation2003) and Månsson, Kibria, and Shukur (Citation2012), the explanatory variables were generated as
The effective factors are chosen to be the number of explanatory variables (p = 3, 5, and 7), the sample size (n = 50, 100, 200, 300, 400, and 500), the correlation among the explanatory variables ( 0.90, 0.95, and 0.99), and the levels of the response variable (C = 5, 7, and 9). In our study, the simulated MSE (SMSE) is used as the criterion of judgment, it is computed by using the following equation
where
is the vector of estimated values at lth experiment of the simulation, while
is the vector of true parameters. The program of the Monte Carlo simulation study is written in R language.
Monte Carlo simulation results are given in and and . Specifically, present SMSE values of the three estimators in the case of a number of explanatory variables () and with the levels of the response variable
While in the cases of
with the same values of
is presented in . Similarly, presents SMSE values of the estimators in the case of
with the same values of
Figure 1. Relative efficiency of the estimators when C = 7.
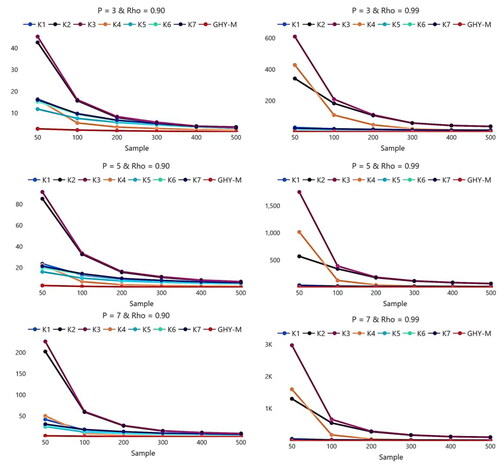
Figure 2. Relative efficiency of the estimators when C = 9.
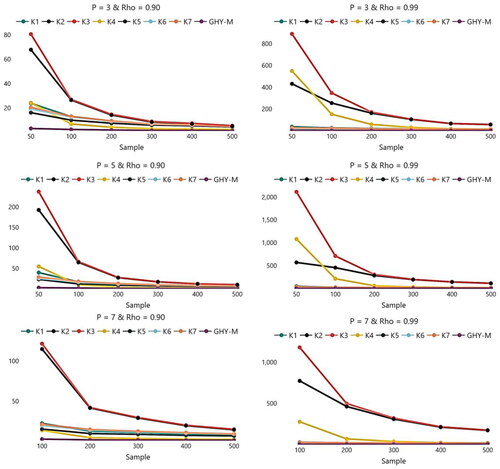
Table 1. MSE values of the estimators when and
Table 2. MSE values of the estimators when and
Table 3. MSE values of the estimators when and
For all simulation situations, it can be noted that SMSE values of GLT-M and GHY-M estimators are less than SMSE values of MLE. This means that theses estimators have better performance than MLE for different cases of and
Moreover, all the estimators have monotonic behaviors according to SMSE values. Namely, when the sample size
increases, the estimated SMSE values decrease. It is obvious from tables and figures that by increasing the sample size affect positively on the performance of all estimators (including MLE). Also, it can be noted that, when
and
are fixed, increasing
causes an increase in SMSE values of all estimators without exception. This increase is much larger in MLE than other estimators. Furthermore, when
and
are fixed, increasing
affects SMSE values of all estimators negatively, especially MLE. In other words, this increase is much larger in MLE than other estimators. Also, increasing
and
with small
inflates SMSE values of all estimators.
As expected, in the case of high multicollinearity, GLT-M and GHY-M estimators showed its best performance by means of the reduction of SMSE values and it is not affected by multicollinearity. But we note that GLT-M estimator for …,
is better than GHY-M estimator in all simulation situations. And there is some difference between the performances of GLT-M estimators according to the shrinkage parameter
that is used. According to our simulation study, it may be concluded that
is the best shrinkage parameter among others in most simulation situations.
5. Application
To illustrate the empirical relevance of the proposed estimators, we analyze Swedish football data in this empirical section. The proposed and existing estimators are elucidated using a dataset regarding the performance of Swedish football teams in the top Swedish league (Allsvenskan) during the year of 2018.Footnote1
This dataset includes 242 observations and include one dependent variable (Y) is the full time results (H = Home win, D = Draw, A = Away win) of the football team, and nine explanatory variables, which are the pinnacle home win odds (PH), pinnacle draw odds (PD), pinnacle away win odds (PA), maximum Oddsportal home win odds (MaxH), maximum Oddsportal draw win odds (MaxD), maximum Oddsportal away win odds (MaxA), AvgH = average Oddsportal home win odds (AvgH), average Oddsportal draw win odds (AvgD), and average Oddsportal away win odds (AvgA). The effect of these regressors on Y, respectively are demonstrated by the A MNLR analysis.
The variance inflation factor (VIF) values of all explanatory variables are given in . From , it appears that the model is suffering from the multicollinearity problem as all VIFs are greater than 10. Also, the values of correlation coefficients between the explanatory variables are greater than 0.85 (in most of the cases). presents estimates and standard errors (SE) values of MLE, GLT-M and GHY-M estimators. indicates that GLT-M and GHY-M estimates have smaller SE values than MLE estimates. This means that GLT-M and GHY-M are efficient than MLE. These results are consistent with the simulation results in Sec. 4.
Table 4. Person correlation matrix of explanatory variables and VIF.
Table 5. Parameter estimates and standard errors of MNLR model.
6. Some concluding remarks
To overcome the problem of multicollinearity, this paper proposes two generalized biased estimators for the multinomial logistic regression model by following the work of Abonazel and Farghali (Citation2019), Farghali (Citation2019), and Huang and Yang (Citation2014). We discuss the MSE properties of the estimators and developed algorithms to estimate the biasing or shrinkage parameters and
A simulation study has been conducted to compare the performance of the estimators and to support the theoretical comparison. Simulation results indicated that increasing the correlation between the independent variables has a negative effect on the MSE, whereas, increasing the number of regressors and amount of correlation have a positive effect on MSE. When the sample size increases, the MSE values of the estimators decrease even when the correlation between regressors is large. It also appeared that proposed GLT-M performed better than both MLE and GHY-M estimator and GHY-M is doing better than MLE. Overall, the estimator based on K3 performed the best followed by K2, K1, and K4. For illustration purposes, Swedish football data are analyzed, which supported the simulation results and consistent with theoretical results of the paper. Finally, we recommend the researchers use the GLT-M estimator with parameter K3.
Notes
1 The data are publicly available on the webpage www.football-data.co.uk.
References
- Abonazel, M. R., and R. A. Farghali. 2019. Liu-type multinomial logistic estimator. Sankhya B 81 (2):203–25. doi: 10.1007/s13571-018-0171-4.
- Agresti, A. 2013. Categorical data analysis. 3rd ed. Hoboken, NJ: John Wiley& Sons, Inc.
- Akram, M. N., M. Amin, and M. Qasim. 2020. A new Liu-type estimator for the inverse Gaussian regression model. Journal of Statistical Computation and Simulation 90 (7):1153–72. doi: 10.1080/00949655.2020.1718150.
- Amin, M., M. Qasim, A. Yasin, and M. Amanullah. 2020a. Almost unbiased ridge estimator in the gamma regression model. Communications in Statistics-Simulation and Computation. Advance online publication. doi:10.1080/03610918.2020.1722837.
- Amin, M., M. Qasim, and M. Amanullah. 2019. Performance of Asar and Genç and Huang and Yang’s two-parameter estimation methods for the Gamma regression model. Iranian Journal of Science and Technology, Transactions A: Science 43 (6):2951–63. doi: 10.1007/s40995-019-00777-3.
- Amin, M., M. Qasim, M. Amanullah, and S. Afzal. 2020b. Performance of some ridge estimators for the gamma regression model. Statistical Papers 61 (3):997–1026. doi: 10.1007/s00362-017-0971-z.
- Asar, Y., and A. Genç. 2018. A new two-parameter estimator for the Poisson regression model. Iranian Journal of Science and Technology, Transactions A: Science 42 (2):793–803. doi: 10.1007/s40995-017-0174-4.
- Asl, M. N., H. Bevrani, R. A. Belaghi, and K. Mansson. 2021. Ridge-type shrinkage estimators in generalized linear models with an application to prostate cancer data. Statistical Papers 62 (2):1043–85. doi: 10.1007/s00362-019-01123-w.
- El-Dash, A., A. El-Hefnawy, and R. Farghali. 2011. Goal programming technique for correcting multicollinearity problem in multinomial logistic regression. The 46th Annual Conference on Statistics, Computer Sciences, and Operation Research, 26–29 Dec., 72–87.
- Farebrother, R. W. 1976. Further results on the mean square error of ridge regression. Journal of the Royal Statistical Society: Series B (Methodological) 38 (3):248–50. doi: 10.1111/j.2517-6161.1976.tb01588.x.
- Farghali, R. 2014. A suggested biased estimator for correcting multicollinearity in multinomial logistic regression. Egyptian Statistical Journal 58:183–97.
- Farghali, R. 2019. Generalized Liu-Type estimator for linear regression. International Journal of Research and Reviews and in Applied Sciences 38:52–63.
- Hoerl, A. E., and R. W. Kennard. 1970. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 12 (1):55–67. doi: 10.1080/00401706.1970.10488634.
- Hosmer, D., S. Lemeshow, and R. Sturdivant. 2013. Applied logistic regression. 3rd ed. New York: John Wiley& Sons, Inc.
- Huang, J., and H. Yang. 2014. A two-parameter estimator in the negative binomial regression model. Journal of Statistical Computation and Simulation 84 (1):124–34. doi: 10.1080/00949655.2012.696648.
- Karlsson, P., K. Månsson, and B. G. Kibria. 2020. A Liu estimator for the beta regression model and its application to chemical data. Journal of Chemometrics 34 (10):e3300. doi: 10.1002/cem.3300.
- Kejian, L. 1993. A new class of blased estimate in linear regression. Communications in Statistics - Theory and Methods 22 (2):393–402. doi: 10.1080/03610929308831027.
- Kibria, B. M. G. 2003. Performance of some new ridge regression estimators. Communications in Statistics - Simulation and Computation 32 (2):419–35. doi: 10.1081/SAC-120017499.
- Kurtoğlu, F., and M. R. Özkale. 2016. Liu estimation in generalized linear models: Application on gamma distributed response variable. Statistical Papers 57 (4):911–28. doi: 10.1007/s00362-016-0814-3.
- Luce, R. D. 1959. Individual choice behaviour: A theoretical analysis. New York: Wiley.
- Lukman, A. F., B. Aladeitan, K. Ayinde, and M. R. Abonazel. 2021. Modified ridge-type for the Poisson regression model: Simulation and application. Journal of Applied Statistics. Advance online publication. doi:10.1080/02664763.2021.1889998.
- Lukman, A. F., K. Ayinde, B. G. Kibria, and E. T. Adewuyi. 2020. Modified ridge-type estimator for the gamma regression model. Communications in Statistics-Simulation and Computation. Advance online publication. doi:10.1080/03610918.2020.1752720.
- Mandal, S., R. Arabi Belaghi, A. Mahmoudi, and M. Aminnejad. 2019. Stein‐type shrinkage estimators in gamma regression model with application to prostate cancer data. Statistics in Medicine 38 (22):4310–22. doi: 10.1002/sim.8297.
- Månsson, K. 2012. On ridge estimators for the negative binomial regression model. Economic Modelling 29 (2):178–84. doi: 10.1016/j.econmod.2011.09.009.
- Månsson, K. 2013. Developing a Liu estimator for the negative binomial regression model: Method and application. Journal of Statistical Computation and Simulation 83 (9):1773–80. doi: 10.1080/00949655.2012.673127.
- Månsson, K., and G. Shukur. 2011a. On ridge parameters in logistic regression. Communications in Statistics – Theory and Methods 40 (18):3366–81. doi: 10.1080/03610926.2010.500111.
- Månsson, K., and G. Shukur. 2011b. A Poisson ridge regression estimator. Economic Modelling 28 (4):1475–81. doi: 10.1016/j.econmod.2011.02.030.
- Månsson, K., B. M. G. Kibria, and G. Shukur. 2012. On Liu estimators for the logit regression model. Economic Modelling 29 (4):1483–8. doi: 10.1016/j.econmod.2011.11.015.
- Månsson, K., B. M. G. Shukur, and B. G. Kibria. 2018. Performance of some ridge regression estimators for the multinomial logit model. Communications in Statistics - Theory and Methods 47 (12):2795–804. doi: 10.1080/03610926.2013.784996.
- Månsson, K., G. Shukur, and B. M. G. Kibria. 2018. Performance of some ridge regression estimators for the multinomial logit model. Communications in Statistics - Theory and Methods 47 (12):2795–804. doi: 10.1080/03610926.2013.784996.
- Naveed, K., M. Amin, S. Afzal, and M. Qasim. 2020. New shrinkage parameters for the inverse Gaussian Liu regression. Communications in Statistics – Theory and Methods. Advance online publication. doi:10.1080/03610926.2020.1791339.
- Noori Asl, M., H. Bevrani, and R. Arabi Belaghi. 2020. Penalized and ridge-type shrinkage estimators in Poisson regression model. Communications in Statistics – Simulation and Computation. Advance online publication. doi:10.1080/03610918.2020.1730402.
- Özkale, M. R., and S. Kaciranlar. 2007. The restricted and unrestricted two-parameter estimators. Communications in Statistics – Theory and Methods —Theory and Methods, 36 (15):2707–25. doi: 10.1080/03610920701386877.
- Qasim, M., B. M. G. Kibria, K. Månsson, and P. Sjölander. 2020a. A new Poisson Liu regression estimator: Method and application. Journal of Applied Statistics 47 (12):2258–71. doi: 10.1080/02664763.2019.1707485.
- Qasim, M., K. Månsson, and B. M. Golam Kibria. 2021. On some beta ridge regression estimators: Method, simulation and application. Journal of Statistical Computation and Simulation. Advance online publication. doi:10.1080/00949655.2020.1867549.
- Qasim, M., K. Månsson, M. Amin, B. M. G. Kibria, and P. Sjölander. 2020b. Biased adjusted Poisson ridge estimators-method and application. Iranian Journal of Science and Technology, Transactions A: Science 44 (6):1775–89. doi: 10.1007/s40995-020-00974-5.
- Qasim, M., M. Amin, and M. Amanullah. 2018. On the performance of some new Liu parameters for the gamma regression model. Journal of Statistical Computation and Simulation 88 (16):3065–80. doi: 10.1080/00949655.2018.1498502.
- Rady, E. A., M. R. Abonazel, and I. M. Taha. 2019. New shrinkage parameters for liu-type zero inflated negative binomial estimator. The 54th Annual Conference on Statistics, Computer Science, and Operation Research 3-5 Dec, 2019. FGSSR, Cairo University.
- Schaefer, R. 1986. Alternative estimators in logistic regression when the data are collinear. Journal of Statistical Computation and Simulation 25 (1/2):75–91. doi: 10.1080/00949658608810925.
- Schaefer, R., L. Roi, and R. Wolfe. 1984. A ridge logistic estimator. Communications in Statistics - Theory and Methods 13 (1):99–113. doi: 10.1080/03610928408828664.
- Segerstedt, B. 1992. On ordinary ridge regression in generalized linear models. Communications in Statistics - Theory and Methods 21 (8):2227–46. doi: 10.1080/03610929208830909.
- Toker, S., G. Üstündağ Şiray, and M. Qasim. 2019. Developing a first order two parameter estimator for generalized linear model. Paper presented at the 11th International Statistics Congress; Muğla, Turkey.
- Trenkler, G., and H. Toutenburg. 1990. Mean squared error matrix comparisons between biased estimators—an overview of recent results. Statistical Papers 31 (1):165–79. doi: 10.1007/BF02924687.
- Yang, H., and X. Chang. 2010. A new two-parameter estimator in linear regression. Communications in Statistics – Theory and Methods 39 (6):923–34. doi: 10.1080/03610920902807911.