
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Normal distribution is commonly assumed distribution in statistical inference. Therefore, goodness-of-fit test for normality is required as a preliminary procedure in the applications. Most relevant testing methods have been evaluated using empirical power. However, the power depends on significance level, sample size, and alternative distributions. This study compares normality testing methods which have been verified excellent based on power, considering significance levels, sample sizes, and alternative distributions in addition to their powers. Furthermore we evaluate the performance of the testing methods using the expected and median values of p-values of the corresponding test statistics.
1. Introduction
Normal distribution is the most commonly assumed distribution in statistical inferential procedures and whose feasibility depends on how well the assumed distribution fits to normal distribution. Therefore the goodness-of-fit (GOF) test for normality is a required preliminary procedure before applying relevant statistical applications. There have been numerous goodness-of-fit tests for normality. Most of them are based on empirical power and their results are often inconsistent and dependent upon significance level α. Thus there have been suggestions of considering sample size and significance level α in addition to the power (Sackrowitz and Samuel-Cahn Citation1999; Yazici and Yolacan Citation2007; Mbah and Paothong Citation2015).
Dempster and Schatzoff (Citation1965) introduced the concept of the expected significance level and discussed the stochastic aspect of the p-value. Sackrowitz and Samuel-Cahn (Citation1999) elaborated the approach, proposed the expected p-value (EPV), and presented extensive potential for the utilization of EPV in various aspects of hypothesis tests. The distribution of p-values under the null hypothesis is known to follow U(0,1). However, its distribution under the alternative hypothesis is skewed to the right and Bhattacharya and Habtzghi (Citation2002) proposed the median of the p-value (MPV) as a better measure of performance than EPV.
In this study we select tests of normality which have been verified excellent based on power, and investigate their performances in terms of power as varying sample size, significance level α, and distributional forms under alternative hypotheses. Furthermore the results of their performances are compared with those of EPV and MPV as well.
2. Normality testing methods
In this section we review briefly the nine testing methods which have been verified excellent by the performance measure of power. presents the acronyms of each method used in this study in reference to tests of normality.
Table 1. Abbreviations for each normality testing method.
2.1. Empirical distribution function
Let be a random sample from a population with cumulative distribution function (CDF)
and its order statistics
The empirical cumulative distribution function (ECDF)
is defined in terms of the indicator function
as follows:
2.1.1. Lilliefors’ revised Kolmogorov-Smirnov test
The Kolmogorov–Smirnov (KS) assumed that two parameters, mean and variance, of normal distribution are known. However it is uncommon to have both parameters known and most cases are with at least one parameter estimated. For such cases, Lilliefors (Citation1967) modified the KS test statistic for the test of normality as follows:
where
and
is the CDF of the standard normal distribution.
2.1.2. Cramer-von Mises test
The Cramer-von Mises test for a hypothesized distribution F0 was developed by Cramer, von Mises, and Smirnov and defined by (Cramer Citation1928; Von Mises Citation1932; Smirnov Citation1936; Conover Citation1999),
2.1.3. Anderson-Darling test
Anderson and Darling (Citation1954) related the concept of the weighted mean to the CVM test statistic, assigning more weight to the tail of and proposed the following test statistic
where
2.1.4. Zhang-Wu test
Not only is Zhang credited with the creation of the KS, CVM, and AD test statistics, but also proposed new and more powerful types of test statistics, as follows (Zhang Citation2002; Zhang and Wu Citation2005):
where
and
2.2. Moments
2.2.1. Jarque-Bera test
The Jarque-Bera test was proposed by Bowman and Shenton and elaborated by Jarque and Bera and defined by (Bowman and Shenton Citation1975; Jarque and Bera Citation1987; Romao, Delgado, and Costa Citation2010) as
where
and
with
2.2.2. Gel-Gastwirth test
Henderson (Citation2006) pointed out that sample moments are not insensitive to outliers as they provide equal weights to all observations. Gel and Gastwirth (Citation2008) proposed the following robust form of the Gel-Gastwirth (R.JB) test statistic
where Jn is an estimate of variance which is less sensitive to outliers, defined by
2.3. Regression and correlation
2.3.1. Shapiro-Wilk test
Shapiro and Wilk (Citation1965) proposed the following test statistic, using the mean vector m and covariance matrix V of order statistics of a random sample of size n from standard normal distribution and a vector of ordered random observations
where
2.3.2. Shapiro–Francia test
In the statistic SW, the values of m and V are not easy to obtain, and especially the calculation of consumes huge time with large sample size. Shapiro and Francia (Citation1972) overcame it by proposing an identity matrix instead of
in the statistic SW, defined as
where
3. The simulation results
In this section we compare the empirical powers of the nine aforementioned normality testing methods as varying sample size n, significance level α and distributional form under alternative hypothesis. Furthermore the distributional characteristics such as mean and median of the p-values of the test statistics are used to evaluate the performances of the testing methods. We did Monte Carlo simulations with 100,000 repetitions for the cases displayed at . The similar simulation has been performed by Uhm (Citation2020) for the scenarios with larger samples and empirical type I error.
Table 2. Simulation conditions: alternative distributions, sample sizes and significance levels.
3.1. Performances by empirical power
summarizes the empirical powers of the testing methods by the test statistics listed on the first row for various alternative distributions as sample size n gets increased at significance level When alternative distribution is symmetric Beta(2,2), the testing methods by ZC and ZA show the best power up to the sample size 30 and the sample size of 100 or larger, respectively. The testing methods by ZA, SW and SF have their powers decreased despite of increasing the sample size from 10 to 20, and the ones by JB and R.JB show the same pattern up to the sample size 100. When alternative distribution is Laplace or t-distribution, the testing method by R.JB has the best power among all the methods considered.
Table 3. Empirical power: empirical power for various normality tests depending on sample size n under each alternative distribution at
When alternative distribution is asymmetric Beta(2,1), the method by R.JB has the power decreased as sample size n increases up to 30, and increased from n = 100, which is the case with Beta(2,2). The power by ZA shows the highest value among all sample cases except for n = 10. When alternative distribution is chi-squared, the method by ZA shows the highest power in all samples. The method by ZA has the highest power in all samples except for n = 10 at the alternative of gamma distribution.
summarizes the power of the nine testing methods at the significance level Compared with
their powers get increased at
which confirms the fact that the power of test gets increased as significance level does. The opposite direction of the power by ZA and SW methods for sample size up to n = 20 shown at
does not appear at
However the methods by JB and SF show the opposite phenomenon up to n = 30 and the ones by R.JB up to n = 100. For the other cases, the method by R.JB is best for the alternative of Laplace and t-distribution, and the one by ZA has the best power for all asymmetric alternative distributions, which are the same as in the case of
Table 4. Empirical power: empirical power for various normality tests depending on sample size n under each alternative distribution at
3.2. Performances by the distributional characteristics of p-values
Let F0 and denote the cumulative distribution of the test statistics T under H0 and
under Ha, respectively. Sackrowitz and Samuel-Cahn (Citation1999) defined the EPV under Ha as
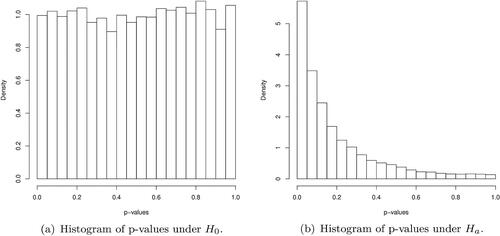
and showed that the EPV is stochastically smaller under Ha than under H0, which implies that the smaller EPV means the stronger evidence for Ha. It is also known that under the null hypothesis F0 follows uniform distribution on (0, 1), and the mean and median of the distribution of p-values are always 0.5. The plots at show the empirical distribution of p-values under
and
respectively. The distribution of p-values under Ha is skewed to the right, in which case the median is a better measure of the central tendency of the distribution than the mean. It motivates the use of the MPV, not the EPV, as a performance measure of the normality testing methods. The testing method with the smaller MPV is a better one, for the smaller p-value tells more clearly the difference between the null and alternative.
Figure 1. The empirical distributions of p-values under and
and are summaries of the EPV and MPV of testing methods, respectively. For the alternative of Beta(2.2), the shows that the testing method by ZC yields the smallest EPV up to n = 100 and the one by ZA does for n greater than or equal to 200. For the alternative of Laplace distribution, the testing method by AD and SF has the smallest mean p-value up to n = 30, while the method by SF does for alternative of t-distribution. When we have the alternative of asymmetric Beta(2,1), the method by ZC has the smallest expected p-value up to the sample size 20, and the one by ZA does for the sample size greater than 20. For the alternative distribution of chi-square and gamma, the method by ZC has the smallest EPV for n = 10 and the one by ZA does for the sample size greater than 10.
Table 5. Expected P-values: The expected value of the distribution of p-values for various normality tests depending on each sample size under each alternative distribution.
Table 6. Median P-values: The median value of the distribution of p-values for various normality tests depending on each sample size under each alternative distribution.
shows the result of MPV for each testing method. When the alternative distribution is symmetric Beta(2,2), the testing methods by ZC up to n = 30 and by ZA for n greater than or equal to 100 produce the smallest median p-value, respectively. For the alternative of Laplace distribution, the methods by SF up to the sample size 20 and by R.JB for the sample size greater than or equal to 30 have the smallest median p-value, respectively. The method by R.JB yields the smallest MPV for the alternative of t distribution. When we have asymmetric Beta(2,1) for the alternative, the performance of the testing methods is the same as that of the symmetric Beta(2,2). When we have the alternative distribution of chi-square and gamma, however, we found the method by SW for n = 10 and by ZA for n greater than 10 the best, respectively.
For the alternative of Beta(2,2) the powers of the testing method by JB and R.JB get decreased while the sample size increases up to 100. However, the EPV and MPV of those two methods decrease monotonically as the sample size increases. The phenomenon that the representative values such as EPV or MPV decrease monotonically as the sample sizes gets increased is observed at all the testing methods under the study. The JB method performs well by the MPV, but does not by the EPV. All the methods by the test statistics except for AD and SF show the same performance as well.
display the pattern of the EPV and MPV according as the sample size changes. All the testing methods by the test statistics except for JB and R.JB show that the lines of the EPV and MPV don’t cross over across the sample size and the line of the MPV converges to zero faster than that of the EPV.
Figure 2. The distributional features of p-values when using Lilliefors’ modified Kolmogorov-Smirnov test statistic with varying sample size under the asymmetric alternative distributions. The dotted line and solid line are the expected value and the median value of the p-values, respectively.
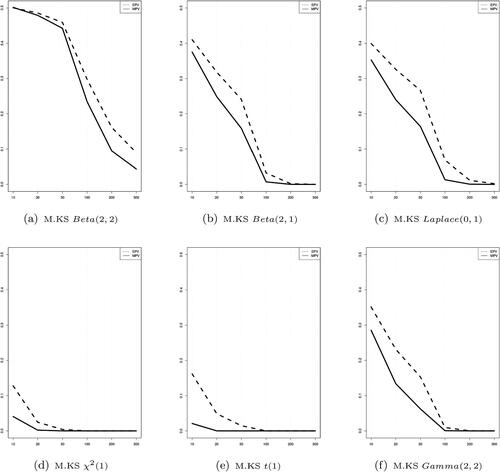
Figure 3. The distributional features of p-values when using Cramer von-Mises and Anderson-Darling test statistics with varying sample size under the asymmetric alternative distributions. The dotted line and solid line are the expected value and the median value of the p-values, respectively.
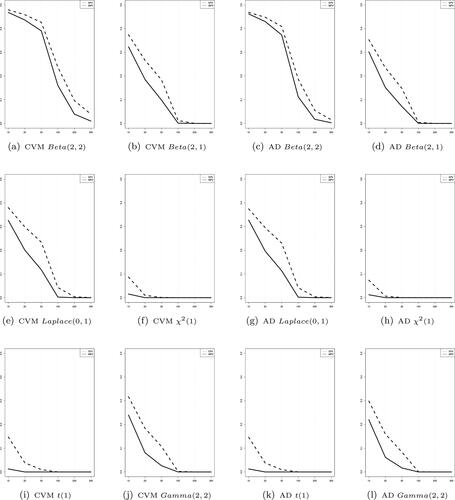
Figure 4. The distributional features of p-values when using Zhang-Wu test statistics with varying sample size under the asymmetric alternative distributions. The dotted line and solid line are the expected value and the median value of the p-values, respectively.
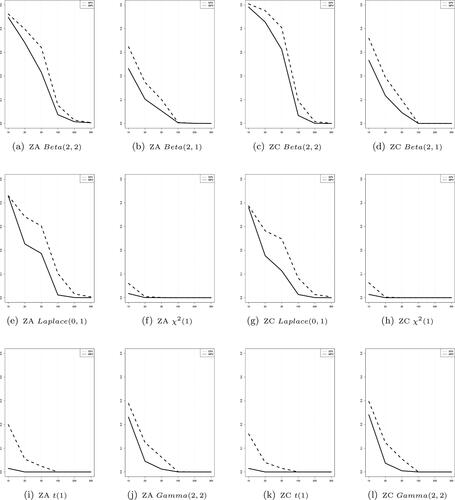
Figure 5. The distributional features of p-values when using Jarque-Bera and Gel-Gastwirth (R.JB) test statistics with varying sample size under the asymmetric alternative distributions. The dotted line and solid line are the expected value and the median value of the p-values, respectively.
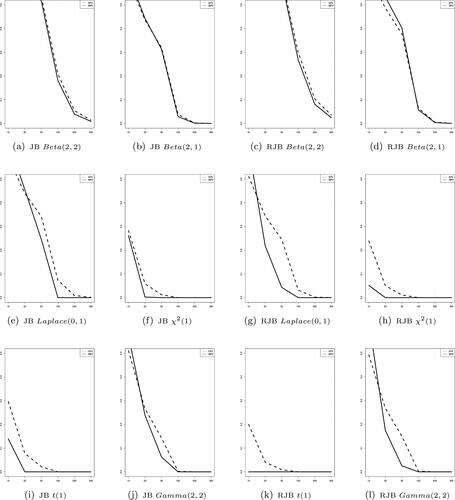
Figure 6. The distributional features of p-values when using Shapiro-Wilk and Shapiro-Francia test statistics with varying sample size under the asymmetric alternative distributions. The dotted line and solid line are the expected value and the median value of the p-values, respectively.
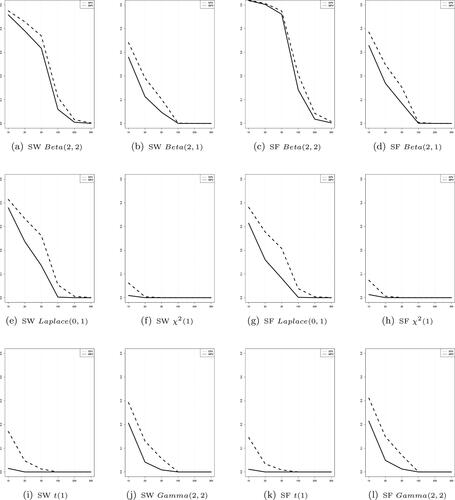
4. Conclusion
In this study we have compared the performances of the widely accepted normality testing methods in terms of testing power and the distributional features of p-values under various conditions of alternative distributions, sample sizes and significance levels. The powers of the testing methods don’t show consistency over the significance level and they get decreased as the sample size increases.
On the contrary the representative values such as the EPV or MPV show consistency, or decrease monotonically as the sample size gets increased. The performances by the EPV are similar to those by the MVP as a whole, but there are some testing methods showing opposite performances. The convergence of the MPV to zero is faster than that of the EPV.
As a recap, we suggest the following guideline in selection of normality testing methods:
ZC when data is of small size
and shows symmetric distribution.
ZA when data is of moderate size
ZC when data is of small size
ZA when data is of moderate size
Considering the above results, as a performance criterion for normality testing method, the MPV is preferred to the EPV in that the distribution of p-values is skewed. The MPV is also preferred to the power of the tests, for the latter does not show insensitivity to the choice of the significance level.
Acknowledgements
This work was supported by the Pukyong National University Research Fund in 2020.
References
- Anderson, T. W., and D. A. Darling. 1954. A test of goodness of fit. Journal of the American Statistical Association 49 (268):765–209. doi:10.1080/01621459.1954.10501232.
- Bhattacharya, B., and D. Habtzghi. 2002. Median of the p-value under the alternative hypothesis. The American Statistician 56 (3):202–206. doi:10.1198/000313002146.
- Bowman, K. O., and L. R. Shenton. 1975. Omnibus test contours for departures from normality based on b1 and b2. Biometrika 62 (2):243–50.
- Conover, W. J. 1999. Practical nonparametric statistics. New York: Wiley.
- Cramer, H. 1928. On the composition of elementary errors: first paper: mathematical deductions. Scandinavian Actuarial Journal 1928 (1):13–74.
- Dempster, A. P., and M. Schatzoff. 1965. Expected significance level as a sensitivity index for test statistics. Journal of the American Statistical Association 60 (310):420–36. doi:10.1080/01621459.1965.10480802.
- Gel, Y. R., and J. L. Gastwirth. 2008. A robust modification of the Jarque-Bera test of normality. Economics Letters 99 (1):30–32. doi:10.1016/j.econlet.2007.05.022.
- Henderson, A. R. 2006. Testing experimental data for univariate normality. Clinica Chimica Acta; International Journal of Clinical Chemistry 366 (1-2):112–29. doi:10.1016/j.cca.2005.11.007.
- Jarque, C. M., and A. K. Bera. 1987. A test for normality of observations and regression residuals. International Statistical Review / Revue Internationale de Statistique 55 (2):163–72. doi:10.2307/1403192.
- Lilliefors, H. W. 1967. On the Kolmogorov-Smirnov test for normality with mean and variance unknown. Journal of the American Statistical Association 62 (318):399–402. doi:10.1080/01621459.1967.10482916.
- Mbah, A. K., and A. Paothong. 2015. Shapiro-Francia test compared to other normality test using expected p-value. Journal of Statistical Computation and Simulation 85 (15):3002–16. doi:10.1080/00949655.2014.947986.
- Romao, X., R. Delgado, and A. Costa. 2010. An empirical power comparison of univariate goodness-of-fit tests for normality. Journal of Statistical Computation and Simulation 80 (5):545–91. doi:10.1080/00949650902740824.
- Sackrowitz, H., and E. Samuel-Cahn. 1999. P values as random variables expected P values. The American Statistician 53 (4):326–31. doi:10.2307/2686051.
- Shapiro, S. S., and R. S. Francia. 1972. An approximate analysis of variance test for normality. Journal of the American Statistical Association 67 (337):215–16. doi:10.1080/01621459.1972.10481232.
- Shapiro, S. S., and M. B. Wilk. 1965. An analysis of variance test for normality. Biometrika 52 (3-4):591–611. doi:10.1093/biomet/52.3-4.591.
- Smirnov, N. V. 1936. Sui la distribution de w2. Comptes Rendus 202:449–52.
- Uhm, T. W. 2020. Comparison of the normality tests using the distribution of p-values. unpublished Ph.D. diss., Pukyong National University, Dept. of Statistics, Korea.
- Von Mises, R. 1932. Wahrscheinlichkeitsrechnung und ihre Anwendung in der Statistik und theoretischen Physik. Bulletin of the American Mathematical Society 38:169–70.
- Yazici, B., and S. Yolacan. 2007. A comparison of various tests of normality. Journal of Statistical Computation and Simulation 77 (2):175–83. doi:10.1080/10629360600678310.
- Zhang, J. 2002. Powerful goodness-of-fit tests based on the likelihood ratio. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 64 (2):281–94. doi:10.1111/1467-9868.00337.
- Zhang, J., and Y. Wu. 2005. Likelihood-ratio tests for normality. Computational Statistics & Data Analysis 49 (3):709–21. doi:10.1016/j.csda.2004.05.034.