
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this note we introduce a new smooth nonparametric quantile function estimator based on a newly defined generalized expectile function and termed the sigmoidal quantile function estimator. We also introduce a hybrid quantile function estimator, which combines the optimal properties of the classic kernel quantile function estimator with our new generalized sigmoidal quantile function estimator. The generalized sigmoidal quantile function can estimate quantiles beyond the range of the data, which is important for certain applications given smaller sample sizes. This property of extrapolation is illustrated in order to improve standard bootstrap smoothing resampling methods.
1. Introduction
It is well known that a continuous random variable X can be described not only in terms of its p.d.f. and its c.d.f.
but also in terms of the lesser known quantile function
For a general distribution function, which is continuous from the right the conventional definition of the quantile function is given by
(1.1)
(1.1)
Furthermore, if is absolutely continuous then
has a unique value. This allows one to also define the density-quantile function as
since
under the assumption that F is absolutely continuous.
The estimators of the population quantiles,
are of interest in a broad spectrum of theories, methods and applications of parametric, robust and exploratory statistical analyses. Their importance is emphasized in the following quote from Parzen (Citation1993) where he wishes to “….emphasize to applied statisticians our opinion that the first step in data analysis should be to form the sample quantile function,
….”
While the population quantile function may be unique there are a variety of estimators each with their respective strengths and weakness. As background let denote the order statistic from an i.i.d. sample of size n from a continuous distribution F with support over the entire real line. Some well-known quantile function estimators take the following forms:
(1.2)
(1.2)
(1.3)
(1.3)
(1.4)
(1.4)
(1.5)
(1.5)
(1.6)
(1.6)
where
denotes the floor function,
and the subscripts correspond to S=simple, L=linear interpolation, H=Hermitian (Mudholkar, Hutson, and Marchetti (Citation2001)), K=Kernel (e.g., see Sheather and Marron (Citation1990)), HD=Harrell-Davis (Harrell and Davis (Citation1982). Other nonparametric estimators include special L-estimators termed generalized order statistics and Bernstein polynomial type estimators as discussed in Cheng (Citation1995). The specific weighting functions for (1.4)-(1.6) are given as follows:
For the
estimator the weights are given as
For the
For the
For the
Kernel quantile estimators have been extensively studied and analyzed for efficiency and bias tradeoffs, e.g., see Sheather and Marron (Citation1990), Reiss (Citation1980, Citation1989) and the references therein. However, few of the more efficient kernel estimators are used in common practice. The most commonly employed estimator, in applications such as Q-Q plots and incorporated in popular software packages such as SAS, R, and MINITAB, is the linear interpolation between two neighboring order statistics. However, lacks smoothness and does not provide a useful density quantile function estimate. It is interesting to note that
at Equation(1.6)
(1.6)
(1.6) can be interpreted as the estimator of the expectation of an order statistic, where order is defined on a continuous scale and termed a fractional order statistic by Stigler (Citation1977). Similarly, the utilization of the simple quantile function
at Equation(1.3)
(1.3)
(1.3) can be used to derive so-called exact bootstrap calculations about a statistical functional T(F), e.g., see Hutson and Ernst (Citation2000) for an example involving L-estimators.
If we let then generating a univariate bootstrap sample with replacement may be viewed as simulating data from
i.e., one bootstrap replicate is given by
Hence, one approach to smoothing a bootstrap resample, particularly in the small sample setting, is to utilize
The choice between quantile estimators is often a tradeoff between bias (rates of convergence), variance and smoothness relative to the application at hand, which is one motivation of our new proposed estimator. See Hutson (Citation2000, Citation2002) for various quantile based resampling approaches. Alternative kernel smoothing approaches include introducing a smoothing function, i.e., add some noise to the resample value for a given kernel bandwidth, e.g., see Polansky and Schucany (Citation1997). We argue that smoothing is less important in fact than extrapolation given small sample sizes. Quantile-based bootstrap extrapolation methods will be an area of investigation in this note.
An alternative formulation of the population uth quantile for the random variable X is given by the value of θ satisfying
(1.11)
(1.11)
The properties of the expression at Equation(1.11)(1.11)
(1.11) are outlined in Abdous and Theodorescu (Citation1992) who generalize the definition of the α-quantile to
space,
Most notably, the assumption that
in Equation(1.11)
(1.11)
(1.11) is not a necessary condition for the existence of the uth quantile. Given
is absolutely continuous Equation(1.11)
(1.11)
(1.11) can be reduced to
(1.12)
(1.12)
A natural extension to the regression setting is to replace θ in Equation(1.12)(1.12)
(1.12) with a continuous function
of a set of p covariates
(oftentimes setting
when an intercept term is involved) and p regression parameters
This substitution defines the population conditional quantile function as an expectation and minimization problem of the form
(1.13)
(1.13)
For example, if and
then Equationequation (1.13)
(1.13)
(1.13) would correspond to assuming a model for which the conditional median of Y given x is linear in x, i.e., least absolute deviations (LAD) regression or L1 regression, e.g., see Hutson (Citation2018). Similar well-known formulations exist that all lend themselves well to the regression setting, e.g., see the classic paper of Bassett and Koenker (Citation1982). Note that none of the estimators at Equation(1.3)
(1.3)
(1.3) -Equation(1.6)
(1.6)
(1.6) readily translates to the quantile regression setting.
The limitations of quantile regression are well-known and center on issues related to the discreteness of the L1 norm and non-uniqueness of solutions. This partially motivated the rise of expectiles where the L1 norm in Equation(1.12)(1.12)
(1.12) may be replaced by the L2 norm. We use a slightly modified definition of an expectile with very similar properties to the original definition such that for our purposes we define the uth expectile as the value of θ such that
(1.14)
(1.14)
assuming
e.g., see Abdous and Remillard (Citation1995), Jones (Citation1994), Koenecker (Citation1993) and more recently Mao, Ng, and Hu (Citation2015) for a set of excellent theoretical treatments of the subject. Newey and Powell (Citation1987) developed the framework for asymmetric least-squares regression methods.
In this note we examine how the well-known sigmoid approach to approximating the absolute value function, which not only provides an alternative quantile smoothing function approach based on Equation(1.12)(1.12)
(1.12) but also interestingly provides a direct link to approximating the expectile function at Equation(1.14)
(1.14)
(1.14) . Applications include smooth quantile estimation and smooth bootstrap resampling procedures, which readily generalize to the regression setting.
In Sec. 1 we provide background into quantile function estimation and introduce several of the well-known quantile function estimators. In Sec. 2 we provide some preliminaries around the sigmoidal function approximation to the absolute value function. In Sec. 3 we implement the sigmoidal function estimator to define a new class of generalized expectiles, which can be used to define a smooth quantile function estimator termed the generalized sigmoidal quantile function estimator. In Sec. 4 we introduce the theoretical properties of this estimator, which is a specific case of an M-estimator. We also intoduce a new hybrid quantile function estimator, which combines the optimal properties of the classic kernel quantile function estimator with the generalized sigmoidal quantile function estimator. In Sec. 5 we compare the various quantile function estimators across light to heavy-tailed distributions in terms of bias and variance tradeoffs across interior and extreme quantiles. In Sec. 6 we illustrate how the two new quantile function estimators provide more accurate bootstrap percentile intervals due to the addition of tail extrapolated based information. In Sec. 7 we provide a real data example comparing the various quantile function estimators. Finally, in Sec. 8 we provide some concluding remarks.
2. Sigmoid function preliminaries
A convenient form of sigmoid function for our application relative to approximating the absolute value function is given through the logistic cumulative distribution function with mean 0 and variance τ and given as:
(2.1)
(2.1)
where
First define the plus function as
where
is the step function
(2.2)
(2.2)
Chen and Mangasarian (Citation1995) illustrate that we can approximate the plus function as follows:
(2.3)
(2.3)
where F is defined at (2.1). Using the result at (2.3) Schmidt, Fung, and Rosales (Citation2007) derive the approximation for the absolute value function given (slightly reparametrized for our purposes) as
(2.4)
(2.4)
as
Note that in the computational optimization world the approximation at (2.4) is often parameterized in terms of
However, we chose the form (2.4) in order to better to align with bandwidth smoothing procedures used in statistical practice.
Framing the absolute value approximation in statistical terms allows one to note that the c.d.f. at Equation(2.1)(2.1)
(2.1) corresponds to a degenerate distribution as
such that it is clearly a step-function at x = 0 in the limit. See for a plot of the approximation at the value
The interest in the sigmoid-based approximation to the absolute value function stems from the fact that higher order derivatives of
with respect to x exist at x = 0. Hence, this provides the ability to derive gradient and Hessian functions for stable numerical optimization routines, which in turn allows for unique numerical solutions, whereas the estimator based on the function Equation(1.14)
(1.14)
(1.14) may not have a unique solution for a given value for u due to discreteness issues.
Figure 1. Plot of
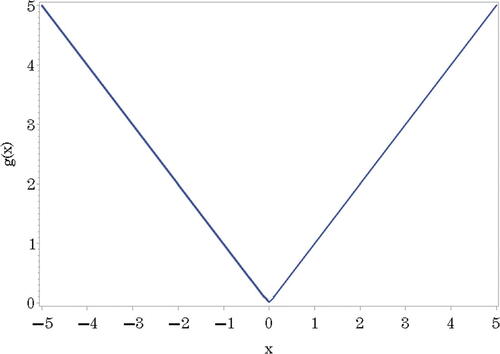
Interestingly and to the best of our knowledge examination of the behavior of at Equation(2.4)
(2.4)
(2.4) as
has not been examined in the computational optimization world for obvious reasons. From a statistical point of view one can view that the logistic distribution will behave similarly to a Bayesian non-informative prior over the real-line such that as
then as
F(y) converges to a uniform (Lebesgue) distribution. It follows straightforward that as
that
approximates a quadratic function of the form
similar to when as
that
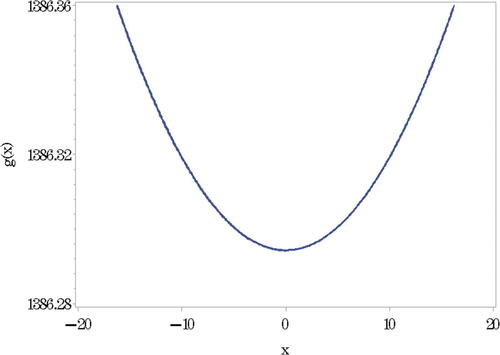
approximates an absolute value function. See for an example at τ = 1000. The ramifications of this simple observation will be of interest in terms of a link between quantiles and expectiles as described in the next section.
Figure 2. Plot of
3. The generalized sigmoidal quantile function: Definition, estimation and properties
The generalized sigmoidal quantile function (GSQF) is based on a modification of Equation(1.12)(1.12)
(1.12) of the quantile function defined as
(3.1)
(3.1)
and described earlier. This is accomplished by substituting the absolute value function
at (3.1) with its smooth counterpart,
defined at (2.4), to arrive at the form of the GSQF given as:
(3.2)
(3.2)
(3.3)
(3.3)
It should be immediately obvious that in the limit as
i.e.,
as
The function
at Equation(3.3)
(3.3)
(3.3) falls within a class of functions termed “smoothed Huber estimators”, as described in Hampel, Hennig, and Ronchetti (Citation2011), albeit the GSQF having a slightly different form of objective function. The smooth Huber estimators rely on a normal c.d.f. to define the smoothing component whereas we employ the logistic c.d.f. as described above to arrive at
which in turn provides more mathematically tractable results for our application.
For a fixed u and τ the sample GSQF estimator for Equation(3.3)(3.3)
(3.3) then becomes
(3.4)
(3.4)
which is similar to the step function estimator
at (1.3) as
and becomes more “smooth” for
In terms of finding the numerical solution for Equation(3.4)(3.4)
(3.4) and arriving at some inferential properties we have that the gradient inherent to the minimization is given by
(3.5)
(3.5)
(3.6)
(3.6)
The gradient at Equation(3.6)(3.6)
(3.6) has the form such that the estimator
falls into the class of classic M-estimators where the solution for
is may be obtained by numerically solving the following equation:
(3.7)
(3.7)
where from (3.6) we have
It follows from classic theory that the corresponding M-functional is then given as
Under smooth conditions, as outlined in Serfling (Citation1980) and for which our estimator satisfies, we have from classic M-estimator theory that
(3.8)
(3.8)
for all fixed
where
given the condition
where
is defined below at (3.10). In this setting
could also be considered a generalized expectile function.
In addition, it should be noted that the Hessian is given by
(3.9)
(3.9)
(3.10)
(3.10)
which in turn can be employed as a component for calculating the sandwich variance estimator for
by noting
may be calculated by replacing the population quantities with the sample counterparts for
and
respectively.
With respect to the properties of the GSQF estimator we present the following results:
Lemma 1.
For a fixed value of and conditional on the observed data
the function
at (3.4) is strictly convex and continuous in
Proof.
Follows from Equationequation (3.10)(3.10)
(3.10) given
and
such that
Theorem 1.
For a fixed value of and conditional on the observed data
there is a unique solution to
at (3.4).
Proof.
Follows straightforward from Lemma 1, which yields that has a unique global minimum.
Theorem 2.
For a fixed value of and conditional on the observed data
the estimator
at (3.4) is a strictly monotone increasing function as a function of
Proof.
For a given u the estimator is obtained by solving for
in (3.7), which may be written as solving:
(3.11)
(3.11)
Noting that is a strictly monotone increasing function in
combined with Theorem 1 completes the proof.
Comment. The u-th expectile can be considered for fixed n by letting i.e., heuristically the expectile is similar to an over-smoothed quantile function relative to choosing a large bandwidth for
at Equation(1.6)
(1.6)
(1.6) . As noted in Koenecker (Citation1993) expectiles are in fact quantiles for a given distribution. This observation generalizes that the GSQF is actually a quantile function for all τ, which in turn can be linked back to a given c.d.f. distinct from the c.d.f. from which the underlying sample was generated from.
4. Quantile smoothing and extrapolation
The primary purpose of the GSQF estimator we are advancing is for it to serve as an an alternative to the well-known kernel quantile estimator defined at Equation(1.6)
(1.6)
(1.6) or to combine it with
to create a hybrid estimator that combines the best features of each distinct quantile function estimator. We argue that the GSQF estimator has better behavior in the tail estimation for Q(u) for densities having support over the whole real line while maintaining the same desirable smoothing properties of those found with the kernel quantile estimator
within the range of the data. The same or similar smoothing strategies can be employed for determining a data based choice for the bandwidth τ for
as are used to determine the bandwidth h for
in terms of bias and variance tradeoffs.
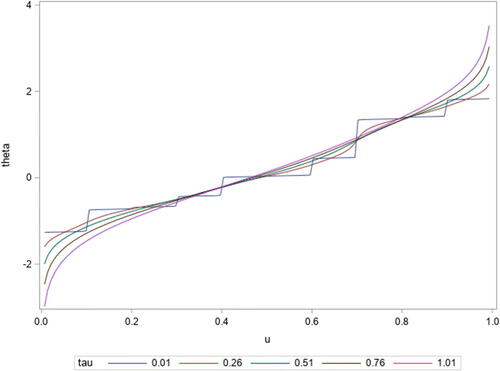
For an introductory illustration of the potential of the GSQF estimator relative to serving as a smooth quantile function estimator we simulated n = 10 observations from a N(0, 1) distribution and calculated from Equation(3.4)
(3.4)
(3.4) . As one can see from that as τ approaches 0 we approach the step function estimator of the quantile function,
However, for very small values of τ we readily start to smooth the quantile function without dramatically modifying the point estimates at a give value of u. So, the theoretical challenge then becomes providing a guideline for the choice of τ if the goal is to use the GSQF as a smooth estimator for the population quantile Q(u). It should be noted that for all of the classic estimators from
to
at Equation(1.3)
(1.3)
(1.3) - Equation(1.6)
(1.6)
(1.6) the function estimates are restricted to the range
regardless of the underlying distribution. The estimator
is also limited to the same range to that of
whereas the estimator
has the feature of extrapolation in the tail regions, which has important applicability to issues such as extreme value estimation, e.g., estimating a 50 year flood values to smooth bootstrap resampling yielding more precise percentile confidence intervals, e.g., see Hutson (Citation2002).
Figure 3. Example GSQF estimator for for n = 10 simulated values for various values of τ.
Due to the form of at Equation(3.7)
(3.7)
(3.7) an analytical expression for the choice of the bandwidth τ in terms of minimizing the mean squared error (MSE) for a given underlying distribution is not readily available. Numerical methods may be applied to solving this problem but are not particularly generalizable. However, data driven choices for the choice of the bandwidth τ may be generated by first noting that from Equation(3.8)
(3.8)
(3.8) we may re-express the asymptotic distribution of
from some fixed
as
(4.1)
(4.1)
where
denotes the bias of the estimator
relative to estimating Q(u) versus being an asymptotically unbiased estimator of
given from M-estimation theory.
We can empirically estimate the MSE of for estimating the quantile function Q(u) at a fixed u by first noting that
(4.2)
(4.2)
and replacing the population quantities with their empirical counterparts, where as before
and
This yields the estimator
(4.3)
(4.3)
where
is defined at (1.6). Now it should be noted that for fixed u we can simultaneously minimize
at (4.3) and the function for obtaining
at (3.4) with respect to τ and
as a dual minimization problem using standard nonlinear programming methods.
Alternatively, a fixed choice for the bandwidth of works well in practice and is numerically stable. It should be clear that as
for
that
We can utilize
for unknown σ, where s denotes the sample standard deviation.
Comment. The function is numerically unstable for very small values of
or smaller. Care needs to be taken when evaluating this function numerically at these extreme small values due to numerical artifacts. Empirically the jackknife variance estimator and the estimator for the variance of
given by
provide virtually identical values for larger values of
however the jackknife variance estimate is also stable for small values of
Comment. If the random variable X has a distribution with known support over the positive real line we suggest using the transformation and then back-transforming to the original scale after estimating Q(u) via the GSQF estimator.
Similar to the approaches found in Hutson (Citation2000, Citation2002) we wish to also consider the hybrid estimator that combines and
and defined as
(4.4)
(4.4)
where we set
and
5. Simulation study
In this section we performed a simulation study to compare the various quantile estimators at Equation(1.3)(1.3)
(1.3) -Equation(1.6)
(1.6)
(1.6) versus the GSQF estimator in terms of bias and variance tradeoffs for quantiles of
across the Lapace, Normal and Logistic distributions for sample sizes of n = 10, 25, 50. These three distributions constitute range from light-tailed to heavy tailed distributions. We utilized 10,000 Monte Carlo replications per scenario. We utilized the bandwidth
for the kernel quantile estimator
defined at Equation(1.6)
(1.6)
(1.6) as per Sheather and Marron (Citation1990). We set
for the GSQF estimator. The same bandwidths were used for the hybrid estimator
defined at Equation(4.4)
(4.4)
(4.4) . We only provide simulation results for
at the extreme quantiles since in the interior the estimator is equivalent to
In general we see from that appears to be the optimal estimator across all three distributions in terms of bias/variance tradeoffs. Also note that
is equivalent to
for
Hence the hybrid estimator benefits through the splicing of
and
at both
and
We will examine these set of estimators in the next section relative to bootstrap smoothing applicability.
Table 1. Monte Carlo bias and standard deviation (SD) estimates across competing quantile estimators for
Table 2. Monte Carlo bias and standard deviation (SD) estimates across competing quantile estimators for
Table 3. Monte Carlo bias and standard deviation (SD) estimates across competing quantile estimators for
6. Bootstrap extrapolation
Hutson (Citation2002) outlined the importance toward considering smooth quantile functions for use in bootstrap estimation procedures: “Nonparametric bootstrap estimation in the i.i.d. continuous univariate setting is traditionally defined as a technique for estimating the probability distribution of a random variable having the form where F(X) denotes the distribution function of X. The estimation consists of “plugging-in” the empirical distribution function estimator
where
denotes the indicator function, in place of F(X) in the population quantity of interest T, e.g., the bootstrap estimator of
conditional on the data, is
However, apparent difficulties arise when closed form expressions based upon
are not easily calculated, e.g.,
Approximate bootstrap solutions to complicated problems such as the one just described may be handled using the well-known bootstrap resampling approach. e.g., see popular bootstrap texts such as those by Efron and Tibshirani (Citation1993), Davison and Hinkley (Citation1997) and Shao and Tu (Citation1995) for details and examples. The appeal of the resampling approach has always been that it provides practitioners a powerful and easy-to-use tool for tackling difficult, and what might otherwise be intractable analytic problems under more relaxed assumptions as compared to parametric methods. However, it is well known that the bootstrap resampling approach has shortcomings and that it can be easily misapplied, e.g., see Young (Citation1994). An important problem is the construction of confidence intervals for
based upon the B bootstrap replicates. There are many different methods. The most straightforward approach is the bootstrap percentile confidence interval method. This method consists of ordering B replicates
calculated from resampling from the data and then defining the
bootstrap percentile confidence interval as the
and
ordered values, where
denotes the floor function. This method is appealing and gets to the heart of bootstrapping since it does not require any formulas, just the ability to calculate and sort bootstrap replications. Unfortunately, for small samples these intervals can suffer severe undercoverage, even for smooth statistics such as the sample mean, e.g., see Polansky (Citation1999).
As noted in the introduction if we let then generating a univariate bootstrap sample with replacement may be viewed as simulating data from
i.e., one bootstrap replicate is given by
Hence, one approach to smoothing a bootstrap resample, particularly in the small sample setting, is to utilize
The choice between quantile estimators is often a tradeoff between bias (rates of convergence), variance and smoothness relative to the application at hand, which is one motivation of our new proposed estimator. However, the more appealing property of the GSQF estimator is the extrapolation component of the estimation procedure relative to providing accurate coverage probabilities for bootstrap percentile confidence intervals.
We ran a small simulation study to examine the benefits of the GSQF estimator in terms of improved percentile confidence interval coverage as compared to using the various quantile estimators at Equation(1.3)(1.3)
(1.3) -Equation(1.6)
(1.6)
(1.6) . We calculated percentile confidence intervals for the location and scale parameters for the normal, Laplace and logistic distributions using their respective maximum likelihood estimators for samples of size n = 10 and n = 25. We utilized 1,000 Monte Carlo simulations per scenario with B = 250 bootstrap replications per simulation. We utilized the bandwidth
for the kernel quantile estimator
defined at Equation(1.6)
(1.6)
(1.6) and
for the GSQF estimator. The results are contained in . As can be seen the GSQF and hybrid quantile based bootstrap resampling approach are much superior to resampling based on other quantile functions, where again resamples of the form
are equilvant to resampling with replacement. With the exception of the GSQF and hybrid approaches we can severe undercoverage relative to the intervals corresponding to the scale parameter σ for each distribution. The superiority of the GSQF and hybrid quantile based bootstrap resampling approaches is the ability to estimate quantiles outside the range of the data thus having a better representation of the variability of the true underlying distribution assuming support over the entire real line. This property is extremely important for small to moderate sample sizes. For large n all variations of these quantile function estimators converge to the same thing. It should also be noted that the location and scale parameter statistics range from smooth statistical functionals for the normal and logisitic distribution to less smooth statistical functionals for the Laplace distribution, where the median and median absolute deviations are the respective estimators for location and scale.
Table 4. Bootstrap percentile confidence interval coverage probabilites for location and scale parameters across quantile function estimators for
7. Example
For our example data we have the ratio of spleen to brain weight ratios in a subset of n = 20 mice where the sorted datavalues rounded to two decimal places are given as The data came from a pre-clinical IND report submitted to the FDA. We left out for
from the graphical comparison to cut to more clearly see the other estimators. Some selected estimated quantiles across estimators are provided in . We see that the primary differences, as expected, are in the tail regions of the estimators. This is further illustrated in . provides the 95% bootstrap percentile confidence intervals based on each estimator for the E(X) and STD(X) for our example dataset. As expected from our simulation study there is not much difference in the confidence intervals for E(X) while there are subtle differences in the upper bound for the confidence interval for STD(X) being slightly longer for the intervals based on the new estimators, which demonstrated better coverage probabilities as compared to their counterparts.
Figure 4. Comparison of six quantile function estimators for example data of n = 20 mouse spleen to brain weight ratios.
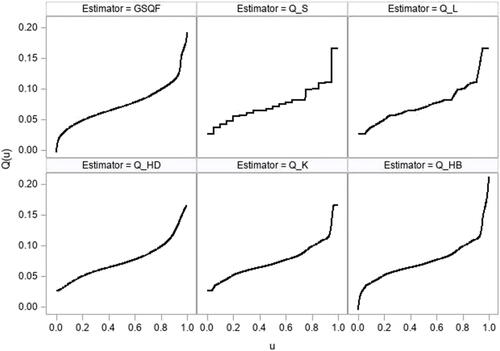
Table 5. Select estimated quantiles for spleen to brain weight ratios for n = 20 mice.
Table 6. 95% Percentile confidence intervals for the E(X) and VAR(X) based on each quantile estimator for spleen to brain weight ratios for n = 20 mice.
8. Concluding remarks
In this note we introduced a new class of smooth estimators based on utilizing the sigmoidal approximation in place of the absolute value function in quantile estimation. Our two quantile function estimators were well behaved and were shown to have strong utility in univariate bootstrap smoothing resampling procedures. The theory for our estimators followed straightforward from classic M-estimation theory. Our future work will be to use this approach to develop generalized expectile regression framework.
Additional information
Funding
References
- Abdous, B., and B. Remillard. 1995. Relating quantiles and expectiles under weighted-wymmetry. Annals of the Institute of Statistical Mathematics 47 (2):371–84. doi:10.1007/BF00773468.
- Abdous, B., and R. Theodorescu. 1992. Note on the spatial quantile of a random vector. Statistics & Probability Letters 13 (4):333–6. doi:10.1016/0167-7152(92)90043-5.
- Bassett, G., Jr., and R. Koenker. 1982. An empirical quantile function for linear models with i.i.d. errors. Journal of the American Statistical Association 77:407–15.
- Chen, C., and O. L. Mangasarian. 1995. Smoothing methods for convex inequalities and linear complementarity problems. Mathematical Programming 71 (1):51–69. doi:10.1007/BF01592244.
- Cheng, C. 1995. The Bernstein polynomial estimator of a smooth quantile function. Statistics & Probability Letters 24 (4):321–30. doi:10.1016/0167-7152(94)00190-J.
- Davison, A. C., and D. V. Hinkley. 1997. Bootstrap methods and their applications. New York: Cambridge University Press.
- Efron, B., and R. Tibshirani. 1993. An introduction to the bootstrap. New York: Chapman & Hall.
- Hampel, F., C. Hennig, and E. Ronchetti. 2011. A smoothing principle for the Huber and other location M-estimators. Computational Statistics & Data Analysis 55 (1):324–37. doi:10.1016/j.csda.2010.05.001.
- Harrell, F., and C. E. Davis. 1982. A new distribution-free quantile estimator. Biometrika 69 (3):635–40. doi:10.1093/biomet/69.3.635.
- Hutson, A. D. 2000. A composite quantile function estimator with applications in bootstrapping. Journal of Applied Statistics 27 (5):567–77. doi:10.1080/02664760050076407.
- Hutson, A. D. 2002. A semiparametric quantile function estimator for use in bootstrap estimation procedures. Statistics and Computing 12 (4):331–8. doi:10.1023/A:1020783911574.
- Hutson, A. D. 2018. Quantile planes without crossing via nonlinear programming. Computer Methods and Programs in Biomedicine 153:185–90. doi:10.1016/j.cmpb.2017.10.019.
- Hutson, A. D., and M. D. Ernst. 2000. The exact bootstrap mean and variance of an L-estimator. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 62 (1):89–94. doi:10.1111/1467-9868.00221.
- Jones, M. C. 1994. Expectiles and M-quantiles are quantiles. Statistics & Probability Letters 20 (2):149–53. doi:10.1016/0167-7152(94)90031-0.
- Koenecker, R. 1993. When are expectiles percentiles? Econometric Theory 9:526–7.
- Mao, T., K. W. Ng, and T. Hu. 2015. Asymptotic expansions of generalized quantiles and expectiles for extreme risks. Probability in the Engineering and Informational Sciences 29 (3):309–27. doi:10.1017/S0269964815000017.
- Mudholkar, G. S., A. D. Hutson, and C. E. Marchetti. 2001. A simple Hermitian estimator of the quantile function. Journal of Nonparametric Statistics 13 (2):229–43. doi:10.1080/10485250108832851.
- Newey, W. K., and J. L. Powell. 1987. Asymmetric least squares estimation and testing. Econometrica 55 (4):819–47. doi:10.2307/1911031.
- Parzen, E. 1993. Change PP plot and continuous sample quantile function. Communications in Statistics - Theory and Methods 22 (12):3287–304. doi:10.1080/03610929308831216.
- Polansky, A. M. 1999. Upper Bounds on the True Coverage of Bootstrap Percentile Type Confidence Interval. The American Statistician 53:362–9.
- Polansky, A. M., and W. R. Schucany. 1997. Kernel smoothing to improve bootstrap confidence intervals. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 59 (4):821–38. doi:10.1111/1467-9868.00099.
- Reiss, R.-D. 1980. Estimation of quantiles in certain nonparametric models. Annals of Mathematical Statists 8:87–105.
- Reiss, R.-D. 1989. Approximate distributions of order statistics: With applications to nonparametric statistics. New York: Springer-Verlag.
- Schmidt, M., G. Fung, and R. Rosales. 2007. Fast optimization methods for L1 regularization: A comparative study and two new approaches. In Machine learning: ECML 2007. Lecture notes in computer science, Vol. 4701, ed. J. N. Kok, J. Koronacki, R. L. Mantaras, S. Matwin, D. Mladenič, and A. Skowron. Berlin, Heidelberg: Springer.
- Serfling, R. J. 1980. Approximation theorems of mathematical statistics. New York: John Wiley & Sons.
- Shao, J., and D. Tu. 1995. The Jackknife and bootstrap. New York: Springer-Verlag.
- Sheather, S. J., and J. S. Marron. 1990. Kernel quantile estimators. Journal of the American Statistical Association 85 (410):410–6. doi:10.1080/01621459.1990.10476214.
- Stigler, S. M. 1977. Fractional order statistics, with applications. Journal of the American Statistical Association 72 (359):544–50. doi:10.1080/01621459.1977.10480611.
- Young, G. A. 1994. Bootstrap: More than a stab in the dark. Statistical Science 9 (3):382–415. doi:10.1214/ss/1177010383.