
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
When analyzing lifetime data in the presence of censoring one is often required to estimate the distribution function of the lifetimes non-parametrically. The most popular estimator used for this purpose is the Kaplan-Meier estimator. Interestingly, in its initial formulation this estimator is only defined up to the observed sample maximum. For values larger than the sample maximum two different assumptions are commonly used in the statistical literature. The first is to set the value of the estimate to one while the second is to use the value of the estimate at the sample maximum when estimating the tail of the distribution function. This paper illustrates the profound effect of these assumptions on the sizes and powers of goodness-of-fit tests for three classes of distributions often used in survival analysis. These differences are illustrated using observed remission time data. The considered classes of distributions are the exponential, Weibull and gamma. As a result of independent interest, we amend two classes of tests developed for the gamma distribution in the full sample case for use with censored data.
1. Introduction
Statistical practitioners and other researchers are often interested in the parametric modeling of observed lifetime data in survival analysis, reliability theory as well as many other fields. In order to perform inference, it is necessary to test the goodness-of-fit hypothesis that the observed lifetimes are realized from a specified class of distributions. This hypothesis is complicated by the fact that random right censoring is often present in the applications of interest. Testing the goodness-of-fit of a specific class of distributions is a topic of continued interest; recent papers on this topic include (Cuparić and Milošević Citation2021) and (Bothma et al. Citation2021) (in which the assumption of exponentiality is tested) as well as (Kim Citation2017) (in which the assumption of the class of Weibull distributions is tested).
In the full sample case, the classical goodness-of-fit tests are based on comparisons between non-parametric and parametric estimates of the distribution function (obtained by estimating the parameters of the specified class of distributions under the null hypothesis). Consider, for example, the Cramér-von Mises test, see D’Agostino and Stephens (Citation1986). The idea underlying this test is to compare the empirical distribution function to a fitted parametric distribution function obtained by estimating the parameters (using consistent estimators) of the specified class of distributions. If the distance between the two estimates, as measured by an integral involving the squared difference between the empirical distribution function and the fitted distribution, is “too large” (to be made precise below), then the null hypothesis is rejected. In fact, this approach also underlies other classical goodness-of-fit tests such as the Kolmogorov-Smirnov test, which is obtained upon replacing the distance measure above by the supremum difference.
A natural approach to the goodness-of-fit problem in the presence of censoring is to extend the techniques described above to account for censoring. That is, in the presence of censoring, the Cramér-von Mises test for a class of distributions is based on a specified distance between a non-parametric estimate of the distribution function, similar to the empirical distribution function, and a parametric estimate of the distribution function under the null hypothesis. Parameter estimation in the presence of random right censoring has been studied extensively in the literature, see e.g. Cox and Oakes (Citation1984) as well as Datta (Citation2005). The most popular estimation technique used is the method of maximum likelihood; this method is used for parameter estimation throughout this paper. It remains to find a non-parametric estimate of the distribution function. This can be achieved using the well-known Kaplan-Meier estimator, see Kaplan and Meier (Citation1958). In order to proceed we introduce some notation below.
Let denote independent and identically distributed (i.i.d.) lifetimes with continuous distribution and density functions F and f, respectively. Let
be i.i.d. censoring variables with continuous distribution function G, independent of
We assume that the censoring mechanism used is non-informative. The observed times are
and we define the indicator variables
The order statistics of Tj are denoted
with
corresponding to
Let
denote a parametric class of distribution functions indexed by some, possibly vector valued, parameter θ. Based on the observed pairs
we wish to test the composite goodness-of-fit hypothesis
against general alternatives. In this paper, we present numerical results relating to three classes of distributions, the exponential, Weibull and gamma. References to recent papers relating to testing for the first two of these are provided above. However, we have been unable to obtain any papers relating to goodness-of-fit testing for the gamma distribution in the presence of censoring. In Sec. 2, we adapt several existing tests for the gamma distribution in the full sample case for use with random right censored data.
Using the notation introduced above, the Kaplan-Meier estimator, is a step function given by
(1)
(1)
Interestingly, in its initial formulation, the Kaplan-Meier estimator of the distribution function is only defined up to the sample maximum, say In cases where the maximum observation is censored, two different assumptions or conventions are commonly used in the statistical literature to define
for
The first is to simply set the value of
see e.g. Efron (Citation1981), while the second is to set
see e.g. Cox and Oakes (Citation1984). For the sake of brevity, we refer to this convention as the “set-to-1” convention; i.e. we refer to the first and second conventions mentioned above as cases where the set-to-1 assumption is made and not made, respectively.
Regardless of the set-to-1 assumption, all jumps in occurring before the sample maximum occur at values of Tj for which
If the sample maximum τ is uncensored, then the final jump in
occurs at τ regardless of the set-to-1 assumption. However, if the sample maximum is censored, then the set-to-1 assumption influences the tail behavior of
i.e. the value of
If the set-to-1 assumption is made the final jump occurs immediately after τ; however, if this assumption is not made there is no jump immediately following τ. The latter case results in an improper distribution with positive probability of realizing the value
In summary, the set-to-1 assumption only influences the estimate
if the sample maximum is censored, and then it only affects
This paper illustrates the profound effect that this seemingly small difference has on the powers of goodness-of-fit tests by conducting an extensive Monte Carlo simulation study. Before we proceed, the effect of the assumption used in the Kaplan-Meier estimator is demonstrated using an example based on observed data below.
A data set containing 66 initial remission times of leukemia patients, 14 of which are censored, is presented in (Lee and Wang Citation2003). The data are shown in , censored observations are indicated using an asterisk in the superscript. Initially, the data were segmented into three groups based on the treatments that the patients received. However, (Lee and Wang Citation2003) found no statistically significant differences between the groups, so we treat the data as realizations from a single distribution. shows the Kaplan-Meier estimate of the distribution function using both of the assumptions discussed above. The two Kaplan-Meier step functions considered coincide up to the sample maximum value of 269 (indicated in using a dotted vertical line). However, since the last observation is censored, the two versions of this estimate differ when t > 269. Under the set-to-1 assumption, If this assumption is not made, then
As can be seen in the figure, the set-to-1 assumption makes a substantial difference in the estimated value of the distribution function for large values of t. Additionally, shows two parametric estimates of the distribution function obtained using exponential and Weibull distributions, respectively. The techniques used to obtain these parametric estimates are discussed.
Figure 1. Kaplan-Meier Estimate of the lifetimes with fitted exponential and Weibull distributions.
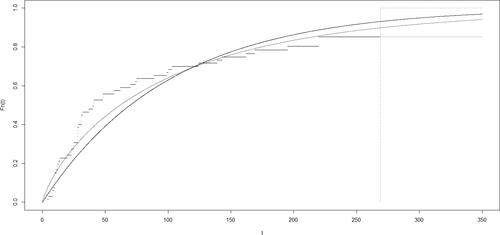
Table 1. Initial remission times of leukemia patients in days.
As a first parametric model, consider the class of exponential distributions, with density We denote a random variable having this density by
The maximum likelihood estimate of the rate parameter of the exponential distribution is
For the example at hand, shows the fitted exponential distribution function using a solid line. Additionally, we fit a Weibull distribution to the observed data. The density of the Weibull distribution with parameters κ and λ is
. A random variable with this density is denoted by
The log-likelihood of the
distribution, given
is
where
Closed form formulae for the maximum likelihood estimators of κ and λ are not available. The required estimates are obtained using numerical optimization. All calculations presented are performed in R, see R Core Team (Citation2019). We estimate the parameters of the Weibull distribution using the
function in the parmsurvfit package, see Jacobson, Wilson, and Pileggi (Citation2018). For the current example, the parameter estimates obtained are
and
The fitted Weibull distribution function is shown in using a dotted line.
provides us with a visual test of fit for both the exponential and Weibull distributions; the fitted Weibull seems to resemble the non-parametric estimates more closely than does the fitted exponential. This is to be expected as the exponential distribution is a special case of the Weibull. In order to formally test the goodness-of-fit hypotheses of interest, we use the Cramér-von Mises test for both classes of distributions in turn. Goodness-of-fit test statistics for the exponential and Weibull distributions are typically performed based on transformed data. In the case of the exponential distribution, we rescale the data by multiplication with the estimated rate parameter. This essentially reduces the null hypothesis to testing for standard exponentiality. In the same way, we may use a transformation to reduce the test for the Weibull class of distributions to a test for the standard extreme value distribution; i.e. if, and only if,
follows a standard extreme value distribution. That is, Y has density
We denote the variables resulting from the sample version of this transformation by
for both the exponential and Weibull classes (as well as for the gamma class later in the paper). Using transformations of this kind is standard practice in the goodness-of-fit literature, see e.g. Allison et al. (Citation2017) and Bothma, Allison, and Visagie (Citation2022) as well as Henze and Visagie (Citation2020). Below, we use
and
to denote the fitted distribution function and the Kaplan-Meier estimate of the distribution function, respectively.
Let CMn denote the Cramér-von Mises test statistic based on As was mentioned above, CMn is a distance measure between the parametric estimate
and the non-parametric estimate
(2)
(2)
We can exploit the fact that is a step function in order to arrive at an easily calculable expression for CMn. Using notation similar to that of (D’Agostino and Stephens Citation1986), denote by
the set of uncensored lifetimes and let
be the transformed value of the sample maximum. The Cramér-von Mises test statistic defined in Equation(2)
(2)
(2) can be expressed as
where
denotes the right limit of the function g. In the case where the set-to-1 assumption is made, the formula above coincides with the formula given in (D’Agostino and Stephens Citation1986).
For the example under consideration, the sample maximum is censored, meaning that the calculated value of and therefore the value of CMn, depends on the set-to-1 assumption. Consider first the case where
is the class of exponential distributions. When making the set-to-1 assumption, CMn is calculated to be 0.543. If this assumption is not made, then CMn equals 0.596.
In order to formally test the hypothesis that the lifetimes are realized from an exponential distribution, we need to approximate the distribution of the test statistic under the null hypothesis. In the full sample case, the fact that the exponential class of distributions is a scale family ensures that the distribution of the CMn under the null hypothesis is independent of the value of λ. However, in the setup considered in this paper, we are unable to exploit this feature of the exponential class as even the hypothesis that lifetimes are standard exponential is a composite hypothesis since the censoring distribution remains unspecified. As a result, we use a bootstrap algorithm in order to approximate the null distribution of CMn. Appropriate bootstrap algorithms for use with the exponential and Weibull classes can be found in (Bothma et al. Citation2021) and (Bothma, Allison, and Visagie Citation2022), respectively. However, the provided algorithms specifically assume that the set-to-1 convention is not used. Below we provide a more general algorithm in which the user can specify whether or not to make the set-to-1 assumption.
In order to proceed, we need to be able to obtain bootstrap samples from both the lifetime and censoring distributions. Generating samples from the lifetime distribution under the null hypothesis is a simple matter; we estimate the parameters of the specified class of distributions and we simulate from this fitted distribution (using, e.g. the inverse transform method). Since the null hypothesis does not specify the censoring distribution, we need to estimate this distribution from the observed data. We use the Kaplan-Meier estimator of the distribution of the censored observations; this is done by calculating in Equation(1)
(1)
(1) , but replacing δj by
in the calculations. Of course, since we are using the Kaplan-Meier estimator to estimate the distribution of the censoring times, we are confronted with the set-to-1 assumption once again. Immediately, one is tempted to argue that whatever convention was used to estimate the distribution function of the lifetimes should be used in order to estimate the distribution function of the censoring times. However, there is no contradiction in, e.g. making the set-to-1 assumption for the censoring times and not for the lifetimes. In order to ease notation in the remainder of the paper we use the notation “TF” in order to indicate this specific combination of conventions since it means that we assume that the set-to-1 assumption is “true” for the censoring distribution and “false” for the lifetime distribution. As a result, we are left with four distinct possibilities:
Case 1: The set-to-1 assumption is not made for either of the estimated distributions (indicated by “FF”).
Case 2: The set-to-1 assumption is made for the lifetime distribution but not for the censoring distribution (indicated by “FT”).
Case 3: The set-to-1 assumption is made for the censoring distribution but not for the lifetime distribution (indicated by “TF”).
Case 4: The set-to-1 assumption is made for both of the estimated distributions (indicated by “TT”).
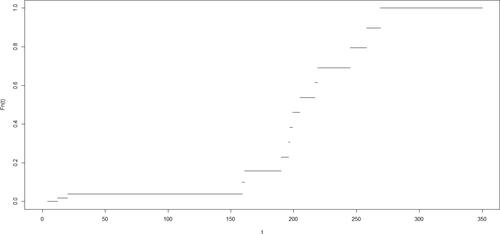
The Kaplan-Meier estimate of the censoring distribution in the practical example is shown in . Since the sample maximum is censored, the Kaplan-Meier estimate achieves the value of 1 at t = 269 regardless of the set-to-1 assumption.
Figure 2. Kaplan-Meier Estimate of the censored remission times.
We now provide the bootstrap algorithm required in order to approximate critical values for goodness-of-fit tests in the presence of random right censoring.
Using
estimate the parameters of the class of distributions as specified in H0.
Obtain a parametric bootstrap sample
Obtain a non-parametric bootstrap sample
Set
Using
Based on the data
Repeat steps 2-6 B times, resulting in
The algorithm presented above is general and not only intended for use with the exponential null hypothesis. Using this algorithm, and setting we obtain an approximation to the null distribution of the CMn statistic when testing for the exponential class. In the current example, the set-to-1 assumption regarding the Kaplan-Meier estimate of the censoring distribution is unimportant since it does not influence the resulting estimated distribution function. However, the set-to-1 convention used influences the value of the test statistic obtained and therefore the p-value of the test. In this case, an approximate p-value of 0.00072 is obtained when making the set-to-1 assumption, while the p-value is estimated to be 0.00032 when not using this assumption. In both cases, we reject the hypothesis that the lifetimes are realized from an exponential distribution at a significance level of 1%.
We now turn our attention to the hypothesis that the lifetimes are realized from the Weibull class of distributions. The value of CMn is calculated to be 0.244 when making the set-to-1 assumption, which corresponds to a p-value of 0.019. If this assumption is not made, the calculated value of CMn is 0.290, corresponding to a p-value of 0.011. As a result, we do not reject the hypothesis that the lifetimes follow a Weibull distribution at a 1% significance level.
The final class of distributions considered is the gamma class. A random variable with density with
is said to have a gamma distribution with shape parameter κ and rate parameter λ. We denote a random variable with this density by
When testing the hypothesis that the remission times considered are realized from a gamma distribution, we calculate CMn to be 0.376 and 0.326 respectively when making the set-to-1 assumption and not making this assumption. In both cases, the corresponding p-value is below 1%, meaning that we reject the class of gamma distributions as a suitable model for the lifetimes.
2. Test statistics for the various classes of lifetime distributions
Below, we provide the details of a number of goodness-of-fit tests for the exponential, Weibull and gamma classes. The performances of the tests in this section are evaluated in a Monte Carlo simulation study presented in Sec. 3. We begin by specifying the classical Kolmogorov-Smirnov test. As is the case for the Cramér-von Mises test, discussed in Sec. 1, the Kolmogorov-Smirnov test is general in the sense that it can be used to test for any of the classes of distributions mentioned above.
After considering the Kolmogorov-Smirnov test, we turn our attention to tests developed for each of the considered classes of distributions separately. The remaining tests are based on the characteristic function and Laplace transform. These functions and their empirical counterparts have been studied extensively in the full sample case, see e.g. Meintanis (Citation2016). However, estimates for the empirical versions of these functions are less well known in the presence of censoring. As a result, we discuss these functions before defining the relevant test statistics.
2.1. The Kolmogorov-Smirnov test
The Kolmogorov-Smirnov (KSn) test measures the supremum distance between and
Similar to the full sample case, the differences need only be evaluated in the jump points of the piecewise constant The value of KSn can be calculated as
(3)
(3)
where
and
with
Note that, if the set-to-1 assumption is made, then
for all samples and the final term in Equation(3)
(3)
(3) can be omitted.
2.2. Empirical characteristic function and Laplace transforms
Recall that the characteristic function of a random variable, Y, with distribution function, F, is defined to be
with
Using the notation introduced above and using
to estimate F, we may estimate the characteristic function based on a censored sample by
see e.g. Csörgö (Citation1984), where Δj denotes the size of the jump in
given by
Additionally, recall that the Laplace transform of a random variable Y is defined as
Upon estimating F by the resulting estimate of the Laplace transform is
2.3. Tests for the exponential distribution
We now consider four tests for the exponential distribution in the presence of random right censoring. The first two tests are based on the empirical characteristic function while the last two are based on the empirical Laplace transform. Three of the tests below contains a user defined tuning parameter a > 0.
2.3.1. Henze-Meintanis (2002a)
A test statistic based on a characterization of the exponential distribution via the characteristic function is introduced in Henze and Meintanis (Citation2002a). In the presence of random censoring, the modified test is given by
where
and
An easily computable form of the test statistic is
In the simulation study in Sec. 3, we set a = 1 in accordance with the recommendation made in Henze and Meintanis (Citation2002a). The null hypothesis of exponentiality is rejected for large values of
2.3.2. Baringhaus-Henze (1991)
Baringhaus and Henze (Citation1991) introduces a test statistic based on a partial differential equation involving the Laplace transform. In the presence of random censoring the test statistic becomes
where
is the derivative of
The calculable form of the modified test is given by
In the simulation study below we use a = 0.25. The null hypothesis of exponentiality is rejected for large values of
2.3.3. Henze-Meintanis (2002b)
A test statistic based on the squared difference between the Laplace transform and its empirical counterpart is proposed in Henze and Meintanis (Citation2002b). In the presence of censoring, the modified test can be expressed as
This test statistic lends itself to the following easily calculable form;
We obtain the results in the simulation study by setting a = 0.25 as is recommended in (Henze and Meintanis Citation2002b). The null hypothesis is rejected for large values of
2.4. Tests for the Weibull distribution
Below we consider three tests for the Weibull distribution in the presence of random right censoring. The first two tests are based on Stein’s method for the approximation of integrals while the final test is based on the Laplace transform of the standard extreme value distribution.
2.4.1. Bothma-Allison-Visagie (2021)
Bothma, Allison, and Visagie (Citation2022) proposes new classes of tests for the Weibull distribution based on Stein’s method. This test statistic is defined as
(4)
(4)
where
is a weight function containing a user-defined tuning parameter a > 0. The use of two weight functions resulted in two different classes of test statistics. For the first weight function,
the test statistic is given by
In the simulation study below we use a = 1 as well as a = 2. The second weight function used is In this case, the test statistic simplifies to
We obtain the results in the simulation study by setting a = 2 in The null hypothesis is rejected for large values of both
and
2.4.2. Krit (Citation2014)
A test that compares the empirical Laplace transform of a random variable Y to the Laplace transform of an EV(0, 1) random variable was introduced in Krit (Citation2014). The resulting test statistic is
(5)
(5)
where
is a user-specified tuning parameter. The following approximation provides an easily implementable form of
where m is the number of points at which the integrand is evaluated. In the numerical results shown below, we use
and m = 100 as recommended in (Krit Citation2014). Large values of KRn result in the rejection of the null hypothesis.
2.5. Tests for the gamma distribution
As was mentioned in the introduction, we have been unable to find published papers on testing for the gamma distribution in the presence of random right censoring. Below we amend three existing tests for this distribution developed for use with full samples using techniques similar to those used above. The first and second tests below are based on the empirical Laplace transform while the third uses the Stein characterization. Below, where
denotes the estimated rate parameter of the gamma distribution.
2.5.1. Henze-Meintanis-Ebner (2012)
Two classes of tests, based on a differential equation involving the Laplace transform, are introduced in Henze, Meintanis, and Ebner (Citation2012). The modified test is defined as
where
is a weight function with a user-defined tuning parameter a > 0. Upon setting
we obtain the first class of test statistics;
In the simulation study, we present powers obtained when setting a = 1. When setting the modified test statistic simplifies to
where
and
denotes the error function. We use a = 4 in
in the next section. The null hypothesis is rejected for large values of both
and
2.5.2. Betsch-Ebner (2019)
Betsch and Ebner (Citation2019) shows that F is the gamma distribution if, and only if,
As a result,
should be approximately zero for all t > 0 if the hypothesis of the gamma class is true. We propose the following statistic based on
where a > 0 is a user defined tuning parameter. In the simulations in Sec. 3, we use a = 0.5 and a = 1.The hypothesis of the gamma class of distributions is rejected for large values of
3. Monte Carlo simulation
This section shows empirical sizes and powers of the tests considered for the exponential, Weibull and gamma classes of distributions; we consider each of these classes in turn. The results presented include two different censoring proportions; 10% and 30%, respectively. All of the results given in the main text are for samples of size n = 50. However, Appendix shows the results corresponding to a sample size of n = 100. Other configurations of sample size and censoring proportion were also considered when performing the numerical analyses. However, for the sake of brevity, we do not present all of these results below.
The numerical results are based on a nominal significance level of 5% throughout. For each lifetime distribution considered, we report the powers obtained using three different censoring distributions; the exponential, uniform and Lindley distributions. For each of these censoring distributions, the parameters used are chosen so as to ensure that the specified censoring proportion is achieved. In the case of the uniform censoring distribution, this entails choosing the value of the maximum of the distribution while the minimum remains fixed at 0. The alternative lifetime distributions considered are listed in .
Table 2. Density functions of the alternative distributions.
For every test considered, we report the empirical powers for each of the four possible combinations of whether or not the set-to-1 assumption is made. The four variations for each of the tests are defined in Sec. 1 and are indicated by FF, FT, TF, and TT. The empirical powers obtained for the various distributions are reported in . and show the results pertaining to testing for exponentiality, while and show the results associated with the Weibull class. The results associated with the gamma class can be found in and . The reported powers represent the percentages (rounded to the nearest integer) of 10,000 independent Monte Carlo samples for which the null hypothesis is rejected. For each alternative considered, the empirical powers associated with the three censoring distributions mentioned above are shown in consecutive rows of the table. The order in which the censoring distributions are arranged is first the exponential, then the uniform and finally the Lindley distributions. In order to ease comparisons, the highest power, including ties, in each row is shown in bold. To obtain a more general overview of the impact of the four assumptions considered, we calculated the estimated power averages across all tests for each of the alternative distributions. Results are reported for the exponential, Weibull, and gamma distributions, considering two levels of censoring, namely 10% and 30%. The empirical sizes and powers shown in in Appendix make use of the same conventions listed above.
Table 3. Estimated powers for the exponential distribution for 10% censoring for a sample size of n = 50 with three different censoring distributions.
Table 4. Estimated powers for the exponential distribution for 30% censoring for a sample size of n = 50 with three different censoring distributions.
Table 5. Estimated powers for the Weibull distribution for 10% censoring for a sample size of n = 50 with three different censoring distributions.
Table 6. Estimated powers for the Weibull distribution for 30% censoring for a sample size of n = 50 with three different censoring distributions.
Table 7. Estimated powers for the gamma distribution for 10% censoring for a sample size of n = 50 with three different censoring distributions.
Table 8. Estimated powers for the gamma distribution for 30% censoring for a sample size of n = 50 with three different censoring distributions.
Samples from censored distributions are generated using the package, see Mazucheli, Fernandes, and de Oliveira (Citation2016), while parameter estimation for the Weibull and gamma classes are performed using the
package, see Jacobson, Wilson, and Pileggi (Citation2018). The tables are produced using the
package, see Hlavac (Citation2018).
3.1. Numerical results
In this section we discuss the performance of the tests against all of the alternative lifetime distributions considered. We start with a general discussion of the results in , thereafter we discuss the estimated powers for the three classes of lifetime distributions under consideration separately. Furthermore, we make recommendations regarding the set-to-1 assumption for the best performing test for each of the three lifetime distributions.
In general, the sizes as well as the estimated powers, reported in , are highly dependent on the set-to-1 assumptions. For a censoring proportion of 10%, the majority of the tests approximately achieve the specified sizes, although some of the tests are conservative for certain assumptions. The impact of the set-to-1 assumptions on the sizes of the tests are pronounced. For example, the test achieves the specified significance level of 5% against the
distribution using both the exponential and uniform censoring distributions when the set-to-1 assumptions are chosen to be FF. On the other hand, when using the same test with the TF assumptions, these sizes are both calculated to be 0%. In the case of 30% censoring, the majority of the tests considered are noticeably conservative, often achieving a size of 0%. It should be noted that the sizes associated the exponential class are somewhat less variable than those associated with the Weibull and gamma classes.
When turning our attention to the powers achieved by the tests, the influence of the set-to-1 assumptions is as important as when considering the sizes above. Again, we use an example to illustrate the effect of these assumptions on the observed empirical powers. Consider the case of testing for the Weibull distribution. The powers calculated for KSn against the distribution using all three of the censoring distributions, with a censoring proportion of 30% are calculated to be 90% when using the assumptions TT. The same three empirical powers are calculated to be 0% when using the TF assumption.
Once more, it can be observed that the sensitivity of tests for the exponential distribution to the choice of censoring distribution is relatively low. The empirical powers are observed to increase with sample size and decrease with the censoring proportion.
Some general remarks are in order. An increase in the censoring proportion results in a more prominent effect of the assumptions under consideration. Overall, it seems that the tests for the exponential distribution are less sensitive to the set-to-1 assumption. The influence of the censoring distribution becomes more pronounced when the censoring proportion is increased. Another interesting result is that, in a substantial proportion of the alternatives considered, the power of a given test is maximized when the set-to-1 assumption is made for one of the lifetime and censoring distributions, but not the other.
3.1.1. Power comparison for the exponential distribution
The nominal significance level is achieved for the majority of the tests for a censoring proportion of 10%. In the case of 30% censoring these sizes are attained for fewer of the tests considered. is the best performing test against the majority of alternatives, regardless of the set-to-1 assumptions or choice of the censoring distribution. Therefore, we recommend using this test when working with a censored sample that is thought to be exponentially distributed.
3.1.2. Power comparison for the Weibull distribution
The specified sizes are attained for the majority of the tests for smaller censoring proportions, but as the censoring proportion increases the sizes as well as the estimated powers are more variable. The choice of the censoring distribution strongly influences the estimated powers for a censoring proportion of 30%, especially against alternatives such as the Chi-squared or beta distributions. The largest differences in power occur when the censoring distribution is specified to be the uniform distribution.
For a censoring proportion of 10% the test outperforms the other tests for the majority of the alternatives, but only for the FT assumption, i.e. the case where the set-to-1 assumptions are made for the lifetime distribution but not for the censoring distribution. The
test performs the best overall against the alternatives considered when the censoring proportion is 30%. Once again, this is only for a specific set of assumptions, in this case TT; i.e. the set-to-1 assumptions are made for both of the estimated distributions. Even though these two tests perform well under a specific set of assumptions their powers are noticeably erratic for some of the alternatives. The
test performs well with competitive estimated powers regardless of the censoring proportion and set-to-1 assumptions. As a result, we recommend using the
test in general.
3.1.3. Power comparison for the gamma distribution
For the gamma distribution the specified sizes are mostly attained for the 10% censoring proportion, but are rarely attained for the 30% censoring proportion. For the majority of alternatives most of the tests perform poorly, exhibiting low estimated powers, especially when the censoring proportion is high. The influence of the censoring distribution increases with an increase in the censoring proportion, specifically for alternatives such as the lognormal distribution. Overall, the powers associated with the CVn test are least affected by the assumptions made. This test is also fairly powerful against the majority of the alternative distributions considered and we recommend using this test when testing for the gamma distribution.
3.1.4. Overall power comparison
Based on the results, it is evident that the four set-to-1 assumptions have a substantial impact on the powers of the tests, particularly for the Weibull and gamma distributions. The impact becomes more pronounced when the censoring proportion is higher.
The reason for the substantial discrepancies between the observed powers associated with the set-to-1 assumptions is not obvious and still under investigation. Although a mathematical motivation for this phenomenon is lacking, we now provide a short discussion on this. The observed discrepancy is necessarily a finite sample phenomenon since the set-to-1 assumption does not influence the Kaplan-Meier estimate of the distribution function asymptotically (since the estimated distribution function tends to 1 in this case regardless of the assumption made). In one of the earliest discussions relating to the bootstrapping of censored data, Efron made the set-to-1 assumption and explicitly called this an arbitrary definition of the distribution (in the cited paper the survival function is used), see Efron (Citation1981).
Consider the set-to-1 assumption specifically for the censoring distribution. When this assumption is made, it ensures that the distribution function from which the censoring times are simulated satisfies the definition of a distribution function. The same level of importance is not afforded this assumption for the lifetime distribution as the bootstrap procedure used simulates from a hypothesized distribution regardless of the set-to-1 assumption. It is interesting to note that, on average, all of the testing procedures for all distributions considered produce higher power when the set-to-1 assumption is made for the censoring distribution (regardless of whether or not this assumption is made for the lifetime distribution). Finally, we investigated the effects of the skewness and the kurtosis of the lifetime distributions used, but there does not appear to be a discernible link between these higher moments of the distribution and the observed power discrepancies.
4. Practical application
In this section, we apply each of the tests for the Weibull distribution discussed in Sec. 3 to another real-world data set. The times to death (in weeks) for patients with cancer of the tongue are displayed in , see Klein and Moeschberger (Citation2003). An asterisk is used in order to indicate that the observation is censored. A study was undertaken to assess how ploidy (the number of sets of chromosomes of a cell) influences the prognosis of individuals with oral cancers. The study involved the selection of patients who had a sample of the cancerous tissue collected during surgery. Follow-up survival data were gathered for each patient. Utilizing a flow cytometer, the tissue samples were scrutinized to identify whether the tumor exhibited an abnormal DNA profile, employing a method outlined in the work of Sickle-Santanello et al. (Citation1988). The estimated p-values for each of the tests, obtained using 10,000 bootstrap replications, are displayed in .
Table 9. Death times of patients with cancer of the tongue, in weeks.
Table 10. p-Values associated with the various tests used for the Weibull distribution.
Since the sample maximum is censored, the Kaplan-Meier estimate of the censoring distribution achieves the value of 1 at t = 400 regardless of the set-to-1 assumption. The results from the practical example show that only the CVn test rejects the hypothesis of the Weibull distribution at the 5% significance level. Although the conclusion drawn by of each of the tests is unaffected by the set-to-1 assumption at the 5% significance level, the same is not true at either the 1% or 10% levels. In the former case, the results of the CVn test depends on the assumption while, in the latter case the KRn test is sensitive to this assumption. Furthermore, we note that there are substantial differences in the obtained p-values for each of the tests, even in the cases where the final conclusion arrived at is not sensitive to the assumption made.
5. Conclusions and further research
The numerical results above indicate that the assumed tail behavior of the Kaplan-Meier estimator plays an unexpectedly important role when testing goodness-of-fit hypotheses. Specifically, in cases where the sample maximum is censored, we consider two options. In the first, the fitted distribution function is set to 1 for all values exceeding the sample maximum, while the second assumes an improper distribution function with positive probability mass at infinity. The results obtained indicates that the assumed tail behavior is important, not only when estimating the lifetime distribution, but also when estimating the censoring distribution.
We consider numerical sizes and powers for testing the composite hypotheses of the exponential, Weibull and gamma classes of distributions. We note that the mentioned assumptions influence both the obtained sizes and powers for each of the considered classes of distributions. Interestingly, the highest powers are often realized when two different assumptions are made when estimating the lifetime and censoring distributions.
As a result of independent interest, we amend two classes of tests for the gamma distribution for use with censored samples. The numerical powers achieved by the resulting tests are competitive against existing tests for the gamma distribution.
Further research is currently underway in which we consider the effect of using kernel distribution function estimation (kdfe) for the lifetime and censoring distributions. The effect of using kdfe’s, as opposed to the dichotomous approaches used at the sample maximum, will be considered in the goodness-of-fit context.
Acknowledgments
The work of the authors is based on research supported by the National Research Foundation (NRF). Any opinion, finding and conclusion or recommendation expressed in this material is that of the author and the NRF does not accept any liability in this regard.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Allison, J. S., L. Santana, N. Smit, and I. J. H. Visagie. 2017. An “apples-to-apples” comparison of various tests for exponentiality. Computational Statistics 32 (4):1241–83. doi: 10.1007/s00180-017-0733-3.
- Baringhaus, L., and N. Henze. 1991. A class of consistent tests for exponentiality based on the empirical Laplace transform. Annals of the Institute of Statistical Mathematics 43 (3):551–64. doi: 10.1007/BF00053372.
- Betsch, S., and B. Ebner. 2019. A new characterization of the gamma distribution and associated goodness-of-fit tests. Metrika 82 (7):779–806. doi: 10.1007/s00184-019-00708-7.
- Bothma, E., J. S. Allison, and I. J. H. Visagie. 2022. New classes of tests for the Weibull distribution using Stein’s method in the presence of random right censoring. Computational Statistics 37 (4):1751–70. doi: 10.1007/s00180-021-01178-0.
- Bothma, E., J. S. Allison, M. Cockeran, and I. J. H. Visagie. 2021. Characteristic function and Laplace transform-based tests for exponentiality in the presence of random right censoring. Stat 10 (1):e394. doi: 10.1002/sta4.394.
- Cox, D. R., and D. Oakes. 1984. Analysis of survival data, vol. 21. Boca Raton, FL: CRC Press.
- Csörgö, S. 1984. Estimating characteristic functions under random censorship. Theory of Probability & Its Applications 28 (3):615–23. doi: 10.1137/1128059.
- Cuparić, M., and B. Milošević. 2021. New characterization-based exponentiality tests for randomly censored data. TEST 31 (2):461–87. doi: 10.1007/s11749-021-00787-7.
- D’Agostino, R. B., and M. A. Stephens. 1986. Goodness-of-fit techniques, vol. 68. Boca Raton, FL: CRC Press.
- Datta, S. 2005. Estimating the mean life time using right censored data. Statistical Methodology 2 (1):65–9. doi: 10.1016/j.stamet.2004.11.003.
- Efron, B. 1981. Censored data and the bootstrap. Journal of the American Statistical Association 76 (374):312–9. doi: 10.2307/2287832.
- Henze, N., and I. J. H. Visagie. 2020. Testing for normality in any dimension based on a partial differential equation involving the moment generating function. Annals of the Institute of Statistical Mathematics 72 (5):1109–36. doi: 10.1007/s10463-019-00720-8.
- Henze, N., and S. G. Meintanis. 2002a. Goodness-of-fit tests based on a new characterization of the exponential distribution. Communications in Statistics - Theory and Methods 31 (9):1479–97. doi: 10.1081/STA-120013007.
- Henze, N., and S. G. Meintanis. 2002b. Tests of fit for exponentiality based on the empirical Laplace transform. Statistics 36 (2):147–61. doi: 10.1080/02331880212042.
- Henze, N., S. G. Meintanis, and B. Ebner. 2012. Goodness-of-fit tests for the gamma distribution based on the empirical Laplace transform. Communications in Statistics - Theory and Methods 41 (9):1543–56. doi: 10.1080/03610926.2010.542851.
- Hlavac, M. 2018. stargazer: Well-formatted regression and summary statistics tables (R Package Version 5.2.2).
- Jacobson, A., V. Wilson, and S. Pileggi. 2018. parmsurvfit: Parametric models for survival data (R Package Version 0.1.0).
- Kaplan, E. L., and P. Meier. 1958. Nonparametric estimation from incomplete observations. Journal of the American Statistical Association 53 (282):457–81. doi: 10.2307/2281868.
- Kim, N. 2017. Goodness-of-fit tests for randomly censored Weibull distributions with estimated parameters. Communications for Statistical Applications and Methods 24 (5):519–31. doi: 10.5351/CSAM.2017.24.5.519.
- Klein, J. P., and M. L. Moeschberger. 2003. Survival analysis: Techniques for censored and truncated data, vol. 1230. New York: Springer.
- Krit, M. 2014. Goodness-of-fit tests for the Weibull distribution based on the Laplace transform. Journal de la Société Française de Statistique 155 (3):135–51.
- Lee, E. T., and J. Wang. 2003. Statistical methods for survival data analysis, vol. 476. New York: Wiley.
- Mazucheli, J., L. B. Fernandes, and R. P. de Oliveira. 2016. LindleyR: The Lindley distribution and its modifications (R Package Version 1.1.0).
- Meintanis, S. G. 2016. A review of testing procedures based on the empirical characteristic function. South African Statistical Journal 50 (01):1–14. doi: 10.37920/sasj.2016.50.1.1.
- R Core Team. 2019. R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing.
- Sickle-Santanello, B. J., W. B. Farrar, S. Keyhani-Rofagha, J. P. Klein, D. Pearl, H. Laufman, J. Dobson, and R. V. O’Toole. 1988. A reproducible system of flow cyto metric DNA analysis of paraffin embedded solid tumors: Technical improvements and statistical analysis. Cytometry 9 (6):594–9. doi: 10.1002/cyto.990090613.
Appendix
show the empirical sizes and powers associated with samples of size n = 100. pertain to the hypothesis of exponentiality while contain results associated with testing for the Weibull class. The results for the gamma class are shown in .
Table A1. Estimated powers for the exponential distribution for 10% censoring for a sample size of n = 100 with three different censoring distributions.
Table A2. Estimated powers for the exponential distribution for 30% censoring for a sample size of n = 100 with three different censoring distributions.
Table A3. Estimated powers for the Weibull distribution for 10% censoring for a sample size of n = 100 with three different censoring distributions.
Table A4. Estimated powers for the Weibull distribution for 30% censoring for a sample size of n = 100 with three different censoring distributions.
Table A5. Estimated powers for the gamma distribution for 10% censoring for a sample size of n = 100 with three different censoring distributions.
Table A6. Estimated powers for the gamma distribution for 30% censoring for a sample size of n = 100 with three different censoring distributions.