
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Many economic theories suggest that the relation between two variables y and x follow a function forming a convex or concave curve. In the classical linear model (CLM) framework, this function is usually modeled using a quadratic regression model, with the interest being to find the extremum value or turning point of this function. In the CLM framework, this point is estimated from the ratio of ordinary least squares (OLS) estimators of coefficients in the quadratic regression model. We derive an analytical formula for the expected value of this estimator, from which formulas for its variance and bias follow easily. It is shown that the estimator is biased without the assumption of normality of the error term, and if the normality assumption is strictly applied, the bias does not exist. A simulation study of the performance of this estimator for small samples show that the bias decreases as the sample size increases.
1. Introduction
Many economic theories suggest that the relation between two variables y and x follow a function forming a convex ( shaped) or concave (
shaped) curve, often called U-shaped and inverted U-shaped relations, respectively. The most famous example is probably the Kuznets hypothesis that the relation between a country’s income equality and economic development is concave, with income equality first increasing and then decreasing as the country’s economy is developing (Kuznets Citation1955). Extensions of this “Kuznets curve” include e.g., the “environmental Kuznets curve”, suggesting a concave relation between a country’s environmental degradation and economic development (Dinda Citation2004). Other examples of concave relations are those between union membership and age (Blanchflower Citation2007) as well as between innovation and competition (Aghion et al. Citation2005). A convex relation has been postulated between e.g., a country’s female labor force participation and economic development (Goldin Citation1995) as well as between life satisfaction and age (Blanchflower and Oswald Citation2016). For a more detailed discussion, see Hirschberg and Lye (Citation2005).
For these situations, the relation between the dependent variable y and the independent variable x may in the classical linear model (CLM) framework be described by the quadratic regression model
(1)
(1)
also known as the second-order polynomial regression model (in one variable), where βk, k = 1, 2, 3, are regression coefficients and ε is an unobserved random error term with expected value
and variance
Usually, it is also assumed that ε is normally distributed, i.e.,
A problem with this model is that the regression coefficients β2 and β3 in general do not have any simple interpretations. The common interpretation of β2 in the CLM framework as giving the change in the expected value of y when x increases with one unit while all other independent variables are held constant (i.e.,
ceteris paribus) is not possible, since x2 will always change when x changes. The same problem of course also affects the interpretation of β3. However, an easily comprehensible interpretation of this model is to look at the extremum value or turning point θ of the model, assuming that this value lies within the range of the independent variable x. It is well-known that this value is obtained by setting the partial derivative of y with respect to x to zero and solving for x,
(2)
(2)
which, with θ denoting the value of x for which this function is zero, gives
(3)
(3)
where it is assumed that
The extremum value θ is a minimum value if
and a maximum value if
In the CLM framework, the values of β2 and β3 are estimated by the ordinary least squares (OLS) estimators and
and a natural estimate of θ is thus the estimated extremum value
given by
(4)
(4)
However, while and
are unbiased estimators of β2 and β3, even without the normality assumption
it is well known that the ratio of two unbiased estimators is not, in general, itself an unbiased estimator. As we will show in this paper,
is not only a biased estimator of the true extremum value θ, i.e.,
in the CLM framework without the normality assumption, when the normality assumption is strictly applied
does not even exist.
Despite these theoretical shortcomings, in most practical applications, where the CLM normality assumption only could be expected to hold approximately, may still be a useful estimator of θ, with a limited bias. However, the extension of this bias and how it is affected by how close θ is to the edge of the range of the observed values of the independent variable x, the sample size n, and the size of the variance of the error term ε, has not previously been studied. Moreover, analytical formulas for the mean, variance, and bias of
have not previously been derived. This study aims to rectify these shortcomings by studying these aspects of
Since many econometric applications of the quadratic regression model (1) only has a small sample of observations available for analysis, the focus of this paper will be on the biasedness of
for small samples, and especially how this bias changes as n increases. The purpose is to provide some insight regarding when the bias of
may be considered small or negligible, thus making it possible for the applied econometrician or statistician to identify situations where
may be used as a reliable estimator of θ.
Section 2 discusses the theoretical properties of and derives an analytical formula for the expected value of
from which formulas for the variance and bias of
follow easily. The setup of a simulation study of the small-sample biasedness of
under varying conditions is described in Section 3, with the results of the simulation study given in Section 4. Section 5 concludes the paper with a discussion of the results as well as a suggestion of topics for future research.
2. Properties of 
This section will introduce the notation and assumptions that will be used in the remaining parts of the paper, review what is known about the expected value of a ratio of random variables, and show how this carries over to insights about the expected value, variance, and bias of
2.1. Notation and assumptions
For a random sample of n independent observations, let denote the pair of observed values of the independent variable x and the dependent variable y for observation
while
denotes the value of the unobserved random error term ε for observation i. The quadratic regression model (1) may then be written as
(5)
(5)
For an column vector y with row elements yi, an n × K matrix X with row elements
an
column vector
with row elements
and a
column vector
with row elements βk, (5) may be written as
(6)
(6)
where
is estimated using the standard OLS estimator
(7)
(7)
with
being a
column vector with row elements
Without loss of generality, for the current study, we have K = 3. Moreover, let
denote an
column vector with 0’s and I denote an n × n identity matrix.
Assumptions.
We make the following standard assumptions for (Equation6(6)
(6) ):
The error terms
The matrix X is fixed in repeated samples.
There is no perfect collinearity, i.e.,
The number of observations n is larger than the number of columns in X, i.e., n > K.
Alternatively, assumption 2 may be replaced with the assumption that X is a random matrix that is independent of in which case assumption 1 is to be interpreted as being conditional on X. These are thus the standard assumptions in the CLM framework without the normality assumption.
2.2. The expected value of a ratio of random variables
For any two random variables X and Y, the covariance is known to be given by
(8)
(8)
A ratio of two random variables is itself a random variable. Thus, as noted by Frishman (Citation1975), it follows from (Equation8(8)
(8) ) that the expected value of the ratio between X and Y, provided that all moments exist, is given by
(9)
(9)
Moreover, it follows from (Equation8(8)
(8) ) that
(10)
(10)
By rearranging these terms, provided that we obtain
(11)
(11)
which corresponds to formula (8) in Frishman (Citation1975).
2.3. The expected value and variance of
The estimator of the extremum value or turning point θ is a ratio between the two random variables
and
Thus, we can derive a formula for the expected value of
using the results in Section 2.2, from which the variance of
follows easily.
Theorem 1.
Under assumptions 1–4, provided that and
, the expected value of
is given by
Proof.
Using (Equation11(11)
(11) ), the expected value of
is given by
(13)
(13)
provided that
and
Under assumptions 1–4, the OLS estimators
and
are unbiased, i.e.,
and
Thus, with
it follows that
(14)
(14)
□
Corollary 2.
Under assumptions 1–4, provided that and
, the variance of
is given by
Proof.
Using the standard variance formula
(16)
(16)
and utilizing that
and
under assumptions 1–4, it follows from (Equation11
(11)
(11) ) that
(17)
(17)
provided that
and
Inserting (Equation12
(12)
(12) ) and (Equation17
(17)
(17) ) in (Equation16
(16)
(16) ) gives (Equation15
(15)
(15) ). □
2.4. The bias of
With the expected value of known from (Equation12
(12)
(12) ), a formula for the bias of
follows easily.
Corollary 3.
Under assumptions 1–4, provided that and
, the bias of
is given by
Proof.
It follows from (Equation12(12)
(12) ) and the definition of bias that
(19)
(19)
□
The estimator is thus in general a biased estimator of the true extremum value θ even if its components
and
are themselves unbiased, with the size of the bias of
depending on both β3 and the covariance between
and the ratio
Since the values of
and
depend on the particular sample values of y and X, the size of the bias of
will also be dependent on the particular sample that is used. With
and
being dependent, the size of this bias is even harder to derive analytically, especially for small samples.
2.5. The normal distribution assumption and the possible nonexistence of and Var
A crucial assumption of (9) is that the moment exists. If it does not exist, then
does not exist either. For the case of
and thus also
this translates into the assumption that
exists. However, as noted by e.g., Craig (Citation1942) and Frishman (Citation1975),
does not exist if Y is normally distributed. In the CLM framework with the normality assumption, where it is assumed that
and
are known to be normally distributed. Thus,
does not exist for this case, and neither does
or
However, in most practical applications, the CLM normality assumption is only expected to hold approximately. Moreover, since the normal distribution is a continuous distribution, and the probability P of observing a single value a is zero for a continuous distribution, we have that
even if the CLM normality assumption holds exactly. Thus, one could usually expect that
and that (Equation18
(18)
(18) ) holds at least approximately for
meaning that
may still be a useful estimator of θ, with a limited bias.
The nonexistence of when Y is normally distributed may not come as a surprise, since zero is included in the range of Y. As noted by Craig (Citation1942), this is also true for the case when Y is uniformly distributed with zero included in its range. However, there are cases when
does exist, although the distribution of Y includes zero in its range. An example of this is given by Craig (Citation1942). Conditions for the existence of
and thus also for the existence of
and
are discussed by Frishman (Citation1971).
3. Setup of the simulation study
Since results on the biasedness of for small samples are hard to derive analytically, we have to resort to the use of simulation techniques. This section describes the setup of the simulation study for model 5, focusing on how the bias of
changes as n increases, varying the values of the true extremum value θ, the true regression coefficients β2 and β3, and the variance of the error terms
under assumptions 1–4.
3.1. Parameter values and distributions
In practical applications of quadratic regression models, the observed values xi of the independent variable x are often centered to have mean zero, in order to decrease the influence of possible multicollinearity on the OLS estimation procedure. Moreover, in order to not extrapolate outside of the observed values of x, it is necessary to ensure that θ lies within the range of xi. Against this background, the values of xi used in this simulation study were constructed by first drawing a random sample of n – 2 observations from a standard normal distribution. Secondly, this sample of n – 2 simulated x values was centered to have a mean of zero. Finally, by setting and xn = 1.65 it was ensured that the true value of θ was always within the range of xi. We thus have that the variance of xi is
Values of θ closer to the edge of the range of xi should be harder to estimate precisely than those being closer to the center. It is thus of interest to study the biasedness of as θ approaches the edge of the range of xi. Against this background, with xi being approximately standard normally distributed, we used values of θ corresponding to the 50th, 75th, and 95th percentile of the standard normal distribution, i.e., θ was set to 0, 0.6744898, and 1.644854, respectively. Thus, the chosen values of θ were at approximately 50%, 25%, and 5%, respectively, of the distance from the upper edge of the range of xi.
Regarding the regression coefficients βk, the intercept term β1 seems to have no influence on the biasedness of Thus, for the sake of simplicity, we use
Obviously, the biasedness of
is mainly influenced by the value of β3. Without loss of generality, we will focus on the case of a convex (
shaped) curve, and thus require that
The main interest is to study the biasedness of
as β3 approaches zero, since
breaks down for
To this end, β3 was set to 0.1, 0.5, and 0.9. From (3), the values of β2 are, for fixed values of β3 and θ, given by
While the values of β1 and β3 are constant over varying values of θ, the values of β2 will thus differ depending on the value of θ. The values of β1, β2, and β3 used in the present simulation study are given in .
Table 1. Values of β1, β2, and β3 used in the simulation study for values of θ corresponding to the 50th, 75th, and 95th percentile.
To get a detailed picture of the development of the biasedness of as n increases, we used the n values 25, 50, 75, 100, 150, 200, 300, 400, 500, 750, and 1000. Although, as noted in Section 2.5,
does not exist if the assumption
is strictly applied, studying the biasedness of
as n increases using this assumption is still of major interest, since this is the standard assumption used for inference in the CLM framework. Moreover, we have that
if the error terms
are normally distributed. Against this background, the error terms
were simulated such that
with the variance of
set to
and
respectively (i.e.,
). Thus, since
under assumptions 1–4, we have that the variance of y is also 1 and 4, respectively.
3.2. Implementation
The simulation study was performed in Microsoft R Open 3.5.1 using the package ‘SimDesign’ version 1.11 (Sigal and Chalmers Citation2016). Let R denote the number of replications in a simulation. Then, for each combination of parameter values, a simulation of model 5 was performed using R = 10,000 replications with random samples of the n – 2 values of xi and the n values of thus resulting in 10,000 simulated values of
At the start of each simulation cycle, the random number generator was set to a common seed. The estimated regression coefficients
were calculated using the lm() command in the package ‘stats’ version 3.5.1. With
denoting the value of
for a single replication, the bias of
given by (Equation18
(18)
(18) ) was then estimated by
(20)
(20)
i.e.,
gives the average deviation of
from the true value θ.
4. Results of the simulation study
This section presents the results of the simulation study, with the aim being to give an overview of the development of the biasedness of over the range n = 10 to n = 1000 for the varying values of β3, θ, and
This will provide some insight regarding when the biasedness of
may be considered small or negligible, making the use of
as an estimate of θ reliable for practical applications. With approximately 95% of the xi values being within the range –2 to 2, we will consider the biasedness of
to be small if the average absolute deviation of
from the true value θ is
of this range and negligible if it is
of this range. Thus, it will be required that
for the biasedness to be considered small and
for the biasedness to be considered negligible.
4.1. Varying β3 and θ for
and give values of for the basic case
i.e.,
follows a standard normal distribution, with values of θ corresponding to the 50th, 75th, and 95th percentile of x and β3 ranging from 0.1 to 0.9. In the ideal case, to be able to estimate θ accurately, we would like to have equally many observations xi below and above θ. For the present study, this is equivalent to setting θ to the 50th percentile, i.e., the median of x. However, even for this ideal case,
results in very volatile values for
mirroring that
has an increasing risk of breaking down as
(). However,
has stabilized at n = 500, with the average absolute deviations of
from the true value θ being
(i.e.,
), and for n = 750 the deviation is negligible at
(i.e.,
).
Figure 1. Graph of for the case
and
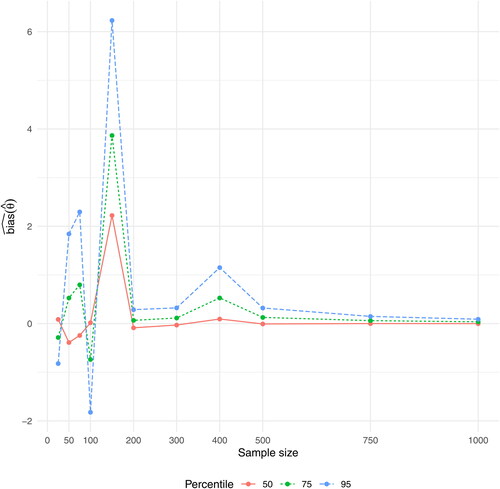
Figure 2. Graph of for the case
and
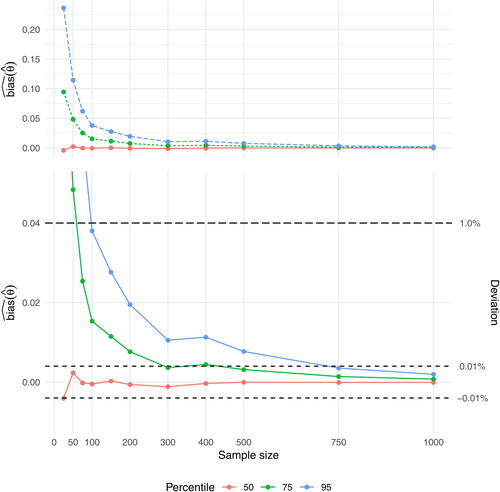
Figure 3. Graph of for the case
and
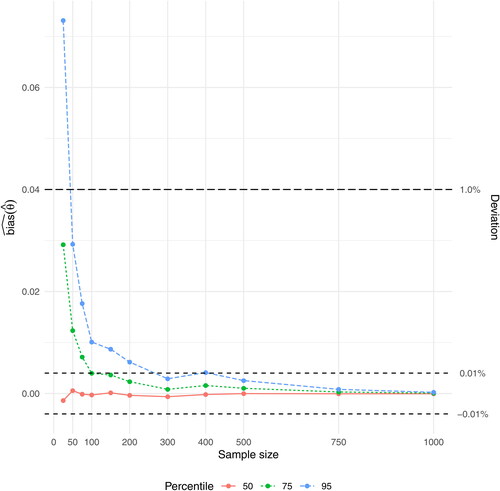
Table 2. Results of for the 50th (θ = 0), 75th (
), and 95th (
) percentile with
and
Having few observations above θ should reduce the ability of to estimate θ accurately. In the present study, this is equivalent to setting θ to the 75th and 95th percentile, thus approaching the maximum value of the range of xi. This reduced ability of
to estimate θ accurately is obvious in the behavior of
for
with overall larger values of
the closer θ gets to the maximum value of the range of xi, and with even mote pronounced volatility than for the 50th percentile (). Thus,
has for the 75th percentile stabilized at a deviation of
only for n = 1000, while it for the 95th percentile never reaches this level.
When β3 is increasing to 0.5 and 0.9, the values of are decreasing for all values of θ. Thus, for
has for the 50th percentile stabilized at
already for n = 25 and has stabilized at
for n = 50, for the 75th percentile it has stabilized at
for n = 75 and at
for n = 500, while it for the 95th percentile has stabilized at
for n = 100 and at
for n = 750 (). For
has for the 50th percentile stabilized at
already for n = 25, while it for the 75th percentile has stabilized at
for n = 25 and at
for n = 150, and for the 95th percentile has stabilized at
for n = 50 and at
for n = 500 ().
4.2. Varying β3 and θ for
and give values of for the case
with values of θ corresponding to the 50th, 75th, and 95th percentile of x and β3 ranging from 0.1 to 0.9. Overall, most of the patterns observed for
are mirrored here, but with an amplified magnitude, and thus larger deviations of
from the true value θ. Thus, for
has even for n = 1000 not stabilized at a deviation of
for any of the studied percentiles.
Figure 4. Graph of for the case
and
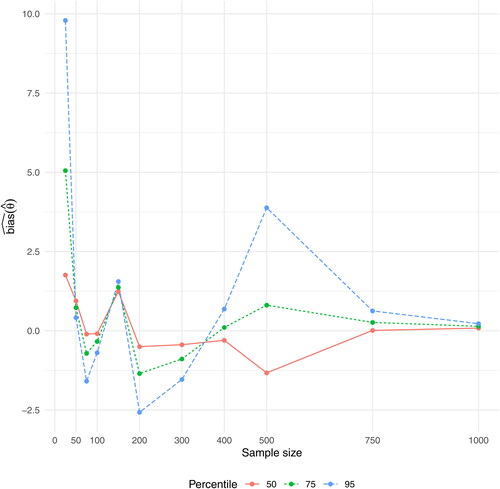
Figure 5. Graph of for the case
and
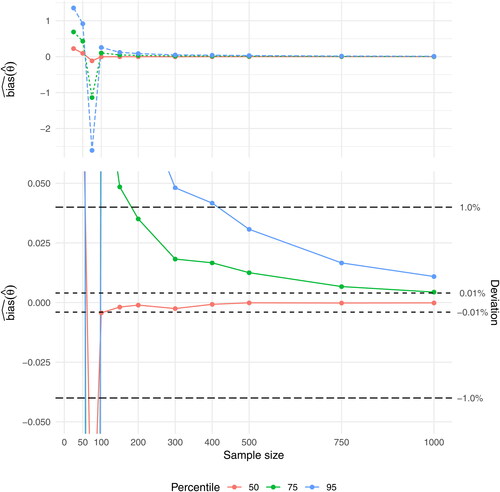
Figure 6. Graph of for the case
and
For has for the 50th percentile stabilized at a deviation of
for n = 100 and at
for n = 150, while it for the 75th percentile has stabilized at
for n = 200, but has not reached
even for n = 1000. For the 95th percentile,
has stabilized at a deviation of
for n = 500, but has not reached
for n = 1000 (). For
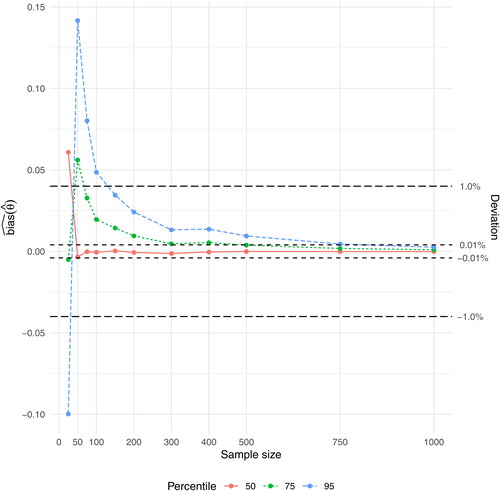
has for the 50th percentile stabilized at both
and
for n = 50, while it for the 75th percentile has stabilized at
for n = 75 and at
for n = 500. For the 95th percentile, finally, has
stabilized at a deviation of
for n = 150 and at a deviation of
for n = 1000 ().
5. Discussion
In this paper, we have derived an analytical formula for the expected value of the OLS based estimator of the extremum value or turning point θ in the quadratic regression model, from which formulas for the variance and bias of
followed easily. Notably, the distributional assumptions for the error term ε were quite weak, not assuming that ε follows any specified distribution, such as e.g., the normal distribution. It was shown that
is in general biased under these weak distributional assumptions for the error term ε, and if the normality assumption is strictly applied, neither
nor
or
exist.
A simulation study of the performance of for small samples showed that, overall, the bias of
decreases as the sample size increases. It seems safe to conclude that
as
The bias is mainly affected by how close β3 is to zero. However, if β3 is reasonably far away from zero, preferably
the bias of
should be small or negligible for
Moreover, the closer β3 is to the median of the observed sample of the independent variable, the lower is the bias of
and the faster is the bias approaching zero. In these situations,
may thus be used as a reliable estimator of θ.
5.1. Topics for future research
In applied econometric and statistical analyses, the point estimate should be accompanied with a confidence interval for the extremum value θ. Moreover, there may also be interest in performing hypothesis tests regarding the value of θ. There has been some previous research on constructing approximate confidence intervals for θ using the OLS based estimator
applying e.g., the delta method, the Fieller method, bootstrap methods, and the likelihood ratio interval method, see Hirschberg and Lye (Citation2005) and Wood (Citation2012). However, none of these methods have taken account of the bias of
in estimating θ, which should be a prerequisite for constructing a reliable confidence interval for θ.
A crucial part in estimating the bias of in order to obtain unbiased estimates of θ, is to estimate the covariance term
in (Equation18
(18)
(18) ). A possible approach to handle this would be to apply bootstrap methods. After obtaining unbiased estimates of θ, these may be combined with bootstrapping of (Equation15
(15)
(15) ) for constructing confidence intervals for θ. It should be of interest to examine in which cases the unbiased estimates of θ obtained in this way would be outside the usual 95% confidence intervals constructed using e.g., the delta or Fieller method, i.e., how large the bias would have to be to shift the confidence intervals away from the true value of θ. Another approach would be to apply the delta method to (Equation18
(18)
(18) ) and (Equation15
(15)
(15) ) to obtain better approximate confidence intervals. These questions will be the topics of forthcoming papers. Further topics for future research, which may be examined in simulation studies, are e.g., the bias of
for other distributions of the independent variable x and the error term ε than the normal distribution, especially non-symmetric distributions such as the log-normal distribution, and the bias of
when estimating the quadratic regression model (Equation1
(1)
(1) ) using least absolute deviation (LAD) or quantile regression methods.
Finally, it should be noted that there are several econometric and statistical application areas where other functional forms for the independent variables in the linear regression model than the quadratic function in (Equation1(1)
(1) ) are used, and where statistical inference regarding ratios of regression coefficients are of interest. An overview of econometric applications, such as e.g., the willingness to pay value, i.e., the maximum price someone is willing to pay for a product or service, is given by Lye and Hirschberg (Citation2018). The method for deriving analytical formulas for the expected values of estimators of ratios of regression coefficients outlined in this paper may be useful even for these cases.
Acknowledgments
The author is thankful to the anonymous reviewer for useful comments that have improved the manuscript considerably.
References
- Aghion, P., N. Bloom, R. Blundell, R. Griffith, and P. Howitt. 2005. Competition and Innovation: An Inverted-U relationship. The Quarterly Journal of Economics 120 (2):701–28. doi:10.1093/qje/120.2.701.
- Blanchflower, D. G. 2007. International Patterns of Union Membership. British Journal of Industrial Relations 45 (1):1–28. doi:10.1111/j.1467-8543.2007.00600.x.
- Blanchflower, D. G., and A. J. Oswald. 2016. Antidepressants and age: A new form of evidence for U-shaped well-being through life. Journal of Economic Behavior & Organization 127:46–58. doi:10.1016/j.jebo.2016.04.010.
- Craig, C. C. 1942. On frequency distributions of the quotient and of the product of two statistical variables. The American Mathematical Monthly 49 (1):24–32. doi:10.1080/00029890.1942.11991175.
- Dinda, S. 2004. Environmental Kuznets curve hypothesis: A survey. Ecological Economics 49 (4):431–55. doi:10.1016/j.ecolecon.2004.02.011.
- Frishman, F. 1971. On the arithmetic means and variances of products and ratios of random variables. Tech. rep. AD-785623. Durham, NC: U.S. Army Research Office.
- Frishman, F. 1975. On the arithmetic means and variances of products and ratios of random variables. In A modern course on statistical distributions in scientific work, ed. G. P. Patil, S. Kotz, and J. K. Ord, 401–6. Dordrecht: Springer Netherlands.
- Goldin, C. 1995. The U-shaped female labor force function in economic development and economic history. In Investment in women’s human capital, ed. T. Paul Schultz, Chap. 3, 61–90. Chicago: University of Chicago Press.
- Hirschberg, J. G., and J. N. Lye. 2005. Inferences for the extremum of quadratic regression models. Tech. rep. 906. Melbourne: Department of Economics, The University of Melbourne.
- Kuznets, S. 1955. Economic growth and income inequality. The American Economic Review 45 (1):1–28.
- Lye, J., and J. Hirschberg. 2018. Ratios of parameters: Some econometric examples. Australian Economic Review 51 (4):578–602. doi:10.1111/1467-8462.12300.
- Sigal, M. J., and R. P. Chalmers. 2016. Play it again: Teaching statistics with Monte Carlo simulation. Journal of Statistics Education 24 (3):136–56. doi:10.1080/10691898.2016.1246953.
- Wood, M. 2012. Bootstrapping confidence levels for hypotheses about quadratic (U-shaped) regression models. Tech. rep. Portsmouth: University of Portsmouth Business School. http://arxiv.org/abs/0912.3880v4.