
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Linear mixed models are standard models to analyze repeated measures or longitudinal data under the assumption of normality for random components in the model. Although the mixed models are often used in both frequentist and Bayesian inference, their evaluation from robustness perspective has not received as much attention in Bayesian inference as in frequentist. The aim of this study is to evaluate Bayesian tests in mixed models for their robustness to normality. We use a general class of exponential power distributions, EPD, and particularly focus on testing fixed effects in longitudinal models. The EPD class contains both light and heavy tailed distributions, with normality as a special case. Further, we consider a new paradigm of Bayesian testing decision theory where the hypotheses are formulated as a mixture model, with subsequent testing based on the posterior distribution of the mixture weights. It is shown that the EPD class provides a flexible alternative to normality assumption, particularly in the presence of outliers. Real data applications are also demonstrated.
1. Introduction
Linear mixed models (LMM) provide standard tools to analyze longitudinal or repeated measures data in both Bayesian and frequentist inference. The LMMs offer much flexibility for modeling a variety of covariance structures and can be used for both balanced and unbalanced data. Furthermore, their implementation is facilitated through the availability of statistical software. Most of the modeling of continuous data in real life problems through LMMs is essentially based on normality assumption for the random components of the postulated model. When the assumption is not tenable, the tests and confidence intervals are no longer valid.
In Bayesian theory of LMMs, the setting of priors may have much flexibility but normality assumption is the main source of likelihood in mixed models. This leads to serious consequences for posterior modeling if the likelihood part is misspecified. The problem obviously exacerbates if the data additionally contain outliers. Such robustness aspect in Bayesian context has not been considered as often as in frequentist case, although there have been a few studies in this direction.
For example, skewness in the random components of the LMM has been considered by Arellano-Valle, Bolfarine, and Lachos (Citation2005), Lin and Lee (Citation2008), Zhang and Davidian (Citation2001). Of particular interest is the study of influence of outliers using multivariate t and Laplace distributions; see e.g., Lange, Little, and Taylor (Citation1989), Pinheiro, Liu, and Wu (Citation2001), Rukhin and Possolo (Citation2011), Yavuz and Arslan (Citation2018). Another approach focuses directly on the log-likelihood by replacing the quadratic term in the normal distribution by a slower growing function (Huggins Citation1993).
The aforementioned references deal with a specific distribution as a replacement of normality, hence lacking a broader perspective of evaluation. Our main objective in this article is to evaluate the robustness aspect for Bayesian testing theory from the perspective of a general class of distributions, called exponential power distributions (EPD), which includes uniform, Laplace and normal distributions. The univariate EPD class was introduced by Box and Tiao (Citation1962) for the purpose of studying robustness of Bayesian t-test; see also Box and Tiao (Citation1964). We use its multivariate extension in the context of Bayesian testing of fixed effects in a mixed model set up for longitudinal data. The EPD class makes a subclass of elliptically contoured distributions which is widely used, particularly in frequentist inference for similar purposes.
Extension of the EPD class to the multivariate case was given in Gómez, Gomez-Viilegas, and Marín (Citation1998). For its use as an alternative to normality in Bayesian inference, see e.g., Choy and Walker (Citation2003), Haro-López and Smith (Citation1999), Lindsey (Citation1999), Walker and Gutierrex-Pena (Citation1998). Like the normal distribution, the EPD is parametrized by location and variance parameters, but with an additional parameter which determines the kurtosis and makes the EPD class particularly attractive to study robustness. Setting this parameter to 1 reduces the EPD to normal. Otherwise, the distribution has heavier or lighter tails than normal, depending on the values of the parameter. For a special application of the EPD class in cross-over experiments, see Lindsey (Citation1999).
The aforementioned aspect needs special emphasis in the context of Bayesian inference. Generally, the setting of priors provides most flexibility in Bayesian inference, whereas the likelihood comes from a relatively restricted assumption. If, however, the likelihood is misspecified, the resulting posterior distribution leads to seriously misleading predictive inference. Considered from this perspective, the EPD class provides alternative likelihood sources for Bayesian testing theory when normality assumption is suspect, apart from being an effective source of assessing robustness. A more technical discussion on the structure of the EPD, supplemented with graphs, is provided in Section 2.
After providing a brief orientation to the EPD class in Section 2, along with the form of mixed models to be considered under the EPD, the Bayesian framework of the problem is given in Secction 3.1, with their corresponding Markov chain Monte Carlo (MCMC) algorithms given in Section 3.2. A detailed simulation study focusing on the use of EPD for robustness in the considered models is provided in Section 3.3, where its application on real data is illustrated in Section 4.
2. Preliminaries
Consider the LMM
(1)
(1)
where
is the response vector on the ith individual,
and
are the design matrices for the fixed and random effects respectively, with
and
the corresponding parameter vectors. We denote
as the total number of observations. For inferential purposes, it is commonly assumed that
(2)
(2)
where
is a symmetric positive definite matrix and
is the
identity matrix.
is assumed unknown and with no specific structure. It is further assumed that
and
are independent.
Model (1) covers a wide variety of models as special cases. One of the simplest special cases is the one-way repeated measures ANOVA model which we shall be particularly dealing with. For this, where
is a
vector of ones. To avoid confusion, the fixed and random effects under the ANOVA model shall be denoted by μ and αi respectively. Model (1) reduces then to its one-way repeated measures ANOVA form as
(3)
(3)
The distributional assumptions correspondingly reduce to
(4)
(4)
where αi and
are assumed independent.
The previously outlined setting is often using in frequentist inference of Model (1) and its special form. Our purpose is to assess the tests of the fixed effects components of these models in a Bayesian context under the EPD class. The normality assumptions stated above will therefore be replaced with their counterparts under the EPD setting. For this, we provide a brief outline of the EPD class and mention some essential ingredients that will be frequently referred to in the sequel.
For a random variable y, the pdf of the univariate EPD is defined as (Box and Tiao Citation1962)
(5)
(5)
with mean and variance
where κ is the kurtosis parameter, indicating the extent of non-normality. For κ = 1, (5) reduces to the normal distribution, where the distribution is leptokurtic for
and platykurtic for
The pdf of the multivariate extension of the EPD is given as (Gómez, Gomez-Viilegas, and Marín Citation1998)
(6)
(6)
with
where
is the mean vector,
is the covariance matrix and
We denote
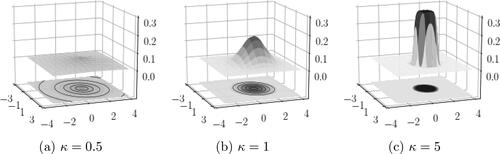
Like the univariate case, the most important parameter in the multivariate EPD, particularly from the perspective of studying it as an extension to the multivariate normal distribution, is κ. depicts the pdf in (6) for
Figure 1. The density function of displayed for
Special cases of multivariate Laplace in (a) and multivariate normal in (b).
For a convenient re-formulation of the multivariate EPD is in terms of scale mixture of normals (Gómez, Gómez-Villegas, and Marín Citation2008), as
(7)
(7)
where
denotes a p-variate normal distribution and
is a one-dimensional distribution function with density function
(8)
(8)
where
in (8) is the density function of a stable distribution with characteristic function (Nolan Citation1997)
When κ = 1,
in (7) is degenerate at 1.
3. Bayesian tests of fixed effects under the EPD
3.1. Model set up
We are interested in evaluating the Bayesian tests for any number of the fixed effects parameters in Model (1), namely,
(9)
(9)
under the EPD class, where
The same hypotheses for the special case in (3) can be stated as
(10)
(10)
To carry out these tests in a Bayesian context, we need to deal with the joint and marginal distributions of the components involved. For this, recall that we can write the distributional assumptions in (2) as
(11)
(11)
Motivated by the procedures for robust estimation using the t-distribution outlined in Bai, Chen, and Yao (Citation2016), Lange, Little, and Taylor (Citation1989), Pinheiro, Liu, and Wu (Citation2001), we recast the joint distributional assumption for EPD as
(12)
(12)
We shall consider the reparametrizations
where D is unknown with no assumed structure as this was assumed for
and
which will allow partial collapsing of the random and fixed regression coefficients in the MCMC algorithms outlined in the next section (Park and Min Citation2016). Thus, with the scale mixture of normal representation of the EPD, (12) can be expressed as
(13)
(13)
where
As interest lies in inference of the fixed effect coefficients, the marginal model of
in (13) could be considered. This corresponds to integrating out the random effects from the posterior distribution, meaning less parameters to sample in a MCMC sampling scheme. However, this approach would lead to an unknown normalizing constant of the conditional distribution of D due to the presence of the inverse and determinant of
in the likelihood. Thus the joint approach is often preferred to a marginal one.
For the matrix form of (13), denote the stacked vectors
and the stacked matrices
and
Then (13) can be expressed as
(14)
(14)
Following the same strategy for the special case in (3, 13) can be expressed as
(15)
(15)
where
and
Denote
and the block diagonal matrices
and
The matrix form of (15) is then
(16)
(16)
Now, under this set up, Bayesian tests of the form (9) and (10) can be carried out for which the models associated with H0 and H1 can be formulated as
(17)
(17)
respectively, with corresponding prior distributions
and
Further, for the hypotheses tests (9) and (10) we have
For example, the parameter spaces stipulated by (10) with model (16) are
Standard procedure is then to compute the marginal likelihoods
with model choice subsequently carried out by the Bayes factor, defined as the quotient of m0 and m1, or the posterior probability of any of the hypotheses (Kass and Raftery Citation1995).
Recently, a new paradigm of Bayesian testing decision theory has been introduced. For models and
in (17), the problem is phrased as a two component mixture (Kamary Citation2016)
(18)
(18)
with
and
as the corresponding priors. In this paper we use (18), where model choice is based on the posterior distribution of ω rather than a discrete choice determined by some threshold.
For hypotheses (9), the model under H0 is considered to be nested in that under H1, thus parametrized by the same Let ζ0 be a
vector with zeros in the positions
and ones in the complement
where complementation is taken with respect to
Denote the model matrix associated with the null hypothesis
and the stacked null matrix
The mixture model used for testing parts of
is then
(19)
(19)
where
The corresponding structure for hypotheses (10) follows as
(20)
(20)
After settling with the likelihood formulation, we need the priors. We consider conjugate prior distributions, conditional on the scale mixture parameters, so that the priors for the general model and its special case, (14) and (16), are, respectively,
(21)
(21)
where
denotes the
distribution with ν degrees of freedom and
denotes the inverse Wishart distribution with ξ degrees of freedom and scale matrix
Moreover, the prior distributions of the kurtosis and mixture parameters are
(22)
(22)
To sample from the posterior of (19), latent indicators are utilized such that
with
and
where
and
is the set theoretic difference. The likelihood augmented by the latent indicators is
where
and
where
is the indicator function. Similarly, the likelihood of (20) augmented by the latent component indicators is
where
The posterior distributions of (19) and (20) are thus given by
(23)
(23)
(24)
(24)
3.2. Sampling from the mixture of hypotheses
To sample from (23) we consider an extension of the partially collapsed Gibbs (PCG) sampler outlined in Park and Min (Citation2016), based on normality and no mixture level. Outlined in Sampler 1, the MCMC sampler is designed to block resulting in faster mixing.
Sampler 1: LMM.
Steps 1 to 3 are a generalization of a blocked sample from
by partial collapsing, given that the internal order of the steps are not changed. The process of partial collapsing is achieved by marginalization, permutation and trimming (van Dyk and Park Citation2008). Denote
and
the conditional distributions of steps 1 to 3 are then given by
(25)
(25)
(26)
(26)
(27)
(27)
where
The conditional distribution of steps 4 to 6 are given by
(28)
(28)
(29)
(29)
(30)
(30)
where
denotes the Bernoulli distribution with mean p. Note that the specification of (19) means that values ω closer to 1 implies that the H0 is more likely and vice versa, as can be seen in (30).
The conditional distribution of vi is given by
(31)
(31)
which does not have a known normalizing constant, so it is sampled by MH. As in (Gómez, Gómez-Villegas, and Marín Citation2008), we utilize the transformation
which has the conditional distribution
(32)
(32)
where
and
By generating proposals independently from the previous state as
the stable densities cancel out in the acceptance probability, given by
(33)
(33)
The conditional density of the kurtosis parameter is given by
(34)
(34)
where
and
are defined as in (8). The normalizing constant of (34) is not known and κ is thus sampled by an MH-step with proposals generated by a normal random walk truncated to
with standard error ϵ. The acceptance probability of proposed
is given by
(35)
(35)
where
denotes the standard normal cumulative distribution function. The conditional distribution (34) is uni-modal and very peaked around its mode. A slice sampler is more suitable but leads to extreme time consumption due to repeated evaluations of the stable density function. A MH step has proved sufficient in our applications and has been compared with a slice sampler. The peakedness of (34) leads to posterior samples of κ being largely determined by the likelihood rather than the prior distribution. Replacing the uniform prior by a more informative one has little impact on the posterior distribution. Mitigating this by a truncated prior generally leads to a situation similar to fixing the kurtosis parameter at either the upper or lower bound of the truncation set.
A similar MCMC algorithm for the posterior distribution of the one-way ANOVA in (24) is outlined in Sampler 2.
Sampler 2: one-way-ANOVA.
As for Sampler 1, steps 1, 2 and 3 form a blocked sample from through partial collapsing, given that their internal order is unchanged. Their conditional distributions are
(36)
(36)
(37)
(37)
(38)
(38)
where
Furthermore,
as
is compound symmetric. The derivation of (36, 37) and (38) are outlined in the Appendix.
The conditional distributions of d, zi and ω are given by
(39)
(39)
(40)
(40)
(41)
(41)
The scale mixture weight is sampled by the same procedure as in Sampler 1, with acceptance probability
(42)
(42)
The kurtosis parameter is sampled as in Sampler 1, with acceptance probability (35).
3.3. Simulation study
To compare performance of the mixture test for varying values of the kurtosis parameter, we consider settings similar to Pinheiro, Liu, and Wu (Citation2001); Yavuz and Arslan (Citation2018) with focus on the LMM and its mixture representation in (19). The kurtosis parameter is treated as a hyper-parameter by considering one-point distributions as prior distributions. Data is simulated as
(43)
(43)
where
and
are defined as
where the null hypothesis is for the second element of
being 0. The random effects and error in (43) are distributed as
To contaminate the data with outliers, bi and
are expressed as mixtures
where f is a constant used to adjust the variance of one of the components. The resulting covariance of
is
Results are based on 500 Monte Carlo simulations for all combinations of and
with pb = 0, as well as a worst case scenario with
f = 6 and
for all κ. We estimate the mixture weight by the posterior median based on 104 samples from Sampler 1, with a transient phase of 103 iterations. The median is considered rather than the mean as ω generally concentrates on its boundaries (Kamary Citation2016). The hyper-parameters are set as
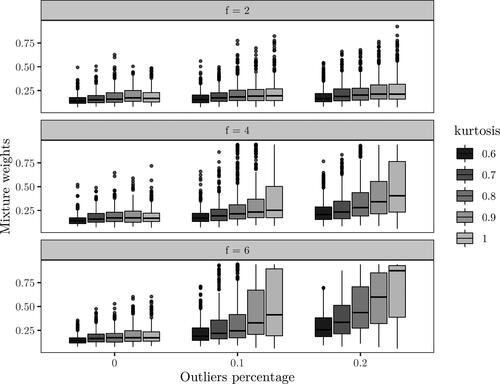
The results with no outliers in the random effects are shown in . The effect of the kurtosis on the posterior median of the mixture weight is negligible for scaling factor f = 2. For scaling factors 4 and 6, the effect over increasing percentage of outliers is more clear. With a higher kurtosis, i.e., closer to the normal distribution, choosing the correct model gets less probable as pe increases. The difference is most clear with scaling factor 6, where the effect of increasing pe is quite small for but drastic for κ = 1. The results with
and f = 6 are displayed in , which are nearly identical to the setting pb = 0 and f = 6. Overall, from and , we see that inference based on lower kurtosis is less affected by increased impairment from outliers. Further, with no or low contamination by outliers, there is little difference in model choice for the different values of kurtosis.
Figure 2. Posterior median of the mixture weight for each κ with and f = 6.
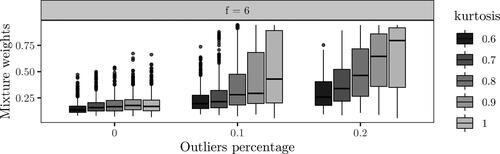
Figure 3. Posterior median of the mixture weight for each combination of κ, pe and f with pb = 0.
3.4. Applications
3.4.1. Example I
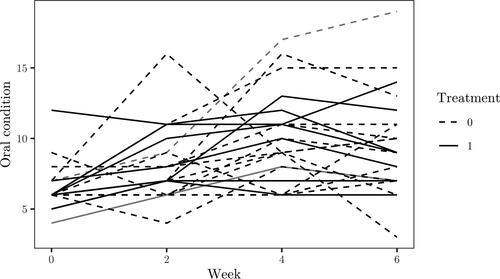
The dataset found in (Mid-Michigan Medical Center Citation1999) consists of repeated measurements of oral condition for 23 cancer patients. Each patient is randomly assigned to a treatment and placebo group, where the treated received aloe juice treatment. For each individual, an initial measure is taken with repeated measurements at weeks 2, 4 and 6. Other variables are initial age, weight and cancer stage of the patients. The data is displayed in .
Figure 4. Cancer data.
The model of interest is defined as
(44)
(44)
where cancer stage has been omitted as its inclusion led to issues in frequentist estimation of the random effects covariance matrix, this did not impact the results in terms of model choice. For testing parts of (44), we consider the null
against
The hyper-parameters are set as
where results shall be compared for
and 10. All results are based on 104 iterations of Sampler 1, with a burn-in phase of
iterations. The trace and posterior densities of the mixture weight are displayed in , where the posterior median is estimated as 0.986 for
and 0.934 for
The null is therefore favored with both settings of
but the difference is quite large based on with much fewer jumps between models for
Posterior samples of the kurtosis, treatment and week fixed effect coefficients and between subject variance are displayed in . The posterior mean of the kurtosis parameter is estimated as 0.91 for both values of
and this result is not sensitive to changes in the hyper-parameters of the prior on κ. Both the treatment and week coefficients are generally sampled by the prior with
For
the posterior mean of the treatment and week coefficient, based on the iterations where one or more observations are assigned to the mixture component corresponding to the alternative hypothesis, are estimated as −0.406 and 0.61 respectively. For the between subjects variance,
the posterior mean with
and
are estimated as 8.72 and 8.02 respectively. The increased oscillation of the mixture weights with
can also be seen in the trace plots of the variance term in , when comparing with the higher value of
The posterior mean of the elements of D for
and
are estimated as
and are thus unaffected by the increased assignment of observations to the alternative hypothesis component with
In , the random effects, e.g.,
and
in (44), are compared for patients with Id’s 6 and 14, which are marked as gray lines in . Patient 6 did receive treatment and thus corresponds to the dashed gray line, whilst patient 14 did not and thus correspond to the solid gray line. There is not much difference between the posterior samples for different
of the random effects.
Figure 5. Posterior sample of the mixture weight for the hypotheses of no treatment effect.
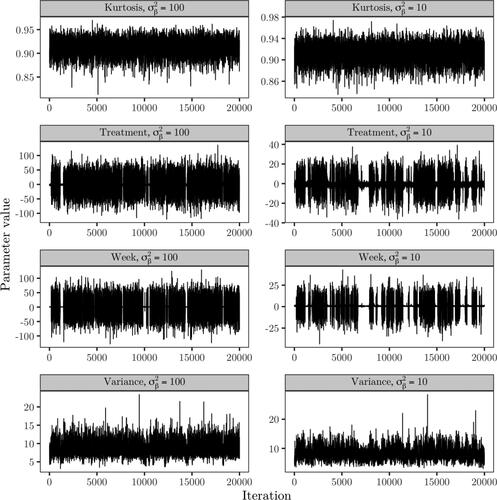
Figure 6. Trace plots of the kurtosis parameter, treatment and week fixed effect coefficients, error variance and elements of the random effects covariance based on Sampler 1.
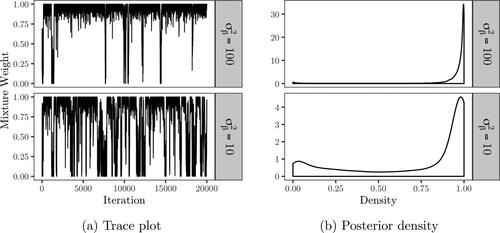
Figure 7. Posterior samples of the random effects of individuals with id 6 and 14.
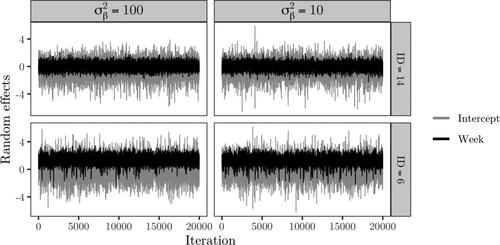
Figure 8. Posterior density of the mixture weights with the kurtosis parameter treated as a hyper-parameter.
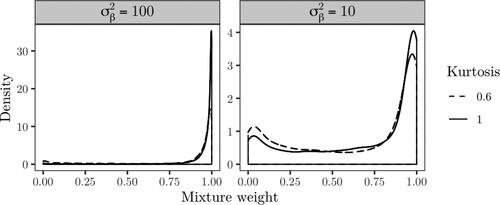
In , the posterior density of the mixture weights are compared when fixing the kurtosis parameter to 0.6 and 1. In all settings, the null is favored. The evidence for the null is slightly weaker with a lower kurtosis for both and 100.
To compare the models in a frequentist setting based on the normal likelihood, the models stipulated by the null and alternative hypotheses are estimated using the lme4 (Bates et al. Citation2015) package in R (R Core Team Citation2020) and compared using the Akaike information criterion (AIC). The AIC is 436.15 for the unrestricted model (44), where the treatment and week fixed effects are estimated as −0.622 and 0.535 respectively. The AIC for the restricted model is 444.69. Thus, the model under the alternative hypothesis is favored in a standard frequentist setting.
3.4.2. Example II
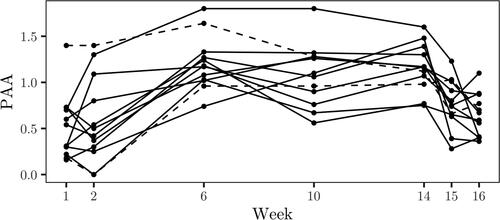
The dataset considered in Example 3.3 in Crowder and Hand (Citation1990) consists of measurements of plasma ascorbic acid (PAA) for twelve patients that underwent dietary regime treatment with measurements taken at weeks 1, 2, 6, 10, 14, 15 and 16. First 2 weeks consist of pretreatment measurements, last 2 consists of post-treatment measurements and the measurements in the remaining weeks were taken during treatment. The data are displayed in .
Figure 9. PAA data.
To test whether the mean for pretreatment, treatment and post-treatment are equal, the data is transformed by taking the mean within the treatment periods. Letting be the vector of 7 measurements for patient i, the data is transformed as
with the model specified as
(45)
(45)
where μj represents the average within the
period. We shall first consider testing
vs. H1: not H0, and subsequently
vs.
To test equality over the periods, (45) is expressed as
(46)
(46)
with corresponding null hypothesis
and where
is 1 if j = 2 and 0 otherwise and similarly
is 1 if j = 3 and 0 otherwise. The hyper-parameters are set as
Results are based on 104 with a burn-in phase of
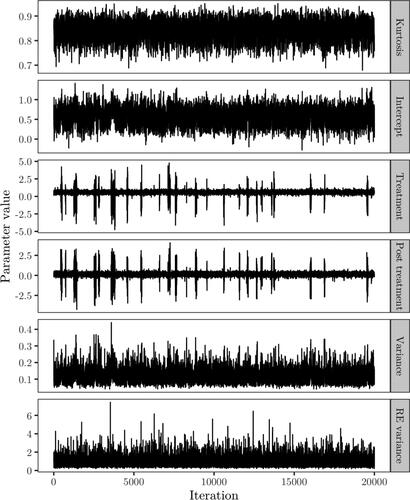
iterations using Sampler 1, where some steps for observations sampled under the null model being identical to Sampler 2. The trace and posterior density of the mixture weight are displayed in , with the posterior median estimated as 0.078, strongly favoring the alternative hypothesis. Posterior samples of the kurtosis, fixed effects, between subjects variance and random effects variance are displayed in . The posterior mean of the kurtosis parameter is estimated as 0.84, and the estimate is not sensitive to changes in the hyper-parameters for the prior on κ. The estimated posterior means of the intercept, treatment and post-treatment coefficients, based on iterations where one or more observations are assigned to the mixture component corresponding to the alternative hypothesis, are 0.546, 0.606 and 0.158 respectively. For the variance components, the posterior mean of the between subjects variance is estimated as 0.117 and for the random effects variance, d, the posterior mean is estimated as 0.921. In , the random intercepts
are displayed for individuals 2 and 10 which are identified by dashed lines in , where patient 10 corresponds to the dashed line with an initial measurement near 1.5. The posterior mean of the random effects for patients 2 and 10 are given by −0.112 and 0.296 respectively.
Figure 10. Posterior sample of the mixture weight for the hypotheses of the fixed effect equal to 0.5.
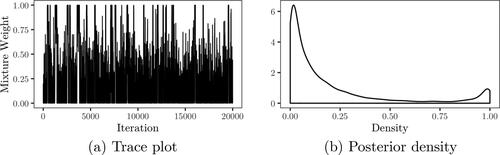
Figure 11. Trace plots of the kurtosis parameter, treatment coefficient and error and random effects variance based on Sampler 2.
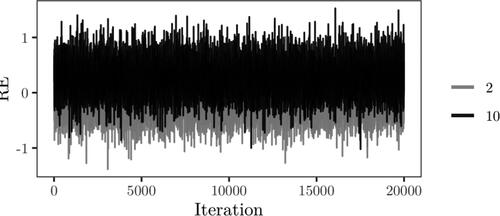
Figure 12. Posterior samples of random coefficients for individuals with id 1 and 20.
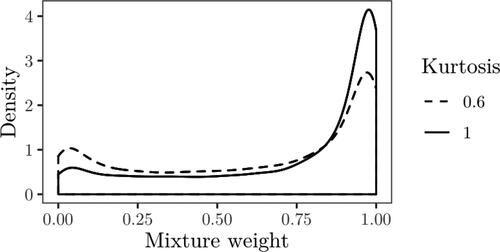
In , the posterior density of the mixture weights are compared when fixing the kurtosis parameter to 0.6 and 1. The posterior median is estimated as 0.046 for the normal case, and 0.102 for The alternative hypothesis is thus strongly favored for both cases.
Figure 13. Posterior density of the mixture weights with the kurtosis parameter treated as a hyper-parameter.
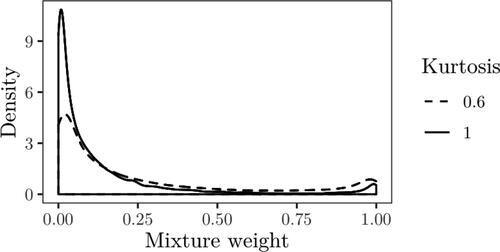
We now consider testing whether the pretreatment levels of PAA are equal to the post-treatment levels, i.e., vs.
in (45). The test is carried out based on model (46) with null hypothesis
We only consider the comparison for
against κ = 1 for this case, with the comparison of the posterior densities of the mixture weights shown in . The difference between the posterior densities is larger in comparison to , with the posterior median for the normal case estimated as 0.90 and 0.772 for the kurtosis parameter set to 0.6. The difference in terms of posterior medians is thus large, although both cases tend to favor the null.
Figure 14. Posterior density of the mixture weights with the kurtosis parameter treated as a hyper-parameter.
For the frequentist model comparison, we consider tests based on Hotelling’s T2 as in Example 4.2 in Crowder and Hand (Citation1990). To test the general null hypothesis
is considered, where
and
When testing equality of pretreatment and post-treatment, H is set to the row vector
For both cases, the test statistic is defined as
(47)
(47)
where
is the sample mean vector with elements
and S is the sample covariance matrix with elements
With the standard assumption of normality,
under the null, where q is the number of rows of H and
is the F distribution with q and n–q degrees of freedom. For the test of equality over all periods,
which is
distributed under the null with p-value virtually 0. For testing equality between pretreatment and post-treatment,
which is
distributed under the null with p-value 0.18. Thus, model choice based on Hotelling’s T2 agrees with our results.
4. Conclusions
In this paper, the EPD class has been considered, in place of the standard normal assumption, in the context of Bayesian hypothesis testing of the fixed effects in LMMs for repeated measures. Tests have been carried out using a mixture representation rather than the traditional Bayes factor or posterior probability of a given hypothesis. In a simulation study, the kurtosis parameter is treated as a hyper-parameter to study its effect on model choice under increasing contamination by outliers. Main focus is on outliers in the error term, but outliers in the random effects are also considered. With no outliers in the random effects, results from the simulation study show that the EPD with a lower kurtosis than that of the normal distribution performs better in terms of consistently choosing the true model. A kurtosis of 0.6 is much less affected by increasing percentage of outliers and scaling factor, in comparison with the normal case. With increasing kurtosis, the sensitivity to outliers also increases. One notable result is that the difference between 0.6 and 0.7 is smaller than the difference between 0.9 and 1, both in terms of spread and average of the posterior median over the Monte Carlo replications. Increasing the outliers of the random effects had no effect on the result with the settings used in our simulation design.
When treating the kurtosis as a hyper-parameter in the applications to real data, we find in Example I that the normal case and generally agree, albeit with the mixture parameter concentrating more around 1, i.e., favoring the null, for κ = 1. This was the case for both hyper-parameters considered for the variance of the fixed effects. Similarly, for Example II, we find that the results generally agree when treating the kurtosis parameter as a hyper-parameter for the test of all periods. When testing only pretreatment and post-treatment however, the difference was larger for the different values of the kurtosis parameter. One notable difference between Examples I and II is that the kurtosis parameter was sampled much closer to 1, i.e., normal, in Example I. When comparing the results in Example I to model choice in a frequentist setting with the usual normal assumption, we found that the full model under the alternative was favored. For Example II, we found that the model choice based on Hotelling’s T2 agreed with our results.
The results from the applications and simulations indicate that using the general EPD class instead of a specific distribution as replacement, when the normality assumption is suspected, provides a flexible solution. For future research, the random effects could be included in the set of hypotheses in conjunction with extending to multiple hypotheses.
Acknowledgements
The authors are thankful to the editor, the associate editor and the two reviewers for their help and suggestions for the improvement of the article. Further, we gratefully acknowledge that the computations were enabled by resources provided by the Swedish National Infrastructure for Computing (SNIC) at UPPMAX partially funded by the Swedish Research Council through grant agreement no. 2018-05973.
References
- Arellano-Valle, R. B., H. Bolfarine, and V. H. Lachos. 2005. Skew-normal linear mixed models. Journal of Data Science 3:415–38.
- Bai, X., K. Chen, and W. Yao. 2016. Mixture of linear mixed models using multivariate t distribution. Journal of Statistical Computation and Simulation 86 (4):771–87. doi: 10.1080/00949655.2015.1036431.
- Bates, D., M. Mächler, B. Bolker, and S. Walker. 2015. Fitting linear mixed-effects models using lme4. Journal of Statistical Software 67 (1):1–48. doi: 10.18637/jss.v067.i01.
- Box, G. E. P., and G. C. Tiao. 1962. A further look at robustness via Bayes’s theorem. Biometrika 49 (3–4):419–32. doi: 10.2307/2333976.
- Box, G. E. P., and G. C. Tiao. 1964. A Bayesian approach to the importance of assumptions applied to the comparison of variances. Biometrika 51 (1–2):153–67. doi: 10.2307/2334203.
- Choy, S. T. B., and S. G. Walker. 2003. The extended exponential power distribution and Bayesian robustness. Statistics & Probability Letters 65 (3):227–32. doi: 10.1016/j.spl.2003.01.001.
- Crowder, M. J., and D. J. Hand. 1990. Analysis of repeated measures. Volume 41 of Monographs on statistics and applied probability. London: Chapman & Hall.
- Gómez, E., M. A. Gomez-Viilegas, and J. M. Marín. 1998. Multivariate generalization of the power exponential family of distributions. Communications in Statistics - Theory and Methods 27 (3):589–600. doi: 10.1080/03610929808832115.
- Gómez, E., M. A. Gómez-Villegas, and J. M. Marín. 2008. Multivariate exponential power distributions as mixtures of normal distributions with Bayesian applications. Communications in Statistics - Theory and Methods 37 (6):972–85. doi: 10.1080/03610920701762754.
- Haro-López, R. A., and A. F. M. Smith. 1999. On robust Bayesian analysis for location and scale parameters. Journal of Multivariate Analysis 70 (1):30–56. doi: 10.1006/jmva.1999.1820.
- Huggins, R. M. 1993. A robust approach to the analysis of repeated measures. Biometrics 49 (3):715–20. doi: 10.2307/2532192.
- Kamary, K. 2016. Non-informative priors and modelization via mixture models. PhD thesis., PSL Research University.
- Kass, R. E., and A. E. Raftery. 1995. Bayes factors. Journal of the American Statistical Association 90 (430):773–95. doi: 10.1080/01621459.1995.10476572.
- Lange, K. L., R. J. A. Little, and J. M. G. Taylor. 1989. Robust statistical modeling using the t distribution. Journal of the American Statistical Association 84 (408):881–96. doi: 10.2307/2290063.
- Lin, T. I., and J. C. Lee. 2008. Estimation and prediction in linear mixed models with skew-normal random effects for longitudinal data. Statistics in Medicine 27 (9):1490–507. doi: 10.1002/sim.3026.
- Lindsey, J. K. 1999. Multivariate elliptically contoured distributions for repeated measurements. Biometrics 55 (4):1277–80. doi: 10.1111/j.0006-341x.1999.01277.x.
- Mid-Michigan Medical Center. 1999. A study of oral condition of cancer patients. http://calcnet.mth.cmich.edu/org/spss/prj_cancer_data.htm.
- Nolan, J. P. 1997. Numerical calculation of stable densities and distribution functions. Communications in Statistics. Stochastic Models 13 (4):759–74. doi: 10.1080/15326349708807450.
- Park, T., and S. Min. 2016. Partially collapsed Gibbs sampling for linear mixed-effects models. Communications in Statistics - Simulation and Computation 45 (1):165–80. doi: 10.1080/03610918.2013.857687.
- Pinheiro, J. C., C. H. Liu, and Y. N. Wu. 2001. Efficient algorithm for robust estimation in linear mixed-effects models using a multivariate t-distribution. Journal of Computational and Graphical Statistics 10 (2):249–76. doi: 10.1198/10618600152628059.
- R Core Team. 2020. R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.R-project.org/.
- Rukhin, A. L., and A. Possolo. 2011. Laplace random effects models for interlaboratory studies. Computational Statistics & Data Analysis 55 (4):1815–27. doi: 10.1016/j.csda.2010.11.016.
- van Dyk, D. A., and T. Park. 2008. Partially collapsed Gibbs samplers: Theory and methods. Journal of the American Statistical Association 103 (482):790–6. doi: 10.1198/016214508000000409.
- Walker, S. G., and E. Gutierrex-Pena. 1998. Robustifying Bayesian procedures (with discussion). In Proceedings of the 6th Valencia International Meeting on Bayesian Statistics, Pages 685–713. Oxford University Press,
- Yavuz, F. G., and O. Arslan. 2018. Linear mixed model with Laplace distribution (LLMM). Statistical Papers 59 (1):271–89. doi: 10.1007/s00362-016-0763-x.
- Zhang, D., and M. Davidian. 2001. Linear mixed models with flexible distributions of random effects for longitudinal data. Biometrics 57 (3):795–802. doi: 10.1111/j.0006-341x.2001.00795.x.
Appendix: Gibbs sampler for repeated measures one-way-ANOVA
The posterior (Equation24(24)
(24) ) is
and
are sampled jointly from
To derive the conditionals of σ and μ with
marginalized out, the likelihood is based on the marginal distribution of
in (Equation15
(15)
(15) ) rather than the conditional. For
Next, μ is integrated out
where
The conditional distribution of
is then
The conditional distribution of μ with
marginalized is
thus