
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
A new mixture autoregressive model based on Student’s t–distribution is proposed. A key feature of our model is that the conditional t–distributions of the component models are based on autoregressions that have multivariate t–distributions as their (low-dimensional) stationary distributions. That autoregressions with such stationary distributions exist is not immediate. Our formulation implies that the conditional mean of each component model is a linear function of past observations and the conditional variance is also time-varying. Compared to previous mixture autoregressive models our model may therefore be useful in applications where the data exhibits rather strong conditional heteroskedasticity. Our formulation also has the theoretical advantage that conditions for stationarity and ergodicity are always met and these properties are much more straightforward to establish than is common in nonlinear autoregressive models. An empirical example employing a realized kernel series constructed from S&P 500 high-frequency intraday data shows that the proposed model performs well in volatility forecasting. Our methodology is implemented in the freely available StMAR Toolbox for MATLAB.
1. Introduction
Different types of mixture models are in widespread use in various fields. Overviews of mixture models can be found, for example, in the monographs of McLachlan and Peel (Citation2000) and Frühwirth-Schnatter (Citation2006). In this paper, we are concerned with mixture autoregressive models that were introduced by Le, Martin, and Raftery (Citation1996) and further developed by Wong and Li (Citation2000, Citation2001a, Citation2001b) (for further references, see Kalliovirta, Meitz, and Saikkonen (Citation2015)).
In mixture autoregressive models the conditional distribution of the present observation given the past is a mixture distribution where the component distributions are obtained from linear autoregressive models. The specification of a mixture autoregressive model typically requires two choices: choosing a conditional distribution for the component models and choosing a functional form for the mixing weights. In a majority of existing models a Gaussian distribution is assumed whereas, in addition to constants, several different time-varying mixing weights (functions of past observations) have been considered in the literature.
Instead of a Gaussian distribution, Wong, Chan, and Kam (Citation2009) proposed using Student’s t–distribution. A major motivation for this comes from the heavier tails of the t–distribution which allow the resulting model to better accommodate for the fat tails encountered in many observed time series, especially in economics and finance. In the model suggested by Wong, Chan, and Kam (Citation2009), the conditional mean and conditional variance of each component model are the same as in the Gaussian case (a linear function of past observations and a constant, respectively), and what changes is the distribution of the independent and identically distributed error term: instead of a standard normal distribution, a Student’s t–distribution is used. This is a natural approach to formulate the component models and hence also a mixture autoregressive model based on the t–distribution.
In this paper, we also consider a mixture autoregressive model based on Student’s t–distribution, but our specification differs from that used by Wong, Chan, and Kam (Citation2009). Our starting point is the characteristic feature of linear Gaussian autoregressions that stationary distributions (of consecutive observations) as well as conditional distributions are Gaussian. We imitate this feature by using a (multivariate) Student’s t–distribution and, as a first step, construct a linear autoregression in which both conditional and (low-dimensional) stationary distributions have Student’s t–distributions. This leads to a model where the conditional mean is as in the Gaussian case (a linear function of past observations) whereas the conditional variance is no longer constant but depends on a quadratic form of past observations. These linear models are then used as component models in our new mixture autoregressive model which we call the StMAR model.
Our StMAR model has some very attractive features. Like the model of Wong, Chan, and Kam (Citation2009), it can be useful for modeling time series with leptokurtosis, regime switching, multimodality, persistence, and conditional heteroskedasticity. As the conditional variances of the component models are time-varying, the StMAR model can potentially accommodate for stronger forms of conditional heteroskedasticity than the model of Wong, Chan, and Kam (Citation2009). Our formulation also has the theoretical advantage that, for a pth order model, the stationary distribution of p + 1 consecutive observations is fully known and is a mixture of particular Student’s t–distributions. Moreover, stationarity and ergodicity are simple consequences of the definition of the model and do not require complicated proofs.
Finally, a few notational conventions. All vectors are treated as column vectors and we write for the vector x where the components xi may be either scalars or vectors. The notation
signifies that the random vector X has a d–dimensional Gaussian distribution with mean
and (positive definite) covariance matrix
Similarly, by
we mean that X has a d–dimensional Student’s t–distribution with mean
, (positive definite) covariance matrix
and degrees of freedom ν (assumed to satisfy
); the density function and some properties of the multivariate Student’s t–distribution employed are given in Appendix A. The notation
(
) is used for a d–dimensional vector of zeros (ones),
signifies the vector
of dimension d, and the identity matrix of dimension d is denoted by Id. The Kronecker product is denoted by ⊗, and vec(A) stacks the columns of matrix A on top of one another.
2. Linear Student’s t autoregressions
In order to formulate our new mixture model, this section briefly considers linear pth order autoregressions that have multivariate Student’s t–distributions as their stationary distributions. First, for motivation and to develop notation, consider a linear Gaussian autoregression zt () generated by
(1)
(1)
where the error terms et are independent and identically distributed with a standard normal distribution, and the parameters satisfy
and
where
(2)
(2)
is the stationarity region of a linear pth order autoregression. Denoting
and
it is well known that the stationary solution zt to (1) satisfies
(3)
(3)
where the last relation defines the conditional distribution of zt given
and the quantities
γ0,
μ, and
are defined via
(4)
(4)
Two essential properties of linear Gaussian autoregressions are that they have the distributional features in Equation(3)(3)
(3) and the representation in Equation(1)
(1)
(1) .
It is not immediately obvious that linear autoregressions based on Student’s t–distribution with similar properties exist (such models have, however, appeared at least in Spanos (Citation1994), Heracleous and Spanos (Citation2006), and Pitt and Walker (Citation2006)). Suppose that for a random vector in it holds that
where
(and other notation is as above in Equation(4)
(4)
(4) ). Then (for details, see Appendix A) the conditional distribution of z given z is
where
(5)
(5)
We now state the following theorem (proofs of all theorems are in Appendix B).
Theorem 1.
Suppose
, and
. Then there exists a process
(
) with the following properties.
The process
(
Furthermore, for
Results (i) and (ii) in Theorem 1 are comparable to properties Equation(3)(3)
(3) and Equation(1)
(1)
(1) in the Gaussian case. Part (i) shows that both the stationary and conditional distributions of zt are t–distributions, whereas part (ii) clarifies the connection to standard AR(p) models. In contrast to linear Gaussian autoregressions, in this t–distributed case zt is conditionally heteroskedastic and has an ‘AR(p)–ARCH(p)’ representation (here ARCH refers to autoregressive conditional heteroskedasticity).
3. A mixture autoregressive model based on Student’s t–distribution
3.1. Mixture autoregressive models
Let yt () be the real-valued time series of interest, and let
denote the σ–algebra generated by
We consider mixture autoregressive models for which the conditional density function of yt given its past,
is of the form
(8)
(8)
where the (positive) mixing weights
are
–measurable and satisfy
(for all t), and the
describe the conditional densities of M autoregressive component models. Different mixture models are obtained with different specifications of the mixing weights
and the conditional densities
Starting with the specification of the conditional densities a common choice has been to assume the component models to be linear Gaussian autoregressions. For the mth component model (
), denote the parameters of a pth order linear autoregression with
and
Also set
In the Gaussian case, the conditional densities in Equation(8)
(8)
(8) take the form (
)
where
signifies the density function of a standard normal random variable,
is the conditional mean function (of component m), and
is the conditional variance (of component m), often assumed to be constant. Instead of a Gaussian density, Wong, Chan, and Kam (Citation2009) considered the case where
is the density of Student’s t–distribution with conditional mean and variance as above,
and a constant
respectively.
In this paper, we also consider a mixture autoregressive model based on Student’s t–distribution, but our formulation differs from that used by Wong, Chan, and Kam (Citation2009). In Theorem 1 it was seen that linear autoregressions based on Student’s t–distribution naturally lead to the conditional distribution in Equation(6)
(6)
(6) . Motivated by this, we consider a mixture autoregressive model in which the conditional densities
in Equation(8)
(8)
(8) are specified as
(9)
(9)
where the expressions for
and
are as in (5) except that z is replaced with
and all the quantities therein are defined using the regime specific parameters
σm, and νm (whenever appropriate a subscript m is added to previously defined notation, e.g., μm or
). A key difference to the model of Wong, Chan, and Kam (Citation2009) is that the conditional variance of component m is not constant but a function of
An explicit expression for the density in (9) can be obtained from Appendix A and is
(10)
(10)
where
(and
signifies the gamma function).
Now consider the choice of the mixing weights in Equation(8)
(8)
(8) . The most basic choice is to use constant mixing weights as in Wong and Li (Citation2000) and Wong, Chan, and Kam (Citation2009). Several different time-varying mixing weights have also been suggested, see, e.g., Wong and Li (Citation2001a), Glasbey (Citation2001), Lanne and Saikkonen (Citation2003), Dueker, Sola, and Spagnolo (Citation2007), and Kalliovirta, Meitz, and Saikkonen (Citation2015, Citation2016).
In this paper, we propose mixing weights that are similar to those used by Glasbey (Citation2001) and Kalliovirta, Meitz, and Saikkonen (Citation2015). Specifically, we set
(11)
(11)
where the
are unknown parameters satisfying
Note that the Student’s t density appearing in Equation(11)
(11)
(11) corresponds to the stationary distribution in Theorem 1(i): If the yt’s were generated by a linear Student’s t autoregression described in Section 2 (with a subscript m added to all the notation therein), the stationary distribution of
would be characterized by
Our definition of the mixing weights in Equation(11)
(11)
(11) is different from that used in Glasbey (Citation2001) and Kalliovirta, Meitz, and Saikkonen (Citation2015) in that these authors employed the
density (corresponding to the stationary distribution of a linear Gaussian autoregression) instead of the Student’s t density
we use.
3.2. The Student’s t mixture autoregressive model
EquationEquations (8)(8)
(8) , Equation(9)
(9)
(9) , and Equation(11)
(11)
(11) define a model we call the Student’s t mixture autoregressive, or StMAR, model. When the autoregressive order p or the number of mixture components M need to be emphasized we refer to an StMAR(p,M) model. We collect the unknown parameters of an StMAR model in the vector
(
), where
(with
and
) contains the parameters of each component model (
) and the αm’s are the parameters appearing in the mixing weights Equation(11)
(11)
(11) ; the parameter αM is not included due to the restriction
The StMAR model can also be presented in an alternative (but equivalent) form. To this end, let signify the conditional probability of the indicated event given
and let
be a sequence of independent and identically distributed random variables with a
distribution such that
is independent of
(
). Furthermore, let
be a sequence of (unobserved) M–dimensional random vectors such that, conditional on
and
are independent (for all m). The components of
are such that, for each t, exactly one of them takes the value one and others are equal to zero, with conditional probabilities
Now yt can be expressed as
(12)
(12)
where
is as in (9). This formulation suggests that the mixing weights
can be thought of as (conditional) probabilities that determine which one of the M autoregressive components of the mixture generates the observation yt.
It turns out that the StMAR model has some very attractive theoretical properties; the carefully chosen conditional densities in Equation(9)(9)
(9) and the mixing weights in Equation(11)
(11)
(11) are crucial in obtaining these properties. The following theorem shows that there exists a choice of initial values
such that
is a stationary and ergodic Markov chain. Importantly, an explicit expression for the stationary distribution is also provided.
Theorem 2.
Consider the StMAR process yt generated by Equation(8)(8)
(8) , Equation(9)
(9)
(9) , and Equation(11)
(11)
(11) (or Equation(12)
(12)
(12) and Equation(11)
(11)
(11) ) with the conditions φm
and
satisfied for all
. Then
(
) is a Markov chain on
with a stationary distribution characterized by the density
. Moreover,
is ergodic.
As can be seen from the proof of Theorem 2 (in Appendix B), the Markov property, stationarity, and ergodicity are obtained as reasonably simple consequences of the definition of the StMAR model. The stationary distribution of is a mixture of M p–dimensional t–distributions with constant mixing weights αm. Hence, moments of the stationary distribution of order smaller than
exist and are finite. Furthermore, the stationary distribution of the vector
is also a mixture of M t–distributions with density of the same form,
(for details, see Appendix B). Thus the mean, variance, and first p autocovariances of yt are (here the connection between
and
is as in Equation(4)
(4)
(4) )
Subvectors of also have stationary distributions that belong to the same family (but this does not hold for higher dimensional vectors such as
).
The fact that an explicit expression for the stationary (marginal) distribution of the StMAR model is available is not only convenient but also quite exceptional among mixture autoregressive models or other related nonlinear autoregressive models (such as threshold or smooth transition models). Previously, similar results have been obtained by Glasbey (Citation2001) and Kalliovirta, Meitz, and Saikkonen (Citation2015) in the context of mixture autoregressive models that are of the same form but based on the Gaussian distribution (for a few rather simple first order examples involving other models, see Tong (Citation2011, Section 4.2)).
From the definition of the model, the conditional mean and variance of yt are obtained as
(13)
(13)
Except for the different definition of the mixing weights, the conditional mean is as in the Gaussian mixture autoregressive model of Kalliovirta, Meitz, and Saikkonen (Citation2015). This is due to the well-known fact that in the multivariate t–distribution the conditional mean is of the same linear form as in the multivariate Gaussian distribution. However, unlike in the Gaussian case, the conditional variance of the multivariate t–distribution is not constant. Therefore, in Equation(13)(13)
(13) we have the time-varying variance component
which in the models of Kalliovirta, Meitz, and Saikkonen (Citation2015) and Wong, Chan, and Kam (Citation2009) is constant (in the latter model the mixing weights are also constants). In Equation(13)
(13)
(13) both the mixing weights
and the variance components
are functions of
implying that the conditional variance exhibits nonlinear autoregressive conditional heteroskedasticity. Compared to the aforementioned previous models our model may therefore be useful in applications where the data exhibits rather strong conditional heteroskedasticity.
In many applications in economics, finance, and other fields, the data is often multimodal and contains periods with markedly different behaviors. In such a situation a multiple regime StMAR model would be more appropriate than a linear model. This applies also to the StMAR model with a single regime (M = 1) which corresponds to the linear Student’s t autoregression considered in Section 2. Furthermore, the conditional mean and variance are much more flexible in a mixture model than in a linear one.
4. Estimation
The parameters of an StMAR model can be estimated by the method of maximum likelihood (details of the numerical optimization methods employed and of simulation experiments are available in the Supplementary Appendix). As the stationary distribution of the StMAR process is known it is even possible to make use of initial values and construct the exact likelihood function and obtain exact maximum likelihood estimates. Assuming the observed data and stationary initial values, the log-likelihood function takes the form
(14)
(14)
where
(15)
(15)
An explicit expression for the density appearing in Equation(15)(15)
(15) is given in Equation(10)
(10)
(10) , and the notation for
and
is explained after Equation(9)
(9)
(9) . Although not made explicit,
and
as well as the quantities μm,
and
depend on the parameter vector
In Equation(14)(14)
(14) it has been assumed that the initial values
are generated by the stationary distribution. If this assumption seems inappropriate one can condition on initial values and drop the first term on the right hand side of Equation(14)
(14)
(14) . In what follows we assume that estimation is based on this conditional log-likelihood, namely
which we, for convenience, have also scaled with the sample size. Maximizing
with respect to
yields the maximum likelihood estimator denoted by
The permissible parameter space of denoted by
needs to be constrained in various ways. The stationarity conditions
the positivity of the variances
and the conditions
ensuring existence of second moments are all assumed to hold (for
). Throughout we assume that the number of mixture components M is known, and this also entails the requirement that the parameters αm (
) are strictly positive (and strictly less than unity whenever M > 1). Further restrictions are required to ensure identification. Denoting the true parameter value by
and assuming stationary initial values, the condition needed is that
almost surely only if
An additional assumption needed for this is
(16)
(16)
From a practical point of view this assumption is not restrictive because what it essentially requires is that the M component models cannot be ‘relabeled’ and the same StMAR model obtained. We summarize the restrictions imposed on the parameter space as follows.
Assumption 1.
The true parameter value is an interior point of
, where
is a compact subset of
Asymptotic properties of the maximum likelihood estimator can now be established under conventional high-level conditions. Denote and
Theorem 3.
Suppose yt is generated by the stationary and ergodic StMAR process of Theorem 2 and that Assumption 1 holds. Then is strongly consistent, i.e.,
almost surely. Suppose further that (i)
with
finite and positive definite, (ii)
, and (iii)
for some
, a compact convex set contained in the interior of
that has
as an interior point. Then
Of the conditions in this theorem, (i) states that a central limit theorem holds for the score vector (evaluated at ) and that the information matrix is positive definite, (ii) is the information matrix equality, and (iii) ensures the uniform convergence of the Hessian matrix (in some neighborhood of
). These conditions are standard but their verification may be tedious.
Theorem 3 shows that the conventional limiting distribution applies to the maximum likelihood estimator which implies the applicability of standard likelihood-based tests. It is worth noting, however, that here a correct specification of the number of autoregressive components M is required. In particular, if the number of component models is chosen too large then some parameters of the model are not identified and, consequently, the result of Theorem 3 and the validity of the related tests break down. This particularly happens when one tests for the number of component models. Such tests for mixture autoregressive models with Gaussian conditional densities (see Equation(8)
(8)
(8) ) are developed by Meitz and Saikkonen (Citation2021). The testing problem is highly nonstandard and extending their results to the present case is beyond the scope of this paper.
Instead of formal tests, in our empirical application we take a pragmatic approach and resort to the use of information criteria to infer which model fits the data best. Similar approaches have also been used by Wong, Chan, and Kam (Citation2009) and others. Note that once the number of regimes is (correctly) chosen, standard likelihood-based inference can be used to choose regime-wise autoregressive orders and to test other hypotheses of interest. Validity of (quantile) residual-based misspecification tests to check for model adequacy also relies on the correct specification of the number of regimes.
5. Empirical example
Modeling and forecasting financial market volatility is key to manage risk. In this application we use the realized kernel of Barndorff-Nielsen et al. (Citation2008) as a proxy for latent volatility. We obtained daily realized kernel data over the period 3 January 2000 through 20 May 2016 for the S&P 500 index from the Oxford-Man Institute’s Realized Library v0.2 (Heber et al. Citation2009). shows the in-sample period (Jan 3, 2000–June 3, 2014; 3597 observations) for the S&P 500 realized kernel data (), which is nonnegative with a distribution exhibiting substantial skewness and excess kurtosis (sample skewness 14.3, sample kurtosis 380.8). We follow the related literature which frequently use logarithmic realized kernel (
), to avoid imposing additional parameter constraints, and to obtain a more symmetric distribution, often taken to be approximately Gaussian. The
data, also shown in , has a sample skewness of 0.5 and kurtosis of 3.5. Visual inspection of the time series plots of the
and
data suggests that the two series exhibit changes at least in levels and potentially also in variability. A kernel estimate of the density function of the
series also suggest the potential presence of multiple regimes.
Figure 1. Left panel: Daily (lower solid) and
(upper solid), and mixing weights based on the estimates of the StMAR(4,2) model in (dot-dash) for the
series. The mixing weights
are scaled from
to
Right panel: A kernel density estimate of the
observations (solid), and the mixture density (dashes) implied by the same StMAR model as in the left panel.
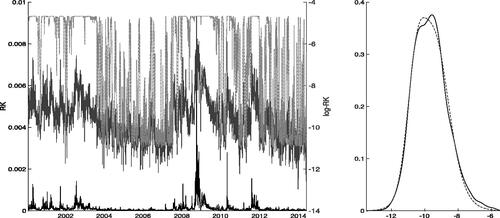
For brevity, we focus our attention on StMAR models with and M = 1, 2, 3; higher-order models were also tried but their forecasting performance was qualitatively similar to the models with
Following Wong and Li (Citation2001a), Wong, Chan, and Kam (Citation2009), and Li et al. (Citation2015), we use information criteria for model comparison. Of these models, the Akaike information criterion (aic) and the Hannan-Quinn information criterion (hqc) favor the StMAR(4,3) model, and the Bayesian information criterion (bic) the simpler StMAR(4,1) model. Estimation results for these two models, as well as the intermediate StMAR(4,2) model, are reported in . As the estimated mixture weight of the third component of the StMAR(4,3) model is rather small (
) and the first two components are very similar to the StMAR(4,2) model, including this intermediate StMAR(4,2) model seems reasonable. In view of the approximate standard errors in , the estimation accuracy appears quite reasonable except for the degrees of freedom parameters (for large values of the degrees of freedom parameters the likelihood function becomes very flat; in particular
and its standard error may be rather inaccurate). Taking the sum of the autoregressive parameters as a measure of persistence, we find that the estimated persistence for the first regime of the StMAR(4,2) is 0.909 and 0.489 for the second regime, suggesting that persistence is rather strong in the first regime and moderate in the second regime.
Table 1. Parameter estimates for three selected StMAR models and the data over the period 3 January 2000–3 June 2014.
Numerous alternative models for volatility proxies have been proposed. We employ Corsi’s (Citation2009) heterogeneous autoregressive (HAR) model as it is arguably the most popular reference model for forecasting proxies such as the realized kernel. We also consider a pth-order autoregression as the AR(p) often performs well in volatility proxy forecasting. The StMAR models are estimated using maximum likelihood, and the reference AR and HAR models by ordinary least squares. We use a fixed scheme, where the parameters of our volatility models are estimated just once using data from Jan 3, 2000–June 3, 2014. These estimates are then used to generate all forecasts. The remaining 496 observations of our sample are used to compare the forecasts from the alternative models. As discussed in Kalliovirta, Meitz, and Saikkonen (Citation2016), computing multi-step-ahead forecasts for mixture models like the StMAR is rather complicated. For this reason we use computer driven forecasts to predict future volatility: For each out-of-sample date T, and for each alternative model, we simulate 1,000,000 sample paths. Each path is of length 22 (representing one trading month) and conditional on the information available at date T. In these simulations unknown parameters are replaced by their estimates. As the simulated paths are for and our object of interest is
an exponential transformation is applied.
We examine daily, weekly (5 day), biweekly (10 day), and monthly (22 day) volatility forecasts generated by the alternative models; for instance, the weekly volatility forecast at date T is the forecast for (the 5-day-ahead cumulative realized kernel). reports the percentage shares of (1, 5, 10, and 22-day) cumulative
out-of-sample observations that belong to the 99%, 95%, and 90% one-sided upper prediction intervals based on the distribution of the simulated sample paths; these upper prediction intervals for volatility are related to higher levels of risk in financial markets. Overall, it is seen that the empirical coverage rates of the StMAR based prediction intervals are closer to the nominal levels than those obtained with the reference models. By comparison, the accuracy of the prediction intervals obtained with the popular HAR model quickly degrade as the forecast period increases. The StMAR model performs well also when two-sided prediction intervals and point forecast accuracy are considered (for details, see the Supplementary Appendix).
Table 2. The percentage shares of cumulative realized kernel observations that belong to the 99%, 95% and 90% one-sided upper prediction intervals based on the distribution of 1,000,000 simulated conditional sample paths.
Supplemental Material
Download PDF (395.7 KB)Acknowledgments
The authors thank the Academy of Finland for financial support, and the editors and an anonymous referee for useful comments and suggestions.
References
- Barndorff-Nielsen, O. E., P. R. Hansen, A. Lunde, and N. Shephard. 2008. Designing realized kernels to measure the ex post variation of equity prices in the presence of noise. Econometrica 76:1481–536.
- Corsi, F. 2009. A simple approximate long-memory model of realized volatility. Journal of Financial Econometrics 7 (2):174–96. doi:10.1093/jjfinec/nbp001.
- Ding, P. 2016. On the conditional distribution of the multivariate t distribution. The American Statistician 70 (3):293–95. doi:10.1080/00031305.2016.1164756.
- Dueker, M. J., M. Sola, and F. Spagnolo. 2007. Contemporaneous threshold autoregressive models: Estimation, testing and forecasting. Journal of Econometrics 141 (2):517–47. doi:10.1016/j.jeconom.2006.10.022.
- Frühwirth-Schnatter, S. 2006. Finite mixture and Markov switching models. New York: Springer.
- Glasbey, C. A. 2001. Non-linear autoregressive time series with multivariate Gaussian mixtures as marginal distributions. Journal of the Royal Statistical Society: Series C (Applied Statistics) 50 (2):143–54. doi:10.1111/1467-9876.00225.
- Heber, G., A. Lunde, N. Shephard, and K. Sheppard. 2009. Oxford-man institute’s realized library v0.2. Oxford: Oxford-Man Institute, University of Oxford.
- Heracleous, M. S., and A. Spanos. 2006. The Student’s t dynamic linear regression: Re-examining volatility modeling. In Econometric analysis of financial and economic time series (advaces in econometrics, Vol. 20 Part 1), ed. D. Terrell and T. B. Fomby, 289–319. Oxford: Emerald Group Publishing Limited.
- Holzmann, H.,. A. Munk, and T. Gneiting. 2006. Identifiability of finite mixtures of elliptical distributions. Scandinavian Journal of Statistics 33 (4):753–63. doi:10.1111/j.1467-9469.2006.00505.x.
- Kalliovirta, L., M. Meitz, and P. Saikkonen. 2015. A Gaussian mixture autoregressive model for univariate time series. Journal of Time Series Analysis 36 (2):247–66. doi:10.1111/jtsa.12108.
- Kalliovirta, L., M. Meitz, and P. Saikkonen. 2016. Gaussian mixture vector autoregression. Journal of Econometrics 192 (2):485–98. doi:10.1016/j.jeconom.2016.02.012.
- Kotz, S., and S. Nadarajah. 2004. Multivariate t distributions and their applications. Cambridge: Cambridge University Press.
- Lanne, M., and P. Saikkonen. 2003. Modeling the US short-term interest rate by mixture autoregressive processes. Journal of Financial Econometrics 1 (1):96–125. doi:10.1093/jjfinec/nbg004.
- Le, N. D., R. D. Martin, and A. E. Raftery. 1996. Modeling flat stretches, bursts, and outliers in time series using mixture transition distribution models. Journal of the American Statistical Association 91:1504–15.
- Li, G., B. Guan, W. K. Li, and P. L. Yu. 2015. Hysteretic autoregressive time series models. Biometrika 102 (3):717–23. doi:10.1093/biomet/asv017.
- McLachlan, G., and D. Peel. 2000. Finite mixture models. New York: Wiley.
- Meitz, M., and P. Saikkonen. 2021. Testing for observation-dependent regime switching in mixture autoregressive models. Journal of Econometrics 222 (1):601–24. doi:10.1016/j.jeconom.2020.04.048.
- Meyn, S., and R. L. Tweedie. 2009. Markov chains and stochastic stability. 2nd ed. Cambridge: Cambridge University Press.
- Pitt, M. K., and S. G. Walker. 2006. Extended constructions of stationary autoregressive processes. Statistics & Probability Letters 76 (12):1219–24. doi:10.1016/j.spl.2005.12.020.
- Ranga Rao, R. 1962. Relations between weak and uniform convergence of measures with applications. The Annals of Mathematical Statistics 33 (2):659–80. doi:10.1214/aoms/1177704588.
- Spanos, A. 1994. On modeling heteroskedasticity: The Student’s t and elliptical linear regression models. Econometric Theory 10 (2):286–315. doi:10.1017/S0266466600008422.
- Tong, H. 2011. Threshold models in time series analysis – 30 years on. Statistics and Its Interface 4 (2):107–18. doi:10.4310/SII.2011.v4.n2.a1.
- Wong, C. S., W. S. Chan, and P. L. Kam. 2009. A Student t-mixture autoregressive model with applications to heavy-tailed financial data. Biometrika 96 (3):751–60. doi:10.1093/biomet/asp031.
- Wong, C. S., and W. K. Li. 2000. On a mixture autoregressive model. Journal of Royal Statistical Society B 62:95–115.
- Wong, C. S., and W. K. Li. 2001a. On a logistic mixture autoregressive model. Biometrika 88 (3):833–46. doi:10.1093/biomet/88.3.833.
- Wong, C. S., and W. K. Li. 2001b. On a mixture autoregressive conditional heteroscedastic model. Journal of the American Statistical Association 96 (455):982–95. doi:10.1198/016214501753208645.
Appendices
Appendix A: Properties of the multivariate Student’s t–distribution
The standard form of the density function of the multivariate Student’s t–distribution with ν degrees of freedom and dimension d is (see, e.g., Kotz and Nadarajah (Citation2004, p. 1))
where
is the gamma function and
and
(d × d), a symmetric positive definite matrix, are parameters. For a random vector X possessing this density, the mean and covariance are
and
(assuming
). The density can be expressed in terms of
and
as
This form of the density function, denoted by is used in this paper, and the notation
is used for a random vector X possessing this density. Condition
and positive definiteness of
will be tacitly assumed.
For marginal and conditional distributions, partition X as where the components have dimensions d1 and d2 (
). Conformably partition
and
as
and
Then the marginal distributions of and
are
and
respectively. The conditional distribution of
given
is also a t–distribution, namely (see Ding (Citation2016, Sec. 2))
where
and
Furthermore,
Now consider a special case: a (p + 1)–dimensional random vector where
and
is a symmetric positive definite Toeplitz matrix. Note that the mean vector
and the covariance matrix
have structures similar to those of the mean and covariance matrix of a (p + 1)–dimensional realization of a second order stationary process. More specifically, assume that
is the covariance matrix of a second order stationary AR(p) process.
Partition X as with X1 and
real valued and
and
both
vectors. The marginal distributions of
and
are
and
where the (symmetric positive definite Toeplitz) matrix
is obtained from
by deleting the first row and first column or, equivalently, the last row and last column (here the specific structures of
and
are used). The conditional distribution of X1 given
is
where expressions for
and
can be obtained from above as follows. Partition
as
and denote
and
(
as
is positive definite). From above,
Appendix B: Proofs of Theorems 1–3
Proof of Theorem 1.
Corresponding to
and
define the notation
γ0,
μ, and
as in Equation(4)
(4)
(4) , and note that
and
are, by construction and due to assumption
symmetric positive definite Toeplitz matrices. To prove (i), we will construct a p–dimensional Markov process
(
) with the desired properties. We need to specify an appropriate transition probability measure and an initial distribution. For the former, assume that the transition probability measure of
is determined by the density function
where
and
are obtained from the last two displayed equations in Appendix A by substituting
for
This shows that
can be treated as a Markov chain (see Meyn and Tweedie (Citation2009, Ch. 3)). Concerning the initial value
suppose it follows the t–distribution
Furthermore, if
we find from Appendix A that the density function of
is given by
(A1)
(A1)
Thus, and, as in Appendix A, it follows that the marginal distribution of
is the same as that of
that is,
(the specific structure of
is used here). Hence, as
is a Markov chain, we can conclude that it has a stationary distribution characterized by the density function
(see Meyn and Tweedie (Citation2009, pp. 230–231)). This completes the proof of (i).
To prove (ii), note that, due to the Markov property, where
signifies the sigma-algebra generated by
Thus we can write the conditional expectation and conditional variance of zt given
as
Denote this conditional variance by (and note that
a.s. due to the assumed conditions
and
). Now the random variables
defined by
follow, conditional on
the
distribution. Hence, we obtain the ‘AR(p)–ARCH(p)’ representation (7). Because the conditional distribution
does not depend on
(or, more specifically, on the random variables
), the same holds true also unconditionally,
implying that the random variables
are independent of
(or of
). Moreover, from the definition of the
’s it follows that
is a function of
and hence
is also independent of
Consequently, the random variables
are IID
completing the proof of (ii). □
Proof of Theorem 2.
First note that is a Markov chain on
Now, let
be a random vector whose distribution has the density
According to (8, 9, 11), and (A1), the conditional density of y1 given
is
It follows that the density of is
Integrating
out (and using the properties of marginal distributions of a multivariate t–distribution in Appendix A) shows that the density of
is
Therefore,
and
are identically distributed. As
is a (time homogeneous) Markov chain, it follows that
has a stationary distribution
say, characterized by the density
(cf. Meyn and Tweedie (Citation2009, pp. 230–231)).
For ergodicity, let signify the p–step transition probability measure of
It is straightforward to check that
has a density given by
The last expression makes clear that for all
and all
Now, one can complete the proof that
is ergodic in the sense of Meyn and Tweedie (Citation2009, Ch. 13) by using arguments identical to those used in the proof of Theorem 1 in Kalliovirta, Meitz, and Saikkonen (Citation2015). □
Proof of Theorem 3.
First note that Assumption 1 together with the continuity of ensures the existence of a measurable maximizer
For strong consistency, it suffices to show that a certain uniform convergence condition and a certain identification condition hold. Specifically, the former required condition is that the conditional log-likelihood function obeys a uniform strong law of large numbers, that is,
a.s. as
As the yt’s are stationary and ergodic and
condition
ensures that the uniform law of large numbers in Ranga Rao (Citation1962) applies.
The validity of condition can be established by deriving suitable lower and upper bounds for
Recall from Equation(10)
(10)
(10) and Equation(15)
(15)
(15) that
where
and
The following arguments hold for some choice of finite positive constants
and all staments are understood to hold ‘for all
’ whenever appropriate. The assumed compactness of the parameter space (Assumption 1) and the continuity of the gamma function on the positive real axis imply that
(A2)
(A2)
Next, recall that
where the matrix
is positive definite and
Thus, by the compactness of the parameter space,
On the other hand, as
is a continuous function of the autoregressive coefficients, the continuity of eigenvalues implies that the smallest eigenvalue of
is bounded away from zero by a constant. This, together with elementary inequalities, yields
Thus, by the compactness of the parameter space, we have
so that also
(A3)
(A3)
Therefore
which, together with the compactness of the parameter space, implies that
(A4)
(A4)
Using (A2)–(A4) it now follows that
Using this and the fact that
we can now bound
from above by a constant, say
Furthermore, for some
Hence, as the StMAR process has finite second moments, we can conclude that
As for the latter condition required for consistency, we need to establish that and that
implies
For notational clarity, let us make the dependence on parameter values explicit in the expressions in Equation(5)
(5)
(5) and write
and
and let
stand for
(see Equation(11)
(11)
(11) ) but with
therein replaced by y and with the dependence on the parameter values made explicit (
). Making use of the fact that the density of
has the form
(see proof of Theorem 2) and reasoning based on the Kullback-Leibler divergence, we can now use arguments analogous to those in Kalliovirta, Meitz, and Saikkonen (Citation2015, p. 265) to conclude that
with equality if and only if for almost all
(A5)
(A5)
For each fixed y at a time, the mixing weights, conditional means, and conditional variances in (A5) are constants, and we may apply the results on identification of finite mixtures of Student’s t–distributions in Holzmann, Munk, and Gneiting (Citation2006, Example 1) (their parameterization of the t–distribution is slightly different than ours, but identification with their parameterization implies identification in our parameterization). Consequently, for each fixed y at a time, there exists a permutation
of
(where this permutation may depend on y) such that
(A6)
(A6)
The number of possible permutations being finite (
), this induces a finite partition of
where the elements y of each partition correspond to the same permutation. At least one of these partitions, say
must have positive Lebesque measure. Thus, (A6) holds for all fixed
with some specific permutation
of
The fact that
for
almost all y, and all
can be used to deduce that
for
(see (4, 5), and Kalliovirta, Meitz, and Saikkonen (Citation2015, pp. 265–266)). Similarly, using condition
(and the knowledge that
), it follows that
so that
(
). Now
(
) follows as in Kalliovirta, Meitz, and Saikkonen (Citation2015, p. 266). In light of Equation(16)
(16)
(16) , the preceding facts imply that
This completes the proof of consistency.
Given conditions (i)–(iii) of the theorem, asymptotic normality of the ML estimator can now be established using standard arguments. The required steps can be found, for instance, in Kalliovirta, Meitz, and Saikkonen (Citation2016, proof of Theorem 3). We omit the details for brevity. □