
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Fused Lasso is one of extensions of Lasso to shrink differences of parameters. We focus on a general form of it called generalized fused Lasso (GFL). The optimization problem for GFL can be came down to that for generalized Lasso and can be solved via a path algorithm for generalized Lasso. Moreover, the path algorithm is implemented via the genlasso package in R. However, the genlasso package has some computational problems. Then, we apply a coordinate descent algorithm (CDA) to solve the optimization problem for GFL. We give update equations of the CDA in closed forms, without considering the Karush-Kuhn-Tucker conditions. Furthermore, we show an application of the CDA to a real data analysis.
1. Introduction
Suppose that there are m groups and nj pairs of data are observed for group
where
is a response variable and
is a p-dimensional vector of non stochastic explanatory variables. Let
be an nj-dimensional vector defined by
and
be an
matrix defined by
For group j, we consider the following linear regression model:
(1)
(1)
where
is a p-dimensional vector of regression coefficients, μj is a location parameter for group j,
is an n-dimensional vector of ones, and
is an nj-dimensional vector of error variables from a distribution with mean 0 and variance
In addition, we assume that the vectors
are independent. Let
be an n-dimensional vector defined by
be an n × p matrix defined by
be an m-dimensional vector defined by
be an
block diagonal matrix defined by
and
be an n-dimensional vector defined by
where
Then, m models in Equation(1)
(1)
(1) are expressed as
In this paper, although we deal with a linear regression model, we consider the case that location parameters of the model are different for each groups, that is, it can be regarded that location parameters express individual effects of groups. We call μj group effect for group j. In such case, one of interesting points is which group effects are equivalence. Hence, we approach it by using penalized least square method. That is, is estimated by minimizing the following penalized residual sum of squares (PRSS):
(2)
(2)
where λ is a positive tuning parameter,
is an index set, and
is a positive weight satisfying
This is called generalized fused Lasso (GFL). The original form of GFL was proposed by Tibshirani et al. (Citation2005) and is called fused Lasso (FL). When
and
GFL coincides with FL. GFL shrinks
toward 0 and the estimates of μj and
are often equal. Hence, using GFL, we can identify groups with equal group effects.
To obtain the GFL estimator of we need an optimization method to minimize Equation(2)
(2)
(2) . For FL, Friedman et al. (Citation2007) proposed a coordinate descent algorithm (CDA). In other cases, the optimization problem can be came down to that of the ordinary Lasso (Tibshirani Citation1996) under some conditions (e.g., Sun, Wang, and Fuentes Citation2016; Li and Sang Citation2019). In this paper, we deal with the case that the above methods cannot be applied. That is, we assume that
Fortunately, GFL can be expressed as generalized Lasso (Tibshirani and Taylor Citation2011). Generalized Lasso type penalty is given by
where
is a penalty matrix. For FL,
is an
matrix given by
In addition, Tibshirani and Taylor (Citation2011) proposed the optimization algorithm for generalized Lasso and the algorithm is implemented via the genlasso package (e.g., Arnold and Tibshirani Citation2019) in R (e.g., R Core Team Citation2019). However, the optimization with the genlasso package has a high calculation cost and cannot be practically executed in large sample data. Moreover, there are issues in terms of numerical error and estimates cannot be exactly equal. Accordingly, we focus on a CDA.
To accurately calculate the GFL estimator of even in large sample data, we give update equations of the CDA in closed form. Our algorithm has advantages compared with several existing algorithms, for example, by Friedman et al. (Citation2007) and Tibshirani and Taylor (Citation2011). Their algorithms are via Lagrange dual problem and must consider several conditions, for example, Karush-Kuhn-Tucker conditions and optimality. On the other hand, using our algorithm, the optimization problem for GFL can be solved by elementary mathematics, without considering these conditions. Moreover, although our algorithm reduces a search range of the minimizer for the jth coordinate direction to
discrete points that are given by closed forms, a numerical search like comparing values for each point in the reduced search range is not required. By checking simple conditions, the unique minimizer for a coordinate direction can be decided. Of course, the unique minimizer is given by closed form and ensures minimization for coordinate direction.
The remainder of the paper is organized as follows: In Section 2, we give closed form update equations of the CDA for GFL. Numerical examples are discussed in Section 3. Section 4 is conclusion of this paper. Technical details are provided in the Appendix.
2. Main results
We derive update equations of the CDA for obtaining the GFL estimator of A CDA updates a solution along coordinate directions. The CDA for FL consists of a descent cycle and a fusion cycle. The descent cycle successively minimizes along coordinate directions. The ordinary CDA only consists of the descent cycle. However, when the ordinary CDA is applied for FL, some estimates are equal and then the solution gets stuck, failing to reach the minimum. To avoid this problem, Friedman et al. (Citation2007) invoked the fusion cycle. Since this problem can also occur for GFL, we give update equations for the descent cycle and the fusion cycle. In this section, we regard that
is fixed at
and minimize the following PRSS:
(3)
(3)
where
2.1. Descent cycle
The descent cycle minimizes along coordinate directions. That is, Equation(3)(3)
(3) is minimized with respect to μi and repeat it for
We fix
at
Then, Equation(3)
(3)
(3) is rewritten as the function of μi by the following lemma (the proof is given in Appendix A):
Lemma 2.1.
The EquationEquation (3)(3)
(3) can be expressed as the following function of
:
(4)
(4)
where
is the ith block of
, that is,
and ui is the term that does not depend on μi.
From Lemma 2.1, essentially, it is sufficient to minimize the following function:
(5)
(5)
Let and let
be the order statistics of
that is,
and
be index sets for
defined by
and Ra be a range defined by
Moreover, we define and va for
as
Then, the minimizer of Equation(5)(5)
(5) is given by the following theorem (the proof is given in Appendix B):
Theorem 2.2.
Let and
be non negative values defined by
Then, either or
uniquely exists, and the minimizer of
in Equation(5)
(5)
(5) is given by
Theorem 2.2
gives the unique minimizer of μi in Equation(4)(4)
(4) . Hence, by applying Theorem 2.2 to Equation(4)
(4)
(4) for
we can obtain the solution of
in the descent cycle. In Theorem 2.2, when
exists, estimate of μi is equal to
(satisfying
), and this means that group effects of groups i and j are equal.
2.2. Fusion cycle
The fusion cycle avoids a solution getting stuck when some estimates are equal in the descent cycle. Suppose that we obtain as estimates of μj and
in the descent cycle. Then, to avoid the solutions of μj and
getting stuck, we regard
and minimize Equation(3)
(3)
(3) along the ηi-axis direction.
After the descent cycle, suppose that we obtain as estimates of
Then, let
be distinct values of
and we define index sets
as
where
and
If b < m, the fusion cycle is executed. In the fusion cycle, Equation(3)
(3)
(3) is minimized with respect to ηi and repeat it for
We fix
at
Moreover, we define
and
as
Then, Equation(3)(3)
(3) is rewritten as the function of ηi by the following lemma (the proof is given in Appendix C):
Lemma 2.3.
The EquationEquation (3)(3)
(3) can be expressed as the following function of
:
(6)
(6)
where
is the term that does not depend on ηi.
From Lemma 2.3, we found that the minimization of Equation(6)(6)
(6) is essentially equal to that of Equation(5)
(5)
(5) . Hence, by applying Theorem 2.2 to Equation(6)
(6)
(6) for
we can obtain the solution of
in the fusion cycle.
2.3. Coordinate descent algorithm for GFL
In the previous subsections, we described the descent and fusion cycles and showed that the solution for each step is given by Theorem 2.2. From the results, the CDA for GFL is summarized as follows:
Coordinate Descent Algorithm for GFL
Input: The λ and initial vector of
Output: The optimal solution of
Step 1. Run the descent cycle:
Update
by applying Theorem 2.2 to (4) for
Step 2. Run the fusion cycle if b < m:
Update
Step 3. Check convergence:
If
Actually, when we use this algorithm, the selection of λ is very important. The reason is that λ adjusts the strength of the penalty term, that is, the value of λ changes the estimate of If λ = 0, the GFL estimator of
is equal to the least square estimator of
For increasing λ, some estimates are equal, that is, b becomes smaller. For a sufficient large λ, denoted by
all estimates are equal. Hence, the optimal λ should be searched in the range
When all estimates are equal, that is,
the estimates are given by
Then, from the update equation of the descent cycle,
is given by
(7)
(7)
Thus, for some is estimated via the CDA for GFL, and the optimal λ is selected via, for example, model selection criterion minimization method.
3. Numerical studies
In this section, we present numerical simulations, discuss estimation accuracy, and consider an illustrative application to an actual data set. The numerical calculation programs are executed by R (ver. 3.6.0) under a computer with a Windows 10 Pro operating system, an Intel (R) Core (TM) i7-7700 processor, and 16 GB of RAM.
In this studies, explanatory variables include dummy variables with 3 or more categories. Then, we split and
as
where
is the number of explanatory variables,
is an
matrix of the
th explanatory variable,
is a
-dimensional vector of regression coefficients for
and
satisfies
and
In particular, when
we denote
and
Assume that
is scaled. Then, the following equations hold:
Although we execute the CDA for GFL, we select explanatory variables at the same time. The explanatory variables are selected by the CDA for group Lasso (Yuan and Lin Citation2006). Then, estimators of and
are given by
where λ1 and λ2 are positive tuning parameters. The update equation of the CDA for group Lasso is given by
where
and
In particular, when pj = 1, the update equation is given by
where S(x, a) is a soft-thresholding operator (e.g., Donoho and Johnstone Citation1994), that is,
The weights of penalties are often used the inverse of
-norm (absolute value) of the estimator (e.g., Zou Citation2006). Hence, we use the following weights:
where
and
are the least-squares estimators of
and μj, respectively. These estimators are obtained by the following algorithm:
Alternate Optimization Algorithm
Input: Initial vectors of and
Output: The optimal solutions of and
Step 1. Optimize λ1 and
1-1. Decide searching points of λ1.
1-2. For fixed λ1, calculate
1-3. Repeat 1-2 for all λ1 and select the optimal λ1 based on minimizing a model selection criterion.
Step 2. Optimize λ2 and
2-1. Decide searching points of λ2.
2-2. For fixed λ2, calculate
2-3. Repeat 2-2 for all λ2 and select the optimal λ2 based on minimizing a model selection criterion.
Step 3: Check convergence:
If and
are both converge, the algorithm completes. If not, return to Step 1.
The λ1 and λ2 are searched in 100 points given by where
is given by
The optimal tuning parameters are selected based on minimizing the extended GCV (EGCV) criterion (Ohishi, Yanagihara, and Fujikoshi Citation2020) defined by
where α is a positive value expressing the strength of model complexity. We use the EGCV criterion with
For an m-dimensional vector
we regard that
converges when the following equation holds:
where (i) is the iteration number and
is the jth element of
3.1. Simulation
In this subsection, we compare the estimation accuracies of the following Method 1 and Method 2 by simulation.
Method 1: The Alternate Optimization Algorithm using the CDA for GFL to optimize
Method 2: The Alternate Optimization Algorithm using the genlasso package (ver. 1.4) to optimize
The number of groups is m = 10, 20, the correlation between explanatory variables is 0.8, and the sample sizes of groups are
Then, total sample size is
and we use
shows simulation groups when m = 10, 20 with adjacent relationships indicated by lines. The figure means, for example,
and
when m = 10. We generated data from the simulation model
with the following
:
where column vectors
and block matrices
are calculated as using the following procedure. Let
be independent n-dimensional vectors that the elements are identically and independently distributed according to U(0, 1) and
be n-dimensional vectors defined by
where ω is the parameter determining the correlation of
and
as ρ, defined by
Figure 1. Simulation groups and adjacent relationship. (a) m = 10. (b) m = 20.
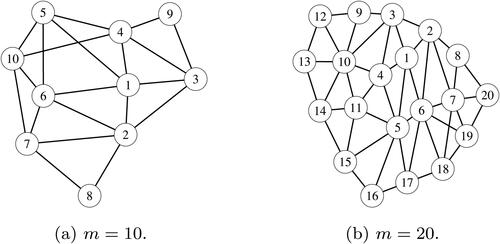
By using these vectors we define the blocks in
as follows: Let
for
let
be dummy variables that take the value 1 or 0 defined by
and let
be
-dimensional dummy variables that are categorized, defined by
where
is a j-dimensional vector in which the
th element is 1 and the others are 0 and
is the
th range when
is split into j ranges. The following 2 cases are used as
and
Case 1: Let the number of true explanatory variables be
and we use the following and
:
Case 2: Let the number of true explanatory variables be
and we use the following and
:
and show true joins of groups when m = 10, 20, respectively. Estimation accuracy is evaluated by the selection probabilities of true variables and true joins by Monte Carlo simulation with 1000 iterations. and show the selection probabilities (SP) of true variables and true joins and running times (RT) of programs in Cases 1 and 2, respectively. The SP is displayed as the combined probability (C-SP) and separate probability about variables and joins. From the tables, since the SP of Method 1 approaches 100% as sample size increases, we found that Method 1 has high estimation accuracy. On the other hand, Method 2 struggles to select the true variables and true joins and its SP is 7.4% (when m = 10, and
in Case 1) at most. In particular, it struggles to select the true joins and its SP is only 7.8% (when m = 10,
and
in Case 1) at most. Moreover, in terms of running time, Method 1 is about 134 times faster than Method 2 (when m = 20,
and
in Case 1) at most.
Figure 2. True joins when m = 10. (a) Case 1. (b) Case 2.
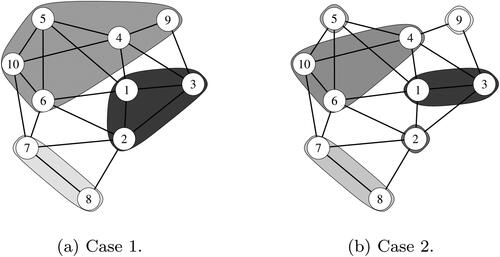
Figure 3. True joins when m = 20. (a) Case 1. (b) Case 2.
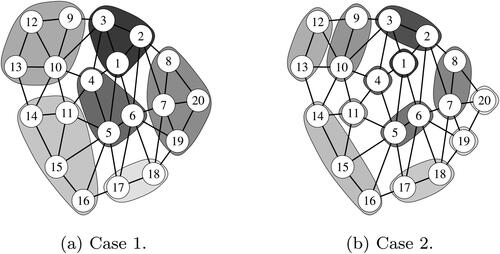
Table 1. Selection probabilities and running times in Case 1.
Table 2. Selection probabilities and running times in Case 2.
3.2. A real data example
In this subsection, we present an illustrative application of the proposed method (Method 1 in Subsection 3.1) to an actual data set. Actually, Method 2 in Subsection 3.1 cannot run the program because the genlasso package causes memory shortage since the applied data have a large sample. This is the motivation of this paper. The data pertain to studio apartment rents and environmental conditions in Tokyo’s 23 wards collected by Tokyo Kantei Co., Ltd. Here, and all data were collected between April 2014 and April 2015 (). In this application, let the response variable be monthly rent with the remainder set as explanatory variables. We estimate regional effects at 852 areas split Tokyo’s 23 wards using the proposed method. shows the split of Tokyo’s 23 wards into 852 areas. shows estimates and clustering result of regional effects in the form of choropleth map. In terms of the former, as with , the 852 areas in Tokyo’s 23 wards are clustered to form 190 areas. summarizes estimates of regression coefficients. As a result of variable selection, B5 and C1 are not selected. is residual plots for quantitative variables. provides information concerning coefficients of determination (R2), median error rate (MER), and running time. From the results, R2 is more than 0.8, MER is less than 10%, and the residual plots are unproblematic. Thus, the proposed method performs well. In this application, we have applied the CDA for GFL to large sample data. For such data, the genlasso package caused memory shortage. Nevertheless the CDA completed program in only about 2 minutes. This is our big contribution.
Figure 4. The 852 areas in Tokyo’s 23 wards.
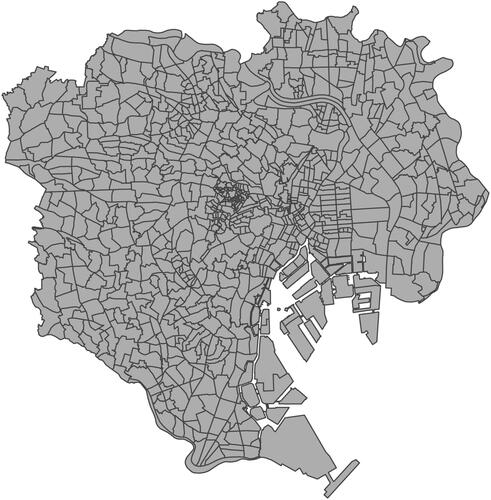
Figure 5. Regional effects estimation results. (a) Estimates. (b) Clustering.
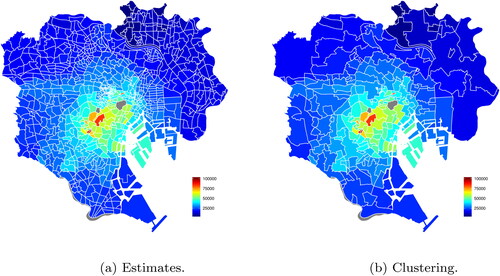
Figure 6. Residual plots. (a) Floor area (A). (b) Age (C3). (c) Interaction (C4). (d) Walking time (C5).
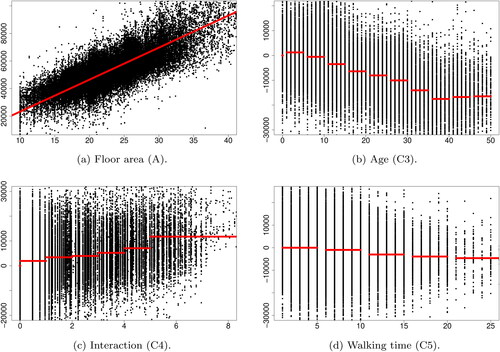
Table 3. Data items.
Table 4. Regression coefficient estimates.
Table 5. Model fit and run time.
4. Conclusion
In this paper, we challenged a coordinate optimization for GFL and derived the update equations for descent cycle and fusion cycle as closed forms, respectively. The update equations can be obtained by only using fundamental mathematics and some complex conditions (e.g., the Karush-Kuhn-Tucker conditions) are not required. In the numerical studies, we found that our proposed method gives accurate solution rapidly than existing method (which is using the genlasso package) and can be applied to even a large sample data that the genlasso package causes memory shortage.
Here, our proposed method was obtained for a linear regression model. However, the method can be also applied to models which are not linear. For example, for generalized linear models, by approximating a negative logarithm likelihood function by a linear function, the GFL-penalized objective function has equal class to Equation(3)(3)
(3) . That is our proposed method can be applied to even generalized linear models. On the other hand, the method cannot work for an extension of GFL penalty. For example, when group-GFL penalty is used instead of GFL penalty (it means the case that μj is a vector), the method cannot be applied.
Acknowledgments
The authors thank Dr. Ryoya Oda and Mr. Yuya Suzuki of Hiroshima University, Mr. Yuhei Sato and Mr. Yu Matsumura of Tokyo Kantei Co., Ltd., and Koki Kirishima of Computer Management Co., Ltd., for helpful comments. Moreover, the authors also thank the associate editor and the reviewers for their valuable comments.
Additional information
Funding
References
- Arnold, T., and R. Tibshirani. 2019. genlasso: Path Algorithm for Generalized Lasso Problems. R package version 1.4. https://CRAN.R-project.org/package=genlasso.
- Donoho, D. L., and I. M. Johnstone. 1994. Ideal spatial adaptation by wavelet shrinkage. Biometrika 81 (3):425–55. doi: https://doi.org/10.1093/biomet/81.3.425.
- Friedman, J., T. Hastie, H. Höfling, and R. Tibshirani. 2007. Pathwise coordinate optimization. The Annals of Applied Statistics 1 (2):302–32. doi: https://doi.org/10.1214/07-AOAS131.
- Li, F., and H. Sang. 2019. Spatial homogeneity pursuit of regression coefficients for large datasets. Journal of the American Statistical Association 114 (527):1050–62. doi: https://doi.org/10.1080/01621459.2018.1529595.
- Ohishi, M., H. Yanagihara, and Y. Fujikoshi. 2020. A fast algorithm for optimizing ridge parameters in a generalized ridge regression by minimizing a model selection criterion. Journal of Statistical Planning and Inference 204:187–205. doi: https://doi.org/10.1016/j.jspi.2019.04.010.
- R Core Team. 2019. R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing. https://www.R-project.org/.
- Sun, Y., H. J. Wang, and M. Fuentes. 2016. Fused adaptive Lasso for spatial and temporal quantile function estimation. Technometrics 58 (1):127–37. doi: https://doi.org/10.1080/00401706.2015.1017115.
- Tibshirani, R. 1996. Regression shrinkage and selection via the Lasso. Journal of the Royal Statistical Society: Series B (Methodological) 58 (1):267–88. doi: https://doi.org/10.1111/j.2517-6161.1996.tb02080.x.
- Tibshirani, R., and J. Taylor. 2011. The solution path of the generalized Lasso. The Annals of Statistics 39:1335–71.
- Tibshirani, R., M. Saunders, S. Rosset, J. Zhu, and K. Knight. 2005. Sparsity and smoothness via the fused Lasso. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 67 (1):91–108. doi: https://doi.org/10.1111/j.1467-9868.2005.00490.x.
- Yuan, M., and Y. Lin. 2006. Model selection and estimation in regression with grouped variables. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 68 (1):49–67. doi: https://doi.org/10.1111/j.1467-9868.2005.00532.x.
- Zou, H. 2006. The adaptive Lasso and its oracle properties. Journal of the American Statistical Association 101 (476):1418–29. doi: https://doi.org/10.1198/016214506000000735.
Appendix A. Proof of Lemma 2.1
We partition Equation(3)(3)
(3) into terms that do and do not depend on μi. The first term in Equation(3)
(3)
(3) can be partitioned as follows:
(A1)
(A1)
Moreover, since the second term in Equation(3)
(3)
(3) can be partitioned as follows:
Consequently, Lemma 2.1 is proved, where ui is given by
Appendix B. Proof of Theorem 2.2
First, we rewrite Equation(5)(5)
(5) in non absolute form. Since
are the order statistics of
the following equation holds when
Thus, we have the following non absolute form of Equation(5)(5)
(5) :
From the above equation, we found that va is the x-coordinate of the vertex of the quadratic function and the minimizer of
is included in
. The piecewise function
has the following properties (the proof is given in Appendix D.1):
Lemma B.1.
The is continuous in
, that is,
and va is a monotonically decreasing sequence with respect to a.
From this lemma, we have the following lemma (the proof is given in Appendix D.2):
Lemma B.2.
Let and
be non negative values defined by
Then, either or
uniquely exists.
Lemma B.2 says that existing or
is a local minimizer. In addition, because
is a continuous function, the local minimizer is the minimizer of
Consequently, Theorem 2.2 is proved.
Appendix C. Proof of Lemma 2.3
From Equation(1)(1)
(1) , we have
Moreover, the second term in Equation(3)(3)
(3) can be partitioned as follows:
All pairs in the second term of the above equation are expressed as the following set:
Regarding this set, we have the following lemma (the proof is given in Appendix D.3):
Lemma C.1.
The following two sets are equal:
This lemma gives that
Consequently, Lemma 2.3 is proved, where is given by
Appendix D. Proof of lemmas in appendix
Proof of Lemma B.1
First, we prove that va is a monotonically decreasing sequence. The following equation holds:
where
Since
is a monotonically increasing sequence with respect to a. Thus, va is a monotonically decreasing sequence with respect to a.
Next, we prove that is a continuous function. The following equation holds about the term of
that depends on a:
Thus, we have
Consequently, Lemma B.1 is proved.
Proof of Lemma B.2
The following statement is true:
The fact says that only either or
exists.
Regarding the uniqueness of assume that
and
exist such that
and
and they satisfy
without loss of generality. Then, although
holds, this is in conflict with
Thus, we have a1 = a2.
Regarding the uniqueness of assume that
and
exist such that
and
and they satisfy
without loss of generality. Then, although
holds, this is in conflict with
Thus, we have a1 = a2.
Consequently, Lemma B.2 is proved.
Proof of Lemma C.1
First, we show that
Let be an element of the above LHS. Then, the following statement is true:
The leads
and
These results say and hence
Notice that
Hence, we have
Next, we show that
Let be an element of the above RHS. Then, the following statement is true:
Moreover, we found that because
Hence, we have
Consequently, Lemma C.1 is proved.