
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This contribution deals with a model of one-dimensional Bernoulli-like random walk with the position of the walker controlled by varying transition probabilities. These probabilities depend explicitly on the previous move of the walker and, therefore, implicitly on the entire walk history. Hence, the walk is not Markov. The article follows on the recent work of the authors, the models presented here describe how the logits of transition probabilities are changing in dependence on the last walk step. In the basic model this development is controlled by parameters. In the more general setting these parameters are allowed to be time-dependent. The contribution focuses mainly on reliable estimation of model components via the MLE procedures in the framework of the generalized linear models.
1. Introduction
The contribution presents a model of discrete time Bernoulli-like random walk with probabilities of the next step depending on the walk past. Namely, the steps of walk are Xt = 1 or 0, as a variant the walk with steps is considered. Probabilities are
starting from certain P1. It is assumed that these probabilities develop and depend on last walk steps making the walk a non-Markovian stochastic process. A practical inspiration of such walk type with steps 1, −1 comes from models of sport matches, for instance of tennis, and sequence of its games, or in finer or rougher setting, its balls or its sets. Similarly, walk with steps 1, 0 can model a series of events (e.g. failures, repairs) in a reliability study, the “step” 1 denoting an event occurrence, “step” 0 then means no event in time interval t. The latter case in fact corresponds to the discrete time recurrent events counting process model, where both event occurrence and absence changes future event probability. Thus, the models can be regarded as a simple discrete variants of “self-exciting” point processes, cf. Hawkes (Citation1971).
One set of studied random walk models, there with steps 1, −1, has been proposed in Kouřim and Volf (Citation2020), application to tennis matches modeling and prediction was presented already in Kouřim (Citation2019). For illustration, let us here recall the simplest form of such a model. Two parameters, the initial probability P1 and change parameter λ are given, both in (0, 1). The development of walk is described via the development of the probability of step “1”:
(1)
(1)
In such a model, after event “1” its probability in the next step is reduced by λ, therefore the model is called “success punishing.” A variant increasing
after the occurrence of event “1,” the “success rewarding” model, has
In the article of Kouřim and Volf (Citation2020) several more complicated model variants, with more parameters, were introduced and the properties of models studied. Their limiting properties were derived theoretically, while their behavior in small time horizon was examined graphically, as it could be expected that in a typical applied task the data would consist of a (sometimes quite large) set of not too long walks. Again, examples include data from a number of sports matches or records on reliability history of several technical devices during a limited time period. Notice also that from a sequence having a simple transformation
leads to a sequence with values
The models like Equation(1)(1)
(1) have an advantage that the impact of parameters λ to probability change is given rather explicitly. Further, the proofs of large sample properties (tendencies, limits) of walks as well as of the sequences of probabilities are quite easy, at least in the simplest model version, as shown in Kouřim and Volf (Citation2020). On the other hand, the computation of likelihood is complicated and the estimation of parameters difficult. In fact, the estimation procedures should use random search methods, approximate confidence intervals of parameters are then obtained by an intensive use of random generator.
That is why the present article introduces slightly different model form, where instead the transition probabilities directly their logits are changing. Thus, the model can be viewed as a case of logistic model and solved by standard MLE approach, yielding simultaneously asymptotic confidence intervals of parameters. Therefore, we shall concentrate here to practical aspects of the model, that is, to aspects of model parameters estimation as well as to model utilization. The question of easy and reliable estimation will be even more important when we allow for time-dependent parameters.
There exists a number of recent articles dealing with discrete random walks and time series. The article of Davis and Liu (Citation2016) contains a rather broad definition of such a process dynamics. Formally, our definition is covered as well, however, certain basic assumptions, for example, the condition of contraction, are not fulfilled.
The monograph of Ch. Weiss (Citation2018) offers a thorough overview of models for discrete valued time series, focusing also on discrete count data and categorical processes. Models are accompanied by a number of real examples. The problem of process prediction and the test of model fit is discussed as well.
The term “self-excited” discrete valued process is used quite frequently today, however in a slightly different sense, see for instance Moeller (Citation2016) dealing with discrete valued ARMA processes and with their regime switching caused by the process development (so called SETAR processes).
The rest of the article is organized as follows: Next section contains model formulation. Further, the method of the ML estimation in the framework of logistic form of the general linear models will be described and broadened to the case of time-dependent model parameters. Then the properties of obtained random sequences, not only of the process of observations but also of the process of probability logits, will be discussed. Model performance and its parameters estimation will be illustrated with the aid of randomly generated examples. An example with time-varying parameters will be included, too. Methods of both parametric and non-parametric estimation of these functional parameters will be proposed and their performance checked. Finally, a simple real data case, consisting of several series of recurrent events – failures and repairs, will be presented. The solution is accompanied by a graphical method of testing the model fit.
2. Model description
Let transition probabilities be expressed in a logistic form, namely that is,
and let their development be described via the following development of at, starting from an initial a1:
In the case of steps Xt = 1 or 0:
(2)
For the walk with steps Xt = 1 or -1:
Parameters as well as a1 can attain all real values (though values far from zero are not expected in real cases), hence it is quite natural to test whether they are significantly different from zero, or whether they are positive (negative), whether c1 = c2, and so on. Notice also that
reduces the probability of success
after Xt = 1, while the value of c2 shows the reaction of probabilities to the opposite result (0 or −1).
Further, it is observed that the model can be re-parametrized, in case 1. Using parameters c2 and in case 2. with
3. Log-likelihood and the MLE
For the case
The likelihood function for one process of length T equals
As a rule we observe N processes, that is, their outcomes
For the case
Now, for one process
In both variants the model can be treated in the framework of logistic regression model. Then, both the 1-st and 2-nd derivatives of L are tractable and the MLE as well as the asymptotic variance of estimates can be computed with the aid of a convenient numerical procedure (e.g. the Newton–Raphson algorithm). In fact, these algorithms are included standardly in data-analysis software packages, mostly as a part of methods for generalized linear models. Numerical examples presented here will utilize the Matlab function glmfit.m.
In the sequel we shall deal just with the first model type considering the random walk with steps 1 or 0.
4. On properties of sequences at and Pt
In Kouřim and Volf (Citation2020) some interesting properties of model (1) have been derived. It focused on the development of the random sequences of probabilities Pt as well as of sums Now, we shall discuss the behavior of random sequences of Pt and their logits at of model (2). Let us summarize here some of its basic properties:
It is seen that
at is a Markov sequence, as
On the other side, the sequences Xt and St are not Markov, while the bi-variate processes (Xt, at) and (St, at) have the Markov property.
Further, from i) it follows that the return of at to some of previous values could be impossible (for instance in the case of irrational
From i) it also follows that when both c1, c2 are positive (negative),
4.1. A model with one parameter
Let us mention here also a special case with unique parameter Then
k is a random integer from
When c < 0, then the sequence reduces the probability of repetition of preceding result, the model is then a variant of the “success punishing” model (1). The opposite case occurs when c > 0. In Kouřim and Volf (Citation2020) dealing with model (1), certain closed formulas for limit of expectations and variances E
Var
were derived. Though now the limit behavior seems to be quite similar, we are not able to describe it precisely. On the other hand, it is easy to compute transition matrices and then to follow the development of distributions of both at and Pt for given c and initial a1.
4.1.1. Case with c < 0
shows an approximation of limit distributions of when
separately for even and odd t, in the case
More precisely, the figure shows the distribution of Pt after 400 and 401 steps, respectively. In both cases, final EPt=0.500002, VarPt=0.003087, the change of distributions in the last 2 steps was already smaller than
Figure 1. Approximate limit distribution of Pt when
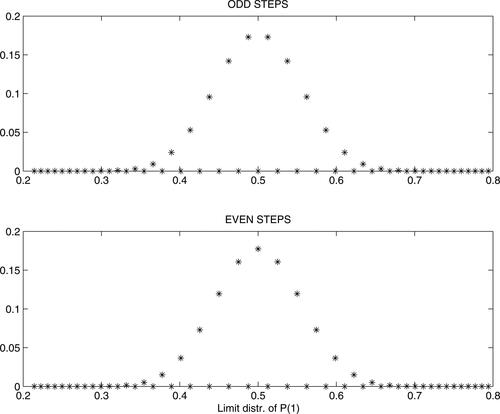
Thus, the figure indicates that both stationary distributions are centered around 0.5 (hence, corresponding limit distributions of at have centers around zero). Further, it was revealed that the limit distribution does not depend on initial a1, however it depends on c: though the mean still tends to 0.5, the limit variance is smaller for c closer to zero.
4.1.2. Case with c > 0
shows the limit behavior of distribution of Pt in the case of positive parameter c. It is seen that now the picture is quite different, the figure indicates that the limit distribution is “unproper,” equal to a Bernoulli distribution with certain such that
while
Notice that it corresponds to at tending to
with the same probabilities. Moreover, it was revealed that
depends on both a1 and c. The upper subplot of shows the distribution of Pt in the process starting from
and with c = 0.05, after 1000 steps (the limit behavior of the sequence with odd and even steps is comparable). In fact, as it is possible to work computationally just with finite matrices and domains of values, we set values
as absorbing states. Regarding the domain of Pt, absorbing states were then
Final distribution had E
(in fact it is the estimate of probability
), Var
while E
E
(this could be taken as an indication how close we are already to Bernoulli distribution).
Figure 2. Approximate limit distribution of Pt: Above for below for
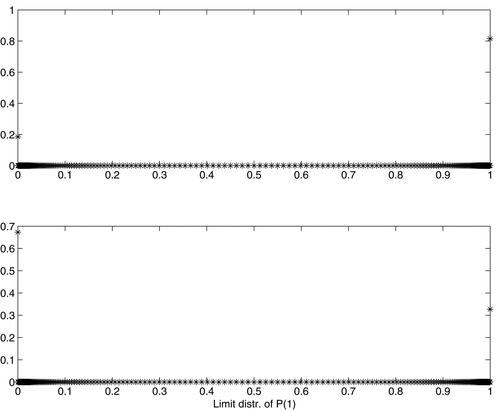
The lower subplot of shows the same for the case with Now, after 1000 steps and with absorbing states constructed as above, we obtained E
Var
while E
E
5. Time dependent parameters
In many instances the impact of walk history to its future steps could be changing during observation period and therefore the time-dependent parameters should be considered. Then
as well. It opens a question of their flexible estimation. The problem is solved quite similarly as in other regression model cases: Either the parameters-functions are approximated by certain functional types (polynomial, combination of basic functions, and regression splines) or constructed by a smoothing method, similar to moving window or kernel regression approach. The method described in Murphy and Sen (Citation1991) is of such a type and concerns the Cox regression model. All these approaches can again be incorporated to the logistic model form, just the number of parameters will be larger. For instance, in the following examples we shall use cubic polynomials for both estimated “parameters”
(hence
will also be a cubic polynomial), each will be given by four parameters of cubic curve.
Further, in the last example the non-parametric moving window ML method was used as well. The estimation procedure started from an initial estimate of parameter a1 (obtained e.g. from constant model or polynomial model described above). Then both and d(t) were estimated like constant parameters, however with data weighted by a Gauss kernel centered sequentially at M time points
selected inside
In such a way a preliminary rough estimates of values
were obtained. After that, these rough estimates were smoothed secondary, again with a Gauss kernel, to obtain smooth curves of
given at all
In the end, the final ML estimate of a1 with
already fixed was computed. The procedure result depends on the choice of “window width” parameter, that is, the standard deviation of Gauss density used as the kernel parameter. By the way, even the Matlab function glmfit.m is able to work with different weights assigned to each data-point.
Another often used method dealing with time-dependent parameters is based on the Bayes approach, it treats each such time-evolving parameter as a random dynamic sequence with a prior model of its development (Gamerman and West Citation1987).
6. Numerical examples
The objective is, first, to study the behavior of processes, and, second, to examine how well the MLE performs in the case of constant parameters as well as in the case when they are time-evolving.
6.1. Artificial data
In the first example the data were generated from the model with initial and constant parameters
Two cases were compared, in the first one just 20 walks of length 20 steps were generated. The MLE yielded the following estimates (their standard errors based on approximate normality of the MLE are in parentheses):
hence
It is seen that even for this case with small number of observations the estimates are quite reasonable, except that the standard error for a1 is rather large (P-value of the test of nullity of a1 equals 0.0610).
In the second attempt with the same model, 100 walks, each with 100 steps, were generated. Now the results of the MLE are much more precise:
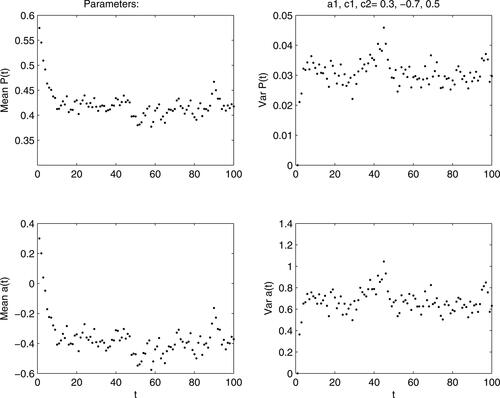
then shows the development of at and Pt, namely their averages and variances from generated 100 walks. It is seen that both stabilize rather quickly, as a consequence of negative c1 and positive c2 reducing after event Xt = 1 and increasing it after Xt = 0.
Figure 3. Sample means and variances of at and Pt.
6.2. Parameters as functions of time
In the next simulated example functional “parameters” were considered. Namely, walks had again length 100 steps, the first
was increasing exponential curve, the second
was decreasing S-curve. Again, 100 such walks were generated. Functions
and
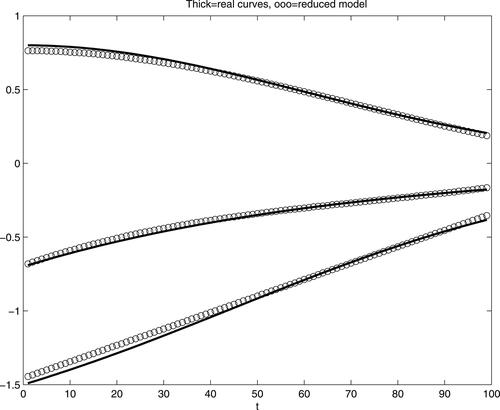
were estimated as cubic polynomials, in the logistic model framework. Results, a sufficiently good approximation to real curves, are seen from . Initial a1 was estimated as −0.1464, with P-value of its nullity test 0.1468 (hence, its nullity cannot be rejected). These results, however, correspond to the full model, some parameters of both cubic curves were not significant, therefore a sequential reduction of the model was performed. Namely, at each reduction step one of the components with non-significant parameters (i.e. the one with the largest p-value of the test based on the MLE asymptotic normality) was removed from the model. Thus, the final model, with all components significant, had functions
and
The values of estimates were
(p-value = 0.0283), further
all corresponding p-values were already quite negligible. shows the results of this last model.
Figure 4. Functional parameters (thick lines, from above ) and their estimates with complete cubic functions (circles).
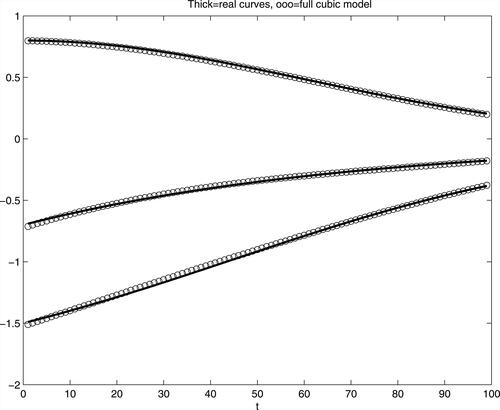
Figure 5. Functional parameters (thick) and their estimates via reduced cubic model (circles).
6.3. Real data case
The following data are taken from Exercise 16.1 of Meeker and Escobar (Citation1998). The data are records of problems (failures, troubles) with 10 computers, each followed for 105 days. The table displays the computer number and then days of reported and repaired troubles.
401: 18, 22, 45, 52, 74, 76, 91, 98, 100, 103.
402: 11, 17, 19, 26, 27, 38, 47, 48, 53, 86, 88.
403: 2, 9, 18, 43, 69, 79, 87, 87, 95, 103, 105.
404: 3, 23, 47, 61, 80, 90.
501: 19, 43, 51, 62, 72, 73, 91, 93, 104, 104, 105.
502: 7, 36, 40, 51, 64, 70, 73, 88, 93, 99, 100, 102.
503: 28, 40, 82, 85, 89, 89, 95, 97, 104.
504: 4, 20, 31, 45, 55, 68, 69, 99, 101, 104.
601: 7, 34, 34, 79, 82, 85, 101.
602: 9, 47, 78, 84.
Thus, from our point of view, 10 walks, each of length 105 time units, were observed. Steps Xt = 1, representing the events = reported troubles, were rather sparse, just 91, in the rest of days Xt = 0, that is, nothing has occurred. Nevertheless, it could be expected that the wear of devices was increasing.
First, the model with constant parameters was fitted. The results were the following (again with asymptotic standard deviations in parentheses):
hence
It is seen that though non-significantly, which means that after a failure and repair the probability of further failure decreased slightly. On the other hand, positive c2 means that the probability of failure increases in time, linearly in the framework of model with constant parameters. Achieved maximal log-likelihood value equaled −295.54.
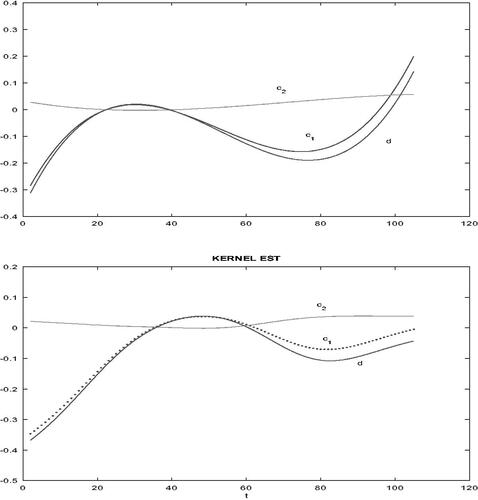
In the next attempt, the model allowing cubic dependence of both on time was applied. Its maximum likelihood estimate was obtained, however the most of the parameters were not statistically significant, that is, they were close to zero and corresponding normal tests of their nullity had large p-values. Again, the model was then reduced sequentially, at each step the parameter with the largest (and larger than 0.1) p-value was eliminated. Quite astonishingly, this procedure lead to a rather plain model with
and function d(t) omitted, namely
corresponding p-values were
It means that in fact
an interpretation is that the influence of events Xt = 1 is rather negligible and the probability of such events is increasing (slightly, but significantly) in time. In fact, its logit a(t) increases cubically, as from expression (2) we have now that
On the other side, while the maximum likelihood corresponding to the full cubic model was −292.49, the value achieved by the reduced model was slightly smaller, −293.86.
Finally, the moving window method was utilized, too. shows both the full cubic model in its upper subplot and the mowing window estimates, in lower subplot. It is seen that they are quite comparable. Final estimate of parameter the maximum of log-likelihood was −293.42. It is seen that the results of all these models, including the model with constant parameters, were quite comparable in terms of maximal log-likelihood. On the other side, certain differences of their fit can be traced from the following graphical analysis.
Figure 6. Estimates of model functions. Above: full cubic model, below: moving window estimates.
6.4. Graphical test of model fit
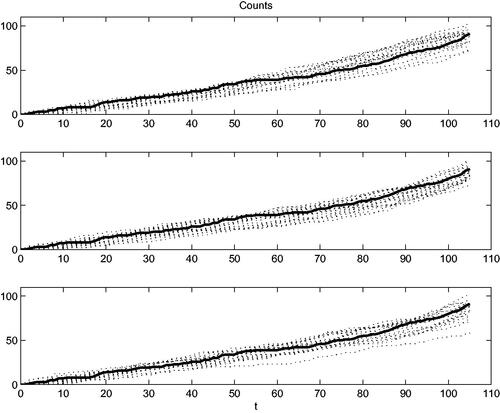
In general, the objective of goodness-of-fit tests is to decide whether the model corresponds to observed data. There are several possibilities, consisting mostly of the comparison of certain characteristics of observed data with the same characteristics derived from the model. We decided to consider, as the characteristics suitable for graphical comparison, the cumulated processes of steps of all walks together. In our case it equals which is in fact the process counting observed events, the discrete-time counting process.
A good model should be able to generate comparable sequences of events. Therefore, when new walks (the same number and length) are generated from the model, their aggregated counting process should be similar to process observed. When such a generation is done many times, a “cloud” of counting processes is obtained. In the graphical test form, this cloud of processes generated from the model should be around the process obtained from data. It is illustrated on the next . All three models presented above were compared with real data. It is seen that the constant model (upper plot) underestimates (from the beginning) and overestimates (for larger times) the real process development. The other two models perform better, the full cubic model’s fit (middle plot) does not seem to be worse than the non-parametric model in the lower plot.
Figure 7. Thick curve = real observed counting process of failures. Clouds of dotted curves = counting processes generated from estimated models. Top: constant model, middle plot: full cubic model, bottom: model from mowing window estimates.
7. Concluding remarks
Standard non-parametric estimator in the count data setting is the Nelson-Aalen estimator of the cumulative hazard function. In the case of our real data example it is given by observed counting process divided by the number of objects, as all objects are “at risk” during the whole observation period. However, such an estimator does not take into account possible dependence of future risk on objects history. It could be incorporated via a regression model modeling the hazard rate change after occurred event. Hence, hazard function is in fact a random function.
Models proposed in the present article offer an explicit description of such an impact of process history to actual count probabilities. A generalization may consist of considering a longer memory, we have explored just models with memory 1. Further generalization could include an influence of covariates to probability logits. The model’s form makes it easy to model using logistic regression. On the other hand, from this point of view certain observable events from the process history could be taken as covariates, too. In models studied here, this role is played by the last preceding process value.
Statistical analysis of processes of recurrent events has, moreover, to take into account possible heterogeneity of studied objects, in particular when dealing with medical, demographic or also with economic data (see e.g. Winkelmann Citation2008, Ch. 4). In such a case, an additional random effect variable (called also the frailty variable) should be added to the logit model. Procedure of estimation then uses an alternation of two steps estimating frailty values and the rest of model, respectively. Thus, the concept of heterogeneity offers another way how the models studied in the present article could be enriched.
Additional information
Funding
References
- Davis, R. A., and H. Liu. 2016. Theory and inference for a class of observation-driven models with application to time series of counts. Statistica Sinica 26:1673–707. doi:10.5705/ss.2014.145t.
- Gamerman, D., and M. West. 1987. An application of dynamic survival models in unemployment studies. The Statistician 36 (2/3):269–74. doi:10.2307/2348523.
- Hawkes, A. G. 1971. Spectra of some self-exciting and mutually exciting point processes. Biometrika 58 (1):83–90. doi:10.1093/biomet/58.1.83.
- Kouřim, T. 2019. Random walks with memory applied to grand slam tennis matches modeling. In Proceedings of MathSport International 2019 Conference (e-Book). Propobos Publications, 220–7.
- Kouřim, T., and P. Volf. 2020. Discrete random processes with memory: Models and applications. Applications of Mathematics 65 (3):271–86. doi:10.21136/AM.2020.0335-19.
- Meeker, W. Q., and L. A. Escobar. 1998. Statistical methods for reliability data. New York: Wiley.
- Moeller, T. A. 2016. Self-exciting threshold models for time series of counts with a finite range. Stochastic Modeling 32:77–98.
- Murphy, S. A., and P. K. Sen. 1991. Time-dependent coefficients in a Cox-type regression model. Stochastic Processes and Their Applications 39 (1):153–80. doi:10.1016/0304-4149(91)90039-F.
- Weiss, C. H. 2018. An introduction to discrete valued time series. New York: Wiley.
- Winkelmann, R. 2008. Econometric analysis of count data. Berlin: Springer.