
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The Poisson point process plays a pivotal role in modeling spatial point patterns. One of its key features is that the variance and the mean of the total number of points in a given region are equal, making it unsuitable for modeling point patterns that exhibit significantly different mean and variance. To tackle such point patterns, we introduce the class of Conway-Maxwell-Poisson point processes. Our model can easily be fitted with a logistic regression, its point counts in different regions are correlated and its log-likelihood in any subregion can be easily extracted. Both simulations and real data analyses have been carried out to demonstrate the performance of the proposed model.
1 Introduction
As the cornerstone of spatial point processes, the Inhomogeneous Poisson Process (IPP) plays a pivotal role in modeling spatial point patterns in a wide range of research areas such as forestry and plant ecology (Thompson Citation1955), astronomy (Babu and Feigelson Citation1996), epidemiology (Waller and Gotway Citation2004), geology (Connor and Hill Citation1995), and wireless networks (Andrews et al. 2010). The IPP consists of a Poisson number of independent and identically distributed (iid) points over a bounded observation region, hence, by assumption, it has two features: the mean and variance of the total count in any subregion are equal (equi-dispersion) and the counts of points in disjoint subregions are independent. In real-world applications, few point patterns exhibit both of these features. When the variance-to-mean ratio is greater than one, the negative binomial point process discussed in Diggle and Milne (Citation1983) can be used but there are few choices of models that can handle point patterns with all possible variance-to-mean ratios.
To model count data, Conway and Maxwell (Citation1962) proposed a Conway-Maxwell Poisson (CMP) distribution that is capable of accommodating both overdispersion (variance-to-mean ratio bigger than one) and underdispersion (variance-to-mean ratio smaller than one). In contrast to the equi-dispersion feature of the Poisson distribution, the CMP distribution includes an extra parameter controlling dispersion which can be tailored to meet the variance-to-mean ratio of the count data. The CMP distribution has also been proposed as a generalization of the Poisson distribution in the context of generalized linear model regressions (Sellers and Shmueli, Citation2010), yielding a wide range of applications. A comprehensive overview regarding the CMP model was provided by Sellers, Borle, and Shmueli (Citation2012). MacDonald and Bhamani (Citation2020), Alqawba and Diawara (Citation2021), Zhu (Citation2012), and Melo and Alencar (Citation2020) extended the CMP to new classes of time series models of count data that is equidispersed, underdispersed, and/or overdispersed. Wu, Holan, and Wikle (Citation2013) modeled spatiotemporal count data using multivariate conditionally independent CMP distributions with intensity process governed by a dynamical spatiotemporal process. Li and Dey (Citation2022) proposed a similar model of COVID-19 mortality in given states in terms of spatial and temporal covariates. All these work have in common that they model aggregated count data, whether it is counts over time or spatiotemporal counts. In contrast, in this work, we will extend the CMP distribution to a CMP point process which can be used to model spatiotemporal point pattern data.
Previous research has attempted to develop a point process model such that the total number of point counts within any given interval follows the CMP distribution, and has stationary and independent increments. Zhu et al. (Citation2017) proposed a homogeneous counting process on the real line by specifying that the numbers of events within unit intervals for
are independent and follow the CMP distribution. However, Proposition 1 in Appendix proves that the CMP process in Zhu et al. (Citation2017)’s work cannot exist unless it is a homogeneous Poisson process. To remedy the problem faced by Zhu et al. (Citation2017), we develop a class of CMP processes (
) that can model random point patterns in both space and time. Moreover, our model accommodates homogeneous or inhomogeneous intensity that are dependent on space and time, in contrast to the strictly time-homogeneous framework of Zhu et al. (Citation2017). We also introduce a quick and reliable inference procedure that eliminates the need for computation the challenging normalizing constant present in the CMP’s probability mass function. Compared to the spatiotemporal CMP models that divide the space into cells and regress the cell counts in Wu, Holan, and Wikle (Citation2013), our
models the rate of occurrence of events directly, without aggregation, by treating the data as arising from a point process. The
also caters for dependence between the counts of points in disjoint subregions (see Proposition 2) and it is easy to extract the likelihood for the point patterns restricted to any subregion in order to make inference on subregions of interest (see Proposition 3). In case studies, we demonstrate that the CMP process serves as a solid model of replicated spatial point patterns, which are commonly observed in practice (Chapter 16 of Baddeley et al. Citation2014).
The article is organized as follows. In Section 2, we elaborate on the definition of the and set up its inference procedure. In Section 3, numerical simulations are carried out to demonstrate its performance. To illustrate its applications, we apply the new point process in Section 4 to the analysis of daily bike trips data in Chicago, to sightings of the wildflower Arctotheca calendula in South-East Australia, as well as to records of flooding in the Rio Negro river. The article concludes with a discussion in Section 5.
2 Methodology and inference
2.1 Methodology
Conway and Maxwell (Citation1962) defined a CMP distribution by its probability mass function
(1)
(1) where
are parameters, and
is the normalizing constant. The level of dispersion can be conveniently characterized by the dispersion parameter ν, with ν = 1,
, and
corresponding to equi-dispersion (i.e., the Poisson distribution), overdispersion, and underdispersion, respectively. The CMP distribution is thus more flexible than the Poisson distribution in capturing complex behaviors exhibited by count data in applications (Sellers, Borle, and Shmueli Citation2012; Mannering and Bhat Citation2014).
General spatial point processes in a region W can be generated by first drawing the number of points N from a probability mass function (hereafter, pmf) f on . Then, conditional on N = n, the point patterns are sampled according to a conditional probability density function
on W (see Kroese and Botev Citation2015 and Proposition 5.3.II in Daley and Vere-Jones Citation2003). For a given probability density function (hereafter, pdf) μ on W, an IPP on W is obtained if
(i.e., f a Poisson pmf with mean λ) and points are drawn independently according to μ. The intensity of the IPP, defined as
, represents the average number of points per unit area. As some of the more remarkable properties of an IPP, the number of points that fall in a set
is again Poisson distributed and the numbers of points in disjoint sets
are independent.
Here we propose a class of Conway-Maxwell-Poisson processes (hereafter, CMPP) by taking f as the CMP pmf Equation(1)(1)
(1) with parameters
and, just as in the IPP setting, drawing points on W independently with pdf μ. Thus, in this more general case, there are two real parameters λ and ν and one functional parameter μ. As in the IPP setting, we set
in our proposed model. However, it is important to note that Λ is in general not the intensity of CMPP, that is, the average number of points per unit area, since λ is in general not the mean of the CMP distribution. We shall delve into this in more detail later on.
This leads us to calling Λ a quasi-intensity function (see Proposition 4 in Appendix for a computation of the intensity). It is easy to check that our proposed is completely parametrized by ν and the function Λ (indeed, the first parameter of the CMP is obtained by integrating both sides of the equation defining Λ over W, yielding
, and the conditional pdf of the points is obtained as
). A
is therefore denoted by
. We observe that the average total number of points in a
is not in general
, but is the mean of the CMP distribution with parameters
and ν, which does not in general have a closed form.
In summary, we draw samples of a , with dispersion parameter ν and quasi-intensity function Λ, in the following two steps:
1. generate the total number of points N from a CMP distribution with parameters and ν;
2. given the observed value N = n, draw n points independently with pdf .
Remark 1.
(i) The IPP is a special case of the in which ν = 1. (ii) If Λ is a constant and W is an interval, then the
has stationary (but in general non independent) increments, achieves the goal of Zhu et al. (Citation2017) and is tractable. (iii) The
point process can be used to model either positive or negative correlation between the counts falling into two disjoint regions; see Proposition 2 in Appendix. The correlation becomes zero when ν = 1, which is a consequence of point (i) above, namely that the
reduces to the IPP model.
The quasi-intensity function Λ in practice is assumed to be influenced by spatial or environmental covariates , such as elevation, temperature, or rainfall at a location s. A common way to model
is through a log-linear model
(2)
(2) where
and the vector
is the regression coefficient for the corresponding covariates. The quasi-intensity Λ governs how the spatial points are distributed, and is also associated with the pmf f via
in our definition. This latter property in particular means that, all else being equal, the larger the quasi-intensity, the higher the average number of points. The log-linear modeling of the quasi-intensity indirectly affects the average total count modeling since
which reduces to a log-linear model on λ if the spatial covariates are constant. Some of the more recent literature has considered other link functions, see, for example, Ribeiro et al. (Citation2020), Huang (Citation2017), and Weiss, Zhu, and Hoshiyar (Citation2020). In any case, a log-linear model of λ was found to be useful and have reasonable properties in Sellers, Borle, and Shmueli (Citation2012).
The Janossy intensity of the point process (Daley and Vere-Jones Citation2003, Section 5.3) is the function j such that
is the probability that there are n points around
. In point process theory, this function plays a role analogous to that of the probability density function of a random variable. It can be shown that the proposed point process has Janossy density given by
(3)
(3)
Denoting the mean of f by , we show in Proposition 4 that the true intensity function ϱ of the
is given by
The quasi-intensity function Λ equals the true intensity function ϱ if and only if , that is, N is a Poisson random variable.
2.2 Inference
In practice, we shall make inference on K > 1 independent samples, where each sample is a with fixed dispersion parameter ν and sample varying intensity given by
(4)
(4) for a unique sample-independent
. The sample-varying intensity allows us in practice to accommodate sample-dependent (for example time-varying) covariates. We use
to denote the data corresponding to the k-th sample of the point process. From Equation(3)
(3)
(3) , the log-likelihood of K independent samples is
(5)
(5)
Although the log-likelihood given by Equation(5)(5)
(5) allows us to estimate the unknown parameters
and ν, the intractable constants
render it an impractical way to make statistical inference. A wide range of inference techniques have been developed in the statistical point process literature. We shall use the technique developed in Baddeley et al. (Citation2014) to estimate
and ν.
The method of Baddeley et al. (Citation2014) hinges on the Papangelou conditional intensity π of the point process (Daley and Vere-Jones Citation2008, Definition 10.4.I). In short, the Papangelou conditional intensity π is a function such that is the probability that there is a point around a location z conditional on the configuration
(outside of
). Contrary to the Janossy intensity, the Papangelou conditional intensity gives information on the conditional probability of finding new individuals, given an existing configuration. The Papangelou conditional intensity of our point process is given by
(6)
(6) where
stands for the indicator function of a set A. By assuming the log-linear form for
in Equation(2)
(2)
(2) , the Papangelou conditional intensity π can now be written in the form of
(7)
(7)
for a vector of parameters and a function t, with
and
(8)
(8)
Baddeley et al. (Citation2014) imply that, given the log-exponential form Equation(8)(8)
(8) , inference can be done by running a logistic regression with an offset term. Using point process fitting software, it suffices to run the logistic regression with an additional artificial covariate with value
. This is particularly easy to do by using the spatstat (Baddeley, Rubak, and Turner Citation2015) package in the R programming language. Since the technique developed in Baddeley et al. (Citation2014) is based on a logistic regression, it is straightforward to generalize it to independent point process samples with log-likelihood Equation(5)
(5)
(5) .
In addition, we summarize the key points to implement the logistic regression for the proposed by hand as follows.
Generate m dummy points, say
, independently from the sample, where m is a realization of a random variable with known mean M.
Compute
Estimate the unknown parameter
In order to set up the logistic regression, we have used the spatstat (Baddeley, Rubak, and Turner Citation2015) package in R. When estimating parameters of the , we have reported parametric bootstrap confidence intervals which have been considered for example in Section 8.3 of Baddeley and Turner (Citation2000). Asymptotic confidence intervals can also be estimated by the technique introduced in Coeurjolly and Rubak (Citation2013) (see also Section 4 and the appendices of Baddeley et al. Citation2014). These latter confidence intervals have been reported when doing inference for the IPP.
3 Numerical simulations
In this section, we demonstrate the performance of the on simulated datasets. The numerical studies have been carried out using the R language (R Core Team, 2019). The CMP random variables were simulated using the COMPoissonReg package in R (based on Minka et al. Citation2002) and the logistic regression was implemented via the spatstat package in R. In all the numerical simulations, we have used 1, 000 dummy points when implementing the inference method of Section 2.2.
3.1 Homogeneous study
We consider 200 iid distributed samples from a distribution with constant quasi-intensity Λ and dispersion parameter ν on an observation window
. Since in this simple case there is no spatial inhomogeneity, a CMP model on the total point counts would yield similar results. We study R = 200 independent replications of this iid sequence, so that we draw
samples from the
distribution in total. For each of the R replications, we construct an estimate
by our inference method. We then compute the 95% bootstrap confidence intervals by sampling Nb = 500 draws from the fitted model, with parameters
. Our focus is then on the mean parameter estimates, obtained by averaging the estimates over the R replications, and the coverage probabilities, that is, the proportion of confidence intervals which contain the true values of the parameters.
In the following analysis, we consider six different pairs of parameters :
, and
. These values of ν are chosen to represent a range of different dispersions, and
is chosen so that in each sample the average number of points is 10 for the first three pairs of values, and 2 for the remaining three pairs. The results of our analysis are shown in , where the mean estimates of the parameters and the coverage probabilities are provided. We see in that the mean estimates and coverage probabilities are reasonably accurate. The coverage probability does not always reach the expected 95%, especially when
or when point count is low, perhaps due to limitations of our bootstrapping method.
Table 1 Estimates of parameters for the homogeneous study.
We now focus on one set of values, and we consider some properties of the joint estimator. We produce R = 200 simulated replications, each containing 200 iid samples of a
on an observation window
. In each of the R replications, we estimate the unknown parameters
and ν according to the inference method described in Section 2.1. The resulting pairs of estimates
are then plotted on the left-hand side of . We find that estimates of
and ν are linearly associated.
Fig. 1 Left-hand side: Distribution of estimates . The true value is
. Right-hand side: Contour plot of the estimation of the mean of a CMP distribution (for 10, 000 Monte-Carlo draws), for different values of Λ and ν.

This linear association was found in Zhu et al. (Citation2017) and partly justifies a reparametrization of the CMP proposed in Ribeiro et al. (Citation2020). In order to further illustrate this linear association, we show a contour plot on the right-hand side of of estimates of the mean of a CMP distribution for values around . We observe that in this range, the mean of a CMP distribution is increasing in Λ and decreasing in ν. Hence, for a given estimate of the mean, a large estimate of Λ would coincide with a large estimate of ν. Indeed, we find that the values of our estimator
are distributed around the curve corresponding to the sample mean 10.
3.2 Inhomogeneous study
In this section, we consider a sequence of independent inhomogeneous samples, coming from a , where
depends on a spatiotemporal covariate
at location
according to
(9)
(9)
Here β0 is the intercept, β is the regression coefficient, and represents a seasonally varying temperature gradient defined as
with y(s) the y-coordinate of location s. The true parameter values are given by
. We have also considered a collection of 50 independent samples, and R = 100 replications have been used in the simulation. The point locations distributed according to Equation(9)
(9)
(9) have been drawn by rejection sampling. Similarly to the analysis carried out in the previous section, we construct mean parameter estimates, along with coverage probabilities associated with parametric bootstrap confidence intervals with Nb = 200 bootstrap samples. The results are presented in .
Table 2 Estimates of parameters for the inhomogeneous study.
As in the homogeneous study, the results in show that the inference works well for the inhomogeneous case. The mean parameter estimates are particularly close to the true values; this is due to the fact that our temperature covariate varies strongly between samples, allowing for a highly accurate fit.
In order to evaluate its performance on large datasets, we also present in the results for the parameters . This corresponds to an average of more than 5, 000 points per sample, that is, over 500, 000 spatial points in total. We reduced the number of bootstrap replications to Nb = 100 to make the computation time more manageable. The mean parameter estimates and coverage probabilities are excellent. The mean estimates are much more precise than those in thanks to the large amount of data used in this case.
Table 3 Estimates of parameters for the inhomogeneous study on a large dataset.
Table 4 Estimate of the Pearson correlation coefficient between point counts in two neighboring subregions.
3.3 Correlation of point counts
In this subsection, we illustrate point (iii) in Remark 1. We consider a point process with quasi-intensity Λ = 1 (constant) and different values of ν on an observation window
. We define two different subregions
and
. The following table shows the estimates of the Pearson correlation coefficients over 106 samples between point counts in W1 and W2 along with the corresponding asymptotic 95% confidence intervals (CI). We clearly observe that point counts are positively correlated when
, negatively correlated when
, and are independent when ν = 1 (recall that this last case corresponds to the Poisson point process).
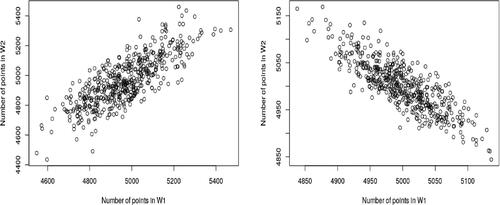
We now illustrate this finding by looking in detail at three possible values for ν, choosing in each case Λ so that the average number of points per sample is equal to 104. In , we show the number of counts in two subregions W1 and W2 with 500 independent replications of the model. On the left side panel of , we choose , in which case the point counts in W1 and W2 are expected to be positively correlated. The two point counts are clearly positively correlated with a 95% CI of
and we reject the hypothesis of zero correlation with p-value
. On the right side panel of , instead, we choose
and the two point counts are clearly negatively correlated (95% confidence interval of
and we reject the hypothesis of zero correlation with p-value
).
Fig. 2 Scatter plots of the total number of individuals in two subregions W1 and W2 for the . The left panel shows the result for the parameters
with positive relation; the right panel corresponds to
with negative relation. The number of replications is 500.
We next consider a Poisson point process with the same average number of points as in the previous two cases of , and the scatter plot of the total number of counts in the two regions is given in . The 95% CI of the Pearson correlation coefficient for the Poisson process is estimated as (with p-value 0.39), indicating that there is no strong evidence to reject the hypothesis of no correlation between point counts. This confirms that the IPP does not exhibit positive or negative correlation of point counts between different regions as does the
.
Fig. 3 Scatter plots of the total number of individuals in two subregions W1 and W2 for the Poisson point process with intensity . The number of replications is 500.
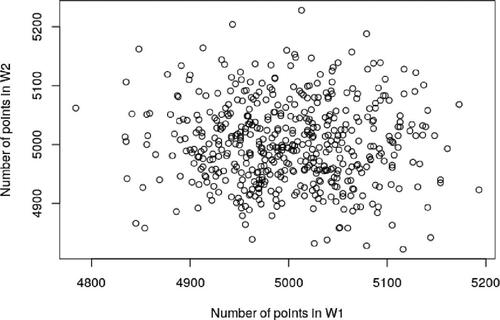
Another feature of these figures is that they show under or over dispersion of point counts compared to the Poisson point process. It can be seen from that when the range of point counts in each region is roughly
, and the range is about
when
. However in the Poisson case in , we observe a range
which is between the two ranges above. In other words, compared to the Poisson point process, point counts are overdispersed when
and underdispersed when
. This is a characterizing feature of the CMP distribution Equation(1)
(1)
(1) which drives the number of points of our CMPP.
4 Real case study
In this section, we study three replicated spatiotemporal point patterns. We start with the analysis of trips made using the bike-sharing app Divvy in Chicago, Illinois, United States. The purpose of this study is to provide a simple model of the number and locations of bike rides, and their dependency on some spatial and temporal variables. Our second case study consists in the locations of sightings in South-East Australia of Arctotheca calendula, commonly known as capeweed. Our purpose in this second example is to disentangle the environmental drivers of the distribution from the observer bias effect. In both of these studies, we shall highlight the important role of the dispersion parameter ν in understanding and studying these datasets. Finally, we study records of flooding of the Rio Negro river in Manaus, Brazil. The corresponding data are underdispersed, indicating some regularity in flooding occurrences that is not properly captured by an IPP model.
4.1 Divvy rides
The dataset that we use has been made freely available by the City of Chicago, and can be obtained from https://data.cityofchicago.org. We consider the location of the start of each trip made on the Divvy app between 11:00:00 AM and 11:00:59 AM on every day between 1 February 2019 and 31 May 2019. The starting time is arbitrary, and we chose a single minute time interval to avoid duplicate points between samples. Due to missing data points, we remove the five days from 23 May to 27 May. We assume that the starts of trips on each day are independent, and the number of independent samples is 115. Although the locations are on a fixed grid of bike stations, less than 10% of the 500 points are duplicates and so we assume that they are continuously distributed.
Temperature and elevation are both thought to be important in explaining the distribution of locations. Indeed, all else being equal, we expect there to be more bike rentals on days where the weather is nice, and in locations that are at a high elevation. Thus, we model the locations as 115 independent draws of a with quasi-intensity on the k-th day given by
(10)
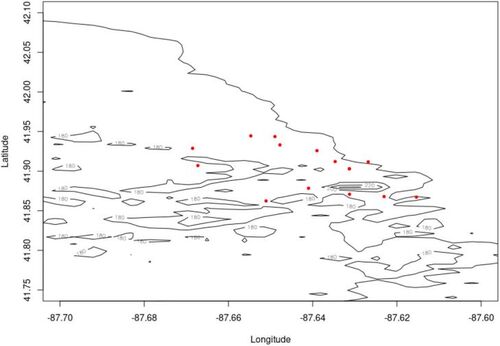
(10) where x(s) is the elevation at a given location s and t(k) is the air temperature at 11 AM on the k-th day. The Digital Elevation data used is in a 30 m spatial resolution and was obtained from the Alaska Satellite Facility. The temperature covariate was obtained from the National Data Buoy Center, and is the ambient temperature at station CHII2 - Harrison-Dever Crib, Chicago, Illinois. The air temperature is recorded at the station every 10 minutes. It can be freely obtained from https://www.ndbc.noaa.gov/station_history.php?station=chii2. To illustrate the dataset, we are working with, we plot in the locations of the points on 18 May along with a contour plot of the elevation covariate. In implementing the inference method described in Section 2.2, we have used in total 1, 000 dummy points.
Fig. 4 Spatial points on 18 May along with a contour plot of the elevation covariate.
In the null model in which there is no dispersion (ν = 1), the locations are distributed as independent draws of IPP random variables with intensity given by Equation(10)(10)
(10) . The results for the
model are reported in while the ones for the null Poisson model are shown in . The 95% bootstrap confidence intervals were computed with 1000 draws from the fitted model. In both models, we find a positive value for
, signalng that a higher elevation is associated with a larger intensity. Indeed, people tend to start their trips at higher elevations and bike downhill. We also observe a positive
, indicating the expected positive association of the intensity of bike rides with temperature. Although the signs of the regression coefficients are comparable between both models, their magnitudes are not (since they model on the one hand a quasi-intensity and on the other an intensity). An analysis following Section 3.3 of the point counts in disjoint regions shows a ubiquitous and statistically significant positive correlation between point counts. For example, if we split the region in two along the y-axis, we estimate a Pearson correlation of point counts of 0.52, with rejection of the null correlation hypothesis with p-value of
. According to Section 3.3, positive correlation between point counts indicates overdispersion and we thus a priori expect
. This is confirmed by our analysis, and since the bootstrap confidence interval of ν does not contain the value corresponding to the null model ν = 1, in our framework we also reject the null Poisson hypothesis and favor the
model over the standard Poisson point process. The fitted value of ν is significantly smaller than 1, indicating an overdispersion existing in the highly variable daily Divvy trips that cannot be captured by the standard IPP model. Our model thus jointly models the daily variability in Divvy trips, as well as the spatial locations at which they occur. This enhances the predictive value of our model compared to the IPP which cannot reliably model the overdispersion of daily trips.
Table 5 Estimated parameters in the Divvy analysis.
Table 6 Estimated parameters in the IPP Divvy analysis.
In order to properly compare our model to the IPP, we compare the AICs and likelihoods of the logistic regressions corresponding to both models. We report them as “pseudo-AIC” and “pseudo-loglikelihood” in . Our results confirm that the model is favored compared to the model without dispersion, both in terms of AIC and likelihood.
Table 7 Comparison of both models in the Divvy analysis.
4.2 Capeweed
The dataset can be found on the GBIF website, that is, https://www.gbif.org/species/3114986, and consists in the locations of sightings of the species Arctotheca calendula, commonly known as capeweed. The dataset contains each individual’s location, along with the year in which it was spotted. Since the data consists of reports that are not independent samples from the underlying species’ distribution, we rely in our modeling on an observer bias covariate (Fithian et al. Citation2015) that helps explain why the observed intensity is larger around cities. We use more specifically a bias layer that is a measure of accessibility to cities measured in travel time, and provided by Weiss et al. (Citation2018), see https://malariaatlas.org/research-project/accessibility-to-cities/. Our focus is on yearly sightings between 2012 and 2018, so that our model is seven independent draws of a with quasi-intensity on the k-th year given by
(11)
(11) where
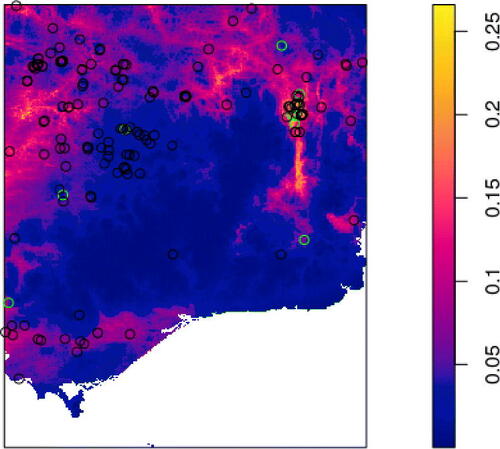
are environmental covariates thought to be important in explaining the distribution of the species, and Y(x) is the accessibility to city bias layer from Weiss et al. (Citation2018). Regarding the environmental covariates, we choose as a purely spatial covariate the pH of the soil at a given location, which can be found at https://www.clw.csiro.au/aclep/soilandlandscapegrid. We also choose as a spatiotemporal covariate the maximum temperature in October of the corresponding year, available from WorldClim at https://worldclim.org/data/monthlywth.html. To illustrate the dataset we are working with, we plot in the locations of all data points considered, as well as the predicted quasi-intensity in 2018. We have used in total 10, 000 dummy points when implementing the method described in Section 2.2.
Fig. 5 Sightings of capeweed between 2012 and 2018 in South-East Australia (in black) with those in year 2017 highlighted in green, along with the predicted quasi-intensity in 2017.
The results for the model are reported in while the ones for the null Poisson model (ν = 1) are shown in . As in the previous case study, the 95% bootstrap confidence intervals were computed with 1000 draws from the fitted model.
Table 8 Estimated parameters in the capeweed analysis.
Table 9 Estimated parameters in the IPP capeweed analysis.
The bias layer is found to be an important covariate. The negative value of its corresponding estimated coefficient confirms that locations close to cities have a higher intensity of reported capeweed individuals. The other two environmental covariates, namely soil pH and the maximum temperature in October, are also found to be important drivers of the distribution of capeweed. Finally, and perhaps more importantly, ν is found to be close to zero, signifying overdispersion from year to year in the number of capeweed reports. Quantifying the overdispersion helps ecologists better understand how volatile the total number of capeweed individuals is from year to year. In addition, since the bootstrap confidence interval of ν does not contain the value corresponding to the null model ν = 1, we reject the null IPP hypothesis and favor the model. More precisely, we compare the AICs and likelihoods of the logistic regressions corresponding to both models. We report them as “pseudo-AIC” and “pseudo-loglikelihood” in . In this study too, our findings confirm that the
model is favored compared to the model without dispersion, both in terms of AIC and likelihood.
Table 10 Comparison of both models in the capeweed analysis.
4.3 Flooding of the Rio Negro river
In this subsection, we consider monthly records of the flooding of the Rio Negro river in Manaus, Brazil between 1903 and 1992. A yearly version of this data was studied in Example 2 in Zhu et al. (Citation2017), see also Brillinger (Citation1995) for the original study. In order to recover the month in which a flooding occurred, we used the R dataset boot::manaus which contains the river heights on the focal period. We analyze the data as a homogeneous point process on the temporal window , see . This analysis differs from that of the previous two studies in some important ways. First, the data are analyzed as a temporal point process, with events being times rather than locations. Second, it has been found to be underdispersed, meaning that there is some regularity in flooding occurrences.
Fig. 6 Monthly records of the flooding of the Rio Negro river in Manaus, Brazil between 1903 and 1992.

The results for the model are reported in . The 95% bootstrap confidence intervals were computed with 10, 000 draws from the fitted model, and we have used in total 10, 000 dummy points. The analysis was also conducted under the null Poisson model (ν = 1), with results reported in .
Table 11 Estimated parameters in the Rio Negro river analysis.
Table 12 Estimated intercept parameter in the IPP Rio Negro river analysis.
Similarly to the findings of Zhu et al. (Citation2017), we find that the data are significantly underdispersed. However, as discussed in the introduction and proved in Proposition 1, their model is not well defined in the non Poissonian case. Therefore, we believe our analysis of this dataset, although done in the same time-homogeneous framework of Zhu et al. (Citation2017), is more theoretically sound than that of Zhu et al. (Citation2017). The confidence interval for the estimation of the dispersion parameter ν unambiguously excludes the null hypothesis corresponding to the IPP case ν = 1. We also compare the AICs and likelihoods of the logistic regressions corresponding to both models, and we report them as “pseudo-AIC” and “pseudo-loglikelihood” in . Our results in confirm that the model is favored compared to the model without dispersion, both in terms of AIC and likelihood.
Table 13 Comparison of both models in the Rio Negro river analysis.
5 Discussion
In this article, we have introduced the as a class of spatial point processes that is more flexible than the inhomogeneous Poisson process model. This allows us to tackle spacial point patterns with a range of variance-to-mean ratios. When there is a single spatial point pattern, it seems impossible to estimate the variance-to-mean ratio so a common approach is to use the IPP, in effect imposing ν = 1. If there are replicated point patterns, it becomes crucial to consider correlations between different regions. shows that the
captures positive and negative correlations between point counts in different locations, which the IPP fails to do, see . We have derived a formula for the point count correlation in Proposition 2 making explicit the relation between point count correlation and the dispersion parameter ν.
The logistic regression (Baddeley et al. Citation2014) has been employed to fit our proposed process, and its usefulness has been demonstrated through numerical simulations. Our model is analytically tractable and we have made explicit some of its theoretical properties. In particular, we are able to compute the Janossy density of its restriction to a subregion (Proposition 3) and its intensity function can be computed explicitly (Proposition 4). The case studies further show that the proposed model has outperformed the Poisson model in a variety of applications involving replicated point patterns.
We remark that in the case of independent and identical samples, the quasi-intensity of the is proportional to that of the Poisson point process. As such, a quasi-intensity that depends log-linearly on covariates via Equation(2)
(2)
(2) will have the same parameter estimates of
as the corresponding Poisson point process. The intercept β0 and the dispersion parameter ν can then be found by analyzing the maximum likelihood estimator corresponding to point counts.
Our work illustrates some of the difficulties involved when working with replicated point patterns, and the complex theoretical ideas that need to be taken into account whenever there is spatial correlation in datasets. Since replicated point patterns are frequently encountered in practice, the avenue of research initiated here should be considered an important first step paving the way for future work in this area. One area that might be of particular interest is the model’s inclusion of a time-varying ν, generalizing the work in Wu, Holan, and Wikle (Citation2013) to the point process setting. This is complicated by the fact that in our framework ν affects both the dispersion of average total point counts, as well as the intensity indirectly through Proposition 4. The time-varying model on ν should thus be carefully parametrized so as to separate both effects. One could also consider generalizations of the CMP distribution such as that introduced in Imoto (Citation2014) and Qian and Zhu (Citation2023).
Data availability
The data used in our case studies is available online. The Divvy dataset can be obtained from https://data.cityofchicago.org. The capeweed data can be found on the GBIF website, i.e., https://www.gbif.org/species/3114986. The Rio Negro river flooding can be imported through the R dataset boot::manaus.
Additional information
Funding
References
- Alqawba, M., and N. Diawara. 2021. Copula-based Markov zero-inflated count time series models with application. Journal of Applied Statistics 48 (5):786–803. doi: 10.1080/02664763.2020.1748581.35707445.
- Andrews, J., R. Ganti, M. Haenggi, N. Jindal, and S. Weber. A primer on spatial modeling and analysis in wireless networks. IEEE Communications Magazine 48 (11):156–63. doi: 10.1109/MCOM.2010.5621983.
- Babu, G. J., and E. D. Feigelson. 1996. Spatial point processes in astronomy. Journal of Statistical Planning and Inference 50 (3):311–26. doi: 10.1016/0378-3758(95)00060-7.
- Baddeley, A., J.-F. Coeurjolly, E. Rubak, and R. Waagepetersen. 2014. Logistic regression for spatial Gibbs point processes. Biometrika 101 (2):377–92. doi: 10.1093/biomet/ast060.
- Baddeley, A., E. Rubak, and R. Turner. 2015. Spatial point patterns: Methodology and applications. London: Chapman and Hall/CRC Press.
- Baddeley, A., and R. Turner. 2000. Practical maximum pseudolikelihood for spatial point patterns. Australian & New Zealand Journal of Statistics 42 (3):283–322. doi: 10.1111/1467-842X.00128.
- Brillinger, D. R. 1995. Trend analysis: binary-valued and point cases. Stochastic Hydrology and Hydraulics 9 (3):207–13. doi: 10.1007/BF01581719.
- Coeurjolly, J.-F., and E. Rubak. 2013. Fast covariance estimation for innovations computed from a spatial Gibbs point process. Scandinavian Journal of Statistics 40 (4):669–84. doi: 10.1111/sjos.12017.
- Connor, C. B., and B. E. Hill. 1995. Three nonhomogeneous Poisson models for the probability of basaltic volcanism: Application to the Yucca Mountain region, Nevada. Journal of Geophysical Research: Solid Earth 100 (B6):10107–25. doi: 10.1029/95JB01055.
- Conway, R. W., and W. L. Maxwell. 1962. A queuing model with state dependent service rates. Journal of Industrial Engineering 12:132–6.
- Daley, D. J., and D. Vere-Jones. 2003. An introduction to the theory of point processes: Volume I: Elementary theory and method. New York: Springer-Verlag.
- Daley, D. J., and D. Vere-Jones, 2008. An introduction to the theory of point processes. In Probability and its applications. Vol. 2. New York: Springer-Verlag.
- Diggle, P. J., and R. K. Milne. 1983. Negative binomial quadrat counts and point processes. Scandinavian Journal of Statistics 10:257–67.
- Fithian, W., J. Elith, T. Hastie, and D. A. Keith. 2015. Bias correction in species distribution models: Pooling survey and collection data for multiple species. Methods in Ecology and Evolution 6 (4):424–38. doi: 10.1111/2041-210X.12242.27840673.
- Geng, X., and A. Xia. 2022. When is the conway-maxwell-poisson distribution infinitely divisible?. Statistics & Probability Letters 181:109264. doi: 10.1016/j.spl.2021.109264.
- Huang, A. 2017. Mean-parametrized Conway–Maxwell–Poisson regression models for dispersed counts. Statistical Modelling 17 (6):359–80. doi: 10.1177/1471082X17697749.
- Imoto, T. 2014. A generalized Conway–Maxwell–Poisson distribution which includes the negative binomial distribution. Applied Mathematics and Computation 247:824–34. doi: 10.1016/j.amc.2014.09.052.
- Kroese, D. P., and Z. I. Botev, 2015. Spatial process simulation. In Stochastic geometry, Spatial statistics and random fields, 369–404. Cham: Springer.
- Li, X., and D. K. Dey. 2022. Estimation of COVID-19 mortality in the United States using Spatio-temporal Conway Maxwell Poisson model. Spatial Statistics 49:377–92. doi: 10.1016/j.spasta.2021.100542.
- Loève, M. 1963. Probability theory, 3rd ed. New York: Van Nostrand.
- MacDonald, I. L., and F. Bhamani. 2020. A time-series model for underdispersed or overdispersed counts. The American Statistician 74 (4):317–28. doi: 10.1080/00031305.2018.1505656.
- Mannering, F. L, and C. R. Bhat. 2014. Analytic methods in accident research: Methodological frontier and future directions. Analytic Methods in Accident Research 1:1–22. doi: 10.1016/j.amar.2013.09.001.
- Melo, M., and A. Alencar. 2020. Conway–Maxwell–Poisson autoregressive moving average model for equidispersed, underdispersed, and overdispersed count data. Journal of Time Series Analysis 41 (6):830–57. doi: 10.1111/jtsa.12550.
- Minka, T. P., G. Shmeuli, J. B. Kadane, S. Borle, and P. Boatwright. 2002. Computing with the com-poisson distribution. Technical Report 776. Department of Statistics, Carnegie Mellon University, Pittsburgh, PA.
- Qian, L., and F. Zhu. 2023. A flexible model for time series of counts with overdispersion or underdispersion, zero-inflation and heavy-tailedness. Communications in Mathematics and Statistics
- Ribeiro, E. E., W. M. Zeviani, W. H. Bonat, C. G. Demetrio, and J. Hinde. 2020. Reparametrization of COM–Poisson regression models with applications in the analysis of experimental data. Statistical Modelling 20 (5):443–66. doi: 10.1177/1471082X19838651.
- Sellers, K. F., S. Borle, and G. Shmueli. 2012. The COM-Poisson model for count data: a survey of methods and applications. Applied Stochastic Models in Business and Industry 28 (2):104–16. doi: 10.1002/asmb.918.
- Sellers, K. F, and G. Shmueli. 2010. A flexible regression model for count data. Annals of Applied Statistics 4:943–61.
- Thompson, H. R. 1955. Spatial point processes, with applications to ecology. Biometrika 42 (1-2):102–15. doi: 10.1093/biomet/42.1-2.102.
- Waller, L. A., and C. A. Gotway. 2004. Applied spatial statistics for public health data, Vol. 368. New Jersey: John Wiley and Sons.
- Weiss, C., F. Zhu, and A. Hoshiyar. 2020. Softplus ingarch models. Statistica Sinica 32:1099–120. doi: 10.5705/ss.202020.0353.
- Weiss, D. J., A. Nelson, H. S. Gibson, W. Temperley, S. Peedell, A. Lieber, M. Hancher, E. Poyart, S. Belchior, N. Fullman, et al. 2018. A global map of travel time to cities to assess inequalities in accessibility in 2015. Nature 553 (7688):333–6. 29320477 doi: 10.1038/nature25181.
- Wu, G., S. H. Holan, and C. K. Wikle. 2013. Hierarchical Bayesian spatio-temporal Conway–Maxwell Poisson models with dynamic dispersion. Journal of Agricultural, Biological, and Environmental Statistics 18 (3):335–56. doi: 10.1007/s13253-013-0141-2.
- Zhu, F. 2012. Modeling time series of counts with COM-Poisson INGARCH models. Mathematical and Computer Modelling 56 (9-10):191–203. doi: 10.1016/j.mcm.2011.11.069.
- Zhu, L., K. F. Sellers, D. S. Morris, and G. Shmueli. 2017. Bridging the gap: A generalized stochastic process for count data. The American Statistician 71 (1):71–80. doi: 10.1080/00031305.2016.1234976.
Appendix
Proposition 1.
Let Ξ be a point process on with T > 0 such that
follows a CMP distribution Equation(1)
(1)
(1) with
. If Ξ has independent and stationary increments, then Ξ is a time homogeneous Poisson process.
Proof.
For each positive integer n, we divide into n subintervals
. Then the numbers of points
, are iid random variables, hence the distribution of
is infinitely divisible. Since
follows a CMP distribution with
, Geng and Xia (Citation2022) used the entire function to show that an infinitely divisible CMP distribution with
must satisfy ν = 1, we conclude that
is a Poisson random variable. Therefore, it follows from Raikov’s theorem (see Section 19.2 of Loève Citation1963) that
, for all
, are Poisson random variables. This implies that Ξ is a time homogeneous Poisson process. □
Proposition 2.
Let W1, W2 be a partition of W and let Y1 and Y2 denote the counts of points in regions W1 and W2, and p1 and p2 be the probabilities of points falling into W1 and W2, respectively. Then the correlation coefficient between Y1 and Y2 satisfies
(A.1)
(A.1)
Proof.
Conditional on N, Yi is a binomial B so
The stated result Equation(A.1)(A.1)
(A.1) is an immediate consequence of these equalities. □
Depending on the dispersion parameter ν, the CMP distribution can be used to model both underdispersion and overdispersion distributions (Conway and Maxwell Citation1962). Specifically when and
when
. Therefore the correlation coefficient given in Equation(A.1)
(A.1)
(A.1) is either positive or negative depending on ν. When ν = 1, that is, in the case of the Poisson distribution, the correlation coefficient
becomes zero.
Proposition 3.
The Janossy density of a restricted to
is
where
Proof.
We use Equation(3)(3)
(3) and integrate over all points outside D to get
as claimed. □
Proposition 4.
The intensity of a is given by
Proof.
Let g be a non negative measurable function defined on W. Denoting by Ξ a point process and by
a sequence of iid random variables with distribution
, we have
Since g can in particular be chosen in the class of indicator functions of subsets of W, the claim follows. □