
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In some situations, square contingency tables with ordered categories are analyzed by considering collapsed tables where adjacent categories are combined. This study proposes measures to represent the degree of departure from symmetry using collapsed tables. The proposed measures are defined as the arithmetic mean of submeasures of each collapsed 3 × 3 table. Additionally, a theorem affirms that the value of the measure for symmetry is equal to the sum of the value of the proposed measures. Finally, examples are given.
1 Introduction
Data is often organized using a square contingency table with the same classifications for categorical data analysis. Examples include matched pairs data comparisons, inter-rater reliability, changes before and after treatment, and social mobility. Independence between the row and column classifications does not hold in these square contingency tables because many observations fall in or near the main diagonal cells. Then analysis focuses on the off-diagonal cells (i.e., symmetry or asymmetry of the row and column classifications) instead of independence.
Various models have been proposed to analyze the symmetry of a square contingency table (e.g., Bowker Citation1948; Read Citation1977; and McCullagh Citation1978). Moreover, a measure to represent the degree of departure from the model is crucial when the model of symmetry does not fit the data well (e.g., Tomizawa Citation1994, Citation1995; and Tomizawa and Saitoh Citation1999).
Furthermore, to simplify the interpretation in data research, analysis of ordinal square contingency tables with many dimensions are often divided into three categories (e.g., “high,” middle,” and low”). Various methods can be used to reclassify the original categories into three groups. Consequently, a comprehensive evaluation of the different collapsed patterns is reasonable when there are numerous ways to combine ordinal categories and it is difficult to decide how to choose unique cutpoints. For example, contingency tables may be collapsed into a 3 × 3 table in clinical research when analyzing data for clinical scales or laboratory data (see Shinoda et al. Citation2020; Aizawa, Yamamoto, and Tomizawa Citation2021). Additionally, social research often treats scales with ordered categories. As an example, we use the General Social Survey conducted by the National Opinion Research Center at the University of Chicago (Davern et al. Citation2021). compares the frequency that low-income respondents spent a social evening with neighbors or friends in 2012 and 2016. shows the frequency that low-income respondents suffer everyday discrimination in 2021. When the dimensions are large or the sample size is small, previous measures cannot be estimated because the sum of symmetric cells is zero. Often analysis not only compares the degree of departure from the models but also examines the relationships among models using the decomposition of a measure from symmetry. As an example, Yamamoto, Shimada, and Tomizawa (Citation2015) proposed a measure to represent the degree of departure from symmetry (S) using collapsed a 3 × 3 table. Noting that the measure
is described in detail in the next section.
Table 1 Frequency of spending evenings with friends and neighbors for low-income respondents in 2012 and 2016 from Davern et al. (Citation2021).
Table 2 Frequency of everyday discrimination of low-income respondents in 2021 from Davern et al. (Citation2021).
This article proposes Kullback-Leibler (KL)-type measures to represent the degree of departure from the collapsed global symmetry (CoGS) or conditional symmetry (CS), which are denoted by or
, and demonstrates that the value of
is equal to the sum of the values of
and
.
2 Materials (reviews)
Consider an R × R square contingency table with the same row and column ordinal classifications. Let X and Y denote the row and column variables, respectively. Additionally, let Pr for
. The S model Bowker (Citation1948) is defined as
Also, see Bishop, Fienberg, and Holland (Citation1975, p.282). The global symmetry (GS) model proposed by Read (Citation1977) is given as
where
and
. The CS model proposed by McCullagh (Citation1978) is defined as
Also, see Agresti (Citation1990, p.361). A special case of this model is the S model when Γ = 1.
Tomizawa (Citation1994) and Tomizawa, Seo, and Yamamoto (Citation1998) proposed measures that represent the degree of departure from S for nominal square contingency tables. Incidentally, Tomizawa (Citation1994) considered KL-type measures using the Shannon entropy and Gini concentration, while Tomizawa, Seo, and Yamamoto (Citation1998) considered a generalization of Tomizawa’s (Citation1994) measures using the power divergence (Cressie and Read Citation1984) or the diversity index (Patil and Taillie Citation1982). For ordinal square contingency tables, Tomizawa, Miyamoto, and Hatanaka (Citation2001) proposed a measure to represent the degree of departure from S. Moreover, Tomizawa (Citation1995) and Tomizawa and Saitoh (Citation1999) considered measures representing the degree of departure from GS and CS, respectively. Tomizawa and Saitoh (Citation1999) also gave the theorem that the measure from S is equal to the sum of the measure from GS and the measure from CS. See Appendixes A, B, and C for the measure , and
proposed by Tomizawa (Citation1994), Tomizawa (Citation1995), and Tomizawa and Saitoh (Citation1999), respectively.
Here, we consider the (being
) ways of collapsing the R × R original table with ordered categories into a 3 × 3 table by choosing cutpoints after the sth and tth rows and after the sth and tth columns for
. We refer to each collapsed 3 × 3 table as the Tst table (
). In the collapsed Tst table, let
denote the corresponding probability for row value
and column value
. That is,
Then the S model is expressed as
for all s and t (
). See Yamamoto, Tahata, and Tomizawa (Citation2012). Similarly, the CS model can be expressed as
for all s and t (
). Here, consider a model defined by
where
and
for all s and t (
). This model is not equivalent to the GS model. This model is referred to as the CoGS model (Yamamoto, Tahata, and Tomizawa Citation2012).
Assuming that for
and
, the measure to represent the degree of departure from S proposed by Yamamoto, Shimada, and Tomizawa (Citation2015) can be expressed as
where
It should be noted that the measure using collapsed 3 × 3 tables completely differs from the measure proposed by Tomizawa, Miyamoto, and Hatanaka (Citation2001).
3 Measures for collapsed 3 × 3 tables
3.1 Measure of departure from CoGS
Assuming that for
, consider a measure representing the degree of departure from CoGS, which is defined as
where
The measure is between 0 and 1.
has the following characteristics:
if and only if CoGS holds;
Note that the definition of the maximum departure from CoGS can also be expressed as pij = 0 (then pji > 0) or pji = 0 (then pij > 0) for all i < j. Although the CoGS model is not equivalent to the GS model, the maximum departure has the same definition in both models.
3.2 Measure of departure from CS
Assuming that and
for
and
, a measure representing the degree of departure from CS is defined as
where
is between 0 and 1.
has the following characteristics:
3.3 Relationships between the measures
Assuming that and
for
and
, the following theorems are obtained.
Theorem 1.
The value of is equal to the sum of the value of
and the value of
.
Proof.
Consider that the sum of the value of and the value of
can be expressed as
where
Consequently, . Then
. □
From Theorem 1, is expressed as
. Therefore, the measure
should indicate the degree of departure from S without the influence of the degree of departure from CoGS. That is,
indicates the degree of departure from S under the condition that there is a structure of CoGS.
Under Theorem 1, Theorem 2 can be obtained considering .
Theorem 2.
The value of is greater than or equal to the value of
. The equality holds if and only if there is a conditional symmetry structure in the R × R table.
From and
(note that
due to the assumption that
), we see that
. Therefore, (i)
if and only if there is a structure of CS (
), and (ii)
and
if and only if
. Moreover, according to the KL information,
represents the degree of departure from CS, and the degree of departure increases as the value of
increases. That is,
is the difference between the degree of departure from S and that from CoGS.
4 Approximate confidence interval for measure
Let nij denote the observed frequency in the ith row and jth column of the table (). The sample version of
(
), which is,
(
), is given by
where
is replaced by
. Here,
and
. Assuming that
results from full multinomial sampling, we consider the approximate standard error for
and a large-sample confidence interval for
. Using the delta method,
has an asymptotically (as
) normal distribution with a mean of zero and a variance
. See Appendixes D and E for details of
and
.
Let denote
where
is replaced by
. Then
is an estimated approximate standard error for
, and
is an approximate
percent confidence interval for
, where
is the
th percentile of the standard normal distribution.
5 Examples
shows the cross classifications of the respondents’ opinions about spending the evening with friends or neighbors in 2012 and 2016. Here, we considered low-income respondents (annual income under $15,000). The response categories are (1) “almost every day,” (2) “once or twice a week,” (3) several times a month,” (4) “about once a month,” (5) “several times a year,” (6) “about once a year,” and (7) “never.” The degree of departure from CS between is compared using . shows that the estimated values of
are 0.100 for and 0.133 for . Although the confidence intervals overlap, the degree of departure from CS is greater in than in . By contrast, the existing measure
cannot be estimated, because the sum of the symmetric cells is 0.
Table 3 Estimates of measures , and
, approximate standard errors, and 95% confidence intervals applied to the data in .
describes the cross classifications of respondent’s opinions regarding everyday discrimination (people act as if they think the respondent is not smart; the respondent is harassed) in 2021. Here, we considered low-income respondents (annual income under $8,000). The response categories are (1) “almost every day,” (2) “at least once a week,” (3) “a few times a month,” (4) “a few times a year,” (5) “less than once a year,” and (6) “never.” The confidence intervals for and
do not include zero (see ), indicating that S and CoGS do not have a structure. By contrast, the confidence interval for
includes zero (see ), suggesting that CS has a structure in the table. Moreover, Theorem 1 shows that the lack of structure of the S model is due to the lack of structure of the CoGS model rather than that of the CS model. Thus, the CS model may reveal that respondents treated as not smart are harassed more often in daily life. By contrast, existing measures
and
cannot be estimated because the sum of symmetric cells is 0.
6 Discussion
The value of increases as the difference between the degree of departure from S and that from CoGS increases. This is especially pronounced as the degree of departure from S increases while that from GS decreases. The value of
reaches the maximum (= 1) when the degree of departure from S is maximized (= 1) and that from CoGS is minimized (= 0). Therefore,
is useful to visualize the degree of departure from CS on the complete asymmetry with the CoGS structure.
It is also meaningful to consider collapsed 3 × 3 tables only when the original square contingency table has ordered categories because the collapsed tables are obtained by combining adjacent categories. The measure in square ordinal tables should depend on the listing order of the categories. The proposed measures are not invariant under arbitrary similar permutations of row and column categories, except for the reverse order. Moreover, whether the submeasures of the collapsed tables are invariant does not matter because each collapsed 3 × 3 table obtained from an original square table is unique.
We show that even if the estimated measures of and
cannot be calculated because the sum of symmetric cells is zero in the original table, the estimated measures of
and
can be calculated in some cases. This property may be useful, especially for a small-size sample or a large dimension of R.
It should be noted that Yamamoto, Shimada, and Tomizawa (Citation2015) gave the power divergence-type (including the KL) measure to represent the degree of departure from S. However, using the power divergence does not provide a result similar to Theorem 1. The CoGS and CS models do not impose restrictions on the diagonal cell probabilities. Therefore, it seems natural that the proposed measures and their ranges are independent of the diagonal cell probabilities.
The asymptotic normal distribution of is not applicable when
or
because
. Additionally, the asymptotic normal distribution of
is not applicable for the same reason. The above issues are common to existing measures not only the proposed measures. As an example to address these issues, we conducted Monte Carlo simulations using the proposed measure (see Appendix F). In the simulations, four contingency tables were assumed with true values of the proposed measure ranging from 0.000 to 0.090, and the sampling distribution of the proposed measures were visualized in a histogram. When the true value of the measure is 0.000, the asymptotic normal distribution may be difficult to be applicable. However, with a large enough sample, the asymptotic normal distribution may be applicable even if the true value of the measure is close to 0.000. Therefore, we would consider using resampling methods or Bayesian methods when the true values of measures are very close to 0.000 or 1.000, or the small sample size. As an example of a Bayesian approach, Momozaki et al. (Citation2021) considered new estimators of measures that can reduce the bias and mean squared error even without a sufficient sample size using the Bayesian estimators of cell probabilities.
7 Conclusion
Considering collapsed 3 × 3 tables can simplify the interpretation. If determining how to choose unique cutpoints is difficult, then it is reasonable to evaluate the collapsed square contingency tables for various patterns. Thus, we consider that all (
) are combined at the same weights
. The proposed measures are useful for comparing the degrees of departure from S, CoGS, and CS in several tables since the proposed measures always range between 0 and 1 and are independent of the sample size and the dimension R. The proposed theorems are also meaningful to comprehend the relation of these three measures.
Acknowledgments
The authors would like to thank the referees for their comments.
Additional information
Funding
References
- Agresti A. 1990. Categorical data analysis. New York: John Wiley.
- Aizawa, M., K. Yamamoto, and S. Tomizawa. 2021. Measure of departure from average marginal homogeneity for the analysis of collapsed ordinal square contingency tables. Biometrical Letters 58 (1):81–94. doi: 10.2478/bile-2021-0006.
- Bishop Y. M. M., Fienberg S. E., and Holland P. W. 1975. Discrete multivariate analysis: Theory and practice.Cambridge: The MIT Press.
- Bowker, A. H. 1948. A test for symmetry in contingency tables. Journal of the American Statistical Association 43 (244):572–4. 18123073 doi: 10.1080/01621459.1948.10483284.
- Cressie, N, and T. R. Read. 1984. Multinomial goodness-of-fit tests. Journal of the Royal Statistical Society: Series B (Methodological) 46 (3):440–64. doi: 10.1111/j.2517-6161.1984.tb01318.x.
- Davern M., Bautista R., Freese J., Morgan S. L., and Smith T. W., Bautista R., Freese J., Morgan S. L., and Smith T. W., 2021. General Social Surveys, 1972-2021 Cross-section [machine-readable data file, 68,846 cases]. Principal Investigator, Davern, M.; Co-Principal Investigators, Bautista, R., Freese, J., Morgan, S.L., and Smith, T.W.; Sponsored by National Science Foundation.-NORC ed.- Chicago: NORC at the University of Chicago [producer and distributor]. Data accessed from the GSS Data Explorer website at gssdataexplorer.norc.org.
- Mccullagh, P. 1978. A class of parametric models for the analysis of square contingency tables with ordered categories. Biometrika 65 (2):413–8. doi: 10.1093/biomet/65.2.413.
- Momozaki T., Cho K., Nakagawa T., and Tomizawa S. 2021. Estimation of measures for two-way contingency tables using the Bayesian estimators. arXiv preprint, https://arxiv.org/abs/2109.09339.
- Patil, G. P., and C. Taillie. 1982. Diversity as a concept and its measurement. Journal of the American Statistical Association 77 (379):548–61. doi: 10.1080/01621459.1982.10477845.
- Read, C. B. 1977. Partitioning chi-squape in contingency tables: A teaching approach. Communications in Statistics- Theory and Methods 6 (6):553–62. doi: 10.1080/03610927708827513.
- Shinoda, S., K. Yamamoto, K. Tahata, and S. Tomizawa. 2020. A measure of asymmetry for ordinal square contingency tables with an application to modified LANZA score data. Journal of Applied Statistics 47 (7):1251–60. 35707026 doi: 10.1080/02664763.2019.1673325.
- Tomizawa, S. 1994. Two kinds of measures of departure from symmetry in square contingency tables having nominal categories. Statistica Sinica 4 (1):325–34.
- Tomizawa, S. 1995. Measures of departure from global symmetry for square contingency tables with ordered categories. Behaviormetrika 22 (1):91–8. doi: 10.2333/bhmk.22.91.
- Tomizawa, S., N. Miyamoto, and Y. Hatanaka. 2001. Theory and methods: Measure of asymmetry for square contingency tables having ordered categories. Australian & New Zealand Journal of Statistics 43 (3):335–49. doi: 10.1111/1467-842X.00180.
- Tomizawa, S., and K. Saitoh. 1999. Kullback-Leibler information type measure of departure from conditional symmetry and decomposition of measure from symmetry for contingency tables. Calcutta Statistical Association Bulletin 49 (1-2):31–40. doi: 10.1177/0008068319990103.
- Tomizawa, S., T. Seo, and H. Yamamoto. 1998. Power-divergence-type measure of departure from symmetry for square contingency tables that have nominal categories. Journal of Applied Statistics 25 (3):387–98. doi: 10.1080/02664769823115.
- Yamamoto, K., F. Shimada, and S. Tomizawa. 2015. Measure of departure from symmetry for the analysis of collapsed square contingency tables with ordered categories. Journal of Applied Statistics 42 (4):866–75. doi: 10.1080/02664763.2014.993362.
- Yamamoto, K., K. Tahata, and S. Tomizawa. 2012. Some symmetry models for the analysis of collapsed square contingency tables with ordered categories. Calcutta Statistical Association Bulletin 64 (1-2):21–36. doi: 10.1177/0008068320120102.
Appendix A
Appendix A
Assuming that for
, the measure to represent the degree of departure from the symmetry proposed by Tomizawa (Citation1994) is given as
where
Appendix B
Appendix B
Assuming that , the measure to represent the degree of departure from the global symmetry proposed by Tomizawa (Citation1995) is given as
where
Appendix C
Appendix C
Assuming that and
for
, the measure to represent the degree of departure from the conditional symmetry proposed by Tomizawa and Saitoh (Citation1999) is given as
Appendix D
Appendix D
Using the delta method, has an asymptotic variance
given as
where
and
is the indicator function.
Appendix E
Appendix E
Using the delta method, has an asymptotic variance
given as
where
and
is the indicator function.
Appendix F
Appendix F
To confirm the sampling distribution of the proposed measures, we conducted Monte Carlo simulations. As a 6 × 6 table, we assumed random sampling by a multinomial random number based on the structures of probabilities in . The sample size was considered (i.e.,
). Each simulation studies were performed based on 1,000 trials.
The true values of both proposed measures were in ,
and
in ,
and
in ,
and
in .
Then, represented the sampling distributions. (the true values are 0.000) showed that the sampling distributions of the proposed measures were not normal centered at the estimates, as expected. (the true values are 0.022, 0.027) showed that the asymptotic normal distribution could be applicable with a large enough sample. Furthermore, if the true value was greater than about 0.060, the sampling distribution was found to be almost normally centered.
Therefore, we must be careful using asymptotic distributions when the true value of a measure is expected to be 0.000 and/or the sample size is not large enough.
Fig. F1 The sampling distribution obtained from the structure of probabilities in .
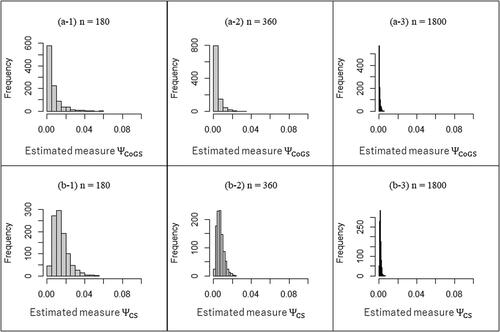
Fig. F2 The sampling distribution obtained from the structure of probabilities in .
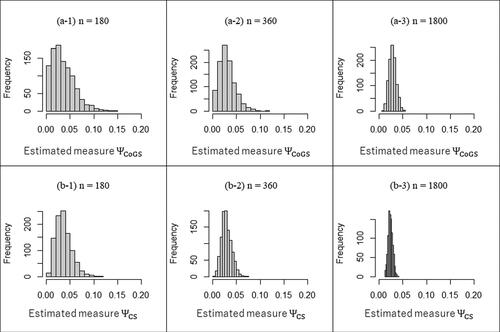
Fig. F3 The sampling distribution obtained from the structure of probabilities in .
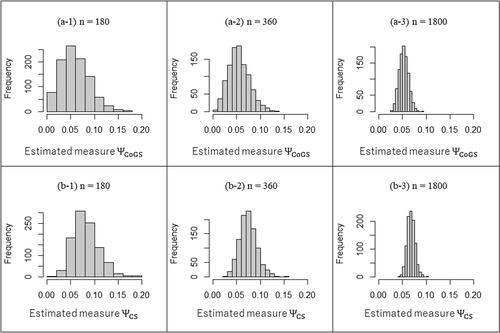
Fig. F4 The sampling distribution obtained from the structure of probabilities in .
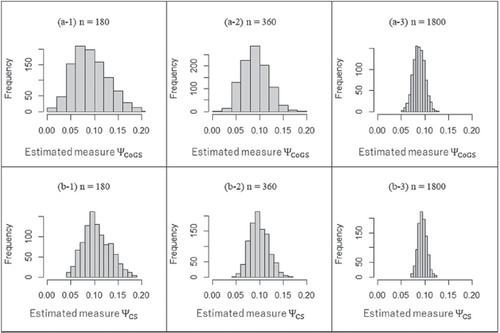
Table F1 Patterns of probability structure in a square contingency table.