
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract.
This study considers excess distribution estimation in iid settings. There are two ways for the estimation; the fitting to the generalized Pareto distribution and the fully non parametric estimation. The fitting estimator is justified by the approximation proven in the extreme value theory; however, the accuracy depends on how extremely large the target is. The non parametric estimator does not need an approximation and has the advantage of wide applicability. This study conducts both theoretical and numerical comparative study on excess distribution estimation. Asymptotic convergence rates of two estimators are obtained, and the mean integrated squared errors are numerically surveyed by simulation study. An illustrative example of Abisko rainfall amount is presented.
1. Introduction
Let be independent and identically distributed random variables with a continuous distribution function F. Suppose that n is sufficiently large. Here, we consider estimating the excess distribution (ED) given by
Shimokihara and Maesono (Citation2018) studied asymptotic properties of a non parametric estimator. The non parametric estimator (NE) is the plug-in type of the kernel distribution estimator
where
is the kernel distribution estimator given by
where W is the cumulative distribution function of a symmetric density w. The bandwidth h is supposed to satisfy h→0.
Under some regularity conditions, the asymptotic mean squared error (MSE) of NE asymptotically equals
(see Theorem 1.1 in Shimokihara and Maesono Citation2018), where the integral range being is omitted in this paper. Both x and u are implicitly assumed to be fixed in Shimokihara and Maesono (Citation2018).
If we want to know the ED Fu(x) on a tail, the Pickands-Balkema-De Haan theorem in the extreme value theory is applicable. The theorem states that Fu(x) converges to the generalized Pareto distribution (GPD) Hγ, c(x) as , where
Thus, parametrically fitting GPD to ED is justified, and
provides good estimates for a sufficiently large u. We will call the parametric estimator PE.
In short, there are mainly two ways to estimate ED. NE is supposed to be used for fixed, that is, not large u. On the other hand, the extreme value approach requires large u. Then, the following question arise: How large u should be for the extreme value approach ?. Preceding researches also states “How far can we extrapolate into the tails?” (Smith Citation1987, p.1194), “That is, an approximation to probabilities of extreme deviation is supposed, which is assumed to become increasingly accurate as one moves further from the range of the data, but whose concise accuracy is unknown” (in the abstract of Hall and Weissman Citation1997). Smith (Citation1987) gave a response in terms of the convergence rate, which is a function of x (Remark of Theorem 8.1).
This study aims at clarifying how large the fitting estimator requires on u by comparing the two ways of ED estimation. Moriyama (Citation2021) conducted a comparative study on the estimation of sample maximum distribution Fm between the extreme-value-based approach and non parametric approach and investigated both theoretical and numerical accuracy, depending on m. Estimators of extreme quantiles are numerically compared in Banfi, Cazzaniga, and De Michele (Citation2022).
To the best of our knowledge, this is the first comparative study between the extreme-value-based approach and the non parametric approach in the distribution tail. This study assumes the tail of the underlying distribution to obtain the explicit form of asymptotic errors. Throughout this study, suppose that F belongs to either one of (i) the so-called Hall class of distributions (see Hall and Welsh Citation1984), (ii) the following Weibull class of distributions, and (iii) the bounded class of distributions (see, e.g., Stupfler Citation2016), which satisfy (i) s.t.
and
(ii) s.t.
and
(iii) s.t.
,
,
, D > 0, E≠0 and
respectively. Then, the limiting GPD is a Fréchet, Gumbel, and Weibull type under the supposition (see Beirlant et al. Citation2004), where
under κ≤1.
Section 2 and 3 give the asymptotic properties of NE, the Kernel-type estimator, and PE, the fitting estimator to GPD, respectively, under the supposition and
as n→∞, where x∞: = ∞ for the Hall class or the Weibull class and x∞: = 0 for the bounded class. Results of the numerically comparative study are shown in Section 4, and the asymptotic convergence rates of the two estimators are provided in some cases. The proofs of theoretical results are in Appendix.
2. Kernel-type estimation
The following theorem on the MSE of NE is a consequence of Theorem 1.1 in Shimokihara and Maesono (Citation2018), where all asymptotic notations in this article refer to n→∞.
Theorem 1.
Suppose F is continuously twice differentiable at x. If and
where
The following Corollary 1 on the bandwidth minimizing the MSE follows from Theorem 1.
Corollary 1.
Suppose and
, where
Under the assumptions of Theorem 1, the optimal bandwidth in the sense of the MSE is
with the optimal bandwidth is asymptotically non degenerate normal with the asymptotic mean
where .
The following Corollary 2 states the special case Un = O(1) of Corollary 1.
Corollary 2.
Suppose s.t. Un→δ. Under the assumptions of Corollary 1, the asymptotically optimal bandwidth in the sense of the MSE is
with the optimal bandwidth has the asymptotic bias
The twice differentiability required in Theorem 1 is the usual regularity condition in smooth distribution estimation or density estimation (see, e.g., Wand and Jones Citation1995).
Remark 1.
x satisfying is called a boundary point in the naive kernel distribution estimation and the convergence rate of
changes (see the proof of Theorem 1). Theorem 1 requires that μ is an integer or
.
3. Fitting estimator to GPD
We employ the maximum likelihood estimation (MLE) based on the peak-over-threthold (POT) for fitting to the GPD, which was developed by Pickands (Citation1975). Let t: = tn be the threshold of the POT and N be the number of exceeding t. Let Yj be the jth number of
exceeding t
. It holds that
, where
.
means the probability convergence. Set
and
where h𝜸 is the density function of H𝜸. Then, t needs to satisfy the following assumption.
Assumption 1.
Either (i) or (ii)
s.t. both Un→δ and Tn→δ holds, where
PE, the fitting estimator, fundamentally depends on the approximation based on the Pickands-Balkema-De Haan theorem shown in the following Proposition 1, whose convergence is ensured by Assumption 1.
Proposition 1.
Under Assumption 1
Remark 2.
The condition (i) in Assumption 1
restricts the threshold t to being asymptotically same as u in the following sense
where the Weibull class additionally needs both x = o(u) and κ < 1. (ii) being true requires t to be asymptotically same as u in a similar sense, as (i).
MLE is asymptotically efficient; however, various approaches are proposed and compared (Zhang Citation2007; Del Castillo and Serra Citation2015; Kang and Song Citation2017). Smith (Citation1987) gave the conditions that show the following scaled version of the MLE
is asymptotically normal with a non trivial bias and
-consistent under the following Assumption 2.
Assumption 2.
s.t. λn→λ, where
We have the following proposition on the accuracy of PE, which is a consequence of Smith (Citation1987).
Proposition 2.
Under Assumptions 1–2
where 𝛍 and the Fisher information matrix Σ0 are given in Smith (Citation1987), and
The following corollary on the convergence rate of PE immediately follows from Proposition 2.
Corollary 3.
Under the assumptions of Proposition 2, converges with the rate larger of τn and
.
4. Comparative study
Suppose and
s.t. Un≡δ throughout in this section, where
Set the threshold ,
,
, or
. Since
for the Hall class, the MSE of PE converges with the rate
. The MSE for the bounded class is of order
. The minimum of the MSE of NE is of order
or
for the Hall class or the bounded class if the minimizing bandwidth converges, that is,
or
, respectively. For the Weibull class, the MSE of PE does not converge to zero when u is of the polynomial order of n, and the MSE of NE tends to infinity. If
, the MSE of PE converges order slower than any polynomial, the asymptotic variance nC−1 converges. The order of the MSE of NE
in the setting.
To sum up, when F belongs to the Hall class or the bounded class, NE converges with the same or faster rate than PE if the optimal bandwidth converges. Specifically, whether PE should be used depends on converges or not. For the Weibull class, the two estimators are not consistent if the threshold u is a polynomial order of n.
Next, the underlying distributions F were supposed to be Burr distributions defined as , where α = cℓ and β = c, Weibull distributions, and inverse Burr distributions defined as
, where μ = cℓ and
. The parameters of the underlying distributions and the convergence rates of MSE without terms slower than any polynomial are summarized in , where the tail index γ is α−1, zero and μ−1, respectively. The hyphen means the distribution breaks the assumption of this study of the estimator. The Weibull class with γ = 0 breaks both the assumptions of PE and NE. For
(small relative to n) and γ far from zero, the convergence rate of MSE of NE is fast and especially close to n−1 for α or μ being close to zero while that of PE is quite slow. The relation to the convergence rate of PE is complicated, unlike that of NE. As u* gets relatively large, the convergence rate of PE becomes faster, but the requirement becomes restrictive in general. Particularly, the assumption is broken for γ being close to zero. NE loses its consistency completely if
converges to some constant, including zero.
Table 1. The polynomial convergence rates of the MSE of the estimators and the lengths.
By simulating the following, the mean integrated squared error (MISE) of PE
and that of NE
, we studied the numerical accuracy in finite-sample cases.
, and Qu(q) denotes the qth quantile of the ED. We suppose
, which is intended that Un = O(1), that is,
. This numerical study employs
as the bandwidth estimator following the result in Corollary 2, where
is the MLE. The kernel functions were the Epanechnikov for the inverse Burr distributions and the Gaussian for the other distributions. We simulated the MISE values 10,000 times, where show the mean values and their standard deviation (sd), where the hyphens mean
numerically equals zero, and so we cannot derive the MISE value. The sample sizes were (n =) 28 or 212. u* is n1∕8, n1∕4 or n1∕2.
Table 2. Scaled MISE values (×100) and sd values (×100) for the estimators.
Table 3. Scaled MISE values (×100) and sd values (×100) for the estimators.
Table 4. Scaled MISE values (×100) and sd values (×100) for the estimators.
Table 5. Scaled MISE values (×100) and sd values (×100) for the estimators.
shows the simulated results on the MISE values for the Burr cases. On the whole, NE surpasses PE for relatively small u* for example, and conversely, PE is better for
. The MISE values of NE are especially large for both α and u* being large. For u* being around n1∕4 they are comparable. For
(e.g.
) it is thought that PE far outperforms NE and NE is of no use.
shows the MISE values for the inverse Burr cases. NE gets inaccurate as u* becomes large relatively to n; however, the performances of PE and NE heavily depend on not only the size of u* but also the tail index γ. This numerical property is slightly different from that of the Burr cases. For (i.e.
) which is closest to zero in this study, NE is always more accurate than PE. Conversely, even though u* is small, PE outperforms NE for some cases γ being around −1 to −3.
shows the MISE values for the Weibull cases. Due to the light-tailness, 1−F(u) numerically equals zero in many cases. The remaining cases shows PE and NE are comparable, while PE is more numerically stable. In order to continue the comparative study on the Weibull cases, we chose relatively smaller (lnn)1∕κ as the threshold u*. shows the simulated results on the MISE values. In this setting, . We chose 1, 1∕2, and 1∕5 as the parameter C, where the tail gets lighter as C becomes small. For κ = 3 and C = 1, NE is quite accurate, but PE is much better than NE for
and C = 1 and κ = 10 and C = 1. For the other cases, they are comparable, and so we cannot conclude which one is better for the Weibull cases. For the light-tailed distribution, ED is considered to be quite sensitive to the distribution parameters. This study concludes PE and NE are comparable for the Weibull cases; however, more detailed numerical study is an important future work.
5. Real data study
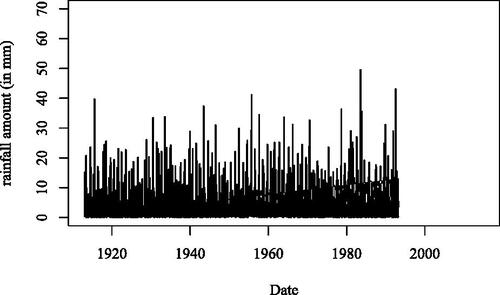
This section considers a real-data study. The data is on Abisko rainfall provided by Abisko Scientific Research Station. It is available in mev package in the R software environment. The data includes the rainfall amount (in mm) and the dates from 1/1/1913 to 1/1/2015, which is given in . The time series trend was analyzed by the annual maximums and found to be not statistically significant (Rudvik Citation2012). Kiriliouk et al. (Citation2019) applied the GPD fitting with the threshold u = 12 and showed .
Figure 1. Abisko rainfall amount (in mm) from 1/1/1913 to 1/1/2015.
Extreme rainfall causes a landslide, and so a probability estimation is required. shows the estimated ED functions of Abisko rainfall amount (in mm) by the non parametric approach (solid line) and by fitting to the GPD (dashed line). The difference between the two approaches is found to be small. is the magnified at the area [7, 14] and shows the little difference; however, the difference is less than around 4%. In this area, the non parametric approach tends to return larger values, which means a pessimistic prospect.
Figure 2. The estimated ED functions of Abisko rainfall amount (in mm) from 1/1/1913 to 1/1/2015 data by the non parametric approach (solid line) and by the fitting to the GPD (dashed line).
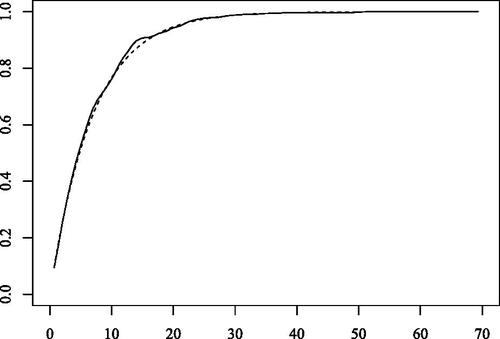
Figure 3. The estimated ED functions in [7, 14] of the Abisko rainfall amount (in mm) by the nonparametric approach (solid line) and by the fitting to the GPD (dashed line).
![Figure 3. The estimated ED functions in [7, 14] of the Abisko rainfall amount (in mm) by the nonparametric approach (solid line) and by the fitting to the GPD (dashed line).](/cms/asset/7da05ca6-332f-4f71-a9e4-5264e97a28c9/lsta_a_2358864_f0003_b.jpg)
6. Conclusion and discussion
This study investigates the two estimators, PE and NE, of the ED above the threshold u and compares their accuracy. Asymptotic MSE of the estimators are derived and numerical study is conducted. Theoretical investigation reveals the followings. The threshold as the hyperparameter of PE denoted by t needs to be asymptotically same as u (see Assumption 1). The MSE of NE and the minimizing hyperparameter (bandwidth h) are presented. For the Weibull class, the two estimators of the ED of a polynomial order are not consistent. For the Hall class or bounded class, the accuracy of the two estimators depends on both u and the parameter γ. As u becomes larger relative to n, the two estimators tend to lose consistency. When u is small relative to n, NE is theoretically superior to PE in general. When u is large relative to n, PE excels NE. If γ > 0, the heavier the tail is, the better NE works. If γ < 0, NE outperforms PE, especially for γ being close to zero. Simulation study mostly demonstrates the asymptotic supremacy of each of the estimators. In the real data study, the difference between the two estimators are surveyed. It is found that the difference is slight, but the non parametric approach returns an estimated probability slightly larger.
The obtained result of the comparative study is different from that of distribution estimation of sample maximum. By comparing the fitting estimator to the generalized extreme value distribution and the non parametric kernel type estimator, Moriyama (Citation2021) demonstrated that the non parametric estimator is good in the case γ≒0, where the fitting estimator loses consistency. That means the performance of non parametric estimation in extreme value analysis depends on at least the target being related to the generalized Pareto distribution or the generalized extreme value distribution. This fact suggests the properties of other non parametric estimators in extreme value analysis. In order to improve the accuracy of extreme value inference, we need to continue to clarify the properties of the non parametric estimators.
Data availability
The dataset analyzed during the current study is available in the mev package in the R software environment.
Acknowledgments
The author appreciates the editor’s and referees’ valuable comments that helped us improve this manuscript.
Disclosure statement
The author declares that there are no conflicts of interest.
Additional information
Funding
References
- Banfi, F., G. Cazzaniga, and C. De Michele. 2022. Nonparametric extrapolation of extreme quantiles: a comparison study. Stochastic Environmental Research and Risk Assessment 36 (6):1579–96. doi:10.1007/s00477-021-02102-0.
- Beirlant, J., Y. Goegebeur, J. Teugels, and J. Segers. 2004. Statistics of extremes: theory and applications. Chichester: John Wiley & Sons, Ltd.
- Del Castillo, J., and I. Serra. 2015. Likelihood inference for generalized Pareto distribution. Computational Statistics & Data Analysis 83:116–28. doi:10.1016/j.csda.2014.10.014.
- Hall, P., and I. Weissman. 1997. On the estimation of extreme tail probabilities. The Annals of Statistics25:1311–26.
- Hall, P., and A. H. Welsh. 1984. Best attainable rates of convergence for estimates of parameters of regular variation. The Annals of Statistics 12 (3):1079–84.
- Kang, S., and J. Song. 2017. Parameter and quantile estimation for the generalized Pareto distribution in peaks over threshold framework. Journal of the Korean Statistical Society 46 (4):487–501. doi:10.1016/j.jkss.2017.02.003.
- Kiriliouk, A., H. Rootzén, J. Segers, and J. L. Wadsworth. 2019. peaks over thresholds modeling with multivariate generalized pareto distributions. Technometrics 61 (1):123–35. doi:10.1080/00401706.2018.1462738.
- Moriyama, T. 2021. Parametric and nonparametric probability distribution estimators of sample maximum, arXiv preprint, arXiv:2111.03765.
- Pickands, J. 1975. Statistical inference using extreme order statistics. The Annals of Statistics 3 (1):119–31.
- Rudvik, A. 2012. Dependence structures in stable mixture models with an application to extreme precipitation. Licentiate thesis, Chalmers University of Technology, Gothenburg, Sweden.
- Shimokihara, A., and Y. Maesono. 2018. Asymptotic mean squared error of kernel estimator of excess distribution function. Bulletin of Informatics and Cybernetics 50:51–64. doi:10.5109/2233859.
- Smith, R. L. 1987. Estimating tails of probability distributions. The Annals of Statistics 15 (3):1174–1207.
- Stupfler, G. 2016. Estimating the conditional extreme-value index under random right-censoring. Journal of Multivariate Analysis 144:1–24. doi:10.1016/j.jmva.2015.10.015.
- Wand, M. P., and M. C. Jones. 1995. Kernel smoothing. London: Chapman & Hall.
- Zhang, Jin. 2007. Likelihood moment estimation for the generalized pareto distribution. Australian & New Zealand Journal of Statistics 49 (1):69–77. doi:10.1111/j.1467-842X.2006.00464.x.
Appendix
Proof of Proposition 1.
For the Hall class, it follows from and ct = γt that
Since
we see
if either (i)
or (ii)
s.t. Un→δ and Tn→δ holds, which means
. Then,
For the Weibull class, it follows from γ = 0 and that
Since
Un→0 when x is same as or larger order than u. We also see
if x = o(u). Then, considering whether
or not we see τn→0 under Assumption 1.
For the bounded class, it holds that
Since
we see
if t = u.
Combining the results, Proposition 1 has been proved. ▪
Proof of Proposition 2 for the Hall class or the bounded class.
First, we decompose the difference as follows:
It holds that
where
and
is between
and 𝜸t with probability 1.
By calculating the derivative, we have
where
. It follows from
that
where
Similarly, it holds that
where
.
Thus, we see ζn is asymptotically equivalent in distribution to , where
and
. Combining the results, Proposition 2 has been proved. Proposition 2 for the bounded class is proved in the same manner.
▪
Proof of Proposition 2 for the Weibull class.
holds, where
is between
and 𝜸t with probability 1. We have
It holds that
In the same manner as the Proof of Proposition 2, we have ζn is asymptotically equivalent in distribution to , where
, sn≡0 and
. Proposition 2 for the Weibull class has now been proved. ▪
Proof of Theorem 1.
𝔹 denotes the asymptotic bias of NE , and 𝕍 denotes the asymptotic variance later. Shimokihara and Maesono (Citation2018) proved
This is seen from is asymptotically
which holds when
. It is true if either F is the Hall class or
holds. The expansion gives
For the Hall class,
For the Weibull class,
For the bounded class,
By combining the results, Theorem 1 is proved. ▪
Proof of Corollary 2.
It follows from Theorem 1 that
where
Each of the first cases is the Hall class, the second case is the Weibull class, and the last case is the bounded class of distribution. By differencing MSE with respect to h, we see that the bandwidth minimizing the MSE is given by
Suppose s.t. Un→δ. Then, minimizing bandwidth is
with the optimal bandwidth has the asymptotic bias
Corollary 2 has been proved. ▪