
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The concepts of entropy and divergence, along with their past, residual, and interval variants are revisited in a reliability theory context and generalized families of them that are based on ϕ-functions are discussed. Special emphasis is given in the parametric family of entropies and divergences of Cressie and Read. For non-negative and absolutely continuous random variables, the dual to Shannon entropy measure of uncertainty, the extropy, is considered and its link to a specific member of the ϕ-entropies family is shown. A number of examples demonstrate the implementation of the generalized entropies and divergences, exhibiting their utility.
1. Introduction
In information theory, the concept of entropy plays a predominant role as a measure of uncertainty, being engaged in different scientific fields such as physics, economics, social sciences, and reliability theory. Since its introduction in 1948 by Shannon (Citation1948), the so called Shannon entropy has been extensively investigated and inspired further developments and generalizations. Entropy measures the uncertainty associated to a single distribution. For measuring the similarity of two distributions, an important and well-known entropy-based measure is the relative entropy, or Kullback-Leibler (KL) divergence, Kullback and Leibler (Citation1951). Shannon entropy and KL divergence have been extensively studied and applied in a wide range of diverse disciplines, especially in statistics. Soofi (Citation1994) dealt with the quantification of information in some statistical problems, focusing on the meaning of the information functions. Soofi (Citation2000) further discussed the development of information theoretic principles of inference and methodologies based on the entropy and its generalizations in statistics, commenting that “the fundamental contribution of information theory to statistics has been to provide a unified framework for dealing with notion of information in a precise and technical sense in various statistical problems”.
To gain an idea of the many possible applications of information theory, we give a few examples below. In the paper by Kang and Kwak (Citation2009), the maximum entropy principle is used to generate a probability distribution with some fixed moment conditions, while Shi et al. (Citation2014) used the maximum entropy method to perform reliability analysis. Singh, Sharma, and Pham (Citation2018) used entropy to quantify the uncertainty due to changes in software made to fix issues of the source code. Iranpour, Hejazi, and Shahidehpour (Citation2020) proposed a reliability assessment model that considers various sources affecting critical infrastructure performance, where the Shannon entropy is applied to detect any variations in the system information fault sources. Regarding the divergences, Weijs, Van Nooijen, and Van De Giesen (Citation2010) proposed the Kullback-Leibler divergence as a score that can be used for evaluating probabilistic forecasts of multicategory events. Moreover, in the context of robust Bayesian analysis for multiparameter distributions, Ruggeri et al. (Citation2021) introduced a new class of priors based on stochastic orders, multivariate total positivity of order 2 and weighted distributions. They considered the Kullback-Leibler divergence to measure the uncertainty induced by such a class, as well as its effect on the posterior distribution.
With a focus on needs of reliability applications, Di Crescenzo and Longobardi (Citation2002) introduced entropy based uncertainty measures in past lifetime distributions, while Rao et al. (Citation2004) considered new entropy-type measures based on the cumulative distribution function of a random variable or its survival function. Di Crescenzo and Longobardi (Citation2009) developed further the cumulative entropies while they also considered cumulative KL divergences Di Crescenzo and Longobardi (Citation2015). On the other hand, the entropy and KL divergence for the residual lifetimes have been proposed in Ebrahimi (Citation1996) and Ebrahimi and Kirmani (Citation1996), respectively.
Shannon’s entropy has been generalized to parametric families of entropies that include it as a special case, with probably Tsallis and Rényi entropies being the two most well-known generalizations. For a review on generalized entropies and their properties, we refer to Amigó, Balogh, and Hernández (Citation2018). For example, Maasoumi and Racine (Citation2002) employed the generalized entropy of Havrda and Charvat (Citation1967) to examine the predictability of stock market returns. A generalization of Shannon entropy, known as ϕ-entropy, was proposed by Khinchin (Citation1957) who replaced the log function in the definition of Shannon entropy by a general function ϕ that preserves important properties. Hence, ϕ-entropy is a family of entropies that contains the Shannon entropy as a special case. Analogously, the KL divergence is a member of the ϕ-divergence family, which was introduced independently by Morimoto (Citation1963) and Ali and Sankaran (Citation1966). Generalized divergences are employed in machine learning methods as well, with applications in several areas such as computational biology, image processing, speech recognition, and text mining (see, e.g., Devarajan, Wang, and Ebrahimi Citation2015).
In this work, we discuss ϕ-entropies and ϕ-divergences in a reliability context. These families provide flexibility in controlling properties of entropy measures or identifying optimal divergences for fitting or discrimination problems. In particular, we first provide in Section 2 preliminaries on measures and entropies in a reliability context, while in Section 3 we give some insight on ϕ-entropies and ϕ-divergences, as well as their dynamic versions, along with basic properties. In the sequel, in Section 4, we focus on the generalized entropies and divergences obtained with the flexible parametric family of ϕ-functions studied by Cressie and Read (Citation1984) and study their properties. Then, we show in Section 5 that the extropy, as approximated by Lad, Sanfilippo, and Agrò (Citation2015) for the continuous case, is equivalent to a specific ϕ-entropy. In Section 6, we give some examples illustrating the usage of the generalized entropies and divergences discussed in the previous sections and proposing ways of employing them in practice. Finally, in Section 7, we summarize the contributions of the paper and provide conclusions.
2. Measures of entropy and divergence in reliability
Shannon initially defined entropy H as the average level of information associated with a discrete random variable X on a finite sample space with a probability mass function (pmf) , given by
, and studied its properties. In the sequel, he extended the notion of entropy for a continuous random variable X with probability density function (pdf) f in a straightforward manner, setting
, where log denotes the natural logarithm.
In the framework of reliability theory and survival analysis, which is the focus here, the random variable X is considered to be non-negative and absolutely continuous. The associated Shannon entropy is then defined as
(1)
(1)
It is also known as differential entropy and, in this context, it measures the failure uncertainty. However, the entropy for continuous distributions does not share all the properties of the discrete case entropy, as discussed among others by Rao et al. (Citation2004). For example, it may take negative values, while the entropy of a discrete distribution is always non-negative.
Among the generalizations of Shannon entropy is the concept of extropy, defined by Lad, Sanfilippo, and Agrò (Citation2015) as the measure of uncertainty dual to Shannon entropy, has attracted the interest of researchers. For a non-negative and absolutely continuous random variable with pdf f, the extropy is defined by
(2)
(2)
For both measures, (Equation1(1)
(1) ) and (Equation2
(2)
(2) ), it is of interest to study the corresponding dynamic versions, which are applied to cases for which some additional information is known, represented by a conditioning event. In this perspective, the prominent dynamic versions are the residual, the past and the interval ones. The first one is related to the residual life of X, represented by
, for which the corresponding versions of the entropy and the extropy are the residual entropy Ebrahimi (Citation1996) and the residual extropy Qiu and Jia (Citation2018), defined as
(3)
(3)
(4)
(4)
respectively, where
denotes the survival function of X, that is,
with F being the cumulative distribution function (CDF) of X. The second one is connected to the past lifetime of X, namely
, which leads to the definition of the past entropy by Di Crescenzo and Longobardi (Citation2002) and past extropy by Kamari and Buono (Citation2021), as given below
(5)
(5)
(6)
(6)
Finally, the third one is based on doubly truncated random variables, that is, , and the corresponding versions of entropy and extropy in this framework are the interval entropy by Sunoj, Sankaran, and Maya (Citation2009) and the interval extropy by Buono, Kamari, and Longobardi (Citation2023), respectively expressed as
(7)
(7)
(8)
(8)
Further types of dynamic entropies and extropies have been considered in the literature, for example, the weighted and interval-weighted cumulative residual extropies in Hashempour, Kazemi, and Tahmasebi (Citation2022) and Mohammadi and Hashempour (Citation2022), respectively.
For two probability density functions f and g with support , the Kullback-Leibler (KL) divergence is defined by
(9)
(9)
We recall that the KL divergence is non-negative and it is equal to 0 if, and only if, f and g are identical almost everywhere. This property consents to using the estimated KL divergence as a goodness-of-fit test statistic, see Arizono and Ohta (Citation1989); Balakrishnan, Rad, and Arghami (Citation2007) for further details in this regard. Although it has many interesting properties, it has to be pointed out that the KL divergence is not a metric as it is not symmetric and does not fulfill the triangle inequality. Moreover, the KL divergence does not take the age of the components into account and thus it is not useful in comparing residual lifetime distributions. For this reason, Ebrahimi and Kirmani (Citation1996) proposed a new version of KL divergence, namely the residual KL divergence, defined as
3. ϕ-entropies and ϕ-divergences
Another generalization of Shannon entropy, known as ϕ-entropy, was proposed by Khinchin (Citation1957) with the idea of replacing the role of the logarithm in the definition of Shannon entropy with a different function while preserving some properties. Here, we recall the definition of non-negative and absolutely continuous random variables, as they are the object of interest in this study. Thus, let Φ be the class of all convex functions with continuous first two derivatives. Then, the ϕ-entropy of a pdf f with support
is defined by
(10)
(10)
The convexity assumption for ϕ is a physical and not mathematical requirement, since it is equivalent to having increasing entropy when mixing probability distributions. More precisely, considering a mixing probability density function of two pdf’s f1 and f2, and for some
, the convexity assumption gives
so that
. See Melbourne et al. (Citation2022) for some recent results and applications about the differential entropy of mixtures. Setting ϕ(x) = xlogx, the expression in (Equation10
(10)
(10) ) gives the definition of Shannon entropy in (Equation1
(1)
(1) ). Other characteristics ϕ-functions and corresponding ϕ-entropies are provided in .
Table 1. Some ϕ-functions and the corresponding ϕ-entropies for density functions with support .
3.1. Dynamic ϕ-entropies
The concept of ϕ-entropy has been further studied and developed in different directions. For example, new results for the corresponding cumulative version are given in Klein and Doll (Citation2020). Moreover, generalized dynamic ϕ-entropies have been introduced by Pape (Citation2015). In particular, for a function ϕ as defined above, the residual, interval, and past ϕ-entropy of a continuous pdf f with support are defined by
(11)
(11)
(12)
(12)
(13)
(13)
respectively.
For the dynamic versions of ϕ-entropies, the time points t can generally be interpreted as the time of an inspection in which it is known if the device, whose lifetime is described in terms of the pdf f, is working or not. Hence, monotonicity properties of ϕ-entropies in terms of t are of special interest. In this regards, the following monotonicity results of residual ϕ-entropies is proved in (Pape Citation2015, Theorem 4.7), for an absolutely continuous pdf f with hazard (or failure) rate function .
Theorem 3.1.
Let ϕ be a function such that is non-decreasing in x > 0. Furthermore, let, for an absolutely continuous pdf f, the survival function hf be non-increasing (non-decreasing). Then, the residual ϕ-entropy
is non-decreasing (non-increasing) in t > 0.
Note that there are many ϕ-functions satisfying the hypothesis in Theorem 3.1, as the function ϕ(x) = xlogx, related to the classical Shannon entropy and its dynamic versions. The Cressie and Read (C & R) ϕ-function (case (ii) in ) satisfies the assumption if, and only if, (and λ≠0). In addition, the ϕ-functions given in cases (iii) to (v) in satisfy such assumption.
3.2. ϕ-divergences and dynamic ϕ-divergences
In analogy to the introduction of ϕ-entropies, the concept of divergence has been generalized by Morimoto (Citation1963) and Ali and Sankaran (Citation1966), who independently introduced the ϕ-divergence. If f and g are two probability density functions with support , then the ϕ-divergence of f from g is defined as
(14)
(14)
where Φ* is the subclass of functions in Φ with ϕ(1) = 0,
,
(cf. Pardo Citation2005). The requirement ϕ(1) = 0 ensures that
if f = g. If ϕ is strictly convex at x = 1, then
if and only if f = g. Setting ϕ(x) = xlogx, (Equation14
(14)
(14) ) is reduced to the KL divergence (Equation9
(9)
(9) ).
Remark 1.
An important property states that two functions ϕ and ψ lead to the same ϕ-divergence, in the sense that for all the probability density functions f and g, if and only if there exists c∈ℝ such that
, for all x≥0 (see Liese and Vajda Citation1987). We call such a function ψ a representative of ϕ.
Based on dynamic ϕ-entropies and motivated by the definition of residual KL divergence in Ebrahimi and Kirmani (Citation1996), dynamic ϕ-divergences are introduced in Pape (Citation2015), to make comparisons between residual, past, and doubly truncated distributions. In particular, if f and g are probability density functions with support in and
, then, the residual, interval and past ϕ-divergence of f and g are, respectively, defined by
(15)
(15)
(16)
(16)
(17)
(17)
Divergences (Equation15(15)
(15) ) to (Equation17
(17)
(17) ) are further studied in Pape (Citation2015) (Chapter 5), proving standard properties of divergences and exploring their bounds. The following two results compare residual ϕ-divergences to ϕ-divergences (see Pape Citation2015, Theorems 5.4 and 5.6). They require the introduction of the concepts of new worse than used (NWU) and new better than used (NBU) for a cumulative distribution function (cdf). A cdf F is NWU (NBU) if
for all
.
Theorem 3.2.
Let ϕ be non-decreasing (or have a non-decreasing representative). Let further f and g be absolutely continuous probability density functions on and assume that
the ratio
is non-increasing (non-decreasing) in t≥0;
F is NWU (NBU) and G is NBU (NWU).
Then, for all t≥0.
Theorem 3.3.
Let ϕ be non-decreasing (or have a non-decreasing representative). Let further f and g be absolutely continuous probability density functions on and assume that
the ratio
hf(t) is non-decreasing (non-increasing) and hg(t) is non-increasing (non-decreasing) in t≥0.
Then, is non-increasing (non-decreasing) in t≥0.
Remark 2.
It is not possible to obtain analogous results of Theorems 3.2 and 3.3 about past ϕ-divergences. In fact, in both cases, it is not reasonable to ask for the requirements (ii) by reformulating them in terms of the cdf and the reversed hazard rate function. For Theorem 3.3, it is not possible to assume, in this case, a non-decreasing reversed hazard rate function. As far as Theorem 3.2 is concerned, the assumptions related to NBU/NWU should be reformulated in terms of the cdf, requiring . But we can easily observe that there do not exist non-negative distributions such that
for all
. In fact, if such a distribution exists, the inequality should be preserved by choosing x = t, such that
, leading to F2(x)≥F(2x) which is a contradiction as
. Moreover, analog results for the interval ϕ-divergences, corresponding to doubly truncated random variables, are not provided. They would require assumptions based on concepts, such as NBU or NWU, that are non established in this context and may also be not reasonable or of interest in this case.
4. Cressie-Read family of entropies and divergences
An important and flexible family of ϕ-functions is the parametric family studied by Cressie and Read (Citation1984). In our setup with x≥0, it is defined by
(18)
(18)
with its members controlled by the parameter λ. It is of interest thus to study H(λ)(f), that is the ϕ-entropy corresponding to the function ϕ(λ) in (Equation18
(18)
(18) ), defined by
(19)
(19)
Note that, if the support of the pdf f is , λ has to be taken greater than −1 in order to have finite entropy H(λ)(f). In fact,
and, with a non-positive exponent, this leads to an integrand function which does not converge to 0 at infinity. For λ→0,
and the corresponding ϕ-entropy in (Equation19
(19)
(19) ) converges to the Shannon entropy (Equation1
(1)
(1) ). An important choice of λ is λ = 1, corresponding to the Pearson entropy. In this case, (Equation18
(18)
(18) ) leads to
and (Equation19
(19)
(19) ) to
(20)
(20)
In reliability applications, truncated distributions may occur. For example, the truncated exponential distribution can be applied to pipeline reliability, wildfire size and earthquake magnitude distribution; see Cumming (Citation2001), Raschke (Citation2012) and Sheikh et al. Sheikh, Boahb, and Younasa (Citation1989) for further details. In case of a continuous density with bounded support, some order comparisons among members of the family in (Equation19(19)
(19) ) are possible, controlling the parameter λ, as stated below.
Theorem 4.1.
Let f be a pdf with bounded support S. Let further and
(c > 0). If
, for all x∈S, then
.
Proof.
From (Equation19(19)
(19) ), consider the difference between
and
, that is
For , the second term above is negative. If the integrand of the first term is positive, then
. Positivity of the integrand is equivalent to
which is the assumed restriction on f. ▪ ▪
The choice has been suggested by Cressie and Read (Citation1984) in the framework of goodness of fit testing, due to its performance in terms of power while, in a contingency table context, Espendiller and Kateri (Citation2016) proposed
for a scaled odds ratio based on the performance of the corresponding asymptotic confidence interval. Hence, for these λ-values, based on Theorem 4.1, in case of a pdf f with bounded support S,
and
, a sufficient condition to have
is given by
, for all x∈S.
Theorem 4.1 leads to the following result for comparing entropies with parameter λ chosen to be a natural number.
Corollary 4.1.
Let f be a pdf with bounded support S and let . If
for all x∈S, then
for all n∈N with n > n0.
Proof.
If we consider steps of size 1 (c = 1) in Theorem 4.1, the condition on the pdf becomes . Since
is decreasing in λ > 0, if this condition is satisfied for λ = n0 (i.e.,
), it will be satisfied for all λ > n0. Then, we obtain
where k∈ℕ with k > 2. ▪ ▪
Example 1.
Consider a truncated exponential distribution with parameter η and truncation point x0 = 0. 5. The pdf is then expressed by
For n0 = 10 and η chosen to be 0. 25, 0. 5, 0. 75, or 1, it is easy to verify that it satisfies the assumption in Corollary 4.1 which guarantees the monotonicity property about the entropies H(n)(f), as also illustrated in .
Figure 1. The values of H(n)(f) in Example 1 as a function of n.
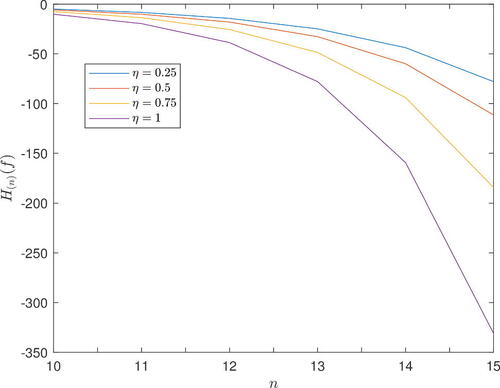
Remark 3.
Among the different generalizations of Shannon entropy, Tsallis entropy (Tsallis Citation1988) has attracted considerable attention due to its physical interpretation. With a parameter α > 0, α≠1, it is defined as
(21)
(21)
It is fair to note that (Equation21(21)
(21) ) was earlier proposed by Burbea and Rao (Citation1982, p. 578). The family of entropies (Equation21
(21)
(21) ) is strictly connected to (Equation19
(19)
(19) ) as, by choosing
, we have
for
, λ≠0. Consequently, also the extropy, corresponding to λ = 1, is closely related to the Tsallis entropy with parameter α = 2. Another example of one-parameter families of entropies that are linked to C & R is that introduced by Mathai and Haubold (Citation2007)
The authors commented that the larger is the value of 1−α, the larger is the information content and smaller the uncertainlty and vice versa. For this, they called 1−α as the strength of information. We can easily verify that , for
, λ≠0. The families of entropies considered so far are of non-logarithmic scale. The most popular family of logarithmic scaled entropies generalizing the Shannon entropy is the Rényi entropy
which is also functionally related to the C & R entropy, since
, for
, λ≠0.
In analogy to (Equation19(19)
(19) ), the ϕ-divergene (Equation14
(14)
(14) ) for the functions ϕ(λ) in (Equation18
(18)
(18) ), leads to the one-parameter family of Cressie–Read (C & R) divergences, defined by
(22)
(22)
For λ→0, D(λ) converges to the KL divergence (Equation9(9)
(9) ) while for λ = 1, it can be shown that D(1) coincides to the well-known Pearson’s X2. Notice that the ϕ-function considered by Pearson (Citation1900) was
. However ϕP is a representative of ϕ(1) (Remark 1 for ϕ = ϕ(1) and ψ(x) = ϕP with
) and thus D(1) = DP. In our context, we use ϕ(1) and not ϕP, since the latter does not define an entropy. An entropy based on ϕP would have been expressed as
, which is always equal to −∞.
5. Extropy as ϕ-entropy
In view of the C & R family of entropies discussed in Section 4, the extropy (Equation2(2)
(2) ) is directly related to the Pearson entropy (Equation20
(20)
(20) ), since
(23)
(23)
Analogously, dynamic versions of the extropy are linked to the corresponding Pearson entropies. Thus, the residual and past Pearson entropy are equal to the residual extropy (Equation4(4)
(4) ) and past extropy (Equation6
(6)
(6) ), respectively, plus a constant, since
(24)
(24)
(25)
(25)
The same connection holds also between the interval ϕ-entropy (Equation12(12)
(12) ) for ϕ(1) and the interval extropy (Equation8
(8)
(8) ), since
(26)
(26)
The expression of extropies in relation to Pearson entropies provides a new insight of extropies and enables the direct transfer of known results for entropies to extropies. Thus, since for given t the residual extropy Jr(f, t) and Pearson residual entropy differ only by a constant, they share the same monotonicity properties. For this, Theorem 3.1 for the ϕ-function ϕ(1), for which
is non-decreasing in x > 0, directly leads to the following result for the residual extropy.
Corollary 5.1.
Let f be an absolutely continuous pdf with non-increasing (non-decreasing) hazard rate function hf. Then, the residual extropy is non-decreasing (non-increasing).
Remark 4.
The monotonicity of the residual extropy has already been studied by Qiu and Jia (Citation2018). In fact, they have proved that if f(F−1(x)) is non-decreasing for x > 0, then the residual extropy is non-increasing in t > 0. Actually, the result given in Corollary 5.1 is more general as it requires a less strict assumption. In fact, if f(F−1(x)) is non-decreasing for x > 0, then hf is non-decreasing. Consider the first derivatives of f(F−1(x)) and hf(x),
Then, for x > 0, f(F−1(x)) is non-decreasing in x if and only if f′(x)≥0, whereas the hazard rate function hf is non-decreasing if, and only if, . Being
and f2(x) non-negative, from the assumption f′(x)≥0, it readily follows that hf is non-decreasing in x > 0. On the contrary, if hf is non-increasing then f(F−1(x)) is non-increasing but there is no result about the monotonicity of the residual extropy based on such an assumption.
In order to study the monotonicity of a past ϕ-entropy, a result analogous to that of Theorem 3.1 for the residual ϕ-entropy is proven next, based on the reversed hazard rate function .
Theorem 5.1.
Let ϕ be a function such that is non-decreasing in x > 0 and let f be an absolutely continuous pdf. If the reversed hazard rate function qf is non-increasing, then the past ϕ-entropy
is non-decreasing in t > 0.
Proof.
Consider the function which is non-decreasing by the assumptions. Then, the past ϕ-entropy can be rewritten in terms of ψ as
(27)
(27)
Now, since the past lifetime has cdf
and pdf
for
, by (Equation27
(27)
(27) ), it follows
where it has been used to change of variable
, such that
.
Since the function ψ is non-decreasing, if is non-increasing then
will be non-decreasing. Recall that for reversed hazard rate function of the past lifetime, we have
Then, it readily follows
(28)
(28)
Note that the inverse function of the cdf of the past lifetime can be obtained by
Then, from (Equation28(28)
(28) ), it follows
As F and F−1 are non-decreasing, then F−1(yF(t)) is non-decreasing in t > 0. Moreover, qf is non-increasing and so is non-increasing in t > 0 as well. Hence,
is non-decreasing and the proof is completed. ▪ ▪
Remark 5.
The result of Theorem 5.1 for the function ϕ(1), which corresponds to the monotonicity of the past extropy, follows as a corollary of Theorem 2.3 in Kamari and Buono (Citation2021). There it is stated that if f(F−1(x)) is non-increasing in x > 0, then the past extropy Jp(f, t) is non-decreasing in t > 0. Note that by considering the function ϕ(1), the hypothesis about the monotonicity of is satisfied. In addition, if
is non-increasing then the reversed hazard rate function qf(⋅) is non-increasing. In fact
and the first derivative of the reversed hazard rate function is expressed as
which is non-positive by assuming that
.
Remark 6.
In analogy with Theorem 3.1, it may seem of interest to consider Theorem 5.1 also for a non-decreasing reversed hazard rate function. But, as our purpose is to apply the results to non-negative random variables, this case is not of interest since there do not exist non-negative random variables with non-decreasing reversed hazard rate function (see Block, Savits, and Singh Citation1998). In addition, note that it is not possible to derive results similar to Corollary 5.1 and Theorem 5.1 related to the interval ϕ-entropy. In fact, the hazard and the reversed hazard rate function of a doubly truncated random variable are not equal to the ones of the original random variable, as it happens for the former and the residual life and for the latter and the past lifetime.
Remark 7.
The dynamic ϕ-divergence versions obtained with the function ϕ(1), provide the expressions for the divergences comparing the corresponding Pearson entropies of two densities. In particular, from (Equation15(15)
(15) ), we get the residual Pearson entropy divergence
Similar expression can be obtained for the interval Pearson entropy divergence and the past Pearson entropy divergence from (Equation16(16)
(16) ) and (Equation17
(17)
(17) ), respectively. Note that the function ϕ(1) has a non-decreasing representative (
), so that the results in Theorem 3.2 and 3.3 can be applied to the residual Pearson entropy divergence.
Due to the connection between the corresponding Pearsonian entropy and extropy expressions (Equation24(24)
(24) )–(Equation26
(26)
(26) ), one would expect that extropy-based divergences can be defined. For example, the residual extropy divergence would have been
. However, this is not possible, since the ϕ-function used for the definition of the extropy,
does not belong to Φ* (ϕ(1)≠0) and thus cannot be used for defining a divergence.
6. Examples
Example 2.
Consider an exponential distribution with parameter η > 0, , x≥0. Then, the generalized ϕ-entropy H(λ)(f) is obtained as
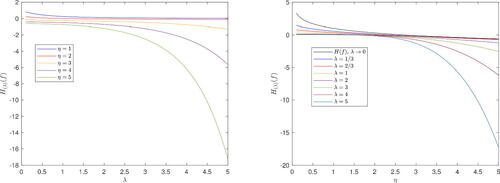
In (left), we plot the generalized entropy as a function of λ for representative fixed values of the parameter of the exponential distribution, while in (right), we fix the parameter λ and consider H(λ)(f) as a function of the parameter of the exponential distribution η. The Shannon entropy H(f), which corresponds to the limiting case λ→0, is also pictured. In both cases, we can observe a decreasing behavior in terms of λ or η. Moreover, in analogy with the classical continuous version of entropy, the generalized entropy H(λ)(f) is not always positive. In particular, the points in which there is a sign change in terms of η, with fixed λ, are reported in . There we can observe a decreasing nature of these change-sign points, which corresponds to a smaller region of the parameter space in which the entropy is non-negative.
Table 2. Values of η for fixed λ such that H(λ)(f) = 0 where f is the pdf of an exponential distribution.
Figure 2. Generalized entropy for exponential distribution in Example 2, plotted as a function of λ with fixed η on the left, and vice versa on the right.
Example 3.
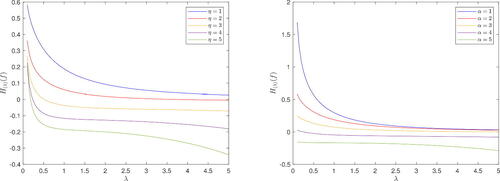
Consider a Weibull distribution with parameters α and η, with pdf , x≥0. In this case, we cannot evaluate analytically the expression of the generalized ϕ-entropies H(λ), but they can be computed numerically. In , H(λ)(f) is plotted as a function of λ with a fixed value of α = 2 and different choices for η, on the left, and a fixed value of η = 1 and different choices for α, on the right.
Figure 3. Generalized entropy for Weibull distribution in Example 3, plotted as a function of λ with fixed α = 2 and different choices for η on the left, and fixed η = 1 and different choices for α on the right.
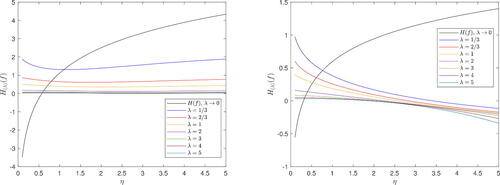
In , H(λ)(f) is plotted as a function of η by keeping fixed α = 0. 5 (on the left) or α = 2 (on the right), and with different choices for the parameter λ. The limiting case for λ→0 (Shannon entropy) is also included in these graphs. We observe a completely different behavior of the Shannon entropy with respect to the generalized versions of entropy. Moreover, in (left) there are some cases of non-monotonic generalized entropies.
Figure 4. Generalized entropy for Weibull distribution in Example 3, plotted as a function of η with fixed α = 0. 5 (left) or α = 2 (right) and different choices for λ.
Next, we make some comparisons between Weibull and exponential distributions by using generalized divergences (the results can be computed only numerically). Consider a Weibull pdf with parameters α and γ, , x > 0 and an exponential pdf with parameter η,
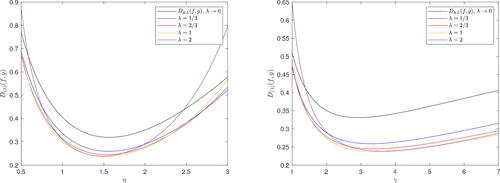
, x > 0. In order to have a finite divergence of f from g, D(λ)(f, g), we need α to be greater than 1. In this example, it will be fixed to 2. Note that if we want to consider the divergence of g from f, that is, D(λ)(g, f), α needs to be less than 1. In , the generalized divergence is plotted as a function of η with fixed γ = 2 (left), and as a function of γ with fixed η = 2 (right), for a selection of λ values, including the limiting case λ→0, which corresponds to DKL(f, g). The values of η and γ, for which the divergence values in reach their minimum, are given in .
Table 3. Values of η and γ for which the divergences in reach the minimum value.
Figure 5. Generalized divergence for exponential and Weibull distributions in Example 3, plotted as a function of η with fixed γ = 2 on the left, and vice versa on the right.
Example 4.
Consider a real data set (see Data Set 4.1 in Murthy, Xie, and Jiang Citation2004) presenting times to failure of 20 units:
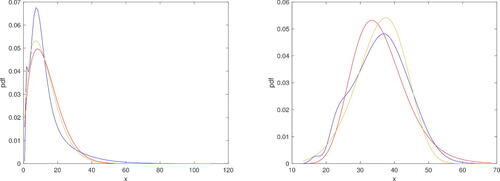
Suppose the data are distributed as a random variable X with pdf f. The probability density function can be estimated by a kernel estimator (e.g., with MATLAB function ksdensity). In order to establish if the distribution of the data is similar to a Weibull distribution W2(α, λ) with pdf g, we consider two different Weibull distribution, , with parameters given by the maximum likelihood method, and Y2∼ W2(1. 6, 0. 0127), already considered in Balakrishnan et al. (Citation2023). We remark that both distributions are accepted by applying the Kolmogorov-Smirnov test at a significance level of 5%. In (left), the estimated pdf of the data and the pdf’s g1, g2 of Y1, Y2 are plotted.
Figure 6. Plot of pdf’s of X (estimated), Y1 and Y2 in Example 4 (left) and in Example 5 (right) (blue, yellow and red lines, respectively).
As already pointed out in Balakrishnan et al. (Citation2023), with these distributions we have the same value of KL divergence,
Hence, to choose the more suitable distribution, an additional criterion was used in Balakrishnan et al. (Citation2023), based on a dispersion index of KL divergence, bringing to choose Y2. Here, we use the generalized divergences D(λ)(f, g) to make comparisons among Y1 and Y2 with different choices of the parameter λ. We find out that Y2 performs better than Y1, that is, it has lower measures of divergence, for λ > 0 with growing difference in λ. The results are presented in for some selected choices of λ. Hence, by using generalized divergences, we are able to overcome the problem of equal KL divergences and our results are consistent with the method proposed in Balakrishnan et al. (Citation2023).
Table 4. Values of D(λ)(f, g1) and D(λ)(f, g2) in Example 4 for different choices of λ.
Example 5.
Consider the crab dataset presented in Murphy and Aha (Citation1994). We focus our attention on the distribution of the width of female crabs, represented by the random variable X with pdf f, so that we have a sample of 100 units. As in Example 4, we first estimate the probability density function through a kernel estimator with MATLAB function ksdensity. We now wish to compare the distribution of the data with Weibull and Lognormal distributions. By using the maximum likelihood estimation, we choose Y1∼W2(5. 6162, 1. 1953e-09) and . We recall that if
, then the pdf is
, x > 0. Note that both distributions are accepted by using the Kolmogorov-Smirnov test at a significance level of 5%. In (right), the estimated pdf of the data and the pdf’s of Y1, Y2 are plotted. The comparison among these two distributions has been already performed in Balakrishnan et al. (Citation2023), where the values of KL divergence were computed as
and
. Although DKL(f, g1) is lower than DKL(f, g2), it can be noted that the values are similar and really close to zero. Hence, in that paper, they used an additional criterion, which brought to choose Y2 instead of Y1 by tolerating a slightly greater value of KL divergence. Now, we use the generalized divergences D(λ)(f, g) to make comparisons among Y1 and Y2 with different choices of the parameter λ. We find out that for λ > λ0 (λ0≃0. 185), Y2 starts to perform much better than Y1, i.e., it has lower measures of divergence with growing difference by increasing the value of λ. In particular for λ0 we have
. The results are presented in for some selected choices of λ. Hence, by using generalized divergences, we are able to overcome the problem of almost equal values of KL divergences and our results are consistent with the method proposed in Balakrishnan et al. (Citation2023).
Table 5. Values of D(λ)(f, g1) and D(λ)(f, g2) in Example 5 for different choices of λ.
7. Conclusion
Parametric families of entropies and associated divergences, generalizing Shannon’s entropy and the Kullback-Leibler (KL) divergence, respectively, play a predominant role in diverse scientific fields, ranging from physics to econometrics and reliability. In this article, we have discussed the concepts of generalized entropies and divergences with their corresponding dynamic versions, which are of special interest in reliability. We showed off that they introduce a kind of scale in measuring entropy. For example, focusing in the Cressie and Read (C & R) family of entropies, if there is a rough prior information about the area of value of η, we can decide for the scale (through the C & R parameter λ) in order to control the level of entropy (see ). We also linked the dual measure of Shannon entropy, namely the extropy, to the ϕ-entropies generated by the C & R ϕ-functions by proving that the extropy is a member of the C & R family of entropies. We provided several examples of generalized entropies for representative lifetime distributions to highlight the effect of the distributions’ parameter values and of the C & R parameter λ. Finally, the generalized divergences are employed for deciding on the distribution underlying real data in two examples. We verified in both cases that specific λ-values performed better than the well-known KL divergence. In reliability applications, various types of censoring often occur. In future research, it would be of interest to investigate the properties of generalized entropies and divergences under censoring. Furthermore, the extension of the study under assumptions corresponding to different reliability aging classes may lead to new results for the associated residual, past and interval measures.
Acknowledgments
FB is member of the research group GNAMPA of INdAM (Istituto Nazionale di Alta Matematica).
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Ali, S. M., and S. D. Silvey. 1966. A general class of coefficients of divergence of one distribution from another. Journal of the Royal Statistical Society Series B: Statistical Methodology 28 (1):131–42. doi:10.1111/j.2517-6161.1966.tb00626.x.
- Amigó, J., S. Balogh, and S. Hernández. 2018. A brief review of generalized entropies. Entropy 20 (11):813. doi:10.3390/e20110813.
- Arizono, I, and H. Ohta. 1989. A test for normality based on Kullback-Leibler information. The American Statistician 43 (1):20–2. doi:10.1080/00031305.1989.10475600.
- Balakrishnan, N., F. Buono, C. Calí, and M. Longobardi. 2023. Dispersion indices based on Kerridge inaccuracy measure and Kullback-Leibler divergence. Communications in Statistics - Theory and Methods 53 (15):5574–92. doi:10.1080/03610926.2023.2222926.
- Balakrishnan, N., A. H. Rad, and N. R. Arghami. 2007. Testing exponentiality based on Kullback-Leibler information with progressively Type-II censored data. IEEE Transactions on Reliability 56:349–56.
- Block, H. W., T. H. Savits, and H. Singh. 1998. The reversed hazard rate function. Probability in the Engineering and Informational Sciences 12 (1):69–90. doi:10.1017/S0269964800005064.
- Buono, F., O. Kamari, and M. Longobardi. 2023. Interval extropy and weighted interval extropy. Ricerche Di Matematica 72 (1):283–98. doi:10.1007/s11587-021-00678-x.
- Burbea, J. 1984. The Bose-Einstein entropy of degree alpha and its Jensen difference. Utilitas Mathematicas 25:225–40.
- Burbea, J., and C. Rao. 1982. Entropy differential metric, distance and divergence measures in probability spaces: A unified approach. Journal of Multivariate Analysis 12 (4):575–96. doi:10.1016/0047-259X(82)90065-3.
- Cressie, N., and T. R. Read. 1984. Multinomial goodness-of-fit tests. Journal of the Royal Statistical Society Series B: Statistical Methodology 46 (3):440–64. doi:10.1111/j.2517-6161.1984.tb01318.x.
- Cumming, S. G. 2001. A parametric model of the fire-size distribution. Canadian Journal of Forest Research 31 (8):1297–303. doi:10.1139/x01-032.
- Devarajan, K., G. Wang, and N. Ebrahimi. 2015. A unified statistical approach to non-negative matrix factorization and probabilistic latent semantic indexing. Machine Learning 99 (1):137–63. doi:10.1007/s10994-014-5470-z. 25821345
- Di Crescenzo, A., and M. Longobardi. 2002. Entropy-based measure of uncertainty in past lifetime distributions. Journal of Applied Probability 39 (2):434–40. doi:10.1239/jap/1025131441.
- Di Crescenzo, A., and M. Longobardi. 2009. On cumulative entropies. Journal of Statistical Planning and Inference 139 (12):4072–87. doi:10.1016/j.jspi.2009.05.038.
- Crescenzo, A. D., and M. Longobardi. 2015. Some properties and applications of cumulative Kullback–Leibler information. Applied Stochastic Models in Business and Industry 31 (6):875–91. doi:10.1002/asmb.2116.
- Ebrahimi, N. 1996. How to measure uncertainty in the residual life time distribution. Sankhyoverlinea: Series A 58:48–56.
- Ebrahimi, N., and S. Kirmani. 1996. A measure of discrimination between two residual life-time distributions and its applications. Annals of the Institute of Statistical Mathematics 48 (2):247–65.
- Espendiller, M., and M. Kateri. 2016. A family of association measures for 2 × 2 contingency tables based on the ϕ-divergence. Statistical Methodology 30:45–61. doi:10.1016/j.stamet.2015.12.002.
- Hashempour, M., M. R. Kazemi, and S. Tahmasebi. 2022. On weighted cumulative residual extropy: characterization, estimation and testing. Statistics 56 (3):681–98. doi:10.1080/02331888.2022.2072505.
- Havrda, J., and F. Charvat. 1967. Concept of structural alpha-entropy. Kybernetika 3:30–5.
- Iranpour, M., M. A. Hejazi, and M. Shahidehpour. 2020. A unified approach for reliability assessment of critical infrastructures using graph theory and entropy. IEEE Transactions on Smart Grid 11 (6):5184–92. doi:10.1109/TSG.2020.3005862.
- Kamari, O., and F. Buono. 2021. On extropy of past lifetime distribution. Ricerche Di Matematica 70 (2):505–15. doi:10.1007/s11587-020-00488-7.
- Kang, H. Y, and B. M. Kwak. 2009. Application of maximum entropy principle for reliability-based design optimization. Structural and Multidisciplinary Optimization 38 (4):331–46. doi:10.1007/s00158-008-0299-3.
- Kapur, J. N. 1972. Measures of uncertainty, mathematical programming and physics. Journal of the Indian Society of Agriculture and Statistics 24:47–66.
- Khinchin, A. I. 1957. Mathematical foundations of information theory. New York: Dover Publications.
- Klein, I., and M. Doll. 2020. (Generalized) maximum cumulative direct, residual, and paired Φ entropy approach. Entropy 22 (1):91. doi:10.3390/e22010091.
- Kullback, S., and R. A. Leibler. 1951. On information and sufficiency. The Annals of Mathematical Statistics 22 (1):79–86. doi:10.1214/aoms/1177729694.
- Lad, F., G. Sanfilippo, and G. Agrò. 2015. Extropy: Complementary dual of entropy. Statistical Science 30:40–58.
- Liese, F., and I. Vajda. 1987. Convex statistical distances. Leipzig: Teubner.
- Maasoumi, E., and J. Racine. 2002. Entropy and predictability of stock market returns. Journal of Econometrics 107 (1-2):291–312. doi:10.1016/S0304-4076(01)00125-7.
- Mathai, A. M., and H. J. Haubold. 2007. Pathway model, superstatistics, Tsallis statistics, and a generalized measure of entropy. Physica A: Statistical Mechanics and Its Applications 375 (1):110–22. doi:10.1016/j.physa.2006.09.002.
- Melbourne, J., S. Talukdar, S. Bhaban, M. Madiman, and M. V. Salapaka. 2022. The differential entropy of mixtures: new bounds and applications. IEEE Transactions on Information Theory 68 (4):2123–46. doi:10.1109/TIT.2022.3140661.
- Mohammadi, M., and M. Hashempour. 2022. On interval weighted cumulative residual and past extropies. Statistics 56 (5):1029–47. doi:10.1080/02331888.2022.2111429.
- Morimoto, T. 1963. Markov processes and the H-theorem. Journal of the Physical Society of Japan 18 (3):328–31. doi:10.1143/JPSJ.18.328.
- Murphy, P. M., and D. W. Aha. 1994. UCI Repository of machine learning databases. Berkeley, CA: University of California, Department of Information and Computer Science, http://www.ics.uci.edu/mlearn/MLRepository.html.Irvine.
- Murthy, D. N. P.,M. Xie, and R. Jiang, 2004. Weibull models. Hoboken, NJ: John Wiley & Sons.
- Pape, N. T. 2015. Phi-divergences and dynamic entropies for quantifying uncertainty in lifetime distributions. M.Sc. thesis, Aachen, Germany: Department of Mathematics, RWTH Aachen University.
- Pardo, L. 2005. Statistical inference based on divergence measures. Boca Raton, FL: Chapman and Hall/CRC.
- Pearson, K. 1900. X. On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling. The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science 50 (302):157–75. doi:10.1080/14786440009463897.
- Qiu, G., and Kai. Jia. 2018. The residual extropy of order statistics. Statistics & Probability Letters 133:15–22. doi:10.1016/j.spl.2017.09.014.
- Rao, M., Y. Chen, B. C. Vemuri, and F. Wang. 2004. Cumulative residual entropy: A new measure of information. IEEE Transactions on Information Theory 50 (6):1220–8. doi:10.1109/TIT.2004.828057.
- Raschke, M. 2012. Inference for the truncated exponential distribution. Stochastic Environmental Research and Risk Assessment 26 (1):127–38. doi:10.1007/s00477-011-0458-8.
- Ruggeri, F., M. Sánchez-Sánchez, M. Á. Sordo, and A. Suárez-Llorens. 2021. On a new class of multivariate prior distributions: Theory and application in reliability. Bayesian Analysis 16:31–60.
- Shannon, C. E. 1948. A mathematical theory of communication. Bell System Technical Journal 27 (3):379–423. doi:10.1002/j.1538-7305.1948.tb01338.x.
- Sheikh, A. K., J. K. Boah, and M. Younas. 1989. Truncated extreme value model for pipeline reliability. Reliability Engineering & System Safety 25 (1):1–14. doi:10.1016/0951-8320(89)90020-3.
- Shi, X., A. P. Teixeira, J. Zhang, and C. Guedes Soares. 2014. Structural reliability analysis based on probabilistic response modelling using the Maximum Entropy Method. Engineering Structures 70:106–16. doi:10.1016/j.engstruct.2014.03.033.
- Singh, V. B., M. Sharma, and H. Pham. 2018. Entropy based software reliability analysis of multi-version open source software. IEEE Transactions on Software Engineering 44 (12):1207–23. doi:10.1109/TSE.2017.2766070.
- Soofi, E. S. 1994. Capturing the intangible concept of information. Journal of the American Statistical Association 89 (428):1243–54. doi:10.1080/01621459.1994.10476865.
- Soofi, E. S. 2000. Principal information theoretic approaches. Journal of the American Statistical Association 95 (452):1349 doi:10.2307/2669786.
- Sunoj, S. M., P. G. Sankaran, and S. S. Maya. 2009. Characterizations of life distributions using conditional expectations of doubly (interval) truncated random variables. Communications in Statistics - Theory and Methods 38 (9):1441–52. doi:10.1080/03610920802455001.
- Tsallis, C. 1988. Possible generalization of Boltzmann-Gibbs statistics. Journal of Statistical Physics 52 (1-2):479–87. doi:10.1007/BF01016429.
- Weijs, S. V., R. Van Nooijen, and N. Van De Giesen. 2010. Kullback–Leibler divergence as a forecast skill score with classic reliability–resolution–uncertainty decomposition. Monthly Weather Review 138 (9):3387–99. doi:10.1175/2010MWR3229.1.