
Abstract
For e-resource librarians, maintaining e-book and e-journal holdings within electronic resource management systems is a labor intensive and often manual process. In 2014, with the aim of saving library staff valuable time and effort, the Online Computer Library Center, Inc. (OCLC) launched a service to provide automated holdings management within the WorldCat knowledgebase. For a select group of content providers, including some of the largest e-book aggregators, holdings information can be populated and updated automatically within the knowledgebase without intervention from library staff. At the University of Toronto Libraries, we conducted a study to assess the accuracy and efficiency of these automated holdings management services. This presentation outlines the results of the study and provides suggestions for further improvement to the current services offered.
INTRODUCTION
Since the early days of e-resource management, holdings maintenance for electronic resources has been a time consuming and manual process. While the emergence of electronic resource management (ERM) systems has improved this process to a significant extent, holdings maintenance tasks remain labor intensive due to the increased volume of electronic content to manage, as well as issues related to metadata quality. To ameliorate many of the problems associated with managing electronic resources, and in recognition of a need for greater accuracy and efficiency, some knowledgebase providers are starting to offer libraries options to automate holdings maintenance for electronic resources. In 2014, the Online Computer Library Center, Inc. (OCLC) developed a service to provide automated holdings management for a select group of content providers. Within the WorldCat knowledgebase, library specific holdings for e-book and e-serial collections can be maintained without the need for library staff to manually intervene. At the University of Toronto Libraries (UTL), we devised a study to test the accuracy and efficiency of OCLC’s automated holdings management service. For three content providers, we conducted an ongoing comparison between the library’s holdings list and the title lists supplied by the automated service. This presentation outlines the results of this investigation, highlighting the benefits and drawbacks of auto loading content, and provides a vision of what automated holdings management services could look like in the future.
THE CURRENT E-RESOURCE ENVIRONMENT
In recent years, most academic library collection budgets have shifted strongly toward digital holdings. At the University of Toronto Libraries, ranked third by Association of Research Libraries (ARL), we now have a collection of well over two million electronic resources. Currently, UTL’s overall acquisitions budget is approximately $29 million dollars, 60% of which is allocated to electronic resources. While the library maintains a strong collection of e-book content, the majority of the e-resource acquisitions budget is consumed by ongoing subscriptions, such as electronic serials and database products.
Just as the nature of the collection and spending patterns of libraries have changed over time, so has the environment in which we operate. In the digital environment, the library is only one of several players that have a role in providing access to electronic resources. In addition to libraries, we now have content providers that create and host electronic resources, knowledgebase and link resolver vendors that help manage access to e-resources, and subscription agents that work to facilitate the purchase of electronic content. We are now working in an environment where there are more interdependencies than ever; the success of these relationships are all based on the accurate and efficient transfer of metadata through the electronic resource supply chain.
How does e-resource metadata flow through the supply chain? As part of the e-resource acquisition process, content providers and subscription agents typically provide libraries with title lists of the purchased content. For libraries using ERM systems, there is an expectation that content providers will also supply knowledgebase vendors with metadata for the electronic content packages that are sold to libraries. Knowledgebase vendors use the metadata supplied by content providers to populate and maintain correct title and target data within the knowledgebase. Once the metadata is available within the knowledgebase, libraries are then able to configure their ERM system to reflect the library’s holdings, thereby enabling user access through library discovery systems.
ELECTRONIC RESOURCE MANAGEMENT CHALLENGES
Despite advances in technology to support electronic resource management, holdings maintenance remains a time consuming and highly manual process. Although there are methods for batch ingesting and outputting metadata, there is still a great deal of selection and data manipulation that is required to properly reflect library holdings within ERM systems. Serial coverage dates often need adjustment to reflect library subscriptions and individual e-book titles must be selected from large aggregator packages. Additionally, since e-resource packages are often nonstandard and do not completely mirror the content packages represented within the knowledgebase, library staff are constantly selecting or deselecting titles to properly reflect the library’s holdings.
Metadata quality is another significant challenge for libraries in managing electronic resources. Quite often, metadata supplied by content providers is incomplete or inaccurate. Some of the most commonly reported problems with e-resource metadata include: missing titles, inconsistencies in the use of standard identifiers, and incorrect coverage dates. Particularly with e-serial publications, it is not uncommon to find title changes, title transfers, and ceased titles improperly recorded in the metadata. These metadata inaccuracies have consequences for libraries, as staff are required to investigate title histories and adjust metadata within the ERM system to correctly document e-resource subscriptions.
Time lags are another shortcoming of the electronic resource management process. Since libraries are dependent on metadata that is produced by external parties, there are often delays in providing access to resources. It is common for libraries to experience a time lag between the purchase of electronic materials and the production of title lists and metadata for discovery purposes. Similarly, there are often delays in loading content provider metadata into knowledgebase systems. With all the time lags within the ERM process, the greater the chance that some e-resources will get neglected.
Perhaps the most fundamental challenge in e-resource management is that there are simply too many intermediaries in the process. Electronic resources exist in remote locations, yet the processes we use to manage them still rely on people to pass around information about a library’s holdings. In the current environment, metadata is pushed from content providers to libraries and from content providers to knowledgebase vendors. Within libraries, metadata is transferred between individuals, usually via e-mail. Metadata is passed through many hands in the e-resource data supply chain; sometimes the chain breaks and resources are lost along the way. To overcome these shortcomings and achieve greater accuracy and efficiency in the e-resource management process, we need to develop ways to transfer metadata from the content provider to the library systems that facilitate user access with as few intermediaries as possible.
OCLC’S AUTOMATED HOLDINGS MANAGEMENT
Starting in late 2013, with a new partnership between OCLC and Proquest, libraries began hearing about processes for automating holdings management for the large e-book aggregators, ebrary and EBL Ebook Library.Footnote1 In this new scenario, the electronic resource management process becomes increasingly streamlined. Libraries can request that content providers supply OCLC with metadata for institution-specific holdings. Using a fully automated process, OCLC then activates the library specific subscriptions in the WorldCat knowledgebase. As part of the automated load process, the content provider resends metadata on a regular schedule, either weekly, biweekly, or monthly. OCLC then reloads metadata to reflect new additions, changes, deletes or enhancement to the master record in WorldCat. Through the automated holdings management process, electronic resources are made available for discovery without the need for library staff to manually intervene. As previously noted, OCLC’s automated holdings management service began with the two largest e-book aggregators: ebrary and EBL Ebook Library. Additional automated load services have been established for Ingram MyiLibrary e-books, JSTOR e-books, Elsevier’s ScienceDirect e-book and e-serial content and Teton Data Systems’ Stat!Ref collection.Footnote2
THE RESEARCH STUDY—DESCRIPTION AND METHODOLOGY
The promise of a fully automated process to maintain electronic resource holdings is, understandably, quite appealing to libraries. To determine whether OCLC’s automated holdings management services live up to expectations, we conducted a research study to investigate the accuracy and efficiency of the service. The study explored the following research questions:
How well do automated loads reflect the library’s purchased electronic content?
What types of collections are ideal for automated holdings maintenance?
How quickly do titles get into the system using the automated service?
How is the loaded content organized in relation to the library’s licensing agreements?
Does the service provide adequate reporting to enable libraries to monitor their collections?
The study began in September 2014 and was initiated by requesting automated data feeds for all content providers for which the University of Toronto Libraries purchased content. For a period of 8 months, the WorldCat knowledgebase was monitored regularly. Each time a new data feed was uploaded into the knowledgebase, a corresponding holdings report was retrieved from the content provider’s website. The resulting title lists were uploaded into a MySQL database where the data was manipulated to make it suitable for comparison. Custom scripting was utilized to query the data to determine the matched and unmatched titles between the files.
STUDY RESULTS
ebrary
The data feed provided by ebrary covers titles contained in the “All Perpetual Purchased and Available Titles” collection. Within the documentation for OCLC’s automatic collection loading service, it states that ebrary content will be loaded every two weeks. In addition to loading individual purchases, the service is also available to manage patron-driven acquisition (PDA).Footnote3 During the course of the study, a total of 10 data feeds were available for analysis. As illustrated in , the number of titles loaded into the WorldCat knowledgebase consistently lags behind the number of titles available in the content provider’s holdings report. It was only in the final load cycle that the number of e-book titles on the content provider’s list matched perfectly with the number of titles represented within the knowledgebase. In cases where purchased titles were absent from the automated feed, the data analysis revealed that the majority of the missing titles were present in the next subsequent data feed. For these e-book titles, it was simply a matter of timing that prevented the titles from being entered into the knowledgebase. Another observation drawn from the data is that the load dates for the ebrary content did not follow a predictable biweekly schedule. Intervals between data loads ranged from a week to up to a month. Within academic libraries, individual title purchases are often initiated by faculty requests and are eagerly awaited. A delay of up to a month between the acquisition of the e-book and availability within the ERM system may go beyond the standard of acceptable service.
Figure 1. Comparison of URLs in ebrary holdings report vs. WorldCat knowledgebase automated data feed.
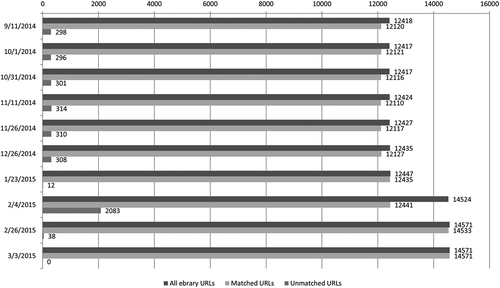
In the analysis of ebrary content, it is important to note that initially the number of e-book titles within the study represented only a fraction of UTL’s ebrary purchases. Content on the ebrary platform that was acquired through various package deals were not represented in the automated data feed. Midway through the study, however, these ebrary content packages were added as separate collections in the knowledgebase, resulting in approximately 77,000 additional titles activated in the ERM and managed by the automated process. To ensure that the comparisons remained consistent through time, only the titles that formed part of the “All Perpetual Purchased and Available Titles” collection were considered for the study.
MyiLibrary
The Ingram MyiLibrary data feed covers all titles available on the MyiLibrary platform. Within the documentation for the automated holdings management service, OCLC states that e-book metadata will be loaded weekly into the WorldCat knowledgebase.Footnote4 As illustrated in , for each data feed uploaded, there was a high degree of matching between the holdings report obtained from the provider and the WorldCat knowledgebase title list. At the outset of the study, these findings appeared to be promising, however, it was later revealed that the holdings report supplied by the content provider was missing a large number of titles that UTL has access to on the MyiLibrary platform. Over 9,600 titles were missing from the content provider’s holdings report, and similarly, the same titles were also missing from the data feed supplied to the WorldCat knowledgebase. Therefore, while the automated data feed almost perfectly matched the MyiLibrary holdings report, neither list accurately reflected the content available to the library on the MyiLibrary platform.
Figure 2. Comparison of URLs in MyiLibrary holdings report vs. WorldCat knowledgebase automated data feed.
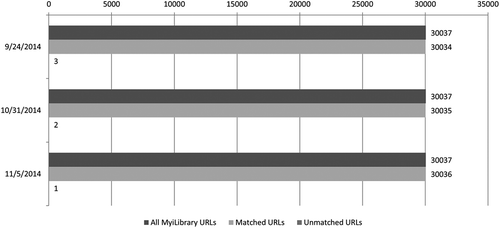
Just as the data feed did not produce satisfactory results, the frequency of metadata delivery also indicates that the MyiLibrary automated load service is not performing up to expectations. As previously noted, MyiLibrary content is loaded weekly into the WorldCat knowledgebase. With only three data feeds loaded throughout the course of the study, it is clear that there are metadata delivery issues that need to be resolved.
A final observation worth noting is that all e-book content, whether individually purchased or part of a package deal, is registered in a single content package within the WorldCat knowledgebase. Within ERM systems, license details are typically attached at the content package level, not at the individual title level. Therefore, if electronic resources are not represented as part of the content packages to which they belong, this becomes an impediment to attaching licensing information to a particular e-resource.
Elsevier ScienceDirect
The Elsevier ScienceDirect automated data feed covers all content available on the ScienceDirect platform. In OCLC’s documentation for the automatic collection loading service, it states that metadata will be loaded weekly into three distinct Elsevier collections in the WorldCat knowledgebase.Footnote5 Of all the collections analyzed in the study, the Elsevier collection was the most challenging to work with due to the fact that ScienceDirect content includes multiple publication types and multiple collections within the knowledgebase. Within the Elsevier holdings report, there were six publication types represented: journals, books, book series, book series volumes, reference works, and handbook series. Each of these publication types had to fit within three collections in the knowledgebase: Elsevier ScienceDirect Journals, ScienceDirect Book Series, and ScienceDirect All Books.
While one would assume that the task of categorizing publication types into knowledgebase collections should be relatively straightforward, it was the book series volumes, reference works and handbook series that caused a great deal of confusion. In the early stages of the study, there was a significant number of book series volumes that were missing from the automated data feed. Another issue with the data feed was that content shifted from one collection to another. For example, it was observed that handbooks series shifted from the book series collection to the journal collection. Additionally, it was noted that e-books were often contained in more than one package in the knowledgebase. With all of the content shifting between content packages within the knowledgebase, this made it difficult to match the titles and analyze the data through time. In order to gain meaningful results, it was necessary to devise a new approach for matching subscribed ScienceDirect titles to the WorldCat knowledgebase. It was determined that by treating ScienceDirect as a singular collection and comparing distinct Uniform Resource Locators (URLs), this would result in a more accurate picture of what content was actually being activated within the knowledgebase.
During the course of the study, a total of 22 data feeds were available for analysis. Unlike the other collections analyzed in the study, what was most striking about the ScienceDirect data feed was its punctuality. Throughout the study, the weekly load schedule was generally consistent, with only a few minor delays. In the analysis of ScienceDirect content, we see progressive improvements to the service through time. As illustrated in , in the early data feeds there were approximately 1,200 titles, primarily book series volumes, that were missing from the data feed. However, at the beginning of November 2014, there appeared to be a reorganization of the content contained in the ScienceDirect collections. This adjustment within the knowledgebase improved the data feed considerably and the number of missing titles dropped dramatically. By analyzing the missing titles from one data feed in relation to the titles available in the next subsequent feed, it was noted that the majority of missing titles were present in the following load. In these cases, it can be argued that these resources were not truly missing from the data feed, they were simply delayed by a week. Upon termination of the study, all unmatched ScienceDirect titles were compared against the Worldcat knowledgebase, resulting in only 20 titles not found. The number of missing titles accounts for only 0.1% of all titles that the University of Toronto Libraries subscribes to on the ScienceDirect platform. With such a low percentage of missing titles, it is difficult to characterize the Elsevier automated holdings management service as anything but a success.
Figure 3. Comparison of URLs in Elsevier ScienceDirect holdings report vs. WorldCat knowledgebase automated data feed.

An ERM promise fulfilled?
What is the verdict on automated holdings maintenance? Is it an ERM promise fulfilled? From the study results, we can conclude that auto loading e-resource content is a welcomed change for electronic resource management. These services can not only save librarians time and effort in maintaining e-resource collections, they can also lead to increased accuracy. Automated holdings management is particularly well suited for collections where manual selection is necessary. For instance, single title purchases from aggregator platforms always require individual selection within ERM systems. The use of automated data feeds is also complimentary to PDA programs; as e-books are triggered for purchase, these titles are activated in the library’s purchased content file. Automated holdings management services can also be extremely useful for frontlist content where the library does not know exactly which titles they will be receiving in the upcoming year. With an automated process, when titles are activated on the content provider’s website, the metadata is automatically sent to the knowledgebase.
SOME REMAINING CHALLENGES
While automated holdings maintenance is a major leap forward for electronic resource management, there are still some challenges that need to be overcome. The most significant challenge associated with automated data feeds is that libraries are completely reliant on the accuracy of the metadata produced by the content provider. If a library experiences problems, particularly in relation to titles not being represented within the data feed, these issues must be addressed by the content provider at the top of the data supply chain. In the current environment, a library would normally make manual corrections within the ERM system to account for content provider data errors. However, with automated data feeds, any manual changes made within the ERM system will be overwritten each time the data is reloaded. Therefore, any metadata corrections must be dealt with at the source. Another challenge associated with automated holdings maintenance is that the time lag between loads can sometimes be too long. Libraries have expectations of an acceptable time between the acquisition and availability of content in discovery systems; a delay of greater than a month seems to push the boundaries of acceptable service.
POSSIBLE AREAS OF IMPROVEMENT
Having now seen what is possible with automated holdings maintenance, this naturally makes one think about ways that the service can be further improved to help libraries cope with the arduous task of e-resource management. What follows is a suggested list of enhancements to the current services offered.
SEAMLESS UPDATES
Throughout the study, electronic resource holdings were updated within the WorldCat knowledgebase, however, the frequency of the loads often did not live up to expectations. A significant improvement to automated holdings management services would be to have content on the vendor site synched daily with the knowledgebase. If there is no human labor involved in the automated load process and if we are relying on scripts to generate holdings reports, there appears to be no reason why data feeds cannot be uploaded more frequently.
BETTER REPORTING CAPABILITIES
Another possible area of improvement concerns the reporting capabilities within the WorldCat knowledgebase. Presently, library staff must actively check the activity history within the WorldShare Collection Manager to see if content has been uploaded. The service would be improved if libraries received automatic notifications when their holdings are loaded into the system. Similarly, it would be helpful to be notified when content could not be loaded into the system due to metadata errors. In the current service, libraries are able to download the OCLC holdings report and identify invalid entries that failed to load into the knowledgebase. However, what is missing from the report is any human readable indication of what the invalid titles are. The reports contain no bibliographic data, no URLs, and no standard identifiers; therefore, they are not very useful to libraries in identifying missing titles. The reports produced by the system would be of greater value to libraries if they contained more metadata elements to identify publications. Along with improved reports, it would also be beneficial to establish an effective feedback loop where libraries can report any anomalies they see in the automated load process. It is only though testing and feedback that we can improve service.
HELP WITH SINGLE JOURNAL SUBSCRIPTIONS
One aspect of the holdings maintenance process that requires significant improvement is the management of single journal subscriptions. Individually purchased serials take up a disproportionate amount of time and they often cause the most problems. It would be helpful to consolidate the process of registering the subscription on the vendor site and activating the journal within the ERM system. There has been much talk recently about the role of subscription agents in the e-resource environment. One wonders if there are some new opportunities for subscription agents in this area. If subscription agents could develop a service that facilitates the purchase, registration, and automated loading of titles within the ERM system, this could be extremely valuable to libraries.
CONCURRENT USERS
Documenting concurrent user limits within the automated holdings management process is another potential area for improvement. At the University of Toronto Libraries, we aim to provide users with information concerning concurrent user limits for e-resources. This information is important because it helps faculty make sound decisions regarding e-reserves and course reading lists and also helps to manage the expectations of our users. With the current automated load services, all e-books for aggregator packages are loaded in a single collection in the knowledgebase. To facilitate better management of these resources, it would be preferable if single-user and multi-user books are loaded into separate collections in the knowledgebase. Such a modification to the system would better facilitate the communication of concurrent user information to library patrons.
GREATER PARTICIPATION
The most fundamental improvement that could be made to the automated holdings management service is to encourage more content providers to participate. The current services available are only the tip of the iceberg. With all of the collections analyzed in the study, including the additional ebrary collections that were added midway through, the number of titles managed using automated data feeds accounts for only 6.5% of the University of Toronto Libraries’ e-resource holdings. For libraries to see a real change to electronic resource management processes, we need greater participation among content providers.
CONCLUSION
How are we going to get there? How do we shift from a process that contains many inefficiencies to one that runs like clockwork? If we are going to change the way we manage electronic resources, we need a few things to come together. Most fundamentally, we need cooperation between the various stakeholders in the the data supply chain. Librarians, content providers and knowledgebase vendors need to agree that autoloading institution-specific e-resource holdings is a viable and achievable solution. Once we agree on the goal, it is essential for content providers and knowledgebase vendors to engage in system development work to make the automatic loading of e-resource content possible. To ensure the success of these services, metadata must be expressed in a standardized format and reflect institutional subscriptions accurately. While the bulk of the technical work will fall on the shoulders of content providers and knowledgebase vendors, libraries can also support these advancements by encouraging providers to supply automated data feeds. In the establishment of automatic loading capabilities, librarians can also play an important role in testing processes and providing feedback. It is only with customer feedback that we can continually improve services.
In 1993, Harold Billings wrote an article entitled “Supping With the Devil: New Library Alliances in the Information Age”. In this article, Billings states: “Above all, perhaps, librarians and publishers should sit down at a table of common purpose and join again in what has always been a necessary partnership: to publish and make available the ideas and creative works of authors.”Footnote6 This statement holds true today with one exception: we need to add knowledgebase vendors into the equation. In a digital environment, we need content providers, knowledgebase vendors, and libraries to work together towards creative solutions that will not only improve the process of e-resource management, but ultimately improve e-resource access for the user at the center of all that we do.
Additional information
Notes on contributors
Marlene van Ballegooie
Marlene van Ballegooie is a Metadata Librarian at the University of Toronto Libraries.
Notes
1. OCLC, “OCLC and ProQuest Work Together to Automate e-Book Collection Management,” https://oclc.org/news/releases/2013/201347dublin.en.html. (accessed July 28, 2015).
2. OCLC, “Providers and Contacts for Automatic Collection Loading,” http://www.oclc.org/support/services/collection-manager/documentation/service-specific-settings/ebookproviders.en.html (accessed July 28, 2015).
3. Ibid.
4. Ibid.
5. Ibid.
6. Harrold Billings, “Supping With the Devil: New Library Alliances in the Information Age,” Wilson Library Bulletin 68, no. 2 (1993): 36.