
ABSTRACT
Traditional methods of collections evaluation and assessment that focus on the journal container are increasingly in tension with both user experience and academic discovery systems design, both of which prioritize the individual item or article. This paper explores the potential applications and limitations of a new metric, the full text coverage ratio (FTCR), for revealing new insights about academic serials collections. Given a discovery service search that represents a particular subject area, the FTCR is the ratio between the number of items returned by a search scoped to full text and its corresponding “expanded” or un-scoped search. While the idea itself offers the potential for valuable and actionable insights, it may be that further analysis and refinement is required before it can be more widely adopted. This paper will describe these ratios in more detail, explain how they can be calculated, discuss some premises or prerequisites they require, present some of their limitations, briefly describe an application already pursued at one particular institution, and suggest additional applications and potential future directions for research in this area.
At its broadest, the basic idea presented in this paper is that discovery services have the potential to provide valuable and unique insights into an academic library’s serials collections. This idea is too broad to explore exhaustively here, but it is hoped that this contribution might spark further investigations into its practical applications.
More specifically, this paper will present and examine one way in which discovery services might provide valuable metrics for collections evaluation and assessment: full text coverage ratios (FTCRs). These very simple ratios represent the percentage of items in a particular subject domain that are held or otherwise accessible compared to all items indexed in that domain. This paper will describe these ratios in more detail, explain how they can be calculated, discuss some premises or prerequisites they require, present some of their limitations, briefly describe an application already pursued at one particular institution, and suggest additional applications and potential future directions for research in this area.
Calculating full text coverage ratios
The full text coverage ratio is a simple metric for evaluating the strength of holdings at the item level within a given subject area. Formally, it might be defined as follows: given a search that approximately represents a given subject area, the full text coverage ratio is the ratio between the number of items that are available (X) and the number of items indexed in the total set (Y). With a number of assumptions in place that will be examined in more detail later, these ratios can allow us to make claims like, “Out of all relevant items Y, our library holds X,” or “Roughly X/Y% of all items published in this area are available to our users.”
It may be that these simple ratios can help libraries better answer elusive questions like:
Which of our undergraduate programs are best supported by our serials collections?
In which programs do we need to invest more?
How much impact will journals package X have on our support of degree program Y?
How much would cancellation of journals package A have on our support of degree program B?
The process for determining a particular full text coverage ratio is straightforward but worth describing in more detail.
The first step is to define the scope of your subject domain. For academic libraries, these might map closely to academic categories such as institutional departments, degree programs, courses or research projects. For example, a library might want to determine a full text coverage ratio for its institution’s business school, its biology program, its introductory organic chemistry course, or a doctoral candidate’s particular proposed dissertation project. In actuality, each of these examples would probably not be gathered in isolation, but as part of a larger project of comparing the strength of holdings across departments, programs, courses, or projects. One such project will be described briefly below.
This first step is also when you would define the scope of your content domain: the boundaries of relevance in facets other than subject, such as date, content type, or any other factor that can be defined in a discovery layer search. For example, you might choose to consider only peer-reviewed articles published in the last five years. This paper’s focus is academic journal articles because that is the content type most thoroughly indexed by academic library discovery services, but there is theoretically no reason why it could not be applied to additional content types, provided that they are covered relatively comprehensively by the relevant discovery service.
The second step is to define a particular discovery layer search that can fairly represent these overlapping domains. Translating the content domain into a particular set of search criteria should be simple, relying on the discovery layer’s content type facets, date filters, peer-reviewed flags, etc. On the other hand, the method of perfectly translating the subject domain into a particular search is less obvious. The limitations of keyword searching are well known.Footnote1 Fortunately, a perfect translation between subject domain and discovery search is not necessary to calculate a useful metric. The concept of a representative search, which will be discussed in more detail later, is key to understanding full text coverage ratios. The goal is not to define a search that will return every relevant item with perfect precision and recall, but to define a search that will be representative of the domain.
With that in mind, it may be that the best keyword to represent a broad subject domain such as an academic discipline will simply be the standard name for that discipline. For example, to calculate the full text coverage ratio for biology, the simple keyword “biology” may return sufficiently representative results. For interdisciplinary subjects or subjects with less clearly defined boundaries, combining several keywords with a Boolean “OR” may return the most representative results.
Once the criteria for relevance are established and a corresponding search has been defined, the third step is to execute two discovery service searches that are identical in every way but one: one is limited to “full text” available items, the other is not thus limited (or to use the terminology of some products, the other is “expanded”). Noting the total items returned by each of these searches and expressing them as a percentage results in the institutional full text coverage ratio for the subject area defined in step one.
Functional prerequisites for full text coverage ratios
From this description, it will be clear that quite a bit depends on the particular implementation of the discovery service being used, and it is worth describing the qualities that make a discovery service an effective tool for calculating full text coverage ratios:
Its full text filter should be accurate, excluding items that are not available while including those that are (both licensed and open access content).
Its index should comprehensively include the complete set of relevant items, however that might be defined at any given institution. While actual comprehensiveness is obviously the ideal for reasons that go far beyond the calculation of any metric, libraries facing shortcomings in this area might provisionally define “the complete set of relevant items” as those indexed in the discovery service, and calibrate their use of full text coverage ratios accordingly. They might claim, for example, “we have seventy-six percent of biology resources of those indexed in the discovery service,” rather than simply “we have seventy-six percent of all biology resources.”
To the extent that its index includes duplicates, these should be effectively deduplicated so that the reported number of returned items can be trusted.
Similarly, since the ratio is based on the total number of items returned in search results lists, these totals should be accurately reported.
There is one feature that is rarely found in standard academic library discovery services but that would greatly enhance the value and flexibility of full text coverage ratios: citation data. In most cases, the only way to include the concept of quality in these ratios is to limit searches to peer-reviewed journals. While certainly not a prerequisite, the ability to consider only papers that have received a certain minimum number of citations would add a significant dimension to this metric.
Note that at least three of the most important attributes that make a discovery service a good tool for full text coverage ratios are also among the most essential attributes of a good discovery service more generally: an accurate full text filter, a comprehensive index, and effective deduplication. So, while it is likely that not all implementations of all discovery products will allow for actionable full text coverage ratios, as these products continue to improve, and as libraries refine their implementations, so will the potential value of this metric.
Those who want to explore the value of full text coverage ratios at their own institutions will do well to reflect on the extent to which these criteria are fulfilled locally.
Representative searches
Another important factor is the construction of the searches from which these ratios are derived. As described above, the searches that we require must be representative, rather than comprehensive. While we candidly admit that a perfectly comprehensive keyword search is out of reach, we can define a representative search as a search that has the same full text coverage ratio as the theoretical idealized search would have. The absolute number of items returned might widely differ from those of the “perfect” search, but the ratio would be the same.
To illustrate with an example, we can acknowledge that many items relevant to biology will be excluded from a keyword search for “biology,” just as some irrelevant items will be included. Such a search may even return only a small fraction of the total number of relevant items. But we can hypothesize that such a search resembles the actual total set of relevant biology items well enough to provide insights into the relative strength of the library’s holdings in this discipline. One possible means of testing the representativeness of any given search would be to compare the ratio of one hypothetically representative search to the average ratio returned by a much larger number of narrower searches. For example, to test “biology” as the representative search for that discipline, we might calculate the average FTCR for a much larger number of individual searches, carefully defined to represent the full scope of the biological sciences. A close similarity between this more rigorously defined FTCR and the more basic “representative” one would help to confirm or invalidate the validity of the latter.
This is just one illustration of how the practical application of full text coverage ratios in libraries will benefit from research and further analysis to clarify how best to define and formulate representative searches in a way that balances rigor and expedience. It may be the case that until this further work has been done, full text coverage ratios should be seen as a provisional heuristic, a number that is better than nothing but should not be leaned on too heavily or to the exclusion of additional analysis.
Some discovery products include filters or tags that allow searches to be limited to particular disciplines or subject areas, and it is tempting to offer these tools as the solution to the complications described above. However, while it may be the case that calculating FTCRs in this way results in a more representative search than a basic keyword search, these filters also cannot perfectly represent a subject area, so the question of representativeness still applies. These tools also lack the flexibility of representative keyword searches, which allow any subject area, no matter how narrow or broad, to be investigated in this manner.
Applications in academic libraries
Even with these reservations, the flexibility of this concept offers many useful applications. Several immediately suggest themselves:
Within an institution, comparing FTCRs across academic degree programs to get a sense of relative support for each program. This information might be used as one factor informing budget allocations.
Tracking FTCRs over time can reveal the trajectory of a library’s support for any given program: are we providing more, or less, relative to the total number of publications indexed?
Comparing FTCRs between institutions for the purpose of benchmarking.
Of these, the last is by far the most fraught with complications and the one offered here most tentatively. It may be that the variabilities between discovery products, and between the various implementations of those products at each institution, are so great as to make such analysis invalid. Limiting such a project to libraries using the same discovery service would help to mitigate this uncertainty. (On the other hand, comparing full text coverage ratios between discovery products may reveal interesting insights into the relative strengths of these competing tools.)
Even within an institution, interpretation of FTCRs should be made with an awareness of both sides of the ratio. For example, if a ratio is high, that may be a sign of the strength of holdings in that area (the numerator), or the weakness of the discovery service’s indexing (the denominator). A comprehensive index was listed earlier as one prerequisite of calculating FTCRs, but no available product is completely and uniformly comprehensive across all areas. The inclusion of abstracting and indexing (A&I) bibliographic databases within a discovery index might also have a significant effect on calculated FTCRs. If a ratio is low, is that a sign of the weakness of holdings in that area, or the strength of the discovery service’s indexing – perhaps due to the inclusion of a discipline-based A&I database? With this in mind, it is clear that FTCRs can inform not only serials collection development, but also discovery service configuration and the role of A&I databases.
A fourth practical application of the FTCR concept was suggested by Sanjeet Mann at the University of Redlands: analysis of the full text coverage ratios of the actual searches performed by institutional end users. This idea elegantly elides all of the uncertainty described above about using a single search to represent an entire subject area. Instead, it allows us to home in on the actual experience of our users and answer the question, “What percentage of relevant items have been hidden from our users behind our discovery product’s full text filter?”
Full text coverage ratios are a timely addition to a library’s selection of collections metrics in at least two ways. First, unlike existing metrics, they allow investigation at the level of the article (as opposed to the journal) during a time when the journal is being deemphasized in various ways – by preprint services, by hybrid open access, and by discovery services themselves.Footnote2 In this environment, it is possible for quite a bit of research to be done without a thought being paid to the journals involved. Second, with the ongoing and accelerating growth of open access publishing models, FTCRs are timely for the way they automatically factor in open access content (assuming that open access content has been included in the discovery tool’s “full text” scope).Footnote3 All other things being equal, a discipline that has broadly embraced open access publishing will have a higher ratio than one that has not. While many aspects of traditional collections evaluation and assessment may be made less relevant by a broad shift to open access publishing, FTCRs would likely retain whatever relevance they had prior to the shift.
A description of how full text coverage ratios were used at one institution will help make these ideas more tangible. During two consecutive years (2018 and 2019) at California Baptist University (CBU) in Riverside, California, full text coverage ratios for peer-reviewed journal articles published in the last five years were calculated for the subjects corresponding to each academic degree program, yielding valuable and actionable insights into our serials holdings in the form of degree program rankings by FTCR in the categories of undergraduate, master’s and doctoral programs. In 2019, the FTCR for all undergraduate programs at CBU ranged from 59 to 95%.
The impact of two new journals packages on their respective disciplinary FTCRs is worth mentioning. One was a very large and expensive collection in electrical and computer engineering; the other was a relatively small collection of journals in social work. To determine how our investment in these two packages was impacting our overall support of these two programs, we compared the full text coverage ratios for each program before and after adding these packages.
The results were dramatic. Majors related to electrical engineering and computer science went from towards the bottom end of our ranking of programs by full text coverage ratio, to very near the top. Software engineering, for example, went from the very lowest-ranked bachelor’s program by FTCR to the fifth best. While impressive, the size and expense of this package meant that this result was not totally unexpected. What was more surprising was the effect on the social work FTCR of the smaller collection added in that field. With a relatively small investment, social work went from being the third lowest-ranked master’s program by FTCR to the third highest.
Thus, not only did this set of FTCRs provide a sense of which programs needed more attention when it came to our serials collection development efforts, but it also helped to confirm the value of these new acquisitions.
Once the ratios were calculated for each program, it was straightforward to further contextualize them by mapping each to its respective enrollment. Visualizing each program as a point on a graph, with the ranking of each program by FTCR along the X axis and program enrollment along the Y axis, allowed us to create a valuable action priority matrix by simply dividing the resulting graph into quadrants (see ):
Programs with low enrollment but high FTCRs (lower right quadrant) and programs with high enrollment and high FTCRs (upper right quadrant) were identified as “least concern”.
Programs with low enrollment and low FTCRs (lower left quadrant) were identified as possibly requiring further investigation.
Programs with high enrollment and low FTCRs (upper left quadrant) were identified as requiring investigation and likely action to increase holdings in these areas.
Figure 1. Master’s programs by FTCR program rank and enrollment
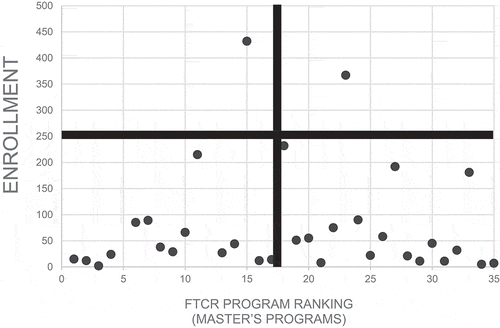
While such a visualization does not tell the whole story of a library’s support for its institutional degree programs, it is full of clues that suggest relatively low effort and high impact ways of enhancing serials collections.
Conclusion
The records excluded by a full text filter are subject to the competing demands of exhaustiveness and expedience. Exhaustiveness wants these records to be seen because they may be important, expedience wants them excluded because they cannot be viewed immediately. Most academic libraries opt to exclude them from searches by default, but whether they are included or excluded, neither option is perfect. The obvious but unachievable ideal is for all relevant items to be included and immediately accessible. In the absence of that ideal, full text coverage ratios can help answer a simple and important question: what percentage of what may be relevant to our users in any given subject area is not immediately available?
Disclosure statement
No potential conflict of interest was reported by the author.
Additional information
Notes on contributors
Matthew W. Goddard
Matthew W. Goddard is Electronic Resources Librarian, Iowa State University, Ames, Iowa.
Notes
1 F. W. Lancaster, “Identifying Barriers to Effective Subject Access in Library Catalogs,” Library Resources & Technical Services 35, no. 4 (1991): 377-91. This is only one example of how these shortcomings were thoroughly documented in the professional literature in the early 1990s, during the advent of online public access catalogs.
2 Bill Cope and Angus Phillips, eds., The Future of the Academic Journal, 2nd ed. (Oxford: Chandos, 2014) provides a holistic look at these trends and much more.
3 Bo-Christer Björk, “Growth of Hybrid Open Access, 2009-2016,” PeerJ 5 (2017): E3878, https://doi.org/10.7717/peerj.3878; and Nicolas Robinson-Garcia, Rodrigo Costas, and Thed N. van Leeuwen, “Open Access Uptake by Universities Worldwide,” PeerJ 8 (2020): E9410, https://doi.org/10.7717/peerj.9410.