
Abstract
This paper examines the quality of data on household assets, liabilities and net worth in the South African National Income Dynamics Study (NIDS) Wave 2. The NIDS is the first nationally representative survey on household wealth in South Africa. The cross-sectionally weighted data are found to be fit for use in terms of the univariate distributions of net worth, assets and liabilities, but population totals are probably underestimated due to the presence of missing wealth data in Phase 2 of Wave 2 that is not taken into account in the weights. When compared with national accounts estimates of household net worth, there is an apparent inversion of the estimated totals of financial assets versus non-financial assets. Further research is required into why this is so. We find that the NIDS wealth module is a suitable instrument for the analysis of household wealth.
1. Introduction
This paper investigates the quality of the data on assets, liabilities and net worth in the National Income Dynamics Study (NIDS) Wave 2 dataset 2010–2011 (SALDRU, Citation2012). The objective of the paper is to provide researchers with an awareness of the issues pertaining to the use of the wealth module, which appears in NIDS for the first time in Wave 2. We undertake a systematic review of the constructs of assets, liabilities and net worth that are found in the NIDS questionnaires and pay careful attention to how estimates are affected by missing data, outliers and weights, before evaluating the univariate distributions of the relevant variables.
The NIDS Wave 2 instrument marks the first time in South Africa that a nationally representative household survey obtained sufficient information to calculate household net worth. As such, it represents a very important contribution to the stock of knowledge on these concepts, and the dataset itself also contains rich information about income, expenditure, savings and debt. These concepts are also measured by the South African Reserve Bank (SARB), and we conduct a comparison of the differences in the estimates of components of net worth between the macro and micro data sources.
Analytically we then focus on household portfolio composition by disaggregating net worth into different asset and liability components. One should note that net worth was not measured in NIDS Wave 1; therefore, the longitudinal nature of NIDS is not applicable to wealth data in Wave 2, which must be evaluated as a cross-section instead (with the correct weights designed for this purpose; for a discussion of the weights in Wave 2, see Brown et al., Citation2012).
The rest of the paper proceeds as follows. Firstly, some background is given on the measurement of wealth. We then discuss the methodology that will be utilised to evaluate the quality of the data, paying particular attention to the integrity of the Horvitz & Thompson (Citation1952) estimate of a population total for household net worth given the NIDS instrument. This mandates an evaluation of the internal and external validity of the data, the latter being achieved by focusing on a similar measure of household net worth calculated by the SARB. Household portfolio composition over the wealth distribution is then analysed, before net worth by age cohort is discussed. Outliers in the distribution of wealth are then discussed before a specific analysis of wealth inequality is conducted. Lastly, portfolio composition over the net worth distribution and over the lifecycle are analysed before concluding remarks are made.
2. Background: The measurement of wealth
Unlike income or expenditure, wealth is a stock variable that reflects the net financial position of an individual or household at a given point in time. It is often measured by the concept of net worth, the value of non-human assets (i.e. material assets such as real property and financial claims) less debts (Davies & Shorrocks, Citation2000:606). Net worth can be negative, reflecting the fact that the relationship between assets and liabilities, savings and credit must be taken into account when interpreting wealth data. While income and consumption are important determinants of current well-being, assets are a key indicator of future, sustainable consumption.
Wealth is particularly challenging to measure in household interview surveys because of its social sensitivity and the difficulties associated with obtaining accurate estimates of the market value of different asset types (whether physical or financial). In the international literature, it has been found that high-income earners are especially reluctant to volunteer information on their income and wealth levels (Juster et al., Citation1999). Furthermore, wealth questions often involve complex calculation tasks, imposing a high cognitive burden on the respondent that can lead to recall bias. The net result of social sensitivity, high cognitive burden and recall bias is data with potentially high non-response and measurement error – both of which must be investigated by researchers in order to understand the influence they exert on point estimation.
The concept of net worth is most often used when measuring wealth, and can be described as the difference between total assets and total liabilities. Assets can broadly be divided into financial assets, real assets and retirement annuities. Financial assets consist of liquid accounts, shares, bonds and insurance while real assets include property, businesses, vehicles, livestock and equipment. Debt consists of mortgages, other real asset debts and loans (Haliassos, 2008). Loans can include personal bank loans and loans from other lenders (including friends, family, employers), and study loans.
Accurate estimates of wealth therefore require detailed questions about the components of assets and liabilities. However, even if we have such detailed measures, wealth data are still challenging to interpret because an individual or household's net worth at a given point in time reveals nothing about the financial behaviour of the respondent. This requires detailed information about the risk and time preferences of individuals, which is not present in the NIDS wealth module. We evaluate how wealth was measured in NIDS Wave 2 below.
3. Methodology
3.1. Estimating household wealth in sample surveys
In nationally representative sample surveys, one of the main concerns when measuring any construct is obtaining accurate estimates of key parameters such as the population total, the population mean and quantiles of the univariate distributions of interest. These estimates must take into account the survey design. Thus, for household wealth, the Horvitz–Thompson estimate (Horvitz & Thompson, Citation1952) of a population total from sample survey data is:
Here, is the estimated population total for household net worth; yi
is the net worth for household i that is summed over all households in the sample n; and
is the inclusion probability of each household. The inverse of the inclusion probability constitutes one of the weights in a sample survey, which means that the Horvitz–Thomson estimator is a weighted estimate of the population total that can provide us with statistically valid estimates of total household wealth in South Africa for the period under investigation.
Total household net worth is also something that is estimated by the SARB, although their methodology for estimating the total is very different due to the different data sources used and the fact that no direct measure of household net worth is available in the national accounts. We conduct a comparison of total household net worth in the NIDS compared with the SARB below.
For the purposes of this paper, our objective is to discuss the extent to which household net worth can be accurately estimated from the NIDS Wave 2 survey. As such, we are concerned with data quality issues that may affect the validity and reliability of the estimates.
3.2 Wealth in the NIDS survey
The first wave of NIDS allowed us to measure certain components of wealth on an individual and household level, but did not include enough questions to calculate a complete measure of net worth for either individuals or households. Wealth was one of the special themes of Wave 2 and the instrument included questions about assets and liabilities as well as an overall question about net worth. Wealth questions were present only in the NIDS household and adult questionnaires, and therefore wealth data can only be calculated for the sample of resident adult members of the household present at the time of interview. There are no wealth questions in the proxy or child questionnaires. Since the wealth module is only included in Wave 2, wealth can only be analysed cross-sectionally until the next time that the wealth module is reintroduced into NIDS.
Furthermore, in NIDS Wave 2 there was a special follow-up phase of fieldwork that sought to find hard-to-reach households that were not contacted in the first phase of data collection. This was called Phase 2 (see Brown et al., Citation2012). The questionnaire in NIDS Wave 2 Phase 2 was shortened to allow for quicker interview times. Part of this shortening was the omission of the wealth module in Phase 2. Consequently, there are values for net worth that are missing by design and these must be omitted from the sample of successfully interviewed households in the data analysis process (there is a variable for Phase 2 in the publicly released Wave 2 data that easily allows researchers to do this).
It is important to note that due to Phase 2 questionnaires excluding wealth questions, a complication arises with respect to the use of the cross-sectional weight. Two weights are included in the NIDS Wave 2: a cross-sectional weight that weights the sample to the population of South Africa; and a panel weight that corrects for attrition between Wave 1 and Wave 2 (for a discussion of weights and attrition in Wave 2, see Brown et al., Citation2012). For the wealth module, the cross-sectional weight must be used for analysis. However, this cross-sectional weight does not take into account Phase 2 households that did not have the wealth questions asked (there were 390 successfully interviewed households in Phase 2, which represents 5.7% of the total number of successfully interviewed households in Wave 2, which is 6809 in data release version 1.0 of Wave 2). This results in underestimated population totals for assets, liabilities and net worth.
For observed households, two variables can be utilised to evaluate household net worth in the NIDS Wave 2 data, while only one variable can be utilised to evaluate individual net worth. This paper is only concerned with household net worth. The two variables at the household level include one that asks the respondent directly their net worth and a second variable that is derived as the sum of the components of disaggregated assets and liabilities (for details of how aggregate net worth was calculated from components of assets and liabilities, see Brown et al., Citation2012:37–41). In the household questionnaire, the direct question to the respondent is:
Suppose you (and your household members living here) were to sell off all your major possessions (including your home), turn all of your investments into cash and pay all your debts – would you have something left over, breakeven or be in debt?
This question asks respondents to estimate their net worth, which can be either positive, zero or negative. If the respondent is unable to provide an exact value, they are led into a series of unfolding brackets (for either positive or negative net worth) that identify a plausible range into which it falls. If they are still unable to identify a value, they can state that they do not know or can refuse to answer the question.
The second variable is a constructed net worth variable and can be found in the derived files dataset. Also found in this file are disaggregated components of wealth that are used in the construction of household net worth. The household net worth variable is constructed as the difference between total assets and total liabilities. The total value of assets is calculated as the sum of real estate, vehicles, business assets, financial assets, retirement annuities and livestock wealth. The total value of liabilities is calculated as the sum of real-estate debt, vehicle, business and financial debt.
3.2.1 Stocks and flows in the components of wealth
Questions relating to household net worth were asked in both the household and the adult questionnaires. These questions often have two components to them – one that measures a monthly flow in Rand associated with the given asset or liability, and one that measures the present value of each asset or the remaining outstanding balance of each liability. The latter two are stocks and these are used to calculate individual and household net worth (for the exact questions utilised, see Brown et al., Citation2012).
3.2.2 Deflating wealth data
Given the fact that fieldwork in NIDS Wave 2 took place over more than 12 months, all financial data are deflated to the modal month of interview (i.e. September 2010). The consumer price index of Statistics South Africa is utilised for this purpose (Stats SA, Citation2012 Footnote4).
3.2.3 The calculation of derived household net worth
outlines how the final net worth measure was calculated from components of wealth for each household in the NIDS household derived dataset. Evident from the diagram is that components of household net worth are estimated from both the household and adult questionnaire variables. Here, all individual-level variables are summed over all residents in the household in order to derive aggregate household net worth.
Figure 1: Derivation of household net worth from components of assets and liabilities
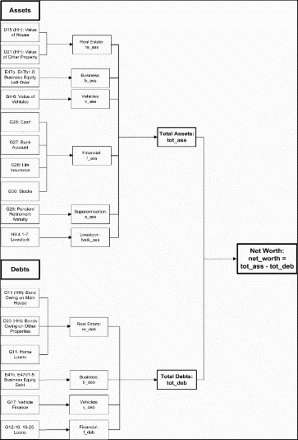
In the next section we conduct an assessment of the quality of the NIDS data, focusing on both the internal and external validity of net worth and its components.
4. Assessment of the quality of NIDS wealth data
In this section we evaluate response rates, the distributions of the wealth variables as well as comparing the aggregates in the Wave 2 dataset with SARB household balance sheet data. This is done in order to benchmark components of wealth at the micro and macro levels. The objective is to assess the overall quality of each variable in the dataset, paying attention to the characteristics of the unweighted sample of respondents. The weighted distributions will be analysed in the next section.
One approach to investigating the quality of household wealth data is to compare it with SARB national accounts wealth data in order to compare the findings. A limitation with doing so is that national accounts data are representative of the country as a whole, whereas the sample in household surveys excludes institutions and the armed forces.
Comparisons with national accounts are often affected by high item non-response as well as underestimated aggregate wealth outcomes from the survey instrument (Juster et al., Citation1999). For example, Headey et al. (Citation2008) identify that in the Household, Income and Labour Dynamics in Australia survey's wealth module, which aimed to measure the market value for all assets and debts, a comparison with government data was complicated by the fact that government agencies often using proxies for market value of components of wealth. This issue pertains directly to NIDS–SARB wealth comparisons, and the differences should be considered indicative of inconsistencies in the methodological approaches used in micro and macro data.
Prior to comparisons, an attempt was made to identify which components of assets and liabilities could be found in the NIDS and SARB data. presents these findings.
Table 1: NIDS and SARB components of assets and liabilities
Another important distinction between the NIDS data and the SARB household-sector institutional account is that the household balance sheet items include non-profit institutions serving households. We thus expect the SARB's figures to exceed those of NIDS household figures. Because NIDS Wave 2 fieldwork was conducted over a period of time greater than 12 months, the data are inflated/deflated to the modal month of interviews, which is September 2010 (the consumer price index was used for this purpose; see Stats SA, Citation2012). This is compared with SARB data that are an annualised total for 2010. Totals for the NIDS household-level data were calculated such that comparable aggregate estimates could be made with the SARB accounting identities.
presents the aggregate figures for the NIDS data as well as the household balance sheet items from the SARB. The categories chosen were such that they could match those from the SARB.
Table 2: Rand value of components of assets and liabilities in NIDS and SARB national accounts
Immediately clear from the table are the large differences in the asset variables. The NIDS and SARB estimates for financial assets and non-financial assets seem to be inverted. The NIDS estimate for aggregate financial assets is about one-third the size of the estimate from the SARB, while the NIDS seems to overestimate non-financial assets relative to the SARB by a factor of 2.5. The estimate of total assets between the NIDS and the SARB correspond more closely.
With respect to liabilities, the main distinction is that NIDS estimates are consistently less than that of the SARB, with neither the real-estate debt nor other debt items constituting 50% of the value of the SARB estimates. Total household debt estimated with NIDS is only 36% of that of the SARB. Finally, comparing the NIDS net worth estimate (aggregated from the net worth household derived variable) we find that it is 1.13 times the estimate of SARB.
Some other important things to note are that when we subtract the NIDS total debt from total assets it gives us R5847 billion, instead of the R6012 billion provided by the household derived net worth figure presented in . This is probably due to the impact of imputations for missing data in the net worth variable in NIDS.
We did expect assets and debt levels to be underestimated in NIDS due to attrition and non-response at the top end of the income distribution as well the SARB data including non-profit institutions serving households. However, the extent of the differences suggests that there are very probably important methodological differences between the estimates of household wealth from NIDS compared with the national accounts. Non-response and attrition between Waves 1 and 2 in NIDS suggest that the top end of the income distribution is under-represented, but the combination of weights and imputations mitigate these impacts to some extent. We now review the non-response rates and distributions for some of the major variables in the NIDS dataset in some detail.
presents responses to the one-shot household net worth question: ‘Suppose you (and your household members living here) were to sell off all your major possessions (including your home), turn all of your investments into cash and pay all your debts – would you have something left over, breakeven or be in debt?’
Table 3: Household-level response for one-shot wealth
The table shows that when taking only successfully interviewed households (6809 / 9170), more than one-third of respondents (2379 / 6809) answered that they did not know their overall net worth. Five per cent refused to answer the question and four observations are missing any information. The overall one-shot wealth question was not asked in Phase 2, resulting in observations missing by design for this subset of households. The overall non-response rate is therefore 46%.
As mentioned above, a second measure of household net worth is present in the data. This measure is derived from the components of assets and liabilities present in both the individual and household questionnaires. schematically presents how this variable is calculated. The advantage of using this variable to analyse net worth is that it sums up the respondent's answers to each of the asset and liability questions. Partly because of this, it has a larger sample size than the one-shot measure. presents the findings.
Table 4: Distributions of two measures of household net worth (2010 Rand, unweighted)
The table shows parameters of the two household net worth variables including percentiles, means and the coefficient of variation (i.e. the standard deviation divided by the mean). One should note that in the household derived dataset the one-shot measure needs to be created by researchers in a sequential fashion that transforms the debt variable into the negative number line, and then replaces otherwise missing observations for those that answer that their net worth breaks even to zero. The latter action results in many more zero observations for the one-shot measure compared with the derived measure – as can be seen in . Given that the zeros are reflecting an approximation by the respondent to break-even point, there is nothing inherently problematic about this variable containing substantially more zeros than the derived variable. However, the differences between the two variables must be borne in mind when conducting any analysis of household net worth.
The reason why the sample size is so much larger for derived net worth is because if a respondent answers any one of the components of net worth questions identified in above, then the derived net worth variable will record that answer as an observation even if all other components of wealth questions have missing data for that respondent. This partly explains why the variance is so much larger for derived net worth, where the coefficient of variation is nearly 50% larger than one-shot net worth.
Despite the differences in the two household net worth variables, the correlation between them is 0.75. Deciding which variable to use for analysis is the task of the researcher. The one-shot net worth variable involves a complex estimation task by the respondent that may be subject to recall bias, which is why there were so many ‘Don't Know’ responses that had to be imputed. The derived net worth variable is preferable if one believes that respondents are better able to recall components of assets and liabilities. We proceed to utilise the derived net worth variable for the latter reason for the remainder of this paper.
The distribution of assets, debt and net worth is summarised in .
Table 5: Distribution of components of assets and liabilities (2010 Rand, unweighted)
We can see from the table that for several variables the minima are recorded as R1.00. This highlights potential measurement error in these variables that may be associated with outliers at the bottom end of the distribution. We evaluate outliers across the entire distribution below. We also see large differences in the range of the coefficient of variation, suggesting once again that skewness in the statistical distributions of these variables is rather pronounced, which is not unexpected for net worth distributions in other countries in the world (Davies & Shorrocks, Citation2000).
Given these characteristics of the data, we now turn to analysing portfolio composition at the household level. Henceforth, all estimates are cross-sectionally weighted to reflect the population of South Africa in 2011.
4.1 Outliers in components of assets, liabilities and net worth
Outliers are a major concern when dealing with wealth data in any country because they have the potential to distort parameter estimates in the univariate distributions of interest. The ratio of the income of the household in the 99th percentile of the income distribution to the median household in the distribution is 24, while the corresponding ratio for assets is 355. The sheer distance of the outliers from the mean (the largest asset outlier is 63 standard deviations from the mean) and the high weights associated with each outlier household prompt further attention to be paid to this potential source of measurement error.
Outliers can be the result of different types of survey error, including measurement error (e.g. the respondent falsely reports the construct of interest or the interviewer records it incorrectly) and processing error (e.g. the data are captured incorrectly). In NIDS, careful attention was paid to processing error during data cleaning, leaving measurement error as the most likely source of outliers.
It is often difficult to identify outliers. Frequently, an arbitrary rule is applied by researchers to this problem, such as trimming the distribution (say at the 99th percentile). However, a useful paper by Bollinger & Chandra (Citation2005) cautions researchers against trimming the distribution in this way, for they note that it actually introduces its own stringent assumptions about the measurement error process underlying the data. Consequently, we apply a multivariate technique for the identification of outliers and discuss its relative advantages.
We employ Billor et al.'s (Citation2000) blocked adaptive computationally efficient outlier nominators algorithm to detect outliers in a multivariate context. The asset, debt and net worth variables are checked for outliers using a range of correlates including employment status (controlling for retirement), race dummies, age and age squared, dummies for level of education, geo-types, home ownership, marital status, household size and household income.
The algorithm reports five observations as asset outliers. The smallest of these is R858 778, which in fact lies below the 95th percentile of the overall unweighted asset distribution. The other four outliers are the four highest in the overall distribution of assets and range from R151 million to R364 million. For liabilities, only two outliers are reported and the values for these are R18.1 million and R59.9 million. These are the two most indebted households in the overall debt distribution.
Owing to the small number of outliers detected, and the fact that our analyses is robust to the presence of these outliers, we proceed to analyse the data leaving all observations in the data (we encourage all researchers to evaluate the sensitivity of their results to the presence of outliers since even a small number can have a very large impact in certain circumstances).
4.2 Estimating measures of wealth inequality
Assessing wealth inequality is an important undertaking, as an unequal distribution of the stock of wealth is likely to be more persistent than its income or consumption expenditure counterpart (Davies & Shorrocks, Citation2000). Assets influence short-term and long-term welfare and financial security, and a high level of inequality in net worth suggests that tackling income inequality will be more challenging than simply transferring income to those at the bottom of the distribution. Income inequality in the NIDS data is discussed in Finn et al. (Citation2012), where it was found that inequality in both waves was very high, with a Gini coefficient of around 0.68 for the sub-sample of balanced panel members.
As indicates, the overall Gini coefficient for net worth stands extremely high at 0.901. The Gini coefficient for total assets is similar to that of net worth, at 0.903, while the corresponding figure for total debt is slightly lower at 0.840. Amongst the components of assets and debts, financial assets are the most unequally distributed, with a Gini coefficient of 0.951. Property debt has the lowest Gini coefficient (0.506), but this is probably driven by the low number of households reporting any figure in this category (n = 253).
Table 6: Gini coefficients of assets and debt variables
The vast majority of assets are concentrated in the top asset decile, as indicates. This decile accounts for about 84% of assets in the data, with a median value of R1.76 million. Even amongst the top decile, assets are very unequally distributed, with the top 5% accruing 79% of all assets.
Table 7: Quantile shares in net worth
The clear take-home message from this analysis is that the South African wealth distribution is very unequally distributed, a finding also similar in high-income countries (Davies & Shorrocks, Citation2000).
5. Household portfolios in NIDS Wave 2
In this section we profile household portfolio composition over the net worth and age distributions. Because people with high levels of assets can also have higher levels of liabilities, resulting in negative net worth, it is useful to compare the composition of assets and liabilities across the net worth distribution. In this regard, see and .
Figure 2: Portfolio of assets by household net worth decile (weighted)
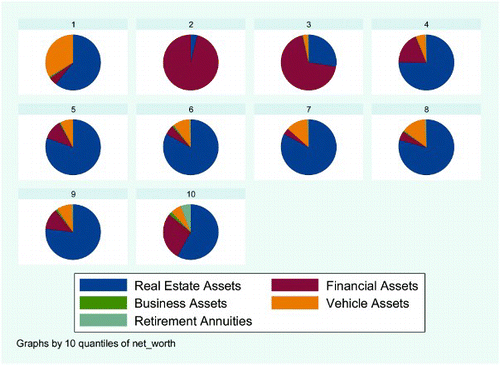
Figure 3: Portfolio of liabilities by household net worth decile (weighted)
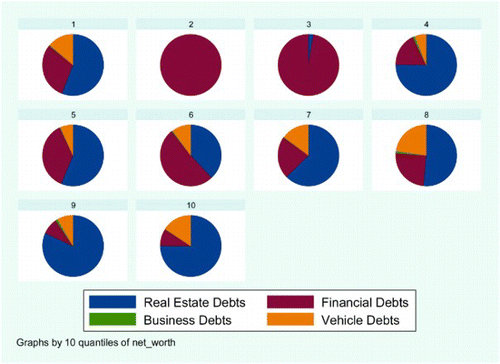
In these two figures we order the asset and liability distributions by net worth deciles. We can see from the figures that in the first wealth decile, which lies in the negative number line owing to liabilities exceeding assets, the profile of both assets and liabilities looks completely different to the second wealth decile, where there is a transition from negative to positive household net worth. Real-estate assets and debts constitute more than 50% of both assets and debts in this first wealth decile. Once again this reflects the fact that individuals who qualify for housing mortgages are likely to be the employed, economically active population.
On the other hand, the second wealth decile probably has a combination of individuals who are employed and unemployed, economically active and inactive (e.g. retired individuals). In the second wealth decile, the profile of both assets and debts looks very similar to the first wealth asset decile and first wealth debt decile (cf. and ). Therefore, there is an important transition that takes place in the second decile of the wealth distribution in the profile and characteristics of households.
When evaluating net worth, it is useful to remember that individuals who have net worth close to or even slightly above zero may not always be ‘richer’ than those with negative net worth. For the unemployed, they are locked out of accessing financial services that allow them to invest in either (ordinarily) appreciating assets such as housing or even depreciating assets such as vehicles. This is because they usually do not qualify for loans, except in instances where rotating credit associations exist or informal credit is available (e.g. from mashonisa). Here, social collateral provides the means to secure credit. Even in these situations, however, this type of credit is unlikely to be of a large enough value to enable an individual to purchase a house, which is the main appreciating asset that can provide long-term wealth creation.
5.1 Portfolio composition over the age distribution
The lifecycle hypothesis (Modigliani & Brumberg, Citation1954) sets the basic premise for this analysis, where, generally, it is expected that households maximise net worth close to retirement age before dissaving. By profiling assets separately from liabilities over seven different age cohorts (where age of the household head is used), we are able to gain insight into the compositional changes in portfolios as people age.
and show a fascinating trend, namely that people gradually pay off their housing loans as they age, and as they do this housing then becomes the largest contributor to total assets. The capacity to gain access into the housing market is therefore a crucial component of wealth creation: the sooner one can enter this market and pay off housing debt, the better.
Figure 4: Portfolio of liabilities by age cohort (weighted)
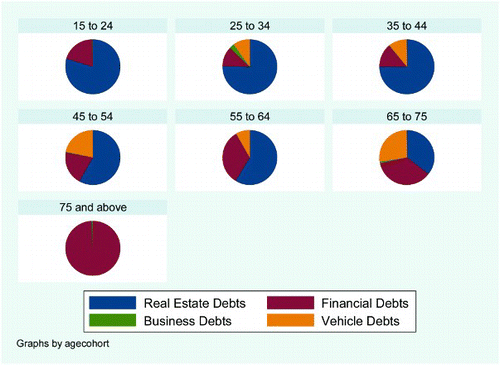
Figure 5: Portfolio of assets by age cohort (weighted)
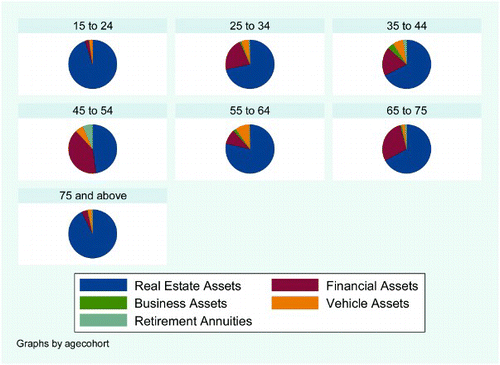
It is also interesting to see that retirement annuities do not feature highly in the 55+ age group (i.e. the three oldest age cohorts), but they do feature in the 45 to 54 age group. Many private-sector retirement annuities are in fact accessible after an individual turns 55 years old. The data then correctly reflect the fact that the value of the retirement annuity itself would be highest before age 55, after which the individual will have access to those funds and probably reinvest it into other asset classes. The data suggest that most people in the 55 to 64 age cohort take their retirement funds and invest it in housing.
5.2 Net worth over the age distribution
The evolution of wealth accumulation is closely tied to the age of individuals. The lifecycle hypothesis provides testable hypotheses concerning this evolution over time. In this section we analyse net worth by age cohort. Since NIDS Wave 2 contains only cross-sectional estimates of net worth, we are restricted to cohort-based analyses. Given that we are dealing with net worth at the household level, we use the age of the head of the household as the basis for assigning a household to an age cohort. The cohorts are for ages 15 to 24, 25 to 34, 35 to 44, and so on (note that using the average age of adults in the household to construct age cohorts yields very similar results to these).
presents the mean and median net worth for each of the seven age cohorts. The households with the lowest average net worth are those in the 15 to 24 and 25 to 34 age cohorts. Assets are accumulated in the next three cohorts, before falling for those entering retirement after 65 years and then increasing again after age 75. The median level of net worth for the youngest two cohorts is between R4000 and R5000. This rises to R25 000 for the pre-retirement cohort of 55 to 64 years old, before dropping for the next cohort, and rising again for the oldest group. The same general pattern holds if we generate five-year rather than 10-year age cohorts, and if we define household age by the average age of adults in the household, rather than simply the age of the household head.
Table 8: Mean and median net worth by age of household head (weighted)
Plotting the relationship between net worth and the age of the household head yields some interesting results, as shown in . We evaluate assets, debts and net worth on the same set of axes for 10-year age cohorts. The net worth curve is simply the asset curve minus the debt curve. Its shape closely follows that of the net worth curve (this is largely because the value of assets is much larger than liabilities and because we have far more households reporting assets than households reporting debts).
Figure 6: Non-parametric smoothing of weighted median net worth by age cohort
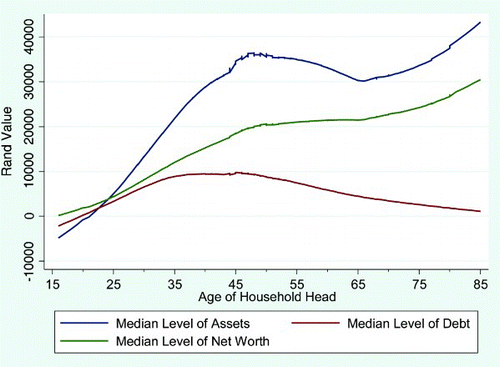
The figure shows an interesting trend, namely that the median household does not simply dissave in retirement but actually increases their stock of assets. This is a predictable feature of the lifecycle hypothesis if one accounts for a bequest motive in household saving behaviour. Further analysis of this finding should be a priority. Note that the trend disappears when the data are unweighted, implying that small sample sizes in the upper age groups that translate into large weights could be driving this finding.
6. Conclusion
This paper has evaluated the data on household wealth in the NIDS Wave 2 datasets, as measured by net worth comprised of various assets and liabilities that are found in both the household and adult questionnaires. The subsample of respondents who were asked wealth questions were resident adult household members present at the time of interview. Proxy respondents were not asked about wealth questions, although to the extent that they contribute to household wealth their contributions are indirectly observed. Also, the wealth questions were not asked in Phase 2 of NIDS Wave 2, which results in an underestimation of population totals for household net worth, assets and liabilities.
From a data quality perspective, we saw there was some evidence that respondents had difficulty with the mental arithmetic needed to obtain an estimate of the one-shot household net worth question. Evidence of this was in the high proportion of respondents who stated that they did not know whether their net worth was positive, about even or negative. On the other hand, when we created the derived household net worth variable by summing up the components of net assets and liabilities, there were higher response rates and potentially lower levels of recall bias. It was this measure that was then used for analysis, but the existence of two measures bodes well for researchers as far as testing the internal validity of the two constructs of net worth is concerned.
The external validity of total net worth shows more variation, however. Evidence from the SARB demonstrated important differences in estimates of total household assets and liabilities. An important part of this difference comes from the manner in which the SARB construct estimates of household sector balance sheets, which itself involves several assumptions concerning the conversion from book to market prices of assets and liabilities. The different methodologies between the macro construct of household net worth and the micro construct of household net worth are consequently not strictly comparable. That said, the SARB data are more likely to capture financial assets better than the NIDS due to the System of National Accounts convention for recording equities and more complex financial instruments, whereas the NIDS data are more likely to capture non-financial assets better than the SARB due to the explicit questions that address this in the questionnaires. A dialogue between NIDS and the SARB would be useful to determine whether the two definitions can converge more closely to the same construct of household net worth. Further research is needed in this area.
As far as portfolio composition is concerned, we analysed the composition of assets and liabilities, as well as portfolio composition over the net worth and age distributions. We saw from the discussion that household portfolios are defined in large measure by the presence of absence of housing as an asset class. This is the single largest component of assets for most households, something that is consistent with observed levels of home ownership in the data. For liabilities, it was found that financial debts dominate the majority of household debt portfolios (for deciles 1 to 7), after which housing becomes the major liability in deciles 8 to 10. This is suggestive of possible barriers to entry in the housing market that are defined by access to credit (i.e. liquidity constraints).
Portfolio composition over the net worth distribution showed that the highest net worth decile had the most diverse asset portfolio. For liabilities, an important finding was that in the lowest net worth decile, housing debt featured strongly. This suggests that there are a non-trivial number of households with negative equity in their homes. Portfolio composition over the age distribution suggested that people gradually pay off housing debt as they age. Access to retirement annuities from the age of 55 onwards seems to be invested in other asset classes, especially housing.
Wealth over the age distribution showed a non-linear trend and one where the most likely explanation for the lack of dissaving after retirement was conjectured to be due to bequest motives in the financial plans of the aged. This hypothesis needs to be evaluated directly in a multivariate context in order to be (dis)proven. In conclusion, it should be stated that none of the data quality concerns identified in this article prevent the NIDS household wealth module from being used as an instrument for the analysis of consumption and saving in a multivariate context. With future waves of NIDS, it will also allow for dynamic models to be estimated. As such, it ushers into existence research possibilities that have never before been possible in South Africa.
Notes
4The Stata syntax file for deflating wealth data can be found on the NIDS website (www.nids.uct.ac.za).
References
- Aron, J, Muellbauer, J & Prinsloo, J, 2007. Balance sheet estimates for South Africa's household sector from 1975 to 2005. South African Reserve Bank (SARB) Working Paper WP/01/07, SARB, Pretoria.
- Billor, N, Hadi, AS & Velleman, PF, 2000. BACON: Blocked adaptive computationally efficient outlier nominators. Computational Statistics & Data Analysis 34, 279–98. doi: 10.1016/S0167-9473(99)00101-2
- Bollinger, CR & Chandra, A, 2005. Iatrogenic specification error: A cautionary tale of cleaning data. Journal of Labor Economics 23(2), 235–57. doi: 10.1086/428028
- Brown, M, Daniels, RC, De Villiers, L, Leibbrandt, M & Woolard, I, 2012. National Income Dynamics Study Wave 2 Beta Release User Manual. Southern Africa Labour and Development Research Unit, Cape Town.
- Davies, JB & Shorrocks, AF, 2000. The distribution of wealth. In AtkinsonAB & BourguignonF (Eds.), Handbook of Income Distribution Volume 1. Elsevier Science, BV, Amsterdam, 605–75.
- Finn, A, Leibbrandt, M & Levinsohn, J, 2012. Income mobility in South Africa: Evidence from the first two waves of the National Income Dynamics Study. NIDS Discussion Paper 2012/5, National Income Dynamics Study, Cape Town.
- Haliassos, M, 2008. Household portfolios. In Durlauf, SN & Blume, LE (Eds.), The New Palgrave Dictionary of Economics. Palgrave Macmillan, Basingstoke, UK.
- Headey, B, Warren, D & Wooden, M, 2008. The structure and distribution of household wealth in Australia: Cohort differences and retirement issues. Social Policy Research Paper No. 33, Melbourne Institute of Applied Economic and Social Research, University of Melbourne.
- Horvitz, DG & Thompson, DJ, 1952. A generalization of sampling without replacement from a finite universe. Journal of the American Statistical Association 47, 663–85. doi: 10.1080/01621459.1952.10483446
- Juster, FT, Smith, JP & Stafford, F, 1999. The measurement and structure of household wealth. Labour Economics 6, 253–75. doi: 10.1016/S0927-5371(99)00012-3
- Modigliani, F & Brumberg, RH, 1954. Utility analysis and the consumption function: An interpretation of cross-section data. In KuriharaKK (Ed.), Post-Keynesian Economics. Rutgers University Press, New Brunswick, NJ.
- SALDRU (Southern Africa Labour and Development Research Unit), 2012. National Income Dynamics Study 2010–2011, Wave 2 (dataset) Beta Release. Southern Africa Labour and Development Research Unit (producer), Cape Town. DataFirst (distributor), Cape Town.
- SARB (South African Reserve Bank), 2010. Balance Sheet: Households and Non-Profit Institutions Serving Households. Historical Macroeconomic Time Series Information. South African Reserve Bank, Pretoria.
- Stats SA (Statistics South Africa), 2012. Consumer Price Index. http://www.statssa.gov.za/keyindicators/CPI/CPIHistory.pdf Accessed 17 May 2012.