
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In view of the fact that a driver's smoking behavior seriously affects the driving safety, a feature pyramid network (FPN)-based smoking behavior identification method has been studied in order to reduce the occurrence of the driver smoking. Most of the existing research has been focused on detection and recognition based on movements while smoking or smog characteristics. Therefore, the probability of misjudgment in such methods is high, thus to address this issue, the present work proposes a method based on FPN to detect the driver's smoking behavior. FPN has been combined with the dilated convolution technique in order to detect a small target object in the driver's image and recognize their smoking behavior. By using the driver behavior images collected from the vehicle platform, a simulation experiment was carried out by employing the behavior identification method proposed in this work. The experimental results show that the accuracy of the proposed method is 94.75%, the recall rate is 96%, the precision rate is 95.05% and the area under the receiver operating characteristic curve is 95.5%.
1. INTRODUCTION
A driver smoking while driving not only harms their own health and that of others in their vicinity but also increases the risk of road accidents. Many drivers have a habit of smoking while driving vehicles, which may lead to many adverse consequences. When smoking, the driver usually controls the steering wheel with one hand that might tilt the body shifting the center of gravity. This uneven force may easily lead to irregular driving. The carbon monoxide in the smoke also affects the blood oxygen saturation in driver’s body. Physiological studies have shown that if the blood oxygen saturation in the human body is less than 80%, it will cause a series of symptoms of hypoxia, such as distraction, weak thinking ability, memory loss, mild motion disharmony, fatigue, etc. These factors are likely to pose a threat to driving safety. In addition, a driver smoking in the car not only affects the air quality inside the car but might also cause a fire inside the car. If the car is loaded with flammable or explosive dangerous goods, smoking may cause serious consequences. Thus, it is obvious that the smoking habit of a driver while driving seriously affects their ability to drive safely. Especially for those drivers who drive the “two passengers and one danger” vehicles, the habit of smoking while driving seriously affects the safety of life and property of the drivers themselves and also others and it is easy to cause irreparable consequences.
With continuous advancements in artificial intelligence, deep learning is being applied in the field of tobacco control and achieving an AI tobacco control has far-reaching consequences. In recent years, a large number of researchers have used deep learning in the recognition of the direction of behavior. Guan et al. [Citation1] proposed a network model for an in-depth study of human behavior recognition. By using the sliding window algorithm to perform motion segmentation, the time series data are transformed into a deep network model and then via end-to-end research, the feature vector is imported into the SoftMax classifier for identification. The recognition accuracy of the network model for the UCI Human Activity Recognition (HAR) dataset is 91.73%. Zhang et al. [Citation2] proposed a dedicated interleaved deep convolutional neural network architecture, which uses the information from a multi-stream input to merge the extracted abstract features through multiple fusion layers and introduces a temporal voting scheme based on historical inference examples to achieve an enhanced accuracy in driver behavior recognition. The recognition accuracy of this method in five kinds of aggregated behavior patterns, namely, grouping tasks that involve the use of a mobile device and eating and drinking, is 81.66%. Yan et al. [Citation3] used the color images on the driver’s side to extract the skin-like regions using the Gaussian mixture model and passed it to the deep convolutional neural network model to generate action labels. Yang et al. [Citation4] proposed a two-layer learning method for a driver's behavior recognition using the electroencephalography (EEG) data, with the highest classification accuracy of 83.5% obtained using this method.
At present, most methods used for identifying smoking behavior focus on processing the experimental data by relying on the use of smoking behavior gestures or smog generated in the vicinity while the driver smokes, for identifying the driver’s smoking behavior. For example, Chiu et al. [Citation5] proposed a smoking behavior recognition based on a spatiotemporal convolutional neural network, using data balance and data enhancement based on GoogleNet and time slice network architecture to achieve an efficient smoking action recognition having an accuracy of 91.67%. But not all datasets have smog and the driver's smoking dataset collected in the present work has almost no smoke. In addition, the data enhancement processing of the experimental data takes a lot of time and effort. At the same time, if only gestures are used for recognition, it easily leads to low recognition accuracy and a high rate of false-positive results.
In order to solve the above problems, the present work aims to study the behavior recognition from another angle, which is, using the cigarette in the dataset as the recognition target. By detecting whether there is a cigarette in the driver's image, in order to identify whether the driver smokes while driving, the occurrence of adverse consequences due to smoking while driving can be prevented and the safety of life and property of the driver and others can be guaranteed. Feature Pyramid Network (FPN) is a network that solves multi-scale problems in object detection and greatly improves the efficiency for detecting small objects without substantially increasing the computation time of the original model [Citation6]. It is widely used in identifying detection tasks such as multi-scale target detection and small object detection and recognition. In this work, based on the characteristics of the research object, the FPN network has been improved to form a new network model, namely, Feature Pyramid Network-dilated convolution (FPN-D), in order to extract the features of cigarettes in the images.
2. APPROACH
2.1 Method Overview
2.1.1 Fpn
At present, people often use the method of constructing multi-scale pyramids in computer vision to solve for the problems caused due to objects of different sizes. For example, the earliest image pyramid consisted of generating multiple images of different resolutions by multi-scale pixel sampling of the original image and then extracting different features from each layer for the purpose of prediction. However, this method requires a large amount of calculation which, in turn, requires a large amount of memory and time. Thus, researchers made improvements in the above methods. Using the characteristics of the convolution itself, the original image was convoluted and a pooling operation was carried out to extract features at different scales from different layers of the network for prediction. However, this method did not use shallow features. Shallow networks focus more on detailed information while deeper networks focus more on semantic information. The information in the shallow features is quite helpful for detecting small objects and this can improve the accuracy of object detection to some extent. Therefore, researchers continuously explored and as a result have proposed the FPN technique. By using deep learning to construct the feature pyramid, an improvement in the robustness of the algorithm is achieved and accurate location information is obtained by accumulating shallow as well as deep features. The algorithm process is shown in Figure .
Figure 1: The FPN structure

First, a deep convolution operation is performed on the input image, following which the features of the second convolution layer are subjected to dimensionality reduction. The features of the third convolution layer are then upsampled so that they have the corresponding dimensions. Then, the processed second and third convolution layers are subjected to an addition operation (addition of corresponding elements). The result thus obtained is added to the result of the processed first convolution layer. The output thus obtained can then be used to make predictions.
2.1.2 Dilated Convolution
The dilated convolution method [Citation7] inserts gaps in the standard convolution map in order to increase the receptive field area. Compared to the normal convolution operation, dilated convolution has a hyperparameter called dilation rate. This hyperparameter refers to the number of kernel intervals (the dilation rate for a normal convolution is 1). Since the receptive field area is increased in this method without pooling, loss of information is avoided and each convolution output contains a large amount of information. A comparison between ordinary convolution and dilated convolution is shown in Figure .
Figure 2: An example showing the comparison between ordinary convolution and dilated convolution
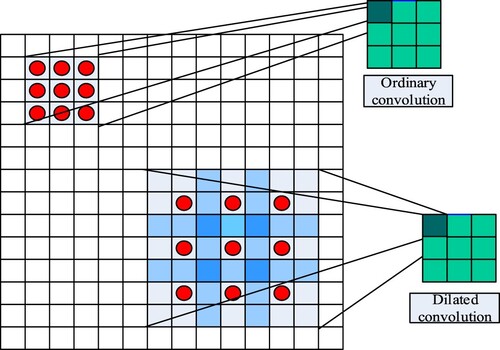
The square on the upper left side in Figure indicates a receptive field of size 3 × 3 for a 3 × 3 kernel in an ordinary convolution. The position of multiplication of each point in the kernel is an adjacent 3 × 3 rectangle (shown by the red dot positions in the upper left side of the picture) and the dilation rate, in this case, is 1. The dilated convolution is represented by the square on the lower right side in Figure showing a receptive field of size 7 × 7 for a 3 × 3 kernel having a dilation rate of 2. Note that its point multiplier position is no longer the adjacent 3 × 3 rectangle, but the red dot positions in the lower right side of the figure.
Calculation of the receptive field in a dilated convolution is done as follows:
The receptive field size of an ordinary convolution layer k is calculated by,
(1)
(1) where
is the receptive field size of the
layer,
is the convolution kernel size of the current layer, and
is the step size of the
layer.
Since the convolution kernel of the dilated convolution changes with the dilation rate, in order to calculate the receptive field size of the dilated convolution, it is necessary to first calculate the convolution kernel size of the current layer. This is done using,
(2)
(2) where r is the dilation rate of the dilated convolution kernel and k is the initial convolution kernel size.
Thus, by obtaining the convolution kernel size of the current layer using Equation (2) and substituting it in Equation (1), the receptive field size of the current layer of the dilated convolution can be calculated.
This paper uses a deep convolution network to detect a driver’s smoking behavior. According to the characteristics of the dataset, the cigarettes in the images are small target objects and thus are represented by only a few pixels in the image. An ordinary convolutional neural network (CNN) continuously reduces the information characteristics of a small target object while carrying out a continuous convolution operation on the image. However, most of the information is concentrated in the shallow feature map. Thus, the final feature map obtained from an ordinary CNN has fewer or sometimes no target features and this makes it impossible to detect cigarettes in the image. In contrast, since the FPN is continuously blending shallow features in the convolution process, the characteristics of the small targets are preserved in the final feature map. Thus, in the dilated convolution process, there is no loss of information without pooling and a large receptive field area enables each convolution output to contain a large amount of information. Due to these advantages, in the present work, FPN combined with the dilated convolution network has been selected to extract the features from the driver’s image to obtain an accurate detection.
2.2 FPN-D Network Structure
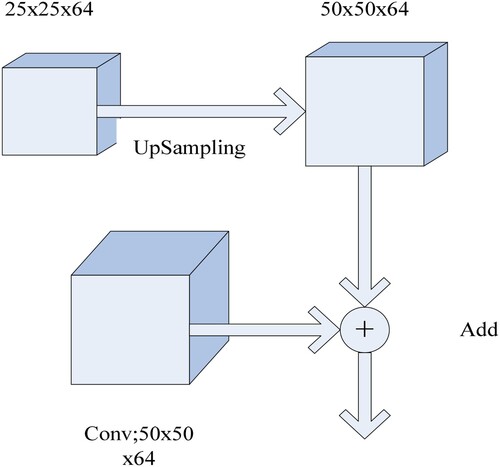
In the present work, a new network structure of FPN-D (schematic is shown in Figure ) consisting of FPN and dilated convolution has been proposed. In this, the image data enter the FPN from the input layer after convolution and the characteristics of the shallow network are continuously aggregated. The feature map obtained from this operation is then subjected to a dilated convolution operation. According to the characteristics of the dataset, three dilation rates (r = 1, r = 2, r = 3) have been used to perform the dilated convolution operation. At the same time, considering that the dilated convolution may lead to grid problems, the method of hierarchical feature fusion [Citation8] has been used to solve this problem. This method uses the feature maps convolved by different dilation ratios and superimposes them step by step. As a result, no additional parameters are introduced, the amount of calculation also does not increase much and thus, the grid effect can be effectively improved. In addition, the input feature map is also added to the final output feature map by doing an element-by-element summation to improve information transfer. The network then undergoes a convolution and the result thus obtained is outputted by the Sigmoid layer. The above network structure can efficiently capture the features of small objects in an image and the dilated convolution can retain a large amount of information so that the characteristics of the small objects can be learned from the driver image. The detailed process of addition to the network is shown in Figure , where the activation functions used by all convolution layers are Rectified Linear Units(ReLu).
Figure 3: Structure diagram of FPN-D
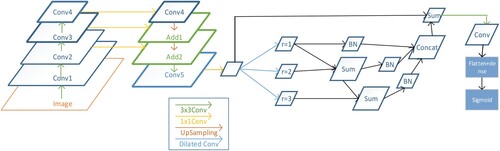
Figure 4: Schematic for the details of the addition process
2.3 Data Preprocessing
The driver image used in this article is provided by the local driver real-time monitoring platform. There are a total of 7,000 training images, which consist of images of drivers driving more than 200 different types of vehicles. Of these, 3,500 are images of the driver smoking and the rest are images of the driver's normal driving. The specific allocation of the data set is as follows: 6000 images are used to constitute the training data set, including 3000 driver smoking images; 600 images are used to constitute the evaluation data set, including 300 normal images of the driver; 400 images are used to constitute the test data set, including 200 driver smoking images. The original data in this article is a video file of the driver during the driving process collected from the vehicle monitoring platform. Then take out the video file frame by frame to form the original driver image as shown in the image on the left in Figure . Then simply crop the original driver image to form the training image in the text as shown in the right image in Figure . In this way, the influence of the background information in the image on the experimental results is reduced. In this work, the original driver image is simply cropped to reduce the influence of background information in the image, as shown in Figure . This is done using a code for face recognition written in the OpenCV environment, that can recognize a face in an image or a video and the program can save the recognized face as an image. Because the size of the image after trimming by the program is not uniform, the image size ranges from 380 × 380 to 410 × 410. Thus, the input size of the image in the model is specified as (400 × 400, 3),which can avoid the situation that the detection target is lost.
Figure 5: Driver image before (left) and after (right) cropping

2.4 Training and Parameter Selection
The network is trained using the preprocessed driver images. The input size of the image is (400 × 400, 3) and the reading mode is RGB mode. Real-time data enhancement, such as horizontal flipping, random clipping, random scaling, etc., is performed before the data is inputted into the network for training and the network is then trained as a whole. The detailed parameter configuration of the network structure is shown in Table .
Table 1: Detailed structure of the network
In the training process, the objective function adopted by the network is a binary cross-entropy function and the adaptive moment estimation (Adam) [Citation9] optimizer has been used. The learning rate of Adam is set to 0.001, the exponential decay rate of the mean of the gradient is set to 0.9, and the exponential decay rate of the uncentered variance of the gradient is set to 0.999. The dilation ratio used in the present work adopts a combination of three dilation ratios of r = 1, r = 2, and r = 3, which can obtain information from a wider range of pixels and avoid grid problems. At the same time, the method can also adjust the size of the receptive field by modifying the dilation rate.
3. EXPERIMENTAL SIMULATION AND RESULTS
In this work, the detection performance of FPN-D was evaluated on the basis of accuracy, precision, recall, specificity, and Receiver Operating Characteristic (ROC). The accuracy rate indicates the ratio of correctly predicted samples to all the samples; the precision rate indicates the ratio of truly correct samples to all the samples that have been classified as correct samples; the recall rate, also known as sensitivity, indicates the ratio of the sample that is predicted to be the correct sample to all the samples that are the correct samples in reality; the specificity refers to the probability of correctly predicting the wrong samples. The above-mentioned performance parameters are required to obtain the confusion matrix (see Table ).
Table 2: Confusion matrix
Following are the formulae used for calculating the different performance parameters:
(3)
(3)
(4)
(4)
(5)
(5)
(6)
(6) In order to make a comprehensive and accurate evaluation of FPN-D proposed in this work, this method has been compared with different network structure methods. The main reason for choosing the VGG network for comparison is to study whether the deep network structure is effective in identifying small targets. Traditional neural networks have more or less problems such as information loss when transmitting information. The residual network optimizes the above problems by directly bypassing the input information to protect the integrity of the information. According to the characteristics of the research object in this article, the target information is originally small, and once the information is lost, it will seriously affect the research results. Therefore, ResNet50 is selected for comparison in the article.
In order to ensure the fairness of comparison, the three benchmark methods of VGG, ResNet50 and FPN have been debugged many times to ensure that they can be well adapted to the experimental environment of this article. Therefore, before the experimental comparison. First, perform multiple debugging trainings for each network structure to be compared. Then select the best training parameters corresponding to the network training to compare the subsequent experiments to ensure the fairness of the experimental comparison. The accuracy rate obtained by applying different methods to the dataset used in the experimental simulation is shown in Figure , while the loss value for the different methods is shown in Figure . From these two plots, it can be seen that FPN-D has certain advantages in accurate detection in the dataset and changes in the loss function value during training. The classification performance of a particular comparison method is expressed by the average classification accuracy, precision, recall rate, and specificity. The values of these parameters have been calculated using Equations (3) to (6) and the numerical values thus obtained are given in Table . From a comparison of the numbers in the table, the FPN-D method is found to be superior as compared to the other three feature extraction methods in terms of accuracy, recall, and precision rate. Table gives the values of the area under the ROC curve (AUC) and the asymptotically 95% confidence interval(CI) for different methods while Figure shows the ROC curves corresponding to the different methods. From the figure, it can be found that the AUC (Area Under the Curve) value of the method studied in the article is closest to 1. So the FPN-D detection method has the highest authenticity.
Figure 6: Plot showing the accuracy rate obtained by applying different network structure training to the dataset
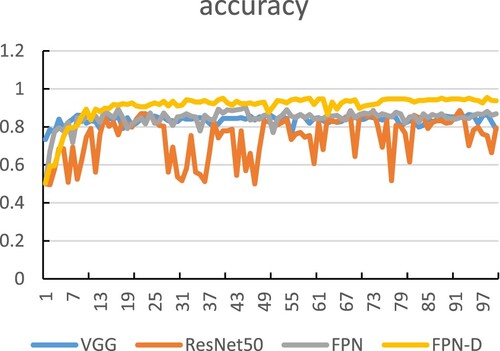
Figure 7: Plot showing the loss value for the validation set for the different network structure training
Figure 8: ROC curves for different methods
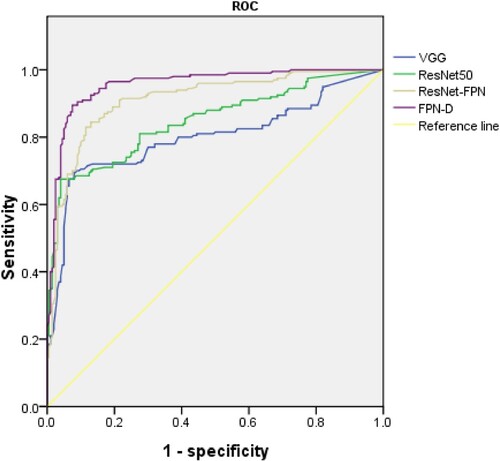
Table 3: Values of the performance of different methods
Table 4: AUC and CI values for the different methods
4. ANALYSIS AND DISCUSSION
The present work uses the deep learning method in order to detect the smoking behavior of drivers. Although there are some investigations on driver behavior detection and recognition based on deep learning [Citation10–14] and research on driver’s smoking behavior, this paper is a first attempt at using FPN to analyze the driver's smoking habit. Compared to the traditional methods, FPN-D can automatically extract the relevant features from the two-dimensional images of the driver without the need to design an algorithm for visual feature extraction. The network can fully utilize the features in the driver’s image, such as color, edge, texture, etc. to automatically train a suitable convolution filter to extract the relevant features from the image.
As shown in Table , the accuracy of detecting images using only FPN is 87.50% and the recall rate is 79.50%. The accuracy of detecting images with FPN-D is 94.75%, with an increase of 7.25 percentage points while the recall rate is 96%, an increase of 16.5 percentage points as compared to that obtained by using only FPN. Since most of the image features of small objects exist in the feature map of the shallow network, the FPN-D network makes full use of this feature. In the process of convolution, the shallow feature fusion is continuously performed, so that the shallow features are well preserved thus well retaining the shallow features. Compared with traditional VGG, ResNet and other networks, it has certain advantages. The FPN-D detection effect is better than the feature pyramid network because the FPN-D network has a hollow convolution layer, which can expand the range of the receptive field without increasing the amount of calculation, so as to better retain the features of the small target in the feature map. Especially for some small targets with large dispersion in the image, the retention of features in the feature map is higher than that of the general convolutional layer. Therefore, from the perspective of the detection range, the hole convolution plays a certain role in the formation of the feature map of small objects. Thus, the FPN-D proposed in the present work is quite effective. In terms of computational cost, the average time for categorization by GPU is not too different and can be neglected in practical applications. In addition, in order to evaluate the advantages of the network studied in this work, its comparison with some traditional network structures has also been done. From the results shown in Table , the accuracy of the most traditional convolutional network, VGG detection method, is 81% and its recall rate is 68.50%. It can be seen that the deep network structure is not ideal for detecting small target objects. The accuracy of the same data obtained by employing the ResNet50 detection method is 82.50% and its recall rate is only 67.50%. It can be seen that the advantages of the residual network cannot be well reflected in the research data in the article. To verify the advantages of the feature pyramid network in the researched data, two networks, ResNet50 and ResNet-FPN, are used for experiments. Through the ROC curve shown in Figure and the data in Table , it can be seen that the feature pyramid network has a good effect on the data studied in the article. Then compare the AUC values of different methods, the FPN-D method has the largest AUC value, which is 95.60%, and is superior in accuracy as compared to the AUC values of the other structures. Comparing the accuracy rate and loss value shown in Figures and for different detection methods, the accuracy of the FPN-D network structure proposed in the present work has the highest value and the value of loss is relatively the lowest. Thus, from the above-described analysis, it can be seen that the FPN-D has a higher probability and accuracy for detecting the driver’s smoking behavior. That is to say that the FPN-D can efficiently learn the relevant features to predict whether the driver in an image is smoking or not.
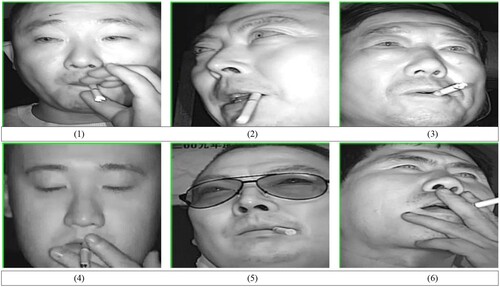
From the analysis, it is observed that the FPN-D method recognizes some images correctly while some incorrectly. Among the images shown in Figure , (1), (2) and (3) are the images that the network correctly recognizes as a driver smoking; (4), (5) and (6) are the images that the network wrongly identifies as the driver not smoking. From a comparative analysis, it can be inferred that the ambient light and the position of the camera inside the vehicle will have some influence on the detection of the driver’s smoking.
Figure 9: Test images of drivers smoking
At present, there is no analysis method for designing hyperparameters in FPN-D (such as learning rate and momentum parameters, number of convolution units, size of convolution kernel, etc.). These are mainly obtained through experience. In addition, for deep convolutional networks, providing more data is necessary to help the network obtain better generalization performance and reduce over-fitting problems. At present, the data set in this article is not enough to obtain higher accuracy, and further research is needed to obtain better performance in the future. And affected by the characteristics of the experimental research data, the network structure proposed in the article has not been tested on other data sets. The network structure proposed in the article has not been tested on other data sets. Later, we will collect enough images of other small objects to explore the recognition effect of FPN-D on other small objects.
5. CONCLUSION
This work proposes a detection method based on the convolutional neural network to detect the driver's smoking behavior. Results of the simulation experiment show that the method proposed in this work can realize the task of detecting the driver's smoking behavior while driving quite accurately. Moreover, artificial intelligence is a very popular research topic at present. There are a lot of studies done on image classification and recognition and human behavior recognition by employing different convolution methods [Citation15–28]. In this paper, we apply deep learning to the driver’s image for a preliminary study on the detection, by the network, of their smoking behavior. The datasets used for the studies were collected from real images captured by drivers while they are driving. Although the data obtained might be sufficient for the present study, as more data are acquired in the future, the network structure can be optimized in order to achieve better detection results. This is because, for the deep convolutional neural network, providing more data helps the network to achieve better generalization performance and reduces the fitting problem. The current dataset is insufficient to achieve higher accuracy than that obtained in the present work. Further work is needed to obtain better performance in order to achieve a better recognition accuracy and improve the possibility of applying the algorithm to real life, thus enabling to achieve an AI smoke control for drivers while they drive. In addition, the network structure in the article is relatively simple compared to other network structures. If the programming language can be converted into the language supported by the hardware running motherboard and embedded in the platform, it should be able to meet the actual driving application. Finally, in real life, the goal of AI smoke control for the driver in the driving process is realized.
Acknowledgements
The authors would like to thank tutor for his guide and help for this paper work.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Notes on contributors

Zuopeng Zhao
Zuopeng Zhao is an associate professor at China University of Mining and Technology, a master's tutor, and a doctor graduated from Peking University. He is mainly engaged in artificial intelligence, Beidou satellite positioning and mobile Internet of Things and other aspects of research. He has published 1 monograph, 7 papers in SCI journals, more than 10 papers in EI journals, and 4 national invention patents. He hosted numerous vertical projects and horizontal topics. He won two second prizes of the 5th Science and Technology Progress Award of the State Administration of Work Safety, and three second prizes of China Coal Industry Association Science and Technology Progress Award. Email: [email protected]

Haihan Zhao
Haihan Zhao is a graduate student at China University of Mining and Technology. She is currently engaged in research on artificial intelligence in transportation. The specific research direction is to identify the driver's behavior.

Chen Ye
Chen Ye is a graduate student of China University of Mining and Technology. He is currently engaged in the research of artificial intelligence in the medical field. His specific research direction is to identify the benign and malignant thyroid gland. Email: [email protected]

Xinzheng Xu
Xinzheng Xu is an associate professor at the China University of Mining and Technology and a master's tutor. He is mainly engaged in machine learning and data mining, artificial intelligence and pattern recognition, medical image processing and other aspects of research. He has published 1 monograph, more than 10 papers in SCI journals, and more than 20 papers in EI journals. Currently, he is a member of the Chinese Computer Society and Chinese Artificial Intelligence Society. Email: [email protected]

Kai Hao
Kai Hao is a graduate student at China University of Mining and Technology. He is currently engaged in the research of artificial intelligence in transportation. The specific research direction is to implement intelligent recognition algorithms on hardware devices. Email: [email protected]

Hualin Yan
Hualin Yan is a graduate student at China University of Mining and Technology. She is currently engaged in the research of artificial intelligence in transportation. Her specific research direction is to identify driver behavior. Email: [email protected]

Lan Zhang
Lan Zhang is a graduate student at China University of Mining and Technology. She is currently engaged in the research of artificial intelligence in transportation. Her specific research direction is to identify the driver's behavior. Email: [email protected]

Yi Xu
Yi Xu is a graduate student at China University of Mining and Technology. He is currently engaged in the research of artificial intelligence in transportation. The specific research direction is to implement intelligent recognition algorithms on hardware devices. Email: [email protected]
References
- S. Guan, Y. Zhang, and Z. Tian. “Research on human behavior recognition based on deep neural network,” in 3rd International Conference on Mechatronics Engineering and Information Technology (ICMEIT 2019). Atlantis Press, 2019.
- C. Zhang, R. Li, W. Kim, D. Yoon, and P. Patras. “Driver behavior recognition via interwoven deep convolutional neural nets with multi-stream inputs.” 2018.
- S. Yan, et al. “Driver behavior recognition based on deep convolutional neural networks,” in 2016 12th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD). IEEE, 2016.
- L. Yang, et al. “Driving behavior recognition using EEG data from a simulated car-following experiment,” Accid. Anal. Prev., Vol. 116, no. SI, pp. 30–40, 2018.
- C. Chiu, C. Kuo, and P. Chang. “Smoking action recognition based on spatial-temporal convolutional neural networks,” in 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC). IEEE, 2018.
- T. Lin, et al. “Feature pyramid networks for object detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
- F. Yu, and V. Koltun. Multi-scale context aggregation by dilated convolutions. arXiv preprint arXiv:1511.07122, 2015.
- S. Mehta, et al. “Espnet: Efficient spatial pyramid of dilated convolutions for semantic segmentation,” in Proceedings of the European Conference on Computer Vision (ECCV). 2018.
- D. P. Kingma, and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Y. Xing, et al. “Driver activity recognition for intelligent vehicles: A deep learning approach,” IEEE Trans. Veh. Technol., Vol. 68, no. 6, pp. 5379–5390, 2019.
- J. Zeng, Y. Sun, and L. Jiang. “Driver distraction detection and identity recognition in real-time.” in 2010 Second WRI Global Congress on Intelligent Systems. IEEE, 2010.
- G. Jianqiang, and Y. Wei. Driver pre-accident behavior pattern recognition based on dynamic radial basis function neural network.” in Proceedings 2011 International Conference on Transportation, Mechanical, and Electrical Engineering (TMEE), 2011.
- P. Li, J. Shi, and X. Liu, “Driving style recognition based on driver behavior questionnaire,” Open J. Appl. Sci., Vol. 07, no. 04, pp. 115–28, 2017.
- C. Yan, et al. “Video-based classification of driving behavior using a hierarchical classification system with multiple features,” Int. J. Pattern Recognit. Artif. Intell., Vol. 30, no. 05, pp. 1650010, 2016.
- S. Maity, D. Bhattacharjee, and A. Chakrabarti, “A novel approach for human action recognition from silhouette images,” IETE J. Res., Vol. 63, no. 2, pp. 160–71, 2017.
- B. V. Baheti, S. N. Talbar, and S. S. Gajre, “A training-free approach for generic object detection,” IETE J. Res., 1–14, 2019. DOI:10.1080/03772063.2019.1611491.
- Z. Cai, et al. “A unified multi-scale deep convolutional neural network for fast object detection.” in European conference on computer vision. Springer, 2016.
- S. N. Sivanandam, and M. Paulraj, “An approach for image classification using backpropagation scheme,” IETE J. Res., Vol. 46, no. 5, pp. 315–7, 2000.
- B. K. Mohan, “Classification of remotely sensed images using artificial neural networks,” IETE J. Res., Vol. 46, no. 5, pp. 401–10, 2000.
- P. O. Glauner, “Deep convolutional neural networks for smile recognition,” Comput. Sci., 2015.
- K. He, et al. “Deep residual learning for image recognition.” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
- P. Dollár, et al., “Fast feature pyramids for object detection,” IEEE Trans. Pattern Anal. Mach. Intell., Vol. 36, no. 8, pp. 1532–45, 2014.
- L. Sun, et al., “Human action recognition using factorized spatio-temporal convolutional networks,” in Proceedings of the IEEE International Conference on Computer Vision. 2015.
- S. Ren, et al., “Object detection networks on convolutional feature maps,” IEEE Trans. Pattern Anal. Mach. Intell., Vol. 39, no. 7, pp. 1476–81, 2016.
- S. Zhao, et al., “Pooling the convolutional layers in deep ConvNets for video action recognition,” IEEE Trans. Circuits Syst. Video Technol., Vol. 28, no. 8, pp. 1839–49, 2018.
- E. H. Adelson, et al., “Pyramid methods in image processing,” RCA Eng., Vol. 29, no. 6, pp. 33–41, 1984.
- K. He, et al., “Spatial pyramid pooling in deep convolutional networks for visual recognition,” IEEE Trans. Pattern Anal. Mach. Intell., Vol. 37, no. 9, pp. 1904–16, 2015.
- P. Wang, et al. “Understanding convolution for semantic segmentation,” in 2018 IEEE winter conference on applications of computer vision (WACV). IEEE, 2018.