
Abstract
Ensemble forecasts present an alternative to traditional deterministic forecasts by providing information about the likelihood of various outcomes. An ensemble can be constructed wherever errors are likely to occur within a hydrometeorological forecasting chain. This study compares the hydrological performance of a multimodel ensemble against deterministic forecasts issued by an operational forecasting system, in terms of accuracy and reliability. This comparison is carried out on 38 catchments in the province of Québec for more than 2 years of 6-day-ahead forecasts. The multimodel ensemble is comprised of 20 lumped conceptual models pooled together, while the reference forecast originates from an operational semi-distributed model. The results show that probabilistic forecast outperforms its deterministic counterpart and the deterministic operational forecast system, thanks to the role that each member plays inside the multimodel ensemble. This analysis demonstrates that the multimodel ensemble is potentially an operational tool, even though the specific setup for this study still suffers from underdispersion and needs to take into account additional sources of uncertainty to reach an optimal framework.
La prévision d'ensemble présente une alternative aux prévisions déterministes traditionnelles en fournissant davantage d'informations sur les probabilités d’occurrence des sorties du système. Les sources d'incertitudes sont nombreuses le long de la chaîne hydrométéorologique et il est possible de créer un ensemble à partir de ces sources pour y faire face. Cette étude présente une comparaison des performances d'un ensemble multimodèle et d'un modèle utilisé dans un système de prévision opérationnel. Cette comparaison se base sur des prévisions hydrologiques émises jusqu'à un horizon de 6 jours sur une période de plus de 2 ans et sur 38 bassins versants situés dans la province de Québec. L'ensemble multimodèle est composé de 20 modèles globaux conceptuels tandis que la prévision émise par le modèle semi-distribué déterministe est utilisée comme référence. Les résultats montrent que les prévisions probabilistes sont plus performantes que leurs homologues déterministes et que les prévisions issues du système opérationnel. Cette amélioration est essentiellement attribuée au rôle spécifique que chaque membre joue au sein de l'ensemble. Même si l'ensemble souffre toujours de sous dispersion et qu'il est donc nécessaire de considérer de nouvelles sources d'incertitudes pour améliorer la fiabilité, cette étude montre qu'un ensemble multimodèle est un potentiel outil de prévision probabiliste.
Introduction
Streamflow forecasting is a cornerstone for water management, civil protection and reservoir operation (Krzysztofowicz Citation1999; Block et al. Citation2009; Dietrich et al. Citation2009; Ramos et al. Citation2010). Despite efforts dedicated toward the development of efficient operational systems, attaining accuracy and reliability remains a daunting challenge as the sources of uncertainty in the hydrometeorological chain are many (Walker et al. Citation2003).
Uncertainty sources are spread from the initialization of meteorological prediction systems to decision-making tools. Among them, it is generally admitted that the main sources include meteorological forcing, hydrological initial conditions, time-invariant parameters and model structure (Ajami et al. Citation2007).
For the last few years, in seeking reliable simulations, the hydrometeorological community has been progressively shifting from deterministic simulations to probabilistic ones based on ensembles: a representative sample of the possible future outcomes. An ensemble allows framing uncertainty but, moreover, its median is frequently more accurate than any of the members (Velázquez et al. Citation2010). This stems mainly from the fact that inaccurate models presenting uncorrelated errors may be combined in a way that is on average better than the members taken individually (Thompson Citation1977). These ensembles can be built wherever uncertainty exists along the hydrometeorological modeling chain.
Many meteorological agencies have now adopted ensemble forecasting (e.g. the Meteorological Service of Canada, the European Center for Medium-Range Weather Forecasts, the Japan Meteorological Agency and more). This venue directly benefits hydrological forecasting for issuing probabilistic hydrological predictions based on an ensemble weather forecast that explicitly takes into account the meteorological forcing uncertainty (Cloke and Pappenberger Citation2009; Velázquez et al. Citation2009). Many studies claim that ensembles allow better decision making and outperform deterministic forecasts (e.g. Boucher et al. Citation2012; Abaza et al. Citation2014).
The uncertainty in hydrological initial conditions has been intensively examined, mainly via data assimilation to reinitialize a model on externally measured variables, creating a pertinent set of initial conditions for the next time step (Liu and Gupta Citation2007). Data assimilation may be used to, among other things, update model states (Clark et al. Citation2008a; Seo et al. Citation2009), possibly along with parameters (Moradkhani et al. Citation2005), or other variables like snowpack or some hydraulic information (DeChant and Moradkhani Citation2011).
A large part of the total uncertainty arises from the hydrological modelling elements of the chain, where model parameters, conceptualization and structure add up to form an aggregate of uncertainty difficult to decipher and predict (Walker et al. Citation2003).
Model parameter uncertainty has been extensively investigated. Beven and Binley (Citation1992) pioneered providing multiple possible answers through the Generalized Likelihood Uncertainty Estimation (GLUE), which allows producing an ensemble of parameter sets equally likely (from a mathematical point of view) to describe the catchment behavior. Because hydrologists have yet to identify a perfect model structure, there is no reason that a particular set of parameters should represent the “truth,” so GLUE allows the estimation of uncertainty related to parameters through the equifinality principle (Beven and Binley Citation1992; Beven and Freer Citation2001). Many other techniques have been proposed to estimate uncertainty related to parameters, focusing on calibration (Vrugt et al. Citation2003), temporal variability of parameters (Thiemann et al. Citation2001), spatial variability (Feyen et al. Citation2008), combining stochastic methods and expert knowledge (Dietrich et al. Citation2009) and varying objective functions (Yapo et al. Citation1998; Gupta et al. Citation1998), sometimes combined with assimilation (Vrugt et al. Citation2005; Liu and Gupta Citation2007).
Gourley and Vieux (Citation2006) carried out a study to identify the sources of uncertainty in a hydrometeorological chain. They argued that dealing with input and parameter uncertainties may not be sufficient for encompassing the streamflow forecast error and that using different conceptualizations would be a more appropriate strategy to overcome this issue. This would create a way out of the endless quest for the perfect model and allow harnessing the inaccuracies of existing models in an ensemble forecasting framework to issue better estimates of predictive error. Georgakakos et al. (Citation2004) combined a set of 11 calibrated and uncalibrated models forced by radar observations to issue forecasts for six catchments, qualifying their set-up as a potential operational tool. Clark et al. (Citation2008b, 10) confirmed that uncertainty arises from the structure of the model itself by assessing 79 unique model structures built out from four pre-existing hydrological models. This framework led them to conclude that “it is unlikely that a single model structure provides the best streamflow simulation for multiple basins” (see also Ajami et al. Citation2006; Breuer et al. Citation2009). They emphasized that taking into account the structural uncertainty is as important as considering parameter uncertainty. It seems that the main limitation to a multimodel ensemble may be the lack of dissimilarity between structures, which leads to underdispersed forecasts. This statement is substantiated by Viney et al. (Citation2009, 1), who argued that “the best ensembles are not necessarily those containing the best individual models,” but those bringing diversity.
Ajami et al. (Citation2006) investigated several simple means for merging members, namely the simple model average, the multimodel superensemble and the weighted average, and concluded that despite their simplicity, the ensemble average generally performs better than any member taken individually. More sophisticated methods, like Bayesian model averaging, were explored by Raftery et al. (Citation2005) and Duan et al. (Citation2007) to create probabilistic forecasts. Ajami et al. (Citation2007) exploited the integrated Bayesian uncertainty estimator scheme to combine input, parameter and structural errors, and confirmed that merging the outputs leads to a more reliable forecast since considering only parameter uncertainty resulted in a large underdispersion. Velázquez et al. (Citation2010) confirmed that retaining all the output members and offering a fully probabilistic forecast is preferable over an aggregate of outputs, preserving all the information available.
To the authors’ knowledge, despite the attention that ensemble and, more specifically, multimodel ensemble modelling have aroused, comparisons have mostly been carried out between an ensemble and one or several members composing the ensemble. These studies have helped to recognize the benefit associated with the use of several members, but the comparisons are mostly not made in an independent way. There is a lack of comparisons of a multimodel ensemble against an independent model, i.e. a model which is not part of the multimodel ensemble. Comparing a multimodel ensemble to one of its members provides information only about the ensemble’s relative performances, and one should ensure that the reference model (the model used for comparison) is proven in order to evaluate the gain of the system under scrutiny.
This study aims to assess gains related to the additional information provided by a hydrological multimodel ensemble over an operational deterministic model, and to investigate multimodel properties. The available data set is larger than that used in most previously mentioned papers, striving for more global and generalized information instead of focusing on a single event of interest. As Andreassian et al. (Citation2009) recommended, tests are carried out on demanding conditions. Hydrological forecasts are issued for catchments that are notably affected by snow accumulation and spring freshet.
Hydrotel, a semi-distributed hydrological model operationally utilized for public dam management (Turcotte 2004) by the Centre d'Expertise Hydrologique du Québec (CEHQ), is driven by deterministic weather forecasts from Environment Canada over a 2.5-year period to create the reference hydrological forecast. The multimodel ensemble is generated from 20 lumped hydrologic models selected for their diversity and forced by the same meteorological inputs as the operational system, to ensure a fair comparison.
The paper is organized as follows: a brief description of the catchments and computing tools is provided in the Methodology section, followed by a comparison between hydrologic forecasts in terms of performance and reliability. Further investigation into the multimodel ensemble is presented at the end of the Results section. Concluding statements are provided in the last section.
Methodology
The case study catchments and data are presented along with the description of scores selected to assess the performance and reliability of the forecasts, followed by a description of the technique used in post-processing to correct simulated streamflows.
Catchments and hydrometeorological data
The case study spans over 387,000 km2 with coverage primarily of the province of Quebec, but also Ontario and the states of New York and Vermont (Figure ). The area is situated between 43°15′N and 52°20′N latitudes and 68°85′E and 81°20′E longitudes, where the climate is classified as wet continental and the hydrologic regime is dominated by a spring freshet. The flows are structured into three major river systems: the Outaouais River, the Saguenay River and the lower part of the St. Lawrence River downstream of its confluence with the Outaouais River. More specifically, the database includes 38 catchments of various sizes and discharge levels (Table ). Snow data are not directly available as no continuous in situ measurements are carried out. To estimate the solid precipitation (Table ), all available precipitation and temperature observations are used to force the snowmelt module. The annual mean is computed next from simulated snow accumulation time series.
Figure 1. Catchments and hydrological stations.
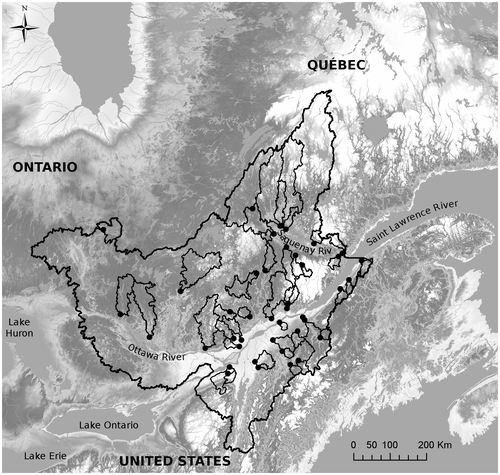
Table 1. Mean annual characteristics of the catchments.
Climatological time series (of minimum and maximum daily temperatures and 24-hour total precipitation) were provided on a 1220-point grid (of 0.1° resolution) by the CEHQ. These data were created by applying kriging to observations made within the study area, and applying an elevation-based temperature correction of –0.005°C/m. The data set extends from 1969 to 2010, yet the 1990–2000 period was chosen for the calibration of the various hydrological models.
Hydrotel pre-processes meteorological inputs. Thiessen polygons are used to define weights associated to each grid point situated inside each catchment. In order to drive all hydrological models with the same meteorological information, the semi-distributed model is run first and the resulting evaluation of the climatology over the entire catchment is provided next to the lumped models.
Rainfall and temperature forecasts
The deterministic meteorological forecasts were issued by the Canadian Meteorological Center regional model over a 2-day horizon at spatial and temporal resolutions of 15 km and 3 hours, respectively. The forecast lead time is extended to 6 days by adjoining forecasts from the 35 km resolution global model. All forecasts from October 2008 to December 2010 were disaggregated by the CEHQ to the 0.1° grid of the climatological data by the nearest neighbor method (Gaborit et al. Citation2013). For the sake of this study, the meteorological data are aggregated to a daily time step.
The 3 years preceding the forecast period are used for model spin-up. Models are then forced with observations to bring their states to values that are representative of the catchment conditions at the beginning of the period of interest. In forecasting mode, hydrological forecasting and model updating based on observations alternate. The forecast is issued by forcing the models with the meteorological forecast from t = 0 to t = 6. Models are then updated by forcing the models with observations from t = 0 to t = 1 to create the new initial condition set for the forecasts from t = 1 to t = 7. These steps are repeated over the entire forecasting period.
Hydrological models
Hydrotel is a semi-distributed model that simulates typical hydrological variables and processes such as soil water content, snow accumulation and melt, evapotranspiration, vertical water balance and surface runoff. It was conceptualized from a physical description of the catchment by J.P. Fortin et al. (Citation1995). The model is mostly used by the CEHQ for the management of public dams in the Province of Québec (Turcotte et al. Citation2004). The present study relies on a calibration performed by the CEHQ using the Shufle Complex Evolution (SCE; Duan et al. Citation1992).
Table 2. Main characteristics of the 20 lumped models (Seiller et al. Citation2012; used with permission).
The multimodel ensemble pools 20 lumped models chosen for their structural diversity. The initial model selection was carried out by Perrin (Citation2000) to investigate structures and parameter complexity performance following an extensive bibliographic research. This selection was revised by Seiller et al. (Citation2012) for hydrological projections. Careful attention has been given to favor parsimony: model complexity should remain low except if more complexity provides a substantial gain in performance and robustness. This also ensures limiting issues related to parameter uncertainty and equifinality (Beven and Binley Citation1992) during the calibration process, as the number of parameters is kept low.
The retained models rely on conceptual reservoirs to describe the principal processes of the hydrological cycle, and were developed in different contexts as some were initially intended for daily or monthly simulation or specifically for Nordic hydrology, for instance.
Some original models needed to be modified to match the ensemble frame. Potential evapotranspiration and snow accumulation and melting are computed externally. Additional model modifications have been performed upon model parameters, structure or space discretization. For some models, the number of calibrated parameters has been reduced by fixing parameters identified according to developers’ comments, or after a sensitivity analysis. Simplifications in the structure may have also been carried out. The new structures were kept if they provided better results than original models. A time-delay function for routing is implemented for models that do not possess one in order to simulate catchments with a time of concentration greater than 1 day. Finally, a parametric logistic function is added to the models that required other catchment characteristics than hydrometeorological series.
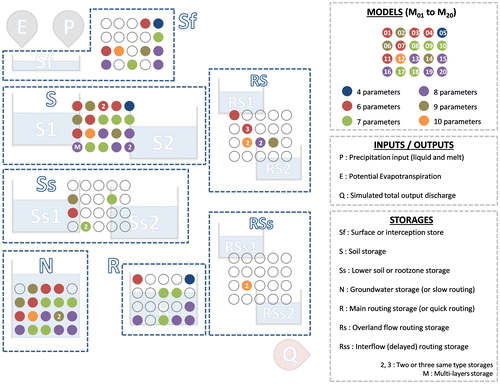
Figure summarizes the repartition of parameters and reservoirs of the 20 models. The final selection exhibits models with low to moderate complexity (four to 10 calibrated parameters and two to seven reservoirs). A more detailed description of model modifications can be found in Perrin (Citation2000). Acronyms are used to emphasize that the models may substantially differ from their original version.
Figure 2. Illustration of model structural diversity (reproduced with permission from Seiller et al. Citation2012).
The lumped models are driven by precipitation and potential evapotranspiration. The latter is calculated from the empirical formulation proposed by Oudin et al. (Citation2005), based on the daily mean air temperature and the calculated extraterrestrial radiation.
A snow module (Cemaneige) (Valery et al. Citation2014) is used prior to running the lumped models. The two-parameter module accumulates solid precipitation and relies on a degree-day approach modulated by an energy balance index. It discretizes the catchment into five bands of equal elevation. The precipitation provided to the lumped models is thus the sum of the liquid precipitation and snowmelt water. The snowmelt module and individual models are calibrated together. The parameter sets retained for the snow module are influenced by the hydrologic model used and their parameterization. The hydrologic ensemble is therefore coupled with a snow accounting process that takes into account the snow module parameter uncertainty.
The lumped models are calibrated using the SCE method and the root mean squared error (RMSE) of square-rooted streamflow as the objective function over the same 10-year period (1990 to 2000) selected by the CEHQ for the calibration of the Hydrotel model.
Hydrologic forecast correction via streamflow assimilation
A simple assimilation technique is used to adjust hydrological forecasts. Output updating (Refsgaard Citation1997) compares forecasted and observed streamflow on the date of forecast. Then the difference between observed and simulated streamflow at time is subtracted from each day of the 6-day forecast with a damping coefficient that depends on lead time, starting with 1 the first day and decreasing to 0 on day 6:
(1)
where is the updated forecast of the ith lead day,
the observed streamflow at the time of forecast emission,
the empirically determined damping coefficient which decreases by 0.2 unit every day (i.e.
= 1 at t = 1,
= 0.8 at t = 2, etc.) and
the streamflow forecast at the ith day.
It is out of the scope of this study to explore statistical post-processing methods specific to hydrological ensemble forecasts for achieving a better representation of the uncertainty, such as regressions (e.g. Gneiting et al. Citation2005), kernel dressing (e.g. Roulston and Smith Citation2003), Bayesian model averaging (BMA; Raftery et al. Citation2005) and Bayesian processor of ensemble (BPE; Krzysztofowicz and Maranzano Citation2004). Exploring a raw multimodel ensemble allows us to investigate the role played by each hydrological model.
Scores
The hydrological forecasts are assessed in terms of resolution and reliability. Reliability indicates the degree of statistical consistency between probability forecasts and the observed frequency of occurrence of a particular event. For instance, a reliable 80% interval should on average contain the observation eight times out of 10. Resolution evaluates the ability of discriminating between two events which are different. In the case of deterministic forecast, resolution is a measure of the distance between forecast and observation.
Traditional deterministic scores like mean absolute error (MAE) cannot be used when using probabilistic forecast, but distinctive scores need to be used in order to compare forecast probability and the observation frequency.
Reliability and resolution are both assessed by the continuous ranked probability score (CRPS) (Matheson and Winkler Citation1976), which is the integral form of Brier's score:
(2)
where is the forecasted probability of occurrence of an event
and
is the heavy side function which is 1 when the event happens, 0 otherwise, and
the length of the time series.
The CRPS is “sensitive to the average ensemble spread and the frequency and magnitude of the outliers” (Hersbach Citation2000, 560).(3)
where is the predictive cumulative distribution function for day
,
is the predicted variable,
is the corresponding observed value and
is the heavy side function. CRPS evaluates the performance for one time step, so the MCRPS is defined as the average of CRPS over the entire period. An advantage of this score is that it can be compared to the MAE (Gneiting and Raftery Citation2007), and consequently allows the comparison of deterministic and probabilistic forecasts.
The reliability diagram and ranked histogram are collectively used to evaluate reliability. The former (Stanski et al. Citation1989) is a graphical method that is obtained by plotting forecasted frequencies as a function of frequencies of the occurrence of the corresponding observed event. A 45° line identifies a perfectly reliable ensemble. In this study, nine quantiles are plotted, ranging from 0.1 to 0.9. The latter, also known as the Talagrand diagram, is an easy way to visualize how the ensemble and its members are located with respect to the observation. It assesses the reliability of the ensembles by subdividing them into boxes which are delimited by the members of the ensemble. The representation gives the frequency at which the observation falls into a specific bin. A flat histogram usually implies a reliable ensemble since the observation is equally likely to be situated in between any two members in average. More rarely, a rank histogram may appear uniform even in the presence of a conditional bias (Hamill Citation2001).
The rank histogram is also used in this study in a non-traditional way to track each member among the ensemble. Instead of looking where the observation falls within the ensemble, attention is paid to where the ensemble falls with respect to the individual members. This produces one rank histogram per member, hereafter called model rank histograms. Flatness is not necessary in that context because shape is not related to reliability anymore, but only to the place where the member under consideration is situated most frequently. This tool allows for an investigation of the role of each member of the ensemble (i.e. each different lumped hydrologic model).
Results
This section addresses three aspects. The first consists of a qualitative hydrograph comparison. The second concerns gains that a multimodel ensemble provides over the deterministic hydrological prediction system. The last one investigates the role and contribution of individual members in the multimodel ensemble.
Hydrograph analysis
An example of streamflow prediction from 7 February to 7 June for the Dumoine River is displayed in Figure . The hydrographs represent the observed and simulated rate of discharge according to time. Unlike traditional forecast hydrographs where the origin of the hydrograph represents the first forecasting day and the x-axes represents the lead time, the hydrographs display the concatenation of values for the same lead times (1, 3 and 6 days ahead). Percentages on the figure and the grey shades associated with them denote the theoretical confidence interval of the multimodel ensemble. The theoretical confidence interval would be equal to the “true” confidence interval in the case where the multimodel ensemble is perfectly reliable.
Figure 3. Multimodel ensemble and Hydrotel hydrographs for the Dumoine River. The grey shades depict the percentage of the theoretical confidence interval.
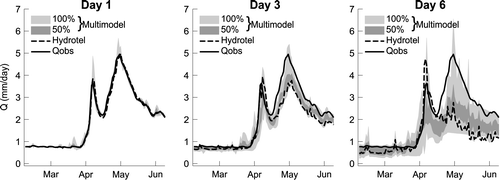
The principal advantage of the multimodel ensemble over the deterministic hydrological prediction system is that it is more often capable of predicting events which are harder to forecast (i.e. rare or extreme events or two consecutive streamflow peaks, as in Figure ). Indeed, using many distinct models increases the possibility of one or few of them encompassing an event. For example, on 29 April for the 6th day in Figure , two models out of 20 surpass the observed streamflow, while Hydrotel strongly underestimates the observation. Multiple models also possess the ability to compensate for an erroneous prediction made by some of the ensemble members. For example, on the first week of April for the 6th day, one lumped model largely underestimates the streamflow, though the 50% ensemble theoretical confidence interval is barely affected.
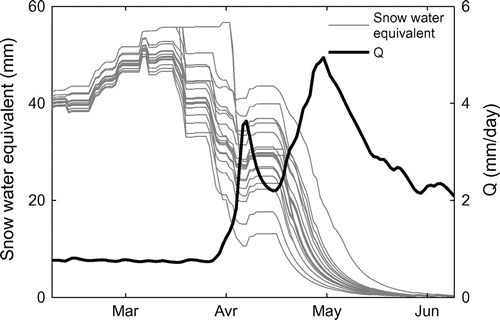
Snowmelt simulations are indirectly influenced by the multimodel. Even if there is only a single snowmelt module, snowmelt uncertainty is partially taken into account thanks to the use of several parameter sets leading to differences in the snow accumulation and melt (Figure – only the middle elevation band is represented, as the behavior of the different bands is very similar because of the weak catchment elevation variations). The dynamic of the simulated snow cover by the different snow module parameterizations does not differ substantially, since it still relies on a single structure (snow water equivalents for each snow module tend to be parallel) but provides an estimate of uncertainty about the snow cover depth.
Figure 4. Simulated snow water equivalent stock for the different snowmelt module parameter sets and the middle elevation band for the Dumoine River.
Deterministic and probability forecast performance
Levels of performance of probabilistic and deterministic forecasts are reported in Figure , in which catchments are sorted by increasing Hydrotel MAE. The MAE allows a comparison of deterministic forecasts (the multimodel ensemble MAE is computed from the median value of the ensemble), while the MCRPS assesses multimodel ensemble forecast. As mentioned earlier, one may compare MAE and MCRPS.
Figure 5. Mean Absolute Error (MAE) and Mean Continuous Ranked Probability score (MCRPS) of the deterministic and probabilistic forecasts for all 6-day horizons and catchments sorted by increasing Hydrotel MAE.
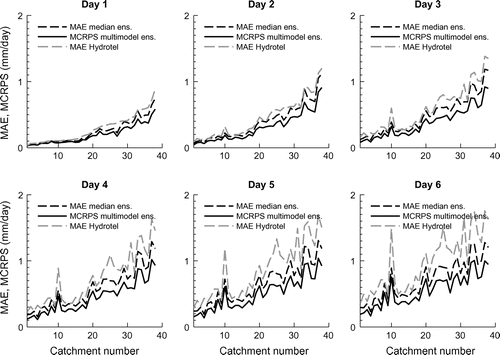
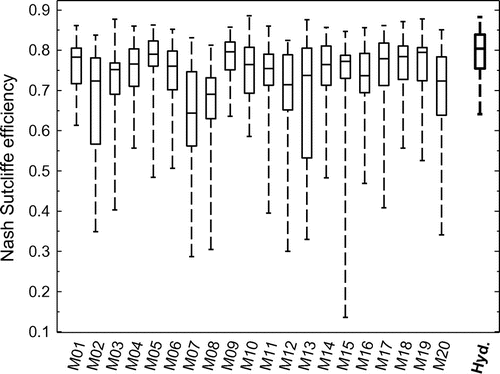
Performance varies with catchments and horizons, but multimodel MAE is systematically better than Hydrotel MAE for all 38 catchments. This demonstrates that, even if the multimodel forecast is reduced to its median, the multimodel outperforms traditional deterministic forecast. This arises from the fact that models, if they are uncorrelated, tend to cancel out each other’s errors. The gain lies in the combination of models, and not in the individual performances of the model used in the multimodel ensemble as shown in Figure . Hydrotel clearly stands among the best models with constant performances for the validation period for all catchments, but is outperformed by the ensemble. These results are in agreement with those in Figure . The multimodel ensemble reduces the risk inherent in relying on a single (possibly misleading) model (Hagedorn et al. Citation2005).
Figure 6. Individual models and Hydrotel Nash Sutcliffe efficiency for a 10-year validation period and the 38 catchments.
There is also a net gain in retaining all multimodel outputs. When the multimodel is reduced to its median (multimodel MAE), performance decreases. This underlines the added value of the probabilistic forecast over the deterministic one, i.e. considering a probability density function rather than a single point forecast. Note that the difference between Hydrotel MAE and MCRPS scores grows as performance decreases.
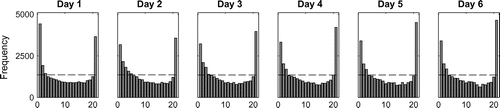
The reliability of the multimodel is assessed. Figure shows rank histograms pooled over all catchments. The multimodel ensemble is consistently underspread. The output updating preserves the rank histogram shape for the different lead times, but harms the spread (the members are corrected individually regardless of their initial position in the ensemble and they are squeezed around a certain value). The predictive uncertainty of the whole system is therefore lower than the multimodel uncertainty estimation without the output updating. The multimodel ensemble reliability may possibly be improved using an assimilation technique that better preserves the spread, and using ensemble meteorological forcing.
Figure 7. Multimodel ensemble rank histograms, for each lead time, combining the time series from all catchments.
Ensemble member characteristics
Model rank histograms are grouped in Figure . They depict the role played by each lumped model in the multimodel ensemble, by illustrating where they tend to fall with respect to other ensemble members. A uniform histogram indicates that the model occupies every rank equally, while a heterogeneous one identifies a model’s preferences to occupy different areas of the ensemble's spread. Contrary to the standard rank histograms illustrated in Figure , they do not assess reliability and there is no expected behavior.
Figure 8. Model rank histograms sorted by increasing mean absolute error (MAE) values for all catchments for the 6-day lead time. Each subplot represents the frequency of falling into a specific rank for the model under consideration (vertical axes) with its corresponding rank (horizontal axes).
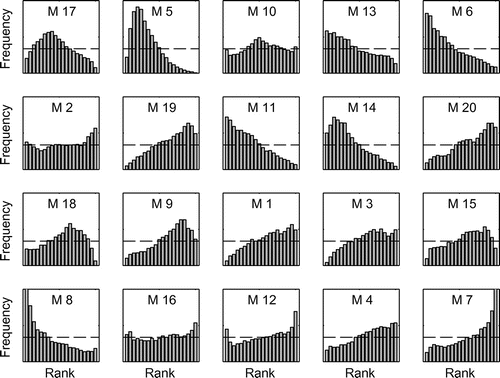
The rank histograms of each model in Figure are sorted in ascending MAE values in order to relate the role of the model within the ensemble to its individual performance. The best model is situated in the top left corner, the worst on the bottom right corner. Only the 6th lead time is shown, as it is representative of model characteristics at other lead times.
The different aspects of the rank histograms illustrate the way that the models complement one another. Some models seem more liable to capture outliers (higher or lower part of the ensemble) while others remain centered. The sorting of the models according to the level of their individual performance does not reveal any particular behaviors. Interestingly, no model presents a pronounced U-shaped rank histogram, which means that no model has a structure/conceptualization that allows it to contribute to both ends of the predictive distribution.
Conclusion
Issuing accurate and reliable hydrological forecasts is still an outstanding challenge. Probabilistic forecasts grow in popularity in particular because they provide information about the uncertainty in the hydrometeorological modeling chain and the resulting forecasts. Within the many sources of uncertainty, hydrologic model structure and conceptualization are among the dominant ones. A multimodel ensemble that samples these sources of error has been proposed to tackle these issues simultaneously.
This study provided a comparison between a semi-distributed deterministic forecast system against one derived from an ensemble of 20 lumped conceptual models chosen for their dissimilar conceptualizations. The multimodel ensemble was also compared to its deterministic counterpart (i.e. ensemble median) to identify the benefits of using probabilistic forecasts. Finally, the characteristics of the multimodel ensemble itself were assessed, exploring the role that each member plays with respect to the rest of the ensemble.
Ensemble forecast was assessed in terms of resolution and reliability. It performs better than its deterministic counterpart in terms of resolution assessing MCRPS and MAE. Even if the multimodel ensemble only takes into account conceptualization and structural uncertainty (when driven by deterministic meteorological forecasts), it provides overall more accurate streamflow prediction than deterministic forecast systems do. Multimodel ensembles also present the advantage of being more likely to encompass events which are harder to predict. Moreover, the hydrological multimodel allows an indirect partial handling of snowmelt simulation error through the calibration process. Relying on several models increases the chance that at least one of them will be able to forecast any specific event (particularly rare extreme events). According to a rank histogram analysis, multimodel ensembles tend to be reliable, but they lack spread and extreme events are still frequently underestimated. Attention has also been given to the role that the members of the multimodel ensemble play. No common pattern between model accuracy and rank was identified, suggesting that members play different roles inside the ensemble and that they contribute in diverse ways.
Despite its success with respect to an operational model, this multimodel setup (exploiting very simple model structures) may still be improved by considering other sources of uncertainty, such as meteorological uncertainty. Since snow accumulation and melt may have a great influence on the spring freshet simulation, the multimodel approach could be extended for those processes too. Generating larger ensembles by including different snow modules may serve to partially encompass this potentially large source of uncertainty. Finally, the streamflow assimilation technique could be improved by taking into account the ensemble's spread.
Acknowledgements
The authors acknowledge the CEHQ for providing a calibrated Hydrotel model and hydrometeorological data. We also wish to thank the student contribution of Pascale Desrochers for carrying out Hydrotel simulation, and the contribution of the reviewers.
References
- Abaza, M., F. Anctil, V. Fortin, and R. Turcotte. 2014. A comparison of the Canadian global and regional meteorological ensemble prediction systems for short-term hydrological forecasting. Monthly Weather Review 142: 2561–2562.
- Ajami, N. K., Q. Duan, X. Gao, and S. Sorooshian. 2006. Multimodel combination techniques for analysis of hydrological simulations: Application to Distributed Model Intercomparison Project results. Journal of Hydrometeorology 7: 755–768.
- Ajami, N. K., Q. Duan, and S. Sorooshian. 2007. An integrated hydrologic Bayesian multimodel combination framework: Confronting input, parameter, and model structural uncertainty in hydrologic prediction. Water Resources Research 43: doi:10.1029/2005WR004745.
- Andreassian, V., C. Perrin, L. Berthet, N. Le Moine, J. Lerat, C. Loumagne, L. Oudin, et al. 2009. HESS Opinions: Crash tests for a standardized evaluation of hydrological models. Hydrology and Earth System Sciences 13: 1757–1764.
- Bergström, S., and A. Forsman. 1973. Development of a conceptual deterministic rainfall-runoff model. Nordic Hydrology 4: 147–170.
- Beven, K., and A. Binley. 1992. The future of distributed models: Model calibration and uncertainty prediction. Hydrological Processes 6: 279–298.
- Beven, K., and J. Freer. 2001. Equifinality, data assimilation, and uncertainty estimation in mechanistic modelling of complex environmental systems using the GLUE methodology. Journal of Hydrology 249: 11–29.
- Beven, K., M. J. Kirkby, N. Schoeld, and A. F. Tagg. 1984. Testing a physically based flood forecasting model (TOPMODEL) for 3 UK catchments. Journal of Hydrology 69: 119–143.
- Block, P. J., F. A. Souza, L. Q. Sun, and H. H. Kwon. 2009. A streamflow forecasting framework using multiple climate and hydrological models. Journal of the American Water Resources Association 45: 828–843.
- Boucher, M. A., D. Tremblay, L. Delorme, L. Perreault, and F. Anctil. 2012. Hydro-economic assessment of hydrological forecasting systems. Journal of Hydrology 416: 133–144.
- Breuer, L., J. A. Huisman, P. Willems, H. Bormann, A. Bronstert, B. F. W. Croke, H. G. Frede, et al. 2009. Assessing the impact of land use change on hydrology by ensemble modeling (LUCHEM). I: Model intercomparison with current land use. Advances in Water Resources 32: 129–146.
- Burnash, R. J. C., R. L. Ferral, and R. A. McGuire. 1973. A generalized streamflow simulation system – Conceptual modelling for digital computers. Sacramento, CA: US Department of Commerce, National Weather Service and State of California.
- Chiew, F. H. S., M. C. Peel, and A. W. Western. 2002. Mathematical models of small watershed hydrology and applications. Littleton, CO: Water Resources Publication.
- Clark, M. P., D. E. Rupp, R. A. Woods, X. Zheng, R. P. Ibbitt, A. G. Slater, J. Schmidt, and M. J. Uddstrom. 2008a. Hydrological data assimilation with the ensemble Kalman filter: Use of streamflow observations to update states in a distributed hydrological model. Advances in Water Resources 31: 1309–1324.
- Clark, M. P., A. G. Slater, D. E. Rupp, R. A. Woods, J. A. Vrugt, H. V. Gupta, T. Wagener, and L. E. Hay. 2008b. Framework for Understanding Structural Errors (FUSE): A modular framework to diagnose differences between hydrological models. Water Resources Research 44: 1–14.
- Cloke, H. L., and F. Pappenberger. 2009. Ensemble flood forecasting: A review. Journal of Hydrology 375: 613–626.
- Cormary, Y., and A. Guilbot. 1973. Étude des relations pluie-débit sur trois bassins versants d’investigation. In Design of water resources projects with inadequate data. Proceedings of the International Association of Hydrological Sciences (IAHS) Madrid Symposium. Madrid: IAHS Publication, 265–279.
- DeChant, C. M., and H. Moradkhani. 2011. Improving the characterization of initial condition for ensemble streamflow prediction using data assimilation. Hydrology and Earth System Sciences 15: 3399–3410.
- Dietrich, J., A. H. Schumann, M. Redetzky, J. Walther, M. Denhard, Y. Wang, B. Pfuetzner, and U. Buettner. 2009. Assessing uncertainties in flood forecasts for decision making: Prototype of an operational flood management system integrating ensemble predictions. Natural Hazards and Earth System Sciences 9: 1529–1540.
- Duan, Q. Y., N. K. Ajami, X. G. Gao, and S. Sorooshian. 2007. Multi-model ensemble hydrologic prediction using Bayesian model averaging. Advances in Water Resources 30: 1371–1386.
- Duan, Q. Y., S. Sorooshian, and V. Gupta. 1992. Effective and efficient global optimization for conceptual rainfall-runoff models. Water Resources Research 28: 1015–1031.
- Feyen, L., M. Kalas, and J. A. Vrugt. 2008. Semi-distributed parameter optimization and uncertainty assessment for large-scale streamflow simulation using global optimization. Hydrological Sciences Journal–Journal Des Sciences Hydrologiques 53: 293–308.
- Fortin, J. P., R. Moussa, C. Bocquillon, and J. P. Villeneuve. 1995. HYDROTEL, un modèle hydrologique distribué pouvant bénéficier des données fournies par la télédétection et les systèmes d'information géographique. Revue des sciences de l'eau/Journal of Water Science 8(1): 97–124.
- Fortin, V., and R. Turcotte. 2007. Le modèle hydrologique MOHYSE, Note de cours pour SCA7420. Département des sciences de la Terre et de l'atmosphère: Université du Québec à Montreal.
- Gaborit, É., F. Anctil, V. Fortin, and G. Pelletier. 2013. On the reliability of spatially disaggregated global ensemble rainfall forecasts. Hydrological Processes 27: 45–56.
- Garçon, R. 1999. Modèle global Pluie–Débit pour la prévision et la prédétermination des crues. La Houille Blanche 7(8): 88–95.
- Georgakakos, K. P., D. J. Seo, H. Gupta, J. Schaake, and M. B. Butts. 2004. Towards the characterization of streamflow simulation uncertainty through multimodel ensembles. Journal of Hydrology 298: 222–241.
- Girard, G., G. Morin, and R. Charbonneau. 1972. Modèle précipitations-débits à discrétisation spatiale. Cahiers ORSTOM, Série Hydrologie 9(4): 35–52.
- Gneiting, T., and A. E. Raftery. 2007. Strictly proper scoring rules, prediction, and estimation. Journal of the American Statistical Association 102: 359–378.
- Gneiting, T., A. E. Raftery, A. H. Westveld, and T. Goldman. 2005. Calibrated probabilistic forecasting using ensemble model output statistics and minimum CRPS estimation. Monthly Weather Review 133: 1098–1118.
- Gourley, J. J., and B. E. Vieux. 2006. A method for identifying sources of model uncertainty in rainfall-runoff simulations. Journal of Hydrology 327: 68–80.
- Gupta, H. V., S. Sorooshian, and P. O. Yapo. 1998. Toward improved calibration of hydrologic models: Multiple and noncommensurable measures of information. Water Resources Research 34: 751–763.
- Hagedorn, R., F. J. Doblas-Reyes, and T. N. Palmer. 2005. The rationale behind the success of multi-model ensembles in seasonal forecasting – I. Basic concept. Dynamic Meteorology and Oceanography 57: 219–233.
- Hamill, T. M. 2001. Interpretation of rank histograms for verifying ensemble forecasts. Monthly Weather Review 129: 550–560.
- Hersbach, H. 2000. Decomposition of the continuous ranked probability score for ensemble prediction systems. Weather and Forecasting 15: 559–570.
- Jakeman, A. J., I. G. Littlewood, and P. G. Whitehead. 1990. Computation of the instantaneous unit hydrograph and identifiable component flows with application to two small upland catchments. Journal of Hydrology 117: 275–300.
- Krzysztofowicz, R. 1999. Bayesian theory of probabilistic forecasting via deterministic hydrologic model. Water Resources Research 35: 2739–2750.
- Krzysztofowicz, R., and C. J. Maranzano. 2004. Hydrologic uncertainty processor for probabilistic stage transition forecasting. Journal of Hydrology 293: 57–73.
- Liu, Y. Q., and H. V. Gupta. 2007. Uncertainty in hydrologic modeling: Toward an integrated data assimilation framework. Water Resources Research 43: doi:10.1029/2006WR005756.
- Matheson, J. E., and R. L. Winkler. 1976. Scoring rules for continuous probability distributions. Management Science 22: 1087–1096.
- Mazenc, B., M. Sanchez, and D. Thiery. 1984. Analyse de l'influence de la physiographie d'un bassin versant sur les paramètres d'un modèle hydrologique global et sur les débits caractéristiques à l'exutoire. Journal of Hydrology 69: 97–188.
- Moore, R. J., and R. T. Clarke. 1981. A distribution function approach to rainfall runoff modeling. Water Resources Research 17(5): 1367–1382.
- Moradkhani, H., S. Sorooshian, H. V. Gupta, and P. R. Houser. 2005. Dual state-parameter estimation of hydrological models using ensemble Kalman filter. Advances in Water Resources 28: 135–147.
- Nielsen, S. A., and E. Hansen. 1973. Numerical simulation of the rainfall-runoff process on a daily basis. Nordic Hydrology 4: 171–190.
- O'Connell, P. E., J. E. Nash, and J. P. Farrell. 1970. River flow forecasting through conceptual models, Part II – The Brosna catchment at Ferbane. Journal of Hydrology 10: 317–329.
- Oudin, L., F. Hervieu, C. Michel, C. Perrin, V. Andreassian, F. Anctil, and C. Loumagne. 2005. Which potential evapotranspiration input for a lumped rainfall-runoff model? Part 2 – Towards a simple and efficient potential evapotranspiration model for rainfall-runoff modelling. Journal of Hydrology 303: 290–306.
- Perrin, C. 2000. Vers une amélioration d'un modèle global pluie-débit. Hydrology. PhD thesis, Institut National Polytechnique de Grenoble – INPG.
- Perrin, C., C. Michel, and V. Andreassian. 2003. Improvement of a parsimonious model for streamflow simulation. Journal of Hydrology 279: 275–289.
- Raftery, A. E., T. Gneiting, F. Balabdaoui, and M. Polakowski. 2005. Using Bayesian model averaging to calibrate forecast ensembles. Monthly Weather Review 133: 1155–1174.
- Ramos, M.-H., T. Mathevet, J. Thielen, and F. Pappenberger. 2010. Communicating uncertainty in hydro-meteorological forecasts: mission impossible? Meteorological Applications 17: 223–235.
- Refsgaard, J. C. 1997. Validation and intercomparison of different updating procedures for real-time forecasting. Nordic Hydrology 28: 65–84.
- Roulston, M. S., and L. A. Smith. 2003. Combining dynamical and statistical ensembles. Tellus Series A – Dynamic Meteorology and Oceanography 55: 16–30.
- Seiller, G., F. Anctil, and C. Perrin. 2012. Multimodel evaluation of twenty lumped hydrological models under contrasted climate conditions. Hydrology and Earth System Sciences 16: 1171–1189.
- Seo, D. J., L. Cajina, R. Corby, and T. Howieson. 2009. Automatic state updating for operational streamflow forecasting via variational data assimilation. Journal of Hydrology 367: 255–275.
- Stanski, H. R., L. J. Wilson, and W. R. Burrows. 1989. Survey of common verification methods in meteorology. WMO World Weather Watch Tech Report 8. Downsview, ON: Atmospheric Environment Service Publication.
- Sugawara, M. 1979. Automatic calibration of the tank model. Hydrological Sciences 24: 375–388.
- Thiemann, M., M. Trosset, H. Gupta, and S. Sorooshian. 2001. Bayesian recursive parameter estimation for hydrologic models. Water Resources Research 37: 2521–2535.
- Thiery, D. 1982. Utilisation d'un modèle global pour identifier sur un niveau piézométrique des influences multiples dues à diverses activités humaines. IAHS Publications 136: 71–77.
- Thompson, P. D. 1977. How to improve accuracy by combining independent forecasts. Monthly Weather Review 105: 228–229.
- Thornthwaite, C. W., and J. R. Mather. 1955. The water balance. Report, Drexel Institute of Climatology, Centerton, New Jersey, USA.
- Turcotte, R., P. Lacombe, C. Dimnik, and J. P. Villeneuve. 2004. Prévision hydrologique distribuée pour la gestion des barrages publics du Québec. Canadian Journal of Civil Engineering 31(2): 308–320.
- Valery, A., V. Andreassian, and C. Perrin. 2014. “As simple as possible but not simpler”: What is useful in a temperature-based snow accounting routine? Part 2 – Sensitivity analysis of the Cemaneige snow accounting routine on 380 catchments. Journal of Hydrology 517: 1176–1187.
- Velázquez, J. A., F. Anctil, and C. Perrin. 2010. Performance and reliability of multimodel hydrological ensemble simulations based on seventeen lumped models and a thousand catchments. Hydrology and Earth System Sciences 14: 2303–2317.
- Velázquez, J. A., T. Petit, A. Lavoie, M. A. Boucher, R. Turcotte, V. Fortin, and F. Anctil. 2009. An evaluation of the Canadian global meteorological ensemble prediction system for short-term hydrological forecasting. Hydrology and Earth System Sciences 13: 2221–2231.
- Viney, N. R., H. Bormann, L. Breuer, A. Bronstert, B. F. W. Croke, H. Frede, T. Grae, et al. 2009. Assessing the impact of land use change on hydrology by ensemble modelling (LUCHEM) II: Ensemble combinations and predictions. Advances in Water Resources 32: 147–158.
- Vrugt, J. A., C. G. H. Diks, H. V. Gupta, W, Bouten, and J.M. Verstraten. 2005. Improved treatment of uncertainty in hydrologic modeling: Combining the strengths of global optimization and data assimilation. Water Resources Research 41: doi:10.1029/2004wr003059.
- Vrugt, J. A., H. V. Gupta, W. Bouten, and S. Sorooshian. 2003. A Shuffled Complex Evolution Metropolis algorithm for optimization and uncertainty assessment of hydrologic model parameters. Water Resources Research 39: doi:10.1029/2002wr001642.
- Wagener, T., D. P. Boyle, M. J. Lees, H. S. Wheater, H. V. Gupta, and S. Sorooshian. 2001. A framework for development and application of hydrological models. Hydrology and Earth System Sciences 5: 13–26.
- Walker, W. E., P. Harremoës, J. Rotmans, J. P. Van Der Sluijs, M. B. A. Van Asselt, P. Janssen, and M. P. Krayer von Krauss. 2003. Defining uncertainty: A conceptual basis for uncertainty management in model-based decision support. Integrated Assessment 4(1): 5–17.
- Warmerdam, P. M., J. Kole, and J. Chormanski. 1997. Modelling rainfall-runoff processes in the Hupselse Beek research basin. In Ecohydrological processes in small basins. Proceedings of the Strasbourg Conference, ed. D. Viville and I. G. Littlewood, 155–161.
- Yapo, P. O., H. V. Gupta, and S. Sorooshian. 1998. Multi-objective global optimization for hydrologic models. Journal of Hydrology 204: 83–97.
- Zhao, R. J., Y. L. Zuang, L. R. Fang, X. R. Liu, and Q. Zhang. 1980. The Xinanjiang model. IAHS Publications 129: 351–356.