Abstract
Although numerical models are increasingly being used to generate operational seasonal forecasts, the reliability of these products remains relatively low. Regression-based post-processing methods have proven useful in increasing forecast skill, but efforts have focused on linear regression. Given the non-linear nature of the climate system and sources of model error, non-linear analogues of these post-processing methods may offer considerable improvements. The current study tests this hypothesis, applying both linear and non-linear regression to the correction of climate hindcasts produced with general circulation models. Results indicate that non-linear support vector regression is better able to extract indices of the Pacific/North American teleconnection pattern and the North Atlantic Oscillation from coupled model output, while linear approaches are better suited to atmosphere-only model output. Statistically significant predictions are produced at lead times of up to nine months and can be obtained from model output with no forecast skill prior to processing.
RÉSUMÉ [Traduit par la rédaction] Même si les modèles numériques sont de plus en plus utilisés pour produire des prévisions saisonnières opérationnelles, la fiabilité de ces produits reste plutôt faible. Des méthodes de post-traitement utilisant la régression se sont avérées utiles pour améliorer l'habileté des prévisions, mais les efforts ont surtout porté sur la régression linéaire. Étant donné la nature non linéaire du système climatique et des sources d'erreur des modèles, des analogues non linéaires de ces méthodes de post-traitement pourraient permettre des améliorations importantes. La présente étude cherche à vérifier cette hypothèse en appliquant une régression linéaire et une régression non linéaire à la correction de prévisions climatiques a posteriori produites à l'aide de modèles de circulation générale. Les résultats indiquent que la régression non linéaire des vecteurs de support arrive à mieux extraire les indices de configuration de la téléconnexion Pacifique/Amérique du Nord et de l'oscillation nord-atlantique de la sortie de modèles couplés alors que les approches linéaires font mieux avec la sortie de modèles atmosphériques seulement. Des prévisions statistiquement significatives sont produites pour jusqu’à neuf mois dans le futur et peuvent être obtenues de la sortie d'un modèle sans habileté de prévision avant le traitement.
1 Introduction
Numerical seasonal climate forecasts are becoming increasingly common as the research community experiments with new tools and techniques while various user groups explore their potential value. Building on improvements in climate models and computing power realized in recent years, several prominent forecasting centres have developed operational systems to predict the state of the climate at lead times of several months to several seasons (Derome et al., Citation2001; Saha et al., Citation2006; Livezey and Timofeyeva, Citation2008). A common approach has been to force an atmospheric general circulation model (GCM) with sea surface conditions observed at the beginning of a forecast period, recognizing that the ocean boundary captures various slowly varying processes with strong atmospheric influences. Several of these atmosphere-only (AGCM) forecasting systems have demonstrated modest skill at lead times of one month to a season, a period over which sea surface anomalies with a climate influence can tend to persist (e.g., El Niño-Southern Oscillation (ENSO) events). These early successes have stoked interest in systems based on coupled atmosphere-ocean GCMs (AOGCMs). The addition of an evolving ocean state has the potential to extend the useful lead time of a forecast if the coupled model responds to initial conditions in a realistic manner. In Canada, an AOGCM-based forecasting system has been developed through the first Coupled Historical Forecasting Project (CHFP1). This effort is a natural extension of the first and second Historical Forecasting Projects (HFP and HFP2), which formed the basis for Environment Canada's current AGCM-based forecasting system (Merryfield et al., Citation2010).
The finite inherent predictability of the climate system presents one of the primary challenges to seasonal forecasting. The influence of the slowly varying climate processes that form the basis for seasonal forecasting is often much smaller than the climate's internal variability (i.e., predictable signals are obscured by climate noise). The magnitude of this problem varies by region; for example, predictability is high in the tropics relative to the extratropics (Rowell, Citation1998). Skilful extratropical forecasts are, therefore, often associated with accurate prediction of processes with the highest signal-to-noise ratios. Much of the seasonal forecast skill in North America can be attributed to the influence of ENSO (e.g., Shukla et al., Citation2000; Derome et al., Citation2001; Livezey and Timofeyeva, Citation2008), which generates a highly predictable signal over much of the continent. Other teleconnection patterns have similar, if smaller, value as North American seasonal climate predictors (e.g., the Pacific/North American (PNA) pattern (e.g., Leathers et al., Citation1991) and the North Atlantic Oscillation (NAO; e.g., Hurrell and van Loon, Citation1997)). The NAO is also known for its decadal or longer time scale fluctuations, related to interactions with Arctic sea ice (Mysak and Venegas, Citation1998).
Other key challenges with numerical forecasts involve the quality of the models being used. All models produce systematic error in their representation of the climate system and its integration from initial conditions. Limitations in resolution and model physics push the model integrations toward a biased interpretation of the true climate, and this drift obscures the simulated evolution from initial conditions. Furthermore, the response itself may deviate considerably from that of the true climate. Although a model may produce a predictable, systematic response to prescribed forcings, the spatial characteristics of this response may differ from that of the true climate. That is, a GCM's response may be statistically related to the true outcome, yet produce forecast fields with limited accuracy. These problems are exacerbated in coupled GCMs, as non-linear interactions between component models can amplify any existing biases.
Much of the effort to improve numerical forecasts focuses on improving the models used. This work is necessary but also expensive and time intensive. A complementary and less resource intensive approach involves the development of post-processing methods that identify and correct systematic model biases. Post-processing techniques typically use computationally efficient linear statistical analyses, such as regression, to relate GCM projections with true climate outcomes. This process has proven useful in improving temperature, precipitation and teleconnection forecasts (Lin et al., Citation2005, Citation2008; Jia et al., Citation2010). However, given that both the climate system and sources of GCM bias involve non-linear processes, it is possible that the use of linear statistics has limited the effectiveness of this approach. If this is the case, non-linear analogues of the statistical methods applied in past studies should give superior results. In many cases, appropriate non-linear methods exist and have already proven useful in climate and weather applications. In particular, non-linear regression techniques are well developed and can be readily adapted to numerical climate forecast correction. Past studies have successfully applied non-linear regression to seasonal forecasting of El Niño events (Wu et al., Citation2006), extreme precipitation (Zeng et al., Citation2011) and air temperatures (Wu et al., Citation2005), among other climate and weather applications.
The current study assesses the potential value of non-linear regression in climate forecast post-processing, applying the method to HFP2 and CHFP1 hindcast data. Classical multivariate linear regression is compared with support vector regression, a machine learning method with non-linear capabilities. The present study focuses on the prediction of key teleconnection patterns influencing the North American climate; these predictions are themselves of limited operational value but are strongly related to forecast variables of interest and provide a simple illustration of the ability of post-processing methods to extract a useful signal from forecast noise.
2 Data
Post-processing methods are tested using numerical climate hindcasts produced for the first phase of Environment Canada's Coupled Historical Forecasting Project (CHFP1; Merryfield et al. Citation2010) and HFP2 (Kharin et al., Citation2009), downloaded from the Canadian Centre for Climate Modelling and Analysis (CCCma). The simulations examined were generated with version three of the CCCma's atmospheric GCM (AGCM3), a global spectral model run at T63 horizontal resolution with 32 vertical levels (Scinocca et al. Citation2008). Both prediction systems generate ensembles of 10 parallel integrations for each hindcast period, facilitating comparison of their predictive skill. Brief descriptions of the initialization and ensemble generation schemes follow; a more detailed discussion is available in Merryfield et al. (Citation2010).
The complete set of HFP2 forecasts includes output from four atmospheric models. For the purposes of the current study, only forecasts generated by AGCM3 were used, in order to ease comparison with the CHFP1. These hindcasts were generated by forcing AGCM3 with static sea surface temperature (SST) anomalies, observed during the month preceding a simulation's start date. Sea-ice extents were also initialized to the previous month's observations, then relaxed to climatology over the first fifteen days of the simulation. Hindcasts extend four months from the start date, a period over which SST anomalies are expected to change relatively little. The ensemble is generated using different atmospheric initial conditions taken from the reanalysis of the National Centers for Environmental Prediction/National Center for Atmospheric Research (NCEP/NCAR) (Kalnay et al., Citation1996) at 12 hr intervals preceding the simulation start date. Twelve hindcasts were generated for each year beginning on the first day of every month. Data cover the period 1969–2001 (Kharin et al., Citation2009).
Version 3 of the CCCma Coupled GCM (CGCM3) is used by CHFP1, which couples the AGCM3 with the National Center for Atmospheric Research Community Ocean Model (NCOM; Gent et al., Citation1998). The inclusion of a dynamic ocean boundary is intended to improve predictive skill at long lead times, and CHFP1 hindcasts have a duration of twelve months. The 10-member ensemble was produced by combining two ocean initializations taken one and five days prior to the start date and five atmospheric initializations, taken at 0000 utc from the five days preceding the simulation. These states were produced by a coupled model run in which SSTs were relaxed strongly to observed values leading up to the forecast so that the atmospheric states contain the influence of the observed SSTs. Unlike the HFP2 initial states, they do not contain details of the atmospheric state as represented by the NCEP/NCAR reanalysis at those times; this difference tends to degrade CHFP1 skill relative to HFP2 in the early stages of the hindcast runs. Four hindcasts were produced for each year, beginning on the first day of December, March, June and September, respectively (Merryfield et al., Citation2010). Data cover the period 1972–2001.
The present study examines December (winter) runs valid for 1972–2001, covering the largest coincident period of the HFP2 and CHFP1 experiments. Winter runs were chosen because of the greater influence of synoptic weather systems and teleconnection indices on winter climate relative to other seasons. Stronger upper level westerlies at this time of year favour Rossby wave propagation, which in turn is influenced by teleconnections such as ENSO. This generally results in more skilful seasonal forecasts relative to other seasons and renders it particularly well suited to numerical climate prediction. Results are evaluated against data from the NCEP/NCAR reanalysis and time series of prominent teleconnection patterns from the National Oceanic and Atmospheric Administration's (NOAA) Climate Prediction Center (CPC; NOAA, Citation2010). Loading patterns in the 500 hPa geopotential height (Z500) field for the NAO and the PNA pattern were generated by regressing NAO and PNA time series from NOAA-CPC onto gridded anomaly fields from the NCEP/NCAR reanalysis, producing regressed anomaly (“loading”) maps that were subsequently normalized to a unit vector (a and a). Separate loading patterns were calculated for overlapping three-month periods (e.g., DJF, JFM, FMA, etc) in order to reflect seasonal variations in the structure and intensity of the two teleconnections. Predictions of the teleconnection indices were then calculated using CHFP1 and HFP2 as the projection of the loading patterns onto the ensemble mean Z500 anomaly hindcast for each three-month period.
Fig. 1 (a) The DJF Z500 PNA loading pattern (unitless), and the first Z500 SVD pattern from (b) NCEP, (c) HFP2, and (d) CHFP1 (in metres).
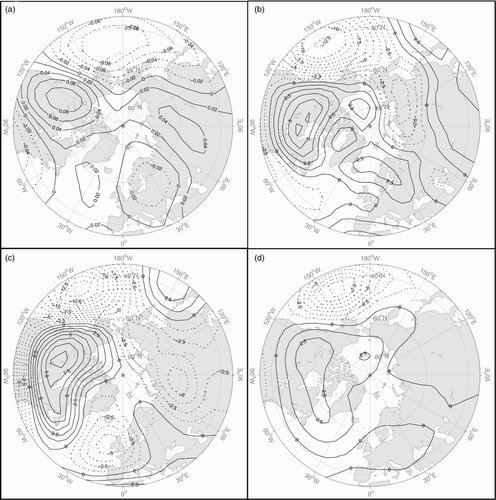
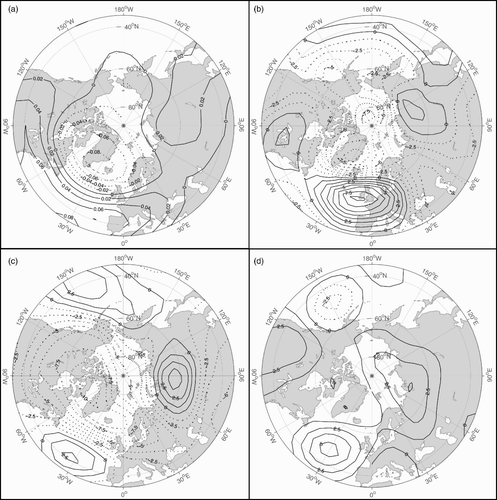
Fig. 2 (a) The DJF Z500 NAO loading pattern (unitless), with the second Z500 SVD pattern from (b) NCEP, (c) HFP2 and (d) CHFP1 (in metres).
3 Methods
a Support Vector Regression
Support vector regression (SVR) is an extension of the support vector machine method (developed originally for classification problems) to regression problems (Vapnik et al., Citation1997). A brief description of the technique is described here; a more detailed explanation can be found in Hsieh (Citation2009).
Let x be a vector of predictor variables and y be a desired predictand. Linear relationships between y and x can be readily identified through classical linear regression while non-linear relationships cannot. However, a non-linear mapping function, Φ, can be used to convert the non-linear relationship into a linear regression problem, that is,
By linearizing a non-linear regression problem using Eq. (1), SVR eliminates the need for non-linear optimization and problems associated with local minima of a non-linear error function. In this regard, SVR presents an advantage over the artificial neural network approach to non-linear regression. The remaining concern is that the mapping function Φ(x) may transform the data into a high dimensional space, thereby becoming computationally expensive to solve. This problem is addressed by uisng a kernel trick, which replaces the inner product ⟨Φ(x), Φ(x′)⟩ with a scalar kernel function K(x, x′). For the purposes of this study, a linear and a non-linear kernel were used for linear and non-linear SVRs, respectively. The linear kernel is simply the inner product K(x , x i ) = ⟨x , x i ⟩ between a predictor vector (x) and a given support vector (x i ). While the linear kernel does not allow the SVR to model non-linear relations, linear SVR is not the same as classic linear regression, because the ε-insensitive error norm renders it a robust linear regression method. Non-linear SVR was performed with the following Gaussian kernel:
The selection of hyperparameters has a significant effect on the performance of the SVR model. Although objective methods for selecting some hyperparameters have been proposed, in practice model optimization requires additional tuning. Here, the approach of Cherkassky and Ma (Citation2004) has been used to generate initial objective estimates of the hyperparameters, which are subsequently tuned using a fine grid search.
For non-linear regression problems, artificial neural network (ANN) models are commonly used and have previously been used for post-processing (Casaioli et al., Citation2003; Marzban, Citation2003). SVR has two main advantages over ANN: (a) the ε-insensitive error norm used by SVR is more robust to outliers in the training data than the mean squared error norm used by ANN, and (b) ANN requires a very complicated non-linear optimization over many model weights which is plagued by the presence of numerous local minima in the error function, a situation not found in the SVR formulation (Hsieh, Citation2009).
b Post-Processing Model Testing
Hindcasts of the NAO and PNA indices were post-processed with three regression algorithms: multivariate linear regression (LR), linear support vector regression (LSVR), and non-linear support vector regression (NLSVR). Post-processing models use five predictors (x in Eqs (1)–(4)): the teleconnection hindcast from the unprocessed model output, and the time series of four leading patterns from one of the following decompositions of GCM output: i) principal components (PCs) of the Z500 anomaly field over the northern hemisphere (45°–90°N), ii) PCs of tropical Pacific SST anomalies (20°S–20°N, 120°–270°E), or iii) a singular value decomposition (SVD) (i.e., maximum covariance analysis; von Storch and Zwiers, Citation2001) of these two fields, giving spatial patterns for both. In the present paper, anomaly refers to deviations from climatology, with monthly mean fields subtracted from the raw data. Because HFP2 does not predict the ocean state, SST predictors for HFP2 were derived from the static SST anomaly driving the AGCM3. CHFP1 predictors were derived from the forecast state of both SSTs and Z500. The predictor sets were chosen for their similarity to sets used in previous post-processing studies (e.g., Lin et al., Citation2008) and for their relative simplicity. The first step in model training selects one of the four PC or SVD time series as the best predictor set, which is then used in subsequent training steps. The result is that individual post-processing models use the unprocessed teleconnection index with additional spatial data related to a single field (SST or Z500), summarized with a single decomposition method (PC or SVD). Although it is possible that combining various predictors from the three GCM decompositions could generate better forecasts, there are concerns that the skill of forecasts produced with screened predictor sets can be overstated (DelSole and Shukla, Citation2009). The approach used here represents a compromise between limiting the complexity of predictor screening, while maintaining some flexibility to account for the possibility that the relative value of the oceanic and atmospheric component models may change as a coupled run progresses.
For CHFP1 data, separate regression models were built for each of ten overlapping three-month periods. Hindcasts used begin in December and run until the end of the following November. The run is then split into ten forecast periods; December to February (DJF), JFM, FMA, MAM, AMJ, MJJ, JJA, JAS, ASO and SON. Predictors are derived from hindcast data valid for a given forecast period (i.e., the DJF post-processing model uses the hindcast output averaged over DJF). DJF forecasts represent prediction at a zero-month lead, JFM at one-month lead, etc. For each lead time, the best predictor set was first identified, using a coarse five-fold cross-validation LR procedure to compare their relative values.
The selected predictor set was then used by the LR, LSVR and NLSVR methods for post-processing. The use of linear regression to select predictor sets may give the LR and LSVR procedures a slight advantage over the NLSVR procedure; hence, any improvement in skill from using the NLSVR method over using the linear methods is likely to be understated. The three methods were each evaluated using a rigorous double cross-validation scheme (). Thirty-fold cross-validation produced predictions for each year, using a model trained with the majority of the remaining years in the study period (outer validation loop, or CV1 in ). Years immediately preceding and following the year being predicted were excluded from the training period, in order to reduce information leakage from autocorrelation.
Fig. 3 Illustration of the double cross-validation approach to model training and testing. An outer validation loop (CV1) is used to test (i.e., verify) the forecast skill of the three post-processing models (LR, LSVR and NLSVR). In CV1, the training data are shown in grey and the 1-year validation data are shaded. The post-processing models are trained using the training data and their forecast performance is evaluated using the validation data. The 1-year data segments (shown in white) bridge the training data and the validation data are not used to avoid autocorrelation leaking information from the training data to the adjacent validation data. In this loop, the validation data segment is moved repeatedly in 1-year increments from the start of the data record to the end of the data record, so forecast performance is tested (verified) over the entire record. For LSVR and NLSVR, the optimal model hyperparameters need to be found by a second (inner) validation loop (CV2). In CV2, the training data from CV1 (in grey) are assembled and divided into nine segments, with eight used for training and one (shaded) for validation. Again the training and validation segments are rotated in the loop so all segments are eventually used for validation. Models with different hyperparameter values are run repeatedly, and the forecast performance over the validation data allow us to choose the optimal hyperparameters. The optimal model determined from CV2 is then used to forecast over the 1-year validation segment in CV1.
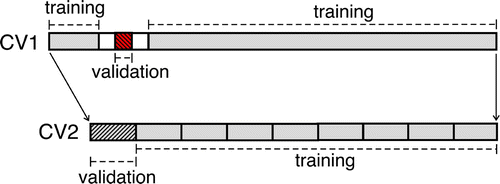
In the case of the LSVR and NLSVR methods, hyperparameters were selected using a second nine-fold cross-validation applied to the training data (inner validation loop, or CV2 in ). Values identified as optimal for the training data were then used in an SVR model to predict the testing year in CV1. This double cross-validation scheme is employed to avoid validating predictive skill with data already used for model training and hyperparameter selection.
4 Results
a Teleconnection Loading Patterns and Relationship to Predictors
It is helpful to begin by examining the physical structure of the teleconnections being predicted and assessing the ability of the forecast models to reproduce these structures. a and 2a, respectively, show the Z500 loading patterns of the PNA and NAO used in the current study for the DJF period. The PNA features two opposing centres of action located over the North Pacific and western North America. Similarly, the NAO places opposing centres over the climatological Icelandic Low in the North Atlantic and the Azores High in the subtropical Atlantic. The spatial characteristics of these correlation-derived patterns are essentially identical to those used by the NOAA-CPC. Time series of the amplitudes of these patterns also agree very closely with the original NAO and PNA time series used to define them, giving correlation scores above 0.9.
Past studies have shown that an SVD of the Z500 and tropical SST fields used to generate predictor sets in the current work produce patterns related to the teleconnections of interest. Specifically, the first Z500 SVD (SVD1) shares spatial characteristics with the PNA, while the second (SVD2) typically resembles the NAO (Lin et al., Citation2005). This emphasizes the influence of coupled atmosphere-ocean processes on these teleconnections and provides insight into the physical mechanisms behind these phenomena. In the context of the present study, it follows that an SVD analysis of GCM output can provide an indication of whether or not the model accurately simulates these mechanisms.
Results of SVD analyses of NCEP data (b and 2b), HFP2 output (c and 2c), and CHFP1 output (d and 2d) for DJF are presented alongside the teleconnection loadings. The NCEP SVDs both feature centres of action similar to the associated loading patterns. However, while the teleconnection patterns de-emphasize regions outside of these centres, the NCEP SVDs also place high loadings in other areas of the northern hemisphere. The two teleconnections appear to be somewhat convoluted in the SVD analysis, with SVD1 emphasizing the PNA centres but also introducing weak loadings in the vicinity of the Icelandic Low and Azores High. SVD2 emphasizes the Icelandic Low and Azores High but shifts their location relative to the teleconnections. It also introduces a dipole between western and eastern North America, resembling a weakened and eastward-shifted PNA pattern.
SVD results for HFP2 output closely resemble NCEP results, particularly for SVD1. There is again a tendency to convolve PNA and NAO-like patterns, although the NAO dipole is less well defined. However, CHFP1 output gives very different results. CHFP1 SVDs feature weaker centres of action and less defined features in general than NCEP or HFP2. This could result from greater variability in atmosphere-ocean interactions, perhaps related to the adjustment process of the component models during the early stages of the coupled runs. Despite this, CHFP1 SVD1 closely resembles the PNA loading pattern, with a well-defined Pacific/North American dipole. The NAO is not captured well in either SVD, with SVD2 showing only an Azores High combined with a weaker PNA dipole. It can be inferred that the model captures PNA-like processes well but may be misrepresenting those related to the NAO.
summarizes relationships between the SVDs and the teleconnection indices, showing correlation scores between SVD time series and observed PNA and NAO indices. The strong relationship between NCEP SVD1 and the PNA is confirmed with high values in both DJF and JFM. The PNA-like aspects of NCEP SVD2 also leads to reasonably strong correlations. However, neither SVD is significantly related to the observed NAO. HFP2 SVD1 also correlates reasonably well with the observed PNA, suggesting this is a relatively useful predictor. This is not the case for CHFP1; although the CHFP1 SVD1 spatial pattern resembles the PNA, the temporal amplitude of this pattern in the CHFP1 output does not provide a useful estimate of the teleconnection's state. Surprisingly, SVD2 does show a statistically significant, if weak, relationship with the observed NAO, suggesting there is a signal related to the NAO embedded in a structurally dissimilar pattern.
Table 1. Pearson correlation scores between the observed teleconnection time series (PNA and NAO) and the first two Z500 SVD time series from observed (NCEP) data, HFP2 data and CHFP1 data. Correlations significant at the 95% are in bold.
gives the number of times the four predictor sets described in the previous section were identified as the best basis for a post-processing model, using the linear regression-based screening process. Z500 SVDs were selected most often, likely because of their marked relationship to the PNA and NAO.
Table 2. Frequency with which the four predictor sets were chosen for model training; a best set is chosen for each of the ten lead times and the two teleconnections.
b Post-Processing Results
Performance of unprocessed and processed model simulations are primarily evaluated in terms of correlation between observed and projected teleconnection indices, with results presented in (HFP2) and 4 (CHFP1). Post-processing of CHFP1 data are also evaluated using mean absolute error (MAE) and index of agreement (Willmott et al., Citation1985), reported as skill scores (SS) relative to the unprocessed CHFP1 output ( and ), with SS defined by
Fig. 4 Correlation and mean absolute error (MAE) skill scores of post-processed CHFP1 output, with the unprocessed CHFP1 output used as the reference prediction. Prediction periods are indicated by the first letter of the central month in each three-month period.
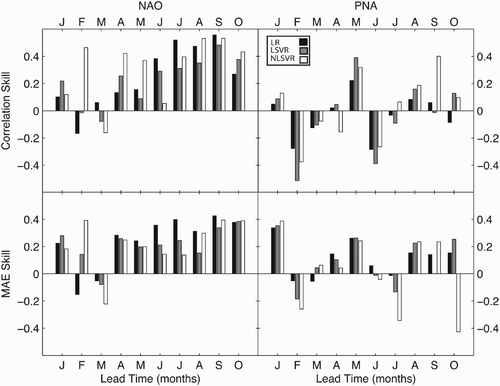
Fig. 5 As in , but showing index of agreement skill scores.
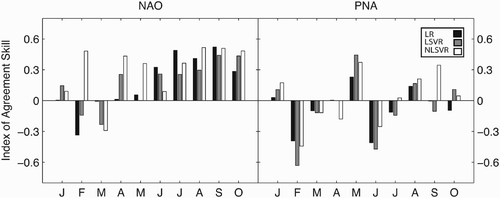
TABLE 3. Pearson correlation scores between the observed NAO and PNA time series and projections from unprocessed and processed HFP2 data. All three-month periods covered by the HFP2 dataset are shown. Correlations significant at the 95% level are in bold.
It is useful to first compare performance of the raw model projections from the two forecasting systems, both to provide a baseline for post-processing assessment and to evaluate the relative strengths of the AOGCM and AGCM approaches. HFP2 performs reasonably well for both teleconnections at all lead times (). Correlation scores larger than 0.33 indicate statistical significance at the 95% confidence level, and this value is exceeded by all unprocessed HFP2 forecasts. However, in absolute terms these correlations are relatively low, with projections capturing only 9%–25% of teleconnection variability. CHFP1 output is considerably less reliable (). Although capable of predicting the PNA index relatively well at short lead times (>0.5 for JFM and FMA), CHFP1 scores decrease rapidly at longer leads. NAO simulation is uniformly poor, with the model producing no statistically significant positive correlations. These results suggest that CHFP1 offers a negligible improvement over the simpler HFP2 forecasting system, extending useful PNA forecasts by one forecast period but degrading simulation of the NAO. Although not shown, MAE values are comparable for the two forecasting systems, ranging from 0.5–1 of the observed teleconnection's standard deviation for all forecast periods.
Table 4. Pearson correlation scores between the observed NAO and PNA time series and projections from unprocessed and processed CHFP1 data. All three-month periods covered by the CHFP1 dataset are shown. Correlations significant at the 95% level are in bold.
The post-processing methods used here vary considerably in their effectiveness when applied to HFP2 output (). Post-processing reduces correlation scores to statistically insignificant values for the NAO, but all methods tend to improve PNA forecasts. This may be because the additional predictors (the SVD and PC time series from Z500 and tropical Pacific SST) are less directly related to the NAO than to the PNA pattern, and extra irrelevant predictors tend to decrease skills. The two linear methods give comparable results and outperform NLSVR, which fails to improve the DJF PNA prediction. The post-processing of CHFP1 output is considerably more effective (; and ). Although the methods used here have difficulty improving the few statistically significant correlations found in the raw forecasts (e.g., PNA at JFM and FMA), they frequently improve on the poorer CHFP1 results. In the case of the NAO, the only significant results are generated through post-processing, which yields relatively high correlations even at a nine-month lead (SON). Similarly, relatively high PNA correlations are generated for most lead times by one or more of the methods. Although no post-processing method consistently generates the highest correlations, NLSVR has the greatest success rate, giving the best scores for five three-month periods for the NAO and four for the PNA, accounting for almost half of the twenty post-processing periods. By contrast, linear regression gives the best correlation in four instances (FMA, MJJ, JJA, and ASO for the NAO), and LSVR performs best in another four cases (NAO at DJF, and PNA at MAM, AMJ and SON). Unprocessed CHFP1 output gives the best results in only three instances (PNA at JFM, FMA and MJJ). It should be noted that the statistically significant post-processed correlations still capture only 10%–30% of teleconnection variability. With the 30-year sample available, it is difficult to assess the source of this skill. However, the ability of all methods to generate significant correlations at extended leads suggests a useful signal is embedded in the model output. The small sample size also explains the lack of a systematic trend in correlation skill, either as lead times increase or in terms of perfect consistency in relative performance of different post-processing methods. Additional training data would likely resolve these issues, better constraining the regression algorithms and reducing the need to extrapolate into conditions unrepresentative of the training data.
also presents MAE skill relative to unprocessed CHFP1 forecasts. As with correlation, MAE results indicate that post-processing generally improves CHFP1 forecasts, but the relative advantage of any single method is less clear. The LR method marginally outperforms the NLSVR method, giving the lowest MAE for eight prediction periods to six for the NLSVR method. Both the LSVR method and the unprocessed model give the best results for only three periods.
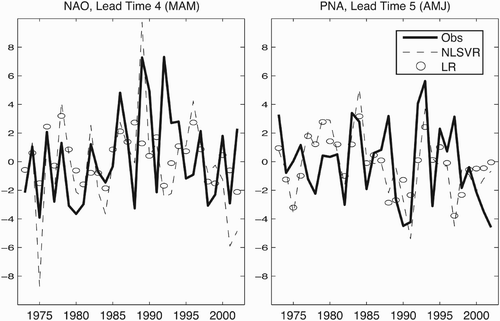
It is notable that there is not a clear, monotonic relationship between correlation and MAE skill in the current study; in particular, there are several instances in which the NLSVR method outperforms the LR method in terms of correlation but underperforms in terms of the MAE. Most notable are three cases when the NLSVR method produces a statistically significant correlation when the LR method does not, yet produces less improvement in raw model MAE (NAO predictions for MAM and AMJ, and PNA prediction for AMJ). This implies that the NLSVR method captures the phase of the teleconnection indices better but not their amplitudes, whereas an ideal post-processing method should do both (Vannitsem and Nicolis, Citation2008). and examine this phenomenon in greater detail, providing additional information on two affected prediction periods (NAO at MAM, and PNA at AMJ). The NLSVR time series in feature several predictions with excessive amplitudes; in the majority of cases, these are in phase with observations, but with larger amplitudes. The LR time series demonstrate few of these predictions with excessive amplitudes. This appears to be related to problems with extrapolation during cross-validation. The excessive predicted values using NLSVR typically occur when the predictor used for forecast testing (verification) lies outside the range of predictor values in the training data used to build the model. The LR method appears to be less prone to wild extrapolation but is also less likely to extract a useful signal (lower correlation) and underestimates observed variability. Hsieh (Citation2009) discusses this phenomenon in greater detail, comparing extrapolation error produced with several machine learning methods.
Table 5. Details on two representative prediction periods. Mean absolute error (MAE) and correlation of each prediction method (raw model and three post-processing methods) relative to observations are given. Standard deviations of all time series are also given, to allow comparison of total variability.
Fig. 6 Time series of teleconnection indices for two representative periods; leads four (MAM) for NAO and five (AMJ) for PNA. Results of post-processing with linear regression (LR) and non-linear support vector regression (NLSVR) are given, along with observations.
To illustrate the relative advantages of various post-processing methods better, Willmott's index of agreement (IA) has also been used to assess the skill of CHFP1-derived forecasts (Willmott et al., Citation1985), with
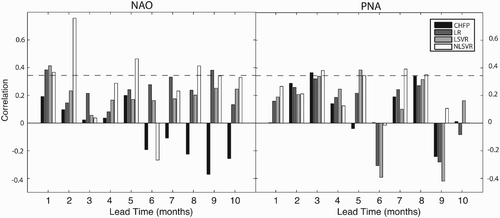
Much of the skill in current North American climate forecasts has been attributed to ENSO (Livezey and Timofeyeva, Citation2008), which produces a persistent, predictable response in large-scale climate. A strong influence is also exerted on the PNA pattern by ENSO, and has been tentatively associated with the NAO (Hoerling et al., Citation2001). In order to assess the influence of ENSO on post-processed forecasts, correlation scores for the CHFP1 were recalculated without years initialized with a strong ENSO signal, defined as a NINO3 index of magnitude 1.5 or higher; results are presented in . Removing strong ENSO events reduces raw CHFP1 skill somewhat, leaving only a single significant correlation (PNA at FMA). Post-processing scores are also generally reduced, particularly the LR and LSVR results. However, the NLSVR method continues to generate statistically significant correlations for almost half the forecasts. A substantial portion of the skill generated by non-linear post-processing is apparently independent of the persistent, predictable influence of strong ENSO events. This approach therefore appears to generate the most versatile and robust forecasts, while the raw model, LSVR and LR forecasts are less suitable for non-ENSO years.
Fig. 7 Correlation scores of raw and post-processed CHFP1 predictions, calculated without years initialized during moderate-to-strong ENSO events. The dashed line indicates a statistically significant positive correlation.
5 Summary and discussion
Results suggest regression-based post-processing is most effective when applied to coupled model output, improving CHFP1 output considerably but only improving PNA forecasts when applied to HFP2. The inference is that CHFP1 output contains a useful signal that is obscured by biases in the model's integration from a prescribed initial condition. Although CHFP1 may not faithfully reproduce loading patterns associated with the NAO and PNA, it does produce a predictable evolution related to the observed teleconnections. The better performance of the NLSVR method relative to the linear post-processing methods suggests that the non-linear capability of the NLSVR method is better at correcting the CHFP1 model errors in the non-linear interactions. The lower performance of the LSVR method relative to the NLSVR one confirms that it is the non-linear capabilities that give this method an advantage, rather than the SVR methodology itself. That is, when a non-linear kernel is used (in this case a Gaussian kernel), SVR is better able to connect raw model predictions to the true climate outcome.
Results indicate that HFP2 captures the structure of the NAO and PNA better than CHFP1 and recreates teleconnection time series relatively well prior to post-processing. This is related to the use of an AGCM in HFP2, which removes the influence of ocean model and coupled atmosphere–ocean errors present in the CHFP1 simulations. However, regression-based post-processing improved only PNA forecasts from HFP2 output, a result not seen in past studies using similar methods (Lin et al., Citation2005). Reduced performance in the current study may be related to differences in predictor selection, the time period examined and the double cross-validation methodology employed here. It is also possible that the HFP2 predictors supplied in this study are not sufficiently related to the NAO; with the addition of irrelevant predictors, it is expected that forecast skill will drop. However, similar predictor sets have produced better skill in previous studies (e.g., Lin et al., Citation2005). Additional experiments indicate skill scores are sensitive to variations in the cross-validation approach, such as changes in the number of cross-validation steps and relaxing the autocorrelation buffer in the outer CV loop (). Less cautious cross-validation methods, in which this buffer is removed entirely, give higher skills that agree better with past studies. Extending the buffer from three to five or seven years around a target year decreases overall skills because of a reduction in the data remaining for model training. However, the relative performance of the various post-processing methods changes little with these adjustments. In contrast, using predictors and periods identical to those in past studies did not have a significant impact on post-processing skill. The LR-processed skill is lower in the present study than previously reported, suggesting the approach used here gives a conservative assessment of performance. It follows that performance of processed CHFP1 output and SVR-processed results may also be underestimated, adding weight to the argument that non-linear post-processing offers valuable improvements to this dataset.
Although the present study demonstrates the value of SVR as a post-processing tool in climate forecasting, significant obstacles remain if it is to prove useful operationally. Of particular concern is the method's greater complexity relative to traditional linear regression and a lack of familiarity with this method in the meteorological community. For SVR post-processing to be adopted by forecasting centres, a clear advantage over linear regression must be displayed. The results presented here suggest the additional complexity yields valuable improvements, even when tested on a relatively short set of hindcast experiments. Although PNA and NAO forecasts are of little operational value themselves, these teleconnections are strongly connected to surface temperature and precipitation over North America. The implication is that SVR post-processing should also be capable of improving climate forecasts of these more valuable fields. A cell-by-cell post-processing approach, similar to that presented by Lin et al. (Citation2008), could be used to test this hypothesis. However, such an exercise with SVR is computationally intensive and beyond the scope of the current paper. The current work suggests the method has some value and could be used to improve seasonal forecasts.
Acknowledgements
J. Finnis and W. Hsieh are grateful for the support of the Canadian Foundation for Climate and Atmospheric Sciences through the Global Ocean-Atmosphere Prediction and Predictability network. W. Hsieh is supported by a Discovery Grant from the Natural Sciences and Engineering Research Council of Canada. The authors also thank Zhen Zeng for input on the execution of support vector regression.
References
- Casaioli , M. , Mantovani , R. , Scorzoni , F. P. , Puca , S. , Speranza , A. and Tirozzi , B. 2003 . Linear and nonlinear post-processing of numerically forecasted surface temperature . Nonlinear Proc. Geoph. , 10 : 373 – 383 .
- Cherkassky, V. and Y.Q. Ma. 2004. Practical selection of SVM parameters and noise estimation for SVM regression. Neural Networks, 17: 113–126.
- Delsole , T. and Shukla , J. 2009 . Artificial skill due to predictor screening . J. Clim. , 22 : 331 – 345 .
- Derome , J. , Brunet , G. , Plante , A. , Gagnon , N. , Boer , G. J. , Zwiers , F. W. , Lambert , S. J. , Sheng , J. and Ritchie , H. 2001 . Seasonal predictions based on two dynamical models . Atmosphere-Ocean , 39 : 485 – 501 .
- GENT , P.R. , Bryan , F. O. , Danabasoglu , G. , Doney , S. C. , Holland , W. R. , Large , W. G. and Mcwilliams , J. C. 1998 . The NCAR climate system model global ocean component . J. Clim. , 11 : 1287 – 1306 .
- Hoerling , M. P. , Hurrell , J. W. and Xu , T. Y. 2001 . Tropical origins for recent North Atlantic climate change . Science , 292 : 90 – 92 .
- Hsieh , W.W. 2009 . Machine Learning Methods in the Environmental Sciences , 299 – 305 . Cambridge , , UK : Cambridge University Press .
- Hurrell , J. W. and van Loon , H. 1997 . Decadal variations in climate associated with the North Atlantic Oscillation . Clim. Change , 36 : 301 – 326 .
- Jia , X. J. , Lin , H. and Derome , J. 2010 . Improving seasonal forecast skill of North American surface air temperature in fall using a postprocessing method . Mon. Weather Rev. , 138 : 1843 – 1857 .
- Kalnay , E. , Kanamitsu , M. , Kistler , R. , Collins , W. , Deaven , D. , Gandin , L. , Iredell , M. , Saha , S. , White , G. , Woollen , J. , Zhu , Y. , Leetmaa , A. , Reynolds , B. , Chelliah , M. , Ebisuzaki , W. , Higgins , W. , Janowiak , J. , Mo , K. C. , Ropelewski , C. , Wang , J. , Jenne , R. and Jospeh , D. 1996 . The NCEP/NCAR 40-year reanalysis project . Bull. Am. Meteorol. Soc. , 77 : 437 – 471 .
- Kharin , V. V. , Teng , Q. B. , Zwiers , F. W. , Boer , G. J. , Derome , J. and Fontecilla , J. S. 2009 . Skill assessment of seasonal hindcasts from the Canadian Historical Forecast Project . Atmosphere-Ocean , 47 : 204 – 223 .
- Leathers , D. J. , Yarnal , B. and Palecki , M. A. 1991 . The Pacific/North American teleconnection pattern and United States climate. Part 2: Regional temperature and precipitation associations . J. Clim. , 4 : 517 – 528 .
- Lin , H. , Derome , J. and Brunet , G. 2005 . Correction of atmospheric dynamical seasonal forecasts using the leading ocean-forced spatial patterns . Geophys. Res. Lett. , 32 : L14804 doi:10.1029/2005GL023060
- Lin , H. , Brunet , G. and Derome , J. 2008 . Seasonal forecasts of Canadian winter precipitation by postprocessing GCM integrations . Mon. Weather Rev. , 136 : 769 – 783 .
- Livezey , R. E. and Timofeyeva , M. M. 2008 . The first decade of long-lead US seasonal forecasts . Bull. Am. Meteorol. Soc. , 89 : 843 – 854 .
- Marzban , C. 2003 . Neural networks for postprocessing model output: ARPS . Mon. Weather Rev. , 131 : 1103 – 1111 .
- Merryfield , W. J. , Lee , W. S. , Boer , G. J. , Kharin , V. V. , Pal , B. , Scinocca , J. F. and Flato , G. M. 2010 . The First Coupled Historical Forecasting Project (CHFP1) . Atmosphere-Ocean , 48 : 263 – 283 .
- Mysak , L. A. and Venegas , S. A. 1998 . Decadal climate oscillations in the Arctic: A new feedback loop for atmosphere-ice-ocean interactions . Geophys. Res. Lett. , 25 : 3607 – 3610 .
- Noaa (National Oceanic and Atmospheric Administration). 2010. National Weather Service – Climate Prediction Center. Retrieved from http://www.cpc.ncep.noaa.gov
- Rowell , D. P. 1998 . Assessing potential seasonal predictability with an ensemble of multidecadal GCM simulations . J. Clim. , 11 : 109 – 120 .
- Saha , S. , Nadiga , S. , Thiaw , C. , Wang , J. , Wang , W. , Zhang , Q. , van den Dool , H.M. , Pan , H.-L. , Moorthi , S. , Behringer , D. , Stokes , D. , Pena , M. , Lord , S. , White , G. , Ebisuzaki , W. , Peng , P. and Xie , P. 2006 . The NCEP climate forecast system . J. Clim. , 19 : 3483 – 3517 .
- Scinocca , J. F. , Mcfarlane , N. A. , Lazare , M. , Li , J. and Plummer , D. 2008 . Technical Note: The CCCma third generation AGCM and its extension into the middle atmosphere . Atmos. Chem. Phys. , 8 : 7055 – 7074 .
- Shukla , J. , Anderson , J. , Baumhefner , D. , Brankovic , C. , Chang , Y. , Kalnay , E. , Marx , L. , Palmer , T. , Paolino , D. , Ploshay , J. , Schubert , S. , Straus , D. , Suarez , M. and Tribbia , J. 2000 . Dynamical seasonal prediction . Bull. Am. Meteorol. Soc. , 81 : 2593 – 2606 .
- Vannitsem , S. and Nicolis , C. 2008 . Dynamical properties of model output statistics forecasts . Mon. Weather Rev. , 136 : 405 – 419 .
- Vapnik , V. , Golowich , S. and Smola , A. 1997 . “ Support vector method for function approximation, regression estimation, and signal processing ” . In Advances in Neural Information Processing Systems , Edited by: Mozer , M. , Jordan , M. and Petsche , T. 281 – 287 . Cambridge , MA : MIT Press .
- Von Storch , H. and Zwiers , F. W. 2001 . Statistical analysis in climate research 1st pbk. ed. Cambridge, UK: Cambridge University Press.
- Willmott , C. J. , Ackleson , S. G. , Davis , R. E. , Feddema , J. J. , Klink , K. M. , Legates , D. R. , Odonnell , J. and Rowe , C. M. 1985 . Statistics for the evaluation and comparison of models . J. Geophys. Res. , 90 : 8995 – 9005 .
- Wu , A. M. , Hsieh , W. W. and Shabbar , A. 2005 . The nonlinear patterns of North American winter temperature and precipitation associated with ENSO . J. Clim. , 18 : 1736 – 1752 .
- Wu , A. M. , Hsieh , W. W. and Tang , B. Y. 2006 . Neural network forecasts of the tropical Pacific sea surface temperatures . Neural Networks , 19 : 145 – 154 .
- Zeng , Z. , Hsieh , W. W. , Shabbar , A. and Burrows , W. R. 2011 . Seasonal prediction of winter extreme precipitation over Canada by support vector regression . Hydrol. Earth Syst. Sci. , 15 : 65 – 74 .