Abstract
In the ensemble Kalman filter (EnKF), ensemble size is one of the key factors that significantly affects the performance of a data assimilation system. A relatively small ensemble size often must be chosen because of the limitations of computational resources, which often biases the estimation of the background error covariance matrix. This is an issue of particular concern in Argo data assimilation, where the most complex state-of-the-art models are often used. In this study, we propose a time-averaged covariance method to estimate the background error covariance matrix. This method assumes that the statistical properties of the background errors do not change significantly at neighbouring analysis steps during a short time window, allowing the ensembles generated at previous steps to be used in present steps. As such, a joint ensemble matrix combining ensembles of previous and present steps can be constructed to form a larger ensemble for estimating the background error covariance. This method can enlarge the ensemble size without increasing the number of model integrations, and this method is equivalent to estimating the background error covariance matrix using the mean ensemble covariance averaged over several assimilation steps. We apply this method to the assimilation of Argo and altimetry datasets with an oceanic general circulation model.
Experiments show that the use of this time-averaged covariance can improve the performance of the EnKF by reducing the root mean square error (RMSE) and improving the estimation of error covariance structure as well as the relationship between ensemble spread and RMSE.
RÉSUMÉ [Traduit par la rédaction] Dans le filtre de Kalman d'ensemble (EnKF), la taille de l'ensemble est l'un des facteurs clés qui ont une influence importante sur la performance d'un système d'assimilation de données. Il faut souvent choisir une taille d'ensemble assez petite à cause des limites des ressources informatiques, ce qui biaise souvent l'estimation de la matrice de covariance de l'erreur de fond. Cette question revêt une importance particulière pour l'assimilation des données Argo, qui fait souvent appel à des modèles de pointe très complexes. Dans cette étude, nous proposons une méthode de covariance moyennée dans le temps pour estimer la matrice de covariance de l'erreur de fond. Cette méthode suppose que les propriétés statistiques des erreurs de fond ne changent pas de façon importante d'une étape d'analyse à la suivante durant un court laps de temps, ce qui permet d'utiliser dans les étapes courantes les ensembles générés aux étapes précédentes. Ainsi, on peut construire une matrice d'ensembles conjoints combinant les ensembles des étapes précédentes et courantes pour former un plus grand ensemble dans le but d'estimer la covariance de l'erreur de fond. Cette méthode peut accroître la taille de l'ensemble sans augmenter le nombre d'intégrations du modèle; elle équivaut à estimer la matrice de covariance de l'erreur de fond en utilisant la covariance moyenne de l'ensemble calculée sur plusieurs étapes d'assimilation. Nous appliquons cette méthode à l'assimilation des ensembles de données Argo et d'altimétrie avec un modèle de circulation océanique générale.
Des essais montrent que l'emploi de cette covariance moyennée dans le temps peut améliorer la performance de l'EnKF en réduisant l’écart-type et en améliorant l'estimation de la structure de la covariance de l'erreur de même que la relation entre l'étalement et l'écart-type l'ensemble.
1 Introduction
Since the ensemble Kalman filter (EnKF) was proposed by Evensen (Citation1994), it has been widely applied in oceanography, meteorology and other fields (Bonavita, Torrisi, & Marcucci, Citation2010; Deng, Tang, & Wang, Citation2010; Oke, Brassington, Griffin, & Schiller, Citation2008; Oke, Schiller, Griffin, & Brassington, Citation2005; Ott et al., Citation2004; Reichle, Mclauglin, & Entekhabi, Citation2002). An important issue in the application of the EnKF is the achievement of a realistic range of ensemble members from which the background error covariance is diagnosed (Turner, Walker, & Oke, Citation2008). A larger ensemble can generally result in a smaller error level and improve agreement between ensemble spread and ensemble mean error (Mitchell & Houtekamer, Citation2002). However, the high computational cost often makes a large ensemble impractical in a realistic data assimilation system and forces modellers to choose a relatively small ensemble size. Unfortunately, a small ensemble often causes problems, such as underestimating the amplitude of background error covariance and generating very noisy correlation functions (Mitchell & Houtekamer, Citation2002). A number of techniques have been proposed to reduce the negative effects of the small ensemble; for example, the covariance localization and covariance inflation methods (Anderson & Anderson, Citation1999; Hunt, Kostelich, & Szunyogh, Citation2007; Mitchell & Houtekamer, Citation2000). Houtekamer and Mitchell (Citation1998) found that the smaller the ensemble, the more severe the localization required to address noisy covariance. Over-localization may generate severe imbalance between state variables and excite unrealistic gravity waves (Mitchell & Houtekamer, Citation2002), causing strong initial shock when assimilation analyses are used to initialize forecasts and, in turn, this results in a sharp decrease in forecast skill. Thus, a challenge in the EnKF assimilation is to find an appropriate compromise between sufficient ensemble members and computational cost.
One approach to allowing sufficient ensemble members without sacrificing computational efficiency is the Ensemble Optimal Interpolation (EnOI), which was proposed and applied in some data assimilation systems (e.g., Evensen, Citation2003; Oke, Allen, Miller, Egbert, & Kosro, Citation2002). This approach assumes that the temporal variability of model states is representative of the forecast error; thus, the analysis is computed in the space spanned by a stationary ensemble of sampled model states (e.g., during a long model integration). The drawback of this method is that the spatial structure of the covariance matrix is assumed to be constant over the assimilation cycles, thus, it cannot reflect the temporal evolution of forecast error.
In this study, we propose a method to increase ensemble size without extra model integrations and use it to assimilate Argo profiles and satellite sea level anomaly (SLA) data into a realistic oceanic general circulation model. The rest of this paper is organized as follows. Section 2 briefly describes the data, model and assimilation system; Section 3 addresses the evaluation methods; Section 4 explores the impacts of this method on the performance of the EnKF; and a summary and concluding remarks are presented in Section 5.
2 The ocean data assimilation system
a Data
The data used for assimilation are the best-copy temperature and salinity profiles (hereafter BCTS) and the delayed low-resolution (1° × 1°, Mercator grid) gridded SLA of the Pacific Ocean derived from satellite altimetric data for the period 2005–07 (Dibarboure, Lauret, Mertz, Rosmorduc, & Maheu, Citation2009). The BCTS data assembles profiles from Argo floats, expendable bathythermographs (XBT), conductivity-temperature-depth (CTD) sensors and the Tropical Atmosphere and Ocean-TRIangle Trans-Ocean buoy Network (TAO/TRITON) to provide the most complete datasets without duplication. These profiles are downloaded from NOAA (Citation2009a). Only the profiles that are flagged “good” are chosen for assimilation.
The SLA data are a homogeneous, inter-calibrated and highly accurate long time series of SLAs from altimetric data downloaded from Aviso (Citation2009). Because the resolution of the SLA data is much higher than the model resolution in most of the model domain, a thinning scheme is used to reduce the resolution of the SLA data assimilated. The datasets used for validation include the Ocean Surface Current Analyses—Real time (NOAA, Citation2009b); NODC_WOA98 (Levitus) data (NOAA, Citation2009c) and the observed Niño3.4 Sea Surface Temperature Anomaly (SSTA) index (NOAA, Citation2009d). The surface current is derived from satellite altimeter and vector wind data, and its details are described by Bonjean and Lagerloef (Citation2002) and Helber, Weisberg, Bonjean, Johnson, and Lagerloef (Citation2007). The delayed mode Argo profiles (NOAA, Citation2009c) and SLAs (Aviso, Citation2009) for the period 2002–04 are also used in this study for estimating the root mean square error (RMSE) of the control run, which will be used to estimate the amplitude of the additive model error.
b The Ocean General Circulation Model (OGCM)
The OGCM is the ocean component (with free-surface) of version 2.3 of the Nucleus for European Modelling of the Ocean (NEMO; Madec, Citation2008). It is constructed based on the ORCA2 configuration. Both global and regional versions of the model are used. The former is for climatology runs and the latter is for control and assimilation runs. The regional model is a subset of the ORCA2 configuration covering the Pacific Ocean between 60°N and 60°S and between 116°E and 66°W, for a total of 90×95 horizontal grid points. The horizontal resolution in the zonal direction is 2°, while the resolution in the meridional direction is 0.5° within 5° of the equator, smoothly increasing to 2.0° at 30°N and 30°S and then decreasing to 1.0° at 60°N and 60°S. There are 31 unevenly spaced levels along the vertical with 24 levels concentrated in the upper 2000 m. The interval of the levels varies from 10 m near the “surface” (within the first 105 m) to 500 m below the 3000 m level. The maximum depth is set to 5000 m, and a realistic topography based on the Earth Topography at 5 arc-minutes (ETOPO5) global atlas is used (Ferry, Rémy, Brasseur, & Maes, Citation2007). The National Centers for Environmental Predication (NCEP) reanalysis wind stress (Behringer, Ji, & Leetmaa, Citation1998; NOAA, Citation2009e) and monthly climatological heat and freshwater fluxes (Esbensen & Kushnir, Citation1981) are used to force the model. During the integration, the heat flux Qs is adjusted by
To reduce the model bias in temperature and salinity, two nudging schemes were used. First, the global version of the OGCM, started from rest, is nudged (with a relaxation time scale of 20 days) towards the Levitus climatological temperature and salinity using the conventional nudging method and the climatological winds for 10 years. Second, the spectral nudging method, proposed by Thompson, Wright, Lu, and Demirov (Citation2006), is used to nudge the global model towards the same climatology at the prescribed frequency of 0.1 cycles per year for 50 years. The seasonal cycle of monthly mean currents derived from the above spectral nudging run of the last 30 years and the seasonal cycles of Levitus climatological temperature and salinity are used to generate the east, west, south and north boundary conditions for the regional OGCM, as proposed by Madec (Citation2008). Furthermore, the regional OGCM, with the same spectral nudging scheme and the initial conditions from the last step of the spectral nudging run of the global model, is forced by the observed (NCEP reanalysis) winds for the period 1980–2004 (control run). The model states are stored every 5 days during the 1985–2004 period (the first 5-year runs are discarded to extract the stable model states) to construct a pool used to generate additive random noises for assimilation runs. Starting from 31 December 2004, two types of runs are conducted from January 2005 to December 2007: 1) the control run without data assimilation, as a reference for the validation of the assimilation system, and 2) the assimilation runs.
To evaluate the effects of spectral nudging on model climatology, we also conducted a control run for the period 1980–2004 using the regional OGCM without the nudging scheme. The initial condition is from the last step of a 200-year climatology run of the global model without nudging starting from rest. The boundary conditions are provided by the mean seasonal cycle of the last 30 years of the 200-year climatology run. The 25-year outputs from the two control runs were used to represent their respective climatologies.
c The Data Assimilation System
The data assimilation system is based on the EnKF (Evensen, Citation1994, Citation2003). The forecast ensemble member is updated by
The localization method proposed by Houtekamer and Mitchell (Citation2001) is used to speed up the analysis processes and eliminate the spurious correlation between distant locations in the background covariance matrix due to the limited ensemble size (e.g., Deng et al., Citation2010; Gaspari & Cohn, Citation1999; Houtekamer & Mitchell, Citation2001; Hunt et al., Citation2007; Oke et al., Citation2005, Citation2008). This localization method assimilates all observations that may affect the analysis of a given model grid point simultaneously and obtains the analysis independently for each model grid point (Ott et al., Citation2004; Szunyogh et al., Citation2008). In this study, we perform local analysis grid by grid for the top 24 model levels. To obtain the analysis at a model grid point, we define a local domain around the model grid point, and all observations within this domain are assimilated. The domain is 3000 km in longitude, 1500 km in latitude and three model levels in the vertical. The grid point is at the centre of this domain. The incremental analysis update (IAU) proposed by Bloom, Takas, da Silva, and Ledvina (Citation1996) is also used to avoid model dynamical instability, which incorporates the analysis increment directly into prognostic equations of the model as an additional forcing term (Balmaseda, Anderson, & Vidard, Citation2007; Castruccio, Verron, Gourdeau, Brankart, & Brasseur, Citation2008). As in Keppenne, Rienecher, Kurkowski, and Adamec (Citation2005), the analysis increment is added to the model state gradually over the 5-day integration. In this study, there are a total of 120 integration steps in the 5-day window. Thus, each integration step accounts for only 1/120 of the increment. To reduce the burden of computation, the assimilation domain is set to the region 116°E–66°W and 30°S–55°N. In the following, we briefly describe the estimation methods used to obtain the model error (q
k
,
i
), the background error covariance matrix () and the observation error covariance matrix (R
k
), respectively.
1 Model Errors
Usually, the model error is composed of systematic errors resulting from imperfections in the physics or dynamics of the model and random errors caused by stochastic noise. In this study, we consider only the latter in assimilation experiments because the former could be expected to be greatly reduced by the spectral nudging scheme.
An important issue in the EnKF is to characterize realistic correlation structures in designing the random model error (q k , i ) in space (horizontal and vertical) and among model variables. Evensen (Citation2003) proposed a simple method to construct a spatially coherent random error (perturbation) that has been widely used in the EnKF. A challenge in applying this method is the determination of the de-correlation scales characterizing the coherences between different variables and different model levels. In this study, we propose an approach to generating a random model error ensemble that can characterize the coherent structure. Theoretically, the random model error covariance at the k th assimilation cycle can be decomposed as
The perturbation amplitude has a significant effect on the performance of the EnKF. A large perturbation amplitude may overestimate random model error, whereas a small amplitude could quickly damp the perturbation, leading to very small ensemble spreads. A straightforward strategy is to assume that the perturbation amplitude is proportional to the RMSE of the model simulation. For temperature, salinity and SLA, the RMSE could be estimated from the control run against their observed counterparts. However, there are insufficient observations to estimate RMSEs for U and V, and thus, their perturbation amplitudes were approximated using their climatological variances from the control run instead of the RMSE values. For simplicity, we only consider the vertical variations of the perturbation amplitudes. We calculate the RMSE for each model level using all paired observation-model data for the period 2002–04 at that level and average the standard deviations over the horizontal model domain to obtain their vertical profiles. After a few sensitive experiments with different combinations of the perturbation amplitudes, we set the amplitude Λ 1/2 to 10% of the RMSE for temperature and salinity at each vertical level and 0.013 m for SLA (10% of SLA RMSE). We set 10% of the standard deviations of U and V as their perturbation amplitudes. It should be noted that these settings are somewhat artificial but were tuned by the sensitive experiments towards the best assimilation performance for the 31-member standard EnKF experiment (hereafter referred to as Exp1), which will act as a reference experiment for comparisons.
2 Background Error Covariance Matrix
In this study, the background error covariance matrix at an assimilation step (k) is estimated using an enlarged ensemble, formed by ensemble members at neighbouring steps k, k − 1 and k − 2. This method increases the ensemble size without increasing the number of model integrations. Thus, it is computationally efficient except that slightly more disk space is required to store previous ensemble members. In principle, this method is somewhat similar to the EnOI but treats the assumption of the background error covariance structures differently. It assumes only that the error covariance structures are similar within a short time window of three neighbouring assimilation steps. The background error covariance estimated from the enlarged ensemble is equivalent to the mean covariance averaged over the neighbouring assimilation steps. Thus, the time-averaged covariance will not significantly modify the main structure of the covariance matrix but can effectively filter the noisy components of the error covariance matrix. It should be noted that this time-averaged covariance is used only to estimate the background error covariance matrix and that all other procedures are kept in the framework of the standard EnKF.
Thus, the model background error covariance matrix at the k th assimilation cycle is calculated from the ensemble members by
The covariance localization function used to reduce spurious correlations between distant locations due to the limited ensemble size is assumed to be Gaussian and defined as below (e.g., Deng et al., Citation2010; Gaspari & Cohn, Citation1999; Houtekamer & Mitchell, Citation2001; Oke et al., Citation2005):
An inflator, γ, similar to that used by Anderson (Citation2001), Zheng (Citation2009) and Li, Kalnay, Miyoshi, and Danforth (Citation2009), is used to adjust the ensemble covariance matrix, i.e.,
The open circle between ρ and denotes a Schur product (an element by element matrix multiplication), and ρ is defined in Eq. (6). Unlike the method used by Hamill, Whitaker, and Snyder (Citation2001) and Anderson (Citation2007), the above inflation is directly applied to the background covariance matrix itself, rather than to the ensemble members. In determining the covariance inflator γ at each assimilation step in Eq. (7), we adopt the relationship between innovation, background error and observation error proposed by Mitchell and Houtekamer (Citation2000) when they estimated the amplitude of additive model error:
In practice, the inflators for temperature, salinity and SLA are calculated independently, and then their minimum value is used to inflate the entire covariance matrix. When the minimum value is less than zero or greater than 1, γ is set to zero and 1.0, respectively. Thus, the value of γ varies between 0 and 1 during the assimilation according to Eq. (8). Such a treatment may not inflate enough for some variables but avoids over-inflation, which might cause an over-fitting problem during the data assimilation. In addition, the value of γ also reflects the consistency between the forecast mean error square and the sum of the background error variance and observation error variance. The closer γ approaches zero, the better the consistency.
3 Observation Error Covariance Matrix
As mentioned in Section 2a, the Argo profiles and other in situ observations are assimilated in this study. Argo floats have a 10-day re-sampling period; thus, the available Argo profiles are sparse on any specific day. To solve the temporal sparsity of Argo data, we treat all Argo data within a time window of 8 days as the observations for the assimilation, with 5 days before the analysis time and 2 days after the analysis time. Oke et al. (Citation2008) and Balmaseda et al. (Citation2007) used this strategy when they assimilated Argo data. The 8-day window is longer than the assimilation interval of 5 days. The longer window was chosen to include more observations at a single assimilation step as used by Huang, Xue, and Behringer (Citation2008), Oke et al. (Citation2008) and Smith and Haines (Citation2009).
Observation errors include measurement error, representation error and the error associated with the time difference between the analysis and observation (called age error), which can be assumed to be Gaussian with a mean of zero and a variance of ,
,
and
, respectively. Thus, we have
Based on previous work (e.g., Cummings, Citation2005; Desroziers, Berre, Chapnik, & Poli, Citation2005; Janic & Cohn, Citation2006) and some assumptions which may contain some arbitrary components, we set these values as shown below:
ε instr = 0.1°C for temperature | |||||
ε instr = 0.1 (practical salinity scale used) for salinity | |||||
The function of the horizontal grid and vertical level is S mod. However, it is difficult to tune the amplitudes of the representation error and age error using a three-dimensional S mod. For simplicity, we assume that S mod changes only with depth and use the averaged value over all horizontal grids at a vertical level.
In this study, the observation perturbation is drawn from the Gaussian distribution with the mean equal to zero and the variance equal to the observation error variance . For SLA, the observation error standard deviation is set to 7 cm. If we denote the observation vector by
at the k
th data assimilation cycle, the i
th member of perturbed observation, yk
,
i
, can be expressed by
3 Metrics used for evaluation
a Amplitude of the Model Bias
The biases of the regional models could be computed at each model grid by comparing the mean states averaged over the 25-year control runs with the Levitus climatology. To estimate the overall impact of the spectral nudging scheme on model climatology, we define the amplitude of model bias (AMB) as
b Root Mean Square Error (RMSE)
The RMSE for the 5-day forecast ensemble mean is defined by
As mentioned in Section 2c, the background error covariance matrix is the only factor that controls the differences among these assimilation experiments. A detailed comparison of the covariance matrices among the three experiments can help us detect the possible reasons for the advantage of the time-averaged covariance method.
c Ensemble Spread and the Correlation Function
All of the data assimilation experiments in this study use the same inflation and localization scheme, therefore, we will focus on the analysis of the ensemble covariance matrix prior to inflation and localization. Instead of examining the covariance matrix directly, we will analyze the ensemble spread and correlation function separately. The former reflects the amplitude of the variance and the latter reflects the spatial structure of the covariance matrix. The advantage of the correlation function over the covariance function is that the correlation function is a dimensionless variable which is convenient for comparisons between the correlation structures among different model variables.
The background error covariance matrix in Eq. (5) at each assimilation cycle can be decomposed into its variance (spread) and its spatial structure (correlation function), namely,
d Agreement Between the Ensemble Spread and the RMSE
The agreement between the ensemble spread and the RMSE for the forecast ensemble mean is a good measure of ensemble quality (Bengtsson, Magnusson, & Källén, Citation2008; Cheng, Tang, Jackson, Chen, & Deng, Citation2010; Jolliffe & Stephenson, Citation2003). The closer the forecast ensemble spread is to the RMSE of the forecast ensemble mean, the better the ensemble represents the uncertainty of the model state. For convenience of comparison, the degree of the agreement is measured using a relative spread, the ratio of the ensemble spread to the RMSE of forecast ensemble mean, defined by
4 Results
a Evaluation of the Spectral Nudging Version of the Ocean Model
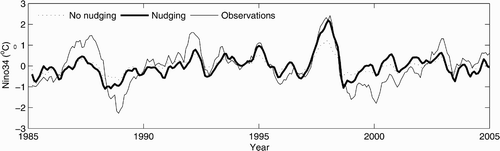
The purpose of the application of the spectral nudging in this study is to reduce the model bias. It is necessary to examine the effects of the spectral nudging scheme on the model climatology prior to performing assimilation experiments. Two runs, one with the spectral nudging scheme and the other without this scheme, are performed for the period 1980 to 2004, as mentioned in Section 2b. The run without the spectral nudging scheme has large biases; for example, there is a large warm bias in the subtropical southern Pacific Ocean and a cold bias in the subtropical northern Pacific Ocean at 180 m (Deng, Tang, & Freeland, Citation2011). However, the mean bias averaged over the entire Pacific Ocean is very small in both runs because of the cancellation between positive and negative biases in different regions. To avoid this cancellation between positive and negative biases at different grids, we calculated the AMB of temperature (salinity) against the Levitus climatological temperature (salinity) to represent the overall amplitude of the model biases over the Pacific Ocean. The model mean temperature (salinity) is based on the output of the two 25-year runs for the Pacific Ocean. The vertical distribution of the AMB is presented in , clearly showing the significant improvement in the spectral nudging scheme in the temperature and salinity model climatology at all depths below approximately 200–250 m. However, the spectral nudging scheme increases the AMB for temperature in the top 200 m. This is most likely because of the difference in time scales between the heat flux adjustment and the spectral nudging. The former only relaxes the model sea surface temperature (SST) to the climatological SST, which corresponds to a relaxation time scale of 2 months for a 50 m mixed-layer depth (Madec, Citation2008), whereas the latter relaxes the model temperature and salinity with 10-year and longer time scales at all levels to the corresponding climatological values. The impact of the former is confined to model levels near the surface because only SST is relaxed. Increments from these two schemes may overestimate (or underestimate) the difference between model temperature and the climatological temperature when their signs are the same (or different). It should be noted that the negative impact of the spectral nudging scheme on the model temperature climatology near the surface is not important for the simulation of signals with a period shorter than 10 years, such as that associated with El Niño-Southern Oscillation (ENSO) variability. is the simulation of the Niño3.4 SSTA index (mean sea surface temperature anomalies averaged over the region 120°W–170°W and 5°S–5°N) from the two runs. Compared to observations, spectral nudging does not destroy the interannual and shorter time-scale variations and even generates more realistic amplitudes of the Niño3.4 SSTA index than the original version of the model during some periods. The spectral nudging scheme is very efficient in reducing model biases in the subsurface temperature and salinity at all model levels, and this advantage will relieve the burden on data assimilation in working with the model biases.
Fig. 1 Amplitude of model biases (AMB) of temperature (a) and salinity (b) as a function of depth from the control run without nudging (dashed line) and the control run with spectral nudging (thick solid line). Here, the AMB is calculated against the Levitus climatological temperature and salinity.
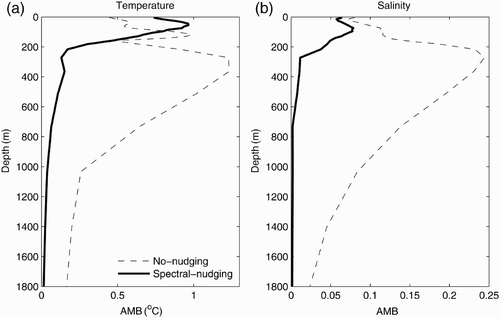
Fig. 2 Monthly Niño3.4 SST anomaly from the control run without spectral nudging (dotted line), the control run with spectral nudging (thick solid line) and from observations (thin solid line) for the period January 1985 to December 2004.
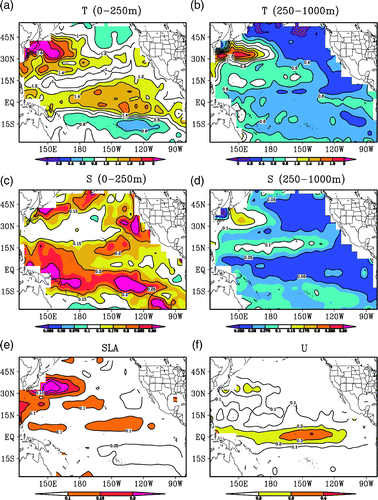
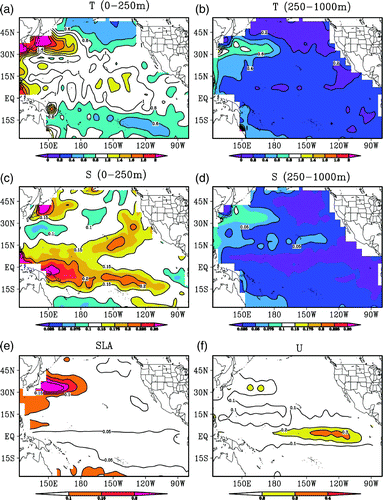
The positive effects of assimilating in situ observations (e.g., Argo profiles) and SLAs into realistic ocean models have been verified by many studies (Cummings et al., Citation2009; Huang et al., Citation2008; Smith & Haines, Citation2009; Xie & Zhu, Citation2010). In this study, we will focus on the effects of the time-averaged covariance method. We performed model validation for the 2005–07 period by calculating the RMSE for temperature and salinity between the control (CTL) run and the observed BCTS profiles within a 5-day window centred on the forecast day. For the same period, we further calculated the RMSE for SLA and the zonal surface current (U) between the CTL and the observations. The RMSE is calculated for each 5° (longitude) × 5° (latitude) bin from 30°S–55°N and 120°E–80°W. The larger size of the bins relative to the model resolution (2°) ensures that there are sufficient observations to obtain robust estimates of the RMSE. The temperature RMSEs averaged over the top 250 m (hereafter layer1) and 250–1000 m (hereafter layer2) are shown in a and b, respectively. a shows two large RMSE areas located in the Kuroshio area and the central and eastern equatorial Pacific Ocean and two relatively small RMSE areas located in the northeast Pacific Ocean and the southeast tropical Pacific region. b shows that large RMSE values in layer2 occur in the Kuroshio area, while small values occur in the northeast Pacific Ocean. c shows that the large RMSE values of salinity in layer1 occur in a belt between the equator and 15°S and areas near the coast of the North Pacific Ocean. In the deep layer, the large salinity RMSEs occur in the Kuroshio region and the RMSEs are very small in the tropical equatorial region and the northeast Pacific region (d). The maximum RMSE values of SLA occur in the Kuroshio region (e), and the maximum RMSE values of zonal surface current occur in the central-to-eastern equatorial region (f). Apparently, there are always large errors in the Kuroshio region and the central-to-eastern equatorial Pacific region, indicating the difficulty of simulating the ocean state in these regions because of the coarse resolution of the model, which lacks the resolution required to reproduce strong eddy activity and is unable to simulate the small-scale variations in these regions. will act as a reference for evaluating the assimilation performances later in the paper.
Fig. 3 Mean RMSEs of temperature (a, b), salinity (c, d), SLA (e) and surface zonal current (f) from the control run for the 2005–07 period; the observations are the BCTS profile data. The contour interval is 0.2°C for temperature, 0.05 for salinity, 0.05 m for SLA and 0.1 m s−1 for the zonal surface current.
b Evaluation of the Data Assimilation System
Considering the sparse distribution of in situ observations, we used a 5-day window, centred on the analysis time, to calculate a 5-day forecast RMSE; that is, all observations falling within this window were used to calculate the RMSE. These observations were not assimilated into the model until the current assimilation step was finished. Therefore, they are independent data relative to the forecast. The overall impacts of the assimilation on the reduction of the RMSE can be demonstrated by the vertical RMSE profiles of temperature and salinity, averaged over the entire assimilation region for the three years, as shown in . Compared to the CTL, all experiments significantly reduce the RMSE of temperature and salinity at all model levels. This is more visible in , which shows the spatial distribution of mean RMSEs for Exp1 obtained using the same procedure as that used for . As shown in , Exp1 significantly reduces the RMSE of temperature and salinity almost everywhere in layer1 compared with CTL (). In layer2, Exp1 also significantly reduces the RMSE of temperature and salinity over almost all regions. For SLA (e) and the zonal surface current (f), Exp1 cannot reduce RMSEs in the Kuroshio area but generates smaller RMSEs in most areas, especially in the tropical equatorial region. These results indicate that this data assimilation system is capable of improving the simulation of the ocean state and is a suitable test bed for the investigation of some new techniques.
Fig. 4 Mean RMSEs of temperature (a) and salinity (b) averaged over the entire assimilation domain as a function of depth, from the control experiment (CTL, dotted black line), the standard EnKF assimilation (Exp1, thin red line), the 62-member time-averaged covariance experiment (Exp2, blue dashed line) and the 93-member time-averaged covariance experiment (Exp3, thick solid line); the observations are the BCTS profiles.
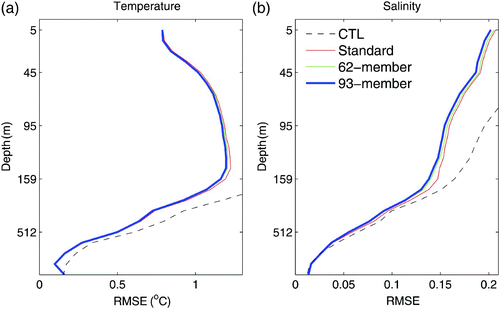
Fig. 5 Mean RMSEs of temperature (a, b), salinity (c, d), SLA (e) and surface zonal current (f) from Exp1 for the 2005–07 period; the observations are the BCTS profile data. The contour interval is 0.2°C for temperature, 0.05 for salinity, 0.05 m for SLA and 0.1 m s−1 for the zonal surface current.
c Effect of the Time-Averaged Covariance Method on the RMSE
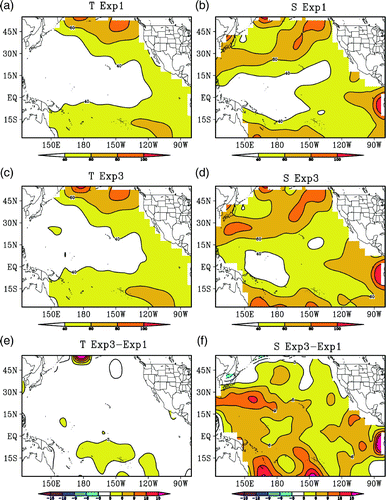
Two experiments are also performed that are the same as Exp1 except for the difference in the construction of the background error covariance as mentioned in Section 2c. The RMSE vertical profiles are also plotted in . Compared with Exp1, Exp2 (62-member) and Exp3 (93-member) reduce more temperature RMSE at some model levels between 50 m and 250 m and salinity RMSE at levels above 500 m, indicating the positive contribution of the time-averaged covariance method on the reduction of forecast error. However, the improvements in Exp2 and Exp3 relative to Exp1 are not very evident at some levels in , especially for temperature. The specific reason is unknown, but there are two possibilities. First, external wind forcing, which is not perturbed in constructing the ensemble, plays a more important role than the internal model process in the top of the ocean, making the forecast in the top ocean layer less sensitive to ensemble size. Second, the spatial and temporal averaging over the entire domain and over the entire period reduces the contrast among these experiments because, as will be shown below, the time-averaged covariance method does not necessarily improve the assimilation everywhere. In addition, the adaptive background error covariance inflation, which “corrects” the covariance matrix, also reduces the difference between Exp1 and Exp2 and Exp3. We will discuss this issue further in the following section.
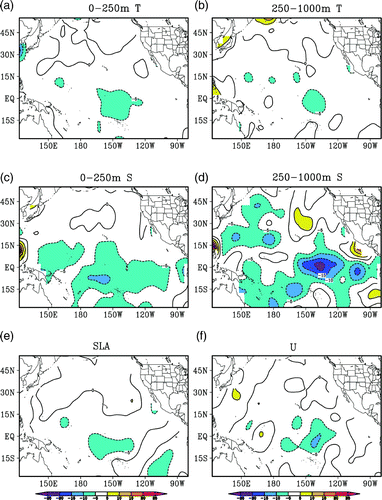
The distribution of the ratio ℜ1 defined in Eq. (15) is shown in . It indicates that the reduction in the RMSE resulting from the time-averaged covariance is not spatially uniform. For convenience, we will compare the mean RMSEs averaged over the top 250 m (layer1) and over depths between 250 and 1000 m (layer2) in Exp3 with those in Exp1. Compared with Exp1, Exp3 reduces more RMSE in most areas south of 30°N in layer1 (a) and layer2 (b). Similarly, Exp3 reduces more salinity RMSE than in Exp1 in most areas in the two layers. The most evident reductions in RMSE occur in the equatorial region centred at 140°W, where Exp3 reduces more than 5% of the RMSEs of temperature, SLA, U and salinity in layer1. For salinity, the reductions reach 20–25% in layer2. However, one also finds that Exp3 generates larger RMSEs than Exp1 in some areas, for example, the region north of 30°N and some regions near the coast. Interestingly, the areas where the time-averaged covariance cannot reduce the RMSE usually have relatively low RMSEs in the CTL and Exp1. We will consider a possible reason for this phenomenon below.
Fig. 6 Ratio, ℜ1 (%), of the mean RMSE differences between Exp3 and Exp1 to the RMSE of Exp1. The contour interval is 10%.
d Effects of the Time-Averaged Covariance on the Ensemble Spread
The ensemble spread significantly affects the performance of ensemble-based data assimilation systems. Many studies have discussed the adjustment of ensemble spread in developing a reliable assimilation system; for example, various inflation methods were proposed (Anderson & Anderson, Citation1999; Mitchell & Houtekamer, Citation2000). In this study, the adaptive scheme (Eq. (9)) is used to adjust the ensemble spread at each assimilation cycle for the three experiments. The mean value of the inflator γ, averaged over the 3-year assimilation period, is 0.203, 0.085 and 0.029 for Exp1, Exp2 and Exp3, respectively. The large γ of Exp1 suggests that the standard EnKF with 31 members greatly underestimates the forecast error variance. The smaller inflator values for Exp2 and Exp3 are evidence of the merits of this time-averaged covariance method (i.e., the amplitudes of the error covariance estimated using the super-ensemble approach is more realistic and does not require strong inflation). It should be noted that the inflation associated with these different inflators for the three experiments prevents the adjusted ensemble covariance in each of the experiments from continuing to underestimate the background error, reducing the impacts of difference in ensemble spreads (before inflation) of the original ensemble in Exp1 and the time-averaged covariance in Exp2 and Exp3. Although, the construction of the background error covariance matrix is different in the three experiments, comparisons show that the differences in absolute spread among the three experiments are not evident. shows the relative spreads of ℜ2 in layer1 for Exp3 and Exp1. As can be seen, the spatial patterns ofℜ2 are similar for Exp1 (a and 7b) and Exp3 (c and 7d). The small differences in ℜ2 for temperature indicate the limited impact of the time-averaged covariance method on ℜ2 for temperature (e). f shows positive values for the differences in salinity ℜ2 in most regions, indicating the stronger positive impact of the time-averaged covariance method on salinity assimilation. It is not surprising that the areas with large relative spreads in a and 7c correspond mostly to small RMSEs in a and 5b and vice versa.
Fig. 7 Ratio, ℜ2 (%), of the ensemble spread to forecast RMSE, averaged over the top 250 m from Exp1 for T and S (a, b), and from Exp3 for T and S (c, d) as well as the differences in ℜ2 between Exp3 and Exp1 for T and S (e, f).
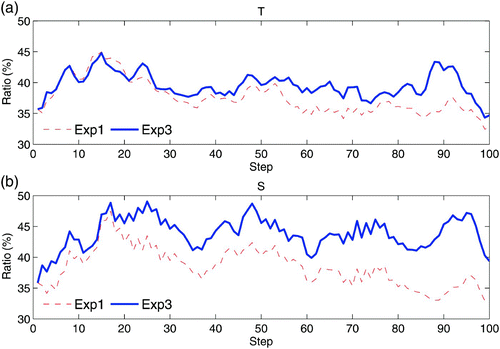
As shown in , the largest improvement in Exp3 relative to Exp 1 occurs in the tropical Pacific region. shows the averaged ℜ2 over the region 140°E–90°W, 10°S–10°N for layer1, as a function of the assimilation step, for the first 100 steps. It is evident that the ℜ2 for Exp3 is almost always greater than that for Exp1 for both temperature and salinity, indicating that the time-averaged covariance helps improve the agreement between the ensemble spread and the forecast error. The benefits of the time-averaged covariance are very clear for salinity assimilation.
Fig. 8 Time series of the mean ℜ2 (%), averaged over the region 140°E–90°W, 10°S–10°N in the top 250 m, from Exp1 (red dashed line) and Exp3 (blue solid line), for (a) temperature and (b) salinity, for the first 100 assimilation steps.
e Comparisons of the Ensemble Correlation Structure
Because the correlation structure of the background error covariance matrix affects the transformation of the observation information between locations and between variables, it is also a key factor that affects the performance of the EnKF assimilation system. A properly constructed correlation structure for the error covariance matrix can improve the data assimilation and vice versa. The dimensional size of the correlation matrix C of is very large for the five-variable model state over the entire model domain. Thus, we present only the correlation function at selected model grids.
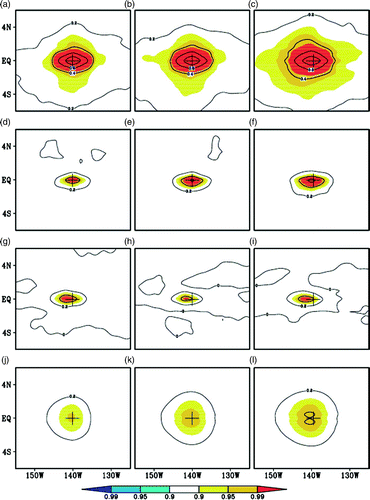
Because the three experiments are run separately, comparing the correlation structure at a specific step cannot detect the essential difference. Therefore, we averaged the correlation functions over the data assimilation period to obtain the mean correlation function. is the averaged correlation function of temperature at a model grid point (140°W, 0°N,150 m, denoted as A), against temperature, salinity and zonal current at the same depth and SLA for the three experiments. Namely, the values are the mean correlation coefficients averaged over the assimilation cycles for the period 2005–07. This model grid point is chosen because the most evident improvement of the time-averaged covariance method occurs around this model grid point. The depth of 150 m is chosen because it is approximately the depth of the thermocline. As seen in , the correlation decreases with distance from the centre of the maximum. For temperature, this centre is exactly at the selected point A. The correlation length is shorter in the meridional direction than in the zonal direction, especially for temperature. A striking feature in is that the increase in ensemble size does not change the main spatial pattern of the correlation structure but a larger ensemble size can generate significant correlation structure. The correlation structure appears to become broader in the meridional direction. This is particularly apparent for the correlation between T-T, T-S and T-SLA (a compared with 9c, 9d compared with 9f, and 9j compared with 9l). Apparently, the 62-member ensemble increases the area of significant correlation more than the 31-member ensemble, and the 93-member ensemble further increases the area. The increase in the significant correlation area in Exp2 and Exp3 indicates that the information from the temperature observation at point A can be transferred to neighbouring model grid points and that the coherence between A and surrounding grid points (or variables) is stronger and more stable. However, the impact on the T-U correlation is not evident.
Fig. 9 Mean correlation functions of the temperature at the grid (140°W, 0°N, 150 m), against T (a–c), S (d–f), U (g–i) and SLA (j–l), obtained from Exp1 (left), Exp2 (middle) and Exp3 (right), averaged over the 2005–07 period. The contour interval is 0.2, and the correlations that pass the 0.90, 0.95 and 0.99 confidence level using a Student's t-test are shaded. The “+” marks the position of the grid.
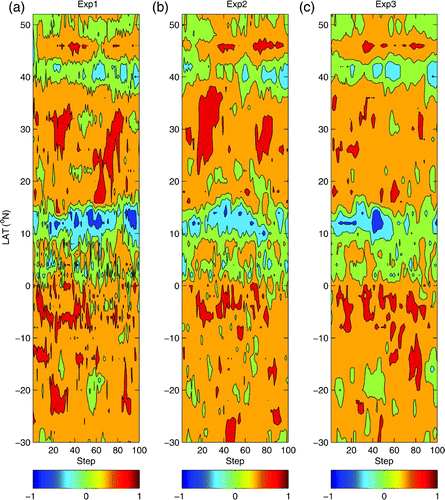
The basic properties of water masses in the ocean are salinity and temperature. The study of the temperature-salinity (T-S) relationship in data assimilation is of great interest. Here, we will further investigate the effects of the time-averaged covariance on the T-S relationship. Shown in is the latitude-time section of the T-S relation at 150 m, along longitude 140°W, for the first 100 steps. Comparing Exp1, Exp2 and Exp3 reveals that the main characteristics of the T-S relationship were unchanged; for example, a strong positive T-S correlation between 15° and 40°N and a strong negative T-S correlation along 12°N and 42°N were observed. However, it is evident that the T-S correlation is much noisier and is dominated by shorter temporal and spatial scales in Exp1 compared with a relatively smoother and more stable T-S correlation in Exp2 and Exp3. In the tropical region, the contrast between Exp3 and Exp1 is more obvious. The better T-S correlation structure in Exp3 is possibly the main reason for its improved assimilation performance relative to Exp1 because temperature data are dense in the equatorial Pacific Ocean. The improvement in the correlation structure in Exp3 is mainly a result of the larger ensemble size, which reduces the impact of sampling error on the estimation of error covariance.
Fig. 10 Latitude-time section of the T-S correlation along 140°W for the first 100 steps. The contours are −0.8, −0.4, 0, 0.4 and 0.8.
5 Summary and discussion
In this study, we assimilate in situ temperature and salinity profiles and sea level height data into an OGCM for the Pacific Ocean using the EnKF. The spectral nudging scheme is used to reduce the model bias online. The results show that the spectral nudging method can significantly reduce model bias, especially in the subsurface, without sacrificing the interannaual and short time-scale variations.
A time-averaged covariance method is proposed to construct a proxy background error covariance matrix in the EnKF. This method averages background error covariance matrices estimated by the ensembles of neighbouring assimilation steps. It is equivalent to estimating the background error covariance matrix with a super ensemble that includes all deviation ensemble members of several neighbouring assimilation cycles. Thus, the ensemble size is enlarged without increasing model integrations. It is in some ways similar to the EnOI but more reasonable in addressing the variations in the background error covariance with the assimilation cycles. EnOI assumes that the background error covariance is unchanged during the assimilation period, whereas this time-averaged covariance method only assumes that the background error covariance structures are not changed within a short time window of several assimilation steps. Thus, the time-averaged covariance method will not significantly modify the main structure of the covariance matrix but will effectively filter out the noisy components in the background error covariance matrix.
Three assimilation experiments with different time-averaged covariances were conducted to examine the impacts of this method. Comparing the results of the three experiments reveals that the time-averaged covariance method can improve the performance of the assimilation system for many regions in terms of the reduction in RMSE. Compared to observations, the improvements are evident in the tropical region. Although this method cannot greatly increase the absolute ensemble spread, the comparison of the relative ensemble spreads shows that the time-averaged covariance can increase the relative ensemble spread and, thus, improve the agreement between the ensemble spread and the forecast error. These improvements are mainly a result of the improved correlation structure of the background error covariance matrix. The correlation functions of the time-averaged covariance are much smoother and more robust than that of the standard EnKF, while the main structure of the correlation functions remains unchanged. This method may be useful for practical assimilation systems when computational resources are limited.
Because the coarse-resolution model lacks the resolution required to reproduce strong eddy activity, it is unable to simulate small-scale variations in the Kuroshio region, which are closely associated with variations in the SLAs and currents. In addition, we consider only the representation error of observations in the vertical direction and ignore the horizontal variation for simplicity. This may degrade the performance of the assimilation system, especially in some regions where the observations have relatively large representation errors, such as the Kuroshio region. In this time-averaged covariance scheme, the ensemble members from previous time steps are used for the current time step. Thus, the time-averaged covariance method provides only a sub-optimal estimation for the forecast error covariance matrix.
Acknowledgements
This work was supported by the BC-China Innovation and Commercialization Strategic Development Program (ICSD-2007-Tang-Y), the open grant of the State Key Laboratory of Satellite Ocean Environment Dynamics, Second Institute of Oceanography, State Oceanic Administration, China and the International Corporation Program of China (2008DFA22230).
References
- Anderson , J. L. 2001 . An ensemble adjustment Kalman filter for data assimilation . Monthly Weather Review , 129 : 2884 – 2903 . (doi:10.1175/1520-0493(2001)129<2884:AEAKFF>2.0.CO;2)
- Anderson , J. L. 2007 . An adaptive covariance inflation error correction algorithm for ensemble filters . Tellus , 59A : 210 – 224 .
- Anderson , J. L. and Anderson , S. L. 1999 . A Monte Carlo implementation of the nonlinear filtering problem to produce ensemble assimilations and forecasts . Monthly Weather Review , 127 : 2741 – 2758 . (doi:10.1175/1520-0493(1999)127<2741:AMCIOT>2.0.CO;2)
- Aviso (Archiving, Validation and Interpretation of Satellite Oceanographic data). (2009). MSLA - Maps of Sea Level Anomalies & geostrophic velocity anomalies [Data]. Retrieved from http://www.aviso.oceanobs.com/en/data/products/sea-surface-height-products/global/msla.html#c5127
- Balmaseda , M. , Anderson , D. and Vidard , A. 2007 . Impact of Argo on analyses of the global ocean . Geophysical Research Letters , 34 : L16605 doi:10.1029/2007GL030452
- Behringer , D. W. , Ji , M. and Leetmaa , A. 1998 . An improved coupled model for ENSO prediction and implications for ocean initialization. Part I: The ocean data assimilation system . Monthly Weather Review , 126 : 1013 – 1021 . (doi:10.1175/1520-0493(1998)126<1013:AICMFE>2.0.CO;2)
- Bengtsson , L. K. , Magnusson , L. and Källén , E. 2008 . Independent estimations of the asymptotic variability in an ensemble forecast system . Monthly Weather Review , 136 : 4105 – 4112 . (doi:10.1175/2008MWR2526.1)
- Bloom , S. C. , Takas , L. L. , da Silva , A. M. and Ledvina , D. 1996 . Data assimilation using incremental analysis updates . Monthly Weather Review , 124 : 1256 – 1271 . (doi:10.1175/1520-0493(1996)124<1256:DAUIAU>2.0.CO;2)
- Bonavita , M. , Torrisi , L. and Marcucci , F. 2010 . Ensemble data assimilation with the CNMCA regional forecasting system . Quarterly Journal of the Royal Meteorological Society , 136 : 132 – 145 . (doi:10.1002/qj.553)
- Bonjean , F. and Lagerloef , G. S. E. 2002 . Diagnostic model and analysis of the surface currents in the tropical Pacific Ocean . Journal of Physical Oceanography , 32 : 2938 – 2954 . (doi:10.1175/1520-0485(2002)032<2938:DMAAOT>2.0.CO;2)
- Castruccio , F. , Verron , J. , Gourdeau , L. , Brankart , J. M. and Brasseur , P. 2008 . Joint altimetric and in-situ data assimilation using the GRACE mean dynamic topography: a 1993–1998 hindcast experiment in the tropical Pacific Ocean . Ocean Dynamics , 58 : 43 – 63 . (doi:10.1007/s10236-007-0131-4)
- Cheng , Y. , Tang , Y. , Jackson , P. , Chen , D. and Deng , Z. 2010 . Ensemble construction and verification of the probabilistic ENSO prediction in the LDEO5 model . Journal of Climate , 23 : 5476 – 5497 . (doi:10.1175/2010JCLI3453.1)
- Cummings , J. A. 2005 . Operational multivariate ocean data assimilation . Quarterly Journal of the Royal Meteorological Society , 131 : 3583 – 3604 . (doi:10.1256/qj.05.105)
- Cummings , J. , Bertino , L. , Brasseur , P. , Fukumori , I. , Kamachi , M. , Martin , M. J. , Mogensen , K. , Oke , P. , Testut , C. E. , Verron , J. and Weaver , A. 2009 . Ocean data assimilation systems for GODAE . Oceanography , 22 ( 3 ) : 97 – 109 . (doi:10.5670/oceanog.2009.69)
- Deng , Z. , Tang , Y. and Freeland , H. J. 2011 . Evaluation of several model error schemes in the EnKF assimilation: Applied to Argo profiles in the Pacific Ocean . Journal of Geophysical Research , 116 C09027, 1–22. doi:10.1029/2011JC006942
- Deng , Z. , Tang , Y. and Wang , G. 2010 . Assimilation of Argo temperature and salinity profiles using a bias-aware localized EnKF system for the Pacific Ocean . Ocean Modelling , 35 : 187 – 205 . (doi:10.1016/j.ocemod.2010.07.007)
- Desroziers , G. , Berre , L. , Chapnik , B. and Poli , P. 2005 . Diagnosis of observation, background and analysis error statistics in observation space . Quarterly Journal of the Royal Meteorological Society , 131 : 3385 – 3396 . (doi:10.1256/qj.05.108)
- Dibarboure, G., O. Lauret, F. Mertz, V. Rosmorduc, & C. Maheu (2009). SSALTO/DUACS user handbook: (M)SLA and (M)ADT near-real time and delayed time products. CLS-DOS-NT-06.034, Retrieved from http://www.aviso.oceanobs.com/fileadmin/documents/data/tools/hdbk_duacs.pdf
- Esbensen, S. K., & Kushnir, Y. (1981). The heat budget of the global ocean: An atlas based on estimates from surface marine observations. (Report No. 29). Climatic Research Institute, Corvallis: Oregon State University.
- Evensen , G. 1994 . Sequential data assimilation with a nonlinear quasigeostrophic model using Monte Carlo methods to forecast error statistics . Journal of Geophysical Research , 99 : 10143 – 10162 . (doi:10.1029/94JC00572)
- Evensen , G. 2003 . The ensemble Kalman filter: Theoretical formulation and practical implementation . Ocean Dynamics , 53 : 343 – 367 . (doi:10.1007/s10236-003-0036-9)
- Ferry , N. , Rémy , E. , Brasseur , P. and Maes , C. 2007 . The Mercator global ocean operational analysis system: Assessment and validation of an 11-year reanalysis . Journal of Marine Systems , 65 : 540 – 560 . (doi:10.1016/j.jmarsys.2005.08.004)
- Gaspari , G. and Cohn , S. E. 1999 . Construction of correlation functions in two and three dimensions . Quarterly Journal of the Roiyal Meteorological Society , 125 : 723 – 757 . (doi:10.1002/qj.49712555417)
- Hamill , T. M. , Whitaker , J. S. and Snyder , C. 2001 . Distance-dependent filtering of background error covariance estimates in an ensemble Kalman filter . Monthly Weather Review , 129 : 2776 – 2784 . (doi:10.1175/1520-0493(2001)129<2776:DDFOBE>2.0.CO;2)
- Helber , R. W. , Weisberg , R. H. , Bonjean , F. , Johnson , E. S. and Lagerloef , G. S. E. 2007 . Satellite-derived surface current divergence in relation to tropical Atlantic SST and wind . Journal of Physical Oceanography , 37 : 1357 – 1375 . (doi:10.1175/JPO3052.1)
- Houtekamer , P. L. and Mitchell , H. L. 1998 . Data assimilation using an ensemble Kalman filter technique . Monthly Weather Review , 126 : 796 – 811 . (doi:10.1175/1520-0493(1998)126<0796:DAUAEK>2.0.CO;2)
- Houtekamer , P. L. and Mitchell , H. L. 2001 . A sequential ensemble Kalman filter for atmospheric data assimilation . Monthly Weather Review , 129 : 123 – 137 . (doi:10.1175/1520-0493(2001)129<0123:ASEKFF>2.0.CO;2)
- Huang , B. , Xue , Y. and Behringer , D. 2008 . Impacts of Argo salinity in NCEP Global Ocean Data Assimilation System: The tropical Indian Ocean . Journal of Geophysical Research , 113 doi:10.1029/2007JC004388
- Hunt , B. R. , Kostelich , E. J. and Szunyogh , I. 2007 . Efficient data assimilation for spatiotemporal chaos: A local ensemble transform Kalman filter . Physica D , 230 : 112 – 126 . (doi:10.1016/j.physd.2006.11.008)
- Janic , T. and Cohn , S. E. 2006 . Treatment of observation error due to unresolved scales in atmospheric data assimilation . Monthly Weather Review , 134 : 2900 – 2915 . (doi:10.1175/MWR3229.1)
- Jolliffe , I. T. and Stephenson , D. B. 2003 . Forecast verification: A practitioner's guide in atmospheric science , Edited by: Jolliffe , I. T. and Stephenson , D. B. West Sussex , , England : John Wiley and Sons Ltd .
- Keppenne , C. L. , Rienecher , M. M. , Kurkowski , N. P. and Adamec , D. A. 2005 . Ensemble Kalman filter assimilation of temperature and altimeter data with bias correction and application to seasonal prediction . Nonlinear Processes in Geophysics , 12 : 491 – 503 . doi:10.5194/npg-12-491-2005
- Levitus, S., & T. Boyer (1998). NOAA/OAR/ERSRL PSD, Boulder, Colorado, USA. Retrieved from http://www.esrl.noaa.gov/psd/data/gridded/data.nodc.woa98.html, 2009
- Li , H. , Kalnay , E. , Miyoshi , T. and Danforth , C. M. 2009 . Accounting for model errors in ensemble data assimilation . Monthly Weather Review , 137 : 3407 – 3419 . (doi:10.1175/2009MWR2766.1)
- Madec, G. (2008). NEMO ocean engine. Note du Pôle de modélisation, Institue Pierre-Simon Laplace (IPSL), Paris, France, No 27, ISSN No 1288–1619.
- Mitchell , H. L. and Houtekamer , P. L. 2000 . An adaptive ensemble Kalman filter . Monthly Weather Review , 128 : 416 – 433 . (doi:10.1175/1520-0493(2000)128<0416:AAEKF>2.0.CO;2)
- Mitchell , H. L. and Houtekamer , P. L. 2002 . Ensemble size, balance, and model-error representation in an ensemble Kalman filter . Monthly Weather Review , 130 : 2791 – 2808 . (doi:10.1175/1520-0493(2002)130<2791:ESBAME>2.0.CO;2)
- NOAA. (2009a). Global Temperature-Salinity Profile Program: Best Copy Data Sets [Data]. Retrieved from the National Oceanographic Data Center website: http://www.nodc.noaa.gov/GTSPP/access_data/gtspp-bc.html
- NOAA (National Atmospheric and Oceanic Administration). (2009b). Ocean Surface Current Analyses—Real time [Data]. Retrieved from http://www.oscar.noaa.gov/datadisplay/oscar_datadownload.php
- NOAA (National Atmospheric and Oceanic Administration). (2009c). Global Temperature-Salinity Profile Program: User-Defined Data Sets [Data]. Retrieved from the National Oceanographic Data Center website: http://www.nodc.noaa.gov/cgi-bin/gtspp/gtsppform01.cgi
- NOAA (National Atmospheric and Oceanic Administration). (2009d). Monthly atmospheric and SST indices [Data]. Retrieved from the Climate Prediction Center website: http://www.cpc.ncep.noaa.gov/data/indices/
- NOAA (National Atmospheric and Oceanic Administration). (2009e). ICOADS 2 Degree [Data]. Retrieved from the Earth System Research Laboratory, Physical Sciences Division website: http://www.esrl.noaa.gov/psd/data/gridded/data.coads.2deg.html
- Oke , P. R. , Allen , J. S. , Miller , R. N. , Egbert , G. D. and Kosro , P. M. 2002 . Assimilation of surface velocity data into a primitive equation coastal ocean model . Journal of Geophysical Research , 107 : 3122 doi:10.1029/2000JC000511
- Oke , P. R. , Brassington , G. B. , Griffin , D. A. and Schiller , A. 2008 . The bluelink ocean data assimilation system (BODAS) . Ocean Modelling , 21 : 46 – 70 . (doi:10.1016/j.ocemod.2007.11.002)
- Oke , P. R. , Schiller , A. , Griffin , D. A. and Brassington , G. B. 2005 . Ensemble data assimilation for an eddy-resolving ocean model of the Australian Region . Quarterly Journal of the Royal Meteorological Society , 131 : 3301 – 3311 . (doi:10.1256/qj.05.95)
- Ott , E. , Hunt , B. H. , Szunyogh , I. , Zimin , Z. V. , Kostelich , E. J. , Corazza , M. , Kalnay , E. , Patil , D. J. and Yorke , J. A. 2004 . A local ensemble Kalman filter for atmospheric data assimilation . Tellus , 56A : 415 – 428 .
- Reichle , R. H. , Mclauglin , D. B. and Entekhabi , D. 2002 . Hydrologic data assimilation with the ensemble Kalman filter . Monthly Weather Review , 130 : 103 – 114 . (doi:10.1175/1520-0493(2002)130<0103:HDAWTE>2.0.CO;2)
- Smith , G. C. and Haines , K. 2009 . Evaluation of the S(T) assimilation method with Argo dataset . Quarterly Journal of the Royal Meteorological Society , 135 : 739 – 756 . (doi:10.1002/qj.395)
- Szunyogh , I. , Kostelich , E. J. , Gyarmati , G. , Kalnay , E. , Hunt , B. R. , Ott , E. , Satterfield , E. and Yorke , J. A. 2008 . A local ensemble transform Kalman filter data assimilation system for the NCEP global model . Tellus , 60A : 113 – 130 .
- Thompson , K. R. , Wright , D. G. , Lu , Y. and Demirov , E. 2006 . A simple method for reducing seasonal bias and drift in eddy resolving ocean models . Ocean Modelling , 13 : 109 – 125 . (doi:10.1016/j.ocemod.2005.11.003)
- Turner , M. R. J. , Walker , J. P. and Oke , P. R. 2008 . Ensemble member generation for sequential data assimilation . Remote Sensing of Environment , 112 : 1421 – 1433 . (doi:10.1016/j.rse.2007.02.042)
- Xie , J. and Zhu , J. 2010 . Ensemble optimal interpolation schemes for assimilating Argo profiles into a hybrid coordinate ocean model . Ocean Modelling , 33 : 283 – 298 . (doi:10.1016/j.ocemod.2010.03.002)
- Zheng , X. 2009 . An adaptive estimation of forecast error covariance parameters for Kalman filtering data assimilation . Advances in Atmospheric Sciences , 26 : 154 – 160 . (doi:10.1007/s00376-009-0154-5)