
ABSTRACT
This paper reports on a series of studies investigating the production and perception of stop voicing contrasts in speakers of Central Australian Aboriginal English (CAAE; Alice Springs, Australia). Study 1 investigated Voice Onset Time (VOT) and Constriction Duration (CD) in stop consonants in naturalistic adult speech, and the speakers produced a VOT-based voicing distinction in word-initial stops, while medial voiceless stops differ from voiced stops in having both longer VOTs and longer CDs, at least for the syllable onset position. Study 2 investigated the implementation of stop voicing contrasts (VOT and CD) in a cohort of child CAAE speakers, and the results are consistent with the adult CAAE data, suggesting predictable intergenerational transmission. Finally, Study 3 tested child speakers’ perception of stop voicing contrasts using a mispronunciation detection task, where the participants demonstrated above-chance performance for the voicing distinction across all places of articulation. Together, the findings suggest that CAAE has phonemic stop voicing distinctions, like Mainstream Australian English, and that CAAE medial stops are jointly cued by both VOT and CD, a feature shared with the contact language, Kriol.
1. Introduction
The present study contributes the first piece of instrumental research on the phonology and phonetics of stop consonants in English spoken by Aboriginal Australians living in the regional centre of Alice Springs (Mparntwe), in the Northern Territory. In the sections that follow, we review the limited literature on the phonology and phonetics of stop consonants in Australian Aboriginal English (AAE) in general (Section 1.1), and specifically as it is spoken in Alice Springs (Section 1.2), with a focus on the acoustic features of Voice Onset Time (VOT) and Constriction Duration (CD) in both voiceless and voiced stops in Central Australian Aboriginal English (CAAE).
1.1 Background: Mainstream Australian English and Australian Aboriginal English
Multilingualism and language contact are longstanding characteristics of the language ecology of the continent of Australia (Bowern & Koch, Citation2004; Koch, Citation1997; McConvell & Bowern, Citation2011) and, since colonization in 1788, the contact influence of English has been pervasive. In some areas of the continent, traditional Indigenous languages are still being spoken and acquired by children as their primary language, while new Indigenous contact languages, including creoles (e.g. Hudson, Citation1981; Sandefur, Citation1979; Schnukal, Citation1985), mixed languages (e.g. McConvell & Meakins, Citation2005; O’Shannessy, Citation2005) and local varieties of English (e.g. Harkins, Citation2000; Malcolm, Citation2001, Citation2008) have emerged as the speakers’ main everyday languages in other areas.
Most Aboriginal and Torres Strait Islander people across Australia (76% of Indigenous Australians (Australian Bureau of Statistics, ABS, Citation2021)), however, now speak English as their first language (L1), and in many places distinct varieties of English almost exclusively spoken by Indigenous people, typically referred to as “Aboriginal English” (AAE), are spoken (Harkins, Citation2000; Malcolm, Citation2001). These varieties reflect the social histories of the communities where they are spoken and may carry important identity functions for speakers (Harkins, Citation1994; Malcolm, Citation2018; Ober & Bell, Citation2012).
1.1.1 Mainstream Australian English
For Mainstream Australian English (MAE), also known as Standard Australian English (SAE), and other mainstream English dialects across the world, it is widely accepted that VOT is the primary cue to stop voicing at the onset/word-initial position (Abramson & Whalen, Citation2017; Clothier & Loakes, Citation2018; Jones & Meakins, Citation2013; Lisker & Abramson, Citation1967; Millasseau, Bruggeman, et al., Citation2021; Millasseau, Yuen, et al., Citation2021). At the word-initial position (therefore the onset of a syllable), VOT measures the duration between the release of the stop to the onset of glottal pulsing (Abramson & Whalen, Citation2017; Cho et al., Citation2019): English voiceless stops have positive VOT values, while voiced stops typically have VOTs close to zero. At the same time, the time lag is also subject to prosodic factors, for instance, voiceless stops in stressed syllables (therefore prosodically strong positions) tend to have longer VOTs than unstressed syllables (Lisker & Abramson, Citation1967). In word-medial positions, voiced stops are characterized by unbroken voicing (therefore a negative VOT), while voiceless stops often lead to a measurable gap in voicing, and therefore maintain a positive VOT, e.g. in the word pair tucking vs tugging (Abramson & Whalen, Citation2017). Similar results are available from MAE speakers’ rendition of non-word pairs, aba vs apa, or ada vs ata, and lexical stress patterns may also influence the VOT values, e.g. voiced stops can have lower negative VOTs (therefore longer continued voicing) if the preceding vowel is stressed, as in Aba, as compared to a stressed following vowel, as in abA (Antoniou et al., Citation2010). Finally, in word-final coda position, VOT might not serve as a robust cue unless there is a following voiced segment. Rather, word-final voicing is cued by a range of correlates, including the vowel duration of the preceding vowel, closure duration, change of first formant (F1) and fundamental frequency (F0), as well as the duration and intensity of the closure release (Penney et al., Citation2018, Citation2021).
Across different languages, it has also been well-documented that VOT is also influenced by phonetic factors such as the place of articulation, contact area (e.g. dorsal/laminal vs apical stops), as well as how fast the articulators move, e.g. in fast vs slow speech (Cho & Ladefoged, Citation1999; Lisker & Abramson, Citation1967; Nearey & Rochet, Citation1994). Typically, stops produced by posterior articulators, e.g. velar stops, tend to have longer VOTs than anterior ones, e.g. labial stops. For adult speakers of MAE, a recent study reports that word-initial /b d ɡ/ have mean VOTs of 11, 19 and 25 ms, while /p t k/ have mean VOTs of 67, 77 and 77 ms; child MAE speakers show the same pattern, but they typically have even longer VOTs in voiceless stops than adult speakers do (Millasseau, Bruggeman, et al., Citation2021). Lastly, articulation with a high velocity leads to a rapid release of the oral closure, and thus a shorter time for building up sub-glottal pressure (Cho & Ladefoged, Citation1999). For instance, English voiceless stops tend to have longer VOTs in slow speech than in fast speech (Kessinger & Blumstein, Citation1997, Citation1998).
In contrast, the role of Constriction Duration (CD) in voicing coding is not entirely clear, and the CD difference between voiced and voiceless stops in the word-medial position remains under-documented and under-studied for MAE and other English varieties in Australia. In American English, very small differences were reported for intervocalic stops, ranging typically from 1 to 6 ms (Byrd, Citation1993; Lisker, Citation1957), well below the Just Noticeable Difference (JND) which in speech is often assessed to be approximately 20–25 ms (Huggins, Citation1968; Klatt & Cooper, Citation1975). At the same time, some recent studies suggest that CD may play a role in the voicing distinction in MAE speakers (Millasseau, Bruggeman, et al., Citation2021; Millasseau, Yuen, et al., Citation2021). At the word-final (therefore a syllable coda) position, voiceless stops typically have longer CD values than their voiced counterparts (Millasseau, Yuen, et al., Citation2021). In utterance-medial but word-initial positions, voiced stops can have longer CDs than voiceless stops, representing a reversed pattern (Millasseau, Bruggeman, et al., Citation2021). In the present study, we do not wish to measure CD for word-initial stops due to the methodological difficulty of controlling prosodic prominence in spontaneous speech, e.g. pauses between words can be extended for as long as the speaker might like.
1.1.2 Australian Aboriginal English
Varieties of AAE in the Northern Territory, Queensland and Western Australia have been described as having “most of the consonants of [Mainstream Australian English], with the exception of /h/ in some cases” (Malcolm, Citation2008, p. 134), but in terms of consonant voicing, stop vs fricative production and some places of articulation, the boundaries between phonemes “are much more porous” than in [MAE] (Malcolm, Citation2008, p. 134). A wider range of consonant inventories is given in Butcher (Citation2008), with some being very like the inventories of traditional Australian languages, and others more like MAE.
Systematic experimental research on stop consonants in AAE varieties has been undertaken only very recently and shows that the stop production is largely similar to that in MAE but with some differences. On Croker Island, Northern Territory, the speech of three AAE speakers shows a clear voicing distinction in word-initial and medial stops based on VOT, and to a lesser extent CD, similar to that in MAE: Voiceless stops /p t k/ have longer VOTs and CDs than voiced stops /b d ɡ/ (Mailhammer et al., Citation2020). Furthermore, a difference in Voice Termination Time (VTT, the duration of voicing into a stop constriction) is also reported between the MAE and Croker Island Aboriginal English speakers in that VTT is present in AAE but not in MAE (Mailhammer et al., Citation2020).
Finally, in two regional centres in Victoria, Warrnambool and Mildura, AAE speakers and MAE speakers use VOT to differentiate word-initial voiced and voiceless stops, and also predominantly use a canonical voiceless aspirated realization of post-vocalic voiceless stops (Loakes et al., Citation2018, Citation2022). However, AAE speakers show more variation in their stop production than MAE speakers do, with a tendency towards “glottal” variants, e.g. full glottal stops [ʔ], pre-glottalized unreleased stops [ʔt̚] and ejective-like stops [t’], while mainstream Australian English speakers show a tendency towards use of an affricated variant [ts] (Loakes et al., Citation2018, Citation2022). Sociophonetic studies suggest that all of these variants are also present in other varieties of English (Gordeeva & Scobbie, Citation2013; McCarthy & Stuart-Smith, Citation2013; Simpson, Citation2014).
1.2 Central Australian Aboriginal English (CAAE)
In what follows, we use the label Central Australian Aboriginal English (CAAE) to refer to AAE spoken in the regional centre of Alice Springs today (cf. Koch, Citation2000, Citation2011). Alice Springs is a regional city in the Northern Territory with a population of 25,912, of whom 20.6% (5,343) identify as Aboriginal Australians (ABS census, 2021Footnote1). Alice Springs is a highly multilingual community, with many traditional Australian languages spoken in the surrounding area, including several Arandic languages (e.g. Eastern & Central Arrernte, Western Arrarnta, Alyawarr, Anmatyerr, Kaytetye), Western Desert (Wati) languages (e.g. Pintupi-Luritja, Pitjantjatjara/Yankunytjatjara) and a Ngumpin-Yapa language, Warlpiri. Unlike English, these Indigenous Australian languages do not implement a phonemic voicing contrast in consonants (Fletcher & Butcher, Citation2014).
Historically, access to and use of English has varied greatly for Aboriginal people in the Northern Territory, with more opportunity and need to acquire and use English in urban and regional centres than in remote locations. Before the 1950s, access to English was largely contingent on personal circumstances (e.g. location, work, travel), but for those born after 1950, English has been accessed primarily through formal schooling (Koch, Citation2000). An absence of a voicing contrast in stop consonants was noticed in the second language (L2) English speech of L1 speakers of Kaytetye, Warlpiri and Warlmanpa (Koch, Citation1985). The L2 English spoken by L1 Kaytetye (traditional language) speakers who lived in remote locations was described by Koch (Citation2000, Citation2011) as showing features potentially resulting from the interaction of several language contact processes. These include features retained from earlier Australian pidgin varieties, some influence of traditional languages in the area, though which languages are not specified, and elements arising as part of the process of learning English as an additional language. These include non-phonological features, for example, dual number in the pronoun system, dyadic kin terms (e.g. mother and child), transitive affixes on transitive verbs (see also Koch, Citation2004) and verbal structures of associated motion that express information in Kaytetye verb affixes. We note that it is difficult to generalize across individuals’ learner histories without detailed information. The English spoken today by Aboriginal people living in Alice Springs might have been influenced historically in similar ways to that reported in Koch (Citation2000), and we might therefore expect to observe differences between MAE and the AAE varieties spoken in, for instance, Victoria (Loakes et al., Citation2018, Citation2022) and on Croker Island (Mailhammer et al., Citation2020), as well as differences between CAAE and MAE.
In addition to contact with MAE speakers, CAAE speakers may have been in contact for many years with two Indigenous languages that show a phonemic voicing contrast in stop consonants, Kriol and Warumungu. In the contact language, Kriol, spoken in the Barkly region and further north across the Northern Territory and into Queensland and Western Australia, VOT is the primary cue to stop voicing in word-initial contexts, but CD is the major cue in word-medial contexts (Baker et al., Citation2014; Bundgaard-Nielsen & Baker, Citation2019; Bundgaard-Nielsen et al., Citation2016, Citation2023). This CD difference between voiced and voiceless stops is much larger than what is observed for American English (Byrd, Citation1993), and in the order of a 1:2 ratio, resulting in voiceless CD durations in excess of 150 ms (Baker et al., Citation2014). The CD contrast may have been incorporated into Kriol from substrate Indigenous languages that implement a [fortis/lenis] contrast, e.g. Ngalakgan and Ngandi (Baker, Citation2008). Similar patterns of reliance on CD to cue word-medial stop contrasts are also present in Light Warlpiri, a mixed language incorporating elements of Warlpiri and Kriol/English (Bundgaard-Nielsen & O’Shannessy, Citation2021b), and Gurindji Kriol (Jones & Meakins, Citation2013). In Central Australia, the traditional language Warumungu (Simpson, Citation2017), spoken to the north, also has a voicing contrast word-medially; but since Warumungu is now spoken less by younger speakers, its influence might be seen more in the local contact variety in the area, Wumpurrarni English (Disbray, Citation2008), rather than through a direct contemporary influence on CAAE.
The earliest reports on the phonology and phonetics of CAAE are on the speech of bilingual children acquiring CAAE in Alice Springs in the 1970s (Sharpe, Citation1979). This work indicates that the children’s English was characterized by variation in implementing voicing contrasts (/b-p/, /t-d/, /k-ɡ/) and stop-fricative (/p-f/, /t-s/) distinctions (i.e. some speakers showed these phonemic distinctions while others did not), consistent with the types of L2 processes experienced by adult L2 English speakers with other traditional language backgrounds (Bundgaard-Nielsen & Baker, Citation2019). Observations of differences in English usage are likely related to differences in the quality and quantity of input, for instance, differences in English sources, the amount of interaction and English use patterns. Similarly, accounts of the phonology and phonetics of CAAE have been provided for speakers in Alice Springs from the 1990s.
There has been no systematic study of the phonological inventory of CAAE for approximately 30 years, since Harkins (Citation1994). The reported variation in stop production in CAAE, and in other varieties of AAE reviewed above, raises the question of whether the CAAE characteristics of the L2 adult speakers from the 1970s (Sharpe, Citation1979) and the children from the 1990s (Harkins, Citation1994) are present in L1 CAAE today. The current study is the first instrumental examination of the implementation (phonetics) of stop voicing contrasts in CAAE, and the first investigation of the degree of intergenerational stability of the putative variety. In the sections that follow, we present three related studies examining:
the acoustic correlates of voiced and voiceless stops in CAAE;
the phonological transmission of stops between adult and child CAAE speakers; and
the correspondence between production and perception of stop voicing in CAAE speakers from an early age.
By analyzing the production and perception data from two generations of speakers – adult caregivers and children – we shed light on the intergenerational transmission of stop voicing, which provides a deeper understanding of the mechanisms of language contact and language transmission in a long-term language contact scenario. The study contributes to an appreciation of linguistic diversity and cultural heritage by providing insights into the effects of historical language practices on contemporary language and culture. Additionally, by comparing commonalities and differences between English varieties, the results of this study may have practical implications for education, language assessment and cross-cultural communication contexts (cf. Butcher, Citation2008; Eades, Citation1982; Malcolm, Citation2008). The studies presented were approved by the Australian National University Human Research Ethics Committee (#2019-183) and the Central Australian Human Research Ethics Committee (#CA-20-3633) as part of the Little Kids Learning Languages project.Footnote2
2. Study 1: Production of stop voicing in adult CAAE speakers
2.1 Methods
2.1.1 Participants
The participants of Study 1 were six women from Alice Springs, Northern Territory, who speak CAAE on a daily basis: A03 (age 26), A04 (age 35), A08 (age 27), A10 (age 38), A11 (age 31) and A12 (age 38). Speaker A08 also speaks Eastern Arrernte and Alyawarr, and speaker A12 speaks Anmatyerr and Pitjantjatjara in addition to CAAE; the other four speakers report speaking English as their everyday language and grew up speaking English as children.
At the time of the recording, all speakers were mothers of young children, and therefore their speech production provides valuable insights into the phonetic input that was available in the CAAE children’s linguistic environment during their phonological development. Speakers were recruited in person by senior Arrernte project researchers, visiting community centres and residential areas with another researcher in the Little Kids Learning Languages project. Adult caregivers completed an informed consent process and were given a $AUD50 supermarket voucher after each recording session. Participants were recorded (video and audio) at their homes (e.g. on the veranda), or at their local community centre.
2.1.2 Procedures
The six speakers were recorded with their child(ren) (age range from 12 months to 5 years) in sessions that included conversational interviews centred on day-to-day activities, conducted by a senior Arrernte researcher who is a bilingual speaker of Arrernte and CAAE, interactions with the children using text-less picture books as prompts (O’Shannessy, Citation2004), and play (20–30 mins each).
Conversations were transcribed using English orthography, and word-initial (N = 663) and medial stops (N = 213) were manually extracted from the recordings using Praat version 6.3 (Boersma & Weenink, Citation2023). For word-initial stops, VOT was measured from the first peak of the stop release (i.e. a sudden spike in the amplitude of the waveform) to the start of the following vowel, which was aligned with the beginning of the complex periodicity on the waveform, and with the strong F2 and higher formants in the spectrogram. For medial stops, continued voicing led to negative VOTs, and they were measured from the termination of the preceding segment (often a vowel) to the time of stop release. Voiceless medial stops were similarly measured as the word-initial stops if a voicing gap was identifiable. For word-medial stops, CDs for both voiced and voiceless stops were measured consistently as the duration between the closure release and the offset of the preceding segment. We did not measure CDs for word-initial stops since the utterances were not controlled for sentence structure, and it is not always possible to identify the closure formation on the waveform or in the spectrogram. A sample spectrogram is presented in . In the annotation procedure, we further specified the lexical prosodic feature of the stop consonants, including the stress pattern (stressed vs unstressed syllables), syllable position (onset or coda) and whether it is in a consonant cluster (singleton vs cluster). For instance, the consonant /p/ in the word potato is a singleton onset of an unstressed syllable. In contrast, the stop in play is part of an onset cluster of a stressed syllable. A special case is the medial /t/ consonant, which is subject to lenition before unstressed syllables (and thus unreliable for measuring VOT/CD), and indeed in the dataset we only observed medial /t/’s before stressed vowels, e.g. guitar. Phrasal and higher-level prosodic features were not controlled, due to the nature of the conversational speech data. Ambisyllabic consonants were consistently annotated as syllable codas, e.g. the medial stop /p/ in the word puppy is a coda consonant of a stressed syllable due to quantity sensitivity; for comparison, the medial stop /k/ in turkey is an onset of an unstressed syllable, following the Maximal Onset Principle.
Figure 1 Waveform and spectrogram of a sample word turkey. Red arrows indicate locations of closure release and constriction duration for the medial stop. Spectrogram settings: Gaussian window, window length = 0.005 s, maximal frequency = 5000 Hz, time step = 0.002 s, frequency step = 20 Hz

2.1.3 Analysis
Our analysis focused on whether voiceless stops /p t k/ and voiced stops /b d ɡ/ in CAAE show differences in VOT and CD measures in each place of articulation (POA). For word-initial stops, only VOT was analyzed, while word-medial stops were measured for both VOT and CD. We also analyzed individual patterns for each participant, to assess whether individual patterns were consistent with the group-level results.
2.2 Results
2.2.1 VOT and CD in CAAE stops
The descriptive results of the VOT and CD measures in stops produced by six adult CAAE speakers are visualized in , and the mean values and standard deviations are reported in . For word-initial stops, we built a linear mixed-effects model (LMM) using the following formula: VOT ∼ Voicing * POA + Stress + Cluster + (1 | Speaker) + (1 | Word). This formula accounted for the two key phonological parameters (and their interaction) whilst controlling the lexical prosodic features as well as random effects from speakers and word items (random slopes were not included since their inclusion would lead to converging errors). We then carried out a Kenward–Roger F-test on the model, which revealed a significant effect of voicing, F(1, 169.38) = 433.94, p < 0.0001, a significant effect of POA, F(2, 168.74) = 8.14, p = 0.0004, as well as a voicing–POA interaction effect, F(2, 169.46) = 4.96, p = 0.0081. At the same time, the effect of lexical stress was not significant (p = 0.8389), and the effect of consonant cluster was not significant either (p = 0.7868), indicating that the VOTs in the current CAAE dataset were not substantially influenced by lexical prosodic features at the word-initial position.
Figure 2 Box charts and density plots of acoustic correlates in CAAE adult speakers
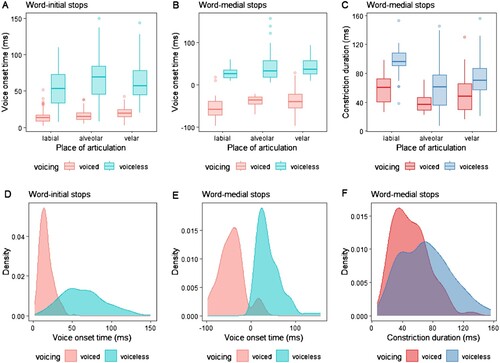
Table 1 Mean values and standard deviations of acoustic correlates in CAAE stops in adult speakers. Standard deviations are listed in parentheses
To further explore the significant effects, we carried out post hoc t-tests based on Estimated Marginal Means (EMM, Tukey-adjusted), which revealed that voiceless stops had significantly longer VOTs than their voiced counterparts across all three POAs (p < 0.0001 for three comparisons), i.e. /p t k/ > /b d ɡ/; for voiced stops alone, the VOT differences were not significant across three POAs, i.e. /b/ ≈ /d/ ≈ /ɡ/; for voiceless stops, labial stops had significantly shorter VOTs than alveolars and velars, i.e. /p/ < /t k/, while the difference between /t/ and /k/ was not significant. In addition to the mean value differences, as seen in the distribution plots (, panel A, D), voiceless stops in CAAE had a higher dispersion level than voiced stops, which had a more concentrated distribution.
For VOTs in word-medial stops, we similarly fitted an LMM using the following formula: VOT ∼ Voicing * POA + Voicing * Coda + Stress + Cluster + (1 | Speaker) + (1 | Word). This model further captures the syllable position and its potential interaction with the voicing distinction. When checked by a Kenward–Roger F-test, there was a significant effect of voicing, F(1, 54.37) = 380.64, p < 0.0001, a significant effect of POA, F(2, 64.12) = 3.88, p = 0.0256, and a significant effect of coda position F(1, 143.50) = 13.10, p = 0.0004. Again, the effects of stress and cluster were not significant (p = 0.5148 and 0.0960). At the same time, voicing did not significantly interact with POA or coda position (p = 0.3347 and 0.6423). The results indicated that for CAAE medial stops, VOTs were primarily determined by voicing, POA and the syllabic position, but these effects had minimal interaction with each other. To further explore these significant effects, we similarly carried out three post hoc tests, which showed that: (a) /p t k/ had significantly longer VOTs than /b d ɡ/ (p < 0.0001); (b) labial stops /p b/ had significantly shorter VOTs than the alveolar stops /t d/ (p = 0.0375) as well as the velar stops /k ɡ/ (p = 0.0465); and finally, (c) coda stops had significantly shorter VOTs than onset stops in word-medial positions (p = 0.0004). In terms of the shape of the distributions, this time, the medial voiced and voiceless stops had similar dispersion levels (see , panel B and E).
Finally, we analyzed word-medial CDs in another LMM: CD ∼ Voicing * POA + Voicing * Coda + Stress + Cluster + (1 | Speaker) + (1 | Word). We again checked the model using a Kenward–Roger F-test, which revealed a significant effect of voicing, F(1, 85.81) = 30.76, p < 0.0001, as well as a significant effect of POA, F(2, 95.57) = 8.94, p = 0.0002. This time, the main effect of coda position, stress pattern and cluster were not significant (p = 0.8288, 0.2699 and 0.5154). According to the model, voicing interacts with coda (p = 0.0174) but not POA (p = 0.3279). In the post hoc analysis, we first confirmed that labial stops were shorter than alveolars but not velars (p = 0.0004 and 0.1616). As for the interaction between voicing and coda, the voicing distinction was observed for onsets (p < 0.0001) but not for codas (p = 0.7490). Other comparisons were not phonologically meaningful. This indicates that the CD difference between voiced and voiceless stops in CAAE is potentially modulated or conditioned by the position of the word-medial stop in the syllable: the difference is more pronounced at the syllable onset position than the coda position, e.g. in CAAE /k/ might have a longer duration in turkey than tickle. At the same time, this pattern is not entirely unexpected because it is common in English that coda voicing is cued by the preceding vowel, for example vowel duration or glottalization (Penney et al., Citation2018, Citation2021).
In terms of dispersion level, the distribution of CD in voiceless stops had a heavier “tail” on the right-hand side (see panel F, ), while the two distributions had substantial overlap between voiced and voiceless consonants. In contrast, the VOT distributions had lower overlap levels.
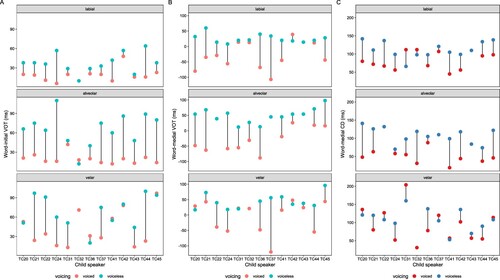
As the last step of the analysis, we explored potential individual differences among the adult CAAE speakers (see ). For medial stops, tokens were excluded if they were at the syllable coda position, since the analyses above showed that the acoustic differences were more salient for onsets. Note that some participants had missing personal mean values because no observations were available in the dataset. From the group-level analysis presented earlier, we concluded that voiceless stops had longer VOTs than voiced stops in both word-initial and word-medial positions, and at the medial position voiceless stops had longer CDs than voiced stops if they were syllable onsets.
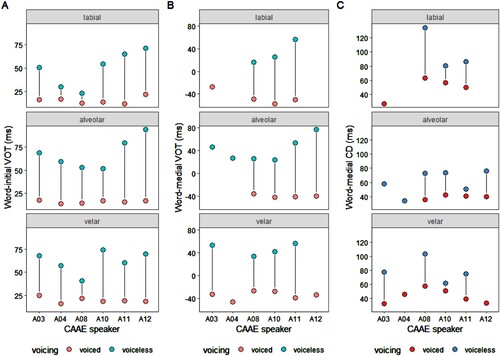
Overall, the patterns are consistent in each speaker’s individual data. However, some individual differences might also exist, and two speakers (A04, A08) may require further attention. For instance, speaker A08 had shorter word-initial VOTs, especially for the labial contrast (23 vs 12 ms), and also the velar contrast (41 vs 22 ms), while the alveolar contrast showed a clearer difference based on VOT (51 vs 13 ms) (see , panel A). Speaker A04 showed a small VOT difference for the labial contrast (30 vs 16 ms), but showed clearer differences for the alveolar contrast (59 vs 14 ms) and the velar contrast (58 vs 16 ms). For word-medial VOTs, the pattern was more consistent across different speakers. At the same time, A08 was also the speaker who showed a more salient usage of CD for medial stops, especially for the labial contrast (134 vs 63 ms), and less sharply for the alveolar contrast (73 vs 36 ms) and the velar contrast (103 vs 58 ms). The same tendency can also be observed in other speakers. To summarize, some individual differences were also observed in the dataset: some speakers showed smaller differences in VOT values, while some showed more variability in their CD values.
Figure 3 Individual patterns in adult CAAE production. Values are averaged across all available tokens for each participant. For medial stops, only syllable onsets are displayed
2.3 Discussion of Study 1
The findings of the first study offer substantial evidence that stop voicing in CAAE is phonemic. VOT in voiceless stops in both word-initial and medial position is significantly longer than in voiced stops, across all POA, similar to reports of MAE (Antoniou et al., Citation2010; Clothier & Loakes, Citation2018; Jones & Meakins, Citation2013; Millasseau et al., Citation2019) and of English elsewhere. Interestingly, CD in word-medial position in CAAE (at least for syllable onsets) also shows a length distinction with longer durations in voiceless stops than in voiced stops, across all POA, suggesting that both VOT and CD are cues to voicing in CAAE. With differences in data collection procedures in mind, the data in indicate that this is similar to what has been reported for Kriol (Baker et al., Citation2014) and Light Warlpiri (Bundgaard-Nielsen & O’Shannessy, Citation2021b).
Table 2 Constriction Duration (CD) ratio between voiceless and voiced medial stops in some Australian contact languages: Light Warlpiri (LW), Kriol and CAAE
As voiced and voiceless CAAE stops clearly differ in their CD implementation, we wish to further understand the magnitude of the durational differences. Calculations of the ratio of long to short CDs in some Australian languages, as well as in the contact varieties Kriol and Light Warlpiri, have been shown to exceed a 1.5–2:1 ratio (long vs short/fortis vs lenis). Note, since prosody structures differ between languages, here the values were calculated based on all available tokens irrespective of their prosodic features. presents these data, alongside data from adult and child Kriol and Light Warlpiri. We also pre-emptively include the stop CD ratios from the child CAAE data which we present in Study 2 below, for ease of comparison. These data indicate that – with appropriate caveats for differences in data collection methods, and potential differences in prosodic structures and speaking rates – the CD ratio for stops in CAAE is similar to that in Kriol.
Taken together, the VOT and CD data suggest that speakers of CAAE implement a stop voicing distinction similar to that in the contact language Kriol (Baker et al., Citation2014; Bundgaard-Nielsen & Baker, Citation2019; Bundgaard-Nielsen et al., Citation2016, Citation2023) and in the traditional language Warumungu (Simpson, Citation2017). In Kriol, word-medial stop voicing distinctions are cued by CD, while VOT is the primary cue in word-initial contexts (Baker et al., Citation2014; Bundgaard-Nielsen & Baker, Citation2019; Bundgaard-Nielsen et al., Citation2016, Citation2023). The length contrast in Kriol is likely influenced by traditional languages in the north that implement a [fortis/lenis] contrast and contributed to its origin (Baker et al., Citation2014; Bundgaard-Nielsen & Baker, Citation2019; Bundgaard-Nielsen et al., Citation2016). This contrast is not a phonological feature of traditional languages in Central Australia. However, the traditional languages in Central Australia do show relatively long CDs. In Warlpiri, word-medial stops /p t k/ tend to have long CDs, in excess of 100 ms (Bundgaard-Nielsen & O’Shannessy, Citation2021a), while prosodic prominence (e.g. the position of the consonant in the utterance) can also modulate the duration of the consonant (Butcher & Harrington, Citation2003; Pentland, Citation2004). In Pitjantjatjara, stop consonants /k/, /c/, and to a lesser extent /p/, have longer closure durations in initial stressed syllables (Tabain & Butcher, Citation2015). In Arrernte, consonants preceding a vowel in stressed syllables are longer in duration (Tabain, Citation2016). It is plausible then that the joint coding of VOT and CD in CAAE may reflect some influence from the traditional languages and from Kriol.
Variation between speakers indicates that designations such as CAAE (and other AAE varieties) should not be taken to reflect monolithic linguistic structures, as the voice characteristics of each speaker are a composite of their life experiences and linguistic background. For instance, the results from speaker A08 indicate identifiable differences in CD between voiced and voiceless stops, with VOT showing less difference, but other speakers appear to rely on both VOT and CD to differentiate stop consonants. We note that A08 was one of two multilingual speakers in the study; she speaks Eastern Arrernte and Alyawarr as well as CAAE regularly (although we do not have a detailed language history for her), while four of the other participants only speak CAAE. Alternatively, individual differences may result from speech rate differences, as preliminary analyses (which were not reported in this paper) showed that A04 and A08 had relatively low speech rates (64 and 65 words per minute, respectively), while some other speakers had higher speech rates, e.g. A10 had the highest speech rate (138 words per minute), and she only demonstrated a minimal tendency to implement CD differences in medial stops. Another similar case was speaker A11 (speaker rate = 82 words per minute). However, speech rate can also reflect a speaker's linguistic command of English, although all speakers use English on a daily basis. Nevertheless, this finding raises the concern that relying solely on impressionistic documentation or transcriptions by L1 (MAE) English listeners may lead to incorrect conclusions, such as mistakenly perceiving that speaker A08 does not distinguish between /b/ and /p/ due to the limited phonological importance of CD in MAE and other mainstream dialects; an MAE-as-L1 listener might not be tuned in to hear a distinction in CD. This highlights the significance and necessity of instrumental acoustic examinations.
In the following studies, we will focus on the transmission of the CAAE phonological system through an examination of child CAAE speakers producing and perceiving stop voicing in their early years.
3. Study 2: Production of stop voicing in child CAAE speakers
3.1 Methods
3.1.1 Participants
In order to examine stop production by child CAAE speakers, we recruited a cohort of 19 young Aboriginal children (age: 2;0 ∼ 11;9) (see Appendix 1). However, two children did not participate in the recording paradigm, and four were excluded due to poor audio recording quality or the speaker not understanding the instructions given. Therefore, production data are available for 13 child speakers. All children speak CAAE as (one of) their first language(s): one child additionally speaks Western Arrarnta; one speaks Alyawarr; and two speak Luritja on a daily basis. Participants were recruited in person by a senior Arrernte project researcher, in the same manner as for Study 1.
3.1.2 Procedures
The elicitation paradigm employed with the child speakers was in the form of a linguistic “game”. During the “game”, the child participants would help a little girl to find her puppy, by producing the target words: producing the target words would lead the girl visually closer to her dog, which she ultimately found (see ).
Figure 4 Procedures of the word production task for child CAAE speakers
The target words (see ) all contained a target stop (voiced or voiceless) and were selected on the basis of semantic familiarity to the children, and ease of being depicted visually (concreteness). A total of 23 unique words were selected to elicit word-initial and word-medial stops at three places of articulation (labial, alveolar and velar). Eight of the words were monosyllabic, including bad, pen, door, day, toes, go, car and cup. Thirteen words were disyllabic, including bottle, bucket, bubble, puppy, apple, daddy, spider, table, water, guitar, yogurt, hugging and kicking. Two trisyllabic words were also included, banana and potato. We acknowledge that the word list does not present a perfectly balanced design that fully captures all permutations of segmental, prosodic and functional parameters. This reflects a number of practical constraints: We were limited in our word selection as we wished to ensure that all target words were familiar to CAAE-speaking children. We were similarly constrained by having to use concrete nouns, and by limits on the duration of the data collection paradigm. As with the adult production dataset, we annotated basic prosodic features of the stop consonants, including the stress pattern, and whether it was a coda position. No consonant clusters were included in the word list.
Table 3 Target words (in English orthography) used as stimuli in the word elicitation procedure for CAAE children
To support the young participants, we used both visual and auditory cues to assist their word production. Each trial began with the presentation of a visual cue on a Microsoft PowerPoint slide, and shortly after that the child also heard a recording of the target word, produced by the same female speaker of CAAE (and Arrernte). We acknowledge that it is possible that the target words elicited using this design may have been shaped by the auditory prompt. However, the advantages of the design are that it ensured that the young children produced the target word instead of other semantically related words, e.g. banana-yellow-yummy, the task is probably the simplest of all speech production tasks, and it is at least as reliable as more spontaneous tasks (Edwards & Beckman, Citation2008). In cases when the child was unsure about the target word or reluctant to speak, the testing item was skipped (approximately 5% across the whole dataset).
3.1.3 Analysis and prediction
The data analysis for Study 2 used the same method as in Study 1: We measured both VOT and CD for stop consonants from all available tokens (N = 368). Under the assumption that the transmission of CAAE from caregivers to children is a stable process (cf. Bundgaard-Nielsen et al., Citation2023), we expect that child CAAE speakers would show a pattern consistent with that of adult speakers in terms of phonetic realizations (e.g. VOT, CD) of voiced and voiceless stops, as a result of intergenerational transmission and first language acquisition.
3.2 Results
The descriptive results of the VOT and CD measures in stops produced by 13 child CAAE speakers are visualized in , and the mean values and standard deviations are reported in . The medial voiced versus voiceless CD ratio is presented in in the previous section. As with the adult production data presented in Section 2, we analyzed child production data using LMM for testing the effect of voicing and POA, while controlling participants and specific word items as random factors (intercepts). For VOTs in word-initial stops, the following formula was used: VOT ∼ Voicing * POA + Stress + (1 | Speaker) + (1 | Word), and the model was then checked using a Kenward–Roger F-test, which revealed a significant main effect of voicing, F(1, 12.93) = 44.45, p < 0.0001, as well as a significant main effect of POA, F(2, 12.54) = 7.87, p = 0.0061, while the voicing–POA interaction effect did not reach the significance level (p = 0.1001). Additionally, effect of lexical stress was not significant (p = 0.3900). We then carried out a series of post hoc tests based on EMMs (Tukey-adjusted), which revealed that voiceless stops had significantly longer VOTs than voiced stops, p < 0.0001, while velar stops had significantly longer VOTs than labial stops, p = 0.0030. No other comparisons were significant. Once again, the data showed that voiced stops had a more concentrated distribution as compared to voiceless stops at the word-initial position (see , panel A and D).
Figure 5 Box charts and density plots of acoustic correlates in CAAE child speakers
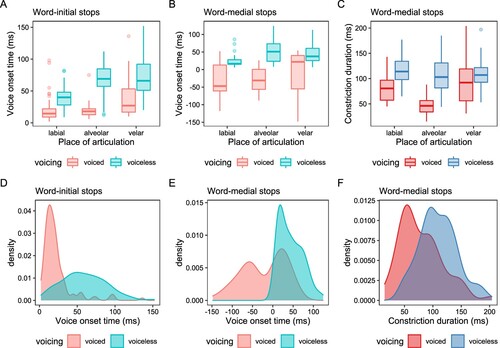
Table 4 Mean durations (in ms) and standard deviation of acoustic correlates in CAAE stops (child speakers). Standard deviations are presented in parentheses
Next, we used a similar method to analyze the word-medial VOTs (VOT ∼ Voicing * POA + Voicing * Coda + Stress + (1 | Speaker) + (1 | Word)), and a Kenward–Roger F-test revealed a significant main effect of voicing, F(1, 9.84) = 80.32, p < 0.0001, while no other effects reached the significance level. It is worth mentioning that the effect of POA had a relatively small p value (0.0798) but still failed to reach the significance level. This also means that we did not observe effects of coda position or stress, or the interaction between voicing and coda position (as seen in the adult production study). Post hoc analysis revealed that voiceless stops had significantly longer VOTs than voiced stops (p = 0.0001).
The word-medial CDs were also analyzed using another LMM: CD ∼ Voicing * POA + Voicing * Coda + (1 | Speaker) + (1 | Word). This time, a Kenward–Roger F-test revealed a significant main effect of voicing, F(1, 8.34) = 24.85, p = 0.0009, but the main effect of POA did not reach the significance level (p = 0.3294). Additionally, the Voicing–POA interaction effect was significant, F(2, 6.84) = 6.59, p = 0.0254. The voicing–coda interaction did not reach the significance level but had a relatively small p value (0.0504), indicating a potential role of syllable position in CD implementation, but the child production dataset might be too small for detecting such nuanced differences (as shown in the adult production data), e.g. we had fewer word items and fewer available tokens in Study 2 as compared to Study 1. To summarize, child CAAE speakers showed a voicing distinction based on VOT for word-initial stops, while voicing in word-medial stops was jointly cued by VOT and CD, consistent with the pattern in the adult data presented in Study 1.
Additional to our statistical analysis of VOT and CD in CAAE, and as we did with the adult data in Study 1 above, we also calculated the CD ratios between voiceless/long and voiced/short stops in child CAAE. These calculations are presented in above, and like the adult CAAE data, the child CAAE data suggest that CAAE CD ratios are similar to those observed in both child and adult Kriol (e.g. Bundgaard-Nielsen et al., Citation2023).
We present individual patterns for each participant in from all available tokens, and we have a number of comments on individual differences in relation to the group-level findings. Firstly, for initial VOTs (, panel A), child speakers showed a more consistent pattern for the labial contrast and the alveolar contrast, while substantial variations are observed in the velar contrast. A very similar pattern can be seen in medial VOTs and CDs (, panel B and C), that the individual results were less consistent for velar stops. In particular, four CAAE children displayed substantial differences from the group-level pattern: TC20 (3;8), TC31 (3;11), TC42 (7;6) and TC45 (3;7). This might be due to their young age, since three of them were younger than four years of age at the time of testing. Overall, when looking across multiple speakers, the individual patterns were consistent with the group-level performance.
Figure 6 Individual patterns in child CAAE production. Values are averaged across all available tokens for each participant. Missing values are not shown
3.3 Discussion of Study 2
The group data collected from the child speakers of CAAE demonstrate that the distinction between voiced and voiceless stops constitutes a phonemic contrast of CAAE, consistent with the data collected from the adult CAAE speakers (Study 1), and indicating stability of the phonemic inventory, and the phonetic implementation of the phonological stop contrasts in CAAE. As in Study 1, the stop voicing distinction in child CAAE relies on a joint-coding pattern based on both VOT and CD in medial stops, in a manner that is very similar to what has been described for both adult and child Kriol.
The individual variation also observed in the child CAAE data is consistent with what has been observed in the production data from child speakers of Kriol (Bundgaard-Nielsen et al., Citation2023), particularly in terms of velar stops. The substantial variability in children’s velar consonants may be attributed to an underdeveloped motor control over the vocal organs: there is a universal tendency across the world’s languages that stop consonants (and nasals) with anterior POAs are acquired earlier in production (McLeod & Crowe, Citation2018). It is also possible that velars differ from labials and alveolars in that a voicing distinction is more challenging to implement due to the long durations (see also, Bundgaard-Nielsen & O’Shannessy, Citation2021b). Regardless, it is expected that children’s perception of voiced and voiceless velar stops will remain robust, as children’s production may lag behind their perception (Best, Citation1995; Kuhl et al., Citation2007). This prediction will be addressed directly in the next experiment.
4. Study 3: Perception of stop voicing in child CAAE speakers
4.1 Methods
4.1.1 Participants
The participants in Study 3 were a sub-group of the CAAE-speaking children recruited for the production study presented in Section 3 (see also Appendix 1). Of the 19 recruited children, six did not participate in the perception task, two did not finish their task, and three failed to understand the research paradigm. Therefore, perception data are available for eight child participants only.
4.1.2 Materials and procedures
The perception task tested the CAAE children’s ability to detect mispronunciations based on different modification strategies, e.g. a shift of POA, or a shift of voice, following Bundgaard-Nielsen et al. (Citation2023). The materials were a list of word stimuli produced by the same female bilingual speaker of CAAE and Arrernte who also assisted in Studies 1 and 2. The word list contained a set of real words and a set of corresponding pseudowords, where there was a change in voicing or POA. The key acoustic parameters (VOT, CD) of the stimuli items are reported in , and the acoustic characteristics of these are consistent with productions by the adult CAAE speakers presented in Study 1.
Table 5 Word stimuli used in the mispronunciation detection task
On each trial, the experimenter presented an image on a tablet, e.g. a banana (see ), and either a correct production, banana, or a mispronounced word, panana, was auditorily presented using the tablet speaker. The child was then required to give a binary response for the correspondence between the audio recording and the target picture, by indicating whether it was a correct or funny pronunciation. The children indicated either by speaking or pointing to a green tick (correct) or red cross (funny). The task consisted of a total of 12 pairs of word stimuli with mismatched voicing specification, counterbalanced by POA and word position. All selected target words were frequent lexical words in CAAE.
Figure 7 Schematic interface of the mispronunciation detection task. In this case, the correct stimulus is banana, while the incorrect stimulus is panana
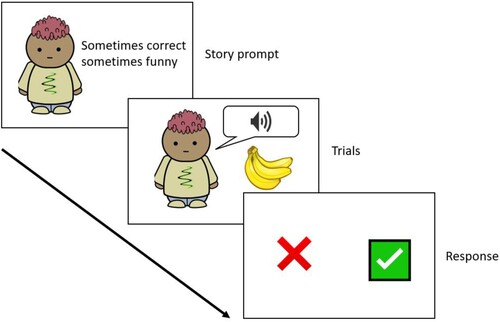
Before the data collection proper, the children undertook a brief practice session which had two pairs of word stimuli with mismatched POA specifications: toes–poes and bubble–dubble. The purpose of the practice session was to help the children familiarize themselves with the task setting, and these items also constituted a control condition of the experiment, as CAAE-speaking children were not expected to encounter substantial perceptual confusion for POA differences. Together, the task had 28 trials (four practice trials plus 24 critical trials, presented in a randomized order). The whole task took up to five minutes to complete. Breaks were offered every four to six trials, and the children were presented with a voice recording saying “You are doing well. Keep going!”, during the breaks.
4.1.3 Predictions and analysis
As the production data in Studies 1 and 2 indicate that both adult and child CAAE speakers exhibit a clear stop voicing contrast in CAAE, implemented through both VOT and CD, across all POAs, we expect child CAAE stop perception to be sensitive to deviations in VOT and CD. However, since the present task design does not include stimuli that present all combinations of VOT and CD values, the result cannot tease apart the relative contribution of these two acoustic cues.
Detection accuracy (%) in the perception task will indicate how often child CAAE speakers accept “canonical” CAAE pronunciations and reject mispronunciations. If voicing is phonemic in CAAE, we would expect child speakers to show above-chance detection accuracy for word pairs with mismatched voicing (and POA) specifications (cf. Bundgaard-Nielsen et al., Citation2023). And, if voicing is phonemic, we would expect children’s perceptual performance to be similar across all POA contexts and in both word-initial and word-medial positions.
4.2 Results
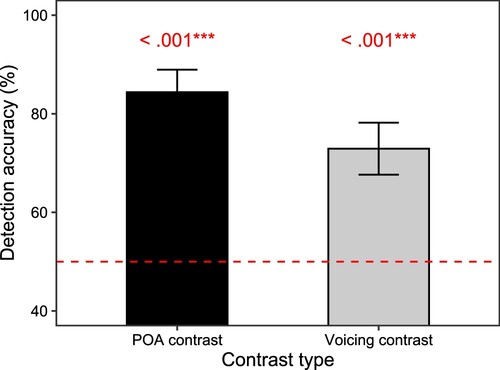
The averaged performance of eight child CAAE participants’ mispronunciation detection is summarized in for both POA and voicing contrasts. To model the responses, we fitted a Generalized Linear Mixed-effects Model (GLMM) using the following formula: response ∼ contrast type + (1 | participant), family = “binomial”. Based on the model, we then carried out contrast analysis based on estimated marginal means (EMMs) for testing whether the mean accuracy was higher than the 50% chance level (i.e. one-tailed z-tests, alternative hypothesis: Mean > 50%). The results showed that detection accuracy was significantly higher than 50% for POA contrasts, z = 3.303 and p = 0.0005, as well as for voicing contrasts, z = 3.736 and p = 0.0001. However, the mean accuracy for POA contrasts (M = 84.4, SD = 12.9) was also slightly higher than voicing contrasts (M = 72.9, SD = 14.9), suggesting a further difference between different contrast types. Due to the relatively small sample size (n = 8), we carried out a rank-based Friedman’s test (i.e. non-parametric one-way ANOVA with repeated measures), which confirmed an effect of contrast type, χ2 = 4.5, p = 0.0339. In other words, although voicing contrasts were detected above-chance, participants found them to be more challenging than POA-based contrasts (cf. Bundgaard-Nielsen et al., Citation2023).
Figure 8 Accuracy in CAAE-speaking children’s mispronunciation detection. Error bars indicate standard errors
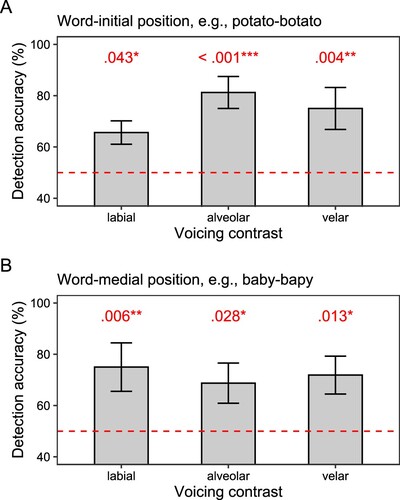
To further investigate the detection performance for voicing contrasts across different phonological contexts, we separated the data by word position and POA specifications. In word-initial position (, panel A), we analyzed the binary responses using another GLMM: response ∼ POA + (1 | participant), family = “binomial”, and accordingly we carried out one-sample z-tests (alternative hypothesis: Mean > 50%) to examine whether accuracy in each case was significantly above-chance. Indeed, the tests showed that the detection accuracy was higher than 50% for the labial contrast, z = 1.718, p = 0.0429, the alveolar contrast, z = 3.184, p = 0.0007, and the velar contrast, z = 2.650, p = 0.0040. To check the differences between POA contexts, we carried out a Friedman’s test, which showed a non-significant effect of articulation place, χ2 = 3.44, p = 0.179. Likewise, we analyzed the detection responses using another GLMM for the word-medial position (, panel B), and again the mean accuracy was significantly above-chance for the labial contrast, z = 2.509, p = 0.0061, the alveolar contrast, z = 1.915, p = 0.0277, and the velar contrast, z = 2.216, p = 0.0133. A Friedman’s test revealed a null effect of POA context, χ2 = 0.7, p = 0.705. Finally, for checking the potential difference in detection accuracy between the word-initial and word-medial contrasts, we carried out an additional Friedman’s test, which revealed a null effect of word position, χ2 = 0.2, p = 0.655. In summary, CAAE-speaking children’s detection accuracy was above-chance across all POAs and in different word positions, and the performance was comparable in different phonological contexts.
Figure 9 Accuracy in CAAE-speaking children’s mispronunciation detection for voicing contrasts by word position and place of articulation (POA). Error bars indicate standard errors
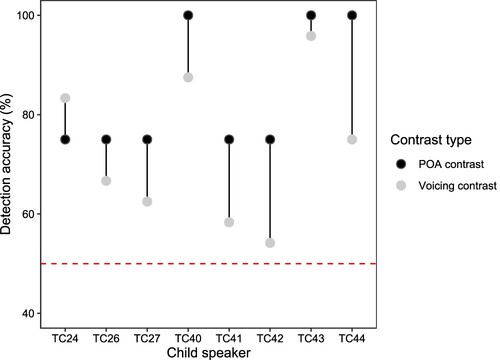
As with the production studies, we also present individual performance in the mispronunciation detection task (see ). The purpose was to check whether the individual patterns were consistent with the group-level observations. Indeed, all participants showed a pattern such that: (1) both POA and voicing contrasts were detected above-chance (i.e. accuracy > 50%); and (2) for almost all participants POA contrasts had higher accuracy compared to voicing contrasts. The only exception was participant TC24, who achieved similar accuracy levels in voicing contrasts (83.3%) compared to POA contrasts (75%). In general, the pattern was consistent in the majority of the participants.
Figure 10 Individual mispronunciation detection accuracy in CAAE children. Red dashed line indicates the 50% chance level
4.3 Discussion of Study 3
The results of the perception task demonstrate that young CAAE-speaking children perceive stop voicing distinctions in CAAE from an early age, although the results cannot separate the relative contribution of VOT and CD in the perception process. Nevertheless, this finding is consistent with the production results, although minor differences are observable between the perception and the production data. Particularly, it appears that POA does not have a significant impact on the children’s perception accuracy (), and this leads us to believe that the reported high variability in velar stops () is likely due to child speakers’ immature motor control.
It is also noteworthy that CAAE listeners seem to have a higher tolerance for mispronounced voice specifications than POA shifts. In the literature on mainstream English varieties, a stop voicing contrast has often been considered a classic example of categorical perception (Goldstone & Hendrickson, Citation2010; Kronrod et al., Citation2016), where listeners often show ceiling-level discrimination performance, and therefore speakers should show very low tolerance towards mismatched voicing specifications in lexical recognition. Although the mispronunciation detection task did not directly test child CAAE speakers’ discrimination of such contrasts (as compared to more rigorous paradigms, e.g. AX or ABX tasks, which require test-taking skills), our results suggest that the listeners showed a certain level of tolerance towards the voicing misplacement. Since we did not have perception data from adult CAAE speakers, it remains unclear whether the children’s tolerance reflects a less categorical perception in CAAE stop voicing in general. Alternatively, POA contrasts such as toes–poes were inherently more salient in perception, since the difference lies in the involvement of different sets of articulators (e.g. coronal vs labial), instead of the relative timing between the same set of articulators (e.g. how long an open glottis is maintained). Relatedly, some studies have similarly found that the perception sensitivity of Kriol listeners to stop voicing is slightly lower than their perception of different POAs (Bundgaard-Nielsen & Baker, Citation2016; Bundgaard-Nielsen et al., Citation2016, Citation2023). It is also interesting to note that emerging work on speech perception in bilingual populations suggests that bilingual hearers may be more likely to perceive stop voicing differences on a gradient scale (e.g. Kultu et al., Citation2022).
5. Conclusion
The present study analyzed the phonetic realizations of stop consonants by adult and child Aboriginal speakers of English in Central Australia (CAAE), with a focus on the acoustic features of Voice Onset Time (VOT) and Constriction Duration (CD) in voiced and voiceless stops. The paper presents the first cross-generational phonetic investigation of the production and perception of stop voicing in CAAE: Study 1 shows that adult CAAE speakers implement a short versus long-lag stop voicing distinction in the word-initial position, and a word-medial stop voicing distinction based on joint coding of VOT and CD, potentially modulated by lexical prosody; Study 2 shows that child CAAE speakers, just like their caregivers, implement a VOT-based voicing distinction word-initially, and a VOT-and-CD-based voicing distinction in word-medial positions; and finally, Study 3 shows that child CAAE speakers, from an early age, have stable lexical representations with clear implementation of contrastive voiced and voiceless stops. Taken together, the results provide compelling evidence for the existence of a phonemic stop voicing contrast, and no evidence of category merge of stops or related new homophony in this Aboriginal English variety (Butcher, Citation2008; Harkins, Citation1994; Sharpe, Citation1979).
The systematic CD differences between /b d ɡ/ and /p t k/ in CAAE word-medial position are consist with the pattern in Kriol (as well as in the mixed language Light Warlpiri), spoken further north. Kriol is assumed to be influenced by traditional languages to the north that implement a [fortis/lenis] contrast and contributed to its origin (Baker et al., Citation2014; Bundgaard-Nielsen & Baker, Citation2019; Bundgaard-Nielsen et al., Citation2016; Bundgaard-Nielsen et al., Citation2023). The origin of the clear CD contrast in CAAE is not as obvious, since a [fortis/lenis] contrast appears in only one traditional Aboriginal language spoken to the north of Central Australia, Warumungu (Simpson, Citation2017). At the same time, the CD differences in CAAE are also similar to those of word-final stops in MAE, according to recent research (Millasseau, Yuen, et al., Citation2021). However, since we do not have a comparable dataset from MAE, it remains unclear whether medial stops in MAE also show systematic CD differences between voiced and voiced stops, and whether these differences were also modulated by lexical prosodic features. Another limitation of the present study is that the spontaneous conversational speech (Study 1) could not control for sentence and utterance structures, and thus we could not account for prosodic influences from phrasal or higher-level prosodic parameters, and future research could try to replicate the current findings using a sentence reading task (e.g. Millasseau, Bruggeman, et al., Citation2021; Millasseau, Yuen, et al., Citation2021), although individual levels of literacy may introduce additional confounding effects in data interpretation. The child production data (Study 2) did not include a more controlled word list to present a balanced design of voicing, word position, prosodic prominence and grammatical category (e.g. nouns vs verbs) or lexical frequency, and thus further research is needed for teasing apart these influences using a variety of word stimuli. Finally, the perception experiment (Study 3) did not use a design to tease apart the relative contributions of VOT and CD in word recognition in CAAE, and therefore a future study is warranted to test participants using manipulated stimuli with different cue combinations, e.g. VOT-only, CD-only, VOT-plus-CD contrasts (e.g. Bundgaard-Nielsen & Baker, Citation2016). Additionally, the present study focused on the phonological contrast between voiceless and voiced stops in CAAE, but we did not analyze how these stops were articulatorily implemented or realized in adults and children, e.g. whether the stops are fricated, affricated, laryngealized or preaspirated (Ford, Citation2018), and whether the realizations in CAAE are similar to those in MAE (Clothier & Loakes, Citation2018; Loakes et al., Citation2018). Nevertheless, the limitations of the present study discussed above also open up new avenues for future research.
Since CD is not often reported as a reliable cue for medial stop voicing in mainstream English varieties (e.g. American English, Byrd, Citation1993), the question remains as to why CAAE implements this distinction. We cannot, of course, determine this based on the present studies: much of the data needed to answer this question are irretrievably lost in the past, and we do not know when the CD contrast entered CAAE, or whether it has always been a feature of CAAE (and its early L2 and/or pidgin predecessors).
We can, however, detail at least two potential paths to the system implemented in CAAE. Firstly, it is possible that the CD contrast in CAAE is borrowed from other contact varieties, such as Kriol, at some point. This explanation most likely would rely on travel to the Alice Springs area by speakers of Kriol from the NT, possibly as part of the expanding cattle industry, as well as travel by individuals from the areas around Alice Springs to regions of Australia where Kriol is spoken (see for instance discussions in Koch, Citation2000, Citation2011).
Alternatively, the present CD contrast in CAAE was a feature of the local pidgin or early L2-English forms carried through into the current variety independently of the development of a similar system of stop implementation in Kriol. We propose that this might be explained as the addition of a phonetically “short” (voiced) stop series to the phonetically “long” stop series (Bundgaard-Nielsen & O’Shannessy, Citation2021b; Butcher & Harrington, Citation2003; Tabain, Citation2016; Tabain & Butcher, Citation2015) in the languages spoken in the Alice Springs area. It is possible that the vehicle for this development could be speaker familiarity with processes of lenition of long stops in certain environments, such as that demonstrated for Gurindji (Ennever et al., Citation2017). It is also possible that CAAE reflects both pathways, and that features of Kriol and the characteristics of the traditional languages of the Central Australian area have jointly shaped the stop voicing system described in the present studies.
The data also offer a clear picture of how phonological transmission occurs in the current generations of L1 CAAE speakers, including both the caregivers (born in the 1980s and 1990s) and the children (mostly born after the 2010s). The high consistency between the two generations in terms of stop voicing production indicates a stabilized stop voicing contrast in CAAE spoken as an L1. The study provides a piece of evidence indicating that there may be a cohesive variety of CAAE spoken in Central Australia, at least in terms of phonology, as suggested by Harkins (Citation1994). Nevertheless, the individual differences in the speech production patterns in the current studies suggest the need for future research into the CAAE production of multilingual adults, as well as the developmental trajectory or time course of stop production and perception in CAAE-speaking children.
Finally, this study has implications for education, language assessment and cross-cultural communication contexts in three main ways. The first is that the stop voicing contrast described here may be a stable feature of L1 CAAE phonology. Second, CAAE-speaking children show a stop voicing contrast in their L1 English variety, as expected given that the adult cohort has the same type of contrast, and the children are successful learners of the variety they hear spoken in their families. But third, since the implementation of the contrast might differ from other English varieties, educators might have difficulty perceiving the contrast in every instance (cf. Harkins, Citation2000). In sum, this study has analyzed stop production and perception by adult and child Aboriginal speakers of English in Central Australia (CAAE) and finds that there is a stable stop voicing contrast across two generations of speakers.
Acknowledgements
We thank the participants in the study, Tangentyere Council Town Camps Community Centres, Central Australian Aboriginal Congress Ampe Rlterrke Amangkeme (Early Childhood Health and Development Centre), Apmere Urlte Transitional Housing Program, Dominica Roebuck, Charles Darwin University; and for comments on the manuscript, Harold Koch.
Disclosure statement
No potential conflict of interest was reported by the authors.
Data availability statement
The recordings that support the findings of this study will be submitted to the Australian Institute for Aboriginal and Torres Strait Islander Studies, Canberra, https://aiatsis.gov.au/. The statistical analysis data that support the findings of this study are available from the ANU Data Commons https://datacommons.anu.edu.au/DataCommons/rest/display/anudc:6306?layout=def:display.
Additional information
Funding
Notes on contributors
Yizhou Wang
Yizhou Wang is a teaching associate in Linguistics and Applied Linguistics at the University of Melbourne. His research areas include phonetics and phonology, speech production and perception, applied linguistics, and languages in Australia.
Carmel O’Shannessy
Carmel O’Shannessy is an Associate Professor in the School of Literature, Languages and Linguistics at the Australian National University. Her research is in language contact and acquisition, including the emergence of Light Warlpiri, a new Australian mixed language, and children’s development of Light Warlpiri and Warlpiri. Her ARC Future Fellowship project explores aspects of Indigenous children’s language development in Central Australia. She has been involved with languages and education in remote Indigenous communities in Australia since 1996, in the areas of bilingual education and research.
Vanessa Davis
Vanessa Davis is a Senior Aboriginal Researcher at the Tangentyere Research Hub in Mparntwe, Alice Springs. She has more than two decades’ experience in social research work, evaluation and data input and analysis. Vanessa has the linguistic and cultural knowledge to conduct respectful, community-identified and community-partnered research, which she undertakes across research topics spanning language acquisition, wellbeing, housing and energy.
Rikke Bundgaard-Nielsen
Rikke Bundgaard-Nielsen is a Senior Lecturer in the School of Languages and Linguistics at the University of Melbourne and an Adjunct Research Fellow at MARCS Institute for Brain, Behaviour and Development at Western Sydney University. Her research areas include the acquisition of first and second language phonology, the role of vocabulary acquisition in phonological development, and first and second language speech perception and processing, with a particular focus on Australian Indigenous languages.
Joshua Roberts
Joshua Roberts holds an MA in Linguistics from Memorial University of Newfoundland, and worked on a potential covert contrast in child acquisition of English rhotics. He was involved in the Little Kids Learning Languages project, and is currently working outside of academia.
Denise Foster
Denise Foster is a Senior Aboriginal Researcher at the Tangentyere Research Hub in Mparntwe, Alice Springs. She has extensive experience in social research work, evaluation and data input and analysis, and conducts respectful, community-identified and community-partnered research.
Notes
1 Australian Bureau of Statistics, available at: https://www.abs.gov.au/census/find-census-data/quickstats/2021/LGA70200.
2 Australian Research Council Future Fellowship project #FT190100243, awarded to Carmel O’Shannessy; see https://little-kids-learning-languages.net/.
References
- Abramson, A. S., & Whalen, D. H. (2017). Voice Onset Time (VOT) at 50: Theoretical and practical issues in measuring voicing distinctions. Journal of Phonetics, 63, 75–86. https://doi.org/10.1016/j.wocn.2017.05.002
- ABS. (2021). Language statistics for Aboriginal and Torres Strait Islander peoples. https://www.abs.gov.au/statistics/people/aboriginal-and-torres-strait-islander-peoples/language-statistics-aboriginal-and-torres-strait-islander-peoples/latest-release.
- Antoniou, M., Best, C. T., Tyler, M. D., & Kroos, C. H. (2010). Language context elicits native-like stop voicing in early bilinguals’ productions in both L1 and L2. Journal of Phonetics, 38(4), 640–653. https://doi.org/10.1016/j.wocn.2010.09.005
- Baker, B. J. (2008). Word structure in Ngalakgan. Center for the Study of Language and Information.
- Baker, B. J., Bundgaard-Nielsen, R. L., & Graetzer, S. (2014). The obstruent inventory of Roper Kriol. Australian Journal of Linguistics, 34(3), 307–344. https://doi.org/10.1080/07268602.2014.898222
- Best, C. T. (1995). A direct realist view of cross-language speech perception. In W. Strange (Ed.), Speech perception and linguistic experience: Issues in cross-language research (pp. 171–204). York Press.
- Boersma, P., & Weenink, D. (2023). Praat, a system for doing phonetics by computer [Computer program]. Version 6.3. https://www.praat.org.
- Bowern, C., & Koch, H. (2004). Introduction: Subgrouping and methodology in historical linguistics. In C. Bowern, & H. Koch (Eds.), Australian languages: Classification and the comparative method (pp. 1–16). John Benjamins Publishing.
- Bundgaard-Nielsen, R. L., & Baker, B. J. (2016). Fact or furphy? The continuum in Kriol. In F. Meakins, & C. O’Shannessy (Eds.), Loss and renewal: Australian languages since colonisation (pp. 177–216). De Gruyter.
- Bundgaard-Nielsen, R. L., & Baker, B. J. (2019). Paa, paa, plack sheep: Nonnative VOT perception in the absence of native VOT experience. In A. M. Nyvad, M. Hejná, A. Højen, A. Bothe Jespersen, & M. Hjortshøj Sørensen (Eds.), A sound approach to language matters (pp. 41–63). Department of English, School of communication and culture, Aarhus University.
- Bundgaard-Nielsen, R. L., Baker, B. J., & Bell, E. A. (2016). Child Kriol has stop distinctions based on VOT and constriction duration. In C. Christopher, & M. D. Tyler (Eds.), Proceedings Of the sixteenth Australasian international conference On speech science and technology (pp. 269–272). https://assta.org/sst-2016-proceedings/.
- Bundgaard-Nielsen, R. L., Baker, B. J., Bell, E. A., & Wang, Y. (2023). Stop contrast acquisition in child Kriol: Evidence from stable transmission of phonology post Creole formation. Journal of Child Language, online, 1–37. https://doi.org/10.1017/S0305000923000430
- Bundgaard-Nielsen, R. L., & O’Shannessy, C. (2021a). Voice onset time and constriction duration in Warlpiri stops (Australia). Phonetica, 78(2), 113–140. https://doi.org/10.1515/phon-2021-2001
- Bundgaard-Nielsen, R. L., & O’Shannessy, C. (2021b). When more is more: The mixed language Light Warlpiri amalgamates source language phonologies to form a near-maximal inventory. Journal of Phonetics, 85, 101037. https://doi.org/10.1016/j.wocn.2021.101037
- Butcher, A. (2008). Linguistic aspects of Australian Aboriginal English. Clinical Linguistics and Phonetics, 22(8), 625–642. https://doi.org/10.1080/02699200802223535
- Butcher, A., & Harrington, J. (2003). An acoustic and articulatory analysis of focus and the word/morpheme boundary distinction in warlpiri. In Proceedings of the 6th international seminar on speech production. Macquarie Centre for Cognitive Science.
- Byrd, D. (1993). 54,000 American stops. UCLA Working Papers in Phonetics, 83, 97–116.
- Cho, T., & Ladefoged, P. (1999). Variation and universals in VOT: Evidence from 18 languages. Journal of Phonetics, 27(2), 207–229. https://doi.org/10.1006/jpho.1999.0094
- Cho, T., Whalen, D. H., & Docherty, G. (2019). Voice onset time and beyond: Exploring laryngeal contrast in 19 languages. Journal of Phonetics, 72, 52–65. https://doi.org/10.1016/j.wocn.2018.11.002
- Clothier, J., & Loakes, D. (2018). Coronal stop VOT in Australian English: Lebanese Australians and mainstream Australian English. In J. Epps, J. Wolfe, J. Smith, & C. Jones (Eds.), Proceedings of the 17th Australasian international conference on speech science and technology (pp. 13–16). Australasian Speech Science and Technology Australia (ASSTA).
- Disbray, S. (2008). More than one way to catch a frog: A study of children’s discourse in an Australian contact language [Unpublished PhD thesis]. School of Languages and Linguistics, the University of Melbourne.
- Eades, D. (1982). You Gotta know how to talk … : information seeking in south-east Queensland Aboriginal society. Australian Journal of Linguistics, 2(1), 61–82. https://doi.org/10.1080/07268608208599282
- Edwards, J., & Beckman, M. E. (2008). Methodological questions in studying consonant acquisition. Clinical Linguistics and Phonetics, 22(12), 937–956. https://doi.org/10.1080/02699200802330223
- Ennever, T., Meakins, F., & Round, E. R. (2017). A replicable acoustic measure of lenition and the nature of variability in Gurindji stops. Laboratory Phonology, 8(1), 20. https://doi.org/10.5334/labphon.18
- Fletcher, J., & Butcher, A. (2014). Sound patterns of Australian languages. In H. Koch, & R. Nordlinger (Eds.), The languages and linguistics of Australia: A comprehensive guide (pp. 91–138). De Gruyter.
- Ford, C. E. (2018). Acquisition of gender-specific sociophonetic cues in the speech of primary school-aged children [Unpublished doctoral thesis]. La Trobe University, Australia.
- Goldstone, R. L., & Hendrickson, A. T. (2010). Categorical perception. Wiley Interdisciplinary Reviews: Cognitive Science, 1(1), 69–78. https://doi.org/10.1002/wcs.26
- Gordeeva, O. B., & Scobbie, J. M. (2013). A phonetically versatile contrast: Pulmonic and glottalic voicelessness in Scottish English obstruents and voice quality. Journal of the International Phonetic Association, 43(3), 249–271. https://doi.org/10.1017/S0025100313000200
- Harkins, J. (1994). Bridging two worlds: Aboriginal English and crosscultural understanding. University of Queensland Press.
- Harkins, J. (2000). Structure and meaning in Australian Aboriginal English. Asian Englishes, 3(2), 60–81. https://doi.org/10.1080/13488678.2000.10801055
- Hudson, J. (1981). Grammatical and semantic aspects of Fitzroy Valley Kriol. The Australian National University.
- Huggins, A. W. F. (1968). The perception of timing in natural speech I: Compensation within the syllable. Language and Speech, 11(1), 1–63. https://doi.org/10.1177/002383096801100101
- Jones, C., & Meakins, F. (2013). Variation in voice onset time in stops in Gurindji Kriol: Picture naming and conversational speech. Australian Journal of Linguistic, 33(2), 196–220. https://doi.org/10.1080/07268602.2013.814525
- Kessinger, R. H., & Blumstein, S. E. (1997). Effects of speaking rate on voice-onset time in Thai. French, and English. Journal of Phonetics, 25(2), 143–168. https://doi.org/10.1006/jpho.1996.0039
- Kessinger, R. H., & Blumstein, S. E. (1998). Effects of speaking rate on voice-onset time and vowel production: Some implications for perception studies. Journal of Phonetics, 26(2), 117–128. https://doi.org/10.1006/jpho.1997.0069
- Klatt, D. H., & Cooper, W. E. (1975). Perception of segment duration in sentence contexts. In Structure and process in speech perception: Proceedings of the symposium on dynamic aspects of speech perception (pp. 69–89). Springer-Verlag.
- Koch, H. (1985). Non-standard English in an Aboriginal land claim. In J. B. Pride (Ed.), Cross-cultural encounters: Communication and mis-communication (pp. 176–95). River Seine Publications.
- Koch, H. (1997). Comparative linguistics and Australian prehistory. In P. McConvell, & N. Evans (Eds.), Archaeology and linguistics: Aboriginal Australia in global perspective (pp. 27–43). Oxford University Press.
- Koch, H. (2000). Central Australian Aboriginal English: In comparison with the morphosyntactic categories of Kaytetye. Aisan Englishes, 3(2), 32–58. https://doi.org/10.1080/13488678.2000.10801054
- Koch, H. (2004). The Arandic subgroup of Australian languages. In C. Bowern, & H. Koch (Eds.), Australian languages: Classification and the comparative method (pp. 127–150). John Benjamins Publishing Company.
- Koch, H. (2011). The influence of Arandic languages on Central Australian Aboriginal English. In C. Lefebvre (Ed.), Creoles, their substrates, and language typology (pp. 437–460). John Benjamins Publishing Company.
- Kronrod, Y., Coppess, E., & Feldman, N. H. (2016). A unified account of categorical effects in phonetic perception. Psychonomic Bulletin and Review, 23(6), 1681–1712. https://doi.org/10.3758/s13423-016-1049-y
- Kuhl, P. K., Conboy, B. T., Coffey-Corina, S., Padden, D., Rivera-Gaxiola, M., & Nelson, T. (2007). Phonetic learning as a pathway to language: New data and native language magnet theory expanded (NLM-e). Philosophical Transactions of the Royal Society B: Biological Sciences, 363(1493), 979–1000. https://doi.org/10.1098/rstb.2007.2154
- Kultu, E., Tiv, M., & Wulff, S. (2022). Does race impact speech perception? An account of accented speech in two different multilingual locales. Cognitive Research: Principles and Implications, 7. https://doi.org/10.1186/s41235-022-00354-0
- Lisker, L. (1957). Closure duration and the intervocalic voiced–voiceless distinction in English. In A. Cohen, & S. G. Nooteboom (Eds.), Language (Vol. 33, Issue 1, pp. 42–49). https://doi.org/10.2307/410949
- Lisker, L., & Abramson, A. S. (1967). Some effects of context on voice onset time in English stops. Language and Speech, 10(1), 1–28. https://doi.org/10.1177/002383096701000101
- Loakes, D., McDougall, K., Clothier, J., Hajek, J., & Fletcher, J. (2018). Sociophonetic variability of post-vocalic /t/ in Aboriginal and mainstream Australian English. In Proceedings of the 17th Australasian international conference on speech science and technology (pp. 5–8.
- Loakes, D., McDougall, K., & Gregory, A. (2022). Variation in /t/ in Aboriginal and mainstream Australian englishes. In R. Billington (Ed.), Proceedings of the eighteenth Australasian international conference on speech science and technology (pp. 61–65). Australasian Speech Science and Technology Association.
- Mailhammer, R., Sheerwood, S., & Stoakes, H. (2020). The inconspicuous substratum: Indigenous Australian languages and the phonetics of stop contrasts in English on Croker Island. English World-Wide, 41(2), 162–192. https://doi.org/10.1075/eww.00045.mai
- Malcolm, I. G. (2001). Aboriginal English: Adopted code of a surviving culture. In D. Blair, & P. Collins (Eds.), English in Australia (pp. 201–222). John Benjamins Publishing.
- Malcolm, I. G. (2008). Australian creoles and Aboriginal English: Phonetics and phonology. In K. Burridge, & K. Bernd (Eds.), Varieties of English 3: The pacific and Australasia (pp. 124–141). Mouton de Gruyter.
- Malcolm, I. G. (2018). Australian Aboriginal English: Change and continuity in an adopted language. De Gruyter.
- McCarthy, O., & Stuart-Smith, J. (2013). Ejectives in Scottish English: A social perspective. Journal of the International Phonetic Association, 43(3), 273–298. https://doi.org/10.1017/S0025100313000212
- McConvell, P., & Bowern, C. (2011). The prehistory and internal relationships of Australian languages. Language and Linguistics Compass, 5(1), 19–32. https://doi.org/10.1111/j.1749-818X.2010.00257.x
- McConvell, P., & Meakins, F. (2005). Gurindji Kriol: A mixed language emerges from code-switching. Australian Journal of Linguistics, 25(1), 9–30. https://doi.org/10.1080/07268600500110456
- McLeod, S., & Crowe, K. (2018). Children’s consonant acquisition in 27 languages: A cross-linguistic review. American Journal of Speech-Language Pathology, 27(4), 1546–1571. https://doi.org/10.1044/2018_AJSLP-17-0100
- Millasseau, J., Bruggeman, L., Yuen, I., & Demuth, K. (2019). Durational cues to place and voicing contrasts in Australian English word-initial stops. In Proceedings of the 19th international conference of phonetic sciences (pp. 3759–3762).
- Millasseau, J., Bruggeman, L., Yuen, I., & Demuth, K. (2021). Temporal cues to onset voicing contrast in Australian English-speaking children. The Journal of Acoustic Society of America, 149(1), 348–356. https://doi.org/10.1121/10.0003060
- Millasseau, J., Yuen, I., Bruggeman, L., & Demuth, K. (2021). Acoustic cues to coda stop voicing contrast in Australian English-speaking children. Journal of Child Language, 48(6), 1262–1280. https://doi.org/10.1017/S0305000920000781
- Nearey, T. M., & Rochet, B. L. (1994). Effects of place of articulation and vowel context on VOT production and perception for French and English stops. Journal of the International Phonetic Association, 24(1), 1–18. https://doi.org/10.1017/S0025100300004965
- Ober, R., & Bell, J. (2012). English language as juggernaut – Aboriginal English and indigenous languages in Australia. In V. Rapatahana, & P. Bunce (Eds.), English language as hydra: Its impact on non-English language cultures (pp. 60–75). Multilingual Matters.
- O’Shannessy, C. (2004). The monster stories: A set of picture books to elicit overt transitive subjects in oral texts [Unpublished ms]. Max Planck Institute for Psycholinguistics.
- O’Shannessy, C. (2005). Light Warlpiri: A new language. Australian Journal of Linguistics, 25(1), 31–57. https://doi.org/10.1080/07268600500110472
- Penney, J., Cox, F., Miles, K., & Palethorpe, S. (2018). Glottalisation as a cue to coda consonant voicing in Australian English. Journal of Phonetics, 66, 161–184. https://doi.org/10.1016/j.wocn.2017.10.001
- Penney, J., Cox, F., & Szakay, A. (2021). Effects of glottalisation, preceding vowel duration, and coda closure duration on the perception of coda stop voicing. Phonetica, 78(1), 29–63. https://doi.org/10.1159/000508752
- Pentland, C. (2004). Stress in Warlpiri: Stress domains and word-level prosody [Unpublished master's thesis]. University of Queensland.
- Sandefur, J. R. (1979). An Australian creole in the Northern Territory: A description of Ngukurr-Bamyili dialects. In G. L. Huttar (Ed.), Working papers of SIL – AAB. Series B 3 (pp. 185). Summer Institute of Linguistics.
- Schnukal, A. (1985). The spread of Torres Strait creole to the central islands of Torres Strait. Aboriginal History, 9(1/2), 220–234.
- Sharpe, M. (1979). Alice Springs Aboriginal children’s English. In S. A. Wurm (Ed.), Australian linguistic studies (pp. 733–748). Pacific Linguistics, The Australian National University. https://doi.org/10.15144/PL-C54.733
- Simpson, A. (2014). Ejectives in English and German: Linguistic, sociophonetic, interactional, epiphenomenal? In C. Celata, & S. Calamai (Eds.), Advances in sociophonetics (pp. 189–204). John Benjamins Publishing Company.
- Simpson, J. (2017). Warumungu (Australian – Pama-Nyungan). In A. Spencer, & A. M. Zwicky (Eds.), The handbook of morphology (pp. 707–736). Wiley-Blackwell. https://doi.org/10.1002/9781405166348.ch32.
- Tabain, M. (2016). Aspects of Arrernte prosody. Journal of Phonetics, 59, 1–22. https://doi.org/10.1016/j.wocn.2016.08.005
- Tabain, M., & Butcher, A. (2015). Lexical stress and stop bursts in Pitjantjatjara: Feature enhancement of neutralized apicals and the coronal/velar contrast. Journal of Phonetics, 50, 67–80. https://doi.org/10.1016/j.wocn.2015.02.004