
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We propose a novel observation-driven finite mixture model for the study of banking data. The model accommodates time-varying component means and covariance matrices, normal and Student’s t distributed mixtures, and economic determinants of time-varying parameters. Monte Carlo experiments suggest that units of interest can be classified reliably into distinct components in a variety of settings. In an empirical study of 208 European banks between 2008Q1–2015Q4, we identify six business model components and discuss how their properties evolve over time. Changes in the yield curve predict changes in average business model characteristics.
1. INTRODUCTION
Banks are highly heterogeneous, differing widely in terms of size, complexity, organization, activities, funding choices, and geographical reach. Understanding this diversity is of key importance, for example, for the study of risks acting upon and originating from the financial sector, for impact assessments of unconventional monetary policies and financial regulations, as well as for the benchmarking of banks to appropriate peer groups for supervisory purposes.Footnote1 While there is broad agreement that financial institutions suffer in an environment of extremely low interest rates, see, for example, Nouy (Citation2016), it is less clear which types of banks (business models) are affected the most. A study of banks’ business models at low interest rates provides insight into the overall diversity of business models, the strategies adopted by individual institutions, and which types of banks are impacted the most by time variation in the yield curve.Footnote2 We study these questions in a novel modeling framework.
This article proposes an observation-driven finite mixture model for the analysis of high-dimensional banking data. The framework accommodates time-varying mean and covariance parameters and allows us to robustly cluster banks into approximately homogeneous groups. We first present a simple baseline mixture model for normally distributed data with time-varying component means, and subsequently consider extensions to time-varying covariance matrices, Student’s t distributed mixture densities, and economic predictors of time-varying parameters. We apply our modeling framework to a multivariate panel of N = 208 European banks between 2008Q1–2015Q4, that is, over T = 32 quarters, considering D = 13 bank-level indicator variables for J groups of similar banks. We thus track banking sector data through the 2008–2009 global financial crisis, the 2010–2012 euro area sovereign debt crisis, as well as the relatively calmer but persistent low-interest rate environment of the post-crises period between 2013–2015. We identify J = 6 business model components and discuss how these adjust to changes in the yield curve.
In our finite mixture model, all time-varying parameters are driven by the score of the local (time t) objective function using the so-called generalized autoregressive score (GAS) approach developed by Creal, Koopman, and Lucas (Citation2013); see also Harvey (Citation2013). In this setting, the time-varying parameters are perfectly predictable one-step ahead. This feature makes the model observation-driven in the terminology of Cox (Citation1981). The likelihood is known in the closed form through a standard prediction error decomposition, facilitating parameter estimation via likelihood-based expectation-maximization (EM) procedures. Our approach extends the standard score-driven approach of Creal, Koopman, and Lucas (Citation2013) by using the scores of the EM-based criterion function rather than that of the usual predictive likelihood function.
Extensive Monte Carlo experiments suggest that our model is able to reliably classify units of interest into distinct mixture components, as well as to simultaneously infer the relevant component-specific time-varying parameters. In our simulations, the cluster classification is perfect for sufficiently large distances between the time-varying cluster means and sufficiently informative signals relative to the variance of the noise terms.Footnote3 This holds under correct model specification as well as under specific forms of model mis-specification. As the simulated data become less informative or the time-varying cluster means are closer together, the share of correct classifications decreases, but generally remains high. Estimation fit and the share of correct classifications decrease further if we incorrectly assume a thin-tailed mixture specification when the data are generated by a fat-tailed mixture distribution. As a result, robust models based on fat-tailed mixtures are appropriate for the fat-tailed bank accounting ratios in our empirical sample.
We apply our model to classify European banks into distinct business model components. We distinguish (A) large universal banks, including globally systemically important banks (G-SIBs), (B) international diversified lenders, (C) fee-based banks, (D) domestic diversified lenders, (E) domestic retail lenders, and F) small international banks. The similarities and differences between these components are discussed in detail in the main text. Based on our component mean estimates and business model classification, we find that the global financial crisis between 2008–2009 affected banks with different business models differently. This is in line with findings by Altunbas, Manganelli, and Marques-Ibanez (Citation2011) and Chiorazzo et al. (Citation2016), who study U.S.-based institutions.
In addition, we study how banks’ business models adapt to changes in yield curve factors, specifically level and slope of the yield curve. The yield curve factors are extracted from AAA-rated euro area sovereign bonds based on a Svensson (Citation1995) model. We find that, as long-term interest rates decrease, banks on average (across all business models) grow larger, hold more assets in trading portfolios to offset declines in loan demand, hold more sizeable derivative books, and, in some cases, increase leverage and decrease funding through customer deposits. Each of these effects—increased size, leverage, complexity, and a less stable funding base—are intuitive, but also potentially problematic from a financial stability perspective. This corroborates the unease expressed by Yellen (Citation2014) and Draghi (Citation2016).
From a methodological point of view, our article also contributes to the literature on clustering of time series data. This literature can be divided into four strands. Static clustering of time series refers to a setting with fixed cluster classification, that is, each time series is allocated to one cluster over the entire sample period. Dynamic clustering, by contrast, allows for changes in the cluster assignments over time. Each approach can be further split into whether the cluster-specific parameters are constant (static) or time-varying (dynamic).
Wang et al. (Citation2013) is an example of static clustering with static parameters. They clustered time series into different groups of autoregressive processes, where the autoregressive parameters are constant within each cluster and cluster assignments are fixed over time.
Fruehwirth-Schnatter and Kaufmann (Citation2008) used static clustering with elements of both static and dynamic parameters. First, they clustered time series into different groups of regression models with static parameters. Later, they generalized this to static clustering into groups of different hidden Markov models (HMMs), each switching between two regression models. The HMM can be regarded as a specific form of dynamic parameters for the underlying regression model. Their method was used by Hamilton and Owyang (Citation2012) to differentiate between business cycle dynamics among groups of U.S. states. Also, Smyth (Citation1996) clustered time series into groups characterized by different hidden Markov models.
Creal, Gramacy, and Tsay (Citation2014b) is an example of dynamic clustering with static parameters. They developed a model for credit ratings based on market data. Their main objective was to classify firms into different rating categories over time. They therefore allowed for transitions across clusters (dynamic clustering), while the parameters in their underlying mixture model are kept constant.
Finally, Catania (Citation2016) is an example of dynamic clustering with dynamic parameters. He proposed a score-driven dynamic mixture model, which relies on score-driven updates of almost all parameters, allowing for time-varying parameters and changing cluster assignments and time-varying cluster assignment probabilities. Due to the high flexibility of the model, a large number of observations is required over time. The application in Catania (Citation2016) to conditional asset return distributions typically has a sufficiently large number of observations.
Our approach falls in the category of static clustering methods with dynamic parameters. We use static clustering as banks do not tend to switch their business model frequently over short periods of time; see, for example, Ayadi and de Groen (Citation2015). Also, in contrast to the application used by for instance Catania (Citation2016), our banking data are observed over only a moderate number of time points T, while the number of units N and the number of firm characteristics D are high. Given static clustering, the properties of bank business models are unlikely to be constant throughout the periods of market turbulence and shifts in bank regulations experienced in our sample. We therefore require the cluster components to be characterized by dynamic parameters using the score-driven framework of Creal, Koopman, and Lucas (Citation2013).
Our article also contributes to the literature on identifying bank business models. Roengpitya, Tarashev, and Tsatsaronis (Citation2014), Ayadi, Arbak, and de Groen (Citation2011), and Ayadi and de Groen (Citation2015) also used cluster analysis to identify bank business models. Conditional on the identified clusters, the authors discussed bank profitability trends over time, study banking sector risks and their mitigation, and consider changes in banks’ business models in response to new regulation. Our statistical approach is different in that our components are not identified based on single (static) cross-sections of year-end data. Instead, we consider a panel framework, which allows us to pool information over time, leading to a more accurate assessment.
We proceed as follows. Section 2 presents a static and baseline dynamic finite mixture model. We then propose extensions to incorporate time-varying covariance matrices, as well as Student’s t distributed mixture distributions, and introduce model diagnostics. Section 3 discusses the outcomes of a variety of Monte Carlo simulation experiments. Section 4 applies the model to classify European financial institutions. Section 5 studies to which extent banks’ business models adapt to an environment of exceptionally low interest rates. Section 6 concludes. A Web appendix provides further technical and empirical results.
2. STATISTICAL MODEL
2.1 Mixture Model
We consider multivariate panel data consisting of vectors of firm characteristics for firms i = 1, …, N and times t = 1, …, T, where D denotes the number of observed characteristics. We model
by a J-component mixture model of the form
(1)
(1) where μj, t and Ωj, t are the mean and covariance matrix of mixture component j = 1, …, J at time t, respectively, ei, t, j is a zero-mean, D-dimensional vector of disturbances with identity covariance matrix, and zi, j are unobserved indicators for the mixture component of firm i. In particular, if firm i is in mixture component j then zi, j = 1, while zi, k = 0 for
. The posterior expectations of zi, j given the data can be used to classify firms into specific mixture components later on. We define
and assume
has a multinomial distribution with
and π1 + ⋅⋅⋅ + πJ = 1. Finally, we assume that
and ei, t, j are mutually, cross-sectionally, and serially uncorrelated. The model could be further enhanced with an error components structure for ei, t, j if for instance cross-sectional correlation is an issue. We leave such extensions for future research.
We specify the precise dynamic functional form of μj, t and Ωj, t later in this section using the score-driven dynamics of Creal, Koopman, and Lucas (Citation2013). For the moment, it suffices to note that μj, t and Ωj, t will both be functions of past data only, and therefore predetermined. Finite mixture models with static cluster-specific parameters have been widely used in the literature. For textbook treatments, see, for example, McLachlan and Peel (Citation2000) and Fruehwirth-Schnatter (Citation2006).
To write down the likelihood of the mixture model in (Equation1(1)
(1) ), we stack the observations up to time t,
, into the matrix
. We also stack the parameters characterizing each mixture component j, such as the μj, t’s and Ωj, t’s for all times t, and any remaining parameters characterizing the distribution of ei, t, j (such as the degrees of freedom of a Student’s t), into a parameter vector
, where
gathers all static parameters of the model. Note that also the multinomial probabilities πj are functions of
, that is,
. However, if no confusion is caused we use the short-hand notation πj and
for
and
, respectively. The likelihood function is given by a standard prediction error decomposition as
(2)
(2) where
and
is the conditional distribution of
given the past data and given the (predetermined) parameters for time t as gathered in
.
Before proceeding, we note that the mixture model in (Equation1(1)
(1) ) describes the firm characteristics using time-invariant cluster indicators
rather than time-varying indicators zi, t. Our choice follows from the specific application in Section 4. Banks are unlikely to switch their business model over limited time spans such as ours. For instance, a large universal bank is unlikely to become a small retail lender from one year to the next, as strategy choices, distribution channels, brand building, and clientele formation are all slowly varying economic processes. This is why we opt for static cluster indicators. In a different empirical context, a different modeling choice might be called for. For example, Creal, Gramacy, and Tsay (Citation2014b) considered corporate credit ratings, which are much more likely to change over shorter periods of time, such that some of their specifications use time-varying cluster assignments. To explicitly check whether the assumption of fixed cluster assignments is supported by our data, we use the diagnostics developed in Section 2.5. Our findings indicate that the vast majority of banks indeed only belongs to one cluster for all time points.
Given our choice for static rather than dynamic cluster allocation, it becomes important to allow for time-variation in the cluster means μj, t (and possibly in the variances Ωj, t). Even though banks are less likely to switch their business model, the average characteristics of business models may change over shorter time spans, particularly if such time spans include stressful periods as is the case in our sample. This allows us to answer questions relating to how the properties of business models changed, and in particular whether some business models (and if so, which) increased their risk characteristics during the low interest rate period we study in Section 4. Such results are also important for policy makers, such as the single supervisory mechanism in Europe to decide on the riskiness of banks and on adequate capital and liquidity levels for peer groups of banks.
2.2 EM Estimation
As is common in the literature on mixture models, we do not estimate directly by numerically maximizing the log-likelihood function in (Equation2
(2)
(2) ). Instead we use the expectation maximization (EM) algorithm to estimate the parameters; see Dempster, Laird, and Rubin (Citation1977) and McLachlan and Peel (Citation2000).Footnote4 To write down the EM algorithm and formulate the score-driven parameter dynamics for μj, t and Ωj, t later on, we define the complete data for firm i as the pair
. If
is known, the corresponding complete data likelihood function is given by
(3)
(3) Because
is unobserved, however, (Equation3
(3)
(3) ) cannot be maximized directly. Following Dempster, Laird, and Rubin (Citation1977), we instead maximize its conditional expectation over
given the observed data
and some initial or previously determined parameter value
, that is, we maximize with respect to
the function
(4)
(4) The conditionally expected likelihood (Equation4
(4)
(4) ) can be optimized iteratively by alternately updating the conditional expectation of the component indicators
(E-Step) and subsequently maximizing the remaining part of the function with respect to
(M-Step).
In the E-Step, the conditional component indicator probabilities are updated using
(5)
(5) We again point out that the τ(k)i, js do not depend on time, as banks in our application in Section 4 are statically assigned to clusters. An alternative would be to use dynamic cluster assignments as in Catania (Citation2016), in which case the densities
above would have to be replaced by their time t counterparts
and would result in time-specific posterior probabilities τ(k)i, j, t; see also the diagnostic statistics introduced in Section 2.5.
Once the τ(k)i, js are updated, we move to the M-Step. Maximizing with respect to πj under the constraint π1 + ⋅⋅⋅ + πJ = 1, we obtain
(6)
(6) The optimization of
with respect to the remaining parameters in
can sometimes be done analytically, for instance in the case of the normal finite mixture model with static location μj, t ≡ μj and scale Ωj, t ≡ Ωj. Otherwise, numerical maximization methods need to be used. The E-step and M-step are iterated until the difference
has converged. The EM algorithm increases the likelihood on each step, and convergence typically occurs within 15 iterations in our application. After convergence, when
has been estimated, we can use the final τ(k)i, j to assign banks to clusters. We do so by assigning bank i to cluster j which has the highest τ(k)i, j across j. Note that due to the EM perspective of the score steps, filtering
for a panel of firms is not a straightforward recursion from time t = 1, …, T as in the standard setting for score-driven models. In particular, for given τ(k)i, j, we can compute μj, t, and the other way around. Given that both quantities need to be estimated, however, the filtering problem for μj, t requires the simultaneous solution of τi, j. We solve this problem via the additional alternation of E-steps and M-steps in the EM algorithm.
2.3 Normal Mixture With Time-Varying Means
As explained in Section 2.1, it is important to allow for time-varying cluster means. We first do so for the case of a normal mixture with time varying means and constant covariance matrices. We set , where φ( · ; μ, Ω) denotes a multivariate normal density function with mean μ and variance Ω. In this section, we introduce a version of the score-driven approach of Creal, Koopman, and Lucas (Citation2013) to the parameter dynamics of μj, t; compare also Harvey (Citation2013) and Creal et al. (Citation2014a). Rather than using the score of the log-density as in Creal, Koopman, and Lucas (Citation2013), however, we use the score of the EM criterion in (Equation4
(4)
(4) ) to drive the parameter dynamics. Our simulation section shows that the score-driven dynamics can fit various patterns for the cluster means, both in correctly specified and mis-specified settings.
For simplicity and parsimony, we consider the integrated score-driven dynamics as discussed by Lucas and Zhang (Citation2016),
(7)
(7) where
is a diagonal matrix that depends on the unknown parameter vector
, and where
is the scaled first derivative of the time t EM objective function
with respect to μj, t, where we dropped the part ∑Ni = 1∑j = 1Jτ(k)i, jlog πj as it does not depend on μj, t. The score is given by
(8)
(8)
The score in (Equation8(8)
(8) ) is based on the EM local objective function. One might ask how this score relates to the standard score as proposed originally in Creal, Koopman, and Lucas (Citation2013). In Web Appendix A, we show that if the density of the mixing variable zi does not depend on ft, then the standard predictive density score and the EM score evaluated at the MLE optimum are identical. The result was also used to account for missing values by Lucas, Opschoor, and Schaumburg (Citation2016). The current finite mixture model is a special case of this more generic result.
To scale our score for μj, t, we compute the inverse of the expected negative Hessian under mixture component j. In particular, we take the derivative of (Equation8(8)
(8) ) with respect to the transpose of μj, t, switch sign, and compute the inverse, thus obtain a scaling matrix Ωj/∑Ni = 1τ(k)i, j. This yields a corresponding scaled score update of the form
(9)
(9) This updating mechanism is highly intuitive: the component means are updated by the prediction errors for that component, accounting for the posterior probabilities that the observation was drawn from that same component. For example, if the posterior probability τ(k)i, j that
comes from component j is negligible, the update of μj, t does not depend on the observation of firm i.
We note that we do not scale the score by the inverse Fisher information matrix as suggested in for instance Creal, Koopman, and Lucas (Citation2013). So far, there is no optimality theory for the choice of the scale for the score, and different proposals can be found in the literature. Computing the information matrix for the mixture model is hard, particularly if we take into account that also τ(k)i, j is a function of . We can show, however, that our proposed way of scaling the score collapses to the inverse information matrix if the mixture components are sufficiently far apart.
All static parameters can now be estimated using the EM-algorithm. Starting from an initial and an initial mean μ(k − 1)j, 1, we compute μ(k − 1)j, 2, …, μjT(k − 1) using the recursion (Equation9
(9)
(9) ). We compute the posterior probabilities as
(10)
(10) Next, the M-Step maximizes
(11)
(11) with respect to A1 and Ωj. The initial values μj, 1 can also be estimated if J and D are not too large. Otherwise, the number of parameters becomes infeasible. Alternatively, one can initialize the time-varying means μj, 1 by the τi, j-weighted average of the first cross-section(s). Given the values of J and D in our empirical study, we opt for this latter approach. We set μj, 1 equal to the weighted unconditional sample average in the simulation study, and to the weighted average of the first cross-section in the empirical application. Given μj, 1 and A1, the optimization with respect to Ωj can be done analytically. The optimization with respect to A1 has to be carried out numerically.
The E-step and M-step are iterated until convergence. To start up the EM algorithm, we initialize the weights τi, j randomly. To robustify the optimization algorithm, we use a large number of random starting values and pick the highest value for the final converged criterion function.
2.4 Extensions
2.4.1 Time-Varying Component Covariance Matrices
This section derives the scaled score updates for time-varying component covariance matrices Ωj, t. If we also want to endow the time-varying covariance matrices with integrated score dynamics, we have
(12)
(12) where
is again defined as the scaled first partial derivative of the expected likelihood function with respect to Ωj, t. Following equation (Equation8
(8)
(8) ), the unscaled score with respect to Ωj, t is
(13)
(13) Taking the total differential of this expression, and subsequently taking expectations
conditional on mixture component j, we obtain
(14)
(14) Vectorizing (Equation14
(14)
(14) ), we obtain
, where
concatenates the columns of a matrix into a column vector, and where the negative inverse of the matrix in front of
is our scaling matrix to correct for the curvature of the score. Multiplying the vectorized version of (Equation13
(13)
(13) ) by this scaling matrix, we obtain the scaled score
(15)
(15) The estimation of the model can be carried out using the EM algorithm as before, replacing Ωj by Ωj, t in equations (Equation10
(10)
(10) ) and (Equation11
(11)
(11) ).
2.4.2 Student’s t Distributed Mixture
This section robustifies the dynamic finite mixture model by considering panel data that are generated by mixtures of multivariate Student’s t distributions. Assuming a multivariate normal mixture is not always appropriate. For example, extreme tail observations can easily occur in the analysis of accounting ratios when the denominator is close to zero, implying pronounced changes from negative to positive values.
To use the EM-algorithm for mixtures of Student’s t distributions, we use the densities
(16)
(16) Both the E-steps and the M-steps of the algorithm are unaffected save for the fact that we use Student’s t rather than Gaussian densities. The main difference follows for the dynamic models, where the score steps now take a different form. Using (Equation16
(16)
(16) ), the scores for the location parameter μj, t and scale matrix Ωj, t are
(17)
(17)
(18)
(18)
(19)
(19) The main difference between the scores of the Student’s t and the Gaussian case is the presence of the weights wi, j, t. These weights provide the model with a robustness feature: observations
that are outlying given the fat-tailed nature of the Student’s t density receive a reduced impact on the location and volatility dynamics by means of a lower value for wi, j, t; compare Creal, Koopman, and Lucas (Citation2011, Citation2013) and Harvey (Citation2013). We use the same scale matrices for the score as in Sections 2.3 and 2.4.1. For the location parameter, which is our main parameter of interest, the scaling matrix for the Student’s t case is proportional to that for the normal, such that any differences are included in the estimation of the smoothing parameter A1. We obtain the scaled scores
(20)
(20)
(21)
(21) The intuition is the same as for the Gaussian case, except for the fact that the scaled score steps for μj, t and Ωj, t are redescending to zero and bounded, respectively, if
is extremely far from μj, t. Also note that for νj → ∞ we see in (Equation19
(19)
(19) ) that wi, j, t → 1, such that we recover the expressions for the Gaussian mixture model.
2.4.3 Explanatory Covariates
The score-driven dynamics for component-specific time-varying parameters can be extended further to include contemporaneous or lagged economic variables as additional conditioning variables. For example, a particularly low interest rate environment may push financial institutions, overall or in part, to take more risk or change their asset composition; see, for example, Hannoun (Citation2015), Abbassi et al. (Citation2016), and Heider, Saidi, and Schepens (Citation2017). Using additional yield curve-related conditioning variables allows us to incorporate and test for such effects. Let Xt be a vector of observed covariates, and a matrix of unknown coefficients that need to be estimated. In the case of a Student’s t distributed mixture, the score-driven updating scheme then changes slightly to
(22)
(22) Again, in the case of a Gaussian mixture, wi, j, t = 1. The covariates can also be made firm and cluster component specific, that is, Xi, j, t.
2.5 Diagnostics: Stability of Cluster Allocation Over Time
The assumption that component membership is time-invariant implies that pooling information over t = 1, …, T is optimal. This is of substantial help to robustly classify each unit i. Although our sample covers only 32 quarters (8 years), it is clear that switches in component membership become more likely as the sample period grows. In such a case, we have to trade off estimation efficiency against estimation bias.
To check whether component probabilities τi, j are time-varying, we consider the point-in-time diagnostic statistic
(23)
(23) which can be viewed as the time t posterior probability that firm i belongs to cluster component j, computed using the estimates under the null of time-invariant cluster assignments. A filtered counterpart using information from time 1 to t can be constructed by replacing
by
. If
is close to 1 or 0 for all t for a specific (i, j), firm i is unlikely to have switched clusters. Otherwise, switches may be a concern. We discuss time series plots of τi, j|t for diagnostic purposes in our application in Section 4.
3. SIMULATION STUDY
3.1 Simulation Design
This section investigates the ability of our score-driven dynamic mixture model to simultaneously (i) correctly classify a dataset into distinct components, and (ii) recover the dynamic cluster means over time. In addition, we investigate the performance of several model selection criteria from the literature in detecting the correct model when the number of clusters is unknown. In all cases, we pay particular attention to the sensitivity of the EM algorithm to the (dis)similarity of the clusters, the number of units per cluster, and the impact of model misspecification.
We simulate from a mixture of dynamic bivariate densities. These densities are composed of sinusoid mean functions and iid disturbance terms that are drawn from a bivariate Gaussian distribution or a bivariate Student’s t distribution with five or three degrees of freedom. The covariance matrices are chosen to be time-invariant identity matrices.
The sample sizes are chosen to resemble typical sample sizes in studies of banking data. We thus keep the number of time points small to moderate, considering T ∈ {10, 30}, and set the number of cross-sectional units equal to N = 100 or to N = 400. The number of clusters used to generate the data is fixed at J = 2 throughout. In our first set of simulation results in Section 3.2, we assume J = 2 is known. In a second set of simulations, we do not assume to know the number of clusters, but determine it using different model selection criteria. To save space in the main text, the description of these criteria has been moved to Web Appendix B, together with the outcomes of these simulations.
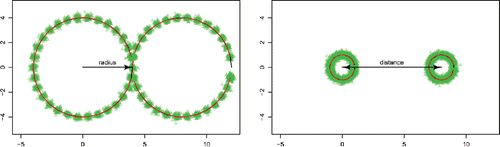
In our baseline setting, visualized in , we generate data from two clusters located around means that move in two nonoverlapping circles over time. Across our different simulation designs, the data have different signal-to-noise ratios in the sense that the radius of the circles is large or small relative to the variance of the error terms. In addition, we also consider two more challenging settings where the two circles overlap completely: the circles have the same center, but differ in the orientation of the time-varying mean component (clockwise vs. counterclockwise). Again, we consider circles with a large and small radius, respectively, while keeping the variance of the error terms fixed and thus changing the signal-to-noise ratio in the simulation set-up.
Figure 1. True mean processes (black) together with median filtered means over 100 simulation runs (red) and the filtered means (green triangles). Both panels correspond to simulation setups under correct specification with circle centers that are 8 units apart (distance = 8). The left panel corresponds to the simulation setup with radius 4, while the right panel depicts the mean circles with radius 1.
Finally, we investigate the impact of two types of model misspecification. First, we incorrectly assume a Gaussian mixture in the estimation process when the data are generated by a mixture of Student’s t densities with five degrees of freedom (ν = 5). Alternatively, we simulate from a t(3)-mixture, but fix the degrees of freedom parameter to five in the estimation. In both cases, we check the effect of misspecifying the tail behavior of the mixture distribution. In total, we consider 96 different simulation settings.
3.2 Simulation Results for Classification and Tracking
Using the score-driven model set-up and EM estimation methodology from Section 2, we classify the data points and estimate the component parameters from the simulated data. The static parameters to be estimated include the distinct entries of the covariance matrices, and the diagonal elements of the smoothing matrix A1, which, for simplicity, we assume to be equal across dimensions and components, that is, A1 = a1ID.
illustrates our simulation setup with two examples. The data-generating processes are plotted as solid black lines. In each panel, the true process is compared to the pointwise median of the estimated paths over simulation runs (solid red line), as well as the filtered mean estimates for each simulation run (green triangles). The actual observations are dispersed much more widely around the black circles, as for each point on the circle they are drawn from the bivariate standard normal distribution, thus ranging from approximately μj, t − 2.5 to μj, t + 2.5 with 99% probability. Our methodology allocates each data point to its correct component and in addition tracks the dynamic mean processes accurately.
presents mean squared error (MSE) statistics as our main measure of estimation fit. MSE statistics for time-varying component means are computed as the squared deviation of the estimated means from their true counterparts, averaged over time and simulation runs. The top panel of contains MSE statistics for eight simulation settings. Each of these settings considers Nj = 100/2 = 50 units per component. The bottom panel of presents the same information for Nj = 400/2 = 200 units per component. In each case, we also report the proportion of correctly classified data points, averaged across simulation runs.
Table 1. Simulation outcomes
Not surprisingly, the performance of our estimation methodology depends on the simulation settings. For a high signal-to-noise ratio (i.e., a large circle radius) and a large distance between the unconditional means, the cluster classification is close to perfect, both under correct specification and model misspecification. Interestingly, the distance between circles is irrelevant for estimation fit and classification ability in the case of large radii (signal-to-noise ratios).
As the distance between means and the circle radii decrease, the shares of correct classifications decrease as well. Both estimation fit and share of correct classification decrease further if we assume a Gaussian mixture although the data are generated from a mixture of fat-tailed Student’s t distributions. This indicates a sensitivity to outliers when assuming a Gaussian mixture in the case of fat-tailed data. Incorrectly assuming five degrees of freedom when the data are generated by a t(3)-mixture, on the other hand, leads to little bias. Consequently, a misspecified t-mixture model allows us to obtain more robust estimation and classification results than a Gaussian mixture model when the data are fat-tailed. This is because also the t(5) based score-dynamics for μj, t already discount the impact of outlying observations, although not as strictly as the score-based dynamics of a Student’s t(3) distribution.
In our empirical study of banking data, the number of clusters, that is, bank business models, is unknown a priori. A number of model selection criteria and so-called cluster validation indices have been proposed in the literature, and comparative studies have not found a dominant criterion that performs best in all settings; see, for example, Milligan and Cooper (Citation1985) and de Amorim and Hennig (Citation2015). We therefore run an additional simulation study to see which model selection criteria are suitable to choose the optimal number of components in our multivariate panel setting. We refer to Web Appendix B for the results. The Davies–Bouldin index (DBI; see Davies and Bouldin (Citation1979)), the Calinski–Harabasz index (CHI; see Calinski and Harabasz Citation1974), and the average Silhouette index (SI; see de Amorim and Hennig Citation2015) perform well.
4. BANK BUSINESS MODELS
4.1 Data
The sample under study consists of N = 208 European banks, for which we consider quarterly bank-level accounting data from SNL Financial between 2008Q1–2015Q4. This implies T = 32. We assume that differences in banks’ business models can be characterized along six dimensions: size, complexity, activities, geographical reach, funding strategies, and ownership structure. We select a parsimonious set of D = 13 indicators from these six categories. We consider banks’ total assets, leverage with respect to CET1 capital (size), net loans to assets ratio, risk mix, assets held for trading, derivatives held for trading (complexity), share of net interest income, share of net fees and commissions income, share of trading income, ratio of retail loans to total loans (activities), ratio of domestic loans to total loans (geography), loans to deposits ratio (funding), and an ownership index (ownership).
We refer to Web Appendix C for a detailed discussion of our data, including data transformations and SNL Financial field keys. Web Appendix C also discusses our treatment of missing observations and banks’ country location.
4.2 Model Selection
This section motivates the model specification employed in our empirical analysis. We first discuss our choice of the number of clusters. We then determine the parametric distribution, pooling restrictions, and choice of covariance matrix dynamics.
presents likelihood-based and distance-based information criteria, as well as different cluster validation indices for different values of J = 2, …, 10. The log-likelihood fit increases monotonically with the number of clusters. Likelihood-based information criteria turn out to be sensitive to the specification of the penalty term. They either select the maximum number (AICc, BIC) or minimum number (AICk, BaiNg2) of components; see Web Appendix B for definitions of the different criteria. Distance-based cluster validation indices such as the CHI, DBI, and SI suggest J = 6. Each of these takes a local maxium/minimum at this value. In practice, experts consider between five and up to more than ten different bank business models; see, for example, Ayadi, Arbak, and de Groen (Citation2011) and Bankscope (Citation2014, p. 299). With these considerations in mind, to be conservative and in line with and the simulation results as reported in Web Appendix B, we choose J = 6 components for our subsequent empirical analysis.
Table 2. Information criteria
motivates our additional empirical choices. We estimate a range of models with varying degrees of flexibility: normal versus Student’s t, static versus dynamic covariance matrices, and a scalar versus a diagonal A1. We observe two large likelihood improvements. First, allowing for fat-tailed rather than Gaussian mixtures increases the likelihood by more than 3400 points for the static covariance case, and more than 7800 points for dynamic covariance matrices. Second, allowing covariance matrices to be dynamic increases the likelihood more than 4100 points for Gaussian mixtures, and more than 9500 points for the Student’s t case. Allowing A1 to be diagonal only results in a minor likelihood increase, and the diagonal elements are all quite similar. We therefore adopt a Student’s t model with scalar A1, estimated degrees of freedom ν, and dynamic covariance matrices Ωj, t as our main empirical specification. The autoregressive matrices are given by A1 = a1 · ID, and A2 = a2 · ID. Unknown parameters to be estimated in the M-step are therefore Θ = (a1, a2, ν)′. Using this parameter specification, we combine model parsimony with the ability to study a high-dimensional array of data.
Table 3. Model specification
Web Appendix D presents the estimated diagnosticstatistics as defined in Section 2.5. Specifically, we report all time t posterior probabilities that unit i belongs to cluster component j for all 208 banks in our sample. In addition, we present histograms of the maximum average point-in-time and filtered component probabilities. The plots indicate that there is one most suitable business model for almost all banks in our data.
Web Appendix E compares our cluster allocation outcomes with a 2016 supervisory ECB/SSM bank survey (“thematic review”) that asked a subset of banks in our sample which other banks they consider to follow a similar business model. We find that our classification outcomes for these banks approximately, but not perfectly, correspond to bank managements’ own views.
Web Appendix F studies to which extent the clustering outcomes change by leaving out variables d = 1, …, D one-at-a-time and then reestimating the model. All variables turn out to be important in the sense that they have a substantial influence on the clustering outcome. In addition, the clustering outcomes are not dominated by a single variable, such as for instance total assets.
4.3 Discussion of Bank Business Models
This section studies the different business models implied by the J = 6 different component densities. Specifically, we assign labels to the identified components to guide intuition and for ease of reference. These labels are chosen in line with , Figure G1 in Web Appendix G, and the identities of the firms in each component. In addition, our labeling is approximately in line with the examples listed in SSM (Citation2016, p. 10).
Figure 2. Time-varying component medians. Filtered component medians for 12 indicator variables; see Table C.1. The component medians coincide with the component means unless the variable is transformed; see the last column of Table C.1 in Web Appendix C. The ownership variable is omitted since it is time-invariant. The component mean estimates are based on a Student's t mixture model with J = 6 components and time-varying component means μj, t and covariance matrices Ωj, t. We distinguish large universal banks, including G-SIBs (black line), international diversified lenders (red line), fee-focused lenders (blue line), domestic diversified lenders (green dashed line), domestic retail lenders (purple dashed line), and small international banks (light-green dashed line).
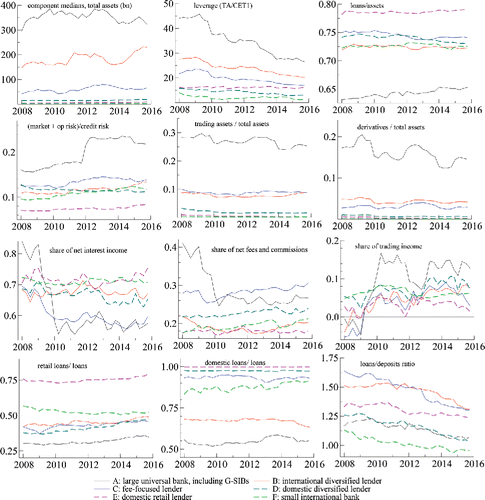
plots the component median estimates for each indicator variable and business model component (except ownership, which is time-invariant). Web Appendix G presents additional figures, such as boxplots of the time series averages of each variable for each business model group. In addition, Web Appendix G presents the filtered component-specific time-varying standard deviations for variables d = 1, …, D − 1. The standard deviations tend to decrease over time starting from the high dispersion observed during the financial crisis (2008–2009). The standard deviation estimates also differ across business models.
We distinguish
| (A) | Large universal banks, including G-SIBs (14.9% of firms; comprising, for example, Barclays plc, Credit Agricole SA, Deutsche Bank AG.) | ||||
| (B) | International diversified lenders (11.1% of firms; for example, ABN Amro NV, BBVA SA, Confederation Nationale du Credit Mutuel SA.) | ||||
| (C) | Fee-focused bank (15.9% of firms; for example, Monte Dei Paschi di Sienna, Banco Populare, Bankinter SA.) | ||||
| (D) | Domestic diversified lenders (26.9 % of firms; for example, Aareal Bank AG, Abanca Corporacion Bancaria SA, Alpha Bank SA.) | ||||
| (E) | Domestic retail lenders (17.8% of firms; for example, Alandsbanken Abp, Berner Kantonalbank, Newcastle Building Society.) | ||||
| (F) | Small international banks (13.5% of firms; for example, Alpha Bank Skopje, AS Citadele Banka, AS SEB Pank.) | ||||
Large universal banks, including G-SIBs (black line) stand out as the largest institutions, with up to € 2 trn in total assets per firm for globally significantly important banks. Approximately 60% of operating revenue tends to come from interest-bearing assets such as loans and securities holdings. This leaves net fees and commissions as well as trading income as significant other sources. Large universal banks are the most leveraged at any time between 2008Q1–2015Q4, even though leverage, that is, total assets to CET1 capital, decrease by more than a third from pre-crisis levels, from approximately 45 to below 30; see . Large universal banks hold significant trading and derivative books, both in absolute terms and relative to total assets. Naturally, such large banks engage in significant cross-border activities, including lending (between 40% and 50% of loans are cross-border loans).
International diversified lenders (red line) are second in terms of firm size, with total assets ranging between approximately € 100–500 bn per firm. As the label suggests, such banks lend significantly across borders and to both retail and corporate clients. The share of nondomestic loans to total loans is approximately 30%, and the share of retail loans ranges between approximately 20%–60%. International diversified lenders also serve their corporate customers by trading securities and derivatives on their behalf, resulting in significant trading and derivatives books. In addition, such banks tend to be non-deposit funded, as indicated by a high loans-to-deposits ratio between 100 and 200%.
Fee-focused banks (blue line) achieve most of their income from net fees and commissions (approximately 30%). This group contains banks that focus on fee-based commercial banking activities, such as transaction banking services, trade finance, credit lines, advisory services, and guarantees. In addition, however, this component appears to contain “weak” banks which do not generate much income in their traditional lines of business. The component mean for net interest income is low, raising the share of net fees and commissions. Fee-focused banks tend to exhibit a relatively high loans-to-assets ratio of approximately 70%, and also tend to focus on domestic loans (approximately 80%). Median total assets are typically below 100 bn per firm.
Domestic diversified lenders (green dashed line) are relatively numerous, comprising approximately 27% of firms, and are of moderate size. Total assets are typically below € 50 bn per firm. Domestic diversified lenders tend to be well capitalized, as implied by relatively low leverage ratios (of typically less than 20). Trading and derivatives books are small. Lending is split approximately evenly between corporate and retail clients. Nondomestic loans are typically below 20%.
Finally, domestic retail lenders and small international banks are the smallest firms, with typically less than € 25 bn in total assets. Domestic retail lenders and small international banks have much in common. Both types of banks display low leverage, suggesting they are well capitalized. The relatively largest part of their risk is credit risk (risk mix). Neither group holds significant amounts of securities or derivatives in trading portfolios. Approximately two-thirds of their income comes from interest-bearing assets, making it the dominant source of income.
Domestic retail lenders differ from small international banks in two ways: asset composition and geographical focus. Domestic retail lenders focus almost exclusively on loans (as indicated by a high loans-to-assets ratio) and domestic retail clients. By contrast, small international banks own substantial nonloan assets, and also serve nondomestic and nonretail (corporate) clients. The loans-to-deposits ratio is low for small international banks, at approximately one.
can also be used to discuss bank heterogeneity during the great financial crisis between 2008–2010 and the euro area sovereign debt crisis between 2010–2012, as well as overall banking sector trends during our sample. We refer the interested reader to Web Appendix H.
5. BANK BUSINESS MODELS AND THE YIELD CURVE
This section studies the extent to which banks adapt their business models to changes in the yield curve. We first review European interest rate developments before discussing parameter estimates.
5.1 Low Interest Rates
plots fitted zero-coupon yield curves for maturities between one and twenty years at different times during our sample (left panel). European government bond yields experienced a pronounced downward shift during our sample, ultimately reaching ultra-low and in part negative values. The yield curve factors underlying the yield curve estimates are based on a Svensson (Citation1995) four-factor model and are extracted daily from market prices of AAA-rated sovereign bonds issued by euro area governments. The yield curve factor estimates can be obtained from the ECB’s website.
Figure 3. Yield curve and factor plots. All yield curve and factor plots refer to AAA-rated euro area government bonds, and are based on a Svensson (Citation1995) four-factor model. Yield factor estimates are taken from the ECB. The left panel plots fitted Svensson yield curves on four dates—mid-2008Q1, mid-2010Q1, mid-2015Q1, and mid-2015Q4, for maturities between one and 20 years, and based on all yield curve factors. The right panel plots the level factor estimate, along with the model-implied short rate (given by the sum of the level and slope factor).
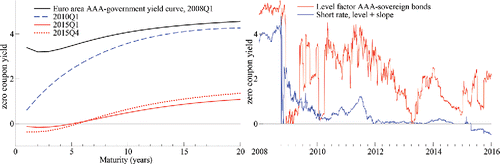
also plots the level factor, along with the implied short rate (right panel). The slope factor fluctuates around a value of approximately −2 in our sample and is not reported. Long-term yields increase up to approximately 4% between 2009–2011 following an initial sharp drop during the global financial crisis. Between 2013–2015, nominal yields decline to historically low levels. In 2015, European 10-year rates are often below 1%. Short-term rates become negative in 2015 following a cut of the ECB’s deposit facility rate to negative values. Low nominal interest rates do not necessarily only reflect unconventional monetary policies, including the ECB’s Public Sector Purchase Programme (PSPP; or “Quantitative Easing”). Decreasing inflation rates, inflation risk premia, demographic factors, and an imbalance between global saving and investment likely also play a role; see, for example, Draghi (Citation2016).
5.2 Fixed Effects Panel Regression Results
presents fixed effects panel regression estimates of bank-level accounting variables Δ4yi, t(d), d = 1, …, 12, on a constant and contemporaneous as well as one-year lagged changes in two yield curve factors, level and slope. We consider four-quarter differences since most banks report at an annual frequency. pools bank data across business model components. reports the regression coefficients for the one-year changes in the yield curve level, pooled as well as disaggregated across business model clusters. Web Appendix I reports all estimates for each variable and business model group.
Table 4. Factor sensitivity estimates
Table 5. Sensitivities to changes in the term structure level (Δ4lt)
We discuss five findings. First, as long-term interest rates decrease, banks on average grow larger in terms of total assets, by approximately 5% in response to a 100 bps drop in the level factor. The coefficient estimates for short-term rates and lagged changes in yields are negative as well. This finding is in line with banks’ incentive to extend the balance sheet to offset squeezed net interest margins for new loans and investments. In addition, and trivially, some bank assets are worth more at lower rates.
Second, bank leverage is predicted to increase as yields decline. This correlation needs to be interpreted with caution. Leverage declined most strongly between 2010 and 2012, when euro area yields were increasing owing to the sovereign debt crisis. In addition, leverage is influenced by changes in financial regulation which we do not control for.
Third, the composition of bank assets is sensitive to changes in the yield curve factors. The loans-to-assets ratio decreases by approximately 2% on average across business models in response to a 100 bps drop in long-term rates. By contrast, the sizes of banks’ trading and derivative books increase to some extent. This change in balance sheet composition is driven mostly by the larger banks (components A to C; ), and could reflect a decreased demand for new loans from the private sector in an environment of strongly declining rates; see Abbassi et al. (Citation2016). In this environment, large banks may invest in tradable securities such as government bonds instead of expanding their respective loan books; see Acharya and Steffen (Citation2015).
Fourth, we observe little variation in the shares of income sources in response to falling yields. In particular, the share of net interest income is not significantly (at 5%) associated with contemporaneous changes in yields. Two opposing effects could be at work. On the one hand, banks funding cost also decrease, and may even do so at a faster rate than long-duration loan rates. In addition, banks’ long-term loans and bond holdings are worth more at lower rates, leading to mark-to-market gains. On the other hand, low long-term interest rates squeeze net interest margins for newly acquired loans and bonds. The former effects could approximately balance the latter in our sample.
Finally, some banks appear to decrease their deposits-to-loans ratio in response to falling short-term rates. We refer to Web Appendix I, Table I.4, for the respective coefficient estimates. As the slope factor declines by 100 bps, banks in components A, B, and D decrease their deposits-to-loans ratio by approximately 2–5%.
Changes in term structure factors can also be added to the econometric specification as discussed in Section 2.4.3. Given the limited number of T = 32 time series observations, however, we need to pool the coefficients Bj across mixture components Bj ≡ B to reduce the number of parameters. Web Appendix J discusses the parameter estimates. The increased log-likelihood values suggest a slightly better fit than the baseline specification. Coefficients in B are, however, rarely statistically significant according to their t-values.
We conclude that bank business model characteristics appear to adjust to changes in the yield curve. Given their direction for falling rates—increased size, increased leverage, increased complexity through larger trading and derivatives books, and possibly less stable funding sources—the effects are potentially problematic and need to be assessed from a financial stability perspective.
6. CONCLUSION
We proposed a novel score-driven finite mixture model for the study of banking data, accommodating time-varying component means and covariance matrices, normal and Student’s t distributed mixtures, and term structure factors as economic determinants of time-varying parameters. In an empirical study of European banks, we classified more than 200 financial institutions into six distinct business model components. Our results suggest that the global financial crisis and the euro area sovereign debt crisis had a substantial yet different impact on banks with different business models. In addition, banks’ business models adapt over time to changes in long-term interest rates.
SUPPLEMENTARY MATERIALS
The Web appendix provides further technical and empirical results.
Supplementary Materials
Download Zip (653.4 KB)ACKNOWLEDGMENTS
Lucas and Schaumburg thank the European Union Seventh Framework Programme (FP7-SSH/2007–2013, grant agreement 320270-SYRTO) for financial support. Schaumburg also thanks the Dutch Science Foundation (NWO, grant VENI451-15-022) for financial support. Parts of this article were written while Schwaab was on secondment to the ECB’s Single Supervisory Mechanism (SSM). We are particularly grateful to Klaus Düllmann, Heinrich Kick, and Federico Pierobon from the SSM. We also thank the three Referees and the Editor whose many insightful suggestions have helped us to reshape and improve the article.
The views expressed in this article are those of the authors, and they do not necessarily reflect the views or policies of the European Central Bank.
Notes
1 For example, the assessment of the viability and the sustainability of a bank’s business model plays a pronounced role in the European Central Bank’s new Supervisory Review and Examination Process (SREP) for Significant Institutions within its Single Supervisory Mechanism; see SSM (Citation2016). Similar procedures exist in other jurisdictions.
2 An improved understanding of the financial stability consequences of low-for-long interest rates is a top policy priority. For example, Fed Chair Yellen (Citation2014) pointed to “... the potential for low interest rates to heighten the incentives of financial market participants to reach for yield and take on risk, and... the limits of macroprudential measures to address these and other financial stability concerns.” Similarly, ECB President Draghi (Citation2016) explained that “One particular challenge has arisen across a large part of the world. That is the extremely low level of nominal interest rates.... Very low levels are not innocuous. They put pressure on the business model[s] of financial institutions... by squeezing net interest income. And this comes at a time when profitability is already weak, when the sector has to adjust to post-crisis deleveraging in the economy, and when rapid changes are taking place in regulation.”
3 We use the terms “component,” “mixture component,” and “cluster” interchangeably.
4 As pointed out by a referee, newer and faster versions of the EM algorithm are available, such as the ECM algorithm of Meng and Rubin (Citation1993) and the ECME algorithm of Liu and Rubin (Citation1994). All of these converge to the same optimum. Computation time for the EM was not a major issue in our setting, with the algorithm typically converging in 15 iterations. We therefore leave such extensions for future work.
REFERENCES
- Abbassi, P., Iyer, R., Peydro, J.-L., and Tous, F. (2016), “Securities Trading by Banks and Credit Supply: Micro-Evidence,” Journal of Financial Economics, 121, 569–594.
- Acharya, V., and Steffen, S. (2015), “The ‘Greatest’ Carry Trade Ever? Understanding Eurozone Bank Risks,” Journal of Financial Economics, 115, 215–236.
- Altunbas, Y., Manganelli, S., and Marques-Ibanez, D. (2011), “Bank Risk During the Financial Crisis: Do Business Models Matter?” ECB working paper No. 1394.
- Ayadi, R., Arbak, E., and de Groen, W. P. (2011), “Business Models in European Banking: A Pre- and Post-Crisis Screening,” CEPS Discussion Paper, 1–104.
- Ayadi, R., and de Groen, W. P. D. (2015), “Bank Business Models Monitor 2014 Europe,” CEPS working paper, 1–68.
- Bankscope (2014), Bankscope User Guide, Amsterdam: Bureau van Dijk, January 2014. Available to subscribers.
- Calinski, T., and Harabasz, J. (1974), “A Dendrite Method for Cluster Analysis,” Communications in Statistics, 3, 1–27.
- Catania, L. (2016), “Dynamic Adaptive Mixture Models,” University of Rome Tor Vergata, unpublished working paper.
- Chiorazzo, V., D’Apice, V., DeYoung, R., and Morelli, P. (2016), “Is the Traditional Banking Model a Survivor?” Unpublished working paper, 1–44.
- Cox, D. R. (1981), “Statistical Analysis of Time Series: Some Recent Developments,” Scandinavian Journal of Statistics, 8, 93–115.
- Creal, D., Koopman, S., and Lucas, A. (2011), “A Dynamic Multivariate Heavy-Tailed Model for Time-Varying Volatilities and Correlations,” Journal of Business & Economic Statistics, 29, 552–563.
- ——— (2013), “Generalized Autoregressive Score Models With Applications,” Journal of Applied Econometrics, 28, 777–795.
- Creal, D., Schwaab, B., Koopman, S. J., and Lucas, A. (2014a), “An Observation-Driven Mixed Measurement Dynamic Factor Model With Application to Credit Risk,” The Review of Economics and Statistics, 96, 898–915.
- Creal, D. D., Gramacy, R. B., and Tsay, R. S. (2014b), “Market-Based Credit Ratings,” Journal of Business & Economic Statistics, 32, 430–444.
- Davies, D. L., and Bouldin, D. W. (1979), “A Cluster Separation Measure,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2, 224–227.
- de Amorim, R. C., and Hennig, C. (2015), “Recovering the Number of Clusters in Data Sets With Noise Features Using Feature Rescaling Factors,” Information Sciences, 324, 126–145.
- Dempster, A. P., Laird, N. M., and Rubin, D. B. (1977), “Maximum Likelihood From Incomplete Data via the EM Algorithm,” Journal of the Royal Statistical Society, Series B, 39, 1–38.
- Draghi, M. (2016), “Addressing the Causes of Low Interest Rates,” Speech in Frankfurt am Main, 2 May 2016.
- Fruehwirth-Schnatter, S. (2006), Finite Mixture and Markov Switching Models, New York: Springer.
- Fruehwirth-Schnatter, S., and Kaufmann, S. (2008), “Model-Based Clustering of Multiple Time Series,” Journal of Business and Economic Statistics, 26, 78–89.
- Hamilton, J. D., and Owyang, M. T. (2012), “The Propagation of Regional Recessions,” The Review of Economics and Statistics, 94, 935–947.
- Hannoun, H. (2015), “Ultra-Low or Negative Interest Rates: What They Mean for Financial Stability and Growth,” Speech given at the BIS Eurofi High-Level Seminar in Riga on 22 April 2015.
- Harvey, A. C. (2013), Dynamic Models for Volatility and Heavy Tails, With Applications to Financial and Economic Time Series, No. 52, Cambridge: Cambridge University Press.
- Heider, F., Saidi, F., and Schepens, G. (2017), “Life Below Zero: Bank Lending Under Negative Policy Rates,” working paper. Available at SSRN: https://ssrn.com/abstract=2788204.
- Liu, C., and Rubin, D. B. (1994), “The ECME Algorithm: A Simple Extension of EM and ECM with Faster Monotone Convergence,” Biometrika, 81, 633–648.
- Lucas, A., Opschoor, A., and Schaumburg, J. (2016), “Accounting for Missing Values in Score-Driven Time-Varying Parameter Models,” Economics Letters, 148, 96–98.
- Lucas, A., and Zhang, X. (2016), “Score-Driven Exponentially Weighted Moving Average and Value-at-Risk Forecasting,” International Journal of Forecasting, 32, 293–302.
- McLachlan, G., and Peel, D. (2000), Finite Mixture Models, New York: Wiley.
- Meng, X.-L., and Rubin, D. B. (1993), “Maximum Likelihood Estimation via the ECM Algorithm: A General Framework,” Biometrika, 80, 267–278.
- Milligan, G. W., and Cooper, M. C. (1985), “An Examination of Procedures for Determining the Number of Clusters in a Dataset,” Psychometrika, 50, 159–179.
- Nouy, D. (2016), “Adjusting to New Realities Banking Regulation and Supervision in Europe,” Speech by Daniele Nouy, Chair of the ECB’s Supervisory Board, at the European Banking Federation’s SSM Forum, Frankfurt, 6 April 2016.
- Roengpitya, R., Tarashev, N., and Tsatsaronis, K. (2014), “Bank Business Models,” BIS Quarterly Review, 55–65.
- Smyth, P. (1996), “Clustering Sequences With Hidden Markov Models,” Advances in Neural Information Processing Systems, 9, 1–7.
- SSM (2016), “SSM SREP Methodology Booklet.” Available at www.bankingsupervision.europa.eu, accessed on 14 April 2016, 1–36.
- Svensson, L. E. O. (1995), “Estimating Forward Interest Rates With the Extended Nelson & Siegel Method,” Quarterly Review, Sveriges Riksbank, 3, 13–26.
- Wang, Y., Tsay, R. S., Ledolter, J., and Shrestha, K. M. (2013), “Forecasting Simultaneously High-Dimensional Time Series: A Robust Model-Based Clustering Approach,” Journal of Forecasting, 32, 673–684.
- Yellen, J. L. (2014), “Monetary Policy and Financial Stability,” Michel Camdessus Central Banking Lecture, International Monetary Fund, Washington, DC, 2 July 2014.