
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We consider estimation of the asymptotic covariance matrix in nonstationary time series. A nonparametric estimator that is robust against unknown forms of trends and possibly a divergent number of change points (CPs) is proposed. It is algorithmically fast because neither a search for CPs, estimation of trends, nor cross-validation is required. Together with our proposed automatic optimal bandwidth selector, the resulting estimator is both statistically and computationally efficient. It is, therefore, useful in many statistical procedures, for example, CPs detection and construction of simultaneous confidence bands of trends. Empirical studies on four stock market indices are also discussed.
1 Introduction
In many real applications, the observed time series is a contaminated version of the ideal stationary time series
. The contamination may consist of an unknown trend, seasonality, and abrupt change points (CPs). This type of nonstationary time series is commonly encountered in Econometrics, Risk Management, Neurology, Genetics, Ecology, etc. (see, e.g., Horváth, Kokoszka, and Steinebach Citation1999; Grangera and Hyung Citation2004; Banerjeea and Urga Citation2005; Mikkonen et al. Citation2014; Kirch, Muhsal, and Ombao Citation2015). As a result, assessing the stationarity of
is usually indispensable before conducting inference and modeling. Many tests for this purpose require estimating the asymptotic covariance matrix (ACM) of
, namely,
. Their performances rely on an efficient estimator of
that is robust against the mean and autocorrelation structures. This article addresses the problem of mean-structure and autocorrelation consistent (MAC) estimation of
.
One classical problem in assessing stability is CP detection. A large class of CP tests is based on the cumulative sum (CUSUM) process (e.g., Brown, Durbin, and Evans Citation1975; Ploberger and Krämer Citation1992; Jirak Citation2015). Among them, the celebrated Kolmogorov–Smirnoff (KS) test is arguably the most commonly used in detecting a mean shift. In the univariate case, the KS test statistic usually requires an estimator of the asymptotic variance constant (AVC) , that is, the univariate analog of
, for standardization (see Csörgö and Horváth Citation1997). However, without a jump robust estimator of
, the KS test may not be monotonically powerful with respect to the jump magnitude (see Vogelsang Citation1999; Crainiceanu and Vogelsang Citation2007; Juhl and Xiao Citation2009). Indeed, the power may even completely vanish (see for a visualization of this phenomenon). However, many existing approaches are either restricted to one CP or do not fully eliminate the nonmonotone problem. Furthermore, for multidimensional CP tests (e.g., Horváth, Kokoszka, and Steinebach Citation1999), there is no robust estimator of
. Although Shao and Zhang (Citation2010) proposed a self-normalized KS test, which does not require estimating
, it sacrifices power for that. Its power may even completely vanish under a misspecified alternative (see Section 5.4).
Besides detection of CPs, there are many more dedicated procedures for assessing the stability of mean, for example, testing the existence of structural breaks in trends, constructing simultaneous confidence bands (SCB) of trends, and testing non-constancy of trends (see Wu, Woodroofe, and Mentz Citation2001; Wu Citation2004; Wu and Zhao Citation2007, and references therein). All of the aforementioned procedures require an estimator of that is jump robust as well as trend robust. It is worth mentioning that even in the absence of CP and trend, estimation of
is already difficult because it requires specifying a bandwidth parameter (see, e.g., Andrews Citation1991; Newey and West Citation1994). To the best of our knowledge, there is no jump and trend robust estimator of
that equips with an optimal bandwidth estimator.
In view of the above problems, this article proposes a single-pass (i.e., neither estimation of CP nor trend is required) and fully nonparametric estimator of for general multidimensional time series. It is consistent and robust even if there are a divergent number of CPs and nonconstant trends of unknown forms. Furthermore, a closed-form formula of the optimal bandwidth is derived so that users do not need to resort to computationally intensive cross-validation. Hence, the resulting estimator is MAC, statistically efficient, and computationally fast.
The remaining part of the article is organized as follows. Section 2 reviews some standard estimation methods of . Section 3 provides motivation of deriving the proposed jump robust estimator; and presents the key theoretical results. Section 4 gives the extension to trend robustness. Implementation issues and generalization are also discussed. Section 5 illustrates finite sample performance Section 6 presents empirical studies on stock market indices. Section 7 concludes the article.
2 Review of Asymptotic Covariance Estimation
2.1 Mathematical Setup
Suppose the observed time series , is generated from
, where
is a mean function; and
is strictly stationary and ergodic with mean
, and autocovariance function (ACVF)
. Also denote the symmetrized ACVF by
. The ACM of
is defined by
(1)
(1) provided that the limit exists. Note that the ACM is also known as the time-average covariance matrix, long-run covariance matrix, and (scaled) spectral density at zero frequency.
The unknown mean combines trend, seasonality and jump discontinuities:
(2)
(2) where
is a sequence of continuous functions;
is the number of CPs;
is the mean-shift from f in the time period
, for
; and
is the jth CP, for
, such that
. Here the indicator
if the event E occurs, otherwise
. Without loss of generality, assume
for all
. For simplicity, we write
.
The unobservable time series is assumed to admit a causal representation
, where
is a d-dimensional measurable function,
; and
are independent and identically distributed multidimensional vectors of innovations (see Wu Citation2005). This framework is general enough to cover many commonly-used models, for example, autoregressive moving average (ARMA) model, Volterra series, bilinear (BL) model, threshold AR model, and generalized AR conditional heteroscedastic (GARCH) model (see, e.g., Wu Citation2011; Degras et al. Citation2012). More multivariate examples defined under this framework can be found in Sections 1 and 2 of Wu and Zaffaroni (Citation2018).
2.2 Mathematical Notations
The following notations are used in the article. Denote and
. For
and
are the floor and ceiling of a, respectively. For
, denote
and
. When the sample size n is clear, denote
. For real sequences
and
, write
if
;
if
; and
if there are M > 0 and N such that
for all
.
Matrices and vectors are written in boldface, while scalars are written in normal face. The (r, s)th element of a matrix A is denoted by . The uth component of a vector
is denoted by
. In one-dimensional case (i.e., d = 1), the ACM in (1) is written as Σ,
or
, and the mean function in (2) is written as
or
.
For any matrix A, denote its entry-wise absolute value by , its trace by
, its transpose by
, its column-by-column vectorization by
, and
. The diagonalization of a vector v is denoted by
, that is, a diagonal matrix whose diagonal elements are the elements of v. Denote the column vector of ones, the column vector zeros, and the identity matrix by 1, 0, and I, respectively.
For any real random variable Z and any , denote
. For any vector-valued random variable Z, we write
if
for all u. If
are identically and independently distributed (iid) as the standard normal distribution, we write
. If
are iid, then we say that
is an iid copy of ε.
2.3 Estimation in Stationary Time Series
Suppose that . There are three standard classes of methods to estimate
. The first one is the subsampling method (see, e.g., Meketon and Schmeiser Citation1984; Carlstein Citation1986; Song and Schmeiser Citation1995; Politis, Romano, and Wolf Citation1999; Chan and Yau Citation2017b). For instance, the overlapping batch means (OBM) estimator is
(3)
(3) where
is the batch-size,
and
. The second one is the kernel method (see, e.g., Newey and West Citation1987; Andrews Citation1991; Politis Citation2011). For example, the Bartlett kernel and the quadratic spectral (QS) kernel estimators are
(4)
(4)
respectively, where
,
, and
. The third one is based on the resampling method (see, e.g., Künsch Citation1989; Politis and Romano Citation1994; Paparoditis and Politis Citation2001; Lahiri Citation2003). Recently, a new class of estimators based on orthonormal sequences is proposed (see, e.g., Phillips Citation2005; Sun Citation2013). The choice of kernel or orthonormal sequences are discussed in Lazarus et al. (Citation2018). Besides, Müller (Citation2014) studied the problem under strong autocorrelation.
Estimation of is important because it is usually required in the inference of
, for example, construction of SCB for
, and output analysis in Markov chain Monte Carlo (see Flegal and Jones Citation2010; Chan and Yau Citation2016, Citation2017a; Liu and Flegal Citation2018). All three methods above require specifying an unknown bandwidth
(or the batch size, block size, etc.) In practice,
is crucial to the performance of estimators but its optimal value is notoriously difficult to estimate (see, e.g., Politis Citation2003; Hirukawa Citation2010).
2.4 Estimation in Nonstationary Time Series
Suppose that for some
. In this case, as far as we know, (i) all existing estimators of
are either restricted to particular forms of mean-structure; and (ii) the estimators are not equipped with the optimal bandwidth. Some representative estimators are listed below, and are summarized in . For reference, the precise formulas of the estimators are presented in Section C.1 of the supplementary materials.
Table 1 A summary of the robust estimators introduced in Section 2.4, where AC, CV, J, W, and WZ represent estimators proposed in Altissimoa and Corradic (Citation2003), Crainiceanu and Vogelsang (Citation2007), Jirak (Citation2015), Wu (Citation2004), and Wu and Zhao (Citation2007), respectively.
Altissimoa and Corradic (Citation2003) proposed estimating by applying a standard kernel estimator to the time series after being de-trended by a local mean estimator. The resulting estimator is consistent when the mean is a piecewise constant function with finitely many breaks. However, there are some drawbacks. First, they did not derive the optimal bandwidth. It is possible that the optimal bandwidth of the modified estimator is different from that of the standard kernel estimator. Second, the modified estimator introduces an extra tuning parameter, that is, the bandwidth for the local mean estimator. This bandwidth has to be chosen carefully to have a consistent estimator of
. However, its optimal value is unsolved. A similar method was proposed by Juhl and Xiao (Citation2009) in a hypothesis testing context. However, their estimator is inconsistent under non-stationarity.
Crainiceanu and Vogelsang (Citation2007) found that a CP test has a non-monotonic power if a non-robust estimator of is used. They proposed an estimator of
that is robust to one CP. Their idea is to estimate a potential CP and then de-mean the observed time series before and after the estimated CP separately. So, the standard methods in Section 2.3 can be applied to estimate
. Their remedy mitigates the non-monotone problem, but it still has some drawbacks. First, it allows a single CP only; and the trend must be a piecewise constant. In reality, these assumptions may not be satisfied (see Section 6.1). Second, the optimal bandwidth is estimated by a parametric plug-in method proposed by Andrews (Citation1991). If the parametric model is misspecified, its performance is doubtful. Recently, Jirak (Citation2015) proposed a similar de-trending method for estimating
robustly, but the optimal bandwidth selection issue was not addressed.
In Wu (Citation2004) and Wu and Zhao (Citation2007), they proposed using the first-order difference of nonoverlapping batch means (NBMs) to construct robust estimators of . There are some drawbacks. First, NBM-type estimators are less efficient than the overlapping batch means counterpart in terms of mean-squared error (MSE) (see Politis, Romano, and Wolf Citation1999). Thus, their estimators have a significant loss in
efficiency. It is worth noting that there is no trivial way to extend their NBM-type estimators to the more efficient OBM-type estimators (see Remark C.2 in the supplementary materials). Second, they did not derive the optimal bandwidth.
Remark 2.1.
Gonçalves and White (Citation2002) proved that two block bootstrap estimators (Künsch Citation1989; Politis and Romano Citation1994) are consistent under a mild nonconstant mean structure, namely , where
is the block size used in the estimators, and
. However,
does not hold if there is one nontrivial jump in mean. For example, if
, that is, the mean jumps from 0 to 1 at
, then
. Gallant and White (Citation1988) documented similar results in the context of heteroscedasticity and autocorrelation consistent (HAC) variance estimation. In Theorem 6.8, they showed that standard HAC estimators are biased unless the mean is a constant.
3 Jump Robustness
3.1 Motivation
Throughout Section 3, is assumed to be a piecewise constant function with J jumps, that is,
. This assumption will be relaxed in Section 4.1. Our proposal is to use a differencing technique consecutively (see Remark 3.1). If the number of jumps J and the magnitude of jumps
are not too large, then each value in the lag-1 difference sequence
is of mean zero approximately. In this case, we have
So, the semi-average of the lag-1 difference sequence is a potential estimator of , the spread between the symmetrized ACVF at lag 0 and lag 1. Similarly, a potential estimator of
is the semi-average of the lag-k difference sequence
(5)
(5)
The convention is used for
. The summability of
in (1) implies
as
. Hence,
approximates
for large L. The bi-differencing estimator
(6)
(6) is, thus, a potential estimator of
when L is large. Observe that the sample mean
is not involved in the definition of
, therefore, we can estimate the ACVFs without estimating the mean
. The concept of bi-differencing is new. The first and second differencing operations (5) and (6) remove the first and second-order offsets, that is,
and
, respectively. A graphical illustration of the bi-differencing concept can be found in Section A of the supplementary materials. Using the representation
in (1), we may use a “naive” estimator of
as follows:
(7)
(7)
where
is a bandwidth,
is a kernel function, and
for some
.
However, slowly for all
. We demonstrate it through a simple Monte Carlo experiment in Section B of the supplementary materials. An explanation of the slow convergence of
is that the “same correction term”
is used for all
, in (7). So, the variance of the “aggregated correction term”
increases with
quadratically. This is a huge loss in
efficiency because the variance of a standard ACM estimator only increases with
linearly (see Andrews Citation1991, Proposition 1(a)). Our strategy is to replace
in (7) by
with an appropriately chosen sequence
. This sequence should satisfy the following two conditions.
(Bias condition)
as
(Variance condition)
Hence, Lk should be increasing with and
. One choice of such Lk is a linear combination of
and
with positive weights, that is,
,
. Note that
sets
, which violates the variance condition. In the remaining part of this article, we will demonstrate that
is sufficient to produce optimal results (see Remark 3.2).
Remark 3.1. D
ifference-based estimators are not new. It has been used in time series analysis and robust estimation (see, e.g., Anderson Citation1971; Hall, Kay, and Titterinton Citation1990; Dette, Munk, and Wagner Citation1998; Hall and Horowitz Citation2013). However, they are restricted to the estimation of the marginal variance . Differently, we aim at estimating the ACM
. It is a harder problem than estimating
, and requires a new technique called bi-differencing. Our bi-differencing technique is partially motivated by the bipower variation (Barndorff-Nielsen and Shephard Citation2004) in the context of testing for jumps in a continuous time series.
Remark 3.2. A
s we will show in Theorems 3.1 and 3.2, a linear form of Lk already achieves the optimal convergence rate. Although an incremental improvement maybe possible by using a more general form of Lk, we leave it for future investigation.
3.2 Proposed Robust Estimators and Overview of Main Results
For estimation of , we can use the polynomial kernel
for some
. Then the jump robust estimator of the ACM
is defined by
(8)
(8) where
. Using other kernels in (8), for example,
, is also possible, however, we only focus on the polynomial kernel
in this article to avoid complication. Extension to other kernels is routine. Users may choose their favorite kernel and their favorite sequence Lk. Relative to
, these choices have slightly less impact on
at least in the first-order asymptotic. The effect of kernel choice on higher order asymptotic (see, e.g., Lazarus et al. Citation2018) is theoretically interesting. However, it is beyond the scope of this article. We leave it for future research.
Suppose that exists and its entries are finite. Under the conditions in Theorems 3.1, 3.2, and part (1) of Corollary 4.1 (to be presented in Sections 3.3 and 4.1), the value of
is given by
(9)
(9) for each r, s. Hence, if
, then
, which is the optimal convergence rate achieved by the standard estimators (see, e.g., Andrews Citation1991). In other words, the proposed robust estimator
is rate-optimal in the
sense.
From (9), the MSE of the proposed estimator depends on
. Hence, its MSE-optimal bandwidth
also depends on
. As a result, a robust estimator of
is also important for estimating the optimal bandwidth. This phenomenon is similar to the classic results in non-robust estimation of
(see, e.g., Andrews Citation1991). It motivates us to study robust estimation for all
. Similar to (8), our proposed jump robust estimator of
(
) is defined as
(10)
(10)
The statistical meanings of p and q are summarized in the first two rows of .
Table 2 Summary of the statistical meanings of p, q, P and their associated quantities.
3.3 Theoretical Results
We develop a general estimation procedure which takes various levels of serial dependence into account. For each , define
. The finiteness of
characterizes the strength of serial dependence, thus it is usually served as an assumption for proving consistency of estimators (see, e.g., Politis Citation2011, Theorem 1). More precisely, we follow Chan and Yau (Citation2017b) to define the coefficient of serial dependence of
by
(11)
(11)
Clearly, the larger the value of , the weaker the serial dependence. For example, consider a univariate fractional Gaussian noise process (Davies and Harte Citation1987) defined as a Gaussian process with ACVF
for each k, where
and
. In this model,
if and only if
. Hence,
. More examples and their associated values of
can be found in Appendix B of Chan and Yau (Citation2017b). Some multivariate examples can be found in Section C.3 of Chan and Yau (Citation2017a). As we shall see in Section 3.3.1, the assumption of CSD plays a critical role in controlling the bias of the estimator
.
Asymptotic theories are built on the framework of dependence measures (see Wu Citation2005). Recall that and
(see Section 2.1). Let
be an iid copy of
. Denote
and
. Define the physical dependence measure and its aggregated value by, respectively,
For example, consider a univariate linear process (Brockwell and Davis Citation1991, Definition 3.2.1) defined as , where
are real coefficients such that
, and
are iid noises such that
. Then
for each i, and
, where
. More univariate examples and their associated values of physical dependence measures can be found in Examples 1–11 of Wu (Citation2011). Also see Models I–VI in Example 1 of Chan and Yau (Citation2017a) for some multivariate examples. Finiteness of
(i.e., Assumption 3.1) is a mild and easily-verifiable condition for studying asymptotic properties (see Wu (Citation2007)).
Assumption 3.1
(Short range dependence). The time series satisfies
.
Assumption 3.1
rules out time series having very strong serial dependence, for example, time series with . Indeed, Assumption 3.1 implies the existence of
. More importantly, it leads to the invariance principle for the (scaled) partial sum
for
. It is required for deriving the variance of
. Assumption 3.1 is satisfied by many important time series models, including the aforementioned linear process, ARMA and BL models (see, e.g., Wu Citation2005; Liu and Wu Citation2010). Note also that some parallel formulations of dependence like strong mixing coefficient (Rosenblatt Citation1985) have been widely adopted by researchers. However, the mixing type assumptions are sometimes difficult to verify. On the contrary, Assumption 3.1 is more easily verifiable (see Wu Citation2011).
We also need to regularize the size of the bandwidth . Denote
and
for
.
Assumption 3.2
(Conditions on ). The bandwidth
satisfies (i)
as
, (ii)
as
, and (iii)
.
In Assumption 3.2, conditions (i) and (ii) require that the size of cannot be too small or too large, respectively. These conditions are commonly required in the small-
subsampling approach (i.e.,
) (see Politis, Romano, and Wolf Citation1999). Condition (iii) states that two consecutive CPs cannot be too close within the same component of the time series. Indeed, condition (iii) is stronger than needed but it makes derivations easier.
3.3.1 Bias and Variance Expressions
Let , where
. Also let
Also recall that J = Jn denotes the number of CPs (see (2)). The bias of the jump robust estimator, , is given below.
Theorem 3.1
(Bias of the estimator). Suppose that ,
, and Assumption 3.2 holds, where
and
. Then, for
and
,
(12)
(12)
In Theorem 3.1, the assumption controls the rate of decay of ACVF. For a fixed p, if the value of
is larger, then q is larger, and the autocorrelation is weaker. Consequently, the autocorrelation at large lags only introduce a small bias to
. Hence, it makes sense that the magnitude of the leading term of the bias in (12), that is,
, is decreasing with q. Besides, Jn and an determine the frequency of the CPs and the magnitude of the jumps, respectively. From (12), if
is not too large so that
, the dominating term of the asymptotic bias is
. Consequently,
is asymptotically unbiased as
. Technical conditions for controlling
are discussed in Corollary 4.1. Moreover, c0 and c1 do not affect the first-order asymptotic bias of
.
Define . The variance of
is given below.
Theorem 3.2
(Variance of the estimator). Suppose that for
,
, and Assumptions 3.1 and 3.2 hold. If
,
and
, then
(13)
(13)
Theorem 3.2 requires Assumption 3.1 because its proof relies on the invariance principle, which is guaranteed by Assumption 3.1 (see, e.g., Wu Citation2005). However, the detailed strength of serial dependence (i.e., the CSD) is not important for deriving (13). Besides, unlike the asymptotic bias, the variance of depends also on Lk. However, only c1 but not c0 is relevant. Since c1 determines the speed of divergence of Lk as
, the variance in (13) is naturally increasing with c1. Note that c0 and c1 are not tuning parameters for balancing the leading terms of the bias and variance because c0 and c1 are not involved in (12). Although c0 and c1 can be chosen optimally by balancing the second-order bias and variance, that is,
and
, the effect on
is relatively incremental.
Consider for some
. The MSE-optimal value of θ can be found by balancing the squared-bias and variance of
so that the MSE is minimized. Assume
sufficiently slow so that
and
(see Corollary 4.1 for explicit conditions to guarantee that). In this case, Theorems 3.1 and 3.2 imply that
(14)
(14)
If , then (14) achieves its minimum order, that is,
, where
(15)
(15)
Note that the superscript “” indicates optimal values. It is worth mentioning that the robust estimator
achieves the same optimal
convergence rate as the non-robust counterparts (see, e.g., Andrews Citation1991; Chan and Yau Citation2017b).
3.3.2 Theoretically Optimal Bandwidth
In this subsection, we derive the optimal ,
, such that the MSE of
is optimized up to the first order including its proportionality constant.
Suppose and
. Let W be a weight matrix specifying the entry-wise importance of
. For example,
puts equal weight on each element of the upper triangular part (including the diagonal) of
. Write
if
for all r, s, and
for at least one pair of r, s. From now on, assume
. Denote
(see Section 2.2 for the definitions of
and
). Then the optimal value of
is the minimizer of
(16)
(16)
The weighted MSE (16) is a generalization of the risk under the Frobenius norm
because, for any square matrix A,
if
. Similar weighting rule is also adopted by Andrews (Citation1991) and Chan and Yau (Citation2017a). By Theorems 3.1 and 3.2, the optimal value of
is
, where
(17)
(17)
(18)
(18)
Here is the Kronecker’s product of A and B. Note that the size of the optimal bandwidth
depends on two parameters
and
.
The parameter
The parameter
Formula (17) handles all entries of simultaneously. If the dependence structures of
vary dramatically across entries, we may construct entry-adaptive optimal bandwidth. Let
be the uth elementary d-vector, that is,
for all
. Setting
, we can produce the optimal bandwidth for the (r, s)th entry of
. The resulting optimal asymptotical MSE (AMSE) of
is given by
(19)
(19)
4 Extension, Discussion, and Implementation
4.1 Extension to Trend Robustness
In this section, we consider the full generalization of , that is, the assumption
is removed. We measure the amount of fluctuation of
by
which is small if the fluctuation of
does not grow too fast with n. The following two theorems state the bias and variance of
when
consists of jumps and trends.
Theorem 4.1
(Bias of the estimator). If the assumption is removed, then, under all other conditions in Theorem 3.1, (12) is satisfied with
being replaced by
Theorem 4.2
(Variance of the estimator). If the assumption is removed, then, under all other conditions in Theorem 3.2, (13) is satisfied with
being replaced by
The optimal bandwidth in (17) and the optimal MSE in (19) remain valid, provided that and
. Consequently,
achieves the optimal convergence rate even in the presence of jumps and continuous trends. The remainder terms
and
are influenced by (i) the jump effect
, (ii) the trend effect
, and (iii) their joint effect
. Using these three factors, we define the following classes of mean functions:
Both and
include only reasonably well-behaved mean functions
such that the aforementioned effects (i), (ii), and (iii) are small. Clearly,
. Simple conditions to control
and
are given below.
Corollary 4.1. A
ssume the conditions in Theorems 4.1 and 4.2. Let .
If
If
The above results remain valid if and
are replaced by
and
, respectively.
Corollary 4.1
ensures that is
consistent if
belongs to the well-behaved class
. If
belongs to a more well-behaved class
, we also have the optimal results (17) and (19), which imply that the convergence rate of the estimator
is not affected by jumps and trends. However, the standard (non-robust) estimators, for example,
in (3) and
in (4), are not guaranteed to be consistent if
.
For example, consider the estimator with
, and any
and
. It is
consistent, and satisfies the optimal results (17) and (19) if
belongs to
(20)
(20)
The class in (20) includes (but not restricted to) mean functions having piecewise Lipschitz continuous trends with at most
bounded jumps. Note that such Jn is allowed to be divergent to infinity as
. See the last row of for a summary and a comparison with existing robust estimators. We illustrate Corollary 4.1 through a simple simulation experiment. Let
, where
. Consider
(21)
(21) which consists of two CPs, an exponentially increasing trend, and a periodic structure. In this case, an = 4,
, and Jn = 2. Hence, the mean function (21) is a member of the class
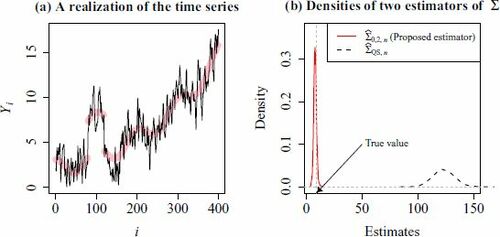
defined in (20). shows a typical realization of
(
). The density functions of
and
are shown in . The proposed estimator
concentrates at around the true value Σ = 9, however, the standard estimator
is obviously off the targeted value.
Fig. 1 (a) A typical realization of the time series with the mean function defined in (21). (b) The density functions of and
when n = 400. The true value is Σ = 9.
4.2 Comparison With Standard Estimators
The estimator sacrifices statistical efficiency to gain robustness. In this section, we investigate how much efficiency is lost.
The proposed robust estimator uses the Bartlett kernel
. So, we compare it with the standard non-robust Bartlett kernel estimator
defined in (4). Denote the optimal bandwidths for
and
by
and
, respectively. According to (15) and (17), and Equation (5.2) of Andrews (Citation1991), they are given by
respectively, where κ1 is defined in (18). Denote the resulting optimal estimators by
and
, respectively. The ratio of their weighted MSEs (see (16)) is given below.
Proposition 4.1. A
ssume the conditions in Theorems 3.1 and 3.2. Let , and
for all
. Then
.
According to Proposition 4.1, the non-robust estimator is more efficient than the robust estimator
asymptotically. It makes sense. Note that the efficiency loss is smaller if c1 is smaller. However, in finite sample, setting
may degenerate the estimator to the naive estimator
defined in (7). Hence, using a small
is suggested only if the sample size n is extremely large. Practical suggestion on selecting c1 is discussed in Section 4.3.
Besides, we also compare our estimator with the most promising (univariate) robust estimator proposed by Wu, Woodroofe, and Mentz (Citation2001), Wu (Citation2004), and Wu and Zhao (Citation2007), namely,(22)
(22) where
, and
is the kth non-overlapping batch mean (NBM) for
. The optimal MSE of
was not derived by the authors. For reference, we derive it under the constant mean assumption. Applying similar techniques as in Theorems 3.1 and 3.2, we have
and
The optimal bandwidth is
. Consequently,
. In particular, when
, our estimator
is uniformly better than
, and satisfies that
when n is large and their respective optimal bandwidths are used.
4.3 Choices of q, c0, c1, and
The best estimator in Wu and Zhao (Citation2007) has a MSE of size , whereas our proposed estimator
has a much smaller MSE, that is,
, if q > 1. In practice, if there is no prior information, we suggest q = 2, that is, assuming
, which is essentially equivalent to the assumption (
) made by Paparoditis and Politis (Citation2001).
Although we develop theories for all , it makes little sense to use
statistically and intuitively. To see it, observe that
is a reasonable estimator of
only if
, which is satisfied for all k if and only if
. Hence, it is sensible (but not necessary) to assume
, among which
minimizes the AMSE. So,
is suggested in practice. For q > 1,
has the same AMSE for any
, hence, c0 does not affect the asymptotic behavior. We illustrate in Section C.4 of the supplementary materials that the finite sample performance of
is essentially the same for any c0 that is not close to zero. In practice, we suggest using
as a default choice.
If an initial pilot estimate of is needed, we can use
with a rate optimal bandwidth
. In practice, we suggest
, where
. According to our simulation experience, this rule-of-thumb bandwidth gives reasonably good performance. Using the notation in (10), we denote the resulting pilot estimator by
(23)
(23)
In particular, for estimating , our recommended default estimator is as simple as
(24)
(24) where
and
. If a more accurate estimate of
is needed, we can use
with a fully optimal bandwidth
. From (17),
is a function of
and
. So, the value of
is unknown. We propose to first estimate
and
by the pilot estimators
and
. Then
is consistently estimated by plugging in these estimated values into (17) and (18), that is,
(25)
(25)
Using the estimator
is equipped with the optimal bandwidth asymptotically. The resulting estimator
(26)
(26) is called the qth order MAC estimator of
. It can be computed by Algorithm 1. The R-package MAC is built for implementing it.
Algorithm 1: Proposed MAC estimator for estimating
[1] Input:
[2] (i) —d-dimensional time series;
[3] (ii) p—order of the estimand (set p = 0 for estimation of the ACM
);
[4] (iii) q—order of the polynomial kernel (set q = 2 by default);
[5] (iv) c0, c1—parameters (set by default); and
[6] (v) W—d × d weight matrix (set for each
by default).
[7] begin
[8] Compute and
according to (23);
[9] Compute according to (25);
[10] Compute the estimated optimal bandwidth ;
[11] Compute according to (10).
return – MAC estimator of
.
4.4 Discussion on Robustness to Heteroscedasticity
Thus far we have assumed that the noise sequence is stationary (i.e., without heteroscedasticity). Now, suppose that
is not stationary but satisfies
. In this case, we define the finite-n version of
by
(27)
(27) where
. Following the arguments in Section 3.1, it is not hard to see that
still approximates
. Thus, it is not surprising that the proposed estimator
continues to be consistent for
. Similar to Section 8 of Andrews (Citation1991), we can extend the consistency results to heteroscedastic time series. Suppose the regularity conditions of Theorem 4.1, Theorem 4.2, and part (1) of Corollary 4.1 are satisfied except the following changes.
The stationarity of the noise sequence
The assumption
We also define, for each , that
Note that implies that
and
for each r, s. Under the modified regularity conditions, the conclusions of Theorems 4.1 and 4.2 are updated to
(28)
(28)
(29)
(29)
for all . If
, then (28) and (29) imply that
for some
. Hence,
is a consistent estimator of
with the optimal convergence rate. Examples and finite-sample performance of
in the heteroscedastic case are shown in Section 5.3.
5 Finite Sample Performance
5.1 Efficiency and Robustness Against One Jump
We compare with the following estimators in terms of efficiency and robustness.
(CV) Crainiceanu and Vogelsang (Citation2007) proposed to estimate one potential CP D1 and then construct a de-trended process, say
(WZ) Wu and Zhao (Citation2007) used NBMs
(AC) Altissimoa and Corradic (Citation2003) proposed using Bartlett kernel estimator after locally detrending the mean. The bandwidth is selected by cross-validation. Denote the resulting estimator by
(MAC) We use the estimators
Their detailed formulas are presented in Section C.1 of the supplementary materials for reference. We recall from that is robust to one CP without trend;
,
and
are proved to be robust to trends only;
is only proved to be robust to finitely many CPs; and the proposed estimators
and
are robust to both trends and a divergent number of CPs. If there is at most one CP, then
is an oracle estimator because, in practice, we rarely know that there is at most one CP.
Consider the ARMA(1,1) model: where
and
, for
. In particular, consider
(Models A1–A3, respectively),
, and five different mean sequences
for
. The MSEs are estimated by using 2000 independent replications. The lack of efficiency (
) is measured by the MSE when ξ = 0, whereas the lack of robustness is measured by the standard derivation (
) of the MSEs across
. Smaller
and smaller
imply higher efficiency and robustness, respectively.
The results are shown in . Clearly, and
perform badly in terms of both efficiency and robustness. The major competitor
performs reasonably well in terms of both two measures, however, it is less efficient than all of our proposed estimators (
,
,
) in nearly all cases. The estimator
is quite efficient when the mean is a constant, however, it loses all of its efficiency when the jump size is large. For example, when n = 400, its MSE inflates 407% when the jump magnitude ξ increases from 0 to 4. Besides, the cross-validation step makes it computationally inefficient.
Fig. 2 The values of and
are plotted against n, where
denotes the MSE when the jump size ξ = 0, and
denotes the standard deviation of the MSEs across different ξ. Recall that smaller
and smaller
imply higher efficiency and robustness, respectively. Note that
is computed only when
because it requires a computationally intensive cross-validation step. Note that horizontal axis is plotted in the logarithmic scale for better visualization.
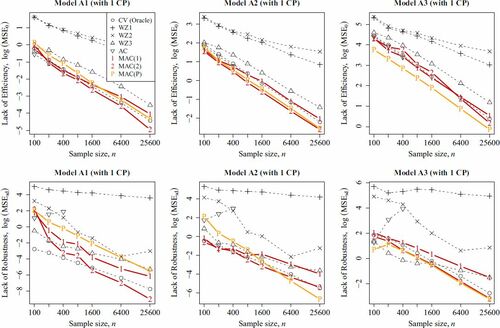
The proposed estimators and
perform the best in nearly all cases. The advantage of
is increasingly obvious when n increases. The pilot estimator
performs quite well, so it is justifiable to use it as an initial guess. It is remarked that
performs very well in Model A3 because its default tuning parameter accidentally matches the theoretically optimal value. However, this privilege is not general (see, e.g., of another experiment in Section 5.3).
5.2 Robustness Against Trend and Multiple Jumps
In this subsection, we investigate the robustness against both trends and jumps. Consider the same models of in Section 5.1, but the mean function is replaced by
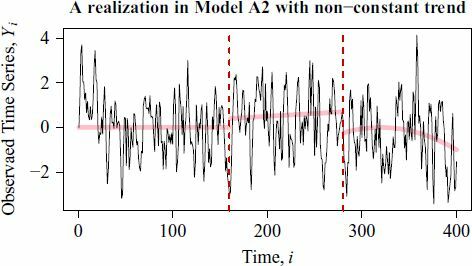
. shows a typical realization of
in Model A2. Observe that the trend effect and jump effect are not obvious because they are masked by the intrinsic variability of the noises
. This scenario mimics the situation in which the observed time series looks stationary but, indeed, it has been contaminated by a hardly noticeable nonconstant trend and structural breaks.
Fig. 3 Thin solid line: A realization of in Model A2 of length n = 400. Thick solid line: The nonconstant mean function
in Section 5.2. Dotted vertical lines: The change points.
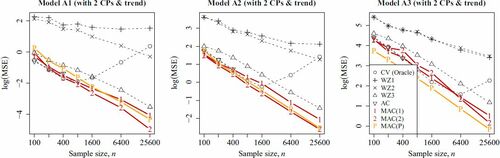
The simulation result is visualized in . First, the MSE of the previous oracle estimator does not decrease with n because it is no longer consistent when the mean is not a piecewise constant function. The estimators
and
perform poorly again. The estimator
and our proposed
,
,
perform well. Among them,
performs least well, whereas
and
perform most promisingly. The take-home message is that even if the trend is relatively insignificant, the impact on the estimators of
can be catastrophic especially when the mean-structure is misspecified.
Fig. 4 The values of of different estimators are plotted against the sample size n in Models A1–A3. Here the mean function consists of nonconstant trends and multiple jumps (see Section 5.2 and ). Note that horizontal axis is plotted in the logarithmic scale.
5.3 Multivariate Time Series With Heteroscedastic Errors
We consider estimation of (defined in (27)) for a bivariate time series
with time-varying means and heteroscedastic errors. Let
for
and j = 1, 2, where μij is the mean, Xij is a stationary noise, and τij creates heteroscedasticity. Two mean sequences are used: (i)
for all i, j, and (ii)
. We set
, and generate
as follows:
where
are independent standard bivariate normal random vectors.
The proposed estimators ,
, and
are evaluated. We compare them with the standard Bartlett kernel estimator
and QS kernel estimators
(see (4)). The bandwidths of
and
are selected by Andrews’s (Citation1991) vector AR(1)-plug-in rule. As far as we know, in the multivariate setting, there exists no other estimator that is proved to be consistent and optimal in the presence of nonconstant mean, autocorrelation and heteroscedasticity. The results are shown in . We also repeat the experiment with homoscedastic errors, that is,
for all i, j. Since the results are very similar to the heteroscedastic case, we only present the result in of the supplementary materials.
Fig. 5 The values of for
,
,
and
in the heteroscedastic case are plotted against n, where
is used, and
is defined in (16). The left and right plots show the results in the constant mean and nonconstant mean cases, respectively. Note that the horizontal axes are plotted in the logarithmic scale.
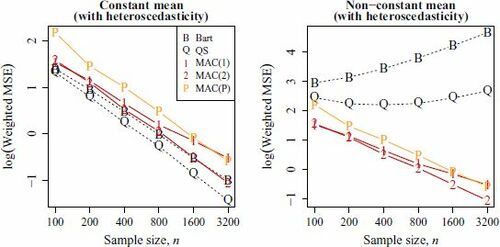
From , all five estimators are consistent in the constant-mean case. However, and
are no longer consistent when the mean is not a constant. On the other hand, the mean-structure does not affect the performance of
,
, and
. It verifies the claimed consistency and robustness. In addition, although the pilot estimator
does not perform as well as the optimal estimator
, it is still able to give sufficiently good results. It supports the use of
as an initial estimator in practice.
5.4 Change-Point Detection
In this subsection, we consider the CP detection problem, that is, to test against
. We analyze (i) whether CP tests are monotonically powerful with respect to the magnitude of jump
; and (ii) their power losses under a misspecified alternative hypothesis.
Let be the CUSUM process of
. The standard KS test statistic is defined by
, where
is a consistent estimator of σ. Then, H0 is rejected at 5% level if
. Alternatively, a self-normalized KS test (Shao and Zhang Citation2010) can be used. Following them, we compare
(SZ) their self-normalized KS test, and
(KS) the standard KS tests with different estimators of
Detailed formulas of the above CP tests and estimators of are presented in Section C.3 of the supplementary materials for reference. Consider the bilinear model:
where
and
, for
. The physical dependence measure decays at the rate
, where
(see Wu Citation2005, Citation2011). If ϱ is larger, the serial dependence is stronger. We use
and
so that
, respectively. Denote them by Models B1–B3, respectively.
Both SZ and KS tests assume that the mean function is a piecewise constant with one CP when H0 is false. If it is actually the case, we call that the alternative hypothesis is correctly specified, otherwise, the alternative hypothesis is said to be misspecified. We consider the following two alternative hypotheses in the experiments:
(correctly specified alternative) H1:
(misspecified alternative)
(Size correctness) The probability of rejecting H0 is close to α when H0 is correct.
(Powerfulness) The probability of rejecting H0 is high when H0 is incorrect.
(Monotonicity of power) The power is increasing with the magnitude of jump
(Robustness) The test is still powerful under misspecified alternative hypotheses.
The simulation is conducted for n = 100, 400, 800 with nominal size . Since the results are similar under different models, we only report the results under Model B2 here (see ). The full results are deferred to Section C.3 in the supplementary materials. The size-adjusted power curves are also presented in the supplementary materials for reference. Under H1, all tests except KS(A) and KS(JX) have monotonic powers with respect to
. The test KS(WZ3) commits the Type I error more frequently than the nominal value even when the sample size is large. This over-size phenomenon is due to the use of inefficiency estimator of
. The power curves are largely the same for KS(CV), KS(AC), and KS(MAC(2)) as they are essentially the same test. Observe that SZ is significantly less powerful when
.
Fig. 6 The powers of the CP tests defined in Section 5.4 are plotted against the jump magnitude ξ under Model B2. The scenarios under well-specified alternative H1 and misspecified alternative are shown in the upper and lower plots, respectively. Dashed horizontal lines indicate the significance level
and zero. Note that horizontal axis is plotted in the logarithmic scale for better visualization.
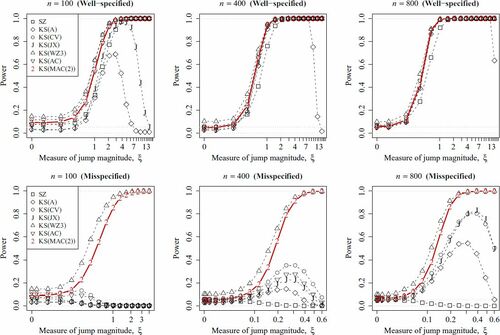
Under , all tests except KS(MAC(2)) and KS(WZ(3)) immediately lose all power when
. In particular, SZ remains powerless even when n and ξ are large. It is not desirable because SZ is very sensitive to whether the alternative hypothesis is well-specified. For KS(A), KS(CV), KS(JX), and KS(AC), they are not powerfully because of using inconsistent or inefficient estimators of
. It gives a sign of warning to use these tests in practice. It is worth emphasizing that KS(WZ3) seems more powerful than KS(MAC(2)). However, it is just because KS(WZ3) rejects too frequently no matter H0 is true or not. Hence, the apparently more powerful KS(WZ3) test is not reliable. Among all tests above, our proposed test KS(MAC(2)) is the only monotonically powerful test that has accurate size and is insensitive to misspecification of the alternative hypothesis.
6 Empirical Studies
6.1 Change Point Detection in S&P 500 Index
The Standard & Poor’s 500 (S&P 500) Index is a stock market index based on 500 representative companies in the USA. The daily adjusted close prices of the index, from 3 January 2006 to 30 December 2011 (n = 1511), are investigated. The dataset can be downloaded from http://finance.yahoo.com/quote/%5EGSPC/history. The financial crisis in 2008 is believed to have a tremendous impact on the global stock market. We suspect that it led to an abrupt change in the stock market. Testing this claim is important since a noncontinuous impact implies that the economy may have a structural change.
Denote the logarithm of the S&P 500 Index by Yi. Observe that there is an obvious trend in Yi (see ). A standard approach is to study the return series to get rid of the trend component. This differencing step is essential for many standard CP tests, for example, SZ and KS tests presented in Section 5.4, because they cannot handle trends. Using the CUMSUM-type CP estimator
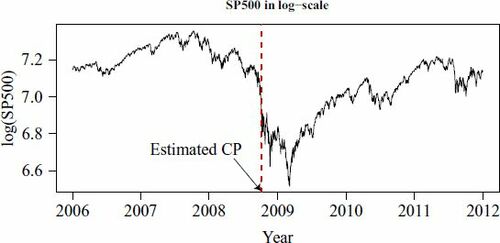
(see (1) of the supplementary materials for its formula), we estimate the CP to be 10 March 2009. It is remarked that the same CP is detected by the method described in Altissimoa and Corradic (Citation2003). Hence, the CP test fails to capture the 2008 financial crisis. Indeed, testing H0: “
” by the KS(MAC) test defined in Section 5.4, we fail to reject H0 at 5% level. We conclude that the 2008 financial crisis has no jump impact on the return yi. Since taking the difference of Yi may cancel out the potential jump effect, it seems desirable to analyze Yi directly (see Vogelsang Citation1999 for a similar analysis). Using the CP test proposed by Wu and Zhao (Citation2007), we can test H0: “The mean function
is continuous” against H1: “The mean function
has a jump-discontinuity.” The test statistic is
where
is a consistent estimator of
, that is, the AVC of
; and
. Then H0 is rejected if Qn is large. Using MAC(2) to estimate σ, we obtain
; and found that H0 is rejected at any reasonable level. It is remarked that σ is estimated to be 0.0434 by using the estimator WZ3. Although this estimate is a bit smaller than our proposed estimate, the same conclusion for testing H0 is obtained if this estimate is used in the test statistic Qn. Although Wu and Zhao (Citation2007) did not provide any estimator of the CP, they argue that if i + 1 is a discontinuity point, then the difference of the averages inside the statistic Qn should be large. Following their idea,
is a reasonable estimator of the CP. The estimated CP,
, is 7 October 2008 (see ). It indicates the 2008 financial crisis quite accurately. It coincides with our understanding of the stock market.
Fig. 7 Time series plot of , that is, the daily S&P 500 Index (3 January 2006–30 December 2011) in the log scale (see Section 6.1). The vertical dotted line indicates the value of
estimated by the statistic in Wu and Zhao (Citation2007). Here
is estimated by MAC(2).
6.2 Simultaneous Change Point Detection in Several Indices
Besides S&P 500 Index mentioned in Section 6.1, there are several other stock market indices that are commonly used by traders, for example, Dow Jones Index, Nasdaq Composite, and Russell 2000. In this subsection, we investigate whether we can make use of these four market indices simultaneously to make a more precise detection of the 2008 financial crisis.
Consider the squared daily returns, which can be used as proxies for daily volatilities, of the aforementioned four indices in the period 1 July 2008–30 December 2008 (see ). Applying the CUSUM-type CP estimator (see (1) of the supplementary materials for its formula) to each index individually, we obtain the same CP 29 September 2018. It is remarked that the no CP null hypothesis is rejected at 5% level by the test KS(MAC(2)) for each individual index.
Fig. 8 The squared returns of four stock indices (1 July 2008–30 December 2008) (see Section 6.2). The two vertical lines denote the CP locations. The earlier and later CPs are detected by the multivariate and univariate CUSUM CP estimators, respectively.
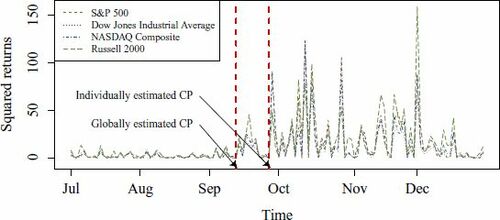
Since these stock market indices are highly correlated and are believed to follow the market trend very closely, a CP (if any) is likely to appear simultaneously. Hence, using multivariate time series for detecting a CP can be more accurate and precise. Applying the multivariate version of the KS CP test (Horváth, Kokoszka, and Steinebach Citation1999) to the four indices, we detect the CP to be 15 September 2008. From , the squared returns between 15 and 29 September are slightly higher than the first portion of the series. Hence, using multivariate time series helps detecting these small changes. Consequently, multivariate tests are potentially more useful in practice. It is also remarked that the no simultaneous CP alternative is rejected at 5% level by the CP test (Horváth, Kokoszka, and Steinebach Citation1999) with our proposed MAC(2) estimator.
7 Conclusions
In this article, we propose an estimator of the ACM in nonstationary time series. The estimator has several desirable features: (i) it is robust against unknown trends and a divergent number of jumps; (ii) it is optimal in the sense that an asymptotically correct optimal bandwidth can be implemented robustly; (iii) it is statistically efficient since it has the optimal convergence rate for different strength of serial dependence; (iv) it is computationally fast because neither numerical optimization, trend estimation, nor CPs detection is required; and (v) it is handy because its formula can be as simple as (24).
Some applications of the estimator are illustrated. In particular, we found that the CP test equipped with the proposed estimator is the only available test which is monotonically powerful and insensitive to a misspecified alternative hypothesis.
Supplementary Materials
Supplementary materials include graphical illustration, additional simulation results, and proofs. The R-package MAC for computing the proposed estimator is also provided.
Supplemental Material
Download Zip (754.5 KB)Acknowledgments
The author thanks the editor Christian Hansen, the associate editor, and two reviewers for their detailed and insightful comments. The author also gratefully thanks Neil Shephard for his helpful advice on improving the estimator as well as Xiao-Li Meng, Jim Stock and Pierre Jacob for fruitful discussions.
Additional information
Funding
Related Research Data
References
- Altissimoa, F., and Corradic, V. (2003), “Strong Rules for Detecting the Number of Breaks in a Time Series,” Journal of Econometrics, 117, 207–244. DOI: https://doi.org/10.1016/S0304-4076(03)00147-7.
- Anderson, T. W. (1971), The Statistical Analysis of Time Series, New York: Wiley.
- Andrews, D. W. K. (1991), “Heteroskedasticity and Autocorrelation Consistent Covariance Matrix Estimation,” Econometrica, 59, 817–858. DOI: https://doi.org/10.2307/2938229.
- Banerjeea, A., and Urga, G. (2005), “Modelling Structural Breaks, Long Memory and Stock Market Volatility: An Overview,” Journal of Econometrics, 19, 1–34. DOI: https://doi.org/10.1016/j.jeconom.2004.09.001.
- Barndorff-Nielsen, O. E., and Shephard, N. (2004), “Power and Bipower Variation With Stochastic Volatility and Jumps,” Journal of Financial Econometrics, 2, 1–37. DOI: https://doi.org/10.1093/jjfinec/nbh001.
- Brockwell, P. J., and Davis, R. A. (1991), Time Series: Theory and Methods, New York: Springer.
- Brown, R. L., Durbin, J., and Evans, J. M. (1975), “Techniques for Testing the Constancy of Regression Relationships Over Time,” Journal of the Royal Statistical Society, Series B, 37, 149–192. DOI: https://doi.org/10.1111/j.2517-6161.1975.tb01532.x.
- Carlstein, E. (1986), “The Use of Subseries Values for Estimating the Variance of a General Statistic From a Stationary Sequence,” The Annals of Statistics, 14, 1171–1179. DOI: https://doi.org/10.1214/aos/1176350057.
- Chan, K. W., and Yau, C. Y. (2016), “New Recursive Estimators of the Time-Average Variance Constant,” Statistics and Computing, 26, 609–627. DOI: https://doi.org/10.1007/s11222-015-9548-7.
- Chan, K. W., and Yau, C. Y. (2017a), “Automatic Optimal Batch Size Selection for Recursive Estimators of Time-Average Covariance Matrix,” Journal of the American Statistical Association, 112, 1076–1089.
- Chan, K. W., and Yau, C. Y. (2017b), “High Order Corrected Estimator of Asymptotic Variance With Optimal Bandwidth,” Scandinavian Journal of Statistics, 44, 866–898.
- Crainiceanu, C. M., and Vogelsang, T. J. (2007), “Nonmonotonic Power for Tests of a Mean Shift in a Time Series,” Journal of Statistical Computation and Simulation, 77, 457–476. DOI: https://doi.org/10.1080/10629360600569394.
- Csörgö, M., and Horváth, L. (1997), Limit Theorems in Change-Point Analysis, New York: Wiley.
- Davies, R. B., and Harte, D. S. (1987), “Tests for Hurst Effect,” Biometrika, 74, 95–101. DOI: https://doi.org/10.1093/biomet/74.1.95.
- Degras, D., Xu, Z., Zhang, T., and Wu, W. B. (2012), “Testing for Parallelism Among Trends in Multiple Time Series,” IEEE Transactions on Signal Processing, 60, 1087–1097. DOI: https://doi.org/10.1109/TSP.2011.2177831.
- Dette, H., Munk, A., and Wagner, T. (1998), “Estimating the Variance in Nonparametric Regression—What Is a Reasonable Choice?,” Journal of the Royal Statistical Society, Series B, 60, 751–764. DOI: https://doi.org/10.1111/1467-9868.00152.
- Flegal, J. M., and Jones, G. L. (2010), “Batch Means and Spectral Variance Estimation in Markov Chain Monte Carlo,” The Annals of Statistics, 38, 1034–1070. DOI: https://doi.org/10.1214/09-AOS735.
- Gallant, A. R., and White, H. (1988), A Unified Theory of Estimation and Inference for Nonlinear Dynamic Models, New York: Basil Blackwell.
- Gonçalves, S., and White, H. (2002), “The Bootstrap of the Mean for Dependent Heterogeneous Arrays,” Econometric Theory, 18, 1367–1384. DOI: https://doi.org/10.1017/S0266466602186051.
- Grangera, C. W. J., and Hyung, N. (2004), “Occasional Structural Breaks and Long Memory With an Application to the S&P 500 Absolute Stock Returns,” Journal of Empirical Finance, 11, 399–421.
- Hall, P., and Horowitz, J. (2013), “A Simple Bootstrap Method for Constructing Nonparametric Confidence Bands for Functions,” The Annals of Statistics, 41, 1892–1921. DOI: https://doi.org/10.1214/13-AOS1137.
- Hall, P., Kay, J. W., and Titterinton, D. M. (1990), “Asymptotically Optimal Difference-Based Estimation of Variance in Nonparametric Regression,” Biometrika, 77, 521–528. DOI: https://doi.org/10.1093/biomet/77.3.521.
- Hirukawa, M. (2010), “A Two-Stage Plug-In Bandwidth Selection and Its Implementation for Covariance Estimation,” Econometric Theory, 26, 710–743. DOI: https://doi.org/10.1017/S0266466609990089.
- Horváth, L., Kokoszka, P., and Steinebach, J. (1999), “Testing for Changes in Multivariate Dependent Observations With an Application to Temperature Changes,” Journal of Multivariate Analysis, 68, 96–119. DOI: https://doi.org/10.1006/jmva.1998.1780.
- Jirak, M. (2015), “Uniform Change Point Tests in High Dimension,” The Annals of Statistics, 43, 2451–2483. DOI: https://doi.org/10.1214/15-AOS1347.
- Juhl, T., and Xiao, Z. (2009), “Tests for Changing Mean With Monotonic Power,” Journal of Econometrics, 148, 12–24. DOI: https://doi.org/10.1016/j.jeconom.2008.08.020.
- Kirch, C., Muhsal, B., and Ombao, H. (2015), “Detection of Changes in Multivariate Time Series With Application to EEG Data,” Journal of the American Statistical Association, 110, 1197–1216. DOI: https://doi.org/10.1080/01621459.2014.957545.
- Künsch, H. R. (1989), “The Jackknife and the Bootstrap for General Stationary Observations,” The Annals of Statistics, 17, 1217–1241.
- Lahiri, S. N. (2003), Resampling Methods for Dependent Data, New York: Springer.
- Lazarus, E., Lewis, D. J., Stock, J. H., and Watson, M. W. (2018), “HAR Inference: Recommendations for Practice,” Journal of Business & Economic Statistics, 36, 541–559. DOI: https://doi.org/10.1080/07350015.2018.1506926.
- Liu, W., and Wu, W. B. (2010), “Asymptomatic of Spectral Density Estimates,” Econometric Theory, 26, 1218–1245. DOI: https://doi.org/10.1017/S026646660999051X.
- Liu, Y., and Flegal, J. M. (2018), “Weighted Batch Means Estimators in Markov Chain Monte Carlo,” Electronic Journal of Statistics, 12, 3397–3442. DOI: https://doi.org/10.1214/18-EJS1483.
- Meketon, M. S., and Schmeiser, B. (1984), “Overlapping Batch Means: Something for Nothing?,” in Proceedings of the 16th Conference on Winter Simulation, pp. 226–230.
- Mikkonen, S., Laine, M., Mäkelä, H. M., Gregow, H., Tuomenvirta, H., Lahtinen, M., and Laaksonen, A. (2014), “Trends in the Average Temperature in Finland, 1847–2013,” Stochastic Environmental Research and Risk Assessment, 29, 1521–1529. DOI: https://doi.org/10.1007/s00477-014-0992-2.
- Müller, U. K. (2014), “HAC Corrections for Strongly Autocorrelated Time Series,” Journal of Business & Economic Statistics, 32, 311–322. DOI: https://doi.org/10.1080/07350015.2014.931238.
- Newey, W. K., and West, K. D. (1987), “A Simple, Positive Semi-Definite, Heteroskedasticity and Autocorrelation Consistent Covariance Matrix,” Econometrica, 55, 703–708. DOI: https://doi.org/10.2307/1913610.
- Newey, W. K., and West, K. D. (1994), “Automatic Lag Selection in Covariance Matrix Estimation,” The Review of Economic Studies, 61, 631–653.
- Paparoditis, E., and Politis, D. N. (2001), “Tapered Block Bootstrap,” Biometrika, 88, 1105–1119. DOI: https://doi.org/10.1093/biomet/88.4.1105.
- Phillips, P. C. B. (2005), “HAC Estimation by Automated Regression,” Econometric Theory, 21, 116–142. DOI: https://doi.org/10.1017/S0266466605050085.
- Ploberger, W., and Krämer, W. (1992), “The CUSUM Test With OLS Residuals,” Econometrica, 60, 271–285. DOI: https://doi.org/10.2307/2951597.
- Politis, D. N. (2003), “Adaptive Bandwidth Choice,” Journal of Nonparametric Statistics, 15, 517–533. DOI: https://doi.org/10.1080/10485250310001604659.
- Politis, D. N. (2011), “Higher-Order Accurate, Positive Semidefinite Estimation of Large-Sample Covariance and Spectral Density Matrices,” Econometric Theory, 27, 703–744.
- Politis, D. N., and Romano, J. P. (1994), “The Stationary Bootstrap,” Journal of the American Statistical Association, 89, 1303–1313. DOI: https://doi.org/10.1080/01621459.1994.10476870.
- Politis, D. N., Romano, J. P., and Wolf, M. (1999), Subsampling, New York: Springer.
- Rosenblatt, M. (1985), Stationary Sequences and Random Fields, Boston: Birkhäuser.
- Shao, X., and Zhang, X. (2010), “Testing for Change Points in Time Series,” Journal of the American Statistical Association, 105, 1228–1240. DOI: https://doi.org/10.1198/jasa.2010.tm10103.
- Song, W. T., and Schmeiser, B. W. (1995), “Optimal Mean-Squared-Error Batch Sizes,” Management Science, 41, 110–123. DOI: https://doi.org/10.1287/mnsc.41.1.110.
- Sun, Y. (2013), “Heteroscedasticity and Autocorrelation Robust F Test Using Orthonormal Series Variance Estimator,” Econometrics Journal, 16, 1–26. DOI: https://doi.org/10.1111/j.1368-423X.2012.00390.x.
- Vogelsang, T. J. (1999), “Sources of Nonmonotonic Power When Testing for a Shift in Mean of a Dynamic Time Series,” Journal of Econometrics, 88, 283–299. DOI: https://doi.org/10.1016/S0304-4076(98)00034-7.
- Wu, W. B. (2004), “A Test for Detecting Changes in Mean,” in Time Series Analysis and Applications to Geophysical Systems, eds. D. R. Brillinger, E. A. Robinson, and F. Schoenberg (Vol. 139), New York: Springer-Verlag, pp. 105–122.
- Wu, W. B. (2005), “Nonlinear System Theory: Another Look at Dependence,” Proceedings of the National Academy of Sciences of the United States of America, 102, 14150–14154.
- Wu, W. B. (2007), “Strong Invariance Principles for Dependent Random Variables,” The Annals of Probability, 35, 2294–2320.
- Wu, W. B. (2011), “Asymptotic Theory for Stationary Processes,” Statistics and Its Interface, 4, 207–226.
- Wu, W. B., Woodroofe, M., and Mentz, G. (2001), “Isotonic Regression: Another Look at the Change Point Problem,” Biometrika, 88, 793–804. DOI: https://doi.org/10.1093/biomet/88.3.793.
- Wu, W. B., and Zaffaroni, P. (2018), “Asymptotic Theory for Spectral Density Estimates of General Multivariate Time Series,” Econometric Theory, 34, 1–22. DOI: https://doi.org/10.1017/S0266466617000068.
- Wu, W. B., and Zhao, Z. (2007), “Inference of Trends in Time Series,” Journal of the Royal Statistical Society, Series B, 69, 391–410. DOI: https://doi.org/10.1111/j.1467-9868.2007.00594.x.