
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Economists are often interested in estimating averages with respect to distributions of unobservables, such as moments of individual fixed-effects, or average partial effects in discrete choice models. For such quantities, we propose and study posterior average effects (PAE), where the average is computed conditional on the sample, in the spirit of empirical Bayes and shrinkage methods. While the usefulness of shrinkage for prediction is well-understood, a justification of posterior conditioning to estimate population averages is currently lacking. We show that PAE have minimum worst-case specification error under various forms of misspecification of the parametric distribution of unobservables. In addition, we introduce a measure of informativeness of the posterior conditioning, which quantifies the worst-case specification error of PAE relative to parametric model-based estimators. As illustrations, we report PAE estimates of distributions of neighborhood effects in the U.S., and of permanent and transitory components in a model of income dynamics.
1 Introduction
In many settings, applied researchers wish to estimate population averages with respect to a distribution of unobservables. This includes moments of individual fixed-effects in panel data, and average partial effects in discrete choice models, which are expectations with respect to some distribution of shocks or heterogeneity. The standard approach in applied work is to assume a parametric form for the distribution of unobservables, and to compute the average effect under that assumption. For example, in binary choice, researchers often assume normality of the error term, and compute average partial effects under normality. This “model-based” estimation of average effects is justified under the assumption that the parametric model is correctly specified.
In this article, we consider a different approach, where the average effect is computed conditional on the observation sample. We refer to such estimators as “posterior average effects” (PAE). Posterior averaging is appealing for prediction purposes, and it plays a central role in Bayesian and empirical Bayes (EB) approaches (e.g., Berger Citation1980; Morris Citation1983). Here, we focus instead on the estimation of population expectations. Our goal is twofold: to propose a novel class of estimators, and to provide a frequentist framework to understand when and why posterior conditioning may be useful in estimation. Our main result will show that PAE have robustness properties when the parametric model is misspecified.
PAE are closely related to EB estimators, which are increasingly popular in applied economics. Consider a fixed-effects model of teacher quality, which is our main example. When the number of observations per teacher is small, the dispersion of teacher fixed-effects is likely to overstate that of true teacher quality, since teacher effects are estimated with noise. An alternative approach is to postulate a prior distribution for teacher quality—typically, a normal—and report posterior estimates, holding fixed the values of the mean and variance parameters. The hope is that such EB estimates, which are shrunk toward the prior, are less affected by noise than the teacher fixed-effects (e.g., Kane and Staiger Citation2008; Chetty et al. Citation2014; Angrist et al. Citation2017). However, while EB estimates are well-justified predictors of the quality of individual teachers, it is not obvious how to aggregate them across teachers when the goal is to estimate a population average such as a moment or a distribution function.
As an example, suppose we wish to estimate the distribution function of teacher quality evaluated at a point. Since this quantity is an average of indicator functions, the PAE is simply an average of posterior means—that is, of EB estimates—of the indicator functions. This estimator is available in closed form. However, the PAE differs from the empirical distribution of the EB estimates of teacher effects. In particular, while the variance of EB estimates is too small relative to that of latent teacher quality, the PAE has the correct variance. Related applications of PAE include settings involving neighborhood/place effects (Chetty and Hendren Citation2018; Finkelstein et al. Citation2017) or hospital quality (Hull Citation2018).
Importantly, although posterior averages have desirable properties for predicting individual parameters, their usefulness for estimating population average quantities is not evident. For example, suppose that teacher quality is normally distributed. In this case, a model-based normal estimator of the distribution of teacher quality is consistent. Moreover, it is asymptotically efficient when means and variances are estimated by maximum likelihood. Hence, in the correctly specified case, there is no reason to deviate from the standard model-based approach and compute posterior estimators. The main insight of this article is that, under misspecification—for example, when teacher quality is not normally distributed—conditioning on the data using PAE can be beneficial.
To study estimators under misspecification, we focus on specification error, which is the population discrepancy between the probability limit of an estimator and the true parameter value. In our main results, we show that PAE have minimum worst-case specification error, where the worst case is computed in a nonparametric neighborhood of the reference parametric distribution (e.g., a normal). Specifically, we show that, when neighborhoods are defined in terms of the Pearson chi-squared divergence, PAE have minimum worst-case specification error within a large class of estimators, for any neighborhood size smaller than a threshold value that we characterize. In addition, when broadening the class of neighborhoods to -divergences, we show that, while PAE do not have minimum worst-case specification error in general in fixed-size neighborhoods, they achieve minimum worst-case specification error under local misspecification, that is, when the size of the neighborhood tends to zero.
In our examples and illustrations, we find that the information contained in the posterior conditioning is setting-specific. This is intuitive, since although PAE have minimum worst-case specification error under our conditions, the specification error is not zero in general and it varies between applications. PAE tend to behave better when the realizations of outcome variables (such as test scores) are more informative about the values of the unobservables (such as the quality of a teacher). Consistently with this intuition, our local result suggests quantifying the “informativeness” of the posterior conditioning using an easily computable R2 coefficient.
While our theoretical results focus on population specification error, in practice PAE are also affected by sampling error, due to the fact that the sample size—for example, the number of teachers—is not infinite. A common approach to account for both sampling variability and specification error is to focus on mean squared error. In general, PAE do not have minimum mean squared error: indeed, in finite samples, model-based estimators can have smaller mean squared error than PAE. In Bonhomme and Weidner (Citation2018), we show how to construct estimators that minimize mean squared error under local asymptotic misspecification. However, such estimators depend on the neighborhood size. In contrast, PAE do not require taking a stand on the degree of misspecification through the size of the neighborhood, and they are simple to implement and do not depend on tuning parameters. To complement the theory, we report the results of a Monte Carlo simulation, where we compare the performance of the PAE to those of a model-based estimator and a nonparametric deconvolution-based estimator. We find that, while the model-based estimator tends to perform best under correct specification, the performance of the PAE appears less sensitive to misspecification than those of the model-based and nonparametric estimators.
To illustrate the scope of PAE for applications, we then consider two empirical settings. In the first one, we study the estimation of neighborhood/place effects in the United States. Chetty and Hendren (Citation2018) reported estimates of the variance of neighborhood effects, as well as EB estimates of those effects. Our goal is to estimate the distribution of effects across neighborhoods. We find that, when using a normal prior as in Chetty and Hendren (Citation2018), our posterior estimator of the distribution function of neighborhood effects across commuting zones is not normal. However, we also show through simulations and computation of our posterior informativeness measure that the signal-to-noise ratio in the data is not high enough to be confident about the exact shape of the distribution. Hence, in this setting, PAE inform our knowledge of the distribution of neighborhood effects, and motivate future analyses using more flexible model specifications and individual-level data.
In the second empirical illustration, our goal is to estimate the distributions of latent components in a permanent-transitory model of income dynamics (e.g., Hall and Mishkin Citation1982; Blundell et al. Citation2008), where log-income is the sum of a random-walk component and a component that is independent over time. Researchers often estimate the covariance structure of the latent components in a first step. Then, in order to document distributions or to use the income process in a consumption-saving model, they often assume Gaussianity. However, there is increasing evidence that income components are not Gaussian (e.g., Geweke and Keane Citation2000; Hirano Citation2002; Bonhomme and Robin Citation2010; Guvenen et al. Citation2016). We estimate posterior distribution functions of permanent and transitory income components using recent waves from the Panel Study of Income Dynamics (PSID). Our PAE estimates suggest some departure from Gaussianity, especially for the transitory income component.
We analyze several extensions. First, we describe the form of PAE in several models, including binary choice and censored regression. Second, we discuss how to construct confidence intervals and specification tests based on PAE. Lastly, we revisit the question of optimality of EB estimates for predicting individual parameters. By extending our misspecification analysis from worst-case specification error of sample averages to worst-case mean squared prediction error, we show that EB estimators remain optimal, up to small-order terms, under local deviations from normality.
1.1 Related Literature and Outline
PAE are closely related to parametric EB estimators (Efron and Morris Citation1973; Morris Citation1983). For the recent econometric applications of shrinkage methods (James and Stein Citation1961; Efron Citation2012), see Hansen (Citation2016), Fessler and Kasy (Citation2018), and Abadie and Kasy (Citation2018). Recent contributions to nonparametric EB methods are Koenker and Mizera (Citation2014) and Ignatiadis and Wager (Citation2019).
Our analysis is also related to deconvolution and other nonparametric approaches. However, in our framework we allow for forms of misspecification under which the quantity of interest is not consistently estimable, and we search for estimators that have the smallest specification error.
In panel data settings, Arellano and Bonhomme’s (Citation2009) study the asymptotic properties of random-effects estimators of averages of functions of covariates and individual effects. They show that, when the distribution of individual effects is misspecified, whereas the other features of the model are correctly specified, PAE are consistent as n and T tend to infinity. By contrast, in our setup, only n tends to infinity, and misspecification may affect the entire joint distribution of unobservables.
Our analysis also connects to the literature on robustness to model misspecification (e.g., Huber and Ronchetti Citation2009; Kitamura et al. Citation2013; Andrews et al. Citation2017, Citation2020; Armstrong and Kolesár Citation2018; Bonhomme and Weidner Citation2018; Christensen and Connault Citation2019). Here, our aim is to propose and justify a class of simple, practical estimators.
The plan of the article is as follows. In Section 2, we motivate the analysis by considering a fixed-effects model of teacher quality. In Section 3, we present our framework and derive our main theoretical results. In Section 4, we illustrate the use of PAE in two empirical settings. In Section 5, we describe several extensions. Finally, we conclude in Section 6. Replication codes are available as online material.
2 Motivating Example: A Fixed-Effects Model
To motivate the analysis, we start by considering the following model:(1)
(1)
To fix ideas, we will think of Yij as an average test score of teacher i in classroom j, αi as the quality of teacher i, and as a classroom-specific shock. There are n teachers and J observations per teacher. For simplicity, we abstract away from covariates (such as students’ past test scores), but those will be present in the framework we will introduce in the next section. Although here we focus on teacher effects, this model is of interest in other settings, such as the study of neighborhood effects, school effectiveness, or hospital quality, for example.
Suppose we wish to estimate a feature of the distribution of teacher quality α. As an example, here we consider the distribution function of α at a particular point a,which is the percentage of teachers whose quality is below a. A first estimator is the empirical distribution of the fixed-effects estimates
, for all teachers
; that is,
(2)
(2)
where FE stands for “fixed-effects.” An obvious issue with this estimator is that
is a noisy estimate of αi, where
. Indeed, due to the presence of noise, for fixed J and n tends to infinity the distribution
tends to be too dispersed relative to
(although one can show that
is consistent for
as J tends to infinity jointly with n under mild conditions; see Jochmans and Weidner Citation2018).
A different strategy is to model the joint distribution of . A simple specification is a multivariate normal distribution with means
and
, and variances
and
. This specification can easily be made more flexible by allowing for different
’s across j, for correlation between the different
’s, or for means and variances being functions of covariates, for example. Under the assumption that all components are uncorrelated,
, and
can be consistently estimated for fixed J as n tends to infinity, using quasi-maximum likelihood or minimum distance based on mean and covariance restrictions.
Given estimates , we can compute EB estimates (Morris Citation1983) of the αi as
(3)
(3) where the expectation is taken with respect to the posterior distribution of α given Y = Yi for
fixed, and
is a shrinkage factor. Here, Yi are vectors containing all Yij,
. The EB estimates in (3) are well-justified as predictors of the αi, since (when treating
as fixed)
is the minimum mean squared error predictor of αi under normality.
Given their rationale for prediction purposes, it is appealing to try and aggregate the EB estimates in order to estimate our target quantity . A possible estimator is
(4)
(4) where PM stands for “posterior means.” For fixed J as n tends to infinity, the EB estimates tend to be less dispersed than the true αi, and
is inconsistent in general. Indeed, while in large samples the variance of the fixed-effects estimates is
, the variance of the EB estimates is
, where
.
Instead of computing the distribution of EB estimates as in EquationEquation (4)(4)
(4) , a related idea is to compute the posterior distribution estimator
where P stands for “posterior.” Using the normality assumption, we obtain(5)
(5) where
denotes the distribution function of the standard normal.
is an example of a PAE. One can check that it is consistent for fixed J as n tends to infinity, when the distribution of
is normal. Under nonnormality,
is generally inconsistent for fixed J as n tends to infinity. Moreover, the mean and variance of
are
and
, respectively, which are consistent for
and
for fixed J as n tends to infinity.
The last estimator we consider here is directly based on the normal specification for α,(6)
(6) where M stands for “model.” This estimator enjoys attractive properties when the distribution of
is indeed normal. In this case,
is consistent for fixed J as n tends to infinity, and it is efficient when
and
are maximum likelihood estimates. Moreover, the mean and variance of
are
and
, which are consistent irrespective of normality. However, when
is not normally distributed,
is generally inconsistent for fixed J as n tends to infinity. Moreover,
only depends on the data through the mean
and the variance
. In particular,
is always normal, even when the data show clear evidence of nonnormality.
Which one of these estimators should one use? The answer is not obvious, since they are all inconsistent as n tends to infinity for fixed J in general. In a framework that allows for misspecification of the normal distribution of , we will show that the PAE
has minimum worst-case specification error in certain neighborhoods around the normal reference distribution. To our knowledge, unlike the other three estimators above, posterior estimators of distributions are novel to practitioners. They are easy to implement, and do not depend on additional tuning parameters. Our characterization provides a rationale for reporting them in applications, alongside other parametric and semiparametric estimators.
Note that one may wish to relax normality by making the specification of α, and possibly , more flexible. Deconvolution and nonparametric maximum likelihood estimators are often used for this purpose (e.g., Delaigle et al. Citation2008; Bonhomme and Robin Citation2010; Koenker and Mizera Citation2014). While these estimators may be consistent even when α is not normal, consistency relies on additional restrictions on the model. For example, the assumptions in Kotlarski (Citation1967) require that α,
, …,
be mutually independent. By contrast, we do not impose any such additional conditions in our framework. In Section 3, we will show that asymptotically linear estimators have larger specification error than PAE under the form of misspecification that we consider.
To illustrate that an independence assumption among α, , …,
can be restrictive, consider a situation where the researcher is concerned that the variance of
depends on α. For instance, the variance of classroom-level shocks may depend on teacher quality. The presence of such conditional heteroscedasticity would invalidate conventional nonparametric deconvolution estimators. By contrast, we will show that
has minimum specification error in neighborhoods of distributions that allow for conditional heteroscedasticity. In Section 4 and the appendix, we will compare the finite-sample behavior of the parametric model-based estimator, the PAE, and a nonparametric deconvolution estimator, in data simulated from various specifications of model (1).
In model (1), the researcher may be interested in estimating other quantities. As an example, consider the coefficient in the population regression of teacher quality α on a vector of covariates W; that is,(7)
(7)
In applications, it is common to regress fixed-effects estimates on covariates to help interpret them (as in Dobbie and Fryer Citation2013; among many others), and to compute(8)
(8)
Alternatively, one may regress the EB estimates of αi, as given by (3), on covariates (as in Angrist et al. Citation2017, and Hull Citation2018, for example), and compute(9)
(9) which is a PAE based on a normal reference specification for α. We will see that, in our framework, the rationale for reporting
or
depends on the form of misspecification that the researcher is concerned about.
The framework we describe next applies to the estimation of different quantities in a variety of settings. In Section 4 we apply PAE to model (1) and estimate the distribution of neighborhood/place effects in the U.S. (Chetty and Hendren Citation2018). In addition, we show that the permanent-transitory model of income dynamics (e.g., Hall and Mishkin Citation1982) has a structure similar to model (1), and we report PAE estimates in this context. Last, in other models—such as static or dynamic discrete choice models and models with censored outcomes—our results motivate the use of PAE as complements to other estimators that researchers commonly report, and we provide examples in Section 5 and analyze them in the appendix.
3 Framework and Main Results
In this section we describe our framework to study PAE, and present our main results.
3.1 Model-Based Estimators and PAE
We consider the following class of models:(10)
(10) where outcomes Yi and covariates Xi are observed by the researcher, and Ui are unobserved. The function
is known up to the finite-dimensional parameter β. Our aim is to estimate an average effect of the form
(11)
(11)
where
is scalar, and known given β. Here, f0 denotes the true density of
. The expectation is taken with respect to the product
, where fX is the marginal density of X. For conciseness we leave the dependence on fX implicit. While we focus on a scalar
, our results continue to hold in the vector-valued case, as we show at the end of this section. In Appendix S5, we discuss how to estimate quantities that depend on f0 nonlinearly.
While the researcher does not know the true f0, she has a reference parametric density for
, which depends on a finite-dimensional parameter σ. We will allow
to be misspecified, in the sense that f0 may not belong to
. However, we will always assume that
is correctly specified. In other words, misspecification will only affect the distribution of U and its dependence on X, not the structural link between (U, X) and outcomes.
To estimate in Equaiton (11), we assume that the researcher has an estimator
that remains consistent for β under misspecification of
. More precisely, we will only consider potential true densities f0 such that
tends in probability to the true value β under f0. For example, in the fixed-effects model (1), consistent estimates of means and variances can be obtained in the absence of normality.
To map model (1) to the general notation of this section, note that in this case there are no covariates X, and the vector of unobservables U is
The vector β is . The reference distribution for U is a standard multivariate normal, so the reference density
is known in this case — in other words, the parameter σ in
can be omitted. We assume that the researcher has computed an estimator
, for example by quasi-maximum likelihood or minimum distance, which remains consistent for β when U is not normally distributed.
In certain applications, the reference density depends on some parameters σ that cannot be consistently estimated absent parametric assumptions. In Appendix S6, we describe discrete choice and censored regression models that have this structure. In such settings, we assume that the researcher has an estimator that tends in probability to some
under f0. Unlike β, the parameter
is a model-specific “pseudo-true value” that is not assumed to have generated the data. However, in our leading example of model (1), as well as in the model’s generalizations that we study in our empirical illustrations in Section 4, the references to
and
can be omitted from all subsequent statements and derivations.
Given , a sample
from (Y, X), and the parametric density
, a model-based estimator of
is
(12)
(12) where, with some abuse of notation, the expectation with respect to
is computed only over U. When not available in closed form, this estimator can be computed by numerical integration or simulation under the parametric density
. It is easy to see that, under standard conditions,
is consistent for
under correct specification; that is, when
is the true density of
.
To construct a posterior estimator, consider the posterior density of
. This posterior density is computed using Bayes rule, based on the prior
on
and the likelihood of
implied by
. Formally, let
. We define, whenever the denominator is non-zero,
(13)
(13)
We will compute analytically in our examples. In Appendix S5 we describe a simulation-based computational approach when an analytical expression is not available. We define the PAE as the posterior estimator
(14)
(14) where, again, the expectation is only taken over U. Under standard regularity conditions, it is easy to see that, like
, the PAE
is consistent for
under correct specification.
From a Bayesian perspective, is a natural estimator to consider when β and σ are known. Indeed,
is then the posterior mean of
, where the prior on Ui is
, independent across i. An alternative Bayesian interpretation is obtained by specifying a nonparametric prior on f0, and computing the posterior mean of
under this prior, as we discuss in Appendix S5 in the case where U has finite support. However, a frequentist justification for
appears to be lacking in the literature. Indeed, under correct specification of
, both estimators
and
are consistent, and, as we pointed out in the previous section,
may have a higher variance than
. The key difference between model-based and posterior estimators is that
is conditional on the observation sample. An intuitive rationale for the conditioning is the recognition that realizations Yi may be informative about the values of the unknown Ui’s. We next formalize this intuition in a framework that accounts for specification error.
3.2 Neighborhoods, Estimators, and Worst-Case Specification Error
Let denote the true density of (Y, U, X), where as before we omit the reference to the marginal density of X for conciseness. We assume that, under
is consistent for the true β, and
is consistent for a model-specific “pseudo-true” value
, where
for some moment function ψ. For example,
and
may be the method-of-moments estimators that solve
. In models with no σ parameters, such as model (1) and its generalizations, we only assume that
is consistent for β, and that
for some ψ. Throughout, we take the estimators
(and possibly
), and the moment function ψ, as given. In particular, we do not address the question of optimal estimation of β under misspecification.
Given a distance measure d and a scalar , we define the following neighborhood of the reference density
:
This neighborhood consists of densities of that are at most ϵ away from
, and under which
and
converge asymptotically to β and
, respectively. The case ϵ = 0 corresponds to correct specification of the reference density, whereas
corresponds to misspecification.
For ease of notation we omit the dependence of on β,
, and ψ, all of which we consider fixed and given in this section. Indeed, we assume that the researcher has chosen an estimator
, and, depending on the setting, an estimator
—our theory is silent about where these choices come from—and that she has already observed their realized values in a large sample. The moment function ψ is determined by this choice of estimators. Moreover, in large samples, the population values β and
are arbitrarily close to the observed values
and
. In our setup, we only consider densities of unobservables f0 that are consistent with those values, in the sense that the moment restriction
holds. This large-sample logic is consistent with our focus on specification error; see (16) below.
Note that the same logic might suggest imposing that other features of the joint population distribution of the data (Y, X), such as means, covariances, higher-order moments, or even the entire distribution, be kept constant for all . Restricting neighborhoods in this way does not affect the results in this section, because those are valid for all possible ψ, and one could thus impose additional moment restrictions on f0.
Let us denote the supports of X and U as and
, respectively. We assume that d is a
-divergence of the form
where
is a convex function that satisfies
and
. This family contains as special cases the
divergence (averaged over X), the Kullback–Leibler divergence, the Hellinger distance, and more generally the members of the Cressie-Read family of divergences (Cressie and Read Citation1984). It is commonly used to measure misspecification, see Andrews et al. (Citation2020) and Christensen and Connault (Citation2019) for recent examples.
We focus on asymptotically linear estimators of that satisfy, for a scalar nonstochastic function γ and as n tends to infinity,
(15)
(15)
Note that depends on
, but for conciseness we leave the dependence implicit in the notation. Many estimators can be written in this form (see, e.g., Bickel et al. Citation1993). Given an estimator
, we define its ϵ-worst-case specification error as
(16)
(16)
We will take the worst-case specification error to be our measure of how well an estimator
performs under misspecification. It quantifies the maximum discrepancy, under any possible f0 in the neighborhood
, between the probability limit of the estimator and the true parameter value. Under suitable regularity conditions,
in (16) is the asymptotic bias of
under
.
By focusing on the worst-case specification error , we abstract from other sources of estimation error. Importantly, we do not account for sampling variability. In Bonhomme and Weidner (Citation2018), we study an alternative approach that consists in minimizing worst-case mean squared error under a local asymptotic — that is, as ϵ tends to zero, n tends to infinity, and ϵn tends to a positive constant. Applying this approach to the present case gives estimators that have a smaller worst-case mean squared error than PAE in general. However, unlike PAE, minimum-MSE estimators depend on ϵ, as we will discuss Subsection 3.5. Relative to such estimators, PAE do not require the researcher to take a stand on the degree of misspecification ϵ, and they are easy to implement.
3.3 Result Under Small-ϵ Misspecification
Before stating our first main result, we first characterize the worst-case specification error of estimators
for small ϵ. For conciseness, in the remainder of this section we suppress the reference to
from the notation, and we denote as
and
expectations and variances that are taken under the reference model
. All proofs are in Appendix S1.
Lemma 1.
Let . Suppose that one of the following conditions holds:
is four times continuously differentiable with
Condition (ii) of Lemma S1 in Appendix S1 holds (this alternative condition allows for unbounded γ, δ, ψ, but at the cost of stronger assumptions on
Then, as ϵ tends to zero we have
where .
To derive the formula for the worst-case specification error in Lemma 1, we maximize the specification error with respect to f0 subject to three contraints: f0 belongs to an ϵ-neighborhood of , it is such that the moment condition is satisfied at
, and it is a density. In part (i), we focus on the case where γ, δ and ψ are bounded. This is satisfied, for example, if those functions and g(u, x) are all continuous, and the domain of U and X is bounded. To accommodate situations where supports are unbounded, such as the example of Section 2, in part (ii), we allow for unbounded functions γ, δ, and ψ, which only requires existence of third moments under the reference distribution. To guarantee that
is well-defined in the unbounded case, we require a regularization of the function
for large values of r.
Lemma 1
implies that the small-ϵ specification error of the PAE is, up to smaller-order terms, proportional to the within-(Y, X) standard deviation of under the reference model:
In the fixed-effects model (1) of teacher quality, the worst-case specification error of the PAE is
where
is Owen’s T function (Owen Citation1956), and
is the standard normal density. The specification error decreases as the number J of observations per teacher increases, and tends to zero as J tends to infinity and the shrinkage factor ρ tends to one.
The next theorem, which holds for all functions , subject to regularity conditions, shows that the PAE has minimum worst-case specification error locally.
Theorem 1.
Suppose that the conditions of Lemma 1 hold, and let(17)
(17)
Then, as ϵ tends to zero we have
3.4 Result Under Fixed-ϵ Misspecification
To show our second main result, let us now focus on the case ; that is, we choose the distance measure
to be the Pearson
divergence. For this quadratic distance measure, we show that PAE satisfy a fixed-ϵ optimality result, which is valid for all values of ϵ that are smaller than
(18)
(18) where
is given by (17).
Theorem 2.
Assume that , and that
and
have finite second moments under the reference model. Then, for
, we have
In Theorem 2 we show that is an exact minimizer of the function
. This is in contrast with Theorem 1, where we relied on a small-ϵ approximation. The condition
guarantees that, for
, the constraint
is non-binding in the optimization problem over f0 in (16), implying that the problem has a simple analytic solution. Although, in many settings such as model (1), the parameter of interest
is not consistently estimable under our assumptions, Theorem 2 shows that PAE achieve the smallest possible worst-case specification error when the true distribution f0 lies sufficiently close to the reference distribution
, as measured according to the
divergence.
If the distance measure is not a
-divergence, or if
, then
is not the exact minimizer of worst-case specification error
. Moreover, in such cases the estimator with minimum worst-case specification error depends on ϵ in general. However, one can still establish a fixed-ϵ bound on worst-case specification error, as the next result shows.
Theorem 3.
Let be as in (17), and assume that
is convex with
. Then, for all
,
In Theorem 3 we establish a fixed-ϵ bound on the worst-case specification error of PAE, which holds for all and all
-divergences such that
is convex with
. The infimum is taken over all possible functions
, subject to measurability conditions, which we implicitly assume throughout the article. Although
may not minimize worst-case specification error for finite ϵ, Theorem 3 shows that its worst-case specification error is never larger than twice the minimum worst-case specification error. In addition, the factor two in Theorem 3 cannot be improved upon in general, as we show in Appendix S5 in the context of a simple binary choice model.
3.5 Discussion
In this subsection, we discuss several features and implications of our main results given by Theorems 1 and 2.
3.5.1 Uniqueness
In the absence of covariates and for known parameters β, , the proof of Theorem 1 shows that
is the unique minimizer of the first-order worst-case specification error. Likewise,
is also unique in Theorem 2. More generally, if covariates are present and the parameters β,
are estimated, then the leading order contribution of
is minimized if and only if
, for some λ and ω such that
—see part (ii) of Theorem S1 in Appendix S1 for a formal statement. Hence, while the PAE is not the unique minimizer of the local worst-case specification error in this case, any minimizer differs from the PAE by a zero-mean function of X and a linear combination of the moment function ψ. In addition,
has smallest variance within the class of minimum worst-case specification error estimators.
3.5.2 Form of Misspecification
Theorems 1 and 2 rely on specific distance measures, divergence for the latter and any member of the
-divergence family for the former. Under other distance measures, the PAE will not have minimum worst-case specification error in general.
Given a distance measure, the theorems are based on nonparametric neighborhoods that consist of unrestricted distributions of , except for the moment conditions that pin down β and
. However, if one is willing to make additional assumptions on f0 that further restrict the neighborhood, then one can construct estimators that are more robust than
within a particular class. As an example, consider the fixed-effects model (1). Suppose that, in addition to assuming that α,
,…,
are mutually uncorrelated, the researcher is willing to assume that they are fully independent. In that case, the distribution of α can be consistently estimated under suitable regularity conditions, provided
(Kotlarski Citation1967; Li and Vuong Citation1998). However, the PAE in (5) is inconsistent for fixed J as n tends to infinity. As a consequence, the PAE does not minimize worst-case specification error in a semi-parametric neighborhood that consists of distributions with independent marginals.
To elaborate further on this point, consider the coefficient in the population regression of α on a covariates vector W, see EquationEquation (7)
(7)
(7) . A possible estimator is the coefficient
in the regression of the fixed-effects estimates
on Wi, see (8). Under correct specification of the reference model,
is consistent for
. However,
may be inconsistent under the type of misspecification that we allow for, since
and W may be correlated under f0. For example, W (e.g., teacher absenteeism) may be influenced by α and factors that correlate with
. Theorem 1 shows that, under such misspecification, the PAE
in (9) has minimum worst-case specification error locally. Nevertheless, if the researcher is confident that W should not enter the outcome equation, and that it is independent of
, then it is natural to report the consistent estimator
.
3.5.3 Posterior Informativeness
Our small-ϵ calculations can be used to compare the worst-case specification errors of the PAE to that of the model-based estimator
. To see this, let
. Using Lemma 1, the ratio of the two worst-case specification errors satisfies
(19)
(19) where v(U, X) is the population residual of
on
, under the parametric reference model; that is,
, where all functions are evaluated at
, and λ is as defined in Lemma 1 for the case
. Intuitively, the robustness of
relative to
depends on how informative the outcome values Yi are for the latent individual parameters
.
In practice, we will report an empirical counterpart to the small-ϵ limit of . This quantity can be simply expressed as the R2 in the population nonparametric regression of v(U, X) on Y, X under the reference model; that is,
(20)
(20) where with some abuse of notation here v(U, X) denotes the sample residual of
on
, and expectations and variances are taken with respect to
. Using a term from Andrews et al. (Citation2020)—albeit in a different setting—we refer to R2 in EquationEquation (20)
(20)
(20) as a measure of the “informativeness” of the posterior conditioning, and we will report it in our illustrations. As an example, for
in model (1), the informativeness of the posterior conditioning is
(21)
(21)
In this case, the R2 increases with the number J of observations per teacher, and it tends to one as J tends to infinity.
3.5.4 Multi-Dimensional PAE
For simplicity, in this section, we have focused on the case where the target parameter in (11) is scalar. However, our results can be extended to multidimensional parameters. The definition of worst-case specification error in (16) is then modified to
where
is a norm over the vector space in which
and
take values.
If denotes the corresponding dual norm, then we can rewrite
, where
. Our minimum worst-case specification error results for PAE for scalar
then apply to
for every given vector v, and the minimum-specification error properties are preserved after taking the supremum over the set of vectors v with
. Thus, in the multidimensional case, PAE minimize worst-case specification error for small ϵ in the sense of Theorem 1, and for fixed ϵ under the conditions of Theorem 2. In our leading example of Section 2, suppose we are interested in the entire distribution function
. In this case, the average effect is a function indexed by a. Taking the supremum norm
over distribution functions, we obtain that, as an estimator of
, the PAE minimizes worst-case specification error under suitable conditions.
3.5.5 Mean Squared Error
While we have shown that PAE minimize worst-case specification error locally under the conditions of Theorem 1, and for fixed ϵ under the conditions of Theorem 2, PAE generally do not have minimum mean squared error (MSE). To see this, let us assume that β and are known. In a local asymptotic framework, where n tends to infinity, ϵ tends to zero, and
tends to a positive constant, and under suitable regularity conditions, we show in Appendix S5 that the estimator with minimum worst-case MSE is given by
(22)
(22) which is a linear combination between the model-based estimator and the PAE. The model-based estimator
, which has the smallest asymptotic variance, will be preferred when ϵ is small relative to
, while the PAE, which has smallest specification error, will be preferred when ϵ is large relative to
. However, in order to implement such estimators
that minimize worst-case MSE, knowledge of ϵ is required. See Bonhomme and Weidner (Citation2018) for an approach to minimum-MSE estimation.
4 Simulations and Empirical Illustrations
In this section, we study two empirical applications: we estimate the distribution of income neighborhood effects in the US, and the distributions of permanent and transitory earnings components in the PSID. We start the section by summarizing the results of a Monte Carlo simulation exercise, in samples generated from various specifications of model (1).
4.1 Monte Carlo Simulation: Summary of Results
While Theorems 1 and 2 show that PAE minimize worst-case specification error under small-ϵ and fixed-ϵ misspecification, respectively, they are silent about other forms of estimation error. In Appendix S4, we report the results of a Monte Carlo simulation exercise, where we compare the performance of PAE and other estimators in finite sample in the fixed-effects model (1), for various specifications. Here, we briefly summarize the results from the simulation exercise.
We compare the performance of four estimators: the fixed-effects estimator given by EquationEquation (2)(2)
(2) , the PAE given by EquationEquation (5)
(5)
(5) , the model-based estimator given by EquationEquation (6)
(6)
(6) , and a nonparametric kernel deconvolution estimator with normal errors (Stefanski and Carroll Citation1990). We analyze two sets of data-generating processes. When the reference normal distribution for αi is correctly specified, the model-based estimator performs best, as expected. We find that, while the PAE has both larger bias and variance than the model-based estimator in this case, it is less biased and less variable than both the nonparametric deconvolution estimator and the fixed-effects estimator, especially when the number of measurements J is small (see Appendix Figure S1).
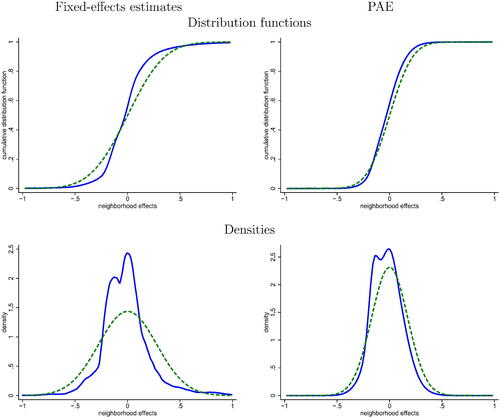
Fig. 1 Distribution of neighborhood effects
NOTE: In the left graphs, we show the distribution of fixed-effects estimates (solid) and its normal fit (dashed). In the right graphs, we show the posterior distribution of μc (solid) and the prior distribution (dashed). The distribution functions are shown in the top panel, the implied densities are shown in the bottom panel. Calculations are based on statistics available on the Equality of Opportunity website.
We next turn to data generating processes where αi is not normal, drawn from a skewed Beta distribution. We find that the model-based estimator is substantially biased in this case. The nonparametric deconvolution estimator has smallest bias when errors are normally distributed, but it is heavily biased when errors are nonnormal. By contrast, although it has no consistency guarantees in these settings, the PAE tends to perform comparatively well in all situations, for bias and variance (see Appendix Figure S2).
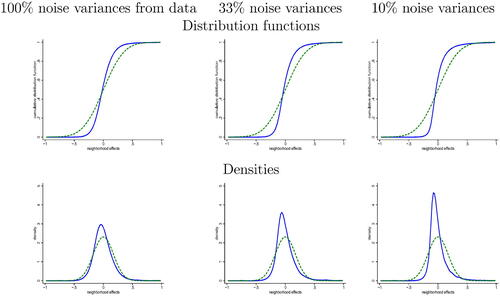
Fig. 2 Simulated data with log-normal μc
NOTE: Simulation with μc log-normal and normal. The posterior distribution is shown in solid, the prior distribution is shown in dashed. The distribution functions are shown in the top panel, the implied densities are shown in the bottom panel. The left graphs correspond to the noise variances
of the data, the middle ones correspond to the noise variances divided by 3, and the right graphs correspond to the noise variances divided by 10.
Overall, the simulations complement our theory by highlighting that, beyond specification error, other sources of estimation error matter in practice. Under correct specification of the reference distribution, the model-based estimator should be preferred. At the same time, our results suggest that, at least in the particular settings we focus on, the performance of the PAE appears less sensitive to misspecification than those of the model-based and nonparametric deconvolution estimators. Moreover, we find that the robustness gains provided by the PAE depend on the signal-to-noise ratio and the informativeness of the posterior conditioning. We provide details on the simulations in Appendix S4.
4.2 Neighborhood Effects
In this subsection and the next, we revisit two applications of models with latent variables. In our first illustration, we focus on a model of neighborhood effects following Chetty and Hendren (Citation2018), using data for the US that these authors made public. In our second illustration, we study a permanent-transitory model of income dynamics (Hall and Mishkin Citation1982; Blundell et al. Citation2008) using the PSID. In both cases, we rely on a normal reference specification and assess how and by how much the posterior conditioning informs the estimates of the parameters of interest.
Here we start with estimates of neighborhood (or “place”) effects reported in Chetty and Hendren (Citation2018, CH hereafter). Those were obtained using individuals who moved between different commuting zones at different ages. The outcome variable that we focus on is the causal estimate of the income rank at age 26 of a child whose parents are at the 25 percentile of the income distribution. This is CH’s preferred measure of place effect.
CH report an estimate of the variance of neighborhood effects, corrected for noise. In addition, they report individual predictors. Here we are interested in documenting the entire distribution of place effects. To do so, we consider the model , for each commuting zone c, where
is a neighborhood-specific fixed-effects reported by CH, μc is the true effect of neighborhood c, and
is additive estimation noise. CH also report estimates
of the variances of
for every c. When weighted by population, the fixed-effects estimates
have mean zero. We treat neighborhoods as independent observations. The statistics we use for calculations are available at: https://opportunityinsights.org/paper/neighborhoodsii/. Given the aggregate data at hand, we necessarily need to assume that estimates
are independent across neighborhoods c, although this might be restrictive in this setting.
We first estimate the variance of place effects μc, following CH. We trim the top 1% percentile of , and weigh all results by population weights. While this differs slightly from CH’s approach, which is based on
precision weights and no trimming, we replicated the analysis using precision weights in the un-trimmed sample and found similar results. We have information about place effects in C = 590 commuting zones c in our sample, compared to 595 in the sample without trimming. We estimate a sizable variance of neighborhood fixed-effects:
. In turn, the mean of
weighted by population is
. Given those, we estimate the variance of place effects as
. In this setting, the shrinkage factor
exhibits substantial heterogeneity across commuting zones. Indeed, the mean of
is 0.62, and its 10% and 90% percentiles are 0.21 and 0.93, respectively.
We use a normal with zero mean and variance as a prior for μc. Then, we estimate the distribution function of neighborhood effects
using the PAE given by (5); that is,
where πc are population weights. In addition, in order to ease the visualization of the results, we will also report estimates of densities, which are the derivatives of the PAE of distribution functions. Note that the density of μ at a can be approximated for arbitrarily small h > 0 by the expectation of
. Taking the limit of the corresponding PAE as h tends to zero gives the derivative of
at a. We thus expect derivatives of PAE of distribution functions to enjoy similar minimum-worst-case specification error properties as PAE, but we do not formalize the required assumptions here.
In the top panel of , we report several estimates of distribution functions. In the bottom panel, we report the corresponding density estimates. In the left graphs, we show nonparametric kernel estimates of the distribution function (respectively, density) of the fixed-effects , weighted by population (in solid), together with the best-fitting normal (in dashed). The graphs show substantial nonnormality of the fixed-effects estimates. In particular, the large variance appears to be driven by some large positive and negative estimates
. In the right graphs, we report the PAE
of the distribution function of true place effects μc, with the associated density (in solid). In addition, we show the normal prior, with zero mean and variance
(in dashed). The posterior distribution of neighborhood effects differs from the normal prior, although the two estimators have the same variance by construction. In comparison, neighborhood-specific EB estimates have a substantially lower dispersion. In appendix (Figure S5, supplementary material), we report an estimate of their distribution function
and associated density. While
and the variance associated with
is 0.030, the variance of the EB estimates is only 0.010. In addition, a specification test that compares model-based estimator and PAE, which we described in Appendix S5 (supplementary material), suggests that these differences are statistically significant. Indeed, assuming independence across commuting zones, we obtain p-values below 0.01 at all deciles except the bottom two.
To assess how likely it is that the posterior estimator approximates the shape of the distribution of true neighborhood effects, we next perform two different exercises, based on a simulation and on numerical calculations motivated by our theory. We start with a Monte Carlo simulation, where μc, for , are log-normally distributed with zero mean and variance
, and
are normally distributed independent of μc with zero mean. We consider three scenarios for the noise variances
: the estimates from CH, one-third of those values, and one-tenth of those values. In this exercise, we again weigh by population. We show the results for
simulated neighborhoods. In the left graphs of , we see that, when the noise variances are the ones from the data, the posterior density is more skewed than the normal, yet the posterior shape is quite different from the true log-normal distribution of μc. When reducing the noise variances in the middle and right graphs, the posterior distribution function and density estimates get closer to the log-normal ones. In the right graphs, where the shrinkage factor is 0.90 on average (as opposed to 0.62 in the data), the posterior distribution function and density approximate the highly nonnormal shape of the true distribution of neighborhood effects very well.
We next turn to our posterior informativeness measure, which is given by EquationEquation (21)(21)
(21) . Note the R2 coefficient varies along the distribution. We find that the weighted average R2 across values of a is 28%, where we weigh across cutoff values a by the reference distribution for α. This value is consistent with the message of , since it suggests that, while the posterior conditioning informs the shape of the distribution of neighborhood effects, the signal-to-noise ratio is not high enough to be confident about the exact shape.
Last, we perform two additional exercises as robustness checks. First, we incorporate the mean income of permanent residents in county c at the 25% percentile as a covariate. CH rely on information on permanent residents’ income to improve the accuracy of individual predictions. Here, we use it to refine the reference distribution and to improve the estimation of the distribution of neighborhood effects. Specifically, our reference model for μc is then a correlated random-effects specification, where the mean depends on
linearly. Appendix (Figure S6, supplementary material) shows small differences with our baseline estimates. Second, we re-do our main analysis at the county level, instead of the commuting zone level. In that case, the signal-to-noise ratio is lower, our posterior informativeness R2 measure is 17% on average, and the appendix (Figure S7, supplementary material) shows that the normal prior and the posterior distributions are closer to each other than in the case of commuting zones.
4.3 Income Dynamics
In this subsection, we consider the following permanent-transitory model of household log-income:where
and Vit are independent at all lags and leads, and independent of
. This process is commonly used as an input for life-cycle consumption/savings models. Researchers often estimate covariances in a first step using minimum distance, and then impose a normality assumption for further analysis. However, there is increasing evidence that income components are not normally distributed. Instead of using a more flexible model—as has been done by Carlton and Hall (Citation1978) and a large subsequent literature—here we compute PAEs. The advantages of this approach are that no additional assumptions are needed, and that implementation is straightforward.
We focus on six recent waves of the PSID 1999–2009 (every other year), see Blundell et al. (Citation2016) for a description of the data. We use the same sample selection as in Arellano et al. (Citation2017), and work with a balanced panel of n = 792 households over T = 6 periods. Yit are residuals of log total pre-tax household labor earnings on a set of demographics, which include cohort interacted with education categories for both household members, race, state, and large-city dummies, a family size indicator, number of kids, a dummy for income recipient other than husband and wife, and a dummy for kids out of the household. Our aim is to estimate the distributions of ηit and . To do so, we compare normal model-based estimates with posterior estimates, by plotting distribution functions as well as the implied densities. The model’s structure is similar to that of the fixed-effects model (1), and analytical expressions for posterior estimators are easy to derive.
In the left graphs of , we show the distribution of the permanent component ηit. In the right graphs, we show the distribution of the transitory component . We show PAE in solid, and model-based estimators in dashed. In the top panel we report estimates of distribution functions, and in the bottom panel we report the implied density estimates. The estimates show mild deviation from Gaussianity for the permanent component, and stronger evidence of non-Gaussianity for the transitory component. In particular, the latter shows excess kurtosis (i.e., “peakedness”) relative to the normal.
Fig. 3 Distribution of income components
NOTE: The top panel shows PAE estimates of distribution functions (in solid), and model-based estimates (in dashed), and the bottom panel shows the associated density estimates. The left graphs correspond to the permanent income component ηit, the right graphs to the transitory income component . Sample from the PSID, 1999-2009.
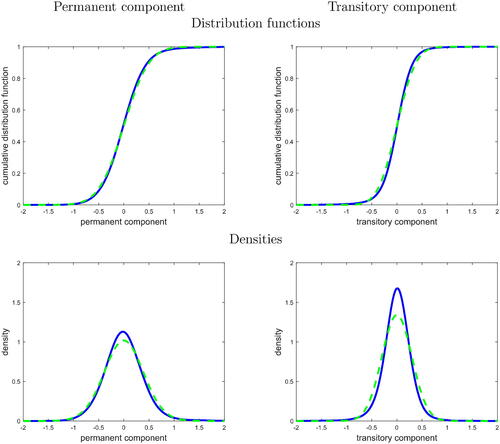
Several articles have already documented the presence of excess kurtosis in income components, particularly in transitory innovations, using parametric or semi-parametric methods. The estimates in share some qualitative similarities with recent findings in the literature. For example, the estimates of a flexible nonnormal and nonlinear model in Arellano et al. (Citation2017, ) are quite similar to the PAE estimates in for permanent components. At the same time, their estimates of the distribution of transitory components show substantially more pronounced non-Gaussianity and excess kurtosis relative to PAE. This finding is in agreement with our posterior informativeness measure R2, which is 12% on average along the distribution for the permanent component, and 8% on average for the transitory component. This degree of informativeness suggests that posterior estimates may suffer from substantial specification error when the reference distribution is misspecified.
Overall, these empirical illustrations give two examples where, starting from a normal prior, the posterior conditioning is informative about the true unknown distributions. In both settings, PAE are not normal. Yet, as indicated by the R2 values we report, the signal-to-noise ratios are not high enough to be certain about the exact shapes of the distributions of interest, thus motivating further analyses using nonnormal specifications. PAE should be useful in other environments where model (1) and its extensions are widely used, for example in teacher value-added applications, where the signal-to-noise ratio is driven by the number of observations per teacher. Moreover, PAE are also applicable to other—nonlinear—econometric models, as we describe in the next section.
5 Complements and Extensions
In this section, we outline several complements and extensions that we analyze in detail in the appendix.
5.1 PAE in Other Models
PAE are applicable to a variety of settings. In many econometric models, semi-parametric estimators—that is, robust to distributional assumptions on unobservables—of β parameters are available; see Powell (Citation1994) for examples. In such models, PAE provide estimators of average effects that enjoy robustness properties when parametric assumptions are violated. In Appendix S6, we study static binary and ordered choice models, censored regression models, and panel data binary choice models. We also show how the White (Citation1980) formula for robust standard errors in linear regression can be interpreted as a PAE.
5.2 Confidence Intervals and Specification Test
Under correct specification of the reference model, it is easy to derive the asymptotic distributions of and
using standard arguments. Moreover, under local misspecification, confidence intervals that account for both model uncertainty and sampling uncertainty can be constructed following Armstrong and Kolesár (Citation2018) and Bonhomme and Weidner (Citation2018). However, such confidence intervals require the researcher to set a value for the degree of misspecification ϵ. In Appendix S5 (supplementary material), we provide details on confidence intervals calculations. In addition, we explain how to construct a specification test of the reference model based on the difference
.
5.3 Robustness in Prediction
In applications such as the fixed-effects model (1) of teacher quality, researchers are often interested in predicting the quality αi of teacher i. Although our focus in this article is on the estimation of population averages, it is interesting to see how different predictors perform under misspecification of the reference distribution. It is well known that EB estimators minimize mean squared prediction error when the normal reference model is correctly specified. However, when normality fails, the best predictor is a different posterior mean, which does not generally coincide with the EB estimate based on a normal prior. Intuitively, conditioning on nonlinear functions of the data may improve prediction accuracy.
In Appendix S3 (supplementary material), we use our framework—applied to worst-case mean squared prediction error instead of worst-case specification error of a sample average—to provide results on the robustness of EB estimators in the presence of misspecification. We show that EB estimators have minimum worst-case mean squared prediction error, up to smaller-order terms, under local deviations from normality. In addition, we derive a fixed-ϵ, nonlocal risk bound in the spirit of Theorem 3.
6 Conclusion
Posterior averages are commonly used to predict individual parameters, such as teacher quality or neighborhood effects, and they play a central role in Bayesian and EB approaches. In this article, we have provided a frequentist justification for posterior conditioning when the goal of the researcher is to estimate a population average quantity. We have shown that PAEs have minimum worst-case specification error under various forms of misspecification of parametric assumptions. PAE are simple to implement, and our analysis provides a rationale for reporting them in applications alongside other parametric and semi-parametric estimators, as well as a simple way to assess the informativeness of the posterior conditioning. As an example, Arnold et al. (Citation2020) recently reported PAE to document judge heterogeneity in the context of bail decisions. While we have used a linear fixed-effects model as a running example due to its popularity, there are other possible applications, some of which we discuss in the appendix.
Supplementary Materials
The supplementary material contains an appendix with proofs, simulations, and extensions, as well as codes for replication.
Supplemental Material
Download Zip (30.9 MB)Acknowledgments
We thank to two anonymous referees, Manuel Arellano, Tim Armstrong, Raj Chetty, Tim Christensen, Nathan Hendren, Peter Hull, Max Kasy, Derek Neal, Jesse Shapiro, Xiaoxia Shi, Danny Yagan, and audiences at various places for comments.
Additional information
Funding
References
- Abadie, A., and Kasy, M. (2018), “The Risk of Machine Learning,” Review of Economics and Statistics, to appear.
- Andrews, I., Gentzkow, M., and Shapiro, J. M. (2017), “Measuring the Sensitivity of Parameter Estimates to Estimation Moments,” Quarterly Journal of Economics, 132, 1553–1592. DOI: 10.1093/qje/qjx023.
- Andrews, I., Gentzkow, M., and Shapiro, J. M. (2020), “On the Informativeness of Descriptive Statistics for Structural Estimates,” Econometrica, 88, 2231–2258. DOI: 10.3982/ECTA16768.
- Angrist, J. D., Hull, P. D., Pathak, P. A., and Walters, C. R. (2017), “Leveraging Lotteries for School Value-Added: Testing and Estimation,” Quarterly Journal of Economics, 132, 871–919. DOI: 10.1093/qje/qjx001.
- Arellano, M., Blundell, R., and Bonhomme, S. (2017), “Earnings and Consumption Dynamics: A Nonlinear Panel Data Framework,” Econometrica, 85, 693–734. DOI: 10.3982/ECTA13795.
- Arellano, M., and Bonhomme, S. (2009), “Robust Priors in Nonlinear Panel Data Models,” Econometrica, 77, 489–536.
- Armstrong, T. B., and Kolesár, M. (2018), “Sensitivity Analysis Using Approximate Moment Condition Models,” arXiv preprint arXiv:1808.07387.
- Arnold, D., W. S. Dobbie, and P. Hull (2020), “Measuring Racial Discrimination in Bail Decisions,” (No. w26999). National Bureau of Economic Research.
- Berger, J. (1980), Statistical Decision Theory: Foundations, Concepts, and Methods, New York: Springer-Verlag.
- Bickel, P. J., Klaassen, C. A. J., Ritov, Y., and Wellner, J. A. (1993), Efficient and Adaptive Inference in Semiparametric Models, Baltimore: Johns Hopkins University Press.
- Blundell, R., Pistaferri, L., and Preston, I. (2008): “Consumption Inequality and Partial Insurance,” American Economic Review, 98, 1887–1921. DOI: 10.1257/aer.98.5.1887.
- Blundell, R., Pistaferri, L., and Saporta-Eksten, I. (2016), “Consumption Smoothing and Family Labor Supply,” American Economic Review, 106, 387–435. DOI: 10.1257/aer.20121549.
- Bonhomme, S., and Robin, J. M. (2010), “Generalized Nonparametric Deconvolution With an Application to Earnings Dynamics,” Review of Economic Studies, 77, 491–533. DOI: 10.1111/j.1467-937X.2009.00577.x.
- Bonhomme, S., and Weidner, M. (2018), “Minimizing sensitivity to model misspecification,” arXiv:1807.02161.
- Carlton, D. W., and Hall, R. E. (1978), “The Distribution of Permanent Income,” in Income Distribution and Economic Inequality, New York: Halsted.
- Chetty, R., Friedman, J. N., and Rockoff, J. E. (2014), “Measuring the Impacts of Teachers I: Evaluating Bias in Teacher Value-Added Estimates,” American Economic Review, 104, 2593–2632. DOI: 10.1257/aer.104.9.2593.
- Chetty, R., and Hendren, N. (2018), “The Impacts of Neighborhoods on Intergenerational Mobility: County-Level Estimates,” Quarterly Journal of Economics, 133, 1163–1228.
- Christensen, T., and Connault, B. (2019), “Counterfactual Sensitivity and Robustness,” unpublished manuscript.
- Cressie, N., and Read, T. R. C. (1984), “Multinomial Goodness-of-Fit Tests,” Journal of the Royal Statistical Society, Series B, 46, 440–464. DOI: 10.1111/j.2517-6161.1984.tb01318.x.
- Delaigle, A., Hall, P., and Meister, A. (2008), “On Deconvolution With Repeated Measurements,” Annals of Statistics, 36, 665–685.
- Dobbie, W., and Fryer, R. G. Jr(2013), “Getting Beneath the Veil of Effective Schools: Evidence from New York City,” American Economic Journal: Applied Economics, 5, 28–60. DOI: 10.1257/app.5.4.28.
- Efron, B. (2012), Large-Scale Inference: Empirical Bayes Methods for Estimation, Testing, and Prediction, Vol. 1. Cambridge: Cambridge University Press.
- Efron, B., and Morris, C. (1973), “Stein’s Estimation Rule and its Competitors – An Empirical Bayes Approach,” Journal of the American Statistical Association, 68, 117–130.
- Fessler, P., and Kasy, M. (2018), “How to Use Economic Theory to Improve Estimators,” to appear in the Review of Economics and Statistics. DOI: 10.1162/rest_a_00795.
- Finkelstein, A., Gentzkow, M., Hull, P., and Williams, H. (2017), “Adjusting Risk Adjustment – Accounting for Variation in Diagnostic Intensity,” New England Journal of Medicine, 376, 608–610. DOI: 10.1056/NEJMp1613238.
- Geweke, J., and Keane, M. (2000), “An Empirical Analysis of Earnings Dynamics Among Men in the PSID: 1968-1989,” Journal of Econometrics, 96, 293–356. DOI: 10.1016/S0304-4076(99)00063-9.
- Guvenen, F., Karahan, F., Ozcan, S., and Song, J. (2016), “What Do Data on Millions of U.S. Workers Reveal about Life-Cycle Earnings Risk?” Econometrica.
- Hall, R., and Mishkin, F. (1982), “The Sensitivity of Consumption to Transitory Income: Estimates from Panel Data of Households,” Econometrica, 50, 261–81. DOI: 10.2307/1912638.
- Hansen, B. E. (2016), “Efficient Shrinkage in Parametric Models,” Journal of Econometrics, 190, 115–132. DOI: 10.1016/j.jeconom.2015.09.003.
- Hirano, K. (2002), “Semiparametric Bayesian Inference in Autoregressive Panel Data Models,” Econometrica, 70, 781–799. DOI: 10.1111/1468-0262.00305.
- Huber, P. J., and Ronchetti, E. M. (2009), Robust Statistics, 2nd ed., Hoboken, NJ: Wiley.
- Hull, P. (2018), “Estimating Hospital Quality with Quasi-Experimental Data,” unpublished manuscript.
- Ignatiadis, N., and S. Wager (2019), “Bias-Aware Confidence Intervals for Empirical Bayes Analysis,” arXiv:1902.02774.
- James, W., and Stein, C. (1961), “Estimation with Quadratic Loss,” in Proc. Fourth Berkeley Symp. Math. Statist. Prob., 1, 361–379. Univ. of California Press.
- Jochmans, K., and Weidner, M. (2018), “Inference on a Distribution From Noisy Draws,” arXiv:1803.04991.
- Kane, T. J., and Staiger, D. O. (2008), “Estimating Teacher Impacts on Student Achievement: An Experimental Evaluation”, National Bureau of Economic Research (No. w14607).
- Kitamura, Y., Otsu, T., and Evdokimov, K. (2013), “Robustness, Infinitesimal Neighborhoods, and Moment Restrictions,” Econometrica, 81, 1185–1201.
- Koenker, R., and Mizera, I. (2014), “Convex Optimization, Shape Constraints, Compound Decisions, and Empirical Bayes Rules,” Journal of the American Statistical Association, 109, 674–685. DOI: 10.1080/01621459.2013.869224.
- Kotlarski, I. (1967), “On Characterizing the Gamma and the Normal Distribution,” Pacific Journal of Mathematics, 20, 69–76. DOI: 10.2140/pjm.1967.20.69.
- Li, T., and Vuong, Q. (1998), “Nonparametric Estimation of the Measurement Error Model Using Multiple Indicators,” Journal of Multivariate Analysis, 65, 139–165. DOI: 10.1006/jmva.1998.1741.
- Morris, C. N. (1983), “Parametric Empirical Bayes Inference: Theory and Applications,” Journal of the American Statistical Association, 78, 47–55. DOI: 10.1080/01621459.1983.10477920.
- Owen, D. B. (1956), “Tables for Computing Bivariate Normal Probabilities,” The Annals of Mathematical Statistics, 27, 1075–1090. DOI: 10.1214/aoms/1177728074.
- Powell, J. L. (1994), “Estimation of Semiparametric Models,” Handbook of Econometrics, 4, 2443–2521.
- Stefanski, L. A., and Carroll, R. J. (1990), “Deconvolving Kernel Density Estimators,” Statistics, 21, 169–184. DOI: 10.1080/02331889008802238.
- White, H. (1980), “A Heteroskedasticity-Consistent Covariance Matrix Estimator and a Direct Test for Heteroskedasticity,” Econometrica: Journal of the Econometric Society, 817–838. DOI: 10.2307/1912934.