
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We introduce the local composite quantile regression (LCQR) to causal inference in regression discontinuity (RD) designs. Kai, Li and Zou study the efficiency property of LCQR, while we show that its nice boundary performance translates to accurate estimation of treatment effects in RD under a variety of data generating processes. Moreover, we propose a bias-corrected and standard error-adjusted t-test for inference, which leads to confidence intervals with good coverage probabilities. A bandwidth selector is also discussed. For illustration, we conduct a simulation study and revisit a classic example from Lee. A companion R package rdcqr is developed.
1 Introduction
Over the past few decades, regression discontinuity (RD) has become a popular quasi-experimental method to identify the local average treatment effect. In its simplest form, the sharp RD design, a unit i receives treatment if and only if an underlying variable Xi attains a prespecified cutoff. Under some smoothness assumptions, units in a small neighborhood of the cutoff share similar characteristics so that the difference between the outcomes above and below the cutoff can be interpreted as the local average treatment effect. For recent discussions of the literature and background references, see, for example, Cattaneo, Idrobo, and Titiunik (Citation2019, Citation2020).
Central to a large portion of the empirical and theoretical work on RD is the use of local linear regression (LLR; see Fan and Gijbels Citation1996), while the goal of this article is to introduce another nonparametric smoother to the estimation and inference in sharp as well as fuzzy RD designs. Although LLR is the best linear smoother, it is possible to use an alternative estimator in RD if we consider the larger class of nonlinear smoothers. One such example is the local composite quantile regression (LCQR) method in Kai, Li, and Zou (Citation2010), who show that LCQR can have some efficiency gain against LLR when data are nonnormal. The literature related to LCQR is growing. Several recent examples include Kai, Li, and Zou (Citation2011), Zhao and Xiao (Citation2014), Li and Li (Citation2016), and Huang and Lin (Citation2021), although none of these studies focuses on RD. To use LCQR, the researcher chooses a finite number of quantile positions, say 5, and uses a local polynomial to estimate the quantile (the intercept) at each of the 5 quantile positions. Averaging the 5 quantile estimates gives an estimate for the conditional mean, whose values above and below the prespecified cutoff are the key components in sharp and fuzzy RD designs.
Our article makes the following contributions to the large and growing literature on RD. First, we introduce the LCQR method to sharp and fuzzy RD designs. Numerical evidence for the efficiency gain of using LCQR instead of LLR in RD is also provided. Second, similar to the robust t-test in Calonico, Cattaneo, and Titiunik (Citation2014) for conducting inference on causal effects, we propose a t-test that adjusts both the bias and the standard error of the LCQR estimator, and the resulting confidence intervals are shown to have good coverage probabilities. Third, we further discuss a new bandwidth selector that is based on an adjusted mean squared error (MSE). As a byproduct of our research, we also develop an R package rdcqr that implements the LCQR method in this article. The rdcqr package can be downloaded from https://github.com/xhuang20/rdcqr.
The rest of the article unfolds as follows. Section 2 sets up the notation for RD designs and introduces the LCQR method. Section 3 presents the bias correction and standard error adjustment for inference on the boundary. Section 4 briefly discusses several extensions, such as allowing for covariates and kink RD designs. Section 5 presents a simulation experiment. An empirical illustration of LCQR for RD is provided in Section 6 using the data from Lee (Citation2008). Section 7 concludes. The online supplement contains all technical details and proofs, as well as additional figures and tables.
2 RD and Local Composite Quantile Regression
We introduce the notation for RD and the application of LCQR in RD in this section.
2.1 RD: Setup and Notation
Consider the triplet in a standard RD setup that nests both the sharp and fuzzy RD designs. Yi
is the observed outcome for individual i, Xi
is the variable that determines the assignment of treatment, and Ti
equals 1 if individual i receives treatment and 0 otherwise. For individual i to receive treatment, a threshold value for Xi
is set. Without loss of generality, we assume the threshold is 0, and the treatment assignment rule becomes that individual i is assigned to the treatment group if
. Throughout the article, the signs + and – will be used to denote data or quantities associated with
and
, respectively.
We use a general nonparametric model to describe the relationship between Yi
and Xi
(1)
(1)
(2)
(2) where
, and
are the conditional mean functions, conditional standard deviation functions, and error terms with unit variance, respectively.
In a sharp RD design, whether individual i receives treatment is determined by whether , so
. One is interested in measuring the average treatment effect at the threshold 0
(3)
(3) where
(4)
(4)
A t-statistic for testing a hypothesized treatment effect τ0 reads(5)
(5) where, under the iid assumption, we have
(6)
(6)
In a fuzzy RD design, the treatment assignment rule remains the same, but Ti
is not necessarily equal to 1 when or 0 when
. It is customary to use a nonparametric function to describe the probability of receiving treatment
(7)
(7)
(8)
(8)
The treatment effect measurement becomes(9)
(9) where
are as defined in EquationEquation (4)
(4)
(4) above, and similarly,
(10)
(10)
The corresponding t-statistic is given by(11)
(11) where
(12)
(12)
and
depends on the variances and covariances of
and
, which we provide in the online supplement (see (A.16) in Section S.2, supplementary material) to conserve space.
To conduct the t-test, we thus need nonparametric estimates for all quantities in EquationEquations (6)(6)
(6) and Equation(12)
(12)
(12) at the boundary point 0.
2.2 Local Composite Quantile Regression
LLR is the leading method to estimate quantities in EquationEquations (6)(6)
(6) and Equation(12)
(12)
(12) . LCQR is introduced in Kai, Li, and Zou (Citation2010) as an alternative to the LLR method due to its potential efficiency gains with nonnormal errors. The probable advantage under non-normality is the key reason we propose to use LCQR in RD as normality can be easily violated in practice.
The same LCQR method can be applied to EquationEquations (1)(1)
(1) , Equation(2)
(2)
(2) , Equation(7)
(7)
(7) , and Equation(8)
(8)
(8) . Because of this similarity, we describe the LCQR method based on EquationEquation (1)
(1)
(1) . For
, let
be the equally spaced q quantile positions and
be the q check loss functions in quantile regression. The loss function for LCQR at the point x is defined as follows:
(13)
(13) where ak
is the kth quantile estimand, b is a slope restricted to be the same across quantiles,
is the bandwidth, and K is a kernel function. Here, we use the linear approximation to the conditional mean function in EquationEquation (1)
(1)
(1) . Let
be the cumulative distribution function of Y given X so that
is the kth quantile, and b is
, the first derivative of the conditional mean function at x. Using a single slope b allows us to combine information across quantiles, since a specification allowing for bk
in EquationEquation (13)
(13)
(13) would be equivalent to estimating each quantile separately. Our point of interest in EquationEquation (13)
(13)
(13) is x = 0.
The parameter q plays an important role here. Once q is chosen, there will be q quantiles corresponding to the q quantile positions τk
. Since we use equally spaced quantile positions, the median will always be selected as the middle quantile if q is odd. For example, if q = 3, the quantile positions are . The goal is to spread the quantile positions on the interval (0, 1) so that LCQR can combine information in multiple quantiles. The value of q is decided by the researcher. Results in Kai, Li, and Zou (Citation2010) and our discussion later on show that a small number such as 5, 7, or 9 may be adequate for many common nonnormal errors. It can be viewed as a hyperparameter and can be tuned.
Minimizing EquationEquation (13)(13)
(13) w.r.t. ak
and b yields
. The LCQR estimator for
is defined as follows:
(14)
(14) and
is the estimator for
, the first derivative of
. In a similar fashion,
, and
can be obtained at x = 0. The average in EquationEquation (14)
(14)
(14) combines information across different quantile estimators. The hope is to possibly improve the relative efficiency of individual nonparametric quantile estimator to the nonparametric mean estimator based on LLR.
Kai, Li, and Zou (Citation2010) discussed the asymptotic bias and variance of the LCQR estimator at an interior point x. The asymptotic properties at a boundary point x are discussed in Kai, Li, and Zou (Citation2009). Given the results in Kai, Li, and Zou (Citation2009), one can immediately implement the t-test for the sharp RD in EquationEquation (5)(5)
(5) with bias correction if needed. To implement the t-test for the fuzzy RD in EquationEquation (11)
(11)
(11) , additional covariance expressions for EquationEquation (12)
(12)
(12) need to be estimated and we provide these results in Lemma 3 in the online supplement. The asymptotic results for the bias and variance of
, and
follow those in Kai, Li, and Zou (Citation2009), and are given in Lemma 2 in the online supplement.
We make the following assumptions. Let c be a positive constant of supp(K).
Assumption 1.
, and
are at least three times continuously differentiable at x.
Assumption 2.
, and
are right or left continuous and differentiable at x.
Assumption 3.
The kernel function K is bounded and symmetric.
Following Assumption 3, we define, for j = 0, 1, 2, ,
Assumption 4.
The marginal density is right continuous, differentiable and positive at x = 0, and
is left continuous, differentiable and positive at x = 0.
Assumption 5.
All error distributions for , and
are symmetric and have positive density. All errors are i.i.d.
Assumption 6.
, and
as
. The same condition also holds for
, and
.
Assumptions 1 and 2 are used for Taylor series expansions in the proof. The bias expressions require only the second-order differentiability of the conditional mean function. Higher-order differentiability permits the study of small order terms in the expansion. The support of the kernel is assumed to be in Assumption 3. If the kernel has a bounded support such as
, then we would have
. Similar changes can be made to the ν variables. The differentiability in Assumption 4 is also used for Taylor expansions in the proof, and we require the positivity of the density at the boundary as it appears in the denominator of the bias expression. The symmetric error distribution assumption in Assumption 5 helps remove an extra term in the bias. When the error distribution is asymmetric, this extra term can be removed during bias correction. In Assumption 6,
and
help establish the consistency of
. The assumption
is used to establish the asymptotic normality of the bias-corrected and s.e.-adjusted t-statistic. Assumption 6 translates to
, and
as
if we use a single bandwidth h for the data above and below the cutoff, and n is the total number of observations. Similar assumptions can be found in Calonico, Cattaneo, and Titiunik (Citation2014) for LLR.
Next we provide two theorems on the LCQR estimator for sharp and fuzzy treatment effects defined in EquationEquations (6)(6)
(6) and Equation(12)
(12)
(12) , respectively. Let X be the σ-field generated by all Xi
.
Theorem 1.
Under Assumptions 1–6, as both and
, we have
(15)
(15)
(16)
(16) where
(17)
(17)
(18)
(18)
(19)
(19)
and the matrices
and similarly,
, are given in the online supplement (Section S.1, Equation (A.1)). eq
is the q-dimensional vector of ones.
Proof of Theorem 1 is a straightforward application of Theorem 2.1 in Kai, Li, and Zou (Citation2009). As long as a symmetric kernel is used, the value of remains the same if kernel moments on the other side of the cutoff are used. Generally, we have
unless error distributions on both sides of the cutoff are assumed to be the same.
When the bandwidths above and below the cutoff are assumed to be the same, Theorem 1 reduces to the following corollary.
Corollary 1.
Under Assumptions 1–6, if we further assume , then we have
(20)
(20)
(21)
(21)
The asymptotic results for the fuzzy RD are similarly provided in the theorem below.
Theorem 2.
Under Assumptions 1–6, as both and
, we have
(22)
(22) and
is provided in the proof; see the online supplement (A.16) in Section S.2.
From Theorems 1 and 2 and using a single bandwidth h, we see a lot of similarities between LCQR and LLR: both biases have order , and both variances have order
. In fact, the asymptotic bias expression is identical for the two methods. The variance from LCQR, however, is smaller than that from LLR under many nonnormal error distributions, for which we provide numerical results in the next subsection.
In addition, in the special case of q = 1, we can show that(23)
(23) where
, k,
, 2,…, q,
, and
are the c.d.f. and p.d.f. of the error distribution, respectively. This result similarly holds for
. However, EquationEquation (23)
(23)
(23) does not hold for
in general.
2.3 Efficiency Gains on the Boundary
We provide some numerical evidence in support of using LCQR in RD. To facilitate the presentation of the results, we consider Corollary 1 with a single bandwidth and replace the conditional density with the unconditional density
so that the product
becomes
. Similarly,
is also replaced by
.
Under standard assumptions, the MSE for the LLR estimator of is given by (see, e.g., Imbens and Kalyanaraman Citation2012)
(24)
(24) where
(25)
(25)
Let . By assuming errors on both sides of the cutoff have the same distribution and letting
, we can further simplify the variance expression in Corollary 1 to have
(26)
(26) where the two MSEs differ by a factor
for the variance term. Minimizing these two MSEs gives optimal bandwidths. Substituting the bandwidths into the MSEs leads to the optimal values,
and
. Similar to Kai, Li, and Zou (Citation2010), we define the asymptotic relative efficiency (ARE) of LCQR with respect to LLR on the boundary as
(27)
(27)
When q = 1, the ratio in EquationEquation (27)(27)
(27) simplifies to
When
, this simplification does not hold. Yet we can evaluate the ratio in EquationEquation (27)
(27)
(27) for many common distributions. Using the triangular kernel as an example, we calculate the ratio for the five error distributions listed in . Using the Epanechnikov kernel gives similar results.
Table 1 Asymptotic relative efficiency (ARE) of LCQR in sharp RD designs.
The ARE for boundary points in largely follows the same pattern for interior points as shown in of Kai, Li, and Zou (Citation2010). When errors are normally distributed (Distribution 1), increasing q will quickly bring ARE close to one, reflecting a very small efficiency loss of LCQR with respect to LLR. For nonnormal errors (Distributions 2–5), there can be large efficiency gains. The column with q = 1 in is identical for both interior and boundary points, a result of using a symmetric kernel function. When , the numbers differ from those in of Kai, Li, and Zou (Citation2010). Overall, provides the numerical evidence in support of using LCQR in RD when data are nonnormal, that is, the corresponding ARE mostly exceeds 1.
3 Inference on the Boundary
The goal of inference is related to but different from that of estimation. While one still needs a precise or
, much of the effort is spent on making t-statistics in EquationEquations (5)
(5)
(5) and Equation(11)
(11)
(11) behave like a standard normal random variable. Common approaches include reducing the impact of bias by under-smoothing, directly adjusting the bias, combining bias correction and standard error (s.e.) adjustment, etc. This section studies the bias-corrected and s.e.-adjusted t-statistics based on LCQR for conducting inference in sharp and fuzzy RD designs.
3.1 The Sharp Case
From Theorem 1, the bias-corrected estimator is given by(28)
(28) where
with
(29)
(29)
and
and
are the estimators for the second derivatives
and
, respectively, which can be computed using LCQR with a second-order polynomial.
Simply replacing in EquationEquation (5)
(5)
(5) with
may still lead to undercoverage of the resulting confidence intervals. Calonico, Cattaneo, and Titiunik (Citation2014) observed that the key to fix this problem is to take into consideration the additional variability introduced by bias correction. Similar idea is applied to inference based on LCQR, that is, instead of using
in the denominator of EquationEquation (5)
(5)
(5) , we use
. The additional variability due to bias correction increases the adjusted variance, and the s.e./variance adjustment naturally improves the coverage of the resulting confidence intervals.
By the iid assumption, we have(30)
(30) where the expressions for
and
are available in Kai, Li, and Zou (Citation2009, Citation2010) and Lemma 2. We contribute to the literature by deriving the explicit forms of the variances of bias and the covariances in EquationEquation (30)
(30)
(30) .
Theorem 3.
Under Assumptions 1–6, as both , the adjusted t-statistic for the sharp RD follows an asymptotic normal distribution
(31)
(31)
The exact form of the adjusted variance is provided in the proof; see the proof of Theorem 3 in the online supplement (Section S.2).
Following Theorem 3, the confidence interval for the nominal 95% coverage becomes , which incorporates the variability introduced by bias correction and will thus improve the coverage probability.
Remark 1.
Theorem 3 assumes that the researcher uses the same bandwidths ( and
) for estimation, bias correction, and s.e. adjustment. This simplifies the presentation of the result and the proof. It is also empirically relevant and appealing since using a single bandwidth throughout estimation and inference greatly reduces the complexity of implementation, though the researcher might want to use a different bandwidth for every required nonparametric estimation. Moreover, Calonico, Cattaneo, and Farrell (Citation2018, Citation2020b) discuss how using the same bandwidths is optimal in some well-defined senses for the robust t-test of Calonico, Cattaneo, and Titiunik (Citation2014).
Remark 2.
We assume two different bandwidths, and
, in Theorem 3. If they are further assumed to be the same,
, then by replacing the conditional density,
and
, with the unconditional one,
, it can be shown that
where the constant C1 can be straightforwardly inferred from the proof of Theorem 3 in the online supplement.
Remark 3.
Instead of bias correction, one may consider under-smoothing (), so that the bias is negligible relative to the square root of the variance, which leads to the conventional 95% confidence interval
. Yet Calonico, Cattaneo, and Farrell (Citation2018, Citation2020b) show that robust bias correction can offer high-order refinements in the sense that its resulting confidence interval tends to have smaller coverage errors than that based on under-smoothing. Their proof is based on coverage error expansions for confidence intervals resulting from local polynomial estimation. It would thus be value-added to this article if one similarly extends the proof to LCQR-based confidence intervals.
3.2 The Fuzzy Case
Similar to the sharp case above, we also propose the adjusted t-statistic for the fuzzy RD design. Following Feir, Lemieux, and Marmer (Citation2016), we use a null-restricted t-statistic to help eliminate the size distortion due to possibly weak identification in the fuzzy RD. Use EquationEquation (9)(9)
(9) to rewrite the the null
as
(32)
(32)
Define . The bias-corrected
is given by
(33)
(33) where
(34)
(34)
We note that and
are defined in EquationEquation (29)
(29)
(29) , while
and
are defined similarly by replacing Y with T. All the bias terms can be estimated using the result in Lemma 2 in the online supplement. To illustrate the components in the adjusted variance, it is helpful to consider first the data above the cutoff (the expressions for the data below the cutoff result by replacing + with –):
(35)
(35)
To operationalize the variance adjustment process, we derive all the required covariance terms in the online supplement.
Theorem 4.
Under Assumptions 1–6, as both , the adjusted t-statistic for the fuzzy RD follows an asymptotic normal distribution:
(36)
(36)
The exact expression for is provided in the proof; see the proof of Theorem 4 in the online supplement (Section S.2).
3.3 A Revised MSE-Optimal Bandwidth
In this subsection, we propose a method to revise the MSE-optimal bandwidth by taking into consideration both bias correction and s.e. adjustment. It is well known in the nonparametric literature that the MSE-optimal bandwidth, when used in inference, often induces undercoverage of conventional confidence intervals. The root cause is that the MSE-optimal bandwidth, , leads to
, while we need
in order to ignore bias and use undersmoothing without bias correction. Hence, using
in EquationEquation (5)
(5)
(5) could lead to poor coverage of confidence intervals. Using a bias-corrected t-statistic without adjusting the variance,
, does not solve this problem; see the discussion in Section 2 of Calonico, Cattaneo, and Titiunik (Citation2014).
It is helpful to revisit the bandwidth selection process in an MSE-optimal setting in order to find a solution. We use a single bandwidth h for illustration. Consider the usual MSE when estimating a conditional mean function by
:
(37)
(37)
It is clear that the MSE-optimal bandwidth aims to balance two terms, and
. After correcting the bias for the numerator of the t-statistic, an optimal bandwidth should balance
, not
, with the variance term. Given
, we need to expand the bias expression up to
in order to compute
. In addition, after incorporating variance adjustment due to bias correction, the adjusted MSE takes the following form:
(38)
(38) where
can take the form in EquationEquation (30)
(30)
(30) in a sharp RD design. The following theorem presents the bandwidth result associated with the adjusted MSE in a sharp RD design, assuming we work with data above the cutoff.
Theorem 5.
Under Assumptions 1 to 5, as , the bandwidth that minimizes the adjusted MSE is given by
(39)
(39) where C2 and C3 are constants provided in the proof; see the online supplement (Section S.2).
The result for the fuzzy design case can be obtained similarly. Theorem 5 assumes that two separate bandwidths are used for the data above and below the cutoff. Similar result holds for . On each side of the cutoff, a single bandwidth is used in both estimation and bias correction. Theorem 5 provides the expression of this bandwidth.
Remark 4.
The bandwidth in EquationEquation (39)(39)
(39) is of order
, while Assumption 6 requires
to establish the asymptotic normality of EquationEquation (31)
(31)
(31) . Notice that the numerator in EquationEquation (31)
(31)
(31) corrects the bias up to
(and
), and the remaining terms of the ratio can be roughly written as
. If the bias correction up to
is truly effective, we can (i) treat it as if bias were completely removed and ignore any remaining
terms on the numerator of the bias-corrected t-statistic in EquationEquation (31)
(31)
(31) so that the assumption
becomes unnecessary; (ii) use a slightly larger bandwidth such as the one in EquationEquation (39)
(39)
(39) to further reduce variance while relying on the bias correction to remove any extra bias due to the use of a larger bandwidth. Our simulation results indeed indicate that bias correction in LCQR is effective. This provides an explanation of why an
bandwidth could work well in our case.
Remark 5.
If equal bandwidth on both sides of the cutoff is preferred, it can be derived in a manner similar to the optimal bandwidth choice in Imbens and Kalyanaraman (Citation2012). To see that, we further assume and let
be the corresponding constants in Theorem 5 for the data above and below the cutoff. The adjusted MSE becomes
, and the optimal bandwidth is given by
(40)
(40)
This bandwidth is shown to have good finite sample performance in our simulation study. One caveat is that the performance of this bandwidth relies on a good estimate of the third derivative of the conditional mean function. If it is difficult to obtain an estimate of the third derivative, one can use a simple, global quintic polynomial for estimation. This is implemented with the option ls.derivative = TRUE in the rdcqr package.
Remark 6.
The bandwidth considered in this section has order or
. To check the robustness (to bandwidth selection) of the adjusted t-statistic, we also experiment with the rule-of-thumb bandwidth in Section 4.2 of Fan and Gijbels (Citation1996) in our simulation. This bandwidth is close to the Mean Integrated Squared Error optimal (MISE-optimal) bandwidth and has order
and
for the data above and below the cutoff. The results are reported in the online supplement (Table 5), and they are found very similar to those obtained from using an
bandwidth.
4 Extensions
In this section, we extend the discussion to several related topics that are of either practical or theoretical importance. Within the framework of LLR, these topics are studied in Calonico, Cattaneo, and Farrell (Citation2018), Calonico et al. (Citation2019), Calonico, Cattaneo, and Farrell (Citation2020a) and Calonico, Cattaneo, and Farrell (Citation2020b). Within the framework of LCQR, we develop the fixed-n approximations for estimation and inference in both sharp and fuzzy RD, while we also provide a brief discussion on several other topics.
4.1 Fixed-n Approximations for Small Samples
Results in previous sections are based on asymptotic approximations as , while Calonico, Cattaneo, and Farrell (Citation2018) point out that fixed-n approximations and the associated Studentization can help local polynomial regression retain the automatic boundary carpentry property in coverage errors. We therefore study the fixed-n approximations of the asymptotic results introduced in early sections for LCQR. Essentially, we re-derive Theorem 3 and 4 by keeping n and h fixed. Details of the fixed-n version of the t-statistics in EquationEquations (31)
(31)
(31) and Equation(36)
(36)
(36) are given in Propositions 1 and 2 and the associated proofs in Section S.3 of the online supplement.
As an example, consider the fixed-n variance of the estimator in Lemma 5
(41)
(41) where eq
is a vector of ones,
and
are defined in Section S.1 Equation (A.7). Compared to the first-order asymptotic variance in Lemma 2, it is clear that the fixed-n expression does not use any of the kernel moments such as
. The op
term at the end is a result of approximating the non-differentiable objective function of LCQR with a differentiable, quadratic function; see Proof of Lemma 5 in Section S.3 for details.
Our simulation presented later on suggests that fixed-n approximations improve the coverage of LCQR-based confidence intervals when the sample size is small, and work particularly well under heteroscedasticity. In , confidence intervals based on fixed-n approximations are found comparable to asymptotic confidence intervals, though fixed-n results seem more conservative and give slightly higher coverage. When the sample size is decreased, fixed-n approximations give better coverage (see Table 6 in Section S.4.4 of the online supplement). The rdcqr package offers both asymptotic and fixed-n approximations in the computation of bias, s.e., and adjusted s.e.
Table 4 Coverage probability of 95% confidence intervals in Lee and LM models.
4.2 Alternative Bandwidth Choices
Although we discuss the bandwidth that results from minimizing the adjusted MSE of the bias-corrected LCQR estimator, other bandwidth choices that satisfy Assumption 6 are also allowed. One possibility is the coverage error (CE)-optimal bandwidth suggested by Calonico, Cattaneo, and Farrell (Citation2020b), who propose to derive the optimal bandwidth by minimizing the coverage error of confidence intervals for the treatment effect. Calonico, Cattaneo, and Farrell (Citation2020a) further showed that this bandwidth choice can make bias-corrected confidence intervals attain the minimax bound on coverage errors. It will thus be interesting to derive such a CE-optimal bandwidth for the LCQR-based confidence interval, which, however, would require a considerable amount of work beyond the scope of this article. We leave it for future research. Our simulation evidence presented in Section 5, however, shows that the bandwidth in Theorem 5 provides good coverage probabilities along with an accurate estimation of the treatment effect.
4.3 Adding Covariates
Many RD applications come with covariates in addition to the treatment assignment variable X. Let denote the additional covariates. Depending on the nature of the data, adding covariates could help reduce bias and make treatment estimates more precise. One can simply add these covariates to LLR to adjust the treatment estimate; see Imbens and Lemieux (Citation2008) for an example. More recently, Calonico et al. (Citation2019) gave an MSE expansion for the covariate-adjusted RD estimator, and provides the corresponding bandwidth selection, bias correction and s.e. adjustment results.
Using a single bandwidth h, similar to EquationEquations (1)(1)
(1) and Equation(2)
(2)
(2) in Calonico et al. (Citation2019), we can write the treatment equation without and with covariates as follows:
(42)
(42)
(43)
(43) where all estimates are LCQR estimates. Theorem 3 and 4 are derived based on EquationEquation (42)
(42)
(42) while EquationEquation (43)
(43)
(43) follows from the following LCQR objective function:
(44)
(44)
Since EquationEquation (44)(44)
(44) leads to a nonlinear problem with no closed-form solution, we cannot use partitioned regression to directly express
as a linear function of other parameters in the equation and study its asymptotics. Instead, one needs to retool the asymptotic methods in Kai, Li, and Zou (Citation2009, Citation2010) to incorporate the covariates based on EquationEquation (44)
(44)
(44) . As a result, all asymptotic results in previous sections need to be revised to reflect the presence of covariates. Developing the rigorous asymptotic results for EquationEquation (43)
(43)
(43) , similar to Calonico et al. (Citation2019), will be a useful addition to make LCQR more appealing to applied researchers, and require future work.
For interested readers who want to try LCQR with covariates in RD, we offer an ad hoc approach. The companion rdcqr package offers a function to estimate in EquationEquation (43)
(43)
(43) , though no bias-correction or s.e. is currently provided. We suggest to proceed by using the bias and adjusted s.e. of
in EquationEquation (42)
(42)
(42) for the t-statistic for
. This ad hoc approach is not completely unwarranted. Imbens and Lemieux (Citation2008, p. 626) wrote: “If the conditional distribution of Z given X is continuous at x = c, then including Z in the regression will have little effect on the expected value of the estimator for τ…” and Z refers to covariates. Hence we conjecture that, although
and
are different, they could be numerically close to each other, and their variance differences could also be relatively small in practice. As a result, using the bias and adjusted s.e. of
for
in the t-test probably will not hurt much. Indeed, our simulation in Section S.4.6 of the online supplement shows that this ad hoc approach works well for the data-generating process (DGP) used in Calonico et al. (Citation2019). When
and
differ to a large extent, one cannot use the ad hoc approach.
4.4 Kink Designs
While the interest of sharp and fuzzy RD designs lies in the levels (i.e. conditional mean functions) at the cutoff, kink RD designs focus on the derivatives of regression functions; see, for example, Card et al. (Citation2015). Kai, Li, and Zou (Citation2009, Citation2010) showed that LCQR can also have efficiency gains when used for estimating derivatives. Therefore, it is natural to extend the LCQR method to kink RD designs. In Table 7 of the online supplement, we report the simulation outcome that shows LCQR could outperform the local polynomial regression for estimating derivatives in a sharp kink design when data are nonnormal. We, however, do not further explore kink RD designs in this article, since they would involve higher-order terms in Taylor series expansions, and are more challenging in practical implementations.
5 Monte Carlo Simulation
In this section, we conduct a Monte Carlo study to investigate the finite sample properties of the LCQR method. We focus on the sharp RD design and separate the Monte Carlo study into two parts, one for estimation (Section 5.1), and the other for inference (Section 5.2).
The sharp designs calibrated to Lee (Citation2008) and Ludwig and Miller (Citation2007) are used in the DGP:where the conditional means are given by
(45)
(45)
and
(46)
(46)
Hence, the treatment effects are 0.04 and –3.45 in (45) and (46), respectively.
We use the same five error distributions in Kai, Li, and Zou (Citation2010) to simulate ϵi
. These five error distributions are listed in , which lead to five DGPs: for DGP 1, ;…; for DGP 5,
.
In addition, the homoscedastic and heteroscedastic specifications in Kai, Li, and Zou (Citation2010) are used for simulating the standard deviation:
We set n = 500 with 5000 replications. The data are i.i.d. draws in all replications. The triangular kernel is used in all estimations.
Since we also study the coverage probability of confidence intervals, we compare the LCQR results with the robust confidence interval of Calonico, Cattaneo, and Titiunik (Citation2014). For ease of exposition, we first summarize in the types of the estimators reported later on.
Table 2 Summary of estimators in the simulation study.
We set q = 7 for all LCQR estimators. is obtained by using the R package rdrobust. We use the option bwselect = mserd in estimation and the option bwselect = cerrd in inference so that
is MSE-optimal and CE-optimal in Section 5.1 and Section 5.2, respectively. The local linear estimator,
, is obtained by applying the main bandwidth used in
.
To calculate the bandwidth in EquationEquations (39)(39)
(39) and Equation(40)
(40)
(40) for LCQR, we use the rule-of-thumb bandwidth selector described in Section 4.2 of Fan and Gijbels (Citation1996) to compute quantities such as C2 and C3 in EquationEquation (39)
(39)
(39) . The bandwidth in EquationEquation (39)
(39)
(39) or (40) is then used to perform the LCQR estimation, bias correction, and s.e. adjustment. Unlike the LLR estimator, the LCQR estimator has no closed-form expression, and is obtained from the iterative MM algorithm.
5.1 Estimation of the Treatment Effect
In this subsection, we compare LCQR with LLR for the treatment effect estimation.
Without bias correction, suggests that the two LCQR estimators, and
, are less accurate than LLR, though the numerical difference is small. This result probably is not a surprise since we use the bandwidth based on the adjusted MSE, which is not MSE-optimal for
and
. Since the employed bandwidth balances the bias of the bias-corrected estimator and adjusted variance in EquationEquation (38)
(38)
(38) , it will be interesting to investigate its bias-correction performance. presents the bias of the bias-corrected LCQR and LLR estimators for estimating the treatment effect in EquationEquation (45)
(45)
(45) with homoscedasticity. It shows that LCQR produces accurate estimates after bias-correction. The improvement can be large, depending on the error distribution; similar results for other models can be found in Figure 3 in the online supplement. It suggests that bias correction will help center the confidence intervals.
Fig. 1 Absolute value of average bias of the bias-corrected estimators, and
for the Lee model with homoscedasticity.
is the bias-corrected LCQR estimator.
is the bias-corrected LLR estimator. The result is based on 5000 replications and the true treatment effect is 0.04.
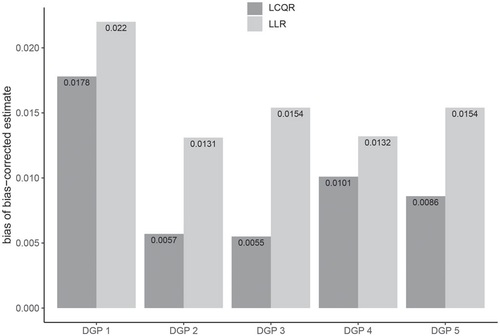
Table 3 Estimation of treatment effects in Lee and LM models.
further presents the standard errors of the studied estimators to facilitate comparison. The s.e. of is consistently smaller than that of
, indicating the efficiency gain of LCQR against LLR. Although DGP 1 has normal errors,
and
do not use the same bandwidth, so the s.e. of
also appears smaller than that of
. As the DGP moves away from normal errors, the LCQR estimator achieves various levels of efficiency gains compared to the LLR estimator. For example, the s.e. of
in DGP 5 of Panel B is 0.137, compared to 0.255 for
, so the LCQR/LLR standard error ratio is close to 50% in this example.
While reading , it is important to bear in mind that the s.e.s of estimators with a superscript “bc” are not suitable to assess the efficiency of the estimators. They are computed by incorporating the additional variability due to bias correction. However, they shed light on the length of confidence intervals. shows that the adjusted s.e. of could be smaller or larger than that of
, so the simulation results for comparing LCQR with LLR appear to be mixed after bias correction.
In addition, using two bandwidths above and below the cutoff also gives mixed results in terms of bias correction for the LCQR estimator, though it is clear that the two-bandwidth approach leads to a small decrease in s.e. for LCQR.
5.2 Inference on the Treatment Effect
This subsection studies the coverage probability of the confidence intervals based on the LCQR estimator, using the adjusted s.e. in Theorem 3 and the adj. MSE-based bandwidth selector. The results are summarized in , where the nominal coverage probability is set to 95%.
Without bias correction or s.e. adjustment, confidence intervals based on the LCQR estimators, and
, are found to have poor coverage probabilities in , which highlights an important difference between estimation and inference: despite the excellent finite sample properties of LCQR in , one has to perform both bias correction and s.e. adjustment in order to produce the desired coverage of confidence intervals. Furthermore, the coverage probability of LCQR-based confidence intervals is lower than that of LLR-based confidence intervals. For example, it is 92.2% under DGP 1 in Panel A of , compared to 93.4% of the LLR-based confidence interval. Although
tends to have a smaller bias and a smaller s.e. than
, it appears that the bias in
is still not small enough to center the estimator close to the true value. A smaller s.e. will further contribute to the decrease in coverage probabilities. This explains the poor coverage for confidence intervals based on
and
.
With bias correction and s.e. adjustment, the proposed bandwidth selectors in EquationEquations (39)(39)
(39) and Equation(40)
(40)
(40) lead to good coverage across the five DGPs in . It is important to recall that the presented LCQR estimators use the bandwidths in EquationEquations (39)
(39)
(39) and Equation(40)
(40)
(40) , which are not designed to optimize the coverage probability of confidence intervals, while the confidence intervals for
in are optimized to minimize coverage errors. In this respect, it is reasonable to conclude that LCQR with bandwidths in EquationEquations (39)
(39)
(39) and Equation(40)
(40)
(40) offers very competitive results.
In the last row of each panel in , we also report the coverage probability based on fixed-n approximations. The benefit of using fixed-n approximations becomes clearer in Table 6 of the online supplement, where the sample size decreases to 300 and fixed-n approximations often give the best coverage.
6 Application to Lee (Citation2008)
In this section, we use the data from Lee (Citation2008) to illustrate the practical usage of LCQR. To facilitate comparison, the findings based on LLR are also presented.
We revisit a classic example from Lee (Citation2008) with 6558 observations depicted in ; see also Imbens and Kalyanaraman (Citation2012). The horizontal running variable is the democratic vote share (margin of victory) in a previous election, while the vertical outcome variable is the democratic vote share in the election afterwards. Consistent with Lee (Citation2008) and several follow-up studies, indicates that there is a positive impact of incumbency on re-election, that is, a visible jump occurs at the threshold zero.
Fig. 2 Comparison of LCQR and LLR using Lee (Citation2008)
NOTES: (a) x-axis, the democratic vote share (margin of victory) in Election t; y-axis, the democratic vote share in Election t + 1. The dots show the sample mean of the vertical variable in each bin of the horizontal variable (50 bins on each side of the cutoff). The solid line represents the fitted fourth-order polynomial. As the bandwidth increases, (b) presents the LCQR estimate ± 2 × standard error; (c) presents the LLR estimate ± 2 × standard error; and (d) presents the ratio of the standard errors by LCQR and LLR. The MSE-optimal bandwidth of Imbens and Kalyanaraman (Citation2012) for the studied dataset is about 0.3. The triangular kernel is used for both LCQR and LLR estimators.
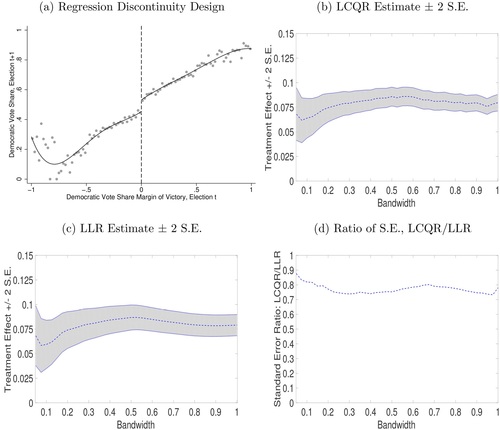
presents the estimated impact of incumbency on re-election by LCQR and LLR methods, respectively. We consider a sequence of bandwidth values ranging from 0.05 to 1 with the step size 0.025: 0.05, 0.075, 0.1,…, 1. This bandwidth sequence thus nests many common choices such as the MSE-optimal bandwidth of Imbens and Kalyanaraman (Citation2012), which is about 0.3 for the studied data.
The comparison of shows that LCQR and LLR yield similar point estimates over a wide range of bandwidths for the studied (Lee Citation2008) application. As the bandwidth increases, indicates that there are data points staying further away from the fitted regression line. These data points affect LCQR and LLR estimators in a different manner, leading to slightly disparate point estimates. Nevertheless, all the point estimates depicted in are significantly positive, since the (vertical) zero value is excluded from the shaded regions generated by ± 2 standard errors.
Most importantly, highlights that the standard error of the LCQR estimator is substantially smaller than that of LLR. The standard error ratio is mostly around 70%–80%, which can also be viewed by comparing the shaded regions in . Moreover, this standard error ratio does not change much as the bandwidth varies. Thus, indicates that a confidence interval for the impact of incumbency on re-election based on the LCQR estimator could be considerably tighter than that by LLR.
Consider, for example, 0.3 as the adopted bandwidth. The LCQR estimate ± 1.96 standard error leads to the 95% confidence interval (0.068, 0.090), while the conventional 95% confidence interval by LLR is (0.065, 0.096). If bias correction is further accounted for at the adopted bandwidth 0.3, then the bias-corrected 95% confidence interval based on LCQR is (0.048, 0.090). This interval is comparable to the bias-corrected 95% confidence interval using the Calonico, Cattaneo, and Titiunik (Citation2014) approach, which is (0.046, 0.089). These empirical findings therefore lend credibility to our proposed LCQR approach.
7 Conclusions
In this article, we study the application of LCQR in Kai, Li, and Zou (Citation2010) to the estimation and inference in RD. We present numerical evidence for the efficiency gain of using LCQR in RD estimation, and also propose a bias-corrected and s.e.-adjusted t-statistic to improve the coverage of confidence intervals. Simulation results show good performance of the proposed method under several nonnormal error distributions.
The current work can be extended in several directions. For instance, throughout the article, we focus on the local linear composite quantile regression, while the general case, local pth-order polynomial composite quantile regression, can be similarly adopted. Kai, Li, and Zou (Citation2009) establish the asymptotic theory for the LCQR estimator in the general case. Following Kai, Li, and Zou (Citation2009), one could extend our results on the bias-corrected and s.e.-adjusted t-statistic to allow for higher-order polynomials. In addition, it will be naturally appealing to formally explore LCQR for kink RD designs as well as RD designs using covariates. It will also be interesting to revisit some of the existing applications in RD with the proposed method as data may deviate from normality. Finally, on the computation side, instead of using the same bandwidth for estimation, bias correction and s.e. adjustment, one can refine the bandwidth selection process, which may also improve the estimation and coverage probability of LCQR. We leave these topics for future research.
Supplemental Material
Download Zip (2.1 MB)Acknowledgments
We thank the editor, the associate editor, and two anonymous referees for their comments that substantially improved the article.
Supplementary Materials
The related codes and data are provided in the R package rdcqr, which can be downloaded from the links in the article and the Supplement.
Additional information
Funding
Related Research Data
References
- Calonico, S., Cattaneo, M. D., and Farrell, M. H. (2018), “On the Effect of Bias Estimation on Coverage Accuracy in Nonparametric Inference,” Journal of the American Statistical Association, 113, 767–779. DOI: 10.1080/01621459.2017.1285776.
- Calonico, S., Cattaneo, M. D., and Farrell, M. H. (2020a), “Coverage Error Optimal Confidence Intervals for Local Polynomial Regression.” arXiv:1808.01398.
- Calonico, S., Cattaneo, M. D., and Farrell, M. H. (2020b), “Optimal Bandwidth Choice for Robust Bias-Corrected Inference in Regression Discontinuity Designs,” The Econometrics Journal, 23, 192–210.
- Calonico, S., Cattaneo, M. D., Farrell, M. H., and Titiunik, R. (2019), “Regression Discontinuity Designs Using Covariates,” The Review of Economics and Statistics, 101, 442–451. DOI: 10.1162/rest_a_00760.
- Calonico S., Cattaneo, M. D., and Titiunik, R. (2014), “Robust Nonparametric Confidence Intervals for Regression-Discontinuity Designs,” Econometrica, 82, 2295–2326. DOI: 10.3982/ECTA11757.
- Card, D., Lee, D. S., Pei, Z., and Weber, A. (2015), “Inference on Causal Effects in a Generalized Regression Kink Design,” Econometrica, 83, 2453–2483. DOI: 10.3982/ECTA11224.
- Cattaneo, M. D., Idrobo, N., and Titiunik, R. (2019), “A Practical Introduction to Regression Discontinuity Designs: Foundations,” Cambridge Elements: Quantitative and Computational Methods for Social Science, Cambridge: Cambridge University Press.
- Cattaneo, M. D., Idrobo, N., and Titiunik, R. (2020), “A Practical Introduction to Regression Discontinuity Designs: Extensions,” Cambridge Elements: Quantitative and Computational Methods for Social Science, Cambridge University Press.
- Fan, J., and Gijbels, I. (1996), Local Polynomial Modelling and Its Applications, London: CRC Press.
- Feir, D., Lemieux, T., and Marmer, V. (2016), “Weak Identification in Fuzzy Regression Discontinuity Designs,” Journal of Business and Economic Statistics, 34, 185–196. DOI: 10.1080/07350015.2015.1024836.
- Huang, X., and Lin, Z. (2021), “Local Composite Quantile Regression Smoothing: A Flexible Data Structure and Cross-Validation,” Econometric Theory, 37, 613–631. DOI: 10.1017/S0266466620000146.
- Imbens, G., and Kalyanaraman, K. (2012), “Optimal Bandwidth Choice for the Regression Discontinuity Estimator,” Review of Economic Studies, 79, 933–959. DOI: 10.1093/restud/rdr043.
- Imbens, G., and Lemieux, T. (2008), “Regression Discontinuity Designs: A Guide to Practice,” Journal of Econometrics, 142, 615–635. DOI: 10.1016/j.jeconom.2007.05.001.
- Kai, B., Li, R., and Zou, H. (2009), “Supplement Material for Local Composite Quantile Regression Smoothing: an Efficient and Safe Alternative to Local Polynomial Regression,” Technical Report. Pennsylvania State University, University Park.
- Kai, B., Li, R., and Zou, H. (2010), “Local Composite Quantile Regression Smoothing: An Efficient and Safe Alternative to Local Polynomial Regression,” Journal of the Royal Statistical Society, 72, 49–69.
- Kai, B., Li, R., and Zou, H. (2011), “New Efficient Estimation and Variable Selection Methods for Semiparametric Varying-Coefficient Partially Linear Models,” The Annals of Statistics, 39, 305.
- Lee, D. S. (2008), “Randomized Experiments From Non-Random Selection in us House Elections,” Journal of Econometrics, 142, 675–697. DOI: 10.1016/j.jeconom.2007.05.004.
- Li, D., and Li, R. (2016), “Local Composite Quantile Regression Smoothing for Harris Recurrent Markov Processes,” Journal of Econometrics, 194, 44–56. DOI: 10.1016/j.jeconom.2016.04.002.
- Ludwig, J., and Miller, D. L. (2007), “Does Head Start Improve Children’s Life Chances? Evidence From a Regression Discontinuity Design,” Quarterly Journal of Economics, 122, 159–208. DOI: 10.1162/qjec.122.1.159.
- Zhao, Z., and Xiao, Z. (2014), “Efficient Regressions Via Optimally Combining Quantile Information,” Econometric Theory, 30, 1272–1314. DOI: 10.1017/S0266466614000176.