
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We develop a universal econometric formulation of empirical power laws possibly driven by parameter heterogeneity. Our approach extends classical extreme value theory to specifying the tail behavior of the empirical distribution of a general dataset with possibly heterogeneous marginal distributions. We discuss several model examples that satisfy our conditions and demonstrate in simulations how heterogeneity may generate empirical power laws. We observe a cross-sectional power law for the U.S. stock losses and show that this tail behavior is largely driven by the heterogeneous volatilities of the individual assets.
1 Introduction
The empirical power law is a fundamental observation for many economic datasets: the tail probability seems to decrease at a polynomial rate rather than an exponential rate. It is also called the heavy-tailed phenomenon since large values occur more frequently than those from, for example, the (log)normal distribution in such a way that high-order sample moments may diverge with the sample size. At least since Pareto (Citation1896) and Zipf (Citation1949), the empirical power law has been well documented for income and wealth; see, for example, Piketty and Saez (Citation2003) for the United States and France, Atkinson (Citation2005) for the UK, the excellent book Piketty and Goldhammer (Citation2014) for a general overview, and the recent survey Zucman (Citation2019) for evidence across many countries. The heavy-tailed phenomenon extends enormously to various contexts, including city and firm size (e.g., Stanley et al. Citation1995; Gabaix Citation1999; Axtell Citation2001; Gabaix and Ioannides Citation2004; Schluter Citation2021), consumption (Toda and Walsh Citation2015), macroeconomic disasters (Barro and Jin 2011), social and economic networking (e.g., Barabási and Albert Citation1999; Jackson Citation2009; Newman, Barabási, and Watts Citation2006), CEO pay (Gabaix and Landier Citation2008), finance (e.g., Mandelbrot Citation1963; Fama Citation1963; Jansen and de Vries Citation1991; Longin Citation1996; Gopikrishnan et al. Citation1999; Gopikrishnan et al. Citation2000; Gabaix et al. 2006; Plerou and Stanley Citation2007; Kyle and Obizhaeva Citation2016), international trade (di Giovanni, Levchenko, and Rancière Citation2011; di Giovanni and Levchenko Citation2012), and many others. For more examples in economics and finance we refer to the excellent surveys Gabaix (Citation2009) and Gabaix (Citation2016). For many examples beyond economics, we refer to, for example, the survey Clauset, Shalizi, and Newman (Citation2009).
The larger observations are often depicted in a log–log plot: plot on logarithmic axes the data ranks in the descending order as a function of the data values. In , we observe a linear pattern in these plots that identifies empirical power laws for four data examples:
Fig. 1 Empirical power laws in log–log plots. The axes are logarithmic.
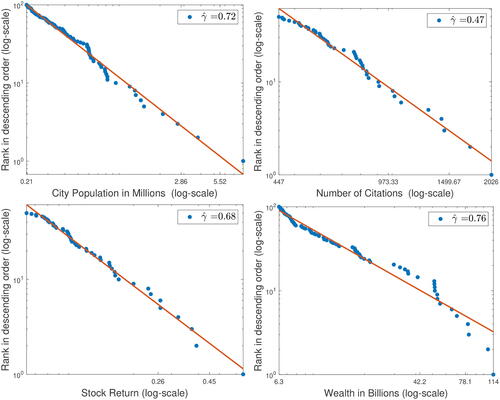
Census 2010 resident population in millions for the largest 100 U.S. cities collected from the online database of the U.S. Census Bureau, Population Division.
The largest 50 numbers of citations, as of June 1997, of the articles cited at least once which were published in volumes 11 through 50 of Physical Review D (Redner Citation1998).
The largest 50 monthly stock returns in March 2020 on the largest 1000 U.S. companies with share codes 10 and 11 collected from the Center for Research in Security Prices (CRSP).
The wealth of top 100 billionaires among the Forbes richest 400 Americans in 2019.
Denote an entire dataset by where the data dimension p is large, and define its empirical distribution function (df) by
(1.1)
(1.1)
The fitted straight line in each log–log plot supports the empirical power law, that is,(1.2)
(1.2) where
is the slope of the fitted line and
is the estimated Extreme Value Index (EVI). The larger the estimated EVI
, the heavier the tail.
In contrast to the increasing complexity of the economic generating mechanisms, the explanation of the power law is remarkably straightforward from a probabilistic point of view. The seminal works by Fisher and Tippett (Citation1928) and Gnedenko (Citation1943) showed that the asymptotic distribution of the maximum of a random sample, up to proper standardization, can only take a specific form depending on a single parameter γ, called the EVI. An equivalent formulation of these results by Balkema and de Haan (Citation1974) and Pickands (Citation1975) showed that the conditional excess distribution beyond a sufficiently large threshold can only approach a generalized Pareto law. The power law immediately follows from the limiting generalized Pareto distribution in case the EVI γ is positive. Historically, these two formulations of the power law led to two different statistical characterizations of empirical power laws, the so-called block-maxima method and peaks-over-threshold method, that model the maxima over subsamples and all large observations in the full sample, respectively. Our log–log plot in uses the latter one. For excellent accounts of extreme value theory, we refer to the books Embrechts, Klüppelberg, and Mikosch (Citation1997), de Haan and Ferreira (Citation2006), and Resnick (2007). For similar results under weak temporal dependence; see, for example, Leadbetter, Lindgren, and Rootzén (Citation1983). Extreme value theory for data generated from a mixture process has recently been developed in Cao and Zhang (Citation2020).
A caveat of the aforementioned classical extreme value theory is that it works with homogeneous, that is, equally distributed data. In fact, Hüsler (Citation1986) showed that the standard formulation does not generalize to arbitrary nonstationary data. This immediately raises questions to econometricians who are dealing with power laws of heterogeneous economic data at a given point in time or dynamic cross-sectional data over time; see, for example, Allen, Bali, and Tang (Citation2012), Kelly and Jiang (Citation2014), and Gabaix et al. (Citation2016). For all practical purposes, however, economists tend to disregard the statistical complexity by directly working with data from a common distribution. This convenience comes at an obvious cost of neglecting the micro heterogeneity, which is then absorbed in the common hypothetical macro distribution. One possible endorsement for such an approach was given recently in Einmahl, de Haan, and Zhou (Citation2016), which shows that the estimated EVI is still consistent for the common EVI γ for heavy-tailed data if they only differ by scale in the tail. In contrast, as we show later on, in general the heterogeneity effect is not only nonnegligible, but also can generate a positive γ, that is, a heavy tail, even for light-tailed Gaussian data.
The motivation of this article is to formalize the econometric theory for the aforementioned practical approach adopted by economists. In Section 2, we introduce Chang’s condition, see Chang (Citation1955) and also Wellner (Citation1978), that states that in the intermediate tail the empirical df of possibly heterogeneous data approaches some limiting df F. Note that Chang’s condition requires no specific form of the dependence structure nor tail homogeneity of the data. We then show that the estimated EVI converges to the EVI of the limiting distribution under a weak stability condition. Most importantly, now we can interpret the empirical power law as a finite sample approximation if the limiting distribution is heavy-tailed.
To illustrate how the micro heterogeneity influences the limiting df, we derive this limiting df and verify Chang’s condition for various interesting models in Section 3. These models reveal that, as noted above, the heavy tail may be directly generated by the parameter heterogeneity of the dataset even if each individual observation comes from a light-tailed distribution.
We then demonstrate how heterogeneity may generate the dynamics of empirical power laws by simulations in Section 4. Our data generating processes are calibrations based on the U.S. income inequality data and financial data. Our model can replicate the rapid rise in the U.S. income inequality, which is driven by the scale heterogeneity of the cross-sectional data. Heterogeneity is a fundamental property of individual incomes (see, e.g., Fagereng et al. Citation2020), and our analysis may provide new insights into the dynamics of inequality (Gabaix et al. Citation2016). Furthermore, our model also suggests that pooling heterogeneous EGARCH data over time may significantly reduce the variability of the EVI estimator but not so much the estimation bias (Kelly and Jiang Citation2014).
Finally, in Section 5, we study cross-sectional daily U.S. stock losses and observe a persistent power law behavior for the entire 10-year period as well as for the 120 periods of a single month. We show that this tail behavior is largely driven by the heterogeneous volatilities of the individual assets.
The proofs of the results in Sections 2 and 3 are deferred to appendix.
2 Unified Estimation Theory for Empirical Power Laws
Throughout we denote our data vector by , where the dimension p is large. In general, X is an arbitrary high-dimensional random vector with unspecified dependence structure and possibly heterogeneous tail distributions. Typically, these data are cross-sectional observations given at a point in time or a pool of possibly imbalanced panel data over a certain time period. Let the empirical df be as defined in Equation(1.1)
(1.1)
(1.1) . For any probability df F on
, we define its generalized quantile function by
.
Our theory relies on the following assumption, which is established in Chang (Citation1955) for iid data.
Assumption 1
(Chang’s condition). In the intermediate tail, the empirical df approaches some increasing df F in such a way that
for some c > 0 and all sequences
such that
.
The universe of limiting dfs F is diversified and F may or may not have a heavy tail. Note that the assumption allows even a deterministic data vector X, such as the growth rate parameters of individuals, stock volatilities or market betas in a cross section. The lower bound c being nondivergent ensures that the limiting df F is unique at each fixed point . To relax this condition, if necessary, one may replace c by another intermediate quantile sequence as in Gardes (Citation2015) and our asymptotic theory generalizes.
For tail inference, we further assume that the limiting distribution is heavy-tailed.
Assumption 2
(Regular variation). The df F is heavy-tailed, that is, is in the maximum domain of attraction with EVI . In other words, the survival function
is regularly varying at infinity with index
:
The EVI quantifies the tail heaviness of F: the larger γ, the heavier tail and less finite moments F has.
Combining Assumptions 1 and 2, one may now interpret the empirical power laws Equation(1.2)(1.2)
(1.2) from an asymptotic perspective: the empirical power law is a finite sample approximation of that of the limiting df F. Our model suggests that, if the practitioners believe that the data exhibit certain tail behavior, the power law is the only possible observation under regular variation. This may explain why the power law is such a widely observed phenomenon in real-life datasets.
As noted in the Introduction, our interest is to estimate the tail of the limiting df F which reflects the asymptotic behavior of the larger observations. The rationale is similar to that behind fitting lines in the empirical power law plots as in the Introduction. Specifically, we order the data to obtain the largest k + 1 order statistics given by for estimation, where
is such that
Assumption 3.
and
as
.
Note that in our very general setting, the usual condition that has to be strengthened slightly. Often k is taken proportional to
, for some
, and then, of course,
is amply satisfied.
We use the Hill (Citation1975) estimator of the EVI given by
(2.1)
(2.1) which is the sample average of the excesses over the intermediate quantile
, on a log scale.
To exclude the very irregular cases where the sample maximum dominates the estimator, we require
Assumption 4
(Stability condition). , as
.
If the data are iid observations from F, then this condition is readily satisfied under the regular variation Assumption 2 for any positive γ (see, e.g., de Haan and Ferreira Citation2006, chap. 1). We argue that this condition is very mild in practice, as the largest point often does not overwhelm the fitting process in the log–log plots such as those in the Introduction.
Now, our unified consistency theorem for empirical power laws is as follows:
Theorem 1.
Under Assumptions 1–4, we have, as ,
3 Applications to Heterogeneous Econometric Models
In this section, we present and discuss some interesting examples of heterogeneous data that satisfy our assumptions and hence the Hill estimator is consistent in those settings.
Our first example is a generalization of the heteroscedastic extremes model in Einmahl, de Haan, and Zhou (Citation2016). Let have independent entries with continuous dfs
. Suppose there exists a df F and a set of nonnegative constants
such that
uniformly for all p and
, where
, as
. Furthermore, assume that the
are bounded and that the
are bounded away from zero.
Theorem 2
(Heteroscedastic extremes). For this generalized heteroscedastic extremes model, Chang’s condition (Assumption 1) holds. Furthermore, if F satisfies the regular variation condition (Assumption 2), then the stability condition (Assumption 4) holds.
Our second example is a heterogeneous scales model defined bywhere the Zi
are iid random variables with df G and the
are positive scale parameters. We assume that the scale parameters resemble the intermediate quantiles of a continuous df
, with positive left endpoint, in such a way that
uniformly for
, for all intermediate sequences
such that
. We require that
is continuous on
and that for some
,
(3.1)
(3.1)
Theorem 3
(Heterogeneous scales). For the heterogeneous scales model, if F defined by , satisfies Assumption 2, then Chang’s condition (Assumption 1) holds. Furthermore, if, for some
, for large x, and
, for large p, then the stability condition holds.
It easily follows that if Y has df and is independent of Z1, then
has df F as in this theorem. If
satisfies Assumption 2, and G has a not-heavier tail, that is,
, then the limiting F has the same EVI as
, see Lemma 4.1 in the survey article Jessen and Mikosch (Citation2006). When G has a heavier tail than
, that is,
, and G satisfies Assumption 2, F has the same EVI as G. In other words, either the scale parameter heterogeneity or the tail of the marginal variables may generate a heavy tail.
Corollary 1
(High-dimensional Gaussian vector with heterogeneous scales). Suppose that the heterogeneous scales model holds withwhere
satisfies Assumption 2 with
. Then Chang’s condition holds with F as in the theorem and G the standard normal df; F is heavy-tailed with the same γ as
.
In this situation, the empirical power law is driven by the heterogeneity of the scales instead of the tail behavior of the marginal variables.
The next corollary to Theorem 3 generalizes it to a certain type of dependent data.
Corollary 2
(Heterogeneous scales and dependence). Consider the heterogeneous scales setup in and above Theorem 3, with μ = 0. Let Y > 0 be a random variable and define
Let be the Hill estimator of the
and
the Hill estimator of the
. Then
and hence
Remark 1
(High-dimensional lognormal vector with dependent components and heterogeneous scales). An interesting example of the is obtained by taking
, with
, and
with
, independent and
-distributed. In this case
and
is multivariate normal with all correlations equal to ρ. Clearly, the
are dependent and all have a lognormal distribution.
The next example is a heterogeneous locations model defined bywhere the Zi
are iid random variables with df G and the
are location parameters. Suppose that for some continuous df
and some weight function
it holds that
(3.2)
(3.2)
for all sequences
such that
. Define for
,
and write F for
.
Theorem 4
(Heterogeneous locations). Assume
for some c,
Then Chang’s condition holds. Furthermore, if, for some and
for large p, then the stability condition holds.
It readily follows that if Y has df and is independent of Z1, then
has df
as defined above the theorem. The limiting df F has the same EVI γ as that of
, if
satisfies Assumption 2, when G has a not-heavier tail such that
by the proposition on (Feller Citation1978, p. 278) about convolutions of regular varying distributions; see also Lemma 3.1 in Jessen and Mikosch (Citation2006). When G has a heavier tail than
, that is,
, the limiting df F has the same EVI as G if G satisfies Assumption 2 with a positive EVI γ. In other words, both the location parameter heterogeneity or the tail of the marginal variables may generate a heavy tail.
The examples in Theorems 2–4 and many other examples can be generalized to the setup where many small possibly heterogeneous sets of possibly dependent observations are pooled. This situation can also be seen as a (general, unbalanced) panel data setup. Let T be a fixed, positive integer. Consider data , with
, and
, where
is a nonempty subset of
, for all
. Now, for the asymptotic theory, we assume that for each fixed
, the number of data points
either tends to infinity or stays bounded, as
. Let pt
be the number of
and denote with
those t for which
as
; naturally we require
. Note that the data
may be dependent here.
Theorem 5.
Assume that for each fixed , the data
satisfy Chang’s condition with F = Ft
and p = pt
. Let
and assume, for
, that
. Consider the empirical df
of all p random variables
. Define
and assume F is continuous. Then, as
, Chang’s condition holds. Denote with
the df of
and assume for all i and t with
that for large x,
for some fixed df H. Then, if for each fixed
, the stability condition holds with p = pt
, then the stability condition holds for the maximum
of all p data.
This theorem states that, quite generally, Chang’s condition and the stability condition remain valid under pooling. Nothing is required for the data subset , for fixed i. As proved in Section 2, these two conditions lead to the consistency of the Hill estimator if k is chosen according to Assumption 3 and if F satisfies Assumption 2. The latter assumption follows easily, if the individual
, satisfy it for some
(but this can be weakened). The pooled or panel data setup provides a very general setting where consistency of the Hill estimator is established.
4 Simulation Study
In this section, we present a simulation study to demonstrate how heterogeneous data generate heavy tails in high dimensions and to evaluate the finite sample performance of the Hill estimator. We consider three data-generating processes:
Heterogeneous lognormal variables
Heterogeneous lognormal variables
A pooled dataset of heterogeneous EGARCH(1,1) data
where the are independent errors and the scale parameters
are the same as in DGP I. We use the initial values
.
All three DGPs satisfy the (pooled) heterogeneous scales model in Section 3. The extreme value indices (EVIs) of DGP I and II are calibrated by using the empirical EVIs for United States income distributions from 1973 to 2018, as shown in . The empirical EVIs (blue line) are calculated as , where S(p) denotes the share of the top pth percentile of the income data taken from Piketty and Saez (Citation2003, ) and the updated dataset downloaded at: https://eml.berkeley.edu/ saez/TabFig2018.xls. For DGP I and the initial values in DGP II, we have set the cross-sectional EVI
equal to the empirical EVI of 1973. For DGP II, the cross-sectional EVIs change over time and obey the first-order difference equation
where γt
denotes the cross-sectional EVI at time t (or year
in ), and the intercept 0.039 and the autoregressive coefficient 0.94 are the least-square estimates for the time series of empirical EVIs. Our model can replicate the rapid rise in the U.S. income inequality and implies a long-run steady state
. For each time period t, the cross-sectional dataset in DGP II can be rewritten as a heterogeneous scales model
where
Fig. 2 Empirical extreme value indices and calibrated extreme value indices for U.S. income (excluding capital gains) distributions between 1973 and 2018.
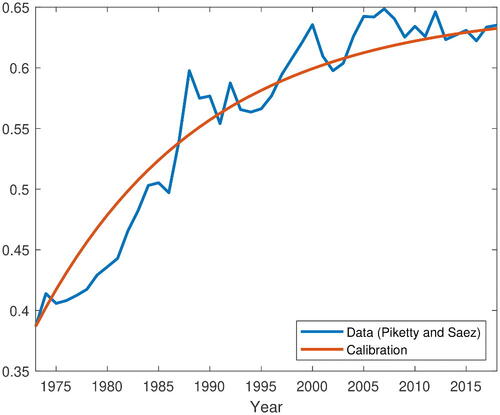
Table 1 Average and mean absolute deviation of the relative estimation errors based on 5000 replications for dimension p = 200, 1000, and 5000.
Although the cross-sectional data are independent at time t, the distribution of the Hill estimator is equivalent to that for a power transformation of DGP I with correlation after cancelling the common random scale component; see Remark 1. We have chosen
such that ρt
dies out in the long run, that is,
We argue that is a reasonably calibrated volatility for (high) income growth; see, e.g., Gabaix et al. (Citation2016). Finally, DGP III is motivated by the financial applications in Kelly and Jiang (Citation2014), where all the daily (idiosyncratic) stock losses in the same month are pooled for the monthly estimation. We have chosen the initial values of
such that the cross-sectional EVIs stabilize over time t for simplicity; otherwise, the cross-sectional EVIs follow a similar dynamics as DGP II.
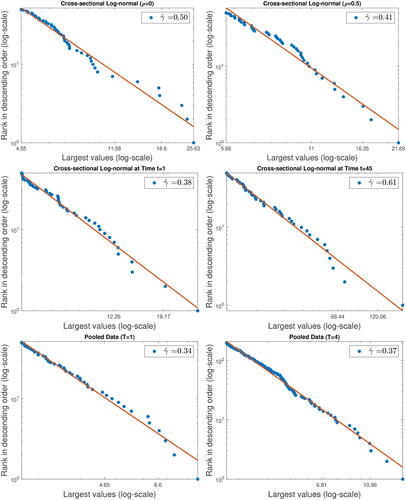
shows the log-log plots for the largest 5% values from one sample of size p = 1000 from DGP I–III. From the first row, for DGP I, we observe that the Hill estimate is closer to the true value for the larger ρ. In the second row, for DGP II, we report the estimates for t = 1 (year 1974) and t = 45 (year 2018). The Hill estimates are both close to the true empirical EVIs, which are different over time as discussed above. In the last row, for DGP III, we observe that the Hill estimate for the pooled data with T = 4 is slightly closer to the true value than that for T = 1.
Fig. 3 Empirical power laws in log-log plots for one sample with p = 1000.
To demonstrate the convergence of the Hill estimator as the dimension p grows, we report in , the average and mean absolute deviation of the relative estimation error of the Hill estimates against the true values based on 5000 replications for dimension p = 200, 1000, and 5000 with k is equal to 10%, 5%, and 2.5% of the dimension p for DGP I and II and of the pooled sample size pT for DGP III, respectively. In general, the absolute bias and the variability decrease as the dimension p grows for all DGPs, in line with the consistency of the Hill estimator. For DGP I, the mean absolute deviation decreases as the correlation ρ grows. This is because the Hill estimator is invariant with respect to the factor Y in Remark 1, while the idiosyncratic component there has a decreasing variance as ρ grows. Indeed, in the extreme case with ρ = 1, the Hill estimator is fully driven by the parameters and becomes deterministic. For DGP II, for each p, the bias and variability of the Hill estimator stabilize as t grows and approaches that for DGP I with ρ = 0 by construction. For DGP III, pooling the cross-sectional data over multiple time periods yields a larger sample size and hence smaller variability.
5 Empirical Analysis of the U.S. Stock Data
In this section, we study the cross-sectional empirical power laws of the U.S. asset returns. Our dataset contains the daily return on all NYSE/AMEX/NASDAQ stocks with share codes 10 and 11 (i.e., ordinary common shares) from January 2010 to December 2019. All these data are downloaded from the Center for Research in Security Prices (CRSP) via the Wharton Research Data Services (WRDS) platform. We fit a GARCH (1,1) model to each stock (with no missing observations) within every month and calculate the estimated daily conditional volatility. We use the largest 1000 stocks by lagged market capitalization each day, yielding a total number of more than 20,000 pooled observations each month. The total sample size is more than 2.5 millions over the entire period of 120 months.
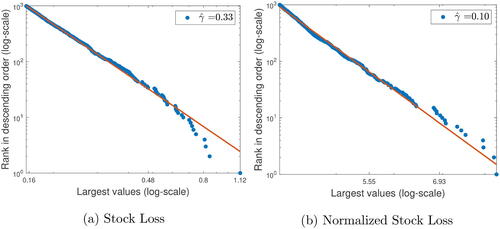
shows the log–log plots for the largest 1000 observations of the daily nominal stock losses and daily normalized stock losses over the entire sampling period, respectively. The normalized stock loss is equal to the stock loss divided by the estimated conditional volatility. We remove the normalized stock losses with the smallest 1% of volatilities to avoid instability. The stock losses exhibit a heavy tail with estimated EVI of 0.33, suggesting an infinite kurtosis of the limiting distribution and resembling the “cubic” power law (i.e., ) widely observed in the empirical asset pricing literature (see, e.g., Cont Citation2001 and Gabaix Citation2009). However, the heavy-tailed phenomenon (almost) vanishes after normalization as the estimated EVI of 0.10 is small and close to that (about 0.08) from a calibrated normal distribution. This suggests that interestingly the empirical power law here is generated by the heterogeneity of volatilities across individual assets rather than the tail of the individual asset itself.
Fig. 4 Empirical power laws of pooled observations over the entire sampling period.
To show that the conclusions are robust over sub-periods, we estimate the EVIs for pooled stock losses month-by-month following the method proposed in Kelly and Jiang (Citation2014) and Kelly (Citation2014): we pool all the positive daily stock losses within the same month and then calculate the Hill estimate of the EVI. In Kelly and Jiang (Citation2014), it is argued that these EVIs (called tail indices therein) measure the time-varying extreme event risk in the U.S. asset market. depicts the time series of estimated monthly cross-sectional EVIs by choosing different numbers of exceedances k: the top 5% (about 500), the top 1% (about 100), and the adaptive choice of Clauset, Shalizi, and Newman (Citation2009). The solid lines are for the nominal stock losses (blue) and standardized stock losses (red).
Fig. 5 Time series of estimated monthly extreme value indices. The solid lines are for nominal stock losses (blue) and standardized stock losses (red). The dotted lines are for the calibrated heterogeneous normal variables (yellow) and standard normal variables (purple). The choices of k from top to the bottom are: top 5% of positive data, top 1% of positive data, and the adaptive choice suggested in Clauset, Shalizi, and Newman (Citation2009).
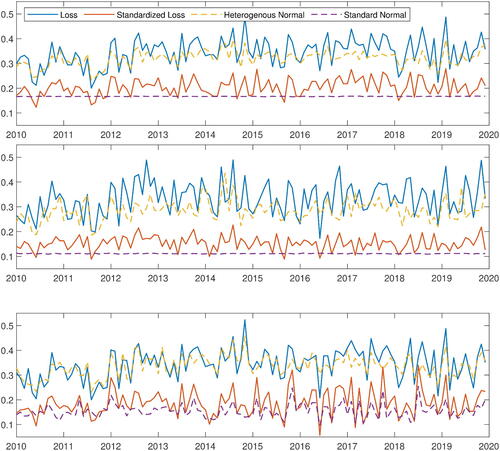
Like in , we observe in , a dramatic reduction in the estimated EVIs after standardization in every month. This suggests that the scale heterogeneity across individuals, rather than the GARCH residuals, generates the empirical power law here. To illustrate that the heterogeneity effect is dominant, we simulate heterogeneous normal variables with the calibrated GARCH variances from the cross-section for each period independently. We also generate independent standard normal variables for comparison. We plot the average of the Hill estimates for these normal variables (dotted yellow and dotted purple, respectively) over 100 replications in the figure as well. Their resemblance to the estimated EVIs of the stock losses is striking, especially when the thresholds are adaptive to monthly databases. In particular, as predicted by our asymptotic theory, the heterogeneous Gaussian model shows a much heavier tail than the homogeneous Gaussian model. Since every individual Gaussian variable is light-tailed, the power law is clearly generated by the scale heterogeneity.
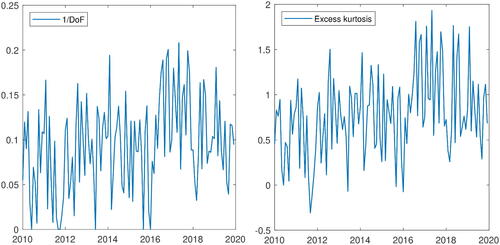
For robustness check, we repeat our residual calibration with the Student-t distribution rather than the Gaussian distribution. We fit a location-scale t-distribution to the GARCH residuals every month and plot the inverse of the degrees of freedom in . In the same figure, we also plot the monthly sample excess kurtosis of the (pooled) GARCH residuals which are almost always positive with an average value of 0.7798. The inverse of the degrees of freedom increases with the kurtosis in general, with a correlation of more than 96%. We typically observe large degrees of freedom around 10, that is, with an inverse value around 0.1 like in Bollerslev and Wooldridge (Citation1992). The degrees of freedom are sometimes very large (that is, its inverse value is close to zero) when the excess kurtosis is small, yielding similar results as for the Gaussian calibrations in those months.
Fig. 6 Monthly time series of the inverse of calibrated degrees of freedom (left) and sample kurtosis (right). The sample correlation between the time series is 0.9649.
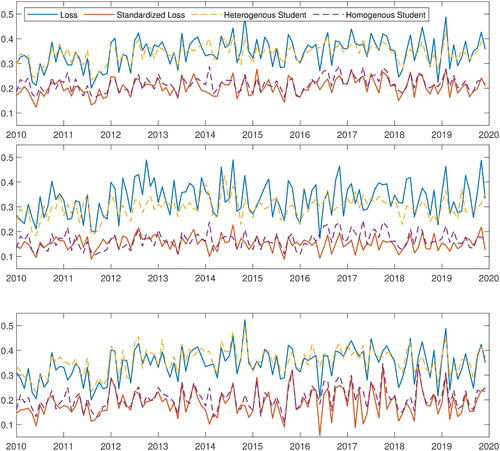
We then simulate heterogeneous Student variables with the calibrated GARCH variances and the fitted degrees of freedom from the cross-section for each period independently. We also generate independent, homogeneous Student variables from the fitted distribution for comparison. We plot the average of the Hill estimates for these Student variables (dotted yellow and dotted purple, respectively) over 100 replications in . Using the t-distribution improves the calibration for the naive choices of k equal to 5% and 1% of the sample size, and produces similar results as the Gaussian distribution for the adaptive choice of k. In all cases, we observe that the heterogeneous models generate a much heavier tail than the homogeneous models.
Fig. 7 Time series of estimated extreme value indices. The solid lines are for nominal stock losses (blue) and standardized stock losses (red). The dotted lines are for the calibrated heterogeneous Student-t variables (yellow) and the homogeneous Student-t variables (purple). The choices of k from top to the bottom are: top 5% of positive data, top 1% of positive data, and the adaptive choice suggested in Clauset, Shalizi, and Newman (Citation2009).
To summarize, our theory reveals that the cross-sectional volatility heterogeneity can generate empirical power laws across stock losses even if the residuals are relatively light tailed. One may consider such heavy tails to be spurious in the sense that they are not related to rare events of risk variables. We alert empirical researchers to these peculiar effects by presenting the much smaller estimates of the cross-sectional EVIs using volatility-standardized losses.
Supplemental Material
Download Zip (33.9 KB)Acknowledgments
We thank the editor, Professor Christian Hansen, an Associate Editor, and two reviewers for their useful comments that led to this improved version of the article. John Einmahl holds the Arie Kapteyn Chair 2019–2022 and gratefully acknowledges the corresponding research support.
Supplementary Material
We provide the replication code in the online supplementary material.
Related Research Data
References
- Allen, L., Bali, T. G., and Tang, Y. (2012), “Does Systemic Risk in the Financial Sector Predict Future Economic Downturns?” The Review of Financial Studies, 25, 3000–3036. DOI: 10.1093/rfs/hhs094.
- Atkinson, A. B. (2005), “Top Incomes in the UK Over the 20th Century,” Journal of the Royal Statistical Society, Series A, 168, 325–343. DOI: 10.1111/j.1467-985X.2005.00351.x.
- Axtell, R. L. (2001), “Zipf Distribution of U.S. Firm Sizes,” Science, 293, 1818–1820. DOI: 10.1126/science.1062081.
- Balkema, A. A., and de Haan, L. (1974), “Residual Life Time at Great Age,” The Annals of Probability, 2, 792–804. DOI: 10.1214/aop/1176996548.
- Barabási, A. L., and Albert, R. (1999), “Emergence of Scaling in Random Networks,” Science, 286, 509–512. DOI: 10.1126/science.286.5439.509.
- Barro, R. J., and Jin, T. (2011), “On the Size Distribution of Macroeconomic Disasters,” Econometrica, 79, 1567–1589.
- Bollerslev, T., and Wooldridge, J. M. (1992), “Quasi-Maximum Likelihood Estimation and Inference in Dynamic Models with Time-Varying Covariances,” Econometric Reviews, 11, 143–172. DOI: 10.1080/07474939208800229.
- Cao, W., and Zhang, Z. (2020), “New Extreme Value Theory for Maxima of Maxima,” Statistical Theory and Related Fields, DOI: 10.1080/24754269.2020.1846115.
- Chang, L. C. (1955), “On the Ratio of the Empirical Distribution Function to the Theoretical Distribution Function,” Acta Mathematica Sinica, 347–368; English translation: Selected Translations in Mathematical Statistics and Probability, vol. 4, American Mathematical Society, 1964, 17–38.
- Clauset, A., Shalizi, C., and Newman, M. (2009), “Power-Law Distributions in Empirical Data,” SIAM Review, 51, 661–703. DOI: 10.1137/070710111.
- Cont, R. (2001), “Empirical Properties of Asset Returns: Stylized Facts and Statistical Issues,” Quantitative Finance, 1, 223–236. DOI: 10.1080/713665670.
- di Giovanni, J., and Levchenko, A.A. (2012), “Country Size, International Trade, and Aggregate Fluctuations in Granular Economies,” Journal of Political Economy, 120, 1083–1132. DOI: 10.1086/669161.
- di Giovanni, J., Levchenko, A. A., and Rancière, R. (2011), “Power Laws in Firm Size and Openness to Trade: Measurement and Implications,” Journal of International Economics, 85, 42–52. DOI: 10.1016/j.jinteco.2011.05.003.
- Einmahl, J. H. J., de Haan, L., and Zhou, C. (2016), “Statistics of Heteroscedastic Extremes,” Journal of the Royal Statistical Society, Series B, 78, 31–51. DOI: 10.1111/rssb.12099.
- Embrechts, P., Klüppelberg, C., and Mikosch, T. (1997), Modelling Extremal Events: for Insurance and Finance, Berlin: Springer.
- Fagereng, A., Guiso, L. and Pistaferri, L. (2020), “Heterogeneity and Persistence in Returns to Wealth,” Econometrica, 88, 115–170. DOI: 10.3982/ECTA14835.
- Fama, E.F. (1963), “Mandelbrot and the Stable Paretian Hypothesis,” The Journal of Business, 36, 420–429. DOI: 10.1086/294633.
- Feller, W. (1978), An Introduction to Probability Theory and Its Applications, Vol. 2, New York: Wiley.
- Fisher, R. A., and Tippett, L.H.C. (1928), “Limiting Forms of the Frequency Distribution of the Largest or Smallest Member of a Sample,” Mathematical Proceedings of the Cambridge Philosophical Society, 24, 180–190. DOI: 10.1017/S0305004100015681.
- Fisk, P. R. (1961), “The Graduation of Income Distributions,” Econometrica, 29, 171–185. DOI: 10.2307/1909287.
- Gabaix, X. (1999), “Zipf’s Law for Cities: An Explanation,” Quarterly Journal of Economics, 114, 739–767. DOI: 10.1162/003355399556133.
- Gabaix, X. (2009), “Power Laws in Economics and Finance,” Annual Review of Economics, 1, 255–294.
- Gabaix, X. (2016), “Power Laws in Economics: An Introduction,” Journal of Economic Perspectives, 30, 185–206.
- Gabaix, X., Gopikrishnan, P., Plerou, V., and Stanley, H. E., “Institutional Investors and Stock Market Volatility,” The Quarterly Journal of Economics, 121, 461–504. DOI: 10.1162/qjec.2006.121.2.461.
- Gabaix, X., and Ioannides, Y. M. (2004), “The Evolution of City Size Distributions,” in Handbook of Regional and Urban Economics (Vol. 4), eds. V. Henderson and J.-F. Thisse, Amsterdam: Elsevier North-Holland, pp. 2341–2378.
- Gabaix, X., and Landier, A. (2008) “Why Has CEO Pay Increased so Much?” Quarterly Journal of Economics, 123, 49–100. DOI: 10.1162/qjec.2008.123.1.49.
- Gabaix, X., Lasry, J. M., Lions, P. L., and Moll, B. (2016), “The Dynamics of Inequality,” Econometrica, 84, 2071–2111. DOI: 10.3982/ECTA13569.
- Gardes, L. (2015), “A General Estimator for the Extreme Value Index: Applications to Conditional and Heteroscedastic Extremes,” Extremes, 18, 479–510. DOI: 10.1007/s10687-015-0220-6.
- Gnedenko, B. (1943), “Sur La Distribution Limite Du Terme Maximum D’Une Série Aléatoire,” Annals of Mathematics, 44, 423–453. DOI: 10.2307/1968974.
- Gopikrishnan, P., Plerou, V., Gabaix, X., and Stanley, H. E. (2000), “Statistical Properties of Share Volume Traded in Financial Markets,” Physical Review E, 62, R4493–R4496. DOI: 10.1103/physreve.62.r4493.
- Gopikrishnan, P., Plerou, V., Nunes Amaral, L. A., Meyer, M., and Stanley, H. E. (1999), “Scaling Of the Distribution of Fluctuations of Financial Market Indices,” Physical Review E, 60, 5305–5316. DOI: 10.1103/PhysRevE.60.5305.
- de Haan, L., and Ferreira, A. (2006), Extreme Value Theory: An Introduction, New York: Springer.
- Hill, B.M. (1975), “A Simple General Approach to Inference about the Tail of a Distribution,” The Annals of Statistics, 3, 1163–1174. DOI: 10.1214/aos/1176343247.
- Hüsler, J. (1986), “Extreme Values of Non-stationary Random Sequences,” Journal of Applied Probability, 23, 937–950. DOI: 10.2307/3214467.
- Jackson, M.O. (2009), “Networks and Economic Behavior,” Annual Review of Economics, 1, 489–511. DOI: 10.1146/annurev.economics.050708.143238.
- Jansen, D. W., and de Vries, C. G. (1991), “On the Frequency of Large Stock Returns: Putting Booms and Busts into Perspective,” The Review of Economics and Statistics, 73, 18–24. DOI: 10.2307/2109682.
- Jessen, A. H., and Mikosch, T. (2006), “Regularly Varying Functions,” Publications de l’Institut Mathematique, 80, 171–192. DOI: 10.2298/PIM0694171J.
- Kelly, B. (2014), “The Dynamic Power Law Model,” Extremes, 17, 557–583. DOI: 10.1007/s10687-014-0193-x.
- Kelly, B., and Jiang, H. (2014), “Tail Risk and Asset Prices,” The Review of Financial Studies, 27, 2841–2871. DOI: 10.1093/rfs/hhu039.
- Kyle, A.S., and Obizhaeva, A. A. (2016), “Market Microstructure Invariance: Empirical Hypotheses,” Econometrica, 84, 1345–1404. DOI: 10.3982/ECTA10486.
- Leadbetter, M.R., Lindgren, G., and Rootzén, H. (1983), Extremes and Related Properties of Random Sequences and Processes, New York: Springer.
- Longin, F.M. (1996), “The Asymptotic Distribution of Extreme Stock Market Returns,” The Journal of Business, 69, 383–408. DOI: 10.1086/209695.
- Mandelbrot, B. (1963), “The Variation of Certain Speculative Prices,” The Journal of Business, 36, 394–419. DOI: 10.1086/294632.
- Newman, M. E., Barabási, A. L. E., and Watts, D. J. (2006), The Structure and Dynamics of Networks, Princeton, NJ: Princeton University Press.
- Pareto, V. (1896), Cours d’Économie Politique, Lausanne: F. Rouge.
- Pickands, J. (1975), “Statistical Inference Using Extreme Order Statistics,” The Annals of Statistics, 3, 119–131.
- Piketty, T., and Goldhammer, A. (2014), Capital in the Twenty-First Century, Cambridge, MA: Harvard University Press.
- Piketty, T., and Saez, E. (2003), “Income Inequality in the United States,” Quarterly Journal of Economics, 118, 1–41. DOI: 10.1162/00335530360535135.
- Plerou, V., and Stanley, H. E. (2007), “Tests of Scaling and Universality of the Distributions of Trade Size and Share Volume: Evidence from Three Distinct Markets,” Physical Review E, 76, 046109. DOI: 10.1103/PhysRevE.76.046109.
- Potter, H. (1942), “The Mean Values of Certain DIrichlet Series, II,” Proceedings of the London Mathematical Society, 2, 1–19. DOI: 10.1112/plms/s2-47.1.1.
- Redner, S. (1998), “How Popular Is Your Paper? An Empirical Study of the Citation Distribution,” The European Physical Journal B-Condensed Matter and Complex Systems, 4, 131–134. DOI: 10.1007/s100510050359.
- Resnick, S. I. (2007), Heavy-tail Phenomena: Probabilistic and Statistical Modeling, New York: Springer.
- Schluter, C. (2021), “On Zipf’s Law and the Bias of Zipf Regressions,” Empirical Economics, 61, 529–548. DOI: 10.1007/s00181-020-01879-3.
- Stanley, M. H., Buldyrev, S. V., Havlin, S., Mantegna, R. N., Salinger, M. A., and Eugene Stanley, H. (1995), “Zipf Plots and the Size Distribution of Firms,” Economics Letters, 49, 453–457. DOI: 10.1016/0165-1765(95)00696-D.
- Toda, A. A., and Walsh, K. (2015), “The Double Power Law in Consumption and Implications For Testing Euler Equations”, Journal of Political Economy, 123, 1177–1200. DOI: 10.1086/682729.
- Wellner, J. A.(1978), “Limit Theorems for the Ratio of the Empirical Distribution Function to the True Distribution Function,” Zeitschrift für Wahrscheinlichkeitstheorie und Verwandte Gebiete, 45, 73–88. DOI: 10.1007/BF00635964.
- Zipf, G. K. (1949), Human Behavior and the Principle of Least Effort, Boston, MA: Addison Wesley Press
- Zucman, G. (2019), “Global Wealth Inequality,” Annual Review of Economics, 11, 109–138. DOI: 10.1146/annurev-economics-080218-025852.
Appendix.
Proofs
Proof of Theorem 1.
Define and consider
Write . Then
, with the function
. Let
be the order statistics of the
. By Assumptions 1 and 2, we have that
. Now, as in the proof of Theorem 3.2.2 (the consistency of the Hill estimator in the iid case) in de Haan and Ferreira (Citation2006), it suffices to prove that, as
,
(A.1)
(A.1)
Let Gp
be the empirical df of the . Then Assumption 1 implies for
(A.2)
(A.2)
Let . Then with probability tending to 1, we have from Equation(A.2)
(A.2)
(A.2) with
(and
)
It is elementary to show that . This yields Equation(A.1)
(A.1)
(A.1) . □
Proof of Theorem 2.
Reshuffle the indices i such that the positive have a lower index than the
equal to 0 and let κp
be the number of positive
. Let
. Then the Ui
are independent uniform-(0,1) random variables, and
Let . For
and
(for some large c), we have
and hence
Define , the uniform empirical df. Then
Using (Wellner Citation1978, theor. 0), we obtain that with probability tending to 1, as ,
Since can be made arbitrarily small, it remains to show that
(A.3)
(A.3)
Let , where
.
Let Bi
, , be independent Bernoulli random variables with
. Write
. Let Vj
,
, be independent uniform variables on (0, 1), independent of the Bi
’s. Pair the Bi
and Vj
in the following way: assign the first Np
, Vj
to the Bi
which are equal to 1 (and the other Vj
to the Bi
which are 0). Define
Then are independent uniform variables on (0, 1). (These Ui
are different from those in Equation(A.3)
(A.3)
(A.3) , but since we consider only convergence in probability that is allowed.) Let
. For x large, since
,
(A.4)
(A.4)
Write . Now we have, for either choice of sign, for large x,
Hence, for large x, the ratio in Equation(A.3)(A.3)
(A.3) can be bounded from below/above by
Clearly . Now by the law of large numbers and again in (Wellner Citation1978, theor. 0), we have that
Since is arbitrary, this in combination with Equation(A.4)
(A.4)
(A.4) yields Equation(A.3)
(A.3)
(A.3) .
The stability condition follows fromand the asymptotic behavior of the minimum of p independent uniform-(0,1) random variables. □
Proof of Theorem 3.
Without loss of generality, we may and will assume μ = 0.
Let be iid uniform-(0,1) random variables and denote their order statistics by
. Let
be i.i.d. random variables from the df G and independent of the Ui
. Consider the empirical survival functions
Note that the are iid with df F as in the theorem. Also observe that
by the exchangeability of the Zi
and the independence of the Ui
and the Zi
.
By (Wellner Citation1978, theor. 0), for any intermediate sequence such that
,
(A.5)
(A.5)
We need to show a similar result, namely(A.6)
(A.6)
We first show(A.7)
(A.7) where
is such that
and
. The Glivenko–Cantelli theorem yields
From this result, we obtain the convergence in Equation(A.7)(A.7)
(A.7) for the supremum over
, by the (uniform) continuity of
on
and
. (Wellner Citation1978, theor. 0) also states that
(A.8)
(A.8)
Using this in combination with Equation(3.1)(3.1)
(3.1) , we obtain the convergence in Equation(A.7)
(A.7)
(A.7) for the supremum over
. Clearly, by the first assumption of the model, Equation(A.7)
(A.7)
(A.7) implies
(A.9)
(A.9)
Now decompose
Note that
Hence for Equation(A.6)(A.6)
(A.6) , it remains to show that
(A.10)
(A.10)
Similarly, we can decompose
Let . Recalling Equation(A.9)
(A.9)
(A.9) , with probability tending to 1, for all x > 0
For we use again
. Hence, for Equation(A.10)
(A.10)
(A.10) , it suffices to show that, for either choice of sign, with probability tending to 1, for some N > 0 and small
For either choice of sign,
Recall from Equation(A.5)(A.5)
(A.5) that, with probability tending to 1,
where
is again an intermediate sequence as the regular variation of F implies that
. Furthermore, by Potter (Citation1942), it readily follows that that there exists an
, not depending on ε, such that
for some c > 0. As
can be made arbitrarily small, we obtain (A.10) and hence (A.6).
For the stability condition, we have for large enough M,as
. □
Proof of Theorem 4.
This proof is somewhat similar to that of Theorem 3, except we need to control the perturbations using the weight function q. Again, let be iid uniform-(0,1) random variables and denote their order statistics by
; also, let
be iid random variables from the df G and independent of the Ui
. Consider the empirical survival functions
Note that the are iid with df
(as defined just above the theorem). Also observe that
by the exchangeability of the Zi
and the independence of the Ui
and Zi
.
Choose another sequence with
and
and write
Observe that and
. Hence for Chang’s condition it suffices to show that
(A.11)
(A.11)
Now recall Equation(A.8)(A.8)
(A.8) and note that
. Using conditions (ii) and (iii),
It follows thatuniformly for
. Hence, for any
, with probability tending to one,
(A.12)
(A.12)
uniformly for
, where for the first inequality we decompose
like
above. For either choice of sign,
Let . Note that by condition (i), we have that, there exists a
such that for
and either choice of sign,
(A.13)
(A.13)
Furthermore, by (Wellner Citation1978, theor. 0), for either choice of sign,(A.14)
(A.14) as
is again an intermediate sequence, by (A.13). Hence, with probability tending to 1,
Combining this with Equation(A.12)(A.12)
(A.12) and recalling that
, we obtain Equation(A.11)
(A.11)
(A.11) .
The proof of the stability condition is straightforward using . □
Proof of Theorem 5.
Let denote the empirical df of the subsample corresponding to a fixed
. Observe that
is a convex combination of the
with weights
, that is,
Recall that . Denote the generalized quantile function of F as Q and that of Ft
as Qt
. Then
For any intermediate sequence ,
Now take another intermediate sequence such that
. We have that
By the assumed Chang’s conditions for each , we have for sufficiently large c,
On the other hand, again by the Chang’s conditions,
Finally,uniformly for
.
The stability condition follows readily. □