
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Dealing with structural breaks is an essential step in most empirical economic research. This is particularly true in panel data comprised of many cross-sectional units, which are all affected by major events. The COVID-19 pandemic has affected most sectors of the global economy; however, its impact on stock markets is still unclear. Most markets seem to have recovered while the pandemic is ongoing, suggesting that the relationship between stock returns and COVID-19 has been subject to structural break. It is therefore important to know if a structural break has occurred and, if it has, to infer the date of the break. Motivated by this last observation, the present article develops a new break detection toolbox that is applicable to different sized panels, easy to implement and robust to general forms of unobserved heterogeneity. The toolbox, which is the first of its kind, includes a structural change test, a break date estimator, and a break date confidence interval. Application to a panel covering 61 countries from January 3 to September 25, 2020, leads to the detection of a structural break that is dated to the first week of April. The effect of COVID-19 is negative before the break and zero thereafter, implying that while markets did react, the reaction was short-lived. A possible explanation is the quantitative easing programs announced by central banks all over the world in the second half of March.
1 Introduction
1.1 Motivation
This article considers what we believe to be a very common scenario in practice. We have in mind a researcher that seeks to infer a linear relationship between a dependent variable and a set of regressors. The dataset has a panel structure, in which there are a large number of cross-sectional units, N, that are observed over a fixed number of time periods, T. This scenario is relevant because while the number of time periods is always limited and cannot be increased other than by the passage of time, statistical agencies keep publishing time series data for individuals, firms and countries. Thus, while N is usually quite large, T need not be. One of the concerns here is therefore that T might not be large enough for many econometric approaches to work properly. Another concern is the presence of unobserved heterogeneity and the detrimental effect that this may have if said heterogeneity is correlated with the regressors. The main worry, however, is that the coefficients of some or indeed all of the regressors may be subject to structural change, because of some major events that may have caused the relationship to change over time. The present article develops a toolbox that enables the researcher to test for the presence of a common structural break and, if a break is detected, to also infer the date of the break. The tools are extremely easy to implement, accommodate general forms of unobserved heterogeneity and they can be used under quite relaxed conditions on T, provided that N is large.
Accounting for structural change has always been an important issue in economics and elsewhere. Panel data are particularly susceptible to such change, because of the large number of time series that they contain. In our empirical application, we consider stock returns for 61 countries, which all plummeted around March 11, 2020, when COVID-19 was declared a global pandemic by the World Health Organisation (WHO). Fortunately, the panel data structure not only makes breaks likely, but it also makes for relatively easy detection. As is well known, with time series data consistent estimation of the breakpoint is not possible, but only consistent estimation of the break fraction. By contrast, in panels breakpoint consistency is usually possible (Bai Citation2010). The accuracy of the procedure is therefore greatly enhanced when compared to the time series case.
The increased estimation accuracy is one of the advantages of using panel data. Another major advantage is the ability to deal with unobserved heterogeneity. Such heterogeneity is important in general, and it is particularly relevant in the type of noisy panels that we have in mind where typically the regressors explain only a small fraction of the variation in the dependent variable (see Capelle-Blancard and Desroziers Citation2020, in the context of COVID-19 and stock returns). This observation motivated Antoch et al. (Citation2019), Baltagi, Feng, and Kao (Citation2016), Boldea, Drepper, and Gan (Citation2020), Hidalgo and Schafgans (Citation2017), and Li, Qian, and Su (Citation2016) to consider models featuring not only breaks but also unobserved heterogeneity in the form of common factors, or “interactive effects.” In particular, while Antoch et al. (Citation2019), and Hidalgo and Schafgans (Citation2017) propose tests for the presence of a structural break, Baltagi, Feng, and Kao (Citation2016), Boldea, Drepper, and Gan (Citation2020), and Li, Qian, and Su (Citation2016) take the existence of a break as given and focus instead on the breakpoint estimation problem. But while highly complementary in terms of the methods they propose, the assumptions employed are materially different.
Antoch et al. (Citation2019) only require N to be large. However, they assume instead that the factor loadings are negligible, which means that strong forms of cross-section dependence are not permitted.Footnote1 It also means that there is no need to account for the factors, and that their effect on the breakpoint estimation problem is in this sense trivial. The weak cross-sectional dependence condition is maintained also in Hidalgo and Schafgans (Citation2017), who in addition require that with
, which in practice means that
. Baltagi, Feng, and Kao (Citation2016) do not require negligible loadings and are therefore more general in this regard. The way they do this is by applying the common correlated effects (CCE) approach of Pesaran (Citation2006), which enables consistent estimation of (the space spanned by) the unknown factors. But then Baltagi, Feng, and Kao (Citation2016) require that both N and T are large, which is again rarely the case in practice. Moreover, the authors only provide a consistency result and they do not consider the asymptotic distribution of the estimated breakpoint, which is necessary for the construction of confidence intervals with correct asymptotic coverage. The same critique applies to the article of Li, Qian, and Su (Citation2016), which uses the principal components method instead of CCE to estimate factors. Boldea, Drepper, and Gan (Citation2020) also do not consider the asymptotic distribution of their estimated breakpoint, although in their article T is fixed. Their approach is similar to the one of Antoch et al. (Citation2019) in the sense that the estimation is carried out while ignoring the factors. This simplicity does, however, come at a cost in terms additional restrictive assumptions. Boldea, Drepper, and Gan (Citation2020) do not require negligible loadings, but they do assume that the omitted variables bias caused by the factors is time-invariant, up to the breakpoint, which limits the type of factors that can be permitted.
1.2 This Article
Motivated by the discussion in the last section, the present article develops tools that enable researchers to both test for the presence of a common structural break, and to infer the breakpoint of an existing break. The interactive effects are handled by using a version of the CCE approach, which is similar yet clearly distinct from the one employed by Baltagi, Feng, and Kao (Citation2016). The reason for focusing on CCE as opposed to the otherwise so popular principal components method is in part because of the extreme simplicity with which the factors are estimated in CCE, in part because CCE is valid even if T is fixed (see, Westerlund, Petrova, and Norkute Citation2019). Needless to say, this last feature, which is not exploited by Baltagi, Feng, and Kao (Citation2016), is an important advantage when wanting to entertain the possibility that T might not be large. The idea, which is laid out along with our model and assumptions in Section 2, is to use the cross-sectional averages of the regressors to estimate the unknown common factors, and to simply augment the regression model with these averages.
We begin by considering the problem of estimating the unknown breakpoint given that a break has occurred. This is done in Section 3. Most articles in the literature are based on the ordinary least squares (OLS) breakpoint estimator, and so is this article. However, instead of minimizing the OLS residuals, which will generally lead to inconsistency because of the unattended factors (Kim Citation2011), we minimize the CCE residuals. We focus on the results for the case when the magnitude of the break is bounded from above and below, although we also allow diverging and shrinking breaks. Moreover, T can be fixed or tending to infinity. According to the results, the proposed breakpoint estimator is consistent as with T fixed or as
with
, and the rate of convergence is given by
. The asymptotic distribution of the breakpoint estimator is obtained under the same set of conditions on N and T, and is used to construct confidence intervals for the true breakpoint. As far as we are aware, this article is the first to provide the rate of convergence and asymptotic distribution in the presence of common factors, and it is the first to establish consistency when T is fixed.
While in Section 3 we assume that a break has occurred, in Section 4 we instead consider the problem of testing for the presence of a break. While very common in the literature, CUSUM-based test statistics like the one of Hidalgo and Schafgans (Citation2017) can suffer from low power in certain directions (see e.g., Andrews Citation1993), and in this article we therefore consider two Wald-type test statistics instead. One is designed to test the null hypothesis of no break against the alternative of a known breakpoint, while in the other the same null is tested against the alternative of a break at some unknown date. To the best of our knowledge, these tests are the first that enable break testing in the presence of common factors. The asymptotic analysis reveals that, while the consistency and asymptotic distribution of the breakpoint estimator only require , unless
with
, the asymptotic distribution of the Wald test statistic that treats the breakpoint as unknown is generally not free of nuisance parameters. Hence, in terms of the size of T, testing for the presence of a structural break is more demanding than estimating the breakpoint. This is what theory tells us. According to the Monte Carlo results reported in the Appendix in the supplementary materials, however, the new toolbox tends to perform well even if T is as small as 10, provided that N is large enough. Hence, even if in theory one of the Wald tests require T to be large, in small samples this requirement does not seem very critical.
Section 5 is concerned with our empirical application to the relationship between stock returns and COVID-19, which is motivated in part by the many recent calls for econometric research into the effects of the pandemic (see e.g., the recent special issue of Journal of Econometrics), in part by existing empirical research. By the end of February, 2020, COVID-19 had led to a world-wide drop in demand, which in turn brought down investment and employment. While stock markets initially reacted to news of the pandemic by losing substantial value, they quickly regained the vast majority of this loss. The fact that this rebound took place even though the number of new cases and deaths were still rising is suggestive of structural change. Most studies of the stock market reaction to COVID-19 either ignore this possibility altogether or split their sample into subperiods based on major events (see e.g., Capelle-Blancard and Desroziers Citation2020; Ramelli and Wagner Citation2020). This means that the breaks are treated as known, if treated at all, which is risky, as misplaced breaks are just as problematic as omitted breaks. In the empirical application of the present article, we offer a more general treatment. This is done by applying the new toolbox to a sample covering 61 countries across 38 weeks, from January 3 to September 25, 2020, which means that T is relatively small. According to the results, the COVID-19-stock return relationship has been affected by the presence a structural break in the first week of April, at about the same time as most central banks announced that they were going to intervene to save the global economy from collapse. While before the break stock markets reacted significantly to news about the pandemic, after the break stock markets became insensitive to such news. This suggests that central banks play a central role in shaping stock market behavior in pandemics.
Section 6 concludes the article. All proofs are provided in the Appendix in the supplementary materials.
2 Model
We consider the following linear panel data model with a structural break at time b:(2.1)
(2.1) where
and
index the cross-sectional units and time periods, respectively. The
vector
contains the regressors and the
vector
is defined as
(2.2)
(2.2)
where
is the indicator function taking the value one when t > b and zero otherwise, and R is an k × r selection matrix of zeros and ones with full column rank r that picks out the elements of
whose coefficients are subject to structural change. For example, if k > r and
, then (2.1) is a partial structural change model in which only the r last regressors in
appear in
. If, on the other hand, k = r, then
, and so the model is one of pure structural change. In the empirical application of Section 5,
is stock returns for country i in week t, and
is comprised of controls and COVID-19 related variables, where the coefficients of the COVID-19 variables may be breaking. As we explain in that section, the model can easily be generalized to include multiple breaks.
The coefficient vectors β and δ are of dimension and
, respectively. In the present article, we follow the bulk of the previous literature (see, e.g., Antoch et al. Citation2019; Boldea, Drepper, and Gan Citation2020), and assume that these are equal across the cross-section. One way to relax this assumption in the large-T case is to follow Pesaran (Citation2006), and to assume that the unit-specific coefficients are randomly distributed with constant means. Unfortunately, this is not possible in the current fixed-T scenario. Moreover, as pointed out by Westerlund, Petrova, and Norkute (Citation2019), the random slope condition comes at a cost of other restrictive conditions.
The error is assumed to admit to a factor structure, which means that it is allowed to be correlated across i. Specifically,
(2.3)
(2.3) where ft and γi are
vectors of common factors and factor loadings, respectively, and
is an idiosyncratic error term. In our empirical application, the presence of ft in (2.3) is just natural because many well-known models in finance, like the capital asset pricing (CAPM) and Fama–French three factor models, imply that returns should have a linear factor structure. In this section and the next, we assume that all the factors are unknown. In Section 5, we demonstrate how the toolbox can be implemented when some of the factors are observed, as when CAPM holds and one has data on (world) market returns.
We want to entertain the possibility that the factors are correlated with the regressors. We therefore follow Pesaran (Citation2006) and assume that(2.4)
(2.4) where Γi is a m × k factor loading matrix and
is a
vector of idiosyncratic errors.
For later use, it is convenient to write the above model in matrix form by stacking the time series observations for each cross-section. The stacked version of (2.1) is given by(2.5)
(2.5) where
and
are
is T × k, and
is T × r. Note that because
can be written as
, where
. Also,
(2.6)
(2.6)
where
and
are T × m and
, respectively. The stacked version of (2.4) is given by
(2.7)
(2.7)
where
is T × k.
The model assumptions depend to a large extent on whether we are estimating the breakpoint or if we are testing for its existence. Assumptions 2.1 and 2.2 will, however, be maintained throughout this article.
Assumption 2.1.
is a covariance stationary process that is independent across i with absolutely summable autocovariances,
Assumption 2.2.
b.
ft is independent of
Assumption 2.1 is standard in the interactive effects literature (see, e.g., Baltagi, Feng, and Kao Citation2016). The only exception known to us is Baltagi, Kao, and Liu (Citation2017). They do not allow for cross-section dependence, but they do allow and
to be unit root nonstationary. We allow for serial correlation and possibly even unit roots in ft (more later) and hence in
(and
), but not in
and
. Bai (Citation1997a) has shown that the existence of both serially correlated errors and lagged dependent variables leads to inconsistent estimation of the break date. Assumption 2.1(c) therefore assumes that
is strictly exogenous (conditional on the factors). Without unit roots Assumption 2.1(a)–(c) are the same as Assumptions 1–3 in Baltagi, Kao, and Liu (Citation2017). Assumption 2.2(a) and (b) are met if ft is stationary and not collinear, which is again a standard requirement in the literature (see, Baltagi, Feng, and Kao Citation2016, Assumption 8). Stationarity is not necessary, though. Note in particular how stationarity is not required if T is fixed. In fact, ft does not even have to be stochastic but can also be deterministic. Assumption 2.2(c) is an identifying condition that is not particularly restrictive. It ensures that ft is the only source of cross-section dependence.
3 Breakpoint Estimation
Let us denote by b0 the true value of b. The purpose of this section is to make inference regarding this parameter.
Assumption 3.1.
.
Assumption 3.2.
Assumption 3.1 requires only that each regime contains at least as many observations as the number of free parameters. It is therefore very general. Baltagi, Feng, and Kao (Citation2016) allow for common factors in very much the same way as we do. However, they require that the loadings follow certain probability laws, and that they are independent of all other random elements of the model. In this section, we treat the loadings as fixed, which means that we do not make any assumption regarding their distribution or their correlation with the other random elements of the model. The main restriction is that must load on the same factors as
, and that the number of regressors must be at least as large as the number of factors. This ensures that the factors can be estimated by applying CCE to
, as we will now explain.Footnote2
Unlike in Antoch et al. (Citation2019), where the factor loadings are assumed to be negligible, under our conditions valid inference on b0 is not possible without proper accounting for ft. The reason is that the factors make correlated with
, which means that (2.1) cannot be estimated consistently using OLS. However, we note that
has a pure factor model representation, suggesting that the factors can be estimated using methods designed for such models. In this article, we follow Baltagi, Feng, and Kao (Citation2016), and use the CCE approach of Pesaran (Citation2006), which is based on using the cross-sectional average of the observables to estimate the space spanned by ft. The difference is that we do not include the cross-sectional average of
, which in the current context is uninformative regarding ft. This is shown in the Appendix in the supplementary materials. Hence, in contrast to Baltagi, Feng, and Kao (Citation2016), in the current article we only use
, where
is the cross-sectional average of any variable
. In view of (2.4), this average can be written as
(3.1)
(3.1)
Let A+ denote the Moore–Penrose inverse of any matrix A. If Assumption 3.2 is true, so that has full row rank, the Moore–Penrose inverse of
is given by
. Hence,
, which in turn means that (3.1) can be solved for ft by left-multiplication by
. It follows that if Assumption 2.1 is also true, so that
, then
(3.2)
(3.2)
We say that is “rotationally consistent” for ft, because it is consistent up to an invertible rotation matrix. Hence, by augmenting (2.1) with
, provided that N is large, we can control for ft, and in this way break the correlation between the regressors and the error term.
Define and
for any T-rowed matrix Ai. The augmented model to be estimated can now be written as
(3.3)
(3.3)
This model can be stacked also over the cross-section, giving(3.4)
(3.4) where
and
are
is NT × k and
is NT × r. Let us further introduce
. With b0 known, the CCE estimator of δ, which is identically the OLS estimator obtained from (3.4), and the associated sum of squared residuals are given by
(3.5)
(3.5)
(3.6)
(3.6)
Of course, in many scenarios of empirical relevance, b0 is not known. The estimator that we will use in its stead is obtained by minimizing over all possible values of b;
(3.7)
(3.7)
We begin by showing that is consistent. For this to be possible, however, in addition to Assumptions 2.1–3.2, we need to ensure that the inverse appearing in
is well-behaved. This is where Assumption 3.3 comes in. It demands that the regressors in
have enough variation across both i and t after projecting out all variation that can be explained by ft. This rules out cross-section-invariant regressors in
.
Assumption 3.3.
and
are positive definite w.p.a.1 for all
, N and T.
We are now ready to state our first main result.
Theorem 3.1.
Suppose that Assumptions 2.1, 2.2 and 3.1–3.3 are met. Then, the following results hold:
If
If
Theorem 3.1 states that is consistent and that the rate of convergence is
or better. The fact that consistency is possible even if T is fixed is very useful in practice, because it means that breaks can be detected very quickly. When
it matters whether m < k or m = k. Note in particular how the rate of convergence is faster when m < k then when m = k, and that this is true even if
under m = k, so that the conditions for (a) and (b) are the same. The reason is that when m < k, unlike what one would expect based on standard theory for regressions in stationary variables, the effect of the redundant cross-section averages contained in
are not negligible but impact the asymptotic theory in very much the same way as unit root regressors do in a spurious regression. Moreover, the redundant averages are correlated with the breaking regressors in
, and this increases the signal coming from
. As far as we are aware, this is the first time redundant regressors have been shown to lead to increased accuracy in breakpoint estimation.
If we are not interested in the distinction between m < k or m = k, the results contained in Theorem 3.1 can be stated as in Corollary 3.1.
Corollary 3.1.
Suppose that conditions of Theorem 3.1 are met, and that and
. Then, as
with T fixed, or as
,
(3.10)
(3.10)
Remark 3.1.
As already mentioned, Baltagi, Feng, and Kao (Citation2016) consider a model that is very similar to ours and that is estimated using CCE. They show that is consistent for b0; however, they only consider the case when
, and they do not provide the rate of convergence. Bai (2010) is the only other article that we are aware of that proves consistency under both fixed and large T; however, his model is very simple in that it does not contain any regressors except for a breaking constant. Under stationarity, the model considered by Baltagi, Kao, and Liu (Citation2017) is very similar to ours but without interactive effects. The rate given in Corollary 3.1 is consistent with the one given in their Theorem 2.
Remark 3.2.
Corollary 3.1 requires that and
. The latter condition is similar to Assumption 2 in Bai (2010), and is tantamount to requiring
with
and
. Hence, while we allow for it, we do not require
, which is in contrast to studies such as Antoch et al. (Citation2019), where the magnitude of the break must be shrinking. The condition that
, which is similar in spirit to Assumption 2 in Baltagi, Feng, and Kao (Citation2016), restricts the relative rate of expansion of N and T, and is only needed when T is large. For example, if
, then we require that
, as otherwise the error coming from the estimation of the factors will tend to accumulate as we sum over time. We also see that the larger is
, the weaker the condition on T/N, as to be expected, because a larger break is easier to discern. If T is fixed, then
is implied by
.
As Corollary 3.1 makes clear, provided that and
, consistency holds irrespectively of whether m = k or m < k, which is of course very useful in practice, as m is unknown here. This invariance is reflected also in the asymptotic distribution of the estimated break date, as our next theorem, Theorem 3.2, makes clear. Before we take the theorem, however, we need to introduce a few more conditions, which are given in Assumption 3.4.
Assumption 3.4.
Assumption 3.4 is restrictive, but is similar to the conditions used in the previous literature (see, e.g., Bai Citation1997a, 2010). It demands that is serially uncorrelated and that the moments of
do not depend on time. While indeed quite strong, because of the presence of ft, which may be serially correlated, the first condition does not rule out serial correlation in
. The second requirement is stronger than necessary, and can be relaxed to accommodate moments that are constant within break regimes but potentially varying between regimes, as in, for example, Bai (Citation1997a), and Yamamoto and Perron (Citation2013).
Theorem 3.2.
Suppose that Assumptions 2.1, 2.2 and 3.1–3.4 are met, and that and
. Then, as
with T fixed, or as
with
,
(3.11)
(3.11) where B(v) is standard two-sided Brownian motion on
.Footnote3
Remark 3.3.
Most articles stop at consistency and do not report the asymptotic distribution of the estimated breakpoint. Bai (2010), Baltagi, Feng, and Kao (Citation2019), and Kim (2011) are exceptions. However, they assume that there are no regressors other than a breaking constant or that the errors are cross-sectionally independent. All three articles require that T is large in their distributional analyses. As far as we are aware, the asymptotic distribution reported in Theorem 3.2 is the first to allow for general regressors and common factors in panels where only N is required to be large.
Theorem 3.2 can be used to construct confidence intervals for b0 with asymptotically correct coverage. Under Assumption 3.4, consistent estimators of ΩX and can be constructed in the following obvious manner:
(3.12)
(3.12)
(3.13)
(3.13) where
with the
vector
being the ith block of the
vector
. The probability density function of
is known analytically and is given in Bai (Citation1997a). Let us denote by
the
th percentile of this distribution function, and let
be the integer part of x. In analogy to Bai (Citation1997a), an asymptotically correctly sized
confidence interval for b0 can now be constructed as
(3.14)
(3.14)
4 Break Testing
Testing for the existence of a structural break is a key first step before estimating the date of the break. In terms of the parameters of (2.1), the null hypothesis of no structural change is given by . The alternative hypothesis can be formulated in (at least) two ways. We begin by considering the alternative that there is a single structural change (
) at a given date b, which may or may not be equal to b0. This hypothesis, henceforth denoted
, can be tested using the following Wald test statistic:
(4.1)
(4.1) where
is a consistent estimator of the asymptotic covariance matrix of
, whose construction will be discussed later. Interestingly, W(b) will not have the expected asymptotic Chi-squared distribution with r degrees of freedom, henceforth denoted
, under H0. The intuition behind this result goes as follows. As already pointed out, because of the presence of ft in both (2.3) and (2.4),
is generally endogenous. The exception is in large-N samples, since here
is rotationally consistent for F, and in this sense
is “asymptotically exogenous.” The problem is that while the use of
takes care of the factors in Xi, it does not take care of those in
, which are breaking. This is a problem because it means that while
is asymptotically exogenous,
is not, which in turn invalidates inference based on W(b). Because of the consistency of
, in Section 3 the endogeneity of
was not an issue. Of course, if we knew that there was a break present, as we did in Section 3, there would be no need to test for it in the first place. The situation considered here is therefore quite different and this requires some changes.
The first change we make when compared to Section 3, which is quite natural given the discussion of the last paragraph, is to replace with
and
with
. The definitions of
and W(b) are adapted accordingly. The idea here is that by augmenting
with
, we can eliminate the factors in both Xi and
, which means that the endogeneity issue is gone. For this to happen, however, we need some additional assumptions. In order to appreciate this, note that
(4.2)
(4.2)
where are the factors in
. Hence, provided that
, such that the
matrix
(4.3)
(4.3) has full column rank
, analogous to the discussion of Section 2,
is rotationally consistent for
. We also need to restrict the type of heterogeneity that can be permitted in γi. The way we do this is by assuming that γi admits to a random coefficient representation, similarly to, for example, Pesaran (Citation2006). Assumption 4.1 below replaces Assumption 3.2 and is enough to ensure that the effect of the estimation of ft is asymptotically eliminated.
Assumption 4.1.
γi is independent across i, and of
Another difference when compared to Section 3, where T could be fixed or large, is that here we focus on the case when T is large. The main reason is that while we can show that the asymptotic null distribution of W(b) for a given b is regardless of whether T is fixed or going to infinity, which we do in the Appendix in the supplementary materials the supremum version of this test that we are going to consider for the unknown break case is generally not free of nuisance parameters when T is fixed. Fortunately, the Monte Carlo results reported in the Appendix in the supplementary materials suggest that our large-T theory provides a very good approximation to actual test behavior even when T is as small as 10. We therefore focus on this theory here and put the fixed-T analysis of W(b) in the Appendix in the supplementary materials.
The required moment conditions, which are less restrictive than the serial uncorrelatedness and time invariant moment conditions of Assumption 3.4, are stated in Assumption 4.2. We also require that Assumption 3.3 holds when is used in place of
.
Assumption 4.2.
Assumption 4.3.
and
are positive definite w.p.a.1 for all
, N and T.
In Section 3, we only required that , which meant that in the large-T case b/T could take on any value in
. Here this is not possible, for it is only when b/T is bounded away from zero and one that W(b) converges in distribution (see Andrews Citation1993, for a discussion). In this section, we therefore assume that
, where
(4.4)
(4.4)
The main implication of this in practice is that we have to truncate, or “trim,” the range of values considered for b at both beginning and end. A very common way to do this is to set , so that the first and last 15% of the observations are discarded (see e.g., Andrews Citation1993; Bai Citation1997a). The condition that b/T should bounded away from zero and one should hold for all b, including b0. The following assumption reflects this.
Assumption 4.4.
, where
.
We now have all the conditions we need in order to obtain the asymptotic distribution of W(b).
Theorem 4.1.
Suppose that H0 holds, and that Assumptions 2.1, 2.2 and 4.1–4.4 are met. Then, uniformly in , as
with
,
(4.5)
(4.5) where
is a
vector standard Brownian motion on
.
Because is a standard Brownian motion,
, where
signifies equality in distribution. Hence, for a given b,
, which in turn implies that
(4.6)
(4.6)
Theorem 4.1 requires that with
. As alluded to earlier, however, the large-T requirement here is not necessary. In particular, as we show in the Appendix in the supplementary materials, (4.6) continues to hold even if T is fixed and only N diverges. The conditions needed are more general than those required for Theorem 4.1 to hold. For example, when T is fixed it is not necessary that
, but it is enough that
. The result in (4.6) therefore holds under very general conditions, and the Monte Carlo results reported in the Appendix in the supplementary materials confirm this.
So far we have taken the date of the break as given. If the date of the break is unknown, as it usually is in practice, H0 can be tested against the alternative hypothesis of a single structural break at some unknown date , which we can formulate as
. Many researchers follow Andrews (Citation1993) and take the supremum of Wald test statistics over all possible breakpoints, and therefore so shall we. The test statistic that we will be considering is therefore given by
(4.7)
(4.7)
The asymptotic distribution of this test statistic depends on the distribution of W(b), and is presented in the following corollary to Theorem 4.1.
Corollary 4.1.
Suppose that H0 holds, and that the conditions of Theorem 4.1 are met. Then, as with
,
(4.8)
(4.8)
The limiting distribution in Corollary 4.1 is the supremum of the square of a standardized tied-down Bessel process of order r, which has appeared previously in Andrews (Citation1993), and Hidalgo and Schafgans (Citation2017), among others. The critical values only depend on r and ϵ, and can be found in of Andrews (Citation1993).
Table 1 Descriptive statistics.
The above results rely on the availability of a consistent estimator of the asymptotic covariance matrix of
, which, in terms of the notation of Assumption 4.2, is given by
. A natural approach in the current large-T setting is to take
(4.9)
(4.9) where
(4.10)
(4.10)
(4.11)
(4.11)
(4.12)
(4.12)
Here is a real-valued kernel, ST is the bandwidth parameter,
is the tth row of the
vector
, which is in turn the ith block of the
vector
, and the
vector
is the corresponding row of the NT × r matrix
. Alternatively,
may be estimated nonparametrically, as in Pesaran and Tosetti (Citation2011).
Remark 4.1.
In the special case when is independently and identically distributed across both i and t with variance
reduces to
, which can in turn be estimated using
(4.13)
(4.13) where
.
Once the presence of a break has been established and its location determined, it is possible to make inference regarding . Let us therefore, define
, such that (2.1) can be written as
(4.14)
(4.14)
The CCE estimator of θ is given by , where
(4.15)
(4.15) with
being
as before, and
being
. By using the results of Westerlund, Petrova, and Norkute (Citation2019), we can show that under the conditions of Section 3 with
in place of
, as
,
(4.16)
(4.16)
where
(4.17)
(4.17)
(4.18)
(4.18)
Hence, is asymptotically normal conditionally on F, which means that it supports standard normal and Chi-squared inference. If
, then the asymptotic distribution of
is the one given by Theorem 4 of Pesaran (Citation2006).
5 Application Stock Market Reaction of COVID-19
5.1 Motivation
COVID-19 broke out in China in December 2019. Roughly one year later, WHO (Citation2021) reports 94 million confirmed cases and over two million deaths. Moreover, because of lockdowns, travel restrictions and social distancing policies, in 2020 GDP dropped by 4.2% globally and real world trade contracted by 10.3% (OECD Citation2020).Footnote4 The economic impact of the pandemic has therefore been substantial. This is what we know. There are some signs of recovery in the years to come; however, the global outlook is extremely uncertain, even in the short term. As an indication of this, the 2020 OECD world GDP projections for 2021 ranges from –2.75% to 5%, depending on, among other things, the evolution of the pandemic, the actions taken to contain the spread of the virus and their economic impact, and the time until effective vaccines can be deployed. Hence, even now, more than a year after the outbreak, much is uncertain.
The uncertainty we face today is nothing compared to what it was in the beginning of the pandemic. At this time, little was known about the new virus, but it was clear that it was very infectious and deadly, as, in contrast to previous infectious disease outbreaks, most countries begun to announce the number of cases and deaths on a daily basis. Many were chocked by how quickly these numbers were increasing. Governments scrambled with emergency actions, such as closing schools and workplaces, travel bans, or even complete curfews, to try to contain the spread. However, since their effectiveness was far from clear and they made it impossible for firms and workers to continue their operations without knowing if and when they would be compensated, these actions added to the already existing uncertainty, leading to widespread public fear (see Mamaysky Citation2020; Phan and Narayan Citation2020). This was visibly apparent with news coming in of supermarkets being stocked out of toilet paper (Aggarwal, Nawn, and Dugar Citation2020).
In times of extreme uncertainty, stock markets often respond dramatically to news about the underlying economic and market conditions (see Mamaysky Citation2020). This is what happened during the global financial crisis of 2007–2009 and it happened again in the initial stages of the pandemic. In January 2020, the news reporting was comparable to what it was in the beginning of the SARS (severe acute respiratory syndrome) and Ebola epidemics. By February, however, COVID-19 started to dominate newspaper discussions of the economy, and by March, almost all such discussions were about COVID-19 (Baker et al. Citation2020).Footnote5 Stock markets responded violently. On March 16, the Chicago Board Option Exchange’s volatility index, the so-called “VIX,” surged past the prior all-time peak reached during the global financial crisis more than a decade ago. The second-worst day ever of the Dow Jones industrial index happened on March 16, and three of the 15 worst days ever of the U.S. market occurred between March 9 and 16 (Wagner Citation2020). Stock markets all over the world reacted similarly.
The unprecedented stock market behavior in the initial stage of COVID-19 has attracted considerable attention not only in the news but also in research. The bulk of the evidence seem to suggest that stock markets have generally responded negatively, although the channel through which this effect works is still largely unknown. Ashraf (Citation2020a) uses data for 64 countries and finds that stock prices have reacted negatively to the pandemic, but only when measured by the number of confirmed cases, as opposed to the death count. This is largely in agreement with the results of Erdem (Citation2020). Ashraf (Citation2020b) employs data for 77 countries. He finds that the COVID-19 effect operates not only through the number of cases, but also through government actions, such as social distancing measures, containment and health responses, and economic support packages. Similar findings have been reported by Aggarwal, Nawn, and Dugar (Citation2020) and Capelle-Blancard and Desroziers (Citation2020).Footnote6
The purpose of the current application is to contribute to the above mentioned literature. This is done in three ways. First, we account for the rebound of returns. Faced with near economic collapse, starting with the Federal Reserve’s decision on March 16 to buy USD 700 billion worth of U.S. treasury bonds and mortgage-backed securities, central banks around the world announced aggressive quantitative easing programs (see Rebucci, Hartley and Jiménez Citation2020). These announcements were followed by an abrupt increase in stock prices. The U.S. S&P500 stock market index, for example, increased by 29% between March 24 and April 17, a surge that left the index back where it stood in August of 2019 when the U.S. economy was booming. The fact that this rebound took place while the pandemic was still ongoing is suggestive of a structural break. Most studies ignore this. The only exceptions known to us are Capelle-Blancard and Desroziers (Citation2020), Mamaysky (Citation2020), and Ramelli and Wagner (Citation2020), who divide their samples into subperiods based on major events. The breaks are therefore treated as known, which is risky, as misplaced breaks are just as problematic as omitted breaks.
The second contribution of this application is that we account for general forms of unobserved heterogeneity. Many studies recognize the problem but assume that it can be handled using country and period fixed effects. However, fixed effects do not work in general when pair-wise cross-section covariances of the regression errors differ across countries, and there is plenty of evidence to support this (see e.g., Zhang, Hu, and Ji Citation2020). Capelle-Blancard and Desroziers (Citation2020) use robust standard errors but they can only handle weak cross-section dependence.
The third contribution is that we account for the smallness of T. As alluded to earlier, with COVID-19 being such a recent phenomenon, studies of it are constrained to data sets with short time span (see e.g., Salisu and Vo Citation2020, for a discussion). Some “compensate” by using a relatively high frequency, such as daily data, but not all. To take an extreme example, Aggarwal, Nawn, and Dugar (Citation2020) use monthly data from December 2019 to May 2020, which means that T = 6. Moreover, even if data are daily, the subperiods considered are very short. It is therefore important to use appropriate small-T techniques.
5.2 Data
Our dependent variable is stock returns (RET), which we compute as the log difference of the price index.Footnote7 We use four control variables; the U.S. Dollar exchange rate (ER), stock market volatility (VOL), which we proxy using the Chicago Board Options Exchange’s CBOE volatility index, world market returns (MRET), as measured by the cross-country average of RET, and the U.S. three-month treasury bill rate (TBILL) (see e.g., Aggarwal, Nawn, and Dugar Citation2020; Capelle-Blancard and Desroziers Citation2020; Mamaysky Citation2020; Salisu and Vo Citation2020, for similar control variable lineups). ER is motivated by the theoretical work of Dornbusch and Fischer (Citation1980), which says that exchange rates will influence stock returns because they capture the value of firms’ future cash flows. VOL can be motivated in part by its ability to predict returns (see e.g., Bollerslev, Tauchen, and Zhou Citation2009; Bollerslev, Xu, and Zhou Citation2015), in part by the theory of Glasserman, Mamaysky, and Shen (Citation2020), according to which information shocks can lead to large drops in stock prices and increases in volatility. TBILL captures both the risk-free interest rate and the importance of the United States in shaping stock markets around the world. The need to control for MRET is due to CAPM.Footnote8
We use all available measures of COVID-19 that have sufficient time series data. A total of six variables meet this criterion. The first two capture the spread of the virus. They are the number of confirmed cases (CASE) and deaths (DEATH). The next four variables are indices that capture government response to COVID-19; a government stringency index (STR), a containment and health index (CONT), a government economic support index (ECON), and an overall government response index (RESP). STR records the strictness of government policies that primarily restrict people’s behavior, such as school and workplace closures, stay-at-home requirements, and travel bans. CONT captures mainly social distancing restrictions, but also health system policies such as testing policy, contact tracing, short term investment in healthcare and investments in vaccine. ECON is an index that captures government income support and debt relief. RESP captures all of the above. All indices are on a scale of 0 to 100 with a larger value indicating greater stringency, greater commitment to health, greater economic support, and greater overall government response. All data are obtained from Datastream, except for TBILL, which is from Federal Reserve Bank St Louis. The data are weekly and cover N = 61 countries.Footnote9 As in many other empirical scenarios, the number of time periods is limited and cannot be increased other than by the passage of time. We take the largest sample period available to us, which covers T = 38 weeks, from January 3 to September 25, 2020. The smallness of T in this case means that it is important to use techniques that work even if T is not large. The Monte Carlo results reported in the Appendix in the supplementary materials suggest that the proposed toolbox should work well here.
5.3 Implementation
Both theory and empirical observations stress the importance of news (see, e.g., Mamaysky Citation2020). We therefore follow the bulk of the existing literature and express all regressors in innovation form by taking first differences. Ashraf (2020b) considers the same stringency, containment and health, and economic support indices as we do. While he includes all three indices at the same time, we do not. The reason is that STR, CONT and RESP are highly collinear with correlations that range from 0.949 to 0.978. We therefore include them one at a time (see Capelle-Blancard and Desroziers Citation2020, for a similar approach).
VOL, MRET and TBILL do not vary by country but only by week. We therefore want to treat these as observed common factors, a possibility that we did not consider in Sections 2–4. As pointed out in Section 2, the type of factors that can be permitted under Assumption 2.2 is very broad. This suggests that there is no need to discriminate between known and unknown factors, but that one can just as well treat them all as unknown to be estimated from the data. In fact, this is the main rationale for writing (2.1) and (2.4) in terms of (the unknown) ft only. The main drawback of this fully unknown factor treatment is that it puts strain on the Assumption 3.2 condition that , as k is fixed and additional factors increase m even if they are known. For this reason, it may be preferable to be able to distinguish between known and unknown factors. Fortunately, in CCE this is very easy. Let us therefore assume that there are two sets of factors, ft and dt, where ft is a
vector of unknown factors, just as before, while dt is a
vectors of known common regressors, which in this section is comprised of a constant (country fixed effects), VOL, MRET and TBILL. Hence, now the total number of factors is equal to m + n, out of which n are known. In order to account for the fact that some of the factors are now known, instead of using
to purge the effect of F in the estimation of b, we use
, where
is T × n. Similarly, to account for the known factors in the break tests we replace
with
, where
. The effect of these changes is that Assumption 3.2 only applies to the unknown factors; that is, we do not require
but only
The above discussion suggests that in terms of the known factor-augmented version of (2.1), in this section is RET, dt is a constant, VOL, MRET and TBILL, and
is ER, CASE, DEATH, ECON, and one of STR, CONT and RESP. We allow the coefficients of the COVID-19 spread and response variables to be breaking, but not the coefficient of ER. The date of the break is treated as unknown not only in the estimation but also on the testing. We therefore focus on the SW test, which we implement using 15% trimming (
) (as in e.g., Andrews Citation1993; Bai Citation1997a). Based on its good performance in the Monte Carlo study reported in the Appendix in the supplementary materials the asymptotic covariance matrix of
is computed based on the Bartlett kernel with the bandwidth parameter ST set equal to
. Similarly to us, Bai (2010) focuses on the single break case, although he also discusses the possibility of having multiple breaks. As he remarks, if the number of breaks is given, the one-at-a-time approach of Bai (Citation1997b) can be used to estimate the breakpoints, and if the number of breaks is unknown, a test for existence of a break can be applied to each subsample before estimating another breakpoint. The same approach can be used also in the current more general context. The results are discussed in the next section.
5.4 Results
We begin this section by considering the descriptive statistics reported in . The first set of results include the mean, standard deviation, minimum and maximum of each variable. RET has a mean value of –0.392 with a standard deviation of 4.44. The fact that the mean is negative indicates that the pandemic has affected stock markets negatively. The mean values of CASE and DEATH are positive, as expected because the pandemic has not settled down yet. The results for the response variables show that governments have responded to the pandemic. also reports the results obtained by applying the CD test of Pesaran (2021), which tests the null hypothesis of no remaining cross-sectional correlation after controlling for fixed effects. The null is rejected at all conventional significance levels for all variables, suggesting that, as expected given the above discussion, fixed effects are not enough to account for the cross-section correlation. The results of the unit root tests of Elliott, Rothenberg, and Stock (Citation1996), and Pesaran (2007) confirm that all the variables are stationary. The latter test allows for common factors in very much the same way as CCE, by using cross-sectional averages to estimate and remove any factors before testing for unit roots. This makes it ideal for our purposes, as it only tests the idiosyncratic errors, which we have assumed to be stationary. In order to also get a feeling for the validity of the interactive effects assumption, reports the average correlation coefficient for all pairs of countries after factor removal. If the interactive effects assumption is correct, the defactored data should be cross-country uncorrelated, whereas if the assumption is incorrect there should be some remaining cross-country correlation. Hence, only if the defactored data are cross-country uncorrelated can we conclude in favor of the interactive effects assumption. According to the results, the average correlation coefficients are very small in absolute value, between –0.007 and 0.023, suggesting that there are no major violations of the interactive effects assumption.
contains our main results. It reports the estimated coefficients and their significance, the SW test values and their significance, the estimated break date, and the associated 95% break date confidence interval.Footnote10 The table only contains the results for the COVID-19 variables, which are our main regressors. The controls are included but we do not report their results. Three specifications are considered, one for each of STR, CONT and RESP.
Table 2 Main results.
The first thing to note is that the SW test is highly significant in all three specifications and that the break date is estimated to the first week of April, which starts on March 30 and ends on April 5. This is consistent with the quantitative easing interventions of major central banks and the sharp stock market rise that followed. For example, the S&P 500 stock market index lost 34% of its value between February 19 and March 23, but abruptly regained the vast majority of this loss, rising 29% between March 24 and April 17. Stock markets all around the world experienced similar surges (see International Monetary Fund, IMF Citation2020). There may be confounding factors that have affected stock returns positively. However, we note that the quantitative easing announcements were among the largest news items at the time (Mamaysky Citation2020). A full table of announcements can be found in Rebucci, Hartley and Jiménez (Citation2020). The dates of some notable announcements in March 2020 are the European Central Bank on the 18th, the Bank of England and the Reserve Bank of Australia on the 19th, the Reserve Bank of New Zealand on the 23rd, the Bank of Korea on the 25th, and the Federal Reserve and the Bank of Canada on the 27th. Most of the emerging economies’ central banks made their announcements during the last 10 days of March. Our estimated break date is located directly after these announcements.
Quantitative easing pushes interest rates down and this has (at least) two effects, which both result in an increase in stock prices (see e.g., Bernanke Citation2012. First, by decreasing the discount rate, quantitative easing increases the present value of future cash flows. Second, quantitative easing makes relatively safe assets unattractive, which creates an incentive for investors to rebalance their portfolios to include more stocks, and this in turn pushes stock prices up. We therefore speculate that it was the quantitative easing announcements that caused the break in the stock return-COVID-19 relationship.Footnote11 As explained earlier in this section, the SW test is applied not only to the full sample but also to the pre- and post-break periods. However, no significant breaks were found in the pre- and post-break periods, and so we conclude that there is just one break.
Another observation is that all the COVID-19 regressors enter significantly but only before the break. Specifically, the estimated pre-break coefficients (β) are all significant, as are the estimated breaks (δ), but they sum up to zero, and the sum is insignificant in all cases. In other words, the estimated post-break effects () are insignificant. Consider CASE and DEATH. Their pre-break effect is significantly negative, which is consistent with existing results (see e.g., Ashraf Citation2020a, 2020b; Capelle-Blancard and Desroziers Citation2020; Erdem Citation2020). Hence, as expected, stock markets initially responded negatively to the news of the outbreak of the virus. This negative effect is, however, completely eliminated by the break, which is estimated to be of the same magnitude but of opposite sign. The post-break effect of CASE and DEATH is therefore estimated to zero, suggesting that the central bank interventions have had a substantial positive effect on stock markets.
Let us now move on to the response regressors, STR, CONT, ECON and RESP. The estimated pre-break effect of ECON is significantly positive, meaning that stock markets initially responded positively to news of increased government support, which is again in accordance with our a priori expectations. After the break, however, stock markets became insensitive to such news. Similarly, while initially markets responded negatively to announcements of stricter and more extensive government restrictions, as measured by STR and RESP, after the break they did not respond at all. The same is true for CONT, which is probably due to the fact that while this variable captures both social distancing restrictions and investments in healthcare, the restrictions are weighted higher in the construction of the index and they did came first. As an illustration of the effect of STR, CONT and RESP, in we plot the cross-sectional averages of these variables against that of RET. We see that while before the break the co-movement between average RET on the one hand and STR, CONT and RESP on the other hand is clearly negative, after the break the co-movement is much weaker. These results are quite different from existing ones. Capelle-Blancard and Desroziers (Citation2020) find that STR has a positive but insignificant effect, which becomes significant only in the absence of fixed effects or other control variables. Ashraf (2020b) reports a significantly negative effect of STR, a significantly positive effect of CONT and an insignificant effect of ECON. However, these other studies only allow for fixed effects and they do not take into consideration our estimated breakpoint, which could very well explain the observed differences in the results.
Fig. 1 Plotting the cross-sectional averages of RET, STR, CONT and RESP.
NOTE: The figure plots the weekly cross-sectional averages of stock returns (RET), government stringency (STR), government containment and health (CONT) and overall government response (RESP). The break date estimate and the associated 95% confidence interval are taken from . The reported dates refer to the last day of the relevant week.
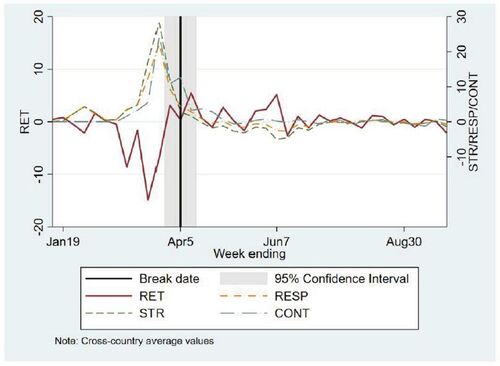
According to the results of Baker et al. (Citation2020) and Mamaysky (Citation2020), in the early phase of the pandemic (late February to late March) stock market movements were driven by news about the virus. In fact, markets were “hypersensitive” and overreacted not only to news themselves but also to other markets’ reaction to news (Mamaysky Citation2020). “Markets started to oscillate wildly, and people suddenly realized that the virus could affect them directly. Panic selling in the stock market went hand-in-hand with panic buying in supermarkets” (Wagner Citation2020, p. 440). This explains why initially stock markets reacted significantly to all COVID-19 related news (CASE, DEATH, STR, CONT, ECON and RESP). The powerful central bank interventions acted as a wake-up call. They signaled a clear commitment to deal with the pandemic, thereby bringing some certainty to an otherwise extremely uncertain future. Stock markets reacted positively and progressed on a path to recovery. This is noteworthy because the economic conditions have been steadily deteriorating as a result of closures and social distancing (see IMF Citation2020). As Krugman (Citation2020) puts it, “[t]he relationship between stock performance—largely driven by the oscillation between greed and fear—and real economic growth has always been somewhere between loose and nonexistent.”
The explanation for our results given in the previous paragraph is consistent with (at least) two theories. The first is the so-called “overreaction” hypothesis of Daniel, Hirshleifer, and Subrahmanyam (Citation1998), and Hong and Stein (Citation1999), which states that investors overreact to negative shocks, such as those that hit stock markets in the early phase of the pandemic. As more information becomes available, however, and the central bank announcement were very informative, investors correct their behavior, which leads to market recovery. The second theory is that of Glasserman, Mamaysky, and Shen (Citation2020). It states that information shocks, such as the outbreak of COVID-19, can lead to large drops in prices and increases in volatility, which in turn cause prices to become hypersensitive to newsflow. However, information can also push prices out of hypersensitivity, and our results show that in the post-break regime returns are no longer reacting to news of the pandemic.
6 Conclusions
The main aim of this article is to provide a toolbox that meets the basic needs of researchers interested in a linear panel data model with a possible structural break. The toolbox allows researchers to test for the presence of a break, and, if a break is detected, to also estimate the location of the break and construct a confidence interval for the true breakpoint. The toolbox does not require that the data are independent, nor that T is large, which means that it is widely is applicable.
The new toolbox is employed to investigate the relationship between stock market returns and COVID-19 in a sample covering 61 countries across 38 weeks. Stock markets all over the world plunged in the early phase of the pandemic but they quickly rebounded, and this rebound took place although the end of the pandemic is still not in sight. Our analysis shows that while initially responsive, the effect of COVID-19 stopped dead at the end of March–beginning of April 2020. We attribute this break to the massive quantitative easing programs announced by central banks around the world in the second half of March.
Supplemental Material
Download PDF (307.9 KB)Acknowledgments
We thank the Editor Professor Christian B. Hansen, an Associate Editor and three referees for helpful comments and suggestions. A previous version of this article was presented in seminars at the University of Duisburg-Essen and the Free University of Bozen-Bolzano, and at the 14th and 15th International Conferences on Computational and Financial Econometrics, the International Association for Applied Econometrics 2021 Annual Conference, the 26th International Panel Data Conference, the 2021 Latin American Meeting of the Econometric Society and the 2021 European Winter Meeting of the Econometric Society. The authors would like to thank all seminar and conference participants, and in particular Jan Ditzen, Christoph Hanck, Yannick Hoga, Sebastian Otten, Thilo Reinschlüssel and Martin Weidner for many valuable comments and suggestions.
Supplementary Materials
This supplement provides (a) the proofs of the results reported in Sections 3 and 4 of the main article, (ii) some additional theoretical results that are commented on but not reported in the main article, and (iii) a Monte Carlo study.
Funding
Westerlund would also like to thank the Knut and Alice Wallenberg Foundation for financial support through a Wallenberg Academy Fellowship.
Additional information
Funding
Notes
1 See Chudik et al. (Citation2011) for a detailed treatment of the concepts of weak and strong cross-section dependence.
2 Strictly speaking, the assumption that and
load on the same set of factors is not necessary. Factors that are unique to either
or
can be accommodated by imposing zero restrictions on γi and Γi. This means that there might be factors in
that are not captured by our CCE approach, and the theory provided here does not consider this possibility. However, this does not mean that our toolbox cannot handle unattended factors. In fact, intuition suggest that the approach should work well as long as there are no unattended factors in
, so that the regressors are conditionally exogenous given the factors, and our unreported Monte Carlo evidence supports this.
3 The two-sided Brownian motion B(v) satisfies , and
for v > 0 and
for v < 0, where
and
are two independent standard Brownian motions.
4 By comparison, the lowest global GDP growth rate during the 2007–2009 global financial crisis was –1.7% in 2009.
5 Not all news were about the economy and many were just rumors, but they still attracted considerable attention and were therefore important in setting the public sentiment at the time. For example, on February 17, a run on toilet paper in Hong Kong was mentioned for the first time, and became a highly contagious story. Some people in locked-down China reportedly were reduced to searching for minnows and ragworms to eat. In Italy, there were stories of medical workers in overwhelmed hospitals being forced to choose which patients would receive treatment (Shiller Citation2020).
6 Many studies focus on single countries. There are also those that focus on the volatility of stock returns, as opposed to stock returns themselves. These are not reviewed here.
7 We experimented using excess returns. However, because the results were qualitatively the same, and since the previous literature focuses almost exclusively on raw returns, here we only report the results based on using raw returns as the dependent variable.
8 While the COVID-19 variables are clearly exogenous, the controls are not. Because of this we tried lagging the controls, which reduces the risk of reversed causality. The results were, however, unaffected by this.
9 The included countries are Argentina, Australia, Austria, Belgium, Brazil, Bulgaria, Canada, Chile, China, Croatia, Cyprus, Czech Republic, Denmark, Egypt, Estonia, Finland, France, Germany, Greece, Hong Kong, Hungary, Iceland, India, Indonesia, Ireland, Israel, Italy, Jamaica, Japan, Jordan, Kenya, Kuwait, Latvia, Luxembourg, Malaysia, Mexico, Morocco, the Netherlands, New Zealand, Norway, Oman, Pakistan, Peru, the Philippines, Poland, Portugal, Romania, Russia, Singapore, Slovakia, Slovenia, South Africa, South Korea, Spain, Sri Lanka, Sweden, Switzerland, Thailand, Tunisia, Turkey, and the United Kingdom.
10 After the break date was estimated, the Stata command xtdcce2 by Ditzen (Citation2018) was used to obtain the regression results.
11 We also note that our estimated breakpoint does not coincide with the sample splits considered by Capelle-Blancard and Desroziers (Citation2020), Mamaysky (Citation2020), and Ramelli and Wagner (Citation2020).
References
- Aggarwal, S., Nawn, S., and Dugar, A. (2020), “What Caused Global Stock Market Meltdown during the COVID Pandemic—Lockdown Stringency or Investor Panic?” Finance Research Letters, 31, 101690.
- Andrews, D. W. K. (1993), “Tests for Parameter Instability and Structural Change with Unknown Change Point,” Econometrica, 61, 821–856. DOI: 10.2307/2951764.
- Antoch, J., Hanousek, J., Horváth, L., Hušková, M., and Wang, S. (2019), “Structural Breaks in Panel Data: Large Number of Panels and Short Length Time Series,” Econometric Reviews, 38, 828–855. DOI: 10.1080/07474938.2018.1454378.
- Ashraf, B. N. (2020a), “Stock Markets’ Reaction to COVID-19: Cases or Fatalities?” Research in International Business and Finance, 54, 101249. DOI: 10.1016/j.ribaf.2020.101249.
- Ashraf, B. N. (2020b), “Economic Impact of Government Interventions during the COVID-19 Pandemic: International Evidence from Financial Markets,” Journal of Behavioral and Experimental Finance, 27, 100371.
- Bai, J. (1997a), “Estimation of a Change Point in Multiple Regression Models,” Review of Economics and Statistics, 79, 551–563. DOI: 10.1162/003465397557132.
- Bai, J. (1997b), “Estimating Multiple Breaks One at a Time,” Econometric Theory, 13, 315–352.
- Bai, J. (2010), “Common Breaks in Means and Variances for Panel Data,” Journal of Econometrics, 157, 78–92.
- Baker S. R., Bloom, N., Davis, S. J., Kost, K. J., Sammon, M. C., and Viratyosin, T. (2020), “The Unprecedented Stock Market Impact of COVID-19,” Covid Economics, 1, 33–42.
- Baltagi, B. H., Feng, Q., and Kao, C. (2016), “Estimation of Heterogeneous Panels with Structural Breaks,” Journal of Econometrics, 191, 176–195. DOI: 10.1016/j.jeconom.2015.03.048.
- Baltagi, B. H., Feng, Q., and Kao, C. (2019), “Structural Changes in Heterogeneous Panels with Eendogenous Regressors,” Journal of Applied Economics, 34, 883–892.
- Baltagi, B. H., Kao, C., and Liu, L. (2017), “Estimation and Identification of Change Points in Panel Models with Nonstationary or Stationary Regressors and Error Term,” Econometric Reviews, 36, 85–102. DOI: 10.1080/07474938.2015.1114262.
- Bernanke, B. (2012), “Monetary Policy Since the Onset of the Crisis.” Remarks at the Federal Reserve Bank of Kansas City Economic Symposium, Jackson Hole, Wyoming, August 31.
- Boldea, O., Drepper, B., and Gan, Z. (2020), “Change Point Estimation in Panel Data with Time-Varying Individual Effects,” Journal of Applied Econometrics, 35, 712–727. DOI: 10.1002/jae.2769.
- Bollerslev, T., Tauchen, G., and Zhou, H. (2009), “Expected Stock Returns and Variance Risk Premia,” Review of Financial Studies, 22, 4463–4492. DOI: 10.1093/rfs/hhp008.
- Bollerslev, T., Xu, L., and Zhou, H. (2015),“Stock Return and Cash Flow Predictability: The Role of Volatility Risk,” Journal of Econometrics, 187, 458–471. DOI: 10.1016/j.jeconom.2015.02.031.
- Capelle-Blancard, G., and Desroziers, A. (2020), “The Stock Market is not the Economy? Insights from the Covid-19 Crisis,” Covid Economics, 28, 29–69.
- Chudik, A., Pesaran, M.H. and Tosetti, E. (2011), “Weak and Strong Cross-section Dependence and Estimation of Large Panels,” The Econometrics Journal, 14, C45–C90. DOI: 10.1111/j.1368-423X.2010.00330.x.
- Daniel, K., Hirshleifer, D., and Subrahmanyam, A. (1998), “Investor Psychology and Security Market Under- and Overreactions,” Journal of Finance, 53, 1839–1886. DOI: 10.1111/0022-1082.00077.
- Ditzen, J. (2018), “xtdcce2: Estimating Dynamic Common Correlated Effects in Stata,” Stata Journal, 18, 585–617. DOI: 10.1177/1536867X1801800306.
- Dornbusch, R., and Fischer, S. (1980) “Exchange Rates and the Current Account,” American Economic Review, 70, 960–971.
- Elliott, G., Rothenberg, T. J., and Stock, J. H. (1996), “Efficient Tests for an Autoregressive Unit Root,” Econometrica, 64, 813–836. DOI: 10.2307/2171846.
- Erdem, O. (2020), “Freedom and Stock Market Performance during COVID-19 Outbreak,” Finance Research Letters, 36, 101671. DOI: 10.1016/j.frl.2020.101671.
- Glasserman, P., Mamaysky, H., and Shen, Y. (2020), “Dynamic Information Regimes in Financial Markets,” working paper.
- Hidalgo, J., and Schafgans, M. (2017), “Inference and Testing Breaks in Large Dynamic Panels with Strong Cross Sectional Dependence,” Journal of Econometrics, 196, 259–274. DOI: 10.1016/j.jeconom.2016.09.008.
- Hong, H., and Stein, J. (1999), “A Unified Theory of Underreaction, Momentum Trading, and Overreaction in Asset Markets,” Journal of Finance, 54, 2143–2184. DOI: 10.1111/0022-1082.00184.
- IMF (2020), “Special Series on COVID-19: The Disconnect between Financial Markets and the Real Economy,” Washington.
- Kim, D. (2011), “Estimating a Common Deterministic Time Trend Break in Large Panels with Cross Sectional Dependence,” Journal of Econometrics, 164, 310–330. DOI: 10.1016/j.jeconom.2011.06.018.
- Krugman, P. (2020), “Crashing Economy, Rising Stocks: What’s Going On?” New York Times, April 30.
- Li, D., Qian, J., and Su, L. (2016), “Panel Data Models With Interactive Fixed Effects and Multiple Structural Break,” Journal of the American Statistical Association, 111, 1804–1819. DOI: 10.1080/01621459.2015.1119696.
- Mamaysky, H. (2020), “News and Markets in the Time of COVID-19,” available at SSRN: DOI: 10.2139/ssrn.3565597..
- OECD (2020), Economic Outlook, Issue 2, Paris: OECD Publishing.
- Pesaran, M. H. (2006), “Estimation and Inference in Large Heterogeneous Panels with a Multifactor Error Structure,” Econometrica, 74, 967–1012. DOI: 10.1111/j.1468-0262.2006.00692.x.
- Pesaran, M. H. (2007), “A Simple Panel Unit Root Test in the Presence of Cross-Section Dependence,” Journal of Applied Econometrics, 22, 265–312.
- Pesaran, M. H. (2021), “General Diagnostic Tests for Cross-Sectional Dependence in Panels,” Empirical Economics, 60, 13–50.
- Pesaran, M. H., and Tosetti, E. (2011), “Large Panels with Common Factors and Spatial Correlation,” Journal of Econometrics, 161, 182–202. DOI: 10.1016/j.jeconom.2010.12.003.
- Phan, D. H. B., and Narayan, P. K. (2020), “Country Responses and the Reaction of the Stock Market to COVID-19—A Preliminary Exposition,” Emerging Markets Finance and Trade, 56, 2138–2150. DOI: 10.1080/1540496X.2020.1784719.
- Ramelli, S., and Wagner, A. F. (2020), “Feverish Stock Price Reactions to COVIS-19,” Review of Corporate Finance Studies, 9, 622–655. DOI: 10.1093/rcfs/cfaa012.
- Rebucci, A., Hartley, J. S., and Jiménez, D. (2020). An Event Study of COVID-19 Central Bank Quantitative Easing in Advanced and Emerging Economies,” NBER working paper 27339.
- Salisu, A. A., and Vo, X. V. (2020), “Predicting Stock Returns in the Presence of COVID-19 Pandemic: The Role of Health News,” International Review of Financial Analysis, 71, 101546. DOI: 10.1016/j.irfa.2020.101546.
- Shiller, R. (2020), “Opinion: Robert Shiller Explains the Pandemic Stock Market and Why it’s Decoupled from the Economy,” Project Syndicate, July 11, 2020.
- Wagner, A. F (2020), “What the Stock Market Tells us about the Post-COVID-19 World,” Nature Human Behaviour, 4, 440. DOI: 10.1038/s41562-020-0869-y.
- Westerlund, J. (2019), “On Estimation and Inference in Heterogeneous Panel Regressions with Interactive Effects,” Journal of Time Series Analysis, 40, 852–857. DOI: 10.1111/jtsa.12432.
- Westerlund, J., Petrova, Y., and Norkute, M. (2019), “CCE in Fixed-T Panels,” Journal of Applied Econometrics, 34, 746–761. DOI: 10.1002/jae.2707.
- WHO (2021), “Weekly Operational Update on COVID-19—January 19, 2021,” available at https://www.who.int/publications/m/item/weekly-operational-update-on-covid-19–-19-january-2021.
- Yamamoto, Y. and Perron, P. (2013), “Estimating and Testing Multiple Structural Changes in Linear Models Using Band Spectral Regressions,” The Econometrics Journal, 16, 400–429. DOI: 10.1111/ectj.12010.
- Zhang, D., Hu, M., and Ji, Q. (2020), “Financial Markets under the Global Pandemic of COVID-19,” Finance Research Letters, 36, 101528. DOI: 10.1016/j.frl.2020.101528.
