
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
This article studies multiple structural breaks in large contemporaneous covariance matrices of high-dimensional time series satisfying an approximate factor model. The breaks in the second-order moment structure of the common components are due to sudden changes in either factor loadings or covariance of latent factors, requiring appropriate transformation of the factor models to facilitate estimation of the (transformed) common factors and factor loadings via the classical principal component analysis. With the estimated factors and idiosyncratic errors, an easy-to-implement CUSUM-based detection technique is introduced to consistently estimate the location and number of breaks and correctly identify whether they originate in the common or idiosyncratic error components. The algorithms of Wild Binary Segmentation for Covariance (WBS-Cov) and Wild Sparsified Binary Segmentation for Covariance (WSBS-Cov) are used to estimate breaks in the common and idiosyncratic error components, respectively. Under some technical conditions, the asymptotic properties of the proposed methodology are derived with near-optimal rates (up to a logarithmic factor) achieved for the estimated breaks. Monte Carlo simulation studies are conducted to examine the finite-sample performance of the developed method and its comparison with other existing approaches. We finally apply our method to study the contemporaneous covariance structure of daily returns of S&P 500 constituents and identify a few breaks including those occurring during the 2007–2008 financial crisis and the recent coronavirus (COVID-19) outbreak. An package “
” is provided to implement the proposed algorithms.
1 Introduction
Estimation of covariance matrices is of fundamental importance in modern multivariate statistics, and has applications in various fields such as biology, economics, finance, and social networks. Suppose that is a collection of n observations from a d-dimensional random vector with
and
, where
is a null vector whose size may change from line to line and
is a d × d positive definite covariance matrix. When the dimension d is fixed or significantly smaller than the sample size n, the population covariance matrix
can be well estimated by the conventional sample covariance matrix (see Anderson Citation2003):
(1.1)
(1.1)
However, when d exceeds n, the sample covariance matrix defined in (1.1) becomes singular. Estimation of such a large covariance matrix is generally challenging and has received increasing attention in recent years. Some techniques have been introduced to regularize covariance matrices and produce reliable estimation (see Wu and Pourahmadi Citation2003; Ledoit and Wolf Citation2004; Bickel and Levina Citation2008a, Citation2008b; El Karoui Citation2008a, Citation2008b; Lam and Fan 2009; Rothman, Levina, and Zhu Citation2009; Cai and Liu Citation2011; Fan, Liao, and Mincheva Citation2013; Huang and Fryzlewicz Citation2019). A comprehensive review on large covariance matrix estimation can be found in Pourahmadi (Citation2013), Cai, Ren, and Zhou (Citation2016) and Fan, Liao, and Liu (Citation2016). All of the aforementioned literature assumes that the large covariance matrix is a constant matrix throughout the entire course of data collection, which may be too restrictive in practical situations. Some recent papers including Chen, Xu, and Wu (Citation2013) and Chen and Leng (Citation2016) attempt to relax this restriction and consider a large dynamic covariance matrix estimation by allowing the covariance matrix to evolve smoothly over time (or with an index variable).
The main interest of this article is to detect and estimate multiple structural breaks in large covariance matrices, to which setting the methodology in Chen, Xu, and Wu (Citation2013) and Chen and Leng (Citation2016) is no longer applicable. Structural breaks are very common in many areas such as economics and finance, and may occur for various reasons. If such abrupt structural changes are ignored in covariance matrix estimation, subsequent statistical analysis would lead to invalid inference and misleading conclusions. The classical Binary Segmentation (BS) technique is commonly used to detect structural breaks, and has been extensively studied since its introduction by Vostrikova (Citation1981). For instance, in the setting of univariate mean regression models, theoretical properties, computational algorithms and relevant empirical applications of the traditional BS and its generalized version have been systematically studied by Venkatraman (Citation1992), Bai (Citation1997), Cho and Fryzlewicz (Citation2012), Killick, Fearnhead, and Eckley (Citation2012), Fryzlewicz (Citation2014, Citation2020) and the references therein. In recent years, there has been increasing interest in extending this technique to high-dimensional settings such as high-dimensional time series and large panel data (see Cho and Fryzlewicz Citation2015; Jirak Citation2015; Cho Citation2016; Aston and Kirch Citation2018; Wang and Samworth Citation2018; Wang et al. Citation2019; Safikhani and Shojaie Citation2022). However, most of the aforementioned literature mainly considers break detection and estimation in the first-order moment structure. Aue et al. (Citation2009) use the BS method with mean-corrected cumulative sum (CUSUM) to detect structural breaks in fixed dimensional covariance matrices, and establish the limit distributions for the test statistics and the convergence rate for the estimated break date. Korkas and Fryzlewicz (Citation2017) detect breaks in the second-order moment structure of time series by combining the wavelet-based transformation and the univariate Wild Binary Segmentation (WBS) algorithm proposed by Fryzlewicz (Citation2014). However, their technique is not directly applicable to our case when the size of the covariance matrix diverges to infinity as the sample size n increases.
In this article, we consider the second-order moment structure of the high-dimensional random vector generated by an approximate factor model, that is,
(1.2)
(1.2) where
is a matrix of factor loadings with λi being an r-dimensional vector,
is an r-dimensional vector of common factors, and
is a d-dimensional vector of idiosyncratic components uncorrelated with
. The approximate factor model is very popular in economics and finance, and has become an effective tool in analyzing high-dimensional time series (see Chamberlain and Rothschild Citation1983; Fama and French Citation1992; Stock and Watson Citation2002; Bai and Ng Citation2002, Citation2006; Chen et al. Citation2018). Our main focus is the contemporaneous second-order moment structure, which plays a crucial role in various fields such as the classic mean-variance portfolio choice theory and risk management. Note that
(1.3)
(1.3)
where
is the covariance matrix of the idiosyncratic components
and
is the covariance matrix of the common components
. In this article, we aim to study multiple structural breaks in the covariance structure of
generated by the approximate factor model, estimating the break points and number of breaks. Structural breaks may occur in either the covariance structure of the common components or that of the idiosyncratic components, indicating that the constant covariance structure in (1.3) is replaced by the following time-varying version:
(1.4)
(1.4)
The main contributions of this article, the fundamental novelty of the proposed methodology and its connection to some recent literature are summarized as follows.
A transformation mechanism is introduced to convert the approximate factor model with multiple structural breaks to that with constant factor loadings, justifying applicability of the classical Principal Component Analysis (PCA) technique (see Bai and Ng Citation2002; Stock and Watson Citation2002) to a more general model setting. Note that breaks in the second-order moment structure of the common components are due to changes in factor loadings, covariance of latent factors or factor number. This makes it challenging to directly estimate the latent common factors and factor loadings via PCA. When there are multiple breaks in factor loadings, we transform the original factor model to one with time-invariant factor loadings and a time-varying covariance structure for transformed factors, and then use the PCA method to estimate the transformed factors and factor loadings, which are shown to be consistent with convergence rates comparable to those in the existing literature on PCA for approximate factor models without breaks (see Bai and Ng Citation2002; Fan, Liao, and Mincheva Citation2013). This transformation technique is also used by Han and Inoue (Citation2015) and Baltagi, Kao, and Wang (Citation2017, Citation2021) to estimate and test factor models with structural instability. However, they assume that the number of factors does not change. In contrast, we consider a more general setting, allowing changes of factor numbers and multiple breaks in the covariance matrices of idiosyncratic components.
With the estimated factors and idiosyncratic errors, we propose an easy-to-implement CUSUM-based detection technique to estimate the location and number of breaks and identify whether they originate in the common or idiosyncratic components. The developed CUSUM statistics are directly computed via the empirical second moments of the estimated factors and idiosyncratic errors. Based on Fryzlewicz’s (Citation2014) WBS algorithm, we propose a Wild Binary Segmentation for Covariance (WBS-Cov) to locate multiple breaks in the common components. For breaks in the idiosyncratic error components, we introduce a Wild Sparsified Binary Segmentation algorithm for Covariance (WSBS-Cov), combining WBS-Cov and the Sparsified Binary Segmentation (SBS) proposed by Cho and Fryzlewicz (Citation2015) in the high-dimensional mean estimation context. A recent paper by Barigozzi, Cho, and Fryzlewicz (Citation2018) combines the wavelet-based transformation and the double CUSUM technique (Cho Citation2016) to estimate the break time as well as break number within the second-order moment structure. However, a disadvantage of the wavelet-based transformation on the piecewise-constant “signals,” involving selection of the wavelet filter and scale parameter, is that it could destroy the piecewise constancy and subsequently affect the estimation accuracy of the break number and location. When we only focus on a specific feature of the data, data transformation, even one-to-one transformation, would distort the interpretation of breaks of the structure. Another recent method to deal with sparsity in high-dimensional break detection is the sparse projection introduced by Wang and Samworth (Citation2018) but their method only detects breaks in the first-order moment structure. Wang, Yu, and Rinaldo (Citation2021) extends the BS and WBS techniques to detect multiple breaks in large covariance matrices, but they limit attention to the independent sub-Gaussian random vector and assume that the dimension is divergent at a slow polynomial rate of n. In contrast, we allow the dimension to grow faster, for example, at an exponential rate of n, a typical setting in big data analysis.
Simulation studies are implemented to assess the finite-sample performance of the proposed method and its comparison with other competing methods. The simulation results show that our method has superior numerical performance in most settings, whereas the method by Barigozzi, Cho, and Fryzlewicz (Citation2018) tends to perform poorly when the number of covariance matrix entries with breaks is small relative to the matrix size. Our simulation also shows that the proposed methods are robust when the factor number is over-estimated.
The developed model and method are applied to the daily return series of S&P 500 constituent which contain 375 firms over the period from January 01, 2000 to February 28, 2021, and detect five breaks in the covariance structure of the common components and three breaks in the idiosyncratic error components. In particular, we identify the breaks occurring during the 2007–2008 global financial crisis and the recent coronavirus (COVID-19) outbreak. With an additional comparison with break detection result of low-dimensional observable risk factor series, we emphasize that the breaks in covariance structure of returns cannot be fully explained by the breaks in the covariance structure of observed risk factors nor the breaks in loadings of these factors.
The rest of the article is organized as follows. Section 2 introduces the setting of multiple structural breaks, the PCA estimation and CUSUM-based detection methods, and the WBS-Cov and WSBS-Cov algorithms. Section 3 presents the asymptotic theory for the developed WBS-Cov and WSBS-Cov methods. Section 4 discusses some practical issues in the detection procedure. Sections 5 and 6 give the simulation studies and the empirical application, respectively. Section 7 concludes the article. The technical assumptions are given in Appendix A and proofs of the main theoretical results are available in Appendices C–E of a supplementary materials. An package “
” for implementing the proposed methods is available from https://github.com/markov10000/BSCOV. Throughout the article, we let
and
denote the Euclidean norm of a column vector and the Frobenius norm of a matrix, respectively; let
denote the half vectorization of a symmetric matrix obtained by vectorizing only the lower triangular part of the matrix; let
denote the floor function; let
and
denote
and
, respectively; and let
denote that
and
hold jointly.
2 Methodology
In this section, we first introduce the setting of multiple structural breaks in the contemporaneous covariance structure of both the common and idiosyncratic components, and transform the approximate factor models to construct PCA estimation of the latent common factors and factor loadings (with appropriate rotation). Using the estimated factors and idiosyncratic errors, we then introduce the CUSUM-based statistics to estimate the location and number of structural breaks as well as the WBS-Cov and WSBS-Cov algorithms.
2.1 Model Structure for Multiple Structural Breaks
We consider the following multiple structural breaks in the covariance matrix of the common components, that is, in (1.4) is specified as
(2.1)
(2.1) where
for
, and
are unobservable breaks with the superscript “c” denoting the “common component.” For convenience, we let
and
. The above structural breaks may be caused by one or a combination of the following cases,
Case (i): sudden changes in the factor loadings;
Case (ii): sudden changes in the covariance matrix for common factors;
Case (iii): sudden changes in the number of factors.
Let be a
factor loading matrix and
be the corresponding factor vector with dimension rk when
, and write the approximate factor model as
(2.2)
(2.2)
Letting , the structural break structure (2.1) can be equivalently written as
Note that, although for
may be the same as
(when cases (i) and (iii) do not occur at the break time). It is worthwhile to point out that case (i) is similar to the approximate factor model with structural breaks; see, for example, Breitung and Eickmeier (Citation2011), Chen, Dolado, and Gonzalo (2014), Han and Inoue (Citation2015), Cheng, Liao, and Schorfheide (Citation2016), Baltagi, Kao, and Wang (Citation2017), Bai, Han, and Shi (Citation2020), and Duan, Bai, and Han (Citation2022). However, the aforementioned papers consider the case of a single structural break in the factor loadings and usually assume that the covariance of the idiosyncratic error components is time invariant. Ma and Su (Citation2018) consider detecting and estimating multiple structural breaks in the factor loadings with a three-step procedure using the adaptive fused group Lasso. Case (iii) is an important type of structure break in the factor model, which has received much attention in recent years (see Baltagi, Kao, and Wang Citation2017; Barigozzi, Cho, and Fryzlewicz Citation2018; Li et al. Citation2019). Section 2.2 will give a unified factor model framework covering cases (i)–(iii) which facilitates the construction of PCA estimation, and then proceed to introduce the relevant CUSUM statistics in Section 2.3 to detect the multiple structural breaks in the common component.
The structural breaks in the covariance matrix of the error components are specified as followsand
for
, where
are unobservable breaks with the superscript “e” denoting the “idiosyncratic error component.” For convenience, we let
and
.
Let(2.3)
(2.3)
In this article, we assume that the minimum length of the subintervals separated by is of order n, see Assumption 4(ii) in Appendix A. Such a restriction is mainly to ensure that the PCA method is applicable to estimate the latent factors and factor loadings. In contrast, the minimum length of the subintervals separated by
is allowed to be of order smaller than n, see Assumption 4(iii). We do not impose any restriction on how the break points in
and those in
are located with respect to each other.
2.2 Transformed Factor Models and PCA Estimation
Although the multiple structural breaks formulated in (2.1) and (2.2) may be caused by one or a combination of cases (i)–(iii) described in Section 2.1, we next show that multiple structural breaks in the factor loadings and factor number can be transformed to breaks in the factor covariance structure.
Proposition 2.1.
The approximate factor model (2.2) can be equivalently written as a transformed factor model like(2.4)
(2.4) where
denotes the transformed factor loading matrix which is time invariant, and
denotes the transformed factors. In addition, the number of factors in the original factor model and that in the transformed factor model, satisfy the following inequalities,
(2.5)
(2.5)
where q0 is the number of transformed factors,
is the column rank of
and rk is the number of original factors
when
.
Remark 2.1.
A representation similar to Proposition 2.1 is also given in Han and Inoue (Citation2015) and Baltagi, Kao, and Wang (Citation2017, Citation2021). Note that construction of in the transformation mechanism is not unique due to the factor model identification issue. When each of
is of full column rank, we have
, and consequently the inequalities in (2.5) would be simplified to
The upper bound for q0 can be achieved if , are linearly independent. Appendix B in the supplementary materials gives a simple motivating example for the above transformation. Proposition 3.1 in Section 3.1 will further explore the limiting behavior of
as
, which is crucial to application of the classic PCA method to estimate the transformed factors and factor loadings. Through the above transformation, it is sufficient to construct the CUSUM statistic using the estimated transformed factors for all of cases (i)–(iii) discussed in Section 2.1.
As the common factors are latent, we have to obtain their estimates (subject to appropriate rotation) in practice. By Proposition 2.1, we consider the transformed factor model like (2.4) with time-invariant factor loadings, and apply the PCA estimation technique. Let be an n × d matrix of observations. For the time being, we assume that the number of transformed factors q0 is known, and will discuss how to determine it later in this section. The estimated factors
as well as the estimated idiosyncratic errors
will be used to construct the CUSUM statistics in Sections 2.3 and 2.4. The algorithm for PCA estimation is given as follows.
Algorithm 1
Standard PCA
Input: , q0 1. Let
be the
matrix consisting of the q0 eigenvectors (multiplied by
) corresponding to the q0 largest eigenvalues of
.
2. The transformed factor loading matrix is estimated as(2.6)
(2.6)
3. The idiosyncratic component is approximated by
(2.7)
(2.7) where Xtj is the jth element of
.
Output: for
A key issue in the PCA estimation is to appropriately choose the number of latent factors. As the above PCA method focuses on the transformed factor model, our aim is to estimate the number of transformed factors rather than that of the original ones. In general, the number of transformed factors q0 could be much larger than maximum of (or rk) over
. However, when both
and K1 are assumed to be fixed, from (2.5) in Proposition 2.1, we have the true number of transformed factors to be upper bounded by a finite positive integer denoted by
. Some existing criteria developed for stable factor models can be applied to the transformed factor model (2.4) to obtain a consistent estimate of q0. In this article, we use a commonly used information criterion proposed by Bai and Ng (Citation2002).
For any , we let
be the estimated factors obtained in Algorithm 1 replacing q0 by q. Define
where
is a d × q factor loading matrix and
denotes the jth largest eigenvalue. Consequently, we can choose the following objective function:
(2.8)
(2.8)
and obtain the estimate
via
(2.9)
(2.9)
where the common components disappear when q = 0. Alternative IC functions with different penalty terms in (2.8) can be found in Bai and Ng (Citation2002) and in Alessi, Barigozzi, and Capasso (Citation2010) for the case of large idiosyncratic disturbances. With the asymptotic results given in Theorem 2 of Bai and Ng (Citation2002), we may show that
is a consistent estimator of the true number q0, indicating that
whose probability converges to one as the sample size increases.
Although accurate estimation of the factor number may be difficult in practice, slight over-estimation of the (transformed) factor number may be not risky in break detection (see Barigozzi, Cho, and Fryzlewicz Citation2018). In Appendix F of the supplementary materials, we provide a simulation to show that over-estimating q0 would not negatively affect accuracy of multiple break detection. It is possible to avoid precisely estimating the factor number by following Barigozzi, Cho, and Fryzlewicz’s (Citation2018) method, multiplying the estimated factors and factor loadings to obtain the estimated common components. However, this would lead to a high-dimensional break detection for the common components.
2.3 Break Detection in the Common Components
We start with the Binary Segmentation for Covariance (BS-Cov) technique to detect breaks in the common components and then introduce the WBS-Cov algorithm. As breaks in the factor loadings and factor number can be transformed to those in the covariance of transformed factors after reformulating the approximate factor model to the one with time-invariant factor loadings, we next define a CUSUM statistic using the estimated factors . For
, define
(2.10)
(2.10)
which is a column vector with dimension . Maximizing
with respect to s, we obtain
(2.11)
(2.11) the first candidate break point (which is not necessarily the estimate of the first break time point
). If the quantity
exceeds certain threshold, say
, we split the closed interval
into two subintervals:
and
. Then, letting
or
, we compute
with s in either of the two subintervals, maximize
with respect to s, estimate the next candidate break points, and examine whether a further split is needed. We continue this until no more split is needed.
Remark 2.2.
It may be possible to extend (2.11) to a weighted version (see Hariz, Wylie, and Zhang Citation2007; Cho Citation2016; Yu and Chen Citation2021)
In the above BS-Cov, we use the l2-type aggregation of the CUSUM quantities. Alternatively, we may use different norms in the aggregation such as the l1-norm and
-norm. It may be also possible to consider a weighted aggregation and seek an optimal projection direction as recommended by Wang and Samworth (Citation2018). However, it is not clear how to implement the optimal direction method in a computationally efficient way for break detection in our model setting, so we do not pursue it in the present article. In Appendix F of the supplementary materials, we compare numerical performance among different types of aggregation on the CUSUM quantities and find that the l2-type aggregation produces the most accurate detection result.
The l2-aggregation in (2.11) ignores possible correlation structure between elements of the vector CUSUM statistic. Such a simplification would not affect estimation consistency of the break number and locations. For break detection in fixed-dimensional covariance matrices, Aue et al. (Citation2009) propose a weighted quadratic form of the CUSUM vector using an estimated long-run covariance matrix. This refinement in the l2-aggregation may improve break estimation efficiency. However, consistent estimation of the long-run covariance structure for
In order to accurately estimate the break time and delete possible spurious spikes in the CUSUM statistics, instead of using BS-Cov, we next extend the WBS algorithm introduced by Fryzlewicz (Citation2014) to detect the multiple structural breaks in the common components. Let be the estimated break points (arranged in an increasing order) and
be the estimate of the unknown break number K1 obtained in the following WBS-Cov algorithm. A discussion on selection of the threshold
can be found in Section 4. The method to draw random intervals in the WBS-Cov algorithm is the same as that in Fryzlewicz (Citation2014) (see also Algorithm 4 in Section 4). Fryzlewicz (Citation2020) provides an alternative recursive method of drawing random intervals in the WBS algorithm. In general, the intervals drawn in Algorithm 2 do not have to be random but can be taken over a fixed grid.
Algorithm 2
WBS-Cov algorithm
Input: generate random intervals
within [1, n] for
set
and
while
do
take an element out of
and denote it as
if
then
add
to
add
and
to
end if
end while
Output:
2.4 Break Detection in the Idiosyncratic Components
We next turn to detection of multiple structural breaks in the covariance structure of the idiosyncratic vector, which is much more challenging as the dimension involved can be ultra large and is unobservable. In the existing literature, to obtain reliable estimation of ultra-high dimensional covariance matrices (without breaks), it is often common to impose certain sparsity condition, limiting the number of nonzero entries. Consequently, the thresholding or other generalized shrinkage methods (Bickel and Levina Citation2008a; Rothman, Levina, and Zhu Citation2009; Cai and Liu Citation2011) have been developed to estimate high-dimensional covariance matrices. A similar thresholding technique is also introduced by Cho and Fryzlewicz (Citation2015) to detect multiple structural breaks in high-dimensional time series setting. We next generalize the latter to detect breaks in the large covariance structure of the idiosyncratic error vector, using the approximation of
obtained in the PCA algorithm. Define the normalized CUSUM-type statistic using
defined in (2.7):
(2.12)
(2.12) for
and
, where
is a properly chosen scaling factor. The value of the scaling factor depends on both the time interval
and the index pair (i, j). The scaling factors ensure that we can choose a common threshold for each index pair. Note that the scaling factor is not needed for the CUSUM statistic (2.10) to detect breaks in the common components since the estimated factors have been normalized. We choose
as the differential error median absolute deviation using
, whose detailed construction is given in Section 4. To derive the consistency result for break detection, we assume that the random scaling factors are uniformly bounded away from zero and infinity over
and
with probability tending to one (see Assumption 5 in Appendix A). As the dimension
and might be much larger than the sample size n (see Assumption 4(i)), a direct aggregation of the CUSUM statistics
over i and j might not perform well in detecting the breaks in particular when the sparsity condition is imposed. Hence, we compare
with a thresholding parameter, say
, and delete the index pair (i, j) when
is smaller than
. For
(to be defined in Algorithm 3) such that
is a random subinterval of
, we define
(2.13)
(2.13)
where
is an indicator function. It is easy to see that the truncation component in (2.13) is independent of the random subintervals
. Therefore, if
, the algorithm will no longer search for breaks within the interval
for the index pair (i, j). The main difference between our method and that in Cho and Fryzlewicz (Citation2015) is that they sparsify the classical Binary Segmentation to locate the break points and estimate the break number, whereas we combine the sparsified CUSUM quantity with the WBS-Cov algorithm introduced as in Section 2.3. Thus, we call the proposed algorithm the Wild Sparsified Binary Segmentation for Covariance or WSBS-Cov. The detailed algorithm is given as follows.
Algorithm 3
WSBS-Cov algorithm
Input: generate random intervals
within
for
set
and
while
do
take an element out of
and denote it as
if
then
add
to
add
and
to
end if
end while
Output:
Note that the sparsified CUSUM statistic cannot take any value between 0 and
and
Hence, the thresholding parameter in WSBS-Cov plays a similar role to
in WBS-Cov. With the WSBS-Cov algorithm, we obtain the estimated break points denoted by
(arranged in an increasing order), where
is the estimate of the break number K2. Finally, the sets of break points
and
defined in (2.3) are estimated by
3 Large-Sample Theory
In this section we establish the large-sample theory for the methods proposed in Section 2 under some technical assumptions listed in Appendix A. The asymptotic properties for the WBS-Cov and WSBS-Cov methods are given in Sections 3.1 and 3.2, respectively.
3.1 Asymptotic Theory of WBS-Cov for the Common Components
We start with the following proposition on some fundamental properties for the transformed factors and factor loadings
in (2.4).
Proposition 3.1.
Suppose that Assumption 2 in Appendix A is satisfied and let . The transformed factor loading matrix
is of full column rank and the transformed factors
satisfy that
when
. If, in addition,
, there exists a
positive definite matrix
such that
(3.1)
(3.1)
The above proposition shows that the sample second-order moment of the transformed factors converges in probability under some regularity conditions in Assumption 2. The convergence result (3.1) is sometimes given directly as a high-level condition in the literature (e.g., Assumption A1 in Ma and Su Citation2018). The restriction is crucial to ensure positive definiteness of
. If the order of the minimum distance between breaks is smaller than n, the limit matrix
may be singular.
We next study the asymptotic theory for the WBS-Cov algorithm in Section 2.3 to detect breaks in the common components. Define an infeasible CUSUM statistic using the latent transformed factors:(3.2)
(3.2) and
is a
rotation matrix defined by
(3.3)
(3.3)
in which
is a
diagonal matrix with the diagonal elements being the first q0 largest eigenvalues of
arranged in a descending order, and
with
being a q0-dimensional vector of transformed factor loadings.
Proposition 3.2.
Suppose that Assumptions 1–3 and 4(i) in Appendix A are satisfied. If ,
(3.4)
(3.4)
Proposition 3.2
plays a crucial role in our proofs, indicating that the CUSUM statistic can be replaced by the infeasible CUSUM statistic
in the asymptotic analysis. The following theorem establishes the convergence result for the estimates of break points and break number in the covariance structure of the common components.
Theorem 3.1.
Suppose that Assumptions 1–3 and 4(i)(ii) in Appendix A are satisfied, and there exist two positive constants and
such that the threshold
satisfies
(3.5)
(3.5) where
is defined in Proposition 3.1 and
denotes the minimum break size (in the common components) defined in Assumption 4(ii). Then there exists a positive constant ιc such that
(3.6)
(3.6)
where
.
Remark 3.1.
The convergence result (3.6) shows that the proposed estimator of the break points in the common components via WBS-Cov has the approximation rate of , which can be further simplified to the rate of
if the minimum break size
is larger than a small positive constant. Note that, even if the factors are observable, the optimal estimation rate of the break points in their covariance structure is
(Korostelev Citation1988; Aue et al. Citation2009) when the binary segmentation is used in break detection. Hence, our approximation rate in Theorem 3.1 is nearly optimal up to a fourth-order logarithmic rate. Since we remove the Gaussian assumption on the observations and further allow temporal dependence in the data over time, our approximation rate is slightly slower than that in Theorem 3.2 of Fryzlewicz (Citation2014).
3.2 Asymptotic Theory of the WSBS-Cov for the Idiosyncratic Components
We next present the asymptotic theory of structural break estimation in the idiosyncratic error components. Similarly to that in Section 3.1, we define the following infeasible CUSUM-type statistics using the unobservable ϵtj,(3.7)
(3.7) for
and
, where
is defined as in (2.12), and
(3.8)
(3.8)
for
.
Proposition 3.3.
Suppose that Assumptions 1–3, 4(i), and 5 in Appendix A are satisfied. If ,
(3.9)
(3.9)
Proposition 3.3
plays a crucial role in our asymptotic analysis, indicating that the CUSUM statistics can be replaced by the infeasible ones
, which are much easier to handle in the proofs. The following theorem establishes the convergence result for the estimates of the break points and break number in the covariance structure of the idiosyncratic components.
Theorem 3.2.
Suppose that Assumptions 1–3, 4(i)(iii), and 5 in Appendix A are satisfied, , and there exist two positive constants
and
such that
(3.10)
(3.10) where
and
denotes the minimum break size (in the idiosyncratic components) defined in Assumption 4(iii). Then there exists a positive constant ιe such that
(3.11)
(3.11)
where
.
Remark 3.2.
The rate in (3.11) relies on both n and d, making it substantially different from the convergence result in Theorem 3.1. If the dimension diverges to infinity at a polynomial rate of n (see Barigozzi, Cho, and Fryzlewicz Citation2018) and assume , the rate
becomes
, slightly faster than that obtained in Theorem 3 of Barigozzi, Cho, and Fryzlewicz (Citation2018) when the breaks are sparse in covariance of the idiosyncratic errors.
4 Practical Issues in the Detection Procedure
In this section, we first extend the so-called Strengthened Schwarz Information Criterion (SSIC) to our model setting to determine the number of breaks, and then discuss the choice of the random scaling quantity in (2.12) and the thresholding parameter
in the WSBS-Cov.
The SSIC is proposed by Fryzlewicz (Citation2014) in the context of univariate WBS, and some modifications are needed to make it applicable to our setting. For the break detection in the covariance structure of the common components, when the algorithm proceeds, we estimate the k candidate break points (arranged in an increasing order) denoted by with the convention of
and
. Letting
for
, we define the SSIC objective function for the univariate process
by
(4.1)
(4.1)
where
for
, and
is a positive constant which is a prespecified upper bound for the break number. If there exists a positive integer Kc such that
(4.2)
(4.2)
no further break exists in any dimension of the transformed factors. Let
be the smallest number such that (4.2) is satisfied, and stop the WBS-Cov algorithm in Section 2.3 when the number of breaks reaches
. By using SSIC, we avoid choosing the tuning parameter
in the WBS-Cov.
Similarly, we can also use the SSIC to obtain the estimated break number for the idiosyncratic error components. Let be defined similarly to
but with
and
replaced by
(4.3)
(4.3)
for . Let
be the smallest number Ke such that
(4.4)
(4.4) for all
, and thus we obtain the estimated break number for the idiosyncratic error component. In the construction of the CUSUM statistic in the WSBS-Cov, we need to define the random scaling quantity
. In the numerical studies, we let
be the differential error median absolute deviation which is defined by
in which
denotes the sample median over the time interval
(e.g., Fryzlewicz Citation2014). An advantage of using the median absolute deviation is that it provides robust scale estimation.
When implementing the WBS-Cov and WSBS-Cov algorithms, we have to guarantee sufficient length of the random intervals to facilitate break detection. When l and u are too close, may be unbounded, leading to violation of Assumption 5 in Appendix A. Consequently, the CUSUM statistics on those small intervals would be smaller than the thresholding parameter so that no breaks could be detected. Therefore, we introduce a quantity Δn as in Barigozzi, Cho, and Fryzlewicz (Citation2018), to control the minimum length of the random intervals. Specifically, Algorithm 4 is used to produce a set of random intervals in WBS-Cov or WSBS-Cov.
Algorithm 4
Drawing random intervals
Input: n, Δn and Mn ( or
)
Draw Mn pairs of random points uniformly from the set ;
For each pair, let lm be the smaller random point, and um be the larger one plus .
Output: random intervals for
We set in the numerical studies. By Algorithm 4, the random intervals are produced with length of at least
. In addition, we also trim each random interval to keep a distance of Δn to both boundaries, indicating that we only maximize the CUSUM statistics over the interval
. Note that Δn should be much smaller than
and
. Thus, we choose
following the discussion in Barigozzi, Cho, and Fryzlewicz (Citation2018).
A crucial issue in constructing the sparsified CUSUM statistic in the WSBS-Cov algorithm is the choice of the thresholding parameter . Cho and Fryzlewicz (Citation2015) suggest choosing this parameter using the CUSUM statistic based on a stationary process (e.g., a simulated AR(1) process) under the null hypothesis of no breaks. However, in practical applications, for the high-dimensional time series data with latent breaks, it is often difficult to recover the underlying stationary structure. To address this problem, we propose an alternative approach to choose
: (i) pre-detect the breaks (e.g., combining the classical BS-Cov and SSIC without knowing
a priori) and remove the breaks from the high-dimensional covariance matrices through demeaning using the estimated breaks, that is, generate
as in (4.3), where
is the preliminary estimate of the break number obtained in the pre-detection of the idiosyncratic components; (ii) calculate the CUSUM statistics of the “stationary” process
for each pair (i, j) and then take the maximum as the chosen thresholding parameter
. This technique is more computationally intensive than any formula-based threshold selection procedures; however, we have found that it performs well in the numerical studies reported in Section 5.
5 Monte Carlo Simulation
In this section, we provide a simulation study to compare the finite-sample performance between the proposed methods and the method proposed by Barigozzi, Cho, and Fryzlewicz (Citation2018), and examine the performance of our methods in the weak factor structure. Additional simulation studies are given in Appendix F of the supplementary materials, where the proposed methods are compared with various other competing methods that we designed. Each of these methods differs from the method presented in our main text in only one step. Like ablation studies that are commonly conducted in deep learning research, they help to gain a better understanding of our methods. Since these alternative methods are not designed for practical use, nor are they theoretically justified, we keep them in the supplementary materials.
We consider the following factor model to generate data:(5.1)
(5.1) where
is used to control the signal-to-noise ratio. The replication number in each simulation cases is set to be R = 100. For the 100 simulated samples, we report the estimated number of break(s) as well as the accuracy measure for each break location ηk defined by
(5.2)
(5.2)
for
, where K denotes the break number K1 or K2,
is the corresponding break number estimate in the ith simulated sample, ηk denotes either
or
, and
, are the break point estimates in the ith simulated sample,
Example 5.1.
We use model (5.1) to generate the data in simulation, where , the number of factors is r = 5, the sample size is n = 400, and the dimension is d = 200. The factor process
is generated from a multivariate normal distribution
independently over t, where
is a covariance matrix with one break specified as follows: for
, the square root of the jth diagonal element of
, is independently generated from a uniform distribution
, and the (i, j)-entry of
is defined as
for
; for
, the (1,2) and (2,1)-entries of
change from
to
, and
is replaced by
resulting in structural breaks in
and
-entries of
. For
, the factor loadings λij are independently generated from a uniform distribution
; whereas for
, the factor loadings corresponding to the first two factors are regenerated by a new uniform distribution
. Therefore, there are two structural breaks in the covariance structure of the common components covering cases (i) and (ii) discussed in Section 2.1.
The idiosyncratic errors follow a multivariate normal distribution
independently over t, where
, the square root of the jth diagonal element of
, is generated from an independent uniform distribution
, and the (i, j)-entry of
is
for
. There are three breaks,
and
, in the idiosyncratic error components. At each of the break points, we swap the orders of
randomly selected pairs of elements of
with
chosen as 1, 0.5 and 0.1. Note that
indicates that the structural breaks are sparse in the high-dimensional error components, whereas
indicates that the breaks are dense.
reports the simulation result, where “W(S)BS-Cov” denotes our proposed methods and “BCF” denotes the method proposed by Barigozzi, Cho, and Fryzlewicz (Citation2018) which combines the wavelet-based transformation and the double-CUSUM method. We find that the proposed WBS-Cov method has better finite-sample performance in detecting breaks in the common components with more accurate estimated break number and the higher , whereas “BCF” tends to neglect the first break and thus under-estimate the number of breaks. For the break detection in the idiosyncratic error components, when
, the proposed WSBS-Cov method and “BCF” perform equally well. However, when
and 0.1, the WSBS-Cov method clearly outperforms “BCF.”
Table 1 Comparison of break detection results.
We next consider an example with breaks in the weak factor structure. When factor loadings for the transformed factor model in (2.4) satisfies , we call the kth factor as a weak factor. Although our asymptotic framework (see Assumption 2(ii)) rules out this scenario, we provide the following simulation to examine the effect of weak factors to the proposed break detection methods.
Example 5.2.
We use model (5.1) with a setting similar to Freyaldenhoven (2021) to generate the data, where the number of factors is r = 9, , the sample size is n = 400, and the dimension is d = 200. The factor process
is generated from a multivariate normal distribution
independently over t. The jth factor only affects dj elements of the d-dimensional observation vector, indicating that the factor loading matrix is sparse with dj nonzero entries in its jth column. The position of nonzero entries are randomly selected, and their values are drawn from
independently. We set
.
We set two breaks for the common components: and
and consider nine cases in the simulation. Case j represents a set-up in which breaks only occur on the jth column of the factor loading matrix. Specifically, independently for the three periods:
, and
, the position of nonzero entries in the jth factor loading vector is randomly selected with its value independently regenerated. For the idiosyncratic error components, as in Freyaldenhoven (2021), we let
and generate
by
where
are independently drawn from
, and
. We set two break points on
:
and
. For
, we first generate a tridiagonal matrix
with all diagonal entries being one and the other nonzero entries drawn from
, and then standardize
by letting each row multiply a constant so that the row sum of squares is one to define
. The matrix
is randomly regenerated in the same way for
and
.
As shown by Freyaldenhoven (2021), the classic PCA estimators are consistent only for the “relevant” factors whose corresponding dj is of an order larger than . Hence, the number of relevant factors is 6 in the simulated weak factor model. By the factor model transformation mechanism in Proposition 2.1, we expect that the number of factors should be 8 for cases 1–6 (6 relevant factors plus 2 extra factors due to factor transformation accommodating breaks), and 6 in cases 7–9. reports the simulation results for the break detection. We find that the factor number is over-estimated in all cases. The break numbers and locations in both the common and idiosyncratic components are correctly estimated in general when breaks occur in the relevant factors which are relatively strong (cases 1–3). The break detection results are less accurate when there are breaks in loadings of relevant factors which are relatively weak (cases 4–6). In cases 7–9, since weak factors with breaks in the loadings are not selected as the relevant factors via the information criterion, the proposed WBS-Cov method cannot detect either of the two breaks in the common components.
Table 2 Detection results with breaks on weak factors.
6 An Empirical Application
In this section, we use the proposed methods to detect breaks in the contemporaneous covariance structure of the daily returns of S&P 500 constituents.
6.1 Break Detection in Covariances
The data are retrieved from Refinitiv Datastream database (formerly Thomson Reuters Datastream), covering the time period from January 01, 2000 to February 28, 2021. We consider 375 firms listed on the S&P 500 index over the entire time period. Let Xit denote the demeaned percentage price change (without reinvesting of dividends) of equity i at time t, where and
. We fit the factor model (2.2) to the data with
, allowing structural breaks in the covariance matrices of both the common and idiosyncratic components.
The information criterion introduced in Section 2.2 selects nine factors (with appropriate transformation), that is, . We set
and
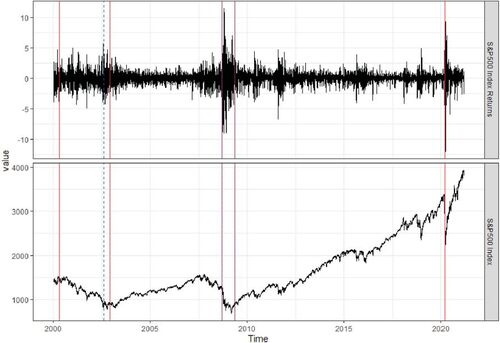
in the WBS-Cov and WSBS-Cov algorithms. Combined with SSIC, the WBS-Cov algorithm detects five breaks in the covariance matrix of the common components, and the WSBS-Cov algorithm detects three breaks in the idiosyncratic components. We plot the estimated break times on the series of the S&P 500 index and its returns in , where the red vertical lines denote breaks in the common components and the blue dotted vertical lines denote breaks in the idiosyncratic components. Among the five breaks in the common components, two occur during the period of a bearish market from 2000 to 2003, two occur in 2008 and 2009 during the global financial crisis, and one occurs recently due to the COVID-19 outbreak. Among the three breaks in the idiosyncratic errors, the first break occurs around the end of 2002, the second and third breaks occur in 2008 and 2009.
Fig. 1 The detected break times in the covariance structure of the 375 daily returns of the S&P 500 constituents from January 01, 2000 to February 28, 2021. The estimated break dates for common components are April 24, 2000, November 25, 2002, September 12, 2008, May 08, 2009 and March 06, 2020 (in red lines); and the estimated break dates for idiosyncratic components are August 06, 2002, September 11, 2008 and May 11, 2009 (in blue dotted lines).
6.2 Calibration
We next provide a simulation using the factor model with calibrated parameters from the empirical study, and aim to further examine the proposed break detection methods in finite samples.
Generate a simulated dataset with n = 5322 and d = 375 as the real data.
Consider six sub-periods separated by the five estimated break dates in the common components (see the red lines in ) and use the PCA estimated factor loadings. The factors are drawn from a standard normal distribution independently over time and across dimension.
Divide the estimated idiosyncratic errors into four segments split by the three estimated breaks in idiosyncratic components (see the blue dotted lines in ), and separately estimate their sample covariance matrices. For each segment, generate idiosyncratic errors by a multivariate normal distribution independently over time with mean zero and covariance matrix being the sample covariance matrix.
The above generating mechanism guarantees the simulated covariance structure to be the same as that for the empirical data. As in the simulation study in Section 5, we repeat the simulation procedure 100 times and report the break detection results. For simplicity, we fix in WSBS-Cov, which is calculated by applying the method in Section 4 to the real data. reports the average break number estimates, the number of times that the estimated break is within a distance of
to the true break, denoted as
, and the root-mean-squared distance of the closest estimated break to the true break, denoted as
. Except for the first two breaks (April 24, 2000 and November 25, 2002) in the common components,
s are larger than 95% and
s are smaller than 4, indicating that the break dates are accurately detected. The low
s and large
s of the first two breaks may be due to the relatively weak break magnitude. The estimated break numbers reported in are slightly larger than the true break numbers (5 for the common components and 3 for the idiosyncratic components). In addition, we also fix
in the break detection procedures and obtain similar simulation results, showing that the proposed methods work when the factor number is over-estimated.
Table 3 Detection results on calibrated data.
6.3 Comparison with Observed Risk Factors
As a benchmark, we also download eight observable risk factors (over January 01, 2000–February 28, 2021) from Kenneth R. French’s data libraryFootnote1 and study breaks in their covariance structure. These risk factors include the excess return (MKT), the size factor (SMB), the value factor (HML), the profitability factor (RMW) and the investment factor (CMA) introduced by Fama and French (Citation1993, Citation2015); the Momentum factor (MOM) proposed by Carhart (Citation1997) in a four-factor model; and the short term reversal factor (STRev) and the long-term reversal factor (LTRev) which are less famous but equally important (see De Bondt and Thaler Citation1987; Lehmann Citation1990). They are often used as observable proxies of latent factors in the approximate factor model. We plot patterns of observed factors in , from which we can see that they vary drastically during the global financial crisis and the COVID-19 outbreak. Let denote the vector containing the eight risk factors,
. As the dimension of
is low, there is no need to impose the approximate factor model framework. Using the WBS-Cov algorithm (without any latent factor structure) in Section 2.3, we detect five break dates: April 19, 2001, July 01, 2008, September 12, 2008, May 13, 2009 and March 06, 2020. Note that the first two estimated break dates (April 19, 2001 and July 01, 2008) are quite different from the first two break dates (April 24, 2000 and November 25, 2002) in the common components obtained by applying the proposed WBS-Cov to the estimated factors, see . shows the canonical correlation between the estimated factors and observed factors for the entire sample and six subsamples divided by the estimated break dates in the common components. p-values are reported in the brackets using the F-approximations of Rao’s test statistic related to Wilks’ Lambda (see Rao Citation1973). Some of the minimum canonical correlations are small and insignificant, indicating that the space spanned by the eight observed factors may be not the same as that spanned by the nine PCA estimated factors.
Fig. 2 Variation of eight commonly used risk factors from January 01, 2000 to February 28, 2021. The estimated break dates are April 19, 2001, July 01, 2008, September 12, 2008, May 13, 2009 and March 06, 2020 (in red lines).
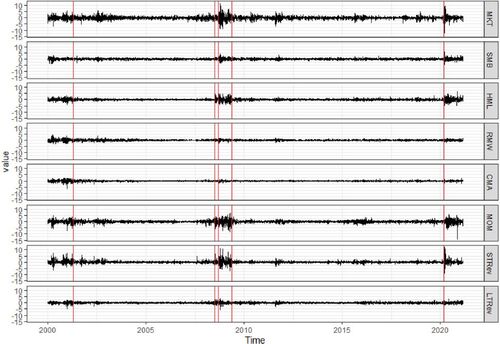
Table 4 Canonical correlation between estimated factors and observed factors.
To further analyze whether breaks in the common components can be explained by the observed factors, we run regression of stock returns on the eight observed factors and detect whether breaks exist in covariances of the regression residuals. We apply the factor model (2.2) to the residual vectors and use the information criterion to select six factors. Using WBS-Cov, we detect six breaks in the common components (of the residual vectors): April 20, 2000, November 22, 2002, July 07, 2008, September 26, 2008, May 08, 2009 and March 06, 2020, and one break in the idiosyncratic components which is August 12, 2002. Note that the first two breaks in the common components April 20, 2000 and November 22, 2002 are very close to April 24, 2000 and November 25, 2002, respectively, which are reported in . Hence, we may conclude that break detection of a low-dimensional observed risk factor cannot fully capture structural breaks in covariance of price changes in the entire stock market.
7 Conclusion
In this article, we detect and estimate multiple structural breaks in the contemporaneous covariance structure of the high-dimensional time series vector. We allow high correlation between the time series variables by imposing the approximate factor model, a commonly-used framework in economics and finance. The structural breaks occur in either the common or idiosyncratic error components. When there are breaks in the factor loadings or factor numbers, we transform the factor model in order to make the classic PCA method applicable and subsequently obtain estimates of the transformed factors and approximation of the idiosyncratic errors. The construction of the CUSUM quantities is based on the second-order moments of the estimated factors and errors. The WBS algorithm introduced by Fryzlewicz (Citation2014), combined with SSIC, is extended to the multivariate setting to detect breaks in covariance structure of the common components, estimating the location and number of breaks. For the idiosyncratic error components, we combine the WBS-Cov algorithm and the sparsified CUSUM statistic to detect structural breaks (which can be either sparse or dense), extending the SBS algorithm proposed by Cho and Fryzlewicz (Citation2015). Under some regularity conditions, we show consistency of the estimated break numbers and derive the near-optimal rates (up to a fourth-order logarithmic factor) for the estimated breaks. Monte Carlo simulation studies are conducted to examine the numerical performance of the proposed WBS-Cov and WSBS-Cov methods in finite samples and its comparison with the method introduced by Barigozzi, Cho, and Fryzlewicz (Citation2018). In addition, we examine performance of the proposed methods when breaks are on weak factors. In the empirical application to the return series of S&P 500 constituent, we detect five break in the common components and three breaks in the idiosyncratic error components by the developed methods.
Supplemental Material
Download PDF (416.4 KB)Acknowledgments
The authors would like to thank an Associate Editor and two reviewers for the constructive comments, which helped to improve the article.
Supplementary Materials
The supplementary materials contains the detailed proofs of the main asymptotic results, a simple motivating example for the factor model transformation as well as additional simulation studies.
Additional information
Funding
Notes
References
- Alessi, L., Barigozzi, M., and Capasso, M. (2010), “Improved Penalization for Determining the Number of Factors in Approximate Factor Models,” Statistics and Probability Letters, 80, 1806–1813. DOI: 10.1016/j.spl.2010.08.005.
- Andrews, D. W. (1993), “Tests for Parameter Instability and Structural Change with Unknown Change Point,” Econometrica, 61, 821–856. DOI: 10.2307/2951764.
- Anderson, T. W. (2003), An Introduction to Multivariate Statistical Analysis, Wiley Series in Probability and Statistics (3rd ed.), New York: Wiley.
- Aston, J. A., and Kirch, C. (2018), “High Dimensional Efficiency with Applications to Change Point Tests,” Electronic Journal of Statistics, 12, 1901–1947. DOI: 10.1214/18-EJS1442.
- Aue, A., Hörmann, Horváth, L., and Reimherr, M. (2009), “Break Detection in the Covariance Structure of Multivariate Time Series Models,” Annals of Statistics, 37, 4046–4087.
- Bai, J. (1997), “Estimating Multiple Breaks on at a Time,” Econometric Theory, 13, 315–352. DOI: 10.1017/S0266466600005831.
- Bai, J., Han, X., and Shi, Y. 2020, “Estimation and Inference of Change Points in High-Dimensional Factor Models,” Journal of Econometrics, 219, 66–100 DOI: 10.1016/j.jeconom.2019.08.013.
- Bai, J., and Li, K. (2012), “Statistical Analysis of Factor Models of High Dimension,” Annals of Statistics, 40, 436–465.
- Bai, J., and Ng, S. (2002), “Determining the Number of Factors in Approximate Factor Models,” Econometrica, 70, 191–221. DOI: 10.1111/1468-0262.00273.
- Bai, J., and Ng, S- (2006), “Confidence Intervals for Diffusion Index Forecasts and Inference for Factor-Augmented Regressions,” Econometrica, 74, 1135–1150.
- Baltagi, B., Kao, C., and Wang, F. (2017), “Identification and Estimation of a Large Factor Model with Structural Instability,” Journal of Econometrics, 197, 87–100. DOI: 10.1016/j.jeconom.2016.10.007.
- Baltagi, B., Kao, C., and Wang, F. (2021), “Estimating and Testing High Dimensional Factor Models with Multiple Structural Changes,” Journal of Econometrics, 220, 349–365.
- Barigozzi, M., Cho, H., and Fryzlewicz, P. (2018), “Simultaneous Multiple Change-Point and Factor Analysis for High-Dimensional Time Series,” Journal of Econometrics, 206, 187–225. DOI: 10.1016/j.jeconom.2018.05.003.
- Bickel, P., and Levina, E. (2008a), “Covariance Regularization by Thresholding,” Annals of Statistics, 36, 2577–2604.
- Bickel, P., and Levina, E(2008b), “Regularized Estimation of Large Covariance Matrices,” Annals of Statistics, 36, 199–227.
- Breitung, J., and Eickmeier, S. (2011), “Testing for Structural Breaks in Dynamic Factor Models,” Journal of Econometrics, 163, 71–84. DOI: 10.1016/j.jeconom.2010.11.008.
- Cai, T. T., and Liu, W. (2011), “Adaptive Thresholding for Sparse Covariance Matrix Estimation,” Journal of the American Statistical Association, 106, 672–684. DOI: 10.1198/jasa.2011.tm10560.
- Cai, T. T., Ren, Z., and Zhou, H. (2016), “Estimating Structured High-Dimensional Covariance and Precision Matrices: Optimal Rates and Adaptive Estimation,” Electronic Journal of Statistics, 10, 1–59.
- Carhart, M. M. (1997), “On Persistence in Mutual Fund Performance,” Journal of Finance, 52, 57–82. DOI: 10.1111/j.1540-6261.1997.tb03808.x.
- Chamberlain, G., and Rothschild, M. (1983), “Arbitrage, Factor Structure and Mean-Variance Analysis in Large Asset Markets,” Econometrica, 51, 1305–1324. DOI: 10.2307/1912276.
- Chen, J., Li, D., Linton, O., and Lu, Z. (2018), “Semiparametric Ultra-High Dimensional Model Averaging of Nonlinear Dynamic Time Series,” Journal of the American Statistical Association, 113, 919–932. DOI: 10.1080/01621459.2017.1302339.
- Chen, L., Dolado, J. J., and Gonzalo, J. (2013), “Detecting Big Structural Breaks in Large Factor Models,” Journal of Econometrics, 180, 30–48. DOI: 10.1016/j.jeconom.2014.01.006.
- Chen, X., Xu, M., and Wu, W. (2013), “Covariance and Precision Matrix Estimation for High-Dimensional Time Series,” Annals of Statistics, 41, 2994–3021.
- Chen, Z., and Leng, C. (2016), “Dynamic Covariance Models,” Journal of the American Statistical Association, 111, 1196–1207. DOI: 10.1080/01621459.2015.1077712.
- Cheng, X., Liao, Z., and Schorfheide, F. (2016), “Shrinkage Estimation of High-Dimensional Factor Models with Structural Instabilities,” Review of Economic Studies, 83, 1511–1543. DOI: 10.1093/restud/rdw005.
- Cho, H. (2016), “Change-Point Detection in Panel Data via Double CUSUM Statistic,” Electronic Journal of Statistics, 10, 2000–2038. DOI: 10.1214/16-EJS1155.
- Cho, H., and Fryzlewicz P. (2012), “Multiscale and Multilevel Technique for Consistent Segmentation of Nonstationary Time Series,” Statistica Sinica, 22, 207–229. DOI: 10.5705/ss.2009.280.
- Cho, H., and Fryzlewicz P. (2015), “Multiple Change-Point Detection for High-Dimensional Time Series via Sparsified Binary Segmentation,” Journal of the Royal Statistical Society, Series B, 77, 475–507.
- Cho, H. (2016), “Change-Point Detection in Panel Data via Double CUSUM Statistic,” Electronic Journal of Statistics, 10, 2000–2038. DOI: 10.1214/16-EJS1155.
- De Bondt, W. F., and Thaler, R. H. (1987), “Further Evidence on Investor Overreaction and Stock Market Seasonality,” Journal of Finance, 42, 557–581. DOI: 10.1111/j.1540-6261.1987.tb04569.x.
- Duan, J., Bai, J., and Han, X. (2022), “Quasi-Maximum Likelihood Estimation of Break Point in High-Dimensional Factor Mmodels,” Journal of Econometrics, forthcoming. DOI: 10.1016/j.jeconom.2021.12.011.
- El Karoui, N. (2008a), “Operator Norm Consistent Estimation of Large-Dimensional Sparse Covariance Matrices,” Annals of Statistics, 36, 2717–2756.
- El Karoui, N. - (2008b), “Spectrum Estimation for Large Dimensional Covariance Matrices Using Random Matrix Theory,” Annals of Statistics, 36, 2757–2790.
- Fama, E. F., and French, K. (1992), “The Cross-Section of Expected Stock Returns,” Journal of Finance, 47, 427–465. DOI: 10.1111/j.1540-6261.1992.tb04398.x.
- Fama, E. F., and French, K. (1993), “Common Risk Factors in the Returns on Stocks and Bonds,” Journal of Financial Economics, 33, 3–56.
- Fama, E. F., and French, K. (2015), “A Five-Factor Asset Pricing Model,” Journal of Financial Economics, 116, 1–22.
- Fan, J., Liao, Y., and Liu, H. (2016), “An Overview on the Estimation of Large Covariance and Precision Matrices,” Econometrics Journal, 19, 1–32.
- Fan, J., Liao, Y., and Mincheva, M. (2013), “Large Covariance Estimation by Thresholding Principal Orthogonal Complements,” (with discussion), Journal of the Royal Statistical Society, Series B, 75, 603–680. DOI: 10.1111/rssb.12016.
- Freyaldenhoven, S. (2022), “Factor Models with Local Factors – Determining the Number of Relevant Factors,” Journal of Econometrics, 229, 80–102. DOI: 10.1016/j.jeconom.2021.04.006.
- Fryzlewicz, P. (2014), “Wild Binary Segmentation for Multiple Change-Point Detection,” Annals of Statistics, 42, 2243–2281.
- Fryzlewicz, P (2020), “Detecting Possibly Frequent Change-Points: Wild Binary Segmentation 2 and Steepest-Drop Model Selection,” Journal of the Korean Statistical Society, 49, 1027–1070.
- Han X., and Inoue, A. (2015), “Tests for Parameter Instability in Dynamic Factor Models,” Econometric Theory, 31, 1117–1152. DOI: 10.1017/S0266466614000486.
- Hariz, S. B., Wylie, J. J., and Zhang, Q. (2007), “Optimal Rate of Convergence for Nonparametric Change-Point Estimators for Nonstationary Sequences,” Annals of Statistics, 35, 1802–1826.
- Huang, N., and Fryzlewicz, P. (2019), “NOVELIST Estimator of Large Correlation and Covariance Matrices and their Inverses,” Test, 28, 694–727. DOI: 10.1007/s11749-018-0592-4.
- Jirak, M. (2015), “Uniform Change Point Tests in High Dimension,” Annals of Statistics, 43, 2451–2483.
- Killick, R., Fearnhead, P., and Eckley, I. (2012), “Optimal Detection of Changepoints with a Linear Computational Cost,” Journal of the American Statistical Association, 107, 1590–1598. DOI: 10.1080/01621459.2012.737745.
- Korkas, K. K., and Fryzlewicz, P. (2017), “Multiple Change-Point Detection for Non-stationary Time Series Using Wild Binary Segmentation,” Statistica Sinica, 27, 287–311. DOI: 10.5705/ss.202015.0262.
- Korostelev, A.P. (1988), “On Minimax Estimation of a Discontinuous Signal,” Theory of Probability & Its Applications, 32, 727–730.
- Lam, C., and Fan, J. (2009), “Sparsity and Rates of Convergence in Large Covariance Matrix Estimation,” Annals of Statistics, 37, 4254–4278.
- Ledoit, O., and Wolf, M. (2004), “A Well-Conditioned Estimator for Large-Dimensional Covariance Matrices,” Journal of Multivariate Analysis, 88, 365–411. DOI: 10.1016/S0047-259X(03)00096-4.
- Lehmann, B. N. (1990), “Fads, Martingales, and Market Efficiency,” Quarterly Journal of Economics, 105, 1–28. DOI: 10.2307/2937816.
- Li, J., Todorov, V., Tauchen, G., and Lin, H. (2019), “Rank Tests at Jump Events,” Journal of Business & Economic Statistics, 37, 312–321.
- Ma, S., and Su, L. (2018), “Estimation of Large Dimensional Factor Models with an Unknown Number of Breaks,” Journal of Econometrics, 207, 1–29. DOI: 10.1016/j.jeconom.2018.06.019.
- Pourahmadi, M. (2013), High-Dimensional Covariance Estimation: With High-Dimensional Data, Hoboken, NJ: Wiley.
- Rao, C. R (1973), Linear Statistical Inference and Its Applications, (2nd ed.), New York: Wiley.
- Rothman, A. J., Levina, E., and Zhu, J. (2009), “Generalized Thresholding of Large Covariance Matrices,” Journal of the American Statistical Association, 104, 177–186. DOI: 10.1198/jasa.2009.0101.
- Safikhani, A., and Shojaie, A. (2022), “Joint Structural Break Detection and Parameter Estimation in High-Dimensional Non-stationary VAR Models,” Journal of the American Statistical Association, 537, 251–264. DOI: 10.1080/01621459.2020.1770097.
- Stock, J. H., and Watson, M. W. (2002), “Forecasting Using Principal Components from a Large Number of Predictors,” Journal of the American Statistical Association 97, 1167–1179. DOI: 10.1198/016214502388618960.
- Venkatraman, E. S. (1992), “Consistency Results in Multiple Change-Point Problems,” Technical Report No. 24, Department of Statistics, Stanford University.
- Vostrikova L. Y. (1981), “Detecting Disorder in Multidimensional Random Processes,” Soviet Mathematics Doklady, 24, 55–59.
- Wang, D., Yu, Y., and Rinaldo, A. (2021), “Optimal Covariance Change Point Localization in High Dimensions,” Bernoulli, 27, 554–575. DOI: 10.3150/20-BEJ1249.
- Wang, D., Yu, Y., Rinaldo, A., and Willett, R. (2019), “Localizing Changes in High-Dimensional Vector Autoregressive Processes,” Working paper. Available at https://arxiv.org/abs/1909.06359.
- Wang, T., and Samworth, R. J. (2018), “High Dimensional Change Point Estimation via Sparse Projection,” Journal of the Royal Statistical Society, Series B, 80, 57–83. DOI: 10.1111/rssb.12243.
- Wu, W., and Pourahmadi, M. (2003), “Nonparametric Estimation of Large Covariance Matrices of Longitudinal Data,” Biometrika, 90, 831–844. DOI: 10.1093/biomet/90.4.831.
- Yu, M., and Chen, X. (2021), “Finite Sample Change Point Inference and Identification for High-Dimensional Mean Vectors,” Journal of the Royal Statistical Society, Series B, 83, 247–270. DOI: 10.1111/rssb.12406.
Appendix A:
Technical Assumptions
The following assumptions are needed to establish the asymptotic theorems in Sections 3.1 and 3.2. Some of the conditions (such as the moment conditions) may be not the weakest possible but can be relaxed at the cost of more lengthy proofs.
Assumption 1.
For each
For
Assumption 2.
For
Letting
(A.1)
Assumption 3.
There exists a positive constant ι0 such that
(A.2)and
(A.3)
There exists a positive constant
(A.4)
Assumption 4.
There exist positive constants ι2, ι3, and ϑ such that
Letting
Letting
where is the number of random intervals drawn in the WSBS-Cov algorithm.
Assumption 5.
There exist such that
with probability approaching one, where
is defined in (2.12). In addition,
.
The assumption of mixing dependence on the latent common factor and idiosyncratic error process in Assumption 1(i) is very mild and covers some commonly-used vector time series models. Note that the α-mixing dependence condition allows the underlying process to be nonstationary with time-varying covariance structure (e.g., the piece-wise stationary time series process with breaks in the covariance matrix). The moment conditions in Assumptions 1(ii) and 3 are crucial to consistently estimate the factors and factor loadings (with rotation) in the transformed factor model (2.4).
Assumption 2 contains some fundamental conditions for the approximate factor model (2.2), which can be seen as a generalized version of those for the stable factor model without breaks (e.g., Bai and Ng Citation2002; Fan, Liao, and Mincheva Citation2013). These conditions, together with in Assumption 4(ii), indicate that there exists a nonsingular limiting matrix for
and
is of full column rank (see Proposition 3.1), which are essential to derive the convergence result for the PCA estimated factors and factor loadings. In addition, Assumption 2 also guarantees that
.
The moment conditions (A.2) and (A.3) in Assumption 3(i) imply that the idiosyncratic errors ϵtj are allowed to be weakly dependent over j. Similar high-level moment conditions can be found in Assumption 4 in Bai and Ng (Citation2002) and Assumption 3.4 in Fan, Liao, and Mincheva (Citation2013). Assumption 3(ii) is similar to the exponential-tail condition commonly used in high-dimensional data analysis and is needed to allow the dimension d to be divergent at an exponential rate of n.
Assumption 4(i) indicates that both d and n diverge to infinity jointly, which is a typical large panel data setting necessary for consistent estimates of the rotated factors and factor loadings. A very similar assumption is also used in Theorem 1 of Fan, Liao, and Mincheva (Citation2013). In particular, Assumption 4(i) shows that d can be divergent to infinity at an exponential rate of n, further relaxing the corresponding condition assumed in Barigozzi, Cho, and Fryzlewicz (Citation2018) and Wang, Yu, and Rinaldo (Citation2021). Although the restriction indicates that n is of smaller asymptotic order than d, our methodology is still applicable if n is much larger than d by switching the role of n and d and the role of the factor loadings and common factors in the PCA estimation (see sec. 3 in Bai and Li 2012). Assumption 4(ii) is mainly used for the asymptotics of WBS-Cov in the common components, and would be automatically satisfied when
and
, where
are two positive constants. Assumption 4(iii) is mainly used to derive the WSBS-Cov asymptotic theory in the idiosyncratic error components. The restriction
is only imposed to facilitate the proofs. The restrictions on
and
are consistent with the argument in Andrews (Citation1993) and Bai (Citation1997) that the break points can be identified only if the size of breaks, that is,
and
in our article, is asymptotically larger than
. Assumption 4(iii) also indicates that there might be more frequent breaks in the idiosyncratic error components than in the common components, and the restriction
would be automatically satisfied when
and
with
. In contrast, the minimum length
of the subintervals separated by break points in the common components is of order n. Assumption 5 requires the random normalizers in the WSBS-Cov to be uniformly bounded away from zero and infinity with probability approaching one.
In Assumption 2(i), we assume that K1 and rk, , are all bounded, which indicates that q0, the number of transformed factors in (2.4), is upper bounded by Proposition 2.1. This assumption facilitates proofs of the consistent estimation theory for the transformed factors and factor loadings and consistent break estimation theory. It would be an interesting extension by allowing the break numbers K1 and K2 to grow slowly as
. In this case, q0 would be divergent as well, and the condition of
would be violated. Consequently, we need to amend the estimation and break detection techniques, and modify some technical assumptions (such as Assumption 4) and the asymptotic proofs. We will further explore this in our future study.