
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This article proposes Bayesian nonparametric inference for panel Markov-switching GARCH models. The model incorporates series-specific hidden Markov chain processes that drive the GARCH parameters. To cope with the high-dimensionality of the parameter space, the article assumes soft parameter pooling through a hierarchical prior distribution and introduces cross sectional clustering through a Bayesian nonparametric prior distribution. An MCMC posterior approximation algorithm is developed and its efficiency is studied in simulations under alternative settings. An empirical application to financial returns data in the United States is offered with a portfolio performance exercise based on forecasts. A comparison shows that the Bayesian nonparametric panel Markov-switching GARCH model provides good forecasting performances and economic gains in optimal asset allocation.
1 Introduction
Over the last 10 years, there has been an increasing interest in the study of volatility of large panels of asset returns, with a special focus on dynamic dependence and heterogeneity across assets. Studies on asset volatility are relevant in strategic investing decisions and useful to professional investors, such as investment companies, pension funds and mutual funds, to improve the portfolio allocation.
In this article we consider a benchmark dataset of the S&P100 constituents and compute the percentage log-returns at weekly frequency from 6th January 2000 to 3rd October 2020.
reports the estimates of the log-volatility and log-kurtosis of the 78 constituents considered in the analysis (top panel). Three dates are selected within the dot.com bubble, the financial crisis and COVID outbreak periods, respectively, where significant volatility in returns was observed. The figure indicates that volatility and kurtosis change over time with time series clustering effects. This calls for the use of Generalized Autoregressive Conditional Heteroscedasticity (GARCH) models with Markov-switching (MS) effects as to deal with regime changes and temporal clustering of the conditional volatility (e.g., see Engle Citation1982; Bollerslev Citation1986; Ang and Timmermann Citation2012; Bauwens and Otranto Citation2016).
Figure 1: Top panel: rolling window estimates of the log-volatility (left) and log-kurtosis (right) for the S&P100’s constituents from 6th January 2000 to 3rd October 2020 (30 weeks window). Vertical bars indicate three reference dates: 6th July 2002, 23rd August 2008 and 22nd February 2020. Bottom panel: cross-sectional distribution of the log-volatility (left) and log-kurtosis (right) in three reference dates.
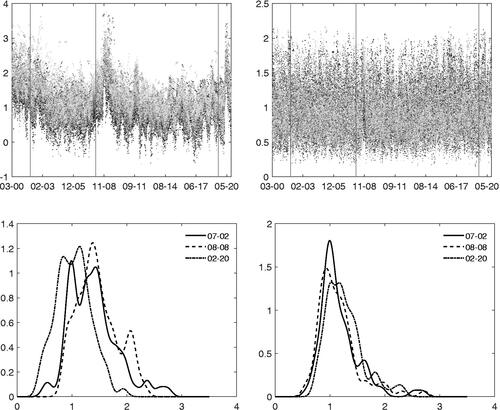
Furthermore, the cross-sectional distribution of the volatility and kurtosis exhibits multiple modes and long tails (see bottom panel). This fact seems to imply cross-section heterogeneity in the data with possible similarities in the dynamics. Given that these effects can only be partially captured by independent MS models, several multivariate GARCH models have been proposed to account for dependence (see Virbickaite, Ausín, and Galeano Citation2015; Bauwens and Otranto Citation2016, Citation2020).
Nevertheless, the estimation of a large number of parameters with the available data dimension may lead to intractability, overfitting and loss of efficiency. Strong restrictions, such as the parameter pooling assumption, can be used, even though those appear to be too restrictive. Instead, different approaches, such as shrinkage or sparse estimation, can be applied. Compared to standard approaches (e.g., see regularization techniques), the Bayesian framework based on hierarchical prior distributions provides a coherent approach to inference that naturally allows for partial pooling and sharing of information across equations. Bayesian inference and hierarchical priors have been successfully used in econometrics to avoid overparameterization and overfitting (e.g., see Canova and Ciccarelli Citation2004). Bayesian inference accommodates for various degrees of shrinking and for sparse estimation through the choice of suitable classes of prior distributions, such as Bayesian Lasso prior (Park and Casella Citation2008) and spike-and-slab (George and McCulloch Citation1993), and can be combined with other dimensionalityreduction strategies.
In this respect, evidence of cluster-wise dependence in the distribution of financial asset returns (see Bauwens and Rombouts Citation2007) has prompted researchers to adopt cross-sectional clustering of the time series as a building block for a dimensionality reduction step in large dimensional problems and over-parameterized models (e.g., see Hirano Citation2002; Billio, Casarin, and Rossini Citation2019; Fisher and Jensen Citation2022). To address this issue, this article uses a panel MSGARCH model with cross-sectional clustering based on a Bayesian nonparametric (BNP) prior (Lo Citation1984). In order to detect the number of regimes, we extend the approach of Otranto and Gallo (Citation2002) to a panelframework.
A hierarchical Pitman-Yor process prior (Pitman and Yor 1997) for the MSGARCH parameters is considered. In the first stage of the hierarchical prior, cross-unit heterogeneity is allowed for, while shrinking all unit-specific parameters toward a common mean. The second stage of the hierarchy allows for mixed effects in the common mean. There are many advantages in using this hierarchical nonparametric prior. First, our approach allows for making inference on the number of mixture components in the cross-sectional clustering. Second, it adds flexibility to the model allowing for different shapes of the prior and posterior predictive distributions. Third, the predictive distribution incorporates uncertainty in the parameters and in the number of mixture components. Nonparametric Bayesian techniques have been largely and successfully used in different fields such as biostatistics (Do, Müller, and Tang Citation2005), biology Arbel, Mengersen, and Rousseau (Citation2016), medicine (Xu et al. Citation2016), and neuroimaging (Zhang et al. Citation2016). For an introduction to Bayesian nonparametrics see Hjort et al. (Citation2010) and for a review of models and applications in different fields see Müller and Mitra (Citation2013).
The inference proposed in this article is novel in some respects. As such, the article contributes to the Bayesian nonparametrics literature for time series analysis (e.g., see Taddy and Kottas Citation2009; Jensen and Maheu Citation2010; Griffin and Steel Citation2011; Di Lucca et al. Citation2013; Bassetti, Casarin, and Leisen Citation2014; Billio, Casarin, and Rossini Citation2019; Nieto-Barajas and Quintana Citation2016; Griffin and Kalli Citation2018). The article innovates on the Bayesian nonparametric dynamic panel model in Hirano (Citation2002) by introducing Markov-switching and GARCH dynamics and extends the nonparametric switching regression in Taddy and Kottas (Citation2009) to a panel model with GARCH dynamics. Our approach differs from those in Hirano (Citation2002) and Taddy and Kottas (Citation2009), and is in line with the strategies for large dimensional and over-parameterized models (e.g., see MacLehose and Dunson Citation2010; Wang Citation2010; Billio, Casarin, and Rossini Citation2019), where nonparametric hierarchical priors are used to combine partial pooling and clustering effects in theparameter space.
Further, differently from Hirano (Citation2002) and Taddy and Kottas (Citation2009), the article uses a MCMC algorithm for posterior approximation that relies on the efficient sampling method developed in Walker (Citation2007), Kalli, Griffin, and Walker (Citation2011), and Hatjispyros, Nicoleris, and Walker (Citation2011). Lastly, the article makes a contribution to the literature on Bayesian Markov-switching panel models (e.g., see Kaufmann Citation2010, Citation2015; Billio et al. Citation2016; Casarin et al. Citation2019) by introducing GARCH effects and allowing for a flexible nonparametric specification.
The estimation of MSGARCH models is also a difficult task given the path dependence problem (Gray Citation1996) and approximation methods have been considered (e.g., see Haas, Mittnik, and Paolella Citation2004; Ardia Citation2008; Bauwens, Preminger, and Rombouts Citation2010; He and Maheu Citation2010; Bauwens, Dufays, and Rombouts Citation2014; Dufays Citation2016; Wee, Chen, and Dunsmuir Citation2022). In this article, we extend the univariate Gibbs sampler by Billio, Casarin, and Osuntuyi (Citation2016) to a multiple time series set-up and provide an efficient MCMC procedure for the hidden states of a panel MSGARCH model. The proposed method relies on a combination of blocking Gibbs and generalized Metropolis samplers.
An empirical application to financial returns of the S&P100 constituents in the United States over the period 6th January 2000–3rd October 2020 is provided. The analysis offers an optimal portfolio comparison based on one-step ahead forecasts generated by the Bayesian nonparametric panel MSGARCH (BNP-MSGARCH) and competitive models, such as a Bayesian nonparametric GARCH model without regime changes (BNP-GARCH), and a parametric GARCH. First, we detect the number of regimes using a new developed panel version of the univariate procedure by Otranto and Gallo (Citation2002), fit the BNP-MSGARCH to the data, and examine the clusters’ composition. For the BNP-MSGARCH model, we consider two different regime identifications: (a) a restriction on the expected returns (BNP-MSGARCH-); and (b) a restriction on the unconditional volatility level (BNP-MSGARCH-
), for example, see Ardia et al. (Citation2019). Second, the BNP-MSGARCH is evaluated against the other GARCH models in out-of-sample forecasts through statistical accuracy measures. Third, a portfolio exercise is carried out to ascertain economic gains. The main results show that the BNP-MSGARCH model is competitive against the other models for point-forecast and superior for density-forecast and portfolio performance.
The article is organized as follows. Section 2 describes the panel MSGARCH model and the Bayesian nonparametric prior distribution. Section 3 presents the data augmentation strategy and the posterior approximation method. Section 4 offers the empirical application. Section 5 concludes.
2 A Bayesian Nonparametric MSGARCH Model
We assume that the observable variable for the ith unit of the panel at time t satisfies
(1)
(1)
where denotes the Gaussian distribution with location
and scale
. The conditional variance is as follows
(2)
(2) which is the MSGARCH model, and
,
is a hidden Markov chain process with transition probability
,
, with K the number of states. The functional form for the switching parameters is
(3)
(3)
(4)
(4)
We cope with the high dimension of the parameter space and related overfitting issues by exploiting cross-sectional clustering of the series. More specifically we propose to combine two modeling strategies. First, we assume soft parameter pooling through a hierarchical prior distribution with two stages, and second we introduce clustering effects in the parameter space through a nonparametric prior. The resulting joint prior distribution for the MSGARCH parameters is given by the following.
In the first stage, the rows of the transition matrix follow a Dirichlet distribution
(5)
(5) for all regimes
, where the precision parameter
shrinks the unit-specific probabilities toward a common value
, that is the Dirichlet distribution parameter. For the second stage we assume
(6)
(6)
To address the high-dimensionality issue, the first stage of the hierarchical prior shrinks the switching parameters toward some common values, and the second stage clusters the units in groups
within each regime, such that
for
and
. In the first stage, for
we assume
(7)
(7)
(8)
(8) where
is the beta distribution with mean
and
. The scale hyperparameters s and r are shrinking
toward the parameter
which is assumed to be constant for all units in the same cluster, that is for all
where
(for further details see Section 3 and (23)).
The second stage of the hierarchy generates the clusters of parameters. For each regime k we assume a Pitman-Yor process (PYP) prior
(9)
(9) with base measure
and concentration and dispersion parameters
and
, respectively. We assume
is the product of independent normal and uniform distributions
,
,
and
, which are usually chosen priors in parametric Bayesian inference for MSGARCH (e.g., see Billio, Casarin, and Osuntuyi Citation2016). The PYP introduced in Pitman and Yor (Citation1997) is a generalization of the Dirichlet process which can be obtained for
(e.g., see Bassetti, Casarin, and Leisen Citation2014).
Through the illustration of the Chinese Restaurant metaphor, the clustering structure of the PYP is defined by a Polya-Urn sampling scheme. The parameter of the ith unit is either equal to one of the other units or a new one from the base distribution
, that is,
(10)
(10)
This sequential allocation procedure generates clusters in the parameter space, where the number of clusters is random with the following prior distribution
with
, where
is a generalized Stirling number of the first kind, and
is the one-parameter gamma function (e.g., see Bassetti, Casarin, and Leisen Citation2014). To evaluate the prior mean of the number of clusters, we use
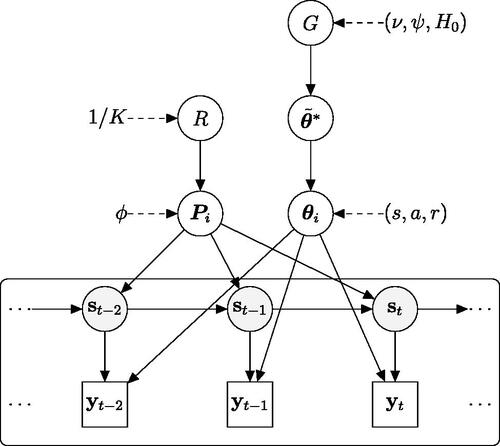
We summarize our Bayesian nonparametric model in the Directed Acyclic Graph (DAG) representation of .
Figure 2: DAG of the Bayesian nonparametric panel MSGARCH model. It exhibits the hierarchical structure of the observations (boxes), the latent state variables
(gray circles), the parameters of the transition probability matrix
,
, the hyperparameters of the first stage
,
and of the second stage G (white circles). The directed arrows show the conditional independence structure of the model.
The PYP clustering effects on the cross section correspond to a probabilistic clustering of the parameters based on an infinite mixture distribution. The PYP can be written in a Sethuraman’s like representation as a discrete random measure (see Sethuraman Citation1994)
(11)
(11)
where the atoms are iid random variables from the base measure
and the random weights
have the stick-breaking representation
(12)
(12) with
,
(see Arbel, Blasi, and Prünster Citation2019).
By integrating out the discrete part of the hierarchical prior, the following infinite mixture representation of the prior distribution on is obtained
(13)
(13) where
is the joint parameter distribution at the first stage of hierarchical prior (see (7)–(8)) and
is the distribution at the second stage. In conclusion the PYP prior allows for probabilistic clustering in the parameter space.
The predictive density induced by our prior assumptions can be written as
(14)
(14) where
is the collection of state-dependent measures,
is the transition kernel of the MSGARCH with
for
and
. This prior predictive density accounts for various forms of possible heterogeneity in the data such as asymmetry, excess of kurtosis and multimodality.
3 Posterior Approximation
In this section we discuss the approximation of the posterior distribution, some identification issues and the selection of the number of regimes. We also summarize the simulation results for approximation efficiency and inference effectiveness. Let be the collection of the units and regime parameters
and
the collection of transition probability matrices. Let
and
be the collection over time of observation vectors
and of latent vectors
, respectively. The likelihood function of the panel MSGARCH model is not tractable being written in integral form. However, a data-augmentation principle can be applied to develop efficient posterior simulation methods (Frühwirth-Schnatter Citation1994). We introduce the set of auxiliary allocation variables
to write the complete-data likelihood function as follows
(15)
(15) where
is the collection of the latent vectors
over time, with
.
The joint hierarchical prior distribution is
(16)
(16) where the infinite mixture priors, for
, are given by
(17)
(17)
where
is the first-stage joint prior distribution given in (7)–(8), and
(18)
(18)
(19)
(19) are the joint distributions of the infinite collection of atoms and stick-breaking variables,
and
, respectively.
The joint prior distribution in a Bayesian nonparametric framework is usually not tractable since its support is the space of the discrete random measures which are infinite-dimensional objects (see (17)–(19)). Nevertheless, the data-augmentation principle can be applied in order to make the inference problem more tractable. Following the recent Bayesian nonparametric literature (e.g., see Bassetti, Casarin, and Leisen Citation2014; Bassetti, Casarin, and Ravazzolo Citation2018; Billio, Casarin, and Rossini Citation2019), we introduce a set of slice variables and define the index set
. Then the infinite mixture can be demarginalized as follows
(20)
(20) which is a almost-surely finite mixture since
a.s., where
is the collection of slice variables.
Following the standard practice in finite mixture modeling we introduce the latent allocation variable and obtain
(21)
(21) where
. Let us denote with
,
and
the collections of regime-specific auxiliary variables and atoms. The joint posterior distribution
is proportional to
(22)
(22)
Note that the allocation variables allow to reconcile the notations used in the hierarchical model of (7) and the random measure representation in (11)–(13) as follows
(23)
(23)
A Gibbs sampler is used to generate random samples from the joint posterior and to approximate the Bayesian estimator. The Gibbs sampler iterates the following steps
Sample slice and stick-breaking variables U and V given
Sample the transition probability matrices P given
Sample the atoms
given
Sample the MSGARCH parameters
Sample the switching allocation variables
Sample the mixture allocation variables D given
The derivation of the full conditional distributions and sampling method are given in Appendix A. The parameter estimator , with
element of
, is approximated as average of MCMC draws from the posterior. The latent state estimator is approximated as
, with
the kth element of the switching allocation variable estimator
, where
is the MCMC approximation of the discrete posterior distribution
, obtained from the Forward Filtering Backward Sampling step.
The likelihood function and the posterior distribution remain unchanged with respect to any state permutation. This identification issue and the related label switching problem are commonly solved by imposing a prior restriction on the parameters , or on a transformation
(see Celeux Citation1998; Frühwirth-Schnatter Citation2001, Citation2006) such as a prior ordering,
, with some economic interpretation. In this article we implement two alternative strategies based on performance regimes
(BNP-MSGARCH-
model) and on volatility regimes
(BNP-MSGARCH-
model). The first identification scheme mimics an investing strategy which classifies risky assets into different groups (styles) and move invested funds among these styles depending on their relative performance. This strategy would be decisive in monitoring the relative performance of style portfolios, especially during large market drops so to better understand where markets are heading (see Bianchi Citation2020). In the literature, this approach for asset allocation is known as “style investing” or “style strategies” (Barberis and Shleifer Citation2003) and the style identification criterion is known as “style features.” The classification of assets usually relies on industry sectors (Jame and Tong Citation2014) or factors (Barberis and Shleifer Citation2003), whereas in this article it is driven by our statistical model. The second identification scheme is more common in volatility modeling and can be used to protect portfolio allocation against excess of volatility (i.e., Barro, Canestrelli, and Consigli Citation2019).
In order to detect the number of regimes, we extend the univariate approach by Otranto and Gallo (Citation2002) to a panel data framework. As in Otranto and Gallo (Citation2002), we exploit the fact that the joint density of a panel MS model is a mixture density with the number of components equal to the number of regimes and specify the following multivariate BNP model ,
, with location
and diagonal precision matrix
, such that
, where
is a PY prior. This approach is flexible and robust to structural change-points at the beginning or at the end of the sample. Procedure details are given in Appendix A. For MCMC approximation efficiency and inference effectiveness, we run simulation experiments for four different data generating processes (DGPs) using BNP-MSGARCH-
. We consider two regimes and various degrees of separation in the cluster intercept and variance. The simulation results show that the MCMC chain converges and a thinning of 10 is needed to reduce the Monte Carlo variance. Details are reported in Appendix B (supplementary materials).
4 Empirical Application
This section presents an empirical application of the BNP-MSGARCH model to the S&P100 constituents over the period 6th January 2000–3rd October 2020. 78 assets of the 101 constituents are selected in order to keep the panel balanced. Further, since style investing uses weekly or monthly predictions (e.g., see Froot and Teo Citation2008; Brookfield, Su, and Bangassa Citation2015), the percentage log-returns at weekly frequency are obtained. As a preliminary evidence, the cross-sectional heterogeneity observed in is robust to the choice of the rolling window size (see Appendix C, supplementary materials). In the analysis, we proceed in three steps: (i) detection of the number of regimes; (ii) forecast comparison; (iii) portfolio analysis.
The number of regimes is detected using the procedure described in Section 3, the BNP-MSGARCH model is fitted to the data (using both BNP-MSGARCH- and BNP-MSGARCH-
), and the clusters’ composition is examined. We set two regimes (the extend procedure of Otranto and Gallo (Citation2002) points to 2 regimes, see ). When ordering the expected returns in the BNP-MSGARCH-
model (
), regime 1 corresponds to a relative over-performance state and regime 2 to an under-performance state. Observations of the assets are assigned to one of the two regimes on the basis of the largest posterior probability (see
in Section 3). We notice that this identification constraint is strongly supported by the data and allows us to separate the assets returns in two performance regimes (see ).
Figure 3: The posterior co-clustering matrix in regime 1 (left) and 2 (right) for expected returns (top) and volatility (bottom) identification constraints. In each block, gray shades represent the sector membership of the assets.
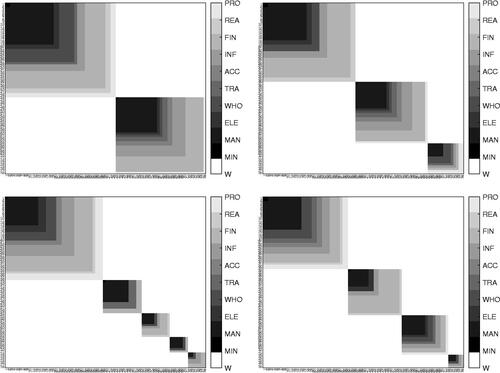
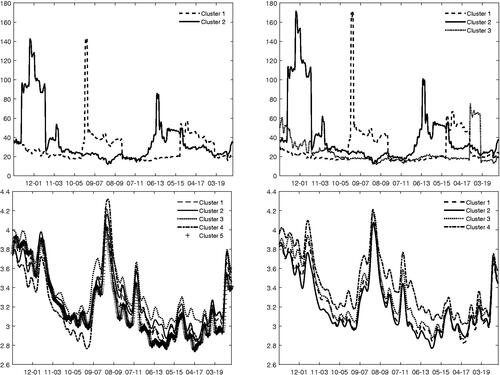
Figure 4: Price-to-Earning for the assets in clusters of regime 1 (left) and of regime 2 (right), constraint on expected returns (top panel). Logarithm of implied volatility for the assets in clusters of regime 1 (left) and of regime 2 (right), constraint on volatility (bottom panel).
For cluster identification, we assume a quite diffuse PYP prior distribution ( and
). The posterior distribution is concentrated (see Figure C5) suggesting a substantial revision of the prior information and the MAP estimates of the number of clusters is 2 and 3 for regime 1 and 2, respectively. To study the composition of the clusters in the two regimes, we use the sector classification (for details, see Appendix C) and some fundamental financial ratios. First, we identify the clusters using the co-clustering probability matrix, which contains the probability
that the parameters
and
are in the same cluster. This probability can be easily approximated by using the MCMC samples as
, where
is a sample of the allocation variable for the i-unit parameters in the regimes k, and
contains the values of MCMC iterations such that the parameters of the panel units are allocated to exactly M mixture components. A spectral clustering algorithm has been applied to reorder the series and provide a better graphical representation of the clusters.
The top panel of reports the co-clustering matrices for the two regimes in case of expected returns identification constraint. In each block matrix, the algorithm identifies a constituent (asset) belonging to a cluster with the label 1 (gray shaded patch) and 0 (white patch) otherwise. The gray shades represent the sectors in the clusters. Following Wade and Ghahramani (Citation2018), we use the variation of information (VI) metric proposed by Meilâ (Citation2007) to compare the two regimes (in terms of clusters). This measure compares the information in the two regimes with the information shared between the two regimes. The normalized value of VI is equal to 0.20 (VI lies in the interval , and a normalized value is obtained dividing VI by
), which suggests a substantial difference between the clustering and composition in the two regimes (see ).
In particular, for cluster 1 in both regimes, the majority of the sectors representing the assets are: manufacturing (about 40% in both regimes), financial and insurance (19% in the first regime), and wholesale and retail (25% in the second regime). Similar results for the sectors are found for cluster 2 in the two regimes: the manufacturing sector represents about 40% of the assets in the two regimes, while the financial and insurance sector is about 18% for regime 2, and information and communication is around 20%.
Further, in order to characterize the clusters in terms of the market size, measured by market capitalization, of the constituents, we first rank the companies by computing the average size of each of them using the last year of the sample period. Then, we classify the assets into three groups, namely small (bottom panel 30%), medium (middle panel 40%) and big (top panel 30%) companies (see Tab. C4). In regime 1, companies with the medium size represent the largest majority about 40%, and a similar outcome is also observed for regime 2.
For the cluster composition, we also compute the value of the Price-to-Earnings ratio (PE) for all the clusters (the average PE is computed over the last 10 years following the standard practice in style analysis). For regime 1, clusters 1 and 2 have values of PE equal to 26.97 and 32.38, respectively. For regime 2, these values are 27.08, 35.69, and 23.72 for clusters 1, 2, and 3, respectively. In both regimes cluster 2 is overvalued. Further to this, shows that dynamics in clusters 1 and 2 in regime 1 resemble those in regime 2.
Compared to the case of constraint on expected returns, the volatility identification strategy returns separated regimes for the single series, while the identification is less effective for the panel as a whole. Further, the posterior distribution concentrates on 5 and 4 cluster for regime 1 and 2, respectively (see Figure C5). The normalized value of VI is equal to 0.41 (see bottom panel of ). The analysis of implied volatility points to a difference in the level rather than in the dynamics (see ). Further details of all the results on cluster composition are reported in Appendix C.
As regards the one-step ahead forecast comparison, we use the following models: BNP-MSGARCH-, BNP-MSGARCH-
, BNP-GARCH, and GARCH. All the models are GARCH(1,1). The forecasts are computed for the period December 26, 2014–October 3, 2020 by a rolling window of 780 observations. We assess the forecasts by the RMSE and CRPS for the full out-of-sample period, and pre-COVID and COVID periods. The RMSE in indicates that models show equal predictive ability, especially for the full out-of-sample period and the pre-COVID period, with marginal differences (Appendix C includes box-plots of RMSEs). In the COVID period, the performance of all models worsens, but the largest flexibility of the nonparametric GARCH models ensures better forecasts.
Table 1: Out-of-sample evaluation. RMSE and CRPS.
When looking at CRPS, BNP-MSGARCH- ranks first and BNP-MSGARCH-
places second. This result is likely due to the fact that CRPS accounts for differences not only in mean but also in higher order moments of the forecast distributions. The BNP-GARCH and the GARCH have similar performance, with the exception of the COVID period.
A Markowitz portfolio allocation based on forecasts is carried out to establish economic gains. An investor deals with the following decision problem , s.t.
, where E is the expected return from a portfolio,
is portfolio weights chosen to minimize the portfolio risk, and
is the expected return of the ith asset.
is assumed to be nonnegative (no short sales). We omit the constraint
to build a minimum variance portfolio (see Hlouskova, Schmidheiny, and Wagner Citation2009). For the portfolio, we compute the Sharpe ratio for each model using the weekly treasury bill rate from Kenneth French’s data library as a risk free (RF) rate (https://mba.tuck.dartmouth.edu/pages/faculty/ken.french/data_library.html)
In terms of Sharpe ratio, BNP-MSGARCH models gain the best portfolio performance (), indicating that the largest flexibility of nonparametric models has an economic value. The portfolio proportion invested in value stocks rises in periods of increasing overperforming probability (see Figure C9). The weights to stocks with large implied volatility decrease when the probability of high-volatility regime increases. In particular, value stocks are undervalued at the beginning of the outbreak and reconvey to a larger portfolio proportion toward the end of 2020.
5 Conclusion
The study of volatility in large panels of financial assets is central for professional investors focusing on protection of invested portfolios, and for policy maker aiming at the stability of the economic system. The evidence of clusters in financial returns has attracted researchers’ attention. This article proposes a new Bayesian nonparametric (BNP) inference for Markov-switching GARCH (BNP-MSGARCH) models with clustering effects to deal with regime changes, temporal and cross-sectional clustering in large panels of financial data.
Within the BNP-MSGARCH framework, the number of regimes is detected using a new BNP procedure that extends the univariate approach of Otranto and Gallo (Citation2002) to panel data. Further, to capture cross-sectional clustering, this article proposes a hierarchical Pitman-Yor process prior for the MSGARCH parameters. The simulations show that our posterior approximation procedure is efficient and our inference is able to recover the true value of the parameters and the number of clusters and regimes.
An application to the S&P100 constituents is offered for forecasting and portfolio allocation purposes. There is clear-cut evidence of asset clustering with heterogenous composition across sectors and style features, which ensures a superior density-forecast performance and a better portfolio allocation for the BNP-MSGARCH model.
Supplementary Materials
Simulation results and further details on the empirical application are given in the online supplementary materials.
Supplemental Material
Download PDF (2.6 MB)Supplemental Material
Download Zip (116.8 KB)Acknowledgments
The authors are grateful to the Editor and the Reviewers for their useful comments which significantly improved the quality of the article. Also, we would like to thank all the conference participants for helpful discussions at the “International Society for Bayesian Analysis World meeting,” 2022, Montreal, Canada, the “Annual Meeting of the Statistical Society of Canada,” 2022, Ottawa, Canada and the “Advances in Bayesian Analysis Workshop,” 2022, Venice, Italy. We benefited greatly from suggestions and discussions with Federico Bassetti, John M. Maheu, Mark J. Jensen and Herman K. van Dijk. This research used the SCSCF and HPC multiprocessor cluster systems at Ca’ Foscari University of Venice.
References
- Ang, A., and Timmermann, A. (2012), “Regime Changes and Financial Markets,” Annual Review of Financial Economics, 4, 313–337. DOI: 10.1146/annurev-financial-110311-101808.
- Arbel, J., Blasi, P. D., and Prünster, I. (2019), “Stochastic Approximations to the Pitman–Yor Process,” Bayesian Analysis, 14, 1201–1219. DOI: 10.1214/18-BA1127.
- Arbel, J., Mengersen, K., and Rousseau, J. (2016), “Bayesian Nonparametric Dependent Model for Partially Replicated Data: The Influence of Fuel Spills on Species Diversity,” The Annals of Applied Statistics, 10, 1496–1516. DOI: 10.1214/16-AOAS944.
- Ardia, D. (2008), Financial Risk Management with Bayesian Estimation of GARCH Models: Theory and Applications, volume 612 of Lecture Notes in Economics and Mathematical Systems, Berlin: Springer.
- Ardia, D., Bluteau, K., Boudt, K., Catania, L., and Trottier, D.-A. (2019), “Markov-Switching GARCH Models in R: The MSGARCH Package,” Journal of Statistical Software, 91, 1–38. DOI: 10.18637/jss.v091.i04.
- Barberis, N., and Shleifer, A. (2003), “Style Investing,” Journal of Financial Economics, 68, 161–199. DOI: 10.1016/S0304-405X(03)00064-3.
- Barro, D., Canestrelli, E., and Consigli, G. (2019), “Volatility versus Downside Risk: Performance Protection in Dynamic Portfolio Strategies,” Computational Management Science, 16, 433–479. DOI: 10.1007/s10287-018-0310-4.
- Bassetti, F., Casarin, R., and Leisen, F. (2014), “Beta-Product Dependent Pitman-Yor Processes for Bayesian Inference,” Journal of Econometrics, 180, 49–72. DOI: 10.1016/j.jeconom.2014.01.007.
- Bassetti, F., Casarin, R., and Ravazzolo, F. (2018), “Bayesian Nonparametric Calibration and Combination of Predictive Distributions,” Journal of the American Statistical Association, 113, 675–685. DOI: 10.1080/01621459.2016.1273117.
- Bauwens, L., Dufays, A., and Rombouts, J. (2014), “Marginal Likelihood for Markov-switching and Change-Point GARCH,” Journal of Econometrics, 178, 508–522. DOI: 10.1016/j.jeconom.2013.08.017.
- Bauwens, L., and Otranto, E. (2016), “Modeling the Dependence of Conditional Correlations on Market Volatility,” Journal of Business and Economic Statistics, 34, 254–268. DOI: 10.1080/07350015.2015.1037882.
- Bauwens, L., and Otranto, E. (2020), “Nonlinearities and Regimes in Conditional Correlations with Different Dynamics,” Journal of Econometrics, 217, 496–522.
- Bauwens, L., Preminger, A., and Rombouts, J. (2010), “Theory and Inference for a Markov Switching GARCH Model,” Econometrics Journal, 13, 218–244. DOI: 10.1111/j.1368-423X.2009.00307.x.
- Bauwens, L., and Rombouts, J. (2007), “Bayesian Clustering of Many GARCH Models,” Econometric Reviews, 26, 365–86. DOI: 10.1080/07474930701220576.
- Bianchi, F. (2020), “The Great Depression and the Great Recession: A View from Financial Markets,” Journal of Monetary Economics, 114, 240–261. DOI: 10.1016/j.jmoneco.2019.03.010.
- Billio, M., Casarin, R., and Osuntuyi, A. (2016), “Efficient Gibbs Sampling for Markov Switching GARCH Models,” Computational Statistics and Data Analysis, 100, 37–57. DOI: 10.1016/j.csda.2014.04.011.
- Billio, M., Casarin, R., Ravazzolo, F., and Van Dijk, H. (2016), “Interactions between Eurozone and US Booms and Busts: A Bayesian Panel Markov-switching VAR Model,” Journal of Applied Econometrics, 31, 1352–1370. DOI: 10.1002/jae.2501.
- Billio, M., Casarin, R., and Rossini, L. (2019), “Bayesian Nonparametric Sparse VAR Models,” Journal of Econometrics, 212, 97–115. DOI: 10.1016/j.jeconom.2019.04.022.
- Bollerslev, T. (1986), “Generalized Autoregressive Conditional Heteroskedasticity,” Journal of Econometrics, 31, 307–327. DOI: 10.1016/0304-4076(86)90063-1.
- Brookfield, D., Su, C., and Bangassa, K. (2015), “Investment Style Positioning of UK Unit Trusts,” The European Journal of Finance, 21, 946–970. DOI: 10.1080/1351847X.2013.788533.
- Canova, F., and Ciccarelli, M. (2004), “Forecasting and Turning Point Prediction in a Bayesian Panel VAR Model,” Journal of Econometrics, 120, 327–359. DOI: 10.1016/S0304-4076(03)00216-1.
- Carter, C. K., and Kohn, R. (1994), “On Gibbs Sampling for State Space Models,” Biometrika, 81, 209–230. DOI: 10.1093/biomet/81.3.541.
- Casarin, R., Foroni, C., Marcellino, M., and Ravazzolo, F. (2019), “Uncertainty Through the Lenses of a Mixed-Frequency Bayesian Panel Markov Switching Model,” Annals of Applied Statistics, 12, 2559–2586.
- Celeux, G. (1998), “Bayesian Inference for Mixture: The Label Switching Problem,” in Compstat, eds. R. Payne and P. Green, pp. 227–232, Heidelberg: Physica.
- Di Lucca, M., Guglielmi, A., Müller, P., and Quintana, F. (2013), “A Simple Class of Bayesian Nonparametric Autoregression Models,” Bayesian Analysis, 8, 63–88. DOI: 10.1214/13-BA803.
- Do, K.-A., Müller, P., and Tang, F. (2005), “A Bayesian Mixture Model for Differential Gene Expression,” Journal of the Royal Statistical Society, Series C, 54, 627–644. DOI: 10.1111/j.1467-9876.2005.05593.x.
- Dufays, A. (2016), “Infinite-state Markov-switching for Dynamic Volatility and Correlation Models,” Journal of Financial Econometrics, 14, 418–460. DOI: 10.1093/jjfinec/nbv017.
- Engle, R. F. (1982), “Autoregressive Conditional Heteroscedasticity with Estimates of the Variance of United Kingdom Inflation,” Econometrica, 50, 987–1007. DOI: 10.2307/1912773.
- Fisher, M., and Jensen, M. J. (2022), “Bayesian Nonparametric Learning of How Skill is Distributed Across the Mutual Fund Industry,” Journal of Econometrics, 230, 131–153. DOI: 10.1016/j.jeconom.2021.04.002.
- Froot, K., and Teo, M. (2008), “Style Investing and Institutional Investors,” Journal of Financial and Quantitative Analysis, 43, 883–906. DOI: 10.1017/S0022109000014381.
- Frühwirth-Schnatter, S. (1994), “Data Augmentation and Dynamic Linear Models,” Journal of Time Series Analysis, 15, 183–202. DOI: 10.1111/j.1467-9892.1994.tb00184.x.
- Frühwirth-Schnatter, S.(2001), “Markov Chain Monte Carlo Estimation of Classical and Dynamic Switching and Mixture Models,” Journal of the American Statistical Association, 96, 194–209.
- Frühwirth-Schnatter, S.(2006), Finite Mixture and Markov Switching Models, New York: Springer.
- George, E. I., and McCulloch, R. E. (1993), “Variable Selection via Gibbs Sampling,” Journal of the American Statistical Association, 88, 881–889. DOI: 10.1080/01621459.1993.10476353.
- Gray, S. F. (1996), “Modeling the Conditional Distribution of Interest Rates as a Regime-switching Process,” Journal of Financial Economics, 42, 27–62. DOI: 10.1016/0304-405X(96)00875-6.
- Griffin, J., and Kalli, M. (2018), “Bayesian Nonparametric Vector Autoregressive Models,” Journal of Econometrics, 203, 267–282. DOI: 10.1016/j.jeconom.2017.11.009.
- Griffin, J. E., and Steel, M. F. J. (2011), “Stick-Breaking Autoregressive Processes,” Journal of Econometrics, 162, 383–396. DOI: 10.1016/j.jeconom.2011.03.001.
- Haas, M., Mittnik, S., and Paolella, M. (2004), “A New Approach to Markov Switching GARCH Models,” Journal of Financial Econometrics, 2, 493–530. DOI: 10.1093/jjfinec/nbh020.
- Hatjispyros, S. J., Nicoleris, T. N., and Walker, S. G. (2011), “Dependent Mixtures of Dirichlet Processes,” Computational Statistics & Data Analysis, 55, 2011–2025. DOI: 10.1016/j.csda.2010.12.005.
- He, Z., and Maheu, J. (2010), “Real Time Detection of Structural Breaks in GARCH Models,” Computational Statistics & Data Analysis, 54, 2628–2640. DOI: 10.1016/j.csda.2009.09.038.
- Hirano, K. (2002), “Semiparametric Bayesian Inference in Autoregressive Panel Data Models,” Econometrica, 70, 781–799. DOI: 10.1111/1468-0262.00305.
- Hjort, N. L., Homes, C., Müuller, P., and Walker, S. G. (2010), Bayesian Nonparametrics, Cambridge: Cambridge University Press.
- Hlouskova, J., Schmidheiny, K., and Wagner, M. (2009), “Multistep Predictions for Multivariate GARCH Models: Closed form Solution and the Value for Portfolio Management,” Journal of Empirical Finance, 14, 330–336. DOI: 10.1016/j.jempfin.2008.09.002.
- Jame, R., and Tong, Q. (2014), “Industry-based Style Investing,” Journal of Financial Markets, 19, 110–130. DOI: 10.1016/j.finmar.2013.08.004.
- Jensen, J. M., and Maheu, M. J. (2010), “Bayesian Semiparametric Stochastic Volatility Modeling,” Journal of Econometrics, 157, 306–316. DOI: 10.1016/j.jeconom.2010.01.014.
- Kalli, M., Griffin, J. E., and Walker, S. G. (2011), “Slice Sampling Mixture Models,” Statistics and Computing, 21, 93–105. DOI: 10.1007/s11222-009-9150-y.
- Kaufmann, S. (2010), “Dating and Forecasting Turning Points by Bayesian Clustering with Dynamic Structure: A Suggestion with an Application to Austrian Data,” Journal of Applied Econometrics, 25, 309–344. DOI: 10.1002/jae.1076.
- Kaufmann, S. (2015), “K-state Switching Models with Time-varying Transition Distributions: Does Loan Growth Signal Stronger Effects of Variables on Inflation?” Journal of Econometrics, 187, 82–94.
- Klaassen, F. (2002), “Improving GARCH Volatility Forecasts with Regime Switching GARCH,” Empirical Economics, 27, 363–394. DOI: 10.1007/s001810100100.
- Lo, A. Y. (1984), “On a Class of Bayesian Nonparametric Estimates: I. Density Estimates,” The Annals of Statistics, 12, 351–357. DOI: 10.1214/aos/1176346412.
- MacLehose, R., and Dunson, D. (2010), “Bayesian Semiparametric Multiple Shrinkage,” Biometrics, 66, 455–462. DOI: 10.1111/j.1541-0420.2009.01275.x.
- Meilâ, M. (2007), “Comparing Clusterings – An Information Based Distance,” Journal of Multivariate Analysis, 98, 873–895.
- Müller, P., and Mitra, R. (2013), “Bayesian Nonparametric Inference – Why and How,” Bayesian Analysis, 8, 269–302. DOI: 10.1214/13-BA811.
- Nakatsuma, T. (1998), “A Markov-chain Sampling Algorithm for GARCH Models,” Studies in Nonlinear Dynamics and Econometrics, 3, 107–117.
- Nieto-Barajas, L. E., and Quintana, F. A. (2016), “A Bayesian Non-parametric Dynamic AR Model for Multiple Time Series Analysis,” Journal of Time Series Analysis, 37, 675–689. DOI: 10.1111/jtsa.12182.
- Otranto, E., and Gallo, G. M. (2002), “A Nonparametric Bayesian Approach to Detect the Number of Regimes in Markov Switching Models,” Econometric Reviews, 21, 477–496. DOI: 10.1081/ETC-120015387.
- Park, T., and Casella, G. (2008), “The Bayesian Lasso,” Journal of the American Statistical Association, 103, 681–686. DOI: 10.1198/016214508000000337.
- Pitman, J., and Yor, M. (1997), “The Two Parameter Poisson-Dirichlet Distribution Derived from a Stable Subordinator,” Annals of Probability, 25, 855–900.
- Sethuraman, J. (1994), “A Constructive Definition of Dirichlet Priors,” Statistica Sinica, 4, 639–650.
- Taddy, M. A., and Kottas, A. (2009), “Markov Switching Dirichlet Process Mixture Regression,” Bayesian Analysis, 4, 793–816. DOI: 10.1214/09-BA430.
- Virbickaite, A., Ausín, M. C., and Galeano, P. (2015), “Bayesian Inference Methods for Univariate and Multivariate GARCH Models: A Survey,” Journal of Economic Surveys, 29, 76–96. DOI: 10.1111/joes.12046.
- Wade, S., and Ghahramani, Z. (2018), “Bayesian Cluster Analysis: Point Estimation and Credible Balls,” (with discussion), Bayesian Analysis, 13, 559–626. DOI: 10.1214/17-BA1073.
- Walker, S. G. (2007), “Sampling the Dirichlet Mixture Model with Slices,” Communications in Statistics - Simulation and Computation, 36, 45–54. DOI: 10.1080/03610910601096262.
- Wang, H. (2010), “Sparse Seemingly Unrelated Regression Modelling: Applications in Finance and Econometrics,” Computational Statistics & Data Analysis, 54, 2866–2877. DOI: 10.1016/j.csda.2010.03.028.
- Wee, D. C., Chen, F., and Dunsmuir, W. T. (2022), “Likelihood Inference for Markov Switching GARCH(1,1) Models using Sequential Monte Carlo,” Econometrics and Statistics, 21, 50–68. DOI: 10.1016/j.ecosta.2020.03.004.
- Xu, Y., Müller, P., Wahed, A. S., and Thall, P. F. (2016), “Bayesian Nonparametric Estimation for Dynamic Treatment Regimes with Sequential Transition Times,” Journal of the American Statistical Association, 111, 921–950. DOI: 10.1080/01621459.2015.1086353.
- Zhang, L., Guindani, M., Versace, F., Engelmann, J. M., and Vannucci, M. (2016), “A Spatiotemporal Nonparametric Bayesian Model of Multi-subject fMRI Data,” The Annals of Applied Statistics, 10, 638–666. DOI: 10.1214/16-AOAS926.
Appendix A
Proof of the Results in Section 3
We introduce for the set of parameters allocated to the hth mixture component in the regime k,
and the set of the non-empty mixture components
. The number of stick-breaking components needed for the finite mixture representation is
. When sampling from the full conditional distribution of
and
, only
element are sampled, where
is the smallest integer such that
, where
.
A.1 Full Conditional Distribution of V and U
Let us split in three blocks:
,
and
. The samples are generated from a collapsed Gibbs step
the full conditional of the elements in
2. the full conditional of the elements of
the full conditional of the elements of
A.2 Full Conditional Distribution of P and R
We apply a collapsed-Gibbs step and sample ,
, given
, and
,
, is the collection of the kth row of the transition probability matrices given
and
. As for the transition probabilities, from standard calculations in Markov-switching regressions we obtain
(25)
(25)
where
. The marginal distribution is
where , and
is the K-dim standard simplex. From the properties of the gamma functions
we have:
, where
,
and
. Samples from this full conditional distribution are obtained by a Metropolis-Hastings (MH) algorithm with independent proposal distribution
.
A.3 Full Conditional Distribution of
The full conditional distribution of can be sampled by simulating iteratively from the following conditional distributions. The full conditional of
is
where
and
The full conditional distribution of
is
(26)
(26)
where
samples from this conditional distribution are obtained by a MH algorithm with independent proposal distribution
. The full conditional of
is
where
. Samples from this conditional distribution are obtained by MH with independent proposal distribution
. Similar argument is applied to derive the full conditional distributions of
.
A.4 Full Conditional Distribution of
The full conditional distribution of the elements of
is discussed. Let
, its full conditional distribution is
(27)
(27) which is not tractable due to the recursive form of
. Thus, we sample from the full conditional by MH with proposal distribution obtained through the approximation
of
. The joint full conditional of
can be approximated by a normal distribution with mean
and diagonal covariance matrix
where
and
, with
and
The constructed mean and variance are used to define the parameters of the normal mixture proposal distribution for
, that is
As regards the parameters of the volatility process, the full conditional is
(28)
(28)
where
,
and
. We follow the ARMA approximation of the MSGARCH process, that is
(29)
(29)
(30)
(30)
Let with
and
. Subject to the above, we assume
(Nakatsuma Citation1998). The auxiliary ARMA model for the squared error term
is
with
, which returns
. Following Ardia (Citation2008) we further express
as a linear function of the
vector of volatility parameters
. To do this, we approximate the function
by the first order Taylor’s expansion about
as
(31)
(31) where
with
.
satisfies the recurrence:
, where
,
and
is a row vector.
Upon defining , it turns out that
. Furthermore, by defining
,the
vectors
and
, and a
matrix
as well as a
diagonal matrix
with
, we have
. Using this linear approximation, the full conditional distribution of
approximates as
(32)
(32) where
and
,
. The mean and variance defined above are used to characterize proposal distribution for
, that is a mixture of truncated normal distributions. In our MCMC exercise, we sample
from the normal mixture
and check that each sample satisfies the constraints.
A.5 Full Conditional Distribution of
The full joint conditional distribution of the state variables, with
, given the parameter values and return series
(33)
(33) is a nonstandard distribution. For this reason, following Billio, Casarin, and Osuntuyi (Citation2016), we propose a MH algorithm with proposal distribution given by an approximation of the smoothed probability
. The algorithm involves running a Forward Filtering Backward Sampling (FFBS) on an auxiliary model to generate proposals at each iteration step (Carter and Kohn Citation1994; Frühwirth-Schnatter Citation1994). Among several alternative collapsing procedures (see Billio, Casarin, and Osuntuyi Citation2016), we adopt the MSGARCH model by Klaassen (Citation2002) as an auxiliary model as it accounts for the highest amount of information in its construction. We denote the proposal distribution by
(34)
(34)
where
, and
is the filtered probability. At time t, given
and
, the predicted and filtered distributions are
(35)
(35)
(36)
(36) where
,
is the
th row of the identity matrix
. The conditional density of the unit i under the auxiliary model is
(37)
(37)
where
with
,
, and
.
Using the output of the forward filtering, we compute and
,
. Then, at each time, step we sample
from
and
from
iteratively for
. This is the backward sampling step. Samples from
can be obtained by multinomial sampling.
A.6 Full Conditional Distribution of D
The full conditional of is
for
, with
where
is the normalizing constant and a a real positive constant.
A.7 Detection of the Number of Regimes
We present the panel version of the univariate approach by Otranto and Gallo (Citation2002). We assume
,
2,…, T, with
, and
. The BNP model allows for the infinite mixture representation
, where
denotes the density of a multivariate normal with location and scale parameters,
and
, respectively. We assume the base measure
is a product of N independent hierarchical prior distributions
. Instead of using the sampler in Otranto and Gallo (Citation2002), we apply a more efficient sampler which relies on the stick-breaking representation (Walker Citation2007). The sampler requires the use of the allocation,
, stick-breaking
and slice
variables. The allocation variable has the interpretation of regime allocation as in Otranto and Gallo (Citation2002). The full conditionals of
,
, and
are
(38)
(38)
(39)
(39)
(40)
(40)
, where
,
,
. Let
be the maximum value of the allocation variables, and
the smallest integer such that
. Since
a.s., the infinite mixture reduces to a finite mixture. The full conditionals of the steak-breaking components, the slice variables and the allocation variables are
(41)
(41)
(42)
(42)
(43)
(43)