
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We propose a general framework to construct self-normalized multiple-change-point tests with time series data. The only building block is a user-specified single-change-detecting statistic, which covers a large class of popular methods, including the cumulative sum process, outlier-robust rank statistics, and order statistics. The proposed test statistic does not require robust and consistent estimation of nuisance parameters, selection of bandwidth parameters, nor pre-specification of the number of change points. The finite-sample performance shows that the proposed test is size-accurate, robust against misspecification of the alternative hypothesis, and more powerful than existing methods. Case studies of the Shanghai-Hong Kong Stock Connect turnover are provided.
1 Introduction
Testing structural stability is critical in statistical inference. There is a considerable amount of literature and practical interest in testing for the existence of change points. Csörgö and Horváth (Citation1988, Citation1997) provided comprehensive solutions to the at-most-one-change (AMOC) problem using both classical parametric and nonparametric approaches. One method assumes a fixed number of change points (m) for the multiple-change-point problem. The test statistics are constructed by dividing the data into segments and maximizing a sum of AMOC statistics computed within each segment; see Antoch and Jarušková (Citation2013) and Shao and Zhang (Citation2010). However, such approaches are vulnerable to misspecification of the true number of change points M and the computational cost often increases exponentially with m. Another method uses sequential estimation (Vostrikova Citation1981; Bai and Perron Citation1998). This class of methods sequentially performs AMOC tests and produces estimates if the no-change-point hypothesis is rejected. Because the structural difference of data before and after a particular change point may be less apparent in the presence of other change points, the AMOC-type tests may lose their power under the multiple-change-point setting.
Localization can be used to improve power. Bauer and Hackl (Citation1980) introduced the moving sum approach. Chu, Hornik, and Kaun (Citation1995) and Eichinger and Kirch (Citation2018) later applied the approach to change-point detection. This method selects a fixed window size and performs inference on each subsample. Fryzlewicz (Citation2014) proposed wild binary segmentation, which draws subsamples without fixing the window size, to avoid window size selection. Both algorithms attempt to find a subsample containing only one change point to boost power without specifying m. If the standard CUSUM process is used, the methods require consistent and change-point-robust estimation of the long-run variance, which can be nontrivial and may require tuning a bandwidth parameter (Andrews Citation1991). Worse still, different bandwidths can noticeably influence the tests (Kiefer and Vogelsang Citation2005). To avoid the challenging estimation, Lobato (Citation2001) first proposed using a self-normalizer that converges to a pivotal distribution proportional to the nuisance parameter. Shao and Zhang (Citation2010) later applied self-normalization to the AMOC problem. In the multiple-change-point problem, Zhang and Lavitas (Citation2018) proposed a self-normalized test that intuitively scans for the first and last change points. However, it may compromise power when larger changes occur in the middle.
In this article, our contributions are as follows: (a) We propose a novel localized self-normalization framework to transform AMOC statistics into powerful and size-accurate multiple-change-point tests, which apply to a broad class of time series models and a large class of AMOC statistics, including the CUSUM process and outlier-robust change-detecting statistics, instead of any specific process as constructed in existing methods. (b) The methods support multiple-change-point detection in general model parameters. The resulting tests achieve promising power. (c) Our test is also shown to be locally powerful asymptotically. (d) The novel self-normalizers can be recursively computed. (e) The test allows an intuitive extension to estimation with good theoretical properties.
The rest of the article is structured as follows. Section 2 reviews the self-normalization method proposed by Shao and Zhang (Citation2010) under the AMOC problem. Section 3.1 presents the proposed framework, and of Sections 3.2–3.4 explore applications of some popular change-detecting processes and extensions to estimation. In Section 4, the differences between various self-normalized approaches are comprehensively discussed. Some implementation issues are also discussed. Simulation results are presented in Section 5, which show good size accuracy and a substantial improvement in power. The article ends with a real-data analysis of the Shanghai-Hong Kong Stock Connect turnover in Section 6. Proofs of the main results are presented in the Appendix. A supplement containing additional simulation results, recursive formulas, algorithms, and an extension to long-range dependent time series is also included. An R-package “SNmct” is available online.
2 Introduction of Self-Normalization
Consider the signal-plus-noise model: , where
for
and
is a stationary noise sequence. The AMOC testing problem is formulated as follows:
(2.1)
(2.1)
(2.2)
(2.2)
Let if
;
otherwise. A popular statistic for detecting a single change point is the CUSUM process, defined as
(2.3)
(2.3) where
and
is the largest integer part of nt. The limiting distribution of the functional in (2.3) is established by the following assumption.
Assumption 2.1.
As where
is the long-run variance,
is the standard Brownian motion and “
” denotes convergence in distribution in the Skorokhod space (Billingsley Citation1999).
Assumption 2.1 is known as the functional central limit theorem or Donsker’s invariance principle. Under standard regularity conditions, Assumption 2.1 is satisfied. For example, Herrndorf (Citation1984) proved the functional central limit theorem for the dependent data under some mixing conditions; Wu (Citation2007) later proved the strong convergence for stationary processes using physical and predictive dependence measures. Under the null hypothesis H0, by the continuous mapping theorem, we have .
Classically, the celebrated Kolmogorov–Smirnov test statistic, defined as , can be used for the AMOC problem. Because σ is typically unknown, we estimate it by an estimator
that is consistent under H0 and H1; see Chan (Citation2022a, Citation2022b) for some possible estimators. Hence,
converges to
, which is known as the Kolmogorov distribution. Shao and Zhang (Citation2010) proposed to bypass the estimation of σ by normalizing
by a nondegenerate standardizing random process called a self-normalizer:
where
. The resulting self-normalized test statistic for the AMOC problem is
, where
(2.4)
(2.4)
Under Assumption 2.1 and H0, the limiting distribution of is nondegenerate and pivotal. The nuisance parameter
is asymptotically cancelled out in the numerator
and the denominator
on the right-hand side of (2.4). Moreover, because there is no change point in the intervals
and
under H1, the self-normalizer at the true change point,
, is invariant to the change, and therefore their proposed test does not suffer from the well-known non-monotonic power problem; see, for example, Vogelsang (Citation1999).
However, this appealing feature no longer exists in the multiple-change-point setting. Moreover, their proposed self-normalizer is specifically designed for normalizing the CUSUM process, which may not be the best choice if the data have a heavy-tailed distribution. In the next section, we propose a framework for extending user-specified AMOC statistics to a multiple-change-point self-normalized test using the localization idea.
3 General Framework
3.1 Locally Self-Normalized Test Statistic
We consider the multiple-change-point testing problem, that is, to test the H0 in (2.1) against
(3.1)
(3.1) for unknown times
, and an unknown number of change points
. In this section, combining the advantages of localization and self-normalization, we lay out the underlying principles to define a general class of statistics for testing the existence of multiple change points.
Generally, for the AMOC problem, one may consider any specific global change-detecting process, . For some positive definite matrix
and some empirical process
with a pivotal distribution,
converges weakly to
in the Skorokhod space. Typically,
is designed to detect whether k is a change point for
. We generalize the input global change-detecting process into a localized change-detecting statistic, defined as
(3.2)
(3.2) where
. By the continuous mapping theorem,
converges in distribution to a random variable proportional to a nuisance parameter σD. A self-normalizer is constructed by a function of the global change-detecting process to cancel σD, defined as
(3.3)
(3.3)
where
for any matrix A. For
, define
(3.4)
(3.4)
and set
otherwise. By the continuous mapping theorem, it is not difficult to see that
is asymptotically pivotal. Consequently,
is a generalized locally self-normalized (LSN) statistic for detecting whether k is a change point over the local window
. To infer whether k is a change point, we aggregate
over all of the symmetric local windows and propose the score function, defined as
(3.5)
(3.5)
where
is a fixed local tuning parameter, which is similarly used in, for example, Huang, Volgushev, and Shao (Citation2015) and Zhang and Lavitas (Citation2018); see Remark 3.1 for the rationale for considering only the symmetric local windows. In particular, they suggested choosing
, which is used throughout this article. Essentially, (3.5) compares the local subsamples of length d + 1 before and after time k, that is,
and
, for each possible width d that is not too small. The statistic
records the change corresponding to the most discernible d; see Section 3.2 for more discussion on the change-detecting ability of the LSN statistic. Finally, to capture the effects of all potential change points, we aggregate the scores
across k and obtain the proposed test statistic,
(3.6)
(3.6)
Our framework constructs multiple-change-point tests through a two-layer aggregation process. The first aggregation across d is to let the data choose the window sizes. We remark that the performance of the moving sum (MOSUM) statistic, which is a special case of the localized CUSUM with a fixed window size, depends critically on the window size (Eichinger and Kirch Citation2018). To handle window size selection, Cho and Kirch (Citation2022) proposed localized pruning by first taking the union of fixed bandwidth change-point estimators produced by the MOSUM method or other multiscale method over a specific grid of bandwidths, and then pruning down the size of the first-step estimator. Although the procedure may work for point estimation, it is unclear whether it can be extended to construct powerful tests. The proposed framework employs an automatic window selection, based on the strength of discrepancy of and
according to the LSN statistic, prior to the estimation stage to avoid additional pruning. Nevertheless, both authors suggested considering multiple bandwidths for robustness.
The purpose of the second layer is to gather all information on all possible change points. Generally, users may choose their preferred aggregation operators, for example, median, trimmed mean, etc, for aggregation. Formally, for any finite set of indices having a size
, we say that
is an aggregation operator if
maps
to a real number. For example, if
gives the maximum; and if
gives the sample mean. Hence, the most general form of our proposed test statistic is
where
and
are some aggregation operators. The optimal choices of aggregation operators depend on the number of change points and their respective sizes. By construction, the scores (3.5) remain large over the neighborhoods of the true change points. Intuitively, the average score captures evidence from all change points and their neighborhoods, whereas the maximum score can only capture evidence from a single change point corresponding to the highest score. According to our experience and the simulation results provided in Section C.12 of the supplement, the gain in power is noticeable when
and all the changes are of the same size. However, the gain diminishes as the portions of smaller changes increase relative to those of larger changes. Nevertheless,
still has greater power in the cases considered. Therefore, we recommend selecting
, as used in the rest of this article.
Our approach is more flexible as it supports a general change-detecting process and general aggregation operators
and
. Moreover, the locally self-normalized statistic is a function of the supplied global change-detecting process. Therefore, recursive computation of the locally self-normalized statistics, regardless of the input change-detecting process, is possible for our approach. Briefly, our framework is an automatic procedure for generalizing any single-change-detecting statistic
to a multiple-change-detecting statistic
. We demonstrate this feature through various examples. Section 3.2 presents the theoretical details of the proposed framework under the popular CUSUM process. An application of outlier robust statistic is demonstrated in Section 3.3. Extension to testing change in general parameters is discussed in Section 3.4.
Remark 3.1
(Symmetric windows). Let the score function based on nonsymmetric windows be
. The corresponding test statistic is
. According to our experience, the gain in power from nonsymmetric windows is marginal, but the computational cost increases exponentially; see the simulation results provided in Section C.10 of the supplement. Therefore, symmetric windows are recommended to balance cost and power.
3.2 CUSUM Statistic
To improve the power of the CUSUM process under the multiple-change-point setting, we generalize it to a CUSUM LSN statistic according to our proposed framework. In particular, the localized CUSUM statistic can be rewritten as
(3.7)
(3.7) where
. Therefore, the localized CUSUM statistic compares the sample means of data from time s to k and k + 1 to e. Because (3.7) is not normalized, according to (3.3)–(3.4), the localized self-normalizer and localized CUSUM statistic are respectively
To infer how likely k is a potential change-point location, we consider all symmetric local windows that centered at k and define the score function according to (3.5) as
(3.8)
(3.8) where
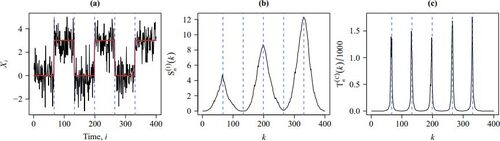
. In , the proposed score function (3.8) is compared with Shao and Zhang (Citation2010) method. Clearly,
achieves the local maxima near all true change-point locations, while
does not. Because the
self-normalizers are not localized, they include data containing change points and are, therefore, inflated by other changes. Other possible reasons include reduced change-point detection capacity of the global CUSUM because of other changes and nonmonotonic change-point configuration. As a remark, the under-performance of
comes with the benefit of smaller computational complexity; for more discussion; see Section 4.1. Finally, we obtain the proposed test statistic by aggregating the scores
across k as follows:
(3.9)
(3.9)
which captures the effects of all potential change points. For
, define
and
be the jth relative change-point time and the corresponding change, respectively. Theorem 3.1 states the limiting distribution and the consistency of
.
Fig. 1 (a) A realization of data (black solid line) with 5 change-points (blue dashed lines) and its mean function (red solid line). (b) Shao and Zhang’s (Citation2010) score function . (c) The proposed score function
.
Theorem 3.1
(Limiting distribution and consistency). Suppose Assumption 2.1 is satisfied. (i) Under H0, for any
, where
(3.10)
(3.10)
(3.11)
(3.11)
(3.12)
(3.12)
(ii) Under , if there exist
and C > 0 such that the jth change-point time satisfies
and the corresponding jth change magnitude satisfies
as
, then
in probability.
The test statistic has a pivotal limiting distribution under H0, the quantiles of which can be found by simulation; see . See also Section 4 for more discussion on the critical value adjustment procedure for handling strong serial correlation when the sample size is small. Under
, the test is of power 1 asymptotically if the change magnitude is at least a nonzero constant. Theorem 3.2 concerns a local alternative hypothesis that contains change points with diminishing change magnitudes.
Table 1. Simulated quantiles of , that is, the limiting distribution of
.
Theorem 3.2
(Local limiting power). Under , parameterize the jth change magnitude
as a function of n. If there exist
and
such that the jth change point satisfies
and
as
, then
in probability.
Motivated by , a natural change-point set estimator can be intuitively obtained from the points corresponding to the local maxima of the general score functions
in (3.5). Specifically, the estimator is defined as
(3.13)
(3.13) where ϱ is a decision threshold and D is the global change-detecting process. In particular, if the CUSUM process is used, that is,
, Lemma 3.3 and Theorem 3.4 show the consistency of the proposed point estimator,
.
Lemma 3.3.
Let πj be the jth relative change point, kj be the jth change-point time such that as
for
,
, and
. Let h be any non-change-point time such that
as
for all j. Define
. If
and
as
, where
for all j, then for
,
Theorem 3.4.
Assume that for all where M is a finite constant,
and
as
where
. Let
be the elements of
. If
where
, then for any small enough
such that
,
By Lemma 3.3, the optimal threshold, ϱ, depends on the unknown change magnitudes. If the sizes of the changes are further assumed to be O(1), then we can set with
. Theoretically, it is challenging to derive an optimal choice of c and
without a specific cost function that trades off the accuracy and size of
. It is possible to select
across a class of change-point models through a large-scale simulation. As point estimation is beyond the scope of this article, we leave it as an open question for further study. From our experience, choosing
yields a reasonable result. Because the score functions are computed during the computation of the proposed test statistics
, the point estimator can be directly computed.
Remark 3.2
(Improving point estimation). The change-point estimation may be improved by further integrating other screening algorithms, for example, the screening and ranking algorithm (Niu and Zhang Citation2012) and the scanning procedure proposed by Yau and Zhao (Citation2016), to perform model selection in order to avoid overestimating the number of change points. Alternatively, our proposed test can be applied to stepwise estimation, for example, binary segmentation (Vostrikova Citation1981), wild binary segmentation (Fryzlewicz Citation2014), and SNCP (Zhao, Jiang, and Shao Citation2021); see Section G of the supplement for information on how to integrate our method with existing screening methods.
3.3 Outlier-Robust Statistics
An outlier-robust nonparametric change-point test can be constructed using the Wilcoxon two-sample statistic. The corresponding is
(3.14)
(3.14) for
, where
is the rank of Xi when there is no tie in
. It is assumed that the data are weakly dependent and can be represented as a functional of an absolutely regular process. Under some mixing conditions, we have
, where
and
is the distribution function of X1 with a bounded density; see Theorem 3.1 in Dehling et al. (Citation2015). From the principles in Section 3.1, we may use (3.14) to construct a self-normalized multiple-change-point Wilcoxon test and eliminate the nuisance parameter
by using the test statistic
; see the corollary below.
Corollary 3.5
(Limiting distribution of ). Under the regularity conditions in Theorem 3.1 of Dehling et al. (Citation2015) and H0, we have
.
The Hodges–Lehmann statistic is another popular alternative to the CUSUM statistic in (2.3). Its global change-detecting process is
(3.15)
(3.15) for
, where
denotes the sample median of a set
. It outperforms the CUSUM test under skewed and heavy-tailed distributions. Under the regularity conditions in Dehling, Fried, and Wendler (Citation2020), we have
, where
, f is the density of X1, and F is the distribution function of X1. Similarly, we can apply the Hodges–Lehmann statistic to test for the existence of multiple change points. The corresponding test statistic is
. Its limiting distribution is presented in Corollary 3.6. To our knowledge, there is no existing self-normalized tests use the Hodges–Lehmann statistic. It is included to demonstrate the generality of the proposed self-normalization framework and to detect change points in heavy-tailed data.
Corollary 3.6
(Limiting distribution of ). Under the regularity conditions in Theorem 1 of Dehling, Fried, and Wendler (Citation2020) and H0, we have
.
3.4 Extension for Testing Change in General Parameters
Instead of testing changes in mean, one may be interested in other quantities, for example, variances, quantiles and model parameters. Let , where
is a functional,
is the joint distribution function of
for
and
. For example, for h = 1,
and
are the marginal mean and variance at time i, respectively. For h = 2, the lag-1 autocovariance at time i is
. The hypotheses in (2.1) and (3.1) are redefined by replacing μi’s by θi’s. A possible global change-detecting process is
(3.16)
(3.16) for
; see, for example, Shao (Citation2010), Shao and Zhang (Citation2010), and Shao (Citation2015). If
, then
. Therefore, (3.16) generalizes (2.3) from testing changes in μi’s to testing changes in θi’s. The final test statistic is
.
The limiting distribution of (3.16) requires standard regularity conditions in handling statistical functionals. Based on the sample , define the empirical distribution of Yi’s by
, where δy is a point mass at
. Assume that
is asymptotically linear in the following sense, as
:
(3.17)
(3.17) where
is a remainder term,
, and
is the influence function; see Wasserman (Citation2006).
Corollary 3.7
(Limiting distribution of ). For
and
, define
, where
under H0. Suppose that (i)
for all i, (ii)
for some positive definite matrix σG and
is q-dimensional standard Brownian motion, where
, and (iii)
. Then
, where
where
is defined as
in (3.11) but with
being replaced by
; and
is defined as
in (3.11) but with
being replaced by
. In particular,
.
4 Discussion and Implementation
4.1 Comparison with Existing Methods
Shao and Zhang (Citation2010) extended the self-normalized one-change-point test (2.4) to a supervised multiple-change-point test tailored for testing m change-points, where m is pre-specified. The test statistic is
(4.1)
(4.1) where
, and
. The trimmed region
prevents estimates from being computed with too few observations. Later, Zhang and Lavitas (Citation2018) proposed an unsupervised self-normalized multiple-change-point test that bypasses specifying m and is defined as,
(4.2)
(4.2)
Although and
use LSN CUSUM statistics, that is,
, as building blocks, they have different restrictions on the local windows and aggregate the LSN statistics in different ways. The Shao and Zhang (Citation2010) multiple-change-point test has strict control over the m local windows because the boundaries of a window relate to preceding and subsequent windows. If the number of change points is misspecified, some windows may not contain only one change point. If m < M, the self-normalizers are not robust to changes. If m > M, some degrees of freedom are lost trying to detect change points that do not exist. Both cases may lead to a significant loss of power. Moreover, their computational cost increases exponentially with m. The Zhang and Lavitas’s (Citation2018) approach sets the left end of the window to 1 in the forward scan, and the right end to n in the backward scan. Therefore, their approach tends to scan for the first change point
and the last change point
for some e and s, which may lead to a loss of power; see Section 5.2. In contrast, our approach scans for all possible change points because windows can start and end at any time with the same computation complexity; see Section C.9 of the supplement. The score function at each time takes O(n) steps to compute and O(1) spaces to store using recursive computation. Because the test statistic is computed as a function of O(n) scores, it has a computational cost of
and a memory requirement of O(n). summarizes the comparison. As a remark, the self-normalized segmentation algorithms proposed by Jiang, Zhao, and Shao (Citation2021) and Zhao, Jiang, and Shao (Citation2021) are also based on localized CUSUM contrast-type change-detecting statistics. In the testing stage, a nested window set is introduced to control the computational cost by considering a finite set of windows. In contrast, we develop recursive LSN statistics that consider all symmetric windows with sizes greater than ϵ. Therefore, our method considers all possible windows with size greater than
and possibly increases power.
Table 2. Comparisons between various different change-point tests in terms of (a) finite-sample size accuracy with respect to the nominal Type-I error rate; (b) power under several change-point numbers M; (c) time complexity of computing the test statistics based on a sample of size n; (d) robustness against outliers; and (e) requirements of computing a long-run variance estimate and specifying a target number of change points m, where
is assumed to be computed in O(n) steps.
4.2 Finite-n Adjusted Critical Values
In the time series context, the accuracy of the invariance principle, that is, Assumption 2.1, may deteriorate when the sample size is small (Kiefer and Vogelsang Citation2005). Therefore, the asymptotic theory in, for example, Theorem 3.1, may not apply when serial dependency is strong and the sample size is small. It may lead to severe size distortion, observed in both existing self-normalized and non-self-normalized methods, including the proposed tests; see Section 5 and Section C.13 of the supplement for simulation evidences. For the multiple-change-point problem (3.1) in mean, a finite-sample adjusted critical value procedure based on the strength of serial dependency is proposed to mitigate this problem.
We propose to compute a critical value by matching the autocorrelation function (ACF) at lag one ρ and n for various specified levels of significance
. The values of
are tabulated in Section D of the supplement for
, and
. The testing procedure is outlined as follows.
Compute the sample lag-1 ACF
of
Obtain the critical value
Reject the null if
The adjustment procedure borrows from the idea of bootstrap-based critical value simulation procedures; see for example, Zhou (Citation2013) and Pešta and Wendler (Citation2020). The limiting distribution is pivotal by Theorem 3.1 and Corollaries 3.5–3.7. Therefore, the critical value simulation procedure can be performed prior to the computation of the test statistic. Because depends on the differenced data with a suitable lag, the change points (if any) have negligible effect on
.
The consistency of is developed on the following framework: Let
, where μi’s are deterministic and Zi’s are zero-mean stationary noises. Define
, where
‘s are independent and identically distributed (
) random variables and g is some measurable function. Let
be an
copy of
and
. For p > 1 and
, the physical dependence measure (Wu Citation2011) is defined as
, where
. Theorem 4.1 states that
is a consistent estimator even under a large number of change points M. In particular, if
and
, then Theorem 4.1 guarantees that
is consistent for ρ if
. The proposed adjustment only affects the finite-sample performance because the critical value
is a constant as a function of ρ when
.
Theorem 4.1.
Assume that and
. Define
. Let bn be an
-valued sequence. If
as
, then
.
Although it is possible to match the ACF at a higher lag, the AR(1) model is considered to balance the accuracy and the computational cost; see Section C.13 of the supplement. The sensitivity analysis of the differencing parameter bn in Section C.14 of the supplement also verifies that the choice has a minimal effect on the performance of the tests. The simulation result shows that the tests have a remarkably accurate size even when the true model is not the AR(1) model; see Section 5 and Section C of the supplement. It indicates that the selected AR(1) model has certain explanatory power. If another approximation model is more appropriate for a specific application, then the AR(1) model should be replaced. Users may choose between the standard testing procedure using or the proposed adjustment, if it is appropriate.
5 Simulation Experiments
5.1 Setting and Overview
Throughout Section 5, the experiments are designed as follows. The time series is generated from a signal-plus-noise model: . The values of μi’s will be specified in Sections 5.2 and 5.3. The zero-mean noises Zi’s are simulated from a stationary bilinear autoregressive (BAR) model:
(5.1)
(5.1) where
‘s are independent standard normal random variables, and
such that
. The BAR model is a class of nonlinear time series models that have been extensively studied in the literature; see, for example, Granger and Anderson (Citation1978), Rao (Citation1981), and Rao and Gabr (Citation1984). The bilinear time series model is widely used in the fields of control theory (Bruni, DiPillo, and Koch Citation1974), econometrics (Weiss Citation1986), and seismology (Dargahi-Noubary, Laycock, and Rao Citation1978), which the phenomenon of occasional sharp spikes occurs in sample paths. Similar findings are obtained under other noise models, including the autoregressive-moving-average model, threshold AR model, and absolute value nonlinear AR model. Because of space constraints, these results are presented in to the supplement. The critical value is chosen according to the adjustment procedure described in Section 4.2.
5.2 Size and Power
In this section, we examine the size and power of different tests when there exist various numbers of change points. Following the suggestion of Huang, Volgushev, and Shao (Citation2015) and Zhang and Lavitas (Citation2018), we choose in
and in our proposed tests for a fair comparison. Suppose that the change points are evenly spaced and the mean change directions are alternating (increasing or decreasing):
(5.2)
(5.2) where
denotes the number of change points, and
controls the magnitude of the mean changes. Then,
under H0.
All tests are computed at the nominal size . The null rejection rates
, for sample sizes
, are presented in . To summarize the result, we further report the sample root mean squared error (RMSE) of
over all cases of
and
for each test and each n. Specifically,
where
is the set of
used in the simulation,
is the cardinality of
, and
is the empirical size under the BAR model with parameter ϑ and ϖ with sample size n. The self-normalized tests generally have a more accurate size than the non-self-normalized test
. This finding is consistent with that of Shao (Citation2015). The self-normalized approach is a special case of the fixed bandwidth approach with the largest possible bandwidth and thus achieves the smallest size distortion, as observed by Kiefer and Vogelsang (Citation2002). In comparison,
and
control the size most accurately among the self-normalized tests. In particular, our proposed tests have the least severe under-size problem, observed in existing self-normalized tests (i.e.,
,
, and
) when
. Moreover, the test proposed by Shao and Zhang (Citation2010),
, suffers from an increasing size distortion as m increases. This finding is consistent with that of Zhang and Lavitas (Citation2018). The fact that
and
outperform
can be attributed to the outlier robustness of rank and order statistics. This advantage is particularly noticeable in bilinear time series, as this model is well known for producing sudden high amplitude oscillations that mimic structures in, for example, explosion and earthquake data in seismology; see Section 5.2 of Rao and Gabr (Citation1984). However, in the more standard ARMA models,
performs as well as
and
; see the supplement for the detailed results.
Table 3. Null rejection rates at nominal size
under BAR model and mean function (5.2).
The power curve against Δ is computed at 5% nominal size using 210 replications with n = 200. displays the size-adjusted power when . The (unadjusted) power is presented in the supplement. The results with various values of ϖ and ϑ are similar, thus, they are presented in the supplement. Generally,
and
have the highest power. They outperform
because of their robustness against outliers. When only the CUSUM-type tests are considered, the non-self-normalized test
performs better than self-normalized tests when M = 1. However, when M > 1,
significantly under-performs because it is tailor-made for the AMOC alternative (2.2). Although
has the highest power among the self-normalized CUSUM tests when M = 1, it suffers from the notorious non-monotonic power problem when M > 1 because its self-normalizer is not robust to multiple change points. Thus,
is not a consistent test when M > 1.
Fig. 2 Size-adjusted power under BAR model with , n = 200 and mean function (5.2).
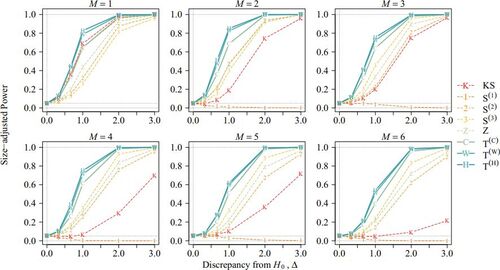
Surprisingly, our proposed test outperforms the tests of Shao and Zhang (Citation2010),
, even when M is well-specified. This finding demonstrates that it is not advantageous to know M because structural change can be identified by observing the data around it without looking at the entire segmented series. Moreover, as discussed in Section 4.1,
defines the local windows restrictively. It accumulates errors if the boundaries of the local windows differ from the actual change points. It is also interesting to see that, compared with
,
, and
are less sensitive to misspecification of M; however, they are still less powerful than our proposed tests.
5.3 Ability to Capture Effects of All Changes
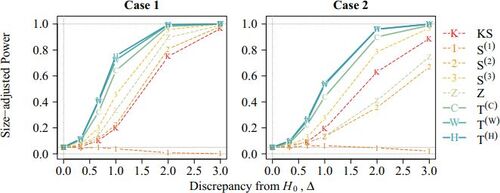
The proposed tests are robust against multiple change points compared with existing methods. Consider the three-change-point setting in which the magnitude of changes at the first and the last change points is only half that of the second change point. Specifically, define the mean function for case 1 as (5.2) with M = 3 and for case 2 as
From , and
lose approximately half of their power in Case 2 compared with that in Case 1. In contrast, the power of our tests only decreases by 1/3 when
, while it remains roughly the same when
. Therefore, our tests are more powerful and can capture a larger class of structural changes than existing methods. In contrast,
and
tend to consider the first and/or the last change points.
Fig. 3 Size-adjusted power under the BAR model with , n = 200 and mean functions as in cases 1 and 2.
5.4 Change in General Parameters
In many applications, trends may exist in the data. Therefore, we consider the multiple-change-point problem in the mean and median trend models. Specifically, we consider the regression model: with
and
under the following multiple-change-point model:
for
, where
, and
. Note that
and
refer to the mean trend and median trend models, respectively. Our goal is to test H0 against
with μi’s replaced by βi’s.
To handle changes in general parameters, the global change-detecting process in (3.16) is used. Let
be an estimator of the common value of
based on observations
under H0. The estimators
are obtained using ordinary least-squares regression under the mean trend model; while they are obtained using quantile regression under the median trend model and computed by the R package “quantreg”. Let
and
be the mean trend version and median trend version of the test statistics
in Section 3.4, respectively. In our simulation, we generate the data as
where Zi’s are simulated from the BAR model (5.1),
denotes the number of change points, and
controls the magnitude of the changes. Briefly, the model implies an uptrend in mean and median before every odd index of change points until level Δ. After reaching Δ at odd change points, the trend shifts downward and decreases to 0 at the next change point. The empirical rejection rates are reported in . From the results,
suffers less severe under-size distortion than
. Both tests have decent powers in the multiple-change-point setting and significantly improve from n = 200 to n = 400. For reference, the size-adjusted power is also reported in Section C.11 of the supplement.
Table 4. Empirical rejection rates (%) of the mean and median trend tests, and
, respectively, at 5% nominal size under the BAR model.
6 Shanghai-Hong Kong Stock Connect turnover
We use our proposed method to perform change-point analysis of the Shanghai-Hong Kong Stock Connect Southbound Turnover index (Bloomberg code: AHXHT index) from March 23, 2017 to March 22, 2022 (n = 1232). The data are retrieved from Bloomberg. The Stock Connect is a channel that allows mainland China and Hong Kong investors to access other stock markets jointly. The southbound line enables investors in mainland China to invest in the Hong Kong stock market. Studies have shown that the Stock Connect improves mutual market liquidity and capital market liberalization (Bai and Chow Citation2017; Huo and Ahmed Citation2017; Xu et al. Citation2020). Therefore, it is of practical interest, to determine whether change points exist in the Stock Connect Southbound daily turnover.
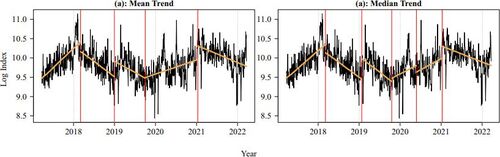
We investigate whether changes in trend exist in the log daily turnovers. Under the mean and median trend models, we consider the tests statistics and
, specified in Section 5.4. The resulting test statistics are 47.46 and 40.64. Both p-values are less than 1%. The trend change-point location estimates are indicated by red vertical lines in . The mean and median trend analyses agree on four estimated change points, estimated on March 7, 2018, January 24, 2019, October 2, 2019, and January 12, 2021. The median trend analysis detects an additional change point on May 25, 2020. The first change point is likely to be the China–United States trade war. After the trade war began in January 2018, the Stock Connect turnover displayed a downtrend. An uptrend is detected after 2019 until the COVID-19 events, while it stops after the beginning of 2021.
Fig. 4 Estimated (a) mean trend and (b) median trend change points are indicated by red vertical lines. The orange lines indicate the fitted regression lines within each region separated by the estimated change points. Data are retrieved from Bloomberg.
7 Conclusion
Our method improves existing change-point tests and has several advantages: (i) it has high power and size accuracy, (ii) it does not require specification of the number of change points nor consistent estimation of nuisance parameters, (iii) a consistent estimate of change points can be naturally produced, (iv) general change-detecting statistics, for example, rank and order statistics, can be used to enhance robustness, (v) it can test a change in general parameter of interest, and (vi) it applies to a wide range of time series models. summarizes the properties of the proposed tests. Moreover, our proposed framework is driven by intuitive principles. If a single-change-detecting statistic is provided, our framework can generalize it to a multiple-change-detecting statistic. We anticipate that future works will apply our framework to non-time-series data, for example, spatial and spatial–temporal data.
8 Proofs of Theorems
Proof of Theorem
s 3.1 and 3.2. (i) Under H0 and by the continuous mapping theorem, Assumption 2.1 implies that . Note that
is a composite function of
through (3.2), (3.3), (3.4), (3.5), and (3.6), each of which is a continuous and measurable map. By the continuous mapping theorem, we obtain
in (3.10). The limiting distribution
is well-defined because
converges to a nonnegative and nondegenerate distribution for any
and
, if
.
(ii) For consistency, we consider the jth relative change-point time πj such that the corresponding change magnitude satisfies , where
. Let
and
. Under this assumption, there exist
and
such that
is satisfied for a large enough n. Therefore, there is only one change point in the interval
. It suffices to consider
. For all k such that
where
, we can decompose
(8.1)
(8.1) where
. EquationEquation (8.1)
(8.1)
(8.1) holds uniformly in k for
. Next, for the self-normalizer
, we consider two cases:
and
. If
, there is only one change point in the interval
. Following similar calculations as in (8.1), we have
for all
, if n is large enough. Also, because there is no change point in the interval
for all
. So,
where
. For the case in which
, the analysis is similar and
are of the same order. Therefore, there exists a constant
such that
for all . Because
for all k, we have
for a large enough n, where is a constant. Consequently,
in probability as
because
. □
Proof of Lemma 3.3.
By the assumption stated in the lemma, there exists an ϵ such that πj is the unique relative change-point time in the interval . Let
and
. Let
, where
. Then,
Because there is no change point in the intervals and
, the self-normalizer
is free of Δj and therefore is of
. Then, let
, as
,
Therefore, . For any time i, there are
change point(s) in the interval
change point(s) in the interval
. Let
and
Therefore, denotes the time of
th change point after time i if a > 0; before time i if a < 0. Likewise, let
be the size of change corresponding to
for
, and
. Let
and a set of time indices in (s, e) that are asymptotically away from all change points be,
Consider non-change-point time . For all
, and time
, we have
and
Using the result, the self-normalizer is at least of the same order because for some c > 0,
Therefore, , implying
. □
Proof of Theorem 3.4.
For any small enough such that
, let
be the event that the absolute difference between the
th true change point and the closest estimator in
is greater than η. Let
. By the definition of
in (3.13) with
, we can represent
as
Using Lemma 3.3, we have, for all as
,
Then,
. □
Supplementary Materials
The supplementary note contains additional simulation results, finite-n adjusted critical values, recursive formulas, algorithms, and proofs of corollaries. Extension to long-range dependent time series is discussed. Implementation code is provided in the R library SNmct.
SNmct_supp.zip
Download Zip (800.3 KB)Acknowledgments
The authors would like to thank the anonymous referees, an associate editor, and the editor for their constructive comments that improved the scope and presentation of the article.
Disclosure Statement
The authors report there are no competing interests to declare.
Additional information
Funding
References
- Andrews, D. W. (1991), “Heteroskedasticity and Autocorrelation Consistent Covariance Matrix Estimation,” Econometrica, 59, 817–858.
- Antoch, J., and Jarušková, D. (2013), “Testing for Multiple Change Points,” Computational Statistics, 28, 2161–2183.
- Bai, J., and Perron, P. (1998), “Estimating and Testing Linear Models with Multiple Structural Changes,” Econometrica, 66, 47–78.
- Bai, Y., and Chow, D. Y. P. (2017), “Shanghai-Hong Kong Stock Connect: An Analysis of Chinese Partial Stock Market Liberalization Impact on the Local and Foreign Markets,” Journal of International Financial Markets, Institutions and Money Rank, 50, 182–203.
- Bauer, P., and Hackl, P. (1980), “An Extension of the MOSUM Technique for Quality Control,” Technometrics, 22, 1–7.
- Billingsley, P. (1999), Convergence of Probability Measures. Wiley Series in Probability and Statistics (2nd ed.), New York: Wiley.
- Bruni, C., DiPillo, G., and Koch, G. (1974), “Bilinear Systems: An Appealing Class of “Nearly Linear” Systems in Theory and Applications,” IEEE Transactions on Automatic Control, 19, 334–348. DOI: 10.1109/TAC.1974.1100617.
- Chan, K. W. (2022a), “Mean-Structure and Autocorrelation Consistent Covariance Matrix Estimation,” Journal of Business & Economic Statistics, 40, 201–215. DOI: 10.1080/07350015.2020.1796397.
- Chan, K. W. (2022b), “Optimal Difference-based Variance Estimators in Time Series: A General Framework,” Annals of Statistics, 50, 1376–1400.
- Cho, H., and Kirch, C. (2022), “Two-Stage Data Segmentation Permitting Multiscale Change Points, Heavy Tails and Dependence,” Annals of the Institute of Statistical Mathematics, 74, 653–684. DOI: 10.1007/s10463-021-00811-5.
- Chu, C.-S. J., Hornik, K., and Kaun, C.-M. (1995), “MOSUM Tests for Parameter Constancy,” Biometrika, 82, 603–617. DOI: 10.1093/biomet/82.3.603.
- Csörgö, M., and Horváth, L. (1988), “20 Nonparametric Methods for Changepoint Problems,” Handbook of Statistics, 7, 403–425.
- Csörgö, M., and Horváth, L. (1997), Limit Theorems in Change-point Analysis, Wiley Series in Probability and Statistics, New York: John Wiley.
- Dargahi-Noubary, G., Laycock, P., and Rao, T. S. (1978), “Non-Linear Stochastic Models for Seismic Events with Applications in Event Identification,” Geophysical Journal International, 55, 655–668. DOI: 10.1111/j.1365-246X.1978.tb05934.x.
- Dehling, H., Fried, R., Garcia, I., and Wendler, M. (2015), “Change-Point Detection Under Dependence based on Two-Sample U-Statistics,” in Asymptotic Laws and Methods in Stochastics, eds. D. Dawson, R. Kulik, M. Ould Haye, B. Szyszkowicz and Y. Zhao), pp. 195–220. New York: Springer.
- Dehling, H., Fried, R., and Wendler, M. (2020), “A Robust Method for Shift Detection in Time Series,” Biometrika, 107, 647–660. DOI: 10.1093/biomet/asaa004.
- Eichinger, B., and Kirch, C. (2018), “A MOSUM Procedure for the Estimation of Multiple Random Change Points,” Bernoulli, 24, 526–564. DOI: 10.3150/16-BEJ887.
- Fryzlewicz, P. (2014), “Wild Binary Segmentation for Multiple Change-Point Detection,” Annals of Statistics, 42, 2243–2281.
- Granger, C. W. J., and Anderson, A. P. (1978), An Introduction to Bilinear Time Series Models, Gottingen: Vandenhoeck & Ruprecht.
- Herrndorf, N. (1984), “A Functional Central Limit Theorem for Weakly Dependent Sequences of Random Variables,” Annals of Probability, 12, 141–153.
- Huang, Y., Volgushev, S., and Shao, X. (2015), “On Self-Normalization for Censored Dependent Data,” Journal of Time Series Analysis, 36, 109–124. DOI: 10.1111/jtsa.12096.
- Huo, R., and Ahmed, A. D. (2017), “Return and Volatility Spillovers Effects: Evaluating the Impact of Shanghai-Hong Kong Stock Connect,” Economic Modelling, 61, 260–272. DOI: 10.1016/j.econmod.2016.09.021.
- Jiang, F., Zhao, Z., and Shao, X. (2021), “Modelling the Covid-19 Infection Trajectory: A Piecewise Linear Quantile Trend Model,” Journal of the Royal Statistical Society, Series B, 84, 1589–1607. DOI: 10.1111/rssb.12453.
- Kiefer, N. M., and Vogelsang, T. J. (2002), “Heteroskedasticity-Autocorrelation Robust Standard Errors using the Bartlett Kernel Without Truncation,” Econometrica, 70, 2093–2095. DOI: 10.1111/1468-0262.00366.
- Kiefer, N. M., and Vogelsang, T. J. (2005), “A New Asymptotic Theory for Heteroskedasticity-Autocorrelation Robust Tests,” Econometric Theory, 21, 1130–1164.
- Lobato, I. N. (2001), “Testing that a Dependent Process is Uncorrelated,” Journal of the American Statistical Association, 96, 1066–1076. DOI: 10.1198/016214501753208726.
- Niu, Y. S., and Zhang, H. (2012), “The Screening and Ranking Algorithm to Detect DNA Copy Number Variations,” The Annals of Applied Statistics, 6, 1306–1326. DOI: 10.1214/12-AOAS539.
- Pešta, M., and Wendler, M. (2020), “Nuisance-Parameter-Free Changepoint Detection in Non-Stationary Series,” Test, 29, 379–408. DOI: 10.1007/s11749-019-00659-1.
- Rao, T. S. (1981), “On the Theory of Bilinear Time Series Models,” Journal of the Royal Statistical Society, Series B, 43, 244–255. DOI: 10.1111/j.2517-6161.1981.tb01177.x.
- Rao, T. S., and Gabr, M. M. (1984), An Introduction to Bispectral Analysis and Bilinear Time Series Models (Vol. 24, 1st ed.), New York: Springer-Verlag.
- Shao, X. (2010), “A Self-Normalized Approach to Confidence Interval Construction in Time Series,” Journal of the Royal Statistical Society, Series B, 72, 343–366. DOI: 10.1111/j.1467-9868.2009.00737.x.
- Shao, X. (2015), “Self-Normalization for Time Series: A Review of Recent Developments,” Journal of the American Statistical Association, 110, 1797–1817.
- Shao, X., and Zhang, X. (2010), “Testing for Change Points in Time Series,” Journal of the American Statistical Association, 105, 1228–1240. DOI: 10.1198/jasa.2010.tm10103.
- Vogelsang, T. J. (1999), “Sources of Nonmonotonic Power When Testing for a Shift in Mean of a Dynamic Time Series,” Journal of Econometrics, 88, 283–299. DOI: 10.1016/S0304-4076(98)00034-7.
- Vostrikova, L. Y. (1981), “Detection Disorder in Multidimensional Random Processes,” Soviet Mathematics - Doklady, 259, 55–59.
- Wasserman, L. (2006), All of Nonparametric Statistics (1st ed.), New York: Springer-Verlag.
- Weiss, A. A. (1986), “Arch and Bilinear Time Series Models: Comparison and Combination,” Journal of Business & Economic Statistics, 4, 59–70. DOI: 10.2307/1391387.
- Wu, W. B. (2007), “Strong Invariance Principles for Dependent Random Variables,” Annals of Probability, 35, 2294–2320.
- Wu, W. B. (2011), “Asymptotic Theory for Stationary Processes,” Statistics and Its Interface, 4, 207–226.
- Xu, K., Zheng, X., Pan, D., Xing, L., and Zhang, X. (2020), “Stock Market Openness and Market Quality: Evidence from the Shanghai-Hong Kong Stock Connect Program,” Journal of Financial Research, 43, 373–406. DOI: 10.1111/jfir.12210.
- Yau, C. Y., and Zhao, Z. (2016), “Inference for Multiple Change Points in Time Series via Likelihood Ratio Scan Statistics,” Journal of the Royal Statistical Society, Series B, 78, 895–916. DOI: 10.1111/rssb.12139.
- Zhang, T., and Lavitas, L. (2018), “Unsupervised Self-Normalized Change-Point Testing for Time Series,” Journal of the American Statistical Association, 113, 637–648. DOI: 10.1080/01621459.2016.1270214.
- Zhao, Z., Jiang, F., and Shao, X. (2021), “Segmenting Time Series via Self-Normalization,” arXiv preprint arXiv:2112.05331.
- Zhou, Z. (2013), “Heteroscedasticity and Autocorrelation Robust Structural Change Detection,” Journal of the American Statistical Association, 108, 726–740. DOI: 10.1080/01621459.2013.787184.