
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We propose FNETS, a methodology for network estimation and forecasting of high-dimensional time series exhibiting strong serial- and cross-sectional correlations. We operate under a factor-adjusted vector autoregressive (VAR) model which, after accounting for pervasive co-movements of the variables by common factors, models the remaining idiosyncratic dynamic dependence between the variables as a sparse VAR process. Network estimation of FNETS consists of three steps: (i) factor-adjustment via dynamic principal component analysis, (ii) estimation of the latent VAR process via -regularized Yule-Walker estimator, and (iii) estimation of partial correlation and long-run partial correlation matrices. In doing so, we learn three networks underpinning the VAR process, namely a directed network representing the Granger causal linkages between the variables, an undirected one embedding their contemporaneous relationships and finally, an undirected network that summarizes both lead-lag and contemporaneous linkages. In addition, FNETS provides a suite of methods for forecasting the factor-driven and the idiosyncratic VAR processes. Under general conditions permitting tails heavier than the Gaussian one, we derive uniform consistency rates for the estimators in both network estimation and forecasting, which hold as the dimension of the panel and the sample size diverge. Simulation studies and real data application confirm the good performance of FNETS.
1 Introduction
Vector autoregressive (VAR) models are popularly adopted for time series analysis in economics and finance. Fitting a VAR model to the data enables inferring dynamic interdependence between the variables as well as forecasting the future. VAR models are particularly appealing for network analysis since estimating the nonzero elements of the VAR parameter matrices, a.k.a. transition matrices, recovers directed edges between the components of vector time series in a Granger causality network. In addition, by estimating a precision matrix (inverse of the covariance matrix) of the VAR innovations, we can also define a network capturing contemporaneous linear dependencies. For the network interpretation of VAR modeling, see for example, Dahlhaus (Citation2000), Eichler (Citation2007), Billio et al. (Citation2012), Ahelegbey, Billio, and Casarin (Citation2016), Barigozzi and Brownlees (Citation2019), Guðmundsson and Brownlees (Citation2021), and Uematsu and Yamagata (Citation2023).
Estimation of VAR models quickly becomes a high-dimensional problem as the number of parameters grows quadratically with the dimensionality. There is a mature literature on estimation of high-dimensional VAR models under the sparsity (Hsu, Hung, and Chang Citation2008; Basu and Michailidis Citation2015; Han, Lu, and Liu Citation2015; Kock and Callot Citation2015; Nicholson et al. Citation2020; Krampe and Paparoditis Citation2021; Masini, Medeiros, and Mendes Citation2022; Adamek, Smeekes, and Wilms Citation2023) and low-rank plus sparsity (Basu, Li, and Michailidis Citation2019) assumptions, see also BańburaBańbura, Giannone, and Reichlin (2010) for a Bayesian approach. In all above, either explicitly or implicitly, the spectral density of the time series is required to have eigenvalues which are uniformly bounded over frequencies. Indeed, this condition is crucial for controlling the deviation bounds involved in theoretical investigation of regularized estimators.
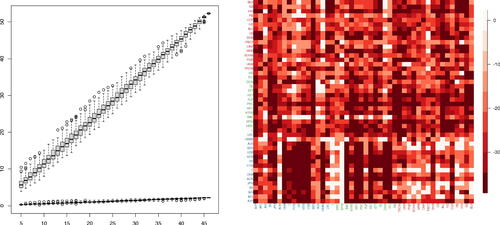
Lin and Michailidis (Citation2020) observe that for VAR processes, this assumption restricts the parameters to be either dense but small in their magnitude (which makes their estimation using the shrinkage-based methods challenging) or highly sparse, while Giannone, Lenza, and Primiceri (Citation2021) note the difficulty of identifying sparse predictive representations in many economic applications. Moreover, some datasets typically exhibit strong serial and cross-sectional correlations and violate the bounded spectrum assumption. The left panel of provides an illustration of this phenomenon; with the increase of dimensionality, a volatility panel dataset (see Section 5.3 for its description) exhibits a linear increase in the leading eigenvalue of the estimate of its spectral density matrix at frequency 0 (i.e., long-run covariance). The right panel visualizes the outcome from fitting a VAR(5) model to the same dataset without making any adjustment of the strong correlations (see the caption for further details), from which we cannot infer meaningful, sparse pairwise relationship.
Fig. 1 Left: The two largest eigenvalues (y-axis) of the long-run covariance matrix estimated from the volatility panel analyzed in Section 5.3 (March 2008 to March 2009, n = 252) with subsets of cross-sections randomly sampled 100 times for each given dimension (x-axis). Right: logged and truncated p-values (truncation level chosen by Bonferroni correction with the significance level 0.1) from fitting a VAR(5) model to the same dataset using ridge regression and generating p-values corresponding to each coefficient as described in Cule, Vineis, and De Iorio (Citation2011). For each pair of variables (corresponding tickers given in x- and y-axes), the minimum p-value over the five lags is reported.
In this article, we propose to model high-dimensional time series by means of a factor-adjusted VAR approach, which simultaneously accounts for strong serial and cross-sectional correlations attributed to factors, as well as sparse, idiosyncratic correlations among the variables that remain after factor adjustment. We take the most general approach to factor modeling based on the generalized dynamic factor model, where factors are dynamic in the sense that they are allowed to have not only contemporaneous but also lagged effects on the variables (Forni et al. Citation2000). We propose FNETS, a suite of tools accompanying the model for estimation and forecasting with a particular focus on network analysis, which addresses the challenges arising from the latency of the VAR process as well as high dimensionality.
We make the following methodological and theoretical contributions.
We propose an
-regularized Yule-Walker estimation method for estimating the factor-adjusted, idiosyncratic VAR, while permitting the number of nonzero parameters to slowly grow with the dimensionality. Estimating the VAR parameters and the inverse of the innovation covariance, and then combining them allow us to define three networks underlying the latent VAR process, namely a direct network representing Granger causal linkages, an undirected one underpinning their contemporaneous relationships, as well as an undirected network summarizing both. Under general conditions permitting weak factors and heavier tails than the sub-Gaussian one, we show the consistency of FNETS in estimating the edge sets of these networks, which holds uniformly over all p2 entries of the networks (Propositions 3.3 and 3.5).
We provide new consistency rates for the estimation and forecasting approaches considered by Forni et al. (2005, Citation2017), which hold uniformly for the entire cross-sections of p-dimensional time series (Propositions 4.1 and B.2). In doing so, we establish uniform consistency of the estimators of high-dimensional spectral density matrices of the factor-driven and the idiosyncratic components, extending the results of Zhang and Wu (Citation2021) to the presence of latent factors.
Our approach differs from the existing ones for factor-adjusted regression problems (Fan, Ke, and Wang Citation2020; Fan, Masini, and Medeiros Citation2021; Fan, Lou, and Yu Citation2023; Krampe and Margaritella Citation2021), as (i) it allows for the presence of dynamic factors, thus including all possible dynamic linear co-dependencies, and (ii) it relies only on the estimators of the autocovariances of the latent idiosyncratic process, and avoids estimating the entire latent process and controlling the errors arising from such a step, which increase with the sample size. The price to pay for the generality of the factor modeling in (i), is an extra term appearing in the rate of consistency which represents the bandwidth for spectral density estimation required for factor-adjustment in the frequency domain. We make explicit the role played by this bandwidth in the theoretical results, and also present the results under a more restricted static factor model for ease of comparison. We mention two more differences between this article and Fan, Masini, and Medeiros (Citation2021) and Fan, Lou, and Yu (Citation2023). First, they additionally consider the problem of testing hypotheses on the idiosyncratic covariance and the adequacy of factor/sparse regression, while we focus on network estimation. Second, their methods accommodate models for the idiosyncratic component other than VAR.
FNETS is another take the popular low-rank plus sparsity modeling framework in the high-dimensional learning literature, Also, it is in line with a frequently adopted practice in financial time series analysis where factor-driven common components representing the systematic sources of risk, are removed prior to inferring a network structure via (sparse) regression modeling and identifying the most central nodes representing the systemic sources of risk (Diebold and Y ilmaz 2014; Barigozzi and Brownlees Citation2019). We provide a rigorous theoretical treatment of this empirical approach by accounting for the effect of the factor-adjustment step on the second step regression.
The rest of the article is organized as follows. Section 2 introduces the factor-adjusted VAR model. Sections 3 and 4 describe the network estimation and forecasting methodologies comprising FNETS, respectively, and provide their theoretical consistency. In Section 5, we demonstrate the good estimation and forecasting performance of FNETS on a panel of volatility measures. Section 6 concludes the article, and all the proofs and complete simulation results are presented in Supplementary Appendix. The R software fnets implementing FNETS is available from CRAN (Barigozzi, Cho, and Owens Citation2023).
Notations
By , and
, we denote an identity matrix, a matrix of zeros, and a vector of zeros whose dimensions depend on the context. For a matrix
, we denote by
its transpose. The element-wise
and
-norms are denoted by
,
,
and
. The Frobenius, spectral, induced L1 and
-norms are denoted by
,
(with
and
denoting its largest and smallest eigenvalues in modulus),
and
. Let
and
denote the ith row and the kth column of
. For two real numbers, set
and
. Given two sequences
and
, we write
if, for some finite constant C > 0 there exists
such that
for all
; we denote by OP
the stochastic boundedness. We write
when
and
. Throughout, L denotes the lag operator and
. Finally,
if the event
takes place and 0 otherwise.
2 Factor-Adjusted Vector Autoregressive Model
Consider a zero-mean, second-order stationary p-variate process , which is decomposed into the sum of two latent components: a factor-driven, common component
, and an idiosyncratic component
modeled as a VAR process. That is,
where
(1)
(1)
(2)
(2)
In (1), the latent random vector , referred to as the vector of common factors or common shocks, is assumed to satisfy
and
, and are loaded on each χit
via square summable, one-sided filters
, where
. This defines the generalized dynamic factor model (GDFM) proposed by Forni et al. (Citation2000) and Forni and Lippi (Citation2001), which provides the most general approach to high-dimensional time series factor modeling.
In (2), the idiosyncratic component is modeled as a VAR(d) process for some finite positive integer d, with innovations
where
is some positive definite matrix and
its symmetric square root matrix, and
and
. We assume that
is causal (see Assumption 2.3(i)), that is, it admits the Wold representation:
(3)
(3)
such that
is seen as a vector of idiosyncratic shocks loaded on each ξit
via square summable, one-sided filters
where
. After accounting for the dominant cross-sectional dependence in the data (both contemporaneous and lagged) by factors, it is reasonable to assume that the dependences left in
are weak and, therefore, that the VAR structure is sufficiently sparse. Discussion on the precise requirement on the sparsity of
, and
is deferred to Section 3.
Remark 2.1.
A special case of the GDFM is the popularly adopted static factor model where the factors are loaded only contemporaneously (see e.g., Stock and Watson Citation2002; Bai Citation2003; Fan, Liao, and Mincheva Citation2013). This is formalized in Assumption 4.1, where we consider forecasting under a static representation. A sufficient condition to obtain a static representation from the GDFM in (1), is to assume for some finite integer
. For example, if s = 0, the model reduces to
while if s > 0, it can be written as
with
and
. Under the static factor model,
admits a factor-augmented VAR representation (see Remark 4.1).
In the remainder of this section, we list the assumptions required for identification and estimation of (1)–(2). Since and
are latent, some assumptions are required to ensure their (asymptotic) identifiability which are made in the frequency domain. Denote by
the spectral density matrix of
at frequency
, and
its dynamic eigenvalues which are real-valued and ordered in the decreasing order. We similarly define
and
.
Assumption 2.1.
There exist a positive integer , constants
with
, and pairs of continuous functions
and
for
and
, such that for all
,
Under the assumption, if for all
, then we are in presence of q factors that are equally pervasive for the whole cross-section. The left panel of depicts the case when
. If
for some j, we permit the presence of “weak” factors and our theoretical analysis explicitly reflects this; see, for example, Onatski (Citation2012) and Freyaldenhoven (Citation2021) for static factor models permitting weak factors. When weak factors are present, the ordering of the variables becomes important as
, whereas the case of linearly diverging factor strengths is compatible with completely arbitrary cross-sectional ordering. The requirement that
is a minimal one, and generally larger values of ρj
are required as the dimensionality increases and heavier tails are permitted as discussed later.
Assumptions 2.2 and 2.3 are made to control the serial dependence in .
Assumption 2.2.
There exist some constants and
such that for all
,
Assumption 2.3.
d is a finite positive integer and
There exist some constants
There exist a constant
There exist some constants
Assumption 2.3 (i) and (ii) are standard in the literature (Lütkepohl Citation2005) and imply that is causal and has finite and nonzero covariance. Under Assumptions 2.2 and 2.3 (iv) (imposed on the Wold decomposition of
in (3)), the serial dependence in
decays at an algebraic rate. Further, we obtain a uniform bound for
under Assumption 2.3 (iv):
Proposition 2.1.
Under Assumption 2.3, uniformly over all , there exists some constant
depending only on
, Ξ and Ϛ, defined in Assumption 2.3 (iii) and (iv), such that
.
Remark 2.2.
Proposition 2.1 and Assumption 2.3 (iii) jointly establish the uniform boundedness of and
, which is commonly assumed in the literature on high- dimensional VAR estimation via
-regularization. A sufficient condition for Assumption 2.3 (iii) is that
for some constant
(Basu and Michailidis Citation2015). Further, when for example, d = 1, Assumption 2.3 (iv) follows if
since
with
.
The two latent components and
, and the number of factors q, are identified thanks to the large gap between the eigenvalues of their spectral density matrices, which follows from Assumption 2.1 and Proposition 2.1. Then by Weyl’s inequality, the qth dynamic eigenvalue
diverges almost everywhere in
as
, whereas
is uniformly bounded for any
and ω. This property is exploited in the FNETS methodology as later described in Section 3.2. It is worth stressing that Assumption 2.1 and Proposition 2.1 jointly constitute both a necessary and sufficient condition for the process
to admit the dynamic factor representation in (1), see Forni and Lippi (Citation2001).
Finally, we characterize the common and idiosyncratic innovations.
Assumption 2.4.
There exist some constants
Assumption 2.4 (i) and (ii) allow the common and idiosyncratic innovations to be sequences of martingale differences, relaxing the assumption of serial independence found in Forni et al. (Citation2017). Condition (iii) is standard in the factor modeling literature. Under (iv), we require that the innovations have moments, which is considerably weaker than Gaussian or sub-Weibull tails assumed in the literature on VAR modeling of high-dimensional time series (Basu and Michailidis Citation2015; Kock and Callot Citation2015; Wong, Li, and Tewari Citation2020; Krampe and Paparoditis Citation2021; Masini, Medeiros, and Mendes Citation2022). Similar approaches to ours, based only on moment conditions, are found in Wu and Wu (Citation2016) who investigate the Lasso performance in deterministic designs under functional dependence, and Adamek, Smeekes, and Wilms (Citation2023) who assume instead near-epoch-dependence. In Appendix F, we separately consider the case when
and
are Gaussian for the sake of comparison.
3 Network Estimation via FNETS
3.1 Networks Underpinning Factor-Adjusted VAR Processes
Under the latent VAR model in (2), we can define three types of networks underpinning the interconnectedness of after factor adjustment (Barigozzi and Brownlees Citation2019).
Let denote the set of vertices representing the p time series. First, the transition matrices
, encode the directed network
representing Granger causal linkages, with
(4)
(4)
as the set of edges. Here, the presence of an edge
indicates that
Granger causes ξit
at some lag
.
The second network contains undirected edges representing contemporaneous dependence between VAR innovations , denoted by
; we have
iff the partial correlation between the ith and
th elements of
is nonzero. Specifically, letting
, the set of edges is given by
(5)
(5)
Finally, we summarize the aforementioned lead-lag and contemporaneous relations between the variables in a single, undirected network by means of the long-run partial correlations of
. Let
denote the long-run partial covariance matrix of
, that is
under (2). Then, the set of edges of
is
(6)
(6)
Generally, is greater than
, see Appendix C for a sufficient condition for the absence of an edge
from
. In the remainder of Section 3, we describe the network estimation methodology of FNETS which, consisting of three steps, estimates the three networks while fully accounting for the challenges arising from not directly observing the VAR process
, and investigate its theoretical properties.
3.2 Step 1: Factor Adjustment via Dynamic PCA
As described in Section 2, under our model (1)–(2), there exists a large gap in , the dynamic eigenvalues of the spectral density matrix of
, between those attributed to the factors (
) and those which are not (
). With the goal of estimating the autocovariance (ACV) matrix of the latent VAR process
, we exploit this gap in the factor-adjustment step based on dynamic principal component analysis (PCA); see Chapter 9 of Brillinger (Citation1981) for the definition of dynamic PCA and Forni et al. (Citation2000) for its use in the estimation of GDFM. Throughout, we treat q as known and refer to Hallin and Liška (Citation2007) for its consistent estimation under (1).
Denote the ACV matrices of by
for
and
for
, and analogously define
and
with
and
replacing
, respectively. Then,
and
satisfy
for all
. Motivated by this, we estimate
by
(7)
(7)
with the sample ACV
when
, and
for
, and the kernel bandwidth
for some
. We adopt the Bartlett kernel as
which ensures positive semi-definiteness of
(see Appendix F.2.4). Then, we evaluate
at the
Fourier frequencies
(
for
, and
for
), and estimate
by retaining the contribution from the q largest eigenvalues and eigenvectors only. That is, we obtain
(with
denoting the transposed complex conjugate), where
, denote the q leading eigenvalues of
and
the associated (normalized) eigenvectors. From this, an estimator of
at a given lag
, is obtained via inverse Fourier transform as
and finally, we estimate the ACV matrices of
with
, by virtue of Assumption 2.4 (iii).
3.3 Step 2: Estimation of VAR Parameters and
Recalling the VAR(d) model in (2), let denote the matrix collecting all the VAR parameters. When
is directly observable,
-regularized least squares or maximum likelihood estimators have been proposed for
, see the references given in Introduction. In the context of factor-adjusted regression modeling where the aim is to estimate the regression structure in the latent idiosyncratic process, it has been proposed to apply the
-regularization methods after estimating the entire latent process by, say,
(Fan, Ke, and Wang Citation2020; Fan, Masini, and Medeiros Citation2021; Fan, Lou, and Yu Citation2023; Krampe and Margaritella Citation2021). However, such an approach possibly suffers from the lack of statistical efficiency due to having to control the estimation errors in
uniformly for all
. Instead, we make use of the Yule-Walker (YW) equation
, where
with
being always invertible since
by Assumption 2.3 (iii). We propose to estimate
as a regularized YW estimator based on
and
, which are obtained by replacing
with
derived in Step 1 of FNETS via dynamic PCA, in the definitions of
and
, respectively.
To handle the high dimensionality, we consider an -regularised estimator for
which solves the following
-penalised M-estimation problem
(8)
(8)
with a tuning parameter
. Note that the matrix
is guaranteed to be positive semi-definite (see Appendix F.2.4), thus the problem in (8) is convex with a global minimizer. We note the similarity between (8) and the Lasso estimator, but our estimator is specifically tailored for the problem of estimating the parameters for the latent VAR process
by means of second-order moments only, and thus differs fundamentally from the Lasso-type estimators proposed for high-dimensional VAR estimation. In Appendix A, we propose an alternative estimator based on a constrained
-minimization approach closely related to the Dantzig selector (Candès and Tao Citation2007).
Once the VAR parameters are estimated, we propose to estimate the edge set of in (4) by the set of indices of the nonzero elements of a thresholded version of
, denoted by
, with some threshold
.
3.4 Step 3: Estimation of and
Recall that the edge sets of and
defined in (5)–(6), are given by the supports of
and
. Given
in (8) which estimates
, a natural estimator of
arises from the YW equation
, as
. Then, we propose to estimate
via constrained
-minimization as
(9)
(9)
where
is a tuning parameter. This approach has originally been proposed for estimating the precision matrix of independent data (Cai, Liu, and Luo Citation2011), which we extend to time series settings. Since
is not guaranteed to be symmetric, a symmetrization step is performed to obtain
with
. Then, the edge set of
in (5) is estimated by the support of the thresholded estimator
with some threshold
.
Finally, we estimate by replacing
and
with their estimators. We adopt the thresholded estimator
, to obtain
and set
. Analogously, the edge set of
in (6) is obtained by thresholding
with some threshold
, as the support of
.
3.5 Theoretical Properties
We prove the consistency of FNETS in network estimation by establishing the theoretical properties of each of its three steps in Sections 3.5.1–3.5.3. Then in Section 3.5.4, we present the results for a special case where admits a static representation,
and
for
, for ease of comparing our results to the existing ones.
Hereafter, we define
(10)
(10)
where the dependence of these quantities on ν is omitted for simplicity.
3.5.1 Factor Adjustment via Dynamic PCA
We first establish the consistency of the dynamic PCA-based estimator of .
Theorem 3.1.
Suppose that Assumptions 2.1, 2.2, 2.3, and 2.4 are met. Then, for any finite positive integer , as
,
Remark 3.1.
Theorem 3.1 is complemented by Proposition F.15 in Appendix which establishes the consistency of the spectral density matrix estimator uniformly over
in both Frobenius and
-norms.
Both ψn and
Consistency in Frobenius norm depends on ψn which tends to zero as
From Theorem 3.1, the following proposition immediately follows.
Proposition 3.2.
Suppose that the conditions in Theorem 3.1 are met and let Assumption 2.1 hold with . Then,
as
, where
(11)
(11)
for some constant
.
From Proposition 3.2, we have -consistency of
in the presence of strong factors. Although it is possible to trace the effect of weak factors on the estimation of
(see Corollary F.17), we make this simplifying assumption to streamline the presentation of the theoretical results of the subsequent Steps 2–3 of FNETS.
Remark 3.2.
In Appendix F.2.8, we show that if admits the static representation discussed in Remark 2.1, the rate in Proposition 3.2 is further improved as
(12)
(12)
The term comes from bounding
. Hence, the improved rate in (12) is comparable to the rate attained when we directly observe
apart from the presence of
, which is due to the presence of latent factors; similar observations are made in Theorem 3.1 of Fan, Liao, and Mincheva (Citation2013).
3.5.2 Estimation of VAR Parameters and
We measure the sparsity of by
and
. When d = 1, the quantity
coincides with the maximum in-degree per node of
.
Proposition 3.3.
Suppose that , where
is defined in Assumption 2.3 (iii). Also, set
in (8). Then, conditional on
defined in (11), we have
Following Loh and Wainwright (Citation2012), the proof of Proposition 3.3 proceeds by showing that, conditional on , the matrix
meets a restricted eigenvalue condition (Bickel, Ritov, and Tsybakov Citation2009) and the deviation bound is controlled as
. Then, thanks to Proposition 3.2, as
, the estimation errors of
in
- and
-norms, are bounded as in Proposition 3.3 with probability tending to one.
Remark 3.3.
As noted in Remark 2.2, the boundedness of follows from that of
, in which case
appearing in the assumed lower bound on λ, does not inflate the rate of the estimation errors. In the light-tailed situation, with the optimal bandwidth
as specified in Remark 3.1(b), it is required that
, which still allows the number of nonzero entries in each row of
to grow with p. Here, the exponent 1/3 in place of 1/2 often found in the literature, comes from adopting the most general approach to time series factor modeling which necessitates selecting a bandwidth for frequency domain-based factor adjustment.
For sign consistency of the Lasso estimator, the (almost) necessary and sufficient condition is the so-called irrepresentable condition (Zhao and Yu Citation2006), which is known to be highly stringent (Tardivel and Bogdan Citation2022). Alternatively, Medeiros and Mendes (Citation2016) propose an adaptive Lasso estimator with data-driven weights for high-dimensional VAR estimation when is directly observed. Instead, we propose to additionally threshold
and obtain
, whose support consistently estimates the edge set of
.
Corollary 3.4.
Suppose that the conditions of Proposition 3.3 are met. If
(13)
(13)
with
, then we have
conditional on
.
3.5.3 Estimation of and
Let , denote the (weak) sparsity of
. Also, define
which, complementing
, represents the sparsity of the out-going edges of
. Analogously as in Proposition 3.3, we establish deterministic guarantees for
and
conditional on
.
Proposition 3.5.
Suppose that the conditions in Propositions 3.3 are met, and set in (9), with C depending only on
and
. Then, conditional on
defined in (11), we have:
If also
Together with Assumption 2.3 (ii), Proposition 3.5(i) indicates asymptotic positive definiteness of provided that
is sufficiently sparse, as measured by
and
. By definition,
combines
and
and consequently, its sparsity structure is determined by the sparsity of the other two networks, which is reflected in Proposition 3.5(ii). Specifically, the term
is related to the out-going property of
, and satisfies
, where the boundedness of the right-hand side is sufficient for the boundedness of
(Remark 2.2). Also,
reflects the sparsity of the edge set of
, and the tuning parameter η depends on the sparsity of the in-coming edges of
through
and
.
Similarly as in Corollary 3.4, we can show the consistency of the thresholded estimators and
in estimating the edge sets of
and
, respectively.
Corollary 3.6.
Suppose that conditions of Proposition 3.5 are met. Conditional on :
If
If
3.5.4 The Case of the Static Factor Model
For ease of comparing the performance of FNETS with the existing results, we focus on the static factor model setting discussed in Remark 2.1, and assume that and
. Then, from Remark 3.2 and the proof of Proposition 3.3, we obtain
provided that
, such that the condition in (13) is written with
. That is,
and its thresholded counterpart proposed for the estimation of the latent VAR process, perform as well as the benchmark derived under independence and Gaussianity in the Lasso literature (van de Geer, Bühlmann, and Zhou Citation2011). In this same setting, the factor-adjusted regression estimation method of Fan, Masini, and Medeiros (Citation2021), when applied to the problem of VAR parameter estimation, yields an estimator
which attains
under strong mixingness, see their Theorem 3. Here, the larger OP
-bound compared to ours stems from that
requires the estimation of ξit
for all i and t, the error from which increases with n as well as p. This demonstrates the efficacy of adopting our regularised YW estimator.
Continuing with the same setting, Propositions 3.5 implies that
The former is comparable (up to ) to the results in Theorem 4 of Cai, Liu, and Luo (Citation2011) derived for estimating a sparse precision matrix of independent random vectors.
4 Forecasting via FNETS
4.1 Forecasting under the Static Factor Model Representation
For given time horizon , the best linear predictor of
based on
, is
(14)
(14)
under (1). Following Forni et al. (2005), we consider a forecasting method for the factor-driven component which estimates
under a restricted GDFM that admits a static representation of finite dimension. We formalize the static factor model discussed in Remark 2.1 in the following assumption.
Assumption 4.1.
There exist two finite positive integers m1 and m2 such that
Let
In part (i), admits a static representation with
factors:
, where
and
. The condition that
is made for convenience, and the proposed estimator of
can be modified accordingly when it is relaxed.
Remark 4.1.
Under Assumption 4.1 (i), the r-vector of static factors, , is driven by the q-dimensional common shocks
. If q < r, Anderson and Deistler (Citation2008) show that
always admits a VAR(h) representation:
for some finite positive integer h and
. Then,
has a factor-augmented VAR representation:
with
and
. This model is a generalization of the factor augmented forecasting model considered by Stock and Watson (Citation2002) where only the factor-driven component is present, and it is also considered by Fan, Masini, and Medeiros (Citation2021).
It immediately follows from Proposition 2.1 that . This, combined with Assumption 4.1 (ii), indicates the presence of a large gap in the eigenvalues of
, which allows the asymptotic identification of
and
in the time domain, as well as that of the number of static factors r. Throughout, we treat r as known, and refer to for example Bai and Ng (Citation2002) and Ahn and Horenstein (Citation2013), for its estimation.
Let , denote the pairs of eigenvalues and eigenvectors of
ordered such that
. Then,
with
and
. Under Assumption 4.1 (i), we have
in (14) satisfy
, where
denotes the linear projection operator onto the linear space spanned by
. When a = 0, we trivially have
for
. Then, a natural estimator of
is
(15)
(15)
where
, denote the pairs of eigenvalues and eigenvectors of
, and
, are estimated as described in Section 3.2. As a by-product, we obtain the in-sample estimator by setting a = 0, as
for
.
Remark 4.2.
Our proposed estimator differs from that of Forni et al. (2005), as they estimate the factor space via generalized PCA on
. This in effect replaces
in (15) with the eigenvectors of
where
is a diagonal matrix containing the estimators of the sample variance of
. Such an approach may gain in efficiency compared to ours in the same way a weighted least squares estimator is more efficient than the ordinary one in the presence of heteroscedasticity. However, since we investigate the consistency of
without deriving its asymptotic distribution, we do not explore such approach in this article.
In Appendix B, we present an alternative forecasting method that operates under an unrestricted GDFM, that is it does not require Assumption 4.1. Referred to as , we compare its performance with that of
in numerical studies.
Once VAR parameters are estimated by as in (8), we produce a forecast of
given
, by estimating the best linear predictor
(with
for
), as
(16)
(16)
When , the in-sample estimators appearing in (16) are obtained as
, with either
or
as
.
4.2 Theoretical Properties
Proposition 4.1 establishes the consistency of in estimating the best linear predictor of
, where we make it explicit the effects of the presence of weak factors, both dynamic (as measured by
in Assumption 2.1) and static (as measured by
in Assumption 4.1 (ii)), and the tail behavior (through ψn
and
defined in (10)).
Proposition 4.1.
Suppose that the conditions in Theorem 3.1 are met and, in addition, we assume that Assumption 4.1 holds. Then, for any finite , we have
As noted in Remark 3.1 (c), weaker factors and heavier tails impose a stronger requirement on the dimensionality p. If all factors are strong (), the rate becomes
. When a = 0, Proposition 4.1 provides in-sample estimation consistency for any given
. The next proposition accounts for the irreducible error in
, with which we conclude the analysis of the forecasting error
when
.
Proposition 4.2.
Suppose that Assumptions 2.2 and 2.4 hold. Then for any finite .
Recall the definition of given in Section 3.5. The next proposition investigates the performance of
when a = 1, which can easily be extended to any finite
.
Proposition 4.3.
Suppose that the in-sample estimator of and
satisfy
(17)
(17)
Also, let Assumptions 2.3 and 2.4 hold. Then,
Either of the in-sample estimators (described in Section 4.1) or
(Appendix B), can be used in place of
. Accordingly, the rate
in (17) is inherited by that of
(given in Proposition 4.1) or
(Proposition B.2 (iii)). From the proof of Proposition 3.3, we have
in (17).
5 Numerical Studies
5.1 Tuning Parameter Selection
We briefly discuss the choice of the tuning parameters for FNETS. For full details, see Owens, Cho, and Barigozzi (Citation2023) that accompanies its R implementation available on CRAN (Barigozzi, Cho, and Owens Citation2023).
Related to
We set the kernel bandwidth at based on the case when sufficiently large number of moments exist and
(Remark 3.1 (b)). In simulation studies reported in Appendix E, we treat the number of factors q (required for Step 1 of FNETS) known, and also treat the number of static factors r (for generating the forecast) as known if it is finite; when
does not admit a static factor model (i.e.
), we use the value returned by the ratio-based estimator of Ahn and Horenstein (Citation2013). In real data analysis reported in Section 5.3, we estimate both q and r, the former with the estimator proposed in Hallin and Liška (Citation2007), the latter as in Ahn and Horenstein (Citation2013).
Related to
We select the tuning parameter λ in (8) jointly with the VAR order d, by adopting cross validation (CV); in time series settings, a similar approach is explored in Wang and Tsay (Citation2022). For this, the data is partitioned into M consecutive folds with indices where
, and each fold is split into
and
. Then with
obtained from
with the tuning parameter μ and the VAR order b, we evaluate
where
, and
are generated analogously as
, and
, respectively, using the test set
. The measure
approximates the prediction error while accounting for that we do not directly observe
. Minimizing it over varying μ and b, we select λ and d. In simulation studies, we treat d as known while in real data analysis, we select it from the set
via CV. For selecting η in (9), we adopt the Burg matrix divergence-based CV measure:
For both CV procedures, we set M = 1 in the numerical results reported below. In simulation studies, we compare the estimators with their thresholded counterparts in estimating the network edge sets with the thresholds and
selected according to a data-driven approach motivated by Liu, Zhang, and Liu (Citation2021). Details are in Appendix D.
5.2 Simulations
In Appendix E, we investigate the estimation and forecasting performance of FNETS ondatasets simulated under a variety of settings, from Gaussian innovations and
with (E1)
and (E2)
, to (E3) heavy-tailed (t5) innovations with
, and when
is generated from (C1) fully dynamic or (C2) static factor models. In addition, we consider the “oracle” setting (C0)
where, in the absence of the factor-driven component, the results obtained can serve as a benchmark. For comparison, we consider the factor-adjusted regression method of Fan, Masini, and Medeiros (Citation2021) and present the performance of their estimator of VAR parameters and forecasts.
5.3 Application to a Panel of Volatility Measures
We investigate the interconnectedness in a panel of volatility measures and evaluate its out-of-sample forecasting performance using FNETS. For this purpose, we consider a panel of p = 46 stock prices retrieved from the Wharton Research Data Service, of US companies which are all classified as “financials” according to the Global Industry Classification Standard; a list of company names and industry groups are found in Appendix G. The dataset spans the period between January 3, 2000 and December 31, 2012 (3267 trading days). Following Diebold and Y ilmaz (2014), we measure the volatility using the high-low range as where
and
denote, respectively, the maximum and the minimum log-price of stock i on day t, and set
; Brownlees and Gallo (Citation2010) support this choice of volatility measure over more sophisticated alternatives.
5.3.1 Network Analysis
We focus on the period 03/2006–02/2010 corresponding to the Great Financial Crisis. We partition the data into four segments of length n = 252 each (corresponding to the number of trading days in a single year) and on each segment, we apply FNETS to estimate the three networks , and
described in Section 3.1.
Each row of plots the heat maps of the matrices underlying the three networks of interest. From all four segments, the CV-based approach described in Section 5.1 returns d = 1 from the candidate VAR order set . Hence in each row, the left panel represents the estimator
, and the middle and the right show the (long-run) partial correlations from the corresponding
and
(with their diagonals set to be zero). Locations of the nonzero elements estimate the edge sets of the corresponding networks, and the hues represent the (signed) edge weights.
Fig. 2 Heat maps of the estimators of the VAR transition matrices , partial correlations from
and long-run partial correlations from
(left to right), which in turn estimate the networks
, and
, respectively, over three selected periods. The grouping of the companies according to their industry classifications are indicated by the axis label colors. The heat maps in the left column are in the scale of
while the others are in the scale of
, with red hues denoting large positive values and blue hues large negative values.
![Fig. 2 Heat maps of the estimators of the VAR transition matrices Â1, partial correlations from Δ̂ and long-run partial correlations from Ω̂ (left to right), which in turn estimate the networks NG,NC, and NL, respectively, over three selected periods. The grouping of the companies according to their industry classifications are indicated by the axis label colors. The heat maps in the left column are in the scale of [−0.81,0.81] while the others are in the scale of [−1,1], with red hues denoting large positive values and blue hues large negative values.](/cms/asset/f1803709-a7e2-406f-9cab-2076e7c64a29/ubes_a_2257270_f0002_c.jpg)
Prior to March 2007, all networks exhibit a low degree of interconnectedness but the number of edges increases considerably in 03/2007–02/2008 due mainly to an overall increase in dynamic co-dependencies and a prominent role of banks (blue group) not only in but also in
. In 03/2008–02/2009, the companies belonging to the insurance sector (red group) play a central role and in 03/2009–02/2010, the companies become highly interconnected with two particular firms having many outgoing edges in
. Also, while most edges in
, which captures the overall long-run dependence, have positive weights across time and companies, their weights become negative in this last segment. We highlight that FNETS is able to capture the aforementioned group-specific activities although this information is not supplied to the estimation method.
5.3.2 Forecasting
We perform a rolling window-based forecasting exercise on the trading days in 2012. Starting from T = 3016 (the first trading day in 2012), we forecast as
, where
(resp.
) denotes the forecast of
(resp.
) using the preceding n data points
. We set n = 252. After the forecast
is generated, we update
and repeat the above procedure until T = 3267 (the last trading day in 2012) is reached.
For , we consider the forecasting methods derived under the static factor model (Section 4.1, denoted by
) and unrestricted GDFM (Appendix B,
). Following the analysis in Section 5.3.1, we set d = 1 when producing
. Additionally, we report the forecasting performance of FarmPredict (Fan, Masini, and Medeiros Citation2021), which first fits an AR model to each of the p series (“AR”), projects the residuals on their principal components, and then fits VAR models to what remains via Lasso. Combining the three steps gives the final forecast
. The forecast produced by the first step univariate AR modeling, denoted by
, is also included for comparison.
We evaluate the performance of using two measures of errors
and
, see for the summary of the forecasting results. Among the forecasts generated by FNETS, the one based on
performs the best in this exercise, which outperforms
and
according to both
and
on average. As noted in Appendix E.2.2, the forecast based on
shows instabilities and generally is outperformed by the one based on
, but nonetheless performs reasonably well. Given the high level of co-movements and persistence in the data, the good performance of FNETS is mainly attributed to the way we forecast the factor-driven component, which is based on the estimators derived under GFDM that fully exploit all the dynamic co-dependencies (see also the results obtained by Barigozzi and Hallin Citation2017 on a similar dataset).
Table 1 Mean, median and standard errors of and
on the trading days in 2012 for
in comparison with AR and FarmPredict (Fan, Masini, and Medeiros Citation2021) forecasts.
6 Conclusions
We propose and study the asymptotic properties of FNETS, a network estimation and forecasting methodology for high-dimensional time series under a dynamic factor-adjusted VAR model. Our estimation strategy fully takes into account the latency of the VAR process of interest via regularized YW estimation which, distinguished from the existing approaches, brings in methodological simplicity as well as theoretical benefits. We investigate the theoretical properties of FNETS under general conditions permitting weak factors and heavier tails than sub-Gaussianity commonly imposed in the high-dimensional VAR literature, and provide new insights into the interplay between various quantities determining the sparsity of the networks underpinning VAR processes, factor strength and tail behavior, on the estimation of those networks. Simulation studies and an application to a panel of financial time series show that FNETS is particularly useful for network analysis as it is able to discover group structures as well as producing accurate forecasts for highly co-moving and persistent time series such as log-volatilities. The R software fnets implementing FNETS is available from CRAN (Barigozzi, Cho, and Owens Citation2023).
supplement.zip
Download Zip (2 MB)Supplementary Materials
The supplementary materials contain the descriptions of the alternative estimation and forecasting methods, selection of the tuning parameters and the complete simulation results, in addition to all the proofs of the theoretical results.
Disclosure Statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Adamek, R., Smeekes, S., and Wilms, I. (2023), “Lasso Inference for High-Dimensional Time Series,” Journal of Economics, 235, 1114–1143. DOI: 10.1016/j.jeconom.2022.08.008.
- Ahelegbey, D. F., Billio, M., and Casarin, R. (2016), “Bayesian Graphical Models for Structural Vector Autoregressive Processes,” Journal of Applied Economics, 31, 357–386. DOI: 10.1002/jae.2443.
- Ahn, S. C., and Horenstein, A. R. (2013), “Eigenvalue Ratio Test for the Number of Factors,” Econometrica, 81, 1203–1227.
- Anderson, B. D., and Deistler, M. (2008), “Generalized Linear Dynamic Factor Models–A Structure Theory,” in 47th IEEE Conference on Decision and Control, pp. 1980–1985.
- Bai, J. (2003), “Inferential Theory for Factor Models of Large Dimensions,” Econometrica, 71, 135–171. DOI: 10.1111/1468-0262.00392.
- Bai, J., and Ng, S. (2002), “Determining the Number of Factors in Approximate Factor Models,” Econometrica, 70, 191–221. DOI: 10.1111/1468-0262.00273.
- Bańbura, M., Giannone, D., and Reichlin, L. (2010), “Large Bayesian Vector Auto Regressions,” Journal of Applied Economics, 25, 71–92. DOI: 10.1002/jae.1137.
- Barigozzi, M., and Brownlees, C. (2019), “NETS: Network Estimation for Time Series,” Journal of Applied Economics, 34, 347–364. DOI: 10.1002/jae.2676.
- Barigozzi, M., Cho, H., and Owens, D. (2023), fnets: Factor-Adjusted Network Estimation and Forecasting for High-Dimensional Time Series, R package version 0.1.5. DOI: 10.1080/07350015.2023.2257270.
- Barigozzi, M., and Hallin, M. (2017), “Generalized Dynamic Factor Models and Volatilities: Estimation and Forecasting,” Journal of Economics, 201, 307–321. DOI: 10.1016/j.jeconom.2017.08.010.
- Basu, S., Li, X., and Michailidis, G. (2019), “Low Rank and Structured Modeling of High-Dimensional Vector Autoregressions,” IEEE Transactions on Signal Processing, 67, 1207–1222. DOI: 10.1109/TSP.2018.2887401.
- Basu, S., and Michailidis, G. (2015), “Regularized Estimation in Sparse High-Dimensional Time Series Models,” The Annals of Statistics, 43, 1535–1567. DOI: 10.1214/15-AOS1315.
- Bickel, P. J., Ritov, Y., and Tsybakov, A. B. (2009), “Simultaneous Analysis of Lasso and Dantzig Selector,” The Annals of Statistics, 37, 1705–1732. DOI: 10.1214/08-AOS620.
- Billio, M., Getmansky, M., Lo, A. W., and Pelizzon, L. (2012), “Econometric Measures of Connectedness and Systemic Risk in the Finance and Insurance Sectors,” Journal of Financial Economics, 104, 535–559. DOI: 10.1016/j.jfineco.2011.12.010.
- Brillinger, D. R. (1981), Time Series: Data Analysis and Theory, Philadelphia, PA: SIAM.
- Brownlees, C., and Gallo, G. (2010), “Comparison of Volatility Measures: A Risk Management Perspective,” Journal of Financial Economics, 8, 29–56. DOI: 10.1093/jjfinec/nbp009.
- Cai, T., Liu, W., and Luo, X. (2011), “A Constrained l1 Minimization Approach to Sparse Precision Matrix Estimation,” Journal of the American Statistical Association, 106, 594–607.
- Candès, E. and Tao, T. (2007), “The Dantzig Selector: Statistical Estimation when p is much larger than n,” The Annals of Statistics, 35, 2313–2351. DOI: 10.1214/009053607000000532.
- Cule, E., Vineis, P., and De Iorio, M. (2011), “Significance Testing in Ridge Regression for Genetic Data,” BMC Bioinformatics, 12, 1–15. DOI: 10.1186/1471-2105-12-372.
- Dahlhaus, R. (2000), “Graphical Interaction Models for Multivariate Time Series,” Metrika, 51, 157–172. DOI: 10.1007/s001840000055.
- Diebold, F. X., and Yilmaz, K. (2014), “On the Network Topology of Variance Decompositions: Measuring the Connectedness of Financial Firms,” Journal of Economics, 182, 119–134. DOI: 10.1016/j.jeconom.2014.04.012.
- Eichler, M. (2007), “Granger Causality and Path Diagrams for Multivariate Time Series,” Journal of Economics, 137, 334–353. DOI: 10.1016/j.jeconom.2005.06.032.
- Fan, J., Ke, Y., and Wang, K. (2020), “Factor-Adjusted Regularized Model Selection,” Journal of Economics, 216, 71–85. DOI: 10.1016/j.jeconom.2020.01.006.
- Fan, J., Liao, Y., and Mincheva, M. (2013), “Large Covariance Estimation by Thresholding Principal Orthogonal Complements,” Journal of the Royal Statistical Society, Series B, 75, 603–680. DOI: 10.1111/rssb.12016.
- Fan, J., Lou, Z., and Yu, M. (2023), “Are Latent Factor Regression and Sparse Regression Adequate?,” Journal of the American Statistical Association (in press). DOI: 10.1080/01621459.2023.2169700.
- Fan, J., Masini, R., and Medeiros, M. C. (2021), “Bridging Factor and Sparse Models,” arXiv preprint arXiv:2102.11341 .
- Forni, M., Hallin, M., Lippi, M., and Reichlin, L. (2000), “The Generalized Dynamic Factor Model: Identification and Estimation,” The Review of Economics and Statistics, 82, 540–554. DOI: 10.1162/003465300559037.
- ———(2005), “The Generalized Dynamic Factor Model: One-Sided Estimation and Forecasting,” Journal of the American Statistical Association, 100, 830–840.
- Forni, M., Hallin, M., Lippi, M., and Zaffaroni, P. (2017), “Dynamic Factor Models with Infinite-Dimensional Factor Space: Asymptotic Analysis,” Journal of Economics, 199, 74–92. DOI: 10.1016/j.jeconom.2017.04.002.
- Forni, M., and Lippi, M. (2001), “The Generalized Dynamic Factor Model: Representation Theory,” Economic Theory, 17, 1113–1141. DOI: 10.1017/S0266466601176048.
- Freyaldenhoven, S. (2021), “Factor Models with Local Factors–Determining the Number of Relevant Factors,” Journal of Economics, 229, 80–102. DOI: 10.1016/j.jeconom.2021.04.006.
- Giannone, D., Lenza, M., and Primiceri, G. E. (2021), “Economic Predictions With Big Data: The Illusion of Sparsity,” Econometrica, 89, 2409–2437. DOI: 10.3982/ECTA17842.
- Guðmundsson, G. S., and Brownlees, C. (2021), “Detecting Groups in Large Vector Autoregressions,” Journal of Economics, 225, 2–26. DOI: 10.1016/j.jeconom.2021.03.012.
- Hallin, M., and Liška, R. (2007), “Determining the Number of Factors in the General Dynamic Factor Model,” Journal of the American Statistical Association, 102, 603–617. DOI: 10.1198/016214506000001275.
- Han, F., Lu, H., and Liu, H. (2015), “A Direct Estimation of High Dimensional Stationary Vector Autoregressions,” Journal of Machine Learning Research, 16, 3115–3150.
- Hsu, N.-J., Hung, H.-L., and Chang, Y.-M. (2008), “Subset Selection for Vector Autoregressive Processes Using Lasso,” Computational Statistics & Data Analysis, 52, 3645–3657. DOI: 10.1016/j.csda.2007.12.004.
- Kock, A. B., and Callot, L. (2015), “Oracle Inequalities for High Dimensional Vector Autoregressions,” Journal of Economics, 186, 325–344. DOI: 10.1016/j.jeconom.2015.02.013.
- Krampe, J., and Margaritella, L. (2021), “Dynamic Factor Models with Sparse VAR Idiosyncratic Components,” arXiv preprint arXiv:2112.07149.
- Krampe, J., and Paparoditis, E. (2021), “Sparsity Concepts and Estimation Procedures for High-Dimensional Vector Autoregressive Models,” Journal of Time Series Analysis, 42, 554–579. DOI: 10.1111/jtsa.12586.
- Lin, J., and Michailidis, G. (2020), “Regularized Estimation of High-Dimensional Factor-Augmented Vector Autoregressive (FAVAR) Models,” Journal of Machine Learning Research, 21, 1–51.
- Liu, B., Zhang, X., and Liu, Y. (2021), “Simultaneous Change Point Inference and Structure Recovery for High Dimensional Gaussian Graphical Models,” Journal of Machine Learning Research, 22, 1–62.
- Loh, P.-L., and Wainwright, M. J. (2012), “High-Dimensional Regression with Noisy and Missing Data: Provable Guarantees with Nonconvexity,” The Annals of Statistics, 40, 1637–1664. DOI: 10.1214/12-AOS1018.
- Lütkepohl, H. (2005), New Introduction to Multiple Time Series Analysis, Berlin: Springer.
- Masini, R. P., Medeiros, M. C., and Mendes, E. F. (2022), “Regularized Estimation of High-Dimensional Vector Autoregressions with Weakly Dependent Innovations,” Journal of Time Series Analysis, 43, 532–557. DOI: 10.1111/jtsa.12627.
- Medeiros, M. C., and Mendes, E. F. (2016), “l1 -regularization of High-Dimensional Time-Series Models with Non-gaussian and Heteroskedastic Errors,” Journal of Economics, 191, 255–271.
- Nicholson, W. B., Wilms, I., Bien, J., and Matteson, D. S. (2020), “High Dimensional Forecasting via Interpretable Vector Autoregression,” Journal of Machine Learning Research, 21, 1–52.
- Onatski, A. (2012), “Asymptotics of the Principal Components Estimator of Large Factor Models with Weakly Influential Factors,” Journal of Economics, 168, 244–258. DOI: 10.1016/j.jeconom.2012.01.034.
- Owens, D., Cho, H., and Barigozzi, M. (2023), “fnets: An R Package for Network Estimation and Forecasting via Factor-Adjusted VAR Modelling,” The R Journal (to appear).
- Priestley, M. (1982), Spectral Analysis and Time Series, London: Academic Press.
- Stock, J. H., and Watson, M. W. (2002), “Forecasting Using Principal Components from a Large Number of Predictors,” Journal of the American Statistical Association, 97, 1167–1179. DOI: 10.1198/016214502388618960.
- Tardivel, P. J., and Bogdan, M. (2022), “On the Sign Recovery by Least Absolute Shrinkage and Selection Operator, Thresholded Least Absolute Shrinkage and Selection Operator, and Thresholded Basis Pursuit Denoising,” Scandinavian Journal of Statistics, 49, 1636–1668. DOI: 10.1111/sjos.12568.
- Uematsu, Y., and Yamagata, T. (2023), “Discovering the Network Granger Causality in Large Vector Autoregressive Models,” arXiv preprint arXiv:2303.15158.
- van de Geer, S., Bühlmann, P., and Zhou, S. (2011), “The Adaptive and the Thresholded Lasso for Potentially Misspecified Models,” Electronic Journal of Statistics, 5, 688–749. DOI: 10.1214/11-EJS624.
- Wang, D., and Tsay, R. S. (2022), “Rate-Optimal Robust Estimation of High-Dimensional Vector Autoregressive Models,” arXiv preprint arXiv:2107.11002.
- Wong, K. C., Li, Z., and Tewari, A. (2020), “Lasso Guarantees for β-mixing Heavy-Tailed Time Series,” The Annals of Statistics, 48, 1124–1142. DOI: 10.1214/19-AOS1840.
- Wu, W.-B., and Wu, Y. N. (2016), “Performance Bounds for Parameter Estimates of High-Dimensional Linear Models with Correlated Errors,” Electronic Journal of Statistics, 10, 352–379. DOI: 10.1214/16-EJS1108.
- Zhang, D., and Wu, W. B. (2021), “Convergence of Covariance and Spectral Density Estimates for High-Dimensional Locally Stationary Processes,” The Annals of Statistics, 49, 233–254. DOI: 10.1214/20-AOS1954.
- Zhao, P., and Yu, B. (2006), “On Model Selection Consistency of Lasso,” Journal of Machine Learning Research, 7, 2541–2563.