
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We propose a dynamic semiparametric framework to study time variation in tail parameters. The framework builds on the Generalized Pareto Distribution (GPD) for modeling peaks over thresholds as in Extreme Value Theory, but casts the model in a conditional framework to allow for time-variation in the tail parameters. We establish parameter regions for stationarity and ergodicity and for the existence of (unconditional) moments and consider conditions for consistency and asymptotic normality of the maximum likelihood estimator for the deterministic parameters in the model. Two empirical datasets illustrate the usefulness of the approach: daily U.S. equity returns, and 15-min euro area sovereign bond yield changes.
1 Introduction
This article proposes a dynamic semiparametric framework to study time variation in tail fatness for long univariate time series. The new method builds on ideas from Extreme Value Theory (EVT) and uses a conditional Generalized Pareto Distribution (GPD) with time-varying parameters to approximate the tail beyond a given threshold. The GPD is an appropriate tail approximation for most heavy-tailed densities used in financial economics, econometrics, and actuarial sciences; see, for example, Embrechts, Klüppelberg, and Mikosch (Citation1997), Coles (Citation2001), McNeil, Frey, and Embrechts (Citation2010, chap. 7), and Rocco (Citation2014). As a result, the GPD plays a central role in the study of extremes, comparable to the role of the normal distribution when studying observations in the center of the distribution. Our framework allows for studying time-variation in the incidence of such extremes.
The time-varying tail shape and tail scale parameters in our model are driven by the score of the GPD density; see Creal, Koopman, and Lucas (Citation2013) and Harvey (Citation2013). As a result, the model is observation-driven in the terminology of Cox (Citation1981) and its time-varying parameters are perfectly predictable one step ahead. In addition, the log-likelihood function is known in closed form and allows for parameter estimation and inference via standard maximum likelihood methods. Our results show that our model is able to recover the time-varying tail shape and tail scale parameters well in both simulated and empirical data. In addition, the model recovers time-variation in EVT-based market risk measures such as Value-at-Risk (VaR) and Expected Shortfall (ES). This is the case even if the model is misspecified or the GPD approximation is not exact. The latter is particularly important in our finite sample setting, where the limiting EVT result of the GPD can only hold approximately given the choice of a finite exceedance threshold in any particular dataset.
We illustrate our modeling framework using two applications: U.S. equity log-returns, and changes in euro area sovereign bond yields.Footnote1 Each dataset consists of two time series that we model separately. We first consider daily log-returns for a stock index (S&P500) and an individual stock (IBM). The S&P500 log-returns range from July 3, 1962 to December 31, 2020, while the IBM stock returns range from January 2, 1926 to December 31, 2020. Focusing on the left tail, and controlling for potential time-variation in the EVT thresholds, we find that both GPD parameters vary significantly over time. The tail shape varies between approximately 0.05 and 0.25 for the S&P 500, and between 0.05 and 0.35 for IBM. These values imply a maximum moment of order to
for the S&P 500, and 3 to 20 for IBM. Confidence bands around the filtered time-varying tail shape parameters suggest that the tail shape parameter is almost always far from the thin-tailed setting.
Our second illustration demonstrates how additional control variables can be included to capture time-variation in tail shapes and tail scales. Specifically, we study changes in Italian and Portuguese five-year benchmark bond yields, sampled at a 15-min frequency, during the extremely adverse euro area sovereign debt crisis between 2010 and 2012. Again, we find that both GPD parameters vary significantly over time. The tail shape varies between 0.1 and 0.4 for Italy and between 0.05 and 0.6 for Portugal, implying moment ranges of 2.5–10 and 1.7–20, respectively, and thus incidences of extreme fat tails. We also find that part of the variation can be explained by including central bank bond purchases as an additional covariate, and provide a way to translate the estimated impact coefficients into their economically-interpretable impact on market risk measures such as VaR.
Our article is closely related to a growing strand of literature on modeling time-variation in EVT tail parameters. Several papers propose methodology to study time variation in the tail index. Davidson and Smith (Citation1990), (Coles, Citation2001, chap. 5.3), and Wang and Tsai (Citation2009), among others, also index the GPD tail parameters with time subscripts and equip them with a parameterized structure. Our approach is different in that their “tail index regression” approach requires conditioning variables that explain (all of) the tail variation. Such variables are not always available. By contrast, our “filtering approach” does not require such conditioning variables, and is arguably better suited for the real-time monitoring of extreme equity or bond market risks. Second, Quintos, Fan, and Phillips (Citation2001), Einmahl, de Haan, and Zhou (Citation2016), Hoga (Citation2017), and Lin and Kao (Citation2018) derive formal tests for a structural break in the tail index. A number of subsequent studies applied such tests to financial time series data. Werner and Upper (Citation2004) identify a break in the tail behavior of high-frequency German Bund future returns. Galbraith and Zernov (Citation2004) argues that certain regulatory changes in U.S. equity markets have altered the tail index dynamics of equities returns. de Haan and Zhou (Citation2021) propose a nonparametric approach to estimating the extreme value index locally. Our article adds to the literature by proposing a framework that allows us to study both the tail shape and tail scale dynamics directly in a semiparametric way. Explanatory covariates can be included in the dynamics of both parameters, and likelihood ratio tests are available to test economically relevant hypotheses. Finally, unlike Patton, Ziegel, and Chen (Citation2019), our tail VaR and ES dynamics explicitly account for fat tail shape beyond a threshold as emerging from EVT. The dynamics based on the score for the GPD contain weights for extreme observations. Such weights are absent in the elicitable score functions of Patton, Ziegel, and Chen (Citation2019). The resulting dynamics in our model are more robust, particularly for the ES.
Whereas de Haan and Zhou (Citation2021) take a nonparametric perspective, the methodological part of this article is closest to Massacci (Citation2017), who also proposes a dynamic parametric model for the GPD parameters. Our framework is different from Massacci (Citation2017) in that we specify both GPD parameters as functions of their respective scores. Massacci (Citation2017), by contrast, uses only the score of the first (tail index) parameter to drive both parameters. This is not optimal in the sense of Blasques, Koopman, and Lucas (Citation2015), who require that each time-varying parameter is associated to its own score. Our article further differs from Massacci (Citation2017) in that we suggest time-varying EVT thresholds to locate the boundary between the center of the distribution and its tail. This implies that we do not need to assume that the time series at hand has no volatility clustering, nor that we need to pre-filter for such volatility clustering. Absence of conditional heteroscedasticity would be hard to defend for the financial data considered in this article. Finally, we differ from Massacci (Citation2017) in that we discuss inference on both deterministic and time-varying parameters by considering the asymptotic properties of the maximum likelihood estimator, provide sufficient conditions for the stationarity and ergodicity and the existence of moments of the factor process and observations, explain how to introduce additional conditioning variables into the model and assess their usefulness in economic terms, and provide Monte Carlo evidence on the model’s performance in a range of challenging settings.
We proceed as follows. Section 2 presents our statistical model, the asymptotic statistical properties of the model and the maximum likelihood estimator. Section 3 discusses simulation results. Section 4 illustrates the model using U.S. equity data and euro area sovereign yields data. Section 5 concludes. Derivations and more results are in the web appendix.
2 Statistical Model
2.1 Time-Varying Tail Shape and Tail Scale
2.1.1 Conditional EVT Framework
Consider a univariate time series yt, , where T denotes the number of observations. This section then describes our model for yt with time-varying tail shape and scale. We assume yt is generated by a conditional probability density function (pdf)
, where
denotes the information set containing all past data. By keeping the conditional density of yt in its current general form, we stay close to the semiparametric nature of an extreme value-based approach and make no modeling assumptions about the center of the distribution. Alternatively, we could specify a parametric distribution for yt with for instance a time-varying conditional location μt and scale σt. The μt and σt could then be used to pre-filter the raw yt. We do not pursue such an approach here. First, modeling the center of the conditional distribution leads away from the focus on the tails only, which is the key aspect in an EVT-based approach. Second, designing an additional model for time-varying location and scale would create another layer of complexity to the model, with accompanying model risk and parameter uncertainty. We therefore keep the general form of
and focus on its tail using a dynamic extension of arguments from extreme value theory (EVT), similar to Patton’s (Citation2006) extension of copula theory to the dynamic, observation driven setting.
We assume has heavy tails with time-varying tail index
. A familiar example is when
is a univariate Student’s t distribution with
degrees of freedom. Other examples include the Pareto, inverse gamma, log-gamma, log-logistic, F, Fréchet, and Burr distribution with one or more time-varying shape parameters (for details and further discussion see e.g., Johnson, Kotz, and Balakrishnan, Citation1994; Embrechts, Klüppelberg, and Mikosch, Citation1997; McNeil, Frey, and Embrechts, Citation2010, chap. 7.3). Rather than modeling the (dynamic) tail shape of an arbitrarily chosen parametric family of distributions, we appeal to well-known results from the EVT literature: the conditional cumulative distribution function (cdf)
of yt can under very general conditions be approximated by
with
for sufficiently high thresholds
. More precisely, we have
(1)
(1) for parameters
and δt, both possibly depending on τt, and with Yt denoting the random variable corresponding to the realization yt. Here,
denotes the cdf of the Generalized Pareto Distribution (GPD), with cdf and pdf given by
(2)
(2)
(3)
(3)
respectively (see, e.g., McNeil, Frey, and Embrechts, Citation2010). The quantity
is the so-called peak-over-threshold (POT), or exceedance, of heavy-tailed data yt over a pre-determined threshold τt, and
and
are the tail scale and tail shape parameter of the GPD, respectively. Most continuous distributions used in statistics and the actuarial sciences lie in the Maximum Domain of Attraction (MDA) of the GPD (see McNeil, Frey, and Embrechts, Citation2010, chap. 7.1), meaning that they allow for the above tail shape approximation. By focusing on the tail area directly using EVT arguments, we avoid having to make more ad-hoc assumptions on the parametric form of the tail.
The result in (1) is a limiting result. In any finite sample, the threshold τt has to be set to a specific, finite value, such that the GPD approximation will be inexact and the distribution is in that sense misspecified. This will also be the case in our setting. The score-driven updates that we define later on for ξt and δt, however, still ensure that the expected Kullback-Leibler divergence between the approximate GPD model and the true, unknown conditional distribution is improved on average at every step for sufficiently small steps, even if the GPD model is (partially) misspecified; see Blasques, Koopman, and Lucas (Citation2015).
The choice of the threshold τt is subject to a well-known bias-variance tradeoff; see, for instance, McNeil and Frey (Citation2000). In theory, the GPD tail approximation only becomes exact for . A high threshold, however, also implies a smaller number of exceedances
, and more estimation error for the parameters of the GPD. Common choices for τt from the literature are the unconditional 90%, 95%, and 99% empirical quantiles of yt; see Chavez-Demoulin, Embrechts, and Sardy (Citation2014). In our setting, such choices are less useful as τt varies over time. As we explain later, we use the approach of Patton, Ziegel, and Chen (Citation2019) to set τt dynamically in line with the data.
2.1.2 Time-Varying Parameters
A key step in (1)–(2) is that we use the conditional probabilities based on the information set . As a result, the tail parameters ξt and δt become time-varying. To capture this time-variation, we model
using the score-driven dynamics introduced by Creal, Koopman, and Lucas (Citation2013) and Harvey (Citation2013). In our time series setting, this implies that both δt and ξt are measurable with respect to
. We ensure positivity of δt and ξt by using an (element-wise) exponential link function
for
. The transition dynamics for ft are given by
(4)
(4) where vector
and matrices
and
depend on the deterministic parameter vector θ, which needs to be estimated. The scaling matrix
may depend both on θ, ft, and
. Effectively, the recursion (4) updates ft at every point in time via a scaled steepest ascent step to improve the expected fit to the GPD; see Creal, Koopman, and Lucas (Citation2013) and Blasques, Koopman, and Lucas (Citation2015). The score of (2) required in (4) is given by
(5)
(5)
where
denotes the natural logarithm; see Web Appendix A.1 for a derivation. We take Ai and Bj as diagonal matrices.
Following Creal et al. (Citation2014) we select the square-root inverse conditional Fisher information of the conditional observation density to scale (5), that is, , with Lt the choleski decomposition of the inverse conditional Fisher information matrix
. Compared to so-called inverse information matrix scaling, the current scaling matrix has the advantage that the conditional variance of the scaled score st is the unit matrix, that is,
. This gives the parameters Ai a more natural interpretation, similar to the standard deviations of the state innovations in a nonlinear state-space model. For the GPD, we have
(6)
(6) see Web Appendix A.2 for a derivation. Combining terms yields the scaled score
(7)
(7)
Though the first element of the scaled score in (7) seems unstable for ξt near zero, the expression actually has a finite left limit equal to .
plots the two elements of (7) as a function of xt for different values of ξt and δt. The behavior of the scaled score is intuitive: large xts imply that both ξt and δt are adjusted upwards and tails thus become fatter. The adjustments are largest when the current tail index ξt and tail scale δt are low. It is precisely in such cases that observing a large xt is unlikely. If it occurs nonetheless, the parameters are (strongly) adjusted to account better for similar effects in the future.
Fig. 1 News impact curves.
The first element (left panel) and second element (right panel) of st in (7) is plotted against xt for different values of ξt and δt.
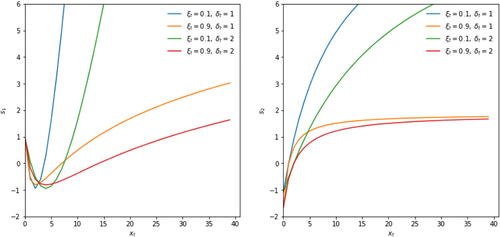
The news impact curves become increasingly concave for lower values of ξt. For such parameters, large xt values are already more likely due to the fat-tailed nature of the GPD itself. As a result, the parameters need to be adjusted less if a large xt actually materializes. This resembles the well-known robustness properties of score-driven updates in the context of time-varying volatility modeling; see Creal, Koopman, and Lucas (Citation2013) and Harvey (Citation2013). It also distinguishes our current set-up sharply from an approach directly based on quantile functions; see Patton, Ziegel, and Chen (Citation2019) and Catania and Luati (in press), in particular for risk measures such as ES. In Patton, Ziegel, and Chen (Citation2019), ES reacts linearly rather than concavely to the VaR exceedance. This can result in noisy or unstable ES estimates. illustrates that the score-driven approach is less susceptible to such instabilities and can therefore result in more interpretable parameter paths.
We also note that small realizations of xt imply downward adjustments of both ξt and δt, up to the point where xt becomes very small. For very small , ξt is adjusted upward: observations near the center of a fat-tailed distribution signal increased peakedness (=leptokurtosis) and thus higher ξt; compare Lucas and Zhang (Citation2016) for a similar effect in the Student’s t setting.
When there is no tail observation, that is , the new observation carries no information about ξt and δt; see (McNeil, Frey, and Embrechts, Citation2010, Chapter 7). In such cases we set the score to zero and continue to use (4) to update ft. Long consecutive stretches of zero scores could potentially lead to mean-reverting paths for ft, and thus
, with only discrete “jumps” when new observations
arrive following such stretches.Footnote2 If so, smoothing the scaled score (7) can help to spread out the impact of the new information in xt. Smoothing the scaled scores can also help when additional conditioning variables zt are available at every
; see (9) and (11) below. Lagged values of the scaled score can be taken into account via an exponentially-weighted moving average specification
(8)
(8) where
is an additional parameter to be estimated or to be fixed ex-ante; see Web Appendix A.3 for the derivation. This alters the values of
in (4) to
. While st is most often zero,
is not. Clearly, (4) is a special case of (8) for λ = 0. The smoothing approach in (8) is similar to the approach in Patton (Citation2006), who uses up to 10 lags of the driver (in our case the score) to smooth the dynamics of the time-varying parameter.
The transition equation for ft can be extended further if additional conditioning variables are available by respecifying (8) as
(9)
(9) where all explanatory variables are stacked into the column vector zt, and C is a conformable matrix of impact coefficients that needs to be estimated. We illustrate this in our second application in Section 4.
2.1.3 Time-Varying Thresholds
For the dynamic thresholds τt, we use the specification suggested by Patton, Ziegel, and Chen (Citation2019),
(10)
(10) where
,
is the (observed) unconditional κ-quantile of yt,
and
are two parameters to be estimated, and
is a sufficiently small tail probability corresponding to the dynamic quantile τt, such as, for example, 10% or 5%. We initialize τt at
. The recursive specification (10) is driven by a zero mean innovation process since
. The threshold
responds to quantile exceedances in an intuitive way: the next quantile value
receives a positive shock of
if
, that is, if the previous quantile was exceeded, and a negative shock of
otherwise. For
, the empirical unconditional quantile
serves as a long-term attractor for (10). The transition equation for τt can also easily be extended to include exogenous variables zt as in
(11)
(11)
for a suitable column vector of coefficients
.
2.1.4 Interpretation of Time-Varying Parameters
It is important to briefly comment on parameter interpretability. The tail shape parameter ξt can always be interpreted as observation yt’s inverse conditional tail index . By contrast, the estimated tail scale parameter δt need not have a straightforward interpretation in terms of yt’s conditional scale σt. For example, assume that yt has a GPD conditional distribution with time-varying tail shape parameter
and scale σt. Web Appendix B.1 demonstrates that the conditional tail probability
then also has a GPD shape (exactly, not only approximately). The tail shape parameter is the same as that of the center:
. However, the tail scale parameter δt is very different from the scale parameter σt that applies to the center, in particular
. As a result, δt increases with the threshold τt, varies positively with the tail shape parameter ξt, and, importantly, should not be expected to provide a good estimate of the scale parameter σt that applies to the center of the distribution of yt. A similar result can be derived if yt were Student’s t-distributed with scale σt and degrees of freedom parameter αt when the tail probability
only has an approximate GPD shape; see Web Appendix B.2. We return to this issue in our simulation Section 3, where we consider pseudo-true values for ξt and δt to benchmark how well the model performs in terms of tracking an unknown data generating process.
2.2 Stationarity and Moments
The score-driven dynamics for ξt and δt are highly nonlinear. Still, the structure of the model allows us to obtain sufficient conditions for the stationarity and ergodicity (SE) of ft and xt, and for the existence of unconditional moments of ft. To this end, we look at our statistical model in (4)–(8) as a data generating process (DGP).
Given the bivariate structure of our time-varying parameter model, the process can be viewed as a stochastic recurrence equation (SRE) of the form
(12)
(12) where
is a Borel measurable function, and
is the true parameter vector contained in the parameter space
. We make the following two assumptions.
Assumption 1.
Assume that xt is drawn from the GPD distribution defined in (2), such that the random variable is an independent and identically distributed noise term with unit exponential distribution,
.
Assumption 2.
For some integer , let
(13)
(13) where
is the Frobenius norm of a real-valued matrix
, and where
, such that
(14)
(14)
with
Assumption A1 considers the model as the data generating process. By inverting the GPD cdf in (2), we obtain that for a standard uniformly distributed ut. Assumption A1 requires that these uniform random variables constitute an iid process.
Assumption A2 requires contraction properties of the bivariate stochastic recurrence equation. We note that we use the general form of the r-fold contractions, that is, r iterations of the transition equation of ft. In univariate models, sharp contraction conditions (that ensure stationarity and ergodicity of the model) can usually be found by assuming that r = 1; see, for example, Blasques et al. (Citation2022). In multivariate systems, however, the contraction condition with r = 1 is often violated, resulting in very small or uninteresting stationarity regions. Working with the more general condition is therefore important. We also show this in . The idea behind A2 is that, when working with a multivariate system, one can still ensure the existence of an SE solution if the system becomes contractive eventually, that is, after a sufficiently large number of r iterations. The contraction condition in A2 results in a meaningful (nondegenerate) SE region, because the supremum of over f has no degeneracies.
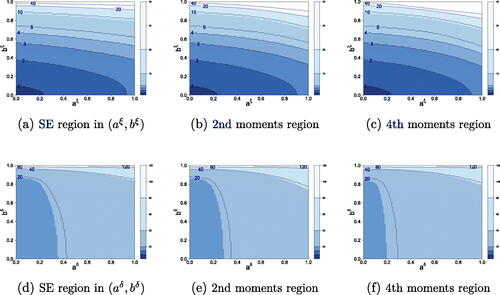
Fig. 2 Stationarity and moments regions.
Top row: the combinations of and
that satisfy A2 (left panel), and (15) for p = 2 (middle panel) and p = 4 (right panel), for an increasing number of iterations
. Bottom row: similar, but for combinations of
and
instead. Other deterministic parameters for each panel are fixed at their empirical estimates for S&P500 returns; see Section 4.1.
Using A1 and A2, we can verify the conditions of (Bougerol, Citation1993, Theorem 3.1). This allows us to show that a unique SE solution exists for the bivariate score-driven process , and for the data
as generated by the DGP in Section 2.1. We summarize this in the following theorem.
Theorem 1.
Consider the model as defined by (2) and (4). Then under A1 and A2, the SRE in (12) admits a unique stationary and ergodic solution such that, for each fixed initial condition
,
where
denotes exponentially fast and almost sure convergence (Straumann and Mikosch, Citation2006). In addition, the process
generated by the model evaluated at θ0 is stationary and ergodic.
Web Appendix C.1 presents the proof of Theorem 1. Next to the SE properties of the ft process, we can also establish the existence of unconditional moments. This can be useful for proving the existence of moments of the log-likelihood function and its derivatives. We note that the contraction condition stated in A2 by its own is insufficient to ensure bounded unconditional moments of ft in the DGP. Requiring the existence of moments typically makes the admissible parameter space smaller. We also note that the existence of unconditional moments of ft does not imply the same (un)conditional moments for xt. For instance, even if ft has a finite 4th order moment, xt may not if ξt can reach levels higher than 1/4. We have the following result.
Theorem 2.
Consider the model as defined by (2) and (4), and let A1 and A2 be true. If in addition
(15)
(15) for some
, then the unique stationary and ergodic solution
to the SRE in (12) satisfies
.
Web Appendix C.2 provides the proof of Theorem 2. Again, Theorem 2 makes use of r-fold contraction conditions rather than the standard r = 1 case.
To give some insight into the size of the SE and moments regions, we compute them numerically in . We let two (out of the six) parameters in Θ vary at a time. Computing the regions is far from trivial. It requires numerically solving a maximization problem embedded inside an integration problem. As a result, the maximization problem has to be solved for every value of the integration variable. Details are provided in Web Appendix D.
clearly illustrates the importance of multiple unfoldings of the SRE. If only r = 1 iteration is used, the SE and finite-moments regions are typically small, or even empty; see for instance the small darkest blue region in panel 2(a) for r = 1, or the fact that panel 2(d) only shows contracting behavior for iterations given the empirical estimates. For r = 1, empirical estimates typically lie outside the SE region. However, by iterating the SRE forward, the SE and finite-moments regions grow considerably to the extent that they also encompass the empirical estimates. For instance, the model may not be SE when evaluated at the empirical estimates for r = 1. For r = 20, 40, or even larger, however, the model’s SE region at the empirical estimates increases such that even fourth order moments of ft exist. Given the S&P500 data (on which is based) are at a daily frequency, we conclude that a time-varying parameter model may not have guaranteed contraction properties at the daily frequency, but may still have such contraction properties at a monthly (r = 22) or lower frequency. The numerical results in the figure stress that analytical conditions for SE, as often encountered in the literature for r = 1, may be quite uninteresting if not accompanied by a numerical check for the size of the resulting parameter space.
2.3 Parameter Estimation
Observation-driven time series models such as (1)–(11) have the appealing feature that the log-likelihood is known in closed form. For a given set of time series observations for
, the vector of unknown parameters θ can then be estimated by maximizing the log-likelihood function of the GPD with respect to θ. The average log-likelihood function is given by
(16)
(16) where
is the number of POT values in the sample. Maximization of (16) can be carried out using a conveniently chosen quasi-Newton optimization method.
To establish consistency and asymptotic normality of the maximum likelihood estimator (MLE), we define the MLE θ̂ as
(17)
(17)
We establish these asymptotic properties by showing that the conditions for Lemma 1 in Jensen and Rahbek (Citation2004) are satisfied. The main point to note is that the first three derivatives of the -likelihood function (and of ft) with respect to θ are stationary and ergodic stochastic recurrence equations that satisfy specific moment conditions. We make the following additional assumption on the parameter space Θ.
Assumption 3.
The parameter vector for a compact parameter space
, and the true parameter vector
. Additionally, for each
, the starting value
is fixed to the true value.
Finally, we impose conditions on the score vector , as defined in (5), and its derivatives up to third-order. Let
and
denote the score vector and first two derivatives with respect to
and
, evaluated at some
, where
denotes a small neighborhood of the true parameter vector θ0. By imposing the conditions in Assumption 4, we can rule out explosive behavior of the first three derivatives of the
-likelihood function with respect to θ. Similar boundedness assumptions have been used in for instance Hetland, Pedersen, and Rahbek (in press) or Hafner and Wang (in press). Effectively, this further reduces the size of the parameter space (see also Blasques et al., Citation2022). Web Appendix E.1 provides the explicit analytic expressions for each of these derivatives.
Assumption 4.
The score vector , and its derivatives
, and
are p-dominated uniformly in
and t by dominating functions
, and
, respectively, such that
where
, and
are p-integrable uniformly in t for p > 0, that is
,
, and
.
The following theorem establishes the asymptotic properties of our MLE.
Theorem 3.
Consider the model as defined by (2) and (4). Let Assumptions 1–3 hold true. Then as
.
If, in addition, Assumption 4 holds true, as well as the contraction condition (15) in Theorem 2 for p = 4, then as
, where ΩI denotes the Fisher information matrix evaluated at the true parameter vector θ0.
The proof of Theorem 3, together with detailed derivations of the derivatives up to the third-order of the -likelihood function
, and of the (bivariate) score-driven process
, for each
can be found in Web Appendix E.2.
All our results are conditional on the time-varying thresholds τt. The parameters and
for τt in (10) cannot be estimated using (16). Another objective function is needed in this case. We suggest using the average quantile regression check function of (Koenker, Citation2005, chap. 3). The optimization problem can be formulated as
(18)
(18) where
, and τt evolves as in (10). See also Engle and Manganelli (Citation2004) and Catania and Luati (in press) for the use of this objective function in a different dynamic context. In practice, we estimate all thresholds τt via (18) before maximizing (16).
2.4 Confidence Bands for Tail Shape and Tail Scale
Given the maximum likelihood estimate , confidence (or standard error) bands around
allow us to visualize the impact of estimation uncertainty. Quantifying the uncertainty of the estimated parameter paths is important, as classical EVT estimators of time-invariant tail shape parameters can have sizeable standard errors; see for example, Hill (Citation1975) and Huisman et al. (Citation2001). Web Appendix F explains how simulation-based and in-sample analytic confidence bands around
can be obtained. These bands are conditional on the estimated time-varying thresholds
, and do not incorporate the associated estimation uncertainty of the thresholds.
2.5 Market Risk Measures
Market risk measurement is a major application of EVT methods in practice; see for example, McNeil, Frey, and Embrechts (Citation2010). The GPD approximation (1)–(2) yields useful closed-form estimators of the VaR and ES for high upper quantiles ; see McNeil and Frey (Citation2000) and Rocco (Citation2014). We can estimate the
tail probability of yt based on the GPD cdf for xt, obtaining
where
is the number of observations with
up to time t, that is, the number of ys for
for
.
The conditional ES is the average conditional VaR in the tail across all quantiles γ (see McNeil, Frey, and Embrechts, Citation2010, chap. 2), provided . The closed-form expression is
see Web Appendix G for a derivation of the equations. Maximum likelihood estimators of the conditional VaR and conditional ES can be obtained by inserting filtered estimates of ξt and δt into the VaR and ES equations, respectively.
3 Simulation Study
3.1 Simulation Design
This section investigates the ability of our dynamic EVT model to simultaneously recover (i) the time variation in tail shape and tail scale parameters ξt and δt, (ii) EVT-based market risk measures VaR and ES
at high confidence levels such as
, and (iii) parameter estimates and their standard errors for all deterministic parameters collected in θ. We do so using two sets of data generating processes (DGPs). The first set of DGPs is discussed in the main text, while the second set of DGPs is discussed in Web Appendix H. In our experiments, we track the performance of our score-driven modeling approach when putting it into a variety of challenging settings, such as when the conditional density is only approximately correct, the time-varying parameter process is misspecified or features (near)-unit roots, and/or when both tail parameters follow similar paths. We also investigate whether the market risk estimates that follow from the model are reliable.
In our first set of DGPs, we consider D = 2 different densities (GPD and Student’s t), P = 4 different parameter paths for tail shape and scale, and H = 3 different ways to obtain the appropriate thresholds τt. This yields simulation experiments. In each experiment, we draw S = 100 univariate simulation samples of length
. We focus on the upper
% tail. As a result, approximately
observations are available in each simulation to compute informative POTs
.
We first simulate yt from a GPD distribution with time-varying tail shape
and scale σt. In a second set-up, we consider a Student’s t distribution with time-varying scale σt and degrees of freedom αt. In the GPD case, our score-driven model uses the exact conditional density for xt, while in the t case the GPD conditional density for xt is only approximately correct (given finite thresholds τt in any given sample); see Web Appendix B.
We consider four different paths for the tail shape and scale σt parameters. For both the GPD and Student’s t densities we consider
Constant:
;
Sine and constant:
Slow sine and frequent sine:
Synchronized sines:
Consequently, paths (1) considers the special case of time-invariant tail shape and scale parameters. Naturally, we would want our dynamic framework to cover constant parameters as a special case. Paths (2) allows the tail shape to vary considerably between 0.2 and 0.8, while keeping the scale (volatility) of the data constant. Paths (3) stipulates that both parameters vary over time. Finally, paths (4) considers the case of synchronized variation in both parameters.
Next, we consider three ways to construct the thresholds τt. First, we use the true time-varying 95%–quantile based on our knowledge of the true density and of αt and σt. This constitutes an infeasible best benchmark. Second, we construct τt as the 95%–quantile of the expanding window of data up to time t, that is . Finally, we use the recursive specification (10), initialized at the full-sample quantile
.
Our main evaluation metric for evaluating model performance is the root mean squared error , where
is the estimated tail shape parameter in simulation s,
is the corresponding (pseudo-)true tail shape,
denotes the simulation run, and
is the number of observations in each draw. The RMSE for the tail scale parameter δt is obtained analogously. The pseudo-true values
and
are obtained by numerically minimizing the Kullback-Leibler divergence between the GPD and the data generating process beyond the true time-varying 95% quantile τt. As the true conditional density is known at all times in a simulation setting, these pseudo-true benchmarks are easily computed numerically for each s and t. Particularly the GPD tail scale parameter
may have very different dynamics from σt, as it combines dynamics in αt and σt via the EVT limiting expression in (1); see also Section 2.1.4.
3.2 Simulation Results
For the first set of DGPs, we are particularly interested in two issues: first, what is the effect of increasing misspecification by moving from a GPD to a Student’s t density in the data generating process of yt, and second, how accurately can we recover high-confidence market risk measures when the conditional GPD density is only approximately correct.
presents the corresponding results. It reports RMSE statistics for tail shape ξ̂ and tail scale . provides a representative example of the simulation outcomes where we compare median estimated parameter paths for
, and
to their (pseudo)-true values. Full results are found in Web Appendix H.1. The true parameters in follow Path 3 from Section 3.1, and time-varying thresholds are estimated based on the recursive specification (10) and objective function (18).
Fig. 3 Simulation results: an example.
Time series data is here generated as t
, where
and
. This is Path 3 in Section 3.1. Pseudo-true parameter values are reported in solid red. The four panels report estimates of ξt, δt, VaRt, and ESt, respectively. Median filtered values are plotted in solid black. The first two panels also indicate the lower 5% and upper 95% quantiles of the estimates (black dots). The time-varying threshold
is estimated based on the recursive specification (10) in conjunction with the objective function (18).
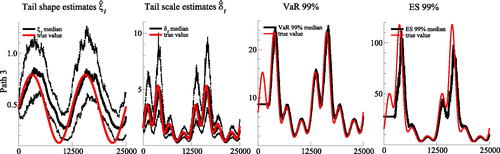
Table 1 RMSE outcomes for DGP1.
We focus on three main findings. First, all models seem to work well in recovering the true underlying ξt and δt dynamics. The median estimates in tend to be close to their (pseudo)-true values. The full results in in Web Appendix H.1 confirm this. Even the highly nonlinear patters of δt are recovered well. The model also captures the peaks of ξt, which correspond to the episodes with the fattest tails. The model needs some time to recognize that the extreme tail has become more benign, that is, that ξt has gone down. The good fit is corroborated by . We also note that both estimation methods for τt only loose about 10% RMSE for ξt and δt compared to the use of the true (infeasible) τt.
Second, when comparing the results for ξt and δt based on the recursive estimate and the dynamic estimate
of Patton, Ziegel, and Chen (Citation2019), shows differences are mostly small and insignificant. If there is no time-variation (Path 1), the estimates of
based on a recursive
fare slightly better (as expected). The converse is true for if the true parameters vary over time (Paths 2–4).
Third, shows that EVT-based market risk measures such as high-confidence level () VaRs and ESs tend to be estimated sufficiently accurately with our dynamic EVT approach. Again, this is confirmed by the full results in Web Appendix H.1. Both the low and high frequency dynamics of VaR and ES are captured well. There only appears some under-estimation of the ES at its highest peak, where tails are extremely fat. Overall, we conclude that the model captures the dynamics of the tails accurately, even in cases where the model does not coincide with the true, unobserved data generating process and the model is thus misspecified.
We conclude this section by briefly summarizing the main simulation results from our second set of DGPs in Web Appendix H.2. Empirical estimates of the autoregressive parameters and
can be close to one; see Section 4. For this reason, we investigate the effect of (near-)unit root type dynamics and of additional covariates on the parameter estimates and their standard errors. We find that models with (near-)unit root type dynamics continue to work reliably. The estimated
, and
continue to be closely aligned to their true values. The usual asymptotic standard error estimates based on the inverse Hessian or sandwich estimates, however, are not always reliable then. In our set-up, these common estimates of the standard errors are typically too large, providing too conservative inference. A bootstrap procedure tailored to integrated processes could then be used to avoid this issue.Footnote3
4 Empirical Illustrations
4.1 Equity Log-Returns
To illustrate our approach, we obtain end-of-day prices for the S&P500 index and for IBM stock as two easily and publicly available series from the CRSP database.Footnote4 The S&P500 data range from July 3, 1962 to December 31, 2020, yielding 14,726 daily observations. The IBM stock data range from January 2, 1926 to December 31, 2020, yielding 25,028 daily observations. To model the adverse left tail of equity log-returns we consider negative log-returns , with pt the price level, before applying our methodology.
4.1.1 Deterministic Parameter Estimates
We rely on the time-variation in the thresholds τt to accommodate time-variation in any parameters describing the center of the distribution. The thresholds evolve over time according to (10), at , and are initialized at
, the 90% empirical quantile of yt. The factor process
is initialized at
.
The first two columns in present our estimates of the deterministic parameters of model (1)–(10). The estimates of and
suggest that the thresholds are time-varying and mean-reverting. Parameters
and
are statistically significant at any reasonable significance level, for both S&P500 and IBM. These parameters can be interpreted as the average size of the scores driving
and
, respectively; see the statements above (6). Parameters
and
are estimated to be close to one for both series, implying that shocks to each time-varying parameter die out only slowly. A numerical check reveals that the deterministic parameters
and
lie within the SE region implied by the sufficient conditions of Theorems 1 and 2. A diagnostic check in Web Appendix J suggests that the bivariate filter (4) is also invertible at these estimates.
Table 2 Parameter estimates.
4.1.2 Tail Parameter Estimates
presents the raw log-returns (top panels) along with filtered estimates of ξt and δt (middle and bottom panels). The filtered tail shape varies between approximately 0.05 and 0.25 for the S&P 500 index, and between approximately 0.05 and 0.35 for IBM. The filtered tail scales vary roughly between 0.2 and 2.0 for the S&P 500 and IBM. The confidence bands around each filtered parameter suggest that both are reasonably precisely estimated, and that the tail shape parameter is often far from zero. The reported confidence bands are conditional on the estimated thresholds .
Fig. 4 Filtered tail parameters for S&P500 (left) and IBM (right) log-returns.
Top panels: daily log-returns for the S&P500 index (left) and IBM common stock (right). Middle and bottom panels: filtered tail shape (ξt, middle) and tail scale (δt, bottom) parameters. The thresholds τt are reported at a 90% confidence level; Value-at-Risk (VaR) and Expected Shortfall (ES) are plotted at an extreme 99% confidence level (top panels). The thresholds τt, VaR, and ES are mirrored at the horizontal axis to correspond to log-returns (instead of percentage losses). The estimation samples range from July 3, 1962 to December 31, 2020 for the S&P500 index, and from January 2, 1926 to December 31, 2020 for the IBM stock. The reported samples range from July 3, 1962 to December 31, 2020.
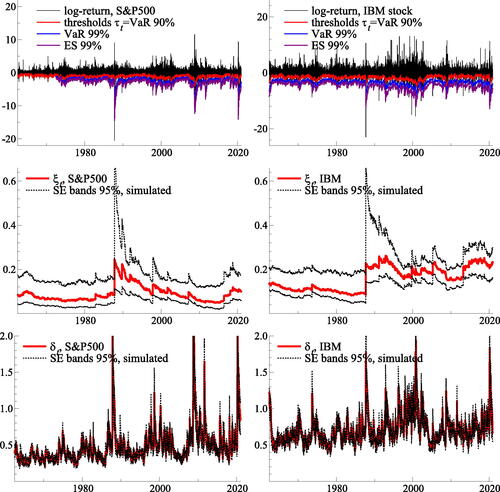
The filtered estimates of ξt and δt suggest that one-off, extremely negative returns affect the filtered tail shape more than the filtered tail scale. Longer-lasting crises, by contrast, appear to affect the tail scale more than the tail shape. For example, the stock market crash on October 19, 1987, also known as “Black Monday,” considerably increases but not
. Similarly, the 2010 “flash-crash” on May 6, 2010 increases
more than
. By contrast, the global financial crisis between 2008 and 2009, and the Covid-19 pandemic recession in early 2020, both temporarily increase
while leaving
less affected.
also plots estimates of VaRt and ESt at a 99% confidence level. We checked that indeed 1.0% of the log-returns lie beyond in the case of the S&P 500 index (0.9% for IBM stock). The average value of
conditional on it exceeding its VaR is –3.54% for the S&P 500, and –4.85% for IBM. These values are approximately in line with the time series average of
at –3.12% for the S&P 500, and –4.59% for IBM, respectively.
4.2 Changes in Sovereign Yields
In our second application we illustrate the inclusion of explanatory variables in the dynamics of ξt and δt as in (9). To do so, we study whether there was any tail risk impact of central bank asset purchases on changes in Italian (IT) and Portuguese (PT) five-year bond yields between 2010 and 2012. Both Italy and Portugal were in the “epicenter” of the existential euro area sovereign debt crisis at that time; see for example, Eser and Schwaab (Citation2016), and Ghysels et al. (Citation2017). Italy is an example for a large euro area country that was affected by the crisis relatively late (in mid-2011), and that benefited from Eurosystem bond purchases only during a relatively short period of time, between August 2011 and March 2012. Portugal, by contrast, is an example for a smaller euro area country that was affected relatively early (already in 2010), and that benefited from Eurosystem bond purchases more uniformly over time, between May 2010 and March 2012.
Eurosystem bond purchases undertaken during the sovereign debt crisis predominantly targeted the 1- to 10-year maturity bracket, with the 5-year maturity approximately in the middle of that spectrum; see for example Eser and Schwaab (Citation2016). We consider the impact on five-year sovereign benchmark bond yields for this reason.
The bond yields yt are sampled at the 15-min frequency, between 9 a.m. and 5 p.m., and are obtained from Bloomberg. We do not consider overnight changes in yield, such that the first 15-min interval covers 9 a.m. to 9:15 a.m. Our sample ranges from January 04, 2010 to December 31, 2012. This yields 32 intra-daily observations per trading day, with observations per country.
Finally, we construct time series data zt of country-specific bond purchases at the high (15-min) frequency. Observations zt contain all sovereign bond purchases at par (nominal) value between t – 1 and t for the respective country, not only purchases of the five-year benchmark bond. Disaggregated data on Eurosystem SMP purchases sampled at a high-frequency are still confidential at the time of writing. At the end of our sample, the Eurosystem held €99.0 bn in Italian sovereign bonds and €21.6 bn in Portuguese bonds; see the ECB Annual Report 2013. We including these as an additional conditioning variable in (9) to see whether they mitigated extreme tail behavior or not.
4.2.1 Deterministic Parameter Estimates
We continue to rely on the time-variation in the thresholds τt to control for time-variation in any parameters describing the center of the distribution. The thresholds now evolve according to (11), also taking account of the SMP purchases zt. We choose , and initialize
, the 90% empirical quantile of yt.
Analyzing changes in the tail shape and tail scale parameters for high-frequency data is challenging given the high persistence of parameters at such frequencies. We therefore introduce two simplifications. First, we fix the smoothing parameter λ at , such that 95% of the smoothing materializes within one day (i.e., 32 15-min intervals). As there are only log-likelihood contribution for the GPD for
, it is hard to identify λ empirically. Second, to keep the model in line with the theory from Section 2.2, we fix
and
to a value close to the unit boundary, as otherwise they are estimated indistinguishably different from 1. We choose
, which implies a similar persistence level as (IBM) equity returns at a daily (= 8h = 32 quarters) frequency. Fixing λ,
, or
at other reasonable values has little effect on the empirical findings.
Columns three to six of present our estimates of the deterministic parameters for the model (1)–(11). Columns three and five refer to a baseline model without central bank purchases. reports bootstrapped standard errors for the deterministic parameters using the procedure outlined in Web Appendix K.
The estimates of and
suggest that the thresholds are time-varying and mean-reverting. Parameter
is estimated to be negative for Portuguese bonds, and close to zero for Italian bonds. Parameters
and
suggest pronounced and statistically significant time series variation in both the tail shape ξt and tail scale δt parameters, both of which are captured by our time-varying parameter model. The impact parameters
and
of bond purchases on tail shape and scale are estimated to be negative in both cases. The log-likelihood increases by 21.9 points for IT, and 37.0 points for PT. A comparison of model selection criteria (AIC, BIC) further supports the inclusion of central bank asset purchases as a useful covariate to explain each time series’ extreme tail dynamics.
4.2.2 Tail Parameter Estimates and VaR Impact
plots the corresponding filtered estimates for time-varying tail shape ξt and tail scale δt. Time series variation is present and pronounced in both parameters. The filtered tail shape varies between approximately 0.1 and 0.4 for Italian yields, and between 0.05 and 0.6 for Portuguese yields. The filtered tail scale varies between approximately 1 and 10.0 for Italian yields, and between approximately 1 and 40 for Portuguese yields. The standard error bands around each time-varying parameter suggest that both parameters are estimated reasonably precisely, and that the tail shape is often far from the Gumbel case of .
Fig. 5 The tail shape and tail scale estimates.
Top row: Five-year sovereign benchmark bond yields for Italy (IT, left column) and Portugal (PT, right column) between 2010 and 2012. Middle row: filtered tail shape (ξt) parameter. Bottom row: filtered tail scale (δt) parameter. Standard error bands are simulated at a 95% confidence level.
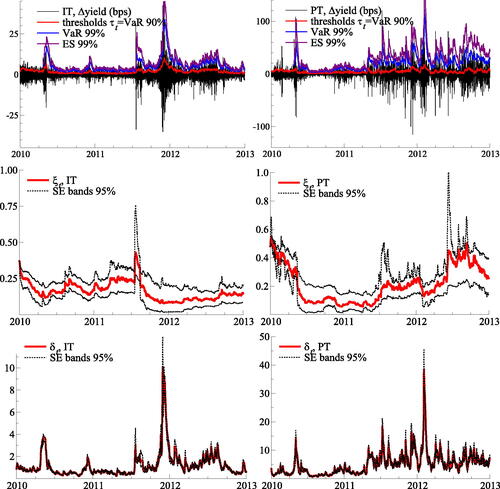
As was clear from , the coefficients and
measure the impact of bond purchases on the tail behavior of yield changes. As these parameters are difficult to interpret by themselves, we show in Web Appendix L how they can be translated into an impact on VaR via their link to τt, δt, and ξt. For Italy, we obtain a total VaR impact of 0.0 (tail threshold) +0.8 (tail scale) – 5.9 (tail shape) = –5.1 bps for a €1 bn Eurosystem intervention. For Portugal, we obtain a larger impact of –0.1 (tail threshold) – 172.5 (tail scale) – 176.4 (tail shape) = –349.0 bps. These point estimates are of course subject to substantial estimation uncertainty; see . The 95% confidence intervals for VaR impact can be bootstrapped along with the parameters. They equal [–17.6, 11.6] for IT and [–664.0, –38.8] for PT. The stronger impact for Portugal than for Italy is likely due to a €1 bn intervention constituting a larger share of the overall market.
5 Conclusion
We introduced a semiparametric modeling framework to study time variation in tail parameters for long univariate time series. To this end we modeled the time variation in the shape and scale parameters of the Generalized Pareto Distribution, which approximates the tail of most heavy-tailed densities used in econometrics and the actuarial sciences. We discussed the handling of nontail time series observations, inference on deterministic and time-varying parameters, and how to relate tail variation to observed covariates if such variables are available. We also established conditions for stationarity and ergodicity of the model and conditions for consistency and asymptotic normality of the maximum likelihood estimator. The model therefore complements and extends recent work based on different methodologies, such as the nonparametric approach to tail index variation of de Haan and Zhou (Citation2021), the time-varying quantile (and ES) approaches of Patton, Ziegel, and Chen (Citation2019) and Catania and Luati (in press), and the parametric approach of Massacci (Citation2017). We applied the model to study variation in the left tail of U.S. equity log-returns, and in the right tail of changes in euro area sovereign bond yields at a high frequency. In the latter case we also studied the impact of Eurosystem bond purchases, concluding that these had a beneficial impact on tail parameters, leaning against the risk of extremely adverse market outcomes.
Evidently, our model for time-varying tail parameters is focussed on capturing marginal features. In many applications it may also be of interest to study the time-varying nature of joint extremes; see for example, Castro-Camilo, de Carvalho, and Wadsworth (Citation2018), Escobar-Bach et al. (Citation2018), and Mhalla, de Carvalho, and Chavez-Demoulin (Citation2019). In terms of our first illustration, for example, one could wonder whether extremely negative log-returns for the S&P 500 and IBM stock were more dependent at certain points in time. We leave such research for future work (see also Lucas, Schwaab, and Zhang, Citation2014; Oh and Patton, Citation2018; Hautsch and Herrera, Citation2020).
Supplementary Materials
Supplementary materials contain proofs and technical details, additional simulation and empirical results, and computer code (language: Ox) for the implementation of the method. The latter is also obtainable via www.gasmodel.com.
supplementary_files.zip
Download Zip (6 MB)Acknowledgments
The views expressed in this article are those of the authors and do not necessarily reflect the views or policies of the BIS, the European Central Bank or Sveriges Riksbank.
Disclosure Statement
The authors report there are no competing interests to declare.
Notes
1 The web appendix considers additional applications to exchange rates and commodity prices.
2 Alternatively, one could opt to not update at all until a new
arrives. Empirically, both approaches seem to work equally well.
3 See for instance Boswijk et al. (Citation2021).
4 Web Appendix I provides two additional illustrations to other asset classes: exchange rates (GBP/USD) and commodities (Brent crude oil).
References
- Blasques, F., Koopman, S. J., and Lucas, A. (2015), “Information Theoretic Optimality of Observation Driven Time Series Models for Continuous Responses,” Biometrika, 102, 325–343. DOI: 10.1093/biomet/asu076.
- Blasques, F., van Brummelen, J., Koopman, S. J., and Lucas, A. (2022), “Maximum Likelihood Estimation for Generalized Autoregressive Score Models,” Journal of Econometrics, 227, 325–346. DOI: 10.1016/j.jeconom.2021.06.003.
- Boswijk, H. P., Cavaliere, G., Georgiev, I., and Rahbek, A. (2021), “Bootstrapping Non-stationary Stochastic Volatility,” Journal of Econometrics, 224, 161–180. DOI: 10.1016/j.jeconom.2021.01.005.
- Bougerol, P. (1993), “Kalman Filtering with Random Coefficients and Contractions,” SIAM Journal on Control and Optimization, 31, 942–959. DOI: 10.1137/0331041.
- Castro-Camilo, D., de Carvalho, M., and Wadsworth, J. (2018), “Time-Varying Extreme Value Dependence with Application to Leading European Stock Markets,” Annals of Applied Statistics, 12, 283–309.
- Catania, L., and Luati, A. (in press), “Semiparametric Modeling of Multiple Quantiles,” Journal of Econometrics.
- Chavez-Demoulin, V., Embrechts, P., and Sardy, S. (2014), “Extreme-Quantile Tracking for Financial Time Series,” Journal of Econometrics, 181, 44–52. DOI: 10.1016/j.jeconom.2014.02.007.
- Coles, S. (2001), An Introduction to Statistical Modeling of Extreme Values, London: Springer Press.
- Cox, D. R. (1981), “Statistical Analysis of Time Series: Some Recent Developments,” Scandinavian Journal of Statistics, 8, 93–115.
- Creal, D., Koopman, S. J., and Lucas, A. (2013), “Generalized Autoregressive Score Models with Applications,” Journal of Applied Econometrics, 28, 777–795. DOI: 10.1002/jae.1279.
- Creal, D., Schwaab, B., Koopman, S. J., and Lucas, A. (2014), “An Observation Driven Mixed Measurement Dynamic Factor Model with Application to Credit Risk,” The Review of Economics and Statistics, 96, 898915. DOI: 10.1162/REST_a_00393.
- Davidson, A. C., and Smith, R. L. (1990), “Models for Exceedances over High Thresholds,” Journal of the Royal Statistical Association, Series B, 52, 393–442. DOI: 10.1111/j.2517-6161.1990.tb01796.x.
- de Haan, L., and Zhou, C. (2021), “Trends in Extreme Value Indices,” Journal of the Americal Statistical Association, 116, 1265–1279. DOI: 10.1080/01621459.2019.1705307.
- Einmahl, J., de Haan, L., and Zhou, C. (2016), “Statistics of Heteroscedastic Extremes,” Journal of the Royal Statistical Society, Series B, 78, 31–51. DOI: 10.1111/rssb.12099.
- Embrechts, P., Klüppelberg, C., and Mikosch, T. (1997), Modelling Extremal Events for Insurance and Finance, Berlin: Springer Verlag.
- Engle, R. F., and Manganelli, S. (2004), “CAViaR: Conditional Autoregressive Value at Risk by Regression Quantiles,” Journal of Business & Economic Statistics, 22, 367–381. DOI: 10.1198/073500104000000370.
- Escobar-Bach, M., Goegebeur, Y., and Guillou, A. (2018), “Local Robust Estimation of the Pickands Dependence Function,” Annals of Statistics, 46, 2806–2843.
- Eser, F., and Schwaab, B. (2016), “Evaluating the Impact of Unconventional Monetary Policy Measures: Empirical Evidence from the ECB’s Securities Markets Programme,” Journal of Financial Economics, 119, 147–167. DOI: 10.1016/j.jfineco.2015.06.003.
- Galbraith, J. W., and Zernov, S. (2004), “Circuit Breakers and the Tail Index of Equity Returns,” Journal of Financial Econometrics, 2, 109–129. DOI: 10.1093/jjfinec/nbh005.
- Ghysels, E., Idier, J., Manganelli, S., and Vergote, O. (2017), “A High Frequency Assessment of the ECB Securities Markets Programme,” Journal of European Economic Association, 15, 218–243. DOI: 10.1093/jeea/jvw003.
- Hafner, C. M., and Wang, L. (in press), “A Dynamic Conditional Score Model for the Log Correlation Matrix,” Journal of Econometrics.
- Harvey, A. C. (2013), Dynamic Models for Volatility and Heavy Tails with Applications to Financial and Economic Time Series, Cambridge: Cambridge University Press.
- Hautsch, N., and Herrera, R. (2020), “Multivariate Dynamic Intensity Peaks-Over-Threshold Models,” Journal of Applied Econometrics, 35, 248–272. DOI: 10.1002/jae.2741.
- Hetland, S., Pedersen, R. S., and Rahbek, A. (in press), “Dynamic Conditional Eigenvalue GARCH,” Journal of Econometrics.
- Hill, B. (1975), “A Simple General Approach to Inference About the Tail of a Distribution,” The Annals of Statistics, 3, 1163–1174. DOI: 10.1214/aos/1176343247.
- Hoga, Y. (2017), “Testing for Changes in (Extreme) VaR,” Econometrics Journal, 20, 23–51. DOI: 10.1111/ectj.12080.
- Huisman, R., Koedijk, K., Kool, C., and Palm, F. (2001), “Tail-Index Estimates in Small Samples,” Journal of Business & Economic Statistics, 19, 208–216. DOI: 10.1198/073500101316970421.
- Jensen, S. T., and Rahbek, A. (2004), “Asymptotic Inference for Nonstationary GARCH,” Econometric Theory, 20, 1203–1226. DOI: 10.1017/S0266466604206065.
- Johnson, N. L., Kotz, S., and Balakrishnan, N. (1994), Continuous Univariate Distributions (Vol. 1, 2nd ed.), New York: Wiley.
- Koenker, R. (2005), Quantile Regression, Cambridge: Cambridge University Press.
- Lin, C.-H., and Kao, T.-C. (2018), “Multiple Structural Changes in the Tail Behavior: Evidence from Stock Market Futures Returns,” Nonlinear Analysis: Real World Applications, 9, 1702–1713. DOI: 10.1016/j.nonrwa.2007.05.011.
- Lucas, A., Schwaab, B., and Zhang, X. (2014), “Conditional Euro Area Sovereign Default Risk,” Journal of Business and Economics Statistics, 32, 271–284. DOI: 10.1080/07350015.2013.873540.
- Lucas, A., and Zhang, X. (2016), “Score Driven Exponentially Weighted Moving Average and Value-at-Risk Forecasting,” International Journal of Forecasting, 32, 293–302. DOI: 10.1016/j.ijforecast.2015.09.003.
- Massacci, D. (2017), “Tail Risk Dynamics in Stock Returns: Links to the Macroeconomy and Global Markets Connectedness,” Management Science, 63, 112–132. DOI: 10.1287/mnsc.2016.2488.
- McNeil, A., and Frey, R. (2000), “Estimation of Tail-Related Risk Measures for Heteroscedastic Financial Time Series: An Extreme Value Approach,” Journal of Empirical Finance, 7, 271–300. DOI: 10.1016/S0927-5398(00)00012-8.
- McNeil, A. J., Frey, R., and Embrechts, P. (2010), Quantitative Risk Management: Concepts, Techniques, and Tools, Princeton, NJ: Princeton University press.
- Mhalla, L., de Carvalho, M., and Chavez-Demoulin, V. (2019), “Regression-Type Models for Extremal Dependence,” Scandinavian Journal of Statistics, 46, 1141–1167. DOI: 10.1111/sjos.12388.
- Oh, D. H., and Patton, A. J. (2018), “Time-Varying Systemic Risk: Evidence from a Dynamic Copula Model of CDS Spreads,” Journal of Business & Economic Statistics, 36, 181–195. DOI: 10.1080/07350015.2016.1177535.
- Patton, A. (2006), “Modelling Asymmetric Exchange Rate Dependence,” International Economic Review, 47, 527–556. DOI: 10.1111/j.1468-2354.2006.00387.x.
- Patton, A. J., Ziegel, J. F., and Chen, R. (2019), “Dynamic Semiparametric Models for Expected Shortfall (and Value-at-Risk),” Journal of Econometrics, 211, 388–413. DOI: 10.1016/j.jeconom.2018.10.008.
- Quintos, C., Fan, Z., and Phillips, P. C. (2001), “Structural Change Tests in Tail Behaviour and the Asian Crisis,” The Review of Economic Studies, 68, 633–663. DOI: 10.1111/1467-937X.00184.
- Rocco, M. (2014), “Extreme Value Theory in Finance: A Survey,” Journal of Economic Surveys, 28, 82–108. DOI: 10.1111/j.1467-6419.2012.00744.x.
- Straumann, D., and Mikosch, T. (2006), “Quasi-Maximum-Likelihood Estimation in Conditionally Heteroscedastic Time Series: A Stochastic Recurrence Equations Approach,” The Annals of Statistics, 34, 2449–2495. DOI: 10.1214/009053606000000803.
- Wang, H., and Tsai, C.-L. (2009), “Tail Index Regression,” Journal of the American Statistical Association, 104, 1233–1240. DOI: 10.1198/jasa.2009.tm08458.
- Werner, T., and Upper, C. (2004), “Time Variation in the Tail Behavior of Bund Future Returns,” Journal of Futures Markets, 24, 387–398. DOI: 10.1002/fut.10120.