
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We consider hypothesis testing in instrumental variable regression models with few included exogenous covariates but many instruments—possibly more than the number of observations. We show that a ridge-regularized version of the jackknifed Anderson and Rubin (henceforth AR) test controls asymptotic size in the presence of heteroscedasticity, and when the instruments may be arbitrarily weak. Asymptotic size control is established under weaker assumptions than those imposed for recently proposed jackknifed AR tests in the literature. Furthermore, ridge-regularization extends the scope of jackknifed AR tests to situations in which there are more instruments than observations. Monte Carlo simulations indicate that our method has favorable finite-sample size and power properties compared to recently proposed alternative approaches in the literature. An empirical application on the elasticity of substitution between immigrants and natives in the United States illustrates the usefulness of the proposed method for practitioners.
1 Introduction
Instrumental variables (IVs) are commonly employed in economics and related fields to estimate causal effects from observational data. The use of a large number of IVs has gained popularity due to weak identification, where researchers aim to capture limited exogenous variation in endogenous covariates and obtain more precise inference. One example is Mendelian randomization in biology, where weakly associated genetic mutations are used as IVs, and the number of IVs can exceed the number of observations (Davies et al. Citation2015; Burgess and Thompson Citation2021). Other prominent examples are the granular IV approach (Gabaix and Koijen Citation2020) and the saturation approach to identify treatment effects (Blandhol et al. Citation2022).Footnote1 However, it is crucial to have reliable inference methods that account for the potential lack of joint informativeness of a large number of weak IVs, especially when pretesting the strength of IVs is impractical or not available due to the excessive number of IVs compared to observations. This article contributes to the literature on the development of such methods.
We propose a ridge-regularized jackknifed Anderson-Rubin (RJAR) test to construct confidence sets for the coefficients of endogenous variables in weakly-identified and heteroscedastic IV models when the number of IVs is large. Jackknife-based methods have recently been used in this context because they are applicable in an asymptotic framework where the number of IVs diverges with the number of observations. However, by relying on existing central limit theorems developed for standard projection matrices, these methods require that the number of IVs be less than the number of observations, and often perform poorly when the number of IVs is close to (but still less than) the number of observations. Recently proposed regularization approaches for inference under many IVs require strong identification or a sparse relationship between the endogenous variables and the IVs to work well. By combining jackknifing with ridge regularization, we provide a test that has the desired asymptotic size under heteroscedasticity, arbitrarily weak identification, and more IVs than observations, all while achieving good power both when the relationship between the endogenous variables and the IVs is sparse and when it is dense.
Throughout this article, we focus on (Anderson and Rubin Citation1949, henceforth AR) tests. This is because, in addition to being robust to weak IVs, they are also robust to arbitrary relationships between the endogenous variables and the IVs, since they make no assumption on the first-stage projection of the endogenous variables on the IVs. In the context of AR tests with an increasing number of IVs, it is helpful to distinguish three different asymptotic regimes.
The first “moderately many” IVs regime allows the number of IVs, kn, to grow with the sample size, n, but still requires it to be asymptotically negligible with respect to the sample size. Examples include Andrews and Stock (Citation2007), who require , and Phillips and Gao (Citation2017), who require
.
The second “many” IVs regime allows the number of IVs to be of the same order of magnitude as the number of observations. Anatolyev and Gospodinov (Citation2011) provide an AR test that remains valid for , provided that the error terms are homoscedastic and the IVs satisfy a restrictive balanced-design assumption.Footnote2 Bun, Farbmacher, and Poldermans (Citation2020) provide analogous results for the GMM version of the AR statistic under the assumption of iid data. These results were recently extended in the form of a jackknifed AR statistic by (Crudu, Mellace, and Sándor Citation2020, henceforth CMS) and (Mikusheva and Sun Citation2022, henceforth MS) to the case where errors are allowed to display arbitrary heteroscedasticity, and the only assumption on the IVs is that the diagonal entries of the projection matrix of the IVs are bounded away from unity from above.Footnote3
The third “very many” IVs regime allows the number of IVs to grow with n, and further allows the number of IVs to be greater than the number of observations. (Belloni et al. Citation2012, henceforth BCCH) propose a Sup Score test that remains valid under mild conditions, and allows the number of IVs to increase exponentially with the sample size. (Carrasco and Tchuente Citation2016, henceforth CT) propose a ridge-regularized AR statistic that allows for more IVs than observations under the assumption of iid data and homoscedasticity. Kapetanios, Khalaf, and Marcellino (Citation2015) extend Bai and Ng (Citation2010) by proposing weak-identification robust factor-based tests that in principle allow for the number of IVs to be larger than the number of observations, provided that the factor structure of the IVs is sufficiently strong.
Using the notation of the model introduced in the next section, provides a schematic overview of the main assumptions and results in the literature on inference that is robust to many weak IVs.
Table 1 Anderson and Rubin (Citation1949) tests with many IVs: schematic comparison of main assumptions and results in the literature.
Our test provides a twofold extension of the existing literature. First, it allows for valid inference under many IVs and heteroscedastic errors while further weakening the assumptions of similar tests proposed by CMS and MS. This is made possible by deriving the limiting behavior of the RJAR statistic from the bottom up, without relying on the existing results in Chao et al. (Citation2012) or Hansen and Kozbur (Citation2014). Second, this test allows for more IVs than observations under arbitrary heteroscedasticity of the error terms. The only other approach currently available in the literature that is robust to heteroscedastic error terms and more IVs than observations is the Sup Score test of BCCH. Simulations show that the RJAR test has power comparable to the Sup Score test of BCCH whenever the signal in the first stage is sparse (i.e., only a few of the IVs are informative), and substantially more power when the signal in the first stage is dense (i.e., not sparse). Simulations also show that the RJAR test is as powerful as, and in some cases more powerful than, the AR test of CT, the validity of which has been established only under homoscedastic error terms. Finally, we provide a comparison of the most recently proposed approaches to conducting inference in possibly heteroscedastic linear IV models when the number of IVs is not negligible with respect to the sample size. Indeed, using extensive simulation evidence and an empirical application based on Card (Citation2009), we provide a comparison between these existing “state-of-the-art” methods in a controlled and comparable setting.
In the rest of the article, we use the following notation. Ip denotes the p × p identity matrix. For an vector
. The entry (i, j) for an m × p matrix A is denoted as Aij for
.
for any m × m matrix A with entries given by Aij for
, and
denotes the Frobenius norm of A. The remaining notation follows standard conventions.
The structure of the article is as follows. Section 2 specifies the linear IV model considered throughout. Section 3 introduces the RJAR test, and provides the main asymptotic results. Section 4 provides simulation evidence on the size and power of our RJAR test and compares it with the tests proposed by BCCH, CT, CMS, and MS. Section 5 considers an empirical application based on Card (Citation2009). Section 6 concludes. All proofs are given in the supplementary material.
2 Model
We consider the heteroscedastic linear IV model given by
(1a)
(1a)
(1b)
(1b) where y is an
vector containing the dependent variable, X is an n × g matrix containing the endogenous variables, β is a
coefficient vector, ε is an
vector containing the structural error terms, Z is an
matrix containing the IVs, Π is a
coefficient matrix, and V is an n × g matrix containing the first-stage errors. kn can diverge with n, but g is fixed. Also, let yi, Xi,
, Zi, and Vi denote the ith row of
, and V, respectively. As in BCCH, CMS, and MS, we treat Z as fixed (non-stochastic),Footnote4 and assume that any exogenous covariates have been partialled out (see the discussion of Assumption 3). We exclusively consider methods that allow for arbitrarily weak identification, that is, methods that control asymptotic size irrespective of the value of Π.
Inference is conducted on the coefficient vector β by testing hypotheses of the following type for a prespecified :
(2)
(2)
For a given non-randomized test of asymptotic size , a confidence set of asymptotic coverage
can be constructed as the collection of those β0 for which H0 in (2) is not rejected. For convenience, define
(3)
(3) which we refer to as the structural error under the null hypothesis.
It will become apparent below that so long as the error term, ε, remains additive, the linearity in the structural Equationequation (1a)(1a)
(1a) and the first-stage Equationequation (1b)
(1b)
(1b) can be relaxed to allow for any (known) real-valued function, without affecting the asymptotic size of the RJAR test.
3 The RJAR Test
This section introduces our proposed RJAR test, derives its large sample properties under the null hypothesis in (2), and discusses its relationship to the most closely related tests in the literature: the ridge-regularized AR test of CT, the jackknifed AR tests of CMS and MS, and the Sup Score test of BCCH.
3.1 Definition of the RJAR Test
The original AR test of the null hypothesis in (2) can be thought of as a test that the IVs are exogenous using the implied structural errors in (3). More specifically, the AR test is a Wald test of the significance of the IVs in the auxiliary regression of the structural errors under the null, , on the IVs, Zi.Footnote5 The weak-IV-robust AR test of the null hypothesis in (2) with asymptotic size α rejects the null if and only if the AR statistic exceeds the
quantile of a
distribution with kn degrees of freedom. When the number of IVs kn grows with n, that is, when there are many (potentially weak) IVs, the
approximation of the original AR statistic breaks down. The recently proposed AR test of CT, which we shall briefly review in Section 3.3, uses ridge-regularization to allow for a growing number of IVs that may even exceed the sample size, but is not robust to arbitrary heteroscedasticity in the error terms. The recent papers by CMS and MS, which we shall also briefly review in Section 3.3, propose jackknifed versions of the AR test that remain valid when kn grows with n, but require
. Our proposed method combines ridge regularization with jackknifing of the auxiliary regression of
on Zi to allow for a weak-identification robust test capable of dealing with both more IVs than observations and arbitrary heteroscedasticity in the error terms.
We first standardize the IVs in-sample (after partialling out any covariates) as in BCCH (p. 2393) so that
(4)
(4)
The RJAR test for the testing problem in (2) is then based on the following statistic:
(5)
(5) where
(assumed to be positive without loss of generality),
(6)
(6)
and
is the ridge-regularized projection matrix with
if rn = kn and
if rn < kn
. γn is a (sequence of) regularization parameter(s) whose choice we discuss below. We note that setting
when rn = kn corresponds to the case where a standard least-squares projection matrix
is used to construct the RJAR statistic. This is the standard jackknife statistic. We also note that the rn-scaling in the denominator of the RJAR statistic cancels with the rn in the denominator of
.
We set the regularization parameter γn to
(7)
(7) where
for some constant
not depending on n. The existence of
is shown in the supplementary material. We let
be an element of
out of conservativeness, that is, to make Assumption 3 as plausible as possible given the IVs. Furthermore, we let
be the maximal element of this set because the maximizer is not necessarily unique without imposing additional assumptions on the singular values and left-singular vectors of the IVs (although in practice we only found unique maximizers). We choose to take the maximum of the maximizers to make the smallest eigenvalues of the ridge-regularized Gram matrix,
, as far away from zero as possible when rn < kn. To see that
maximizes the smallest eigenvalue of
among the elements of
, notice that due to the symmetry of
, its smallest eigenvalue can be expressed as
where the first equality used that
, and the second equality used that the smallest eigenvalue of
is 0 when the rank rn of Z is less than kn.
We now have all the ingredients to define our new test.
Definition 3.1.
The RJAR test rejects in (2) at significance level
if and only if
(8)
(8) where
is defined in (5),
is defined in (7), and
is the
quantile of the Standard Normal distribution.
3.2 Asymptotic Properties of the RJAR Test
We make the following assumptions to derive the limiting distribution of under the null hypothesis in (2).
Assumption 1.
is a sequence of independent random variables satisfying
, and
.
Assumption 2.
as
.
Assumption 3.
If rn = kn, then there exists a
such that
If rn < kn, then there exists a
Assumption 1 is a mild condition on the structural error terms, and allows for conditional heteroscedasticity. It is the same as in CMS. It is slightly less restrictive than the one in MS (who require finite sixth moments on the structural error terms), and slightly more restrictive than the one in BCCH (who require finite third moments).Footnote6
Assumption 2 is a weak technical assumption. It implies that both kn and n diverge. It also allows for the sum of the number of IVs and the number of exogenous covariates to be larger than the number of observations, provided that the number of exogenous covariates that have been partialled out be sufficiently small (so that the rank of the matrix of partialed IVs continues to diverge).Footnote7 This assumption is weaker than the restriction on the dimensionality in MS and CMS, who require rn = kn, and for each
, as well as
as
. BCCH prove asymptotic size control of their Sup Score test under the assumption that
.
3.2.1 Assumption 3 when rn = kn
Assumption 3 is a high-level assumption on the number of IVs and their correlation structure. Assumption 3 implies that satisfies
. In the absence of exogenous covariates and when
(as in CMS and MS), Assumption 3 is weaker than the balanced-design assumption in CMS and MS which requires for
that
(9)
(9) for some
. This is stated formally in part 1 of the following Proposition.
Proposition 3.1.
Suppose (as in CMS and MS) that .
If there exists a
For any
Part 2. of Proposition 3.1 implies that Assumption 3 can be satisfied—even when the balanced-design assumption is not—as long as the number of diagonal elements of P “close to 1” increases slower than kn. Note also that if for some it holds that
for all
, then
. Thus, part 1. of Proposition 3.1 actually follows from Part 2. However, we have chosen to keep part 1. as a separate statement to explicitly state that the balanced-design assumption implies Assumption 3.
3.2.2 Assumption 3 When rn < kn
When the number of instruments exceeds the sample size, that is when , one has that
. The following proposition provides sufficient conditions for Assumption 3 to be satisfied with probability one in this situation in case Z is random.
Proposition 3.2.
Let the entries of Z be iid with a mean zero and variance one. In addition, let p > 2 satisfy and let
for
. Then, if the distribution of Z11 is absolutely continuous with respect to the Lebesgue measure, there exists a constant
such that for
it holds with probability one that
Note that Assumption 3 is satisfied in particular when the entries of Z are iid Gaussian. The latter was used in Hansen and Kozbur (Citation2014) to provide a set of sufficient conditions for their assumptions to be satisfied. The proof of Proposition 3.2 also sheds further light on the exact value of η. To summarize, Propositions 3.1 and 3.2 show that Assumption 3 is likely to be satisfied; this can be the case even in settings in which the assumptions underlying previous methods are violated.
If very small values of are observed, then Assumption 3 may be questionable. If this is the case, practitioners could make Assumption 3 more plausible by suitably modifying the matrix of IVs, Z. This could include the dropping of IVs (either randomly or motivated by economic reasoning, but not informed by the in-sample correlation of the IVs with the endogenous variable), or the (iterative) removal of certain observations. If sufficient data is available to split the sample, a data-driven selection of IVs on one split of the sample for use on the other is also possible.
3.2.3 Asymptotic Normality of the RJAR Test Statistic
We are now in a position to state the asymptotic distribution of the RJAR test under the null hypothesis.
Theorem 3.1.
Suppose Assumptions 1–3 and the null hypothesis in (2) hold. Consider any sequence γn such that . Then, the statistic
defined in (5) satisfies
Corollary 3.1.
Under Assumptions 1–3 and the null hypothesis in (2), the RJAR test given in Definition 3.1 (i.e., using for all
) has asymptotic size α.
Notice that we did not impose any assumption on the coefficients of the instruments Π in the first-stage regression in (1). Therefore, the RJAR test is robust to arbitrarily weak identification.
3.3 Closest Alternatives in the Literature
The RJAR test combines two existing approaches in the literature. It uses ridge-regularization as in CT to allow for rn < kn, and jackknifing as in CMS and MS to allow for arbitrary heteroscedasticty in the error terms.
The RJAR test is similar to the ridge-regularized AR test proposed by CT given by
where
for some fixed scalar θ that does not depend on n, where
if rn = kn, and
if rn < kn. CT show that under the assumption of homoscedastic error terms, ARCT converges to an infinite sum of weighted
distributions. Since the limiting distribution depends on an infinite number of unobserved weights, CT propose a bootstrap procedure to derive the critical values for ARCT. The distinguishing features of the RJAR test are the data-driven and unique penalty parameter used to regularize the projection matrix (we find substantial sensitivity of the performance of ARCT to different values of θ), the robustness to arbitrary heteroscedasticiy in the error terms, and its computational speed (it uses standard Normal asymptotic critical values instead of the bootstrap).
Robustness to arbitrary heteroscedasticity in the error terms is achieved through jackknifing, as in CMS and MS. The distinguishing feature of the RJAR test to the tests proposed in CMS and MS is the use of a ridge-regularized projection matrix , which makes the RJAR test applicable also when kn > rn, unlike the aforementioned two tests that use the standard least-squares projection matrix
, and cannot be computed when kn > rn.
CMS assume , and propose the jackknifed AR statistic given by
where
, and D is the diagonal matrix containing the diagonal elements of P.
. Under the null hypothesis in (2), CMS show that
converges to a Standard Normal distribution. The CLT underlying this result is a modified version of Lemma A2 of Chao et al. (Citation2012) proposed in (Bekker and Crudu Citation2015, Appendix A.4).
MS also assume that , and propose a different jackknifed AR statistic than CMS that can be obtained from
in (5) by setting
, and replacing
with
(10)
(10) where
, and Mi is the ith row of M. The reason why the unregularized jackknifed AR test in MS uses
instead of the variance estimator given in (6) evaluated at
, is because, according to their Theorem 4, and the discussion in Section 4.2.1, the former yields higher power than the latter. It follows that the unregularized version of our RJAR test, which arises when
in (7), will be dominated by the jackknifed AR test of MS in terms of power, and practitioners may prefer the latter when rn = kn and the balanced-design assumption is satisfied. This can have implications for the finite-sample performance of the jackknifed AR test of MS compared to the RJAR, which we investigate in Section 4.
The only other existing test that allows for rn < kn and arbitrary heteroscedasticty is the Sup Score test of BCCH. BCCH first standardize the IVs as in (4), and then propose the Sup Score statistic given by
BCCH propose to use the critical value , cBCCH > 1 and
. They show that comparing their Sup Score statistic to this critical value yields a test of the null hypothesis in (2) that has asymptotic size less than or equal to α. Being a supremum-norm test suggests that the BCCH Sup Score test will work well with a sparse first stage (i.e., where only a few elements of Π are zero), but may have lower power than the RJAR test when the first stage is dense. This is verified in the simulations in Section 4.
4 Simulations
We now investigate the size and power properties of the RJAR test and compare them to those of the tests proposed in CT, CMS, MS, and BCCH. We take our simulation setup from Hansen and Kozbur (Citation2014) who in turn take theirs from BCCH. The DGP is given by
(11a)
(11a)
(11b)
(11b) for
. The IVs Zi are independent and identically Gaussian with mean 0 and
and
.Footnote8 The error terms are given by
with
and
.
, where κ is a vector of zeros and ones that varies with the type of DGP considered (sparse or dense, as modeled below), and ζ is some scalar that ensures that for a given concentration parameter,
, the following relationship is satisfied:
This implies that
To illustrate how the sparsity structure of the first stage in (11b) can affect the size and power of the studied tests, we consider both a sparse first stage and a dense first stage. Sparsity in the first stage is modeled by setting , where ιq is a
vector of ones, and
is a
vector of zeros. Denseness in the first stage is modeled by setting
.
We consider . In the context of Assumption 3, we search over values greater than 1 when choosing
in case rn < kn. For the case of 30 IVs, the RJAR test does not impose any regularization (
). For the case of 90 IVs,
. We note that in the latter case
. This shows that even in the case where
, ridge regularization can make Assumption 3 strictly more plausible. For the case of 190 IVs,
.
The variance estimator of MS occasionally yields a negative value. These cases are conservatively interpreted as a failure to reject the null hypothesis. As recommended by BCCH, cBCCH = 1.1. As in the simulation section in CT, we set . The number of Monte Carlo replications is 10,000.
The supplementary material provides additional simulation evidence on inference with heteroscedastic error terms. The supplementary material provides additional simulation evidence on projection-based inference.
4.1 Size
shows the simulation results with a sparse first stage for tests of size 0.01 to 0.99, that is the rejection frequency under . As far as the illustration of the tests’ size properties is concerned, the dense first stage yields virtually the same results, and is hence omitted. Since all tests are robust to weak IVs, the rejection frequencies of the tests are not affected by the strength of identification. For the case of 30 IVs, the AR tests of CT, CMS, and MS and the RJAR test have correct size, while the BCCH Sup Score test is undersized.
Fig. 1 PP Plots for Sparse IVs, homoscedastic errors, β = 1, .
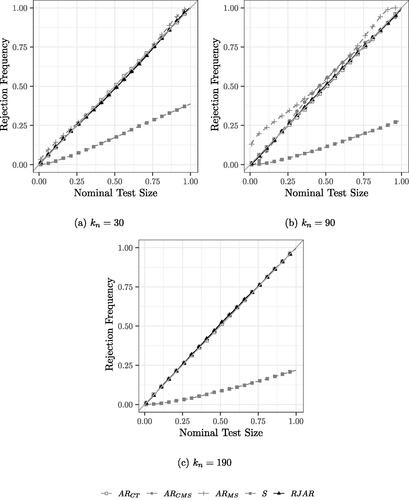
For the case of 90 IVs, the AR test of CT and the RJAR test control size. The AR test of CMS appears to control size for common small nominal test sizes (e.g., 0.05 or 0.1). The AR test of MS appears to be generally oversized. For example, at nominal level 0.05, the rejection frequency of the test is 0.189.Footnote9 The BCCH Sup Score test continues to be undersized.
For the case of 190 IVs, only the AR test of CT, the BCCH Sup Score test, and the RJAR test are feasible. As before, the BCCH Sup Score test is undersized, while the AR test of CT and the RJAR test have correct size.
4.2 Power
show the power of the tests when the number of IVs and the sparsity pattern of the first stage is varied. It is still the case that .
Fig. 2 Power curves for 30 IVs. Nominal test size of 5% indicated by the grey horizontal line. .
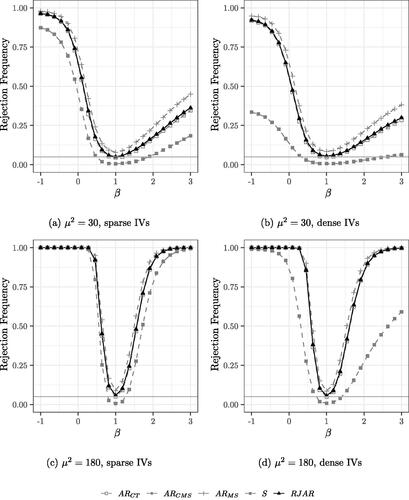
Fig. 3 Power curves for 90 IVs. Nominal test size of 5% indicated by the grey horizontal line. .
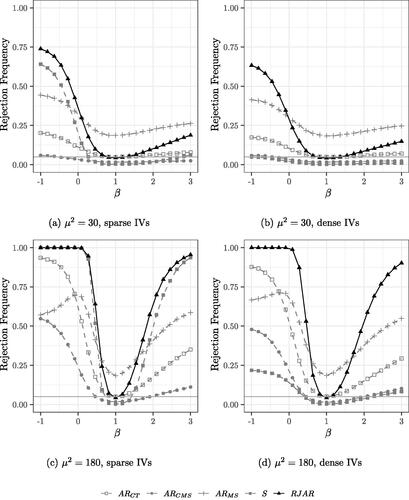
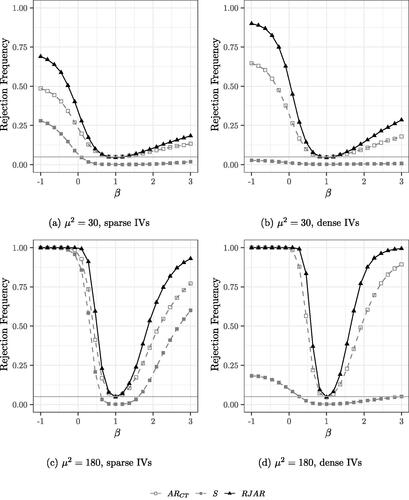
Fig. 4 Power curves for 190 IVs. Nominal test size of 5% indicated by the gray horizontal line. .
For the case of 30 IVs (), the AR tests of CT and CMS have similar power to the RJAR test, while MS is slightly more powerful than the RJAR test. The BCCH Sup Score test is less powerful than all other tests.
For the case of 90 sparse IVs (), the RJAR test is slightly more powerful than the BCCH Sup Score test. The AR test of MS fails to control the size, while the AR tests of CT and CMS exhibit power properties substantially worse than those of the BCCH Sup Score test and the RJAR test. For the case of 90 dense IVs (), the RJAR test is substantially more powerful than all other alternatives. For the case of 190 sparse and dense IVs (), the RJAR test is more powerful than the BCCH Sup Score test.Footnote10 The RJAR test is also more powerful than the AR test of CT. Thus, for all the DGPs that are considered here, the RJAR test is as powerful as existing methods whenever these are applicable, and sometimes much more powerful.
5 Empirical Application
We consider an empirical application based on Card (Citation2009). The coefficient of interest is given by βs in the following model:
(12)
(12) where yis is the difference between residual log wages for immigrant and native men in skill group s in city i,Footnote11 Xis is the log ratio of immigrant to native hours worked in skill group s of both men and women in city i, and Wi is a vector of city-level controls with coefficient vector δs, and
is the structural error. In the context of the production function specified in (Card Citation2009, sec. I), βs can be interpreted as the (negative) inverse elasticity of substitution between immigrants and natives in the United States in their respective skill group. As in Card (Citation2009), we consider two skill groups
(high school or college equivalent) separately.
Card (Citation2009) raises the concern that unobserved factors in a city may lead to both higher wages and higher employment levels of immigrants relative to natives, causing Xis to be endogenous. Card (Citation2009) proposes to use the ratio of the number of immigrants from country l in city i to the total number of immigrants from foreign country l in the United States as an IV. The rationale for these IVs is that existing immigrant enclaves are likely to attract additional immigrant labor through social and cultural channels unrelated to labor market outcomes. We consider two sets of IVs. First, we consider the original setup of Card (Citation2009), using as IVs the kn = 38 different countries of origin of the immigrants. Second, motivated by the saturation approach of Blandhol et al. (Citation2022), we consider the setup where these 38 original IVs are interacted with the q = 9 available controls (including a constant). This yields kn = 342 IVs. In both cases, the number of observations (i.e., the number of cities) is .Footnote12
We construct (weak-identification robust) confidence sets for βs by inverting the AR tests of CT, CMS, and MS, the Sup Score test, and the RJAR test. Thus, the 95% confidence set for any test is obtained as the collection of for which that test does not reject the null at 5% level of significance. As in the simulation exercise in Section 4, we search over values greater than 1 when choosing
in case rn < kn. Again cBCCH = 1.1 and
. The number of boostrap replications for the AR test of CT is set to 2,500. A grid of 100 values for
is used for
. Data is taken from a single cross section, as made available by Goldsmith-Pinkham, Sorkin, and Swift (Citation2020).
shows the confidence sets when kn = 38 for high-school workers and college workers. We find that , implying that no regularization is needed. This is in line with our simulations in Section 4, where we found that regularization was not needed to maximize the sum in Assumption 3 when
. Furthermore,
, and
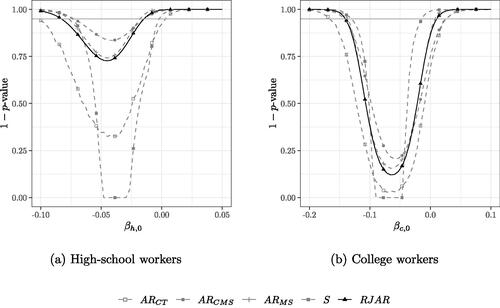
. We also point out that only three diagonal entries of P are larger than 0.9, which suggests that Assumption 3 is reasonably satisfied by part 2. of Proposition 3.1. The 95% confidence sets for each test are given by all the points below the grey horizontal line. The confidence sets for both skill groups broadly confirm the results in Card (Citation2009). We find that the confidence sets for high-school workers is smallest for the jackknifed AR statistic of CMS, whereas the BCCH Sup Score test yields the smallest confidence interval for the application to college workers. For both cases, the AR test of CT yields the largest confidence interval. Based on the power results in Section 4, this suggests a very sparse first stage for college workers, that is, a few nationalities being highly predictive of inflows of immigrant labor.
Fig. 5 95% confidence sets for βs for the application in (12) with kn = 38 IVs. .
.
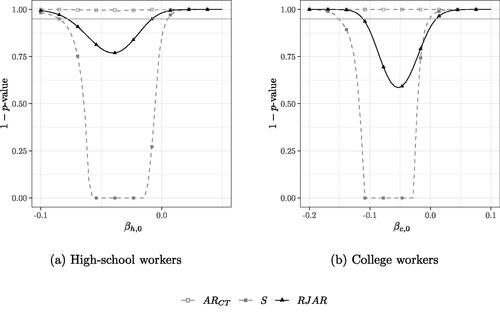
shows the confidence sets when for high-school workers and college workers, respectively. Since
, the jackknifed AR statistics of CMS and MS are not applicable. We find that
and
. The 95% confidence sets obtained by inverting the AR test of CT are empty for both βh and βc. This could be due to heteroscedasticity in the error terms. In line with the simulation results on power reported in Section 4, the RJAR test yields smaller confidence intervals than the BCCH Sup Score test. The qualitative conclusions with respect to the case of 38 IVs remain unchanged.
Fig. 6 95% confidence sets for βs for the application in (12) with kn = 342 IVs. .
Conclusion
We contributed to the literature on (very) many IVs in the cross-sectional linear IV model by proposing a new, ridge-regularized jackknifed AR test. Our test compares favorably with existing methods in the literature both theoretically, by allowing for high-dimensional IVs and weakening a common assumption on the IVs’ projection matrix, and practically, by having correct asymptotic size and displaying favorable power properties even when the number of IVs approaches or exceeds the number of observations.
Supplementary Materials
The supplementary material contains the proofs of the theoretical results reported in Section 3 of the article and the additional Monte Carlo simulation results mentioned in Section 4 of the article.
RJARSupplementaryMaterial (2).zip
Download Zip (5.3 MB)Acknowledgments
The views expressed herein are those of the authors and should not be attributed to the IMF, its Executive Board, or its management. We thank Frank Kleibergen, Damian Kozbur, Anna Mikusheva, Bent Nielsen and Alexei Onatski for useful comments and discussions.
Disclosure Statement
The authors report there are no competing interests to declare.
Additional information
Funding
Notes
1 Recent examples of applications with many IVs include Mueller-Smith (Citation2015), who uses judge dummies interacted with individual covariates as IVs to identify causal effects of incarceration; van Duijn and Rouwendal (Citation2021), who derive an equation for residential sorting that produces many more IVs than observations; and Lönn and Schotman (Citation2022), who derive structural asset-pricing models that lead to a vast number of moment conditions.
2 See Anatolyev and Yaskov (Citation2017) and Crudu, Mellace, and Sándor (Citation2020) for a discussion of the restrictiveness of the balanced-design assumption of Anatolyev and Gospodinov (Citation2011). See also Kaffo and Wang (Citation2017) for a bootstrapped version of the Anatolyev and Gospodinov (Citation2011) AR test.
3 Boot and Ligtenberg (Citation2023), Matsushita and Otsu (Citation2022), and Lim, Wang, and Zhang (Citation2024) propose weak-identification robust jackknife-based procedures for inference with many IVs. However, these methods make additional assumptions on the first-stage projection of the endogenous variables on the IVs, and hence fall outside of the scope of this article.
4 The treatment of IVs as non-stochastic is an assumption that has been commonly used in several of the papers that are most closely related to ours, see . With stochastic IVs, one can interpret the results as holding conditional on Z, see also CMS Footnote 1.
5 The AR statistic is defined as , where
is a consistent estimator of
.
6 It is difficult to allow for autocorrelated errors in our framework, since our proof relies on casting the RJAR statistic as a degenerate U-statistic, which requires that be independent of
for
.
7 More formally, suppose that W is an matrix of covariates with rank ln, and define
. Furthermore, let
be the
matrix of IVs prior to partialling out the controls W, and let
, such that
and
. Therefore, ln can diverge as
without contradicting
, which means that a growing number of exogenous controls can be accommodated.
8 Simulations in the supplementary material show that the results remain qualitatively unchanged if uncorrelated Gaussian IVs are considered instead.
9 Simulations in the supplementary material show that if n and kn are increased to about 1000 and 900, respectively, there is virtually no more size distortion.
10 The poor power of the BCCH Sup Score is likely a consequence of the Union Bound underlying their Lemma 5. We note that the poor power properties of the BCCH Sup Score are acknowledged in BCCH, and are what leads them to recommend using their main estimator (Post-LASSO two-stage least squares) whenever weak identification is not a concern, and the first stage is sufficiently sparse.
11 As discussed in (Card Citation2009, p. 11, footnote 17), residual wages are wages once observed characteristics of the entire U.S. workforce are controlled for.
12 We note that the controls and the IVs are at the city level, and hence the same for the applications to high-school workers and college workers. Therefore, the projection matrix and the ridge-regularized projection matrix will also be the same across these two skill groups.
References
- Anatolyev, S., and Gospodinov, N. (2011), “Specification Testing in Models with Many Instruments,” Econometric Theory, 27, 427–441. DOI: 10.1017/S0266466610000307.
- Anatolyev, S., and Yaskov, P. (2017), “Asymptotics of Diagonal Elements of Projection Matrices Under Many Instruments/Regressors,” Econometric Theory, 33, 717–738. DOI: 10.1017/S0266466616000165.
- Anderson, T., and Rubin, H. (1949), “Estimation of the Parameters of a Single Equation in a Complete System of Stochastic Equations,” The Annals of Mathematical Statistics, 20, 46–63. DOI: 10.1214/aoms/1177730090.
- Andrews, D., and Stock, J. (2007), “Testing with Many Weak Instruments,” Journal of Econometrics, 138, 24–46. DOI: 10.1016/j.jeconom.2006.05.012.
- Bai, J., and Ng, S. (2010), “Instrumental Variable Estimation in a Data Rich Environment,” Econometric Theory, 26, 1577–1606. DOI: 10.1017/S0266466609990727.
- Bekker, P., and Crudu, F. (2015), “Jackknife Instrumental Variable Estimation with Heteroskedasticity,” Journal of Econometrics, 185, 332–342. DOI: 10.1016/j.jeconom.2014.08.012.
- Belloni, A., Chen, D., Chernozhukov, V., and Hansen, C. (2012), “Sparse Models and Methods for Optimal Instruments With an Application to Eminent Domain,” Econometrica, 80, 2369–2429.
- Blandhol, C., Bonney, J., Mogstad, M., and Torgovitsky, A. (2022), “When is TSLS Actually LATE?” Becker Friedman Institute Working Papers (2022-16), 1–68.
- Boot, T., and Ligtenberg, J. (2023), “Identification- and Many Instrument-Robust Inference via Invariant Moment Conditions,” arXiv preprint arXiv:2303.07822.
- Bun, M., Farbmacher, H., and Poldermans, R. (2020), “Finite Sample Properties of the GMM Anderson-Rubin Test,” Econometric Reviews, 39, 1042–1056. DOI: 10.1080/07474938.2020.1761149.
- Burgess, S., and Thompson, S. G. (2021), Mendelian Randomization: Methods for Causal Inference Using Genetic Variants, Boca Raton, FL: CRC Press.
- Card, D. (2009), “Immigration and Inequality,” American Economic Review Papers and Proceedings, 99, 1–21. DOI: 10.1257/aer.99.2.1.
- Carrasco, M., and Tchuente, G. (2016), “Regularization Based Anderson Rubin Tests for Many Instruments,” University of Kent, School of Economics Discussion Papers (1608), 1–34.
- Chao, J., Swanson, N., Hausmann, J., Newey, W., and Woutersen, T. (2012), “Asymptotic Distribution of JIVE in a Heteroskedastic IV Regression with Many Instruments,” Econometric Theory, 28, 42–86. DOI: 10.1017/S0266466611000120.
- Crudu, F., Mellace, G., and Sándor, Z. (2020), “Inference in Instrumental Variable Models with Heteroskedasticity and Many Instruments,” Econometric Theory, 77, 1–30. DOI: 10.1017/S026646662000016X.
- Davies, N. M., von Hinke Kessler Scholder, S., Farbmacher, H., Burgess, S., Windmeijer, F., and Smith, G. D. (2015), “The Many Weak Instruments Problem and Mendelian Randomization,” Statistics in Medicine, 34, 454–468. DOI: 10.1002/sim.6358.
- Gabaix, X., and Koijen, R. (2020), “Granular Instrumental Variables,” NBER Working Paper Series (28204), 1–98.
- Goldsmith-Pinkham, P., Sorkin, I., and Swift, H. (2020), “Bartik Instruments: What, When, Why, and How,” American Economic Review, 110, 2586–2624. DOI: 10.1257/aer.20181047.
- Hansen, C., and Kozbur, D. (2014), “Instrumental Variables Estimation with Many Weak Instruments Using Regularized JIVE,” Journal of Econometrics, 182, 290–308. DOI: 10.1016/j.jeconom.2014.04.022.
- Kaffo, M., and Wang, W. (2017), “On Bootstrap Validity for Specification Testing with Many Weak Instruments,” Economics Letters, 157, 107–111. DOI: 10.1016/j.econlet.2017.06.004.
- Kapetanios, G., Khalaf, L., and Marcellino, M. (2015), “Factor-Based Identification-Robust Interference in IV Regressions,” Journal of Applied Econometrics, 31, 821–842. DOI: 10.1002/jae.2466.
- Lim, D., Wang, W., and Zhang, Y. (2024), “A Conditional Linear Combination Test with Many Weak Instruments,” Journal of Econometrics, 238, 105602. DOI: 10.1016/j.jeconom.2023.105602.
- Lönn, R., and Schotman, P. (2022), “Empirical Asset Pricing with Many Assets and Short Time Series,” SSRN, 1–53.
- Matsushita, Y., and Otsu, T. (2022), “A Jackknife Lagrange Multiplier Test with Many Weak Instruments,” Econometric Theory, 1–24. DOI: 10.1017/S0266466622000433.
- Mikusheva, A., and Sun, L. (2022), “Inference with Many Weak Instruments,” Review of Economic Studies, 1–37 (forthcoming).
- Mueller-Smith, M. (2015), “The Criminal and Labor Market Impacts of Incarceration,” mimeo, 1–59, University of Michigan.
- Phillips, P. C. B., and Gao, W. Y. (2017), “Structural Inference from Reduced Forms with Many Instruments,” Journal of Econometrics, 199, 96–116. DOI: 10.1016/j.jeconom.2017.05.003.
- van Duijn, M., and Rouwendal, J. (2021), “Sorting Based on Urban Heritage and Income: Evidence from the Amsterdam Metropolitan Area,” Regional Science and Urban Economics, 90, 1–18. DOI: 10.1016/j.regsciurbeco.2021.103719.