
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The Unconditional Quantile Regression (UQR) method, initially introduced by Firpo et al. has gained significant traction as a popular approach for modeling and analyzing data. However, much like Conditional Quantile Regression (CQR), UQR encounters computational challenges when it comes to obtaining parameter estimates for streaming datasets. This is attributed to the involvement of unknown parameters in the logistic regression loss function used in UQR, which presents obstacles in both computational execution and theoretical development. To address this, we present a novel approach involving smoothing logistic regression estimation. Subsequently, we propose a renewable estimator tailored for UQR with streaming data, relying exclusively on current data and summary statistics derived from historical data. Theoretically, our proposed estimators exhibit equivalent asymptotic properties to the standard version computed directly on the entire dataset, without any additional constraints. Both simulations and real data analysis are conducted to illustrate the finite sample performance of the proposed methods.
1 Introduction
Quantile regression (QR) models proposed by Koenker and Bassett (Citation1978) are more robust to outliers than the classical mean regression models, and any quantile can be used in any part of the outcome distribution. The most commonly used QR framework is the conditional quantile regression (CQR). It is used to assess the impact of a covariate on a quantile of the outcome conditional on specific values of other covariates (Jiang and Yu Citation2023). CQR is widely seen as an ideal tool to understand complex predictor-response relations, however, CQR models do not average up to their unconditional population counterparts. As a result, the estimates obtained cannot be used to estimate the impacts of an explanatory variable X on the corresponding unconditional quantile of the outcome variable Y. To overcome this restriction, Firpo et al. (Citation2009) proposed a regression of the (recentered) influence function of the unconditional quantile of the Y on the X, or UQR estimates the impact of changing the distribution of Y on marginal distribution of X. The advantage of the UQR model is that the quantiles are defined preregression; therefore, the model is not influenced by any right-hand-side variables. In UQR, one can, for instance, include fixed effects to adjust for selection bias without redefining the quantiles (Borgen Citation2016). The UQR method has attracted substantial attention in statistics and econometrics with many applications in different fields. By January 2023, Firpo et al. (Citation2009) has attracted 2500+ Google Scholar citations, such as Ghosh (Citation2021), Inoue, Li, and Xu (Citation2021), Sasaki, Ura, and Zhang (Citation2022), and Martinez-Iriarte, Montes-Rojas, and Sun (Citation2022) and so on.
In spite of its rapidly growing popular method for modeling and analyzing data, however, UQR faces challenges to obtaining parameter estimates from “big data.” The concept of “big data” may have different meanings to people from different fields and has since become a dominant topic in nearly all academic disciplines and in applied fields. In a broad sense, big data is data on a larger scale in terms of volume, variety, velocity, variability, and veracity. In this article, we consider one type of big data: streaming data, which grows rapidly in volume and velocity. Due to the explosive growth of data onto nontraditional sources such as mobile phones, social networks and e-commerce, streaming data is becoming a core component of big data analysis.
Streaming data grows rapidly in volume and velocity. Then storing and combing data becomes increasingly challenging. To reduce the demand on computing memory and achieve real-time processing, the nature of streaming data calls for the development of algorithms which require only “one pass” over the data. This means that in order to reduce storage requirements and computation time, data is only used once. Therefore, the primary goal of processing such streaming data is to sequentially update some statistics of interest upon the arrival of a new data batch, in the hope to not only free up space for the storage of massive historical individual-level data, but also provide real-time inference and decision-making. Online updating approaches are distinct from the massive data analysis because they target problem where data arrive in streams or large chunks and address statistical problems in an updating framework without storage requirements for previous data, as shown in . There are three online updating methods for analyzing streaming data in the literature as follows: average updating methods (Schifano et al. Citation2016), subsampling methods (Xie, Bai, and Ma Citation2023) and renewable methods based on estimation equations (Luo and Song Citation2020). The average updating methods developed in Schifano et al. (Citation2016) require the total number of batches smaller than the sample size of each batch to establish the same statistical properties as that of the oracle estimators with the full datasets, see Theorem B.1 in the Appendix, supplementary materials. This means that streaming data cannot be unlimited, which is not very suitable for the practical application of streaming data. The estimators obtained by subsampling-based approaches are -consistent instead of
-consistent, where
is the sample size of subsample and n is the sample size of all data, see Wang, Min, and Stufken (Citation2019) and Xie, Bai, and Ma (Citation2023). This means that there is information loss in this method. The estimators obtained by the renewable methods based on estimation equations in Luo and Song (Citation2020) can achieve
-consistent and overcome the above unnatural restriction for average updating methods. Other references on the online updating methods can see Deshpande, Javanmard, and Mehrabi (Citation2023), Luo, Zhou, and Song (Citation2023), Yang and Yao (Citation2023) and so on.
Fig. 1 Online-updating algorithm for streaming datasets.
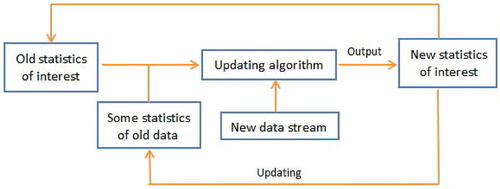
Specifically, the difficulties faced in analyzing UQR under streaming data are as follows.
First, it is difficult to perform standard logistic regression based on the loss function (3.4) in Section 3 under streaming data according to the term . Although the method in Luo and Song (Citation2020) can be used to construct a renewable estimator, due to the term
, the error of the estimator of
increases as the number of streams increases. To solve the above problem, we adopt a smoothing technique to smooth the above indicative function, which helps to reduce the error from
to
, so that the error can be ignored. The smoothing technique are often used in QR, see Horowitz (Citation1998), Chen, Liu, and Zhang (Citation2019), Fernandes, Guerre, and Horta (Citation2021), He et al. (Citation2023) and so on. But, to the best of our limited knowledge, there is no literature on the application of smoothing technique to UQR.
Second, as we all known that the bandwidth h is important for the kernel density estimator (3.6) in Section 3, and it depends on the sample size. For streaming data, we cannot know the total sample size at the beginning, so h needs to change with the arrival of new data. Kong and Xia (Citation2019) developed an online density estimate with a single point of update. In this article, we extend the single point update estimation method to batch update estimation. Moreover, the kernel density estimator (3.6) contains , thus, we take Taylor expansion to construct a renewable estimator.
Finally, the unconditional quantile partial effect defined in (3.3) involves the quantile of Y. The above methods for streaming data based on the least squares or estimating equations are not suitable for the QR because the quantile regression estimator has no display expression like the least squares estimator and the loss function of the quantile regression is not differentiable, even though loss function needs to be second-order differentiable in the estimation equation (Luo and Song Citation2020). In order to overcome the non-differentiable of the QR loss function, Jiang and Yu (Citation2022) used a convolution-type smoothing method to develop a renewable estimation. Chen, Liu, and Zhang (Citation2019) and Wang, Wang, and Li (Citation2022) also studied QR estimation for streaming data. However, their methods are all required additional strict conditions on the sample size of each bath. In this article, we adjust method of Jiang and Yu (Citation2022) to estimate in the (3.3).
To summarize, we develop a renewable estimation for UQR. Our statistical contributions include: (i) Note that the loss function (3.4) in Section 3 is different to the standard logistic regression according to the term . Therefore, the method of Luo and Song (Citation2020) does not work. To solve the above problem, we adopt a smoothing technique to smooth the above indicative function, which helps to produce a renewable estimator. (ii) We develop a renewable kernel density estimator and a renewable QR estimator. (iii) We propose a renewable UQR estimation that only requires the availability of the current data batch in the data stream and sufficient statistics on the historical data at each stage of the analysis. The asymptotic properties of the proposed renewable estimator under the conditions are similar to those in an offline setting and no restrictions on number of batches, which means that the new methods are adaptive to the situation where streaming datasets arrive fast and perpetually.
The remainder of this article is organized as follows. Section 2 presents a motivational example. The review of the standard UQR is given in Section 3. In Section 4, the streaming datasets analysis method is proposed. Both simulation studies and empirical applications are given in Sections 5 and 6 to illustrate the proposed procedures. We conclude the article with a brief discussion in Section 7. All technical proofs are deferred to the Appendix, supplementary materials.
2 Motivating Example
We exemplify the application of streaming data in economics using the following stock price and exchange rate data.
As the process of financial globalization continues to deepen, the financial markets of various countries become increasingly interconnected, underscoring the pivotal role of the exchange rate system in the capital market. The exchange rate represents the international price of a country’s currency. Changes in the exchange rate signify alterations in the international purchasing power of the currency, making it a crucial policy tool for maintaining national economic security and ensuring financial stability. Stock prices act as a “barometer” of macroeconomics, offering timely reflections of microeconomic changes. The fluctuation in exchange rates not only impacts the macroeconomic operations of a country but also influences the behavior of microeconomic entities, subsequently affecting the stock prices of companies. A comprehensive understanding of the relationship between exchange rates and stock indexes is instrumental for countries and international organizations to manage their exposure to foreign exchange risks. Moreover, it proves invaluable for investors seeking to hedge or predict returns on their foreign investments.
The relationship between the foreign exchange market and the stock market has garnered significant attention from scholars. Bahmani-Oskooee and Sohrabian (Citation1992) used Granger causality tests and co-integration methods to investigate the connection between the foreign exchange market and the stock market in the United States. The research indicates the presence of a short-term two-way causal relationship. Pan, Fok, and Liu (Citation2007) delved into East Asia using data from January 1988 to October 1998, discovering that, before the Asian financial crisis in 1997, there was a causal relationship from the exchange rate to the stock market in Hong Kong, Japan, Malaysia, and Thailand. Additionally, there was a causal relationship from the stock market to the exchange rate in Hong Kong, South Korea, and Singapore. Amba and Nguyen (Citation2019) examined the relationship between stock prices and exchange rates in the Mexican and Canadian markets, employing weekly data from January 2013 to December 2018. The Granger causality test affirmed the existence of a short-term one-way causal relationship between exchange rates and stock prices in the Mexican market.
In this section, we will provide a detailed introduction to the Chinese A-share stock market and explore the relationship between daily stock returns and exchange rates. China’s A-share stock market, encompassing the Shenzhen Stock Exchange and Shanghai Stock Exchange, was officially established in 1990. The trading data within the stock industry is substantial, reaching the gigabyte level. As of March 31, 2023, the A-share market in China comprises 4495 stocks, with 1824 listed on the Shanghai Stock Exchange and 2671 on the Shenzhen Stock Exchange. A study by Zhang and Li (Citation2010) investigated the correlation between exchange rate changes and the stock market in China post the reform of the exchange rate system and the split structure of the stock market in 2005. The study revealed a long-term co-integration relationship between the exchange rate and the stock market. The results indicate that, in the long run, the relationship between exchange rate changes and the stock market primarily follows the flow-oriented model, with the Shanghai A-share index being more noticeably affected by exchange rates. Both stock transaction and exchange rate datasets undergo real-time changes with each transaction, adhering to the typical characteristics of streaming data: (a) the data object is real-time and online; (b) the scale of the data is extensive and theoretically limitless, making it optimal to read each data object only once, thereby reducing data storage requirements. Simultaneously, both institutional and individual investors seek real-time insights into the stock market. Consequently, the analysis of stock trading data should offer real-time analysis functions. Fulfilling these requirements is unattainable with traditional data analysis techniques.
For instance, when examining the relationship between the daily returns in the Shanghai Stock Exchange in China and the exchange rate between the Chinese currency and the US dollar, we can collect approximately 1600 data points per day (excluding suspended trading and stocks under special treatment). Considering the 871 trading days between January 1, 2020, and August 25, 2023, the total data volume amounts to 1,339,591. If we break down the data per minute, the volume becomes (accounting for the 4 hr of daily trading). As established in Section 6.2, analyzing 1,339,591 data points takes 65.37 sec, indicating that processing minute-level data, totaling 321,501,840, would certainly exceed a minute, which is deemed unacceptable. However, employing stream data analysis techniques, specifically update estimation methods, allows for the processing of the last batch of incoming data and some statistics from past data, resulting in an analysis time of just 0.02 sec. Whether considering daily or minute data, the volume of the last batch typically hovers around 1600, making this approach highly efficient.
3 Standard Unconditional Quantile Regression
In this section, we first review the standard unconditional quantile regression with full data (assuming that streaming data can be pooled into a dataset and can be analyzed and stored by a computer). Consider a general structural model:
(3.1)
(3.1) where the unknown mapping
is invertible on the second argument,
is an unobservable determinant of the outcome variable Y and X is a p-dimensional covariates.
According to the definition in Firpo et al. (Citation2009), we use another name unconditional quantile partial effect () for UQR. The
at quantile level τ proposed by Firpo et al. (Citation2009) is defined as
where
is the distribution function of X,
is the recentered influence function,
is the indicator function,
and
are the τth quantile and the density function of Y, respectively. Assume that
(3.2)
(3.2)
where
and
is the logistic distribution function. Then, by the assumption (3.2),
is equal to
(3.3)
(3.3)
where
is the derivative of
. Note that the assumption (3.2) is the assumption 11 in Firpo et al. (Citation2009) and (3.3) is the RIF-Logit in Firpo et al. (Citation2009).
We first review the standard estimation method of in Firpo et al. (Citation2009). Let
be an iid sample from
in model (3.1). Based on the assumption (3.2), the estimator of
based on
is
(3.4)
(3.4) where
is the estimator of
as
(3.5)
(3.5)
where
is the check loss function. Moreover, the kernel density estimator for the density of Y at
is
(3.6)
(3.6)
where
is a smooth kernel function and h is a bandwidth.
Then, the estimator of based on (3.3)–(3.6) is
(3.7)
(3.7)
4 Streaming Datasets Analysis
Now let us discuss how to develop a renewable estimator for based on streaming datasets. Assume we have the streaming datasets
up to the bth batch, where
is the jth batch dataset with a sample size of Nj. We suppose that the
for all is and js are iid samples from
in model (3.1). The sample size up to the bth batch is
.
The key idea of the following renewable estimation is to use the Taylor expansion of the score function so that the new estimation equation uses only the combined information of the previous data and the data of the current batch. In the non-differentiable case, smoothing techniques will be used to enable Taylor expansion of the scoring function.
4.1 Estimate  for Streaming Datasets
for Streaming Datasets
Note that for a quantile regression, the loss function is non-differentiable. Therefore, the QR estimator has no display expression, so it is impossible to construct a renewable estimator for streaming data. To circumvent the non-differentiable of the QR loss function, we smooth quantile regression loss function
to a twice continuously differentiable function (Nadaraya Citation1964; Fernandes, Guerre, and Horta Citation2021):
(4.1)
(4.1)
For example, we take Logistic kernel in (4.1), the explicit expression of
is
. By (4.1), the
based on
satisfies,
(4.2)
(4.2) which is the derivative of
on dataset
, and where
and
is a bandwidth for jth batch. We propose a new estimator
for streaming data
as a solution to the equation of the form
(4.3)
(4.3)
which is according to
where the last equation is according to (4.2),
means bounded with probability and the error term
is asymptotically ignored.
Generalizing (4.3) to streaming datasets , a renewable estimator
of
is defined as a solution to the following incremental estimation equation:
(4.4)
(4.4) where
. The asymptotic property of
can see Lemma 2 in the Appendix, supplementary materials. Numerically, it is quite straightforward to find
from (4.4) using the Newton-Raphson method as
(4.5)
(4.5)
Only one iteration in (4.5) is due to that is
-consistent by Lemma 2 in the Appendix, supplementary materials and condition
for
. Therefore, the estimators
can converge in one iteration.
4.2 Estimate for Streaming Datasets
It is easy to estimate based on the first batch as
where
is a bandwidth for the jth batch. When the next data
arrive, the estimator of
should be
As we all known that we can not know the sample size of next batch, thus, it is difficult to use in
because of
always depending on
. We will prove in Theorem 4.1 that the following estimator is also effective
Moreover, we use Taylor expansion to in
as
where
is the derivative of
and
. Then, we can obtain the estimator of
based on
and
as
Generalizing the above method to streaming datasets , a renewable estimator
of
is defined as
(4.6)
(4.6) where
and
.
The item in (4.6) is to extend the single point update estimation method in Kong and Xia (Citation2019) to batch update estimation, and the term
makes approximate to the density estimation of point
. To reveal the merits of the proposed method, we now establish the asymptotic normality of
.
To establish the asymptotic properties of the proposed estimator, the following technical conditions are imposed.
C1. Density function is positive and has second-order derivative, whose second-order derivative is bounded and continuous in a neighborhood of a grid of selected points
. Moreover,
.
C2. The kernel function is even, integrable, and twice differentiable with bounded first and second derivatives such that
and
.
Remark 4.1.
Conditions C1 and C2 are Assumptions 2, 3, 6, and 7 in Firpo et al. (Citation2009). The Logistic kernel satisfies condition C2.
Theorem 4.1.
Assume that conditions C1 and C2 hold. If and
with
and
for
, where b can be a fixed number or a divergent number, we have
where
and
means
with a positive and bounded constant c.
If , we have
Note that by Lemma 1 in the Appendix, supplementary materials, we obtain the same convergence rate and asymptotic variance as the full data estimator (3.6).
4.3 Estimate for Streaming Datasets
Note that (3.2), the estimate contains
. Thus, it is difficult to construct the estimator of
according to indicative function
with unknown parameter
. Therefore, we approximate the indicator factor
in the score equation with a smooth function
and h is the bandwidth. For the first streaming data
, the smoothing logistic regression estimator
satisfies,
(4.7)
(4.7) where hj is a bandwidth for the jth batch and
is the up to jth batch estimator of
in Section 4.1. In the Lemma 3 in the Appendix, supplementary materials, we prove that
achieves optimal efficiency and its asymptotic covariance matrix is the same as that of estimator in (3.4) by ordinary logistic regression estimator.
Then, for streaming data
satisfies the following aggregated score equation:
(4.8)
(4.8) where
. Note that
in (4.8) should be
, we can prove that the difference between h1 and h2 in (4.8) can be ignored, see the proof of Theorem 4.2 in the Appendix, supplementary materials.
Solving (4.8) for actually involves the use of subject-level data in both
and
, where
may no longer to accessible. Our renewable estimation is able to handle this issue. To proceed, we take the first-order Taylor series expansion of the
around
and
as
(4.9)
(4.9) where the last equation is according to (4.7),
,
is the derivative of
and
.
By (4.8) and (4.9), and removing the asymptotically ignored term , we propose a new estimator
as a solution to the equation of the form
(4.10)
(4.10)
Generalizing the (4.10) to streaming datasets , a renewable estimator
of
is defined as a solution to the following incremental estimation equation:
(4.11)
(4.11) where
and
. Through (4.11), the initial
is renewed by
only using the historical summary statistics, including sample variance matrices
and estimators
instead of the subject-level raw datasets
. Numerically, it is quite straightforward to find
from (4.11) using the Newton-Raphson method as
(4.12)
(4.12)
where only one iteration in (4.12) is due to that
is
-consistent and condition
for
in the following Theorem 4.2. Therefore, the estimators
can converge in one iteration.
To establish the asymptotic property of the proposed estimator , the following technical conditions are imposed.
C3. Conditional density function is bounded away from zero and Lipschitz continuous in a neighborhood of a grid of selected points
.
C4. is a positive definite matrix.
C5. The smoothing function is twice differentiable and its second derivative is bounded. Moreover, (i)
if u > 1 and
if
and
. (ii)
,
and
, where
is the second derivative of
.
Remark 4.2.
Condition C3 is a smoothing condition of the conditional density function , which is a standard condition for smoothing method, see Jiang and Yu (Citation2021). The condition C4 ensures that
exists. Condition C5 is a mild condition on
for smoothing approximation. For example, a biweight kernel
satisfies condition C5.
Theorem 4.2.
Assume that conditions C1–C5 hold. If and
with
, for
, where b can be a fixed number or a divergent number, we have
where
and
.
Through the result of Theorem 4.2, it is interesting to notice that the renewable estimator achieves optimal efficiency and its asymptotic covariance matrix is the same as that of estimator
in (3.4) which is computed directly on all the samples, as shown in Firpo et al. (Citation2009). This implies that the proposed renewable estimator achieves the same asymptotic distribution as
.
4.4 Estimate for Streaming Datasets
Finally, we estimate based on the streaming datasets
by (4.5), (4.6), (4.12) and Taylor series expansion of the
as
where
and
is the derivative of
. Thus, we can obtain a renewable estimator of
as
(4.13)
(4.13)
Theorem 4.3.
Assume that conditions in Theorems 4.1 and 4.2 hold, we have
(4.14)
(4.14) where
and
.
From the analysis in Theorem 4.1, which is the same convergence rate as the full data estimator h. Thus,
is equal to
. Therefore, the renewable estimator
achieves optimal convergence speed and its asymptotic covariance matrix is the same as that of the estimator
in (3.7) which is computed directly on all the samples.
We can estimate the in (4.14) by a renewable estimator as
where
,
,
,
,
is the ith of
and
.
From Theorems 4.1–4.3, we can see that there are no restrictions on the number of batches b, so b can be a very large number, even greater than .
4.5 Algorithm
We summarize the general algorithm for the proposed renewable method to estimate by (4.13)) as follows.
Algorithm 1:
Renewable estimation for streaming datasets.
1: Input: streaming datasets , the quantile level τ, kernel function
, smoothing function
and bandwidths
, hb with
;
2: Initialize: calculate by Fernandes, Guerre, and Horta (Citation2021) with
by (4.7) with
and compute
, and
;
3: for: do
4: read in dataset ;
5: obtain by (4.5);
6: obtain and
by (4.6) and (4.12) with
, respectively;
7: compute by (4.13);
8: update to
;
9: save , and
, and release dataset
and other statistics from the memory;
10: end
11: Output: .
Note that in step 9 in Algorithm, we only need to save and
. The scale of the data to be stored is
instead of
, which is the sample size of the streaming datasets up to b batches. Because p is assumed to be a fixed number in this article, our method greatly reduces the amount of data storage.
5 Simulation Studies
In this section, we use Monte Carlo simulation studies to assess the finite sample performance of the proposed procedures in Sections 4. All programs are written in R code. We generate data from the following linear model:
(5.1)
(5.1) where
is a covariate vector and
are drawn from a normal distribution N(0, 1). The true value of the parameter is
. Three error distributions of
are considered: a standard normal distribution N(0, 1), a t distribution with 3 degrees of freedom t(3) which is a symmetric thick-tailed distribution and a Chi-square distribution with 1 degree of freedom
which is a skewed distribution. Quantile levels
are considered in all of the simulation experiments. Simulation results are all the average of 200 simulation replications.
For streaming datasets, we fix the sample size of each batch Nj = 500 for and vary the number of batches
. Then the total sample size is
. We take the Logistic kernel
and
as used in He et al. (Citation2023), and choose
for
as in Jiang and Yu (Citation2022).
5.1 Choosing the Bandwidths for the Density Estimations
We first study the selection of bandwidths for density estimations by f-Streaming (4.6). From Theorems 4.1, we choose as
(5.2)
(5.2) where C > 0 is the scaling constant. We vary the constant C from 0.1 to 100. We use the relative absolute errors (RAE=
) to evaluate the performance of the different estimation methods. We only consider
for model (4.1) because of
under this case. Then
at
are 0.0663, 0.1508, and 0.0663, respectively.
The simulation results of RAEs are shown in . (i) As can be seen from that C = 10 is a good choice for because of smallest RAEs in most cases. (ii) The method (4.6) of density estimation for streaming data is effective and very close to f-All (the full data estimation by (3.6)) in case C = 10.
Table 1 The means and standard deviations (in parentheses) of the RAEs (×100) for f-Streaming under different C, quantile levels and
for simulation study 5.1.
5.2 Study the Sensitivity of to Bandwidths
We study the sensitivity of in (4.13) to bandwidths
. From Theorem 4.3, we choose
similar to
for
, where C > 0 is the scaling constant. We vary the constant C from 0.01 to 100.
To evaluate the performance of the different estimation methods, we calculate the root-mean-square error (RMSE):
(5.3)
(5.3) where the true value
is
under settings of model (5.1). According to the analysis of Section 5.1, we choose
for
. The simulation results of the RMSE in show that the performances of
are better under
than those of
, and
is insensitive to bandwidths
under
. Therefore, we can choose
based on the smallest RMSEs in most cases for
.
Table 2 The means and standard deviations (in parentheses) of the RMSEs (×100) under different C, quantile levels and errors for simulation study 5.2.
5.3 Simulation Studies for Renewable Estimation Methods
Building upon the analysis in Sections 5.1 and 5.2, we proceed to investigate the performance of the proposed renewable estimation method. In order to assess the effectiveness of various estimation methods, we compute the Root Mean Square Error (RMSE) as outlined in (5.3), along with the corresponding computation time in seconds. It’s worth noting that, for brevity, we only present the computation time for the normal error, as the computation time for different errors is closely comparable.
The simulation results presented in lead to the following conclusions:
Table 3 The means and standard deviations (in parentheses) of the RMSEs (×100) under different estimation methods, quantile levels and b for simulation study 5.3 with
.
Table 4 The means and standard deviations (in parentheses) of the RMSEs (×100) under different estimation methods, quantile levels and b for simulation study 5.3 with
.
Table 5 The means and standard deviations (in parentheses) of the RMSEs (×100) under different estimation methods, quantile levels and b for simulation study 5.3 with
.
Table 6 The means of computing time t (in seconds) under different estimation methods, quantile levels and b for simulation study 5.3 with
.
(i) Regarding the RMSEs in , both UQPE-A (using the all data estimator (3.7)) and UQPE-S (our proposed renewable estimator for streaming data (4.13)) closely approximate the true values. The RMSE results are consistently small across various numbers of batches b, quantile levels τ, and errors. Notably, UQPE-S demonstrates proximity to UQPE-A in terms of accuracy. (ii) Examining the computation time t in , it is evident that UQPE-S is significantly faster to compute than UQPE-A across all scenarios. (iii) As the number of batches b increases, RMSEs decrease, and computation time t expands, aligning with expectations.
6 Empirical Application
6.1 Labor Income and Minimum Wage Dataset
To illustrate the proposed methods in Sections 4, we employ a substantial sample consisting of 941,174 observations derived from the 2011 to 2020 Current Population Survey (CPS)-merged outgoing rotation group earnings data. This dataset is accessible online for replication at https://www.nber.org/research/data/current-population-survey-cps-merged-outgoing-rotation-group-earnings-data. Additionally, we use a dataset documenting the minimum wage (minimum hourly wage) set by U.S. states from 2011 to 2020, obtainable at http://www.dol.gov/whd/state/stateMinWageHis.htm. This dataset is also considered streaming data, as data continually enters the stream over time, resulting in a substantial volume of data. The objective is to evaluate the effects of Minwage (minimum wage) on the quantile of the unconditional distribution of log wages. In this application, (log hourly wage),
(our focal covariate), and other covariables include
(1 for female and 0 for male),
(the highest grade completed),
(marital status), and
(full-time or part-time status). Additional details on data processing can be found at https://data.nber.org/morg/docs/cpsx.pdf.
The minimum wage system serves as a government policy tool aimed at adjusting income distribution in the primary stage and is often a crucial means of poverty alleviation. Numerous scholars in the literature have delved into the CPS dataset and examined the minimum wage. For instance, Lee (Citation1999) used CPS data spanning from 1979 to 1989 to explore the relationship between labor income (hourly wage) and the minimum wage. Their analysis suggests that the minimum wage can significantly contribute to the increase in dispersion in the lower tail of the wage distribution, especially for women. In a similar vein, Dube (Citation2019) examined individual-level data from the CPS covering the period between 1984 and 2013. Their study provided an assessment of how U.S. minimum wage policies impact the distribution of family incomes for the non-elderly population. They comprehensively characterized how minimum wage increases shift the cumulative distribution of family incomes, subsequently using this information to estimate the unconditional quantile partial effects (UQPE) of the policy.
For comparison with standard OLS (conditional mean) estimates and with standard (conditional) quantile regressions (CQR), we use the following linear model for OLS and CQR:
(6.1)
(6.1) where
. The mean relative absolute errors (MRAE=
) of OLS and CQR with quantile level 0.5 are 5.318% and 5.317%, respectively. Therefore, model (6.1) is assumed to be reasonable for OLS and CQR. reports the estimated coefficients of model (6.1) by methods OLS, UQPE-A, and CQR for the 10th, 50th, and 90th quantiles, which shows the difference between conditional and unconditional quantiles regressions.
Table 7 The estimated coefficients by methods OLS, CQR, UQPE-A, UQPE-S-Year, and UQPE-S-Month for Labor income and minimum wage dataset.
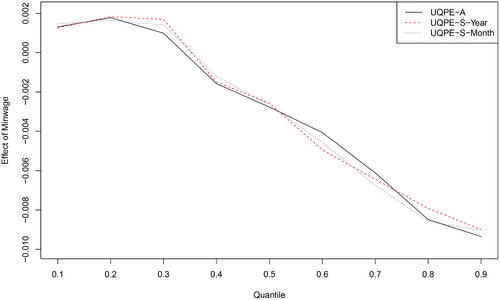
Next, we consider the proposed method UQPE-S in Sections 4. Since the data of minimum wage is recorded in years and the data of CPS is recorded in months, we consider b = 10 (year) and 120 (month), respectively. The data of 2011 and January 2011 are regarded as for UQPE-S-Year (b = 10) and UQPE-S-Month (b = 120), respectively. The difference between the estimated effect of Minwage for UQPE-A, UQPE-S-Year and UQPE-S-Month is illustrated in , which plots at nine different quantiles (from the 10th to the 90th). From and , we can see that the estimated coefficients and the effects of Minwage on log wages under different quantiles by UQPE-A, UQPE-S-Year, and UQPE-S-Month are all very close.
Fig. 2 The estimates of the effect of Minwage on log wages by UQPE-A, UQPE-S-Year, and UQPE-S-Month for Labor income and minimum wage dataset.
Finally, as with the streaming data setup, when the last batch of data arrives (2020 and December 2020 are regarded as for UQPE-S-Year (b = 10) and UQPE-S-Month (b = 120), respectively), the total running time of UQPE-A with nine quantiles is also 52.98 sec, which needs to compute all the data. However, UQPE-S-Year is 0.87 sec and UQPE-S-Month is 0.08 sec, because only
and some past statistics are required. In addition, for the setting of massive data, that is, all data can be stored, the cumulative time from 1 to b of UQPE-S-Year (b = 10) and UQPE-S-Month (b = 120) with nine quantiles is 21.58 sec and 18.51 sec, respectively. Therefore, UQPE-S (UQPE-S-Year and UQPE-S-Month) is much faster to compute than UQPE-A.
6.2 Daily Return of Stocks and Exchange Rate Dataset
In order to illustrate the proposed methods in Sections 4 for large batches b, we used data from 871 trading days between January 1, 2020 and August 25, 2023 for all companies listed on the Shanghai Stock Exchange in China and exchange rate between the U.S. dollar and the Chinese currency. The dataset contains 1,339,591 observations, where suspension and special treatment stock transactions have been deleted. There were 1546 stocks in 2020, 1629 stocks in 2021, 1665 stocks in 2022 and 1689 stocks in 2023. We focus on the effects of Return (daily return of stock) on the quantile of the unconditional distribution of ERF (exchange rate fluctuation).
In this application, , which is (closing price of the day–closing price of the previous day)/closing price of the previous day,
, which is our interested covariate,
(daily turnover rate of stock) and
(daily trading volume of stock). Similar to the analysis of streaming time series data conducted in Deshpande, Javanmard, and Mehrabi (Citation2023) and Jiang, Choy, and Yu (Citation2023), the dataset in this study is not independent and identically distributed. However, we employ OLS, UQPE-A, CQR, and UQPE-S to analyze the dataset. It is important to note that this application poses a limitation on the iid assumption commonly used in practical time series data analysis. and report the estimated coefficients
of model (6.1) with
by methods OLS, CQR, UQPE-A, and UQPE-S under nine different quantiles (from the 10th to the 90th), which shows the difference between conditional and unconditional quantiles regressions.
Fig. 3 The estimates of the effect of ERF on Return by OLS, CQR, UQPE-A, and UQPE-S.
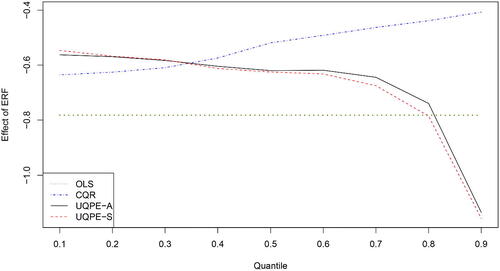
Table 8 The estimated coefficient of ERF by methods CQR, UQPE-A, and UQPE-S for Daily return of stocks and exchange rate dataset.
Next, we consider the proposed method UQPE-S in Sections 4. For different stocks, the exchange rate is the same every day, so we choose for the first 30 trading days. Since the data between January 1, 2021 and August 25, 2023 is recorded in days, we consider b = 842. The difference between the estimated effect of ERF for UQPE-A and UQPE-S is illustrated in and . From and , we can see that the effects of ERF on Return under different quantiles by UQPE-A and UQPE-S are all very close.
Finally, as with the streaming data setup, when the last batch of data arrives (the transaction data as of August 25, 2023 is regarded as ), the total running time of UQPE-A with nine quantiles is also 65.37 sec and UQPE-S is 0.02 sec. In addition, for the setting of massive data, that is, all data can be stored, the cumulative time from 1 to b of UQPE-S (b = 842) with nine quantiles is 18.11 sec. Therefore, UQPE-S is much faster to compute than UQPE-A.
7 Discussion
In this article, we delve into renewable parameter estimation for unconditional quantile regression applied to streaming datasets. A pivotal insight derived from our work is the introduction of a smoothing logistic regression estimator, a crucial tool in generating renewable estimators for unconditional quantile regression. This innovative approach necessitates only the availability of the current data batch within the stream, along with sufficient statistics on the historical data at each stage of analysis. Notably, our proposed renewable methods do not impose constraints on the number of batches, allowing them to adapt seamlessly to situations where streaming data arrives rapidly and continuously.
Theoretical analysis reveals that the proposed estimators for streaming datasets attain optimal efficiency, with asymptotic covariance matrices mirroring those of estimators derived from full data. The algorithm’s swiftness stems from its reliance on the Newton-Raphson method. Empirical results presented in Sections 5 and 6 demonstrate that our proposed method closely approximates the estimator derived from complete data, yet boasts a shorter running time.
Furthermore, the smoothing technique employed for the logistic regression estimator in this article can be extended to benefit other estimation methods, such as quantile regression and Huber estimation. As highlighted in Kong and Xia (Citation2019) and Jiang and Yu (Citation2022), our renewable estimation method is not confined solely to streaming data, but is also apt for the analysis of massive data. “Massive data” denotes data that exceeds a computer’s storage or computational capacity, often originating from a distributed system. Specifically, we can employ the divide-and-conquer method to partition the dataset into b blocks, or the dataset itself may stem from b sub-devices. This empowers us to analyze massive data with the aid of our renewable estimation method.
Supplementary Materials
The proofs of the proposed theorems are given in the supplementary material file.
Supplementary Material-11.pdf
Download PDF (99.2 KB)Acknowledgments
We thank the editor, associate editor and two reviewers for their constructive comments, which helped us improve the article.
Disclosure Statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Amba, S. M., and Nguyen, B. H. (2019), “Exchange Rate and Equity Price Relationship: Empirical Evidence from Mexican and Canadian Markets,” The International Journal of Business and Finance Research, 13, 33–43.
- Bahmani-Oskooee, M., and Sohrabian, A. (1992), “Stock Prices and the Effective Exchange Rate of the Dollar,” Applied Economics, 24, 459–64. DOI: 10.1080/00036849200000020.
- Borgen, N. (2016), “Fixed Effects in Unconditional Quantile Regression,” The Stata Journal, 16, 403–415. DOI: 10.1177/1536867X1601600208.
- Chen, X., Liu, W., and Zhang, Y. (2019), “Quantile Regression Under Memory Constraint,” Annals of Statistics, 47, 3244–3273.
- Deshpande, Y., Javanmard, A., and Mehrabi, M. (2023), “Online Debiasing for Adaptively Collected High-Dimensional Data with Applications to Time Series Analysis,” Journal of the American Statistical Association, 118, 1126–1139. DOI: 10.1080/01621459.2021.1979011.
- Dube, A. (2019), “Minimum Wages and the Distribution of Family Incomes,” American Economic Journal: Applied Economics, 11, 268–304. DOI: 10.1257/app.20170085.
- Fernandes, M., Guerre, E., and Horta, E. (2021), “Smoothing Quantile Regressions,” Journal of Business & Economic Statistics, 39, 338–357. DOI: 10.1080/07350015.2019.1660177.
- Firpo, S., Fortin, N. M., and Lemieux, T. (2009), “Unconditional Quantile Regressions,” Econometrica, 77, 953–973.
- Ghosh, P. (2021), “Box-Cox Power Transformation Unconditional Quantile Regressions with An Application on Wage Inequality,” Journal of Applied Statistics, 48, 3086–3101. DOI: 10.1080/02664763.2020.1795817.
- He, X., Pan, X., Tan, K. M., and Zhou, W. (2023), “Smoothed Quantile Regression with Large Scale Inference,” Journal of Econometrics, 232, 367–388. DOI: 10.1016/j.jeconom.2021.07.010.
- Horowitz, J. (1998), “Bootstrap Methods for Median Regression Models,” Econometrica, 66, 1327–1352. DOI: 10.2307/2999619.
- Inoue, A., Li, T., and Xu, Q. (2021), “Two Sample Unconditional Quantile Effect,” arXiv:2105.09445v1.
- Jiang, R., Choy, S. K., and Yu, K. (2023), “Non-Crossing Quantile Double-Autoregression for the Analysis of Streaming Time Series Data,” Journal of Time Series Analysis. DOI: 10.1111/jtsa.12725.
- Jiang, R., and Yu, K. (2021), “Smoothing Quantile Regression for a Distributed System,” Neurocomputing, 466, 311–326. DOI: 10.1016/j.neucom.2021.08.101.
- ——(2022), “Renewable Quantile Regression for Streaming Data Sets,” Neurocomputing, 508, 208–224.
- ——(2023), “No-Crossing Single-Index Quantile Regression Curve Estimation,” Journal of Business & Economic Statistics, 41, 309–320.
- Koenker, R., and Bassett, G. (1978), “Regression Quantile,” Econometrica, 46, 33–50. DOI: 10.2307/1913643.
- Kong, E., and Xia, Y. (2019), “On the Efficiency of Online Approach to Nonparametric Smoothing of Big Data,” Statistica Sinica, 29, 185–201. DOI: 10.5705/ss.202015.0365.
- Lee, D. S. (1999), “Wage Inequality in the United States during the 1980s: Rising Dispersion or Falling Minimum Wage?” The Quarterly Journal of Economics, 114, 977–1023. DOI: 10.1162/003355399556197.
- Luo, L., and Song, P. (2020), “Renewable Estimation and Incremental Inference in Generalized Linear Models with Streaming Data Sets,” Journal of the Royal Statistical Society, Series B, 82, 69–97. DOI: 10.1111/rssb.12352.
- Luo, L., Zhou, L., and Song, P. (2023), “Real-Time Regression Analysis of Streaming Clustered Data with Possible Abnormal Data Batches,” Journal of the American Statistical Association, 118, 2029–2044. DOI: 10.1080/01621459.2022.2026778.
- Martinez-Iriarte, J., Montes-Rojas, G., and Sun, Y. (2022), “Location-Scale and Compensated Effects in Unconditional Quantile Regressions,” arXiv:2201.02292v1.
- Nadaraya, E. (1964), “Some New Estimates for Distribution Functions,” Theory of Probability and Its Applications, 9, 497–500. DOI: 10.1137/1109069.
- Pan, M.-S., Fok, R., and Liu, Y. (2007), “Dynamic Linkages between Exchange Rates and Stock Prices: Evidence from East Asian Markets,” International Review of Economics & Finance, 16, 503–520. DOI: 10.1016/j.iref.2005.09.003.
- Sasaki, Y., Ura, T., and Zhang, Y. (2022), “Unconditional Quantile Regression with High-Dimensional Data,” Quantitative Economics, 13, 955–978. DOI: 10.3982/QE1896.
- Schifano, E., Wu, J., Wang, C., Yan, J., and Chen, M.-H. (2016), “Online Updating of Statistical Inference in the Big Data Setting,” Technometrics, 58, 393–403. DOI: 10.1080/00401706.2016.1142900.
- Wang, H., Min, Y., and Stufken, J. (2019), “Information-based Optimal Subdata Selection for Big Data Linear Regression,” Journal of the American Statistical Association, 114, 393–405. DOI: 10.1080/01621459.2017.1408468.
- Wang, K., Wang, H., and Li, S. (2022), “Renewable Quantile Regression for Streaming Datasets,” Knowledge-Based Systems, 235, 107675. DOI: 10.1016/j.knosys.2021.107675.
- Xie, R., Bai, S. Y., and Ma, P. (2023), “Optimal Sampling Designs for Multi-Dimensional Streaming Time Series with Application to Power Grid Sensor Data,” arXiv:2303.08242v1.
- Yang, Y., and Yao, F. (2023), “Online Estimation for Functional Data,” Journal of the American Statistical Association, 118, 1630–1644.
- Zhang, B., and Li, X. (2010), “Currency Appreciation and Stock Market Performance: Evidence from China,” Frontiers of Economics in China, 5, 393–411. DOI: 10.1007/s11459-010-0104-2.